
Abstract
Census counts of marine microfossils in surface sediments represent an invaluable resource for paleoceanography and for the investigation of macroecological processes. A prerequisite for such applications is the provision of data syntheses for individual microfossil groups. Specific to such syntheses is the necessity of taxonomical harmonisation across the constituent datasets, coupled with dereplication of previous compilations. Both of these aspects require expert knowledge, but with increasing number of records involved in such syntheses, the application of expert knowledge via manual curation is not feasible. Here we present a synthesis of planktonic foraminifera census counts in surface sediment samples, which is taxonomically harmonised, dereplicated and treated for numerical and other inconsistencies. The data treatment is implemented as an objective and largely automated pipeline, allowing us to reduce the initial 6,984 records to 4,205 counts from unique sites and informative technical or true replicates. We provide the final product and document the procedure, which can be easily adopted for other microfossil data syntheses.
Design Type(s) | observation design • data integration objective • biodiversity assessment objective |
Measurement Type(s) | fossil |
Technology Type(s) | data item extraction from journal article |
Factor Type(s) | geographic location |
Sample Characteristic(s) | Foraminifera • Arabian Sea • Atlantic Ocean • Earth • Eastern Indian Ocean • Mediterranean Sea • Northwest Atlantic Ocean • Pacific Ocean • Red Sea • Southeast Pacific Ocean coastal waters of Chile • West Europe Basin • West Sumatra Province • marine sediment |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others
Background & Summary
The composition of marine plankton communities reflects the properties of their surface-layer habitat1. In groups of plankton that produce fossils, information on community composition is preserved in marine sediments. Their fossil record can thus be used to reconstruct past surface-layer conditions. This procedure is contingent on the availability of observations on present-day communities, generated under the same conditions of spatiotemporal averaging and preservational bias as is the case for the fossil samples. This prerequisite is best met by census counts from surface sediment samples. Due to extensive efforts in exploration of the ocean floor, a large amount of observations on surface sediment properties, including composition of their constituent microfossil assemblages, have been generated. Such data have been used extensively in paleoceanography to calibrate assemblage compositions to surface ocean properties, in form of so-called transfer functions2, facilitating quantitative reconstructions of past ocean states.
The microfossil group with a particularly long history of usage in this regard are the planktonic foraminifera. Their shells can be easily identified to morphospecies level, are preserved in marine sediments across large parts of the world ocean and their species distribution shows a strong relationship to surface water hydrography3. Because of a distinct morphology that can be observed under standard stereomicroscopes combined with a limited diversity of the group, census counts of planktonic foraminifera can be generated with relatively little effort. As a result, planktonic foraminifera species distribution in surface sediments has been characterised in thousands of samples, collected by different methods. A standardisation of taxonomy of the group carried out within the CLIMAP project allowed the assembly of the first global calibration dataset4 (Data Citation 1), representing a substantial advance over pre-existing datasets generated by individual researchers often in a limited regional context5.
Since the pioneering effort of CLIMAP, data on planktonic foraminifera species abundance in surface sediments rapidly grew in number6,7 (Data Citation 2), facilitating the development of increasingly sophisticated transfer function approaches8. The data have been used to calibrate numerical models of foraminifera production9, explore their biodiversity patterns10,11 and develop methods to quantify carbonate dissolution on the sea floor12. With the accumulation of new data, the assembly and harmonisation of global datasets became increasingly difficult. Due to divergent taxonomic practice and human error during assembly of digital products, the latest global compilation7 suffers from internal inconsistency, uncontrolled duplication, and unsatisfactory documentation of taxonomic resolution. Since the release of the MARGO compilation, many new datasets have been generated and the taxonomy of the group has been better understood using molecular methods13, but no further systematic effort of data integration has been made.
Here we present the results of a long-term effort to provide a harmonised and consistent dataset of planktonic foraminifera census counts in surface sediment samples with curated taxonomy, accounting for different levels of taxonomic resolution. We explain and document the approach, which combines sequential dereplication of four previous syntheses, assembly of new data, and numerical and taxonomical treatment to achieve internal consistency. The resulting dataset is comprehensively commented for all modifications and includes the original data. The data-assembly procedure is objective and allows easy incorporation of new data. The final product provides an optimal starting point for the development of transfer functions, testing of ecological models and analyses of macroecological patterns. The approach itself can potentially guide similar efforts for other types of paleontological data syntheses.
