
Abstract
Amyotrophic Lateral Sclerosis (ALS) disease severity is usually measured using the subjective, questionnaire-based revised ALS Functional Rating Scale (ALSFRS-R). Objective measures of disease severity would be powerful tools for evaluating real-world drug effectiveness, efficacy in clinical trials, and for identifying participants for cohort studies. We developed a machine learning (ML) based objective measure for ALS disease severity based on voice samples and accelerometer measurements from a four-year longitudinal dataset. 584 people living with ALS consented and carried out prescribed speaking and limb-based tasks. 542 participants contributed 5814 voice recordings, and 350 contributed 13,009 accelerometer samples, while simultaneously measuring ALSFRS-R scores. Using these data, we trained ML models to predict bulbar-related and limb-related ALSFRS-R scores. On the test set (n = 109 participants) the voice models achieved a multiclass AUC of 0.86 (95% CI, 0.85–0.88) on speech ALSFRS-R prediction, whereas the accelerometer models achieved a median multiclass AUC of 0.73 on 6 limb-related functions. The correlations across functions observed in self-reported ALSFRS-R scores were preserved in ML-derived scores. We used these models and self-reported ALSFRS-R scores to evaluate the real-world effects of edaravone, a drug approved for use in ALS. In the cohort of 54 test participants who received edaravone as part of their usual care, the ML-derived scores were consistent with the self-reported ALSFRS-R scores. At the individual level, the continuous ML-derived score can capture gradual changes that are absent in the integer ALSFRS-R scores. This demonstrates the value of these tools for assessing disease severity and, potentially, drug effects.
Similar content being viewed by others
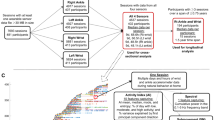


Introduction
ALS is a progressive motor neuron disease presenting with both upper and lower motor neuron signs. It is generally agreed that clinical symptoms and pathophysiology in ALS are usually focal initially, spreading contiguously from the onset site in both upper motor neuron (UMN) and lower motor neuron (LMN) compartments1,2,3,4,5. However, clinical presentations of motor neuron diseases and ALS are highly heterogeneous—particularly at symptom onset and early during disease6. Hence, medical assessments of ALS onset and severity rely on subjective evaluation of overall functionality of the patient, particularly through qualitative evaluation of UMN, LMN and bulbar symptoms. However, the design of efficient clinical trials largely requires identifying signals of therapeutic efficacy in large numbers of patients with demonstrably similar rates of disease progression7. This makes it challenging to test many promising therapeutics. The combination of qualitative symptom evaluation and heterogeneous disease presentation are major challenges for both disease diagnosis, prognosis, and for identifying effective therapeutics8. For instance, of more than 54 potential therapeutics having been tested in ALS clinical trials, only one (riluzole) has been shown to extend survival, and only two (riluzole and edaravone) may marginally slow ALS disease progression9,10,11. Thus, the lack of diagnostic and/or prognostic biomarkers for ALS and the similar lack of objective clinical outcome measures (that balance robustness and sensitivity) have contributed to inefficient and unsuccessful efforts to effectively treat or cure ALS12,13,14. As a step to overcome this, our work aims to provide an objective measure for ALS disease severity.
The current standard tool for monitoring ALS disease severity is the ALS Functional Rating Scale (ALSFRS) and ALS Functional Rating Scale-Revised (ALSFRS-R)15,16. These measures are based on multiple choice questionnaires designed to assess the global function of the person living with ALS. Specifically, the ALSFRS-R questionnaire asks participants to rate their functional abilities on an integer scale of 0 (“can’t do”) to 4 (“normal ability”) on three bulbar functions (speech, salivation, swallowing), six limb-related functions (handwriting, cutting_food, dressing_hygiene, turning_in_bed, walking, climbing_stairs), and three respiratory functions (dyspnea, orthopnea, respiratory_insufficiency). Individual scores are summed to produce a global score of between 0=worst and 48=best. As the disease progresses, global function measurably declines15,16. ALSFRS-R is a non-invasive and cost-effective approach to monitor disease severity which strongly correlates with survival time in ALS patient populations and can serve as a linear predictor for the future rate of progression17,18. Clinical settings utilize ALSFRS-R scores assessed by a variety of examiners. Most often, scores are assigned by neurologists specializing in ALS and or nurse practitioners16,19. However, in some instances, self-assessment of ALSFRS-R has been utilized for clinical research20,21. Differences between the examiner—neurologist, nurse, self-report—does introduce variability in the measure22,23. While early studies24 showed low interobserver reliability due to its categorical nature, more recent studies25 have shown high correlation (0.93) between in-clinic ALSFRS-R and smartphone self-report. Other efforts, such as the Rasch-Built Overall Amyotrophic Lateral Sclerosis Disability Scale (ROADS)26 aim to improve on the test-retest reliability and item targeting of ALSFRS-R. However, ROADS also relies on a subjective questionnaire. Nevertheless, ALSFRS-R is still the most popular and well-studied measure.
Development of objective measures of disease severity is a critical unmet need. Recent efforts26,27 have explored frequent data collection at home using relatively inexpensive technologies including hand-grip dynamometry, electric impedance myography, speech recordings, and self-reported ALSFRS-R scores towards developing more objective ALS symptom progression endpoints. As early as 2013, accelerometry data have been used to study Parkinson’s disease progression28. Recently, Rutkove et al have shown that good response rates for at-home data collection is possible with good design. Similarly, Berry et al. have shown high correlation with in-clinic and smartphone self-report of ALSFRS-R25. Our work takes these a step further.
