
Abstract
We present a fast and accurate non-invasive brain-machine interface (BMI) based on demodulating steady-state visual evoked potentials (SSVEPs) in electroencephalography (EEG). Our study reports an SSVEP-BMI that, for the first time, decodes primarily based on top-down and not bottom-up visual information processing. The experimental setup presents a grid-shaped flickering line array that the participants observe while intentionally attending to a subset of flickering lines representing the shape of a letter. While the flickering pixels stimulate the participant’s visual cortex uniformly with equal probability, the participant’s intention groups the strokes and thus perceives a ‘letter Gestalt’. We observed decoding accuracy of 35.81% (up to 65.83%) with a regularized linear discriminant analysis; on average 2.05-fold, and up to 3.77-fold greater than chance levels in multi-class classification. Compared to the EEG signals, an electrooculogram (EOG) did not significantly contribute to decoding accuracies. Further analysis reveals that the top-down SSVEP paradigm shows the most focalised activation pattern around occipital visual areas; Granger causality analysis consistently revealed prefrontal top-down control over early visual processing. Taken together, the present paradigm provides the first neurophysiological evidence for the top-down SSVEP BMI paradigm, which potentially enables multi-class intentional control of EEG-BMIs without using gaze-shifting.
Similar content being viewed by others

Introduction
BMIs allow a systematic decoding of brain states for communication, control, and monitoring1,2,3,4. Among several neuroimaging techniques, EEG has been shown to be a practical and versatile tool for operating general BMIs because of its excellent temporal resolution (approximately 1 ms), non-invasiveness, and portability3,5,6. EEG-based BMI studies7 have established a number of frequently used robust paradigms, including event-related P3008,9, slow cortical potential10, mu rhythm11,12, and SSVEPs13. Among these paradigms, SSVEP-BMIs provide very accurate high temporal and spectral resolution information (usually less than 0.1 Hz)14 at high information transfer rates (ITRs)15; depending on the number of classes, even though ITR is high, accuracy can still be too low for effective communication16. An SSVEP is a physically driven electrical oscillatory response in the brain, induced by the repetitive presentation of a visual stimulus14; occipital SSVEP can be detected at the same flicker frequency (and harmonics) as the presented flickering stimulus, a paradigm that has many applications in BMI and neurotechnology17,18,19. The basic concept for an SSVEP-mediated BMI system dates back to the late 1970s20, and the application of SSVEPs to BMIs was introduced almost 20 years later21. The SSVEP-BMI has been further generalized to encode user commands in flickering stimuli that induce SSVEPs at different frequencies. The user chooses one of the commands by focusing attention on one of the oscillating stimuli, and by analyzing the subsequent SSVEPs, the BMI system tries to decode which stimulus the user chose15,22. As SSVEP signals are triggered by external stimuli, which are more robust and easier to control than internally generated stimuli, SSVEPs can be potent and stable BMI control signals. Moreover, SSVEP-BMI systems can be used by more than 90% of users without much training22,23. Nevertheless, SSVEP-based BMIs still have several limitations to overcome. For instance, the flicker stimulation can produce visual fatigue or discomfort24. In addition, most SSVEP-based BMIs are not free from gaze-shift issues25,26,27,28. Therefore, an SSVEP-based BMI is usually regarded as a dependent BMI, because it requires some neuromuscular control of the eyes and/or head29. In addition, there is a limit to the number of classes that are reliably decodable using conventional EEG-based BMIs30,31. Therefore, a breakthrough allowing the decoding of multi-class intention with sufficient accuracy would be highly welcomed.
In the present study, we advance the classical (occipital or bottom-up) SSVEP paradigm15,22,32,33,34,35,36, allowing a greater variety of human intentional top-down processes to be identified in a significantly more subtle manner for intentional BMI control. For this purpose, we introduce a flickering grid-shaped line array (Fig. 1 and Supplementary video clip 1), from which the shape of the symbol intended to be communicated (e.g., different letters, numbers, or symbols) can be perceived by the study participant as a “symbol Gestalt” using selective visuospatial attention. Gestalt means “the shape of the whole”, and the underlying assumption of the Gestalt school of thought is that psychological phenomena are better understood when viewed as organized wholes, rather than when broken down into their component parts37. Before the rise of post-behaviorist cognitive psychology, the Gestalt psychologists (who actively emerged from Germany in the 1920s to 1940s) resisted behaviorism, with this differing approach to understanding behavior. A user places his/her attention on the randomly flickering sets of pixels and his/her brain constructs the desired percept by top-down processing, i.e., the specific shape is cognitively formed from combinations of flickering line configurations (for an overview, see Fig. 1b). Although most SSVEP-based BMI studies have so far employed a single stimulation frequency to encode each selection, in the present study, we adopt a multiple-frequency stimulation method. In earlier studies, dual-frequency38, three- or four-frequency19,39, and more-than-four-frequency27,28,36 stimulations have been proposed to enhance SSVEP-based BMI information transfer, but these methods are still restricted in their ability to express a variety of symbols and are accompanied by unavoidable gaze-shift. In principle, symbols or letters can be encoded by a combination of selected line segments (individually flickering at their own frequencies), which are components of the SSVEP-inducing grid-shaped line array. In order to demonstrate the proposed principle for an example with six stimulus categories, we suggest a machine learning decoding framework that can resolve multiple top-down modulated responses to external stimulation. Using a cross-validation method40, new, previously unseen EEG trials in the prediction phase were classified based on extracted (hyper-) parameters from labelled training EEG trials in the calibration phase (see Fig. 2 for the workflow). We then compared the decoding accuracies, activation patterns, and directed functional connectivities of the newly proposed top-down SSVEP condition with those of a classical SSVEP condition (that we refer to as bottom-up; see Supplementary video clip 3). To investigate an intermediate effect between these top-down and bottom-up conditions, we included an intermediate experimental condition, in which the luminance of task-irrelevant flickering lines is reduced by 1/10 of the original (see Supplementary video clip 2). Although changes in the luminance of task-irrelevant flickering lines still require knowledge of the target stimulus (i.e., task-relevant flickering lines), we anticipated gradual (or systematic) changes in both decoding accuracies and neurophysiological EEG measures from bottom-up to intermediate and from intermediate to top-down conditions. Therefore, although the intermediate condition is irrelevant for BMI-mediated free communication, we introduce it in the present study.

A schematic design of an SSVEP-inducing grid-shaped line array.
(a) Grid-shaped line array consisting of three rows (R1, R2, and R3) and three columns (C1, C2, and C3) of individually flickering lines. (b) Example of an attended flickering line composite (in red) when a participant pays particular attention to the Korean letter ‘⊤’ while looking at the flickering grid-shaped line array.

Schema for the workflow of a top-down SSVEP paradigm for multi-class decoding BMI technology.
