
Abstract
The optimal operation of reservoir groups is a strongly constrained, multi-stage, and high-dimensional optimization problem. In response to this issue, this article couples the standard Pelican optimization algorithm with adaptive ε constraint methods, and further improves the optimization performance of the algorithm by initializing the population with a good point set, reverse differential evolution, and optimal individual t-distribution perturbation strategy. Based on this, an improved Pelican algorithm coupled with adaptive ε constraint method is proposed (ε-IPOA). The performance of the algorithm was tested through 24 constraint testing functions to find the optimal ability and solve constraint optimization problems. The results showed that the algorithm has strong optimization ability and stable performance. In this paper, we select Sanmenxia and Xiaolangdi reservoirs as the research objects, establish the maximum peak-cutting model of terrace reservoirs, apply the ε-IPOA algorithm to solve the model, and compare it with the ε-POA (Pelican algorithm coupled with adaptive ε constraint method) and ε-DE (Differential Evolution Algorithm) algorithms, the results indicate that ε. The peak flow rate of the Huayuankou control point solved by the IPOA algorithm is 12,319 m3/s, which is much lower than the safe overflow flow rate of 22,000 m3/s at the Huayuankou control point, with a peak shaving rate of 44%, and other algorithms do not find effective solutions meeting the constraint conditions. This paper provides a new idea for solving the problem of flood control optimal operation of cascade reservoirs.
Similar content being viewed by others
Introduction
Flood is one of the most frequent and serious natural disasters faced by human beings. In China, floods occur frequently and extensively, seriously endangering people's lives and property1. In addition, 60–80% of the rainfall occurs mainly during the flood season, which exacerbates the severity of floods2. For example, a once-in-a-millennium extraordinarily heavy rainstorm hit Zhengzhou on July 20, 2021, causing millions of people to be affected and causing huge economic losses.
As an engineering measure, reservoirs play the role of storing flood water, reducing flood peaks and protecting downstream safety during the flood season3. Reservoir flood control operation, as a non-engineering measure corresponding to reservoirs, has always been a hot spot for research. There are often multiple reservoirs in the flood control system, and it is difficult for a single reservoir to fully play its role in flood control. However, there are complex hydrological and hydraulic connections and some strong constraints between reservoirs, making it more difficult to solve the reservoir flood control operation problem4.
In the past, scholars often used dynamic programming5,6,7 and linear programming8 to solve this problem, but as the number of reservoirs and the operation period in-crease, the convergence speed is slow and the problem of "dimensional disaster" occurs. The emergence of heuristic algorithms has solved this problem well, and some scholars have started to use heuristic algorithms to solve this problem. Cheng applied the chaotic genetic algorithm9 to the reservoir scheduling of hydropower station, and the convergence speed is much better than dynamic programming and standard genetic algorithm. He proposed an improved chaotic particle swarm algorithm10 based on logistic mapping to solve the reservoir flood control scheduling model. Chen coupled the Yin-Yang Firefly Algorithm algorithm11 and ε-constraint method to establish the three-reservoirs flood control scheduling model. Liu12 uses particle swarm optimization algorithm with coupled penalty function to solve the maximum peak clipping model of cascade reservoirs. Zhang13 proposed a genetic algorithm coupled with penalty function to solve the flood control operation problem of cascade reservoirs. Although the penalty function method is often used to solve constraint problems, the selection of penalty parameters is difficult to grasp and too small to play a penalty role; If it is too large, it will cause errors due to the influence of errors. Although intelligent algorithms have been widely used, they are too stochastic and easily fall into local optimal solutions, and the solution results are not stable.
