
Abstract
Accurately measuring sleep and its quality with polysomnography (PSG) is an expensive task. Actigraphy, an alternative, has been proven cheap and relatively accurate. However, the largest experiments conducted to date, have had only hundreds of participants. In this work, we processed the data of the recently published Multi-Ethnic Study of Atherosclerosis (MESA) Sleep study to have both PSG and actigraphy data synchronized. We propose the adoption of this publicly available large dataset, which is at least one order of magnitude larger than any other dataset, to systematically compare existing methods for the detection of sleep-wake stages, thus fostering the creation of new algorithms. We also implemented and compared state-of-the-art methods to score sleep-wake stages, which range from the widely used traditional algorithms to recent machine learning approaches. We identified among the traditional algorithms, two approaches that perform better than the algorithm implemented by the actigraphy device used in the MESA Sleep experiments. The performance, in regards to accuracy and F1 score of the machine learning algorithms, was also superior to the device’s native algorithm and comparable to human annotation. Future research in developing new sleep-wake scoring algorithms, in particular, machine learning approaches, will be highly facilitated by the cohort used here. We exemplify this potential by showing that two particular deep-learning architectures, CNN and LSTM, among the many recently created, can achieve accuracy scores significantly higher than other methods for the same tasks.
Similar content being viewed by others
Introduction
Short and poor quality sleep have been directly linked to a series of chronic health problems, including obesity, insulin resistance, and hypertension.1,2,3,4 Thus, measuring sleep and its quality are increasingly important beyond the diagnosis of specific sleep disorders.
While polysomnography (PSG) is the gold standard approach for diagnosing specific sleep disorders, it is impractical for use in the identification of more prevalent issues with sleep loss and sleep quality. An attractive alternative to PSG is the use of wearables, such as accelerometer-based technology (Actigraphy), which may be used as a diagnostic aid for specific sleep disorders such as circadian rhythm disorders.
Actigraphy devices allow several weeks of unobtrusive, continuous recording, enabling prospective, and naturalistic assessment of sleep.5 While the signals captured by an actigraphy device are not as detailed as the ones obtained by PSG, it allows the identification of sleep-wake states, sleep timing, and sleep quality.5
Over the past three decades, a number of studies have demonstrated the reliability and validity of actigraphy to replace PSG for nocturnal sleep-wake scoring.5,6,7,8,9,10,11,12,13 These studies show an epoch-by-epoch agreement between activity-based sleep-wake scoring algorithms and traditional PSG-based scoring ranging between 80 and 95%. This accuracy helped in making the usage of actigraphy devices a part of sleep medicine guidelines for the diagnosis of a number of sleep disorders.14
Nevertheless, an existing challenge for actigraphy studies is the relative difficulty in comparing the performance of different actigraphy algorithms due to the lack of standardized datasets.15 Although recent studies have assessed the validity of scoring algorithms in comparison with PSG,8,16 they are usually made with a small number of participants due to the complexity of conducting these studies.
Until very recently, one of the main barriers for the development and enhancement of artificial intelligence methods in sleep research was the lack of public repositories of actigraphy data and tools. However, that trend is changing with recent initiatives, such as sleepdata.org from the National Sleep Research Resource (NSRR), which allows researchers to freely access large collections of well-characterized research cohorts and clinical trials.17,18 One such dataset is the Multi-Ethnic Study of Atherosclerosis (MESA).
MESA was a research study investigating factors associated with the development of subclinical cardiovascular disease and the progression of subclinical to clinical cardiovascular disease in 6814 individuals. The participants were men and women between 45 and 84 years of age at the beginning of the study, from different ethnic communities (Black, White, Hispanic, and Chinese-American). Between 2010 and 2012, approximately one-third of the participants (2237) were enrolled for sleep assessment (MESA Sleep), which included one full overnight unattended PSG session, 7-day wrist-worn actigraphy, and a sleep questionnaire.
In this work, we propose to use the MESA dataset as a cohort to compare the performance of existing and future sleep-wake scoring algorithms. We leveraged the fact that the MESA Sleep dataset is the largest dataset to date for studying actigraphy-based sleep-wake scoring algorithms, being a hundred times bigger than previously used datasets. The Supplementary Table 1 summarizes the basic statistics of the part of MESA Sleep dataset used in this work and compares it to the related work.
The contribution of this work is threefold:
-
First, we build a standardized benchmark to serve the development of new ideas and approaches. We propose two specific research tasks for this cohort: Task Night and Task Night&Day.
-
Second, we review, investigate and validate the main heuristics to identify wake-sleep patterns from actigraphy devices. In our study, we include both well-established heuristics and algorithms, and new state-of-the-art machine learning algorithms. We aim to foster future artificial intelligence research into sleep medicine, and the methods described here will serve as baselines for future research.
-
Third, we make available to the community, a Python library for sleep-wake scoring with all algorithms implemented in this paper (and tools to facilitate the implementation of new algorithms in the future). The code and data used can be found online at https://github.com/qcri/sleep_awake_benchmark.
Results
The performance of machine learning methods is influenced by the choices of optimal hyperparameters. The only hyperparameter optimized for the traditional scoring formulas was Oakley’s threshold θ, which was set to 10, the value that yielded the highest accuracy score in the training set. We show results for θ = 40 and θ = 80 as well, as these values are commonly used in the literature.16 In particular, θ = 40 is the device algorithm.19,20 Hyperparameters of ML and DL algorithms were obtained via the standard fivefold cross-validation while optimizing for accuracy. A detailed list of all the hyperparameters for each model that we explored in this work are provided in the Supplementary Material.