(a) EEG recording, (b) Calibration by supervised machine learning from training EEG trials, and (c) Decoding process on test EEG trials to correctly predict participant perception. When a participant conceives the letter ‘⊤’, the corresponding flickering line composite on the grid-shaped array is subsequently attended and a classification algorithm using feature extraction (i.e., rLDA), calibrated through supervised machine learning, enables the successful decoding of the originally conceived letter ‘⊤’. FFT stands for ‘fast Fourier transform’ and rLDA represents ‘regularized linear discriminant analysis’.
Results
Decoding accuracy
Twenty healthy volunteers participated in this study, which consisted of the three experimental conditions (i.e., top-down, intermediate, and bottom-up SSVEP conditions). Each experimental condition had six classes of stimuli (see Table 1), and each class was composed of 40 trials. Consequently, each experimental condition had 240 trials. Although the chance level is theoretically 21.19% based on these parameters41, we designate the empirical chance level for the present study as the six-class choice accuracy computed by randomly shuffling all the obtained data, which is 17.44% on average. We observed significant differences in decoding accuracies across the classification models for all three experimental conditions: top-down SSVEP (F(3,57) = 49.684, p < 0.0001), intermediate SSVEP (F(3,57) = 81.938, p < 0.0001), and bottom-up SSVEP (F(3,57) = 138.197, p < 0.0001). Post hoc comparisons revealed that our novel top-down SSVEP paradigm for multi-class decoding of EEG signals by regularized linear discriminant analysis (rLDA) with shrinkage8,40,42 performed well; i.e., classification was, on average, 2.05-fold (35.81%) and as high as 3.77-fold (65.83%) greater than chance (i.e., 17.44%; t(19) = 7.283, p < 0.0001, false discovery rate [FDR] corrected). The decoding accuracies from each classification model (i.e., rLDA of EEG signals, randomly-shuffled rLDA of EEG signals, rLDA of EOG signals, and canonical correlation analysis (CCA)43 of EEG signals) were statistically compared using two-tailed paired t-tests, and multiple comparisons were corrected using the FDR (detailed in the Analysis method section). When the EEG signals from just three occipital electrodes were computed, the decoding accuracy was significantly enhanced (42.52%; t(19) = −2.685, p < 0.05). In comparison, CCA of the EEG signals yielded decoding accuracies that were not significantly different from chance (19.23%; t(19) = −1.403, n.s., FDR corrected). Therefore, it is noteworthy that LDA provided significantly improved decoding accuracies in the top-down condition compared to CCA (t(19) = 7.955, p < 0.0001, FDR corrected). When using LDA to analyze EOG signals, decoding accuracies were not significantly different from chance (t(19) = 0.742, n.s., FDR corrected). Therefore, EOG signals did not significantly contribute to decoding accuracies in the top-down SSVEP condition. In accordance with this observation, decoding accuracies by LDA of EOG signals (16.69%) were significantly lower than those by LDA of EEG signals (35.81%) in the top-down SSVEP condition (t(19) = 8.445, p < 0.0001, FDR corrected).
As shown in Fig. 3a, systematic enhancement of classification accuracies by LDA was observed from top-down (35.81%) to intermediate (56.73%) and finally to bottom-up condition (75.44%; F(2,57) = 38.885, p < 0.001), which were all significantly greater than chance. The decoding accuracies of the EEG signals from only the three occipital electrodes were significantly increased in the intermediate condition (60.02%; t(19) = −2.094, p < 0.05) but not in the bottom-up condition (73.79%; t(19) = 0.855, n.s.). The decoding accuracies using EOG signals only were not significantly different from chance in either the intermediate (t(19) = −2.035, n.s., FDR corrected) or bottom-up conditions (t(19) = −5.685, n.s., FDR corrected) in which the same grid-shaped stimulus-configuration as in the top-down condition was used. In accordance with the top-down condition results, EEG signals yielded significantly higher decoding accuracies than EOG signals in both intermediate (t(19) = 9.181, p < 0.0001, FDR corrected) and bottom-up conditions (t(19) = 10.967, p < 0.0001, FDR corrected). The decoding accuracies using CCA were significantly higher than chance in both the intermediate (t(19) = −12.2817, p < 0.0001, FDR corrected) and bottom-up conditions (t(19) = −12.584, p < 0.0001, FDR corrected). Moreover, the decoding accuracies using CCA gradually increased from the top-down (19.23%) to the intermediate (35.04%) and further to the bottom-up condition (53.79%; F(2,57) = 68.463, p < 0.001). However, similarly to the top-down condition, LDA yielded significantly higher decoding accuracies than CCA in both the intermediate (t(19) = 6.453, p < 0.0001, FDR corrected) and bottom-up conditions (t(19) = 8.360, p < 0.0001, FDR corrected).

Decoding accuracies, topographical activation patterns, and Granger causality.
(a) Comparison of decoding accuracies across EEG rLDA (red bars), randomly shuffled EEG rLDA (blue bars), EOG rLDA (green bars), and EEG CCA (purple bars). The accuracy of random selection (i.e., 17.44%) is computed by the randomly shuffled rLDA method (blue bars), and error bars indicate ±1 standard error of the mean across participants. *p < 0.0001, two-tailed paired t-tests were conducted across these comparisons, and multiple comparisons were corrected using the false discovery rate (FDR). (b) Topographical activation patterns of neural bases for BMI features are computed for the top-down, intermediate, and bottom-up SSVEP paradigms. The degree of differences in normalized classifier weights is depicted in a coloured scale; large weights are strongly related to the task condition. Note the gradual decrease in the amplitude of activation patterns from the top-down to bottom-up SSVEP paradigms. Black dots represent the electrode positions. (c) Directional information flows between BA 10 (anterior prefrontal cortex) and BA 18 (occipital visual association cortex) by Granger causality analysis. Using the estimated time courses of the two ROIs, the directed transfer function (DTF) analysis identified directional information flow across cortical sources. Note the directions of the arrows that indicate the direction of information flow. The coloured scale and the line thickness represent the degree of directed functional connectivity (ranging from 0 to 1). Only statistically significant directed functional connectivity patterns are illustrated. The view of the topography is from the vertex, with the nasion at the top of the image.
Activation pattern and Granger-causal connectivity
Based on the activation patterns of neural sources that were obtained from analyzing the BMI classifier, the top-down SSVEP condition resulted in a distinctive topographical distribution of activation, which showed a higher degree of focus around the occipital electrodes. Conversely, the bottom-up SSVEP condition showed a more dispersed BMI feature activity (Fig. 3b). The intermediate SSVEP condition showed a moderately focalised BMI-feature scalp distribution in between that of the other two conditions. In addition, the maximum amplitudes of these activation-pattern maps systematically decreased from the bottom-up (averaged maximum, 0.281) to the intermediate (averaged maximum, 0.187), and finally to the top-down condition (averaged maximum 0.093; F(2,57) = 49.117, p < 0.001, see Fig. 3b). Furthermore, it is noteworthy that only the top-down SSVEP condition showed anterior prefrontal (i.e., Brodmann’s area (BA) 10) regularization over the occipital visual association region BA 18 (see the direction of arrows in Fig. 3c) when Granger causality analysis44 was conducted. The intermediate and bottom-up conditions demonstrated the opposite directional information flow: from the occipital to the frontal region. In addition, there was strong crosstalk between the left and right anterior prefrontal areas (BA 10L and BA 10R), particularly in the top-down SSVEP condition. All of these directed functional connectivity measures were reliably confirmed by additional observations using time-reversed data45,46 (see the Supplementary information). However, neither the intermediate nor the bottom-up SSVEP conditions showed true directed functional connectivity because their time-reversal results in Granger causality were not significantly different from those of the original data, which is indicative of spurious causal relations, such as a volume conduction effect45,46.