In addition, simple optimization algorithms are difficult to solve the multi constraint and strong constraint problems of reservoir group flood control operation models, so constraint processing techniques need to be combined in the solving process to solve the relevant constraint conditions. ε Constraint method is a commonly used method for handling constraint conditions, however, research has shown that based on ε. The constrained optimization algorithm has achieved good results in handling constrained optimization problems, but further improvement is still needed in terms of convergence accuracy and robustness. Literature14 proposes an adaptive approach ε Constraint method, by improving constraint processing technology and adaptive settings ε, avoid falling into local optima, improve the robustness and search efficiency of the algorithm. The Pelican Optimization Algorithm (POA) is a novel heuristic algorithm pro-posed by Pavel Trojovský and Mohammad Dehghani15 in 2022, which simulates the behavior of pelicans hunting in nature. Experimental simulations comparing the POA algorithm with eight common algorithms such as Genetic Algorithm (GA), Differential Evolution (DE), and Grey Wolf Optimization Algorithm (GWO) in the literature demonstrate that the POA algorithm has high local search ability and convergence toward the global optimum. However, like other heuristic algorithms, it also has the drawback of too much randomness, which affects its exploration toward the global optimum. Therefore, this paper proposes a pelican algorithm (IPOA) based on good point set and reverse differential evolution. First, the inclusion of the good point set makes the initial population distribution more uniform and improves the diversity of the population16; second, the reverse differential evolution algorithm is incorporated to improve the diversity, convergence speed and optimality-seeking accuracy of the algorithm; finally, an adaptive t-distribution variation strategy is introduced for the optimal pelican individuals to avoid the algorithm from falling into local optimal solutions. The contributions of this article are as follows: to address the above issues, this paper proposes an IPOA algorithm with coupled adaptive ε-constraint method and the cec2006 test function set were used for simulation experiments. The experiment shows that the algorithm proposed in this paper not only finds the global optimal solution when solving constrained optimization problems, but also has good robustness compared to the original algorithm. Take ε-IPOA algorithm was applied to solve the flood control operation model of the Sanmenxia-Xiaolangdi cascade reservoir, and compared with other algorithms. The results indicate that, the application of ε-IPOA algorithm in reservoir operation problems has strong practicality, and the proposed scheme has a high peak clipping rate, which is more beneficial for downstream disaster prevention and reduction. This algorithm provides a new approach for solving the joint flood control operation of reservoir groups.
This paper is structured as follows: “Flood control operation model of cascade reservoirs” section shows the joint flood control and operation model for reservoir groups; “IPOA algorithm based on adaptive ε-constraint” section introduces the ε-IPOA algorithm and performs functions tests to prove its superiority; “Case analysis” section case study illustrates the results of joint operation of reservoir groups in the study area and discusses them; “Conclusion” section presents the conclusions of this paper.
Flood control operation model of cascade reservoirs
Objective function
In order to reduce the flood control burden of the downstream reservoirs and the safety of the downstream flood control points, the flood control operation model of cascade reservoirs is established based on the maximum peak clipping criterion. The maximum peak clipping criterion not only ensures that the maximum peak flow at the downstream control point is reduced, but also makes the discharge flow of the reservoir more uniform, reducing the flood risk of the basin.
As shown in Fig. 1, suppose that the basin flood control system has N cascade reservoirs, 1 flood control point, the inflow of the first reservoir and the interval flood flow between reservoirs are known, the number of dispatching periods is T, and the maximum peak clipping objective function of the downstream control point is as follows:
where \(q_{n,t}\) is the discharge flow of the n-th reservoir in the t period; \(Q_{n,t}\) is the interval flood flow between the n-th reservoir and the (n + 1)-th reservoir; \(\Delta t\) is the operation interval.

N-class reservoir generalization map.
Constraint condition
-
1.
Water balance constraint
$$V_{n,t} = V_{n,t - 1} + \left( {I_{n,t} - q_{n,t} } \right)\Delta t$$(2) -
2.
Water level constraint
$$Z_{n,\min } \le Z_{n,T} \le Z_{n,\max }$$(3) -
3.
Initial water level, end of period water level constraint
$$Z_{n,0} = Z_{n,begin}$$(4)$$Z_{n,T} = Z_{n,end}$$(5) -
4.
Discharge capacity constraint
$$q_{n,t} \le q\left( {Z_{n,t} } \right)$$(6) -
5.
Maximum safe discharge constraint
$$q_{n,t} \le Q_{\max }$$(7) -
6.
Non-negative constraint
All the above variables are non-negative.
Where \(V_{n,t - 1}\), \(V_{n,t}\) is the initial storage capacity and final storage capacity of the nth reservoir in the t period;\(I_{n,t}\) is the inflow of the n-th reservoir in the t period;\(q_{n,t}\) is the outflow of the n-th reservoir in the t period;\(Q_{\max }\) is the maximum downstream flow allowed to ensure the safety of the downstream river;\(q\left( {Z_{n,t} } \right)\) is the maximum discharge capacity of the nth reservoir when the initial water level is \(Z_{n,t}\);\(Z_{n,0}\) is the initial water level at the initial time of the n-th reservoir operation;\(Z_{n,begin}\) is the starting water level of the n-th reservoir;\(Z_{n,T}\) is the water level at the end of the n-th reservoir operation period.\(Z_{n,end}\) is the expected water level at the end of the n-th reservoir operation period.