We develop ML-based objective measures of ALS disease severity based on voice samples of prescribed speech and accelerometer measurements of limb-based tasks. Here we collected these physiological measurements—voice recordings and accelerometer recordings—together with the self-reported ALSFRS-R scores. We then build ML models, a voice model that takes as input the speech data and accelerometer models that take as input the accelerometer measurements. These models objectively assess ALS severity by learning to predict the ALSFRS-R scores corresponding to one or more functions. These were then used to compare the objective ML-predicted scores with self-reported scores to study the real-world effects of edaravone in people living with ALS.
Results
A key requirement for developing an objective measure is collecting a dataset from a sufficiently large cohort of ALS patients. In 2014, ALS-TDI launched the Precision Medicine Program (PMP), which has enrolled more than 600 people with ALS (as of January 2021). For each participant, the PMP collects a rich dataset including biological samples (skin biopsy, whole genome sequencing and blood-based biomarkers), as well as regular measurements of self-reported ALSFRS-R scores together with physiological indicators–voice recordings and accelerometer measurements tracking prescribed limb exercises.
The dataset used in this work is derived from 584 people living with ALS, who consented to participate in the research study and contributed voice recordings, accelerometer measurements or both over about four years (Sep’14 - Aug’19). We used this data to build ML models by associating the data to self-reported ALSFRS-R scores, within 60 days of their recording i.e. for each voice or accelerometer sample we associate the ALSFRS-R score that is closest to and within 60 days of the recorded sample, failing which the sample is discarded. The average time delta between recording and ALSFRS-R assessment was 3.2 days for voice and 5.3 days for accelerometer samples. This gave us 542 participants with 5814 voice samples, and 350 participants with 13,009 accelerometer samples. To assess clinical intervention outcomes, we took advantage of the fact that a subset of the Precision Medicine Program participants had enrolled in the translational research program before the FDA approval of edaravone (Radacava). All of the participants who began using edaravone following its approval in May 2017 (n = 54) were identified. Participants self-reported edaravone use by email correspondence or through the PMP web portal. Edaravone use was subsequently confirmed this by telephone conversations and learned when treatment with edaravone commenced for each participant. These participants were placed in the test set. The remaining participants were split randomly into the train, validation and test set to get an overall ratio of 70:15:15. Demographic details and distribution of the participants (and recordings) in the splits for model development are reported in Table 1.
The speech data consisted of audio recordings (collected via phone) of participants speaking a sentence, “I owe you a yoyo today”29, repeated five times. The participants login to a secure portal and opt-in to receive an automated call where they utter the sentence that gets recorded. Most participants have multiple recordings taken every few weeks over a year or more.
The accelerometer measurements, obtained from Actigraph GT3X devices (one for each limb), came from 5 limb-based exercises each about 45 s long with a short 15 s break in between. A full set of measurements is approximately 5 minutes in ˜ length (Supplementary Material- Video of movements).
Approach overview
Using the physiological measurements—voice and accelerometer recordings—and the self-reported ALSFRS-R scores, we developed 2 types of models: (1) voice model and (2) accelerometer model. The voice model is a convolutional neural network (CNN) that takes as input the speech recording and was trained to predict the probability distribution over the 5 ALSFRS-R score classes (0–4) corresponding to the speech (bulbar) function and degree of dysarthria. This was trained on 3776 speech samples from 389 participants. The set of accelerometer models take as input the accelerometer measurements and were trained to predict the probability distribution over the 5 ALSFRS-R score classes (0–4) for 9 functions (the 6 limb-related and 3 respiratory functions). We developed different accelerometer models to compare the performance of (a) various architectures—CNN, linear regression, logistic regression, MLP), (b) input types—high resolution (Raw 30 Hz) or down-sampled versions (Uniform-1Hz and FFT-1Hz) and (c) output types—a single function’s score or all 9 functions’ score jointly (multi-label). These were trained on 7448 accelerometer measurements from 209 participants. The details of the data processing and the models themselves are described in the Methods section. Our results in this section report the performance of the single best performing accelerometer model (MLP multi-label FFT-1Hz) and the voice CNN model.
ALSFRS-R analyses
ALSFRS-R data of 109 test participants were analyzed for pairwise correlation between individual ALSFRS-R assessments (Fig. 1). Strong correlations were found (a) between speech, salivation, and swallowing (R2 = 0.74–0.80), (b) between handwriting, cutting food, and dressing/hygiene (R2 = 0.69–0.80), and (c) between scores meant to evaluate lower limb functions (walking and climbing stairs) (R2 = 0.8). Unsurprisingly, dyspnea, orthopnea, and respiratory insufficiency self-assessments were also strongly correlated (R2 0.74–0.76) (Fig. 1A). Interestingly, some ALSFRS-R metrics of progression were very poorly correlated. For example, scores for respiratory functions were not correlated with scores for bulbar functions, and neither were scores for limb functions correlated with scores for bulbar functions, e.g., scores for walking were also not correlated with scores for salivation or speech (R2 = 0.02 and 0.08) (Fig. 1A).

