
Abstract
Goblet cells (GCs) in the conjunctiva are specialized epithelial cells secreting mucins for the mucus layer of protective tear film and playing immune tolerance functions for ocular surface health. Because GC loss is observed in various ocular surface diseases, GC examination is important for precision diagnosis. Moxifloxacin-based fluorescence microscopy (MBFM) was recently developed for non-invasive high-contrast GC visualization. MBFM showed promise for GC examination by high-speed large-area imaging and a robust analysis method is needed to provide GC information. In this study, we developed a deep learning framework for GC image analysis, named dual-channel attention U-Net (DCAU-Net). Dual-channel convolution was used both to extract the overall image texture and to acquire the GC morphological characteristics. A global channel attention module was adopted by combining attention algorithms and channel-wise pooling. DCAU-Net showed 93.1% GC segmentation accuracy and 94.3% GC density estimation accuracy. Further application to both normal and ocular surface damage rabbit models revealed the spatial variations of both GC density and size in normal rabbits and the decreases of both GC density and size in damage rabbit models during recovery after acute damage. The GC analysis results were consistent with histology. Together with the non-invasive high-contrast imaging method, DCAU-Net would provide GC information for the diagnosis of ocular surface diseases.
Similar content being viewed by others


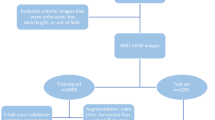
Introduction
Goblet cells (GCs) in the conjunctiva are specialized epithelial cells that secrete mucins on the ocular surface. Mucins from GCs form the innermost mucus layer of tear film, and the mucus layer spreads the tear film for protection. GC dysfunction or loss is associated with various ocular surface diseases including dry eye disease1,2. Therefore, GC examination is important for both diagnosis and treatment monitoring. However, GC examination has been difficult due to the limitations of current examination methods. Impression cytology (IC) and reflection confocal microscopy (RCM) have been used for GC examination in human subjects. IC is a simple examination method that removes superficial cells including GCs with filter papers. GCs on the filter paper are visualized after various histological processes including periodic acid-Schiff (PAS) staining. IC has several limitations of long examination time, lack of standardization, and invasiveness, etc. RCM is a non-invasive 3D imaging method based on light reflection. RCM was used to visualize various cells in the eye, and an RCM study of conjunctival CGs was previously conducted3. However, RCM has limitations of low image contrasts, small fields of view, and inconvenient contact imaging. We recently developed a high-contrast GC imaging method, called as moxifloxacin-based fluorescence microscopy (MBFM)4,5,6. MBFM is a fluorescence imaging method based on specific GC labeling of a Food and Drug Administration (FDA)-approved moxifloxacin ophthalmic solution. MBFM demonstrated high-contrast CG visualization in various live animal models and the imaging was non-invasive by using excitation energy much less than the phototoxicity threshold. MBFM can be applied to human subjects for GC examination. A robust image analysis method needs to be developed to make GC information available for diagnosis.
There are various cell image analysis methods. Conventional methods use basic image processing algorithms for cell segmentation such as intensity thresholding, filtering, morphological operations, and deformable model fittings7,8,9. A region growing method expanding seed points for segmentation was successfully used in some studies10,11. However, conventional methods often faced challenges, requiring continuous parameter adjustments dealing with new dataset, making it laborious to achieve consistent results. With the advent of deep learning methods, particularly those using convolutional neural networks (CNNs), these shortcomings have been addressed12,13. CNNs demonstrated their effectiveness in automating biomedical image analysis by learning the characteristics. Deep-learning methods include regression- and detection-based methods that learn the number and morphology of cells, respectively14,15,16. Detection-based methods are useful for detail cell analysis17. U-Net is a widely used detection-based method in medical image analysis by exhibiting high pixel-level discrimination and good segmentation performance on small data sets18. Enhanced U-Net models introduced novel attention methods to skip connections for selective integration of encoder information with decoders19,20,21,22. Because GCs are densely distributed either individually or in clusters on the conjunctival surface with irregular background shadowed by underlying blood vessels, it is necessary to develop a feature extraction method optimized for the characteristics of GC images.