IPOA algorithm based on adaptive ε-constraint
POA algorithm
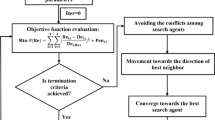
In the Pelican optimization algorithm, the behavior and strategies of the pelicans during attack and hunting were simulated to update candidate solutions. The hunting process is divided into two stages: approaching the prey (exploration stage) and flying on the water surface (development stage).
Initialization
In the equation, Xij is the position of the j-th dimension of the i-th pelican; N is the number of populations; D is the dimension of the decision variable; lb and ub are the lower and upper bounds of the decision variables respectively.
Phase 1: Exploration phase
In the first stage, the pelican determines the location of its prey and then moves towards this designated area. The mathematical model is as follows:
In the formula, \(X_{i,j}^{new1}\) is the position of the j-th dimension of the i-th pelican based on the first stage update; I is a random integer of 1 or 2; Pj is the position of the prey in the jth dimension; Fp is the objective function value of the prey; Fi is the objective function value of the i-th pelican.
Phase 2: Development phase
In the formula, \(X_{i,j}^{new2}\) is the position of the j-th dimension of the i-th pelican based on the second stage update; R is a random integer of 0 or 2; iter is the number of current iterations; Maxiter is the maximum number of iterations.
IPOA algorithm
In order to improve the performance of the POA algorithm, the following improvements are made in this paper on the basis of the POA algorithm.
Goodpoint set principle
The standard POA algorithm uses a random method to initialize the pelican population, which is highly randomized and some better pelican individuals are easily ignored. In this paper, we adopt the good point set theory proposed by Chinese mathematician Hua Luogeng to initialize the pelican population. Good point set is an effective method that can select points uniformly, and compared with the random method, the points taken using the good point set method can be more uniformly distributed in the search space. The literature17,18 demonstrated that the population initialized with good point set theory is more uniform and can increase the diversity of the population during the initialization process. The formula is as follows:
where p is the smallest prime number satisfying \(\frac{p - 3}{2} \ge D\);
Fusion of reverse differential evolution strategy
The main idea of the reverse learning strategy19 is that when searching for the optimal solution, the current solution and the reverse solution are searched simultaneously, and the optimal solution is selected by comparing the fitness values of the current solution and its reverse solution. The initial population can increase the diversity of the population20 by adding a reverse population through the reverse learning strategy, and the reverse population solving formula is as follows:
where \(\hat{X}\) is the reverse solution.\(X\) is the current solution.
Differential evolution algorithm21 comes from the genetic algorithm proposed earlier, and also has the evolution process of crossover, mutation and selection. Differential evolution of pelican population after reverse learning is carried out as follows:
First, each pelican individual of the current population and the reverse population was subjected to a mutation operation by Eq. (13) to obtain mutant individuals.
where \(x_{i}\) is the current pelican individual; \(u_{i}\) is the mutant individual corresponding to the current pelican individual; K is the scaling factor; \(x_{r1}\), \(x_{r2}\) are two pelican individuals randomly selected.
Then, a new pelican individual is generated by the crossover operation of Eq. (14).
where CR is the crossover probability.
Finally, more suitable individual pelicans were selected by comparing the magnitude of the fitness values, as shown in Eq. (15).
Optimal individual adaptive t-distribution variation
The convergence of the algorithm to the local extremum depends on the optimal position of the individual22. Therefore, in this paper, the adaptive t-distribution variation strategy in the literature23 is applied to the variation of the optimal pelican individual, and the current number of iterations is used as the degree of freedom of the t-distribution. At the beginning of the iteration, the t-distribution variation is close to the Coasean distribution variation, which is conducive to enhancing the search ability of the pelican individual at the global level and increasing the diversity of the population; at the end of the iteration, the t-distribution variation is close to the Gaussian distribution variation, which can enhance the search ability of pelican individuals near the optimal point and accelerate the convergence speed of the algorithm. The optimal individual adaptive t-distribution variance is formulated as follows:
where \(X_{best}^{t}\) are mutated pelican individuals; \(X_{best}\) are currently the best pelican individuals; iter is the number of current iterations; t represents t-distribution.
Adaptive ε constraint method
The ε-constraint method24 is a method proposed by Takahama for solving constrained optimization problems, which retains infeasible individuals with low constraint violation and low objective function values by relaxing the constraints, and gives these excellent solutions a chance to enter the next generation population, which in turn explores to more regions and finds better objective function values. To overcome the problem that the traditional ε-constraint method tends to fall into local optimal solutions, an adaptive ε-constraint method is proposed in the literature14 with the following improvements:
-
1.
