
Abstract
Understanding the fine scale spatial distribution of births and pregnancies is crucial for informing planning decisions related to public health. This is especially important in lower income countries where infectious disease is a major concern for pregnant women and new-borns, as highlighted by the recent Zika virus epidemic. Despite this, the spatial detail of basic data on the numbers and distribution of births and pregnancies is often of a coarse resolution and difficult to obtain, with no co-ordination between countries and organisations to create one consistent set of subnational estimates. To begin to address this issue, under the framework of the WorldPop program, an open access archive of high resolution gridded birth and pregnancy distribution datasets for all African, Latin America and Caribbean countries has been created. Datasets were produced using the most recent and finest level census and official population estimate data available and are at a resolution of 30 arc seconds (approximately 1 km at the equator). All products are available through WorldPop.
Design Type(s) | data integration objective • source-based data analysis objective |
Measurement Type(s) | population measurement |
Technology Type(s) | computational modeling technique |
Factor Type(s) | Data Source • geographic location |
Sample Characteristic(s) | Homo sapiens • Anguilla • Antigua and Barbuda • Argentina • Aruba • The Bahamas • Barbados • Belize • Bolivia • Bonaire, Saint Eustatius and Saba • Brazil • British Virgin Islands • Cayman Islands • Chile • Colombia • Costa Rica • Cuba • Country of Curacao • Dominica • Dominican Republic • Ecuador • El Salvador • Falkland Islands • Guyane • Grenada • Department of Guadeloupe • Guatemala • Guyana • Haiti • Honduras • Jamaica • Department of Martinique • Mexico • Montserrat • Nicaragua • Panama • Paraguay • Peru • Puerto Rico • Saint-Barthelemy • Saint Kitts and Nevis • Saint Lucia • Saint Martin • Saint Vincent and the Grenadines • Sint Maarten • Suriname • Trinidad and Tobago • Turks and Caicos Islands • Uruguay • Venezuela • United States Virgin Islands • Algeria • Angola • Benin • Botswana • Burkina Faso • Burundi • Cameroon • Cape Verde • Central African Republic • Chad • Comoros • Republic of Congo • Democratic Republic of the Congo • Cote d'Ivoire • Djibouti • Egypt • Equatorial Guinea • Eritrea • Ethiopia • Gabon • Gambia • Ghana • Guinea • Guinea-Bissau • Kenya • Lesotho • Liberia • Libya • Madagascar • Malawi • Mali • Mauritania • Mauritius • Mayotte • Morocco • Mozambique • Namibia • Niger • Nigeria • Reunion Island • Rwanda • Saint Helena • Sao Tome and Principe • Senegal • Seychelles • Sierra Leone • Somalia • Republic of South Africa • South Sudan • Sudan • Swaziland • Tanzania • Togo • Tunisia • Uganda • Western Sahara • Zambia • Zimbabwe |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others
Background & Summary
Accurate and detailed information on the spatial distribution and numbers of births and pregnancies is crucial for informing planning decisions related to public health1. The survival and health of women and their new-born babies in low income countries is a key priority, with the reduction of maternal and neonatal mortality central for meeting a number of the United Nations Sustainable Development Goals (specifically goals 3.1 and 3.2)2. Whilst progress has been made, there were still 303,000 maternal deaths in 2015 (ref. 3) and children in lower income countries are 14 times more likely to die during their first 28 days of life compared to their higher income counterparts. Despite this, the spatial detail of basic data on the numbers and distribution of births and pregnancies is often of a coarse resolution and difficult to obtain4, with no co-ordination between countries and organisations to create one consistent set of subnational estimates for planning.