Methods
Design of the analysis
Every effort in producing a globally harmonised synthesis of micropaleontological data will be confronted with three essential challenges. First, census counts generated by different authors across a considerable amount of time are not taxonomically harmonised. This problem arises because of inconsistent naming of the same taxonomic units (synonymy), inconsistent level of taxonomic resolution (splitting or lumping) and inconsistent documentation of the list of considered species (completeness). Second, in the presence of earlier compilation efforts, every subsequent data synthesis requires dereplication against earlier products. This is substantially complicated by the third challenge, which is the inconsistency in data and metadata recording. This leads to artificial inflation of the synthesis by ‘synonymous’ data entries that differ in aspects ranging from the syntax of the site identifiers, over composition differences resulting from rounding, to seemingly inexplicable differences in data associated with identical site identifiers. In our approach, we attempted to address all of these issues objectively.
To assemble the dataset, we decided to restrict the synthesis to data generated by the CLIMAP methodology, involving counting of about 300 specimens of planktonic foraminifera in the size class larger 150 μm. We considered four existing key compilations, the dataset of CLIMAP4 (Data Citation 1), the Brown University Foraminiferal Database (BUFD) (Data Citation 2), the ATL947 database6 (Data Citation 3) and MARGO7 (Data Citations 4–7). In addition, we searched the PANGAEA and NOAA paleoclimatology data repositories for datasets not incorporated in these and added those to the synthesis. In a first step, the taxonomy was manually standardised to a list of categories, following Hemleben et al.14 with modifications by Morard et al.13. For all included samples, metadata catalogues have been standardised and missing data were complemented from original publications as far as possible. New metadata categories were added to flag the discovered inconsistencies, facilitate reconstitution of the four main constituent datasets and allow geographical subdivision.
The following steps involved standardisation and correction of the counts. Deviations from the expected sum of constituent categories within a sample may occur because of rounding errors for relative abundances but also due to human error during digital data input or during cloning from earlier databases. Consequently, samples of insufficient quality were flagged and excluded from further processing. This concerned samples with severely inconsistent sum of categories, small sample size, samples taken using inappropriate sampling device, samples where too many specimens were left unidentified and samples with assemblage composition that is at odds with the known endemism pattern in modern planktonic foraminifera. The census counts in those samples are deemed likely to deviate from what would be expected for the sampling location for reasons other than the already considerable variability imposed by the spatial inhomogeneity of marine plankton flux. For example, census counts from plankton tows or sediment traps have been excluded because they do not account for the integration of seasonal and interannual variability in sedimentary assemblages.
The remaining samples were subjected to a dereplication procedure, the identification and treatment of duplicates (multiples) in the dataset, a key motivation for the analysis. It was carried out individually for each dataset and then sequentially to account for the known order of cloning among the four key datasets. Because the counts and metadata suffer from rounding errors and human error and the names (labels) for identical samples vary between compilations, a detection of duplicates is non-trivial. We used a series of conservative criteria avoiding the loss of potentially informative samples, such as technical replicates (the same assemblage of foraminifera counted twice by different taxonomists) and true replicates (multiple samples taken from the same location, even with the same device—such as different multicorer tubes, and counted independently). Counts and metadata in samples identified as duplicates were merged such that the retained sample contained the maximum amount of information. All steps and decisions were recorded and the data can be recovered at any stage of processing.
Outliers, samples that significantly differ in their assemblage composition from samples in their immediate surrounding, are not considered by our procedures. Outliers can result from plain errors (typographic errors, swapped latitude and longitude, etc.) taxonomic inconsistency among researchers or post-depositional processes such as dissolution of fragile tests at depth below the lysocline. Whilst the latter process can be objectively quantified and used to exclude samples, the other remain largely subjective. As a result, an outlier treatment cannot be implemented entirely objectively without a knowledge of the purpose of the intended analysis and we therefore leave this aspect of data processing to future users.
Data sources
The compilation is based on all planktonic foraminifera assemblage count data from surface sediment samples in the size class larger 150 μm that we could identify in the PANGAEA and NOAA Paleoclimatology data repositories. The search was carried out on October 1st 2016, using search strings combining <planktic, planktonic, foraminifer*, census, assemblage, faunal distribution, counts>. The outcome was filtered to include only datasets of census counts in recent surface sediments. The data comprise the compilations of CLIMAP (Data Citation 1), the Brown University Foraminiferal Database (BUFD) (Data Citation 2), the ATL947 database (Data Citation 3) and MARGO (Data Citation 4–7) as well as the individual datasets of Huels et al. (Data Citation 8), Mohtadi et al. (Data Citation 9 and Data Citation 10), Salgueiro et al. (Data Citation 11), Siccha et al. (Data Citation 12) and Munz et al. (Data Citation 13). Also found but not included in the new compilation were the datasets of Cortese et al. (Data Citation 14) and Haddam et al. (Data Citation 15), the reasons are summarized in the section Technical Validation. All individual datasets found were of a later publication date than the MARGO database, except the dataset by Huels et al. (Data Citation 8). The data by Mohtadi et al. (Data Citation 9) were complemented to include counts of all species, following personal communication with the author. In the case of Munz et al. (Data Citation 13) the complete count data was obtained by personal communication and used instead of the published version in PANGAEA. The new datasets were merged and labelled as ‘Additions’ in tables and figures of this study.
