
Abstract
Spiking neural networks (SNNs) incorporating biologically plausible neurons hold great promise because of their unique temporal dynamics and energy efficiency. However, SNNs have developed separately from artificial neural networks (ANNs), limiting the impact of deep learning advances for SNNs. Here, we present an alternative perspective of the spiking neuron that incorporates its neural dynamics into a recurrent ANN unit called a spiking neural unit (SNU). SNUs may operate as SNNs, using a step function activation, or as ANNs, using continuous activations. We demonstrate the advantages of SNU dynamics through simulations on multiple tasks and obtain accuracies comparable to, or better than, those of ANNs. The SNU concept enables an efficient implementation with in-memory acceleration for both training and inference. We experimentally demonstrate its efficacy for a music-prediction task in an in-memory-based SNN accelerator prototype using 52,800 phase-change memory devices. Our results open up an avenue for broad adoption of biologically inspired neural dynamics in challenging applications and acceleration with neuromorphic hardware.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout






Similar content being viewed by others

Data availability
Publicly available datasets were used and referenced with their descriptions in the paper.
Code availability
Open source frameworks were used for the implementation. Sample source code in TensorFlow is provided in the Supplementary Information.
References
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 1097–1105 (NeurIPS, 2012).
Szegedy, C. et al. Going deeper with convolutions. In 2015 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) 1–9 (IEEE, 2015); https://doi.org/10.1109/CVPR.2015. 7298594.
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (IEEE, 2016); https://doi.org/10.1109/CVPR.2016.90
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: unified, real-time object detection. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (IEEE, 2016); https://doi.org/10.1109/CVPR.2016.91
He, K. et al. in IEEE Int. Conf. on Computer Vision (ICCV) 2980–2988 (IEEE, 2017); https://doi.org/10.1109/ICCV.2017.322.
Sutskever, I., Vinyals, O. & Le, Q. V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems 3104–3112 (NeurIPS, 2014).
Amodei, D. et al. Deep Speech 2: end-to-end speech recognition in English and Mandarin. In Proc. 33rd Int. Conf. on on Machine Learning Vol. 48, 173–182 (JMLR, 2016).
Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Cho, K., van Merrienboer, B., Bahdanau, D. & Bengio, Y. On the properties of neural machine translation: encoder-decoder approaches. In Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8) (Association for Computational Linguistics, 2014).
Dayan, P. & Abbott, L. F. Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems (MIT Press, 2005).
Eliasmith, C. How to Build a Brain: A Neural Architecture for Biological Cognition (Oxford Univ. Press, 2013).
Gerstner, W., Kistler, W. M., Naud, R. & Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition (Cambridge Univ. Press, 2014).
Eliasmith, C. et al. A large-scale model of the functioning brain. Science 338, 1202–1205 (2012).
Rasmussen, D. & Eliasmith, C. A spiking neural model applied to the study of human performance and cognitive decline on Raven’s Advanced Progressive Matrices. Intelligence 42, 53–82 (2014).
Maass, W. On the computational power of Winner-Take-All. Neural Comput. 12, 2519–2535 (2000).
Maass, W., Natschläger, T. & Markram, H. Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531–2560 (2002).
Markram, H., Lübke, J., Frotscher, M. & Sakmann, B. Regulation of synaptic efficacy by coincidence of postsynaptic APs and EPSPs. Science 275, 213–215 (1997).
Song, S., Miller, K. D. & Abbott, L. F. Competitive Hebbian learning through spike-timing-dependent synaptic plasticity. Nat. Neurosci. 3, 919–926 (2000).
Moraitis, T. et al. Fatiguing STDP: learning from spike-timing codes in the presence of rate codes. In 2017 Int. Joint Conf. on Neural Networks (IJCNN) (IEEE, 2017); https://doi.org/10.1109/IJCNN.2017.7966072
Tuma, T., Pantazi, A., Le Gallo, M., Sebastian, A. & Eleftheriou, E. Stochastic phase-change neurons. Nat. Nanotechnol. 11, 693–699 (2016).
