
Abstract
Disease incidences increase with age, but the molecular characteristics of ageing that lead to increased disease susceptibility remain inadequately understood. Here we perform a whole-blood gene expression meta-analysis in 14,983 individuals of European ancestry (including replication) and identify 1,497 genes that are differentially expressed with chronological age. The age-associated genes do not harbor more age-associated CpG-methylation sites than other genes, but are instead enriched for the presence of potentially functional CpG-methylation sites in enhancer and insulator regions that associate with both chronological age and gene expression levels. We further used the gene expression profiles to calculate the ‘transcriptomic age’ of an individual, and show that differences between transcriptomic age and chronological age are associated with biological features linked to ageing, such as blood pressure, cholesterol levels, fasting glucose, and body mass index. The transcriptomic prediction model adds biological relevance and complements existing epigenetic prediction models, and can be used by others to calculate transcriptomic age in external cohorts.
Similar content being viewed by others
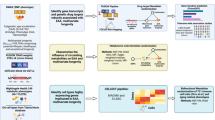


Introduction
Chronological age is a major risk factor for many common diseases including heart disease, cancer and stroke, three of the leading causes of death. Although chronological age is the most powerful risk factor for most chronic diseases, the underlying molecular mechanisms that lead to generalized disease susceptibility are largely unknown. Genome-wide association studies (GWAS) have identified thousands of single-nucleotide polymorphisms (SNPs) associated with common human diseases and traits1,2. Despite this success, APOE, FOXO3 and 5q33.3 are the only identified loci consistently associated with longevity3,4,5,6,7,8,9,10,11. Ageing has proven difficult to dissect in part due to its interactions with environmental influences (for example, lifestyle choices, diet and local exposures), other genetic factors, and a large number of age-related diseases11, making the individual factors difficult to detect.
Since studies in model organisms have shown that ageing is characterized by many alterations at the molecular, cellular and tissue level12, a transcriptome analysis might lend greater insight than a static genetic investigation. Therefore, the aim of this study was to exploit a large-scale population-based strategy to systematically identify genes and pathways differentially expressed as a function of chronological age. In contrast to the relatively invariable genome sequence, the transcriptome is highly dynamic and changes in response to stimuli. Previous gene expression studies in the context of ageing have primarily focused on model organisms13,14,15 or have been confined to specific ageing syndromes such as Hutchinson–Gilford progeria16. One report identified age-related expression modules across four separate data sets17, while other studies examined age-associated gene expression changes in relatively small cohorts18,19,20,21,22.
To our knowledge, we perform here the first large-scale meta-analysis of human age-related gene expression profiles with well powered discovery and replication stages. In addition, this is the first large-scale study testing the hypothesis that changes in gene expression with chronological age are epigenetically mediated by changes of methylation levels at specific loci. Finally, we take advantage of our large set of samples to build a transcriptomic predictor of age, and we compare our transcriptomic prediction model with the epigenetic prediction models of Horvath23 and Hannum et al.24.
We identified 1,497 genes that are differentially expressed with chronological age. These genes are enriched for the presence of potentially functional CpG-methylation sites in enhancer and insulator regions. Our transcriptomic age predictor complements the existing epigenetic prediction models, and can be used by others to calculate transcriptomic age in external cohorts.
Results
1,497 genes differentially expressed with chronological age
The discovery stage included six European-ancestry studies (n=7,074 samples) with whole-blood gene expression levels for roughly half of the genes in the human genome (n=11,908 significantly expressed genes across different platforms). We identified 2,228 genes with age-associated expression in the discovery stage (P<4.2E−6) after adjusting for technical variables and confounding factors such as sex, cell counts and cigarette smoking (Supplementary Fig. 1A). The replication stage included 7,909 additional whole-blood samples, in which we replicated association results for 1,497 genes (P<2.2E−5). Discovery and replication results were highly correlated (r=0.972, Supplementary Fig. 1B) and complete results are shown in Supplementary Data 1. After meta-analysis of discovery and replication stages, the expression levels of 897 genes were negatively associated and 600 genes were positively correlated with chronological age. The top 50 most significantly associated genes are presented in Table 1.
Transferability of ageing transcriptome signatures
To examine the generalizability of the results of our differential expression meta-analysis, we tested whether the 1,497 identified genes were also differentially expressed in relation to chronological age in other ancestry samples, in brain tissue, and in specific blood sub-cell-types (Supplementary Data 1). In Native Americans (n=1,457), 95% of the 1,497 genes were significantly expressed, and 71% (1,005 genes) were associated with chronological age (P<0.05). In Hispanic Americans (n=1,244), 40% of the 1,497 genes were significantly expressed, and 74% (440 genes) were associated with chronological age in the same direction (P<0.05). In African Americans (n=359), 99% of the genes were significantly expressed, and 27% (392 genes) were associated with chronological age in the same direction (P<0.05) (Supplementary Table 1).
In both types of brain tissue studies (cerebellum and frontal cortex, n=394), approximately 58% of the 1,497 genes were significantly expressed. Of these, 19% (163 genes) and 26% (229 genes) were associated with chronological age in the same direction (P<0.05) in cerebellum and frontal cortex, respectively (Supplementary Table 2, Supplementary Fig. 2, and Supplementary Table 3). Among the top 50 age-associated genes, three genes were associated with chronological age in all tissues: SERPINE2, LDHB and BZW2 (P<0.05; Supplementary Data 2).
Novel and known age-associated genes and pathways
To differentiate between changes caused by cell composition and other biological mechanisms, we clustered genes based on co-expression networks in GeneNetwork (see Methods) and performed pathway analysis on the clusters of co-expressed genes. Among the negatively age-correlated genes, three major clusters were identified (Fig. 1a, Supplementary Data 3A–M). The largest group (cluster #1, 109 genes) consisted of three sub-clusters enriched for: (1a) RNA metabolism functions, ribosome biogenesis and purine metabolism; (1b) multiple mitochondrial and metabolic pathways including 10 mitochondrial ribosomal protein (MRP) genes consistent with earlier ageing studies in mice, Caenorhabditis elegans25 and Drosophila melanogaster26,27,28; and (1c) DNA replication, elongation and repair, and mismatch repair26. The second cluster of negatively correlated genes (cluster #2, 57 genes) contained factors related to immunity; including T- and B-cell signalling genes, and genes involved in hematopoiesis. The third tight cluster (cluster #3) included 12 genes, of which 11 encoded cytosolic ribosomal subunits: 7 RPL-genes (RPL8, RPL11, RPL18, RPL28, RPL30, RPL35 and RPL36), 3 RPS-genes (RPS14, RPS16 and RPS29) and UBA52 (ribosomal protein L40). The other gene of the cluster (#12) was NACA, a nascent polypeptide-associated complex alpha subunit. The protein encoded by the NACA gene forms the nascent polypeptide-associated complex (NAC), which binds to nascent proteins as they emerge from the ribosome29. Strikingly, the mRNA abundance of many genes encoding ribosomal subunits and mitochondrial ribosomal proteins were significantly associated with chronological age: 34 ribosomal genes were significantly associated, of which 33 were negatively correlated with chronological age (Supplementary Table 4), and 10 MRP genes were significantly negatively correlated with chronological age (Supplementary Table 5).