Discussion
This study proposes a novel approach to decode a user’s multi-class intention in the context of SSVEP-BMI. It is noteworthy that EOG signals could not explain the observed effects. Although the decoding accuracy of the grid-shaped top-down SSVEP paradigm can still be improved as compared with other SSVEP-based BMIs (Table 2), it has shown promising first results toward future BMI technology able to recognize complex multi-class intention without gaze-shifting (i.e., covertly). The proposed grid-shaped SSVEP-based BMI technique is substantially different from classical SSVEP-BMI paradigms in the following aspects.
First, when inspecting the neural activation patterns obtained from analyzing the BMI classifier47, the discriminant neural correlates of the top-down SSVEP paradigm are more localized around the occipital area (Fig. 3b), suggesting more focused visuospatial attention processing. Previous studies consistently reported that anticipatory biasing of visuospatial attention by task-strategy focalizes brain activity on the occipital area48,49, which may reflect preparatory top-down processing in early information processing stages in occipital visual areas50,51. Since participants had to allocate more selective visuospatial attention (i.e., increased top-down control) to the specific flickering lines corresponding to the conceived letter and simultaneously inhibit information processing for the task-irrelevant flickering lines, the activated occipital visual area is more focalized during the top-down condition.
Second, strong communication between the left and right anterior prefrontal areas (i.e., BA 10L/R) is only observed during the top-down SSVEP condition, in which robust prefrontal cortical (PFC)-dependent top-down control over the occipital visual association area BA 18 is detected by Granger causality analysis (Fig. 3c). It is likely that prefrontal top-down processing influences low-level early visual processing stages. BA 10 is the anterior prefrontal area, which is involved in the cognitive processing of attention52, semantic monitoring53, working memory54, rule learning55, decision-making56, inhibitory control57, and the compromised functioning of top-down regulation58. On the other hand, BA 18 is affiliated with the extrastriate visual cortex, where the visual information from the primary visual cortex (specifically visuospatial selective attention59) is further processed. Since attention enhances extrastriate neuronal responses to a stimulus at one spatial location in the visual field60, prefrontal top-down influence when placing one’s attention selectively on a corresponding line combination among six flickering lines might downregulate BA 18 activity. In contrast, the intermediate and bottom-up SSVEP conditions show the opposite direction of information flow: from the occipital to the frontal cortex. These observations reflect the difference between the top-down SSVEP condition and the passively induced bottom-up processing of the typical occipital SSVEP paradigm that is physically driven by externally flickering visual stimuli. However, this is not the case in the top-down SSVEP condition, because the stimulus-driven (bottom-up) properties of the early visual cortices are common across the six class-stimuli. Instead, higher-order cognitive processing stages such as those in prefrontal regions might be involved as a control centre for selectively attending to a specific line composite structure across this similar stimulus, based on the intentionally conceived letter. It has been consistently reported that stimulus-driven attention processes are neuroanatomically dissociable from the intentionally driven top-down processes of visuospatial selective attention61. Therefore, our findings provide neurophysiological evidence that the present paradigm requires top-down control (e.g., selective attention processing) when users intend to conceive of letters for task performance. The interaction between PFC-dependent top-down control and occipital bottom-up processing might be anatomically accomplished through the fronto-occipital fasciculi, providing reciprocal connections between the PFC and the occipital cortices62. This notion is in line with reports that slow oscillatory activity is associated with long-distance neural network function63, since we observed such directed fronto-occipital functional connectivity in the theta band. The extensive and reciprocal connections between the PFC and all other brain regions provide a neuroanatomical substrate for the role of the PFC in controlling diverse cognitive processes64.
In addition, it is noteworthy that CCA, which is commonly used for decoding SSVEP signals26,36, showed lower performance for the proposed top-down SSVEP condition compared to rLDA (Fig. 3a; the intermediate SSVEP condition consistently shows moderate CCA decoding accuracy between top-down and bottom-up SSVEP conditions). The CCA approach has an advantage for classification when the SSVEPs are physically driven by the repetitive presentation of a visual stimulus at a given flickering frequency. As shown in Fig. 3a, the decoding accuracies using CCA gradually increased from the top-down to bottom-up conditions. These different characteristics of the typical SSVEP-BMI classification technique also provide additional evidence that the proposed top-down SSVEP paradigm is quite distinct from the classical bottom-up SSVEP paradigm. The extracted features of the top-down SSVEP paradigm seem to be highly associated with higher-order top-down attributes as opposed to the bottom-up properties of classical SSVEP stimuli.
Taken together, the proposed grid-shaped top-down SSVEP paradigm provides potential to expand the gaze-shift-free intention recognition BMI repertoire. This technique has further advantages. First, the SSVEP-based BMI conveys very precise information14 and has a high ITR, requiring the fewest number of recording electrodes possible15,65, which enables this technology to be easily wearable. Indeed, since only three occipital electrodes can efficiently represent discriminative features in the top-down SSVEP BMI paradigm, this system may feasibly be used as a wearable BCI device. In addition, users do not need to explicitly move their eyes; as shown above, communication is more successfully achieved by decoding EEG than EOG. Therefore, the extracted physiological signature of this technique reflects genuine brain activity, not eye movement. Some of the recently proposed SSVEP-mediated BMIs inevitably require eye movements for attributing focal attention to a flickering symbol25,26,27,28. This may alternatively be detectable by an eye tracker; however, the present technique avoids the necessity of macroscopic eye movements by using a small-sized grid-shaped line array corresponding approximately to the foveal visual angle.
