
Abstract
The dynamic multi-objective optimization problem is a common problem in real life, which is characterized by conflicting objectives, the Pareto frontier (PF) and Pareto solution set (PS) will follow the changing environment. There are various dynamic multi-objective algorithms have been suggested to solve such problems, but most of the methods suffer from the inability to balance the diversity of populations with convergence. Prediction based method is a common approach to solve dynamic multi-objective optimization problems, but such methods only search for probabilistic models of optimal values of decision variables and do not consider whether the decision variables are related to diversity and convergence. Consequently, we present a prediction method based on the classification of decision variables for dynamic multi-objective optimization (DVC), where the decision variables are first pre-classified in the static phase, and then new variables are adjusted and predicted to adapt to the environmental changes. Compared with other advanced prediction strategies, dynamic multi-objective prediction methods based on classification of decision variables are more capable of balancing population diversity and convergence. The experimental results show that the proposed algorithm DVC can effectively handle DMOPs.
Similar content being viewed by others

Introduction
Dynamic multi-objective optimization problems (DMOPs)1 are common practical problems that typically have multiple conflicting objectives. At present, most multi-objective optimization solutions2,3,4 are used to solve static optimization problems5,6,7,8. Nevertheless, a reality multi-objective optimization problem is a complex optimization problem with a dynamic environment, changing parameters, conflicting objectives. Due to the constantly changing environment, the Pareto optimal front (POF) and the Pareto optimal set (POS) are not fixed. Static optimization methods have been widely used in the field of evolutionary computation, but they often suffer from the lack of fast response mechanisms. In particular, the populations in Dynamic Multi-Objective Optimization Problems (DMOPs) tend to lose diversity over time, which results in a gradual convergence of the populations at later stages of evolution. This convergence makes it increasingly difficult for the populations to adapt to new environments9. To address this issue, it is important to develop improved Multi-Objective Evolutionary Algorithms (MOEAs)10,11 that have fast response mechanisms, which can help to maintain the diversity of populations and ensure their adaptability to changing environments. In recent years, many dynamic multi-objective algorithms have been proposed, and these methods can be roughly divided into: diversity introduction methods, diversity maintenance methods, prediction-based dynamic multi-objective methods, and classification based on decision variables.
The ultimate goal of the diversity introduction method12 and the diversity maintenance method13 is to increase the diversity of the population. Some mutant individuals are introduced into the population. With the help of mutant individuals, the population can better follow the environment changes and converge, instead of falling into convergence prematurely and unable to adapt to the environment changes. However, diversity-based methods have very significant disadvantages. Diversity-based methods rely too much on static algorithms, and can only find new optimal solution sets through static algorithms, so the convergence speed will continue to decline. Therefore, how to stop relying on static methods to find diversity points and how to add diversity points to make the population reach the ideal state?
The prediction-based dynamic multi-objective approach14 uses predictive models to predict quality populations after changing environments. Although, predictive models play a role in the convergence of populations. Nevertheless, most predictive models require training cycles and the performance of predictive models on certain problems is sometimes generally poor. Consequently, the predictive models required for prediction-based methods need to have two conditions: 1. They need to have a short training cycle and be able to respond quickly; 2. For predictive models to be robust they need to be able to cope with different types of test problems.
The classification of decision variables15 can be divided into three broad ways: (1) dominance relationship-based classification of decision variables16. At its core, the idea is to perturb the detected decision variables and observe whether all perturbations are mutually dominant. If all perturbations are not mutually dominant, then the decision variables are defined as diversity correlated. All cases other than this are defined as convergence-related. Adopting this category usually causes populations to be overly enmeshed in dominance relationships at the expense of population diversity. (2) Angle-based classification of decision variables17. A fitting line is formed using the perturbation points, and the angle between the fitting line and the hyperplane normal is judged by the angle between the fitting line and the hyperplane normal. An acute angle is close to a right angle, then the decision variables are defined as diversity related, otherwise they are defined as convergence related. (3) Monotonic-based classification of decision variables18. The method defines positive and negative correlations between decision variables and objectives. And on this basis, the Spearman rank correlation coefficient (SRCC)19,20 is used to evaluate the correlation between variables and objectives to avoid the defect of dominance relationship failure. These three approaches to categorizing decision variables all suffer from the same problem: how to design different evolutionary strategies to address different decision variables?
In summary, the dynamic optimization algorithm design needs to face the following problems:
-
1.
How to introduce diversity correctly and keep the population convergence and diversity balanced?
-
2.
In order to respond quickly to environmental changes, what is the best way to design a prediction strategy that is both robust and efficient?
-
3.
If the decision variables are classified, what kind of method should be used and what is the response strategy after classification?
Based on the above problems, this paper proposes a dynamic multi-objective optimization method based on the classification of decision variables. The classified decision variables can better predict the populations after environmental changes. Different prediction strategies are effective in balancing the diversity and convergence of populations. The main contributions of this paper are as follows:
-
A static classification strategy is proposed to classify decision variables into three categories, which enables the algorithm to better identify the uses of decision variables. The different decision variables are explored more effectively to balance the diversity and convergence of the new middle group.
-
One strategy is proposed to correct the classification of decision variables in a dynamic environment. The population is prompted to respond to environmental changes and adjust the evolutionary direction of decision changes to ensure that the population evolves in the right direction.
-
Different prediction strategies are provided for different decision variables, and adaptive prediction strategies are selected according to different decision variable categories, thus enabling adaptation to dynamic environments. (3) Different prediction strategies are provided for different decision variables, and adaptive prediction strategies are selected according to different decision variable categories, thus enabling adaptation to dynamic environments.