We ran a co-functionality network analysis on 897 downregulated genes with age (negative effect direction) and 600 upregulated genes with age (positive effect direction) using GeneNetwork. With a correlation threshold of 0.7, we selected all clusters bigger than four genes and ran per-cluster pathway analyses using KEGG, Reactome, and GO-terms in WEBGESTALT. Benjamini & Hochberg FDR was used for multiple testing corrections. The significant threshold 0.05 after correction for multiple testing was applied. (a) Three clusters of downregulated genes with age and (b) four clusters of genes upregulated with age were enriched for functional pathways in KEGG, Reactome, and GO terms; the specific pathways are mentioned next to the (sub)cluster names.
The positively age-correlated genes revealed four major clusters (Fig. 1b, Supplementary Data 3N–V): cluster#1 (77 genes): innate and adaptive immunity, cluster#2 (9 genes): actin cytoskeleton, focal adhesion, and tight junctions, cluster#3 (8 genes): fatty acid metabolism and peroxisome activity and cluster#4 (6 genes): lysosome metabolism and glycosaminoglycan degradation.
For both brain tissue studies, we checked the number (and %) of overlapping age-associated genes for the different functional clusters: 24 genes (11.7% of the genes expressed in cerebellum) and 33 genes (of the genes expressed in frontal cortex) of all pathway genes (278 genes) were associated with chronological age (Supplementary Tables 6 and 7). In cerebellum, the best replicating pathway was the positively age-correlated cluster #4: lysosome metabolism and glycosaminoglycan degradation. In frontal cortex, the best-replicating pathway was the positively age-correlated cluster #2: actin cytoskeleton, focal adhesion and tight junctions.
Associations with prior ageing candidate genes
We investigated the intersection between genes significantly associated with chronological age in our study and candidate genes from previous human and animal studies (170 genes, see Supplementary Tables 8 and 9). Thirty-three of the 170 candidate genes were significantly associated with chronological age in our whole blood meta-analysis, including members of the mTOR/FOXO pathways (FOXO1, VEGFB, EIF4G3, SREBF1, STAT3 and RPS6KB1)30, DNA repair (ATM)31, and prior multispecies candidates (LDHB, IGJ, IRF8and FCGR1A). Twenty-eight of the 33 significant age-associated genes (∼85%) have the same expression directionality in our CHARGE meta-analysis as previously reported in a variety of studies in humans and other model organisms.
Premature ageing syndrome genes ATM (ataxia-telangiectasia), DKC (dyskeratosis congenita) and WRN (werner syndrome) all exhibited lower transcript abundance in older individuals, concordant with loss-of-function alterations in disease-related mutations. On the basis of the co-expression analyses, these genes clustered together with genes encoding proteins involved in DNA and RNA metabolism, DNA repair, and purine/pyrimidine metabolism. The Hutchinson–Gilford progeria gene LMNA showed higher mRNA levels in the elderly, consistent with earlier findings in muscle32, and clustered with actin remodelling genes.
Methylation association patterns for top age-associated loci
Given the possible role of the methylome in ageing, we investigated whether age-associated methylation accompanied age-associated expression for the 1,497 age-associated genes. We analysed methylation of 135,230 CpG sites (regions of DNA where a cytosine nucleotide occurs next to a guanine nucleotide) in or near (±250 kb) the age-associated genes in whole blood or peripheral blood mononuclear cells (PBMCs) from seven cohorts (N=3,073). We chose CpGs in a 250 kb vicinity because earlier studies have shown that methylation can regulate gene expression levels at this distance33, and that long-range enhancer activities are present and actively regulate gene expression at a wide scale34. We observed significant associations between methylation and chronological age for 31,331 CpG sites, and between expression and methylation for 12,280 CpG sites, based on a conservative Bonferroni threshold (P<3.7E−7) (top results for each gene in Supplementary Data 4). In all, 1,248 of the 1,497 age-associated genes (83%) had ≥1 significant mediating CpGs and the number of significant mediating CpGs per gene ranged from 1 to 154 (Supplementary Data 4).
To test whether the age-associated genes were enriched for nearby CpG methylation sites associated with chronological age or expression, we performed a similar analysis for a set of 1,497 randomly selected genes matched for similar gene length and mean whole blood expression (see Methods and Supplementary Fig. 3A–D). Compared to the set of random genes, age-associated genes had only mild enrichment for CpG methylation sites associated with chronological age (Fig. 2a; odds ratio (OR)=1.04; 95% confidence interval (CI)=1.02–1.06; P=7.9E−5), but strong enrichment for CpG methylation sites associated with expression (Fig. 2b; OR=2.68; 95% CI=2.58–2.78; P<1E−300). This pattern was consistent across all cohorts (Supplementary Fig. 4) and within subsets of CpG methylation sites annotated to specific biological features (that is, enhancer regions, promoter regions, CpG islands and so on.) (Supplementary Fig. 5), and was robust to the entire range of significance thresholds (see Methods). This is consistent with a scenario where many methylation sites associate with chronological age, but only those with regulatory potential lead to altered transcript expression with chronological age.

(a) Quantile–quantile (QQ) plot of the observed P-values (−log10P) for the methylation–age associations. The plot in black shows pvalues from the 1,497 significant age-associated genes, whereas the plot in red shows pvalues for 1,497 random genes. We do not see enrichment for the 1,497 age-associated genes. (b) QQ plot of the observed P-values (−log10P) for the expression–methylation associations. The plot in black shows P values from the 1,497 significant age-associated genes, whereas the plot in blue shows pvalues for 1,497 random genes. The age-associated genes are enriched for CpG methylation sites that associate with gene expression levels.
We used Sobel tests (see Methods) for all CpG methylation sites to investigate whether the observed patterns could potentially reflect a methylation-mediated relationship between chronological age and transcript levels. In total, 1,248 of the 1,497 age-associated genes (83%) had ≥1 CpG site with a significant Sobel test after Bonferroni adjustment for the number of CpGs tested (Supplementary Data 4). These potentially mediating CpG sites were less likely to reside in CpG islands (OR=0.28; 95% CI=0.26–0.30; P<1E−300) or in promoters (OR=0.38; 95%CI=0.36–0.40; P<1E−300) and more likely to be located in enhancers (OR=2.29; 95%CI=2.17–2.41; P=2.7E−188) and insulators (OR=1.44; 95% CI=1.23–1.67; P=6.6E−6), compared with non-mediating CpGs within 250 kb of age-associated genes (Supplementary Fig. 6). This pattern is again consistent with the mediation of age-associated transcripts by age-associated methylation of CpG sites with specific regulatory roles.
Transcriptomic age prediction as a surrogate biomarker
All 11,908 discovery genes were used to build a predictor for age using a leave-one-out-prediction meta-analysis (see Methods). For each cohort in turn, we left out that cohort as the validation sample and re-ran the discovery meta-analysis on the other cohorts to avoid overlap between the discovery and validation sample (Supplementary Data 5A). The difference between the predicted transcriptomic age and chronological age (delta age) may be a reflection of altered biological age (see Methods). The correlation between chronological age and transcriptomic age was significant in all cohorts (P<2E−29; Fig. 3a–h). The average absolute difference between predicted age and chronological age was 7.8 years (n=8,847 samples, Supplementary Table 10). A positive delta age, interpreted as reflecting more rapid biological ageing, was consistently associated with higher systolic and diastolic blood pressure, total cholesterol, HDL cholesterol, fasting glucose levels and body mass index (BMI) (Table 2, Supplementary Table 11). All analyses were adjusted for chronological age, and after adjustment for BMI all phenotypes remained associated in the same direction (Table 2, Supplementary Table 12). For systolic blood pressure, the added predictive value of the transcriptomic predictor over chronological age is shown for the Rotterdam Study (Fig. 4a–c). Other phenotypes showed the same pattern.

This figure represents the correlations between chronological age (x axis) and transcriptomic age (y axis) in eight different cohorts: (a) RS-III, (b) DILGOM, (c) KORA, (d) InCHIANTI, (e) SHIP-TREND, (f) FHS-OFFSPRING, (g) NIDDK/PHOENIX and (h) EGCUT. Transcriptomic age was calculated using a cohort-specific prediction formula and the measured gene expression levels of 11,908 genes. The correlation between chronological age and transcriptomic age was significant in all cohorts (P<2E−29).