Correlation between ground-truth (y-axis) ALSFRS-R scores with A Groundtruth ALSFRS-R and B ML-predicted ALSFRS-R scores (x-axis) on the full test set of 109 participants. A There is a strong correlation between ALSFRS-R scores for speech, salivation, and swallowing. We also observed correlations between other sets of limb-related functions, specifically, handwriting, cutting food, dressing hygiene and turning in bed, and then between walking, and climbing stairs, and the respiratory-related functions dyspnea, orthopnea, and respiratory insufficiency. B We observed that the predicted ALSFRS-R for speech (based on the voice model) is most correlated with groundtruth speech ALSFRS-R followed by strong correlations with salivation and swallowing. Additionally, as with the ground-truth FRS scores, we observed that the accelerometer models’ predictions for the limb-related functions (handwriting, cutting_food, dressing_hygiene, turning_in_bed, walking, climbing_stairs) are also correlated. We further note that the accelerometer models’ predictions and the speech models are not correlated with the respiratory-related functions’ scores.
ML-predicted ALSFRS-R vs. ground-truth self-reported ALSFRS-R
We defined self-reported ALSFRS-R values as ground-truth against which to compare predicted ALSFRS-R values derived from objective data collection tools, including voice recordings or accelerometer recordings. The ML-predicted ALSFRS-R scores for speech derived from voice recordings were strongly correlated with ground-truth scores for speech, salivation, and swallowing (R2 = 0.75, 0.65, and 0.68 respectively) (Fig. 1B). Similarly, accelerometer reading-derived ALSFRS-R score predictions for handwriting, cutting food, dressing/hygiene, turning in bed, walking, and climbing stairs were correlated with their respective ground-truth ALSFRS-R values (R2 = 0.49, 0.62, 0.64, 0.64, 0.59, and 0.62 respectively). Unsurprisingly, neither voice recording derived ALSFRS-R speech predictions, nor accelerometer-based ALSFRS-R limb predictions achieved high correlation with respiratory function ALSFRS-R ground-truth scores, with the highest R2 at 0.59 (Fig. 1B).
Next, we sliced the correlations by looking at the participants’ scores at baseline (when they enrolled into the PMP) and their slopes over time. Figure 2 presents the correlation between ground-truth and model predicted ALSFRS-R scores at baseline for speech (Fig. 2A) and the average of 6 limb functions (Fig. 2C). The correlation for speech scores at baseline is 0.80 and that of the limb functions at baseline is 0.67. The correlation of the slopes for the speech scores is 0.68 (Fig. 2B) and is 0.60 for the slopes from the limb scores (Fig. 2D). Not surprisingly, the correlation of the slopes computed over time from the ground-truth and predicted values is lower for both models compared to the correlations of the raw scores at just the baseline which is just a single point in time.

The plots depict pearson correlation between ground-truth and predicted scores based on A speech ALSFRS-R scores at baseline, B slopes over time from ALSFRS-R speech scores, C limb ALSFRS-R scores (averaged over 6 limb-based movements) at baseline, and D slopes over time from averaged limb-movement scores. The x-axis in the subfigures denotes the ground-truth values, and the y-axis denotes the predicted values. Subfigures A and B for speech include scores on 90 participants, subfigures C and D for limb show scores on 83 participants.
Table 2 presents ROC-AUC values with bootstrapped confidence intervals for the predicted ALSFRS-R scores for speech, 6 limb-related functions, and the 3 respiratory functions for our best performing models, using the voice CNN model and accelerometer (FFT 1 Hz MLP multi-label) model. Confusion matrices for these two models’ predictions are presented in Supplementary Table 1a and b. The voice CNN model, evaluated on 1333 samples from 90 test participants, attained the highest AUC (0.86 [CI:0.85-0.88]). For the limb related functions, the MLP multi-label FFT-1Hz model evaluated on 3833 accelerometer samples from 83 test participants performed best, with an AUC between 0.70–0.75 on 5 of the 6 limb related functions, with the lowest performance for handwriting (AUC = 0.64). Somewhat surprisingly, the accelerometer model also achieved AUCs between 0.63–0.75 on the respiratory functions. Supplementary Table 2 presents performance of other accelerometer model variants, and compares it with the previous best method of normalizing the accelerometer data based on TBVM (Premasiri et al. 2017). Prediction of the models on individual participant recordings on 54 test participants in the edaravone cohort, along with self-reported ALSFRS-R speech scores and slopes, are shown in Supplementary Fig 3 (voice) and Supplementary Fig 4 (accelerometer).
Changes in ML-predicted and self-reported ALSFRS-R scores with real-world Edaravone use in PMP Participants with ALS
Having established that voice and accelerometer recording based ALSFRS-R predictions correlate with their related ground-truth ALSFRS-R scores, we applied these technologies to study the real-world performance of edaravone, approved in the United States for the treatment of ALS disease progression, retrospectively on 54 test participants. We used the date of edaravone commencement to define time ‘0’ and plotted self-reported ALSFRS-R scores (Fig. 3A and C), ML model predicted speech ALSFRS-R (Fig. 3B), and ML model predicted limb-function ALSFRS-R (Fig. 3D). Individual participant plots are in Supplementary Figs 3 and 4. Based on these figures we can observe that for an individual function (speech in particular), the ML-predicted continuous score is able to show gradual changes compared to the integer self-reported score. This is also more apparent in individual participant plots.

