
Abstract
Contagion phenomena are often the results of multibody interactions—such as superspreading events or social reinforcement—describable as hypergraphs. We develop an approximate master equation framework to study contagions on hypergraphs with a heterogeneous structure in terms of group size (hyperedge cardinality) and of node membership (hyperdegree). By mapping multibody interactions to nonlinear infection rates, we demonstrate the influence of large groups in two ways. First, we characterize the phase transition, which can be continuous or discontinuous with a bistable regime. Our analytical expressions for the critical and tricritical points highlight the influence of the first three moments of the membership distribution. We also show that heterogeneous group sizes and nonlinear contagion promote a mesoscopic localization regime where contagion is sustained by the largest groups, thereby inhibiting bistability. Second, we formulate an optimal seeding problem for hypergraph contagion and compare two strategies: allocating seeds according to node or group properties. We find that, when the contagion is sufficiently nonlinear, groups are more effective seeds than individual hubs.
Similar content being viewed by others
Introduction
Mathematical models of contagion processes enhance our understanding of spreading dynamics and our predictive capabilities1. To account for the interconnected nature of real-world systems, the past two decades of network science and computational epidemiology research have focused on modeling frameworks of increasing complexity1,2,3. From the spreading of infectious diseases to rumors and innovations4,5,6, a crucial aspect remains the interplay between the contact patterns enabling transmission and the dynamics that unfolds on top. As a representation for these contacts, graphs have been widely exploited to better represent real-world patterns with increasing levels of accuracy1,2,7.
While graphs remain a reference for the representation of complex systems, they come with a fundamental limitation: they can only encode pairwise interactions (represented by edges). Groups are instead the foundational units of many biological, ecological and social systems, whose processes can involve multibody interactions between any number of elements. To overcome this limitation, higher-order network representations8 are becoming more and more popular9,10,11,12 to describe the structure of interacting systems13,14, their growth15,16,17,18, and dynamics in groups19,20,21. Simplicial complexes and hypergraphs can encode relationships and interactions between any number of elements. They have been used to investigate the implications of higher-order interactions for landmark dynamical processes like synchronization22,23,24, diffusion25,26,27, and other social dynamics28,29,30. Battiston et al.11 provide a comprehensive review of early efforts in this direction.
Recently, a model of simplicial contagion has been proposed31. This is a standard Susceptible-Infected-Susceptible (SIS) compartmental model in which a susceptible individual can become infected through different transmission channels, beyond infectious edges. In models of simple contagion, the transition from susceptible to infected happens independently with each exposure to an infectious edge1. In models of complex contagion instead32, the transition requires multiple infectious edges or is reinforced by multiple exposures, thus accounting for the empirically observed mechanisms of social influence33,34,35,36. In simplicial contagions, or more generally hypergraph contagions, a susceptible individual can become infected because of a multibody process, i.e., through exposure to an infectious group31. In this way, the node is simultaneously exposed to the state of the entire group, whose effect can be interpreted as a mechanism of social reinforcement33. In addition, the study of higher-order contagion models has applications as well in biological sciences: it has indeed recently been shown that the combination of multibody interactions, heterogeneous temporal activity, and the concept of a minimal infective dose lead to nonlinear infection kernels in a model of biological contagions37.
The analytical approaches derived so far have confirmed the rich phenomenology emerging from the contagion dynamics, characterized by discontinuous phase transitions, bistability, and critical mass effects31,38,39,40,41,42. Most approaches follow a heterogeneous mean-field (HMF) framework in which nodes are divided into hyperdegree classes. These descriptions are analytically tractable, but do not consider the details of the structure and ignore the dynamical correlations within groups, which are especially important for hypergraph contagions since multibody interactions naturally reinforce these correlations.
Other approaches like quenched mean-field theory43 and microscopic Markov-chains44 can explicitly take the entire contact patterns into account. Along this line, the microscopic epidemic clique equations capture dynamical correlations as well, thereby highlighting the important impact these correlations have on critical points45. The analytical tractability of these approaches is, however, sacrificed in favor of a more precise description of the structure. To fully understand the consequences of multibody interactions in contagions on higher-order networks, we thus need a framework that is both analytically tractable and captures dynamical correlations.
In particular, we are interested in better understanding the notion of influence in hypergraph contagions. In classic contagion models on random networks, individual hubs are influential in the sense that they are the best seeds of contagions, but they are also the most apt at sustaining seeded contagions46. However, in hypergraph contagions, we must consider the influence of both individuals and groups, because dynamical correlations can allow groups to be more influential than sets of uncorrelated hubs. Regimes of bistability and hysteresis also imply a potential decoupling between the ability of nodes to seed a contagion and their ability to sustain it. We thus wish to determine (i) which set of groups can best maintain the stationary state of a hypergraph contagion, and when this becomes a dominant effect (ii) which set of groups and their configuration offer optimal initial conditions for a contagion, as compared to the classic notion of influential spreaders as individual hubs, and (iii) whether or not these two notions of group influence are aligned.
In this work, we use approximate master equations (AMEs)20,21,47,48,49,50 to study hypergraph contagions, capturing exactly the inner dynamics of groups. We consider a model where the infection rate is a nonlinear function of the number of infected nodes in groups. First, we provide a detailed characterization of the phase transition and derive analytical expressions for the critical and tricritical points. We find that large values for the third moment of the membership (hyperdegree) distribution suppress the emergence of a discontinuous phase transition. Furthermore, we show that heterogeneous group sizes and superlinear contagion facilitate the onset of a mesoscopic localization regime49,50, where contagion is sustained by the largest groups, and, incidentally, inhibit bistability. Second, we define and solve an influence maximization problem based on two strategies: allocating seeds according to either node individual properties or according to group properties. When the contagion is sufficiently nonlinear, the latter is more effective. Altogether, our results highlight the role of influential groups to drive both the stationary state of contagion on hypergraphs and its behavior in the transient state.
Results
Hypergraph contagion model
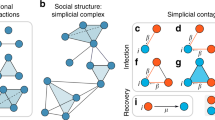
In the original version of the simplicial contagion model31, the spreading process takes place on a simplicial complex [see Fig. 1] and obeys the following rule. If all nodes in a d-simplex are infected except a susceptible one, this remaining node gets infected at a rate βd, and also receives contributions from the lower-dimensional simplices included in the d-simplex with rates respectively equal to βd−1, …, β1. For instance, in Fig. 1, two of the three nodes composing a 2-simplex are infected, hence the susceptible node gets infected at rate 2β1 + β2, considering the contributions both from the two edges and from the “triangle.”

We use a bipartite representation, where nodes (white circles) belong to groups (black circles). A facet of dimension n − 1 is mapped onto a group of size n. In the simplicial contagion model, contributions from higher-order interactions are taken into account by additional transmission rates (e.g., β2 for the 2-simplex) when all but one node of the simplex are infected31. With our hypergraph representation, infections within a group are simply modeled by a general infection function β(n, i) that depends on both the size n of the group and the number i of infected nodes in the group (with i ≤ n).
A simplicial complex is a specific type of hypergraph, and thus we can always map the former on the latter—note that the reverse direction is not always possible. To do so, each facet—a simplex that is not a face of any larger simplex—is represented by a single hyperedge (group). In this paper, we relax the requirement of the simplicial complex in favor of a more general hypergraph structure. We make use of the bipartite representation of hypergraphs8,11, in which the two sets of nodes of the bipartite graph correspond respectively to the sets of nodes and groups of the original hypergraph, as illustrated in Fig. 1.
The size n of a group corresponds to the number of nodes belonging to this group, and it is therefore equivalent to the hyperedge cardinality. Note that a d-simplex consist of d + 1 nodes and is therefore mapped onto a group of size n = d + 1. Similarly, the membership m of a node, the node hyperdegree, corresponds to the number of groups to which it belongs, regardless of their size.
The hypergraph contagion model is defined as follows: for a group of size n, where i ≤ n members are infected, each of the n − i susceptible nodes gets infected at rate β(n, i). For susceptible nodes that belong to multiple groups, their total transition rate to the infected state is simply the sum of the infection rates associated with each group to which they belong—in other words, the infection processes are independent. All infected nodes transition back to the susceptible state at the same constant recovery rate μ.
Notice that the hypergraph contagion model allows representing any type of simplicial contagion. For instance, in the simplicial contagion model case of Fig. 1, we would use β(3, 2) = 2β1 + β2. In fact, the description offered by the infection rate function β(n, i) yields a variety of models more general than the original simplicial contagion—in which a function β(i) would be sufficient to encode contributions from facets of any dimension.
In all our case studies, we will use an infection rate function of the form
However, many results we derive hold true for a general infection rate function β(n, i). The parameter ν controls the nonlinearity of the contagion. A linear contagion is recovered by setting ν = 1, which is equivalent to a standard SIS model on networks, where each group is a clique20. We intentionally chose the infection rate function independent of n to focus on the impact of a nonlinear dependence on i; it would be straightforward to generalize the results by considering β(n, i) ↦ Λ(n)iν.
The infection rate function in Eq. (1) is the simplest nonlinear generalization of standard epidemiological models, where β(n, i) ∝ i. Moreover, we can motivate the choice of exponents ν ≠ 1 in the context of social contagions, by comparing our approach to the original formulation of the simplicial contagion model. A value of β2 > 0 in Fig. 1 represents social reinforcement31, and to correctly map the infection rate for a triangle, we need to use an exponent ν > 1 in our model. Similarly, a value β2 < 0 represents social inhibition, and this case can be obtained with an exponent ν < 1.
Another motivation for the infection rate function at Eq. (1) is a recent study that shows this general form emerges in the occurrence of heterogeneous temporal patterns37. More specifically, if you consider that the participation time of nodes—representing individuals—to higher-order interactions is distributed according to a power law and that individuals become infected according to a threshold mechanism based on the dose received in the interaction, then the probability for a node to get infected in a group is ∝iν, where ν is related to the temporal heterogeneity. In the continuous time limit, one recovers the infection rate function defined at Eq. (1).
The infection mechanism is motivated in the context of biological contagions37, where the infective dose received could represent viral particles for instance, and the threshold would correspond to the minimal infective dose to develop a disease. While such types of complex contagions are rarely used in the context of biological contagions, they could help explain certain observed phenomena, such as super-exponential spread for certain diseases51. Moreover, threshold models are very common in social contagions33,52,53,54, thus Eq. (1) could be interpreted as an effective mechanism of social spread accounting for heterogeneous temporal patterns.