Related work
DMOPs are defined as minimization problems, and their mathematical formulation can be defined as follows:
where \(x=\left( x_1,x_2,\ldots ,x_n \right)\), represent the n-dimensional decision variables. m is the number of objectives, \(h_i\) and \(g_i\) represent the equation and inequality constraint, correspondingly. \(n_h\) and \(n_g\) represent the number of constraints, respectively.The variable t included in the objective function of DMOPs represents the time variable, which is calculated as follows:
The value of t is related to the number of iterations of EA, so \(\tau\) in the formula represents the number of iterations, which directly affects the value of t.
Definition 1
(Dynamic Pareto Dominance) At time t, assume that any two individuals \(x_1\) and \(x_2\) in the population satisfy the condition:
consider that individual \(x_1\) dominates individual \(x_2\), written mathematically as: \(x_1\prec x_2\).
Definition 2
(Dynamic Pareto-Optimal Set) At time t, assume that there is no decision vector \(x^{\prime }\in R^n\) dominating x, then x is a pareto optimal solution, the set of all non-dominated solutions is called the Pareto-Optimal set (POS), that is:
Definition 3
(Dynamic Pareto-Optimal front) At time t, the mapping of the \(POS_t\) in the objective space is called \(POF_t\) expressed as:
According to the different combinations of dynamic changes in the POF and POS, identified four different types of DMOPs in Table 1.
In practical scenarios, when the environment changes, the four types of changes mentioned above may occur simultaneously, and we mainly study the first three types of changes. Dynamic multi-objective evolutionary algorithms generally have the following steps:
-
Step 1: Initialize the population and set the relevant parameters.
-
Step 2: Detect environmental changes, if the environment changes, go to Step 4. If not, go to Step 3.
-
Step 3: Optimize the population using an evolutionary algorithm.
-
Step 4: Adopt certain response strategies, such as diversity maintenance, diversity introduction, prediction mechanism and memory mechanism, to cope with the changes in the environment.
-
Step 5: Determine the termination condition, if it is not met, go to Step 2, and if it is met, exit.
Diversity introduction method
In recent years, various DMOAs have been proposed to address DMOPs, and the core idea of these DMOAs is to balance diversity and convergence in response to environmental changes. The first consideration after environmental changes is to maintain the diversity of the population and to introduce random or mutant individuals in relation to the detection of environmental changes, so the introduction of diversity becomes one of the solutions. The introduction of diverse individuals cannot be introduced randomly, as the dynamic problem Pareto solution set and Pareto frontier change with the environment. In other words, increasing population diversity needs to be added through theoretical methods, while blindly adding random points will only generate populations in a bad direction. Consequently, Deb et al.21 introduced diverse individuals by tracking the Pareto frontier according to this feature, and the new population formed can be better adapted to the population. An extended algorithm for dynamic vector evaluation particle swarm optimization (VEPSO) was proposed by Harrison et al.22 to address the shortcoming that the change detection mechanism relies on the observation of changes in the target space. Based on NSGA-II23,24, the DNSGA-II25 algorithm was proposed, which was divided into two adaptive algorithms, DNSGA-II-A26 as well as DNSGA-II-B, but was not conducive to solving complex environmental change problems.
Diversity maintenance methods
The diversity maintenance approach, which can also be called a memory-based strategy, focuses on using historical information in the stored environment and reusing them after the environment changes. In contrast to diversity introduction methods, diversity maintenance mechanisms usually directly store historical PS as initialized populations. Nevertheless, this method is limited to solving continuum optimization problems, and it is also difficult to cope with high degree of environmental changes. Li et al.27 proposed a novel dynamic multi-objective optimization algorithm (DMOA-DM) based on region local search and memory, using NSGA2-DM to store useful information (memory) to guide the optimization of populations. Liang et al.28 proposed a novel dynamic multi-objective evolutionary algorithm which incorporates a hybrid algorithm of memory and prediction strategy (HMPS)29,30 and decomposition-based multi-objective evolutionary algorithm (MOEA/D31). Differential prediction based on two consecutive population centroids is utilized if the detected change is not similar to any historical change; otherwise, memory-based techniques are applied to predict the new position of the population.
Prediction-based methods
The prediction-based dynamic multi-objective optimization algorithm also exploits some historical information, but in contrast to the diversity maintenance approach, the prediction-based approach is more reliant on the prediction strategy, and the optimal solution after the change of environment is dependent on the strength of the prediction model. Unfortunately, this method only takes into account changes in the center of the flow pattern and is only relevant to the historical information of the last moment, so it has significant limitations for population updating. Zhou et al.32 proposed a population prediction strategy (PPS) that can initialize the entire population by combining the prediction center and the estimated stream shape. Zou et al.33 combined special points and centroids to create a prediction mechanism. This prediction mechanism uses the adjacent time interval as the prediction step and directly predicts the set of non-dominated solutions. Jiang et al.34 developed an inflection point-based migration learning method called KT-DMOEA. in the proposed method, a trend prediction model (TPM) was developed to generate predicted inflection points, and then an unbalanced migration learning method along with the TPM predicted inflection points were used to generate high-quality initial populations.