Whilst there are clear inequalities of maternal and neonatal healthcare between nations5, there are also large disparities within individual countries, with growing recognition that national levels and trends could be masking important sub-national variations6. For example, a study in Indonesia found that under-5 mortality was nearly four times higher in the poorest fifth of the population than in the richest fifth7, and gaps like these are more likely to occur at the sub-national level7–9. Although progress has been made in reducing such inequalities, there is still substantial work to be done. As such, understanding sub-national variation and inequity in health status, wealth and access to resources is increasingly being recognised as central to meeting developmental goals10. To understand and tackle inequalities related to maternal and neonatal health, the first step is to have a detailed knowledge of the distribution of births and pregnancies, which is known to vary substantially due to population age and sex distribution and age specific fertility rates (ASFR)4. These are also valuable data for subnational planning and estimation, and calculation of subnational indicators that rely on births or pregnancies as a denominator. When considering maternal and neonatal health in lower income countries, infectious disease is a major concern as pregnant women and new-borns are particularly at risk from many diseases, such as malaria11 and HIV12. This issue has recently been highlighted by the Zika virus outbreak in Latin America, further intensifying the need for detailed information on the number and distribution of births and pregnancies. Currently there is a clear lack of data for such analysis, with complete and continuous datasets of numbers of births only available at the national level (e.g., United Nations Population Division13). Whilst sub-national datasets are readily available for some countries, their spatial detail is often coarse with differences in the recorded metrics, sampling framework and data formats meaning that it is extremely difficult to assess burden within and across multiple nations.
This study aims to overcome the data gap identified above by producing continental scale, gridded datasets of numbers of births and pregnancies with a spatial resolution of 30 arc seconds (approximately 1 km at the equator). Advances in computational power and spatial econometric techniques, as well as the increasing availability of geo-located data, have increased the ability to produce these fine spatial resolution datasets. As such, in the framework of the WorldPop project (www.worldpop.org), and extending the approaches described by Tatem et al.4, an open access archive of gridded birth and pregnancy distribution datasets for all African, Latin America and Caribbean (LAC) countries has been created. This process used the most recent and finest level census, census microdata, household survey data and official population estimate data available to the authors at the time of writing, alongside a range of geospatial datasets.
Methods
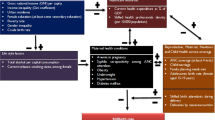
Gridded estimates of live births were produced for 50 Latin American and Caribbean and 58 African countries at a spatial resolution of 30 arc seconds. This was achieved by combining the latest datasets on population distribution, population age and sex structure and fertility rates in a GIS environment. Estimates of pregnancies were additionally generated using national-level estimates for stillbirths, miscarriages and abortions from the Guttmacher Institute14. The workflow develops the methods presented by Tatem et al.4, using a variety of data sources to construct continent wide datasets. The process is fully automated by a Python Script, allowing the rapid processing of multiple countries and alignment to a standard grid for the production of seamless continental scale datasets. The workflow is shown in Fig. 1 and described in detail below. Maps of the data sources and date for each country and whether urban and rural ASFR estimates were available can be found in the Supplementary Figures 1 and 2 respectively.

ASFR=Age Specific Fertility Rate, DHS=Demographic and Health Survey, MICS=Multiple Indicator Cluster Survey, UNPD=United Nations Population Division.
The basis for estimation: population distributions
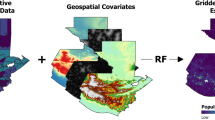
The population distribution forms a major component of the births and pregnancy estimation process. The WorldPop project has recently completed construction of gridded population distribution datasets for all low- and middle-income countries at a resolution of 30 arc seconds. Full details are provided on the WorldPop website (www.worldpop.org.uk) along with links describing the methods in detail15–17. This study uses the relevant regions of Africa (Data Citation 1) and Latin America and the Caribbean (Data Citation 2), whose total population is adjusted to match the most recent United Nations Population Division (UNPD)18 2015 estimates available when the population distribution datasets were produced. Figure 2a shows the gridded population distribution dataset for Bolivia as an example. To ensure data consistency, a WorldPop standard grid was used in processing; this is a gridded dataset providing ISO country codes at a resolution of 30 arc second (Data citation 3).

(a) Gridded population input (WorldPop), (b) Age and sex structure disaggregated by administrative unit, (c) Derived gridded age and sex structure, (d) ASFRs disaggregated by region and urban vs rural, (e) Gridded births output, (f) Gridded pregnancies output.
Calculating the proportion of women of reproductive age
Sub-national information on age and sex structure was collected, specifically women of childbearing age grouped in seven 5-years age groups (i.e., 15–19, 20–24, 25–29, 30–34, 35–39, 40–44, 45–49), as defined by the UNPD18. Datasets for the majority of Africa were provided by Pezzulo et al.19 whilst datasets for the remaining African, Latin America and the Caribbean countries were assembled from a variety of sources, following the protocols defined by Pezzulo et al.19. Table 1 (available online only) shows the source, spatial detail (i.e., administrative unit level) and reference year used for the countries processed in this study.
