
Abstract
Human chromosome 16 features one of the highest levels of segmentally duplicated sequence among the human autosomes. We report here the 78,884,754 base pairs of finished chromosome 16 sequence, representing over 99.9% of its euchromatin. Manual annotation revealed 880 protein-coding genes confirmed by 1,670 aligned transcripts, 19 transfer RNA genes, 341 pseudogenes and three RNA pseudogenes. These genes include metallothionein, cadherin and iroquois gene families, as well as the disease genes for polycystic kidney disease and acute myelomonocytic leukaemia. Several large-scale structural polymorphisms spanning hundreds of kilobase pairs were identified and result in gene content differences among humans. Whereas the segmental duplications of chromosome 16 are enriched in the relatively gene-poor pericentromere of the p arm, some are involved in recent gene duplication and conversion events that are likely to have had an impact on the evolution of primates and human disease susceptibility.
Similar content being viewed by others

Main
The US Department of Energy (DOE) initiated the mapping and sequencing of human chromosome 16 in 1988 to contribute to the generation of a reference human genome sequence to be used in assessing the effects of radiation and for the study of human biology. This particular chromosome was in part targeted for sequencing because of the localization of the DNA repair gene ERCC4 to the p arm of chromosome 16 (ref. 1), the availability of a unique flow-sorted chromosome-specific cosmid library2, and access to a mouse–human hybrid cell panel enabling the localization of clones to discrete cytogenetic intervals3. Further interest in human chromosome 16 stemmed from the clustering of metallothionein genes on this chromosome, which participate in heavy metal transport and detoxification, coinciding with important biological interests of the DOE4,5. Here we describe the finished human chromosome 16 sequence, which provides a reference for the further exploration of genomic sequence alterations and their relationship to human biology.
Mapping and sequencing
To provide the foundation for sequencing human chromosome 16, we constructed a physical map based on previous sequence-tagged site (STS) content maps6,7,8 with a minimal final tiling path of 716 clones, which include 618 bacterial artificial chromosomes (BACs), 79 cosmids, seven fosmids, five phage-derived artificial chromosomes (PACs), three yeast artificial chromosome (YAC) subclones, two P1 phages, two phage vectors and five genomic polymerase chain reaction (PCR) fragments. The final sequence contains four gaps, with two in each of the chromosome arms. One of the gaps is found in the highly duplicated pericentromeric region in the p arm, while two of the remaining non-pericentromeric gaps are resistant to stable cloning with conventional vectors, and efforts are ongoing to close the estimated ∼25 kilobases (kb) of missing sequence using alternative vectors9. The final gap is found near the telomere of the q arm in a region of subtelomeric repeats distal to the last identifiable cosmid subclone (AC137934) of a 16q telomere half-YAC as previously described10.
The high degree of segmental duplication of chromosome 16, coupled with the multiple haplotypes represented in the numerous clone libraries comprising the tiling path, hindered efforts to construct a valid clone-based representation of this chromosome. To resolve this issue, we adopted a strategy of high depth clone coverage from a library constructed from a single individual11. This enabled the determination of both of the diploid haplotypes across the segmentally duplicated intervals. Overall, these efforts resulted in the generation of 78,884,754 base pairs (bp) of finished euchromatic sequence with an estimated accuracy12 exceeding 99.9% and covering in excess of 99.9% of its euchromatin. Including the centromere and its adjacent heterochromatic portion of the q arm, sized together at 9.8 megabases (Mb) (see Methods), the total size of the chromosome is estimated at 88.7 Mb.
As a further assessment of the physical sequence, we compared it to the existing physical and genetic maps. We were able to account for all sequence-tagged sites from the Genethon13 microsatellite, the deCODE14 and the Marshfield15 genetic maps. We also compared the final DNA sequence with recombination distances in the deCODE female, male and sex-averaged meiotic maps (Fig. 1). We found the female recombination distances for chromosome 16 were similar to other human chromosomes, showing a linear relationship between recombination and physical distances at an average of 1.93 cM Mb-1, excluding heterochromatin. However, the male meiotic map displayed substantial differences in the region from 17–72 Mb with a meiotic distance of only 22.5 cM, yielding an average of 0.50 cM Mb-1. Finally, we found a marked increase in male recombination near the telomeres, exceeding 3 cM Mb-1, consistent with other human chromosomes16.

Comparison of meiotic distance to the physical map of chromosome 16, from the telomere of the short arm to the telomere of the long arm and reading left to right.
