
Abstract
Targeted contact-tracing through mobile phone apps has been proposed as an instrument to help contain the spread of COVID-19 and manage the lifting of nation-wide lock-downs currently in place in USA and Europe. However, there is an ongoing debate on its potential efficacy, especially in light of region-specific demographics. We built an expanded SIR model of COVID-19 epidemics that accounts for region-specific population densities, and we used it to test the impact of a contact-tracing app in a number of scenarios. Using demographic and mobility data from Italy and Spain, we used the model to simulate scenarios that vary in baseline contact rates, population densities, and fraction of app users in the population. Our results show that, in support of efficient isolation of symptomatic cases, app-mediated contact-tracing can successfully mitigate the epidemic even with a relatively small fraction of users, and even suppress altogether with a larger fraction of users. However, when regional differences in population density are taken into consideration, the epidemic can be significantly harder to contain in higher density areas, highlighting potential limitations of this intervention in specific contexts. This work corroborates previous results in favor of app-mediated contact-tracing as mitigation measure for COVID-19, and draws attention on the importance of region-specific demographic and mobility factors to achieve maximum efficacy in containment policies.
Similar content being viewed by others

Introduction
Severe Acute Respiratory Syndrome coronavirus 2 (SARS-CoV-2), is a novel coronavirus strain, discovered in 2019, responsible of a severe respiratory illness named Coronavirus Disease 2019 (COVID-19) that has been declared a public health emergency since January 2020. As of August 18th 2020 more than 13 million people worldwide have developed COVID-19 and more than 773,000 have died from it.
The spread of COVID-19 has raised new challenges for healthcare systems all over the world, hitting with particular strength Europe and USA, after China. According to the available data, Italy had among the highest number of contagions and dead toll from COVID-19, with over 200,000 confirmed cases and more that 30,000 deceased as of May 14th 2020. However, the spread of COVID-19 has been quite heterogeneous in speed, reach, and lethality, not only from country to country, but also in different regions of the same country. The main possible explanation is given by the delay between the onset of the epidemic, the first diagnosis, and the kick-off of containment measures. Other reasons may be due to region-specific variables, such as population density and mean age, societal structure, and behaviors. A third factor depends also on the adopted policies for containment and testing, in particular for what concerns the fraction of infectious individuals that never display symptoms (asymptomatic).
In fact, it is now known that the course of infection includes an incubation pre-symptomatic period, during which the patients show no sign of disease but are still potentially infectious (likely to a lesser degree), after which some individuals progress to a symptomatic state, while others remain asymptomatic, but still potentially infectious1. This behavior has important consequence on how we model COVID-19’s epidemiology and plan countermeasures.
Most countries dealing with the epidemics have resorted to nation-wide lock-downs and social distancing to slow down the outbreak; the strategy has been effective in slowing down the epidemic, but lock-downs are temporary measures by nature and simply releasing them without any other parallel containment strategy could very well lead to a new increase of cases. Dedicated works in the scientific literature show that this scenario is avoidable as long as extensive policies of testing and contact tracing are adopted2,3.
However, the effectiveness of such measures in controlling the epidemic strictly depends on efficiency in isolating positive and symptomatic cases, as well as their contacts. Earlier work on the topic showed that efficient outbreak control may require tracing and isolation of up to 80% of the contacts, and with very short delay from onset to isolation4. This is hardly feasible on a large scale using only traditional methods for contact tracing, and managing the epidemics in the long term will likely require the use of information technology to help implement measures of containment and mitigation. In particular, precise identification of cases and contact tracing and isolation can hardly be performed with traditional methods, and the use of targeted phone apps could highly improve the efficiency of these processes, as shown by the experience of multiple Asian countries – such as South Korea.
Different infrastructures and working interfaces for such an instrument have already been proposed5, and its potential impact on the virus’s reproductive rate has also been studied6,7,8. Tracing apps could play a key role in ensuring that the epidemic remains sustainable on the healthcare systems, not exceeding their capabilities, which would otherwise lead to excess mortality.