Group-based AMEs
To describe hypergraph contagions, we make use of group-based AMEs20,21,49,50. This means that we do not rely on specific hypergraph realizations. Instead, we assume that the structure is drawn from a random hypergraph ensemble described by the distributions pn, for the size n of a group, and gm, for the membership m of a node. Each of the m membership stubs of a node is assigned uniformly at random to a group available spot. Therefore, the membership m of a node and the sizes of the groups to which it belongs are uncorrelated.
To track the evolution of a contagion process on this ensemble of hypergraphs, we define two sets of quantities: sm(t), representing the fraction of nodes with membership m that are susceptible at time t and fn,i(t), the fraction of groups of size n having i infected members at time t. The last quantity can also be interpreted as a conditional probability (of observing i infected nodes in a group of size n) satisfying the normalization condition ∑ifn,i = 1.
We further define two mean-field quantities. First, let us take a random susceptible node. The mean-field infection rate resulting from a random group to which it belongs is defined as
Indeed, the joint distribution for the size n and the number of infected nodes i in this group is proportional to (n − i)fn,ipn, and we just average β(n, i) over this distribution.
Second, let us randomly choose a susceptible node inside a group. The mean-field infection rate caused by all the external groups to which the susceptible node belongs (excluding the one from which we picked the node) can be written as
To obtain ρ(t), we assume that infections coming from different groups are independent processes. We multiply r(t) with the mean excess membership of a susceptible node, i.e., if we pick a susceptible node in a group, it is the expected number of other groups to which it belongs. Since the membership distribution of a susceptible node picked in a group is proportional to msm(t)gm, we simply average m − 1, its excess membership, over this distribution.
Using the definitions in Eqs. (2) and (3), we can write the following system of AMEs
This system is composed of \({{{{{{{\mathcal{O}}}}}}}}({n}_{\max }^{2}+{m}_{\max })\) equations. It is approximate in the sense that the evolution of the fractions of infected nodes of membership m, sm, are treated in a mean-field fashion (still considering dynamic correlations between pairs node-group), while the evolution equations of the fn,i are treated as master equations. In the right-hand side of Eq. (4b), the first two terms are due to the recovery process, and the last two to the infection. The infection rate due to infected nodes inside the group is exact, while the infection rates associated with external groups (the terms making use of ρ) are treated in an approximate way. Without loss of generality (up to a change of time scale) we set μ ≡ 1 for the remainder of the document.
From Eqs. (4a)-(4b), we can calculate the global prevalence
and the group prevalence
which correspond to the average fraction of infected nodes in the whole system and within groups of size n respectively.
In the stationary state, we obtain the following self-consistent relations:
The latter equation can be simplified by noting that \({f}_{n,i}^{* }\) must respect detailed balance in the stationary state, i.e.,
expressing that the probability to decrease the number of infectious nodes in a group of size n from i + 1 to i by a recovery process is equal to the probability of the opposite change (from i to i + 1 infectious nodes) obtained through a contagion event. We thus finally obtain
where fn,0 = 1 − ∑i>0fn,i.
Comparison with simulations
We provide a comparison of our approach with Monte Carlo simulations. To do this, we consider empirical higher-order structures constructed from real-world data and their randomized counterparts. Details on the simulations and the data collection and aggregation are provided in the subsection “Contagion on real-world hypergraphs” in “Methods”.
The motivation for this a priori validation is threefold: first, it allows us to illustrate the validity and accuracy of our analytical framework when our assumptions are met—namely when the structure is drawn from an ensemble of uncorrelated hypergraphs with fixed gm and pn. Second, because of the excellent agreement with simulations for random hypergraphs, we omit further comparison with Monte Carlo simulations for the many results we present in the following sections. Finally, it showcases the possible sources of discrepancies—and how our results could vary—when considering real datasets.
In Fig. 2, we show the phase diagram, i.e., the fraction I* of infectious nodes in the stationary state, of contagion dynamics on hypergraphs that encode higher-order social (face-to-face) interactions between individuals from a primary school in Lyon. Both the membership and group size distributions are homogeneous for this dataset. We considered linear contagion (ν = 1), equivalent to the standard SIS model, and superlinear contagion (ν = 4). In both cases, our analytical formalism (continuous lines) agrees quite well with the Monte Carlo simulations (symbols) on the original (empirical) hypergraph [Fig. 2a]. The main source of errors for the observed discrepancy can be attributed to structural correlations, which do not appear to affect the threshold values but reduce the stationary prevalence. Indeed, in Fig. 2b, the agreement improves by randomizing the hypergraph while preserving the memberships and the group sizes. The remaining discrepancies are due to the fact that simulations are affected by finite-size effects, while our formalism assumes an infinite size system: the agreement becomes almost perfect in Fig. 2c by additionally increasing the size of the hypergraph by a factor of 10.

See “Contagion on real-world hypergraphs" in “Methods.” The hypergraph contains 242 nodes and 1188 groups. Both the membership and the group size distributions are homogeneous, with 〈m〉 ≈ 11.79, 〈n〉 ≈ 2.40, \({m}_{\max }=32\), and \({n}_{\max }=5\). We compare the results of Monte Carlo simulations (symbols) with the predictions of our approach (solid and dashed lines for stable and unstable solutions, respectively) for the fraction I* of infectious nodes in the stationary state. Note that in the “Phase transition" subsection in the main text, we omit the asterisk for stationary quantities to simplify the notation. The infection rate function is β(n, i) = λiν, where ν controls the nonlinearity of the contagion. We rescale λ with the invasion threshold λc, which is computed using Eq. (15). The symbols represent the average infected fraction measured over long runs and averaged over randomized hypergraphs when this applies. The error bars (sometimes too small to be seen) correspond to one standard deviation. The green circles are obtained with the quasistationary-state method, starting with a large fraction of infected nodes (I = 0.8) to sample the upper branch of the hysteresis loop when the phase transition is discontinuous. We use a the original hypergraph, b 10 uniformly randomized versions of the original hypergraph, or c 10 uniformly randomized versions of the original hypergraph with its size expanded by a factor of 10, with either linear (ν = 1) or superlinear contagion (ν = 4). For superlinear contagion in c, the blue triangles are obtained by ordinary simulations, starting with a small fraction of infected nodes (I = 0.02) to sample the lower branch of the hysteresis loop. We only do it for the expanded hypergraphs because finite-size effects make unreliable the estimation of the lower branch for small hypergraphs.
Let us remark that the error is more important for ν = 4 on the original hypergraph [Fig. 2a], which suggests that structural correlations have a greater effect on nonlinear contagions. In Supplementary Note 1, we show how to generalize our framework to account for structural correlations.
We also considered a completely different dataset, which represents coauthorship relations in computer science publications, obtained from major journals and proceedings in the field. The resulting hypergraph is considerably larger than the previous one, and it also presents a very different structure. The results are shown in Fig. 3, where we plot the same phase diagram curves as in Fig. 2, using a superlinear contagion (ν = 2). In this case, however, the membership distribution is heterogeneous [Fig. 3a], approximately of the form \({g}_{m} \sim {m}^{-{\gamma }_{m}}\) with γm ≈ 2.3, while the group size distribution is more homogeneous [inset of Fig. 3a], but still extends to rather large values with \({n}_{\max }=25\). By comparing the results for the original hypergraph [Fig. 3b] against those for a randomized ensemble [Fig. 3c], we see that structural correlations account for the major part of the discrepancies between simulations and theory, affecting both the invasion threshold and the stationary prevalence. However, Fig. 3c shows that structural correlations are not the only source of errors at high prevalence.

See “Contagion on real-world hypergraphs" in “Methods.” The hypergraph has been obtained by using a breadth-first search to extract a subhypergraph of 57,501 nodes and 55,204 groups; the original data contained more than 106 nodes and groups. a The membership distribution is heterogeneous, approximately of the form \({g}_{m} \sim {m}^{-{\gamma }_{m}}\) with 〈m〉 ≈ 3.75 and \({m}_{\max }=903\), while the group size distribution (inset) is more homogeneous, with 〈n〉 ≈ 3.90 and \({n}_{\max }=25\). b, c We compare the results of Monte Carlo simulations (circle markers) with the predictions of our approach (solid lines). The infection rate function is β(n, i) = λiν. We rescale λ with the invasion threshold λc, which is computed using Eq. (15). The infected fraction I* has been obtained as averages over time with long runs (and averaging over randomized hypergraphs when this applies). The error bars (too small to be seen) correspond to one standard deviation. We used ordinary simulations, starting with I = 0.8. b We use the original hypergraph. c We use 10 uniformly randomized versions of the original hypergraph.
Let us recall that our formalism correctly captures the dynamical correlations within a group through a master equation description [Eq. (4b)] of the possible states, but it does not capture the dynamical correlations around nodes, since we use a HMF description [Eq. (4a)]. These correlations become especially important in the presence of hubs with a large membership, which is the case for the hypergraph considered in Fig. 3. In fact, when we use the same group size distribution as in Fig. 3, but with a more homogeneous membership distribution, the discrepancy at high prevalence disappears (see Supplementary Note 2).
Phase transition
In this section, we unveil the important role of influential groups in the phase transition of hypergraph contagions. We first derive a general expression for critical points, marking the limit of the domain of validity of a stationary solution. Secondly, we obtain an expression for tricritical points, indicating when the phase transition switches from continuous to discontinuous, and a bistable regime appears. These results are valid for any infection rate function such that β(n, i) > 0 for all i > 0 (see Supplementary Note 3 for a consideration of threshold models).
We then concentrate our study on the infection rate function β(n, i) = λiν. This allows us to define important threshold values, the invasion threshold λc above which the disease-free solution I* = 0 is unstable, and the bistability threshold νc, the smallest nonlinear exponent allowing for a discontinuous phase transition. In particular, we will show how heterogeneous membership and group size distributions alter these thresholds, especially in the presence of a mesoscopic localization driven by influential groups.
In the following, we assume that the system has reached the stationary state and we drop the asterisk to simplify the notation throughout this section.
Critical points and the invasion threshold
Equations (7a) and (8) imply that each sm and fn,i can be written in terms of r and ρ. In turn, r and ρ can be written in terms of sm and fn,i through Eqs. (2) and (3), which means the stationary solutions are determined by a set of self-consistent equations.
Satisfying all self-consistent equations means we can reexpress all quantities (sm, fn,i, ρ, r) as functions of a single mean-field quantity, which we choose to be r. sm(r) is given by Eq. (7a), and ρ(r) is given by Eq. (3), which is rewritten as
fn,i is more simply written as a composite function, fn,i[ρ(r)], given by Eq. (8). Finally, r itself must satisfy Eq. (2), which we can write as \(r={{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\) where
This relation is used to solve numerically for the fixed points and evaluate their stability (see Supplementary Note 4).