Woźniak, S., Tuma, T., Pantazi, A. & Eleftheriou, E. Learning spatio-temporal patterns in the presence of input noise using phase-change memristors. In IEEE Int. Symp. on Circuits and Systems (ISCAS) 365–368 (IEEE, 2016).
Pantazi, A., Woźniak, S., Tuma, T. & Eleftheriou, E. All-memristive neuromorphic computing with level-tuned neurons. Nanotechnology 27, 355205 (2016).
Tuma, T., Le Gallo, M., Sebastian, A. & Eleftheriou, E. Detecting correlations using phase-change neurons and synapses. IEEE Electron Device Lett. 37, 1238–1241 (2016).
Gütig, R., Aharonov, R., Rotter, S. & Sompolinsky, H. Learning input correlations through nonlinear temporally asymmetric Hebbian plasticity. J. Neurosci. 23, 3697–3714 (2003).
Diehl, P. U. & Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 9, (2015).
Sidler, S., Pantazi, A., Woźniak, S., Leblebici, Y. & Eleftheriou, E. Unsupervised learning using phase-change synapses and complementary patterns. In ENNS Int. Conf. on Artificial Neural Networks (ICANN) 281–288 (Springer, 2017).
Querlioz, D., Bichler, O. & Gamrat, C. Simulation of a memristor-based spiking neural network immune to device variations. In Int. Joint Conf. on Neural Networks (IJCNN) 1775–1781 (IEEE, 2011).
Bichler, O., Querlioz, D., Thorpe, S. J., Bourgoin, J.-P. & Gamrat, C. Extraction of temporally correlated features from dynamic vision sensors with spike-timing-dependent plasticity. Neural Netw. 32, 339–348 (2012).
Burbank, K. S. Mirrored STDP implements autoencoder learning in a network of spiking neurons. PLoS Comput. Biol. 11, 1–25 (2015).
Woźniak, S., Pantazi, A., Leblebici, Y. & Eleftheriou, E. Neuromorphic system with phase-change synapses for pattern learning and feature extraction. In Int. Joint Conf. on Neural Networks (IJCNN) (IEEE, 2017); https://doi.org/10.1109/IJCNN.2017.7966325
Mead, C. Neuromorphic electronic systems. Proc. IEEE 78, 1629–1636 (1990).
Meier, K. A mixed-signal universal neuromorphic computing system. In 2015 Int. Electron Devices Meet. (IEDM) 4.6.1–4.6.4 (IEEE, 2015); https://doi.org/10.1109/IEDM.2015.7409627.
Benjamin, B. V. et al. Neurogrid: a mixed-analog-digital multichip system for large-scale neural simulations. Proc. IEEE 102, 699–716 (2014).
Cassidy, A. S. et al. Real-time scalable cortical computing at 46 giga-synaptic OPS/Watt with ~100x speedup in time-to-solution and ~100,000x reduction in energy-to-solution. in Proc. Int. Conf. for High Performance Computing, Networking, Storage and Analysis 27–38 (IEEE, 2014). https://doi.org/10.1109/SC.2014.8.
Davies, M. et al. Loihi: a neuromorphic manycore processor with on-chip learning. IEEE Micro 38, 82–99 (2018).
Kuzum, D., Jeyasingh, R. G. D., Lee, B. & Wong, H.-S. P. Nanoelectronic programmable synapses based on phase change materials for brain-inspired computing. Nano Lett. 12, 2179–2186 (2012).
Burr, G. W. et al. Neuromorphic computing using non-volatile memory. Adv. Phys. X 2, 89–124 (2017).
Sebastian, A. et al. Tutorial: brain-inspired computing using phase-change memory devices. J. Appl. Phys. 124, 111101 (2018).