Gene catalogue
We manually curated gene models as previously described17 and identified a total of 880 protein-coding gene loci (Table 1, Supplementary Information Table 1 and http://www.jgi.doe.gov/human_chr16) supported by 1,670 full-length (or nearly full-length) transcripts. These provided an average of 1.9 annotated transcripts per locus with 450 of the loci showing strong evidence for alternative splicing with two or more annotated messenger RNA transcripts. Additionally, 208 loci have ‘expressed sequence tag’ (EST) evidence for alternative splice forms, resulting in nearly 75% of loci displaying some evidence for alternative splice variants. Loci were further classified as ‘known genes’, ‘novel genes’ or ‘pseudogenes’, consistent with our previous definitions17, excluding loci without unique open reading frames, and ab initio predictions without supporting evidence. Seven hundred and seventy-one known genes were modelled on the basis of 2,435 Refseq transcripts as well as other complementary DNA sequence evidence in GenBank. Nearly one-third (36%) of these known genes were extended by more than 50 bp at the 5′ end and 18% at the 3′ end relative to Refseq transcripts while maintaining their original open reading frame.
We identified thirty ‘novel genes’ based on cDNA sequence, spliced ESTs and protein similarity to known human or mouse genes, and we modelled an additional 79 putative novel genes using orthologous mouse cDNA sequences and ab initio predictions. Additionally, we annotated 19 tRNA genes and three tRNA pseudogenes based on previous data18. Finally we identified 341 pseudogenes and pseudogene fragments of which 120 appear to be non-processed because they displayed an exon structure similar to the parent locus and are therefore likely to have resulted from genomic duplication events. The remaining 221 appear to be processed pseudogenes, presumably resulting from viral retrotransposition of spliced mRNAs or from mitochondrial genome insertion. At least one frameshift or premature stop codon (in comparison to the parent gene) was identified in 233 pseudogenes and the remaining 108 were processed pseudogenes lacking introns and displaying poly-A's in the adjacent genomic sequence. This supports the likely nonfunctional nature of these vestigial genes. To assess the quality of our pseudogene collection, we compared it to an earlier analysis19 describing 250 processed pseudogenes on chromosome 16. Initially we were able to map 233 of these 250 pseudogenes to 429 loci on chromosome 16 using BLAT20 with 100% coverage and >99% identity. We then eliminated loci consisting of repetitive DNA21 (Smit, A. F. A. and Green, P., unpublished results), those covering less than 50% of the parent gene and cases where there was clearly a retained intron/exon structure. This resulted in 146 processed pseudogenes in agreement between a previous study19 and our study, and suggested that our manual curation of the finished sequence identified 75 additional members.
Large structural polymorphisms
We observed several large structural polymorphisms based on the finished sequence of chromosome 16, which were often associated with segmental duplications. For instance, we further characterized a previously described stable length polymorphism within the 16p subtelomeric region22,23. Whereas the shortest and most common allele was previously finished (represented in NCBI Build 35), we isolated and sequenced the majority of a longer allele derived from a 16p telomere half-YAC, located within close proximity of the TTAGGG telomere repeat as defined in ref. 10. This allele is ∼137.5 kb longer than the current assembly, however the shorter allele is not simply a truncation of the longer form; rather the telomeric 21,056 bp of the short allele is not present in the long allele and the telomeric 158,607 bp of the long allele is not shared with the short allele. Both of these unique regions contain genes with the short allele containing a putative gene(s) represented by cDNAs MGC:75272 and MGC:52000 and with the long allele containing genes encoding hypothetical protein XP_375548 (similar to septin), hypothetical protein XP_379920 (similar to capicua) and beta-tubulin 4Q (AAL32434).
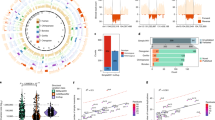
We also identified one of the most extensively duplicated regions on chromosome 16 corresponding to a 500-kb interval at 16p11.2-12.1 composed of approximately 54 intrachromosomal duplications (Fig. 2 and Supplementary Table 2). This interval includes seven full or partial gene duplicates including the eukaryotic translation initiation factor 3 subunit 8 (EIF3S8), sulphotransferase 1A (SULT1A1) and the Batten disease gene (CLN3). Assembly of the region was initially complicated by the fact that the duplications were long (∼ 200 kb) and showed an extraordinary degree of homology (98.33%). During the mapping of this region, sequence for a second haplotype variant from the RPCI-11 BAC library was nearly completed except for one gap of ∼100 kb. Sequence comparison of these two haplotypes (EIFvar1 and EIFvar2) revealed a 452-kb inversion between them (Fig. 2). Analysis of the breakpoints suggests that a large duplication palindrome is responsible for this rearrangement.

The duplication and inverted structure for two chromosome 16 haplotypes (EIFvar1 and EIFvar2) are compared. Top and bottom panels: interchromosomal (red) and intrachromosomal duplications (blue) alignments (> 90%, >1 kb) are depicted as a function of percentage identity below the horizontal line with different colours corresponding to the location of the pairwise alignment on different human chromosomes (chromosome 16 is shown as magenta, chromosome 18 as sky blue). The middle panel shows a 450-kb inversion between EIFvar1 and EIFvar2, using Miropeats (threshold = 3,000). Interhaplotype (red) and intrahaplotype (blue) sequence alignments are shown based on chromosome assembly for EIFvar1. A palindromic duplication structure (200 kb) demarcates the breakpoint region. Genes are depicted as light-blue bars above the horizontal line in the top panel. These include: (1) eukaryotic translation initiation factor 3, subunit 8 (EIF3S8); (2) LOC39068; (3) LOC11286; (4) sulphotransferase 1A (SULT1A2); (5) sulphotransferase 1A (SULT1A1); (6) JGI-495; and (7) EIF3S8.