In Fig. 4, the stationary solutions correspond to the intersections of \({{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\) (solid lines) and r (dashed line). We see that r = 0 is always a solution, while the solution r > 0 only exists for certain values of the parameter λ. This indicates the presence of a critical point.

Each intersection with the dashed line represents a stationary solution of Eqs. (7a)-(7b). Results refer to the infection rate function β(n, i) = λiν and a hypergraph with gm = (δm,2 + δm,3)/2 and pn = (δn,4 + δn,5)/2. a We fix ν = 1 and vary λ. For λ > λc, a nontrivial solution emerges. b We fix λ = λc and vary ν. Note that the slope of all solid lines is 1 at the origin. A nonlinear exponent ν > νc is associated with a discontinuous phase transition, since \({\partial }_{r}^{2}{{{{{{{\mathcal{M}}}}}}}} \, > \,\, 0\) in this case.
Critical points mark the limit of the domain of validity of a solution to the equation \(r={{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\). They arise when r is tangent to \({{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\), which implies
as can be seen in Fig. 4a, where \({{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\) is tangent to r at the point r = 0 for some value λ = λc.
Note that, for an infection rate function of two parameters, like β(n, i) = λiν, we have critical points when one of the parameters (and the structure) is kept fixed, but in general we have critical lines when both parameters can vary. For instance, in Fig. 4b, r is tangent to \({{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\) at r = 0 for different values of ν. Hence, there exists a critical line λ = ϕ(ν) where \({\partial }_{r}{{{{{{{\mathcal{M}}}}}}}}{| }_{r = 0}=1\).
When the tangent point r > 0, Eq. (11) needs to be solved numerically. However, when the solution r → 0, we are able to obtain an analytical expression. In this limit, we expect to have sm → 1, ρ → 0 and fn,i → δi,0 ∀ n, i.e., all nodes are susceptible. Therefore, from Eq. (9) we have
where \( \langle \cdots \rangle\) stands for the expectation value with respect either to gm or pn. From Eq. (10) (and using the fact that β(n, 0) ≡ 0) we also obtain
To evaluate hn,i, we apply the derivative d/dρ to Eq. (8). We obtain hn,1 = n and
Also, ∑ihn,i ≡ 0 as ∑ifn,i = 1, hence
Combining Eqs. (12)–(14) with Eq. (11), we obtain the following implicit expression for critical points (or lines) in the limit r → 0
For the infection rate function β(n, i) = λiν, Eq. (15) allows us to define the invasion threshold λc, i.e., the critical value of λ marking the limit of the validity for a solution r → 0. This solution is not always stable, but we always have that the trivial solution r = 0, corresponding to I = 0, is unstable for all λ > λc. This is illustrated in Fig. 5a, b for regular hypergraph structures with fixed membership and group size. The invasion threshold depends on both the structure (gm, pn) and the nonlinear exponent ν. The resulting phase diagram in the (λ, ν) plane is shown in Fig. 5c. The invasion threshold spans the critical line (solid line) λ = λc in the phase diagram.

The membership and group size distributions are of the form \(({g}_{m},{p}_{n})=({\delta }_{m,{m}_{0}},{\delta }_{n,{n}_{0}})\). The infection rate function is β(n, i) = λiν. Solid and dashed lines in a, b represent stable and unstable solutions, respectively, for the stationary fraction of infected nodes. a ν = 1.8, but different structures were used, with a node always having the same number of different neighbors. From bottom to top, we have (gm, pn) = (δm,6, δn,3), (δm,4, δn,4), and (δm,3, δn,5). Note that for the middle curve (δm,4, δn,4), νc ≈ 1.81. b The hypergraph structure is fixed with gm = δm,3 and pn = δn,4. Values of \(\nu \in \left\{1.5,1.7,{\nu }_{{{{{{{{\rm{c}}}}}}}}},2.1,2.3\right\}\) (bottom to top curves) were used, with νc ≈ 1.91. c Phase diagram for the same hypergraph as in b. The dashed critical line (λ = λp) and the solid critical line (λ = λc) coalesce at the tricritical point (λc, νc) indicated by the star marker.
The dashed critical line λ = λp is associated with the limit of validity of a solution where \({{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\) is tangent to r for some r > 0—it is thus solved numerically. We call λp the persistence threshold as it is the smallest value of λ such that a nontrivial solution is locally stable. For continuous phase transitions, λc = λp, but for discontinuous phase transitions, λp < λc.
Tricritical points and the bistability threshold
Depending on the structure and the form of β(n, i), we can have a continuous or a discontinuous phase transition, as can be seen in Fig. 5. When the phase transition is continuous, we have possibly two solutions for the stationary fraction of infected nodes, I1 = 0 and I2 > 0. When I2 exists (for instance when λ > λc), I1 is unstable.
When the phase transition is discontinuous, we have typically three solutions, I1 = 0 and 0 < I2 < I3. In the bistable regime [for instance, when λ ∈ (λp, λc)], all three solutions coexist, I2 is unstable, and I1 and I3 are locally stable. In the endemic regime [for instance, when λ ≥ λc], only I1 and I3 exist, and only I3 is locally stable.
We are interested in knowing when the phase transition changes from continuous to discontinuous. In Fig. 5c, the bistable regime starts at a tricritical point (star marker), where two critical lines meet. For the infection rate function β(n, i) = λiν and a fixed hypergraph structure, the tricritical point happens at (λ, ν) = (λc, νc), where νc is what we call the bistability threshold, since a bistable regime only exists for ν > νc.
To get some insights on the properties of tricritical points, we show in Fig. 4b the function \({{{{{{{\mathcal{M}}}}}}}}[\rho (r)]\) at λ = λc and for values of ν below, at, and above the bistability threshold. For ν < νc, we have \({\partial }_{r}^{2}{{{{{{{\mathcal{M}}}}}}}}{| }_{r\to 0} \; < \; 0\) and I3 does not exist. For ν > νc, we have \({\partial }_{r}^{2}{{{{{{{\mathcal{M}}}}}}}}{| }_{r\to 0} \; > \; 0\) and there exists a solution I3 > 0. At the tricritical point, I3 = I2 → 0, hence the nontrivial solution is degenerate, which is possible only if
Since a tricritical point is also a critical point, from Eq. (11) \({{{{{{{\rm{d}}}}}}}}{{{{{{{\mathcal{M}}}}}}}}/{{{{{{{\rm{d}}}}}}}}\rho ={({{{{{{{\rm{d}}}}}}}}\rho /{{{{{{{\rm{d}}}}}}}}r)}^{-1}\), so the condition can be rewritten as
The derivatives on ρ with respect to r at a critical point where r → 0 can be easily evaluated, and the condition now becomes
To evaluate the last term of Eq. (16), let us rewrite
In the limit ρ → 0, fn,i → δi,0, which implies u(ρ) → 0 and \(v(\rho )\to \langle n \rangle\), therefore
First-order derivatives can be evaluated using
For the second-order derivative, let us define ln,i ≡ d2fn,i/dρ2∣ρ→0, so that we can write
Finally, we can apply the second-order derivative to Eq. (7b) to obtain the recurrence relation
Again, ln,0 = − ∑i>0ln,i by definition.
Even though it is possible to express the ln,i in an explicit form, the expression does not give us more intuition, and it is simpler to calculate the ln,i using the recurrence equation just given. After rewriting \({{{{{{{{\rm{d}}}}}}}}}^{2}{{{{{{{\mathcal{M}}}}}}}}/{{{{{{{\rm{d}}}}}}}}{\rho }^{2}{| }_{\rho \to 0}\equiv F[{p}_{n},\beta (n,i)]\), tricritical points are obtained by solving the equation
Tricritical points result from an intricate relation between the structure (gm, pn) and the infection rate β(n, i). Figure 5 shows that either changing the structure [Fig. 5a] or the shape of the infection rate function [Fig. 5b, c] can lead to a change of behavior, from a continuous phase transition to a discontinuous one with a bistable regime.
The first hypothesis we can make from these simple examples is that more nonlinear infection rates (larger ν) and larger groups promote bistability. However, we will see that this intuition does not hold in general for heterogeneous structures due to the onset of mesoscopic localization.
Heterogeneous memberships
In this section, we investigate the effects of a heterogeneous membership distribution gm while keeping \({p}_{n}={\delta }_{n,{n}_{0}}\) homogeneous to disentangle the impact of the different types of heterogeneity. A first remark we can make about the invasion threshold [Eq. (15)] is that it is coherent with heterogeneous pair-approximation frameworks55 on random networks when only dyadic interactions are considered, i.e., when pn = δn,2. In this case, we can set ν = 1 without loss of generality, thus recovering the standard SIS model. The associated threshold is
where gm can now be interpreted as the standard degree distribution of graphs. This threshold, although quite accurate for most structures, does not capture the hub reinfection mechanism56, and thus could be inaccurate for graphs with hubs of a very large degree.
More generally, for group interactions (pn ≠ δn,2) we can see that a larger average excess membership 〈m(m − 1)〉/〈m〉 always leads to a smaller invasion threshold λc, akin to the standard SIS model, but the relationship is now nonlinear. To see this, let us rewrite Eq. (15) as
Since β(n, i) is a monotonically increasing function of λ for all n, i, then the left-hand side of Eq. (22) is a monotonically increasing function (of λ) as well. Consequently, if the right-hand side decreases, λc must decrease as well.
Assessing the impact of membership heterogeneity on the bistability threshold νc is more complicated. In fact, Eq. (21) explicitly depends on the first three moments of gm, but it also depends on the first two moments implicitly through λc, at which F must be evaluated.
In order to build our intuition, let us assume that we are able to keep fixed the first two moments 〈m〉 and 〈m2〉 while increasing 〈m3〉. This means that λc would not change, hence the only dependence on gm would be explicit in Eq. (21). Since the term depending on 〈m3〉 is negative, increasing the third moment implies that F must increase if we want to balance Eq. (21). But since \({{{{{{{{\rm{d}}}}}}}}}^{2}{{{{{{{\mathcal{M}}}}}}}}/{{{{{{{\rm{d}}}}}}}}{r}^{2}{| }_{r\to 0}\) increases with ν [see Fig. 4], and thereby F as well, we can conclude that increasing 〈m3〉 while keeping the first two moments fixed leads to an increase of the bistability threshold νc. This is validated in Supplementary Note 5, where we consider two distributions gm sharing the same first two moments, but a different third moment. The larger third moment suppresses the emergence of a bistable regime.