Therefore, the proposed top-down SSVEP paradigm may become a potent future technology for intentional control of a multi-class BMI. However, this paradigm needs further improvement in subsequent studies. The limitations of this study are as follows. First, the decoding accuracy and ITR of the grid-shaped top-down SSVEP paradigm have room for improvement. For example, by using a shorter epoch size and selecting optimal electrodes for feature-discrimination, the ITR and accuracy, respectively, could be further enhanced. Second, as users must look at flickering stimuli in order to generate such SSVEPs, they inevitably experience eye-fatigue24. However, this can be overcome using high-frequency SSVEP technology29,66. The high-frequency flickering produces much less visual fatigue than that at lower frequencies67,68, making the SSVEP-based BCI a more comfortable and stable system67. However, it still remains to be further studied for practical BMI application. Third, since the grid-shaped SSVEP technique is currently implemented using the Korean letter system, a study in which it is transferred to other languages is required for its versatile usage. Fourth, the number of letters that can be formed through grid-shaped stimulation is currently limited. Further refinement, by adding more rows and columns to the grid-shaped line array (which enables decoding of a larger set of letter-like shapes), would, in principle, allow the technology to be used for a variety of accurate mind-reading applications ranging from communication and neuro-rehabilitation to general consumer electronics. Unlike most previous studies in SSVEP-based BMIs, which generally use fewer than four flickering frequencies that may even be located in different parts in the visual field15 and thus require ocular movements, the present top-down SSVEP uses a highly compact stimulus presentation size. Therefore, our novel paradigm provides multi-class intention decoding, which could in principle decode a combinatorial number of letter-like configurations – a technique that may ultimately become useful for both patients and healthy user groups. In particular, our gaze-independent SSVEP-BMI paradigm will benefit for paralyzed end-users suffering from amyotrophic lateral sclerosis (ALS) or complete locked-in syndrome.
As compared with our findings of decoding covert attentional shift to subsets of external stimuli, there are other recent studies decoding visuospatial attention directly from the intrinsically driven brain activity patterns evoked by attention69,70,71,72,73. As our study demonstrates the possibility of seamlessly decoding human top-down processes, if a further refined grid-shaped line array is developed and combined with a more elaborated classification method, a recent study74 provides advances in extending previous studies of decoding visuospatial attention69,70,71,72,73, which were limited to decoding up to four discrete locations/classes. The authors found a neuronal signature of direct two-dimensional access to the spatial location of covert attention in macaque prefrontal cortex74. Together, these efforts in both externally triggered and internally driven manners may cooperatively open new perspectives to decoding technology in a multi-class and continuous mental representation space.
Methods
Participants
Twenty healthy subjects (10 female; mean age 25.7 y) participated in this study, which was conducted in accordance with the ethical guidelines established by the Institutional Review Board of Korea University and the Declaration of Helsinki (World Medical Association, 2013). All experimental protocols were approved by the Institutional Review Board of Korea University (No. KU-IRB-13–43-A-2). Participants provided informed consent prior to the start of the experiment. All had normal or corrected-to-normal vision.
SSVEP-inducing grid-shaped line array
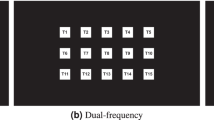
In order to present a mentally generated letter within the participant’s restricted visual angle to evoke the corresponding SSVEP, a 6 cm × 6 cm grid-shaped line array was designed (see Fig. 1 and Supplementary video clip 1). In this array, three rows (R1, R2, and R3 in Fig. 1a) and three columns (C1, C2, and C3 in Fig. 1a) of lines with mean luminance of 136.26 cd/m2 were lit on a black monitor (Full HD LED 27-in., S27B550, Samsung, Seoul, Korea). Each line had a width of 6 mm and the distance between two adjacent rows or columns was 1 cm. This grid-shaped line array was within the visual angle of 6.4° at a distance of 65 cm75, falling on the retinal region centred at the fovea (the most sensitive portion of the retina) without macroscopic eye-movement. In order to generate individual SSVEPs based on each flickering line, each row and column had an individual flickering frequency ranging from 5 to 7.5 Hz (see Table 1 and Fig. 1a), which have been shown to be effective frequencies for inducing SSVEPs in humans76,77. The frequencies were assigned randomly to each line in the overall array. A sampled sinusoidal stimulation method26 was used to implement visual stimulus presentation on the LED screen for eliciting SSVEP responses.
The underlying idea of decoding a participant’s top-down modulated responses to external stimulation by means of SSVEPs induced by this grid-shaped line array was as follows. When a participant paid attention to a subset of flickering lines representing the shape of a letter or symbol, the corresponding frequencies of those lines were expected to be detected as the dominant SSVEP features. The frequencies driving the SSVEP signals could be analyzed using a pattern recognition algorithm (detailed in the Analysis method section) and decoded to identify the symbol shape intended by the participant. The experiment consisted of three conditions: top-down, intermediate, and bottom-up SSVEP. In order to make all the conditions’ results comparable, the grid-shaped line array structure discussed above was used in all three conditions. In order to rule out luminance effects across the top-down and bottom-up conditions, overall stimulus luminance was maintained as closely as possible. However, in the bottom-up condition, all lines belonging to the same object had the same flickering frequency (5, 5.5, 6, 6.5, 7, or 7.5 Hz; see Supplementary video clip 3). In an intermediate SSVEP condition between the top-down and bottom-up conditions, the luminance of task-irrelevant flickering lines was reduced by 1/10 of the original (see Supplementary video clip 2). Thus, the task-relevant lines were much brighter, in order to facilitate the participant’s recognition of the appropriate symbol. Each condition comprised 4 blocks with a short break in between; each block included 60 trials. In each block, each of 6 Korean letters (phonemes) was presented 10 times in a random order. The inter-trial intervals ranged from 1000 ms to 1500 ms, centred at 1250 ms. After a 1 s auditory cue pronouncing the Korean letter to which a participant was required to attend, and a subsequent 500 ms buffer period, the grid-shaped line array was presented for 5 s. During these 5 s, the participant was expected to focus his/her attention on the instructed combination among all 6 flickering lines. In the bottom-up SSVEP condition, an auditory cue (an analogue instruction sound) was presented in a random order to control for possible linguistic region activation induced by the spoken instruction itself. In other words, a randomly selected auditory cue from the six Korean letters was presented during the bottom-up SSVEP condition, in which all six line segments in the grid-shaped line array flickered at the same frequency as a single object. Using the same stimulus object (i.e., the grid-shaped line array), we accomplish a classical SSVEP paradigm (i.e., a single flickering object is presented to evoke SSVEPs)22,32. Through this bottom-up experimental design, we tried to minimize any confounding effects possibly introduced by differing stimulus size and shape, and thus to make its results comparable with the observations from both the top-down and intermediate conditions.
EEG acquisition
The EEG was measured using a BrainAmp DC amplifier (Brain Products, Germany) with 32 Ag/AgCl electrodes in an actiCAP (Brain Products, Germany) in accordance with the international 10–10 system. An electrode was placed on the tip of the nose as reference, and a ground electrode was placed at electrode AFz. Eye movement activity was monitored with an EOG electrode placed sub-orbitally to the left eye, and vertical and horizontal electro-ocular activity was computed using two pairs of electrodes placed vertically and horizontally with respect to both eyes (i.e., Fp1 and EOG for the vertical EOG, F7 and F8 for the horizontal EOG). The EOG was used to track gaze-shifts. Electrode impedances were maintained below 5 kΩ prior to data acquisition. The EEG was recorded at 500 Hz.