Chen, W. et al. A 65nm 1Mb nonvolatile computing-in-memory ReRAM macro with sub-16ns multiply-and-accumulate for binary DNN AI edge processors. In IEEE Int. Solid-State Circuits Conf. (ISSCC) 494–496 (IEEE, 2018); https://doi.org/10.1109/ISSCC.2018.8310400.
Mochida, R. et al. A 4M synapses integrated analog ReRAM based 66.5 TOPS/W neural-network processor with cell current controlled writing and flexible network architecture. In IEEE Symp. on VLSI Technology 175–176 (IEEE, 2018). https://doi.org/10.1109/VLSIT.2018.8510676.
Xue, C.-X. et al. A 1Mb multibit ReRAM computing-in-memory macro with 14.6 ns parallel MAC computing time for CNN based AI edge processors. In IEEE Int. Solid-State Circuits Conf. (ISSCC) 388–390 (IEEE, 2019); https://doi.org/10.1109/ISSCC.2019.8662395.
O’Connor, P., Neil, D., Liu, S.-C., Delbruck, T. & Pfeiffer, M. Real-time classification and sensor fusion with a spiking deep belief network. Front. Neurosci. 7, 178 (2013).
Diehl, P. U., Zarrella, G., Cassidy, A., Pedroni, B. U. & Neftci, E. Conversion of artificial recurrent neural networks to spiking neural networks for low-power neuromorphic hardware. In IEEE Int. Conf. on Rebooting Computing (ICRC) 1–8 (IEEE, 2016).
Hunsberger, E. & Eliasmith, C. Spiking deep networks with LIF neurons. Preprint at https://arxiv.org/abs/1510.08829 (2015).
Shrestha, A. et al. A spike-based long short-term memory on a neurosynaptic processor. In IEEE/ACM Int. Conf. on Computer-Aided Design (ICCAD) 631–637 (IEEE, 2017); https://doi.org/10.1109/ICCAD.2017.8203836.
Bohte, S. M., Kok, J. N. & La Poutré, H. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 48, 17–37 (2002).
Kulkarni, S. R. & Rajendran, B. Spiking neural networks for handwritten digit recognition—supervised learning and network optimization. Neural Netw. 103, 118–127 (2018).
Bengio, Y., Mesnard, T., Fischer, A., Zhang, S. & Wu, Y. STDP-compatible approximation of backpropagation in an energy-based model. Neural Comput. 29, 555–577 (2017).
Tavanaei, A. & Maida, A. BP-STDP: approximating backpropagation using spike timing dependent plasticity. Neurocomputing 330, 39–47 (2019).
Esser, S. K. et al. Convolutional networks for fast, energy-efficient neuromorphic computing. Proc. Natl Acad. Sci. USA 113, 11441–11446 (2016).
Lee, J. H., Delbruck, T. & Pfeiffer, M. Training deep spiking neural networks using backpropagation. Front. Neurosci. 10, 508 (2016).
Werbos, P. J. Generalization of backpropagation with application to a recurrent gas market model. Neural Netw. 1, 339–356 (1988).
Huh, D. & Sejnowski, T. J. Gradient descent for spiking neural networks. Adv. Neural Inform. Processing Syst. 31, 1433–1443 (2018).
Bellec, G., Salaj, D., Subramoney, A., Legenstein, R. & Maass, W. Long short-term memory and learning-to-learn in networks of spiking neurons. In Advances in Neural Information Processing Systems 787–797 (NeurIPS, 2018).
Wu, Y., Deng, L., Li, G., Zhu, J. & Shi, L. Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 12, 331 (2018).
Pfeiffer, M. & Pfeil, T. Deep learning with spiking neurons: opportunities and challenges. Front. Neurosci. 12, 774 (2018).
Ambrogio, S. et al. Unsupervised learning by spike timing dependent plasticity in phase change memory (PCM) synapses. Front. Neurosci. 10, 56 (2016).