Improving the individual comparison criterion to make full use of good infeasible individuals to explore to more solution space, thus increasing the population diversity. The specific criterion is shown in Eq. (17):
$$X_{1} {\text{ is better than }}X_{2} \Leftrightarrow \left\{ \begin{aligned} & f\left( {X_{1} } \right) < f\left( {X_{2} } \right),G\left( {X_{1} } \right) = 0,G\left( {X_{2} } \right) = 0 \hfill \\ & f\left( {X_{1} } \right) < f\left( {X_{2} } \right),0 < G\left( {X_{1} } \right) \le \varepsilon ,0 < G\left( {X_{2} } \right) \le \varepsilon \hfill \\ & 0 < G\left( {X_{1} } \right) \le \varepsilon ,G\left( {X_{2} } \right) > \varepsilon \hfill \\ & G\left( {X_{1} } \right) < G\left( {X_{2} } \right),G\left( {X_{1} } \right) > \varepsilon ,G\left( {X_{2} } \right) > \varepsilon ,rand \le Ps \hfill \\ & f\left( {X_{1} } \right) < f\left( {X_{2} } \right),G\left( {X_{1} } \right) > \varepsilon ,G\left( {X_{2} } \right) > \varepsilon ,rand \le Ps \hfill \\ & f\left( {X_{1} } \right) < f\left( {X_{2} } \right),G\left( {X_{1} } \right) = 0,0 < G\left( {X_{2} } \right) \le \varepsilon \hfill \\ & G\left( {X_{1} } \right) = 0,G\left( {X_{2} } \right) > \varepsilon \hfill \\ &f\left( {X_{1} } \right) < f\left( {X_{2} } \right),0 < G\left( {X_{1} } \right) \le \varepsilon ,G\left( {X_{2} } \right) = 0 \hfill \\ \end{aligned} \right.$$(17)where f(x) is the function fitness value;G(x) is the constraint violation value; Ps is a random number on the interval [0.9,1].
-
2.
Adaptive ε adjustment strategy, the ε value of the traditional ε constraint method depends only on the number of iterations, the adaptive ε value fully considers the relationship between the objective function value and the size of constraint violation and the proportion of feasible individuals in the population, and makes adaptive adjustments at each generation. ε equation is as follows:
$$\varepsilon \left( t \right) = \left\{ \begin{array}{ll} \varepsilon \left( 0 \right) \times e^{{ - \alpha \times \left( {t/Te} \right)}} , & \quad t \le Te \hfill \\ 0, & \quad t > Te \hfill \\ \end{array} \right.$$(18)$$\varepsilon \left( 0 \right) = 0.6 \times \sum\limits_{i = 1}^{N} {G\left( {X_{i} } \right)/N}$$(19)$$\alpha = \alpha_{\min } + \lambda \times \left( {\alpha_{\max } - \alpha_{\min } } \right)$$(20)where Te is the number of truncated evolutionary iterations;\(\lambda\) is the proportion of viable individuals in the population. The value of Te should be appropriate, too large will make a large number of infeasible individuals appear in the late iteration and affect the population convergence to a feasible solution; too small will eliminate a large number of infeasible individuals in the early iteration and easily fall into a local optimum solution.
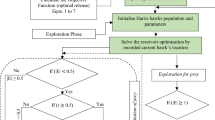
Computational flow of the ε-IPOA algorithm
The steps of the ε-IPOA algorithm are as follows, and the flowchart is shown in Fig. 2.

ε-IPOA algorithm flow chart.
- Step 1::
-
Initialize the parameters, including the number of populations N, the maximum number of iterations T, the number of truncated evolutionary iterations Te, \(\alpha_{\min }\), \(\alpha_{\max }\), the boundary conditions and the dimensionality of the decision variables.
- Step 2::
-
Generate the pelican population by initializing the set of good points according to Eq. (11) and calculate the fitness value.
- Step 3::
-
Perform the reverse differential evolution operation on the pelican population according to Eqs. (12)–(15).
- Step 4::
-
Performing t-distribution variation on the optimal pelican individuals according to Eq. (16).
- Step 5::
-
Updating the position of the next generation of pelican individuals and calculating the fitness value.
- Step 6::
-
Comparing individuals and performing selection according to Eq. (17).
- Step 7::
-
Determine whether the condition to terminate the iteration is met, if so, go to step 8, otherwise go to step 3.