Analysis methods
A supervised machine learning method78 was trained during a calibration phase using labelled training EEG trials. The task of the multi-class classifier is to extract a task-relevant signal from the EEG, which is used to assign the recorded samples to a given stimulus category7. In the present study, rLDA with shrinkage8,40 was applied to channel-wise computed power spectral densities. The power spectral densities of all channels were obtained by fast Fourier transform (FFT) using the Berlin Brain-Computer Interface (BBCI) toolbox79. Classical LDA is optimal in the sense that it minimizes the risk of misclassification for new samples drawn from known Gaussian distributions80. Particularly, rLDA is a powerful and robust machine learning technique that yields excellent results for single-trial event-related potential classification, which are superior to classical LDA when the ratio of features to trials is low8,40,42. The power spectral densities ranging from 5 Hz to 13.5 Hz (in 0.5 Hz increments) of the 5 s EEG signals were used for feature extraction. This frequency range includes the stimulus flickering frequencies along with the sum of letter-corresponding combination frequencies. After fixing the parameters of the rLDA on the training data, the resulting calibrated classifier was used for out-of-sample prediction, i.e., novel unseen EEG trials could be decoded (Fig. 2). We performed 4-fold chronological cross-validation40 to obtain out-of-sample classification performance; we thus designated 180 trials for training and the remaining 60 trials for testing, out of all 40 trials per stimulus per participant (i.e., 240 trials including all stimuli per participant). First, all trials were chronologically split into 180 and 60 trials. During the cross-validation process, model (hyper-) parameters were chosen using the 180 trials and then the remaining 60 trials were tested using the trained model. This procedure was iterated 4 times to provide different combinations of training and test data sets and the resulting decoding accuracies were averaged. This decoding procedure was performed separately for each participant. The decoding accuracy was computed based on the signals of all 30 electrodes. In order to compare this result with the accuracy of the EEG signals from the three occipital electrodes (i.e., Oz, O1, and O2), the decoding accuracy of these three channels was also computed. The decoded signals were evaluated in terms of whether the information encoded in the set of attended flickering lines could be successfully reconstructed, i.e., whether the Korean letter that the participant was requested to conceive was correctly decoded. For the six-class classification, the rates of successful classification of the test data were compared across models for evaluating the decoding performance. In addition, rLDA-based classification was also performed using the EOG signals only, in order to compare EOG decoding accuracy with that based on EEG signals. We also conducted CCA36,81 on the same dataset to compare with the classification efficiency of rLDA. CCA is a multivariable statistical method to measure the linear correlation relationship between two sets of variables. Since CCA has been most frequently and successfully used in typical bottom-up SSVEP-based BMIs26,36, the results of this analysis would provide a solid comparison between classical bottom-up and the proposed top-down SSVEP paradigms in this work. In order to statistically examine whether the decoding accuracies were significantly different across the following models, the accuracies were analyzed with a repeated-measures analysis of variance (ANOVA) with one within-subjects factor: labeled ‘classification model’ (rLDA of EEG, randomly-shuffled rLDA of EEG, rLDA of EOG, and CCA of EEG). When necessary, the Greenhouse–Geisser correction was used. If statistical significance was observed, two-tailed paired t-tests were performed as post hoc pairwise comparisons: (1) rLDA of EEG vs. randomly-shuffled rLDA of EEG, (2) rLDA of EEG vs. rLDA of EOG, (3) rLDA of EEG vs. CCA of EEG, (4) rLDA of EOG vs. randomly-shuffled rLDA of EEG, (5) CCA of EEG vs. randomly-shuffled rLDA of EEG, and (6) rLDA of EOG vs. CCA of EEG. The randomly shuffled rLDA decoding accuracies were computed on the same training data but with randomly shuffled labels; thus its decoding accuracy represented the chance performance of the six-class classification. In addition, a one-way ANOVA was applied for testing any effects across the three experimental conditions. A FDR of q < 0.282 was used to correct for multiple comparisons, since q-values between 0.1 and 0.2 after FDR correction are known to be acceptable for this purpose83. All analyses were performed using MATLAB (ver. R2015b, MathWorks, USA) or SPSS Statistics (ver. 22, IBM, USA).
In order to gain better understanding of the classifier with respect to the neurophysiological basis of the extracted task-relevant signal, an ‘activation pattern’ approach47 was adopted in the present study (see Fig. 3b). The learned parameters of linear classifiers such as rLDA and CCA (i.e., their weight vectors) cannot be interpreted with respect to the origin of the signal of interest because the parameters of the models are a function of the task-relevant signal and the task-uninformative signals (i.e., noise signals)8,40,47. Therefore, in order to visualize how the extracted signal is encoded in the features that are used by the classifier, a so-called ‘activation pattern’ has to be computed47,84. Assuming that the task-relevant and task-uninformative signals are uncorrelated, the activation pattern is given by the covariance between the classifier output and the time-course of individual features47. In order to make the activation patterns comparable across conditions, we computed their correlation instead of their covariance. We estimated an activation pattern involving all scalp electrodes by computing the correlation between the continuous trial-wise classifier output and the time-course of spectral features (i.e., trial-wise spectral power in the chosen frequency bins) from all channels. In order to arrive at a single activation pattern for each condition that could be visualized as a scalp map, the activation patterns were averaged across frequency bins and participants (see Fig. 3b).
The spatiotemporal distribution of brain activity and network behaviour provide significant psychophysiological information. Given that it is important to image functional connectivity to understand brain function85,86, Granger causality44 analysis was also conducted in this study. In particular, the directed transfer function (DTF) has been developed to describe causality among an arbitrary number of signals87. Granger causality analysis has shown potential for non-invasively delineating brain network connectivity88. Using the eConnectome software86, functional connectivity was mapped for each experimental condition. Granger causality was investigated in the frequency band from 5 Hz to 8 Hz, which includes the range of the stimulus-flickering frequency. The eConnectome software enables cortical source imaging and subsequent connectivity analysis of cortical source activity. To estimate the source-level cortical activity, a source-localization software, LORETA, or low-resolution electromagnetic tomography, (version 20151222, The KEY Institute for Brain-Mind Research, Switzerland) was employed herein89. LORETA is one method that estimates the electric neural generators and computes images of neural activity from EEG data. eLORETA is tested under computer-controlled conditions, using a realistic head model, with 7002 cortical voxels90. We calculated eLORETA images during task performance in the time frame from 0 to 5 s. Based on the most pronounced cortical activity estimated by the LORETA software, two regions of interest (ROIs) were bilaterally selected (i.e., BA 10 and 18) to map directional connectivity. Source waveforms at the two ROIs were estimated and the DTF analysis showed directional information flow across sources (see Fig. 3c). Statistical assessment of the connectivity was performed using the surrogate approach (1000 surrogates, p < 0.05). In order to avoid spurious causal relations, we conducted the same Granger causality analysis using time-reversed data45,46. That is, the reversed temporal order of all data points in the same EEG dataset was used to double-check the robustness of the inferred Granger-causal connectivity measures.
