
Abstract
The capacity of cells and organisms to respond to challenging conditions in a repeatable manner is limited by a finite repertoire of pre-evolved adaptive responses. Beyond this capacity, cells can use exploratory dynamics to cope with a much broader array of conditions. However, the process of adaptation by exploratory dynamics within the lifetime of a cell is not well understood. Here we demonstrate the feasibility of exploratory adaptation in a high-dimensional network model of gene regulation. Exploration is initiated by failure to comply with a constraint and is implemented by random sampling of network configurations. It ceases if and when the network reaches a stable state satisfying the constraint. We find that successful convergence (adaptation) in high dimensions requires outgoing network hubs and is enhanced by their auto-regulation. The ability of these empirically validated features of gene regulatory networks to support exploratory adaptation without fine-tuning, makes it plausible for biological implementation.
Similar content being viewed by others


Introduction
The ability to organize a large number of interacting processes into persistently viable states in a dynamic environment is a striking property of cells and organisms. Many frequently encountered perturbations (temperature, osmotic pressure, starvation and more), trigger reproducible adaptive responses1,2,3. These were assimilated into the organism by variation and selection over evolutionary time. Despite the large number and flexible nature of these responses, they span a finite repertoire of actions and cannot address all possible scenarios of novel conditions. Indeed, cells may encounter severe, unforeseen situations within their lifetime, for which no effective response is available. To survive such challenges, a different type of ad-hoc response can be employed, utilizing exploratory dynamics4,5,6,7,8.
The capacity to withstand unforeseen conditions was recently demonstrated and studied using dedicated experimental models of novel challenge in yeast9,10,11,12 and flies13. Adaptive responses exposed in these experiments involved transient changes in the expression of hundreds of genes, followed by convergence to altered patterns of expression. Analysis of repeated experiments showed that a large fraction of the transcriptional response can vary substantially across replicate trajectories of adaptation10,12. These findings suggest that coping with unforeseen challenges within one or a few generations relies on induction of exploratory changes in gene regulation over time in an individual5,6.
Several properties of gene regulatory networks may support such exploratory adaptation. These include a large number of potential interactions between genes14, context-dependent plasticity of interactions15,16,17,18 and multiplicity of microscopic configurations consistent with a given phenotype19. Despite these properties, the feasibility of acquiring adaptive phenotypes by random exploration within a single organism remains speculative and poorly understood. In particular, it is not known how exploration may converge rapidly enough in the high dimensional space of possible configurations? what determines the efficiency of this exploration? and what ensures the stabilization of new phenotpes?
Here we address these open questions by introducing a network model of gene regulation, which demonstrates the capacity to adapt by exploratory dynamics in a single cell (as opposed to selection on existing variation in a population). Exploration is triggered by failure to satisfy a newly-imposed external demand, and is implemented by a random walk in the space of network configurations. Exploration relaxes if and when the system reaches a stable state satisfying this demand. We show that the success of this exploratory adaptation in high dimension requires that the network include outgoing hubs. Adaptive capability is further enhanced by autregulation of these outgoing hubs. Since these are both well-known properties of gene regulatory networks, our findings establish a basis for a biologically plausible mode of adaptation by exploratory dynamics.
Results
Exploratory adaptation model
To investigate the feasibility of exploratory adaptation, we introduce a model of gene regulatory dynamics incorporating random changes over time in a single network. The model consists of a large number, N, of microscopic components x=(x1, x2 ... xN), governed by the following nonlinear equation of motion (Fig. 1a):

(a) Schematic representation of the model: a random N × N network, composed of an adjacency matrix T and an interaction strength matrix J, governs a nonlinear dynamical system (equation in box; φ(x)=tanh(x)). The resulting spontaneous dynamics are typically irregular for large enough interactions. A macroscopic variable, the phenotype y, is subject to an arbitrary constraint y≈y* with finite precision ɛ. When the constraint is not met (left; ‘hot’ regime), the connections strengths Jij undergo a random walk with magnitude determined by the coefficient D and the mismatch function  (y−y*). The random walk stops when the mismatch is stably reduced to zero (right; ‘frozen’ regime). (b–d) Example of exploration and convergence. Shown are representative trajectories of connection strengths (b), microscopic variables (c) and the phenotype y (d) before and after convergence to a stable state satisfying the constraint. The network in this example has scale-free (SF) out-degree distribution (a=1, γ=2.4) and Binomial in-degree distribution
(y−y*). The random walk stops when the mismatch is stably reduced to zero (right; ‘frozen’ regime). (b–d) Example of exploration and convergence. Shown are representative trajectories of connection strengths (b), microscopic variables (c) and the phenotype y (d) before and after convergence to a stable state satisfying the constraint. The network in this example has scale-free (SF) out-degree distribution (a=1, γ=2.4) and Binomial in-degree distribution  . N=1,000, y*=10, D=10−3, g0=10. See Methods for more details.
. N=1,000, y*=10, D=10−3, g0=10. See Methods for more details.