With the raw data recorded and documented according to different protocols determined by national governments, the project was presented with a wide range of table data formats and schemas. Data restructuring was achieved using scripting (R 3.3.1, Python 2.7) and table processing software (Microsoft Excel 2013). The resultant standardised tables contained fields corresponding to the proportionate values of people (both sexes) in each 5-year age group, and the overall proportion of males and females in each region. Table 2 shows an example of the standardised tables, for regions of Peru.
Age and sex structure information was matched to vector geographical boundaries from the Global Administrative Areas (GADM) database20, with the exceptions of Chile and Colombia where boundaries from the National Statistics Office were used. The extent of these boundaries was standardised to those defined by the WorldPop gridded ISO country code dataset using the Clip and Nibble tools in ArcGIS 10.3, executed as part of the Python21 script. Figure 2b shows the distribution of females between the ages of 20 and 24 for Bolivia. Similar distributions were created for all other 5-year age groupings in the 15–49-year range.
Estimating fertility rates
Data on fertility was collected on a country-by-country basis to provide the most up to date and spatially detailed information. Data sources were chosen using a hierarchical approach as shown in Fig. 1, prioritising sources which included information on age specific fertility and those of the highest spatial detail. The type of fertility data used for each country is shown in Table 3 (available online only) and described in detail below. As with the age and sex structure datasets, restructuring and table processing was carried out using a variety of scripting and software packages (Python 2.7, R 3.3.1, Microsoft Excel 2013) to produce a common format and schema for each data type, as described in detail below.
To provide the finest spatial detail of the distribution of fertility across each country, ASFRs were estimated by 5-year age groups, disaggregated sub-nationally according to the relevant Demographic and Health Surveys (DHS), Multiple Indicator Cluster Surveys (MICS) or National Statistics Agency survey regions and by urban vs rural if available. Table 3 (available online only) indicates which countries had the required data for estimation. ASFRs for each 5-year age group were commonly derived from DHS or MICS, with the exceptions of Aruba, Chile and Eritrea where the relevant datasets were available from the corresponding National Statistics Office.
For DHS and MICS surveys, ASFRs were estimated using a Stata program developed by Pullum50, as discussed in Tatem et al.4. The program calculated the basic demographic indicator by deriving ASFRs for each of the seven 5-year age groups covering the reproductive life span from 15–49 years based on dividing the number of births to women in each age group, during a retrospective 3-years reference period, by the number of women-years during the same period. Data restructuring and table processing was carried out using R 3.3.1 and Microsoft Excel 2013 to produce a common format, as that shown in Table 4.
Datasets representing the boundaries of subnational regions (Table 3) (available online only) were assembled and the relevant ASFRs matched to them. If the ASFR data was available for urban and rural areas within the subnational regions, the MODIS 500 m Global Urban Extent dataset51 was used to distinguish urban and rural areas and allocate the constant value within them. Figure 2d shows an example ASFR dataset for Bolivia, showing the ASFRs for one reproductive age range: the 20–24 age group by sub-region. Similar datasets were constructed for all other 5-year age groups within the 15 to 49 range.
For countries where ASFRs disaggregated sub-nationally and by urban/rural were not available, information on the spatial variation of age structured fertility was sought from vital registration systems, census records and other national sources. This was routinely in the form of births registered per administrative unit per 5-year age grouping. Table 3 (available online only) shows for which countries this type of data (registered births per age group) was used, with Table 5 showing an example of the standardised table format for Venezuela.
Sub-national ASFRs were calculated by dividing the number of births in each age group (e.g., Table 5) by the number of females in the corresponding group. The latter was derived from the WorldPop population distribution15 and age-sex distributions produced following the methodology of Pezzulo et al.19 and outlined in Table 1 (available online only).
The UNPD provides national estimates of AFSRs by 5-year age grouping for the majority of countries18,24. These datasets were used where subnational information was not available. As with all other datasets, the country boundaries defined by WorldPop15 were used to define the geographical extent.
