
Abstract
To investigate the genetic basis of type 2 diabetes (T2D) to high resolution, the GoT2D and T2D-GENES consortia catalogued variation from whole-genome sequencing of 2,657 European individuals and exome sequencing of 12,940 individuals of multiple ancestries. Over 27M SNPs, indels, and structural variants were identified, including 99% of low-frequency (minor allele frequency [MAF] 0.1–5%) non-coding variants in the whole-genome sequenced individuals and 99.7% of low-frequency coding variants in the whole-exome sequenced individuals. Each variant was tested for association with T2D in the sequenced individuals, and, to increase power, most were tested in larger numbers of individuals (>80% of low-frequency coding variants in ~82 K Europeans via the exome chip, and ~90% of low-frequency non-coding variants in ~44 K Europeans via genotype imputation). The variants, genotypes, and association statistics from these analyses provide the largest reference to date of human genetic information relevant to T2D, for use in activities such as T2D-focused genotype imputation, functional characterization of variants or genes, and other novel analyses to detect associations between sequence variation and T2D.
Design Type(s) | individual genetic characteristics comparison design • parallel group design • data integration objective |
Measurement Type(s) | genetic sequence variation analysis |
Technology Type(s) | whole genome sequencing • exome sequencing |
Factor Type(s) | ethnic group |
Sample Characteristic(s) | Homo sapiens • Finland • Germany • United Kingdom • Sweden • United States of America • South Korea • Singapore • Israel |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others


Background & Summary
Genome wide association studies (GWAS) have provided a valuable but incomplete window into the genetic basis of type 2 diabetes (T2D)1. Common (minor allele frequency [MAF]>5%) variants at over 100 loci have been robustly associated with disease risk, but most have not yet been translated to causal variants, effector transcripts, or disease mechanisms2. Because common variants from GWAS have modest effect sizes, and because those previously published explain in aggregate only 10–15% of the genetic basis of T2D3, it has been hypothesized that variants unexplored by GWAS might have a greater impact on efforts to understand or treat T2D4,5.
To produce a more complete catalogue of rare, low-frequency, and common variants, the GoT2D and T2D-GENES consortia analysed whole-exome and genome sequence data in up to 12,940 individuals (6,504 T2D cases and 6,436 controls; Fig. 1a, Tables 1 and 2)3. First, to interrogate lower-frequency (MAF>0.5%) variation genome-wide, 2,657 Northern and Central European individuals were selected by GoT2D (1,326 cases, 1,331 controls) and characterized with a combination of low-pass (~5x) whole-genome sequencing, deep (~82x) whole-exome sequencing, and high-density (2.5M) SNP genotyping. Genetic variants from these assays were incorporated into a phased integrated panel (WGS panel), capturing an estimated 99% of variants, genome-wide, present in more than 0.5% of individuals (Table 3). Second, additional individuals from 10 cohorts spanning five ethnicities (European, Hispanic, South Asian, East Asian, and African American) were characterized by deep (~82x) whole-exome sequencing by T2D-GENES. The resultant T2D-GENES exome sequence data were combined with the GoT2D exome sequence data to produce a second panel of variation (WES panel), capturing an estimated 99.7% of coding variants present in more than 0.5% of the combined 12,940 individuals (Tables 4 and 5).

Shown is a flowchart for variant calling, quality control, and propagation of variants in both the WGS panel and WES panel. (a) Variant calling and quality control in the WGS and WES panels. Individuals were characterized with one or more sequencing and genotyping technologies, and then individuals and variants were excluded based on quality control metrics. The final WGS panel consists of data from 2,857 individuals and 28.5M variants, while the final WES panel consists of data from 13,008 individuals and 3.04M variants. (b) Assessing variants in larger sample sizes. Non-coding variants from the WGS panel were studied via statistical imputation in 44,414 additional individuals from cohorts within the DIAGRAM consortium. Coding variants from the WES panel were genotyped on the exome array in 79,854 additional individuals. Modified from Extended Data Fig. 1 of Fuchsberger et al.8.
Each variant was tested for association with T2D under an additive genetic model. To increase power, variants were then assessed in larger sample sizes via one of two means (Fig. 1b). Coding variants were analysed in 79,854 additional individuals (28,305 T2D cases, 51,549 controls) via the Illumina Exome Array, which captures 81.6% of European MAF>0.5% coding variants in the WES panel. Non-coding variants (and coding variants absent from the Exome Array) were analysed in up to 44,414 additional individuals (11,645 cases, 32,769 controls) via statistical genotype imputation; after quality control, this analysis included 89% of variants observed in three or more individuals in the WGS panel. Each variant was tested for association with T2D in the additional individuals, under an additive genetic model, and association statistics were then combined with those from the sequence data via meta-analysis.
Collectively, these analyses suggest a limited role for low-frequency variation in the genetic basis of T2D3. However, they also demonstrate an ability to identify novel hypotheses about the effects of gene inactivation6, a resource of coding variants for calibrating cellular assays7, and a catalogue of noncoding variants for use in statistical or functional fine mapping of GWAS signals3. The WGS panel also provides a novel resource for genotype imputation8, with increased resolution for T2D-specific variants relative to the 1000 Genomes (1000G) reference panel, as well as a means to calibrate simulation-based models of population history9 or disease genetic architecture10.
Methods
These methods are a modified version of the descriptions contained in Fuchsberger et al.3.
Ethics statement
All human research was approved by the relevant institutional review boards and conducted according to the Declaration of Helsinki. All participants provided written informed consent.
