
Abstract
Large-scale transitions in societies are associated with both individual behavioural change and restructuring of the social network. These two factors have often been considered independently, yet recent advances in social network research challenge this view. Here we show that common features of societal marginalization and clustering emerge naturally during transitions in a co-evolutionary adaptive network model. This is achieved by explicitly considering the interplay between individual interaction and a dynamic network structure in behavioural selection. We exemplify this mechanism by simulating how smoking behaviour and the network structure get reconfigured by changing social norms. Our results are consistent with empirical findings: The prevalence of smoking was reduced, remaining smokers were preferentially connected among each other and formed increasingly marginalized clusters. We propose that self-amplifying feedbacks between individual behaviour and dynamic restructuring of the network are main drivers of the transition. This generative mechanism for co-evolution of individual behaviour and social network structure may apply to a wide range of examples beyond smoking.
Similar content being viewed by others

Introduction
Behaviour is shaped by interactions between the individual and its environment1. As a result of evolutionary pressures emanating from intensified group lifestyles, humans acquired a diverse and specialised social behavioural repertoire2,3. The human cognitive capacity for enduring collaborative social interaction has been extensively investigated in various disciplines related to the field of cognitive sciences (for an overview cf. refs 4, 5, 6). Theories about how behaviours are shaped by social and individual factors have a longstanding tradition in psychology and social sciences7,8. Examples of quantitative models include dynamic models of segregation in urban neighbourhoods9, models of cultural dissemination10 and a wealth of literature aiming at the inclusion of social decision making into economic theory11,12. An overview on mathematical approaches to social dynamics is provided in ref. 13. Importantly, social relations can be represented as graphs, which renders them accessible to network theoretical analysis14. It has been shown that the overall structure of connections between individuals in social networks and face-to-face interactions between individuals systematically affects a wide range of social and individual characteristics, such as happiness, divorce rates, smoking and obesity15,16,17,18,19. We refer to this effect as behaviour selection emphasising an evolutionary process rather than mere individual decision-making.
In this context, networks statistics enable more targeted characterisations of social dynamics. For example, social distance modulates similarity and behavioural synchrony between individuals. It is commonly measured using the shortest path length between two individuals in a social network and has been shown to preferentially shape individual behaviour up to a distance of three social ties19. Likewise, the contents of social interactions between individuals depend on their relationship, i.e., perceived friendship status, which suggests nonlinear interdependencies between network dynamics and social interaction20. Opinion formation and imitation have been advocated as candidate mechanisms of behaviour induction21,22. This puts emphasis on cognitive processes and biases for selective spread of behaviours in social networks23,24.
These findings motivate process-based techniques for modelling dynamical social networks highlighting time-varying aspects of social connections25. One such approach is represented by adaptive networks that model the temporal co-evolution of network structure and dynamic node states26,27,28. The most commonly modelled social processes include imitation, collaboration dynamics and social tie formation as a function of antipathy and sympathy (sometimes referred to as homophily and heterophily, respectively) between agents. Adaptive network models have then been used to investigate complex phenomena in social networks such as phase transitions and tipping points in opinion formation on single-29 and multi-layer30 networks, epidemic spreading31, swarm behaviour32, friendship structure in social media networks33, sustainable use of renewable resources34 and coalition formation35. Opinion formation has been intensively investigated using the adaptive voter model29, its generalisations and related models26,27,28 with a focus on consensus formation36, opinion diversity37 and network fragmentation38.
In adaptive network models, the selection of update rules critically determines the co-evolutionary dynamics of node states and network structure. When considering real-world social systems, social connections are very unlikely to be established randomly and in disregard of the underlying network structure, but rather are the outcome of agents’ interactions in a complex network39,40,41. At the same time, interaction between agents along social ties is a key process to induce individual behavioural change42. Therefore, choosing update rules such that they explicitly take into account peculiarities of micro-scale social interactions seems promising for obtaining more realistic models. Such an interaction-resolved adaptive network approach would then also allow to study the co-evolution of micro-scale social influence and large-scale network structures.
More empirical findings have become available that explicitly describe social network structures. In the work presented here, we will focus on a study on smoking habits by Christakis and Fowler17. Based on a detailed long-term survey, they analysed smoking habits of 12,067 inhabitants of a small town in the US between 1971 and 2003 while concomitantly tracking their social relationship structure, i.e., mutual assessment of friendship status. Their analysis revealed that over that time period, the prevalence of smoking declined from about 50% to about 10%. At the same time, the structure of social connections changed almost selectively for the remaining smokers. Their average eigenvector centrality, a measure of how much a node is in the “centre” of its social network, significantly declined. At the same time, the probability of an individual being a smoker conditional on the prevalence of smoking in its neighbourhood (referred to as conditional probability below, see Methods) increased up to the level of third degree contacts (contacts of contacts of contacts). In other words, individuals who did not adapt to the decreasing societal support for smoking preferentially interacted with similar individuals, forming subgroups or clusters of increasingly marginalized smokers.
An Adaptive Network Model of Behaviour Selection
In the following, we will introduce an interaction-resolved adaptive network approach that we evaluate in terms of its capacity to reproduce characteristics of empirically studied time-varying social networks. We first outline the general modelling framework that contains core conceptual ideas of our adaptive network model of behaviour selection presented in Fig. 1. In a next step, we describe specific modifications and additions made to model social dynamics of changing smoking behaviour to reproduce findings from the empirical reference case17.

Adaptive network model of behaviour selection.
For a group of individuals, the proposed model predicts selection of behaviour as a function of two factors: local interaction between individuals and the global structure of their social connections. The proximity matrix describes how similar a given pair of individuals is based on their individual characteristics such as smoking behaviour. Assuming restricted resources, agents maintain a limited number of social contacts. In the proposed model, individuals only keep their most proximate contacts. Based on the proximity matrix, it can be determined which individuals are current neighbours in the contact network. The distance between nodes in this network is then used to compute the interaction probability matrix for stochastically generating current interactions between a given pair of individuals. Importantly, this interaction network exerts feedback on the individual behaviour and thus closes the co-evolutionary loop: The probability of changing the smoking behaviour is modelled as a function of the individual smoking disposition and the dominance of smoking behaviour in the local neighbourhood of the interaction network. Note that only individuals who have actually interacted can establish a tie in the contact network in the next time step.