For 9 countries, there was no information available on age specific fertility, either sub-nationally or nationally. In these cases, crude birth rates were obtained from a variety of official sources (Table 3 (available online only)) which were subsequently matched to the appropriate GIS country boundaries supplied by WorldPop15.
Estimating the number of births from fertility, population and age structure
For countries where measures of age specific fertility were available, the distribution of live births was estimated by multiplying the number of females in each age group (e.g., Fig. 2c) by the corresponding ASFR gridded dataset (e.g., Fig. 2d) or value (in the case of national ASFR estimates). The resultant seven age specific gridded datasets were summed to generate an estimate of total births. For countries where fertility was expressed simply as a crude birth rate (Table 3 (available online only)), the births distribution was calculated by multiplying the crude birth rate by the initial 30 arc second UNPD adjusted WorldPop population grid for 2015 (ref. 15).
Finally, for each country, the distribution was scaled to match the UNPD estimate of the total number of births18. For countries where the UNPD does not provide an estimate of the total number of births, the initial total was used. An example of the final distributed births gridded dataset for Bolivia is shown in Fig. 2e, with results for Africa, Latin America and the Caribbean shown in Fig. 3 and Supplementary Table 1.

The grid cell resolution is 30 arc seconds (approximately 1 km at the equator) and co-ordinates refer to GCS WGS 1984.
Estimating the distribution of pregnancies
The Guttmacher institute has published country specific estimates of the number of stillbirths, miscarriages and abortions at the national level14. These estimates for 2014 were integrated with UNPD national estimates on numbers of live births18 to construct a ratio between numbers of births and pregnancies. This ratio was applied to the live births distribution to generate an estimate of the distribution of pregnancies. For countries not covered by the Guttmacher dataset, the nearest suitable geographical country value was used. An example of the final distributed pregnancies gridded dataset for Bolivia is shown in Fig. 2f whilst results for the entire Africa, Latin America and the Caribbean are shown in Fig. 3.
Code availability
The Python code developed for production of the births and pregnancies datasets is publicly and freely available through Figshare52. The code consists of a Python programming language script (version 2.7; www.python.org) and relies on the ArcGIS 10.4.1 ArcPy site package for performing GIS specific spatial operations. The script is internally documented to both explain its purpose (including a description of the GIS-specific spatial operations it performs) and, when required, guiding the user through its customisation.
Data Records
The high-resolution births and pregnancies datasets described in this article referring to the 108 countries listed in Table 3 (available online only) are publicly and freely available through the WorldPop Repository (http://www.worldpop.org.uk/data/). A collection of these datasets has been compiled for the births for LAC (Data Citation 4) and Africa (Data Citation 5) and pregnancies for LAC (Data Citation 6) and Africa (Data Citation 7), as described in Table 6.
Technical Validation
All data collected, assembled and used were (i) already validated by the corresponding data collector, owner and/or distributor, and (ii) further checked, in the framework of this project. The gridded 5-year age and sex count datasets constructed for Latin America and the Caribbean (e.g., Fig. 2c) were verified following the protocol outlined in Pezzulo et al.19, who compiled and assessed similar datasets for Africa and Asia. Briefly, this comprised of summing all the layers into a single dataset (representing the total numbers of people for all age and sex groups at the grid cell level) and then subtracting it from the corresponding WorldPop continental gridded population count dataset to make sure that the country totals matched the UNPD estimates for the year in question. All fertility rates used in this study were checked, on a county-by-country basis, to make sure they were within reasonable ranges. Additionally, for countries where additional sources of fertility data were available, estimates were produced using all available sources to compare the adjusted total births. These results showed that, although differences may be observed at the grid cell level, the totals at the administrative unit level are very similar. Endeavours were made to assemble the most recent, reliable and spatially detailed data at the time of writing. However, additional input from readers who may have knowledge or access to more recent and/or better datasets are welcome for improving future iterations of the outputs.