A corollary of this argument is that for certain structures, it is impossible to have bistability. To see this, let us consider a power-law membership distribution of the form \({g}_{m} \sim {m}^{-{\gamma }_{m}}\). In this case, since the bistability threshold depends on the third moment of gm, while the invasion threshold only depends on the first two, by setting the exponent 3 < γm < 4, the invasion threshold converges to a value λc > 0, but νc does not exist. In other words, it is impossible to have a discontinuous phase transition.
This second statement is validated in Fig. 6a, where we show that that the bistability threshold νc appears to grow without bound as \({m}_{\max }\to \infty\) for γm ≤ 4. Instead, for γm ≥ 4, the bistability threshold appears to converge, as expected, since the first three moments of gm converge as well. What is more surprising is the nonmonotonic behavior of νc with respect to γm, which we present in Fig. 6b. The bistability threshold has a well-defined maximum at a value of γm that appears to converge to γm = 3 for \({m}_{\max }\to \infty\). In other words, γm = 3 is the optimal value of membership exponent in suppressing the emergence of a discontinuous phase transition and the related bistability.

We considered hypergraphs with power-law membership distributions \({g}_{m} \sim {m}^{-{\gamma }_{m}}\) with various exponents γm, different maximal values \({m}_{\max }\), a minimal value \({m}_{\min }=2\), and a regular group size distribution pn = δn,4. We obtain the bistability threshold by solving Eq. (21). Lower values of γm imply a more heterogeneous membership distribution. a The bistability threshold grows logarithmically or faster for γm ≤ 4 but converges for γm > 4. b The bistability threshold shows a maximum near γm = 3, suggesting that this is the maximum in the limit \({m}_{\max }\to \infty\).
This can be understood from Eq. (21): for γm > 3, the invasion threshold does not vary much since the first two moments of gm are finite. Hence maximizing the third moment maximizes νc, which corresponds to γm → 3. One could still be surprised that the bistability threshold grows more slowly with \({m}_{\max }\) in the range 2 < γm < 3, since the invasion threshold λc tends toward zero. In this case, the bistable regime exists, but its width (λp, λc) simply vanishes as λc → 0.
Heterogeneous group sizes
Let us now consider hypergraphs with heterogeneous group size distribution pn, and homogeneous membership distribution, namely, \({g}_{m}={\delta }_{m,{m}_{0}}\). In this case, the invasion threshold, as defined by Eq. (15), depends on the whole distribution pn, which makes drawing general conclusions on the impact of a heterogeneous distribution pn more difficult.
To get some intuitions, let us consider the standard SIS model, i.e., the case ν = 1 in Eq. (1). With our AMEs, it was shown that50
for power-law distributions \({p}_{n} \sim {n}^{-{\gamma }_{n}}\) with large cut-offs \({n}_{\max }\). The first term on the right-hand side of Eq. (23) suggests that more heterogeneous groups-size distributions pn (smaller values of γn) lead to smaller invasion thresholds. Intuition tells us that we should expect this behavior for ν ≠ 1 as well. We have therefore investigated numerically in Fig. 7a the invasion threshold as a function of the group size exponent for different values of ν, confirming that more heterogeneous group sizes (smaller γn) do lead to a smaller invasion threshold, even for nonlinear infection functions (ν ≠ 1). However, this effect is mitigated when larger values of ν are considered. For large ν and large \({n}_{\max }\), the value of the invasion threshold is dominated by the cut-off, and scales as \({\lambda }_{{{{{{{{\rm{c}}}}}}}}} \sim {n}_{\max }^{-\nu }\), as illustrated in Fig. 7b.

We considered hypergraphs with power-law group size distributions \({p}_{n} \sim {n}^{-{\gamma }_{n}}\) with various exponents γn, a regular membership distribution gm = δm,4, and various exponents ν for the infection function in Eq. (1). We obtain the invasion threshold using Eq. (15). Lower values of γn imply a more heterogeneous group size distribution. a For a fixed \({n}_{\max }=20\), the invasion threshold increases with larger γn, but the effect is more limited for larger ν. b For a fixed γn = 3, the invasion threshold decreases like \({n}_{\max }^{-\nu }\) for large \({n}_{\max }\), indicating the onset of mesoscopic localization49, 50. c Stationary distribution fn,i for the starred case in b, i.e., γn = 3 and ν = 1.5, with λ = 1.1λc, illustrating localization in the largest groups.
This behavior can be attributed to the onset of mesoscopic localization49,50. It was shown analytically for ν = 1 that, for certain combinations of (γm, γn), the epidemic near the invasion threshold [λ = λc(1 + ϵ) with ϵ ≪ 1] is dominated by the largest most influential groups. In these scenarios, the second term on the right-hand side in Eq. (23) dominates the first one, and, near λc, the group prevalence In grows exponentially with n, i.e., \({I}_{{n}_{\max }}/{I}_{2}={{\Omega }}\left({{{{{{{{\rm{e}}}}}}}}}^{a{n}_{\max }}\right)\) for some positive constant a. While an analytical characterization of mesoscopic localization in the general case of ν ≠ 1 is out of the scope of this paper, we provide clear numerical evidence of localization phenomena in Fig. 7c. The stationary distributions of the fraction of infected nodes in groups of increasing size n are concentrated in the largest group (n = 50) near the invasion threshold λc.
Since mesoscopic localization was characterized using a linear contagion (ν = 1) and a continuous phase transition49,50, two natural questions arise: How does ν ≠ 1 affect localization? And what happens in the context of discontinuous phase transitions? In Fig. 8, we present the phase diagram of the group prevalence In for different scenarios. Comparing Fig. 8a, b, we see that increasing ν from 0.5 to 1.5 (while keeping gm = δm,4) strengthens localization effects, which is expected since reinforcement effects are more important when the group prevalence is high. In Fig. 8c, we show a similar diagram, but for a discontinuous phase transition. We see that the concentration of infected nodes in the largest groups is still possible, but the phenomenon is now associated with the unstable solution near the invasion threshold [λ = λc(1 − ϵ) with ϵ ≪ 1]. Therefore, mesoscopic localization affects both continuous and discontinuous phase transition with a bistable regime, but the exponential growth of In with n near λc concerns the stable solution in the former and the unstable solution in the latter.

We illustrate \({I}_{n}^{* }\), the average stationary fraction of infected nodes in groups of various size n. We considered hypergraphs with power-law group size distributions \({p}_{n} \sim {n}^{-{\gamma }_{n}}\) with γn = 3, regular membership distributions of the form \({g}_{m}={\delta }_{m,{m}_{0}}\), and various exponents ν for the infection function in Eq. (1). Near the invasion threshold λc, \({I}_{n}^{* }\) is larger for larger groups in a with ν = 0.5, but localization is much more pronounced for b with ν = 1.5. c For discontinuous phase transitions, mesoscopic localization is still possible, but near λc we must look at the unstable solution for \({I}_{n}^{* }\) in the bistable regime.
If we now reinterpret the results of Fig. 7 in light of these considerations, larger values of ν facilitate the onset of mesoscopic localization, where the largest groups drive the onset of the endemic phase, and make the invasion threshold scale as \({\lambda }_{{{{{{{{\rm{c}}}}}}}}} \sim {n}_{\max }^{-\nu }\). This explains why λc varies only slightly with γn for ν = 2 in Fig. 7a.
In Fig. 9, we finally investigate the role of heterogeneous group sizes on the bistability threshold by varying the group exponent γn and the maximal group size \({n}_{\max }\). From Fig. 9a, we see that a more heterogeneous group distribution, thereby increasing the fraction of larger groups, decreases the value of the bistability threshold νc. This is consistent with our observation of regular structures [Fig. 5], for which larger groups appear to promote bistability. However, Fig. 9b brings some nuance to this statement: for a fixed exponent γn, there is a nonmonotonic relationship between νc and the largest group \({n}_{\max }\). As such, the presence of larger groups does not always promote bistability.

We considered hypergraphs with power-law group size distributions \({p}_{n} \sim {n}^{-{\gamma }_{n}}\) with various exponents γn and a regular membership distribution gm = δm,4. We solve the bistability threshold using Eq. (21). Lower values of γn imply a more heterogeneous group size distribution. a For a fixed \({n}_{\max }\), the bistability threshold increases with larger γn. b For a fixed γn, the bistability threshold has a nonmonotonic relationship with \({n}_{\max }\). c Phase transition using gm = δm,4 and ν = 2.3. We use pn = δn,4 for the regular case, and pn = (1 − ϵ)δn,4 + ϵδn,15 with ϵ = 10−3 for the perturbed case. Mesoscopic localization49, 50 inhibits bistability in the perturbed case.
We can again attribute this behavior to localization effects. In fact, we are able to illustrate this via a very simple example in Fig. 9c. We look at the phase transition for a regular hypergraph with fixed group size, pn = δn,4, and a perturbed version of it, where we introduce a small proportion of larger groups, pn = (1 − ϵ)δn,4 + ϵδn,15 with ϵ = 10−3. For the regular distribution, the phase transition is discontinuous, while for the perturbed distribution it is continuous, with the contagion localized in the largest groups near the invasion threshold. The bistability threshold νc is larger for the perturbed distribution since mesoscopic localization reduces considerably the invasion threshold λc. The largest most influential groups drive and self-sustain an endemic state for smaller values of λ, hence preventing a bistable regime.
Influence maximization
Influence maximization broadly refers to the problem of selecting a subset of nodes to initially spark a diffusion process in order to maximize the effect. The process could represent the spread of information, the diffusion of innovations, or a viral marketing campaign6,57.
There is a large body of literature on influence maximization in complex networks, where various models have been used: threshold models58,59,60,61, independent cascade58, and simple contagion models (SI, SIS, SIR)62,63,64,65, to name a few. Recently, these ideas have been also exported to higher-order networks66,67.
The effectiveness of an influence maximization procedure is often measured by the fraction of affected nodes (in the limit t → ∞) for processes that terminate. However, because the final epidemic size in the SIS dynamics does not depend on the seeds (other than for stochastic extinction), we will consider the simpler task of maximizing \(\dot{I}(0)\), the initial spreading speed. This is often a straightforward task to solve for graphs. Considering the SIR model, for instance, one just needs to maximize the number of outgoing edges from infected to susceptible nodes, which implies that nodes of maximal degree would be optimal influencers. However, we will show that additional considerations need to be accounted for in higher-order networks. More specifically, our goal is to use our formalism to answer the following question: Should we focus on finding influential nodes, or seed the spread from influential groups?