Additional Information
How to cite this article: Min, B.-K. et al. Decoding of top-down cognitive processing for SSVEP-controlled BMI. Sci. Rep. 6, 36267; doi: 10.1038/srep36267 (2016).
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Vidal, J. J. Real-Time Detection of Brain Events in EEG. P. IEEE 65, 633–641 (1977).
Lebedev, M. A. & Nicolelis, M. A. L. Brain-machine interfaces: past, present and future. Trends Neurosci. 29, 536–546 (2006).
Kübler, A. & Müller, K.-R. In Towards Brain-Computer Interfacing (eds Dornhege, G. et al.) Ch. 1, 1–25 (MIT Press, 2007).
Müller, K.-R. et al. Machine learning for real-time single-trial EEG-analysis: from brain–computer interfacing to mental state monitoring. J. Neurosci. Methods 167, 82–90 (2008).
Wolpaw, J. R. & Wolpaw, E. W. In Brain-Computer Interfaces: Principles and Practice (eds Wolpaw, J. R. & Wolpaw, E. W. ) Ch. 1, 3–12 (Oxford University Press, 2012).
Min, B. K., Marzelli, M. J. & Yoo, S. S. Neuroimaging-based approaches in the brain-computer interface. Trends Biotechnol. 28, 552–560, doi: 10.1016/j.tibtech.2010.08.002 (2010).
Pfurtscheller, G. & Neuper, C. In Electroencephalography: Basic principles, clinical applications, and related fields (eds Schomer, D. L. & Lopes da Silva, F. H. ) 1227–1236 (Lippincott Williams & Wilkins, 2011).
Blankertz, B., Lemm, S., Treder, M., Haufe, S. & Müller, K.-R. Single-trial analysis and classification of ERP components—a tutorial. NeuroImage 56, 814–825 (2011).
Holz, E. M., Botrel, L., Kaufmann, T. & Kübler, A. Long-term independent brain-computer interface home use improves quality of life of a patient in the locked-in state: a case study. Arch. Phys. Med. Rehabil. 96, S16–S26 (2015).
Birbaumer, N. et al. A spelling device for the paralysed. Nature 398, 297–298, doi: 10.1038/18581 (1999).
Blankertz, B., Dornhege, G., Krauledat, M., Muller, K. R. & Curio, G. The non-invasive Berlin Brain-Computer Interface: fast acquisition of effective performance in untrained subjects. NeuroImage 37, 539–550, doi: 10.1016/j.neuroimage.2007.01.051 (2007).
Pfurtscheller, G. & Neuper, C. Motor imagery and direct brain-computer communication. P. IEEE 89, 1123–1134, doi: 10.1109/5.939829 (2001).
Cheng, M., Gao, X., Gao, S. & Xu, D. Design and implementation of a brain-computer interface with high transfer rates. IEEE Trans. Biomed. Eng. 49, 1181–1186 (2002).
Nunez, P. L. & Srinivasan, R. In Electric fields of the brain: The neurophysics of EEG (eds Nunez, P. L. & Srinivasan, R. ) 402–409 (Oxford University Press, 2006).
Vialatte, F. B., Maurice, M., Dauwels, J. & Cichocki, A. Steady-state visually evoked potentials: focus on essential paradigms and future perspectives. Prog. Neurobiol. 90, 418–438, doi: 10.1016/j.pneurobio.2009.11.005 (2010).
Dal Seno, B., Matteucci, M. & Mainardi, L. T. The Utility Metric: A Novel Method to Assess the Overall Performance of Discrete Brain-Computer Interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 18, 20–28, doi: 10.1109/Tnsre.2009.2032642 (2010).
Kwak, N.-S., Müller, K.-R. & Lee, S.-W. A lower limb exoskeleton control system based on steady state visual evoked potentials. J. Neural Eng. 12, 056009 (2015).
Acqualagna, L. et al. EEG-based classification of video quality perception using steady state visual evoked potentials (SSVEPs). J. Neural Eng. 12, 026012 (2015).
Müller-Putz, G. R. & Pfurtscheller, G. Control of an electrical prosthesis with an SSVEP-based BCI. IEEE Trans. Biomed. Eng. 55, 361–364 (2008).
Regan, D. Electrical responses evoked from the human brain. Sci. Am. 241, 134–146 (1979).
Cheng, M. & Gao, S. An EEG-based cursor control system. In Proceedings of the First Joint BMES/EMBS Conference.1, 669 (1999).
Middendorf, M., McMillan, G., Calhoun, G. & Jones, K. S. Brain-computer interfaces based on the steady-state visual-evoked response. IEEE Trans. Rehabil. Eng. 8, 211–214 (2000).
Wang, Y., Wang, R., Gao, X., Hong, B. & Gao, S. A practical VEP-based brain-computer interface. IEEE Trans. Neural Syst. Rehabil. Eng. 14, 234–240 (2006).
Zhu, D., Bieger, J., Garcia Molina, G. & Aarts, R. M. A survey of stimulation methods used in SSVEP-based BCIs. Computat. Intell. Neurosci. 702357, doi: 10.1155/2010/702357 (2010).
Shyu, K. K., Lee, P. L., Liu, Y. J. & Sie, J. J. Dual-frequency steady-state visual evoked potential for brain computer interface. Neurosci. Lett. 483, 28–31, doi: 10.1016/j.neulet.2010.07.043 (2010).
Chen, X., Chen, Z., Gao, S. & Gao, X. A high-ITR SSVEP-based BCI speller. Brain Comput. Interfaces 1, 181–191, doi: 10.1080/2326263X.2014.944469 (2014).
Hwang, H.-J. et al. Development of an SSVEP-based BCI spelling system adopting a QWERTY-style LED keyboard. J. Neurosci. Methods 208, 59–65 (2012).
Wang, Y., Wang, Y. T. & Jung, T. P. Visual stimulus design for high-rate SSVEP BCI. Electron. Lett. 46, 1057–U1027, doi: 10.1049/el.2010.0923 (2010).
Diez, P. F. et al. Commanding a robotic wheelchair with a high-frequency steady-state visual evoked potential based brain–computer interface. Med. Eng. Phys. 35, 1155–1164 (2013).
Simon, N. et al. An auditory multiclass brain-computer interface with natural stimuli: Usability evaluation with healthy participants and a motor impaired end user. Front. Hum. Neurosci. 8, 1039, doi: 10.3389/fnhum.2014.01039 (2014).
Dornhege, G., Blankertz, B., Curio, G. & Muller, K. R. Boosting bit rates in noninvasive EEG single-trial classifications by feature combination and multiclass paradigms. IEEE Trans. Biomed. Eng. 51, 993–1002, doi: 10.1109/TBME.2004.827088 (2004).
Gao, X., Xu, D., Cheng, M. & Gao, S. A BCI-based environmental controller for the motion-disabled. IEEE Trans. Neural Syst. Rehabil. Eng. 11, 137–140 (2003).