South Korea pioneered in this approach, both by suggesting to the public the use of applications able to notify contacts with infected subjects, and by mandatory installation, for travelers, of an app implemented by the Ministry of Health and Welfare to monitor COVID-19 symptoms and quarantine for 14 days. Another app, by the Ministry of Interior and Safety, was aimed at monitoring trajectories and contacts of infected subjects and to apply self-surveillance and self-quarantine9.
Despite concerns over potential privacy violations, the South Korean approach managed to achieve efficient control of the epidemics in its earliest phases, and represents a good example of how such an approach could work.
Notable efforts have been done by epidemiologist to model epidemic trends for COVID-19 and the effect of containment measures.
In this proof-of-concept study we built a comprehensive framework to model the COVID-19 epidemic, taking into account population density, the different contributions of symptomatic, pre-symptomatic and asymptomatic contagions, and using it to test the efficacy of targeted interventions such as the aforementioned contact tracing app. In contrast to previous work7,8 aimed at modeling the two-way dynamic between individual behaviors and containment policies, we chose to build a global compartmental modeling framework that can account for region-specific factors, such as the effect of population density on contact rate or the role of expected compliance to containment procedures.
Our research builds a model that allows testing the effect of both case isolation and app-mediated interventions in a region-specific fashion.
Results
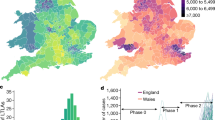
We built an improved Susceptible-Infectious-Recovered (SIR) model10 with the aims of a) faithfully reproducing the dynamics of the SARS-CoV-2 epidemics, including the respective roles of asymptomatic infection and population density; b) testing the effects of distinct interventions, and specifically the use of phone apps for contact tracing. As Italy was the first western country affected by the SARS-CoV-2 and for which region-specific and intervention-related data was readily available, our analysis is focused on the Italian case. This has allowed us to study how the virus spreads at a very different pace in different Italian districts (Figs 1 and 2).

Compared to low density regions (a), epidemics may be significantly harder to contain through contact tracing apps in areas with very high population density (b).

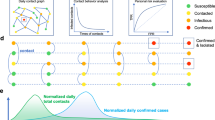
Graphical representation of the interactions among the different compartments of the extended SIR model. S susceptible, I infected, R recovered, A asymptomatic, P pre-symptomatic, QS quarantined susceptible, QI quarantined infected, QA quarantined asymptomatic, QP quarantined pre-symptomatic. Rates of transfer between compartments are a function of the parameters annotated on the arrows. A detailed description of such parameters is provided in “Methods” and Table 1.
Results of the simulations from the model are summarized in Figs 3 and 4, showing the time curves of the sum of the infected (I) and quarantined infected (QI) compartments and expected mortality. Clearly the epidemic peak is expected to vary with increasing contact rate, assuming that transmissibility and recovery rate are constant. As expected, in all simulated scenarios, app-aided contact tracing significantly decreased the effective reproductive number Rt and height of the epidemic peak. In our sensitivity analyses, using the slightly longer incubation time had no significant impact in our simulations, whereas the increased infectiousness causes an expected delay in the complete suppression of infections, in particular under conditions of normal mobility.

Total symptomatic population (red) and simulated mortality (black) in the 48 scenarios. Density-dependent contact rate simulations on the left (plots a–f); fixed contact rate simulations on the right (plots g–l). Each curve results from the sum over 110 districts averaged over 50 replicates per district. Solid lines represent no app users; dashed, dotted and dashed–dotted lines show increasing fractions of the population using the app (25, 50, 75%). All simulations can be interactively explored at https://flowmaps.life.bsc.es/shiny/ct_app/.

Detail of Fig. 3. Density-dependent contact rate simulations on the left (a, c, e); fixed contact rate simulations on the right (b, d, f). Suppression is achieved in the most optimistic scenario (contact rate 7.5, app users 75%) with fixed contact rate (b), whereas its success varies from district to district in scenarios with density-dependent contact rate.