In this section, to simplify the notation, all dynamic quantities are evaluated at t = 0, e.g., I(0) ≡ I.
Let us assume that we are given a fixed hypergraph and an initial fraction of nodes that can be infected at the initial time I = ϵ ≪ 1 (the seeds of the contagion). Our task is to invade the system as fast as possible by maximizing \(\dot{I}\) for a hypergraph contagion, which is equivalent to maximizing the objective function
where we define the initial node states \({{{{{{{\mathcal{S}}}}}}}}\equiv {\left\{{s}_{m}\right\}}_{m = 1}^{{m}_{\max }}\) and the initial group states \({{{{{{{\mathcal{F}}}}}}}}\equiv {\left\{{f}_{n,i}| 0\ \le \ i\ \le \ n\right\}}_{n = 2}^{{n}_{\max }}\). The optimization problem is also constrained by
While the first four constraints come from the definitions of the variables, the last one is less straightforward. Equation (25e) ensures the consistency between \({{{{{{{\mathcal{S}}}}}}}}\) and \({{{{{{{\mathcal{F}}}}}}}}\), more specifically that the fraction of all memberships stubs belonging to susceptible nodes [left-hand side of Eq. (25e)] matches the fraction of susceptible nodes in groups [right-hand side of Eq. (25e)].
By combining the constraint of Eq. (25e) with the definition of r as given by Eq. (2), the objective function can be simplified as
Although it appears to be independent of \({{{{{{{\mathcal{S}}}}}}}}\), it depends on it implicitly through Eq. (25e).
It is worth stressing that our formalism assumes that the membership stubs of nodes are assigned to groups uniformly at random, and thus we cannot engineer both \({{{{{{{\mathcal{S}}}}}}}}\) and \({{{{{{{\mathcal{F}}}}}}}}\), i.e., choose at the same time the seeds according to their membership and the repartition of the seeds among the various group sizes. Indeed, if we decide for instance to infect only nodes of a certain membership \(m^{\prime}\) and we try to engineer \({{{{{{{\mathcal{F}}}}}}}}\), there are no guarantees we can achieve such configuration in practice—e.g., we cannot infect a node in a group if none of its nodes have membership \(m^{\prime}\).
We therefore compare two strategies to optimize the early spread:
-
A.
The influential spreaders strategy: we engineer \({{{{{{{\mathcal{S}}}}}}}}\), i.e., we choose the fraction of seeds to assign to each membership class, and we assume a random configuration for the groups, i.e., all \({\{{f}_{n,i}\}}_{i = 0}^{n}\) are binomial distributions with probability q (to be determined).
-
B.
The influential groups strategy: we engineer \({{{{{{{\mathcal{F}}}}}}}}\), i.e., we assign a certain number of seeds in the groups depending on their sizes, and assume that nodes are infected at random through the group to which they belong.
Influential spreaders
In this strategy, we are free to engineer \({{{{{{{\mathcal{S}}}}}}}}\) in order to maximize Φ, with respect to the constraints of Eqs. (25a)-(25e). Let us assume that fn,i is a binomial distribution,
Using Eq. (25e), we can identify
An optimal solution \({{{{{{{{\mathcal{S}}}}}}}}}^{\star }\) can be found by first finding the value q⋆ that maximizes the objective function Eq. (26), and then identifying any set \({{{{{{{\mathcal{S}}}}}}}}\) that satisfies the relation for q = q⋆ above.
There are in general many optimal solutions possible, but they collapse into a single one when q is sufficiently small, which is reasonable for ϵ ≪ 1. In this case, we simply have that Φ ≈ q, and the optimal solution is intuitive: one needs to infect nodes of maximal membership first in order to maximize q. This is true irrespective of β(n, i), pn, and gm.
The infection function and the structure affect the maximal value of ϵ such that this solution is unique and optimal. For example, in the simplest case of linear contagion, where β(n, i) ∝ i, it is possible to show that this strategy is optimal up to q = 1/2 for all gm and pn, and we expect even higher values for ν > 1. For all practical purposes, targeting nodes of the highest membership is optimal, and this is the case in all experiments we considered.
Influential groups
In this second strategy, we want to engineer \({{{{{{{\mathcal{F}}}}}}}}\) in order to maximize Φ with respect to the constraints Eqs. (25a)-(25e). Let us assume that we can do so by choosing a certain number of groups and infecting a certain portion of their nodes. Following this procedure, one can realize that not all sets \({{{{{{{\mathcal{F}}}}}}}}\) satisfying Eqs. (25a)-(25e). are allowed. For instance, if we decide to infect i nodes in all groups of size n, the outcome is different from just having fn,i = 1. Indeed, nodes belong to more than one group, hence we need to account for spillover effects—groups of size \(n^{\prime} \;\ne\; n\) would have some infected nodes as well, and more than i nodes could be infected in some groups of size n.
To do so, let us first define \({\tilde{f}}_{n,i}\) as the fraction of all the groups of size n for which we infect i nodes at random. Note that if a node belongs to multiple groups, it can be chosen more than once for infection, but the duplicates have no effect. Spillovers are taken into account by considering that each of the n − i nodes that have not been chosen for infection in a group of size n could have been infected in another group, with probability u (to be determined). Therefore, we can write
where
Second, let us define η as the fraction of all spots in groups that have been chosen for infection,
Since nodes within groups are chosen at random, a node of membership m is susceptible if it has not been chosen for infection in any of the groups to which it belongs, i.e.,
As a consequence, η is constrained by Eq. (25c),
The probability u still needs to be obtained. It corresponds to the fraction of all memberships that are not matched with a spot chosen for infection in a group but that are still associated with an infected node:
With this formulation, we engineer \({{{{{{{\mathcal{F}}}}}}}}\) indirectly through \(\tilde{{{{{{{{\mathcal{F}}}}}}}}}={\{{\tilde{f}}_{n,i}| 0\ \le \ i\ \le \ n\}}_{n = 2}^{{n}_{\max }}\). The objective function can be rewritten
Since the objective function is a linear function of each \({\tilde{f}}_{n,i}\), the optimization problem can be solved using linear programming.
However, there is an intuitive and more efficient way to solve this problem exactly. We just need to identify the most cost-effective \({\tilde{f}}_{n,i}\) by looking at the effect on Φ of increasing \({\tilde{f}}_{n,i}\),
versus the cost of increasing \({\tilde{f}}_{n,i}\), i.e., the variation of η
The most cost-effective \({\tilde{f}}_{n,i}\) maximizes the ratio
Obviously, i = 0 is always the most cost-effective for all n (since it has zero cost), but to satisfy Eq. (28), we must also fill some \({\tilde{f}}_{n,i}\) with i > 0.
Optimal solutions tend to fill the \({\tilde{f}}_{n,i}\) with i > 0 that maximizes R(n, i), especially for sufficiently small ϵ. A general solution can be obtained using the procedure presented in the “Influential groups solutions" subsection of the Methods, building on this idea of cost-effectiveness. In the worst case, the computational complexity to obtain an optimal solution \({{{{{{{{\mathcal{F}}}}}}}}}^{\star }\) under the influential groups strategy is \({{{{{{{\mathcal{O}}}}}}}}({m}_{\max }+{n}_{\max }^{3})\), which is much more efficient than using a general-purpose linear-programming method.
Equation (29) also gives us an intuition of what defines influential groups when trying to maximize the early spread. If ϵ ≪ 1, then u ≪ 1, hence we have
when considering β(n, i) = λiν. For simple contagions (ν = 1), picking the largest group with a single seed (i = 1) is always optimal. For hypergraph contagions with ν > 1, the largest groups are the most influential as well, but the optimal number of seeds is generally i > 1. Hence, beyond its size, the initial configuration of a group determines whether or not it is influential.
Experiments
To compare the influential spreaders and the influential groups strategies, we measure the ratio
where \({{{\Phi }}}_{{{{{{{{\mathcal{F}}}}}}}}}^{\star }\) and \({{{\Phi }}}_{{{{{{{{\mathcal{S}}}}}}}}}^{\star }\) are the values of the objective function for the optimal solution of the influential groups and influential spreader strategies, respectively. Therefore, ζ > 1 indicates that the influential groups strategy is better to maximize \(\dot{I}\), and vice versa if ζ < 1.
In Supplementary Note 6, we show that
where \((n^{\prime} ,i^{\prime} )\) is the pair that maximizes the ratio R(n, i), restricted to i > 0, in the limit ϵ → 0. For general ϵ, we need to solve numerically the optimization problem as discussed in the previous sections.
With β(n, i) = λiν, ζ is independent of λ, since Φ ∝ λ. As a consequence, ζ is agnostic to the underlying phase of the system (healthy, bistable, or endemic). Equation (31) simplifies to
In Fig. 10, we illustrate how ζ varies as we change ν, ϵ, and the underlying structure. For homogeneous memberships and group sizes [Fig. 10a], we see that the influential groups strategy performs better as soon as the contagion process is sufficiently nonlinear (ν ≈ 2); for highly nonlinear contagions (ν ≈ 4), the influential group strategy is much more effective, with ζ up to 100. When considering heterogeneous memberships, but still homogeneous group sizes [Fig. 10b], the influential spreaders strategy performs better for moderately nonlinear contagions (ν ≲ 2.8); otherwise, the influential groups strategy is still a better choice. Finally, considering a heterogeneous pn as well [Fig. 10c] helps the performance of the influential groups strategy, especially for larger ϵ.

a–c If \({{{{{{{\mathrm{log}}}}}}}\,}_{10}\zeta \; > \; 0\), this indicates that the influential groups strategy is better to maximize \(\dot{I}\), and vice versa if \({{{{{{{\mathrm{log}}}}}}}\,}_{10}\zeta \; < \; 0\). We use different combinations of homogeneous and heterogeneous distributions. More specifically, for homogeneous distributions we use gm ∝ ame−a/m! and pn ∝ ane−a/n!, with a = 5, \({m}_{\min }=1\), \({n}_{\min }=2\), and \({m}_{\max }={n}_{\max }=20\). For heterogeneous distributions, we use \({g}_{m}\propto {m}^{-{\gamma }_{m}}\) and \({p}_{n}\propto {n}^{{\gamma }_{n}}\), with γm = γn = 3, \({m}_{\min }={n}_{\min }=2\), and \({m}_{\max }={n}_{\max }=100\). The dashed lines indicate when ζ = 1 and the star markers correspond to the limit ϵ → 0, using Eq. (32). Irregularities of the level curves are due to the discrete nature of gm and pn, not to numerical errors. d–f Time evolution of the fraction of infected nodes for different strategies, with ϵ = 10−2 and ν ∈ {1, 1.88, 3}, corresponding to the three empty markers in a. We use λ = 3λc in each case. The random strategy corresponds to sm = 1 − ϵ for all m, and fn,i is a binomial distribution with probability ϵ.