Task night results: predicting sleep quality metrics during night
The results of the experiments of Task Night are shown in Table 1. We group the results according to the technique used (traditional algorithms, ML algorithms and DL algorithms), and whether Webster rescoring rules were used or not. Within each group, we sort the results by mean accuracy in descending order.
Results of the baseline approaches Always Sleep and Always Wake show that 58.4% of the epochs in Task Night dataset are sleep and thus the minimum accuracy score that we should expect is 58.4. The proprietary Device Algorithm and the Manual Annotation have, respectively, an accuracy of 76.2 and 79.8, in line with other traditional algorithms, which vary from 73.3 (Webster) to 77.5 (Oakleyθ=10). Note that this accuracy range is lower than the reported accuracy of 80–95% in original papers that introduced new algorithms (upper part of Table S1, e.g., refs 6,21), but it is similar to the reported 70–85% range of validation papers (lower part of Table S1, e.g., refs 11,22,23). Note that both Manual Annotation and Device Algorithm underestimate the number of wake epochs, resulting in the overestimation of sleep efficiency when compared to the Oracle. Also note that, as expected, Oakleyθ=40 and Device Algorithm present very similar results, with no significant differences between the results of these two approaches.
Apart from Sazonov, all other traditional algorithms have a high sensitivity score (as high as 98.3 for Sadeh algorithm), but relatively smaller average precision score (highest is Oakleyθ=10 with 77.5). This means that although these algorithms are highly effective in detecting epochs of sleep, they do not identify wake time so well, thus overestimating sleep epochs. This is a well-known behavior in the literature that is validated in our experiments,11 as seen by the low values of WASO (and the high values for sleep efficiency) when compared to the Ground Truth. Scripps Clinic algorithm achieved the highest F1 score, 81.8, which is not statistically different from the Device Algorithm (p = 0.47, n = 363), nor the Manual Annotation method (p = 0.10, n = 363).
On average, all results for the traditional algorithms are lower than both Device Algorithm and Manual Annotation baselines. This is somewhat expected as the Device Algorithm is optimized to be used with the particular actigraphy device employed in the experiments and the Manual Annotation resorts to human expert knowledge annotating the dataset.
The use of Webster’s rescoring rules shows gains in both specificity and precision for all the traditional algorithms but at the cost of sensitivity. This implies in a large proportion of epochs previously classified as sleep being reclassified as awake. For the top six traditional algorithms in terms of accuracy, Resc. Oakleyθ=40, Resc. Cole-Kripke, Resc. Scripps Clinic, Resc. Oakleyθ=80, Resc. Sadeh, and Resc. Webster, the use of rescoring rules resulted in higher accuracy and F1 scores. The opposite was found for the other two algorithms. The results show that the rescoring rules are, in general, effective in increasing the accuracy score (the average accuracy score increased from 75.1 to 78.0) but they should be applied with caution, as they could negatively impact the F1 score (average F1 score decreased from 80.3 to 79.8) or overestimate wake epochs (the group average WASO for the traditional algorithms went from 59 to 111 min). Note that there was no significant difference between WASO for Resc. Scripps Clinic and the Ground Truth (p = 0.901, n = 363). That was the case also for Resc. Oakleyθ=40, (p = 0.07, n = 363), Oakleyθ=10 (p = 0.13, n = 363), and Perceptron (p = 0.14, n = 363), for all the rest the differences were statistically significant.
Apart from the Perceptron, the ML algorithms have a very similar performance to each other for all the metrics evaluated. The sensitivity and F1 scores of the Perceptron algorithm were significantly lower than the second worst ML algorithm, Linear SVM (for both p < 0.001). Perceptron was also the only algorithm among the ML ones that overestimated WASO. The best ML algorithm with respect to accuracy score and F1 score, Extra Trees, was significantly better than the Device Algorithm (p < 0.001 for both accuracy and F1). While Extra Trees were significantly better than the Manual Annotations for accuracy (p = 0.016, n = 363), it was not significantly better for F1 (p = 0.26, n = 363).
Similar to the Extra Trees algorithm, the performance of DL algorithms were significantly better than the Device Algorithm for all metrics. Additionally, the F1 performance of LSTM 100, LSTM 50, CNN 100 and CNN 50 was also statistically better than Manual Annotation (p = 0.012, p = 0.046, p = 0.023, p = 0.039, ∀n = 363). Increasing the input size of both CNN and LSTM algorithms from 20 to 100 significantly increased the accuracy score (p = 0.014 for CNN and p = 0.035 for LSTM, ∀n = 363), but did not increase the F1 score significantly (p = 0.111 for CNN and p = 0.120 for LSTM, ∀n = 363). No significant differences were found between CNN 100 and LSTM 100 for accuracy and F1 (p = 0.789 and p = 0.817, ∀n = 363). All DL algorithms underestimated WASO and overestimated the sleep efficiency when compared to the Ground Truth.
The use of rescoring rules had a similar effect in both ML and DL algorithms as it did in the traditional algorithms: increased specificity and precision, but decreased sensitivity (i.e., increased WASO and decreased the sleep efficiency). This time, though, both accuracy and F1 went down after the usage of Webster’s rescoring rules, which indicate that these rules should not be used with ML and DL algorithms.