To show the added value of the transcriptomic predictor, we choose one biological ageing phenotype systolic blood pressure (SBP), and plotted its correlation with chronological age (a), delta age (b) and the transcriptomic age (c) in the Rotterdam Study (n=597 samples with SBP data available). Delta age represents the difference between chronological age and transcriptomic age. SBP was plotted on the y axis, and the age-related values were plotted on the x axes. SBP was significantly associated with chronological age (P=4.0E−04), but SBP was even stronger associated with transcriptomic age (calculated with a cohort-specific prediction formula based on gene expression levels) (P=8.7E−09), Therefore, the transcriptomic predictor adds value over chronological age alone. Other biological ageing phenotypes showed the same pattern.
We compared our transcriptomic predictor with two already published epigenetic predictors of age of Horvath23 and Hannum et al.24 in 1,396 individuals from the KORA study and the Rotterdam Study, all having gene expression levels and methylation data available. The transcriptomic predictor was less strongly correlated with chronological age than the two epigenetic predictors (Supplementary Fig. 7), which can be explained by the different data types used: we used gene expression data instead of DNA methylation data.
Transcriptomic age and epigenetic age (both Hannum and Horvath) were positively correlated, with r2 values varying between 0.10 and 0.33 (Supplementary Fig. 7). Interestingly, all three age predictors were associated with different ageing phenotypes (Supplementary Tables 13 and 14), that is, the transcriptomic predictor was significantly associated with systolic blood pressure, waist-hip-ratio, and smoking; the epigenetic Horvath predictor was associated with waist-hip-ratio only; and the epigenetic Hannum predictor was associated with fasting glucose, waist-hip-ratio and smoking (all analyses were adjusted for chronological age, sex and BMI). By adding two predictors into one formula (one transcriptomic predictor and one epigenetic predictor), both predictors added value (significant effect) to the phenotype associations, that is, for waist-hip-ratio in KORA (explained variance transcriptomic predictor=0.015%, Horvath predictor=0.005%, Hannum predictor=0.006%; transcriptomic+Horvath=0.017% and transcriptomic+Hannum=0.016%) (Supplementary Tables 15 and 16).
Discussion
Age-associated changes in gene expression levels point towards altered activity in defined age-related molecular pathways that may play vital roles in the mechanisms of increased susceptibility to ageing diseases. In contrast to earlier, smaller studies17,18,19,20,21 of human age-related molecular differences, we detected and replicated 1,497 age-associated genes in 14,983 individuals of European ancestry. In addition, many of our associations were generalized across different ancestries and multiple cell and tissue types. Because we had much smaller sample sizes for both brain tissue (n=394) and the other ancestry groups (1,244 Hispanic Americans, 1,457 Native Americans, and 359 African Americans), we used a nominal P-value threshold (P<0.05) in these specific sub-analyses. Larger sample sizes will ultimately be needed to fully understand the transferability of the ageing-transcriptome signatures.
A potential limitation of our study is that we relied on a linear regression model to identify age-associated genes. A linear model assumes constant change over age, which may not be always correct in biological processes that stretch over several decades (adulthood). A recent study demonstrated that a quadratic regression model has a higher statistical fit to cross-sectional gene expression datasets over linear models35. Although we chose to apply a linear regression model in our study, we recognize that more complex models could be investigated in future studies.
Our human age-expression and pathway enrichment analysis results were consistent with known ageing mechanisms including dysregulation of transcription and translation, metabolic function, DNA damage accumulation, immune senescence, ribosome biogenesis and mitochondrial decline. Houtkooper et al.25, McCarroll et al.26 and Landis et al.27 highlighted the key role of mitochondria in ageing and longevity in model organisms. Mitochondria regulate a multitude of different metabolic and signalling pathways and also play an important role in programmed cell death36. The number of mitochondria decreases and their capacity to produce energy is reduced with chronological age37,38,39. Consistent with these reports, a large number of mitochondrial ribosomal proteins (MRPL24, MRPL3, MRPL35, MRPL45, MRPS18B, MRPS26, MRPS27, MRPS31, MRPS33 and MRPS9) showed lower expression at higher chronological age in our study, supporting the hypothesis that age-dependent mitochondrial dysfunction plays a causal role in human ageing.
The large immune function associated clusters (cluster #2 and cluster #1 of the negatively and positively correlated genes, respectively) reflect immune senescence. The relative abundance of immune cells in whole blood shifts with ageing, with naive T cells decreasing and highly differentiated effector and memory T cells increasing with chronological age28,40,41,42,43,44. Consistent with immune senescence, the mRNA abundance of the chemokine receptor CCR7 and cell differentiation antigens CD27 and CD28 was lower in older individuals (P=1.0E−208, P=2.8E−162, and P=5.8E−59). Notably, these results were consistent in many of the blood sub-cell-types. For example, CCR7 was lower in older individuals across multiple cell types including CD4+ cells (P=1.0E−08), CD8+ cells (P=3.0E−15), CD14+ cells /monocytes (P=8.5E−3), and PBMCs (P=3.0E−3). This suggests that genes in the immune associated clusters reflect a biological function related to a more general ageing phenotype , at least in multiple immune cell types, and are not solely accountable to cell-count differences. We also note that cell subset classification is to a greater or lesser extent artificial, reflecting our current ability to distinguish cells based on specific small sets of available markers. Accepted subpopulation of cells can often be further broken down into additional subgroups as the tools for such classification become more sophisticated. The analysis of unfractionated cell populations (such as our study) adds a layer of complexity to the interpretation, but is not necessarily less informative than the analysis of marker defined subpopulations.
Aside from the immune clusters, we identified and newly emphasized pathways associated with human ageing, for example, glycosaminoglycan degradation and actin remodelling. These pathways have previously been implicated in life span regulation of the model organisms C. elegans and D. melanogaster45,46,47. Glycosaminoglycans (GAGs) influence cell migration, proliferation and differentiation and play a role in wound healing48,49. Impaired degradation of GAGs in extreme lysosomal storage disorders lead to chronic, progressive effects on a variety of organs and physiologic systems50. Tissue repair and regeneration are known to be impaired in the elderly and inhibition of GAG degradation may be therapeutic in these contexts51. Our findings suggest GAG degradation as a candidate mechanism for the age-associated changes. The actin cytoskeleton is a critical structural element in eukaryotic cells that is crucial in mediating cell responses to both internal and external signals in yeast52. Actin dynamics have clearly been linked to yeast replicative ageing through both reactive oxygen species-mediated apoptosis and through selective sequestration of healthy mitochondria to new daughter cells during cell division52,53. Our pathway analysis indicates that the actin cytoskeleton may be similarly important in human ageing. While much prior effort in targeting actomyosin dynamics has been aimed at cancers, recent studies indicate that targeted modulation of these systems could also have benefits in immune-mediated pathologies48.
In addition to these novel candidate pathways, our 1,497 age-associated genes contain genes in many pathways known to be associated with ageing. Beyond the immune-related pathways, we confirm an age-associated role for mitochondrial function54, metabolic function12, ribosome biogenesis55, DNA replication, elongation and repair56,57, focal adhesion58 and lysosome metabolism59, and suggest a number of new potential age-related targets within these pathways, including TTC27 (ribosome biogenesis); CCDC34 (ribosomal cluster); ARHGAP15, DOCK10, FAM129C, FCRLA, GIMAP7 and VPREB3 (T- and B-cell signalling genes and genes involved in haematopoiesis); GZMH, SAMD9L and TAGAP (innate and adaptive immunity). Of note, overexpression of the full-length ARHGAP15 protein in COS-7 and HeLa cells resulted in an increase in actin stress fibres and cell contraction, relating the newly ageing emphasized actin remodelling pathway and the focal adhesion pathway in ageing to immune cell changes60. Thus, by using co-expression networks, we identified new genes and pathways that are likely important in human ageing, opening new avenues of enquiry for future studies.
Age-related epigenetic changes have recently been examined including a large study combining data across 7,844 non-cancer samples from 82 individual data sets to define a set of age-methylation clock genes. Only 35 of our 1,497 age-related genes were found among the genes harbouring the 353 age-methylation clock CpG sites reported by Horvath23, suggesting that our age-associated genes may not be particularly enriched for age-associated CpG methylation sites. To test this formally, we analysed the DNA methylation sites (CpG sites only) within 250 kb (upstream and downstream) of all 1,497 age-associated genes, as well as a comparison set of 1,497 randomly chosen unassociated genes. We observed that the genes exhibiting age-associated transcript levels in blood are much more likely than other genes to harbour CpG methylation sites that associate with expression levels, but are not substantially more likely to harbour methylation differences in close CpG sites associated with chronological age. These results suggest that genes showing age-related expression differences are characterized primarily by the presence of nearby CpG sites with regulatory potential, rather than by the presence of age-associated CpG methylation sites, which are abundant everywhere in the genome. A limitation of our study is that we used the Illumina Infinium HumanMethylation450K BeadChip Array for measuring methylation levels: this array queries only 1.6% of all CpGs in the genome and the CpG selection is biased towards CpG islands. In addition, we did not examine non-CpG methylated sites, which have recently been suggested to play a role in regulating gene expression as well61. Other techniques—whole-genome bisulfite sequencing62 and methylC-capture (MCC) sequencing63, for example—have definite technical advantages (higher resolution and no CpG island selection bias), but these have currently not been applied to a large number of samples.
Although the CpG selection on the methylation array is biased towards CpG islands, the CpG sites for which methylation was associated with both expression and chronological age were strongly enriched for enhancer activity. This is consistent with the concept that methylation at enhancers is more variable and may regulate gene expression in development64 and/or in environmental responses, while promoter methylation is comparatively stable. Interestingly, the age- and expression-associated CpGs were also enriched at insulators, which function to block the communication between an enhancer and a promotor, thereby preventing inappropriate gene activation. Taken together, these results suggest that the age-associated genes reported here may be regulated by methylation of CpG sites in specific functional regions, and that studying both methylation and expression as potential joint effectors of the ageing process may significantly improve the prediction of age and identification of novel age-related genes and pathways.
Using gene expression levels as a predictive biomarker indicated that individuals having higher predicted than chronological age also have clinical features consistent with an older age, such as higher blood pressure and total cholesterol levels. Developing a strongly predictive gene expression set as a biomarker panel has clinical potential to identify subjects at risk for early biological ageing, and provide a tool for targeting susceptible individuals for early intervention. It remains to be seen whether the transcriptomic age can serve as a surrogate marker to predict age-associated decline in other tissues. Therefore, the development of a robust transcriptomic predictor for age will require independent and prospective validation across different tissues.
We observed that both the transcriptomic predictor and the epigenetic predictors were significantly associated with a number of phenotypes, but that the pattern of association differed among the predictors. Therefore, the transcriptomic age and the epigenetic age should be combined to obtain the optimal biological age prediction. A general transcriptomic prediction formula has been calculated that is freely available (Supplementary Data 5B). These results suggest that the biological mechanisms behind the transcriptomic and the epigenetic predictors are different. The exact mechanism of these differences need further examination in larger sample sizes and subgroup analysis were different diseases are studied. In addition, the predictors need to be evaluated for their prognostic value. In conclusion, gene expression levels are likely to become a valuable addition to evolving indicators of age based on epigenetic and telomeric age predictors. Ideally, a combination of transcriptomic, epigenetic and telomeric elements could further improve and refine age prediction.
In conclusion, we have identified a compendium of genes and pathways associated with human chronological age. By leveraging transcriptional information across large, multiethnic cohorts, different tissue types and genomic repositories, we captured an unprecedented overview of the complex and temporally dynamic biological pathways orchestrating the ageing process. Our list of genes should provide a rich trove of data for future ageing studies. While the pursuit of an anti-ageing panacea in humans remains a distant goal, our work has generated new biological hypotheses and will serve as a roadmap for future studies aimed at translating findings into treatment strategies for age-related diseases.
Methods
Study design
We performed a differential expression meta-analysis in 7,074 human peripheral blood samples from six independent cohort studies, including EGCUT (n=1,086), FHS—2nd generation (n=2,446), INCHIANTI (n=698), KORA (n=993), ROTTERDAM STUDY (n=881), and SHIP-TREND (n=970; Supplementary Table 17). Gene expression data for each dataset was obtained using either PAXGene (Becton Dickinson) or Tempus Tubes (Life Technologies), followed by hybridization to Illumina Whole-Genome Expression BeadChips (HT12v3 or HT12v4) or Affymetrix Human Exon 1.0 ST GeneChips.
We replicated the significantly associated transcripts in 7,909 peripheral blood samples from seven independent cohort studies, including BSGS (n=862), DILGOM (n=512), FEHRMANN (n=1,191), FHS—3rd generation (n=3,180), GTP (n=359), HVH (n=121 on the Illumina HT12v3 platform and n=227 on the Illumina HT12v4 platform), and NIDDK/PHOENIX (n=1,457) (Supplementary Table 18). Gene expression data for these datasets was also obtained using either PAXGene (Becton Dickinson) or Tempus Tubes (Life Technologies), followed by hybridization to Illumina Whole-Genome Expression BeadChips (HT8v2, HT12v3, or HT12v4 arrays) or Affymetrix Human Exon 1.0 ST GeneChips.
We generalized the significantly replicated transcripts in 4,644 samples with other tissue types, including: CD4+ cells of EGCUT (n=302) and a Boston sample (n=213), CD8+ cells of EGCUT (n=299), CD14+ cells (or monocytes) of a Boston sample (n=213) and MESA (n=354), LCLs of GENOA (n=869), lymphocytes of SAFHS (n=1,244), PBMCs of GARP (n=134) and PMBC-MS (n=228), and brain tissue (cerebellum and frontal cortex) of NABEC-UKBEC (n=394) (Supplementary Table 19). Gene expression data of these data sets was obtained by tissue specific RNA isolation and hybridization to Illumina Whole-Genome Expression BeadChips (WG6v1, HT12v3 or HT12v4), Affymetrix Human Exon Arrays, or Affymetrix Human Gene Arrays.
The study outline is summarized in Supplementary Fig. 8. The study populations, the RNA isolation methods, the amplification and labelling methods and the array types used for each study are described in the Supplementary Methods. The covariates used in each study are presented in Supplementary Tables 17–19.
Phenotype
Chronological age was defined as the length of time in years between birth and blood draw, using two decimals. Detailed descriptions of the chronological age distributions, fasting status and the available covariates from the participating cohorts are presented in Supplementary Tables 17–19 and Supplementary Fig. 9A–V.
Illumina pipeline: gene expression probes and normalization procedure
The different Illumina platforms used by the different cohorts share a large number of probes with identical 50-mer probe sequences. Therefore, we harmonized the probes across the HT12-v3 and the HT12-v4 platforms by determining the probe sequences from the different annotation files for each platform; renumbering the probes on the basis of unique probe sequences. In total, we identified 56,330 unique Illumina probes (11,453 probes measured only on the HT12-v3 platform, 7,529 probes measured only on the HT12-v4 platform, 37,348 probes measured on both platforms). Genes were declared significantly expressed in the discovery data when (1) the detection P-values calculated by GenomeStudio were <0.05 in >10% of all discovery samples and (2) the probes were measured in at least two cohorts. This resulted in 23,170 transcripts considered as being significantly expressed in our Illumina discovery; these transcripts code for 15,639 well characterized unique genes. 3,484 genes have more than one Illumina probe on the HT12 platform. Illumina gene expression data was quantile normalized to the median distribution and subsequently log2-transformed. The probe and sample means were centered to zero.
Affymetrix pipeline: gene expression probes and normalization procedure
The Affymetrix platform generated CEL files, containing both gene-based and exon-based expression levels. We used the gene-based expression levels and normalized the data using Affymetrix Power Tools: probes with RLE mean values >3.0 (range 1.34–12.71) were considered to be significantly expressed. This resulted in 16,798 well characterized unique genes in the Affymetrix discovery. Samples with all probeset RLE means > 0.7 were defined as outliers and excluded from further analysis. A genetic expression SNP analysis was undertaken to locate mislabeled samples and reidentify them where possible with high confidence. After exclusions and reidentification, the RMA normalization was repeated.
Differential expression with chronological age
All Illumina studies ran a least squares linear regression model (lm) using the normalized and standardized gene expression values as dependent variables, chronological age as an explanatory variable and with adjustments for the potential confounders: sex (factor), fasting and smoking status (both factors), plate origin (factor), RNA quality (RIN/RQS) and cell counts (number of granulocytes, lymphocytes, monocytes, erythrocytes and platelets), so:

The Affymetrix cohort ran a multivariate stepwise PC regression, using the normalized and standardized gene expression values as dependent variables, chronological age as an explanatory variable, and the significant technical covariates: all_probeset_mean, all_probeset_stdev, neg_control_mean, neg_control_stdev, pos_control_mean, pos_control_stdev, all_probeset_rle_mean, all_probeset_mad_residual_mean, RNA quality (RIN), and RNA processing batch. Batch was included in modelling as a random factor while all others were fixed factors.
Meta-analysis of significantly expressed genes
We ran four separate meta-analyses: one for the studies using the Illumina platforms in the discovery phase, one for the Illumina discovery studies plus the FHS Affymetrix discovery results, one for the replication sample combined, and one for the discovery samples plus replication samples for validated results to re-rank the final results list. For these meta-analyses, we used a sample size weighted meta-analysis based on P-values and the direction of the effects; using P-values, a Z-statistic characterizing the evidence for association was calculated. The Z-statistic summarized the magnitude and the direction of the effect. An overall Z-statistic and P-value was calculated from the weighted sum of the individual statistics. Weights were proportional to the square-root of the number of individuals examined in each sample and standardized such that the squared weights sum to 1.
We calculated the Z-scores and P-values using the Meta-Analysis Tool for genome-wide association scans (METAL)65. METAL is a flexible and computationally efficient command line tool that was developed for meta-analyzing GWAS studies, but can easily be adapted to gene expression studies. Because we are dealing with gene expression levels and not SNPs, we changed the SNPID column to probe IDs and gave all probes a minor allele A and a major allele G, a minor allele frequency=0.10, and a + strand. For the positions, the probe chromosomes and the midpoint position of the probes were used. Sample sizes, effect directions, and P-values were extracted from the linear model results files. We extensively tested what input parameters to use for meta-analysing gene expression data. By using similar allele names, allele frequencies, and allele strands for all cohorts, we forced METAL to use the default meta-analysis approach. We tested an inverse variance weighted meta-analysis (using the effect size estimates and the standard errors), and found that our METAL meta-analysis results were identical to the meta-analysis results using the R package Meta.
Meta-analysis of discovery samples. To calculate which genes are significantly associated with chronological age, we ran a sample size weighted meta-analysis based on P-values and the direction of the effects of the results of the Affymetrix and the Illumina meta-analyses. Combining the 16,798 Affymetrix probes and the 15,639 Illumina probes, these platforms have 11,908 genes significantly expressed in whole blood samples in common.
Replication phase. Genes with a P-value <4.20E−6 (0.05/11,908 genes tested) were considered transcriptome-wide significantly associated with chronological age. We replicated these findings in an additional 8,009 samples (Supplementary Table 18). Replication cohorts used the same analysis plan and R-scripts as the discovery phase, however, some covariates were not available in these cohorts and ethnicities could be different than European-ancestry.
Meta-analysis of the replication cohorts. We meta-analysed the summary statistics of the replication cohorts using METAL. Genes were considered significantly replicating if P<2.23E−5 (0.05/2,238 genes tested) and the overall Z-score was in the same direction as the overall Z-score of the discovery meta-analysis.
Meta-analysis of discovery and replication cohorts. We additionally performed a meta-analysis based on the summary statistics of all discovery and all replication cohorts and obtained two-sided P-values.
Generalization phase
To see whether our findings are specific for whole blood, we tried to generalize our significantly replicating transcripts in samples of other tissue types, including CD4+ cells, CD8+ cells, CD14+ cells (monocytes), LCLs, lymphocytes, PBMCs and brain tissue (both cerebellum and frontal cortex; Supplementary Table 19). If we had data of one tissue type of more than one cohort, then we ran a meta-analysis based on the summary statistics of both cohorts. Because sample sizes of these tissue types were very small, we considered P-values <0.05 (with an identical effect direction) sufficient to document generalization of the effect.
Pathway analysis of significant genes
We used WEBGESTALT ( http://bioinfo.vanderbilt.edu/webgestalt/analysis.php) and GeneNetwork ( http://genenetwork.nl:8080/GeneNetwork/pathway_network.html) for pathway analysis of age-associated transcripts. First, we ran the co-functionality network analysis separately on 897 down-regulated genes and 600 up-regulated genes, using a correlation threshold of 0.7. Of 897 downregulated genes, 192 formed cluster groups at this threshold, and of 600 upregulated genes, 114 formed cluster groups. We next re-ran the co-expression cluster analysis on these 192 and 114 genes, using a correlation threshold of 0.65 to see if small clusters could be merged together if a lower co-expression threshold was applied. We selected clusters with five and more genes for pathway analysis; in total 178 and 100 down- and upregulated genes respectively. On the basis of the clustering analysis, we performed per-cluster pathway analysis. Pathways were selected using KEGG, Reactome and GO-terms. In WEBGESTALT Benjamini & Hochberg FDR was used for multiple testing corrections. The significant threshold 0.05 after correction for multiple testing was applied.
Analysis of chronological age, methylation and expression
For 3,073 blood samples with methylation data available from the Illumina 450 K array, we analysed methylation for CpG sites within 250 kb of the 1,497 genes identified in the differential expression meta-analysis. For this analysis we performed a new meta-analysis of samples from seven cohorts including EGCUT (n=82), InChianti (n=485), KORA (n=735), Rotterdam Study (n=726), BSGS (n=610), GTP (n=315) and GARP (n=120); all samples were derived from whole-blood except for GARP (PBMCs). After filtering (to remove non-specific probes and probes with SNPs in the probe target as documented by Price et al.66), 135,230 CpG sites within 250 kb of the 1,497 age-associated genes were eligible for analysis.
Within each cohort, we fit two linear regression models where we considered as our dependent variable either standardized gene expression values for a particular gene or methylation β-values, which are measures of the proportion of DNA methylated within a sample, for a particular CpG site. In Model 1, we regressed methylation β-values on chronological age. In Model 2, we regressed gene expression on both methylation and chronological age. In both models we adjusted for the following potential confounders as available in each cohort: sex, fasting and smoking status (both modelled as categorical variables or factors), and cell counts (number of granulocytes, lymphocytes, monocytes, erythrocytes and platelets). In Model 1, where methylation was the dependent variable we adjusted for chip and row on chip (both as factors). In Model 2, where the dependent variable was gene expression we adjusted for plate origin (factor) and RNA quality (RIN/RQS). For each of the age-associated genes, we fit these models separately for each CpG site within 250 kb (upstream or downstream) of the gene.
To combine results from these models across cohorts, we performed a sample size weighted meta-analysis based on the t-statistics from these models. For each model, we calculated a Z-score as the weighted sum of t-statistics across the seven cohorts. As above, weights were proportional to the square-root of the number of individuals analysed in each cohort and selected such that the squared weights sum to 1. To test for mediation of the age-expression relationship by methylation of a particular CpG site, we used the Z-scores from Model 1 and Model 2 to perform a Sobel test67, such that our Sobel Z-score was equal to:

where Z1 is the meta-analysis Z-score from the association between methylation and chronological age in Model 1, and Z2 is the meta-analysis Z-score from the association between expression and methylation, adjusted for chronological age, in Model 2. To assess overall significance for each model (Model 1, Model 2 and the Sobel test), we used a Bonferroni-adjusted α-level of .05/135,230=3.70 × 10−7 for all CpG sites tested. To assess whether sites in each gene were significant, we assessed Bonferroni significance for each gene according to the number of CpG sites tested in that gene.
To test whether the genes were enriched for CpG sites associated with chronological age in Model 1, or CpG sites associated with expression in Model 2, we performed similar analyses on a set of 1,497 random genes. We chose these genes by first selecting the 5,000 least-associated genes from the original age-expression analysis. We then used the optmatch R package68 to select a subset of 1,497 random genes that were well-matched to the 1,497 age-associated genes in terms of gene length (bp) and the log of mean expression in whole blood. By doing this, we obtained a set of 1,497 random genes that were similar to the 1,497 age-associated genes in distributions of gene length, mean expression, and number of CpG sites within 250 kb (Supplementary Fig. 3A–D). We then performed the meta-analysis for Models 1 and 2 for all eligible CpG sites (after filtering to remove sites with probes that were non-specific or harboured genetic variants) within 250 kb of these genes. We used Fisher’s exact test to test whether there was an increased proportion of significant (P<α) CpG sites in each model in the age-associated genes compared to the random genes. For our main enrichment test we set α=2.37 × 10−7 as in the original analysis but to ensure robustness we re-performed the enrichment test for a wide range of α-levels, ranging from 10−20 to 0.05, and observed that results were consistent for all α-levels considered.
To identify whether the mediating CpG sites were located in functionally relevant regions, we took two main approaches. First, we intersected the CpG positions with the hg19 CpG island annotation track from UCSC Genome Browser ( http://genome.ucsc.edu), to determine whether each site was located in a CpG island, CpG shore (+/−1.5 kb from island) or CpG shelf (+/−1.5 kb from shore). Second, we intersected the CpG positions with ENCODE’s ChromHMM annotation for lymphoblastoid cell line GM12878, which uses a hidden Markov model to assign genomic features based on the combinatorial pattern of various chromatin marks69. The ChromHMM annotation allowed us to identify CpGs located in promoters, enhancers and insulators. We then used Fisher’s exact test to assess whether there was significant enrichment of each feature in mediating CpG sites compared to other CpG sites within the 1,497 genes.
Query of candidate age-expression associated genes and pathways
A total of 204 candidate genes were identified from a variety of sources including Mendelian ageing disorders, longevity genetics candidates11,12,70,71,72 and members of key ageing pathways, mainly FOXO/mTOR, key DNA repair genes, regulators of telomere maintenance, and mitochondrial ribosomal proteins12,25,71,73. Additional candidates included those from past human or multispecies expression studies74,75,76, and markers of naive or differentiated immune cells77. Animal model gene names were translated to human homologue names. All genes and their known human alias names were searched against the discovery and replication results. Thirty-three genes were not tested due to lack of measurement or blood expression below filtered levels. Most candidate genes (n=126) were analysed but did not meet the strict discovery thresholds to be carried forward to the replication phase (Supplementary Table 9). Of 45 genes carried into replication, 33 convincingly replicated in whole blood (Supplementary Table 8).
Transcriptomic age prediction as surrogate biomarker
To investigate how accurate biological age can be predicted from gene expression levels, we performed a leave-one-out prediction analysis, that is, re-running the meta-analysis excluding each of the validation cohorts. For all models, we used the standardized residuals of the gene expression levels, which were obtained by adjusting the gene expression levels for the technical covariates (RNA quality, batch effects) and some biological covariates (sex, fasting status, smoking status and cell counts).
To predict age, we needed to have the estimated effect sizes of the gene expression levels on chronological age (model 1: chronological age ∼gene expression). However, effect sizes from the meta-analysis were for chronological age on gene expression levels (model 2: gene expression ∼chronological age). We used an equivalent transformation to convert the effect size in model 2 to that in model 1 by the following equation:

where  is the effect size of the gene expression level on chronological age (model 1), based on standardized chronological age and standardized gene expression levels, so that it needs to be interpreted in s.d. unit for both chronological age and gene expression level; z is the z-statistic for association from the meta-analysis; and n is the sample size. We then conducted an approximate ridge regression analysis based on a random effect model, which is analogue to the best linear unbiased prediction approach in mixed linear model analysis, to estimate the effect sizes of all 11,908 genes jointly taking correlations between probes into account. The random effect model can be written as:
is the effect size of the gene expression level on chronological age (model 1), based on standardized chronological age and standardized gene expression levels, so that it needs to be interpreted in s.d. unit for both chronological age and gene expression level; z is the z-statistic for association from the meta-analysis; and n is the sample size. We then conducted an approximate ridge regression analysis based on a random effect model, which is analogue to the best linear unbiased prediction approach in mixed linear model analysis, to estimate the effect sizes of all 11,908 genes jointly taking correlations between probes into account. The random effect model can be written as:

where y is the vector of age phenotype and X is the matrix of gene expression level, bR is a vector of effects of gene expression on age with:

and e is a vector of residual with:

In a ridge regression analysis, bR can be estimated as

where

In a single probe based meta-analysis, the analysis is equivalent to:

where b is a vector of effect sizes estimated from the meta-analysis and D is the diagonal matrix of  . If the gene expression level of each probe is standardized, the ith diagonal element of D is:
. If the gene expression level of each probe is standardized, the ith diagonal element of D is:

with n being the sample size. We therefore have

so that

where R is the correlation matrix between probes. This method largely follows the method that was proposed to estimate the joint effect sizes of SNPs using summary data from GWAS and linkage disequilibrium between SNPs from a reference sample78. We estimated bR using  from the meta-analysis (excluding the validation cohort) and probe correlation matrix R from reference samples (also independent from the validation cohort).
from the meta-analysis (excluding the validation cohort) and probe correlation matrix R from reference samples (also independent from the validation cohort).
We calibrated the parameter λ using BSGS as the validation cohort (finding a λ value that maximized prediction accuracy in BSGS; Supplementary Fig. 10) and applied it to the prediction analysis in the other validation cohorts (Supplementary Data 5A). We call this an approximate method because the correlation matrix R consisted of weighted averages (weighted by sample size) from up to six of the discovery cohorts rather than all the samples pooled together. We applied the estimates of the individual genes from the ridge regression analysis to the left-out sample (validation sample) to predict age, and calculated the correlation coefficient of chronological age and the predicted transcriptomic age (Fig. 3a–h).
Since the effect sizes of the probes were estimated from the meta-analyses excluding the validation sample, the validation set is completely independent from the discovery (training) set, so that the prediction accuracy is unbiased. We created the predictor of an individual in the validation cohort as

with xv(i) being the gene expression level of ith probe in the validation cohort. We scaled Z using the mean and s.d. of chronological age from the validation cohort:

where μage and σage are the mean and s.d. of chronological age from the validation cohort, and μz and σz are the mean and s.d. of the predictor Z. Delta age was defined as the difference between the scaled transcriptomic predicted age (SZ) and chronological age for each individual.
We explored whether delta age was associated with any multi-systemic biological parameter (or biomarker) of ageing, such as sex, blood pressure, cholesterol levels, glucose levels, and so on. For all biomarkers used, outliers were excluded from the analysis. Associations were tested using a linear model, including the phenotype of interest as the outcome (the dependent variable) and the delta age as the independent variable; all associations were adjusted for chronological age. To overcome the effects of obesity on cardiovascular disease and other traits, we additionally adjusted for BMI in a second model. In additional, we tested whether the biological parameters were directly associated with chronological age (Supplementary Table 20), so:

Transcriptomic age prediction for external cohorts
A general transcriptomic predictor (Z) was generated which can be used by external researchers for future purposes. This predictor was calculated using the prediction meta-analysis of all cohorts (except BSGS on which we calibrated the λ parameter; Supplementary Fig. 10). Cohorts that have chronological age available should scale the predictor as we did for the validation cohorts (equation (13)), using the mean and s.d. of chronological age and the mean and s.d. of the predictor (Z).
To make our predictor useful to cohorts that do not have chronological age available, we further transformed the predictor to a scaled transcriptomic predictor (in years). This scaled predictor was calculated using the mean and s.d. of chronological age from all discovery cohorts in the meta-analysis (equation (13)). Since the individual level age data were not available, the s.d. of chronological age was calculated using the pooled variance method (Supplementary Table 21).
The Transcriptomic Age Prediction (TRAP) webpage contains information on how to calculate transcriptomic age based on data measured with the Illumina HumanHT-12 (v3/v4) Gene Expression BeadChips or the Affymetrix Human Exon (1.0 ST) Arrays. After uploading your gene expression data, the function will return a text file whose rows report the estimated transcriptomic age of each subject. The online Transcriptomic Age Predictor can be accessed at: https://trap.erasmusmc.nl/.
Additional information
How to cite this article: Peters, M. J. et al. The transcriptional landscape of age in human peripheral blood. Nat. Commun. 6:8570 doi: 10.1038/ncomms9570 (2015).
References
Eicher, J. D. et al. GRASP v2.0: an update on the Genome-Wide Repository of Associations between SNPs and phenotypes. Nucleic Acids Res. 43, D799–D804 (2014).
Welter, D. et al. The NHGRI GWAS Catalog, a curated resource of SNP-trait associations. Nucleic Acids Res. 42, D1001–D1006 (2014).
Anselmi, C. V. et al. Association of the FOXO3A locus with extreme longevity in a southern Italian centenarian study. Rejuvenation Res. 12, 95–104 (2009).
Broer, L. et al. GWAS of longevity in CHARGE consortium confirms APOE and FOXO3 candidacy. J. Gerontol. A Biol. Sci. Med. Sci. 70, 110–118 (2014).
Nebel, A. et al. A genome-wide association study confirms APOE as the major gene influencing survival in long-lived individuals. Mech. Ageing Dev. 132, 324–330 (2011).
Schachter, F. et al. Genetic associations with human longevity at the APOE and ACE loci. Nat. Genet. 6, 29–32 (1994).
Soerensen, M. et al. Replication of an association of variation in the FOXO3A gene with human longevity using both case-control and longitudinal data. Aging Cell 9, 1010–1017 (2010).
Walter, S. et al. A genome-wide association study of aging. Neurobiol. Aging 32, 2109 e2115–2109 e2128 (2011).
Willcox, B. J. et al. FOXO3A genotype is strongly associated with human longevity. Proc. Natl Acad. Sci. USA 105, 13987–13992 (2008).
Ganna, A. et al. Genetic determinants of mortality. Can findings from genome-wide association studies explain variation in human mortality? Hum. Genet. 132, 553–561 (2013).
Sebastiani, P. et al. Genetic signatures of exceptional longevity in humans. PLoS ONE 7, e29848 (2012).
Kenyon, C. J. The genetics of ageing. Nature 464, 504–512 (2010).
Jin, W. et al. The contributions of sex, genotype and age to transcriptional variance in Drosophila melanogaster. Nat. Genet. 29, 389–395 (2001).
Jones, S. J. M. et al. Changes in gene expression associated with developmental arrest and longevity in Caenorhabditis elegans. Genome Res. 11, 1346–1352 (2001).
Weindruch, R., Kayo, T., Lee, C. K. & Prolla, T. A. Microarray profiling of gene expression in aging and its alteration by caloric restriction in mice. J. Nutr. 131, 918s–923s (2001).
Ly, D. H., Lockhart, D. J., Lerner, R. A. & Schultz, P. G. Mitotic misregulation and human aging. Science 287, 2486–2492 (2000).
van den Akker, E. B. et al. Meta-analysis on blood transcriptomic studies identifies consistently coexpressed protein-protein interaction modules as robust markers of human aging. Aging Cell 13, 216–225 (2014).
Glass, D. et al. Gene expression changes with age in skin, adipose tissue, blood and brain. Genome Biol. 14, R75 (2013).
Harries, L. W. et al. Human aging is characterized by focused changes in gene expression and deregulation of alternative splicing. Aging Cell 10, 868–878 (2011).
Kent, J. W. et al. Genotype x age interaction in human transcriptional ageing. Mech. Ageing Dev. 133, 581–590 (2012).
Zeller, T. et al. Genetics and beyond—the transcriptome of human monocytes and disease susceptibility. PLoS ONE 5, e10693 (2010).
Tan, Q. et al. Genetic dissection of gene expression observed in whole blood samples of elderly Danish twins. Hum. Genet. 117, 267–274 (2005).
Horvath, S. DNA methylation age of human tissues and cell types. Genome Biol. 14, R115 (2013).
Hannum, G. et al. Genome-wide methylation profiles reveal quantitative views of human aging rates. Mol. Cell 49, 359–367 (2013).
Houtkooper, R. H. et al. Mitonuclear protein imbalance as a conserved longevity mechanism. Nature 497, 451–457 (2013).
McCarroll, S. A. et al. Comparing genomic expression patterns across species identifies shared transcriptional profile in aging. Nat. Genet. 36, 197–204 (2004).
Landis, G., Shen, J. & Tower, J. Gene expression changes in response to aging compared to heat stress, oxidative stress and ionizing radiation in Drosophila melanogaster. Aging (Albany NY) 4, 768–789 (2012).
Landis, G. N. et al. Similar gene expression patterns characterize aging and oxidative stress in Drosophila melanogaster. Proc. Natl Acad. Sci. USA 101, 7663–7668 (2004).
Lauring, B. et al. Nascent-polypeptide-associated complex: a bridge between ribosome and cytosol. Cold Spring Harb. Symp. Quant. Biol. 60, 47–56 (1995).
Johnson, S. C. et al. mTOR inhibition alleviates mitochondrial disease in a mouse model of Leigh syndrome. Science 342, 1524–1528 (2013).
Park, J. et al. ATM-deficient human fibroblast cells are resistant to low levels of DNA double-strand break induced apoptosis and subsequently undergo drug-induced premature senescence. Biochem Biophys. Res. Commun. 430, 429–435 (2013).
Luo, Y. B. et al. Investigation of age-related changes in LMNA splicing and expression of progerin in human skeletal muscles. Int. J. Clin. Exp. Pathol. 6, 2778–2786 (2013).
Bonder, M. J. et al. Genetic and epigenetic regulation of gene expression in fetal and adult human livers. BMC Genomics 15, 860 (2014).
Kundaje, A. et al. Integrative analysis of 111 reference human epigenomes. Nature 518, 317–330 (2015).
Gheorghe, M. et al. Major aging-associated RNA expressions change at two distinct age-positions. BMC Genomics 15, 132 (2014).
Shigenaga, M. K., Hagen, T. M. & Ames, B. N. Oxidative damage and mitochondrial decay in aging. Proc. Natl Acad. Sci. USA 91, 10771–10778 (1994).
Ojaimi, J., Masters, C. L., Opeskin, K., McKelvie, P. & Byrne, E. Mitochondrial respiratory chain activity in the human brain as a function of age. Mech. Ageing Dev. 111, 39–47 (1999).
Short, K. R. et al. Decline in skeletal muscle mitochondrial function with aging in humans. Proc. Natl Acad. Sci. USA 102, 5618–5623 (2005).
Yen, T. C., Chen, Y. S., King, K. L., Yeh, S. H. & Wei, Y. H. Liver mitochondrial respiratory functions decline with age. Biochem. Biophys. Res. Commun. 165, 944–1003 (1989).
Sallusto, F., Lenig, D., Forster, R., Lipp, M. & Lanzavecchia, A. Two subsets of memory T lymphocytes with distinct homing potentials and effector functions. Nature 401, 708–712 (1999).
Lee, W. W., Yang, Z. Z., Li, G., Weyand, C. M. & Goronzy, J. J. Unchecked CD70 expression on T cells lowers threshold for T cell activation in rheumatoid arthritis. J. Immunol. 179, 2609–2615 (2007).
Moro-Garcia, M. A., Alonso-Arias, R. & Lopez-Larrea, C. Molecular mechanisms involved in the aging of the T-cell immune response. Curr. Genomics 13, 589–602 (2012).
Pletcher, S. D. et al. Genome-wide transcript profiles in aging and calorically restricted Drosophila melanogaster. Curr. Biol. 12, 712–723 (2002).
Rera, M., Clark, R. I. & Walker, D. W. Intestinal barrier dysfunction links metabolic and inflammatory markers of aging to death in Drosophila. Proc. Natl Acad. Sci. USA 109, 21528–21533 (2012).
Landis, G. N., Bhole, D. & Tower, J. A search for doxycycline-dependent mutations that increase Drosophila melanogaster life span identifies the VhaSFD, Sugar baby, filamin, fwd and Cctl genes. Genome Biol. 4, R8 (2003).
Liu, Y. L. et al. Reduced expression of alpha-1,2-mannosidase I extends lifespan in Drosophila melanogaster and Caenorhabditis elegans. Aging Cell 8, 370–379 (2009).
Landis, G., Bhole, D., Lu, L. & Tower, J. High-frequency generation of conditional mutations affecting Drosophila melanogaster development and life span. Genetics 158, 1167–1176 (2001).