- Step 8::
-
Output the optimal pelican individual and the optimal fitness value.
Simulation test of ε-IPOA algorithm
To verify the effectiveness and feasibility of the POA algorithm, this article selects 24 test functions from the internationally recognized cec2006 test function set for simulation experiments, and compares them with DE and POA algorithms. Among them, each test function runs independently 50 times, with a population of 200, a maximum iteration count of 10,000, a maximum function evaluation count of 500,000, a truncated evolution iteration count of 1000, and a tolerance value of 0.0001 for equation constraint violations. The experimental results are shown in Table 3.
The experimental results are shown in the table above, and the bolded font indicates the optimal effect. From Table 1, it can be seen that:
-
1.
Adaptive ε-constraint method can effectively assist the IPOA algorithm in handling constrained optimization problems.
-
2.
The three algorithms run independently on each function for 50 times. When the evaluation times are consistent, the average value of the results obtained by ε-IPOA algorithm is lower than that of the other two algorithms. This shows that when the Time complexity is consistent, the performance of ε-IPOA algorithm is better than that of ε-POA algorithm and ε-DE algorithm, and it has stronger global search ability. Except for the g20 and g22 functions, ε-IPOA algorithm has found the optimal solution that satisfies the constraint conditions.
-
3.
The three algorithms were independently run 50 times on each function, and the standard deviation of the results obtained by ε-IPOA algorithm was smaller than that of the other two algorithms, demonstrating the good robustness of ε-IPOA algorithm.
-
4.
ε-IPOA algorithm only achieves a standard deviation of 0 when solving functions g01 and g12, indicating that this algorithm still has potential for development and needs to further improve its exploration and development capabilities.
Case analysis
Study area
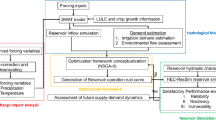
The Yellow River is the second largest river in China, with a total field of 5464 km and a basin area of 795,000 km2, originating from the Bayankara Mountains on the Qinghai-Tibet Plateau, flowing from west to east that through nine provinces and regions, including Qinghai, Sichuan, Gansu, Ningxia, Inner Mongolia, Shanxi, Shaanxi, Henan and Shandong, and injecting into the Bohai Sea in Kenli County, Shandong Province. In this paper, the area from Sanmenxia to Huankou in the middle and lower reaches of the Yellow River is selected as the study area, and flood control and scheduling research is carried out for Sanmenxia and Xiaolangdi tandem reservoirs. The geographical location is shown in Fig. 3. The tandem reservoir flood control and scheduling model takes the storage capacity of each reservoir at each time period as the decision variable, contains constraint constraints such as water balance, safe river discharge and gate discharge flow, and is solved by the ε-IPOA algorithm.

Geographical location map of the research object.
Sanmenxia Reservoir and Xiaolangdi Reservoir are both backbone reservoirs on the main stream of the middle and lower reaches of the Yellow River, mainly for flood control, taking into account the role of irrigation and power generation. Sanmenxia Reservoir controls a basin area of 688,000 km2, accounting for 91.5% of the total basin area of the Yellow River, and controls the flooding in the area above Sanmenxia. Xiaolangdi Reservoir controls a watershed area of 694,000 km2, accounting for 92.3% of the total area of the Yellow River basin, and is the only large comprehensive water conservancy project with large reservoir capacity in the middle and lower reaches of the Yellow River, except for Sanmenxia. The characteristic parameters of the two reservoirs are shown in Table 2.
Flood process analysis
The floods in the area from Sanmenxia to Huayuankou mainly come from the upstream water of Sanmenxia reservoir, the floods between Sanmenxia and Xiaolangdi reservoir area and the floods between Xiaolangdi reservoir and Huayuankou control point. These three kinds of floods rise fiercely with high peaks and large amounts, causing a great threat to the downstream. In this paper, we select the 1000-year flood of 1958, which is the largest flood in the Yellow River since the availability of measured hydrological data, mainly caused by persistent heavy rainfall. The flood process is shown in Table 3.
Figure 4 shows the flood evolution process from Sanmenxia reservoir to Huayuankou interval. It is assumed that the inlet flow of Sanmenxia reservoir is Q1, the interval flood from Sanmenxia to Xiaolangdi reservoir is Q2, and the interval flood from Xiaolangdi reservoir to the control point of Huayuankou is Q3. The flood process of Huayuankou section is composed of floods in each area through the action of river evolution and reservoir regulation.