Taxonomic standardization
Taxonomic standardization was performed individually on all datasets. Data in their original taxonomic form (i.e., with uncorrected taxonomy) are only available through access to their original repository (see data citations below). The harmonised taxonomy as applied in this analysis follows Hemleben et al.14 as implemented in Morard et al.13 and expanded by Weiner et al.15 and Spezzaferri et al.16. The taxonomic list we use comprises 47 species categories, three multi-species categories and six sub-species (morphospecies) categories (Table 1 (available online only)). Six of the 47 species categories have no entries as the abundances of the respective species have not been recorded so far. Of these, four categories refer to species that are too small to be recorded in the analysed size fraction and two categories (G. elongatus, G. radians) have only recently been established during taxonomic revisions15,17 and have thus not been counted before. Synonymy has been resolved manually as documented in Table 2. All synonyms could be unambiguously assigned to categories in Table 2 except for the cases described below.
In the CLIMAP database, following the BUFD (Data Citation 2) and ATL947 (Data Citation 3) compilations the category ‘G. pachyderma’ was interpreted as ‘P/D intergrades’. This category was then merged with the ‘N. pachyderma d’ category into the category ‘N. incompta’. The category G. flexuosa was removed and the abundances of this category merged with the category G. menardii. This is because there is no evidence for the morphotype represented by G. flexuosa being a separate species13. In the ATL947 database the category ‘P/D intergrades’ was removed and the abundances of this category merged with the category N. incompta. The justification for this decision is documented in the MARGO synthesis7. In the Brown University Foraminiferal Database, the category G. flexuosa was removed and the abundances of this category were merged with the category G. menardii. The category G. crassula was removed and the abundances of this category merged with the category ‘unidentified’. The species G. crassula appears to be extinct18 but its morphology cannot be unambiguously linked to an extant species, making it impossible to decide to which of the known species the counts for this category should be assigned. The category ‘other identified’ was merged with the category ‘unidentified’. In the MARGO database the category ‘P/D intergrades’ was removed and the abundances of this category was merged with the category N. incompta. The category G. crassula was removed and the abundances of this category merged with the category ‘unidentified’. The category ‘other identified’ was merged with the category ‘unidentified’. For the dataset of Munz et al. (Data Citation 13) we could obtain the original raw count data, which includes more categories than the version with relative abundances published via PANGAEA. In the raw data the category G. puncticulata was removed and the abundances of this category merged with the category G. inflata. Globorotalia puncticulata is an extinct species19, but its morphology is partly overlapping with that of its descendant G. inflata. The category ‘P/D intergrades’ was removed and the abundances of this category was merged with the category N. incompta.
The datasets of CLIMAP, BUFD and ATL947 were compiled in such a way that their constituent taxonomic categories are resolved for all records. The most comprehensive species list in the CLIMAP dataset contains 37 unique categories common with Table 3. The remaining four categories included in Table 1 (available online only) but not in CLIMAP refer mostly to small and rare species. Rather than setting their abundances to zero artificially, we have labelled these as ‘not available’, realising that it the vast majority of the cases the observed abundances would have been zero. In several studies among the Additions, the taxonomic resolution was not sufficiently clearly documented (Table 3). Notably, the species lists in Mohtadi et al. (Data Citations 9 and 10) and Salgueiro et al. (Data Citation 11) contain about 1/3 fewer categories than the average of other studies. These datasets are regionally constrained and it is likely that they only reported species that were abundant in the studied region. This is confirmed by an inspection of the methods description in Salgueiro et al.20, who mention the occurrence of rare species like G. crassaformis in the paper, but the category is not provided in the data file (Data Citation 11). Therefore, we assigned the value of ‘not available’ to all entries for categories not included in the data file for a given study.
In cases where the original taxonomy admitted lumping of species, we retained these categories as multi-species categories. This applies for example to G. ruber as a sum of G. ruber pink and white in the Mediterranean (Data Citation 7). In these cases, the constituent categories could be unambiguously identified as not available. In addition to formally described species, we retained in the counts the separation of distinct morphotypes. Even though these likely do not represent different species, their abundance has been frequently and consistently recorded. This applies specifically to the separation of T. sacculifer and T. trilobus, G. truncatulinoides sinistral and dextral and T. quinqueloba sinistral and dextral. Where separate counts are available, these are included under the label ‘morphotypes’ of the recognised species. This approach provides flexibility to accommodate future taxonomic revisions.