The plots depict ALSFRS-R scores based on A groundtruth speech scores, B speech scores as predicted by the voice model, C groundtruth limb scores (averaged over 6 limb-based movements), and D averaged limb-movement scores as predicted by the accelerometer model. The x-axis represents days with 0 (vertical blue line) as the point where the participant starts the drug. Y-axis represents the ALSFRS-R score. Subfigures A and B for speech include scores on 49 participants, subfigures C and D for limb show scores on 44 participants. 6 representative participants (IDs: 489, 810, 823, 883, 911, and 1076) are highlighted in color in all panels, other participants are shown in lighter color in the background. Predicted scores are plotted for each available recording (on the recorded date/day). The groundtruth and predicted scores for each of the 54 participants is included in Supplementary Fig. 3 (for voice) and Supplementary Fig. 4 (for limb).
Where there were at least 3 data points both before and after initiation of edaravone treatment, we calculated slopes (r-values) using linear regression analyses of ground-truth self-reported ALSFRS-R, predicted voice ALSFRS-R, and predicted limb-function ALSFRS-R both pre- and post- edaravone initiation. These are shown in Supplementary Fig 1A–D. Based on work by Takahashi et al.30, to study the association of edaravone with respiratory functions, in Supplementary Fig 2A–E, we also plotted the slopes (r-values) of participants computed after initiation of edaravone against their respiratory ALSFRS-R (averaged over the 3 respiratory functions) prior to and at the time of initiation of edaravone. This compares progression of participants (slopes) computed on ground-truth respiratory, speech, and limb scores as well as the ML-predicted speech and limb scores. From these figures, we did not observe any cohort-level changes after edaravone initiation.
Discussion
This real-world study of ALS symptom progression using digital measures—accelerometer readings and speech recordings—demonstrated the feasibility of applying digital outcomes in conjunction with machine learning (ML) to predict self-assessed ALSFRS-R. Our results, in particular the AUC values and ALSFRS-R correlation analyses, show that the predictions of the ML models are consistent with self-reported ALSFRS-R. Additionally, the continuous ML-predicted score is also able to capture the gradual transition in ALSFRS-R scores (over the duration of the study) in comparison to the integer self-reported ones (Fig. 3 and Supplementary Figs. 3 and 4), making it a useful tool to monitor disease severity objectively. In terms of their practical application within the PMP cohort, for the analysis of real-world use of edaravone retrospectively, both ML-predicted and self-reported ALSFRS-R did not show observable cohort-level changes (Fig. 3 and Supplementary Figs. 1 and 2) and indicated variable outcomes from person to person.
We were able to apply similar ML approaches to two distinct types of data: voice recordings, and limb movement as measured by accelerometry. While neither the digital voice recording phrase selected nor accelerometer-based prescribed movements were optimized to maximize signal31, we learned that the ML methods were still effective at predicting ALSFRS-R subscores (Table 2 and Fig. 1). The effectiveness of the accelerometer-based models (median multiclass AUC of 0.73 on 6 limb-related and 3 respiratory functions) was somewhat surprising because cutting food, dressing-hygiene, and handwriting can be considered largely fine-motor functions32, while the prescribed exercise movements captured by the accelerometer emphasized gross motor function by way of deltoid and quadriceps strength and endurance while de-emphasizing fine motor coordination. Perhaps the respiratory functions are also correlated with strength and endurance. Thus, it is interesting that the ML models were still able to effectively predict functional assessment of skills that require both strength and fine motor coordination.
Another key observation from this study is how closely the predicted ALSFRS-R scores tracked variations in self-assessed ALSFRS-R scores in many cases (Fig. 2, Fig. 3, and Supplementary Figs. 3 and 4). The correlation between ground-truth and predicted scores at baseline (Fig. 2) are substantially better than the correlations of the slopes themselves. Self-assessment-based measures present the risk of being subjective and, thus have low interobserver reliability33, and show volatility over time32. We had hypothesized that this volatility would not be evident using objective digital outcome measures coupled with ML tools. The volatility does manifest as lower correlation of slopes over time (Fig. 2) perhaps not to the extent one would assume. Thus, although the predictions (AUCs and individual correlations) especially for speech are fairly good, there is still variance that is not captured.
As the supplementary figures show, in some instances, a participant’s self-assessed score at the time of study enrollment (baseline) was quite different from the predicted score. However, surprisingly when transient downturns or upturns in self assessed ALSFRS-R scores were apparent, the ML/digital outcomes would sometimes vary similarly (Supplementary Fig 4). This indicates that the participants are self-consistent, in the sense that if they reported a lower score their functional ability does truly decline. This is what we believe is reflected in the ML model predictions. Although the participant might score themselves differently from a clinician, they seem to consistently associate their functional ability to the same score and are attuned to their own declines. Hence the ML model picks up on the signal. Further, since we always only consider self-assessments, this eliminates any issues due to interobserver reliability in collection of ALSFRS-R scores.
As a proof of concept, these tools were applied to the assessment of the effectiveness of edaravone in a real-world clinical setting. Neither self-assessed ALSFRS-R nor the ML/digital predictions revealed cohort-level changes in slope (Supplementary Fig 1) that might have suggested overall slowing of ALS disease progression. We also explored (in Supplementary Fig 2) whether participants who began edaravone treatment with higher respiratory function ALSFRS-R self-assessment would perform better on the drug based on the clinical trial reports demonstrating that people with ALS in Japan with higher slow vital capacity (SVC) responded to edaravone treatment while others did not30. In the retrospective study, on our small cohort we did not see indications that the patients with higher self-assessed respiratory function ALSFRS-R scores performed differently than the rest of the test cohort. This requires additional study.