WGS GoT2D integrated panel generation
Ascertainment of individuals
Individuals were sampled from four studies: the Finland-United States Investigation of NIDDM Genetics (FUSION) Study (493 cases, 486 controls), KORA (101 cases, 104 controls), the UKT2D Consortium (322 cases, 322 controls), and the Malmö-Botnia Study (410 cases, 419 controls). All individuals were of Northern or Central European ancestry. Cases were preferentially lean, had (relatively) early onset T2D, or had a familial history of T2D; controls by comparison were preferentially overweight or had low fasting glucose levels11. To decrease the likelihood of selecting T2D cases who in fact had type 1 diabetes (T1D) or monogenic forms of diabetes (such as Maturity Onset Diabetes of the Young), cases with an age of diagnosis below 35, testing positive for GAD antibodies, or with a first-degree relative known to have T1D were not included. Statistics of the 2,657 individuals ultimately included in the association analysis are provided in Table 1.
Many of these individuals were measured for cardiometabolic phenotypes other than T2D, including glucose and insulin, anthropometrics, lipids, and blood pressure (Table 6).
DNA sample preparation
De-identified DNA samples were sent to the Broad Institute in Cambridge, MA, USA (Malmö-Botnia and FUSION), the Wellcome Trust Centre for Human Genetics in Oxford, UK (UKT2D), or the Helmholtz Zentrum München in Germany (KORA). DNA quantity was measured by Picogreen (all samples) to ensure sufficient total DNA and minimum concentrations for downstream experiments. Samples (Malmö-Botnia, FUSION, UKT2D) were then genotyped on a Sequenom iPLEX assay for a set of 24 SNPs (one X chromosome and 23 autosomal SNPs), with only samples with high-quality genotypes advanced for subsequent sequencing or genotyping.
Exome sequencing
Genomic DNA was sheared, end repaired, ligated with barcoded Illumina sequencing adapters, amplified, size selected, and subjected to in-solution hybrid capture using the Agilent SureSelect Human All Exon v2.0 (Malmö-Botnia, FUSION, UK2T2D) or v3.0 (KORA) bait set (Agilent Technologies, USA). Resulting Illumina exome sequencing libraries were qPCR quantified, pooled, and sequenced with 76-bp paired-end reads using Illumina GAII or HiSeq 2,000 sequencers to ~82-fold mean coverage.
Genome sequencing
Whole-genome Illumina sequencing library construction was performed as described for exome sequencing above, except that genomic DNA was sheared to a larger target size and hybrid capture was not performed. The resulting libraries were size selected to contain fragment insert sizes of 380 bp±20% (Malmö-Botnia, FUSION, KORA) and 420 bp±25% (UKT2D) using gel electrophoresis or the SAGE Pippin Prep (Sage Science, USA). Libraries were qPCR quantified, pooled, and sequenced with 101-bp paired-end reads using Illumina GAII or HiSeq 2,000 sequencers to ∼5-fold mean coverage.
HumanOmni2.5 array genotyping and quality control (QC)
SNP array genotyping was performed by the Broad Genetic Analysis Platform. DNA samples were placed on 96-well plates and assayed using the Illumina HumanOmni2.5-4v1_B SNP array. Genotypes were then called using Illumina GenomeStudio v2010.3 with default clusters. SNPs with GenTrain score <0.6, cluster separation score <0.4, or call rate <97% were considered technical failures at the genotyping laboratory and excluded from further analysis. Next, 85 individuals with a genotype call rate below 98%, low genetic fingerprint (24-marker panel) concordance, or estimated gender discordance were excluded from further analysis. Finally, SNPs monomorphic across all individuals, failed by the 1000G Omni 2.5 QC filter, or with Hardy-Weinberg equilibrium P<10−6 were excluded from analysis.
Processing, quality control, and variant calling of sequence data
Sequence data were processed and aligned to the human genome (build hg19) using the Picard (http://broadinstitute.github.io/picard/), BWA12, and GATK13,14 software packages, following best-practice pipelines.
Sequencing coverage of each individual was computed based on the fraction of target bases with >20 reads aligned (exome sequencing) or average number of reads aligned across all bases genome-wide (genome sequencing). Based on these metrics, we excluded from further analysis exome sequence data (from 151 individuals) with coverage ≤20x in >20% of the target bases and genome sequence data (from 68 individuals) with average coverage ≤5x.
Possible DNA contamination of sequence data was assessed using verifyBamID15, either by direct comparison of sequence and HumanOmni2.5 array genotypes (where available) or by indirect estimates of contamination based on HumanOmni2.5 array allele frequencies. DNA samples with estimated contamination >2% using either method were excluded from further analysis (data from 7 individuals in the exome sequencing dataset and 59 individuals in the genome sequencing dataset). Uncontaminated DNA sample swaps were also detected via comparison of sequence and array data and corrected prior to variant calling.
To identify single nucleotide variants (SNVs) from the whole-genome sequence data, we used two independent SNV calling pipelines: GotCloud16 and the GATK UnifiedGenotyper14. We merged unfiltered SNV calls across the two call sets and then processed the merged site list through the SVM and VQSR filtering algorithms implemented by those pipelines. SNVs that failed both filtering algorithms were excluded from further analysis. To identify SNVs from the whole-exome sequence data, we used the GATK UnifiedGenotyper best-practices pipeline14.
To identify short insertions and deletions (indels) from the whole-genome sequence data, we called variants using the GATK UnifiedGenotyper best-practices pipeline. Because indels are known to have high false positive rates17, we applied more stringent criteria for indel QC than for SNV QC, excluding indels that failed either the SVM or VQSR filtering algorithms. To identify indels from the whole-exome sequence data, we used the GATK UnifiedGenotyper best-practices pipeline14.