In Fig. 1 we show the Pearson’s r correlation between the results of the 41 different algorithms shown in Table 1. The correlation coefficients show that Sensitivity is the metric that best (negatively) correlates with WASO and sleep efficiency, the sleep quality metrics studied in this work. However, an algorithm that reaches high values for WASO or sleep efficiency does not necessarily correctly assess one’s sleep quality. For that, we should rely on the mean absolute error between an algorithm and the ground truth for both WASO and sleep efficiency. The metrics that best correlated with MAE WASO is F1 (r = −0.98, p < 0.001), while the one that best correlates with MAE sleep efficiency is accuracy (r = −0.93, p < 0.001).

Pearson’s r correlation coefficients between the results of different metrics for Task Night (shown in Table 1) (n = 41)
Task Night&Day results: algorithm performance metrics during day time and night
Task Night&Day results are shown in Table 2. Once again the Manual Annotation method had the highest accuracy among the baseline methods. For Task Night&Day, though, the performance difference between the Manual annotation method and the Device Algorithm was high: for example, the Manual Annotation accuracy of 86.5 was 13% higher than Device Algorithm’s accuracy of 76.6. The accuracy results of Always Wake and Always Sleep show how the data now has more awake epochs (69.2%) than sleep ones.
Among the group of traditional algorithms, Table 2 shows that in terms of accuracy score, Sadeh and Webster fall short even to the Always Wake method by not being significantly different from it (p = 0.37 and p = 0.55, ∀n = 363). Sazonov achieved the highest accuracy score for Task Night&Day (82.7), even though it did not do well for Task Night, having an accuracy score lower than the Device Algorithm for Task Night. Oakleyθ=10 and Scripps Clinic algorithms were the only ones that outperformed the Device Algorithm baseline for accuracy in both tasks.
The rescoring rules applied in addition to the traditional algorithms improved both accuracy and F1 score for all methods in Task Night&Day, contrary to the results of Task Night, with the sole exception of accuracy and F1 score for Resc. Sazonov, which decreased, respectively, from 82.7 to 82.5 and from 71.7 to 62.4. The minimum accuracy of the rescoring methods was found for Resc. Webster (82.2), which was still significantly higher than the accuracy of the Device Algorithm (76.5, p = 0.005, n = 363).
The performance of the ML algorithms shown in Table 2 for Task Night&Day is similar to the performance of the same algorithms for Task Night, i.e., the ranking with regards to accuracy and F1 for the four ML algorithms studied was the same: Extra Trees followed by the Logistic Regression, Linear SVM and the Perceptron. The best accuracy of 86.7 for the Extra Trees was significantly higher than the Device Algorithm (p < 0.001, n = 363), but not significantly different from the Manual Annotation (p = 0.95, n = 363).
The rescoring methods applied in addition to the ML algorithms improved the accuracy and F1 scores for all but one method, the Extra Trees. The highest accuracy was 87.3 for the Resc. Logistic Regression, which was significantly higher than the Manual Annotation (p < 0.001, n = 363), while its F1 was not found significantly different from the Manual Annotation (p = 0.79, n = 363). Table 2 also shows that the average accuracy of the ML group went from 83.1 to 86.4 (improvement of 3%) when using the rescoring rules.
Table 2 shows that the DL algorithms can reach an accuracy as high as 88.2 for LSTM 100 without rescoring rules and 87.6 for CNN 100 with rescoring rules. LSTM 100, CNN 100, and CNN 50 were the only approaches performing better than the Manual Annotation for accuracy, but the difference was not statistically significant (p = 0.287, p = 0.495, and p = 0.528, ∀n = 363). Finally, similar to Task Night, differences between CNN 100 and LSTM 100 were not significant for accuracy (p = 0.734, n = 363) and F1 (p = 0.995, n = 363).
Discussion
In this study, we introduced a new benchmark for sleep-wake scoring algorithms, based on data from the MESA Sleep study.17,18 While the original MESA Sleep dataset can be obtained upon request from https://sleepdata.org/datasets/mesa, we make freely available for download all the scripts required to process the data and generate the same datasets and results reported here for both Task Night and Night&Day, at https://github.com/qcri/sleep_awake_benchmark. By providing this resource, we hope that future research in developing new sleep-wake scoring can be easily facilitated.
The results of our experiments showed that the proprietary algorithm used by the actigraphy device, although likely optimized for it, did not perform the best for Task Night and Night&Day. The average accuracy and F1 scores achieved by both Oakleyθ=10 or Scripps Clinic algorithms were higher than the Device Algorithm.
Our experiments validated the use of four ML algorithms, which presented statistically significant improvements compared to the Device Algorithm. It must be noted that in this work we devised only features based on the distribution of activity counts. In the Supplementary Material, we show our initial experiments with features extracted from the demographic and clinical information of the participants. More complex feature engineering, which can likely improve the current results even further, is left as future work.