Important questions remain for ALS research and clinical communities. First, regarding bulbar symptom assessment, could recordings of other phrases be used to improve bulbar symptom assessment? Speech pathologists with experience in ALS assessment have been developing batteries of phrases for improved bulbar symptom assessment30,34. Deploying part or all of these batteries and coupling them with ML tools could reveal even more sensitive disease progression measures. Second, we used a limited set of prescribed movements to capture arm and leg function using accelerometers. The prescribed movements have not been optimized to capture fine motor function or gross coordination. More work needs to be done to improve these protocols. Third, the PMP did not include any direct or surrogate sensory measures of respiratory function that could be used in developing ML models. That is worth further investigation.
Overall, this work demonstrates the value of digital outcome measures, specifically voice recordings and accelerometry, to study ALS. It shows that ML can be applied to such digital outcome measures to objectively predict ALS disease severity and to monitor and reveal progression patterns. Further, the proposed measure was used to assess edaravone’s real-world performance retrospectively, on a small cohort of people with ALS enrolled in the ALS-TDI PMP, as a proof-of-concept demonstration. This is a study that combines digital clinical outcome measures with ML to study an approved medication’s post-market effectiveness for ALS. Our work suggests that the proposed methods can be helpful in assessing medicines used to treat ALS, without imposing additional financial or travel burden on patients. Such an approach may be amenable for use in clinical trials, but may also be an essential strategy for assessing experimental therapies made available outside of the clinical trial setting in expanded access programs.
Methods
This research program has been conducted in accordance with the ethical principles posited in the Declaration of Helsinki - Ethical Principles for Medical Research Involving Human Subjects. Protocol approval was provided by the institutional review board (ADVARRA CIRBI). Every participant consented to participate in this research by signing and IRB approved informed consent form.
Data preprocessing
The speech data was uniformly resampled to 8 kHz mono-stream. The audio samples are then converted to spectrograms, the details of which are described in the voice model section. For the exercise-based accelerometer recordings, the original accelerometer measurements (on 3 axes) are recorded at 30 Hz (referred to as Raw 30 Hz). We also obtained a low-resolution 1 Hz version from the Actigraph software [ActiLife version 6.13.3] (referred to as Raw 1 Hz). We used measurements from 4 exercises, one from each of the four limbs, i.e. Left Ankle (LA), Left Wrist (LW), Right Ankle (RA), and Right Wrist (RW). A fifth exercise involving both wrists together, which was less emphasized, was often missing and thus discarded. For all our models, we considered measurements from the four limbs, and built and evaluated models on the 30 Hz data or the following variants derived from the 1 Hz data:
-
Total Body Vector Magnitude (TBVM): We reproduced this baseline from our previous report which is based on the Raw 1 Hz measurements where each limb value is normalized31. To normalize, a control 1 Hz vector magnitude (VM) dataset was created by collecting four to six months of accelerometer data from 18 healthy volunteers. They calculated the average VM from each limb across the prescribed movements from the healthy volunteer cohort and chose the largest value to create vector magnitude normalization coefficient for each prescribed movement (i.e., they divide by the largest value to get a scaling coefficient for each limb in the health volunteer cohort, and multiply by that co-efficient to normalize data from participants; we report these values in the Supplementary materials). Following this process31, for each month of VM data for each patient, we normalized each prescribed movement VM and summarized the VM for all limbs into a single value by adding them together to obtain the TBVM value.
-
FFT 1 Hz: We applied a discrete Fast Fourier Transform on the Raw 1 Hz data and for each of the 4 limbs, leading to a total of 8 features for each accelerometer measurement.
-
Uniform 1 Hz: This is a variant of the Raw 1 Hz data consisting of 70 measurements per limb, (truncating shorter samples or padding zeros to longer samples). We normalized the training set’s values and applied the same parameters to normalize the validation and test sets.
Voice model
To build a model for predicting ALSFRS-R scores from the voice recordings, we used a convolutional neural network (CNN) architecture proposed in35, suited for audio classification tasks. Our model and approach is illustrated in Fig. 4. The details regarding selection of parameters (mentioned below) for modeling the data and the training details are described in the Supplement.

Our approach segments audio/accelerometer recordings into non-overlapping frames. We then convert the waveforms to derive spectrogram grayscale images. A classifier is trained on the image patches to predict the score label for each non-overlapping frame which is then aggregated to predict an ALSFRS-R score for the entire voice sample. The CNN depicted here is the architecture that was used to train the speech ALSFRS-R prediction model. (The kernel shape (mxn), and number of filters are denoted for convolutions, while for maxpool the shape and stride are noted). We note that this overall approach is also identical to how the CNN model is applied to the accelerometer data.