Decision variable classification methods
The methods of diversity introduction as well as the prediction methods do not consider the properties of the decision variables during the iteration, and these methods can be regarded as a probabilistic model for searching for optimal values of the decision variables. In other words, these methods assume that all decision variables have the same probability of functioning in diversity as well as convergence on the population. Nonetheless, in most DMOPs, the probabilities are different, and different nature of decision variables should be corresponded to different search models to get better solutions. In static MOPs, the categories of decision variables can be determined by perturbing the decision variables to produce a large number of individuals and then using fitness assessment35,36,37,38. While the decision variable classification in static MOEAs is performed only once and the categories of decision variables will not revert after classification, for dynamic MOPs these strategies lose their effectiveness. Liang et al.39 proposed a dynamic multi-objective evolutionary algorithm based on the classification of decision variables. The Spearman rank correlation coefficient (SRCC)18 was used to determine the categories of the decision variables in static classification. A nonparametric t-test was utilized to further correct for variable categories after environmental changes when dynamic environments were in place. Liu et al.16 introduced a new DVC classification method for decision variables based on the monotonicity of the optimization objective, which does not make use of dominance relations but uses reference vectors to guide the analysis of decision variables.
Proposed algorithm
To address the above problems, we propose a dynamic multi-objective optimization algorithm based on classification prediction. The algorithm consists of three important parts: The first part is the classification strategy of static decision variables, which divide decision variables into two categories: diversity-related decision variables and convergence-related decision variables. The diversity-related decision variables will be an important reference after environmental changes to prevent the population from falling into a local optimum and converging prematurely. The second part is the dynamic classification adjustment strategy after the environment changes, which further determines the predictability of the decision variables. The third part uses different prediction strategies based on the results of the dynamic classification respectively. The components of the algorithm are shown in Fig. 1.

General flowchart of the algorithm.
RM-MEDA
Under relaxed conditions, the Karush-Kuhn-Tucker criterion40 demonstrates that the POS of a continuous multi-objective optimization problem is a segmentally continuous \(\left( m-1 \right)\)-dimensional manifold. The algorithm works as algorithm 1:

Classification strategy in static environment
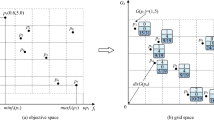
Classification with static decision variables in DMOEA helps populations to be able to search for quality individuals quickly when the environment changes. DMOEA ought to have not only efficient convergence performance but also good distributivity on PF. Nevertheless, the dynamic environment limits the diversity of populations, and early convergence and falling into local optima are common problems of DMOPs. The problem of classification of decision variables is mentioned in the literature42, where decision variables are perturbed and divided into three different categories according to different dominance: (a) The relationship between the representative solution and the disturbance solution is nondominated; (b) The relationship between the representative solution and the perturbation solution is dominated; c) Both dominated and nondominated relations exist between the representative solution and the perturbation solution.
Among them, category a as well as category b are defined as diversity-related variables, while category c is defined as convergence-related. The classification after perturbation is shown in Fig. 2. Consequently, the key argument for solving DMOPs is to determine the type of decision variables.

Classification of dominance relationships.
This section presents a classification method for decision variables in static environments, as shown in Fig. 3:

Points are selected from the decision space and perturbed.
Firstly, representative variables should be selected in the decision space. For the decision space in two-dimensional coordinates, the extreme value points on each objective value are found and defined as boundary points. Considering the first objective value, the region from the minimum of the boundary point to the maximum of the boundary point is evenly divided into three equal parts, in each region the nearest non-dominated point to the line of the boundary point and the farthest non-dominated point are selected respectively (if there is no point in the region then two points are randomly generated). In the decision space a total of 6 decision variables are selected and the selected decision variables are perturbed (the number of perturbations is 5).

Convergence-related and diversity-related variables are identified using angles.
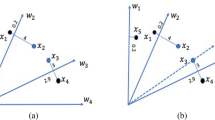
In order to be able to determine the class of the decision variables, the values of the perturbation points generated by the decision variables are normalized and the normalized points are fitted to a reference line \(L_{fitted}\). We consider that the normal to the hyperplane can represent the direction of convergence, so the normal \(L_{normal}\) to the hyperplane \(f_1+f_2+\cdots f_m=1\) (m representing the number of objectives) is computed. As shown in Fig. 4, for the reason of clear presentation of the angle we make an example with two selected obtained points. Points 1 and 2 are represented by green dots and blue dots, respectively, in the figure. The decision variables \(x_1, x_2, x_3, x_4\) are separately perturbed, and the fitted line \(L_{fitted}\) and the normal line of hyperplane \(L_{normal}\) will form 8 different angles after perturbation (only acute angles are chosen here). The angle is denoted as \(\theta _{ij}\), where i represents the selected point and j indicates the pinch mark. Whether the decision variable \(x_1\) is related to convergence can be determined by the angles. Theoretically, such judgments can be made by summing all \(\theta _{i1}\) and taking the mean value, and the smaller \(\overline{\sum _i{\theta _{i1}}}\) means that \(L_{fitted}\) is closer to \(L_{normal}\). Then the decision variable \(x_1\) is determined to be related to convergence, otherwise it is related to diversity. At a brief level, the larger of the angle contributes more to diversity and the smaller of the angle contributes more to convergence. Since some decision variables have both diversity and convergence, in order to avoid overly absolute division, \(k-means\) is used here to divide the correlation angles of decision variables \(x_1, x_2, x_3\) and \(x_4\) into three categories. As shown in Fig. 5, the four decision variables given are divided into three different categories. Algorithm 2 presents the detailed steps of decision variable category classification.

Three categories are classified according to the angle: diversity correlation, convergence correlation, and both diversity convergence correlation.