Finished sequence was also generated across a recently duplicated 360-kb polymorphism of the human homologue of the hydrocephalus inducing gene (HYDIN) at 16q22, which is inserted in some humans at chromosome 1q21.1. The RPCI-11 BAC library seems to be heterozygous for this insertional polymorphism, with the current genomic assembly for chromosome 1 containing the haplotype version lacking the insertion. We further investigated a recently described24 copy number polymorphism between 16p11.2 and 6p25, which contains the DUSP22 gene. On the basis of extensive drafting of RPCI-11 BACs in the region and comparisons with drafted clones from monochromosomal libraries for chromosomes 6 and 16, we were able to determine that the RPCI-11 library is homozygous and lacking the DUSP22 duplication on chromosome 16. Taken together, these recently arisen large structural polymorphisms are striking examples of variability in the human genome and support a potential mechanism that contributes to phenotypic or disease susceptibility differences among humans. It is worth noting that 91 genes on chromosome 16 are located within segmental duplications, any of which could be unstable and challenge researchers studying phenotypes linked to these gene-containing regions. These observations are particularly relevant on the basis of recent findings24,25 of abundant copy number polymorphisms within the genomes of normal individuals, which include those described here.
Duplication analysis of chromosome 16
We performed a detailed analysis of duplicated genomic sequence (≥ 90% sequence identity and ≥1 kb in length) comparing chromosome 16 against the July 2003 assembly of the human genome. We found that 9.89% (7.8 Mb) of chromosome 16 consists of segmental duplications (Supplementary Table 2). In comparison to other finished chromosomes and to the human genomic average (5.3%), chromosome 16 is one of the most enriched chromosomes for segmental duplications (Supplementary Table 2 and Supplementary Fig. 1). Nearly 9% of genome-wide human duplication alignments map to this chromosome. Intrachromosomal duplications are longer and show higher sequence identity when compared with interchromosomal duplications (Fig. 3a and Supplementary Fig. 2). Whereas there is a general inverse correlation between duplication length and divergence, the effect is most pronounced for intrachromosomal duplication in which the average length of duplicated DNA exceeds 16 kb. A clear bimodal distribution pattern of sequence identity is distinguishable based on the distribution pattern of the alignments. Most interchromosomal duplication alignments show 93–95% sequence identity whereas intrachromosomal duplications show greater than 97% sequence identity, consistent with a recent expansion of intrachromosomal duplications along the chromosome26,27. On the basis of substitution rates between great apes, we estimate that as much as 7% of the mass of human chromosome 16 was added by segmental duplication events within the last 10 million years of human evolution28.

a, The scatter plot depicts the length (log 10) and divergence of inter- (red) and intra- (blue) chromosomal segmental duplication. Divergence is calculated as the number of substitutions per site between the two sequences. b, The parasight view depicts the pattern of interchromosomal (red) and intrachromosomal (blue) duplications (> 20 kb, >95%) for chromosome 16. Chromosome 16 is drawn at 20 × greater scale than the other chromosomes. Centromeres are shown as purple bars.
Segmental duplications are particularly clustered along the p arm of the chromosome (Supplementary Figs 1 and 3). As described previously29, the 16p11 pericentromeric region represents the largest zone of interchromosomal duplications (Fig. 3b) accounting for 44% (937 of 2,146) of the total number of chromosome 16 alignments (Supplementary Table 4) and 55% (752 of 1,365) of all chromosome 16 interchromosomal alignments. Most of the interchromosomal duplications in this region map to the pericentromeric regions of other chromosomes (Fig. 3b). Large tracts of interstitial alpha-satellite DNA have been finished within proximal 16p11 and it is possible that such sequences have played a part in the frequent evolutionary exchange of pericentromeric DNA among non-homologous chromosomes30. In stark contrast to 16p11, there is little evidence for extensive pericentromeric duplication on the q arm despite the fact that centromeric satellite boundary sequences have been traversed.
An additional 19 blocks of extensive duplication (> 100 kb and >5 duplication alignments) were identified within the euchromatic portion of chromosome 16. These regions are composed of as many as 119 underlying duplicons (also known as low-copy repeats on chromosome 16, LCR16) that have been juxtaposed in different combinations within the duplication blocks. These contain various genes and gene fragments, such as NPIP, SULT1A, EIF3S8 and SMG1 (Supplementary Table 3). Most are duplicated several times in varying copy numbers with a high degree of sequence identity to their putative ancestral genes. Most seem to have been duplicated in concert with LCR16a, a segment that contains one of the most rapidly evolving gene families of the human genome27,31.