When picking a pair (ϵ, ν) such that ζ < 1, we confirm that the influential spreader strategy invades the system faster in Fig. 10d. However, sufficiently close to ζ = 1, maximizing \(\dot{I}\) does not necessarily imply that I(t) will be larger for all t > 0. For instance, in Fig. 10e, ζ ≈ 1, but the influential spreader strategy is slightly better. Therefore, one must be careful when interpreting the results of Fig. 10. One way to improve on our approach would be to consider higher-order temporal derivatives of I to assess which strategy performs best or refine the optimization procedure by trying to maximize these higher-order derivatives as well. For a pair (ϵ, ν) such that ζ > 1, we confirm that the influential group strategy invades the system faster in Fig. 10f.
Figure 10d–f suggests that the initial speed, \(\dot{I}(0)\), roughly correlates with the time taken by the disease to infect a given fraction of the population, a metric that has been used to measure influence for SI and SIR dynamics68,69,70.
Figure 10f also illustrates a particular feature of highly nonlinear contagions: the time to reach the stationary state can be excessively long for suboptimal strategies, despite λ = 3λc (see the Supplementary Note 7). In this regime, the initial conditions have a much more important impact on the capacity of the contagion to invade the system, especially considering the possibility of stochastic extinction in real systems due to finite size.
These results again highlight the importance of considering an accurate description of the inner dynamics of groups when studying hypergraph contagions. In the context of influence maximization, optimizing group configurations is a crucial component; one should not focus exclusively on identifying the most central nodes. Ultimately, an optimal strategy would capitalize on the synergy of these two important aspects.
Discussion
We have introduced group-based AMEs to describe hypergraph contagions. Our framework is analytically tractable, allowing us to obtain closed-form implicit expressions for the critical and tricritical points. In addition, we have shown that it describes the dynamical process with remarkable accuracy when compared with Monte Carlo simulations. Our formulation in terms of an infection rate function β(n, i) makes it extremely flexible, allowing us to consider arbitrary group distribution with large group interactions, contrarily to existing HMF theories31,39,40 that instead require specifying the rule for each different type of interaction separately.
Motivated by simplicity and recent results37, we analyzed in depth the consequences of a nonlinear infection rate function β(n, i) = λiν, highlighting the important role of influential groups in hypergraph contagions.
With our analytical results about the invasion and bistability thresholds, we were able to perform an exhaustive analysis of the phase transition and better understand the influence of a heterogeneous structure, both in terms of membership m and group size n. We found that the third moment of the membership distribution gm plays a crucial role, with large \(\left\langle {m}^{3}\right\rangle\) suppressing the onset of a discontinuous phase transition with a bistable regime, in line with other approaches39,40. This is best exemplified for power-law membership distributions \({g}_{m} \sim {m}^{-{\gamma }_{m}}\), where γm = 3 most suppresses bistability, and in the limit \({m}_{\max }\to \infty\), a discontinuous phase transition is only possible for γm > 4.
The phenomenon of mesoscopic localization49,50, driven by the most influential groups, also has important consequences on the phase diagram, with the effects being enhanced by superlinear infection (ν > 1). In this case, the invasion threshold scales as \({\lambda }_{{{{{{{{\rm{c}}}}}}}}} \sim {n}_{\max }^{-\nu }\), and for λ close to λc, infected nodes are found almost exclusively in the largest groups. This localization of the contagion thereby inhibits bistability by enforcing an endemic state with a very small global fraction of infected nodes.
Our approach, furthermore, provided insights concerning the problem of influence maximization for hypergraph contagions. We focused on the problem of maximizing the early spread and proposed two strategies: allocating seeds to the influential spreaders (engineering sm), or to the influential groups (engineering fn,i). For various types of structures, the latter strategy performs better for contagions that are sufficiently nonlinear, highlighting the key role of influential groups on the transient state of the system.
For the process we considered, the notion of influential groups to seed and sustain hypergraph contagions are mostly aligned—in both cases, the largest groups typically have a dominant role. In the case of influence maximization, however, we showed that a careful seed allocation is also essential to determine whether or not a group is influential. Moreover, a more realistic infection function β(n, i) that actually depends on n could affect which groups are most influential in both scenarios.
Our work constitutes the first step towards a better understanding of the role of higher-order interactions on the outreach of information spreading6, and resonates with other recent theoretical findings on higher-order naming games, where big groups facilitate the takeover of committed minorities in social convention30. AMEs thus provide an analytical avenue to study recent empirical results showing how social contagions and movements defy classic influence maximization. As one example, networked counterpublics71 are public spaces used by underrepresented groups to gather legitimacy and form tight-knit communities. Therein, nondominant forms of knowledge can still spread and reach widespread attention through dense communities (influential groups) despite the limited connectivity of their members (noninfluential spreaders). These results provide one more addition to the mounting evidence that groups of elementary elements are the foundational unit of many complex systems.
Many avenues are now left open to explore and broaden the applicability of our group-based AMEs. While we restrained ourselves to a particular nonlinear infection rate function β(n, i) and a constant recovery rate, other dynamical processes could be considered, each having its own phenomenology and a rich dynamical behavior. In Supplementary Note 3 for instance, we briefly discuss how our framework can be applied to threshold models of the form β(n, i) = δn−1,i, but one could consider other traditional dynamical processes, such as voter models72.
In Supplementary Note 1, we provide a roadmap to include structural two-point correlations, but a thorough characterization of the impact of correlation patterns on bistability, mesoscopic localization, and influence maximization is still lacking. The inclusion of dynamical correlation around nodes is a more tedious task that would require a fusion between degree-based47,48,73 and group-based20,21,49,50 AMEs. This would allow describing almost exactly short-range dynamical correlations, namely correlations between the states of nodes and their direct neighbors. Incorporating long-range correlations—beyond first neighbors—in AME frameworks, without a prohibitive computational time due to combinatorial explosion, is still an open problem.
Finally, many directions could be taken with regards to the influence maximization problem on hypergraphs. One avenue would be to analyze the notion of influential groups and influential spreaders from the perspective of centrality measures for hypergraphs74. Another would be to investigate the closely related problem of targeted immunization1,75.
Methods
Contagion on real-world hypergraphs
Simulation of contagions
We used a standard Gillespie algorithm for the simulation of contagions on hypergraphs. We decompose the whole process into events j ∈ J, that each happens at rate ωj. The next event to happen is chosen with probability
and the time step between two events Δt is distributed exponentially with mean 〈Δt〉 = 1/∑j∈Jωj.
There are two types of events: infection and recovery. On the one hand, all susceptible nodes in a group can be considered equivalent with regard to infection. Consequently, each group is chosen for an infection event with a rate
Once a group is chosen for an infection event, one of the (n − i) susceptible nodes is chosen uniformly at random to become infected. On the other hand, all infected nodes perform a recovery event with the rate ωrec = 1.
We store all possible events in an efficient data structure called a SamplableSet76, where insertion, deletion, and sampling of elements (events) all have a computational complexity \({{{{{{{\mathcal{O}}}}}}}}\left[{{{{{{\mathrm{log}}}}}}}\,{{{{{{\mathrm{log}}}}}}}\,\left({\omega }_{\max }/{\omega }_{\min }\right)\right]\)77, where \({\omega }_{\max }\) and \({\omega }_{\min }\) are, respectively, the maximal and minimal rates among \({\{{w}_{j}\}}_{j\in J}\). This makes the sampling and the updating of the data structure extremely fast, which is especially useful when \({\{{w}_{j}\}}_{j\in J}\) spans multiple scales.
Once an event is performed—for instance, a node recovers—we need to update the rate \({\omega }_{\inf }\) of all groups to which this node belongs. This is the most costly part of the algorithm, which unfortunately cannot be overcome. This essentially means the simulation procedure is slower for hypergraphs with large average excess membership 〈m(m − 1)〉/〈m〉.
In Figs. 2 and 3, we compare the stationary state solutions from our formalism with estimates from Monte Carlo simulations. To compute estimates, we let the system relax during a burn-in period τb ∈ [102, 104] then we sample \({{{{{{{\mathcal{N}}}}}}}}\in [10,1{0}^{4}]\) states, both depending on the size of the hypergraph and if multiple randomized hypergraphs are being used. Sampled states are separated by a decorrelation period τd = 1.
To simulate contagions in the stationary state, we used two approaches, ordinary simulations and the quasistationary-state method.
-
a.
Ordinary simulation method: With this approach, we simply let the simulation run and do not intervene. This is usually not the method of choice, especially for small hypergraphs near the invasion threshold, because finite size systems all eventually reach the absorbing state where all nodes are susceptible. This is, however, more practical to obtain the lower branch for the superlinear case in Fig. 2(c), or faster for large hypergraphs, as in Fig. 3.
-
b.
Quasistationary-state method: This approach aims at sampling the quasistationary distribution of the contagion process78, which is defined as the probability distribution for all states in the limit t → ∞, except for the absorbing state. We used a state-of-the-art method78, where we keep a history of past states (in our case up to 50 states). We update the history by removing one uniformly at random and storing the current state after each decorrelation period τd ∈ [0.1, 1]. Each time the absorbing state is reached during the simulation, we pick a state from the history uniformly at random to replace the current one. This method is well suited for finite-size analysis and especially useful for simulations on small hypergraphs, such as in Fig. 2.
Datasets
The simulations shown in Figs. 2 and 3 run on two different empirical social structures that encode different types of social higher-order interactions. Here we briefly describe the nature of these two datasets and the techniques used to construct the associated higher-order structures.
The first social structure is based on face-to-face interactions in a French primary school. Originally collected as part of the SocioPatterns collaboration, this dataset79 contains information of face-to-face interactions between children of a primary school in Lyon recorded over 2 days. Participants are given wearable sensors (placed on their chests), and contact is detected whenever two sensors are in close proximity (1.5m). The initial temporal resolution of this dataset is 20 s, but contacts have been further preprocessed in order to construct a static hypergraph from the temporal sequence of interactions31. In particular, considering each child as a node, we aggregated different snapshots using a temporal window of 15 min and computed all the maximal cliques appearing in each window. Cliques were then aggregated across the entire time range, retaining only those that appeared at least 3 times, and finally “promoted” to groups. Some properties of the obtained structure are reported in the caption of Fig. 2.