Metadata standardization and addition of descriptors
Metadata standardization was also performed individually on the individual datasets (Table 4). The unit of the variable ‘Sample_depth’ was standardized to meters. Entries of zero in ‘Sample_depth_lower’ were corrected into entries of zero for ‘Sample_depth_upper’. The variable ‘Sample_depth_average’ was calculated where possible. Entries in the variable ‘Device’ were standardized into the categories ‘Piston’, ‘Gravity’, ‘Trigger’, ‘Grab’, ‘Giant Box’, ‘Box’, ‘Multi’ and ‘CTD’ where applicable. All entries in the variable ‘Sample_name’ were transformed to uppercase. We realise that in many cases the pattern of capitalisation of the names has a meaning, but we note that capitalisation has been used so inconsistently, that it is not possible to reconstitute it. Ignoring capitalisation makes automated processing of names much more tractable. Missing metadata in the input data was completed by searching the original publications where possible. The variable ‘Count_min’ denoting the minimum number of counted individuals was introduced and populated with information where available. In case where no information was available, the value was set to the common standard of 300 counted individuals. Detailed information on the original publication was added in form of the variables ‘Author’, ‘Journal’, ‘Year’ and ‘Publication_doi’. Three binary flag variables were added to the metadata, ‘Error’, ‘Ocean’ and ‘Database’, describing the treatment of the data, the source of the count data and the oceanographic region of the sampling site, respectively (Tables 5,6,7). The binary flags are constructed in a way that their value can express any combination of the possible states. For example, a ‘Database’ flag value of 7 for a count would indicate the inclusion of the count in the CLIMAP, the BUFD and the ATL947 compilations (1+2+4).
Standardization and correction of count data
All relative count data were standardized to the range of 0 to 1. The ‘total count’ of samples with absolute counts was corrected if it did not correspond to the sum of the categories. Many of the analysed counts have an explicitly mentioned category ‘unidentified’. In theory, where this category is given, and its value is zero, all of the categories not explicitly considered by such study could be set to zero. We assumed the rounding error of individual categories to be 0.1% and the average total rounding error Er of a sample expressed as a fraction to be Rr=(n*0.001)/2 with n being the number of given categories. Therefore, in case of the sum of all categories being within rounding errors (sum of relative categories >1-Er) of the given sum and where zero is given for the ‘unidentified’ category, the sample was assumed to be complete and all non-present categories were filled with zeros. The relative abundances for all samples were recalculated to sum up to 1, except for samples where the sum of relative categories deviated by more than 5% of the expected sum of 1, which were flagged (Table 5, ‘Error’ flag bit 7) and excluded from further analyses. All samples that had a total count below 150 individuals were also flagged (Table 5, ‘Error’ flag bit 8) and excluded from further analyses.
Removal or correction of counts in records of insufficient taxonomical quality
All counts with entries in the ‘unidentified’ category larger than 5% were flagged (Table 5, ‘Error’ flag bit 6) and excluded from further analyses. Counts from the Pacific, Indian Ocean or Red Sea with relative abundances >1% in the category G. ruber pink were also flagged (Table 5, ‘Error’ flag bit 5) and excluded from further analyses. In samples from the Pacific, Indian Ocean or Red Sea with relative abundances <1% in the category G. ruber pink, the abundances of this category were merged with the category ‘unidentified’. All values in the merged category G. ruber pink and white from the Pacific, Indian Ocean or Red Sea were resolved into the category G. ruber white. The reason for this revision is the observation that G. ruber pink has been extinct in the Indopacific since the last Interglacial21 and recent genetic studies confirmed the endemicity of G. ruber pink in the Atlantic13. In addition, counts from the Atlantic and the Mediterranean Sea with relative abundances >1% in the categories G. conglomerata or G. hexagonus or G. adamsi were flagged (Table 5, ‘Error’ flag bit 5) and excluded from further analyses. In counts from the Atlantic or Mediterranean with relative abundances <1% in the categories G. conglomerata or G. hexagonus or G. adamsi, the abundances of these categories were merged with the category ‘unidentified’. This treatment reflects the known endemicity of these three species in the Indopacific region14.
Removal of counts for other reasons
All records without geographical coordinates were flagged (Table 5, ‘Error’ flag bit 10) and excluded from further analyses. All counts obtained from samples that have been taken with a non-standard sampling device, being neither ‘Box’ or ‘Giant Box’ or ‘Piston’ or ‘Gravity’ or ‘Grab’ or ‘Trigger’ or ‘Multi’ or ‘Mini’ or ‘CTD’ were flagged (Table 5, ‘Error’ flag bit 9) and excluded from further analyses.