To identify structural variants (SVs, or >100-bp deletions) from the whole-genome sequence data, we used GenomeSTRiP18. To increase sensitivity after initial discovery of SVs, we merged the discovered sites with deletions identified in 1,092 sequenced individuals from the 1000G Project17 and then genotyped the merged site lists across the whole-genome sequenced individuals. After applying the default filtering implemented in GenomeSTRiP, pass-filtered sites variable in any of the individuals were identified as candidate variant sites. Among these candidate sites, we excluded variants in known immunoglobin loci to reduce the impact of possible cell-line artifacts. We did not call SVs from the whole-exome sequence data.
Integrated panel generation
We merged variants discovered from the three experimental platforms into one site list. For individuals who had data from each of the three platforms, we then calculated genotype likelihoods across all sites separately by platform: for the whole-genome sequence data, we used GotCloud; for the exome sequence data, we used the GATK UnifiedGenotyper; and for the HumanOmni2.5 data, we converted hard genotype calls into genotype likelihoods assuming a genotype error rate of 10−6. If a site was not assayed by one of the three platforms, it was ignored in likelihood calculation for that platform.
We then calculated combined genotype likelihoods as the product of the genome, exome, and HumanOmni2.5 likelihoods, assuming independence across platforms. Following a strategy originally developed for the 1000G Phase 1 project17, we then phased the integrated likelihoods using Beagle19 (with 10,000 SNVs per chunk and 1,000 overlapping SNVs between consecutive chunks) and refined phased genotypes using Thunder20 as implemented in GotCloud (with 400 states).
Using the genotypes from the integrated panel, we performed principal component analysis (PCA) separately for each of the three variant types (SNVs, indels, SVs), using EPACTS on an LD-pruned (r2<0.20) set of MAF>0.01 autosomal variants (with variants in large high-LD regions21,22 or with Hardy-Weinberg P<10−6 removed). Inspecting the first ten PCs for each variant type, we identified 43 outlier individuals based on PCs from SNVs and indels and 136 additional outliers based on PCs from SVs; these 179 individuals were excluded from further analysis. Additionally, 38 individuals with close relationships with other study individuals (estimated genome-wide identity-by-descent proportion of alleles shared >0.20) were excluded from further analysis.
The final WGS panel contains genotypes from 2,874 individuals at 26.85M SNVs, 1.59M indels, and 11.88 K SVs. The final analysis set includes genotypes from 2,657 individuals at 26.20M SNVs, 1.50M indels, and 8.88K SVs SVs (Table 3).
WES (GoT2D+T2D-GENES Multiethnic) panel generation
Ascertainment of individuals
In addition to the individuals within the WGS panel, additional individuals, 10,242 of which were included in the final analysis, were chosen for whole-exome sequencing from 10 studies: the Jackson Heart Study (500 African-American cases, 526 matched controls), the Wake Forest School of Medicine Study (518 African-American cases, 530 matched controls), the Korea Association Research Project (526 East-Asian cases, 561 matched controls), the Singapore Diabetes Cohort Study and Singapore Prospective Study Program (486 East-Asian cases, 592 matched controls), Ashkenazi (506 European cases, 355 matched controls), the Metabolic Syndrome in Men (METSIM) Study (484 European cases, 498 matched controls), the San Antonio Mexican American Family Studies (272 Hispanic cases, 218 matched controls), the Starr County Texas study (749 Hispanic cases, 704 matched controls), the London Life Sciences Population (LOLIPOP) Study (531 South-Asian cases, 538 matched controls), and the Singapore Indian Eye Study (563 South-Asian cases, 585 matched controls). Potential T1D or MODY cases were excluded via similar approaches as for the whole-genome sequencing experiment. Statistics of the individuals ultimately included in the association analysis are provided in Table 2.
As for the WGS panel, many individuals were measured for additional cardiometabolic phenotypes (Table 6).
Exome sequencing
DNA samples were obtained and sequenced in the same manner as described for the exome sequencing component of the WGS panel.
Processing, QC, and variant calling
As for the exome sequence data within the WGS panel, sequence data for the WES panel were processed and aligned to the human genome (build hg19) using the Picard, BWA12, and GATK13,14 software packages and best-practice pipelines. Genotype likelihoods were computed controlling for contamination. Hard calls (the GATK-called genotypes but set as missing at a genotype quality [GQ] <20 threshold14) and dosages (the expected value of the genotype, defined as Pr(RX|data)+2Pr(XX|data), where R is the reference and X the alternative allele) were computed for each individual at each variant site. Hard calls were used only for quality control, while dosages were used in downstream association analyses. Multi-allelic SNVs and indels were dichotomized by collapsing alternate alleles into one category.
Individuals were excluded from analysis if they were outliers on one of multiple metrics: poor array genotype concordance (where available), high number of variant alleles or singletons, high or low allele balance (average proportion of non-reference alleles at heterozygous sites), or excess mean heterozygosity or ratio of heterozygous to homozygous genotypes. Within this reduced set of individuals, we then further excluded variants based on hard call rate (<90% in any cohort), deviation from Hardy-Weinberg equilibrium (P<10−6 in any ancestry group), or differential call rate between T2D cases and controls (P<10−4 in any ancestry group).
The final WES panel contains genotypes for 13,008 individuals at 2.93M SNVs and 111.9 K indels. The set ultimately included in coding variant association analysis (after removal of individuals with close relatives or of uncertain ancestry) contains genotypes for 12,940 individuals at 2.89M SNVs and 110.2 K indels (Tables 4 and 5).