Furthermore, we evaluated two state-of-the-art deep- learning techniques (DL), such as CNN and LSTM. Owing to the success of DL algorithms in areas such as computer vision, speech recognition, and bioinformatics, new architectures are continually being proposed. The use of a benchmark like the one proposed in this paper can potentially accelerate the adoption of new techniques in the sleep science field. Most of the traditional algorithms, as well as the features devised in this work for the traditional ML and DL algorithms, make use of future activity counts, i.e., when predicting the epoch n, these algorithms use the activity counts in proceeding epochs, n + 1, n + 2, and so on. The only exception is the Sazonov algorithm (refer to the Supplementary Material for the description and formula of each algorithm). Real-time applications should not use future activity counts. However, the typical usage of sleep-wake scoring algorithms does not require real-time predictions.
The experiments with sleep quality metrics in Task Night show that the choice of scoring algorithm can highly influence the interpretation of people’s sleep behavior. For example, while the mean sleep efficiency of our cohort is 58% (as shown by the ground-truth), the device algorithm reports a sleep efficiency of 73%. An algorithm that systematically overestimates sleep efficiency might fail to identify and report sleep-related diseases. Conversely, an algorithm that systematically underestimates sleep efficiency might cause too many false-positive, which can lead to unnecessary clinical evaluations. Noteworthy, the traditional formulas showed a larger variance in terms of WASO (from 26 min to 149 min) and sleep efficiency (from 54 to 82%) than ML and DL algorithms. For sleep efficiency, ML algorithms vary only from 61 to 66%, while the DL algorithms vary from 64 to 67%. Finally, significant improvements in the clinical metrics can be achieved by new algorithms. When using the device algorithm, the average absolute error of sleep efficiency compared to the ground truth is 17pp, while the average error for WASO is 53 min. By using the best DL algorithm, LSTM 100, the sleep efficiency error goes down to <10pp (70% better) while WASO error goes down to 44 min (20% better).
The Task Night, which studies sleep-wake scoring algorithms to be exclusively used during sleep, and Task Night&Day, which studies sleep-wake algorithms to be used on a 24-h period, are not the only possibilities with this dataset. Other tasks, such as predicting the sleep and awake onset, which are essential for the assessment of sleep quality, are left as future work as there is a wide range of potential sleep quality metrics. Nevertheless, the results of Task Night and Night&Dday show that those tasks have significant differences. For example, our experiments show that the use of Webster’s rescoring rules should be limited to the traditional algorithms for Task Night, while they worked well for most of the algorithms for Task Night&Day, avoiding overestimation of sleep. Based on our results, we advocate that the algorithm of modern actigraphy devices and wearables could adaptively switch from an algorithm specialized for the night (as in Task Night) to another specialized for the day (as in Task Night&Day) depending on the time of the day.
A primary limitation of our work is that, although the MESA Sleep study includes a diverse population from different ethnicities, it is exclusively composed of adults. An ideal cohort for sleep-wake scoring should include other populations, such as toddlers, kids or adolescents, as well as, people with disorders that affect movements, such as Parkinson’s disease,24 or specific sleep disorders, such as insomnia,25 sleep apnea or restless legs syndrome. The expansion of the cohort proposed in our work is highly desirable and appreciated, but is left as future work. Additionally, actigraphy as a device is incapable of discriminating the different sleep stages (e.g., sleep stage 1, stage 2, stage 3, and REM sleep). Another minor limitation is that the nights for which the participants undergo PSG are usually easier to interpret than nights “in the wild” as PSG imposes a normal sleep and wake time, which may be absent for some of these subjects. An additional constraint of this study is that it is based only on one actigraphy device (Philips Actiwatch Spectrum). We need to be aware that the device used can impact the generalization of the results. Although some studies use consumer-grade devices, there are concerns with the accuracy of these devices, among other factors.26
Finally, given the great importance of sleep to health and human functioning, developing accurate analytic approaches for actigraphy data is the key to precisely determine sleep quality. This is also important given the increasing use of wearable devices that use different algorithms to assess and optimize sleep.
Methods
The methodology used in this study has several components, which are introduced in this section. The main component of this study is the MESA Sleep dataset. In a dataset such as this one, researchers usually devise and evaluate new algorithms to score nocturnal sleep-wake epochs. For our study, we identified this common task as Task Night and proposed to extend the benchmark of such algorithms to a 24-h period, our Task Night&Day. The use of large datasets opens the possibility of validating, comparing and evaluating new approaches, in particular, machine learning algorithms. This section also describes the state-of-the-art approaches validated in this work and evaluation metrics used in our experiments.
MESA sleep dataset
The MESA Sleep17,18 experiments were conducted using the Compumedics Somte System to record PSG data and the Actiwatch Spectrum, Philips Respironics to record actigraphy data. The data was acquired in six field centers that are located at different places across the United States.Institutional review board approval was obtained at each participating center and written informed consent was obtained from all participants.17,18,27
In this work, we used the synchronized PSG and actigraphy data for 1817 subjects out of the initial 2237 subjects that participated in the MESA Sleep study. The data from the other 420 subjects were discarded because of at least one of the following reasons: (1) PSG and actigraphy studies did not occur concurrently;20 (2) data failed the minimal actigraphy or PSG quality standard (i.e., <3 h of useable data);20 (3) PSG recorded for over 16 h. This last criterion was adopted in this work to increase the quality of the dataset by making it consistent w.r.t. all participants. This resulted in the removal of only nine participants.