Complex systems, such as the human brain, social networks, or the backbone structure of the internet, typically implement functional hierarchies43,44,45,46. Although dynamics with multiple temporal hierarchies also apply to the emergence of complex macroscopic structure in social systems in which agents repeatedly interact over time47,48,49, hierarchical social network dynamics have rarely been explicitly modelled26,27,50,51. Here we considered functional hierarchies as coupling between an interaction network with fast updates and contact network with slow updates that together shape individual characteristics as their states change over time with preferential formation of social ties. A schematic overview of the model and its components is depicted in Fig. 1 and a detailed formal description of our model is given in the methods description below.
The contact network’s structure is based on an overall similarity between individual’s characteristics such as preferences, socio-economic status or genetic factors (cf. refs 52, 53, 54, 55) that generate a social proximity between individuals. Here, contacts are understood as the number of other agents an individual may regularly interact with (a counterexample for this are entries in a Facebook contact list that only require a single interaction to be established). The total number of such contacts that can be maintained by a human individual is constrained by temporal and cognitive capacities2. General cognitive capacity and the number of contacts are both subject to individual differences56,57. We therefore restricted the maximum degree of social contact that an agent in the contact network is capable or willing to maintain by introducing an individual degree preference parameter that is normally distributed. An agent cannot maintain more contacts than prescribed by its degree preference, which implies that establishing new contacts (by a new edge in the contact network) may require disbanding old ones (deleting the edge in the contact network).
The interaction network provides the basis for establishing new contacts while at the same time also inducing change in the individual characteristics. It is generated stochastically at each time step based on the contact network. Reflecting empirical findings19, the probability of interactions between two individuals in a given time step (represented by an edge in the interaction network) decreases with the shortest path distance between them in the contact network. The minimal interaction probability is a constant positive value, thereby allowing for unlikely, incidental meetings (“by chance”) between distant or disconnected individuals.
In our model, tie formation in the contact network is constrained by the social proximity that may change as a result of the interaction58. To update the contact network, the social proximities to neighbours in the interaction network are compared with proximity values to contact network neighbours. Only the top ranking contacts are maintained, both in the contact and the interaction network up to the agent specific degree preference. Importantly, to establish a contact between two agents, each of them has to be included in the other’s set of preferred contacts. By this requirement of reciprocity, previous contacts can be replaced actively, but also lost passively, reminiscent of forgetting. Such a process can be illustrated by an agent moving from city A to another city B in which she establishes new contacts and at the same time gradually forgets about her previous social network in A. In turn, also her previous contacts in A loose contact with her.
At the same time, the social influence dynamics play out on the interaction network. Individual characteristics such as behaviours are subject to peer-influence by direct neighbours in the interaction network as will be described below. The model design also allows to account for individual dispositions as node-dependent constraints on behaviour exogenous to the model, i.e., weights on choice options, that do not depend on the interaction network. Such dispositions may be understood as culturally transmitted norms, values, knowledge and slowly changing collective contexts (e.g. health campaigns or climate change). Intuitively, by altering these weights according to a simulation protocol, one can emulate changes in global societally relevant factors. The hierarchical coupling between components in our model supports decomposition into partial models (see Table 1 and Methods). This allows us to differentiate the relative importance of model components and their associated social processes for behaviour selection in response to changing global trends.
Modelling Social Dynamics of Changing Smoking Behaviour
In the following, we apply the proposed adaptive network model of behaviour selection to the specific case of network-dependent changes in smoking behaviour to investigate empirically observed social transitions.
In particular, we introduce an update mechanism for the agent’s smoking behaviour as the individual characteristic of interest. We conceptualise smoking behaviour as a binary variable (either smoking or non-smoking) endogenously in the model. The individual’s smoking behaviour can be altered over time by an Ising-type model of social influence13. At each time step, we determine the probability of an agent to alter its smoking behaviour as a function of balanced peer-influence of smoking and non-smoking behaviour of its neighbours in the interaction network (see Methods). In addition to the peer-influence, we introduce an individual smoking disposition that reflects individual preferences in the probability to switch smoking behaviour. As this individual smoking disposition is exogenous to the model, its distribution can be altered externally and the dynamic response of the model can be investigated.
Importantly, it is only the endogenous binary smoking behaviour that dynamically affects agents’ social proximity in our model. As in actual social networks, however, the social proximity also reflects many dimensions of which most remain latent during an interaction. Our proximity matrix thus includes two components: the time-invariant background proximity that largely determines the position of agents in the social network, e.g. reflecting long-term social ties such as family relationships and a time-dependent component that depends on the co-occurrence of smoking behaviour for pairs of individuals. As a consequence, adopting a new behaviour will modify an agent’s entries in the proximity matrix and may thus lead to changes in the contact network.
We then emulated dynamics of societal changes that historically lead to reduced prevalence of smoking (e.g. health campaigns and changes in public opinion17) by gradually modifying the exogenous distribution of smoking disposition. Over 1000 model time steps, we gradually converted a bimodal distribution, representing a balanced share of smokers and non-smokers in the network, into a quasi unimodal distribution favouring non-smoking attitudes as depicted in Fig. 2. We subsequently performed simulations over an ensemble of 1000 model runs using different seeds to initialise the pseudo-randomisation of the time-invariant background proximity matrix and the smoking disposition (see Methods). The model dynamics of interest were robust with respect to the specific choice of the distributions and the speed of the change in external forcing.

Smoking behaviour and centrality before and after the social transition.
Panel (a,b) illustrate the initial and the final state of the contact network as simulated by the proposed adaptive network model of behaviour selection. Circles represent individual nodes. Their colour and size represent smoking behaviour and the individual’s centrality, respectively. At the initial state of the simulation (panel (a)), smoking behaviour is homogeneously distributed across the network with random centrality values and the number of smokers equals the number of non-smokers resulting from the initial distribution of smoking dispositions. As the normative support for smoking gradually declined, behaviour and centrality changed over repeated interactions within the network. In the final state of the simulation (panel (b)), the number of smokers has considerably declined. As a consequence of the adaptive network dynamics, the centrality of smokers is selectively reduced. In comparison, non-smokers are characterised by a wide distribution of centrality.