Control for duplication and removal of duplicates
The identification of duplicates (multiples) in the dataset was one of the main motivations for the generation of the new database. The simple detection of identical samples with exactly the same name at exactly the same location with identical count data is not sufficient as the position and assemblage data suffer from rounding errors and human error and the sample names for identical samples vary between compilations. Initial tests revealed the presence of three different types of duplicates in the data: ‘plain duplicates’, samples with identical names located a short geographic distance apart, containing a highly similar species assemblage, ‘incorrect position duplicates’, samples with identical name containing a highly similar species assemblage, but potentially located far apart and ‘different name duplicates’, samples with different names but located close to each other and containing a highly similar species assemblage.
The automatic detection of duplicates was carried out using conservative criteria. Basic criteria for all types of duplication were a maximum deviation in counts of individual categories <1% ignoring categories with no information and a maximum deviation in total counted individuals of 3% (of the average of the total count value for the sample pair). Sample pairs (and multiples) satisfying these criteria were sequentially subjected to a test for one of the following additional criteria. For the case of a ‘plain duplicate’ the additional criteria were maximum geographical distance between the pair of samples shorter than 2.621 km (the distance between 0.5′N 0.5′W and 0.5′S 0.5′E across the equator) and an identical name (Levenshtein distance between sample names of zero). For the case of an ‘incorrect position duplicate’ the additional criterion was an identical name (Levenshtein distance between sample names of zero). Lastly, for the case of a ‘different name duplicate’ the additional criterion was a maximal geographical distance between samples shorter than 0.5242 km (the distance between 0.1′N 0.1′W and 0.1′S 0.1′E across the equator). Counts that satisfied any one of these criteria were collected in lists of ‘duplicates’ and treated and removed sequentially, that is the test for ‘incorrect position’ duplicates was only conducted after all ‘plain’ duplicates had been treated.
The existence of combinations of the three duplication reasons makes such duplicates particularly resistant to detection. Indeed, we identified cases where both the name and the geographical position were different beyond threshold, but the samples still could be identified as duplicates. (‘ELT44.27-PC’ is identical to ‘E44-27B’/‘M8_12-1’ is identical to ‘M8/12-1’/‘A260210A’ is identical to ‘AII-15-602-10A’). Therefore, we implemented a final manual step in the duplication control, where, after all other cases have been treated automatically, a new list of possible duplicates was generated using only the basic criteria of faunal similarity, and inspected by the compiler.
The obtained lists of duplicate samples were subjected to a merging procedure designed to retain a maximum of the available information of all the involved samples. If a pair or a multiple of samples were merged, assemblage data with the highest number of counted taxa was carried over to the new merged sample. The geographic position with a highest precision was assigned to the merged sample. In case of a set of ‘incorrect position duplicates’, the ‘correct’ position was determined by first checking whether the discrepancy in location is a result of incorrect transformation of the coordinates (decimals/minutes). To this end, the coordinates of the counts in question were transformed assuming that the decimal places were not fractions of degrees but untransformed minutes. All geographical distances for the combinations of transformed and untransformed coordinates (excluding combinations with more than two incorrectly transformed coordinates) were calculated and checked whether the transformation translocated the sample more than 3.7 km from the original position (an ill-transformation of at least 5’). If this conditions was met and the samples in question would come to lie within a distance of less than 2.621 km, the transformation was accepted and the samples considered as duplicates. If the screening for incorrectly transformed coordinates was negative, the ‘correct’ position was determined by cross checking with ETOPO1 (Data Citation 16). The position data of the sample whose given water depth matched best with the water depth for the respective position in the ETOPO1 data was carried over to the merged sample. In terms of sample depth in the sediment the most complete set of information was given precedence (upper and lower boundary and average available), if only one number was available precedence was given to the available average depth. For all other sample metadata precedence was given to the existence of information in contrast to no available information (e.g., Sampling device). In case of conflicting metadata, the data of the older publication was used.
Data Records
The ForCenS dataset is published as a single tab-delimited text file (Data Citation 17). Sample metadata are stored in columns 1 to 21 as described in Table 4. Variable names are given in the first row, variable units in the second row. Three blocks of species categories (Table 1 (available online only)) abundance data follow the metadata: first the original data as found in the data sources, reformatted only taxonomically. Next are the absolute count data, where available, with applied corrections and modifications, where applicable. The last block represents the data expressed as relative proportions, with applied corrections and modifications where applicable. This type of data is provided for all records in the dataset. This dataset comprises all records included in the analysis. The users are advised that at the end of each block, six columns contain data on morphotype abundances, the sums of which are already included in their parent taxonomic category.
