
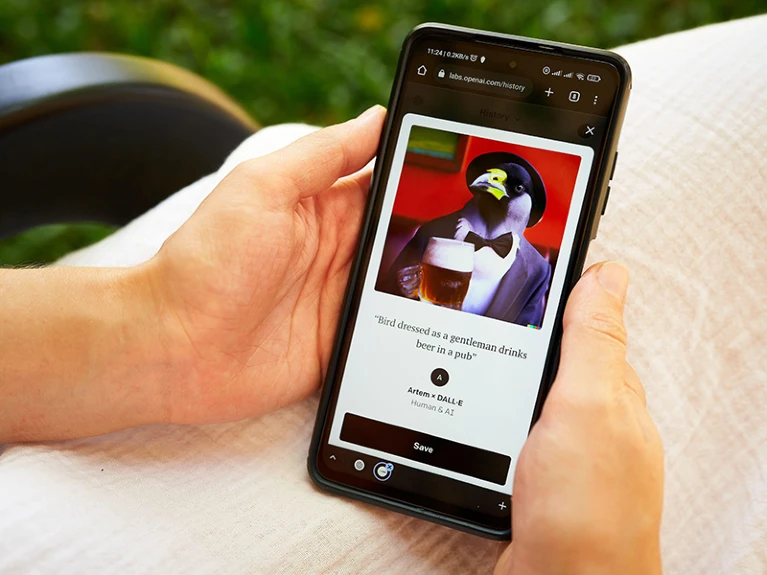
Nature will not publish imagery created wholly or partly using generative AI.Credit: Artem Medvediev/Alamy
Should Nature allow generative artificial intelligence (AI) to be used in the creation of images and videos? This journal has been discussing, debating and consulting on this question for several months following the explosion of content created using generative AI tools such as ChatGPT and Midjourney, and the rapid increase in these platforms’ capabilities.
Apart from in articles that are specifically about AI, Nature will not be publishing any content in which photography, videos or illustrations have been created wholly or partly using generative AI, at least for the foreseeable future.
Artists, filmmakers, illustrators and photographers whom we commission and work with will be asked to confirm that none of the work they submit has been generated or augmented using generative AI (see go.nature.com/3c5vrtm).
Tools such as ChatGPT threaten transparent science; here are our ground rules for their use
Why are we disallowing the use of generative AI in visual content? Ultimately, it is a question of integrity. The process of publishing — as far as both science and art are concerned — is underpinned by a shared commitment to integrity. That includes transparency. As researchers, editors and publishers, we all need to know the sources of data and images, so that these can be verified as accurate and true. Existing generative AI tools do not provide access to their sources so that such verification can happen.
Then there’s attribution: when existing work is used or cited, it must be attributed. This is a core principle of science and art, and generative AI tools do not conform to this expectation.
Consent and permission are also factors. These must be obtained if, for example, people are being identified or the intellectual property of artists and illustrators is involved. Again, common applications of generative AI fail these tests.
Generative AI systems are being trained on images for which no efforts have been made to identify the source. Copyright-protected works are routinely being used to train generative AI without appropriate permissions. In some cases, privacy is also being violated — for example, when generative AI systems create what look like photographs or videos of people without their consent. In addition to privacy concerns, the ease with which these ‘deepfakes’ can be created is accelerating the spread of false information.
Appropriate caveats
For now, Nature is allowing the inclusion of text that has been produced with the assistance of generative AI, providing this is done with appropriate caveats (see go.nature.com/3cbrjbb). The use of such large language model (LLM) tools needs to be documented in a paper’s methods or acknowledgements section, and we expect authors to provide sources for all data, including those generated with the assistance of AI. Furthermore, no LLM tool will be accepted as an author on a research paper.
The world is on the brink of an AI revolution. This revolution holds great promise, but AI — and particularly generative AI — is also rapidly upending long-established conventions in science, art, publishing and more. These conventions have, in some cases, taken centuries to develop, but the result is a system that protects integrity in science and protects content creators from exploitation. If we’re not careful in our handling of AI, all of these gains are at risk of unravelling.
Many national regulatory and legal systems are still formulating their responses to the rise of generative AI. Until they catch up, as a publisher of research and creative works, Nature’s stance will remain a simple ‘no’ to the inclusion of visual content created using generative AI.
 Tools such as ChatGPT threaten transparent science; here are our ground rules for their use
Tools such as ChatGPT threaten transparent science; here are our ground rules for their use
 How Nature readers are using ChatGPT
How Nature readers are using ChatGPT
 ‘Arms race with automation’: professors fret about AI-generated coursework
‘Arms race with automation’: professors fret about AI-generated coursework