Results
To evaluate our co-evolutionary model of behaviour selection, we gradually modified the exogenous smoking disposition and studied the response of several metrics of our social adaptive network. These metrics were motivated by previous empirical studies that documented co-evolution between behaviour and social network structure (cf. refs 17 and 19) and include the prevalence of smokers in the network, the eigenvector centrality of each individual and the probability that an individual smokes given that her contacts smoke (conditional probability of smoking).
Over time, the fraction of smokers in the network reduces from about 50% to 10% (Fig. 3), which is consistent with the empirical findings reported in ref. 17. In a second step, we compared different generative mechanisms by repeating the analysis for the remaining three partial models (see Table 1 and coupled model in Fig. 3). We found that models considering social influence dynamics (interaction, mean-field and coupled) reduced the smoking prevalence twice as much as the network model (Fig. 3), in which agent’s behaviour is determined solely by the exogenous smoking disposition.

Gradual transition from a smoker to a non-smoker society is reflected in the prevalence of smoking.
We considered four distinct models of behaviour selection. Over the course of the simulation, the distribution of the smoking disposition was gradually transformed from a bimodal to a quasi unimodal distribution and the smoking behaviour was computed at each time step. The coupled model assumes that behaviour is shaped by a local interaction based on a time-varying contact network. In the network model, no local interactions are considered. Here, the behaviour is only determined by the individual disposition while the contact network changes over time. In the interaction model, only local interactions shape the behaviour on a static contact network. Similarly to the coupled model, social influence and network dynamics are considered in the mean-field model, but smoking behaviour is shaped by non-local influences only. In all four (partial) models, the proportion of smokers changes in the course of the normative transition (time is represented in arbitrary units, AU). Notably, the absolute change is higher in the models that assume social interaction. Solid lines show mean values across 1000 runs with different pseudo-random initialisations. The variation across runs was negligible.
Only models considering the evolution of the contact network reduced the eigenvector centrality of remaining smokers below baseline (Fig. 4a). These effects were most pronounced for models combining social influence and network dynamics (mean-field and coupled). These models suggest a preferential reduction of centrality for smokers, reminiscent of the empirical results reported in ref. 17 (Fig. 4b). Here the mean-field model exhibits somewhat more drastic effects with less temporal variability as compared to the coupled model and even initially increases the eigenvector centrality of nodes, however not selectively for smokers. This is consistent with the deactivation of local influence that might give rise to “clusters of resistance”. When considering the conditional probability of smoking up to fifth degree contacts (Fig. 5), we found changes between four to eight times higher in the coupled model as compared to all other models. This suggests that the feedback between specific local dynamics of social influence greatly amplifies such social clustering behaviour. Taken together, the results from our fully coupled co-evolutionary model support key findings from the empirical reference study17. At the same time, these results suggest that the residual pattern of clustered smokers of reduced centrality reflect a synergy between local interaction and network dynamics.

During the normative transition, local interactions between individuals and the evolution of the network structure rendered smokers less influential in the network.
The eigenvector centrality (EVC) was computed at each time step for 1000 model runs with different random seeds. All models were initialised to the equilibrium run of the coupled model and values were normalised to the initial state of the model parameters. Panel (a,b) depict changes in EVC according to the four (partial) models for smokers and non-smokers, respectively. Solid lines show mean values and areas indicate bootstrapped 95% and 99% confidence intervals. It is noteworthy that only in models reflecting network effects, EVC was substantially reduced. These effects were strongest in models that in addition considered social interactions between individuals.

During the normative transition, joint effects of individual interaction and the evolution of the network structure led remaining smokers to cluster in marginalized groups.
The probability of an individual being a smoker conditional on the prevalence of smoking in its neighbourhood at a given social distance or degree of separation (conditional probability, CP) was computed for 1000 model runs with different pseudo-random seeds at each time step and normalised to the percentage of change relative to the initial value. Panels (a–d) show the CP at social distance 1–5 for the network, the interaction, the coupled and the mean field models, respectively. CP increased with simulated time for lower social distances (1–3) across all models, whereas decreases of CP were observed for larger social distances in some models. Notably, this pattern was between four to eight times more pronounced in the coupled model compared to all other models. Solid lines depict mean values and areas represent bootstrapped 95% and 99% confidence intervals, barely visible as a result of the high signal to noise ratio for this metric.
Discussion
We proposed a co-evolutionary model of behaviour selection in adaptive social networks and evaluated it through computational models targeting historical changes of smoking behaviour in social networks. Our computational models emulated gradual changes of network-wide smoking norms. We observed a reduced prevalence of smoking, a decreased eigenvector centrality and an increased conditional probability of smoking. Notably, the patterns of smoking behaviour and network characteristics computed by our model closely resemble empirical findings from a large-scale and long-term social network study investigating smoking behaviour in a North American small town17. Results of a partial model analysis suggest that selective modelling of either network dynamics, social influence or non-local social induction yields less match with empirical findings and underscore the empirical relevance of behaviour-network co-evolution. Only the fully coupled co-evolutionary model was capable of explaining non-trivial structural change in complex social systems.
In particular, we would like to highlight the relevance of local generative mechanisms for social interaction as indicated by the deviating results for a mean-field forcing. The apparent imminent relevance of locality in interactions underscores the need for meaningful, social network based update mechanisms to study complex social phenomena.
It is important to highlight that our models did neither involve any data-fitting nor predictive analyses. Instead we provided simulations with outputs according to their parameters and components. Thus the reported evidence is qualitative in nature and emphasises one distinct generative model through comparisons to empirical data and prior knowledge. The variance across ensembles assumes different values metric-wise, reflecting their algebraic properties as well as the effect of network size. Hence, our analyses do not imply statistical inference. The specific parameter choices in our model were adapted from the empirical study17 and motivated from social sciences, evolutionary biology and neurosciences findings2,19,52,59,60.