where W is a random matrix, representing the intracellular network of interactions; φ(x) an element-wise saturating function restricting the dynamic range of the variables; and the relaxation rates are set to unity. Previous work has used similar equations to address evolutionary aspects of gene regulation20,21 as well as interactions and relaxation in neuronal networks22. Most studies have focused on networks with uniform (full or sparse) connectivity; much less is known about the dynamics for networks with non-uniform topological structures, which may be of relevance to gene regulation.
Here we consider sparse random networks with different types of topological properties. For all cases, the interaction matrix W is composed of an element-wise (Hadamard) product,

where T is a random topological backbone (adjacency) matrix with binary (0/1) entries representing potential interactions between network elements; and J is a random matrix specifying the actual interaction strengths. To represent context-dependent regulatory plasticity, we assume that the backbone remains fixed, whereas the interaction strengths are plastic and amenable to change over time. We will emphasize below network sizes and topological structures that are relevant to gene regulatory networks.
On a macroscopic level we consider a cellular phenotype, y, which depends on the microscopic components and can affect the cell’s functionality and state of stress. We define this phenotype as a linear combination of microscopic variables

with an arbitrary vector of coefficients b. To model an unforeseen challenge, the system is subjected to an arbitrary contstraint of maintaining the phenotype in a given range y(t)≈y*. Importantly, any given value of the phenotype can be realized by many alternative microscopic combinations.
Deviation from compliance with the constraint is represented by a global cellular function  (y−y), corresponding to the level of mismatch between the current phenotype and the demand. This mismatch is effectively zero inside a ‘comfort zone’ of size ɛ around y and increases sharply beyond it. Biologically, the comfort zone can be interperted as a range of phenotypes that can be tolerated in a given environment without invoking significant stress. This is represented mathematically by a range of values which satisfy the constraint (in contrast to many optimization problems which require adherence to a specific value).
(y−y), corresponding to the level of mismatch between the current phenotype and the demand. This mismatch is effectively zero inside a ‘comfort zone’ of size ɛ around y and increases sharply beyond it. Biologically, the comfort zone can be interperted as a range of phenotypes that can be tolerated in a given environment without invoking significant stress. This is represented mathematically by a range of values which satisfy the constraint (in contrast to many optimization problems which require adherence to a specific value).
When the phenotype deviates from the comfort zone, the mismatch drives an exploratory search, realized by small random changes in the interaction strengths, forming a random walk in the elements of the matrix J:

where  is the standard Wiener process. The amplitude of the random walk is controlled by a scale parameter, D, and the mismatch level,
is the standard Wiener process. The amplitude of the random walk is controlled by a scale parameter, D, and the mismatch level,  . These random changes can arise from diverse sources of variation affecting the levels of transcription regulators3,23,24, as well as regulatory interactions (for example, alternative splicing, conformations of transcription factors and their post-translational modifications17,18).
. These random changes can arise from diverse sources of variation affecting the levels of transcription regulators3,23,24, as well as regulatory interactions (for example, alternative splicing, conformations of transcription factors and their post-translational modifications17,18).
The random walk constitutes an exploratory search for network configurations in which the dynamical system in equation (1) satisfies the constraint in a stable manner. Random occurrence of such a configuration decreases the search amplitude, thereby promoting relaxation by reducing the drive for exploration6,25. Convergence of this process to a stable state satisfying the constraint is not a priori guaranteed. Intuitively, it may be expected that randomly varying a large number of parameters in a nonlinear high-dimensional system will cause the dynamics to diverge. Surprisingly, we find that the adaptation process can in fact converge; however, as shown below, convergence depends on key properties of the network.
Adaptation depends on network topology
An example of adaptive convergence is shown in Fig. 1b–d. At t=0, the system is confronted with a demand and starts an exploratory process in which the connection strengths are slowly modified. Figure 1b displays the time trajectories of four of these connection strengths. During this exploration, the microscopic variables, x, and the phenotype, y, exhibit highly irregular behavior, rapidly sampling a large dynamic range (Fig. 1c,d respectively). At t∼400, the system manages to stably reduce the mismatch to zero and converges to a fixed point (Fig. 1). In some cases the dynamics converges to a small-amplitude limit-cycle (Supplementary Note 3, Convergence to a limit cycle), and remain within the comfort zone ±ɛ around y. The state of convergence is found to be a stable attractor that is robust against small perturbations of the dynamic variables, x, and the interactions strengths, Wij (Supplementary Note 3, Stability of the adapted state). The differences between the amplitude of temporal changes in Fig. 1b–d reflects the separation of timescales between the slowly accumulating changes in interaction strengths, governed by the small value of D in equation (4), and the intrinsic dynamics of equation (1).
To investigate the dependence of exploratory adaptation on network topology we constructed random matrix ensembles with different topological backbones, manifested by distinct in- and out-going degree distributions26 (detailed in the Methods section). Each ensemble was evaluated with respect to the probability of convergence, estimated as the fraction of simulations which converged within a given time window. Figure 2a compares ensembles of networks with in- and out-degrees drawn from Binomial (Binom), Exponential (Exp) and Scale-Free (SF) distributions. It shows high fractions of convergence, 0.5 or higher, only for ensembles with SF out-degree distributions. In contrast, the in-degree distribution affects convergence only mildly. For example, the convergence fraction (CF) of networks with SF out-degree and Binomial in-degree distributions (dark blue) is 0.5, whereas it is only 0.03 in the transposed case (light blue). This asymmetry between outgoing and incoming connections indicates that convergence of exploratory adaptation does not rely on spectral properties of the interaction matrix ensemble.