Comparative genomics
We compared human chromosome 16 to the chimpanzee, dog, mouse32, rat33, chicken and fish34 (Fugu rubripes) draft genomes to further explore the evolution and constraint of sequences found along this chromosome. By first building segmental maps from DNA alignments of all the vertebrate species described above, we were able to examine the global homologous chromosomal relationships between these vertebrate genomes and human chromosome 16 (see Methods). We found no major rearrangements relative to the homologous chimpanzee chromosome 18. Comparison with the mouse and rat genomes revealed 26 chromosomal segments unbroken in any of the three species, ranging in size from 250 kb to 10.7 Mb (Fig. 4a). Further addition of the chicken genome to the multi-dimensional map yielded 33 segments ranging in size from 250 kb to 8.7 Mb (Fig. 4a). These segmental maps provide the substrates to precisely define the breakpoints that, in some cases, may have disrupted gene loci in the species containing the rearrangement.

a, Segmental homology maps between human chromosome 16 and the chimpanzee, mouse, rat, dog and chicken genomes. Syntenic segments are colour-coded by chromosome, with arrowheads indicating the strand. b, Gene density (blue) and noncoding conservation density (magenta) over the entire chromosome. Densities are normalized so that the darkest shade in each track denotes 3.5 times the genomic average. c, Conservation in the second largest human/mouse/dog/chicken synteny block on human chromosome 16, which spans 8.19 Mb at 16q21 (NCBI34 chr16: 58,626,110–66,811,606), and contains four cadherin genes. The upper plot shows coding (blue) and noncoding (magenta) conservation P-values in the human/mouse/rat comparison. The lower plot shows the human/mouse/dog/chicken comparison. d, Similar plots of ENCODE region ENr313 (NCBI34 chr16: 62,051,662–62,551,661), which lies near the centre of the gene-poor region in c. e, ENCODE region ENr211 (NCBI34-chr16:25,839,478–26,339,477), another gene-poor region on 16p12.1. Rat is excluded because of a large sequencing gap. In c, d and e, the height of the bars is proportional to -log (conservation P-value) (Gumby and Rank-VISTA, see Methods).
We next identified slowly evolving regions, presumably under evolutionary constraint, through fine-scale DNA comparison of chromosome 16 with other vertebrate genome assemblies. Four different species combinations were selected to represent the accessible range of vertebrate evolutionary divergence times: human/mouse/rat, human/mouse/rat/dog, human/mouse/dog/chicken, and human/mouse/Fugu (see Methods). To explore potential noncoding functional elements on chromosome 16, the results were filtered for overlap with annotated genes, spliced ESTs or mRNAs in human, mouse and rat, which resulted in the identification of 5,187 discrete conserved noncoding regions between human/mouse/rat, 6,159 between human/mouse/rat/dog, 1,862 between human/mouse/dog/chicken, and 191 between human/mouse/Fugu (Fig. 4b and Supplementary Table 1). Compared with genome-wide averages, the densities of human/mouse/rat and human/mouse/dog/chicken elements were only slightly higher for human chromosome 16 (Supplementary Table 1). In contrast, human/mouse/Fugu elements are present at ∼2.4 times the genome-wide density, indicating that although chromosome 16 as a whole has had ‘normal’ levels of noncoding constraint since the mammal/bird split, it has conserved more ancient functions to a surprising degree. Functional studies on these conserved elements are warranted to assess their possible biological activity in the ∼98% of the human genome that is noncoding.
We further explored an 8.7-Mb region at 16q12, on the basis of extreme features of evolutionary conservation. This region was first identified as the largest unbroken synteny segment between human/mouse/dog/chicken on chromosome 16 and contains 59% (112 of 191) of the human/mouse/Fugu noncoding elements. These elements are entirely clustered in a gene-poor 5-Mb subregion, which contains at least six developmental transcription factors, including SALL1 and three iroquois genes (IRX3, IRX5 and IRX6). This clustering is an example of the general bias of human–fish conserved sequences towards developmental genes35. Interestingly, at least nine of these human/mouse/Fugu elements have significant sequence similarity to counterparts in the paralogous IRX gene cluster on chromosome 5, which is similarly located in a ‘forest’ of human–fish conservation36. In vivo mouse transgenic data indicate that a significant percentage of these IRX conserved noncoding sequences behave as gene enhancers (Pennacchio, L. A., unpublished observation), suggesting that in addition to the well described conservation of the protein-encoding portions of genomic duplications, evolutionary constraint is also observable in adjacent gene regulatory sequences following genomic duplication events. This synteny block is an outlier even in terms of more recent noncoding conservation, with 917 (105 per Mb) human/mouse/rat and 590 (67.5 per Mb) human/mouse/dog/chicken elements.