Woźniak, S., Pantazi, A., Bohnstingl, T. & Eleftheriou, E. Deep learning incorporating biologically-inspired neural dynamics. Preprint at https://arxiv.org/abs/1812.07040 (2018).
Neftci, E. O., Mostafa, H. & Zenke, F. Surrogate gradient learning in spiking neural networks. Preprint at https://arxiv.org/abs/1901.09948 (2019).
Neftci, E. O., Mostafa, H. & Zenke, F. Surrogate gradient learning in spiking neural networks: bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 36, 51–63 (2019).
Hodgkin, A. L. & Huxley, A. F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 117, 500 (1952).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Marcus, M. P., Marcinkiewicz, M. A. & Santorini, B. Building a large annotated corpus of English: The Penn Treebank. Comput. Linguist 19, 313–330 (1993).
Boulanger-Lewandowski, N., Bengio, Y. & Vincent, P. Modeling temporal dependencies in high-dimensional sequences: application to polyphonic music generation and transcription. In Proc. 29th Int. Conf. on Machine Learning 1881–1888 (Omnipress, 2012).
Bengio, Y., Léonard, N. & Courville, A. Estimating or propagating gradients through stochastic neurons for conditional computation. Preprint at https://arxiv.org/abs/1305.2982 (2013).
Chollet, F. Deep Learning with Python (Manning, 2017).
Simard, P. Y., Steinkraus, D. & Platt, J. C. Best practices for convolutional neural networks applied to visual document analysis. In Proc. Seventh Int. Conf. on Document Analysis and Recognition Vol. 1, 958–963 (IEEE Comput. Soc., 2003).
Press, O. & Wolf, L. Using the output embedding to improve language models. in Proc. 15th Conf. Eur. Chap. Association for Computational Linguistics Vol. 2 Short Papers 157–163 (Association for Computational Linguistics, 2017).
Greff, K., Srivastava, R. K., Koutník, J., Steunebrink, B. R. & Schmidhuber, J. LSTM: a search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 28, 2222–2232 (2017).
Chung, J., Gulcehre, C., Cho, K. & Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In NIPS Workshop on Deep Learning (NeurIPS, 2014).
Papandreou, N. et al. Programming algorithms for multilevel phase-change memory. In IEEE Int. Symp. on Circuits and Systems (ISCAS) 329–332 (IEEE, 2011).
Burr, G. W. et al. Experimental demonstration and tolerancing of a large-scale neural network (165,000 synapses), using phase-change memory as the synaptic weight element. In 2014 IEEE Int. Electron Devices Meet. (IEDM) 29.5.1–29.5.4 (IEEE, 2014); https://doi.org/10.1109/IEDM.2014.7047135.
Gers, F. A., Schmidhuber, J. & Cummins, F. Learning to forget: continual prediction with LSTM. Neural Comput. 12, 2451–2471 (1999).
Nair, V. & Hinton, G. E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning 807–814 (Omnipress, 2010).
Maas, A. L., Hannun, A. Y. & Ng, A. Y. Rectifier nonlinearities improve neural network acoustic models. In ICML Workshop on Deep Learning for Audio, Speech and Language Processing (JMLR, 2013).
TensorFlow. An end-to-end open source machine learning platform; http://www.tensorflow.org.
Glorot, X. & Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Int. Conf. on Artificial Intelligence and Statistics 249–256 (2010).
Mikolov, T. Penn Treebank dataset; http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz.
Zaremba, W., Sutskever, I. & Vinyals, O. Recurrent neural network regularization. Preprint at https://arxiv.org/abs/1409.2329 (2014).
Close, G. F. et al. Device, circuit and system-level analysis of noise in multi-bit phase-change memory. In IEEE Int. Electron Devices Meeting (IEDM) 29.5.1–29.5.4 (IEEE, 2010); https://doi.org/10.1109/IEDM.2010.5703445.
Nandakumar, S. R. et al. A phase-change memory model for neuromorphic computing. J. Appl. Phys. 124, 152135 (2018).