(a) Seven ensembles of networks of size N=1,500 and different topologies exhibit remarkably different convergence fractions (CFs). Ensembles are characterized by the out- and in- degree distributions of the adjacency matrix T: ‘SF’, scale free distribution; ‘Exp’, exponential distribution; ‘Binom’, Binomial distribution. (b) CF as a function of network size for the same ensembles of (a) with matching colours. N=1,500, y=0, g0=10, D=10−3. Parameters for degree distributions: SF, (a=1, γ=2.4); Binom,  ; Exp, (β=3.5).
; Exp, (β=3.5).
Analysis of convergence as a function of network size shows that the effect of topology becomes pronounced for large networks (Fig. 2b). The CF in small to intermediate-sized networks (N≲200) is higher and relatively independent of topology. However, as N increases towards sizes that are relevant to genetic networks, the benefit of having SF out-degree distribution becomes progressively prominent.
Outgoing hubs enable adaptation in large networks
Among the topological ensembles tested, an outgoing SF degree distribution was found to be crucial for convergence in large enough networks. Such distributions are characterized by a broad range of heterogeneous connectivities, with a small number of extremely highly connected nodes (hubs). To evaluate the relative contribution of outgoing hubs to convergence within this ensemble, we ranked the backbones of the connectivity matrices drawn from the SF-Binom distributions according to the out-degree of the largest hub. Figure 3a shows that the CF increases with the connectivity of the largest outgoing hub. As a second approach to characterize hub contribution, we deleted a small number of outgoing hubs from these networks27; this leads to a significant reduction in CF that is not observed upon removal of randomly chosen nodes (Fig. 3b).

(a) CF versus out-degree of the largest hub in a collection of SF-Binom networks binned according to their largest hub. (b) Changes in Convergence Fraction (CF) following deletion of a number of leading hubs (red) or deletion of the same number of random nodes (blue) from networks with SF-Binom topology. (c) Effect of adding a small number of outgoing hubs to a Binon-Binom ensemble. The out-degrees of the added hubs were chosen to mimic the SF-out ensemble of Fig. 2. (d) Effect of adding autoregulatory loops on a specific number (1, 3 and 10) of the leading outgoing hubs on a background of a SF-Binom ensemble. N=1,500, y=0, g0=10, D=10−3. Parameters for degree distributions: SF, (a=1, γ=2.4); Binom,  ; Exp, (β=3.5).
; Exp, (β=3.5).
These results indicate that, in networks from the SF-Binom ensemble, outgoing hubs have a major positive influence on the success of exploration. We therefore asked whether the addition of a few hubs to an otherwise poorly converging ensemble is enough to induce significant convergence. Figure 3c indeed shows that addition of as few as 8 hubs to a Binom-Binom ensemble increases the CF from zero to about 0.4.
These findings are in-line with reported properties of gene regulatory networks, particularly the existence of ‘master regulatory’ transcription factors that control the expression of hundreds of other genes28,29,30. Since many of these master regulators are also autoregulated31, we evaluated the influence of hub autoregulation on the success of exploratory adaptation in our model. Figure 3d shows that autoregulation of the leading hubs in the SF-Binom ensemble further increases the CFs.
Since autoregulation motifs are commonly observed in gene regulatory networks (not only in hubs)32, we investigated whether these motifs could also contribute to convergence when over-represented uniformly throughout the network. Figure 4 depicts the results of adding such motifs randomly to 10% of the nodes in networks from the SF-Binom and Binom-SF ensembles. It is seen that positive autoregulation enhances convergence for intermediate sized networks (N=1,000) in both ensembles; this effect is particularly notable for the Binom-SF ensemble, which has small CF without these motifs. This contribution, however, decreases with network size and vanishes in the same type of networks with N=3,000. We conclude that the presence of autoregulatory motifs ranodmly positioned in the network cannot substitute for hub contribution in the limit of very large networks. These results highlight the interplay of several networks properties in exploratory adaptation: network size, topology and autoregulatory motifs. The addition of common network motifs other than autoregulation did not lead to a conclusive effect on convergence (Supplementary Note 3, Dependence of convergence on network motifs).

Positive autoregulatory loops were added randomly to 10% of the nodes in four ensembles, each comprising 500 networks of a given size (N=1,000 or 3,000) and topology (SF-Binom or vice versa). Convergence in each ensemble is compared to controls without extra loops, with and without matching of the degree distributions to the enriched ensemble (Null 1 and Null2, respectively). Parameters of the SF and Binom distributions (prior to addition of loops) are: SF, (a=1, γ=2.4) and Binomial, (p= and N). Other parameters are g0=10, α=100, ɛ=3, c=0.2, D=10−3 and y=0.
and N). Other parameters are g0=10, α=100, ɛ=3, c=0.2, D=10−3 and y=0.
