
Abstract
Clinicians are often faced with situations where published treatment guidelines do not provide a clear recommendation. In such situations, evidence generated from similar patients’ data captured in electronic health records (EHRs) can aid decision making. However, challenges in generating and making such evidence available have prevented its on-demand use to inform patient care. We propose that a specialty consultation service staffed by a team of medical and informatics experts can rapidly summarize ‘what happened to patients like mine’ using data from the EHR and other health data sources. By emulating a familiar physician workflow, and keeping experts in the loop, such a service can translate physician inquiries about situations with evidence gaps into actionable reports. The demand for and benefits gained from such a consult service will naturally vary by practice type and data robustness. However, we cannot afford to miss the opportunity to use the patient data captured every day via EHR systems to close the evidence gap between available clinical guidelines and realities of clinical practice. We have begun offering such a service to physicians at our academic medical center and believe that such a service should be core offering by clinical informatics professional throughout the country. Only if we launch such efforts broadly can we systematically study the utility of learning from the record of routine clinical practice.
Similar content being viewed by others

Introduction
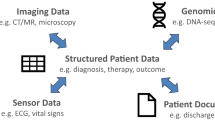
Randomized controlled trials (RCTs) are the gold standard of clinical evidence and the bedrock of evidence-based medicine. However, the cost of conducting RCTs, their narrow inclusion criteria, and their focus on only a subset of patient demographics, conditions, and treatments limits their applicability in the majority of scenarios encountered daily by clinicians.1 In 2011, Frankovich et al.2 reported a case of using electronic health records (EHRs) to guide the clinical care of a patient in the absence of RCT-based evidence, and in 2014, Longhurst et al.3 outlined a future in which health information systems help clinicians leverage patient data stored in the EHR at the point of care. Despite the promise of unlocking the treasure trove of EHR data to improve patient care, the state of affairs has not advanced much since 2011. The primary barriers are the methodological and operational challenges of distilling patient data into digestible clinical evidence that a physician can act on.
A common narrative in the popular press is that EHRs, combined with advanced computing and data science methods, are ready to transform healthcare. Given the prevalence of this perspective, and the increasing volume and availability of EHR data, one could imagine that it is feasible to extract knowledge with a high clinical value from EHRs in a fully automated manner with little expert input. However, much of the promise of the healthcare data revolution4 is hype that fails to acknowledge the complex nature of clinical decision making.5 A “one size fits all” solution is unlikely to work in such settings. Furthermore, medical practitioners have highlighted ethics and safety concerns6,7 in turning over care decisions to machine-based systems that operate over incomplete and biased EHRs8 without physician input. Shortliffe et al.9 recently highlighted the six capabilities a system must possess in order to support clinical decisions including transparency, rapid turnaround, ease of use, the relevance of answer, respect for users, and solid scientific footing.
We believe that such challenges—of getting reliable data out of the EHR and satisfying the criteria of successful clinical decision support—are best overcome via a specialty consultation service. Such a service would use state-of-the-art analytic methods to glean reliable insights out of the EHR and have medical domain expertise to contextualize results for clinical decision making. Such a service would be staffed by a team comprised of a clinical informatics trained physician for interfacing with the requesting provider and to provide clinical context when interpreting findings, an EHR data specialist to create patient cohorts, and a data scientist to perform statistical analyses. The setup as a specialty consult is radically different from the popular paradigm of self-serve AI-enabled tools that undertake data processing behind the scenes and directly present the results to a physician for interpretation. We believe that an “expert in the loop” set up is necessary to strike a balance between efficiency and rigor given the limitations of the data, and the inference methods.10
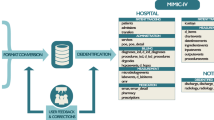
We launched an IRB approved pilot of such a service at our academic medical center, to study the feasibility of integrating on-demand evidence into routine patient care. We propose that such a service should be core offering by clinical informatics professionals throughout the country. For many medical centers, a significant challenge in offering such a service—beyond the staffing—is the rapid creation of patient cohorts. Depending on available tools and personnel, cohort generation may take several weeks, which is untenable for care decisions that must be made within days. To enable the consult service, we have developed a search engine that indexes patient timelines for building cohorts matching a clinical phenotype, identifying controls for comparative analyses, and searching for outcomes of interest, with sub-second response times.11 After cohorts are created, established analysis approaches, including propensity score matching to identify similar patients, survival analysis, and causal inference can be used to compare outcomes and provide support for clinical decisions.10 Upon completion of a consult, the requesting clinician receives a report which includes a summary of the cohort(s) of interest, a description of the analyses, the results, and, most importantly, a clinical interpretation to contextualize the results and explain their limitations (see an example consult request and summary of results in Box 1).
The idea of examining “patients like mine” to estimate risk and select the optimal treatment is not new—the first efforts date back to the 1970s.12 The informatics consult service we envision connects clinicians with researchers capable of answering different kinds of clinical questions using state-of-the-art analysis methods; removing the bottlenecks in generating and using evidence learned from the EHR. Having such a service does not eliminate the issue of data incompleteness. The importance of clinicians’ role in accurately defining patient phenotypes, and that of data scientists in empirically assessing the robustness of statistical analyses and their results, thus cannot be overemphasized.