The accuracy and quality of fertility estimates from survey data such as those provided by the DHS, have been assessed in several reports, by testing the quality of the birth history data in a large number of countries. These checks were mainly aimed to identify potential omission and displacement of births, potential displacement of births, or misreporting of date of birth53,54. Overall, although a number of issues were identified for some countries, these studies found that most estimates were either good or of acceptable quality. Furthermore, outcomes from Pullum and Becker53 show that in general the latest DHS surveys are less prone to issues like incomplete birthdates, omissions and displacement of births and deaths. Similarly, a more recent report from Pullum and Staveteig55, exploring the quality and consistency of age and date reports in DHS surveys, demonstrates that DHS data is constantly evaluated to improve its quality.
Modelled estimates of total number of births per country prior to adjustments (to match UNPD estimate) were also plotted against the UNPD estimates18 to assess the size of differences obtained through using subnational data sources. Figure 4 shows the correlation for the 95 countries for which UNPD provides an estimate, with a corresponding R2 value of 0.982. Analysis was not possible for the 9 countries for which the UNPD does not provide an estimate, although these make up a very small proportion (0.01%) of the total births across the whole study area.

Usage Notes
The datasets presented here can be used both to (i) support applications measuring sub-national metrics of maternal and new-born health and (ii) to inform planning decisions. However, considering that they represent modelling outputs generated using ancillary covariates for producing the underlying WorldPop population distribution datasets, to avoid circularity, they should not be used to make predictions or explore relationships about any of those ancillary datasets56. Thus, before using the births and pregnancies datasets in correlation analyses against factors which are included in the construction of the population distribution datasets (e.g., correlating birth distribution with land-cover), ideally the population modelling process should be re-run using the WorldPop-RF code57 with the applicable covariates removed.
Additional information
How to cite this article: James, W. H. M. et al. Gridded birth and pregnancy datasets for Africa, Latin America and the Caribbean. Sci. Data 5:180090 doi: 10.1038/sdata.2018.90 (2018).
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
References
Ruktanonchai, C. et al. Equality in maternal and newborn health: modelling geographic disparities in utilisation of care in five East African countries. PLoS ONE 11, e0164519 (2016).
United Nations. Transforming Our World: The 2030 Agenda for Sustainable Development, A/RES/70/1 (United Nations, 2016).
World Health Organisation. Trends in maternal mortality: 1990 to 2015, WHO/RHR/15.23 (WHO, 2016).
Tatem, A. et al. Mapping for maternal and newborn health: the distributions of women of childbearing age, pregnancies and births. International Journal of Health Geographics 13, 2 (2014).
Graham, W. et al. The geography of maternal death. in Maternal and Infant Deaths: Chasing Millennium Development Goals 4 and 5 Royal College of Obstetricians and Gynaecologists Study Group (eds Neilson J., Norman J. & Kehoe S. ) 3–28 (Cambridge University Press, 2010).
Victora, C. et al. The contribution of poor and rural populations to national trends in reproductive, maternal, newborn, and child health coverage: analyses of cross-sectional. The Lancet Global Health 5, e402–e407 (2017).
Victora, C. et al. Applying an equity lens to child health and mortality: more of the same is not enough. The Lancet 362, 233–241 (2003).
United Nations. The state of the world's midwifery: analysis of the sexual, reproductive, maternal, newborn and adolescent health workforce in East & Southern Africa. (United Nations Population Fund (UNFPA) East and Southern Africa Regional Office (ESARO), 2017).
Armstrong, C. E. et al. Subnational variation for care at birth in Tanzania: is this explained by place, people, money or drugs? BMC Public Health 16, 795 (2016).
United Nations and Social Council. Progress towards the Sustainable Development Goals, Report of the Secretary-General (United Nations Economic and Social Council, 2016).
Dellicour, S., Tatem, A. J., Guerra, C. A., Snow, R. W. & ter Kuile, F. O. Quantifying the Number of Pregnancies at Risk of Malaria in 2007: A Demographic Study. PLoS Medicine 7, e1000221 (2010).
Joint United Nations Programme on HIV/AIDS (UNAIDS). Global report: UNAIDS report on the global AIDS epidemic 2010 (UNAIDS, 2010).
United Nations. World Population Prospects. Key findings and advance tables. 2017 revision, Working Paper No. ESA/P/WP/248 (Department of Economic and Social Affairs Population Division, 2017).