Adaptation occurs over a wide range of model parameters
We investigated how the capacity to adapt is affected by various model parameters. To examine the dependence on the severity of the constraint, we varied the size of the comfort zone ɛ. Figure 5a reveals a sharp decrease of the CF as ɛ is reduced, indicating that a non-vanishing comfort zone is crucial for successful exploratory adaptation. This requirement is biologically plausible, as one expects a range of phenotypes capable of accommodating a given environment rather than a unique optimal phenotype. Another way of increasing the adaptation challenge is by shifting the required phenotypic range away from the origin. Reaching a shifted region is challenging because it is more rarely visited by spontaneous dynamics (Fig. 5b, grey curve). Figure 5b indeed shows that the CF decreases as y* moves away from zero (blue curve). Importantly however, it remains much larger than the probability of encountering the required phenotype spontaneously. For example, a non-negligible convergence (CF∼0.2) is observed even for an interval around  which is spontaneously encountered with probability of 0.02.
which is spontaneously encountered with probability of 0.02.

(a) CF versus ɛ, the width of the comfort zone around y*. (b) CF (blue) versus the constraint value y. For comparison, the grey curve shows the fraction of time in which y(t) spontaneously reaches the constraint-satisfying range. (c) CF versus the strength of exploratory random walk in connection strengths, D. (d) CF versus g0 (proportional to the s.d. of connection strengths; see Methods for details). Network ensemble with SF-out (a=1, γ=2.4) and Binom-in  degree distributions. Unless otherwise specified, all ensembles have N=1,000, y*=0, g0=10, and D=10−3.
degree distributions. Unless otherwise specified, all ensembles have N=1,000, y*=0, g0=10, and D=10−3.
To evaluate the sensitivity of adaptation to exploration speed, we varied the effective diffusion coefficient in the space of connection strengths, D. Figure 5c shows that a non-zero convergence fraction is achieved for a wide range of this parameter and remains between 0.2 and 0.7 over more than 5 orders of magnitude. As the value of D increases beyond a certain level where the separation of timescales ceases to hold, the convergence fraction decreases rapidly.
For a given adjacency matrix T, interactions within the network are determined by the connections strengths, Jij. These are initially drawn from a Gaussian distribution with a zero mean and a given s.d. The s.d. normalized to network size, g0 (also called network gain; for details see Methods) determines the contribution of the first versus second term in equation (1). In large homogeneous networks, this parameter has a strong effect on the dynamics of equation (1) (ref. 33). In contrast, we find that the capacity to adapt by exploration in our model is relatively weakly dependent on g0 (Fig. 5d).
Broad non-exponential distributions of adaptation times
The analysis presented so far was based on convergence fractions within a fixed time interval. To characterize the temporal aspects of exploratory adaptation, we evaluated the distribution of convergence times in repeated simulations. Figure 6 reveals a broad distribution (CV≈1.1), well fitted by a stretched exponential (see Supplementary Note 3, Stretched exponential fit to the distribution of convergence times). Such distributions are common in complex systems34 and were suggested to reflect a hierarchy of timescales35. While the general shape of the distributions were similar in all topological ensembles tested, networks with SF out-degree distributions typically converged faster than their transposed counterparts (Fig. 6a). Moreover, deletion of a small number of leading outgoing hubs causes a significant shift towards longer convergence times (Fig. 6b). Thus, networks with larger heterogeneity in out-degrees are both more likely to converge within a given time window (Figs 2 and 3), and typically converge faster (Fig. 6).

Solid lines depict stretched exponential fits. (a) Probability density distribution (PDF) of convergence time for three topological ensembles. (b) PDFs after deleting the 8 largest hubs (red) or the same number of randomly-chosen nodes (light blue) from the SF-Binom ensemble. All ensembles have N=1,000, y=0, g0=10, and D=10−3. Degree distribution parameters: SF, (a=1, γ=2.4); Binom,  ; Exp, (
; Exp, ( ).
).
Adaptation success correlates with abundance of attractors
In the typical example shown in Fig. 1, exploratory dynamics culminates in reduction of drive for exploration and convergence to a stable attractor of equation (1). The significant differences between adaptive performance of network ensembles (Fig. 2a,b) may reflect the abundance of networks supporting relaxation to attractors in the different ensembles. Previous work has shown that for networks with uniform degree distributions and sufficiently strong interactions, the number of attractors of equation (1) decreases with network size and vanishes in the limit of infinite size (leading to chaotic motion only33). A related result was recently found for Boolean networks36. It is not known, however, how the number of attractors scales with system size for networks of arbitrary topological structure.
To address this question, we simulated many independent networks in each ensemble and estimated the fraction which relaxed to fixed points without exploration or feedback (equation (1) alone). For any given network, the probability of relaxation to a fixed point was largely insensitive to the initial conditions in x-space (not shown). With that in mind we computed, for each topological ensemble, the fraction of networks supporting relaxation within a given time window, starting with random initial conditions. This measure is analogous to the CF used in Fig. 2, but without any constraint, feedback or random walk in connection strengths. To highlight the dependence on network size we extended the simulations up to N=10,000. Figure 7a reveals topology-dependent differences that are qualitatively in line with the ability for exploratory adaption shown above (Fig. 2b). This suggests that a substantial contribution to successful adaptation is indeed provided by a high abundance of networks exhibiting fixed points in their dynamics.