Constant contact rate
In scenarios with constant contact rate equal to 7.5, symptomatic cases isolation was per se very effective in slowing the epidemic, so much so that app-mediated contact tracing managed to achieve suppression even with only 75% (Fig. 4b) of the population using the app and complying to self-quarantine, whereas with 50% peak height was reduced more than 2-fold (Fig. 3b). This shows that, in scenarios with lower baseline contact rate and efficient isolation of cases, app-mediated contact tracing can achieve epidemic suppression.
On the other hand, nation-wide suppression was not achieved in the less optimistic scenarios with 10 and 14.8 contact rate; however, the app induced a very effective mitigation, with peak number of infectious reduced roughly 4-fold in the worst-case scenario and with 75% of the population using the app (Fig. 3d, f).
Density-dependent contact rate
In scenarios where contact rate was allowed to vary with population density the epidemic trend was, as expected, significantly different from region to region. In Fig. 3, left panels, the curves of symptomatic infections over time are shown; compared to simulations with constant contact rate, it is evident the presence of two more or less distinct epidemic peaks; this may reflect the presence of groups of districts with different population densities. However, the distinction tends to disappear with increasing proportions of app users. The simulations show that suppression can be achieved in most regions even with only 25% of the population using the app (dashed lines), but the epidemics does not die out, being almost entirely sustained by the districts with the highest population density (Milan, Monza, Neaples; Fig. 5). This result is, clearly, achieved by using the app to augment an efficient tracking and isolation of new symptomatic cases, and indicates that, as for all interventions, effectiveness of app-mediated contact-tracing and voluntary quarantine should be evaluated in the light of region-specific differences.

Epidemic curve for individual nodes (districts) in the scenario with average velocity \(\bar{v}=1.5\) and fraction of app users j = 25%. The epidemic outbreak is entirely sustained by the three highest-density districts, whereas in the others the effective reproductive number is below 1.
Quarantine measures impact
The model allows to also keep track of the number of I subjects successfully quarantined ("true positives”) and of the subjects that underwent quarantine without actually being infected ("false positives”), by tracing the population in the QI (subjects that were rightfully quarantined) and QS (Quarantined-Susceptible, subjects that were quarantined but did not contract infection) compartments. The maximum number of subjects in each compartment at the same time is summarized in Table 1.
Both false positives and true positives are naturally dependent on the success or failure of epidemics suppression, and will be very low when suppression is achieved. In density-dependent scenarios with 75% of app users the maximum number of SUSCEPTIBLE subjects quarantined at the same time ranged from 200, 000 to 2, 000, 000, whereas in scenarios with fixed density the variation was much higher, mainly due to the fact that with contact rate C = 7.5 and 75% app users suppression is achieved.
As expected, true positives decrease as app coverage increases and epidemic spread is impaired, but at the same time the number of subjects that are subjected to voluntary quarantine without reason increases. The two quantities cross over between j = 0.25 and j = 0.5, where subjects that are wrongly quarantined surpass those that are actually infectious.
Discussion
The use of targeted app for contact tracing has been proposed as a means to control the COVID-19 epidemics when lockdown measures are lifted. It has been shown that, given certain combinations of efficacy in case identifications and compliant use of such an instrument, the approach can contribute to the effective reproductive number Rt of the disease below 16. Here we aimed to model the effect of app-mediated contact tracing taking into account population density and transportation, at the same time making it possible to monitor the number of patients that are quarantined and their status concerning the infection.
This is a much needed approach if we wish to implement precise and timely specific intervention making the infections and contagion sustainable for healthcare systems.