Furthermore, the models we evaluated in our simulations clearly suffer from conceptual limitations. The cognitive make-up of our simulated individual constitutes a bold simplification, particularly the assumption of an exogenously prescribed behavioural disposition. Human behaviour is clearly not binary but continuous and more complex model assumptions can therefore be easily motivated. Decision making is governed by multiple interacting factors, involving individual cognitive-emotional dispositions, but also by collaboration dynamics integrating social and cultural factors. Social support for a certain behaviour is often ambiguous, reflecting conflicting values and social interactions can be asymmetric and unequally weighted. In this context, our model of behavioural change should be regarded as a prototype. We do not assess the validity of a specific mechanism of behavioural change or opinion formation. Instead we emphasise the structural importance of co-evolutionary processes that coalesce social cognition with network dynamics. But we hope that our simulation method stimulates future validation of specific social cognition theories against the background of evolving social networks. Nevertheless, our model generalises to other empirically documented examples of behaviour-network co-evolution including the spread of happiness, the spread of obesity but also the conditioning of food choices61, as well as large data sets available from monitored social dynamics in massive multiplayer online games20. Assessing behavioural changes in social networks thereby complements spatial analysis62, as social ties and physical distance tend to be substantially correlated17 albeit a spatial and a network approach highlight fundamentally different qualities of the environment.
In particular, the example of food choices illustrates the potential outreach of our model for diverse interdisciplinary research questions. For example, the environmental foot-print of meat-centred diets is considerably higher than that of a vegetarian diet63. Against the historical background of strong positive correlations between meat consumption and economic prosperity64 and given the rise of the global middle-class, diet habits represent a key challenge affecting several planetary boundaries65,66. At the same time, modifying nutritional behaviour has been targeted by health-related disciplines such as clinical psychology and behavioural medicine in preventive and therapeutic contexts. Capitalising on contingencies between individual behaviour and environment, therapeutic efforts might therefore benefit from models that specifically detail the relationship between microscopic and macroscopic social dynamics. Furthermore, co-evolutionary dynamics of behaviour and networks have been found to promote cooperation in public good games67,68, thereby illustrating their transformative potential69. In the neuroscientific context it would be worthwhile to explore adaptive networks of spontaneous brain activity. Such models might help to overcome the limitations of ubiquitous “flat models” which do not resolve functional and structural connectivity hierarchically.
At a theoretical level, our study promotes a synergistic, co-evolutionary and interdisciplinary approach to social dynamics which gains explanatory momentum by integrating interpersonal cognitive processes with network dynamics as explanatory factors.
Methods
Detailed model description
In the following, we provide a detailed mathematical model description, including definitions of the model variables and parameters, their initialisation, the algorithm for computing their temporal dynamics, the general modelling protocol and partial models. The model code is publically available and can be assessed and reviewed here: https://github.com/pik-copan/pycopanbehave. The implementation is based on the Python complex network software package pyunicorn70 that is available at https://github.com/pik-copan/pyunicorn.
Model entities
We model individuals as agents or nodes i ∈ V, where V denotes the population or set of N = |V| agents in the social system considered. The system is assumed to be closed and, hence, V does not depend on time, i.e. agents cannot enter or leave the population. The following entities define the system on the individual and population levels:
Agent properties
Each agent i carries a vector of scalar agent properties. Agent properties are parameters prescribed externally, they are fixed at initialisation and can be changed over time only by forcing external to the model (see below). The current model setup implements two agent properties:
-
1
Degree preference qi ≤ N − 1 is a discrete quantity serving as an upper bound of an agent’s degree in the contact network
 (i.e. its number of neighbours in the contact network). This reflects the varying and limited capability of individuals to establish, manage and maintain sustained social relationships2. qi is drawn from a discretised Gaussian distribution with mean μ and standard deviation σ at initialisation of the model. Specifically, we choose μ = 10 and σ = 3 in the smoking experiment.
(i.e. its number of neighbours in the contact network). This reflects the varying and limited capability of individuals to establish, manage and maintain sustained social relationships2. qi is drawn from a discretised Gaussian distribution with mean μ and standard deviation σ at initialisation of the model. Specifically, we choose μ = 10 and σ = 3 in the smoking experiment. -
2
Smoking disposition γi(t) ∈ [0, 1] is a continuous variable measuring an agent’s individual and network-independent preference for smoking. Agents with small smoking disposition γi(t) have a low probability to start smoking if they are non-smokers, while those with large γi(t) have a low probability to stop smoking if they are smokers. γi(0) is drawn at initialisation from a bimodal, parabolic probability density distribution that is optionally modified by stochastic external forcing towards a quasi unimodal distribution over time (see below).
 (i.e. its number of neighbours in the contact network). This reflects the varying and limited capability of individuals to establish, manage and maintain sustained social relationships
(i.e. its number of neighbours in the contact network). This reflects the varying and limited capability of individuals to establish, manage and maintain sustained social relationshipsAgent characteristics
Each agent i also carries a vector of scalar agent characteristics. The latter are dynamic variables that are by definition subject to social influence (induction), i.e. they are internal variables of the model obeying the social influence loop (Fig. 1). In this work, the following single agent characteristic is implemented: smoking behaviour si(t) ∈ {0, 1} is a binary variable describing an agent’s actual smoking behaviour. si(t) = 0 means that an agent does not smoke at time t, si(t) = 1 implies that an agent does smoke at time t.
Contact network
The contact network resembles the social relationships between agents. By contacts we refer explicitly to people that interact on a regular basis and are able to follow each other’s affairs. We describe it as an undirected and simple time-dependent graph GC(t). It can be represented by its adjacency matrix AC(t). The neighbourhood of agent i in the contact network is denoted by  .
.
Interaction network and interaction probability matrix
The interaction network represents all short-term interactions established between agents at each time step t. It is the basis for updating both the agent characteristics and the contact network at each time step. We describe it as an undirected and simple time-dependent graph GI(t). It can be represented by its adjacency matrix AI(t). The neighbourhood of agent i in the interaction network is denoted by  .
.