(a) Fraction of networks within an ensemble which relaxed to a fixed point under the nonlinear dynamics of equation (1), with fixed connections, no constraint and no feedback. Topological ensembles which exhibited higher success in exploratory adaptation in Fig. 2b, relaxed to fixed points in a larger fraction of simulations. (b) Distribution of relaxation times to fixed points for two of the ensembles. Note the shorter typical timescale for the SF-Exp ensemble (the more successfully adapting ensemble). N=1,000, g0=10. Dergree distribution parameters: SF, (a=1, γ=2.4); Binom,  ; Exp, (
; Exp, ( ).
).
For each network ensemble that supports fixed points, we further analysed the distribution of relaxation times into these fixed points. Figure 7b demonstrates the effect of topology by comparing the SF-Exp ensemble to the transposed Exp-SF. It shows that networks with SF-out degree distribution typically support faster relaxation to their respective fixed points. This may allow the adaptation to converge before exploration has had a chance to significantly modify network connections. Further work is required to test this hypothesis and to broaden the theoretical understanding of these dynamics in random ensembles with heterogeneous topologies.
Discussion
Overall, we have introduced a model of exploratory adaptation driven by mismatch between an internal global variable and an external constraint. Adaptation is achieved by a purely exploratory process which relies on the plasticity of regulatory interactions17,18. Our model was described in terms of gene regulation but could equally well represent adaptation in other cellular interactions, such as the protein-protein interaction network. We have found that convergence of exploratory adaptation depends crucially on structural properties of the network. It requires the existence of outgoing hubs and is enhanced by auto-regulation of these hubs. These results offer an important, but hitherto unrealized, rationale for the overwhelming abundance of autoregulation motifs on master regulatory transcription factors31. These master regulators act as network hubs by virtue of the large numbers of their downstream gene targets. Our findings show that autoregulation of such hubs improves their ability to drive the network into a stable state which satisfies a phenotypic demand.
The contribution of outgoing hubs to the success of adaptation may reflect their ability to coordinate changes in a large set of affected nodes. In a network with a narrow distribution of out-degrees (without hubs), each node has the same relatively small influence as any other node. In the absence of a hierarchy in the extent of influence, irregular dynamic variation in the microscopic variables is unlikely to accumulate into a macroscopic coherent change in phenotype. On the other hand, the existence of a few hubs with a much broader influence can promote correlations between many downstream nodes, leading to an ability to drive a coherent change in a given direction. These effects may be related to other aspects of stability in network dynamics that vary with topology37,38,39.
Beyond the structural aspects promoting exploratory adaptation, the process of convergence appears to be complex and is characterized by an extremely broad distribution of times. Successful convergence likely depends on a delicate interplay between the space of possible network configurations, their connectivity properties and the typical timescales of their intrinsic dynamics.
While our model draws from neural network models40,41,42, it is substantially different in relying on purely stochastic exploration. In the language of learning theory, the ‘task’ is modest: convergence to a stable attractor which satisfies a low-dimensional approximate constraint. Without exploration, this task could be fulfilled by chance with a very small probability. This probability increases dramatically by exploratory dynamics within a class of networks of a given structure. The ability to achieve high success rates without a need for complex computation or fine-tuning makes this type of adaptation particularly plausible for biological implementation. The relevance of similar processes in neural networks remains to be investigated.
Random network models were previously used to address evolutionary dynamics of gene regulation over many generations. These studies considered a population of networks undergoing random mutations and selection according to an assigned fitness21,43. In contrast, the model presented in the current study considers random variations over time within a single network, as an abstraction of a particular aspect of single cell adaptation within its lifetime. While these two approaches differ in timescales, level of organization and biological phenomena, it seems that they cannot be completely decoupled and that biological networks have basic properties that reflect on both contexts44. For example, in the context of selection in a population of networks, marked differences in evolutionary dynamics were found between homogeneous and SF networks45. In fact, the reproducible and exploratory responses in single cells, and the evolutionary processes at the population level, correspond to complementary aspects of gene-environment interactions at different scales3,46. A major future goal would be to integrate these aspects into a general picture of adaptive responses to diverse types of challenges over a broad range of timescales.
Methods
Constructing network backbone T for topological ensembles
Interactions between the intracellular dynamical variables are governed by the network matrix W, defined as the element-wise (Hadamrd) product of the binary backbone, the adjacency matrix T, and a Gaussian random matrix J of connection strengths (equation (2)). We construct an ensemble of a given topology by sampling the connectivities of the backbone from a particular choice of in-degree and out-degree distributions, Pin(Kin) and Pout(Kout), and by sampling the random strengths of J independently from a Gaussian distribution. In practice, T is constructed first by randomly sampling a list of N out-going degrees  from the distribution Pout(Kout) with
from the distribution Pout(Kout) with  ; and then sampling a list of N in-coming degrees
; and then sampling a list of N in-coming degrees  from the distribution Pin(Kin) (again
from the distribution Pin(Kin) (again  ), conditioned on the graphicality of the in- and out- degree sequences47. The network is then constructed from these sequences using the algorithm described in48.