The model uses a series of Q* compartments to model the behavior and status of subjects that are quarantined for symptomatic infection or based on contact tracing. To our knowledge, this is the first model that allows simulation and prediction of the outcomes of the epidemic both accounting for differential population density and quarantine measures. This is particularly important since it allows to visualize the effect of contact-tracing apps along the entire duration of the epidemics, and also because the management of the infection has to take into account the specific characteristics of a given region and implement measures accordingly. In fact, the application of containment policies disregarding region-specific conditions can result in measures which are not needed or too drastic. As a consequence, rather than providing support, such policies might result in a burden for the psychological well-being of people as well as detrimental for the economy11.
Compartmentalization of quarantined subjects has a remarkable potential usefulness in studying the socio-economic impact of voluntary self-quarantine suggested by app tracing. Clearly, a larger proportion of app users entails better epidemic control. However, it is expected that the number of false positives in the QS compartment increases accordingly, with increased losses in terms of well-being and resources.
Despite the many parameters considered in our model, our work still falls into a classic compartmental epidemiologic framework; this is a net advantage in terms of interpretability of results and generalizability. To our knowledge, this is also the first model that allows keeping track of subjects that undergo voluntary quarantine.
According to our model, case isolation is per se a very effective containment measure that, as long as cases are identified and isolated with a very high success rate, can achieve suppression of the epidemics in a series of theoretical scenarios. However, coupling case isolation with immediate app-mediated contact tracing produces a remarkable improvement in success of the strategy, achieving in all scenarios a very effective mitigation of contagion and, in some scenarios, full suppression. These results highlight the benefit of introducing contact-tracing as a measure of pandemic prevention and control as well as the positive impact that this would have especially upon critical circumstances.
Feasibility of epidemic control by app-mediated contact tracing has been suggested already by Ferretti et al.6; by decomposing contributions to R0 from symptomatic, pre-symptomatic, asymptomatic, and environmental sources, they show that Rt < 1 can be attained for certain combinations of efficiency in case isolation and compliance in contact tracing. Our model allows to directly simulate such scenarios while at the same time keeping track of the trends in isolated and quarantined cases. This is particularly relevant as it allows to quantify the effect of interventions on specific compartments, e.g., it is possible to trace the number of individuals that are quarantined at a specific time-point, a piece of data that is potentially very helpful in designing cost-effectiveness analyses of containment measures.
Another important result comes from our simulations with a density-dependent contact rate. In our simulation different Italian districts behaved very differently, and in all scenarios suppression was easily attained in the less densely populated regions, whereas it failed in the others (Fig. 5). This is consistent with the different epidemic trends that have been observed to date in Italian districts; however, it must be pointed out that differences between districts may as well be justified by different approaches in dealing with the epidemics, time to first diagnosed case versus numbers of people already infected in the population and not yet recognized and, most importantly, is influenced by the nation-wide/region-wide lockdown put in place by the central government.
It is also of note that by making contact rate dependent on both density and daily distance traveled, our model takes into account the potential effectiveness of policies aimed at optimizing and regulating transportation, especially in high-density regions. According to the model, effective suppression of the epidemics in such areas is strongly dependent on such measures.
The main limitation of our work is that there is some uncertainty in the parameters that have to be plugged-in the simulations; anyway, we were able to derive reasonable estimates for all of them, and performed a sensitivity analysis to check that our results are robust to changes in the most uncertain parameters. We adopted some credible figures for the asymptomatic/symptomatic infections ratio and for relative decrease in infectiousness in asymptomatic subjects, as well as for probability of infection per contact; however the greatest uncertainty is precisely in estimation of contact rate, as this is a variable that is influenced by specific environmental and cultural factors, e.g., individual mobility, social interactions, transportation systems, as well as general social distancing measures that have been implemented wherever the epidemics took place. Our first choice estimate for contact rate came from the experience of the Diamond Princess, based on which we estimated it at a very impressive figure of 14.8, a condition that would hardly allow for suppression in a nation-wide context. However, it is evident that the situation in a closed environment favors a higher contact rate, thus this number is likely to be significantly overestimated. This makes the scenario a worst-case one, suggesting that, in real world experience, case isolation and contact tracing may be more effective than predicted.