Each entry πij(t) of the interaction probability matrix Π(t) gives the probability that two agents i, j will interact in time step t. For computing πij(t), the social distance between two agents i, j is measured by the shortest path length  between them in the contact network at time t − 1 (the minimum number of steps needed to reach agent i from agent j over the contact network). Empirical results reveal that social influence decays approximately exponentially with
between them in the contact network at time t − 1 (the minimum number of steps needed to reach agent i from agent j over the contact network). Empirical results reveal that social influence decays approximately exponentially with  19. Following these findings reporting a so-called “three degrees of separation law” of social influence, we define the interaction probability matrix as
19. Following these findings reporting a so-called “three degrees of separation law” of social influence, we define the interaction probability matrix as

where ε is a baseline probability of interaction irrespective of the contact network. To account for the distribution of shortest path lengths between nodes, a normalisation factor  is introduced with L(1) and L(dij) being the absolute number of shortest paths between nodes of length equal to 1 or dij, respectively. πij(t) is scaled such that the probability of interaction between direct neighbours is always equal to the interaction probability scaling factor β. Here we set β = 0.8 and ε = 0.03. The parameter δ gives the typical social distance for the exponential decay of interaction probability and is chosen as δ = 2 in line with empirical evidence19.
is introduced with L(1) and L(dij) being the absolute number of shortest paths between nodes of length equal to 1 or dij, respectively. πij(t) is scaled such that the probability of interaction between direct neighbours is always equal to the interaction probability scaling factor β. Here we set β = 0.8 and ε = 0.03. The parameter δ gives the typical social distance for the exponential decay of interaction probability and is chosen as δ = 2 in line with empirical evidence19.
Proximity matrix
The proximity matrix P(t) with elements Pij(t) measures the social proximity of two agents i, j. If social proximity is large, both agents are more likely to establish or maintain a contact. Hence, the proximity matrix is used in updating the contact network (see below). In our case of a single binary individual characteristic, the social proximity Pij(t) of two agents is only determined by the smoking behaviour si(t) and sj(t) and their initially prescribed background proximity Bij describing rigid social ties such as family relationships and other factors that are not explicitly included in the model. We choose a simple linear relationship

where α is a weight parameter balancing the influence of smoking behaviour and background proximity. Here, we choose α = 0.2 to allow for a typical network mobility of between one and two degrees in the Watts-Strogatz network that underlies the background proximity generation.
The background proximity matrix B with elements Bij is constructed on the basis of a Watts-Strogatz small-world network45 with N nodes, mean degree z = 10 and a rewiring probability pw = 0.03. The individual proximities Bij are derived as a linear combination of the social distance  in a realisation of a Watt-Strogatz random network and a uniformly distributed stochastic component ζ ∈ [0, 1). This choice allows to emulate the typical small-world property of empirical social networks. Bij is derived as
in a realisation of a Watt-Strogatz random network and a uniformly distributed stochastic component ζ ∈ [0, 1). This choice allows to emulate the typical small-world property of empirical social networks. Bij is derived as

After computation of Bij using the above formula, all entries with Bij < 0.2 are reset to a minimum value of 0.2, which is in line with the assumption that for very high degrees of separation, no further meaningful distinction can be motivated.
Model dynamics
The temporal update scheme describes the dynamics of the main variables of interest in the model (Fig. 1): smoking behaviour si(t) and contact network GC(t). The model evolves in discrete time steps. It is deterministic with the exception of the stochastic generation of the interaction network from the interaction probability matrix and the stochastic switching of the agents’ smoking behaviours in each time step. After initialisation, the algorithm proceeds from step 1 to step 6 in the full co-evolutionary setup and then starts again at step 1. Modified model dynamics implemented to isolate the effects of specific mechanisms in the model are described below.
Step 1: Calculate interaction probabilities based on social distance
The interaction probability matrix Pi(t) is computed based on the social distance  between agents i, j in the contact network GC(t − 1) from the previous time step t − 1 following Eq. 1.
between agents i, j in the contact network GC(t − 1) from the previous time step t − 1 following Eq. 1.
Step 2: Generate interaction network
The interaction network’s adjacency matrix is randomly generated for all i, j ∈ V independently. An interaction takes place with probability πij(t) corresponding to setting  , while no interaction takes place with probability 1 − πij(t) leading to
, while no interaction takes place with probability 1 − πij(t) leading to  .
.
Step 3: Change agent characteristics (social influence/induction step)
In the considered case of a single binary individual characteristic (smoking behaviour), social influence reduces to a probabilistic switching of smoking behaviour similar to the flipping of spins in an Ising model in physics13. At time step t, the probability pi(t) to switch the smoking behaviour is assumed to depend to both the smoking disposition γi(t − 1) of agent i and the average smoking behaviour in the agent’s neighbourhood in the interaction network GI(t) at time t. For all agents i, the smoking behaviour is determined as follows. For a non-zero number of interactions  :
:
-
If si(t − 1) = 0 (non-smoker):
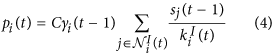
-
The smoking behaviour switches to “smoker” with probability pi(t), i.e. si(t) = 1 and remains the same with probability 1 − pi(t), i.e. si(t) = 0.
-
If si(t − 1) = 1 (smoker):
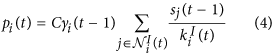

The smoking behaviour switches to “non-smoker” with probability pi(t), i.e. si(t) = 0 and remains the same with probability 1 − pi(t), i.e. si(t) = 1.
If no interactions take place for agent i ( ), we set si(t) = si(t − 1).
), we set si(t) = si(t − 1).
The smoking behaviour switching probability scaling factor C scales the switching probability pi(t) of the smoking behaviour. C controls the amplitude of equilibrium stochastic noise of the smoking behaviour that is introduced by the Ising-like implementation. Here we set C = 0.1.
Step 4: Calculate proximity matrix
The proximity matrix P(t) is computed from the current agent characteristics (smoking behaviour si(t)) and background proximity matrix B according to the diagnostic relationship given in Eq. 2.
Step 5: Update contact network
New ties in the contact network GC(t) can only be established between agents that interacted in the same time step. In contrast, potentially any edge may disappear from the contact network depending on the outcome of the following update scheme. Let Ui(t) be the ordered set of neighbours  of i included in its interaction and contact neighbourhoods that is sorted in descending order of social proximity Pij(t). The number of potential contacts of agent i is determined by the agent’s degree preference qi. Specifically, the agent’s potential contact neighbourhood at time t consists of the set Ti(t) of the first qi entries of Ui(t). Additionally, we require bidirectionality of contacts. This implies that only those agents can establish or maintain a contact relationship at time t that are included in each other’s potential contact lists Ti(t). Thus, the contact network at time t is derived as follows:
of i included in its interaction and contact neighbourhoods that is sorted in descending order of social proximity Pij(t). The number of potential contacts of agent i is determined by the agent’s degree preference qi. Specifically, the agent’s potential contact neighbourhood at time t consists of the set Ti(t) of the first qi entries of Ui(t). Additionally, we require bidirectionality of contacts. This implies that only those agents can establish or maintain a contact relationship at time t that are included in each other’s potential contact lists Ti(t). Thus, the contact network at time t is derived as follows:

This means that a new contact relation can only be formed if the corresponding social proximity value is large enough to enter the potential contact neighbourhood of both involved agents. On the contrary, a contact is lost if either alter is not element of ego’s own list of potential contacts or if ego is not element of alter’s own list, or if both is the case. Thus ego can loose a contact actively (by dropping alter) or passively (by being dropped by alter).