Flood evolution of Sanmenxia and Xiaolangdi reservoirs.
The process of flood water moving from upstream to downstream in a river is called flood evolution. The study of flood evolution allows staff at downstream sites to forecast the flood process at downstream sites based on the flow process measured at upstream sites, providing a basis for downstream flood forecasting and flood control. The commonly used calculation methods are hydrological method and hydrodynamic method, the hydrological method is simple to calculate and requires less information, the hydrodynamics is limited by the measured topographic information25, this paper selects the hydrological method based on the tank storage equation and water balance principle—Muskingum method26 calculation, the parameter values used are shown in Table 4, Where K is the tank storage coefficient, x is the flow specific gravity coefficient, and △t is the time interval (hour).
Results and discussion
This paper aims to minimize the peak flow of Huayuankou section, and adopts ε-IPOA algorithm solvethe model. In the solution, the population size and the maximum number of iterations are 200 and 30w, respectively, and the number of truncation iterations Te is 1000. based on the measured hydrological data, the flood calendar time and reservoir operation period in this paper are 13d, and the calculation period is 4 h.
Analysis of operation results
According to the maximum peak-clipping objective function of the garden mouth section established in “Objective function”, the ε-IPOA algorithm proposed in this paper is used to solve the flood control operation model of Sanmenxia and Xiaolangdi cascade reservoirs, and the flood process of the Huayuankou section is shown in Fig. 5 and Table 5, and the operation results of Sanmenxia and Xiaolangdi reservoirs are shown in Table 6, Figs. 6 and 7.

Huayuankou flood process.

Sanmenxia Reservoir operation process.

Xiaolangdi Reservoir operation process.
It can be seen from Tables 6 and 7 that after the joint dispatching, the peak flow of Huayuankou section is 12,319 m3/s, which does not exceed the controlled discharge of 22,000 m3/s of Huayuankou, and the peak clipping rate has reached 44%. Through the joint operation of the two reservoirs, the peak clipping rate have reached 27.1% and 64.1% respectively, which is conducive to the safety of the reservoir itself and reduces the flood control pressure in the downstream. Figures 6 and 7 are the operation process charts of Sanmenxia Reservoir and Xiaolangdi Reservoir respectively. It can be seen from the figure that the water level processes of the two reservoirs are between the flood limit water level and the flood control high water level, indicating that the solution results meet the constraints and reach the feasible solution. The inflow flood of Xiaolangdi Reservoir has reached a "double peak", with the maximum peak flow exceeding 25,000 m3/s, which greatly exceeds the safe discharge of the river channel and increases the risk of flood disaster. After regulation, the discharge flow of Xiaolangdi Reservoir is stable within 10,000 m3/s, and the flood process is generally stable, ensuring the safety of flood discharge of the downstream river channel.
Comparison of operation results
Algorithm comparison
To verify the feasibility and applicability of the ε-IPOA algorithm, the ε-POA and ε-DE algorithms are chosen to solve the above model in this paper. To ensure the fairness of the algorithms, the parameters and initial conditions of the ε-POA and ε-DE algorithms are kept the same as those of the ε-IPOA algorithm. Unfortunately, neither algorithm found a feasible solution for the model, further illustrating the superiority of the ε-IPOA algorithm in solving the reservoir scheduling problem. Figures 8 and 9 show the solution results of the ε-POA and ε-DE algorithms for the Sanmenxia reservoir, respectively.

ε-POA solves the scheduling process of Sanmenxia reservoir.

ε-DE solves the scheduling process of Sanmenxia reservoir.
Comparison with single reservoir scheduling results
In order to illustrate more intuitively the effect of joint operation than single reservoir operation, this paper also calculates the flooding process of the Huayuankou section under single reservoir operation, and the results are shown in Tables 7 and 8.
It can be seen from the above table that under the two modes, the peak flow of Huayuankou section does not exceed the control flow, but the peak clipping effect of Huayuankou section under the joint dispatching mode is better than that of single reservoir dispatching. By comparing Tables 6 and 8, under the single reservoir operation mode, the water levels of Sanmenxia and Xiaolangdi reservoirs have not recovered to the initial water level at the end of the operation period, which is not conducive to coping with the arrival of the next flood in the flood season. In addition, under the single reservoir operation mode, the peak clipping rate of Sanmenxia and Xiaolangdi reservoirs is lower than that of joint operation. Therefore, the peak clipping effect of the joint operation mode is the best, which can play a more important role in flood control of the reservoir.