Gallo, M. L., Sebastian, A., Cherubini, G., Giefers, H. & Eleftheriou, E. Compressed sensing with approximate message passing using in-memory computing. In IEEE Trans. Electron Devices 1–9 (2018); https://doi.org/10.1109/TED.2018.2865352.
Nandakumar, S. R. et al. Mixed-precision architecture based on computational memory for training deep neural networks. In IEEE Int. Symp. on Circuits and Systems (ISCAS) 1–5 (IEEE, 2018); https://doi.org/10.1109/ISCAS.2018.8351656.
Stimberg, M., Brette, R. & Goodman, D. F. M. Brian 2, an intuitive and efficient neural simulator. eLife 8, e47314 (2019).
Kheradpisheh, S. R., Ganjtabesh, M. & Masquelier, T. Bio-inspired unsupervised learning of visual features leads to robust invariant object recognition. Neurocomputing 205, 382–392 (2016).
Lee, C., Panda, P., Srinivasan, G. & Roy, K. Training deep spiking convolutional neural networks with STDP-based unsupervised pre-training followed by supervised fine-tuning. Front. Neurosci. 12, 425 (2018).
Mikolov, T., Kombrink, S., Burget, L., Cernocky, J. & Khudanpur, S. Extensions of recurrent neural network language model. In IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP) 5528–5531 (IEEE, 2011); https://doi.org/10.1109/ICASSP.2011.5947611.
Acknowledgements
We thank U. Egger for assistance with the setup, R. Khaddam-Aljameh for assistance in the analysis of the energy consumption and the computation time of a PCM crossbar array in 14-nm CMOS technology, M. Dazzi and M. Stanisavljevic for assistance in the system-level analysis of the energy consumption and the computation time, M. Stanisavljevic for assistance in the design of digital circuitry implementing both artificial and spiking neurons, N. Gustafsson for editing the manuscript, O. Simeone, B. Rajendran and N. S. Rajalekshmi for comments on the initial draft, W. Maass, E. Neftci and colleagues from IBM’s Neuromorphic and In-Memory Computing team for discussions.
Author information
Authors and Affiliations
Contributions
S.W. and A.P. conceived the idea of SNU. E.E. and A.P. proposed the idea of in-memory acceleration based on SNUs. S.W., A.P. and E.E. designed the benchmarks. S.W. implemented and performed the software benchmarks. T.B. implemented the hardware in-the-loop functionality and performed the experiments. All authors developed the biologically inspired functional extensions. T.B. and E.E. analysed the stability of the gradient-based training. All authors analysed the results. S.W., A.P. and E.E. co-wrote the manuscript. All authors compiled the Supplementary Notes. E.E. supervised the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended Data
Extended Data Fig. 1 Correspondence between an SNU and an LIF neuron.
a, The respective LIF parameters directly correspond to the SNU parameters, such that the same set of parameter values can be used in an SNU-based network, implemented by utilizing standard ANN frameworks, as well as in a native LIF-based implementation, utilizing standard SNN frameworks. b, To demonstrate this, we used TensorFlow78 to produce sample plots of the spiking dynamics for a single SNU. The state variable of the SNU increases each time an input spike arrives at the neuron, and decreases following the exponential decay dynamics. When the spiking threshold is reached, an output spike is emitted (vertical dashed line) and the membrane potential is reset. These dynamics are aligned with the reference LIF dynamics, which we obtained for the corresponding parameters by running a simulation in the well-known Brian286 SNN framework.
Extended Data Fig. 2 Training an SNU with backpropagation through time.
The temporal dynamics of an SNU are unfolded over time during the forward pass, and error gradients are propagated backwards through the computational graph to determine the parameters’ adjustments during the backward pass.
