
Abstract
Learning classification tasks of \(({2}^{n}\times {2}^{n})\) inputs typically consist of \(\le n(2\times 2\)) max-pooling (MP) operators along the entire feedforward deep architecture. Here we show, using the CIFAR-10 database, that pooling decisions adjacent to the last convolutional layer significantly enhance accuracies. In particular, average accuracies of the advanced-VGG with \(m\) layers (A-VGGm) architectures are 0.936, 0.940, 0.954, 0.955, and 0.955 for m = 6, 8, 14, 13, and 16, respectively. The results indicate A-VGG8’s accuracy is superior to VGG16’s, and that the accuracies of A-VGG13 and A-VGG16 are equal, and comparable to that of Wide-ResNet16. In addition, replacing the three fully connected (FC) layers with one FC layer, A-VGG6 and A-VGG14, or with several linear activation FC layers, yielded similar accuracies. These significantly enhanced accuracies stem from training the most influential input–output routes, in comparison to the inferior routes selected following multiple MP decisions along the deep architecture. In addition, accuracies are sensitive to the order of the non-commutative MP and average pooling operators adjacent to the output layer, varying the number and location of training routes. The results call for the reexamination of previously proposed deep architectures and their accuracies by utilizing the proposed pooling strategy adjacent to the output layer.
Similar content being viewed by others
Introduction
Classification tasks are typically solved using deep feedforward architectures1,2,3,4,5,6. These architectures are based on consecutive convolutional layers (CLs) and terminate with a few fully connected (FC) layers, in which the output layer size is equal to the number of input object labels. The first CL functions as a filter revealing a local feature in the input, whereas consecutive CLs are expected to expose complex, large-scale features that finally characterize a class of inputs1,7,8,9,10.
The deep learning (DL) strategy is efficient only if each CL consists of many parallel filters, the layer’s depth, which differ by their initial convolutional weights. The depth typically increases along the deep architecture, resulting in enhanced accuracy. In addition, given a deep architecture and the ratios between the depths of consecutive CLs, accuracies increase as a function of the first CL depth.11.
The deep learning strategy resulted in several practical difficulties, including the following. First, although the depth increases along the deep architecture, the input size of the layers remains fixed. The second difficulty is that the last CL output size, depth \(\times \) layer input size, becomes very large, serving as the first FC layer input, which consists of a large number of tunable parameters. These computational complexities overload even powerful GPUs, limited by the accelerated utilization of a large number of filters and sizes of the FC layers. One way to circumvent these difficulties is to embed pooling layers along the CLs1. Each pooling reduces the output dimension of a CL by combining a cluster of outputs, e.g., \(2\times 2\), at one, and \(n\) such operations along the deep architecture reduce the CL dimension by a factor \({4}^{n}\). The most popular pooling operators are max-pooling (MP)12, which implements the maximal value of each cluster, and average pooling (AP)13,14, which implements the average value of each cluster; however, more types of pooling operators exist12,15,16,17.
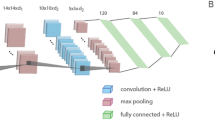
The core question in this work is whether accuracies can be enhanced depending on the location of the pooling operators along the CLs of a given deep architecture. For instance, VGG16 consists of 13 CLs, three FC layers, and five \((2\times 2)\) MP operators located along the CLs2 (Fig. 1A). The results indicate that accuracies can be significantly increased by a smaller number of pooling operators adjacent to the last CL with optionally larger pooling sizes, for example, the advanced VGG16 (Fig. 1B). The optimized accuracies of these types of advanced VGG architectures with \(m\) layers (A-VGGm) are first presented for selected \(m\) values (\(6\le m\le 16\)). Next, the underlying mechanism of the enhanced A-VGGm accuracies is discussed.