Sedgh, G., Singh, S. & Hussain, R. Intended and Unintended Pregnancies Worldwide in 2012 and Recent Trends. Studies in Family Planning 45, 301–314 (2014).
Lloyd, C., Sorichetta, A. & Tatem, A. High resolution global gridded data for use in population studies. Sci. Data 4, 170001 (2017).
Stevens, F., Gaughan, A., Linard, C. & Tatem, A. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PLoS ONE 10.2, e0107042 (2015).
Tatem, A. WorldPop, open data for spatial demography. Sci. Data 4, 170004 (2017).
United Nations. World Population Prospects: The 2017 Revision, DVD edition (United Nations Department of Economic and Social Affairs Population Division, 2017).
Pezzulo, C. et al. Sub-national mapping of population pyramids and dependency ratios in Africa and Asia. Sci. Data 4, 170089 (2017).
Hijmans, R. et al. Global Administrative Areas http://www.gadm.org/ (2017).
Rossum, G. V. & Boer, J. D. Interactively testing remote servers using the Python programming language. CWi Quarterly 4, 283–304 (1991).
Central Bureau of Statistics-Aruba. Age Specific Fertility Rates 1990-2000 (Aruba, 2016).
ICF International. Demographic and Health Surveys. https://dhsprogram.com/data/available-datasets.cfm (1994-2016).
United Nations. World Fertility Data 2008, POP/DB/Fert/Rev2008 (United Nations Department of Economic and Social Affairs Population Division, 2008).
Ministerio de Salud Republica Argentina. Estadicias Vitales 2012 (Argentina, 2013).
CBS- Statistics Netherlands. Trends in the Caribbean Netherlands 2016 (The Netherlands, 2016).
Department of Statistics of the Ministry of Finance of The Bahamas. Vital Statistics Report 2013 (The Commonwealth of the Bahamas, 2013).
Institut National de la Statistique et des Etudes Economiques France. Comparateur de territoire, Commune de Saint-Barthélemy, Report No. 50450 (France, 2013).
Instituto Brasileiro de Geografia e Estatística. Estatísticas do Registro Civil. Tabela 2609 (Brazil, 2016).
Statistics Botswana. Vital Statistics Report 2014 (Botswana, 2014).
Instituto Nacional de Estadísticas e Informacion de Salud de Chile. Estadísticas de Natalidad y Mortalidad, Chile 2013 (Chile, 2013).
Instituto Nacional de Estadística y Censos-Costa Rica. Nacimiemtos (Costa Rica, 2011).
United Nations International Children's Fund (UNICEF). Multiple Indicator Cluster Survey (MICS) http://www.childinfo.org/mics4_surveys.html (2011-2014).
Curaçao Central Bureau of Statistics. Statistical Yearbook 2013 (Curaçao, 2013).
Economics and Statistics Office Government of the Cayman Islands. Population and vital statistics (Cayman Islands, 2015).
Instituto Nacional de Estadísticas-Ecuador. Estadística de Nacimientos (Ecuador, 2012).
National Statistics Office (NSO) [Eritrea] and Fafo Institute For Applied International Studies. Eritrea Population and Health Survey 2010 (The State of Eritrea and Fafo Institute for Appled International Studies, 2013).
Falkland Islands Government. Statistical year book 2014 (Falkland Islands, 2014).
Government of Jamaica. Vital statistics (Jamaica, 2013).
The World Bank. World Development Indicators (The World Bank, 2014).
Instituto Nacional de Estadística y Geografia-Mexico. Nacimientos registrados (Mexico, 2015).
Instituto Nacional de Estadística y Censos-Panama. Estadísticas Vitales, Volumen II - Nacimientos Vivos y Defunciones Fetales: Año 2012 (Panama, 2012).
Gobierno de Puerto Rico - Departamento de Salud. Informe anual de estadisticas vitales (Puerto Rico, 2010).
Dirección General de Estadística Encuestas y Censos-Paraguay. Anexo 3: Nacidos vivos inscriptos por año de nacimiento (Paraguay, 2016).
Statistics Office Corporate Policy and Planning Unit (CPPU)-Saint Helena. Statistical Yearbook 2012/13 (Saint Helena, 2013).
Instituto Nacional de Estadística-Uruguay. Estadicias Vitales (Uruguay, 2015).