Extended Data Fig. 3 Image classification details.
a, Complete spiking CNN architecture. b, CNN learning curve for rate-coded inputs without preprocessing. The accuracy was calculated by averaging over ten different initializations (vertical brackets) or over the last 50 epochs (horizontal brackets). c, Analogous CNN learning curve for rate-coded inputs obtained from MNIST images preprocessed with elastic distortions. d, Table comparing the state-of-the-art fully-connected (FC) and convolutional (CNN) SNN architectures27,46,49,53,57,87,88 in terms of parameters and obtained MNIST accuracy.
Extended Data Fig. 4 Sequence prediction details.
The values in all the panes of this figure were obtained by averaging over ten different initializations. Standard deviation is reported along the results and marked with error bars in the plots. a, Language modelling training perplexity evolution for SNU- and sSNU-based architectures. b, Comparison of test perplexity with other results70,81,89. ANN results using standard architectures with similar training techniques were considered, that is no pre- or post-processing, single network, truncated BPTT, no dropout. WT denotes weight tying of the output layer with the embedding layer. c, Music prediction loss evolution for sSNU-based network. d, Comparison with other results71,72.
Extended Data Fig. 5 Impact of limited precision for the handwritten digit recognition dataset.
Final test performance of a neural network using a, sSNUs and b, LSTMs. The numbers below the test performance indicate the standard deviation over five different runs.
Extended Data Fig. 6 Schematic diagram of the experimental setup.
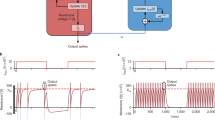
a, The network architecture is designed using SNUs and standard tools from the TensorFlow framework. The training is performed in the same way as in other networks: a loss function is defined, and an optimizer is configured to minimize it using gradient descent. b, A wrapper provides functions to read and write the weights similarly to any regular TensorFlow variable. These functions manage the communication with the hardware through a Python-MATLAB interface that translates the read or write requests into FPGA commands, and converts conductance values obtained from the FPGA board back to TensorFlow. The writing can be performed without rereading the updated values from the hardware: steps 3 and 4 are optional. c, The FPGA board interacts with the prototype chip holding the PCM devices (not at scale): indirectly, through the Analog Front-End Board, to provide the power supply, and to clock and generate the current pulses; and directly, to control the chip operation and read conductance values from the on-chip analog-to-digital converter. d, An inference example: information about a chord propagates through the network with spikes to the sigmoidal output layer that generates next notes’ probabilities. e, At each layer, the weights of activated 2-PCM synapses are constructed from f, and conductance values are returned by the on-chip analog-to-digital converter.
Extended Data Fig. 7 Hardware experiment details.
a, A 2-PCM synapse is implemented with two PCM devices operating in a differential configuration, that is a weight w is proportional to the difference between the conductances of the G + and the G- device. Weight increase is performed through crystallization of the positive device with programming pulses and weight decrease is performed through crystallization of the negative device with programming pulses. The plot on the left contains an example of an evolution of the 2-PCM synapse over the course of training. Aside from programming pulses, the fluctuations in the conductance values arise owing to PCM-specific physical phenomena, such as read noise or conductance drift. b, Snapshots of the weight distributions over the course of training, depicted for the two trainable layers.
Supplementary information
Supplementary Information
Supplementary Notes
Supplementary software
Source code
Rights and permissions
About this article

Cite this article
Woźniak, S., Pantazi, A., Bohnstingl, T. et al. Deep learning incorporating biologically inspired neural dynamics and in-memory computing. Nat Mach Intell 2, 325–336 (2020). https://doi.org/10.1038/s42256-020-0187-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s42256-020-0187-0
This article is cited by
-
Mosaic: in-memory computing and routing for small-world spike-based neuromorphic systems
Nature Communications (2024)
-
Accurate online training of dynamical spiking neural networks through Forward Propagation Through Time
Nature Machine Intelligence (2023)
-
On the visual analytic intelligence of neural networks
Nature Communications (2023)
-
Echo state graph neural networks with analogue random resistive memory arrays
Nature Machine Intelligence (2023)
-
An ultrasmall organic synapse for neuromorphic computing
Nature Communications (2023)