Assaying variants in larger sample sizes
Imputation from the WGS panel
We carried out genotype imputation, using existing SNP array data, from the WGS panel into 44,414 individuals (11,645 T2D cases and 32,769 controls) from 13 studies participating in the DIAGRAM consortium. Each study performed quality control independently. A more detailed description of the analyzed individuals is available elsewhere3.
Exome array genotyping from the WES panel
We considered 28,305 T2D cases and 51,549 controls from 13 studies of European ancestry, each genotyped with the Illumina exome array. Studies independently called genotypes using the Illumina GenCall algorithm (http://www.illumina.com/Documents/products/technotes/technote_gencall_data_analysis_software.pdf ) or Birdseed23. Individuals were excluded if they had a low call rate (<99%), excess heterozygosity, high singleton counts, evidence of non-European ancestry, discrepancy between recorded and genotyped sex, or discordance with prior SNP array or genotyping platform fingerprint data (where available). Variants were excluded if they had a low call rate (<99%), deviation from Hardy-Weinberg equilibrium (P<10−6), GenTrain score <0.6, cluster separation score <0.4, or a suspect intensity plot based on manual inspection. After quality control, missing genotypes were re-called using zCall24, and additional quality control was performed to exclude poorly genotyped individuals (call rate <99% or excess heterozygosity) or variants (call rate <99%). A more detailed description of the analyzed individuals is available elsewhere3.
Association analysis
WGS panel single variant analysis
For each variant in the WGS panel, we tested for association between genotype and T2D in the 2,657 sequenced individuals. We used a logistic regression framework (assuming an additive genetic model) with the Firth bias-corrected likelihood ratio test25,26 to test for significance. Tests were adjusted for sex, the first two PCs computed based on genotypes from the HumanOmni2.5M array, and an indicator function for observed temporal stratification based on sequencing date and center.
Analysis of imputed datasets
In each of the thirteen studies within which variants from the WGS panel were imputed, SNVs with minor allele count (MAC)≥1 were tested for T2D association under an additive genetic model. Association tests were adjusted for study-specific covariates and performed using either the Firth, likelihood ratio, or score tests as implemented in EPACTS (https://genome.sph.umich.edu/wiki/EPACTS) or SNPTEST27. Residual population stratification for each study was accounted for using genomic control28. Association statistics were then combined across studies, using a fixed-effects sample-size weighted meta-analysis as implemented in METAL29.
WES panel single variant analysis
For each variant in the WES panel, we tested for association between genotype and T2D in the 12,940 sequenced individuals. We computed separate association statistics for each ancestry group using EMMAX30. Additionally, we performed association tests using the Wald statistic, adjusting for ethnic-specific principal components after exclusion of related individuals. For each test, we calculated genomic control inflation factors and corrected association summary statistics (P-values and standard errors) to account for residual population structure.
We subsequently performed a fixed-effects meta-analysis of ancestry-specific association summary statistics for each variant using (i) a sample-size weighting of P-values from the EMMAX analysis and (ii) an inverse-variance weighting of effect size estimates from the Wald analysis. For the final results, P-values were taken from the EMMAX analysis, and effect size estimates from the Wald analysis.
Analysis of exome array datasets
In each study within which exome array genotyping was applied, variants were tested for association with T2D via both the EMMAX and Wald tests. For the Wald test, related individuals were excluded and statistics were adjusted for study-specific principal components. For each study, P-values and standard errors were corrected based on the calculated genomic control inflation factor.
Variants were then combined via a fixed-effects meta-analysis. EMMAX P-values were combined via a sample-size weighted analysis, and Wald effect sizes were combined via an inverse-variant weighted analysis. For the final results, P-values were taken from the EMMAX analysis, and effect sizes were estimated from the Wald analysis.
Gene-level analysis
We first generated four variant lists (‘masks’) based on functional annotations and observed allele frequencies. Annotations were computed based on transcripts in ENSEMBL 66 (GRCh37.66) using CHAoS v0.6.3, SnpEFF v3.131, and VEP v2.732. We then identified variants predicted by at least one of the three algorithms in at least one mapped transcript to be protein-truncating ('for example, nonsense, frameshift, essential splice site), denoted PTVs, or other protein-altering (for example, missense, in-frame indel, non-essential splice site), denoted missense. We additionally used a previously described procedure33 to identify subsets of missense variants bioinformatically predicted to be deleterious: those annotated as damaging by each of Polyphen2-HumDiv, PolyPhen2-HumVar, LRT, Mutation Taster, and SIFT were considered to meet ‘strict’ criteria, while those annotated as damaging by one of these algorithms was considered to meet ‘broad’ criteria. We then calculated the MAF of each variant based on the highest frequency across each of the five ancestry groups. We finally combined these annotations to produce four masks: the PTV-only mask included PTVs, the PTV+NSstrict mask included variants in the PTV-only mask as well as those meeting ‘strict’ criteria for deleteriousness, the PTV+NSbroad mask included variants in the PTV-only mask as well as those with MAF<1% meeting ‘broad’ criteria for deleteriousness, and the PTV+missense mask included variants in the PTV+NSbroad mask as well as those with MAF<1% annotated as missense.
We performed gene-level analysis using the MetaSKAT software package (v0.32)34, employing the SKAT v0.93 library to perform a SKAT-O35 analysis within each ancestry group as well as across all ancestry groups via meta-analysis. Within each ancestry group, we assumed homogenous allele frequencies and genetic affects and adjusted for ethnic-specific axes of genetic variation after exclusion of 96 related individuals. For the meta-analysis, we used the MetaSKAT option to analyze genotype-level data, allowing for heterogeneity of allele frequencies and genetic effects between ancestry groups. All analyses were completed using the recommended ρ vector for SKAT-O: (0, 0.12, 0.22, 0.32, 0.52, 0.5, 1).