Conclusion
In this paper, the adaptive ε-constrained method is coupled with the Pelican algorithm, and then the ε-IPOA algorithm is proposed by initializing the population with good point set, reverse differential evolution and optimal individual adaptive strategy to improve the Pelican algorithm. The case of Sanmenxia and Xiaolangdi reservoirs is also selected, and the joint flood control operation model of the cascade reservoirs is established based on the maximum peak clipping criterion, and this algorithm is applied to the solution of the model. The conclusions are as follows.
-
1.
Select 24 test functions from the cec2006 test set to validate the ε-IPOA algorithm and compare them with ε-DE and ε-POA algorithms. The experimental results show that the ε-IPOA algorithm is superior to the other two algorithms, with stable solving performance and high accuracy, and can effectively handle constrained optimization problems. The Pelican optimization algorithm can improve its global search ability by initializing the population with a good point set, reverse difference mixing, and perturbing the optimal individual t-distribution.
-
2.
In this paper, the ε-IPOA algorithm is used to solve the cascade reservoirs flood control operation problem, and the results obtained satisfy all the constraints, and the peak clipping rates of Sanmenxia reservoir, Xiaolangdi reservoir and Huayuankou control point are 27.1%, 64.1% and 44%, respectively, which effectively ensure the flood safety of the Huayuankou section. And the ε-POA algorithm and ε-DE algorithm with which for did not find a feasible solution. In addition, the results of the optimal operation of single reservoir are compared, and the joint operation is better than the single reservoir operation.
-
3.
The results indicate that the ε-IPOA algorithm is feasible for solving the optimization operation problem of reservoir flood control, and can effectively address the strong constraints, multi-stage, and high-dimensional problems of reservoir operation models. This algorithm provides a new approach to solve the optimization scheduling problem of reservoir groups.
-
4.
In the future, the performance of this algorithm will be further optimized through other strategies and applied to more complex series parallel hybrid reservoir groups. In addition, this algorithm is also applied to other engineering constrained optimization problems.
Data availability
The datasets generated and/or analyzed during the current study are not publicly available but are available from the corresponding author on reasonable request.
References
Xiao, G., Xie, J. & Luo, J. Improved NSGAII algorithm for flood dispatching of multi-objectives reservoir. J. Hydroelectric Eng. 31, 77–83 (2012).
Wanliang, W. et al. Multi-objective culture whale optimization algorithm for reservoir flood control operation. Comput. Integr. Manuf. Syst. 28, 3494–3509. https://doi.org/10.13196/j.cims.2022.11.014 (2022).
Luo, J., Qi, Y., Xie, J. & Zhang, X. A hybrid multi-objective PSO–EDA algorithm for reservoir flood control operation. Appl. Soft Comput. https://doi.org/10.1016/j.asoc.2015.05.036 (2015).
Di, Z., Yadong, M., Xinfa, X. & Zhangjun, L. Triple parallel progressive optimality algorithm for optimal operation of the complicated flood control system. J. Hydraul. Eng. 51, 1199–1211. https://doi.org/10.13243/j.cnki.slxb.20200148 (2020).
Mei, Y. D. Dynamic programming model and method of cascade reservoirs optimal operation for flood control. J. Wuhan Univ. Hydraul. Electr. Eng. 5, 10–12 (1999).
Zhang, J., Liu, P., Lei, X., Chen, X. & Zhang, W. Optimal operation methods of baise reservoir for flood control. J. Water Resour. Res. 03, 315–325. https://doi.org/10.12677/JWRR.2014.34039 (2014).
Saadat, M. & Asghari, K. Reliability improved stochastic dynamic programming for reservoir operation optimization. Water Resour. Manag. https://doi.org/10.1007/s11269-017-1612-y (2017).
Du, J., Han, L., Wang, L. & Yan, S. A linear programming for optimal operation of multireservoir flood control system. J. Naijing Univ 2, 301–309 (1995).
Cheng, C.-T., Wang, W.-C., Xu, D.-M. & Chau, K. W. Optimizing hydropower reservoir operation using hybrid genetic algorithm and chaos. Water Resour. Manag. https://doi.org/10.1007/s11269-007-9200-1 (2008).
He, Y., Xu, Q., Yang, S. & Liao, L. Reservoir flood control operation based on chaotic particle swarm optimization algorithm. Appl. Math. Model. https://doi.org/10.1016/j.apm.2014.02.030 (2014).