VGG16 and A-VGG16 architectures. (A) VGG16 architecture (13 \(\left(3\times 3\right)\) CLs and in between 5 \((2\times 2)\) MP operators, followed by 3 FC layers) for the CIFAR10 database consisting of \(32\times 32\) RGB inputs. A CL is defined by its square filters with dimension K and depth D, \(\left(K, D\right)\). (B) A-VGG16 architecture for CIFAR10 inputs consisting of 7 \((3\times 3)\) CLs, \((4\times 4)\) average pooling (AP), 6 \((3\times 3)\) CLs, \(\left(2\times 2\right)\) MP and 3 FC layers.
A-VGGm accuracies
A-VGG16 consists of \(\left(4\times 4\right)\) average pooling (AP) and \(\left(2\times 2\right)\) MP after the 7th and 13th CL, respectively (Fig. 1B and Table 1), with a maximal depth of \(512\) as in VGG16. The maximum average accuracy, 0.955, is superior to the accuracy, 0.935, obtained for the standard VGG1611,18 and the fine-tuned optimized accuracy 0.9410 (Fig. 1A) and is comparable with the Wide-ResNet4,5 median accuracy consisting of 16 layers with widening factor 10 (WRN16-10).
Note that the replacement of the pair of pooling operators, \([AP(4\times 4), MP\left(2\times 2\right)]\) along A-VGG16 (Fig. 1B), by several other options, for example, \(\left[MP(2\times 2\right), AP\left(4\times 4\right)\)] and \(\left[AP(2\times 2\right), MP\left(8\times 8\right)\)], also yielded an average accuracies \(>0.95\), indicating the superior robustness of A-VGG16 accuracies over VGG16. Removing the last three CLs (the fifth block of A-VGG16) resulting in A-VGG13, with an average accuracy of \(0.955\), identical to that of A-VGG16 up to the first three leading digits (Table 1). One possible explanation to the same accuracies is that the receptive field19 of the last three CLs of A-VGG13 is \(7\times 7\) saturating the \(8\times 8\) layers’ input size. It also suggests that accuracies are only mildly affected by \(m>13\).
The A-VGG8 architecture that consists of only 8 layers, results in \(0.940\) averaged accuracy, exceeding the optimized VGG8 accuracy of \(0.915\), which consists of 5 \(MP(2\times 2)\) one after each CL2,20, and also exceeds the average accuracy of VGG16. Here again, \(AP(2\times 2)\) and \(MP(4\times 4)\) were placed after the 3rd and the 5th CLs, respectively (Table 1). This result indicates that a shallow architecture, with fewer pooling operators adjacent to the output, can imitate the accuracies of a deeper architecture with double the number of layers, while the receptive field covers a small portion of the layers’ input size.
Using only one FC layer reduces the number of layers by two, from A-VGG16 to A-VGG14, and from A-VGG8 to A-VGG6 (Table 1). The results indicate that accuracies are only mildly affected by such modifications, where A-VGG6 achieves an average accuracy of 0.936, which slightly exceeds that of VGG16 and A-VGG14 exceeds 0.954 (Table 1). We note that this type of architectures with only one FC layer consists of fewer parameters and can be mapped onto tree architectures (unpublished)21.
Similarly, the A-VGG13 and A-VGG16 architectures with linear activation functions for the FC layers achieved similar averaged accuracies of \(0.954\) and \(0.955\), respectively, both with small standard deviations (Supplementary Information). The three linear FC layers can be folded into one in the test procedure22, minimizing its latency; however, training must be performed with three separated FC layers.
The gap between the average accuracies of A-VGG8 and A-VGG6 (\(\sim 0.004\)) was slightly greater than that between the enhanced accuracies of A-VGG16 and A-VGG14 (Table 1), indicating that the gap decreases with \(m\). Nevertheless, the comparable average accuracies of A-VGG13 and A-VGG14 with A-VGG16 indicate that removing two out of three FC layers or removing three out of the thirteen CLs does not affect accuracies. Hence, it is interesting to examine the average accuracies of VGG11 where two FC layers as well as the last three CLs are removed.
Optimized learning gain using pooling operators
The backpropagation learning step23 updates the weights towards the correct output values for a given input. Typically, such a learning step can add noise and is destructive to a fraction of the training set24,25,26,27. However, the average accuracy increases with epochs and asymptotically saturates at a value that identifies the quality of the learning algorithm for a given architecture and database.