In this study, we propose a dual-channel attention U-Net (DCAU-Net) that employs dual-channel convolution and a novel global channel attention mechanism for robust GC segmentation from MBFM GC images. There are two main contributions. First, we developed DCAU-Net which had a modified encoder to extract features with dual-channel modules and a modified skip connection to retain the global information. The dual-channel modules integrated semantic and texture feature information and delivered it to the next layer. The global channel attention module strengthened feature representation and reduced redundancy. Second, we applied DCAU-Net to the GC analysis in MBFM images of live rabbit models in comparison with PAS labeled histological images in terms of both GC density and morphological characteristics. GC density from DCAU-Net was compared with that from the manual counting by experts in MBFM images. Moreover, DCAU-Net was applied to GC analysis in MBFM images of ocular surface damage rabbit models to visualize their changes.
Results
Performance comparison between DCAU-Net and U-Net in GC segmentation
The performance of DCAU-Net in GC segmentation was evaluated in comparison with the standard U-Net model. The evaluation results are summarized in Table 1 and Fig. 1.

Comparison of the precision-recall curves of the standard U-Net and DCAU-Net models. AP the area under precision-recall curve.
The comparison testing was repeated 5 times, and DCAU-Net achieved better performance in dice coefficient and IoU than the standard U-Net. The standard U-Net exhibited imbalanced results with relatively high recall and low precision scores compared to DCAU-Net. The precision-recall curve was used to indicate the discriminating ability of these models with respect to the variation in discrimination threshold. It was an evaluation index that did not contain true negatives. For recall values of 0.8 or higher, DCAU-Net showed higher precision values than U-Net.
The segmentation results of U-Net and DCAU-Net in three representative GC images with different cell densities are presented in Fig. 2. Input GC images, GT images, U-Net segmentation images and their difference images with GT images, DCAU-Net images and their difference images are presented in different columns. Both U-Net and DCAU-Net segmented GCs well in all three GC images in general. The difference images revealed that U-Net tend to segment GCs smaller than GT images. U-Net also missed some GCs and misclassified non-GC objects with strong signals as GCs. U-Net did not resolve aggregated GCs, however, DCAU-Net segmented GCs better and had lower rates of missing and misclassification than U-Net. Therefore, DCAU-Net performed better than the standard U-Net in GC segmentation.

Comparison of original U-Net and DCAU-Net in the segmentation of GCs at different densities. (a) Raw image. (b) Image GT. (c) U-Net. (d) Difference between GT and U-Net. (e) DCAU-Net. (f) Difference between GT and DCAU-Net.
GC density analysis with DCAU-Net in normal rabbit models
DCAU-Net was applied to GC density analysis of normal rabbit models. GC densities were obtained by counting the number of segmented GCs per unit area. GC densities from DCAU-Net segmentation were compared with GC densities from manual counting by plotting the pair densities in a 2D scatter plot as shown in Fig. 3a. GC densities in various conjunctival regions including the fornix and bulbar conjunctiva were analyzed. The obtained GC densities varied in a large range from 1050 ± 640 to 2350 ± 630 cells/mm2, depending on the conjunctiva location. GC densities from DCAU-Net showed a linear relationship with those from manual counting with a correlation coefficient value of 0.98. As illustrated in Fig. 3b, the estimated GC densities were 94.3% of the true GC densities on average, and 95% of all GC density estimations were within − 12.4% and + 2.0% of the true GC densities. The slight underestimation of GC density with DCAU-Net was due to the counting of aggregated GCs as ones, as depicted in the representative images in Fig. 3c.

DCAU-Net application to GC density analysis in MBFM images of live normal rabbit models in comparison with manual counting by experts. (a) A scatter plot presenting GC densities obtained from DCAU-Net and the ones from expert manual counting. (b) A scatter plot presenting GC density errors which were obtained via (GC densities from DCAU-Net) − (GC densities from expert counting). (c) A representative MBFM input image, GT image, DCAU-Net prediction image, and difference between GT and prediction images. Orange arrows in (c) mark aggregated GCs.