To be sure, providing such a service incurs costs for personnel and IT infrastructure, and it is unclear if these will be reimbursable via existing payment models. However, as reimbursement models move away from fee for service models to value-based models, and given the fact that a small number of conditions result in a large fraction of healthcare costs, the economics of improving population management using such insights may be favorable. Extrapolating from current operating costs, we estimate that a service which can answer 15–20 high complexity consults a week would require an operating budget of ~$600,000 a year; which comes to about $550 per consult. This cost could be justified via improved clinical outcomes obtained for complex cases but more data must be gathered before a proper return on investment (ROI) analysis can be conducted for such a novel service.13 Additional considerations for the ROI include potential new reimbursement models for a “second opinion” from aggregate patient data and cost offsetting by savings from quality improvement or value-based care initiatives. Furthermore, demonstrating value to the ordering providers is a crucial piece in justifying the service’s impact. Therefore, in the current pilot, we ask participating clinicians their likelihood of recommending the service to others, as well as track repeat usage.
The demand for and benefits gained from such a consult service will naturally vary by practice type and data robustness. However, the existing gap between the evidence available in clinical guidelines and what is needed for safe, effective personalized treatment costs both resources and lives.14 We cannot afford to miss the opportunity to leverage the tremendous value of patient data captured every day via EMR systems to close this evidence gap. Only if we launch such efforts to bring evidence distilled from similar patients to bear on decision making at the bedside, can we systematically study the utility of learning from the record of routine clinical practice in a true learning healthcare system.15,16 The availability of data and effective methods to analyze it have been transformative in many other settings—it is time for healthcare to test the same potential.
References
Stewart, W. F., Shah, N. R., Selna, M. J., Paulus, R. A. & Walker, J. M. Bridging the inferential gap: the electronic health record and clinical evidence. Health Aff. 26, w181–w191 (2007).
Frankovich, J., Longhurst, C. A. & Sutherland, S. M. Evidence-based medicine in the EMR era. N. Engl. J. Med. 365, 1758–1759 (2011).
Longhurst, C. A., Harrington, R. A. & Shah, N. H. A ‘green button’ for using aggregate patient data at the point of care. Health Aff. 33, 1229–1235 (2014).
Obermeyer, Z. & Emanuel, E. J. Predicting the future - big data, machine learning, and clinical medicine. N. Engl. J. Med. 375, 1216–1219 (2016).
Chen, J. H. & Asch, S. M. Machine learning and prediction in medicine - beyond the peak of inflated expectations. N. Engl. J. Med. 376, 2507–2509 (2017).
Char, D. S., Shah, N. H. & Magnus, D. Implementing machine learning in health care - addressing ethical challenges. N. Engl. J. Med. 378, 981–983 (2018).
Verghese, A., Shah, N. H. & Harrington, R. A. What this computer needs is a physician: humanism and artificial intelligence. JAMA 319, 19–20 (2018).
Zulman, D. M., Shah, N. H. & Verghese, A. Evolutionary pressures on the electronic health record: caring for complexity. JAMA 316, 923–924 (2016).
Shortliffe, E. H. & Sepúlveda, M. J. Clinical decision support in the era of artificial intelligence. JAMA 320, 2199–2200 (2018).
Schuler, A., Callahan, A., Jung, K. & Shah, N. H. Performing an informatics consult: methods and challenges. J. Am. Coll. Radiol. 15, 563–568 (2018).
Callahan, A. & Polony, V. Search engine powering the Informatics Consult. YouTube (2017). http://www.tinyurl.com/search-ehr. Accessed 6 Dec 2018.
Rosati, R. A. et al. A new information system for medical practice. Arch. Intern. Med. 135, 1017–1024 (1975).
Schulman, K. A. & Richman, B. D. Toward an effective innovation agenda. N. Engl. J. Med. https://doi.org/10.1056/NEJMp1812460 (2019).
Califf, R. M. et al. Transforming evidence generation to support health and health care decisions. N. Engl. J. Med. 375, 2395–2400 (2016).
Krumholz, H. M. Big data and new knowledge in medicine: the thinking, training, and tools needed for a learning health system. Health Aff. 33, 1163–1170 (2014).
Dahabreh, I. J. & Kent, D. M. Can the learning health care system be educated with observational data? JAMA 312, 129–130 (2014).
Acknowledgements
This project received funding from the National Institutes of Health, grant number: R01LM011369-06 as well as the Dean’s office, the Department of Medicine, and Department of Pathology at Stanford University.
Author information
Authors and Affiliations
Contributions
S.G., A.C., and N.S. contributed to the conception, drafting, and editing of the manuscript. R.H. and R.C. made significant contributions in critical review and concept development.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gombar, S., Callahan, A., Califf, R. et al. It is time to learn from patients like mine. npj Digit. Med. 2, 16 (2019). https://doi.org/10.1038/s41746-019-0091-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-019-0091-3
This article is cited by
-
Personalized treatment options for chronic diseases using precision cohort analytics
Scientific Reports (2021)
-
Fast prototyping of a local fuzzy search system for decision support and retraining of hospital staff during pandemic
Health Information Science and Systems (2021)
-
An informatics consult approach for generating clinical evidence for treatment decisions
BMC Medical Informatics and Decision Making (2021)