Classification strategies in dynamic environments
Environmental change is an important element in DMOPs that has an impact on the evolution of populations, and it is the change in the environment that leads to problems such as goal conflict and consequently the problem of responding during the evolution of the population. In the absence of environmental changes, population convergence can only reach the optimal state in the current environment. However, in order to prevent the population from being trapped in an optimum state and failing to respond to environmental changes, the categorization of decision variables needs to be adjusted in dynamic environments. This adaptive adjustment of decision variable categorization enables populations to efficiently and effectively respond to changes in their environment, thereby promoting their survival and evolution. Therefore, incorporating dynamic adjustments to decision variable categorization is crucial for population convergence in a changing environment. In a static environment, decision variables are divided into three categories: those related to diversity, those related to convergence, and those related to both diversity and convergence. The classification of decision variables in a static environment serves as a guide for the classification of decision variables in a dynamic environment. The classification of decision variables needs to be adjusted due to changes in the environment, and different decision variables correspond to different prediction strategies. In the case where a decision variable remains constant across several consecutive changing environments, it is possible that the variable may not change in the next environmental shift. Such variables can be considered similar variables and do not require initialization in the prediction process. When a variable undergoes significant changes between two consecutive environmental shifts, it can be identified as a variable with a longer prediction process. Conversely, when a decision variable shows no significant change between two consecutive environmental shifts, it is classified as a variable with a shorter prediction process. In response to environmental changes, we employ non-parametric t-tests to adjust the categorization of decision variables to adapt to different predictive strategies. The formula for the non-parametric t-test is as follows:
where \(\overline{x_i}\left( t \right)\) indicates the mean value of the decision variable of point i at time t. \(Var\left( x_i\left( t \right) \right)\) expresses the variance of the decision variable of point i at time t. \(\beta\) (a predetermined threshold) is set as a criterion for testing the attributes of the decision variables. \(\beta\) is set as a criterion to test the properties of the decision variable, and if \(t-test_i\leqslant \beta\), then the decision variable is considered to remain essentially constant over two successive environmental changes, thus defining that this decision variable is not a similar variable. The points on these variables as well as the perturbation points are added directly to the new population without initialization. If \(t-test_i>\beta\), then the decision variable needs to be further subdivided into diversity-related and convergence-related, in other words, it needs to be further determined what prediction strategy should be assigned to this decision variable. Further determination of the decision variables needs to be adjusted based on historical information. First assume that \(C_{}^{t}\) is the centroid of the non-dominated solution set POS, which can be obtained by the following equation:
where \(C_{}^{t}\) denotes the centroid of the non-dominated solution set at moment t. \(P_{Non-dom}^{t}\) indicates the size of the population of non-dominated individuals at moment t. \(x_{}^{t}\) is specified as a non-dominated individual at moment t. Then, the results of the classification of decision variables are observed historically. Subsequently, n points \(X_{}^{t}\left[ i \right] \left( i=1,2,3\ldots n \right)\) are generated by modifying the i-th decision variable in the \(C_{}^{t}\) to the value of the selected points as well as the value of the perturbed point on the i-th decision variable at moment \(t-1\). The generated points are compared with the \(C_{}^{t}\) for domination, and if \(X_{}^{t}\left[ i \right]\) can dominate the \(C_{}^{t}\), then the category of decision variable i s adjusted to \(\left( Con^t \right) ^{\prime }\), otherwise to \(\left( Div^t \right) ^{\prime }\). The corresponding selected points and perturbed points on the decision variables in \(\left( Con^t \right) ^{\prime }\) and \(\left( Div^t \right) ^{\prime }\). The corresponding selected points and perturbed points on the decision variables in \(\left( Con^t \right) ^{\prime }\) and \(\left( Div^t \right) ^{\prime }\) are composed into two point sets \(\left( pop_{Con}^{t} \right) ^{\prime }\) and \(\left( pop_{Div}^{t} \right) ^{\prime }\), respectively. The two sets are adapted to different prediction strategies, which will be described in the nex section. The detailed steps of dynamic classification of decision variables are shown in Algorithm 3.

Predictive strategy
As described in the section above, the selected points as well as the perturbed points are classified into three categories based on the classification of the decision variables:
-
(1)
Similar decision variables, directly add the point \(pop_{similar}^{t}\) to the next iteration without initialization.
-
(2)
The set of points corresponding to the diversity-related decision variables \(\left( pop_{Div}^{t} \right) ^{\prime }\) uses the following strategy:
$$\begin{aligned} \begin{aligned}{}&dir=C_t-C_{t-1} \\&pop_{Div}^{t+1}=\left( pop_{Div}^{t} \right) \prime +rand*dir \end{aligned} \end{aligned}$$(8)where dir indicates the step between the centroid at time t, and the centroid at time \(t-1\), which is used to predict the \(pop_{Div}^{t+1}\), \(rand\in \left[ 0.5,1.5 \right]\) is a random value.
-
(3)
The prediction strategy for the point set \(\left( pop_{Con}^{t} \right) ^{\prime }\) corresponding to the decision variables associated with convergence is as follows:
$$\begin{aligned} pop_{Div}^{t+1}=\left( pop_{Con}^{t} \right) \prime +\frac{dir}{U_i\left( t \right) -L_i\left( t \right) }+Gaussian\left( 0,d \right) \end{aligned}$$(9)where \(U_i\left( t \right)\) and \(L_i\left( t \right)\) represent the maximum and minimum values on the ith dimensional vector at time t, \(Gaussian\left( 0,d \right)\) expresses a Gaussian perturbation with mathematical expectation dimension 0 and variance d.