Spatial variation of GC density and size in normal rabbit conjunctiva
DCAU-Net segmentation helped to accurately estimate the GC density in MBFM images of live rabbit models. Automated GC density analysis was applied to mosaic MBFM images to visualize the spatial variation of GC density in the entire upper conjunctiva of ex-vivo normal rabbit models. A representative mosaic MBFM image covering a 20 × 20 mm2 conjunctival region is presented in Fig. 4a, and a GC density map in a different colormap was overlaid on the mosaic MBFM image. The mosaic GC image was generated by combining equally spaced 8 × 8 MBFM images. The GC density map indicated high spatial variations of GC density depending on the location in the upper rabbit conjunctiva. It was the highest (2030 ± 620 cells/mm2) in the fornix conjunctiva and the lowest (1150 ± 630 cells/mm2) in the bulbar conjunctiva (Fig. 4b). In the fornix region, GC density was higher on the nasal side than on the temporal side. These results were consistent with those of the previous studies23,24. DCAU-Net segmentation was used to analyze the size of GCs in addition to their density. The analysis results revealed a spatial variation of GC size depending on the conjunctival regions (Fig. 4c,d). GC sizes were 66 and 46 μm2 on average in the bulbar and fornix conjunctivas, respectively. GCs in the fornix conjunctiva were smaller and denser than those in the bulbar conjunctiva. The size variation of GCs has not been reported before and needs to be verified by statistical analysis of conventional PAS histological images in the future. The eccentricities of GCs in the bulbar and fornix conjunctiva were 0.54 and 0.49, respectively, indicating no significant difference.

Analysis of GC density and size variations in the upper conjunctiva of a normal rabbit model, ex-vivo. DCAU-Net was used in the GC analysis. (a–c) Histograms of GC densities in the fornix and bulbar conjunctiva, a map of GC densities in the upper conjunctiva together with representative input and predicted GC images in the fornix and bulbar conjunctiva. (d) A histogram of GC sizes in the fornix and bulbar conjunctiva.
GC analysis in ocular surface damage rabbit models
DCAU-Net, which was trained with the GC images of normal rabbit models, was applied to the analysis of GC images of ocular surface damage rabbit models. Damage was induced by the topical instillation of povidone iodine (PI). PI is a disinfectant commonly used in general ophthalmic surgeries including cataract surgery for the preoperative prevention of endophthalmitis, and it is known to induce damage to epithelial cells on the ocular surface25. Ocular surface damage was induced by one-time PI instillation. Significant GC damage was observed in the first week, after which GCs recovered gradually in later weeks. As shown in Fig. 5, MBFM images in 2 and 4 weeks after damage were used to observe GC changes in the recovery phase. GCs in the bulbar conjunctiva were analyzed mainly owing to the ease of in-vivo assessment. In 2 weeks, GCs were relatively sparse compared to the control, indicating recovery in progression. GC density was measured to be 1000 ± 500 cells/mm2, lower than the density before damage (1560 ± 90 cells/mm2). The size of GCs in 2 weeks after damage was approximately 20 ± 20 μm2, significantly smaller than the size of GCs before damage (78 ± 14 μm2). In 4 weeks, GC density was 1540 ± 90 cell/mm2, the same level as normal. However, the size of GCs was 60 ± 20 μm2, smaller than normal. The decrease of GC density in 2 weeks after damage and the complete recovery to normal level in 4 weeks were consistent with a previous study4,25. To determine the difference in GC size, PAS histology was performed in rabbit models both before damage and 4 weeks after damage. On PAS histology, the size of GCs was 76 ± 11 μm2 before damage and 61 ± 12 μm2 in 4 weeks after damage. Although the GC size from PAS histology could be affected by deformation during sample preparation including fixation and holding, the tendency of GCs being smaller than normal in 4 weeks after damage was consistent.