One important ingredient of DL is downsizing the input size as the layers progress. This can be done by either pooling operators or using the stride of the CLs. Although both reduce the size of the input, the pooling operators transfer specific output fields, such as maximal field in the MP operators. It aims to select the most influential field from a small cluster on a node in the successive layer, for example, MP \(\left(2\times 2\right)\). Its underlying logic is to maximize the learning step gain for the current input while minimizing the added noise by zeroing other routes; maximize learning with minimal side-effect damage. However, this local maximization does not ensure a global one.
Commonly, several MP operators are placed among the CLs, for example, five times in the case of VGG16 (Fig. 1A), and apparently solve simultaneously the following two difficulties. First, although the depth, \(D\), increases along the CLs (Fig. 1A), the input size, \(K\), of the layers shrinks accordingly such that the output sizes of the CLs, \(K\times D\), do not grow linearly with depth. Second, successive MP operators appear to select the most influential routes on the first FC layer, which is adjacent to the output layer. However, these local decisions following consecutive MP operators do not necessarily result in the most influential routes in the first FC layer, as elaborated below using a toy model.
Assume a binary tree, where its random nodal values are low, medium, or high (Fig. 2A). The tree output is equal to the branch with the maximal field, which is calculated as the product of its three nodal values. The first strategy is based on local decisions, similar to MP operators. For each node the maximal child, among the two, is selected (gray circles in Fig. 2A), and the selected route is the one composed of gray nodes only, where its value is \(M\cdot M\cdot M\) (the brown branch in Fig. 2A). However, a global decision among the eight branches results in a maximal field \(H\cdot H\cdot L\)(green branch in Fig. 2A). This toy model indicates that a global decision differs from local decisions; however, the probability of such an event is unclear.

Comparison between several small MP operators along CLs and a large one at their end. (A) A binary tree where the random nodal values are low (L), medium (M), or high (H), e.g., \(1, 10\), and \(1000\). A local decision selects the path to the maximal nodal child (gray), resulting in the brown route connecting three gray nodes. A global decision selects the green route, maximizing the product of its nodal values. (B) Gaussian random \(\left(1024\times 1024\right)\) input followed by ten \((3\times 3)\) CLs, where \(\left(2\times 2\right)\) MP is placed after the first four CLs (Top), and similar architecture where a single \(\left(16\times 16\right)\) MP is placed after the 10 CLs. The \(\left(64\times 64\right)\) output values are denoted by \({O}_{SP}\) (Top) and \({O}_{TP}\) (bottom) (Supplementary Information). (C) The probability \(P( \frac{{O}_{SP}}{{O}_{TP}}>1)\) as a function of the number, \(n\), of \(\left(2\times 2\right)\) MP (\(n=4\) is demonstrated in B).
A more realistic model, imitating deep architectures (Fig. 1), is Gaussian random \((1024\times 1024)\) inputs followed by ten \((3\times 3)\) CLs with unity depth (Fig. 2B). Two scenarios, local decisions and a global decision, are discussed. In the first, \((2\times 2)\) MP operators are placed after each of the first \(n\) CLs (Fig. 2B top, exemplified \(n=4\)), where in the second one a single \(({2}^{n}\times {2}^{n})\) MP operator is placed after the ten CLs (Fig. 2B bottom, exemplified \(n=4\)). For both scenarios, there are \(({2}^{10-n}\times {2}^{10-n})\) non-negative (ReLU) outputs, denoted by \({O}_{SP}\) (Sequence Pooling), representing local decisions and \({O}_{TP}\) (Top Pooling), representing a global decision. For a given \(n\), the \({2}^{10-n}\times {2}^{10-n}\) ratios, \({O}_{SP}/{O}_{TP}\), were calculated and averaged over many Gaussian random inputs and several sets of ten randomly selected convolutional filters, which were identical for both scenarios. The probability \(P(\frac{{O}_{SP}}{{O}_{TP}}>1)\) indicates that local decisions, \(n\) consecutive MPs, result in a larger output than a global decision, a single \({(2}^{n}\times {2}^{n})\) MP (Supplementary Information). This probability rapidly decreased with \(n\), possibly exponentially (Fig. 2C), and even for \(n=2\) it was below \(0.1\).