In scenarios where we modeled contact rate as a function of population density, the most relevant scaling factor is \(\bar{v}\), i.e., the theoretical average daily distance traveled by individuals. This is a measure that is not readily estimable, which is why in the present work we showed results for a series of credible scenarios; however, using mobility data from European cities we managed to obtain credible figures to plug-in the model. Our model does take into account interpersonal distance in the form of R parameter; a potential expansion of this framework is to account for time spent within the 1 m interpersonal distance, as well as distinguishing between high-risk (e.g., taxis, buses) and low-risk (e.g., walking, personal car) means of transportation.
However, this work proves the feasibility of including population density and transportation in an expanded SIR model, and suggests that, even if travel between districts is forbidden, the epidemics may still be significantly harder to contain in areas with very high population density (for example, in Italy, the districts of Milano, Monza, and Napoli). The model can be further improved and expanded by adding age-specific compartments, sex and gender factors, and risk classes, by refining the implementation of vital dynamics, and by modeling different methods for contact tracing with varying degree of compliance.
We approached the model with a simulation-based approach; this is computationally intensive but still manageable by most software and hardware and less demanding than stochastic models based on individual data, and allows for a high degree of customizability by fine-tuning its parameters on specific interventions.
The model constitutes a viable framework to monitor epidemic trends and assess the effect of interventions. Our results show that (1) voluntary self-quarantine based on contact-tracing apps, together with efficient case isolation, can give a relevant, and in some scenarios decisive, contribution to epidemics mitigation/suppression; (2) at the same time, the success of this strategy can depend heavily on population density and transportation.
Methods
Model design
The typical SIR model assumes that some degree of immunity, at least temporary, is acquired after SARS-CoV-2 infection; therefore, it is assumed that subjects move from the S (SUSCEPTIBLE) compartment to the I (INFECTIOUS) compartment, and from there, with a daily rate equal to the inverse of recovery time, to the R (RECOVERED) compartment, until the relative densities of S and I become too low for the epidemic to continue. In order to simulate the behavior of asymptomatic and pre-symptomatic individuals, an A (ASYMPTOMATIC) and P (PRE-SYMPTOMATIC) compartment were added to the model.
To simulate the effect of targeted quarantine measures, we introduced a series of Q* compartments indicating the number of subjects that are quarantined and their status regarding the disease. To model the reversible transition from the different compartment into the state-specific quarantine compartments, there are four different Q compartments: QS, QI, QA, and QP. Whenever they are infected, individuals are supposed to move from the S compartment to the A or P compartments, with respective probabilities pa and pi = 1 − pa. Subjects in the P compartments then transfer to the I compartment with a daily rate of 1/τi, where τi is the incubation period. We also assume that asymptomatic and pre-symptomatic patients are less infectious than symptomatic individuals by a factor f.
However, there is evidence that pre-sympromatic individuals are highly infectious already about τd = 2 days before symptom onset12, and the focus of our model is transmission dynamics, rather than symptoms manifestations. Under this profile, a P subject is already akin to a I subject τd days before symptom onset. Therefore, we let P subjects move into I compartment after an incubation period that is τd = 2 days shorter, while at the same time increasing the recovery period by the same amount.
Our model assumes the use of a phone app that keeps track of contacts and, once a symptomatic case is identified, notifies the event to everyone who had contacts with them in the pre-symptomatic period, so that they can enter a voluntary quarantine (Fig. 1). Such an application is heavily reliant, on one hand, on effectiveness of case isolation on the part of the authorities, and on the other hand on compliance and widespread use of the system by the population. Thus, we assume, for our model, that a J fraction of symptomatic cases is identified and undergoes perfect quarantine with zero contacts. We call j the fraction of the population using the app and we assume that once in quarantine, they reduce the contact rate by a factor q. Therefore, j2 is the fraction of contacts that happen between individuals using the app. Quarantined subjects that develop the infection undergo the entire course of the disease, whereas those that were not infected in the contact eventually exit quarantine after the quarantine period τq (15 days) and become SUSCEPTIBLE again. In the classic SIR model, the rate of transfer between the S and I compartments depends on transmission rate β, that is, the product of number of contacts per subject, C, and probability of transmission during a single contact μ13.