Using the flags defined in Tables 5,6,7, users can reduce the list to reconstitute any of the original datasets, exclude replicates or produce a regionally constrained dataset. For convenience a second data file is published as tab-delimited text file with the same metadata structure as above, but only including records passing all selection criteria (Error flag <=1) and showing only the relative abundances of species. Both datasets are available via PANGAEA (Data Citation 17). The current implementation of the PANGAEA data portal facilitates versioning of datasets. This means that any expansion of the synthesis with new, overlooked or previously unavailable records can be carried out by the authors following the procedure described in this contribution and then uploaded as a new version.
Technical Validation
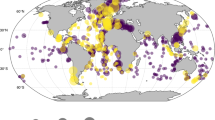
The initially assembled dataset including four previous compilations and six new datasets contained 6,984 census counts (Table 8). The initial processing (Table 9) excluded 229 counts, the majority for numerical reasons (53.7% of the excluded cases) or taxonomical issues (37.6%). The subsequent dereplication of the individual datasets showed that the MARGO database held 486 internal duplicates (12.9% of the samples). These duplicates were included intentionally in the MARGO datasets as outgroups for the regional calibration datasets, e.g., some samples from the Atlantic were included in the Indian Ocean and the Mediterranean datasets and there was an intentional overlap across the tropics between the South and North Atlantic datasets (Data Citation 4). The six new datasets contained 624 census counts, of which 56 were excluded during initial processing, no internal duplicates were found. The final processed and dereplicated ForCenS database (Data Citation 17) comprises 4,205 singular census counts (Table 8, Fig. 1). The distribution of all excluded samples, with identification of the reason for exclusion is shown in Fig. 2.

Colours denote the sample source, the first occurrence of a sample in a compilation taking precedence over reuse in later compilations.

Location of all census counts excluded from the ForCenS compilation with colours denoting the reason of exclusion.
In its present form, ForCenS (Data Citation 17)contains not only counts from unique sites but also a small number of informative technical or true replicates. To illustrate the origin of these replicates, we provide an example. The original CLIMAP dataset contains 375 counts of which the initial processing retained 351 counts. After the sequential dereplication procedure up to and including the ATL947 dataset the database contained 492 counts with ‘CLIMAP Projects members’ in the ‘Author’ metadata category, an inflation by 141 counts. This inflation occurs already in the individual compilations and is not the result of our dereplication. For example, there are 212 counts from the Atlantic in the original CLIMAP database, but 266 counts attributed to CLIMAP were found in ATL947. Individual inspection of count pairs with identical name between the CLIMAP and ATL947 datasets reveals that they differed significantly in assemblage composition and were therefore not recognized as duplicates during our dereplication procedure. Although the reason is not mentioned in the original publications by Pflaumann et al.6,22, we conclude that the inflation is the result of recounting of the same samples (probably to check for taxonomic consistency) and the samples are correctly retained because they represent informative technical replicates.
Cortese et al.23 published a compilation of planktonic foraminifera census counts containing 1,223 samples, which was based on a previous compilation by Crundwell et al.24, the MARGO Indo-Pacific dataset (Data Citation 6), Mohtadi et al. (Data Citations 9 and 10) and additional unpublished data of Crundwell. The dataset of Crundwell et al.24 has not been published; but it was reported to consist of 891 samples of which all except for 24 samples were taken from datasets that were included in the MARGO compilation7. Therefore, we could establish that in theory, a dereplication of Cortese dataset (Data Citation 14) with the ForCenS dataset should have led to an addition of a maximum of 230 samples (assuming that only a single sample of the MARGO Indo-Pacific dataset (Data Citation 6) was added and all other were unpublished data). However, our dereplication procedure retained 427 samples of the Cortese dataset (Data Citation 14) (before manual dereplication), most of which had a partner with the same name in the MARGO dataset7 but had a significantly different assemblage composition from this partner sample. As no modifications to the data from the MARGO compilation7 were mentioned in the publication of Cortese et al.23, and we cannot reconstruct the reason for the differences in the data for apparently identical samples, we chose to exclude the full dataset even though several unique and valuable new census counts must have been included.
A similar situation occurred during the processing of the dataset published by Haddam et al.25 In contrast to the Cortese dataset (Data Citation 14) the dataset of Haddam (Data Citation 15) is annotated with the source of the individual census count. Amongst the 598 samples in the dataset, 125 are annotated with ‘French database, unpublished’, the remainder are labelled with either ‘MARGO database’ or ‘Cortese database’. In an attempt to avoid the problems that occurred with the addition of the Cortese dataset (Data Citation 14) to our compilation, we reduced the dataset of Haddam (Data Citation 15) to the 125 samples labelled as unpublished before processing. The sequential dereplication procedure retained only 45 out of these 125 samples as unique (before the manual dereplication step). Again, many of the retained samples have the same name as a sample from the MARGO dataset7 but a significantly different assemblage composition. Among the samples labelled ‘French database, unpublished’, many were identified to occur amongst the oldest census counts included in the initial CLIMAP (Data Citation 1) compilation. We can exclude the possibility of recounts (technical replicates) as the census counts are identical. Because we were unable to unambiguously identify which census counts in the dataset of Haddam (Data Citation 15) were unique, the dataset was excluded from the ForCenS compilation.