Code availability
All analyses were performed using publically available software packages, using versions and parameters as described above.
Data Records
Genotypes and phenotypes from the WGS and WES panels are available at the European Genome-phenome Archive (EGA, Data Citation 1 and Data Citation 2) and the database of Genotypes and Phenotypes (dbGAP, Data Citation 3 to Data Citation 12).
The data in EGA are covered under a single data use agreement, which complies with all of the cohort-specific data use restrictions. While this does limit data access according to the criteria of the most restrictive cohort, it is the only mechanism through which the entire WES and WGS panels are available to investigators. Additionally, the EGA contains data from one cohort that could not be released to a US-based repository. To download either the WGS or WES panel from the EGA, investigators must obtain approval from a data access committee (DAC, t2dgenes-got2d-dac@broadinstitute.org) to analyze data from all cohorts included in the study. The requester will receive an application packet that includes a project proposal document and a Data Transfer Agreement (DTA). The requester must then provide to the DAC a short description of their study, the proposed use of the data, an approval from the Institution's IRB, and a signed DTA. Assuming IRB approval and an executed DTA, the process for obtaining final approval from the DAC takes 4–6 weeks. Once approved, investigators can download either a single VCF file with genotypes from all individuals in the WGS panel (Data Citation 1) or a single VCF file with genotypes from all individuals in the WES panel (Data Citation 2).
If investigators cannot obtain approval to analyze all cohorts in the WES panel (e.g., commercial uses) they can download cohort-specific data from dbGAP. Each cohort in dbGAP is subject to distinct data use restrictions, and investigators can obtain separate VCF files, as well as the raw sequence reads, for each of the cohorts.
The WGS and WES panels are accompanied by exclusion lists of variants and individuals (Data Citation 1 and Data Citation 2). The WGS VCF file contains data from the full set of 2,874 individuals and 28.45M variants that passed QC, with additional lists provided containing the 2,657 individuals and 17.69M variants included in association analysis. The WES VCF file contains the full set of 13,008 individuals that passed QC, with additional lists provided containing the 3.04M variants that passed QC (the VCF includes a small number of variants that failed QC) and the 12,940 samples and 2.93M variants included in association analysis. Additionally, the WES dataset includes lists of variants included in gene-level analysis for each of the four analyzed masks.
Five datasets of association statistics are also available for download. Association statistics for variants in the WGS panel are available from the whole-genome sequenced individuals or from those with imputed genotypes (Data Citation 1). Association statistics in the WES panel are available from the whole-exome sequenced individuals or from those genotyped on the exome array (Data Citation 2). Additionally, gene-level association statistics from the whole-exome sequenced individuals are available for each of the four variant masks (Data Citation 2).
A description of the datasets is available in Table 7. All association statistics are also available for browsing and searching via the public Type 2 Diabetes Knowledge Portal at www.type2diabetesgenetics.org. Through the portal, users can construct queries to find variants satisfying specified annotations and association thresholds, both across the WES and WGS analyses as well as other GWAS datasets. Users can also dynamically construct a set of variants within a gene and obtain a P-value from aggregate association analysis within the WES individuals.
Technical Validation
Evaluation of variants in the WGS panel
We evaluated the variant sensitivity (fraction of true variant sites detected) of the WGS panel, based on the 2,538 individuals with data from all three experimental platforms (low-pass whole-genome sequencing, whole-exome sequencing, and HumanOmni2.5M array genotyping). To assess the sensitivity of low-pass whole-genome sequencing alone, we computed the fraction of variants detected from whole-exome sequencing that were also detected by low-pass whole-genome sequencing. Sensitivity estimates were 99.8, 99.0, and 48.2% for common (MAF>5%), low-frequency (0.5%<MAF<5%), and rare (MAF<0.5%) SNVs, respectively, and >99.9, 93.8, and 17.9% for common, low-frequency, and rare short indels, respectively. We also assessed the coding SNV sensitivity of low-pass whole-genome sequence data combined with exome sequence data, based on the proportion of HumanOmni2.5 SNVs detected by either sequencing platform. Because HumanOmni2.5 SNVs are enriched for common variants, we calculated an averaged sensitivity at each allele count, weighted by the number of exome-detected variants given the allele count. Sensitivity estimates were 99.9, 99.7, and 83.9% for common, low-frequency, and rare variants, respectively. These sensitivity estimates provide lower bounds on the sensitivity of the full WGS panel, which combines HumanOmni2.5 SNP array data as well as the two types of sequence data (Fig. 2a).

We computed several metrics to verify the sequencing accuracy of the study individuals. (a) Estimates of sensitivity of WGS panel. Shown is the fraction of variants, as a function of minor allele count in the WGS sequenced individuals, estimated as included in the WGS panel. Green circles show the total fraction of variants; green crosses show the fraction of variants for hypothetical variants with a T2D odds ratio of 5 (because T2D cases are overrepresented in our sample, the sensitivity to detect risk variants is increased). For comparison, shown are the fraction of variants that are included in the 1000G Phase 1 dataset (blue circles) or HapMap panel (red circles). (b) Distribution of minor alleles carried by individuals in the WES panel. For different populations within the WES panel, the distribution of minor alleles carried is plotted across all individuals. A normal distribution indicates a lack of systematic sequencing artefacts for any one individual, at least according to this metric. Afr-Am: African American. (c) Comparison of principal components computed from SNPs and indels versus indels alone. We calculated principal components for the European individuals in the WES panel using all variants in the panel and then again using only indels. Adapted from Supplementary Tables 5 and 6, and Fig. 1a, in Fuchsberger et al.8.