Longitudinal changes of GCs in ocular surface damage rabbit models during recovery from acute damage. (a) Representative MBFM images and DCAU-Net images at 3 different time points of before damage (normal), 14 and 28 days post damage. (b) GC densities at 3 time points. MBFM images in the bulbar conjunctiva of 5 rabbit models were analyzed. (c) GC size at 3 time points, red plot: size comparison in PAS histology result at normal and recovered rabbit for 4 weeks.
Discussion
DCAU-Net was developed for automatic segmentation of GCs from MBFM images of live rabbit models. DCAU-Net was trained with GC images of normal rabbit models and used for the analysis of GC density and size in both normal and ocular surface damage rabbit models. DCAU-Net exhibited a superior performance in GC segmentation by modifying the U-Net structure for MBFM GC images. DCAU-Net segmented individually distributed GCs correctly and was not confused with small non-GC objects caused by overstaining. Although it was able to resolve some aggregated GCs, DCAU-Net performed well in general in MBFM GC images of rabbit models.
GC density estimation based on DCAU-Net segmentation revealed the high accuracy of approximately 94%. A slight underestimation was due to the miscounting of closely spaced GCs. DCAU-Net based GC analysis exhibited high spatial variations of GC densities depending on the conjunctival regions, consistent with the literature. The high spatial variations of GC density indicated that large area imaging is required for reliable GC density measurement. DCAU-Net based GC analysis revealed a statistically significant variation of GC size depending on the conjunctival regions: with fornix 58 ± 12 μm2 and bulbar 100 ± 18 μm2. The spatial variation of GC size was consistent with the one of PAS histology results. Although DCAU-Net was trained with GC images of normal rabbit models, it could be used for GC image analysis of ocular surface damage rabbit models and its GC density estimation in the damaged rabbit models showed comparable accuracy to that in the normal rabbit models. DCAU-Net based GC analysis showed decreases of both GC density and size in the damage rabbit models in the recovery phase from acute damage.
DCAU-Net analysis of the MBFM images took approximately 1 min per image. Although the processing time was quite long, the processing could be completed in time for the diagnosis which would occur in more than 10 min after the examination. Faster image processing would be desirable in the future. The current MBFM system had 1 fps imaging speed. Although it was enough for imaging anesthetized rabbit models, the higher imaging speed is required to image awake human subjects with minimal motion artifact and discomfort. We recently developed a high-speed extended depth-of-field (EDOF) microscopy running at 15 fps and demonstrated real-time mosaic imaging in rabbit models26. For fast and accurate analysis of GC images from the high-speed microscopy, further studies are needed to reduce computational resources by applying lightweight algorithms to the proposed model.
In conclusion, DCAU-Net was developed for the robust and automated segmentation of conjunctival GCs in MBFM images of live rabbit models. DCAU-Net based GC analysis showed approximately 94% accuracy with a slight underestimation in GC density and revealed the spatial variation of both GC density and size depending on the conjunctival regions in normal rabbits and the decreases of both parameters in ocular surface damage rabbit models. In combination with non-invasive MBFM, DCAU-Net based GC analysis might have potential for non-invasive GC examination and precision diagnosis of ocular surface diseases.
Methods
Overview of DCAU-Net architecture
The architecture of DCAU-Net is illustrated in Fig. 6. DCAU-Net had an encoder–decoder framework. The encoder consisted of dual-channel convolution (DCC) modules, which had a semantic channel and a texture channel. The semantic channel module was to extract features using a multi-scale kernel for small objects. The texture channel module had a large asymmetric filter to examine the overall texture information and cell boundaries. The global channel attention (GCA) module was introduced both to strengthen feature calibration and to propagate encoder information. GCA combined the spatial attention algorithm and channel-wise pooling.

Overview of DCAU-Net. DCAU-Net is an end-to-end GC segmentation network that tracks GCs in the MBFM image. Each encoder consists of a dual-channel convolution (DCC) and executes propagation through the global channel attention (GCA).