Test problems and performance indicators
Test instances
We tested 12 benchmarks featuring the FDA1-FDA443 test suite, the dMOP1-dMOP344 test suite and the F5–F1045 test suite. Among them, FDA1-FDA4 are non-convex, continuous or discontinuous, time-varying as well as non-time-varying. FDA4 and F8 are three objectives test problems, the others are problems with two objectives. Both the FDA test suite and the DMOP test suite have linearly correlated decision variables, and non-linearly correlated decision variables are present in the F5–F10 test suite.
Performance indicators
Inverted generational distance (IGD)
The metric under consideration represents a comprehensive evaluation metric, whereby its underlying calculation concept involves computing the minimum sum of distances that exist between individuals belonging to the actual POF and individuals generated by the algorithm under evaluation. It is noteworthy that the smaller the distance, the better the algorithm’s convergence and distribution performance. The IGD46 is calculated as follows:
At time t, \(POF_t\) denotes the uniform distribution of the set of Pareto optimal points, and \(P_t\) is the approximate set of \(POF_t\). This can be interpreted as measuring the shortest distance between the true POF and the algorithm’s optimal solution. \(d\left( v,P_t \right)\) represents the minimum Euclidian distance between v and the point in \(P_t\).
The average of IGD (MIGD)
For DMOPs, MIGD provides a better evaluation of MOEAs. MIGD is expressed as:
where T is a set of discrete time points in a run and |T| is the cardinality of T.
Hypervolume difference (HVD)
HVD45 is used to measure the distance between the hypervolume of POF obtained by the algorithm and the real POF. HVD can be calculated as:
where \(HV\left( POF_t \right)\) represents the volume of the region in the target space enclosed by the set of non-dominated solutions and reference points obtained by the algorithm. the larger the HV value, the better the comprehensive performance of the algorithm. \(P_t\) is an approximation set of POF at time t.
The mean of HVD (MHVD)
It can be set as:
Experimental results and analysis
Parameter settings
In this paper, a comparison is made between the proposed algorithm DVC and six dynamic multi-objective algorithms, and all of them use the RM-MEDA algorithm in the optimization of the problem. The six compared algorithms are: feedforward prediction strategy (FPS), population prediction strategy (PPS), centroid and inflection point-based prediction strategy (CKPS), special point-based prediction strategy (SPPS), change response mechanism combining hybrid prediction and mutation strategy (HPPCM), and a prediction method based on diversity screening and special point prediction to solve dynamic optimization problems (DSSP). In order to compare the algorithms fairly, the parameters of each algorithm were basically set to the values of the parameters provided in the original paper, and some of the parameters were adjusted to ensure that they were compared in the same state as the present method. The experimental parameters are summarized as follows.
Each problem was tested 20 times independently, and 100 environmental changes were generated in each experiment. The degree of change of the environment \(n_t\) is set to 10. The environment change frequency \(\tau _t\) is set to 25. The number of iterations is 2500. The population size is 100 and the decision space dimension is 20.
-
Feed-forward prediction strategy (FPS)47 The order in \(AR\left( p \right)\) model was \(p=3\), the number of cluster was set 5 and the maxi-mum length of history center point sequence was \(M=23\). n the initial population, there are \(3\left( m+1 \right)\) predicted points, 70% of the rest points are inherited from the previous population and the other 30% are randomly sampled from the search space.
-
Population prediction strategy (PPS)32 PPS used the same \(AR\left( p \right)\) model as FPS, and \(p=3\), \(M=23\).
-
A novel prediction strategy based on center points and knee points (CKPS)33 The number of knee points is 9.
-
A predictive strategy based on special points (SPPS)48 In the process of predicting the non-dominated set by feed-forward center points, set the Gaussian perturbation d to be 0.1.
-
Change response mechanism combining hybrid prediction and mutation strategy (HPPCM)49 The autonomic evolution of the algebra \(\varDelta t\) is set to 2.
-
A dynamic multi-objective evolutionary algorithm based on prediction (DSSP)42 The number of knee points is 9. The number of perturbations is set to 5.
Comparison of performance evaluation results
Analysis of FDA and dMOP evaluation results
Table 2 shows the average values along with the variance of MIGD for all compared algorithms on the FDA1-FDA4 and dMOP1-dMOP3 test problems. In the course of the experiment we ensured that the population underwent 100 environmental changes, 100 environmental changes were observed in three stages and assessed them using evaluation metrics. The first 20 environmental changes were identified as \(1^{st}\) stage, the middle 40 environmental changes were recognized as \(2^{nd}\) stage, and the last 40 were deemed to be \(3^{rd}\) stage.