The model takes as input the spectrogram of the waveform, a visual representation of the spectrum of a signal’s frequencies as it varies with time. To create the spectrogram inputs, the audio recording is processed into non-overlapping 960 ms audio “frames”. These frames are then decomposed with a short-time Fourier transform applied to 25 ms windows every 10 ms, with the last window zero-padded. The resulting spectrogram is integrated into 64 mel-spaced frequency bins, and the magnitude of each bin is log-transformed after adding a small offset of 0.001 to avoid numerical issues. This gives log-mel spectrogram context-windows of 96×64 bins that form the input. The spectrogram windows are then input to a 2-dimensional convolutional network (architecture depicted in Fig. 4) with a logistic loss for each score class (0-4). During training, all audio frames (equivalently, spectrogram context-windows) from a recording get the same ALSFRS-R score as the entire audio clip’s label, i.e., the patient’s reported speech ALSFRS-R score on the date closest to the recording. The model’s output is a probability distribution for each of the 5 ALSFRS-R score classes (0-4) for each audio frame. During training, we fetch mini-batches of 64 input examples by randomly sampling context-windows from all audio samples. Since the number and length of audio samples from each participant (and correspondingly the frequency of occurrence of the label/score) can be different, the loss for each window is weighted inversely to the frequency of the class label at the frame-level. During inference, we first aggregate the window/frame-level scores by taking a mean across all spectrogram context windows to get a probability distribution of the scores over the entire audio recording. The final ALSFRS-R score predicted by our approach is the average of the score values weighted by the model’s predicted probability of each score for the audio recording.
Accelerometer models
We evaluated several methods to model the accelerometer measurements. In particular, on the Uniform 1 Hz data and the FFT 1 Hz data, we applied linear regression, logistic regression, as well as multi-layer perceptron (MLP) models. The models are trained to predict the probability distribution over the 5 ALSFRS-R score classes (0-4) for 9 functions (the 6 limb-related and 3 respiratory functions). For each ML model (linear regression, logistic regression, MLP) and data type (Uniform 1 Hz and FFT 1 Hz), 9 models were trained to predict each of the 9 functions individually. Additionally, for the MLP, a tenth model that jointly predicts scores for all 9 functions was trained. This joint model is termed the multi-label classification model.
To model the high-resolution (Raw 30 Hz) accelerometer data, we use a small CNN similar to the voice model described above. In this case, the accelerometer measurements are processed into non-overlapping 75 s “frames.” These are decomposed with a short-time Fourier transform applied to 7 s windows every 3 s, with the last two windows zero-padded. These result in linear spectrogram patches of 19×129 bins. The details of these parameter choices and computation of spectrogram patch sizes are described in the Supplement. The accelerometer CNN model also differs in that it uses a multi-task classification to learn and predict scores for all the respiratory and limb-related ALSFRS-R scores. The rest of the training and evaluation procedure is identical as with the voice model.
Evaluation metric
As described in the section on Voice model, our models output a probability for each score class (0-4) for each function, from which we derive the predicted ALSFRS-R score for each function (speech, walking etc.). To evaluate the overall performance of the model, we use the probabilities predicted for each score class to compute the ROC-AUC (1 vs all AUC) and take the average to report the multiclass AUC for each function. For all the other analysis, such as to compute correlations, or participant slopes, we directly use the predicted ALSFRS-R score for the function.
Voice and accelerometer model parameter choices and training details
Developing the voice and accelerometer models from the original data samples involve a number of choices, both in terms of parameters for processing the data, as well as hyper-parameters chosen for the optimization/training process. To determine a number of these parameters, we first used a subset of the data (from Sep’14 - July’18) and created a training, validation, and test split (each containing roughly a third of the participants). This dataset was used to select many of the parameters used to model and process the data. Specifically, the duration of the spectrogram frames (960 ms for audio, 300 s for accelerometer), the overlap between frames (non-overlapping frames, or an overlap of 75 s duration) and verify the choice of spectrogram i.e., log-mel spectrogram of 64 bins for audio, and a linear spectrogram for the accelerometer. In the case of the accelerometer frames, the spectrogram images are of size 19×129 calculated from the window-size, stride and frequency as: 75/(7-3) = 19; and 129 = 128 + 1 (30hz*7 rounded up to the nearest power of 2, then divided by 2, and then add 1). We treated both CNN models as a multi-class multi-label task to be able to predict ALSFRS-R scores for multiple functions. So we used a sigmoid function and a logistic loss for each label i.e. function+rating (e.g. speech-FRS-4, speech-FRS-3, and so on). With these parameters set, we used the validation set of the final dataset splits described in the ‘Data’ section to choose the training hyper-parameters.
Regarding training, our CNN voice and accelerometer models used batch normalization. We compared mini-batch sizes of 32, 64, and 128 frames, and learning rates of 1e-5, 1e-6, and 3e-6, and the Adam optimizer. While these parameters in themselves didn’t result in significant differences in performance some models trained faster achieving better performance sooner. For our final models, the voice model used a mini-batch size of 64 and learning rate of 1e-5, and the accelerometer model used a mini-batch of size 32 and a learning rate of 1e-5. The models were trained for around 25 epochs. The simpler accelerometer model variants (linear regression, logistic regression, and multi-layer perceptron) used a batch size of 100 and were trained for 60 epochs, and the model performing best on the validation set was used to run evaluations on the final test set.