Additional Information
How to cite this article: Siccha, M. & Kucera, M. ForCenS, a curated database of planktonic foraminifera census counts in marine surface sediment samples. Sci. Data 4:170109 doi: 10.1038/sdata.2017.109 (2017).
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
References
Lima-Mendez, G. et al. Determinants of community structure in the global plankton interactome. Science 348, 6237 (2015).
Guiot, J. & de Vernal, A. Proxies In Late Cenozoic Paleoceanography, Chapter thirteen transfer functions: methods for quantitative paleoceanography based on microfossils. (Developments in marine geology, Elsevier, 2007).
Morey, A. E. et al. Planktonic foraminiferal assemblages preserved in surface sediments correspond to multiple environment variables. Quat. Sci. Rev. 24, 7-9 925–950 (2005).
CLIMAP Project Members. The Surface of the Ice-Age Earth. Science 191, 4231 1131–1137 (1976).
Williams, D. F. & Johnson, W. C. II Diversity of recent planktonic foraminifera in the southern Indian Ocean and Late Pleistocene paleotemperatures. Quaternary Research 5, 2 237–250 (1975).
Pflaumann, U. et al. Glacial North Atlantic: Sea-surface conditions reconstructed by GLAMAP 2000. Paleoceanography 18, 1065 (2003).
Kucera, M. et al. Multiproxy approach for the reconstruction of the glacial ocean surface (MARGO). Quaternary Science Reviews 24, 813–819 (2005).
Kucera, M. et al. Reconstruction of sea-surface temperatures from assemblages of planktonic foraminifera: multi-technique approach based on geographically constrained calibration data sets and its application to glacial Atlantic and Pacific Oceans. Quat. Sci. Rev. 24, 951–998 (2005).
Fraile, I. et al. Predicting the global distribution of planktonic foraminifera using a dynamic ecosystem model. Biogeosciences 5, 3 891–911 (2007).
Tittensor, D. P. et al. Global patterns and predictors of marine biodiversity across taxa. Nature 466, 1098–1102 (2010).
Allen, L. P. & Savage, V. M. Setting the absolute tempo of biodiversity dynamics. Ecol. Lett. 10, 7 637–646 (2007).
Anderson, D. M. & Archer, D. Glacial-interglacial stability of ocean pH inferred from foraminifer dissolution rates. Nature 416, 70–73 (2002).
Morard, R. et al. PFR2: a curated database of planktonic Foraminifera 18S ribosomal DNA as a resource for studies of plankton ecology, biogeography, and evolution. Mol. Ecol. Resour. 49, 1–14 (2015).
Hemleben, C., Spindler, M. & Anderson, R . Modern Planktonic Foraminifera (Springer New York, 1989).
Weiner, A. K. M., Weinkauf, M. F. G., Kurasawa, A., Darling, K. F. & Kucera, M. Genetic and morphometric evidence for parallel evolution of the Globigerinella calida morphotype. Mar. Micropaleontol. 114, 19–35 (2015).
Spezzaferri, S. et al. Fossil and genetic evidence for the polyphyletic nature of the planktonic foraminifera ‘Globigerinoides’, and description of the new genus. Trilobatus. PLoS ONE 10, 5 (2015).
Aurahs, R., Treis, Y., Darling, K. F. & Kucera, M. A revised taxonomic and phylogenetic concept for the planktonic foraminifer species Globigerinoides ruber based on molecular and morphometric evidence. Mar. Micropaleontol. 79, 1-2 1–14 (2011).
Weaver, P. P. Late Miocene to recent planktonic foraminifera from the north Atlantic: Deep sea drilling project Leg 94 (ed. Ruddiman, W. et al.). Init. Repts. DSDP 94 (2007).
Scott, G. H., Kennett, J. P., Wilson, K. J. & Hayward, B. W. Globorotalia puncticulata: Population divergence, dispersal and extinction related to Pliocene-Quaternary water masses. Mar. Micropaleontol. 62, 4 235–253 (2007).
Salgueiro, E. et al. Planktonic foraminifera from modern sediments reflect upwelling patterns off Iberia: Insights from a regional transfer function. Mar. Mic 66, 3-4 135–164 (2008).
Thompson, P. R., Bé, A. W. H., Duplessy, J. & Shackleton, N. J. Disappearance of pink-pigmented Globigerinoides ruber at 120,000 yr BP in the Indian and Pacific Oceans. Nature 280, 5723 554–558 (1979).