Taylor, K. R. & Gallo, R. L. Glycosaminoglycans and their proteoglycans: host-associated molecular patterns for initiation and modulation of inflammation. FASEB J. 20, 9–22 (2006).
Pittman, J. Effect of aging on wound healing: current concepts. J. Wound Ostomy Continence Nurs. 34, 412–415 quiz 416–417 (2007).
Loegel, T. N., Trombley, J. D., Taylor, R. T. & Danielson, N. D. Capillary electrophoresis of heparin and other glycosaminoglycans using a polyamine running electrolyte. Anal. Chim. Acta 753, 90–96 (2012).
Didsbury, A. et al. Rotavirus NSP4 is secreted from infected cells as an oligomeric lipoprotein and binds to glycosaminoglycans on the surface of non-infected cells. Virol. J. 8, 551 (2011).
Gourlay, C. W. & Ayscough, K. R. A role for actin in aging and apoptosis. Biochem. Soc. Trans 33, 1260–1264 (2005).
Higuchi, R. et al. Actin dynamics affect mitochondrial quality control and aging in budding yeast. Curr. Biol. 23, 2417–2422 (2013).
Bratic, A. & Larsson, N. G. The role of mitochondria in aging. J. Clin. Invest. 123, 951–957 (2013).
Ebersberger, I. et al. The evolution of the ribosome biogenesis pathway from a yeast perspective. Nucleic Acids Res. 42, 1509–1523 (2014).
Kenyon, J. & Gerson, S. L. The role of DNA damage repair in aging of adult stem cells. Nucleic Acids Res. 35, 7557–7565 (2007).
Petes, T. D., Farber, R. A., Tarrant, G. M. & Holliday, R. Altered rate of DNA replication in ageing human fibroblast cultures. Nature 251, 434–436 (1974).
Wolfson, M., Budovsky, A., Tacutu, R. & Fraifeld, V. The signaling hubs at the crossroad of longevity and age-related disease networks. Int. J. Biochem. Cell. Biol. 41, 516–520 (2009).
Boya, P. Lysosomal function and dysfunction: mechanism and disease. Antioxid. Redox Signal. 17, 766–774 (2012).
Seoh, M. L., Ng, C. H., Yong, J., Lim, L. & Leung, T. ArhGAP15, a novel human RacGAP protein with GTPase binding property. FEBS Lett. 539, 131–137 (2003).
Patil, V., Ward, R. L. & Hesson, L. B. The evidence for functional non-CpG methylation in mammalian cells. Epigenetics 9, 823–828 (2014).
Lister, R. et al. Human DNA methylomes at base resolution show widespread epigenomic differences. Nature 462, 315–322 (2009).
Allum, F. et al. Characterization of functional methylomes by next-generation capture sequencing identifies novel disease-associated variants. Nat. Commun. 6, 7211 (2015).
Jones, P. A. Functions of DNA methylation: islands, start sites, gene bodies and beyond. Nat. Rev. Genet. 13, 484–492 (2012).
Willer, C. J., Li, Y. & Abecasis, G. R. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 26, 2190–2191 (2010).
Price, M. E. et al. Additional annotation enhances potential for biologically-relevant analysis of the Illumina Infinium HumanMethylation450 BeadChip array. Epigenet. Chromatin 6, 4 (2013).
Sobel, M. E. Sociological Methodology Vol. 13, 290–312 (1982).
Hansen, B. B. & Klopfer, S. O. Optimal full matching and related designs via network flows. J. Comput. Graph. Stat. 15, 609–627 (2006).
Ernst, J. et al. Mapping and analysis of chromatin state dynamics in nine human cell types. Nature 473, 43–49 (2011).
Barzilai, N. et al. Genetic studies reveal the role of the endocrine and metabolic systems in aging. J. Clin. Endocrinol. Metab. 95, 4493–4500 (2010).
Kenyon, C. The first long-lived mutants: discovery of the insulin/IGF-1 pathway for ageing. Philos. Trans R Soc. Lond. B Biol. Sci. 366, 9–16 (2011).
Newman, A. B. & Murabito, J. M. The epidemiology of longevity and exceptional survival. Epidemiol. Rev. 35, 181–197 (2013).
Harries, L. W. et al. Advancing age is associated with gene expression changes resembling mTOR inhibition: evidence from two human populations. Mech. Ageing Dev. 133, 556–562 (2012).
de Magalhaes, J. P., Curado, J. & Church, G. M. Meta-analysis of age-related gene expression profiles identifies common signatures of aging. Bioinformatics 25, 875–881 (2009).
Passtoors, W. M. et al. Transcriptional profiling of human familial longevity indicates a role for ASF1A and IL7R. PLoS ONE 7, e27759 (2012).
Zahn, J. M. et al. AGEMAP: a gene expression database for aging in mice. PLoS Genet. 3, e201 (2007).
Chou, J. P., Ramirez, C. M., Wu, J. E. & Effros, R. B. Accelerated aging in HIV/AIDS: novel biomarkers of senescent human CD8+ T cells. PLoS ONE 8, e64702 (2013).
Yang, J. et al. Conditional and joint multiple-SNP analysis of GWAS summary statistics identifies additional variants influencing complex traits. Nat Genet. 44, 369–375 S361–363 (2012).
Acknowledgements
The infrastructure for the CHARGE Consortium is supported in part by the National Heart, Lung, and Blood Institute grant R01HL105756. This study was funded by the European Commission (HEALTH-F2-2008-201865, GEFOS; HEALTH-F2-2008 35627, TREAT-OA), the Netherlands Organization for Scientific Research (NWO) Investments (nr. 175.010.2005.011, 911-03-012), the Netherlands Consortium for Healthy Aging , the Netherlands Genomics Initiative (NGI)/Netherlands Organization for Scientific Research (NWO) project nr. 050-060-810 and VIDI grant 917103521. Additional acknowledgments to specific cohorts and their support are found in Supplementary Notes 1 and 2.
Author information
Authors and Affiliations
Consortia
Contributions
M.J.P., J.B.J.M., and A.D.J. conceived and designed the study. A.D.J., A.T., A.Z., C.Sc., E.R., G.G.N., G.L.S., H.P., J.B.J.M., J.K., J.P., J.Y., K.N.C., K.S., L.C.P., L.Fe., L.Fr., M.J.P., P.M.V., R.Joe., R.K., R.L.H., T.E., and Y.A.W. developed the methods and experimental design. A.Z., B.E.S., C.Sc., E.R., G.L.S., H.H.H.G., J.P., K.N.C., K.S., L.C.P., M.A.N., M.F., M.J.P., P.L.D., R.Joe., S.A.G., S.Ko., T.T., Y.A.W., Y.F.M.R., and Y.L. performed the experiments and statistical analyses. A.A., A.B.S., A.B.Z., A.D., A.D.J., A.F.M, A.G.U., A.H., A.K.H., A.K.S., A.Me., A.Mu., A.M.S-D., A.P., A.R., A.T., B.M.P., B.T., C.H., C.K.W.C., C.Sm., D.A.E., D.G.H, D.L., D.L.L., D.Meh., D.Mel, D.T., E.B.B, E.K.M., E.M.K., F.R., G.G.N., G.H., G.W.M., H.G., H.P., H.V., H.Y., H-J.W., I.H., I.M., J.A.S., J.Bl., J.Br., J.B.J.M., J.D., J.E.C., J.H., J.H.D., J.I.R., J.K., J.M.M., J.R., J.T., J.W.K.Jr., J.Y., K.J.R., K.M.N., L.B., L.Fe., L.Fr., L.J.O., L.M, L.Ste., L.Sto, L.T., M.B., M.E.W., M.J., M.K., M.M.P.J.V., M.P., M.P.J., M.Ro., M.Ry., M.R.C., M.W., N.B., N.G.M., N.J.S., P.A., P.E.S., P.J.M., P.M.V., P.P., P.S., Q.H., Q.P.W., R.H.Z., R.Joh., R.J.G., R.K., R.L.H., R.O B., R.P.T, R.W., S.A., S.Ba., S.Be., S.Ka., S.L.K., S.R., S.T.T., S.W.B., S.Z., T.E., T.H., T.I., T.Kl., T.Ko., T.R., V.C., V.S., W.H., and Y.I.C. collected study subjects or measured/analyzed phenotypic data. M.J.P., K.N.C., A.D.J., J.B.J.M., A.Z., C.Sc., G.L.S., J.P., J.Y., L.C.P., and P.M.V. wrote the manuscript, and all authors critically reviewed and approved the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Additional information
A full list of consortium members appears below.
Supplementary information
Supplementary Information
Supplementary Figures 1-10, Supplementary Tables 1-21, Supplementary Notes 1-2, Supplementary Acknowledgements and Supplementary References (PDF 2531 kb)
Supplementary Data 1
Discovery, replication and generalization results. Y = yes, N = no; - is negative direction, + = positive direction; weight = sample size, P = p-value; WB = whole blood. (XLSX 1716 kb)
Supplementary Data 2
Number of genes that associate with age across all tissues. 2A: A gene-based overview for age-association across all tissues. 2B: A gene-based overview for significant expression across all tissues. (XLSX 323 kb)
Supplementary Data 3
Up/down regulated gene set analyses in WEBGESTALT and GENENETWORK. (XLSX 321 kb)
Supplementary Data 4
Methylation results: Sobel test for methylation-based mediation of age-expression association. (XLSX 205 kb)
Supplementary Data 5
Transcriptomic age prediction formulas. 5A: Prediction formula weights for all participating cohorts (based on Leave-One-Out Meta-Analyses). 5B: The average "transcriptomic predictor formula" - the GENERAL predictor - for external cohorts (XLSX 2082 kb)
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Peters, M., Joehanes, R., Pilling, L. et al. The transcriptional landscape of age in human peripheral blood. Nat Commun 6, 8570 (2015). https://doi.org/10.1038/ncomms9570
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/ncomms9570
This article is cited by
-
Telomere-based treatment strategy of cardiovascular diseases: imagination comes to reality
Genome Instability & Disease (2024)
-
From Phoebus to witches to death clocks: why we are taking predictive technologies to the extreme
AI & SOCIETY (2024)
-
T-cell lymphocytes’ aging clock: telomeres, telomerase and aging
Biogerontology (2024)
-
A miRNA-based epigenetic molecular clock for biological skin-age prediction
Archives of Dermatological Research (2024)
-
Deciphering dynamic changes of the aging transcriptome with COVID-19 progression and convalescence in the human blood
Signal Transduction and Targeted Therapy (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