The second social structure concerns coauthorship relations in computer science. DBLP is an online bibliography containing information on major computer science journals and proceedings. This dataset, already preprocessed80 (from the release 3, 2017), consists of a list of publications and respective authors that naturally calls for higher-order representations81. In particular, each author corresponds to a node and any collaboration of n (co-)authors in a single publication corresponds to a group of size n. We constructed a hypergraph by aggregating all the resulting groups together, but without considering single-author publications (these have been removed in order to avoid disconnected nodes). In addition, the original dataset contained 1 831 127 nodes and 2 954 518 groups, which is too large to perform simulations on a personal computer in a reasonable time. Therefore, we obtained a subhypergraph by performing a breadth-first search, starting from a random group, then visiting all groups at a maximum distance of 2 when considering the one-mode projection of the original hypergraph on the groups. This ensures that the resulting subhypergraph is connected. Some properties of the obtained structure are reported in the caption of Fig. 3.
The authors state that in the country where the work was performed additional ethical approval or a license to reuse the datasets is not required given that the datasets are in the public domain.
Randomization and data augmentation
In Figs. 2 and 3, we make use of randomized versions of the original hypergraph. In Fig. 2, we also use expanded versions, where the size of the network is increased by a factor x. In all cases, we use the same procedure (x = 1 if the hypergraph is not expanded).
Let us first note m = [m1, m2, … ] and n = [n1, n1, … ] the membership sequence and the group size sequence of the original hypergraph, i.e., the list for the membership of each node and the list for the size of each group. From these sequences, we create two expanded sequences \({{{{{{{\bf{m}}}}}}}}^{\prime}\) and \({{{{{{{\bf{n}}}}}}}}^{\prime}\), which are formed of x copies of m and n respectively. This can be seen as the membership and group size sequences for a hypergraph that is x times larger.
For each expanded sequence, we create a stub list. For instance, for the node j of the expanded hypergraph, we include \(m^{\prime}\) copies of the label j in the stub list for the nodes. Similarly, we include \(n^{\prime}\) copies of the label ℓ in the stub list for the groups. By definition, these two stub lists are of the same length, \(M^{\prime}\), which corresponds to the number of edges in the bipartite representation of the hypergraph. We can thus shuffle them and match the entries of both lists, thereby assigning nodes to groups—or equivalently creating edges between nodes and groups in the bipartite representation of the hypergraph.
We then remove multi-edges (nodes assigned multiple times to the same group) by performing edge swaps82. We then perform \(M^{\prime}\) additional edge-swap attempts at random—picking two random edges, swapping the groups, and accepting the swap if it does not create multi-edges. This ensures the uniformity of the generation process (see Supplementary Note 8). The resulting hypergraph is a randomized version of the original hypergraph, expanded by a factor x.
Influential groups solutions
An intuitive approach to solve the problem would be to sort all pairs (n, i) in decreasing order of their R(n, i) values (for i > 0), then fill \({\tilde{f}}_{n,i}\) up to 1 following this order, until I = ϵ, or more directly until η reaches the value prescribed by ϵ. However, this approach does not account for the fact that one may encounter multiple times the same n value before the condition I = ϵ is reached. For instance, let us assume (n, i) is the next pair with the highest value R(n, i), but there exists a pair \((n,i^{\prime} )\) with \(R(n,i^{\prime} )\ge R(n,i)\) and we have already assigned \({\tilde{f}}_{n,i^{\prime} }=1\). What is the best option?
-
1.
Discard the (n, i) pair.
-
2.
Fill the associated \({\tilde{f}}_{n,i}\) up to 1 and decrease the value of \({\tilde{f}}_{n,i^{\prime} }\) accordingly.
It turns out that an optimal solution is constructed by choosing one or the other depending on certain conditions. Option 1 is chosen whenever \(i \; < \; i^{\prime}\), because it can only reduce the total contribution to Φ. If \(i \; > \; i^{\prime}\), we assign a new cost-effective ratio to the pair (n, i), accounting for the fact that we need to decrease \({\tilde{f}}_{n,i^{\prime} }\):
This can be interpreted as the cost-effective ratio for the additional infected nodes \((i-i^{\prime} )\) that we add to the configuration. Note that \(\hat{R}(n,i)\) can be negative, which is not a problem: this only means that infecting these nodes decreases the objective function Φ. If \(\hat{R}(n,i)\) is still the highest ratio when compared with the ratios from other available pairs, option 2 is chosen. An algorithm for this procedure is presented in the Supplementary Methods.
Data availability
The hypergraphs analyzed during the current study are available in the “Influential groups data” repository on Zenodo83: https://doi.org/10.5281/zenodo.5662206. The hypergraphs can also be obtained from the original sources: (1) Face-to-Face data79: http://www.sociopatterns.org/datasets/primary-school-temporal-network-data/; (2) Coauthorship data80: https://github.com/arbenson/ScHoLP-Data/tree/master/coauth-DBLP. See the subsection “Contagion on real-world hypergraphs” of “Methods” for the preprocessing of the data.
Code availability
The code used to produce all results is available on Zenodo84: https://doi.org/10.5281/zenodo.5662446
References
Pastor-Satorras, R., Castellano, C., Van Mieghem, P. & Vespignani, A. Epidemic processes in complex networks. Rev. Mod. Phys. 87, 925–979 (2015).
Barrat, A., Barthélemy, M. & Vespignani, A. Dynamical Processes on Complex Networks (Cambridge University Press, 2008).
Kiss, I. Z., Miller, J. C. & Simon, P. L. Mathematics of Epidemics on Networks: From Exact to Approximate Models (Springer, 2017).
Daley, D. J. & Kendall, D. G. Epidemics and rumours. Nature 204, 1118 (1964).
Moreno, Y., Nekovee, M. & Pacheco, A. F. Dynamics of rumor spreading in complex networks. Phys. Rev. E 69, 066130 (2004).
Rogers, E. M. Diffusion of Innovations 4th edn (Simon and Schuster, 2010).
Newman, M. E. J. Networks (Oxford University Press, 2018).
Torres, L., Blevins, A. S., Bassett, D. S. & Eliassi-Rad, T. The why, how, and when of representations for complex systems. SIAM Review 63, 435–485 (2021).
Salnikov, V., Cassese, D. & Lambiotte, R. Simplicial complexes and complex systems. Eur. J. Phys. 40, 014001 (2018).
Lambiotte, R., Rosvall, M. & Scholtes, I. From networks to optimal higher-order models of complex systems. Nat. Phys. 15, 313–320 (2019).
Battiston, F. et al. Networks beyond pairwise interactions: structure and dynamics. Phys. Rep. 874, 1–92 (2020).
Battiston, F. et al. The physics of higher-order interactions in complex systems. Nat. Phys. 17, 1093–1098 (2021).
Petri, G. & Barrat, A. Simplicial activity driven model. Phys. Rev. Lett. 121, 228301 (2018).
Cencetti, G., Battiston, F., Lepri, B. & Karsai, M. Temporal properties of higher-order interactions in social networks. Sci. Rep. 11, 7028 (2021).
Hébert-Dufresne, L., Allard, A., Marceau, V., Noël, P.-A. & Dubé, L. J. Structural preferential attachment: network organization beyond the link. Phys. Rev. Lett. 107, 158702 (2011).
Young, J.-G., Hébert-Dufresne, L., Allard, A. & Dubé, L. J. Growing networks of overlapping communities with internal structure. Phys. Rev. E 94, 022317 (2016).
Bianconi, G. & Rahmede, C. Emergent hyperbolic network geometry. Sci. Rep. 7, 41974 (2017).
Courtney, O. T. & Bianconi, G. Weighted growing simplicial complexes. Phys. Rev. E 95, 062301 (2017).
House, T. & Keeling, M. J. Deterministic epidemic models with explicit household structure. Math. Biosci. 213, 29–39 (2008).
Hébert-Dufresne, L., Noël, P.-A., Marceau, V., Allard, A. & Dubé, L. J. Propagation dynamics on networks featuring complex topologies. Phys. Rev. E 82, 036115 (2010).
O’Sullivan, D. J. P., O’Keeffe, G. J., Fennell, P. G. & Gleeson, J. P. Mathematical modeling of complex contagion on clustered networks. Front. Phys. 3, 71 (2015).
Bick, C., Ashwin, P. & Rodrigues, A. Chaos in generically coupled phase oscillator networks with nonpairwise interactions. Chaos 26, 094814 (2016).
Skardal, P. S. & Arenas, A. Abrupt desynchronization and extensive multistability in globally coupled oscillator simplexes. Phys. Rev. Lett. 122, 248301 (2019).
Millán, A. P., Torres, J. J. & Bianconi, G. Explosive higher-order Kuramoto dynamics on simplicial complexes. Phys. Rev. Lett. 124, 218301 (2020).
Schaub, M. T., Benson, A. R., Horn, P., Lippner, G. & Jadbabaie, A. Random walks on simplicial complexes and the normalized hodge 1-Laplacian. SIAM Rev. 62, 353–391 (2020).
Carletti, T., Battiston, F., Cencetti, G. & Fanelli, D. Random walks on hypergraphs. Phys. Rev. E 101, 022308 (2020).
Torres, J. J. & Bianconi, G. Simplicial complexes: higher-order spectral dimension and dynamics. J. Phys. Complex. 1, 015002 (2020).
Neuhäuser, L., Mellor, A. & Lambiotte, R. Multibody interactions and nonlinear consensus dynamics on networked systems. Phys. Rev. E 101, 032310 (2020).
Alvarez-Rodriguez, U. et al. Evolutionary dynamics of higher-order interactions in social networks. Nat. Hum. Behav. 5, 586–595 (2021).
Iacopini, I., Petri, G. Baronchelli, A. & Barrat, A. Group interactions modulate critical mass dynamics in social convention. Preprint at http://arxiv.org/abs/2103.10411 (2021).
Iacopini, I., Petri, G., Barrat, A. & Latora, V. Simplicial models of social contagion. Nat. Commun. 10, 2485 (2019).
Lehmann, S. & Ahn, Y.-Y. (eds) Complex Spreading Phenomena in Social Systems, Computational Social Sciences (Springer, 2018).