Statistical Office Central Planning Division. St. Vincent and the Greanadines: Population and Vital Statistics (St. Vincent and the Greanadines, 2013).
Instituto Nacional de Estadística-Venezuela. Demograficos - Estadísticas Vitales (Venezuela, 2016).
Statistics South Africa. Recorded Live Births (South Africa, 2013).
Pullum, T. Program to produce ASFRs, TFR, GFR for specific windows of time, with covariates. Pers. Comm (2012).
Schneider, A., Friedl, M. & Potere, D. A new map of global urban extent from MODIS satellite data. Environmental Research Letters 4, 044003 (2009).
James, W. H. M. et al. Source code for: Gridded birth and pregnancy datasets for Africa, Latin America and the Caribbean. Figsharehttps://doi.org/10.6084/m9.figshare.5464147.v1 (2017).
Pullum, T. & Becker, S. Evidence of omission and displacement in DHS birth histories. Report No. 11 (ICF International, 2014).
Schoumaker, B. Quality and consistency of DHS fertility estimates, 1990 to 2012, Report No. 12 (ICF International, 2014).
Pullum, T. & Staveteig, S. An assessment of the quality and consistency of age and date reporting in DHS surveys, 2000-2015, Report No. 19 (ICF International, 2017).
Balk, D. et al. Determining global population distribution: methods, applications and data. Advances in parasitology 62, 119–156 (2006).
Stevens, F. et al. Source code for: WorldPop-RF, Version 2b.1.1. Figsharehttps://doi.org/10.6084/m9.figshare.1491490.v3 (2015).
Data Citations
WorldPop. University of Southampton https://doi.org/10.5258/SOTON/WP00004 (2017)
WorldPop. University of Southampton https://doi.org/10.5258/SOTON/WP00138 (2017)
WorldPop. University of Southampton https://doi.org/10.5258/SOTON/WP00530 (2017)
WorldPop. University of Southampton https://doi.org/10.5258/SOTON/WP00529 (2017)
WorldPop. University of Southampton https://doi.org/10.5258/SOTON/WP00528 (2017)
WorldPop. University of Southampton https://doi.org/10.5258/SOTON/WP00527 (2017)
WorldPop. University of Southampton https://doi.org/10.5258/SOTON/WP00526 (2017)
Acknowledgements
This work was principally funded by the Wellcome Trust (grant number: 204613/Z/16/Z) and UK Department for International Development (DFID). A.J.T was also supported by funding from the National Institute of Allergy and Infectious Diseases at the National Institutes of Health (U19AI089674), the Bill & Melinda Gates Foundation (OPP1106427, OPP1134076, OPP1094793), the Clinton Health Access Initiative, and the Wellcome Trust (106866/Z/15/Z).
Author information
Authors and Affiliations
Contributions
W.H.M.J. drafted the manuscript. W.H.M.J., N.T.G, S.E.H., A.C.S., K.N., A.C., C.P., G.M.H., D.K., C.W.R and A.S., acquired and assembled the raw data. W.H.M.J. produced the final datasets and technical validation of the data. N.T.G, S.E.H., K.N., A.C., C.P., G.M.H., C.W.R and A.S., A.J.T. and Z.M. aided drafting the manuscript. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Supplementary information accompanies this paper at
ISA-Tab metadata
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files made available in this article.
About this article

Cite this article
James, W., Tejedor-Garavito, N., Hanspal, S. et al. Gridded birth and pregnancy datasets for Africa, Latin America and the Caribbean. Sci Data 5, 180090 (2018). https://doi.org/10.1038/sdata.2018.90
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/sdata.2018.90
This article is cited by
-
Flood exposure and pregnancy loss in 33 developing countries
Nature Communications (2024)
-
World’s human migration patterns in 2000–2019 unveiled by high-resolution data
Nature Human Behaviour (2023)
-
Surrounding greenness is associated with lower risk and burden of low birth weight in Iran
Nature Communications (2023)
-
Targeted policy intervention for reducing red meat consumption: conflicts and trade-offs
BMC Nutrition (2022)
-
Estimation of stillbirths attributable to ambient fine particles in 137 countries
Nature Communications (2022)