The second longest chromosome 16 synteny block in human/mouse/dog/chicken neighbours the highly conserved SALL1-IRX segment and is similar in length (8.19 Mb) (Fig. 4c). Once again this region is gene poor, with its telomeric 7.6 Mb containing only three annotated genes, all members of the cadherin family: CDH8, CDH11 and CDH5. Within the full 8.19-Mb interval, we identified 968 (118 per Mb) human/mouse/rat conserved noncoding sequences. This is twice the genome-wide density, as was the case in the SALL1-IRX region. However, in stark contrast to the neighbouring SALL1-IRX region, this synteny block has no noncoding conservation between human/mouse/Fugu, suggesting that its noncoding functions, though just as constrained among mammals, are more diverged in distant species.
As a special category of constrained DNA, we also searched for ultra-conserved noncoding sequences, recently defined by the stringent criterion of at least 200 bp in length and 100% identity between the human, mouse and rat genomes37. Of the 482 ultra-conserved elements found in the entire human genome, 15 (3.1%) were found on chromosome 16, with 11 having some evidence of being transcribed and processed into mature mRNAs. The above-mentioned bias towards developmental genes has also been noted37 for ultra-conserved human/rodent elements. Indeed, 9 of the 15 ultra-conserved elements found on chromosome 16 lie in the same SALL1-IRX synteny block that contains the mammal/fish conservation cluster. This contrasts with the similarly sized cadherin synteny block that contains no human–fish noncoding conservation and only one ultra-conserved element.
Finally, three regions on chromosome 16 have been selected by the National Human Genome Research Institute as part of the Encyclopaedia of DNA Elements (ENCODE) project, an effort aimed at rigorously analysing 1% of the human genome sequence38 (http://www.genome.gov/10005107). These three ENCODE regions include the well-studied alpha-globin-containing interval (ENm008) and two randomly chosen regions (ENr211 on 16p12.1 and ENr313 on 16q21). Interestingly, ENr313 is located within the large cadherin gene desert described above and is completely devoid of genes (Fig. 4d). Nonetheless, it harbours the same high density of human/mouse/rat and human/mouse/dog/chicken conserved noncoding elements as the rest of the cadherin synteny block, suggesting the presence of numerous unassigned functional sequences within this region. Ongoing studies by ENCODE will better define the overlap of functionality and comparative sequence data such as that presented here.
Discussion
The primary sequence of human chromosome 16, as well as the human genome as a whole, now provides a key foundation for ongoing efforts such as ENCODE to deeply annotate all types of information encoded in our genome. This represents an enormous long-term challenge because genomic signatures embedded within the sequence of DNA perform a vast number of different operations across the trillions of cells within our bodies. These features range from relatively easily identified genes, to sequences involved in gene regulation—which use a plethora of signals to determine when and where a given gene is expressed and under what conditions—to probably even more complicated features such as higher-order chromosome structure and DNA involvement in replication and repair. It is inspiring to reminisce that it was only 50 years ago that we had our first glimpse into the structure of DNA, which provided the foundation for generating the nearly entire human euchromatic sequence. The next 50 years will probably also bring similarly impressive gains and enable us to precisely relate our primary genomic sequence to functional genomic signatures and their relationship to human biology.
Methods
Sizing of heterochromatic gaps
To estimate the size of the alpha satellite bands (16p11.1-16q11.1) encompassing the centromere and the satellite II heterochromatin in band 16q11.2, we used contour-clamped homogeneous electric field (CHEF) pulsed-field gel electrophoresis at various pulse times to resolve macrorestriction fragments between 100 kb and >7,000 kb. DNA from CY18 (a mouse–human hybrid containing a single human chromosome 16) was digested with several different rare cutting restriction enzymes and separated on CHEF gels. Hybridization to blots of these gels with 16-1 (16-specific alpha satellite) and pHuR 195 (16-specific satellite II) probes revealed a single band of alpha satellite (in three different enzyme digests) that did not overlap with any satellite II bands (data not shown). The smallest of these bands was an 1,800-kb Xho I fragment, which provided an upper size limit for the alpha satellite array, encompassing the centromere on chromosome 16. SalI fragmented the satellite II heterochromatin into well resolved large restriction fragments without cutting within the alpha satellite array. The sum of the SalI satellite II fragments was estimated at ∼7,800 kb providing a upper size limit of the 16q11.2 satellite II heterochromatin at nominally 8 Mb. Together these account for 9.8 Mb of unsequenced heterochromatin encompassing cytogenetic bands 16p11.1-16q11.2, although it is likely that we did sequence partially into the boundaries of these regions in the adjacent tiling set clones.