The PSG and actigraphy records were synchronized in 30-s epochs, and the 1817 subjects were randomly split into a training set of 1454 subjects—80% of the subjects—and a test set of 363 subjects—the other 20%. The training set was used to tune and optimize model hyperparameters, i.e., the set of tunable parameters that control the quality of the model (e.g., number of leaves in a tree, the learning rate of an algorithm) in terms of training accuracy, generalization performance and prevention of over/under-fitting, while the test set was used to obtain the results reported in this work. A summary of the statistics for the training and test set are shown in Table 3.
Sleep-wake tasks
In this work, we propose two complementary tasks using the synchronized PSG and actigraphy data of the MESA Sleep dataset.
Task Night
Traditionally, actigraphic sleep-wake scoring algorithms are compared to PSG gold standard with overnight experiments only (e.g., refs 5,6,28). For instance, apart from the Granovsky algorithm13 of Table S1, all others were devised and optimized for scoring sleep-wake patterns during the period that PSG is also used. We name this typical task—the direct comparison of actigraphy algorithms with PSG—as Task Night. Note that this is also the usual setting in validation studies (e.g., refs 7,8,22). As common in the literature, the activity counts are adjusted to 30-s epochs and synchronized to the PSG signals. The PSG-identified sleep periods (sleep phases 1, 2, 3, 4, and rapid eye movement (REM)) were scored as sleep, while awake periods were scored as wake. These two non-overlapping periods are coded here into numerical scores: 1 for sleep and 0 for wake. With recordings starting when the PSG equipment was turned on, and finishing when the PSG was turned off, a total of 2,266,659 30-s epochs were recorded from the 1817 subjects. Thus, our training dataset (80% of the whole cohort) comprised of over 1.75 million samples.
Task Night&Day
During night time, traditional actigraphy scoring algorithms are known for their high sensitivity (i.e., algorithms score most of the actual sleep as sleep) and low specificity (i.e., a limited proportion of all epochs are classified as wake8,29). During the day, actigraphy scoring algorithms over detect naps, as epochs with low activity tend to be scored as sleep.30,31 In Task Night&Day, we propose to investigate the behavior of different scoring algorithms both during night and day by extending the Task Night data to include epochs before and after the use of PSG. We include all actigraphy data recorded up to 8 h before and after PSG was conducted. While PSG annotations are the gold standard used in Task Night, these annotations are not provided to individuals during the day. Instead of simply assuming that individuals are awake in the 8 h after PSG was conducted, we take advantage of the manual annotations that are provided in the original MESA dataset. The expert annotations were collected following a clinical research protocol in which the expert is instructed to set the beginning and end of the rest interval based on multiple signals, which include drops/increases in activity counts, as well as event markers, sleep diaries, and light levels.19,20 Two experts scored the MESA dataset with an inter-scorer reliability larger than 90% (n = 19).19,20 We assume that all epochs during naps in the day period were sleep epochs.
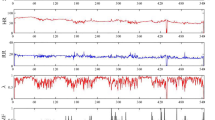
Figure 2 shows the activity counts for one subject (MesaID 345) randomly selected from the dataset. The data lying between the yellow lines correspond to Task Night: it is the time range when both actigraphy and PSG were used. The extended data outside this range (up to 8 h before and after PSG) is also used in Task Night&Day. Note that in this example, the subject started using the actigraphy device just a few hours before the sleep period was recorded with the PSG.

Activity counts by time for MesaID 345. Each point corresponds to the activity count measured by the actigraphy device for an interval of 30 s. The yellow lines mark the borders of the data used for Task Night—the start and end of PSG period (in this case, from 9:15 p.m. to 09:24 a.m.). The extended period before and after the use of PSG (from 9:00 p.m. to 6:00 p.m. in the next day) is the data used for Task Night&Day
Scoring algorithms
In this section, we start by discussing the role of traditional sleep-wake scoring algorithms. We also present the rescoring rules, a set of rules to amend known shortcomings of the traditional algorithms, as well as machine learning approaches. All the reviewed algorithms are systematically evaluated in our experiments.
Traditional algorithms
A number of sleep-wake scoring algorithms were devised in the previous 40 years. These scoring algorithms aim to estimate whether the user wearing the actigraphy device was asleep or awake at a given epoch T based on the activity counts measured by the actigraphy device.
In this work, we study six of these algorithms: Webster,28 Cole-Kripke algorithm,6 Sadeh,5 Oakley,32 Sazonov,9 Scripps Clinic.21 The historical information about each one of these algorithms, as well as their details, is described in the Supplementary Material. Also note that Table S1 summarizes and compares the datasets used to devise the traditional algorithms to the dataset used in this work.
Rescoring rules
Webster et al.28 detected that the most common error in their scoring method was scoring wake as sleep. They proposed a set of simple rescoring rules to correct for such systematic errors. Their set of rules were posteriorly validated by different researchers.33
In this work, we systematically evaluate their set of rules by applying them to each of the evaluated scoring methods. Their five rules can be defined as: (R1) after at least four epochs scored as wake, the first epoch scored sleep is rescored wake; (R2) after at least ten epochs scored as wake, the first three epochs scored sleep are rescored wake; (R3) after at least 15 epochs scored as wake, the first four epochs scored sleep are rescored wake; (R4) six epochs or less scored sleep surrounded by at least ten epochs (before or after) scored as wake are rescored wake; and (R5) ten epochs or less scored as sleep surrounded by at least 20 epochs (before or after) scored as wake are rescored wake. These five rules were applied sequentially from (R1) through (R5) as previously done by Cole et al.6.