To estimate contact rate as a function of population density we built on previous results by Rhodes and Anderson14 who derived a formula for estimation of daily contact rate of a subject in a population with density ρ moving with velocity \(\bar{v}\) as
where R is the minimum distance within which two individuals can be said to have a “contact”; for COVID-19, and other air-borne diseases transmitted by droplets expelled from nose or mouth, it is commonly estimated as 1 m15.
In our model we assume that SUSCEPTIBLE subjects move to the P compartment with a rate proportional to the probability of meeting an A, I, or P subject, assuming that at least one of the two does not use the tracing app and/or the case is not successfully identified. This is modeled by making the rate dependent on 1 − Jj2. The remaining Jj2 fraction of the contacts between S and I individuals leads to a transfer from S to one of the three QP, QA, and QS compartments, each with probability equal to pi, pa, or 1 − pi − pa, i.e., the probability of the contact leading to symptomatic infection, asymptomatic infection, or no infection. Individuals in the QP compartment eventually transfer to the QI compartment after incubation, whereas QA and QS transfer to R and to S, respectively, with rates equal to 1/τi and 1/τq.
The structure of the model is shown in Fig. 2 and it is described by the following set of differential equations. By defining α = Jj2 as the proportion of contacts that are successfully contained, we have:
The model is governed by a set of ordinary differential equations (2–10) that depend on different parameters. Model parameters are based on values found in different bibliographic references (see Table 2).
For COVID-19 attack rate μ we adopted data from the epidemic in Shenzen, where secondary attack rate was estimated between 0.10 and 0.1516. According to Ferretti et al.6 the most likely estimates for f and pa are 0.1 and 0.4. The 0.4 estimate for the asymptomatic fraction is corroborated by a recent epidemiological study on COVID-19 prevalence in Veneto17.
In the simulations, we included some basic vital dynamics by adding a D (DECEASED) compartment (not shown), for which we assumed an overall mortality of 1% in symptomatics. Mortality estimates for COVID-19 are actually still quite uncertain, but INFECTIOUS removal by mortality is not expected to significantly affect epidemic trends.
The parameter estimates have a degree of uncertainty and, most importantly, the body of evidence supporting them is continuously growing. Incubation time τi, for example, has been recently suggested to be higher than our 5.1 days estimate, at 7.7618. Relative infectiousness of A and P versus I, f is another parameter that has strong uncertainty. For this reason, we performed a sensitivity analyses on the two most uncertain parameters (see Supplementary Figs. 1 and 2).
The simulations were run using R package SimInf, a system for stochastic simulation of compartmental models of epidemics19.
Experiments
For our experiments we assumed that J = 75% of symptomatic cases are identified and perfectly quarantined at symptom onset, i.e., two days after their infectiousness increases. On the other hand, contacts undergoing voluntary self-quarantine are supposed to reduce their contact rate ten-fold (q = 0.1).
We simulated 12 scenarios with varying contact rate C and, most importantly, assuming a different proportion j of app users in the population (0, 0.25, 0.5, and 0.75). Each simulation was run on 110 nodes representing Italian districts (with data on area and resident population updated to 2016), and was repeated 50 times, with globally 5500 simulations per scenario.
For a first set of simulations we assumed a constant population density for all the nodes; this equals the assumption of a unique transmission rate and, therefore, a unique R0 for the entire set, so that the only region-specific factor affecting the outcome was relative population. Transmissibility has been previously estimated, based on data from the Diamond Princess outbreak, at 1.4820; accordingly, assuming 0.10 attack rate, in this scenario we set a contact rate equal to 14.8. However, this was calculated in a particular scenario where contact rate was supposedly higher than in normal conditions, thus we simulated two more scenarios with lower contact rates, 10 and 7.5.