Importantly, we do not derive “second best” solutions by iteratively updating the potential contacts after the bidirectionality check. We account for this refinement implicitly via the iterative network update dynamics cycle in the model (Fig. 1).
Step 6: Apply external forcing (optional)
External forcing can change agent properties and other system parameters. In our smoking case study, we change the smoking dispositions γi(t) of agents over time according to prescribed initial and target distributions to emulate the effects of changing values, political and health campaigns, etc. For all time steps, we ensure that the set {γi(t)}i is consistent with being drawn from a parabolic probability distribution of the form y(x; t) = a(t)(b(t) − x)2 + c(t) for x ∈ [0, 1] with parameters implicitly defined by the conditions  , y(x = 0; t) = C1 and y(x = 1; t) = C2(t). Specifically, the initial {γi(0)}i are drawn from a bimodal and symmetric distribution y(x; t = 0) with C2(t) = C1.
, y(x = 0; t) = C1 and y(x = 1; t) = C2(t). Specifically, the initial {γi(0)}i are drawn from a bimodal and symmetric distribution y(x; t = 0) with C2(t) = C1.
Then, the target distribution is changed over time by gradually reducing the parameter C2(t). To compute the set of smoking distributions {γi(t)}i at time step t, the previous set {γi(t − 1)}i is stochastically transformed by stepwise addition of two-tailed log-normal distributed noise ε that is linearly weighted by the deviation from the target distribution. Noise is added iteratively until a Kolmogorov-Smirnoff criterion with significance level 90% of {γi(t)}i being drawn from the target distribution y(x; t) is fulfilled. By this procedure, individual γi are modified following a Markov process, whereas the overall system property, in this case the smoking disposition distribution, is externally controlled. Using this procedure, the randomly sampled initial set of smoking dispositions {γi(0)}i following a bimodal distribution (C2(t = 0) = C1) is gradually transformed into a sample {γi(tf)}i following a quasi unimodal distribution (C2(t = tf) = Cf; see Fig. 1).
Modelling protocol
Model runs proceed in three steps: (i) The interaction network is initialised as  for all pairs i, j. In the following, the initial contact network
for all pairs i, j. In the following, the initial contact network  is established based on the fully connected interaction network. Smoking behaviour si(0) is initialised consistently with the initial smoking disposition γi(0) as
is established based on the fully connected interaction network. Smoking behaviour si(0) is initialised consistently with the initial smoking disposition γi(0) as

where Θ(⋅) is the Heaviside function. (ii) The system is then integrated without applying external forcing for 200 time steps to a quasi-equilibrium state. We choose system parameters interaction probability scaling factor β = 0.8 and smoking behaviour switching probability scaling factor C = 0.1 to limit the system’s internal noise level in equilibrium. More specifically, this choice guarantees that the maximum deviation from the median number of smokers in equilibrium that is induced by the stochastic dynamics of the model is smaller than 5% of the population size N. (iii) The system is then further integrated under continuous application of the stochastic external policy forcing acting on the smoking dispositions γi(t).
Partial models
Besides the fully coupled model described above, we study three additional partial models that focus on a subset of processes of behaviour formation (Table 1): (i) an interaction model focussing on local social influence by assuming a static contact network (omitting step 5), (ii) a network model not considering local social influence, but inducing behavioural change only whenever the exogenously modified smoking disposition γi(t) of an individual i crosses a threshold of 0.5 (modifying step 3), (iii) a mean-field model, where the agents react to the mean-field effect of the average smoking prevalence S(t)/N instead of their local neighbourhood in the social influence process (modifying step 3). S(t) is the number of smokers in time step t.
Network metrics
Eigenvector centrality
The eigenvector centrality ci(t) of agent i (also referred to simply as centrality above) is a non-local centrality measure implicitly defined to be proportional to the sum of i’s contact neighbours’ eigenvector centralities71. An agent has a high centrality if it is connected to many high centrality neighbours in the contact network that also have many high centrality neighbours. This implies that large values of eigenvector centrality ci(t) are observed in high density cliques or substructures embedded within the contact network. ci(t) is given by the i-th component of the leading eigenvector (associated to the largest eigenvalue) of the contact network’s adjacency matrix AC(t) at time t and is computed by applying the evcent method from the igraph package72.
Conditional probability of smoking
The conditional probability that a randomly drawn agent i (ego) smokes given that another agent j (alter) randomly drawn from a neighbourhood shell at social distance  smokes is defined as
smokes is defined as

Here,  denotes the set of smokers at a given time-step and
denotes the set of smokers at a given time-step and  . Similarly,
. Similarly,  is the set of agents at a social distance d (measured by distance on shortest paths) from agent i in the contact network and
is the set of agents at a social distance d (measured by distance on shortest paths) from agent i in the contact network and  is the total number of agents in this set. In our study, P(d; t) is employed as a measure of the mean effect of social distance in the contact network on smoking behaviour17.
is the total number of agents in this set. In our study, P(d; t) is employed as a measure of the mean effect of social distance in the contact network on smoking behaviour17.
Additional Information
How to cite this article: Schleussner, C.-F. et al. Clustered marginalization of minorities during social transitions induced by co-evolution of behaviour and network structure. Sci. Rep. 6, 30790; doi: 10.1038/srep30790 (2016).
References
Skinner, B. F. Selection by consequences. Science 213, 501–504 (1981).
Dunbar, R. I. M. Coevolution of neocortical size, group size and language in humans. Behavioral and Brain Sciences 16, 681 (1993).
Herrmann, E., Call, J., Hernández-Lloreda, M. V., Hare, B. & Tomasello, M. Humans have evolved specialized skills of social cognition: The cultural intelligence hypothesis. Science 317, 1360–1366 (2007).