From an overall perspective, the DVC algorithm performs well in all phases, although it is slightly inferior to HPPCM in the FDA3 problem and the dMOP3 problem, but performs better in all other test problems, thus demonstrating that DVC has a strong ability to respond to environmental changes. FDA3 is a nonlinear test problem with large fluctuations in the set of Pareto solutions following environmental changes. Observing the characteristics of HPPCM, the HPPCM algorithm which uses the strategy of precisely controlling the polynomial mutation, this strategy effectively controls the updating and keeping of new populations. In contrast, our proposed DVC strategy relies more on the effect of decision variables in the population. This may be the reason why HPPCM outperforms DVC. dMOP3 test problem has no connection between the decision variables, which affects the results of DVC to a certain extent, but on closer inspection, it is easy to find that DVC is only slightly inferior to HPPCM, which also shows that DVC and HPPCM have their own advantages. HPPCM performed slightly better on the FDA3 issue, but DVC’s MIGD values were near parity with HPPCM. In the first stage, DVC was only marginally inferior to HPPCM for the FDA3 problem, and DVC was only a bit worse than the other methods for the dMOP problem, but performed well for FDA1, FDA2, FDA4, dMOP1, and dMOP2. This indicates that DVC is able to respond to environmental changes faster in the early stages of environmental changes. The MIGD values for the FDA2 problem in both phase 2 and phase 3 show superiority over the other five strategies.
Table 3 shows the MHVD metrics of seven different algorithms for the FDA and dMOP problems, and it can be seen from the table that the results of the seven different algorithms are similar to MIGD. Overall DVC has a strong competitive ability, especially in the FDA4 problem DVC’s results are obviously better than other algorithms.
DVC differs from CKPS, SPPS, HPPCM, and DSSP in that DVC does not focus on the selection and prediction of particular points, but more on the classification of decision variables and their changes in the environment. In CKPS, SPPS, HPPCM, and DSSP, these comparison algorithms adopt the strategy of special points, which are employed to increase the diversity of populations. Conversely, in contrast to randomly adding diversity to the population, increasing the diversity of the population using special points removes the instability of randomly adding special points. Nevertheless, the definition of special points is to some extent a coarse-grained definition. The advantage of DVC is that only the categories of decision variables need to be analyzed and then the attributes of decision variables are judged by historical information, and different attributes correspond to different prediction strategies, which can balance the diversity and convergence of populations.
Analysis of F5–F10 evaluation results
Tables 4 and 5 show the values of the MIGD and MHVD metrics on the F5–F10 test suite, respectively. It is clearly seen that HPPCM, DSSP, and DVC algorithms are much superior to the rest among the seven compared algorithms. Among these three algorithms, the better results of DVC prevailed. F5–F7 are nonlinearly correlated problems and DVC clearly exhibits better performance than HPPCM and DSSP comparison algorithms. The nonlinear correlation problem also implies that PF changes are complex and requires a more demanding strategy for responding to environmental changes. For the three-objective problem F8, DSSP outperforms DVC to some extent because DSSP takes more objectives into account when sampling at special points. but the results of DVC are not comparable to DSSP, and the values of MIGD outperform DSSP in the first and third stages. The resilience of the DVC approach is also demonstrated by the standard deviation values presented in Tables 2, 3, 4 and 5. These results reveal that the DVC method exhibits a remarkable robustness and can swiftly and efficiently adapt to environmental variations, displaying an exceptional ability to tackle problems of varying complexities with ease.
Distribution diagram of final population
Figure 6 visualizes the tracking ability of the POF on the FDA1 problem for DVC and the other six comparison algorithms. It can be seen from Fig. 6 that DVC has a more uniform POF distribution compared to the other six comparison algorithms, which also shows that the DVC algorithm is able to better balance diversity and convergence. The dMOP2 problem has the qualities of a changing POF as well as a changing POS. On the dMOP2 problem, we have selected different algorithms to demonstrate the late state of the changing environment, and it can be seen in Fig. 7 that most of the algorithms basically track the POF well, but DVC demonstrates a more superior performance on the uniform distribution.

(a–g) exhibit the results of algorithms FPS, PPS, CKPS, SPPS, HPPCM, DSSP, and DVC with \(n_t=10\) and \(\tau _t=25\) on the FDA1 problem, respectively.
Discussion
In order to examine the effectiveness and robustness of the algorithm, we conducted a specific comparison with its formidable competitor, HPPCM. In our experiment, we maintain the value of \(n_t\) unchanged while observing the algorithm’s adaptability to dynamic environments by varying the value of \(\tau _t\), which represents the frequency of environmental changes. From the table 6, it can be clearly seen that DVC outperforms HPPCM significantly in both MIGD and MHVD metrics. This further illustrates that DVC is more capable of adapting to environments with varying frequencies of changes. During 100 phased environmental changes, HPPCM indeed demonstrates comparable results to DVC. However, when altering the frequency of environmental changes, DVC exhibits a certain advantage. HPPCM’s precise and controllable abrupt mutation strategy indeed holds some advantage under highly changing environments, whereas DVC’s stability relies on the relationships between decision variables, demonstrating superiority under different environmental change frequencies. Both algorithms have their respective strengths and weaknesses, but DVC’s stability stands as a robust competitive advantage.
Conclusions and future work
The role of decision variables in environmental change is fully considered in this paper, and a DMOP-DVC based on decision vector classification is proposed by integrating the historical information of static classification of decision variables. The proposed method reflects the evolutionary direction for decision variables in the current environment, and different classes of prediction strategies are used to optimize the evolution of populations to balance convergence and diversity.
From the experiments, many advantages are shown on DMOP-DVC, but the algorithm also has some drawbacks. For example, the accuracy of prediction can be further improved in the prediction strategy, and future work can consider introducing some training models to consider global historical changes. If the environment changes little or the environment changes drastically, whether different prediction strategies are needed to cope with it, these are the future works that are worth looking forward to.

(a–g) exhibit the results of algorithms FPS, PPS, CKPS, SPPS, HPPCM, DSSP, and DVC with \(n_t=10\) and \(\tau _t=25\) on the dMOP2 problem at the late stage of environmental changes, respectively.