), conditioned on the graphicality of the in- and out- degree sequences47. The network is then constructed from these sequences using the algorithm described in48.
Scale-free (SF) sequences are obtained by a discretization to the nearest integer of the continuous Pareto distribution P(K)= . Sampling SF degree sequences using the discrete Zeta distribution gives qualitatively similar results. Binomial sequences are drawn from a Binomial distribution
. Sampling SF degree sequences using the discrete Zeta distribution gives qualitatively similar results. Binomial sequences are drawn from a Binomial distribution  , with p=
, with p= . Exponential sequences are obtained by a discretization to the nearest integer of the continuous exponential distribution
. Exponential sequences are obtained by a discretization to the nearest integer of the continuous exponential distribution  with
with  . A Binomial degree sequence is implemented using MATLAB Binomial random number generator. Exponential and Scale-free sequences are implemented by a discretization of the continuous MATLAB Exponential and Generalized Pareto random number generators with parameters k=1/(γ−1), σ=a/(γ−1) and θ=a.
. A Binomial degree sequence is implemented using MATLAB Binomial random number generator. Exponential and Scale-free sequences are implemented by a discretization of the continuous MATLAB Exponential and Generalized Pareto random number generators with parameters k=1/(γ−1), σ=a/(γ−1) and θ=a.
Comparison between different ensembles
To compare adaptation performance between different ensembles, interaction matrices need to be properly normalized. In the study of uniform random matrices, the elements are usually normalized such that their variance is  , providing a well-defined thermodynamic limit N→∞ in which the matrix eigenvalues of are uniformly distributed within a disc of size g0 in the complex plane49,50.
, providing a well-defined thermodynamic limit N→∞ in which the matrix eigenvalues of are uniformly distributed within a disc of size g0 in the complex plane49,50.
In our model, the initial interaction matrix  is defined as a random Gaussian matrix with mean 0 and variance
is defined as a random Gaussian matrix with mean 0 and variance  ,
,  being the average connectivity. Neglecting correlations in the adjacency matrix T, the variance of its elements is
being the average connectivity. Neglecting correlations in the adjacency matrix T, the variance of its elements is  , which implies Var(Wi j)≈
, which implies Var(Wi j)≈ . In principle both finite-size effects and correlations in Wi j result in deviations from a uniform distribution of eigenvalues in the circle. However empirically we find that for matrices of relevant size, the spectral radius of W is still ∼g0, establishing a basis for comparison between the different ensembles based on spectral radius. We note however that the eigenvalue distribution is far from being uniform (see Supplementary Note 1, Empirical spectrum of interaction matrices W).
. In principle both finite-size effects and correlations in Wi j result in deviations from a uniform distribution of eigenvalues in the circle. However empirically we find that for matrices of relevant size, the spectral radius of W is still ∼g0, establishing a basis for comparison between the different ensembles based on spectral radius. We note however that the eigenvalue distribution is far from being uniform (see Supplementary Note 1, Empirical spectrum of interaction matrices W).
Another model component that needs to be normalized for proper comparison is the macroscopic phenotype y(x)=b·x. The arbitrary weight vector b is characterized by a degree of sparseness c, the fraction of non-zero components,  ; and by the typical magnitude of those components. In order to compare between networks of different size and weight vectors of different sparseness, the variance of the non-zero components is scaled by their number, cN and by the matrix gain g02. The non-zero components of b are thus distributed as
; and by the typical magnitude of those components. In order to compare between networks of different size and weight vectors of different sparseness, the variance of the non-zero components is scaled by their number, cN and by the matrix gain g02. The non-zero components of b are thus distributed as  , where α is a single parameter determining the scale of phenotype fluctuations in different network sizes and gains (See Supplementary Note 1, Distributions of phenotype y).
, where α is a single parameter determining the scale of phenotype fluctuations in different network sizes and gains (See Supplementary Note 1, Distributions of phenotype y).
Computing convergence fractions
Convergence fractions were computed over 2,000 time steps in samples of 500 networks drawn from specified in- and out-degree distributions, averaging over T, J0 and x0. For fully or sparsely connected homogeneous random networks of size N=1,500, the CF is close to zero (not shown). Alternative ensemble definitions (for example, keeping T fixed) do not change the main results (see Supplementary Note 1, Convergence of different network ensembles).
Saturating function φ(x)
The saturating function is defined as an element-wise function φ(xj)=tanh(xj) operating separately on each of the components of x. Model results are insensitive to the exact shape of this function (Supplementary Note 2, Robustness of model to saturating function φ) and to placing the saturation inside or outside of the interactions (Supplementary Note 2, Robustness of model to position of saturating function φ).