Machine learning algorithms
Machine learning (ML) and deep-learning (DL) techniques have been successively used in many domains, including sleep science,11,13 to discover and classify patterns in the data. These techniques aim to learn with data, i.e., they create a mathematical model after a number of learning examples (training set). These learned models can be used to make predictions when a new set of data is used (test set). Tilmanne et al.,11 for example, investigated the use of two ML techniques, Multilayer Perceptrons and Decision Trees, as sleep-wake scoring algorithms, finding them more accurate than Sazonov and Sadeh’s algorithms. Granovsky et al.13 employed a state-of-the-art DL technique, Convolutional Neural Networks (CNN),34 to score sleep-wake stages based on actigraphy data of 35 chronic cluster headache patients. Granovsky et al. results are promising, although, different from all other related work, their evaluation was not conducted with PSG as ground truth, thus not as fine-grained.
In this work, we evaluate both ML and DL techniques. We investigate a variety of ML techniques: Logistic Regression,35 Support Vector Machines (SVM),36 Extra Trees37, and Perceptron,38 all of which have been successfully employed in tasks in the bioinformatics domain, such as protein function prediction,39,40 gene regulatory network inference41,42,43 and human activity prediction.44 In case of DL techniques, we investigate Convolutional Neural Networks (CNN), which can capture local contextual features, and long short-term memory (LSTM)45 recurrent network, which can not only capture local information but also retain long-term dependencies.
The feature set used by the ML techniques follows previous work.11 We manually devised a total of 370 features based on the raw signal extracted from the actigraphy device. For the current epoch T, apart from the raw value and natural logarithm value of the activity count at T, features are based both on a centered and non-centered (i.e., considering only activity counts in previous epochs) sliding window of N epochs (with 1 ≤ N < 20). For each sliding window, we calculated summary statistics such as the mean, variance and standard deviation of the activity counts of the window.
Owing to the fact that the DL techniques used—CNN and LSTM—are able to infer new features from the data, their input is a window of a fixed size (either 20, 50 or 100) containing the raw signal from the actigraphy device. When we run multi-layered CNNs with multiple filters, we capture non-linear interactions between adjacent raw activity counts and obtain a new vector space representation for the raw signals. Similarly, with LSTMs, we abstract long-term and short-term raw activity-based non-linear dependencies in a new vector space, which helps to discriminate sleep stage from wake state.
A full list and examples of the features set used in this work is presented in the Supplementary Material.
Evaluation metrics
In this work, we adopted commonly used metrics to evaluate the performance of the scoring algorithms: accuracy, sensitivity, specificity, precision, F1 score, area under the receiver operating curve, and area under the precision-sensitivity curves. As done in other works in the literature,8,11,12,22 the sleep-wake scoring task is treated as a binary classification in which the positive label is sleep and the negative label is awake. This way, an algorithm with a high score for precision, for example, is an algorithm that correctly classifies sleep epochs as sleep. A detailed description of the metrics is shown in the Supplementary Material. Tests of statistical significance were conducted with a two-tailed t-test.46
In particular, for Task Night, we investigated two additional metrics for sleep quality, which are of clinical relevance. They are the number of minutes wake after sleep onset (WASO) and the sleep efficiency. Sleep efficiency is calculated as the percentage of sleep epochs in the entire record. We used the first epoch recorded as sleep by PSG as sleep onset epoch for WASO, whereas we used the entire record to calculate sleep efficiency. Both metrics are frequently used in the literature.6,22,47,48
We also calculated the mean absolute error (MAE) between WASO and sleep efficiency across participants for each algorithm, comparing the performance of an algorithm with the ground truth data.
Baseline
In our experiments for both Task Night and Night&Day, we use four different baselines for comparison: (1) Device algorithm: the proprietary algorithm of the actigraphy device used in the MESA Sleep experiments—MESA documentation states that Oakley θ = 40 was the algorithm used by the device;20 (2) Manual Annotation: the manual annotation made by an expert without knowledge of the PSG annotations, solely based on the device algorithm, participant’s sleep journals and variables such as the activity patterns and the time of the day19,20 – the same used in Task Night&Day for the day period; (3) Always Sleep: an algorithm that classifies any epoch as Sleep; and (4) Always Wake: an algorithm that classifies any epoch as Wake. Additionally, for Task Night, we show the performance of an oracle method that always predicts the correct labels (Ground Truth). This is useful to inspect the expected values for WASO and sleep efficiency metrics.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The original MESA Sleep dataset can be obtained upon request from https://sleepdata.org/datasets/mesa.
Code availability
We make freely available for download all the scripts required to process the data and generate the same datasets and results reported here for both Task Night and Night&Day at https://github.com/qcri/sleep_awake_benchmark.
References
Taheri, S. The link between short sleep duration and obesity: we should recommend more sleep to prevent obesity. Arch. Dis. Child. 91, 881–884 (2006).
Gangwisch, J. E. et al. Short sleep duration as a risk factor for hypertension: analyses of the first national health and nutrition examination survey. Hypertension 47, 833–839 (2006).
Shigeta, H., Shigeta, M., Nakazawa, A., Nakamura, N. & Yoshikawa, T. Lifestyle, obesity, and insulin resistance. Diabetes Care 24, 608–608 (2001).