The increase in CLs depth beyond unity does not qualitatively affect the probability \(P\left(\frac{{O}_{SP}}{{O}_{TP}}>1\right),\) as indicated by simulations of VGG8 with five consecutive \((2\times 2)\) MP operators after each CL and a single \((32\times 32)\) MP after five CLs. The same five random \(\left(3\times 3\right)\) convolutions were used for both architectures, and the \(512\) ratios, \(\frac{{O}_{SP}}{{O}_{TP}}\) for the single output of each filter, were calculated. Averaging over CIFAR10 training inputs and several selected sets of fixed random convolutions results in \(O\left({10}^{-3}\right)\) for probability \(P(\frac{{O}_{SP}}{{O}_{TP}}>1)\) \(.\)
The results clearly indicate that a global decision selects the most influential routes to the first FC layer. Hence, pooling adjacent to the output layer, is superior to the selection following consecutive local pooling decisions. This supports that using larger pooling operators adjacent to the output of the CLs enhances accuracies (Table 1). It is expected that using pooling operators solely after the entire CLs will enhance accuracies even further; however, its validation in simulations of A-VGGm architectures is difficult. The running time per epoch of such large \(K\times D\) deep architectures is several times longer, and the optimization of accuracies is currently beyond our computational capabilities.
A simpler architecture is the LeNet528,29, with much lower depth and total number of CLs, consisting of two CLs followed by \((2\times 2)\) MP each and three FC layers (Fig. 3A). The optimized average accuracy on the CIFAR10 database is \(0.77\)11. Advanced LeNet5 (A-LeNet5) architectures consist of pooling operators only after the second CL (Fig. 3A). In particular, the two pooling options, \(\left(2\times 2\right) AP \circ \left(2\times 2\right) MP\) and \(\left(2\times 2\right) MP\circ \left(2\times 2\right) AP\) were examined (examples \(a\) and \(b\) in Fig. 3A), imitating the dimensions of the two \(\left(2\times 2\right)\) \(MP\) of LeNet5. Indeed, these A-LeNet5 architectures enhance average accuracies by up to ~ 0.02, in comparison to LeNet5 (Fig. 3B), as predicted by the abovementioned argument. Similarly, using either \(\left(4\times 4\right)\) \(MP\) or \(\left(4\times 4\right)\) \(AP\) after the second FC layer resulted in \(\sim 0.79\) maximized average accuracies (not shown). The shift of the MP by only one CL, from the first to the second, improves the accuracies, and an enhanced effect might be expected by skipping over more CLs in deeper architectures (Fig. 2C). An interesting aspect of A-LeNet5 is that accuracies improved although the receptive field covers only a small portion of the input, in contrast to A-VGG16.

A-LeNet5 accuracies’ architectures and the role of non-commutative pooling operators. (A) A-LeNet5 architectures, where the pooling layers (exemplified in the dashed rectangle) are placed after the second CL. (B) Detailed architectures and average accuracies for the five schemes of A-LeNet5 in A (see Supplementary Information for detailed parameters and standard deviations). (C) Non-commutative pooling operators, where the number of active backpropagation routes is \(9\) for \(\left(3\times 3\right) AP\circ \left(2\times 2\right) MP\), \(4\) delocalized routes for \(\left(3\times 3\right) MP\circ \left(2\times 2\right) AP\) and \(4\) localized routes for \(\left(2\times 2\right) AP\circ \left(3\times 3\right) MP\).