Normalization coefficient values used in TBVM computation
To compute TBVM values in our work, we used the previously described process31. To normalize, they created a control 1 Hz vector magnitude (VM) dataset by collecting four to six months of accelerometer data from 18 healthy volunteers. They calculated the average VM from each limb across the prescribed movements from the healthy volunteer cohort and chose the largest value (which corresponded to the left-wrist and was 717.9) to create vector magnitude normalization coefficient for each prescribed movement (i.e. they divide by the largest value to get a scaling coefficient for each limb in the health volunteer cohort, and multiply by that co-efficient to normalize data from participants). The coefficients they obtained (and which we used after dividing the VM values by 717.9) are: 2.497844 (for the left-ankle), 2.492674 (for the right-ankle), 1.0 (for the left-wrist), 1.01044 (for the right-wrist), and 3.123886 (for both wrists together).
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Code availability
Code for ML models are available at: https://github.com/pmphelp/paper-code
There are no restrictions with regard to use of the code.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Jean-Martin, C. Amyotrophies spinales deuteropathiques sclérose latérale amyotrophique Sclérose latérale amyotrophique. (Bureaux du progrès médical, 1874).
Swash, M., Leader, M., Brown, A. & Swettenham, K. W. Focal loss of anterior horn cells in the cervical cord in motor neuron disease. Brain 109, 939–952 (1986).
Ravits, J., Paul, P. & Jorg, C. Focality of upper and lower motor neuron degeneration at the clinical onset of ALS. Neurology 68, 1571–1575 (2007).
Ravits, J., Laurie, P., Fan, Y. & Moore, D. H. Implications of ALS focality: rostral-caudal distribution of lower motor neuron loss postmortem. Neurology 68, 1576–1582 (2007).
Sekiguchi, T. et al. Spreading of amyotrophic lateral sclerosis lesions-multifocal hits and local propagation? J. Neurol. Neurosurg. Psychiatry 85, 85–91 (2013).
Swinnen, B. & Robberecht, W. The phenotypic variability of amyotrophic lateral sclerosis. Nat. Rev. Neurol. 10, 661–670 (2014).
Gordon, P. H. et al. Defining survival as an outcome measure in amyotrophic lateral sclerosis. Arch. Neurol. 66, 758–61(2009).
Richards, D., Morren, J. A. & Pioro, E. P. Time to diagnosis and factors affecting diagnostic delay in amyotrophic lateral sclerosis. Amyotroph. Lateral Scler. 15–34 (2021). https://doi.org/10.36255/exonpublications.amyotrophiclateralsclerosis.diagnosticdelay.2021
Lacomblez, L., Bensimon, G., Meininger, V., Leigh, P. N. & Guillet, P. Dose-ranging study of riluzole in amyotrophic lateral sclerosis. Lancet 347, 1425–1431 (1996).
Miller, R. G., Mitchell, J. D. & Moore, D. H. Riluzole for amyotrophic lateral sclerosis (als)/motor neuron disease (MND). Cochrane Database Syst. Rev. (2012). https://doi.org/10.1002/14651858.cd001447.pub3
Rothstein, J. D. Edaravone: a new drug approved for ALS. Cell 171, 725 (2017).
Cudkowicz, M. E. et al. Toward more efficient clinical trials for amyotrophic lateral sclerosis. Amyotroph. Lateral Scler. 11, 259–265 (2009).
Nicholson, K. A., Cudkowicz, M. E. & Berry, J. D. Clinical trial designs in amyotrophic lateral sclerosis: does one design fit all? Neurotherapeutics 12, 376–383 (2015).
Sykes, N. End-of-life care in ALS. Palliative Care in Amyotrophic Lateral Sclerosis 277–292 (2014). https://doi.org/10.1093/acprof:oso/9780199686025.003.0018
Cedarbaum, J. M. & Stambler, N. Performance of the amyotrophic lateral sclerosis functional rating scale (ALSFRS) in multicenter clinical trials. J. Neurol. Sci. 152 Suppl 1:S1–9 (1997).
Cedarbaum, J. M. et al. The ALSFRS-R: a revised ALS functional rating scale that incorporates assessments of respiratory function. J. Neurol. Sci. 169, 13–21 (1999).
Kaufmann, P. et al. The ALSFRSR predicts survival time in an ALS clinic population. Neurology 64, 38–43 (2005).
Kollewe, K. et al. ALSFRS-R score and its ratio: a useful predictor for ALS-Progression. J. Neurol. Sci. 275, 69–73 (2008).
Atassi, N. et al. Analysis of start-up, retention, and adherence in ALS clinical trials. Neurology 81, 1350–1355 (2013).
Smith, R. A. et al. Assessment of bulbar function in amyotrophic lateral sclerosis: validation of a self-report scale (center for Neurologic Study Bulbar functionscale). Eur. J. Neurol. 25, 907.e66 (2018).
Maier, A. et al. Online assessment of ALS Functional Rating Scale compares well to in-clinic evaluation: a prospective trial. Amyotroph. Lateral Scler. 13, 210–216 (2012).
Healy, B. C. & Schoenfeld, D. Comparison of analysis approaches for phase III clinical trials in amyotrophic lateral sclerosis. Muscle Nerve 46, 506–511 (2012).
Taylor, A. A. et al. Predicting disease progression in amyotrophic lateral sclerosis. Ann. Clin. Transl. Neurol. 3, 866–875 (2016).
Franchignoni, F., Mandrioli, J., Giordano, A. & Ferro, S. A further Rasch study confirms that ALSFRS-R does not conform to fundamental measurement requirements. Amyotroph. Lateral Scler. Frontotemporal Degeneration 16, 331–337 (2015).