Mismatch function 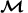 (y−y*)
(y−y*)
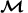 (y−y*)
(y−y*)The mismatch function is defined here as  , a symmetric sigmoid around y*, where ɛ=3 controls the size of the low-mismatch ‘comfort-zone’ around y*, μ=0.01 the steepness of the sigmoid and
, a symmetric sigmoid around y*, where ɛ=3 controls the size of the low-mismatch ‘comfort-zone’ around y*, μ=0.01 the steepness of the sigmoid and  0=2 its maximal value. Main model results are insensitive to the exact shape of this function as long as it has a flat region with zero or very low mismatch around y*. (see Supplementary Note 2, Robustness of model to mismatch function
0=2 its maximal value. Main model results are insensitive to the exact shape of this function as long as it has a flat region with zero or very low mismatch around y*. (see Supplementary Note 2, Robustness of model to mismatch function  ).
).
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Additional information
How to cite this article: Schreier, H. I. et al. Exploratory adaptation in large random networks. Nat. Commun. 8, 14826 doi: 10.1038/ncomms14826 (2017).
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Gasch, A. P. et al. Genomic expression programs in the response of yeast cells to environmental changes. Mol. Biol. Cell 11, 4241–4257 (2000).
Causton, H. C. et al. Remodeling of yeast genome expression in response to environmental changes. Mol. Biol. Cell 12, 323–337 (2001).
López-Maury, L., Marguerat, S. & Bhler, J. Tuning gene expression to changing environments: from rapid responses to evolutionary adaptation. Nat. Rev. Genet. 9, 583–593 (2008).
Gerhart, J. & Kirschner, M. Cells, Embryos, and Evolution: Toward a Cellular and Developmental Understanding of Phenotypic Variation and Evolutionary Adaptability Blackwell Science (1997).
Braun, E. The unforeseen challenge: from genotype-to-phenotype in cell populations. Rep. Prog. Phys. 78, 036602 (2015).
Soen, Y., Knafo, M. & Elgart, M. A principle of organization which facilitates broad Lamarckian-like adaptations by improvisation. Biol. Direct 10, 68 (2015).
West-Eberhard, M. J. Phenotypic accommodation: adaptive innovation due to developmental plasticity. J. Exp. Zool. 304B, 610–618 (2005).
Vojta, A. & Vlatka, Z. Adaptation or malignant transformation: the two faces of epigenetically mediated response to stress. BioMed Research International 2013, 954060 (2013).
Stolovicki, E., Dror, T., Brenner, N. & Braun, E. Synthetic gene recruitment reveals adaptive reprogramming of gene regulation in yeast. Genetics 173, 75–85 (2006).
Stern, S., Dror, T., Stolovicki, E., Brenner, N. & Braun, E. Genome-wide transcriptional plasticity underlies cellular adaptation to novel challenge. Mol. Syst. Biol. 3, 106 (2007).
David, L., Stolovicki, E., Haziz, E. & Braun, E. Inherited adaptation of genome-rewired cells in response to a challenging environment. HFSP J. 4, 131–141 (2010).
Katzir, Y., Stolovicki, E., Shay, S. & Braun., E. Cellular plasticity enables adaptation to unforeseen cell-cycle rewiring challenges. PLoS ONE 7, e45184 (2012).
Stern, S., Fridmann-Sirkis, Y., Braun, E. & Soen., Y. Epigenetically heritable alteration of fly development in response to toxic challenge. Cell Rep. 1, 528–542 (2012).
Tong, A. H. Y. et al. Global mapping of the yeast genetic interaction network. Science 303, 808–813 (2004).
Harbison, C. T. et al. Transcriptional regulatory code of a eukaryotic genome. Nature 431, 99–104 (2004).
Luscombe, N. M. et al. Genomic analysis of regulatory network dynamics reveals large topological changes. Nature 431, 308–312 (2004).
Niklas, K. J., Bondos, S. E., Dunker, A. K. & Newman, S. A. Rethinking gene regulatory networks in light of alternative splicing, intrinsically disordered protein domains, and post-translational modifications. Front. Cell Dev. Biol. 3, 8 (2015).
Bondos, S. E., Liskin, S.-K. & Matthews, K. S. Flexibility and disorder in gene regulation: LacI/GalR and Hox proteins. J. Biol. Chem. 290, 24669–24677 (2015).
Weiss, K. M. & Fullerton, S. M. Phenogenetic drift and the evolution of genotypephenotype relationships. Theor. Popul. Biol. 31, 187–195 (2000).
Kauffman, S. A. Origins of Order: Self-Organization and Selection in Evolution Oxford University Press (1993).
Wagner, A. The Origins of Evolutionary Innovations: A Theory of Transformative Change in Living Systems Oxford University Press (2011).
Amit, D. J. Modeling Brain Function: The World of Attractor Neural Networks Cambridge University Press (1992).
Furusawa, C. & Kunihiko., K. A generic mechanism for adaptive growth rate regulation. PLoS Comput. Biol. 4, e3 (2008).
Furusawa, C. & Kaneko, K. Epigenetic feedback regulation accelerates adaptation and evolution. PLoS ONE 8, e61251 (2013).
Shahaf, G. & Marom, S. Learning in networks of cortical neurons. J. Neurosci. 21, 8782–8788 (2001).