Dual-channel convolution (DCC) modules
Detailed DCC modules are illustrated in Fig. 7. The semantic channel module had multi-scale convolutions, as illustrated in Fig. 7a. The multi-scale convolution module had both a single 3 × 3 convolution layer and two 3 × 3 convolution layers in stack to obtain a wider receptive field than a single layer. Each convolution layer consisted of a stack of layer components, including residual convolution layers, batch normalization (BN) layers, and Rectified Linear Unit (ReLU) activation layers27. A max-pooling layer was added to the stacked layer to serve the purpose of downsampling the feature maps, reducing their spatial dimensions while retaining essential information, and extracting the maximum value from local regions to improve computational efficiency28. These layers maintained nonlinear properties to prevent internal covariate shift in the propagation process and to stabilize the gradient29,30. The texture channel module was used to obtain adaptive feature information. The texture channel module made dense predictions per pixel based on large kernel sizes31. The texture channel consisted of two convolution layers, as presented in Fig. 7b. The asymmetric convolution kernels were used to capture large receptive fields, enhancing the model to recognize textures and patterns with varying orientations while reducing the number of parameters.

Overview of dual-channel convolution in the DCAU-Net. (A) Semantic channel module contains multi-scale convolution layers and a max-pooling layer. (B) Texture channel module utilizes asymmetric convolution kernels with stride controls.
Global channel attention module (GCA)
The skip connection of the DCAU-Net was modified with a global channel attention (GCA) module. The GCA module was designed to highlight features that propagate to the decoder path, as illustrated in Fig. 8. The semantic and texture features of DCC were added element-wise to fuse information of the extracted convolutional feature map. The GCA performed a squeeze operation to element-wise fused feature map \({I}{\prime}\in {R}^{C\times H\times W}\), where C, H, and W represent the dimensions of the \({I}{\prime}\) in terms of channels, height, and width, respectively. The module generated channel-wise descriptor \({I}^{s}\in {R}^{C\times 1\times 1}\) by employing global average pooling and aggregated the feature map \({I}{\prime}\) input to the GCA in the entire channel32.

Structure of global channel attention module.
An attention map \({I}^{A}\in {R}^{1\times H\times W}\) was modified through the sigmoid activation connected to the 1 × 1 convolution. Although \({I}^{A}\) condenses the channel depth information with the pointwise 1 × 1 convolution, it maintained the same size and height of the input data. Accordingly, these features were refined using matrix multiplication to form a channel-wise attention map. The final output of the module was obtained by
where σ is the sigmoid activation. The refined information \({I}^{R}\in {R}^{C\times H\times W}\) was multiplied to the encoder features and propagated to the decoder features.
Ground truth production process
In producing ground truth (GT), three steps were taken to minimize manual processes and to increase accuracy: (1) to produce the initial GT (cell and background binary image), (2) to generate the GT prediction using standard U-Net, (3) to produce the final GT with manual refinement.
Step 1 Initial GT was created by manually setting thresholds on the image to distinguish bright GCs and background including blood vessels. Blood vessels underneath the conjunctival surface appeared in relatively low intensity levels due to both absorption and scattering of excitation light. Given the spatial variation in brightness of background and GCs, we divided the image into sections manually and adjusted the threshold adaptively to account for variations in goblet cell-background contrast33 (Supplementary Fig. 1A).
Step 2 Initial GT was cropped to 512 \(\times\) 512 pixels, augmented through rotation, flip, and random crop processes, and used for the training of standard U-Net (Supplementary Fig. 1B) For standard U-Net, the network parameters of the published paper were applied as is18. 6 rabbit data was used (6 original data) in the training. The standard U-Net was trained for 50 epochs and the Adam optimizer with a learning rate of 0.0001 was employed. The rough prediction results of 16 rabbit data were obtained using the trained standard U-Net.
Step 3 Manual denoising processes, such as dividing clumped cells, annotating missing cells and removing incorrected identified cells, were employed to produce the final GT.