Segmental duplication analysis
We used a BLAST-based detection scheme39 to identify all pairwise similarities representing duplicated regions (≥ 1 kb and ≥90% identity) within the finished sequence of chromosome 16 and compared it with all other chromosomes in the NCBI genome assembly (build 34). A total of 2,146 pairwise alignments representing 26.12 Mb of aligned basepairs and 7.8 Mb of non-redundant duplicated bases were analysed on chromosome 16. The program Parasight (http://humanparalogy.gene.cwru.edu/parasight/) was used to generate images of pairwise alignments. Divergence of duplication, the number of substitutions per site between the two sequences, were calculated using Kimura's two-parameter method, which corrects for multiple events and transversion/transition mutational biases40. Analysis of haplotype structural variation was performed using the program Miropeats (threshold = 3,000)41. Gene content of each 1% duplicated regions of 90–100% identity was analysed using a non-redundant/non-overlapping set of known genes. A gene feature (exon) was considered duplicated if >50 bp of the feature overlapped duplication. Thus, exons less than 50 bp were lost in this analysis.
Pseudogene identification
Pseudogenes were defined as gene models built by homology to known human genes in which the alignment between the model and the homologue shows at least one stop codon or frameshift. We identified homologies42 of human IPI (International Protein Index; http://www.ebi.ac.uk/IPI/IPIhelp.html) proteins on repeat-masked21 (Smit, A. F. A and Green, P., unpublished results) genomic chromosome 16 sequence. For each such fragment of genomic sequence we built gene models using the GeneWise43 program. Overlapping models were then clustered and the top-scoring model was analysed for the presence of premature stop codons and frameshifts. Remaining models were then manually checked to confirm their pseudogene status.
Comparative analysis
Multi-species segmental homology maps were computed using PARAGON (v2.2; Couronne, unpublished work), which is based on BLASTZ44 pairwise alignments of all genomes to human. After filtering out segments shorter than 250 kb in humans, MLAGAN45 alignments of homologous blocks were scanned for evolutionarily conserved regions using Gumby (v1.5; Prabhakar, unpublished work). These were visualized using Rank-VISTA (Prabhakar, unpublished work). Gumby goes through the following three-step process to identify statistically significant conservation in the input global alignment: (1) first, noncoding regions in the alignment are used to estimate the local neutral mutation rates46 between all pairs of aligned sequences. The rates are used to derive a log-likelihood scoring scheme for slow versus neutral evolution47, in which the slow rate is set at half the neutral rate; (2) each alignment position is then assigned a conservation score using a phylogenetically weighted sum-of-pairs scheme; (3) finally, a dynamic programming step scans the alignment for high-scoring segments (conserved regions) of any length. Conserved regions detected in this manner are assigned P-values using the same statistical formalism48 as the BLAST algorithm42. Whereas BLAST assigns P-values relative to random permutations of the query and target sequences, Gumby P-values relate to random permutations of the columns in the input alignment. Here, all the results were generated using a Gumby P-value threshold of 0.01 and a baseline human sequence length of 100 kb. Conserved noncoding regions were defined as conserved segments that overlap annotated exons, spliced ESTs or mRNAs from human, mouse or rat over no more than 25% of their length. At a Gumby P-value threshold of 0.01, 2.2% of the ungapped positions in the human genome were assigned to human/mouse/rat conserved noncoding segments.
References
Siciliano, M. J. Chromosomal assignment of human genes coding for DNA repair functions. Isozymes Curr. Top. Biol. Med. Res. 15, 217–223 (1987)
Deaven, L. L. et al. Construction of human chromosome-specific DNA libraries from flow-sorted chromosomes. Cold Spring Harb. Symp. Quant. Biol. 51, 159–167 (1986)
Callen, D. F. et al. High-resolution cytogenetic-based physical map of human chromosome 16. Genomics 13, 1178–1185 (1992)
Hildebrand, C. E. & Enger, M. D. Regulation of Cd2 + /Zn2 + -stimulated metallothionein synthesis during induction, deinduction, and superinduction. Biochemistry 19, 5850–5857 (1980)
Stallings, R. L., Munk, A. C., Longmire, J. L., Hildebrand, C. E. & Crawford, B. D. Assignment of genes encoding metallothioneins I and II to Chinese hamster chromosome 3: evidence for the role of chromosome rearrangement in gene amplification. Mol. Cell. Biol. 4, 2932–2936 (1984)
Han, C. S. et al. Construction of a BAC contig map of chromosome 16q by two-dimensional overgo hybridization. Genome Res. 10, 714–721 (2000)
Doggett, N. A. et al. An integrated physical map of human chromosome 16. Nature 377, 335–365 (1995)
Cao, Y. et al. A 12-Mb complete coverage BAC contig map in human chromosome 16p13.1-p11.2. Genome Res. 9, 763–774 (1999)
Kouprina, N. et al. Construction of human chromosome 16- and 5-specific circular YAC/BAC libraries by in vivo recombination in yeast (TAR cloning). Genomics 53, 21–28 (1998)
Riethman, H. C. et al. Integration of telomere sequences with the draft human genome sequence. Nature 409, 948–951 (2001)
Osoegawa, K. et al. A bacterial artificial chromosome library for sequencing the complete human genome. Genome Res. 11, 483–496 (2001)
Schmutz, J. et al. Quality assessment of the human genome sequence. Nature 429, 365–368 (2004)