Another type of A-LeNet5 is a combination of a pair of \(\left(2\times 2\right)\) and \(\left(3\times 3\right)\) pooling operators after the two CLs (\(c\), \(d\) and \(e\) in Fig. 3A). Although the input size of the first FC layer decreased from \(400\) in LeNet5 to \(256\), the average accuracies was enhanced by \(\sim 0.011\) (\(d\) in Fig. 3B). This result exemplifies the improved A-LeNet5 accuracies even when the input size of the first FC layer decreases. Examples \(d\) and \(e\) (Fig. 3A) consist of the same pooling operators, \(\left(2\times 2\right) AP\) and \(\left(3\times 3\right) MP\), but with the exchanged order of the operators. Their average accuracies differ by \(\sim 0.016\) (Fig. 3B), indicating that these pooling operators do not commute with the exchanged order. Another possible class of commutation is the exchanged type of operation (color) while maintaining their size; exchanged \(MP\) and \(AP\) (\(c\) and \(d\) or \(a\) and \(b\) in Fig. 3A). Average accuracies indicate that pooling operators do not necessarily commute with exchanged colors.
The two non-commutative classes, order and type of operations, stem from different numbers and locations of the backpropagation active routes in the lower layers (Fig. 3C). The number of locally active backpropagation routes in a \(\left(6\times 6\right)\) window is \(9\) for \(\left(3\times 3\right) AP\circ \left(2\times 2\right) MP\), whereas for \(\left(3\times 3\right) MP\circ \left(2\times 2\right)A P\) is \(4\). For the exchanged order of operators (\(d\) and \(e\) in Fig. 3A), the number of backpropagation active routes is the same, \(4\), in both cases. However, these \(4\) routes were localized in \(\left(2\times 2\right)\) (\(e\) in Fig. 3B, C), but delocalized over \(\left(6\times 6\right)\) (\(d\) in Fig. 3B, C). Hence, the non-commutation of pooling operators can stem either from the different numbers of active backpropagation routes or from their different locations.
Discussion
The aim of pooling operators, is downsizing the input size as the layers progress while transferring specific output fields, such as maximal field in the MP operators. It selects the most influential local field, but does not ensure a most influential global field on the output. The proposed enhanced learning strategy is based on updating the most influential routes, that is, the maximal fields, on the output units. This is supported by the A-VGGm and A-LeNet5 simulations, where the average accuracies are enhanced using pooling operators placed closer to the output layer (Figs. 1 and 3, Table 1). Its underlying mechanism is aimed at maximizing the learning gain for the current input, while simultaneously minimizing the average damage on the current learning of the entire training set. Each learning step for a given input induces noise on the learning of other inputs. Hence, increasing the signal-to-noise ratio (SNR) of a learning step, average over the training set, requires updating the most influential routes of the current input; maximize learning with minimal side-effect damage.
The realization of the proposed advanced learning strategy entails a discussion of the following three theoretical and practical aspects. First, the selection of the most influential routes on the first FC layer is not necessarily equivalent to the selection of the most influential routes on the output units. However, a backpropagation step initiated at the most influential input weight on an output unit, updates all the CLs’ routes since the spatial structure disappears within the one-dimensional FC layers. Hence, the proposed strategy approximates only the most influential routes on the outputs. The exceptional architectures were A-VGG6 and A-VGG14 (Table 1), consisting of one FC layer, demonstrating accuracies that were only slightly below A-VGG8 and A-VGG16, respectively.
The second aspect concerns the computational complexity of the proposed advanced learning strategy. Selecting the most influential routes after all CLs with their fixed depth overloaded even advanced GPUs since the depth increases while the layer’s dimension does not decrease. For instance, the running time per epoch of \(\left(32\times 32\right)\) MP placed after all CLs of A-VGG16 was slowed down by a factor of \(\sim 10\). To circumvent this difficulty, the advanced learning strategy was approximated by placing the first pooling operator before the CLs with maximal depth and the second operator after all CLs (Fig. 1 and Table 1). Nevertheless, it is interesting to examine, using advanced GPUs, whether placing pooling operators after all CLs further advances accuracies.
