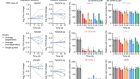
- NEWS AND VIEWS
Global genomics project unravels cancer’s complexity at unprecedented scale
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Rent or buy this article
Prices vary by article type
from$1.95
to$39.95
Prices may be subject to local taxes which are calculated during checkout
Nature 578, 39-40 (2020)
doi: https://doi.org/10.1038/d41586-020-00213-2
References
ICGC/TCGA Pan-Cancer Analysis of Whole Genomes Consortium. Nature 578, 82–93 (2020).
Rheinbay, E. et al. Nature 578, 102–111 (2020).
Alexandrov, L. B. et al. Nature 578, 94–101 (2020).
Li, Y. et al. Nature 578, 112–121 (2020).
Gerstung, M. et al. Nature 578, 122–128 (2020).
PCAWG Transcriptome Core Group et al. Nature 578, 129–136 (2020).
Priestley, P. et al. Nature 575, 210–216 (2019).
Nowell, P. C. Science 194, 23–28 (1976).
Fearon, E. R. & Vogelstein, B. Cell 61, 759–767 (1990).
Robinson, D. R. et al. Nature 548, 297–303 (2017).
 Read the paper: Pan-cancer analysis of whole genomes
Read the paper: Pan-cancer analysis of whole genomes
 Read the paper: The repertoire of mutational signatures in human cancer
Read the paper: The repertoire of mutational signatures in human cancer
 Read the paper: Analyses of non-coding somatic drivers in 2,658 cancer whole genomes
Read the paper: Analyses of non-coding somatic drivers in 2,658 cancer whole genomes
 Read the paper: Patterns of somatic structural variation in human cancer genomes
Read the paper: Patterns of somatic structural variation in human cancer genomes
 Read the paper: The evolutionary history of 2,658 cancers
Read the paper: The evolutionary history of 2,658 cancers
 Read the paper: Genomic basis for RNA alterations in cancer
Read the paper: Genomic basis for RNA alterations in cancer
 Huge whole-genome study of metastatic cancers
Huge whole-genome study of metastatic cancers