Dib, C. et al. A comprehensive genetic map of the human genome based on 5,264 microsatellites. Nature 380, 152–154 (1996)
Kong, A. et al. A high-resolution recombination map of the human genome. Nature Genet. 31, 241–247 (2002)
Broman, K. W., Murray, J. C., Sheffield, V. C., White, R. L. & Weber, J. L. Comprehensive human genetic maps: individual and sex-specific variation in recombination. Am. J. Hum. Genet. 63, 861–869 (1998)
Yu, A. et al. Comparison of human genetic and sequence-based physical maps. Nature 409, 951–953 (2001)
Grimwood, J. et al. The DNA sequence and biology of human chromosome 19. Nature 428, 529–535 (2004)
Lowe, T. M. & Eddy, S. R. tRNAscan-SE: a program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 25, 955–964 (1997)
Zhang, Z., Harrison, P. M., Liu, Y. & Gerstein, M. Millions of years of evolution preserved: a comprehensive catalog of the processed pseudogenes in the human genome. Genome Res. 13, 2541–2558 (2003)
Kent, W. J. BLAT–the BLAST-like alignment tool. Genome Res. 12, 656–664 (2002)
Jurka, J. Repbase update: a database and an electronic journal of repetitive elements. Trends Genet. 16, 418–420 (2000)
Flint, J. et al. The relationship between chromosome structure and function at a human telomeric region. Nature Genet. 15, 252–257 (1997)
Wilkie, A. O. et al. Stable length polymorphism of up to 260 kb at the tip of the short arm of human chromosome 16. Cell 64, 595–606 (1991)
Sebat, J. et al. Large-scale copy number polymorphism in the human genome. Science 305, 525–528 (2004)
Iafrate, A. J. et al. Detection of large-scale variation in the human genome. Nature Genet. 36, 949–951 (2004)
Loftus, B. et al. Genome duplications and other features in 12 Mbp of DNA sequence from human chromosome 16p and 16q. Genomics 60, 295–308 (1999)
Johnson, M. E. et al. Positive selection of a gene family during the emergence of humans and African apes. Nature 413, 514–519 (2001)
Chen, F. C. & Li, W. H. Genomic divergences between humans and other hominoids and the effective population size of the common ancestor of humans and chimpanzees. Am. J. Hum. Genet. 68, 444–456 (2001)
She, X. et al. The structure and evolution of centromeric transition regions within the human genome. Nature 430, 857–864 (2004)
Guy, J. et al. Genomic sequence and transcriptional profile of the boundary between pericentromeric satellites and genes on human chromosome arm 10p. Genome Res. 13, 159–172 (2003)
Eichler, E. E. et al. Divergent origins and concerted expansion of two segmental duplications on chromosome 16. J. Hered. 92, 462–468 (2001)
Waterston, R. H. et al. Initial sequencing and comparative analysis of the mouse genome. Nature 420, 520–562 (2002)
Gibbs, R. A. et al. Genome sequence of the Brown Norway rat yields insights into mammalian evolution. Nature 428, 493–521 (2004)
Aparicio, S. et al. Whole-genome shotgun assembly and analysis of the genome of Fugu rubripes. Science 297, 1301–1310 (2002)
Boffelli, D., Nobrega, M. A. & Rubin, E. M. Comparative genomics at the vertebrate extremes. Nature Rev. Genet. 5, 456–465 (2004)
Schmutz, J. et al. The DNA sequence and comparative analysis of human chromosome 5. Nature 431, 268–274 (2004)
Bejerano, G. et al. Ultraconserved elements in the human genome. Science 304, 1321–1325 (2004)
The ENCODE (ENCyclopedia Of DNA Elements) Project. Science 306, 636–640 (2004)
Bailey, J. A., Yavor, A. M., Massa, H. F., Trask, B. J. & Eichler, E. E. Segmental duplications: organization and impact within the current human genome project assembly. Genome Res. 11, 1005–1017 (2001)
Kimura, M. A simple method for estimating evolutionary rates of base substitutions through comparative studies of nucleotide sequences. J. Mol. Evol. 16, 111–120 (1980)
Parsons, J. D. Miropeats: graphical DNA sequence comparisons. Comput. Appl. Biosci. 11, 615–619 (1995)
Altschul, S. F. et al. Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 25, 3389–3402 (1997)
Birney, E., Clamp, M. & Durbin, R. GeneWise and Genomewise. Genome Res. 14, 988–995 (2004)
Schwartz, S. et al. Human-mouse alignments with BLASTZ. Genome Res. 13, 103–107 (2003)
Brudno, M. et al. LAGAN and Multi-LAGAN: efficient tools for large-scale multiple alignment of genomic DNA. Genome Res. 13, 721–731 (2003)
Cooper, G. M. et al. Characterization of evolutionary rates and constraints in three mammalian genomes. Genome Res. 14, 539–548 (2004)
Boffelli, D. et al. Phylogenetic shadowing of primate sequences to find functional regions of the human genome. Science 299, 1391–1394 (2003)
Karlin, S. & Dembo, A. Limit distributions of maximal segmental score among Markov-dependent partial sums. Adv. Appl. Prob. 24, 113–140 (1992)
Acknowledgements
We thank the International Chimpanzee Sequencing Consortium for pre-publication access to and permission to analyse the relevant portions of the chimpanzee genomic sequence; the Broad Institute for pre-publication access to the dog genome assembly; and the Washington University Genome Sequencing Center for pre-publication access to the chicken genomic assembly. We also thank D. Gordon of the University of Washington for his assistance in developing and customizing finishing tools, and T. Furey and G. Schuler for their efforts towards assessing the quality and completeness of our assemblies. This work was performed under the auspices of the US Department of Energy's Office of Science, Biological and Environmental Research Program and by the University of California, Lawrence Livermore National Laboratory, Lawrence Berkeley National Laboratory, Los Alamos National Laboratory, and Stanford University.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no competing financial interests.