Model training
The input dataset was prepared by applying Contrast Limited Adaptive Histogram Equalization (CLAHE) application34 and augmented through random cropping the original 2048 × 2048 pixel images to 512 \(\times\) 512 pixels. These resulting images were further processed with rotation and flipping transformations, as part of our training process. We did not apply these transformations during the test phase, ensuring a clear differentiation between training and testing procedures. Using 16 rabbit data images, after excluding those with defocus or rabbit motion artifacts, a total of 4858 augmented images were generated. Considering the small number of rabbit cases in the data, we trained DCAU-Net by using 5 fold cross validation. Data from 16 rabbits were divided into 5 fold, ensuring that data acquired from the same case were allocated evenly to the 5 fold. It was repeated 5 times by using a different fold as the validation set and the remaining 4 fold as the training set, yielding a mean validation dice score of 0.913. We conducted evaluation by dividing the dataset into 4138 training images and 720 test images. This dataset division was utilized to retrain our model from scratch. To cope with the segmentation task, the loss function was constructed by combining dice and focal losses with weights of 0.7 and 0.3, respectively35,36.
Experimental setup
Evaluation metric
Dice coefficient, sensitivity (SE), and precision were calculated to evaluate the performance of DCAU-Net. Additionally, the area under precision-recall curve was also employed. The pixels of the probability map were compared with the GT label, and classified into true positive (TP), false positive (FP), true negative (TN), and false negative (FN) in the confusion matrix.
Regions of individual GCs were captured in the binarized probability map. Cell density and morphology studies were performed. In the morphology study, cell area and eccentricity were analyzed.
Training detail
For training, both the standard U-Net and DCAU-Net models were trained for 100 epochs each, and the Adam optimizer with a learning rate of 0.0001 was employed37. With a step decay scheduler adjusting the learning rate every 20 epochs, we also implemented early stopping. For the standard U-Net model, binary cross-entropy loss was employed, while for our proposed model, the combination of dice loss and focal loss was used as the loss function. Training was implemented on an Intel i9-10900 CPU @ 2.80 GHz desktop with NVIDIA 3090 graphics processor unit (GPU) using Pytorch version 1.7.1, Cuda 11.0, and Python 3.8.538.
Animal model preparation
Twenty-four New Zealand white female rabbits weighing between 3.0 and 3.6 kg were used: 15 rabbits for in-vivo normal models, 5 rabbits for PI ocular damaged model, 4 rabbits for PAS histology. Imaging of rabbit was conducted under anesthesia via subcutaneous injection of Tiletamine-zolazepam (Zoletil®, Virbac, Carros, France; 0.2 cc/kg) and Xylazine (Rompun®, Bayer AG, Leverkusen, Germany; 0.2 cc/kg) mixture. For the ocular damaged group, 5 mL of 5% povidone-iodine (PI) solution was topically instilled onto the conjunctiva and excessive solution was allowed to run freely. After 3 min incubation, the conjunctiva was rinsed with 5 mL of balanced salt solution (BSS, Alcon). Moxifloxacin solution was instilled and the eyelids were closed for 1 min.
Periodic acid Schiff (PAS) staining and conjunctival GC evaluation
The conjunctiva tissue was placed on a slide with the epithelial surface up. The mounted tissue was left in air for approximately 1 min for tight adhesion to the slide. The mounted conjunctiva was excised and fixed in 10% neutral buffered formalin over night at 4 °C. The tissue was hydrated with 100% to 70% alcohol solutions, and the hydrated slide was oxidized in 0.5% periodic acid solution for 10 min and rinsed in water for 3 min three times. After that, the slide was placed in Schiff reagent for 20 min and rinsed in water for 10 min three times. They were then dehydrated in alcohol and finally covered with histological mounting medium. En-face PAS-positive GC images were evaluated under a light microscope.
Ethics approval
The study protocol was approved by the Institutional Animal Care and Use Committee of the Seoul National University Biomedical Research Institute (IACUC No. 20-0143-S1A1) and was conducted in accordance with ARRIVE guidelines. This study was performed in accordance with relevant guidelines and regulations.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Uchino, Y. The ocular surface glycocalyx and its alteration in dry eye disease: A review. Investig. Ophthalmol. Vis. Sci. 59, 157–162. https://doi.org/10.1167/iovs.17-23756 (2018).