The third aspect is the selection of the types, dimensions, and locations of pooling operators along the deep architecture to maximize accuracies. For a given A-VGGm, several pooling arrangements result in similar accuracies, and we report only the one that maximizes the average accuracies under a given number of epochs. Nevertheless, the maximized average A-VGGm accuracies hint at preferred combinations where the AP is placed before CLs with maximal depth and the MP operates after all CLs (Table 1 and Fig. 1), which might stem from the following insight. MP after all CLs carefully selects only one significant backpropagation route among a cluster of routes, whereas an AP close to the input layer spreads its incoming backpropagation signal to multiple routes. This arrangement was found to maximize accuracies for several A-VGGm architectures (Table 1). However, A-LeNet indicated an opposite trend, where AP at the top of two adjacent pooling operators maximized accuracies (Fig. 3). The role is not yet clear and may depend on the database and details of the training architecture.
We present an argument indicating that pooling decision adjacent to the output layer enhances accuracy (Table 1). However, one might attribute this improvement to the increase in the number of parameters in the first FC layer, where the number of parameters in the rest of CLs and FC layers remain the same. In order to pinpoint the accuracy improvement to the location of the pooling operators, we obtained ~ 0.954 for A-VGG16 with \(4\times 4\) AP after the 7th CL and with \(8\times 8\) MP operator after the 13th CL. In this architecture the size of the first FC layer is the same as in VGG16, and therefore the number of parameters in both remain the same, yet there is a clear improvement in the accuracy.
The non-commutative pooling operator features exemplify the sensitivity of the maximal average accuracies to their order and type, and significantly enrich the possible number of pooling operators with a given dimension. For \(\left(8\times 8\right)\) pooling dimension, for instance, one can find \(8\) possible pooling operators; \(\left(2\times 2\right)XP\circ \left(2\times 2\right)YP\circ \left(2\times 2\right)ZP\), where \(X, Y\) and \(Z\) equal either to \(M\) (Max) or \(A\) (Average). Similarly, the number of pooling operators with dimension \(\left({2}^{n}\times {2}^{n}\right)\) is \({2}^{n}\), and exponentially increases when more than two types of \((2\times 2)\) pooling operators are allowed. The results for A-LeNet indicate that enhanced accuracies can be achieved using combinations of consecutive pooling operators after the second CLs (Fig. 3). However, the identification of preferred combinations to maximize the accuracies in general deep architectures deserves further research.
The non-commutative features of pooling operators also stem from their different number of backpropagation downstream updated routes (Fig. 3C). For instance, A-VGG16 with \(\left(32\times 32\right)\) MP, before the first FC layer, consists of a single backpropagation downstream updated route per filter, whereas for \(\left(32\times 32\right)\) AP there are \(1024\) routes. Nevertheless, the preferred pooling operators to maximize accuracies need to be determined. The most influential route is favored to correct the output of the current input; however, it induces output noise on other training inputs, resulting in a low SNR. Similarly, updating \(1024\) downstream routes using AP, including the weak ones, increases the correct output of the current input in comparison to MP; however, with enhanced side-effect, noise on other training inputs, resulting in a possibly low SNR. Hence, for a given architecture and dataset, the selection of pooling operators that maximize the averaged SNR per epoch is yet unclear.
The accuracies of A-VGG6 and A-VGG14 with only one FC layer were only slightly below those of the three FC layers, A-VGG8 and A-VGG16, respectively (Table 1). Architectures with only one FC layer are characterized by lower learning complexity and number of tunable parameters. In addition, these architectures can be mapped onto tree architectures30,31, generalizing recent LeNet mapping into tree architecture without affecting accuracies but with lower computational learning complexity31. Tree mapping of architectures comprising more than two CLs, inspired by dendritic tree learning30,31,32,33,34,35, is beyond the scope of the presented work and will be discussed elsewhere21.
It was observed that shallower architectures can yield the same accuracies as deeper ones, for instance, A-VGG13 and A-VGG16. This result can be attributed to fact that the last CLs’ receptive field completely covers the input, suggesting that the last three CLs are redundant. Another example, is A-VGG8 which achieves the same accuracy as VGG16. In this case the last CLs of A-VGG8, the receptive field does not fully cover the CLs’ input. Hence, the enhanced accuracy is attributed to the advanced location of the pooling operators. Similarly, A-LeNet5 enhances the accuracies of LeNet5, while the receptive field covers a small portion of the input, in contrast to A-VGG16.