Müller-Putz, G. R., Scherer, R., Brauneis, C. & Pfurtscheller, G. Steady-state visual evoked potential (SSVEP)-based communication: impact of harmonic frequency components. J. Neural Eng. 2, 123–130 (2005).
Herrmann, C. S. Human EEG responses to 1–100 Hz flicker: resonance phenomena in visual cortex and their potential correlation to cognitive phenomena. Exp. Brain Res. 137, 346–353, doi: 10.1007/s002210100682 (2001).
Regan, D. Comparison of Transient and Steady-State Methods. Ann. Ny. Acad. Sci. 388, 45–71, doi: 10.1111/j.1749-6632.1982.tb50784.x (1982).
Bin, G., Gao, X., Yan, Z., Hong, B. & Gao, S. An online multi-channel SSVEP-based brain-computer interface using a canonical correlation analysis method. J. Neural Eng. 6, 046002, doi: 10.1088/1741-2560/6/4/046002 (2009).
Purves, D. et al. In Principles of Cognitive Neuroscience Ch. 2, 33–55 (Sinauer Associates, Inc., 2008).
Srihari Mukesh, T. M., Jaganathan, V. & Reddy, M. R. A novel multiple frequency stimulation method for steady state VEP based brain computer interfaces. Physiol. Meas. 27, 61–71, doi: 10.1088/0967-3334/27/1/006 (2006).
Wu, Z., Lai, Y., Xia, Y., Wu, D. & Yao, D. Stimulator selection in SSVEP-based BCI. Med. Eng. Phys. 30, 1079–1088, doi: 10.1016/j.medengphy.2008.01.004 (2008).
Lemm, S., Blankertz, B., Dickhaus, T. & Müller, K.-R. Introduction to machine learning for brain imaging. NeuroImage 56, 387–399 (2011).
Müller-Putz, G., Scherer, R., Brunner, C., Leeb, R. & Pfurtscheller, G. Better than random: A closer look on BCI results. Int. J. Bioelectromagn. 10, 52–55 (2008).
Tomioka, R. & Müller, K.-R. A regularized discriminative framework for EEG analysis with application to brain–computer interface. NeuroImage 49, 415–432 (2010).
Härdle, W. & Simar, L. In Applied Multivariate Statistical Analysis. 321–330 (Springer, 2007).
Granger, C. W. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 424–438 (1969).
Haufe, S., Nikulin, V. V., Müller, K.-R. & Nolte, G. A critical assessment of connectivity measures for EEG data: a simulation study. NeuroImage 64, 120–133 (2013).
Winkler, I., Panknin, D., Bartz, D., Müller, K.-R. & Haufe, S. Validity of time reversal for testing Granger causality. IEEE Trans. Signal Process. 64, 2746–2760 (2016).
Haufe, S. et al. On the interpretation of weight vectors of linear models in multivariate neuroimaging. NeuroImage 87, 96–110, doi: 10.1016/j.neuroimage.2013.10.067 (2014).
Bressler, S. L., Tang, W., Sylvester, C. M., Shulman, G. L. & Corbetta, M. Top-down control of human visual cortex by frontal and parietal cortex in anticipatory visual spatial attention. J. Neurosci. 28, 10056–10061 (2008).
Worden, M. S., Foxe, J. J., Wang, N. & Simpson, G. V. Anticipatory biasing of visuospatial attention indexed by retinotopically specific-band electroencephalography increases over occipital cortex. J. Neurosci. 20, 1–6 (2000).
Min, B. K. & Hermann, C. S. Prestimulus EEG alpha activity reflects prestimulus top-down processing. Neurosci. Lett. 422, 131–135 (2007).
Foxe, J. J., Simpson, G. V. & Ahlfors, S. P. Parieto-occipital similar to 10 Hz activity reflects anticipatory state of visual attention mechanisms. Neuroreport 9, 3929–3933 (1998).
Pollmann, S. Anterior prefrontal cortex contributions to attention control. Exp. Psychol. 51, 270–278 (2004).
MacLeod, A., Buckner, R., Miezin, F., Petersen, S. & Raichle, M. Right anterior prefrontal cortex activation during semantic monitoring and working memory. NeuroImage 7, 41–48 (1998).
Koechlin, E., Basso, G., Pietrini, P., Panzer, S. & Grafman, J. The role of the anterior prefrontal cortex in human cognition. Nature 399, 148–151 (1999).
Strange, B., Henson, R., Friston, K. & Dolan, R. Anterior prefrontal cortex mediates rule learning in humans. Cereb. Cortex 11, 1040–1046 (2001).
Koechlin, E. & Hyafil, A. Anterior prefrontal function and the limits of human decision-making. Science 318, 594–598 (2007).
Garavan, H., Ross, T. & Stein, E. Right hemispheric dominance of inhibitory control: an event-related functional MRI study. Proc. Natl. Acad. Sci. USA 96, 8301–8306 (1999).
Miyashita, Y. Cognitive memory: cellular and network machineries and their top-down control. Science 306, 435–440 (2004).
Clark, V. P. & Hillyard, S. A. Spatial selective attention affects early extrastriate but not striate components of the visual evoked potential. J. Cogn. Neurosci. 8, 387–402 (1996).
Desimone, R. Visual attention mediated by biased competition in extrastriate visual cortex. Philos. Trans. R. Soc. Lond. B Biol. Sci. 353, 1245–1255 (1998).
Hahn, B., Ross, T. J. & Stein, E. A. Neuroanatomical dissociation between bottom–up and top–down processes of visuospatial selective attention. NeuroImage 32, 842–853 (2006).
Hwang, K. & Luna, B. In Principles of frontal lobe function (eds Stuss, D. T. & Knight, R. T. ) Ch. 12, 164–184 (Oxford University Press, 2013).
Sauseng, P., Klimesch, W., Schabus, M. & Doppelmayr, M. Fronto-parietal EEG coherence in theta and upper alpha reflect central executive functions of working memory. Int. J. Psychophysiol. 57, 97–103, doi: 10.1016/j.ijpsycho.2005.03.018 (2005).
Barbas, H. Connections underlying the synthesis of cognition, memory, and emotion in primate prefrontal cortices. Brain Res. Bull. 52, 319–330 (2000).
Volosyak, I. SSVEP-based Bremen-BCI interface–boosting information transfer rates. J. Neural Eng. 8, 036020, doi: 10.1088/1741-2560/8/3/036020 (2011).
Diez, P. F., Mut, V. A., Perona, E. M. A. & Leber, E. L. Asynchronous BCI control using high-frequency SSVEP. J. Neuroeng. Rehabil. 8, 39, doi: 10.1186/1743-0003-8-39 (2011).
Yijun, W., Ruiping, W., Xiaorong, G. & Shangkai, G. Brain-computer interface based on the high-frequency steady-state visual evoked potential. in Proceedings of the first International Conference on Neural Interface and Control. 37–39 (2005).