Supplementary information
Supplementary Table 1
Chromosome features as determined by identical annotation methods across the 3 chromosomes annotated by JGI and comparison to select genome wide figures. PCG = Protein Coding Genes, PCT = Protein Coding Transcripts, CNS = Conserved Noncoding sequences as described in methods. Genome data derived from http://genome.ucsc.edu and Ensembl data from http://www.ensembl.org. N/D=Not Determined. (DOC 41 kb)
Supplementary Table 2
Bases involved in segmental duplication and pairwise alignment. Percent of non-redundant duplications are based on the total non-gap genome size 2,865,069,170 bp and chromosome 16 length of 78,884,752 bp. Segmental duplications with >90% sequence identity and > 1 kb were considered. (XLS 16 kb)
Supplementary Table 3
Duplicated genes. Duplications are binned by percent identity in 1% increment. Genes with at least one exon duplicated are listed. Exons with at least 50 bp of duplication were deemed duplicated. A gene could be duplicated multiple times at different percent identity. (XLS 12 kb)
Supplementary Table 4
Segmental duplication in pericentromeric and telomeric regions. Segmental duplication within 5 Mb of centromere and 2 Mb of the telomere of chromosome 16 are counted as pericentromeric and subtelomeric respectively. (XLS 14 kb)
Supplementary Table 5
Sequencing contributions by center and phase of completion. (DOC 20 kb)
Supplementary Figure 1
Distribution of segmental duplications. This schematic of chromosome 16 segmental duplications depicts the location of interchromosomal (red) and intrachromosomal (blue) duplicated sequence. Each horizontal line represents 5 Mb of sequence, with tick marks every 500 kb. Sequence gaps are represented as discontinuities within the horizontal line. The centromere is shown as a purple bar. Duplications detected by whole genome shotgun sequence are represented as green bars above the chromosome sequence. (PDF 44 kb)
Supplementary Figure 2
Sequence similarity and aligned bases of segmental duplications. For all pairwise alignments, the total number of aligned bases was calculated and binned based on percent sequence identity. Sequence identity distributions for interchromosomal (red) and intrachromosomal (blue) duplicated bases are shown. (PDF 560 kb)
Supplementary Figure 3
Sequence identity of segmental duplications on chromosome 16. Interchromosomal (red) and intrachromosomal duplications (blue) are shown to scale along the horizontal line in 2Mb increments. Green bars above the horizontal line correspond to duplications detected by other method, whole genome shotgun sequence detection 9. The underlying pairwise alignments of segmental duplications (>90% >1kb) are depicted as a function of % identity below the horizontal line. Different colors correspond to the location of the pairwise alignment on different human chromosomes. (i.e. chromosome 16 is shown as magenta, chromosome 18 as light blue). (PDF 89 kb)
Rights and permissions
About this article
Cite this article
Martin, J., Han, C., Gordon, L. et al. The sequence and analysis of duplication-rich human chromosome 16. Nature 432, 988–994 (2004). https://doi.org/10.1038/nature03187
Received:
Accepted:
Issue Date:
DOI: https://doi.org/10.1038/nature03187
This article is cited by
-
The scaffold protein AXIN1: gene ontology, signal network, and physiological function
Cell Communication and Signaling (2024)
-
16p13.11p11.2 triplication syndrome: a new recognizable genomic disorder characterized by optical genome mapping and whole genome sequencing
European Journal of Human Genetics (2022)
-
Submicroscopic aberrations of chromosome 16 in prenatal diagnosis
Molecular Cytogenetics (2019)
-
Mutations of N-Methyl-D-Aspartate Receptor Subunits in Epilepsy
Neuroscience Bulletin (2018)
-
Analyses of the genetic diversity and protein expression variation of the acyl: CoA medium-chain ligases, ACSM2A and ACSM2B
Molecular Genetics and Genomics (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