We further evaluated the genotype accuracy of the WGS panel for each of the three classes of variant (SNVs, indels, and SVs). Across chromosome 20, concordance of low-pass whole-genome-sequence-based SNV genotypes with exome-sequence-based genotypes was 99.86%, with homozygous reference, heterozygous, and homozygous non-reference concordances of 99.97, 98.34, and 99.72%, respectively. Concordance between exome-sequence-based SNV genotypes and HumanOmni2.5 genotypes was 99.4%, with homozygous reference, heterozygous, and homozygous non-reference concordances of 99.97, 99.69, and 99.88%, respectively. For indels genotyped with both low-pass whole-genome-sequence data and exome-sequence data, concordance was 99.4%, with homozygous reference, heterozygous, and homozygous non-reference concordances of 99.8, 95.8, and 98.6%, respectively.
To evaluate the genotype accuracy of SVs detected from the low-pass whole-genome sequence data, we took advantage of the 181 individuals in our study who were previously included in the WTCCC array-CGH based structural variant detection experiment36. Taking the WTCCC data as a gold standard, we estimated genotype accuracy across 1,047 overlapping SVs (with reciprocal overlap >0.8) genome-wide. The overall genotype concordance was 99.8%, with homozygous reference, heterozygous, and homozygous non-reference concordances of 99.9, 99.6, and 99.7%, respectively.
Evaluation of variants in the WES panel
We assessed the overall sequencing quality of individuals in the WES panel by computing distributions of global statistics, stratified by reported ancestry (Fig. 2b). After quality control, the number of non-reference variants, mean heterozygosity, and average allele balance (fraction of non-reference reads at heterozygous sites) per individual approximately matched a Gaussian distribution within each ancestry. Concordance between genotypes from exome-sequence data and those from independent SNP arrays was above 99% for the vast majority of individuals, with non-reference concordance above 99.5% for individuals genotyped on the (highest-quality) OMNI array.
We also assessed bulk properties of indels within the WES panel. The length distribution of indels showed an excess of variants with lengths a multiple of three, as expected. Additionally, principal components computed from indels alone closely matched those computed from SNVs and indels together (Fig. 2c).
Evaluation of imputation from the WGS panel
We computed the mean imputation quality as measured by the average squared correlation between imputed genotypes and actual genotypes from leave-one-out cross-validation analysis. For variants of allele count ≈100 or above in the WGS panel (corresponding to a frequency of 1.8%), average r2 values were in excess of 0.8 for Finnish individuals and in excess of 0.6 for British individuals (Fig. 3a).

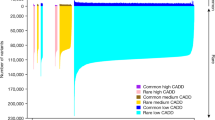
We calculated the fraction of variants in the WGS and WES panel that were captured via either imputation or exome array genotyping, respectively. (a) The mean imputation quality of variants in the WGS panel, as a function of their allele count in the WGS panel. Green circles show imputation quality in Finnish individuals, while green crosses show imputation quality in British individuals. For comparison, blue circles and crosses show imputation quality using the 1000G Phase 1 dataset as a reference panel (instead of the WGS panel). (b) The number of coding variants in the WES panel present on the exome array. Variants are stratified by annotation and frequency, and sensitivity calculations are shown for variants in each ancestry group as well as overall. Panel (b) is reproduced from Supplementary Fig. 17 in Fuchsberger et al.8.
Evaluation of exome array sensitivity
We assessed the overlap of variants present on the exome array with those observed in the WES panel. As the exome array primarily contains SNVs that are predicted to be protein altering, we focused on nonsense, essential splice site, and missense variants; only variants passing QC in both sequence and array data were included in the assessment. The fraction of variants in the WES panel on the exome array was highest for Europeans, at 81.6%, and lowest in African-Americans, at 49.0% (Fig. 3b).
Evaluation of association tests
We used the genetic power calculator (http://zzz.bwh.harvard.edu/gpc/) to estimate power to detect T2D association for each of the single variant analyses. All calculations assumed a T2D prevalence of 8%. Figure 4 shows power estimates under optimistic scenarios, in which a variant is present in the WGS panel (Fig. 4a), observed at equal frequency in all ancestries in the WES panel (Fig. 4b), imputed with high (r2=0.8) accuracy (Fig. 4c), or included on the exome array (Fig. 4d). We also computed power for less optimistic scenarios3; if, for example, a MAF 1% variant is present in only one ancestry, it must have an odds ratio of ~3.5 to achieve significance of P=10−4, rather than an odds ratio of ~1.8 were it to be present in all ancestries.

Shown is the power to detect an association with variants of varying population frequencies and T2D odds ratios, at a relatively lenient significance level of α=10−4. Such a significance level would be insufficient to establish an association due to the burden of multiple testing, but lack of association at this significance level can place bounds on the maximum effect a variant has in the population. (a) Power for a variant of constant frequency and effect across all populations in the WGS panel. (b) Power for a variant of constant frequency and effect across all populations in the WES panel. (c) Power for a variant imputed from the WGS panel with imputation accuracy r2=0.8. (d) Power for a variant in both the WES panel and on the exome array. NA: number of affecteds (cases); NU: number of unaffecteds (controls); K: presumed prevalence of T2D in the population.
For gene-based tests in the WES panel, we used a simulated haplotype data set (http://cran.r-project.org/web/packages/SKAT/vignettes/SKAT.pdf) and estimated power as a function of (i) the phenotypic variance, under a liability scale, explained by additive genetic effects and (ii) the percentage of variants that were causal (50% or 100%). As for single-variant power calculations, we considered variants of constant frequency across all five ancestry groups, as well as variants specific to one ancestry group. These calculations suggested3 that, even under optimistic scenarios, genes must explain >1% of genetic variance in order to achieve a moderately significant (P<10−3) association in the WES panel.