Watanabe, H. Significance of mucin on the ocular surface. Cornea 21, S17–S22. https://doi.org/10.1097/00003226-200203001-00005 (2002).
Messmer, E. M., Mackert, M. J., Zapp, D. M. & Kampik, A. In vivo confocal microscopy of normal conjunctiva and conjunctivitis. Cornea 25, 781–788 (2006).
Kim, S. et al. Non-invasive high-contrast imaging of conjunctival goblet cells for the precision diagnosis of ocular surface diseases. Ocul. Surf. 24, 100–102. https://doi.org/10.1016/j.jtos.2022.03.003 (2022).
Kim, S. et al. In vivo fluorescence imaging of conjunctival goblet cells. Sci. Rep. 9, 15457. https://doi.org/10.1038/s41598-019-51893-4 (2019).
Lee, J., Kim, S., Yoon, C. H., Kim, M. J. & Kim, K. H. Moxifloxacin based axially swept wide-field fluorescence microscopy for high-speed imaging of conjunctival goblet cells. Biomed. Opt. Express 11, 4890–4900. https://doi.org/10.1364/BOE.401896 (2020).
Cheewatanon, J., Leauhatong, T., Airpaiboon, S. & Sangwarasilp, M. A new white blood cell segmentation using mean shift filter and region growing algorithm. Int. J. Appl. Biomed. Eng. 4, 31 (2011).
Gamarra, M., Zurek, E., Escalante, H. J., Hurtado, L. & San-Juan-Vergara, H. Split and merge watershed: A two-step method for cell segmentation in fluorescence microscopy images. Biomed. Signal Process Control 53, 101575. https://doi.org/10.1016/j.bspc.2019.101575 (2019).
Wahlby, C., Sintorn, I. M., Erlandsson, F., Borgefors, G. & Bengtsson, E. Combining intensity, edge and shape information for 2D and 3D segmentation of cell nuclei in tissue sections. J. Microsc. 215, 67–76. https://doi.org/10.1111/j.0022-2720.2004.01338.x (2004).
Anoraganingrum, D. Proc. 10th International Conference on Image Analysis and Processing 1043–1046 (IEEE).
Qi, X., Xing, F., Foran, D. J. & Yang, L. Robust segmentation of overlapping cells in histopathology specimens using parallel seed detection and repulsive level set. IEEE Trans. Biomed. Eng. 59, 754–765. https://doi.org/10.1109/TBME.2011.2179298 (2012).
Long, J., Shelhamer, E. & Darrell, T. Proc. IEEE Conference on Computer Vision and Pattern Recognition 3431–3440.
Zhao, T. & Yin, Z. International Conference on Medical Image Computing and Computer-Assisted Intervention 677–685 (Springer).
Christ, P. F. et al. Automatic liver and tumor segmentation of CT and MRI volumes using cascaded fully convolutional neural networks. Preprint at http://arXiv.org/1702.05970 (2017).
Li, H. et al. Fully convolutional network ensembles for white matter hyperintensities segmentation in MR images. Neuroimage 183, 650–665. https://doi.org/10.1016/j.neuroimage.2018.07.005 (2018).
Xue, Y., Ray, N., Hugh, J. & Bigras, G. European Conference on Computer Vision 274–290 (Springer).
Al-Kofahi, Y., Zaltsman, A., Graves, R., Marshall, W. & Rusu, M. A deep learning-based algorithm for 2-D cell segmentation in microscopy images. BMC Bioinform. 19, 365. https://doi.org/10.1186/s12859-018-2375-z (2018).
Ronneberger, O., Fischer, P. & Brox, T. International Conference on Medical Image Computing and Computer-Assisted Intervention 234–241 (Springer).
Fabijanska, A. Segmentation of corneal endothelium images using a U-Net-based convolutional neural network. Artif. Intell. Med. 88, 1–13. https://doi.org/10.1016/j.artmed.2018.04.004 (2018).