Mullington, J. M., Haack, M., Toth, M., Serrador, J. M. & Meier-Ewert, H. K. Cardiovascular, inflammatory, and metabolic consequences of sleep deprivation. Prog. Cardiovasc. Dis. 51, 294–302 (2009).
Sadeh, A., Sharkey, M. & Carskadon, M. A. Activity-based sleep-wake identification: an empirical test of methodological issues. Sleep 17, 201–207 (1994).
Cole, R. J., Kripke, D. F., Gruen, W., Mullaney, D. J. & Gillin, J. C. Automatic sleep/wake identification from wrist activity. Sleep 15, 461–469 (1992).
Jean-Louis, G., Zizi, F., Von Gizycki, H. & Hauri, P. Actigraphic assessment of sleep in insomnia: application of the actigraph data analysis software (adas). Physiol. Behav. 65, 659–663 (1998).
de Souza, L. et al. Further validation of actigraphy for sleep studies. Sleep 26, 81–85 (2003).
Sazonov, E. et al. Activity-based sleep-wake identification in infants. Physiol. Meas. 25, 1291 (2004).
Littner, M. et al. Practice parameters for the role of actigraphy in the study of sleep and circadian rhythms: an update for 2002. Sleep 26, 337–341 (2003).
Tilmanne, J., Urbain, J., Kothare, M. V., Wouwer, A. V. & Kothare, S. V. Algorithms for sleep–wake identification using actigraphy: a comparative study and new results. J. Sleep. Res. 18, 85–98 (2009).
Hjorth, M. F. et al. Measure of sleep and physical activity by a single accelerometer: can a waist-worn actigraph adequately measure sleep in children? Sleep. Biol. Rhythms 10, 328–335 (2012).
Granovsky, L., Shalev, G., Yacovzada, N., Frank, Y. & Fine, S. Actigraphy-based sleep/wake pattern detection using convolutional neural networks. arXiv preprint arXiv:1802.07945 (2018).
Smith, M. T. et al. Use of actigraphy for the evaluation of sleep disorders and circadian rhythm sleep-wake disorders: an american academy of sleep medicine clinical practice guideline. J. Clin. Sleep. Med. 14, 1231–1237 (2018).
Sadeh, A. The role and validity of actigraphy in sleep medicine: an update. Sleep. Med. Rev. 15, 259–267 (2011).
Tonetti, L., Pasquini, F., Fabbri, M., Belluzzi, M. & Natale, V. Comparison of two different actigraphs with polysomnography in healthy young subjects. Chronobiol. Int. 25, 145–153 (2008).
Dean, D. A. et al. Scaling up scientific discovery in sleep medicine: the national sleep research resource. Sleep 39, 1151–1164 (2016).
Zhang, G. -Q. et al. The national sleep research resource: towards a sleep data commons. J. Am. Med. Infor. Assoc. 25, 1351–1358 (2018).
MESA: Multi-Ethnic Study of Atherosclerosis. MESA Actigraphy Scoring and Processing Guidelines. Tech. Rep. (2016). Report available at https://sleepdata.org/datasets/mesa/files/documentation/MESA_Sleep_Actigraphy_Scoring_Manual.pdf. Accessed on 24 March, 2019.
MESA: Multi-Ethnic Study of Atherosclerosis. MESA Exam 5-Sleep Data Documentation Guide. Tech. Rep. (2014). Report available at https://sleepdata.org/datasets/mesa/files/m/browser/documentation/MESA_Sleep_Data_Documentation_Guide.pdf. Accessed on 24 March, 2019.
Kripke, D. F. et al. Wrist actigraphic scoring for sleep laboratory patients: algorithm development. J. Sleep. Res. 19, 612–619 (2010).
Kushida, C. A. et al. Comparison of actigraphic, polysomnographic, and subjective assessment of sleep parameters in sleep-disordered patients. Sleep. Med. 2, 389–396 (2001).
Marino, M. et al. Measuring sleep: accuracy, sensitivity, and specificity of wrist actigraphy compared to polysomnography. Sleep 36, 1747–1755 (2013).
Lonini, L. et al. Wearable sensors for parkinsons disease: which data are worth collecting for training symptom detection models. Npj Digit. Med. 1 (2018). https://www.nature.com/articles/s41746-018-0071-z.
Luik, A. I., Machado, P. F. & Espie, C. A. Delivering digital cognitive behavioral therapy for insomnia at scale: does using a wearable device to estimate sleep influence therapy?. Npj Digit. Med. 1, 3 (2018).
Piwek, L., Ellis, D. A., Andrews, S. & Joinson, A. The rise of consumer health wearables: promises and barriers. PLoS Med. 13, e1001953 (2016).
Bild, D. E. et al. Multi-ethnic study of atherosclerosis: objectives and design. Am. J. Epidemiol. 156, 871–881 (2002).
Webster, J. B., Kripke, D. F., Messin, S., Mullaney, D. J. & Wyborney, G. An activity-based sleep monitor system for ambulatory use. Sleep 5, 389–399 (1982).
Ancoli-Israel, S. et al. The role of actigraphy in the study of sleep and circadian rhythms. Sleep 26, 342–392 (2003).
Patel, S. R. et al. Reproducibility of a standardized actigraphy scoring algorithm for sleep in a us hispanic/latino population. Sleep 38, 1497–1503 (2015).