Berry, J. D. et al. Design and results of a smartphone‐based digital phenotyping study to quantify ALS progression. Ann. Clin. Transl. Neurol. 6, 873–881 (2019).
Fournier, C. N. et al. Development and validation of the Rasch-built overall amyotrophic lateral sclerosis disability scale (roads). JAMA Neurol. 77, 480 (2020).
Rutkove, S. B. et al. ALS longitudinal studies with frequent data collection at home: study design and baseline data. Amyotroph. Lateral Scler. Frontotemporal Degeneration 20, 61–67 (2018).
Pan, W. et al. Actigraphy monitoring of symptoms in patients with parkinson’s disease. Physiol. Behav. 119, 156–160 (2013).
Green, J. R. et al. Bulbar and speech motor assessment in ALS: challenges and future directions. Amyotroph. Lateral Scler. Frontotemporal Degeneration 14, 494–500 (2013).
Takahashi, F., Takei, K., Tsuda, K. & Palumbo, J. Post-hoc analysis of MCI186-17, the extension study to MCI186-16, the confirmatory double-blind, parallel-group, placebo-controlled study of Edaravone in amyotrophic lateral sclerosis. Amyotroph. Lateral Scler. Frontotemporal Degeneration 18, 32–39 (2017).
Premasiri, A., Mosko, O., McNally, M., Vieira, F. ELE-18 Accelerometers as non-invasive tools for the objective measure ment of limb specific range of motion and force in ALS. (2017) Theme 7 Electrophysiology, Amyotrophic Lateral Sclerosis and Frontotemporal Degeneration, 18:sup2, 200-211, https://doi.org/10.1080/21678421.2017.1374595
Allison, K. M., Yunusova, Y. & Green, J. R. Shorter sentence length maximizes intelligibility and speech motor performance in persons with Dysarthria due to amyotrophic lateral sclerosis. Am. J. Speech-Lang. Pathol. 28, 96–107 (2019).
Bakker, L. A. et al. Assessment of the factorial validity and reliability of the ALSFRS-R: a revision of its measurement model. J. Neurol. 264, 1413–1420 (2017).
Green, J. R. et al. Additional evidence for a therapeutic effect of dextromethorphan/quinidine on bulbar motor function in patients with amyotrophic lateral sclerosis: a quantitative speech analysis. Br. J. Clin. Pharmacol. 84, 2849–2856 (2018).
Hershey, S. et al. CNN architectures for large-scale audio classification. 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2017). https://doi.org/10.1109/icassp.2017.7952132
Acknowledgements
This research could not be possible without the immense contributions from people living with ALS who have participated for months and years in the ADVARRA CIRBI IRB approved Translational Research Program for ALS. We thank each participant for their contributions. We thank Oltiana Mosko, Amy Lummen, Taylor Charbonneau, Melissa Nollstadt, and Beth Levine for their stewardship of patient participants. We thank the ALS patient and caregiver community, in particular Augie’s Quest for a Cure, for financially supporting this research. We thank Philip Nelson and Rif A. Saurous from Google Research for their support and encouragement through the duration of this project, and thank Dave Parrish, Joel Shor and Dotan Emmanuel for early research contributions. We also thank Yun Liu, Akinori Mitani, Michael McConnell, and Michael Howell from Google Health for feedback on a draft of this work.
Author information
Authors and Affiliations
Contributions
S.P. and F.G.V. conceived of the translational research program that resulted in the data collected and analyzed in this manuscript. F.G.V., S.V., M.P.B., and S.P. conceived of the study objectives. S.V., M.P.B., A.J., and K.M. conceived and executed model tranining. F.G.V., A.S.P., MM, and SP contributed to data collection efforts. F.G.V., S.V., A.S.P., M.M., A.J., K.M., M.P.B., and S.P. contributed to the interpretation of the results. F.G.V. and S.V. took the lead in writing the manuscript and are co-first authors. All authors provided critical feedback and helped shape the research, analysis, and manuscript.
Corresponding authors
Ethics declarations
Competing interests
S.V., A.J., K.McC., and M.P.B. are employees of Google, which sells hardware and software for machine learning. S.P. is an employee of Eledon Pharmaceuticals which aims to develop and market pharmaceuticals for ALS and other disease indications. The remaining authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vieira, F.G., Venugopalan, S., Premasiri, A.S. et al. A machine-learning based objective measure for ALS disease severity. npj Digit. Med. 5, 45 (2022). https://doi.org/10.1038/s41746-022-00588-8
Published:
DOI: https://doi.org/10.1038/s41746-022-00588-8
This article is cited by
-
Exploratory study to evaluate the acceptability of a wearable accelerometer to assess motor progression in motor neuron disease
Journal of Neurology (2024)
-
The use of digital outcome measures in clinical trials in rare neurological diseases: a systematic literature review
Orphanet Journal of Rare Diseases (2023)
-
At-home wearables and machine learning sensitively capture disease progression in amyotrophic lateral sclerosis
Nature Communications (2023)
-
A systems approach towards remote health-monitoring in older adults: Introducing a zero-interaction digital exhaust
npj Digital Medicine (2022)
-
A systematic review of digital technology to evaluate motor function and disease progression in motor neuron disease
Journal of Neurology (2022)