The extension of the proposed idea to deeper architectures on CIFAR-10, e.g. DenseNet36 and EfficientNet37, results in the following several difficulties which at the moment are beyond our computational capabilities. The accuracy of deeper architectures approaches one and thus the enhancement of the accuracy by preforming pooling decisions adjacent to the output is expected to be in a sub-percentage increase. The observation of such minor accuracy improvements will require fine-tuned optimization in high resolution on the hyper-parameter space as well as large statistics. We note that the running time per epoch even for A-VGG16 where a \(\left(32\times 32\right) MP\) was placed after all CLs was slowed down by a factor of \(\sim 10,\) which made its optimization beyond our computational capabilities.
Using datasets with higher complexity, more classes and a lesser number of training examples per class, e.g., CIFAR-10038 and ImageNet39, result in significant fluctuated accuracy among samples. These fluctuations make observing the effect of the pooling operators adjacent to the output layers much more difficult, and deserves careful further examination using more advanced computational capabilities.
The original VGG architectures were constructed for large input image sizes of \(224\times 224\). The presented work demonstrates enhanced accuracies using A-VGGm architectures on small input image sizes, \(32\times 32\). Extrapolating these enhancements on large images is much beyond our computational capabilities. Nevertheless, preliminary results using online learning (one epoch) on images of size \(128\times 128\) indicate a slight improvement of the average accuracies of A-VGG16 in comparison to VGG16. In general one might expect that the kernel size in A-VGGm might require scaling with the size of the input images in order to have the entire input covered by the receptive field.
Finally, the reported average accuracies for A-VGG16 and A-VGG13 approach Wide-ResNet16 (widening factor of 10) median accuracies, consisting of an architecture with three main ingredients: skip connections, CLs with stride \(= 2\) and \((8\times 8)\) AP after all CLs. This similarity hints that the ingredient dominating the enhanced accuracies, among the three, is a pooling operation after all CLs.
Data availability
Source data were provided in this study. All data supporting the plots within this paper, along with other findings of this study, are available from the corresponding author upon reasonable request.
Code availability
The simulation code is provided in this study, parallel to its publication in GitHub.
References
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Szegedy, C. et al. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 1–9.
Zagoruyko, S. & Komodakis, N. Wide residual networks. arXiv preprint arXiv:1605.07146 (2016).
He, K., Zhang, X., Ren, S. & Sun, J. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778.
Szegedy, C., Ioffe, S., Vanhoucke, V. & Alemi, A. in Proceedings of the AAAI Conference on Artificial Intelligence.
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2017).
Hertel, L., Barth, E., Käster, T. & Martinetz, T. in 2015 International Joint Conference on Neural Networks (IJCNN). 1–4 (IEEE).
Wiatowski, T. & Bölcskei, H. A mathematical theory of deep convolutional neural networks for feature extraction. IEEE Trans. Inf. Theory 64, 1845–1866 (2017).
Tzach, Y. et al. The mechanism underlying successful deep learning. arXiv preprint arXiv:2305.18078 (2023).
Meir, Y. et al. Efficient shallow learning as an alternative to deep learning. Sci. Rep. 13, 5423 (2023).
Yu, D., Wang, H., Chen, P. & Wei, Z. in Rough Sets and Knowledge Technology: 9th International Conference, RSKT 2014, Shanghai, China, October 24–26, 2014, Proceedings 9. 364–375 (Springer).
LeCun, Y. et al. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems 2 (NIPS 1989) (ed. Touretzky, D. S.) 396–404 (1989).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580 (2012).
Wan, L., Zeiler, M., Zhang, S., Le Cun, Y. & Fergus, R. in International Conference on Machine Learning. 1058–1066 (PMLR).
Sermanet, P., Chintala, S. & LeCun, Y. in Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012). 3288–3291 (IEEE).