To ensure that association statistics were well calibrated, we computed quantile-quantile (QQ) plots comparing observed statistics to those expected under the null distribution. The vast majority of statistics matched the expected distribution (suggesting good calibration of the association tests) with a deviation from the null for common variant associations from the WGS panel, imputed genotypes, and exome array genotypes (suggesting power to detect known positive control T2D-associated non-coding common variants).
Usage Notes
The WGS and WES panels may be useful for simulation-based approaches that require individual-level genotypes and phenotypes. In this case the full list of ‘QC+’ variants (not merely those included in the T2D analysis) should be used, as the association analysis omitted very rare variants that might be useful in other settings. The WGS panel can also serve as a reference panel for genotype imputation, particularly in cases where an excess of haplotypes from T2D cases are required. Although more recent and larger efforts such as the Haplotype Reference Consortium8 will provide greater imputation power for most use cases, the WGS panel is not restricted based on minor allele count and includes indels and SVs.
The most valuable data from the T2D-GENES and GoT2D studies are likely the catalogues of T2D association statistics for low-frequency and common variation. These statistics may prove useful for fine mapping or functional studies of T2D GWAS signals, in which enumeration of potential causal variants is required, or for ‘reverse genetic’ approaches, in which estimates of the phenotypic effects of variants with strong molecular effects are desired. For this usage, we advise investigators to query the T2D Knowledge Portal at www.type2diabetesgenetics.org as a first step, as its goal is to provide a simple and continuously updated means to query these and other association statistics. The portal is designed specifically for queries about individual variants or those within a single gene or genomic locus, as well as variant- or gene-level analyses for which investigators desire to adjust included variants, covariates, or individuals. Users should note that data from the T2D-GENES and GoT2D studies are included in, and thus should not be combined with data from, the Exome Aggregation Consortium (exac.broadinstitute.org).
Should investigators desire access to all association statistics, genome-wide, the files at EGA should be used (as the T2D Knowledge Portal does not support bulk download of association statistics). For single variant associations, a statistic in the largest available sample size should be used. Coding variant association statistics present in both the WES panel analysis and the exome chip analysis can be safely combined via meta-analysis, as can non-coding variant association statistics present in both the WGS panel analysis and the imputation-based analysis; statistics should not, however, be combined across the non-coding and coding variant analyses. Association results from the sequence or exome chip data should not need to be filtered, but it is advisable to filter results from the imputation-based analysis according to a threshold on imputation quality (e.g., r2>0.3). For gene-level analyses, investigators should first use the aggregate association statistics and then dissect results by examining variant-level statistics for each variant in the mask.
The pre-computed statistics should be sufficient for most investigators. Cases where recalculation of associations may be appropriate include (a) conditional analyses, such as variant association controlling for additional individual phenotypes or genotypes at different variants, (b) association analyses with phenotypes other than T2D, and (c) novel statistical tests. In these cases, usage of the tests and inclusion of the covariates described in the methods section is recommended, and only variants and individuals present in the final ‘QC+’ analysis lists should be included.
Additional information
How to cite this article: Flannick, J. et al. Sequence data and association statistics from 12,940 type 2 diabetes cases and controls. Sci. Data 4:170179 doi: 10.1038/sdata.2017.179 (2017).
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
References
Manolio, T. A. et al. Finding the missing heritability of complex diseases. Nature 461, 747–753 (2009).
Flannick, J. & Florez, J. C. Type 2 diabetes: genetic data sharing to advance complex disease research. Nature Reviews Genetics 17, 535–549 (2016).
Fuchsberger, C. et al. The genetic architecture of type 2 diabetes. Nature 536, 41–47 (2016).
Bodmer, W. & Bonilla, C. Common and rare variants in multifactorial susceptibility to common diseases. Nature Genetics 40, 695–701 (2008).
Cirulli, E. T. & Goldstein, D. B. Uncovering the roles of rare variants in common disease through whole-genome sequencing. Nature Reviews Genetics 11, 415–425 (2010).
Flannick, J. et al. Loss-of-function mutations in SLC30A8 protect against type 2 diabetes. Nature Genetics 46, 357–363 (2014).
Majithia, A. R. et al. Rare variants in PPARG with decreased activity in adipocyte differentiation are associated with increased risk of type 2 diabetes. Proceedings of the National Academy of Sciences of the United States of America 111, 13127–13132 (2014).
McCarthy, S. et al. A reference panel of 64,976 haplotypes for genotype imputation. Nature Genetics 48, 1279–1283 (2016).
Wang, S. R. et al. Simulation of Finnish population history, guided by empirical genetic data, to assess power of rare-variant tests in Finland. American Journal of Human Genetics 94, 710–720 (2014).
Agarwala, V., Flannick, J., Sunyaev, S., Go, T. D. C. & Altshuler, D. Evaluating empirical bounds on complex disease genetic architecture. Nature Genetics 45, 1418–1427 (2013).
Guey, L. T. et al. Power in the phenotypic extremes: a simulation study of power in discovery and replication of rare variants. Genetic Epidemiology 35, 236–246 (2011).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 25, 1754–1760 (2009).
McKenna, A. et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Research 20, 1297–1303 (2010).
DePristo, M. A. et al. A framework for variation discovery and genotyping using next-generation DNA sequencing data. Nature Genetics 43, 491–498 (2011).
Jun, G. et al. Detecting and estimating contamination of human DNA samples in sequencing and array-based genotype data. American Journal of Human Genetics 91, 839–848 (2012).