Newman, M. E. J. The structure and function of complex networks. SIAM Rev. 45, 167–256 (2003).
Albert, R., Jeong, H. & Barabsi, A. L. Error and attack tolerance of complex networks. Nature 406, 378–382 (2000).
Guelzim, N., Bottani, S., Bourgine, P. & Kps, F. Topological and causal structure of the yeast transcriptional regulatory network. Nat. Genet. 31, 60–63 (2002).
Teichmann, S. A. & Babu, M. M. Gene regulatory network growth by duplication. Nat. Genet. 36, 492–496 (2004).
Babu, M. M. Structure, evolution and dynamics of transcriptional regulatory networks. Biochem. Soc. Trans. 38, 1155–1178 (2010).
Pinho, R., Garcia, V., Irimia, M. & Feldman, M. W. Stability depends on positive autoregulation in boolean gene regulatory networks. PLoS Comput. Biol. 10, e1003916 (2014).
Alon, U. Network motifs: theory and experimental approaches. Nat. Rev. Genet. 8, 450–461 (2007).
Sompolinsky, H., Crisanti, A. & Sommers, H. J. Chaos in random neural networks. Phys. Rev. Lett. 61, 259–262 (1988).
Laherrere, J. & Sornette, D. Stretched exponential distributions in nature and economy:’fat tails’ with characteristic scales. Eur. Phys. J. B 2, 525–539 (1998).
Palmer, R. G., Stein, D. L., Abrahams, E. & Anderson, P. W. Models of hierarchically constrained dynamics for glassy relaxation. Phys. Rev. Lett. 53, 958–961 (1984).
Pinho, R., Borenstein, E. & Feldman, M. W. Most networks in Wagners model are cycling. PLoS ONE 7, e34285 (2012).
Aldana, M. ‘Boolean dynamics of networks with scale-free topology. Physica D 185, 45–66 (2003).
Hazan, H. & Manevitz, L. M. Topological constraints and robustness in liquid state machines. Expert Syst. Appl. 39, 1597–1606 (2012).
de Espan, P. M., Osses, A. & Rapaport, I. Fixed-points in random Boolean networks: the impact of parallelism in the BarabsiAlbert scale-free topology case. Biosystems 150, 167–176 (2016).
Maass, W., Natschlger, T. & Markram, H. Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531–2560 (2002).
Sussillo, D. & Abbott., L. F. Generating coherent patterns of activity from chaotic neural networks. Neuron 63, 544–557 (2009).
Barak, O. et al. From fixed points to chaos: three models of delayed discrimination. Prog. Neurobiol. 103, 214–222 (2013).
Bergman, A. & Siegal, M. L. Evolutionary capacitance as a general feature of complex gene networks. Nature 424, 549–552 (2003).
Barzel, B. & Barabasi, A. L. Universality in network dynamics. Nat. Phys. 9, 673–681 (2013).
Oikonomou, P. & Cluzel, P. Effects of topology on network evolution. Nat. Phys. 2, 532–536 (2006).
Yona, A. H., Frumkin, I. & Pilpel, Y. A relay race on the evolutionary adaptation spectrum. Cell 163, 549–559 (2015).
Chartrand, G. & Lesniak, L. Graphs & Digraphs 2nd Ed. Wadsworth Publications Co (1986).
Kim, H., del Genio, C. I., Bassler, K. E. & Toroczkai, Z. Constructing and sampling directed graphs with given degree sequences. New J. Phys. 14, 023012 (2012).
Sommers, H. J., Crisanti, A., Sompolinsky, H. & Stein, Y. Spectrum of large random asymmetric matrices. Phys. Rev. Lett. 60, 1859–1899 (1988).
Wood, P. M. Universality and the circular law for sparse random matrices. Ann. Appl. Prob. 22, 1266–1300 (2012).
Acknowledgements
We thank O. Barak, E. Braun, R. Meir and M. Stern for valuable discussions and S. Marom, A. Rivkind, L. Geyrhofer and H. Keren for critical reading of the manuscript.
Author information
Authors and Affiliations
Contributions
Y.S. and N.B. conceived the general approach for modelling adaption by exploratory dynamics. H.I.S. and N.B. constructed the model. H.I.S. performed all the simulations and computations. All authors evaluated model findings and designed simulations to identify requirements and properties of exploratory adaptation. All authors wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Supplementary Information
Supplementary figures, supplementary notes and supplementary references. (PDF 4340 kb)
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Schreier, H., Soen, Y. & Brenner, N. Exploratory adaptation in large random networks. Nat Commun 8, 14826 (2017). https://doi.org/10.1038/ncomms14826
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/ncomms14826
This article is cited by
-
Dimensional reduction and adaptation-development-evolution relation in evolved biological systems
Biophysical Reviews (2024)
-
Emergent stability in complex network dynamics
Nature Physics (2023)
-
Sustaining a network by controlling a fraction of nodes
Communications Physics (2023)
-
Darwin’s agential materials: evolutionary implications of multiscale competency in developmental biology
Cellular and Molecular Life Sciences (2023)
-
Reviving a failed network through microscopic interventions
Nature Physics (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