Long, F. Microscopy cell nuclei segmentation with enhanced U-Net. BMC Bioinform. 21, 8. https://doi.org/10.1186/s12859-019-3332-1 (2020).
Oda, H. et al. International Conference on Medical Image Computing and Computer-Assisted Intervention 228–236 (Springer).
Taghanaki, S. A. et al. International Workshop on Machine Learning in Medical Imaging 417–425 (Springer).
Doughty, M. J. Assessment of goblet cell orifice distribution across the rabbit bulbar conjunctiva based on numerical density and nearest neighbors analysis. Curr. Eye Res. 38, 237–251. https://doi.org/10.3109/02713683.2012.754901 (2013).
Kishishita, H. & Nakayasu, K. Distribution of conjunctival goblet cells and observation of goblet cells after conjunctival autotransplantation in rabbits. Nippon Ganka Gakkai Zasshi 100, 433–442 (1996).
Kim, S., Ahn, Y., Lee, Y. & Kim, H. Toxicity of povidone-iodine to the ocular surface of rabbits. BMC Ophthalmol. 20, 359. https://doi.org/10.1186/s12886-020-01615-6 (2020).
Lee, J. et al. Moxifloxacin-based extended depth-of-field fluorescence microscopy for real-time conjunctival goblet cell examination. IEEE Trans. Med. Imaging 41, 2004–2008. https://doi.org/10.1109/TMI.2022.3151944 (2022).
He, K., Zhang, X., Ren, S. & Sun, J. Proc. IEEE Conference on Computer Vision and Pattern Recognition 770–778.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Proc. IEEE Conference on Computer Vision and Pattern Recognition 2818–2826.
Agarap, A. F. Deep learning using rectified linear units (relu). Preprint at http://arXiv.org/1803.08375 (2018).
Ioffe, S. & Szegedy, C. International Conference on Machine Learning 448–456 (PMLR).
Peng, C., Zhang, X., Yu, G., Luo, G. & Sun, J. Proc. IEEE Conference on Computer Vision and Pattern Recognition 4353–4361.
Hu, J., Shen, L. & Sun, G. Proc. IEEE Conference on Computer Vision and Pattern Recognition 7132–7141.
Ko, B., Seo, M. & Nam, J. Y. Microscopic cell nuclei segmentation based on adaptive attention window. J. Digit. Imaging 22, 259–274. https://doi.org/10.1007/s10278-008-9129-9 (2009).
Pizer, S. M. et al. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 39, 355–368. https://doi.org/10.1016/s0734-189x(87)80186-x (1987).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Proc. IEEE International Conference on Computer Vision 2980–2988.
Milletari, F., Navab, N. & Ahmadi, S.-A. 2016 Fourth International Conference on 3D Vision (3DV) 565–571 (IEEE).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. Preprint at http://arXiv.org/1412.6980 (2014).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32 (2019).
Acknowledgements
This research was supported in part by the Samsung Research Funding and Incubation Center of Samsung Electronics under Project SRFC-IT2101-05, in part by the National Research Foundation of Korea (NRF) Grant by the Korean Government through the Ministry of Science and ICT (MSIT) under Grant NRF-2020R1A2C3009309, RS-2023-00219421.
Author information
Authors and Affiliations
Contributions
Conceptualization, S.J. and S.K.; methodology, S.J. and S.K.; software, S.J.; validation, S.Y. and K.H.K.; animal experiment, S.K., C.H.Y. and W.J.C.; resources, S.K. and J.L.; data curation, S.J. and S.K.; writing—original draft preparation, S.J. and S.K.; writing—review and editing, S.Y. and K.H.K.; visualization, S.J. and S.K.; project administration, S.Y. and K.H.K.; funding acquisition, S.Y. and K.H.K. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jang, S., Kim, S., Lee, J. et al. Deep learning framework for automated goblet cell density analysis in in-vivo rabbit conjunctiva. Sci Rep 13, 22839 (2023). https://doi.org/10.1038/s41598-023-49275-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-49275-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