Hasanpour, S. H., Rouhani, M., Fayyaz, M., Sabokrou, M. & Adeli, E. Towards principled design of deep convolutional networks: Introducing simpnet. arXiv preprint arXiv:1802.06205 (2018).
Luo, W., Li, Y., Urtasun, R. & Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Advances in Neural Information Processing Systems (NeurIPS) 29 (2016).
Cai, Y. et al. Low bit-width convolutional neural network on RRAM. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 39, 1414–1427 (2019).
Le Cun, Y., Kanter, I. & Solla, S. A. Eigenvalues of covariance matrices: Application to neural-network learning. Phys Rev Lett 66 2396 (1991).
Dror, A. B. et al. Layer Folding: Neural Network Depth Reduction using Activation Linearization. arXiv preprint arXiv:2106.09309 (2021).
LeCun, Y. in Computer Vision–ECCV 2012. Workshops and Demonstrations: Florence, Italy, October 7–13, 2012, Proceedings, Part I 12. 496–505 (Springer).
Minsky, M. L. & Papert, S. A. Perceptrons - Expanded Edition MIT Press (1988).
Gardner, E. The space of interactions in neural network models. J. Phys. A Math. Gen. 21, 257 (1988).
Kirkpatrick, J. et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. 114, 3521–3526 (2017).
Kaushik, P., Gain, A., Kortylewski, A. & Yuille, A. Understanding catastrophic forgetting and remembering in continual learning with optimal relevance mapping. arXiv preprint arXiv:2102.11343 (2021).
LeCun, Y. et al. Learning algorithms for classification: A comparison on handwritten digit recognition. Neural Netw. Stat. Mech. Perspect. 261, 2 (1995).
LeCun, Y. et al. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1, 541–551 (1989).
Hodassman, S., Vardi, R., Tugendhaft, Y., Goldental, A. & Kanter, I. Efficient dendritic learning as an alternative to synaptic plasticity hypothesis. Sci. Rep. 12, 6571 (2022).
Meir, Y., Ben-Noam, I., Tzach, Y., Hodassman, S. & Kanter, I. Learning on tree architectures outperforms a convolutional feedforward network. Sci. Rep. 13, 962 (2023).
Sardi, S. et al. Adaptive nodes enrich nonlinear cooperative learning beyond traditional adaptation by links. Sci. Rep. 8, 5100 (2018).
Sardi, S. et al. Brain experiments imply adaptation mechanisms which outperform common AI learning algorithms. Sci. Rep. 10, 6923 (2020).
Sardi, S. et al. Long anisotropic absolute refractory periods with rapid rise times to reliable responsiveness. Phys. Rev. E 105, 014401 (2022).
Uzan, H., Sardi, S., Goldental, A., Vardi, R. & Kanter, I. Biological learning curves outperform existing ones in artificial intelligence algorithms. Sci. Rep. 9, 1–11 (2019).
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4700–4708.
Tan, M. & Le, Q. in International Conference on Machine Learning. 10096–10106 (PMLR).
Krizhevsky, A. & Hinton, G. Learning multiple layers of features from tiny images. (2009).
Deng, J. et al. in 2009 IEEE Conference on Computer Vision and Pattern Recognition. 248–255 (IEEE).
Acknowledgements
We thank for the much helpful suggestions and insights of both reviewers which helped improving the final version of this paper. I.K. acknowledges the partial financial support from the Israel Science Foundation (Grant Number 346/22).
Author information
Authors and Affiliations
Contributions
Y.M., Y.T., R. D. G., and O.T. contributed equally to this study. R. V. discussed the results and commented on the manuscript. I.K. initiated and supervised all aspects of the study.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Meir, Y., Tzach, Y., Gross, R.D. et al. Enhancing the accuracies by performing pooling decisions adjacent to the output layer. Sci Rep 13, 13385 (2023). https://doi.org/10.1038/s41598-023-40566-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-40566-y
This article is cited by
-
Towards a universal mechanism for successful deep learning
Scientific Reports (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