Chen, H. T., Wang, W. C., Chau, K. W., Xu, L. & He, J. Flood control operation of reservoir group using Yin-Yang firefly algorithm. Water Resour. Manag. https://doi.org/10.1007/s11269-021-03005-z (2021).
Deyou, L., Qunming, L. & Shoulun, C. Mathematical model and PSODP solution method for optimal for flood control dispatching of cascaded reservoirs. Water Resour. Power, 25, 025. https://doi.org/10.3969/j.issn.1000-7709.2007.01.010 (2007).
Gai-Hong, Z., Wang, G. L., Jing, Z. & Li, T. Optimal method to establish joint flood control operation rules with flood forecast information for cascade reservoirs. J. Dalian Univ. Technol. https://doi.org/10.7511/dllgxb201001023 (2010).
Xiaojun, B. & Lei, Z. Self-adaptiveεconstrained optimization algorithm. Syst. Eng. Electron. 37, 1909–1915. https://doi.org/10.3969/j.issn.1001-506X.2015.08.29 (2015).
Pavel, T. & Mohammad, D. Pelican optimization algorithm: A novel nature-inspired algorithm for engineering applications. Sensors https://doi.org/10.3390/s22030855 (2022).
Xiali, S., Shixin, L., Qingqing, L. & Kun, W. Improved sparrow algorithm based on good point set and inertia weight. Adv. Appl. Math. 10, 8. https://doi.org/10.12677/AAM.2021.1010337 (2021).
Shaoqiang, Y., Ping, Y., Donglin, Z., Fengxuan, W. & Zhe, Y. Improved sparrow search algorithm based on good point set. J. Beijing Univ. Aeronaut. Astronaut. https://doi.org/10.13700/j.bh.1001-5965.2021.0730 (2022).
Li, Y., Ni, Z., Jin, F., Li, J. & Li, F. Research on clustering method of improved glowworm algorithm based on good-point set. Math. Probl. Eng. https://doi.org/10.1155/2018/8724084 (2018).
Tizhoosh, H. R. In International Conference on International Conference on Computational Intelligence for Modelling, Control & Automation. 695–701.
Yun-xuan, L. & Liang-xi, Q. Squirrel search algorithm improved by opposition-based learning and differential evolution. J. Guangxi Univ. (Nat. Sci. Ed.) 47, 164–173. https://doi.org/10.13624/j.cnki.issn.1001-7445.2022.0164 (2022).
Peng, Z., Ni-suo, D. & Zhi, O. Sparrow search algorithm based on differential evolution and hybrid multi strategy. Comput. Eng. Des. 43, 1609–1619. https://doi.org/10.16208/j.issn1000-7024.2022.06.014 (2022).
Zhigang, L., Jiajun, Z. & Zhiwei, H. Adaptive mutation disturbance particle swarm optimization algorithm based on personal best position. J. Southwest Jiaotong Univ. 47, 761–768. https://doi.org/10.3969/j.issn.0258-2724.2012.05.006 (2012).
Sheng, H.F.-F.L. Adaptivesatin bower birdoptimization algorithm based on tdistribution mutation. Microelectron. Comput. 35, 117–121. https://doi.org/10.19304/j.cnki.issn1000-7180.2018.08.025 (2018).
Takahama, T. & Sakai, S. Constrained Optimization by ε Constrained Differential Evolution with Dynamic ε-Level Control (Springer, 2008). https://doi.org/10.1007/978-3-540-68830-3_5.
Zhijia, L. et al. Applications of channel flood routing methods in middle part of Huaihe River and Hutuo River. J. Hohai Univ. (Nat. Sci.) 48, 7. https://doi.org/10.3876/j.issn.1000-1980.2020.02.001 (2020).
Kai-bin, Y., Hao, X., Tian-qing, L., Jian-rong, X. & Zi-jun, Y. Application of Muskingum methods in dam-breach flood routing of “11.03” Baige barrier lake on Jinsha river. Water Resour. Power 40, 71–74 (2022).
Funding
The authors are grateful to the project of key science and technology of the Henan province (No: 222102320333).
Author information
Authors and Affiliations
Contributions
J.H. was responsible for the initial concept and writing the thesis. X.-Q.G. and H.-T.C. build models and program. S.-L.W. and F.-X.C. revised the manuscript and shared many comments and suggestions to improve research quality. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
He, J., Guo, X., Wang, S. et al. Study on reservoir optimal operation based on coupled adaptive ε constraint and multi strategy improved Pelican algorithm. Sci Rep 13, 14093 (2023). https://doi.org/10.1038/s41598-023-41447-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-41447-0
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