Tudor-Locke, C., Barreira, T. V., Schuna, J. M. Jr, Mire, E. F. & Katzmarzyk, P. T. Fully automated waist-worn accelerometer algorithm for detecting children’s sleep-period time separate from 24-h physical activity or sedentary behaviors. Appl. Physiol., Nutr. Metab. 39, 53–57 (2013).
Oakley, N. Validation with Polysomnography of the Sleepwatch Sleep/wake Scoring Algorithm Used by the Actiwatch Activity Monitoring System. (Technical report to Mini Mitter, Cambridge Neurotechnology, 1997).
Jean-Louis, G., Kripke, D. F., Cole, R. J., Assmus, J. D. & Langer, R. D. Sleep detection with an accelerometer actigraph: comparisons with polysomnography. Physiol. Behav. 72, 21–28 (2001).
LeCun, Y. et al. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 3361, 1995 (1995).
McCullagh, P. & Nelder, J. Generalized Linear Models 2nd edn. (Chapman & Hall, Boca Raton, Florida, 1989).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
Geurts, P., Ernst, D. & Wehenkel, L. Extremely randomized trees. Mach. Learn. 63, 3–42 (2006).
Freund, Y. & Schapire, R. E. Large margin classification using the perceptron algorithm. Mach. Learn. 37, 277–296 (1999).
Khurana, S. et al. Deepsol: a deep learning framework for sequence-based protein solubility prediction. Bioinformatics 34, 2605–2613 (2018).
Elbasir, A. et al. Deepcrystal: A deep learning framework for sequence-based protein crystallization prediction. Bioinformatics bty953, (2018).
Mall, R. et al. Rgbm: regularized gradient boosting machines for identification of the transcriptional regulators of discrete glioma subtypes. Nucl. Acids Res. 46, e39–e39 (2018).
Mall, R. et al. Differential community detection in paired biological networks. In Proc. 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, (eds Haspel, N., Cowen, L. J., Shehu, A., Kahveci, T. & Pozzi, G.) 330–339 (ACM, Boston, Massachusetts, USA, 2017).
Mall, R., Cerulo, L., Bensmail, H., Iavarone, A. & Ceccarelli, M. Detection of statistically significant network changes in complex biological networks. BMC Syst. Biol. 11, 32 (2017).
Sathyanarayana, A. et al. Robust automated human activity recognition and its application to sleep research. In Data Mining Workshops (ICDMW), 2016 IEEE 16th International Conference on, 495–502 (IEEE, Barcelona, Spain, 2016).
Gers, F. A., Schmidhuber, J. & Cummins, F. Learning to forget: Continual prediction with lstm. In International Conference on Artificial Neural Networks ICANN, 850–855 (IEEE, Edinburgh, UK, 1999).
Freund, J. E. Modern Elementary Statistics. (Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1988).
Hedner, J. et al. A novel adaptive wrist actigraphy algorithm for sleep-wake assessment in sleep apnea patients. Sleep 27, 1560–1566 (2004).
Chae, K. Y. et al. Evaluation of immobility time for sleep latency in actigraphy. Sleep. Med. 10, 621–625 (2009).
Acknowledgements
We would like to thank Sara Mariani from BWH Harvard, Abdelkader Baggag from Qatar Computing Research Institute, and Odette Chagoury from Weill Cornell Qatar for their thorough comments and discussion. MESA is supported by NHLBI funded contracts HHSN268201500003I, N01-HC-95159, N01-HC-95160, N01-HC-95161, N01-HC-95162, N01-HC-95163, N01-HC-95164, N01-HC-95165, N01-HC-95166, N01-HC-95167, N01-HC-95168, and N01-HC-95169 from the National Heart, Lung, and Blood Institute, and by cooperative agreements UL1-TR-000040, UL1-TR-001079, and UL1-TR-001420 funded by NCATS. MESA Sleep was supported by NHLBI R01 L098433. Dr. Sathyanarayana was supported by T32HD040128 from the NICHD/NIH.
Author information
Authors and Affiliations
Contributions
J.P. has led, coordinated and written the manuscript, designed the study, and developed the methodology. R.M. participated in development of the DL methods. R.M., M.A., M.R., M.S., A.S., S.T., and L.F.L. have reviewed the paper, validated the methodology, and contributed to the discussion. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Palotti, J., Mall, R., Aupetit, M. et al. Benchmark on a large cohort for sleep-wake classification with machine learning techniques. npj Digit. Med. 2, 50 (2019). https://doi.org/10.1038/s41746-019-0126-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-019-0126-9
This article is cited by
-
IoT-Enabled Smart Mental Health Assessment Using Deep Hybrid Regression Models Over Actigraph-Based Sequential Motor Activity Data
Arabian Journal for Science and Engineering (2024)
-
Bald Eagle Search Algorithm with Hierarchical Deep Learning for Internet of Things Assisted Sleep Quality Recognition
SN Computer Science (2024)
-
Method for Activity Sleep Harmonization (MASH): a novel method for harmonizing data from two wearable devices to estimate 24-h sleep–wake cycles
Journal of Activity, Sedentary and Sleep Behaviors (2023)
-
40 years of actigraphy in sleep medicine and current state of the art algorithms
npj Digital Medicine (2023)
-
An interpretable framework for sleep posture change detection and postural inactivity segmentation using wrist kinematics
Scientific Reports (2023)