Tomasello, M., Carpenter, M., Call, J., Behne, T. & Moll, H. Understanding and sharing intentions: The origins of cultural cognition. Behavioral and Brain Sciences 28, 675–691 (2005).
Fehr, E. & Camerer, C. F. Social neuroeconomics: The neural circuitry of social preferences. Trends in Cognitive Sciences 11, 419–427 (2007).
Engemann, D. A., Bzdok, D., Eickhoff, S. B., Vogeley, K. & Schilbach, L. Games people play–toward an enactive view of cooperation in social neuroscience. Frontiers in Human Neuroscience 6 (2012).
Festinger, L. A theory of cognitive dissonance, vol. 2 (Stanford university press, 1962).
Janis, I. L. & Mann, L. Decision making: A psychological analysis of conflict, choice and commitment. (Free Press, 1977).
Schelling, T. C. Dynamic models of segregation†. Journal of Mathematical Sociology 1, 143–186 (1971).
Axelrod, R. The dissemination of culture a model with local convergence and global polarization. Journal of Conflict Resolution 41, 203–226 (1997).
Akerlof, G. A. Social distance and social decisions. Econometrica 65, 1005–1027 (1997).
Steinbacher, M., Steinbacher, M. & Steinbacher, M. Interaction-based approach to economics and finance, 161–203 (Springer International Publishing, Cham, 2014).
Castellano, C., Fortunato, S. & Loreto, V. Statistical physics of social dynamics. Reviews of Modern Physics 81, 591 (2009).
Newman, M. Networks: an introduction (Oxford University Press, 2010).
Christakis, N. A. & Fowler, J. H. The spread of obesity in a large social network over 32 years. The New England Journal of Medicine 357, 370–9 (2007).
Fowler, J. H., Christakis, N. A. et al. Dynamic spread of happiness in a large social network: longitudinal analysis over 20 years in the Framingham Heart Study. British Medial Journal 337, a2338 (2008).
Christakis, N. A. & Fowler, J. H. The collective dynamics of smoking in a large social network. The New England Journal of Medicine 358, 2249–58 (2008).
McDermott, R., Fowler, J. H. & Christakis, N. A. Breaking up is hard to do, unless everyone else is doing it too: Social network effects on divorce in a longitudinal sample. Social Forces 92, 491–519 (2013).
Christakis, N. A. & Fowler, J. H. Social contagion theory: Examining dynamic social networks and human behavior. Statistics in Medicine 32, 556–77 (2012).
Szell, M. & Thurner, S. Measuring social dynamics in a massive multiplayer online game. Social Networks 32, 313–329 (2010).
Girvan, M. & Newman, M. E. J. Community structure in social and biological networks. Proceedings of the National Academy of Sciences of the United States of America 99, 7821–6 (2002).
Asch, S. E. Opinions and social pressure. Readings about the Social Animal 193, 17–26 (1955).
Crandall, D., Cosley, D., Huttenlocher, D., Kleinberg, J. & Suri, S. Feedback effects between similarity and social influence in online communities. Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining - KDD’ 08 160 (2008).
Colman, A. M. Cooperation, psychological game theory and limitations of rationality in social interaction. Behavioral and Brain Sciences 26, 139–153 (2003).
Snijders, T. A., Van de Bunt, G. G. & Steglich, C. E. Introduction to stochastic actor-based models for network dynamics. Social Networks 32, 44–60 (2010).
Gross, T. & Blasius, B. Adaptive coevolutionary networks: a review. Journal of The Royal Society Interface 5, 259–271 (2008).
Gross, T. & Sayama, H. (eds.) Adaptive networks (Springer, Berlin Heidelberg, 2009).
Sayama, H. et al. Modeling complex systems with adaptive networks. Computers & Mathematics with Applications 65, 1645–1664 (2013).
Holme, P. & Newman, M. E. Nonequilibrium phase transition in the coevolution of networks and opinions. Physical Review E 74, 056108 (2006).
Diakonova, M., Eguluz, V. M. & San Miguel, M. Noise in coevolving networks. Physical Review E 92, 032803 (2015).
Gross, T., D’Lima, C. J. D. & Blasius, B. Epidemic dynamics on an adaptive network. Physical Review Letters 96, 208701 (2006).
Huepe, C., Zschaler, G., Do, A.-L. & Gross, T. Adaptive-network models of swarm dynamics. New Journal of Physics 13, 073022 (2011).
Li, M. et al. A coevolving model based on preferential triadic closure for social media networks. Scientific Reports 3, 2512 (2013).
Wiedermann, M., Donges, J. F., Heitzig, J., Lucht, W. & Kurths, J. Macroscopic description of complex adaptive networks coevolving with dynamic node states. Physical Review E 91, 052801 (2015).
Auer, S., Heitzig, J., Kornek, U., Schöll & Kurths, J. The dynamics of coalition formation on complex networks. Scientific Reports 5, 13386 (2015).
Nardini, C., Kozma, B. & Barrat, A. Who’s talking first? Consensus or lack thereof in coevolving opinion formation models. Physical Review Letters 100, 158701 (2008).
Demirel, G., Prizak, R., Reddy, P. N. & Gross, T. Cyclic dominance in adaptive networks. European Physical Journal B 84, 541–548 (2011).
Böhme, G. A. & Gross, T. Analytical calculation of fragmentation transitions in adaptive networks. Physical Review E 83, 035101 (2011).
Bozon, M. & Heran, F. Finding a spouse: A survey of how french couples meet. Population English Selection No. 1 91–121 (1989).
Kossinets, G. & Watts, D. J. Empirical analysis of an evolving social network. Science 311, 88–90 (2006).
Henry, A., Pralat, P. & Zhang, C. Emergence of segregation in evolving social networks. Proceedings of the National Academy of Sciences of the United States of America 108, 8605 (2011).
Hegselmann, R. & Krause, U. Opinion dynamics and bounded confidence models, analysis and simulation. Journal of Artifical Societies and Social Simulation (JASSS) 5 (2002).
Van Essen, D. C., Anderson, C. H. & Felleman, D. J. Information processing in the primate visual system: An integrated systems perspective. Science 255, 419–423 (1992).