Pflaumann, U., Duprat, J., Pujol, C. & Labeyrie, L. SIMMAX: A modern analog technique to deduce Atlantic sea surface temperatures from planktonic foraminifera in deep-sea sediments. Paleoceanography 11, 1 15–35 (1996).
Cortese, G. et al. Southwest Pacific Ocean response to a warmer world: Insights from Marine Isotope Stage 5e. Paleoceanography 28, 3 585–598 (2013).
Crundwell, M., Scott, G., Naish, T. & Carter, L. Glacial-interglacial ocean climate variability from planktonic foraminifera during the Mid-Pleistocene transition in the temperate Southwest Pacific, ODP Site 1123. Paleogeogr., Paleoclim., Paleoecol 260, 202–229 (2008).
Haddam, N. et al. Improving past sea surface temperature reconstructions from the Southern Hemisphere oceans using planktonic foraminiferal census data. Paleoceanography 31, 6 822–837 (2016).
Data Citations
National Institute of Oceanography and Experimental Geophysics (OGS) National Institute of Oceanography and Experimental Geophysics (OGS) PANGAEA https://doi.org/10.1594/PANGAEA.5192 (2009)
Prell, W., Martin, A., Cullen, J., & Trend, M. NOAA https://www.ncdc.noaa.gov/paleo-search/study/5908 (1999)
Pflaumann, U. et al. PANGAEA https://doi.org/10.1594/PANGAEA.77352 (2003)
Kucera, M. et al. PANGAEA https://doi.org/10.1594/PANGAEA.227322 (2005)
Kucera, M. et al. PANGAEA https://doi.org/10.1594/PANGAEA.227323 (2005)
Barrows, T. T., & Juggins, S. PANGAEA https://doi.org/10.1594/PANGAEA.227317 (2005)
Hayes, A., Kucer, M., Kalle, N., Sbaffi, L., & Rohling, E. PANGAEA https://doi.org/10.1594/PANGAEA.738564 (2005)
Hüls, M. PANGAEA https://doi.org/10.1594/PANGAEA.55758 (1999)
Mohtadi, M., Hebbeln, D., & Marchant, M. PANGAEA https://doi.org/10.1594/PANGAEA.351143 (2005)
Mohtadi, M. PANGAEA https://doi.org/10.1594/PANGAEA.733339 (2010)
Salgueiro, E. et al. PANGAEA https://doi.org/10.1594/PANGAEA.743252 (2008)
Siccha, M., Trommer, G., Schulz, H., Hemleben, C., & Kucera, M. PANGAEA https://doi.org/10.1594/PANGAEA.877924 (2017)
Munz, P. et al. PANGAEA https://doi.org/10.1594/PANGAEA.853966 (2015)
Cortese, G. et al. PANGAEA https://doi.org/10.1594/PANGAEA.821243 (2013)
Haddam, N. et al. PANGAEA https://doi.org/10.1594/PANGAEA.860938 (2016)
Amante, C., & Eakins, B. W. NOAA https://doi.org/10.7289/V5C8276M (2009)
Siccha, M., & Kucera, M. PANGAEA https://doi.org/10.1594/PANGAEA.873570 (2017)
Locarnini, R. A. et al. NOAA http://iridl.ldeo.columbia.edu/SOURCES/.NOAA/.NODC/.WOA09/ (2010)
Acknowledgements
We thank M. Mohtadi and P. Munz for provision of unpublished data. The project benefited from community consultations and discussions in the SCOR/IGBP Working Group 138 ‘Planktonic foraminifera and ocean changes’. We thank the two referees for their constructive comments.
Author information
Authors and Affiliations
Contributions
M.S. conceived the study design and performed the sample processing procedures. M.K. initiated the study and contributed to the study design and manuscript. Both authors wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
ISA-Tab metadata
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files made available in this article.
About this article

Cite this article
Siccha, M., Kucera, M. ForCenS, a curated database of planktonic foraminifera census counts in marine surface sediment samples. Sci Data 4, 170109 (2017). https://doi.org/10.1038/sdata.2017.109
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/sdata.2017.109
This article is cited by
-
Biogeographic response of marine plankton to Cenozoic environmental changes
Nature (2024)
-
ForCenS-LGM: a dataset of planktonic foraminifera species assemblage composition for the Last Glacial Maximum
Scientific Data (2024)
-
Intrusion of Arabian Sea high salinity water and monsoon-associated processes modulate planktic foraminiferal abundance and carbon burial in the southwestern Bay of Bengal
Environmental Science and Pollution Research (2024)
-
Intermediate water circulation drives distribution of Pliocene Oxygen Minimum Zones
Nature Communications (2023)
-
Strong temperature gradients in the ice age North Atlantic Ocean revealed by plankton biogeography
Nature Geoscience (2023)