Materka, A., Byczuk, M. & Poryzala, P. A virtual keypad based on alternate half-field stimulated visual evoked potentials. in Proceedings of International Symposium on Information Technology Convergence (ISITC 2007). 296–300 (2007).
Astrand, E. et al. Comparison of classifiers for decoding sensory and cognitive information from prefrontal neuronal populations. PLos One 9, e86314 (2014).
Astrand, E., Ibos, G., Duhamel, J.-R. & Hamed, S. B. Differential dynamics of spatial attention, position, and color coding within the parietofrontal network. J. Neurosci. 35, 3174–3189 (2015).
Gunduz, A. et al. Decoding covert spatial attention using electrocorticographic (ECoG) signals in humans. NeuroImage 60, 2285–2293 (2012).
Morioka, H. et al. Decoding spatial attention by using cortical currents estimated from electroencephalography with near-infrared spectroscopy prior information. NeuroImage 90, 128–139 (2014).
Tremblay, S., Doucet, G., Pieper, F., Sachs, A. & Martinez-Trujillo, J. Single-trial decoding of visual attention from local field potentials in the primate lateral prefrontal cortex is frequency-dependent. J. Neurosci. 35, 9038–9049 (2015).
Astrand, E., Wardak, C., Baraduc, P. & Hamed, S. B. Direct Two-Dimensional Access to the Spatial Location of Covert Attention in Macaque Prefrontal Cortex. Curr. Biol. (2016).
Kaashoek, I. Automatic determination of the optimum stimulation frequencies in an SSVEP based BCI. Report No. Technical note TN-2008/00511, 1-85 (Koninklijke Philips Electronics, 2008).
Gao, X., Xu, D., Cheng, M. & Gao, S. A BCI-based environmental controller for the motion-disabled. IEEE Trans. Neural Syst. Rehabil. Eng. 11, 137–140, doi: 10.1109/TNSRE.2003.814449 (2003).
Pastor, M. A., Artieda, J., Arbizu, J., Valencia, M. & Masdeu, J. C. Human cerebral activation during steady-state visual-evoked responses. J. Neurosci. 23, 11621–11627 (2003).
Mohri, M., Rostamizadeh, A. & Talwalkar, A. Foundations of Machine Learning. (The MIT Press, 2012).
Krepki, R., Blankertz, B., Curio, G. & Muller, K. R. The Berlin Brain-Computer Interface (BBCI) - towards a new communication channel for online control in gaming applications. Multimed. Tools Appl. 33, 73–90, doi: 10.1007/s11042-006-0094-3 (2007).
Duda, R. O., Hart, P. E. & Stork, D. G. Pattern Classification. 2nd edn (Wiley & Sons, 2001).
Lin, Z., Zhang, C., Wu, W. & Gao, X. Frequency recognition based on canonical correlation analysis for SSVEP-based BCIs. IEEE Trans. Biomed. Eng. 54, 1172–1176, doi: 10.1109/TBME.2006.886577 (2007).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. Royal Stat. Soc. B 57, 289–300 (1995).
Genovese, C. R., Lazar, N. A. & Nichols, T. Thresholding of statistical maps in functional neuroimaging using the false discovery rate. NeuroImage 15, 870–878, doi: 10.1006/nimg.2001.1037 (2002).
Dähne, S. et al. Multivariate Machine Learning Methods for Fusing Multimodal Functional Neuroimaging Data. P. IEEE 103, 1507–1530, doi: 10.1109/Jproc.2015.2425807 (2015).
Ioannides, A. A. Dynamic functional connectivity. Curr. Opin. Neurobiol. 17, 161–170, doi: 10.1016/j.conb.2007.03.008 (2007).
He, B. et al. eConnectome: A MATLAB toolbox for mapping and imaging of brain functional connectivity. J. Neurosci. Methods 195, 261–269, doi: 10.1016/j.jneumeth.2010.11.015 (2011).
Astolfi, L. et al. Comparison of different cortical connectivity estimators for high-resolution EEG recordings. Hum. Brain Mapp. 28, 143–157, doi: 10.1002/hbm.20263 (2007).
Ding, L., Worrell, G. A., Lagerlund, T. D. & He, B. Ictal source analysis: Localization and imaging of causal interactions in humans. NeuroImage 34, 575–586, doi: 10.1016/j.neuroimage.2006.09.042 (2007).
Pascual-Marqui, R. D. Standardized low-resolution brain electromagnetic tomography (sLORETA): technical details. Methods Find. Exp. Clin. Pharmacol. 24 Suppl D, 5–12 (2002).
Pascual-Marqui, R. D. et al. Assessing interactions in the brain with exact low-resolution electromagnetic tomography. Philos. Trans. R. Soc. A 369, 3768–3784, doi: 10.1098/rsta.2011.0081 (2011).
Chen, X. et al. High-speed spelling with a noninvasive brain-computer interface. Proc. Natl. Acad. Sci. USA 112, E6058–E6067, doi: 10.1073/pnas.1508080112 (2015).
Nakanishi, M., Wang, Y., Wang, Y.-T., Mitsukura, Y. & Jung, T.-P. A high-speed brain speller using steady-state visual evoked potentials. Int. J. Neural Syst. 24, 1450019 (2014).
Chen, X., Chen, Z., Gao, S. & Gao, X. Brain-computer interface based on intermodulation frequency. J. Neural Eng. 10, 066009, doi: 10.1088/1741-2560/10/6/066009 (2013).
Martinez, P., Bakardjian, H. & Cichocki, A. Fully Online Multicommand Brain-Computer Interface with Visual Neurofeedback Using SSVEP Paradigm. Comput. Intell. Neurosci. 2007, 94561 (2007).
Acknowledgements
This work was supported by the Basic Science Research Program (2015R1A1A1A05027233 to B.-K.M.) and the BK21 Plus program (to B.-K.M. and K.-R.M.), which are funded by the Ministry of Science, ICT and Future Planning through the National Research Foundation of Korea; the German Federal Ministry for Education and Research (BMBF: 01IS14013A to K.-R.M.)
Author information
Authors and Affiliations
Contributions
B.-K.M. designed the grid-shaped top-down SSVEP paradigm, performed research, and wrote the main manuscript text. B.-K.M., S.D., M.-H.A., Y.-K.N. and K.-R.M. analyzed data and reviewed the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Min, BK., Dähne, S., Ahn, MH. et al. Decoding of top-down cognitive processing for SSVEP-controlled BMI. Sci Rep 6, 36267 (2016). https://doi.org/10.1038/srep36267
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep36267
This article is cited by
-
Review of brain encoding and decoding mechanisms for EEG-based brain–computer interface
Cognitive Neurodynamics (2021)
-
Simultaneous acquisition of EEG and NIRS during cognitive tasks for an open access dataset
Scientific Data (2018)
-
Development of an electrooculogram-based human-computer interface using involuntary eye movement by spatially rotating sound for communication of locked-in patients
Scientific Reports (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