Data availability
The datasets used during the study are available from the corresponding author upon reasonable request.
References
Ruan, G., Yu, G., Zheng, J., Zou, J. & Yang, S. The effect of diversity maintenance on prediction in dynamic multi-objective optimization. Appl. Soft Comput. 58, 631–647 (2017).
Peng, J., Feng, Y., Zhang, Q. & Liu, X. Multi-objective integrated optimization study of prefabricated building projects introducing sustainable levels. Sci. Rep. 13, 1–17 (2023).
Zhang, H., Liu, Z., Yin, S. & Xu, H. A hybrid multi-objective optimization of functional ink composition for aerosol jet 3d printing via mixture design and response surface methodology. Sci. Rep. 13, 2513 (2023).
Shree Soundarya, S. V. et al. Multi-objective goal-directed optimization of de novo stable organic radicals for aqueous redox flow batteries. Nat. Mach. Intell. 4, 720–730 (2022).
Li, X., Zhang, S. & Wong, K.-C. Multiobjective genome-wide rna-binding event identification from clip-seq data. IEEE Trans. Cybern. 51, 5811–5824 (2020).
Deb, K., Thiele, L., Laumanns, M. & Zitzler, E. Scalable multi-objective optimization test problems. In Proceedings of the 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No. 02TH8600), vol. 1, 825–830 (IEEE, 2002).
Wang, Z., Chen, H., Liang, X. & He, M. Decomposition based moea with unique subregions and stable matching. In 2021 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS) 264–270 (IEEE, 2021).
Liu, Z., Song, E., Ma, C., Yao, C. & Song, T. Multi-objective optimization of a dual-fuel engine at low and medium loads based on moea/d. In 2022 34th Chinese Control and Decision Conference (CCDC) 1655–1661 (IEEE, 2022).
Chen, R. & Zeng, W. Multi-objective optimization in dynamic environment: A review. In 2011 6th International Conference on Computer Science & Education (ICCSE) 78–82 (IEEE, 2011).
Son, P. V. H. & Nguyen Dang, N. T. Solving large-scale discrete time-cost trade-off problem using hybrid multi-verse optimizer model. Sci. Rep. 13, 1987 (2023).
Wang, G.-G. & Tan, Y. Improving metaheuristic algorithms with information feedback models. IEEE Trans. Cybern. 49, 542–555 (2017).
Zhang, Q., Jiang, S., Yang, S. & Song, H. Solving dynamic multi-objective problems with a new prediction-based optimization algorithm. PLoS ONE 16, e0254839 (2021).
Zheng, J., Zhou, F., Zou, J., Yang, S. & Hu, Y. A dynamic multi-objective optimization based on a hybrid of pivot points prediction and diversity strategies. Swarm Evol. Comput. 78, 101284 (2023).
Guo, Y., Yang, H., Chen, M., Cheng, J. & Gong, D. Ensemble prediction-based dynamic robust multi-objective optimization methods. Swarm Evol. Comput. 48, 156–171 (2019).
Du, W., Zhong, W., Tang, Y., Du, W. & Jin, Y. High-dimensional robust multi-objective optimization for order scheduling: A decision variable classification approach. IEEE Trans. Ind. Inform. 15, 293–304 (2018).
Liu, Q., Zou, J., Yang, S. & Zheng, J. A multiobjective evolutionary algorithm based on decision variable classification for many-objective optimization. Swarm Evol. Comput. 73, 101108 (2022).
Ma, L., Huang, M., Yang, S., Wang, R. & Wang, X. An adaptive localized decision variable analysis approach to large-scale multiobjective and many-objective optimization. IEEE Trans. Cybern. 52, 6684–6696 (2021).
Zhang, X., Tian, Y., Cheng, R. & Jin, Y. A decision variable clustering-based evolutionary algorithm for large-scale many-objective optimization. IEEE Trans. Evol. Comput. 22, 97–112 (2016).
Sedgwick, P. Spearman’s rank correlation coefficient. Bmj 349, 7321 (2014).
Susiana, D. & Lannasari, L. Tingkat Pengetahuan Berhubungan Dengan Tingkat Kecemasan Masyarakat Terhadap Pandemi Covid-19 Tahun 2021: The level of knowledge is related to the level of public anxiety about the 2021 covid-19 pandemic. J. Nurs. Educ. Pract. 2, 216–225 (2023).
Deb, K. & Gupta, S. Understanding knee points in bicriteria problems and their implications as preferred solution principles. Eng. Optim. 43, 1175–1204 (2011).
Harrison, K. R., Ombuki-Berman, B. M. & Engelbrecht, A. P. Dynamic multi-objective optimization using charged vector evaluated particle swarm optimization. In 2014 IEEE Congress on Evolutionary Computation (CEC) 1929–1936 (IEEE, 2014).
Doerr, B. & Qu, Z. A first runtime analysis of the nsga-ii on a multimodal problem. IEEE Trans. Evol. Comput. 2023, 13750 (2023).
Deb, K., Pratap, A., Agarwal, S. & Meyarivan, T. A fast and elitist multiobjective genetic algorithm: Nsga-II. IEEE Trans. Evol. Comput. 6, 182–197 (2002).
Helbig, M. Change reaction strategies for dnsga-ii solving dynamic multi-objective optimization problems. In 2017 IEEE 4th International Conference on Soft Computing & Machine Intelligence (ISCMI) 50–54 (IEEE, 2017).