Roberts, J. A., Boonstra, T. W. & Breakspear, M. The heavy tail of the human brain. Current Opinion in Neurobiology 31, 164–172 (2015).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440–2 (1998).
Dehaene, S., Sergent, C. & Changeux, J.-P. A neuronal network model linking subjective reports and objective physiological data during conscious perception. Proceedings of the National Academy of Sciences of the United States of America 100, 8520–8525 (2003).
Flack, J. C. & Krakauer, D. C. Challenges for complexity measures: A perspective from social dynamics and collective social computation. Chaos 21, 037108 (2011).
Flack, J. C. Multiple time-scales and the developmental dynamics of social systems. Philosophical Transactions of the Royal Society of London B: Biological Sciences 367, 1802–1810 (2012).
DeDeo, S. Collective phenomena and non-finite state computation in a human social system. PloS One 8, e75818 (2013).
Luhmann, C. C. & Rajaram, S. Memory transmission in small groups and large networks an agent-based model. Psychological Science 26, 1909–1917 (2015).
DeDeo, S., Krakauer, D. C. & Flack, J. C. Inductive game theory and the dynamics of animal conflict. PLoS Computational Biology 6, e1000782 (2010).
Domingue, B. W., Fletcher, J., Conley, D. & Boardman, J. D. Genetic and educational assortative mating among us adults. Proceedings of the National Academy of Sciences of the United States of America 111, 7996–8000 (2014).
Werner, C. & Parmelee, P. Similarity of activity preferences among friends: Those who play together stay together. Social Psychology Quarterly 62–66 (1979).
Eiser, J. R., Morgan, M., Gammage, P., Brooks, N. & Kirby, R. Adolescent health behaviour and similarity-attraction: Friends share smoking habits (really), but much else besides. British Journal of Social Psychology 30, 339–348 (1991).
Kobus, K. Peers and adolescent smoking. Addiction 98, 37–55 (2003).
Bickart, K. C., Hollenbeck, M. C., Barrett, L. F. & Dickerson, B. C. Intrinsic amygdala-cortical functional connectivity predicts social network size in humans. The Journal of Neuroscience 32, 14729–14741 (2012).
Deary, I. J., Penke, L. & Johnson, W. The neuroscience of human intelligence differences. Nature Reviews Neuroscience 11, 201–211 (2010).
Onnela, J.-P. & Reed-Tsochas, F. Spontaneous emergence of social influence in online systems. Proceedings of the National Academy of Sciences of the United States of America 107, 18375–80 (2010).
Buzsáki, G. & Mizuseki, K. The log-dynamic brain: How skewed distributions affect network operations. Nature Reviews Neuroscience 15, 264–278 (2014).
Linkenkaer-Hansen, K., Nikouline, V. V., Palva, J. M. & Ilmoniemi, R. J. Long-range temporal correlations and scaling behavior in human brain oscillations. The Journal of Neuroscience 21, 1370–1377 (2001).
Pachucki, M. A., Jacques, P. F., Christakis, N. A., Wood, R. & Health, J. Social network concordance in food choice among spouses, friends and siblings. American Journal of Public Health 101, 2170–2177 (2011).
Gallos, L. K., Barttfeld, P., Havlin, S., Sigman, M. & Makse, H. A. Collective behavior in the spatial spreading of obesity. Scientific Reports 2 (2012).
Stehfest, E. et al. Climate benefits of changing diet. Climatic Change 95, 83–102 (2009).
Popp, A., Lotze-Campen, H. & Bodirsky, B. Food consumption, diet shifts and associated non-CO2 greenhouse gases from agricultural production. Global Environmental Change 20, 451–462 (2010). Governance, Complexity and Resilience.
Rockström, J. et al. A safe operating space for humanity. Nature 461, 472–475 (2009).
Steffen, W. et al. Planetary boundaries: Guiding human development on a changing planet. Science 347, 1259855 (2015).
Fowler, J. H. & Christakis, N. A. Cooperative behavior cascades in human social networks. Proceedings of the National Academy of Sciences of the United States of America 107, 5334–8 (2010).
Fehl, K., van der Post, D. J. & Semmann, D. Co-evolution of behaviour and social network structure promotes human cooperation. Ecology Letters 14, 546–551 (2011).
Benn, S., Dunphy, D. & Griffiths, A. Organizational change for corporate sustainability (Routledge, 2014).
Donges, J. F. et al. Unified functional network and nonlinear time series analysis for complex systems science: The pyunicorn package. Chaos 25, 113101 (2015).
Bonacich, P. Factoring and weighting approaches to status scores and clique identification. Journal of Mathematical Sociology 2, 113–120 (1972).
Csárdi, G. & Nepusz, T. The igraph software package for complex network research. InterJournal Complex Systems CX. 18, 1695 (2006).
Acknowledgements
The reported research was conducted within the scope of the COPAN flagship project on co-evolutionary pathways at the Potsdam Institute for Climate Impact Research (http://www.pik-potsdam.de/copan). The authors acknowledge support by the German National Academic Foundation. D.A.E. is supported by the ERC StG 263584 awarded to Virginie van Wassenhove, the Amazon in Education Grant awarded to D.A.E., as well as the INSERM, CEA and University Paris Sud. J.F.D. thanks the Stordalen Foundation (via the Planetary Boundary Research Network PB.net) and the Earth League’s EarthDoc program for financial support. The authors gratefully acknowledge the European Regional Development Fund (ERDF), the German Federal Ministry of Education and Research and the Land Brandenburg for supporting this project by providing resources on the high performance computer system at the Potsdam Institute for Climate Impact Research. The publication of this article was funded by the Open Access Fund of the Leibniz Association. Danilo Bzdok, Guillaume Dumas, Jobst Heitzig, Reik V. Donner, Wolfram Barfuss and Virginie van Wassenhove are acknowledged for valuable comments and discussions.
Author information
Authors and Affiliations
Contributions
C.-F.S., J.F.D., D.A.E. and A.L. designed the research. C.-F.S., J.F.D. and D.A.E. performed the research and wrote the manuscript. All authors reviewed the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Schleussner, CF., Donges, J., Engemann, D. et al. Clustered marginalization of minorities during social transitions induced by co-evolution of behaviour and network structure. Sci Rep 6, 30790 (2016). https://doi.org/10.1038/srep30790
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep30790
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