A second set of simulations accounted for different population densities across the 110 districts. Here, contact rate was allowed to vary following population density under an assumed average daily distance traveled by the subjects, according to Eq. (1). Mobility data from two sample European cities (Berga and Barcelona) show an average daily distance traveled per person varying between 1.2 and 5.2 km (personal communication); starting from these figures we simulated scenarios in which subjects travel, on average, 1.5, 2.5, and 5 km per day.
An interactive R Shiny web application, enabling the exploration of simulation scenarios, is available at https://flowmaps.life.bsc.es/shiny/ct_app/.
Data
Our simulations were based on population and surface area data from 110 Italian districts updated to 2016. This kind of data is subject to frequent administrative rearrangements, but actual demographics have remained substantially stable for the aims of this work, and since some districts have since be grouped together, older data has actually higher spatial resolution.
Table 3 summarizes population data about the five most and least densely populated districts. Over the entire national territory, density was 2.01/km2, and in districts it ranged from 0.03 to 2.65. Corresponding surface area ranged from 212 to 7400 km2. Globally, population was 60, 589, 085. Ogliastra was both the least populated and least densely populated district, with 57, 185 inhabitants and a density of 0.03/km2; the district with most residents was Rome (4, 353, 738 residents), but the most densely populated was Neaples.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Data about population density is provided as supplementary material. Mobility data has been provided by the Spanish Ministry of Transport, Mobility and Urban Agenda (https://www.mitma.gob.es/ministerio/covid-19/evolucion-movilidad-big-data).
Code availability
The code used for the simulations is provided as supplementary material.
References
Koh, W. C. et al. What do we know about SARS-CoV-2 transmission? A systematic review and meta-analysis of the secondary attack rate, serial interval, and asymptomatic infection. PLOS ONE 15, e0240205 (2020).
Giordano, G. et al. Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat. Med. 26, 855–860 (2020).
Peto, J. Covid-19 mass testing facilities could end the epidemic rapidly. BMJ 368, m1163 (2020).
Hellewell, J. et al. Feasibility of controlling COVID-19 outbreaks by isolation of cases and contacts. Lancet Glob. Health 8, e488–e488 (2020).
Ahmed, N. et al. A survey of COVID-19 contact tracing apps. IEEE Access 8, 134577–134601 (2020).
Ferretti, L. et al. Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing. Science 368, eabb6936 (2020).
Matabuena, M. et al. COVID-19: estimating spread in Spain solving an inverse problem with a probabilistic model. Preprint at https://arxiv.org/abs/2004.13695 [q-bio.PE] (2020).
Lorch, L. et al. A spatiotemporal epidemic model to quantify the effects of contact tracing, testing, and containment. Preprint at https://arxiv.org/abs/2004.07641 [cs.LG] (2020).
Lee, D. & Lee, J. Testing on the move: South Koreaas rapid response to the COVID-19 pandemic. Transp. Res. Interdiscip. Perspect. 5, 100111 (2020).
Kermack, W. O. & McKendrick, A. G. A contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. 115, 700–721 (1927).
Morley, J. et al. Ethical guidelines for COVID-19 tracing apps. Nature 582, 29–31 (2020).
He, X. et al. Temporal dynamics in viral shedding and transmissibility of COVID-19. Nat. Med. 26, 672–675 (2020).
Lipsitch, M. et al. Transmission dynamics and control of severe acute respiratory syndrome. Science 300, 1966–1970 (2003).
Rhodes, C. J. & Anderson, R. M. Contact rate calculation for a basic epidemic model. Math. Biosci. 216, 56–62 (2008).
WHO. Report of the WHO-China Joint Mission on Coronavirus Disease 2019 (Covid-19) (2020). available at: https://www.who.int/docs/default-source/coronaviruse/who-china-joint-mission-on-covid-19-final-report.pdf.