Ismayilov, G. & Topcuoglu, H. R. Dynamic multi-objective workflow scheduling for cloud computing based on evolutionary algorithms. In 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion) 103–108 (IEEE, 2018).
Li, S., Wang, Y. & Yue, W. A regional local search and memory based evolutionary algorithm for dynamic multi-objective optimization. In 2020 39th Chinese Control Conference (CCC) 1692–1697 (IEEE, 2020).
Liang, Z., Zheng, S., Zhu, Z. & Yang, S. Hybrid of memory and prediction strategies for dynamic multiobjective optimization. Inf. Sci. 485, 200–218 (2019).
Liu, T., Cao, L. & Wang, Z. A multipopulation evolutionary framework with Steffensen’s method for dynamic multiobjective optimization problems. Memetic Comput. 13, 477–495 (2021).
Chen, L. et al. Dynamic multiobjective evolutionary algorithm with adaptive response mechanism selection strategy. Knowl.-Based Syst. 246, 108691 (2022).
Wang, Q., Gu, Q., Chen, L., Guo, Y. & Xiong, N. A moea/d with global and local cooperative optimization for complicated bi-objective optimization problems. Appl. Soft Comput. 137, 110162 (2023).
Zhou, A., Jin, Y. & Zhang, Q. A population prediction strategy for evolutionary dynamic multiobjective optimization. IEEE Trans. Cybern. 44, 40–53 (2013).
Zou, J., Li, Q., Yang, S., Bai, H. & Zheng, J. A prediction strategy based on center points and knee points for evolutionary dynamic multi-objective optimization. Appl. Soft Comput. 61, 806–818 (2017).
Jiang, M., Wang, Z., Hong, H. & Tan, K. C. Knee point based imbalanced transfer learning for dynamic multi-objective optimization. IEEE Trans. Evol. Comput. 99, 4027 (2020).
Zhang, X., Ye, T., Ran, C. & Jin, Y. A decision variable clustering-based evolutionary algorithm for large-scale many-objective optimization. IEEE Trans. Evol. Comput. 22, 97–112 (2018).
Ma, X. et al. A multiobjective evolutionary algorithm based on decision variable analyses for multiobjective optimization problems with large-scale variables. IEEE Trans. Evol. Comput. 20, 275–298 (2016).
Goh, C. K., Tan, K. C., Liu, D. S. & Chiam, S. C. A competitive and cooperative co-evolutionary approach to multi-objective particle swarm optimization algorithm design. Eur. J. Oper. Res. 202, 42–54 (2010).
Omidvar, M. N., Li, X., Mei, Y. & Yao, X. Cooperative co-evolution with differential grouping for large scale optimization. IEEE Trans. Evol. Comput. 18, 378–393 (2014).
Liang, Z., Wu, T., Ma, X., Zhu, Z. & Yang, S. A dynamic multiobjective evolutionary algorithm based on decision variable classification. IEEE Trans. Cybern. 52, 1602–1615 (2020).
Agarwal, D., Singh, P. & El Sayed, M. The karush-kuhn-tucker (kkt) optimality conditions for fuzzy-valued fractional optimization problems. Math. Comput. Simul. 205, 861–877 (2023).
Zhang, Q., Zhou, A. & Jin, Y. Rm-meda: A regularity model-based multiobjective estimation of distribution algorithm. IEEE Trans. Evol. Comput. 12, 41–63 (2008).
Wu, F., Chen, J. & Wang, W. A dynamic multi-objective evolutionary algorithm based on prediction. J. Comput. Des. Eng. 10, 1–15 (2023).
Farina, M., Deb, K. & Amato, P. Dynamic multiobjective optimization problems: Test cases, approximations, and applications. IEEE Trans. Evol. Comput. 8, 425–442 (2004).
Goh, C.-K. & Tan, K. C. A competitive-cooperative coevolutionary paradigm for dynamic multiobjective optimization. IEEE Trans. Evol. Comput. 13, 103–127 (2008).
BenMansour, I. An effective hybrid ant colony optimization for the knapsack problem using multi-directional search. SN Comput. Sci. 4, 164 (2023).
Yuan, Y., Xu, H., Wang, B., Zhang, B. & Yao, X. Balancing convergence and diversity in decomposition-based many-objective optimizers. IEEE Trans. Evol. Comput. 20, 180–198 (2015).
Hatzakis, I. & Wallace, D. Topology of anticipatory populations for evolutionary dynamic multi-objective optimization. In 11th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference 7071 (2006).
Li, Q., Zou, J., Yang, S., Zheng, J. & Ruan, G. A predictive strategy based on special points for evolutionary dynamic multi-objective optimization. Soft Comput. 23, 3723–3739 (2019).
Chen, Y. et al. Combining a hybrid prediction strategy and a mutation strategy for dynamic multiobjective optimization. Swarm Evol. Comput. 70, 101041 (2022).
Acknowledgements
This work is partially supported by National Natural Science Foundation of China under Grant (No. 61873240), the Key Research and Development Program of Zhejiang Province (No. 2023C01168) and Research incubation Foundation of Zhejiang University City College No.J202316.
Author information
Authors and Affiliations
Contributions
F.W.: Conceptualization, Methodology, Software, Writing—original draft. W.W.: Supervision, Funding acquisition, Project administration. J.C.: Data curation, Writing—review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, F., Wang, W., Chen, J. et al. A dynamic multi-objective optimization method based on classification strategies. Sci Rep 13, 15221 (2023). https://doi.org/10.1038/s41598-023-41855-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-41855-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