Jun, G., Wing, M. K., Abecasis, G. R. & Kang, H. M. An efficient and scalable analysis framework for variant extraction and refinement from population-scale DNA sequence data. Genome Research 25, 918–925 (2015).
Abecasis, G. R. et al. An integrated map of genetic variation from 1,092 human genomes. Nature 491, 56–65 (2012).
Handsaker, R. E., Korn, J. M., Nemesh, J. & McCarroll, S. A. Discovery and genotyping of genome structural polymorphism by sequencing on a population scale. Nature Genetics 43, 269–276 (2011).
Browning, S. R. & Browning, B. L. Rapid and accurate haplotype phasing and missing-data inference for whole-genome association studies by use of localized haplotype clustering. American Journal of Human Genetics 81, 1084–1097 (2007).
Li, Y., Sidore, C., Kang, H. M., Boehnke, M. & Abecasis, G. R. Low-coverage sequencing: implications for design of complex trait association studies. Genome Research 21, 940–951 (2011).
Price, A. L. et al. Long-range LD can confound genome scans in admixed populations. American Journal of Human Genetics 83, 132–135, author reply 135-139 (2008).
Weale, M. E. Quality control for genome-wide association studies. Methods in Molecular Biology 628, 341–372 (2010).
Korn, J. M. et al. Integrated genotype calling and association analysis of SNPs, common copy number polymorphisms and rare CNVs. Nature Genetics 40, 1253–1260 (2008).
Goldstein, J. I. et al. zCall: a rare variant caller for array-based genotyping: genetics and population analysis. Bioinformatics 28, 2543–2545 (2012).
Firth, D. Bias reduction of maximum-likelihood-estimates. Biometrika 80, 27–38 (1993).
Ma, C., Blackwell, T., Boehnke, M., Scott, L. J. & Go, T. D. i. Recommended joint and meta-analysis strategies for case-control association testing of single low-count variants. Genetic Epidemiology 37, 539–550 (2013).
Marchini, J., Howie, B., Myers, S., McVean, G. & Donnelly, P. A new multipoint method for genome-wide association studies by imputation of genotypes. Nature Genetics 39, 906–913 (2007).
Devlin, B. & Roeder, K. Genomic control for association studies. Biometrics 55, 997–1004 (1999).
Willer, C. J., Li, Y. & Abecasis, G. R. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 26, 2190–2191 (2010).
Kang, H. M. et al. Variance component model to account for sample structure in genome-wide association studies. Nature Genetics 42, 348–354 (2010).
Cingolani, P. et al. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strain w1118; iso-2; iso-3. Fly 6, 80–92 (2012).
McLaren, W. et al. The Ensembl Variant Effect Predictor. Genome Biology 17, 122 (2016).
Purcell, S. M. et al. A polygenic burden of rare disruptive mutations in schizophrenia. Nature 506, 185–190 (2014).
Lee, S., Teslovich, T. M., Boehnke, M. & Lin, X. General framework for meta-analysis of rare variants in sequencing association studies. American Journal of Human Genetics 93, 42–53 (2013).
Lee, S., Wu, M. C. & Lin, X. Optimal tests for rare variant effects in sequencing association studies. Biostatistics 13, 762–775 (2012).
Wellcome Trust Case Control Consortium. Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature 447, 661–678 (2007).
Data Citations
The European Genome-phenome Archive EGAS00001001459 (2016)
The European Genome-phenome Archive EGAS00001001460 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001097.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001099.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001098.v1.p1 (2016)
Duggirala, R. dbGAP phs000849.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001096.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001095.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001093.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001100.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs001102.v1.p1 (2016)
Altshuler, D., Boehnke, M., McCarthy, M., & Florez, J. dbGAP phs000840.v1.p1 (2016)
Acknowledgements
Grant support and acknowledgments are listed in the Supplementary Information.
Author information
Authors and Affiliations
Contributions
Author contributions are described in the Supplementary Information.
Corresponding author
Ethics declarations
Competing interests
Ralph A DeFronzo has been a member of advisory boards for Astra Zeneca, Novo Nordisk, Janssen, Lexicon, Boehringer-Ingelheim, received research support from Bristol Myers Squibb, Boehringer- Ingelheim, Takeda and Astra Zeneca, and is a member of speaker’s bureaus for Novo-Nordisk and Astra Zeneca. Jose C Florez has received consulting honoraria from Pfizer and PanGenX. Erik Ingelsson is an advisor and consultant for Precision Wellness, Inc., and advisor for Cellink for work unrelated to the present project. Mark McCarthy has received consulting and advisory board honoraria from Pfizer, Lilly, and NovoNordisk. Gilean McVean and Peter Donnelly are co-founders of Genomics PLC, which provides genome analytics.
ISA-Tab metadata
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files made available in this article.
About this article

Cite this article
Flannick, J., Fuchsberger, C., Mahajan, A. et al. Sequence data and association statistics from 12,940 type 2 diabetes cases and controls. Sci Data 4, 170179 (2017). https://doi.org/10.1038/sdata.2017.179
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/sdata.2017.179
This article is cited by
-
Whole genome sequence association analysis of fasting glucose and fasting insulin levels in diverse cohorts from the NHLBI TOPMed program
Communications Biology (2022)
-
Relationship between insulin sensitivity and gene expression in human skeletal muscle
BMC Endocrine Disorders (2021)
-
Loss of Znt8 function in diabetes mellitus: risk or benefit?
Molecular and Cellular Biochemistry (2021)
-
Multi-omics analysis identifies CpGs near G6PC2 mediating the effects of genetic variants on fasting glucose
Diabetologia (2021)
-
Mutations and variants of ONECUT1 in diabetes
Nature Medicine (2021)