Bi, Q. et al. Epidemiology and transmission of COVID-19 in Shenzhen China: analysis of 391 cases and 1,286 of their close contacts. MedRxiv, https://doi.org/10.1101/2020.03.03.20028423 (2020).
Lavezzo, E. et al. Suppression of COVID-19 outbreak in the municipality of Vo, Italy. Nature 584, 425–429 (2020).
Qin, J. et al. Estimation of incubation period distribution of COVID-19 using disease onset forward time: a novel cross-sectional and forward follow-up study. Sci. Adv. 6, eabc1202 (2020).
Widgren, S. et al. SimInf: an R package for data-driven stochastic disease spread simulations. J. Stat. Softw. 91, 1–42 (2019).
Rocklöv, J., Sjödin, H. & Wilder-Smith, A. COVID-19 outbreak on the Diamond Princess cruise ship: estimating the epidemic potential and effectiveness of public health countermeasures. J. Travel Med. 27, taaa030 (2020).
Peak, C. M., Childs, L. M., Grad, Y. H. & Buckee, C. O. Comparing nonpharmaceutical interventions for containing emerging epidemics. Proceedings of the National Academy of Sciences 114, 4023–4028 (2017).
Ling, Y. et al. Persistence and clearance of viral RNA in 2019 novel coronavirus disease rehabilitation patients. Chin. Med. J. 133, 1039–1043 (2020).
Lauer, S. A. et al. The Incubation Period of Coronavirus Disease 2019 (COVID-19) From Publicly Reported Confirmed Cases: Estimation and Application. Ann. Intern. Med. 172, 577–582 (2020).
Wells, W. F. ON AIR-BORNE INFECTION: STUDY II. DROPLETS AND DROPLET NUCLEI. Am. J. Epidemiol. 20, 611–618 (1934).
Acknowledgements
This material is based upon work supported by the European Commission’s Horizon 2020 Program, H2020-ICT-12-2018-2020, “INFORE - Interactive Extreme-Scale Analytics and Forecasting” (ref. 825070). The authors would like to acknowledge the Spanish Ministry of Transport, Mobility and Urban Agenda for assistance and support with mobility data.
Author information
Authors and Affiliations
Contributions
A.F., E.S., and N.M. conceived the experiments; A.F. designed the model and ran simulations; A.F. and E.S. wrote the paper; D.C. and M.P.-d.-L. revised the model and code; D.C. wrote the web app; M.T.S., A.S.C., N.M., and A.V. revised the paper and helped with interpretation and discussion; A.V. supervised model design and provided mobility data. All of the authors approved the final version of the paper.
Corresponding author
Ethics declarations
Competing interests
E.S. works for Bayer, is collaborating to COVID Safe Paths app, by MIT, and advising LEMONADE tracing app, by Nuland. A.S.C. works for Roche Pharma. M.T.F is consultant for Ely Lilly. The other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ferrari, A., Santus, E., Cirillo, D. et al. Simulating SARS-CoV-2 epidemics by region-specific variables and modeling contact tracing app containment. npj Digit. Med. 4, 9 (2021). https://doi.org/10.1038/s41746-020-00374-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-020-00374-4
This article is cited by
-
Feasibility of digital contact tracing in low-income settings – pilot trial for a location-based DCT app
BMC Public Health (2023)
-
Exploring computer-aided health decision-making on cervical cancer interventions through deliberative interviews in Ethiopia
npj Digital Medicine (2023)
-
A Case Study of Bluetooth Technology as a Supplemental Tool in Contact Tracing
Journal of Healthcare Informatics Research (2022)
-
Geographic and demographic heterogeneity of SARS-CoV-2 diagnostic testing in Illinois, USA, March to December 2020
BMC Public Health (2021)
-
COVID-19 Flow-Maps an open geographic information system on COVID-19 and human mobility for Spain
Scientific Data (2021)