Centola, D. The spread of behavior in an online social network experiment. Science 329, 1194–1197 (2010).
Karsai, M., Iñiguez, G., Kaski, K. & Kertész, J. Complex contagion process in spreading of online innovation. J. R. Soc. Interface 11, 20140694 (2014).
Hodas, N. O. & Lerman, K. The simple rules of social contagion. Sci. Rep. 4, 4343 (2014).
Mønsted, B., Sapieżyński, P., Ferrara, E. & Lehmann, S. Evidence of complex contagion of information in social media: an experiment using Twitter bots. PLoS ONE 12, e0184148 (2017).
St-Onge, G., Sun, H., Allard, A., Hébert-Dufresne, L. & Bianconi, G. Universal nonlinear infection kernel from heterogeneous exposure on higher-order networks. Phys. Rev. Lett. 127, 158301 (2021).
Barrat, A. Ferraz de Arruda, G., Iacopini, I. & Moreno, Y. Social contagion on higher-order structures. Preprint at http://arxiv.org/abs/2103.03709 (2021).
Jhun, B., Jo, M. & Kahng, B. Simplicial SIS model in scale-free uniform hypergraph. J. Stat. Mech. 2019, 123207 (2019).
Landry, N. W. & Restrepo, J. G. The effect of heterogeneity on hypergraph contagion models. Chaos 30, 103117 (2020).
Ferraz de Arruda, G., Tizzani, M. & Moreno, Y. Phase transitions and stability of dynamical processes on hypergraphs. Commun. Phys. 4, 24 (2021).
Cisneros-Velarde, P. & Bullo, F. Multi-group SIS epidemics with simplicial and higher-order interactions. Preprint at http://arxiv.org/abs/2005.11404 (2021).
Ferraz de Arruda, G., Petri, G. & Moreno, Y. Social contagion models on hypergraphs. Phys. Rev. Res. 2, 023032 (2020).
Matamalas, J. T., Gómez, S. & Arenas, A. Abrupt phase transition of epidemic spreading in simplicial complexes. Phys. Rev. Res. 2, 012049 (2020).
Burgio, G., Arenas, A., Gómez, S. & Matamalas, J. T. Network clique cover approximation to analyze complex contagions through group interactions. Commun. Phys. 4, 1–10 (2021).
Pastor-Satorras, R. & Castellano, C. Eigenvector localization in real networks and its implications for epidemic spreading. J. Stat. Phys. 173, 1110–1123 (2018).
Marceau, V., Noël, P.-A., Hébert-Dufresne, L., Allard, A. & Dubé, L. J. Adaptive networks: coevolution of disease and topology. Phys. Rev. E 82, 036116 (2010).
Gleeson, J. P. High-accuracy approximation of binary-state dynamics on networks. Phys. Rev. Lett. 107, 068701 (2011).
St-Onge, G., Thibeault, V., Allard, A., Dubé, L. J. & Hébert-Dufresne, L. Social confinement and mesoscopic localization of epidemics on networks. Phys. Rev. Lett. 126, 098301 (2021).
St-Onge, G., Thibeault, V., Allard, A., Dubé, L. J. & Hébert-Dufresne, L. Master equation analysis of mesoscopic localization in contagion dynamics on higher-order networks. Phys. Rev. E 103, 032301 (2021).
Scarpino, S. V., Allard, A. & Hébert-Dufresne, L. The effect of a prudent adaptive behaviour on disease transmission. Nat. Phys. 12, 1042 (2016).
Granovetter, M. Threshold models of collective behavior. Am. J. Sociol. 83, 1420–1443 (1978).
Watts, D. J. A simple model of global cascades on random networks. Proc. Natl Acad. Sci. USA 99, 5766–5771 (2002).
Dodds, P. S. & Watts, D. J. Universal behavior in a generalized model of contagion. Phys. Rev. Lett. 92, 218701 (2004).
Mata, A. S., Ferreira, R. S. & Ferreira, S. C. Heterogeneous pair-approximation for the contact process on complex networks. New J. Phys. 16, 053006 (2014).
St-Onge, G., Young, J.-G., Laurence, E., Murphy, C. & Dubé, L. J. Phase transition of the susceptible-infected-susceptible dynamics on time-varying configuration model networks. Phys. Rev. E 97, 022305 (2018).
Domingos, P. & Richardson, M. Mining the network value of customers. In Proc. Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 57–66 (Association for Computing Machinery, 2001).
Kempe, D., Kleinberg, J. & Tardos, É. Maximizing the spread of influence through a social network. In Proc. Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 137–146 (Association for Computing Machinery, 2003).
Dodds, P. & Watts, D. J. The Oxford Handbook of Analytical Sociology Ch. 20 (Oxford University Press, 2009).
Morone, F. & Makse, H. A. Influence maximization in complex networks through optimal percolation. Nature 524, 65–68 (2015).
Chen, W., Yuan, Y. & Zhang, L. Scalable influence maximization in social networks under the linear threshold model. in 2010 IEEE International Conference on Data Mining 88–97 (IEEE, 2010).
Kitsak, M. et al. Identification of influential spreaders in complex networks. Nat. Phys. 6, 888–893 (2010).
Chen, D., Lü, L., Shang, M.-S., Zhang, Y.-C. & Zhou, T. Identifying influential nodes in complex networks. Phys. A 391, 1777–1787 (2012).
Erkol, Ş., Castellano, C. & Radicchi, F. Systematic comparison between methods for the detection of influential spreaders in complex networks. Sci. Rep. 9, 15095 (2019).
Poux-Médard, G., Pastor-Satorras, R. & Castellano, C. Influential spreaders for recurrent epidemics on networks. Phys. Rev. Res. 2, 023332 (2020).
Amato, F. Moscato, V., Picariello, A. & Sperlí, G. in Green, Pervasive, and Cloud Computing 207–221 (Springer International Publishing, 2017).
Zhu, J., Zhu, J., Ghosh, S., Wu, W. & Yuan, J. Social influence maximization in hypergraph in social networks. IEEE Trans. Netw. Sci. Eng. 6, 801 (2019).
Karsai, M. et al. Small but slow world: How network topology and burstiness slow down spreading. Phys. Rev. E 83, 025102 (2011).
Starnini, M., Machens, A., Cattuto, C., Barrat, A. & Pastor-Satorras, R. Immunization strategies for epidemic processes in time-varying contact networks. J. Theor. Biol. 337, 89–100 (2013).
Lawyer, G. Understanding the influence of all nodes in a network. Sci. Rep. 5, 8665 (2015).
Jackson, S. J. & Foucault Welles, B. Hijacking #myNYPD: social media dissent and networked counterpublics. J. Commun. 65, 932–952 (2015).
Sood, V. & Redner, S. Voter model on heterogeneous graphs. Phys. Rev. Lett. 94, 178701 (2005).
Gleeson, J. P. Binary-state dynamics on complex networks: pair approximation and beyond. Phys. Rev. X 3, 021004 (2013).
Tudisco, F. & Higham, D. J. Node and edge eigenvector centrality for hypergraphs. Commun. Phys. 4, 1–10 (2021).
Pastor-Satorras, R. & Vespignani, A. Immunization of complex networks. Phys. Rev. E 65, 036104 (2002).
St-Onge, G. Samplableset. https://github.com/gstonge/SamplableSet (2018).
St-Onge, G., Young, J.-G., Hébert-Dufresne, L. & Dubé, L. J. Efficient sampling of spreading processes on complex networks using a composition and rejection algorithm. Comput. Phys. Commun. 240, 30–37 (2019).
de Oliveira, M. M. & Dickman, R. How to simulate the quasistationary state. Phys. Rev. E 71, 016129 (2005).
Stehlé, J. et al. High-resolution measurements of face-to-face contact patterns in a primary school. PLoS ONE 6, e23176 (2011).
Benson, A. R., Abebe, R., Schaub, M. T., Jadbabaie, A. & Kleinberg, J. Simplicial closure and higher-order link prediction. Proc. Natl Acad. Sci. USA 115, E11221–E11230 (2018).
Patania, A., Petri, G. & Vaccarino, F. The shape of collaborations. EPJ Data Sci. 6, 18 (2017).
Fosdick, B. K., Larremore, D. B., Nishimura, J. & Ugander, J. Configuring random graph models with fixed degree sequences. SIAM Rev. 60, 315 (2018).
St-Onge, G. et al. Influential groups data. https://doi.org/10.5281/zenodo.5662206 (2021).
St-Onge, G. et al. gstonge/influential-groups. https://doi.org/10.5281/zenodo.5662446 (2021).
Acknowledgements
The authors acknowledge Calcul Québec for computing facilities. This work was supported by the Fonds de recherche du Québec - Nature et technologies (to G.S.-O.), the Natural Sciences and Engineering Research Council of Canada (to G.S.-O., A.A.), the Sentinelle Nord program of Université Laval, funded by the Canada First Research Excellence Fund (to G.S.-O., A.A.), the United Kingdom Regions Digital Research Facility (RDRF)-Urban Dynamics Lab under EPSRC Grant No. EP/M023583/1 (to I.I.), the James S. McDonnell Foundation 21st Century Science Initiative Understanding Dynamic and Multi-scale Systems (to I.I.), the Agence Nationale de la Recherche (ANR) project DATAREDUX [ANR-19-CE46-0008] (to A.B. and I.I.), the National Science Foundation under grant No. OIA-2019470 (to L.H.-D.), Google Open Source under the Open-Source Complex Ecosystems and Networks (OCEAN) project (to L.H.-D.), and the National Institutes of Health 1P20 GM125498-01 Centers of Biomedical Research Excellence Award (to L.H.-D.). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
G.S.-O., I.I., V.L., A.B., G.P., A.A., and L.H.-D. conceptualized the study. G.S.-O. and L.H.-D. developed the model. G.S.-O. derived the theoretical results, implemented the algorithms, and performed the numerical experiments. G.S.-O., I.I., V.L., A.B., G.P., A.A., and L.H.-D. analyzed the results and contributed to writing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review information
Communications Physics thanks Nicholas Landry and the other anonymous reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
St-Onge, G., Iacopini, I., Latora, V. et al. Influential groups for seeding and sustaining nonlinear contagion in heterogeneous hypergraphs. Commun Phys 5, 25 (2022). https://doi.org/10.1038/s42005-021-00788-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s42005-021-00788-w
This article is cited by
-
Hyper-cores promote localization and efficient seeding in higher-order processes
Nature Communications (2023)
-
Group interactions modulate critical mass dynamics in social convention
Communications Physics (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
