
Abstract
To simultaneously overcome the limitation of the Gini index in that it is less sensitive to inequality at the tails of income distribution and the limitation of the inter-decile ratios that ignore inequality in the middle of income distribution, an inequality index is introduced. It comprises three indicators, namely, the Gini index, the income share held by the top 10%, and the income share held by the bottom 10%. The data from the World Bank database and the Organization for Economic Co-operation and Development Income Distribution Database between 2005 and 2015 are used to demonstrate how the inequality index works. The results show that it can distinguish income inequality among countries that share the same Gini index but have different income gaps between the top 10% and the bottom 10%. It could also distinguish income inequality among countries that have the same ratio of income share held by the top 10% to income share held by the bottom 10% but differ in the values of the Gini index. In addition, the inequality index could capture the dynamics where the Gini index of a country is stable over time but the ratio of income share of the top 10% to income share of the bottom 10% is increasing. Furthermore, the inequality index could be applied to other scientific disciplines as a measure of statistical heterogeneity and for size distributions of any non-negative quantities.
Similar content being viewed by others
Introduction
The Gini index was devised by an Italian statistician named Corrado Gini in 1912. By far, it has arguably been the most popular measure of socioeconomic inequality, especially in income and wealth distribution, given that there are well over 50 inequality indices as reported in Coulter (1989) (see Eliazar, 2018; McGregor et al., 2019 for recent updates on the inequality measures). The use of the Gini index is not limited to the field of socioeconomics, however. According to Eliazar and Sokolov (2012), the application of the Gini index has grown beyond socioeconomics and reached various disciplines of science. Examples include astrophysics—the analysis of galaxy morphology (Abraham et al., 2003); ecology—patterns of inequality between species abundances in nature and wealth in society (Scheffer et al., 2017); econophysics—wealth inequality in minority game (Ho et al., 2004); scale invariance in the distribution of executive compensation (Sitthiyot et al., 2020); engineering—the analysis of load feature in heating, ventilation, and air conditioning systems (Zhou et al., 2015); finance—the analysis of fluctuations in time intervals of financial data (Sazuka and Inoue, 2007); human geography—measuring differential accessibility to facilities between various segments of population (Cromley, 2019); informetrics—the analysis of citation (Bertoli-Barsotti and Lando, 2019); medical chemistry—the analysis of kinase inhibitors (Graczyk, 2007); population biology—heterogeneities in transmission of infectious agents (Woolhouse et al., 1997); public health—the analysis of life expectancy (De Vogli et al., 2005); the analysis of real biological harm (Sapolsky, 2018); renewable and sustainable energy—the analysis of irregularity of photovoltaic power output (Das, 2014); sustainability science—the study of land change (Rindfuss et al., 2004); transport geography—equity in accessing public transport (Delbosc and Currie, 2011); selection of tram links for priority treatments (Pavkova et al., 2016). In effect, the Gini index is applicable to any size distributions in the context of general data sets with non-negative quantities such as count, length, area, volume, mass, energy, and duration (Eliazar, 2018). However, in order to demonstrate our method for measuring inequality, we focus our analysis on the subject of income.
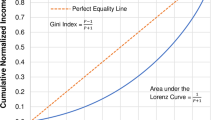
The Gini index can be derived from the Lorenz curve framework (Lorenz, 1905), which plots the Cartesian coordinates where the abscissa is the cumulative normalized rank of income from the lowest to the highest (x) and the ordinate is the cumulative normalized income from the lowest to the highest (y) as illustrated in Fig. 1. According to Gini (2005), the Gini index can be calculated as the ratio of the area between the perfect equality line and the Lorenz curve (A) divided by the total area under the perfect equality line (A + B). The Gini index takes values in the unit interval. The closer the index is to zero (where the area A is small), the more equal the distribution of income. The closer the index is to one (where the area A is large), the more unequal the distribution of income.

The Gini index is calculated as the ratio of the area between the perfect equality line and the Lorenz curve (A) divided by the total area under the perfect equality line (A + B).
The advantage of the Gini index is that inequality of the entire income distribution can be summarized by using a single statistic that is relatively easy to interpret since it takes values between 0 and 1. This allows for comparison among countries with different population sizes. In addition, the data on the Gini index is easy to access, regularly updated and reported by countries and international organizations. Despite its advantages as a statistical measure of income inequality, Atkinson and Bourguignon (2015) note that a country with lower Gini index does not always imply that income distribution in that country is more equal than that of a country with higher Gini index. This is because the Lorenz curves of the two countries may intersect, reflecting different income distributions.
To obtain a complete ranking of and to quantify the difference in income inequality among countries, Atkinson (1970) devises a social welfare-based inequality index as follows:
where yi denotes the individual income, \({\bar{y}}\) denotes the average income, N is the number of population, and ε is the inequality aversion parameter. This index takes values between 0 and 1. The cornerstone of the Atkinson index is the concept of equally distributed equivalent level of income (yEDE), which is defined as the percentage of total income that a given society would have to forego in order to have more equal shares of income among individuals in that society. Note that if \(\varepsilon \ne 1\), \(y_{{\mathrm{EDE}}} = \left( {\frac{1}{N}\mathop {\sum }\nolimits_{i = 1}^N y_{\mathrm{i}}^{1 - \varepsilon}} \right)^{\frac{1}{{1 - \varepsilon}}}\). When \(\varepsilon = 1\), \(y_{{\mathrm{EDE}}} = {\prod \nolimits_{i = 1}^N} (y_{\mathrm{i}})^{\frac{1}{N}}\).
The notion of yEDE depends on the degree of inequality aversion parameter ε, which technically could range between 0 and ∞. As ε increases, a society attaches more weight to transfers at the lower end of the income distribution and less weight to transfers at the top. By using ε = 2, Atkinson (1970) finds that, of the 50 pairwise comparisons where the Lorenz curves intersect, his inequality index would disagree with the Gini index in seventeen cases. For a lower degree of inequality aversion with ε = 1, there are only five cases that would disagree with the Gini index. According to Atkinson (1970), the Gini index tends to give the rankings that are similar to those reached with a relatively low degree of inequality aversion.
Although the advantages of the Atkinson index are that it provides a complete ranking of income distributions and makes explicit the social welfare function underlying the income inequality measure, which could be useful for policy decisions, Cowell (2011) and McGregor et al. (2019) note that the ranking of income distributions can vary widely depending upon the choice of social welfare functions and the intrinsic aversion to inequality, which may not necessarily be the same among countries.
To avoid the social welfare judgment, a class of generalized entropy (GE) indices can be used as an alternative measure for ranking income inequality when the Lorenz curves of the two countries intersect. The GE index is defined as follows:
The theoretical values of the GE(α) index vary between 0 and ∞, with 0 representing equal income distribution and higher values representing higher levels of income inequality. The GE(α) index as shown in Eq. (3) defines a class because it assumes different forms depending upon the value assigned to the parameter α, which is a weight given to inequalities in different parts of the income distribution. The less positive the parameter α is, the more sensitive the index is to inequalities at the bottom of the income distribution while the more positive the parameter α is, the more sensitive the index is to inequalities at the top (Bellù and Liberati, 2006). Bellù and Liberati (2006) also note that, in principle, the parameter α can take any real values from −∞ to ∞. However, from a practical point of view, α is normally chosen to be positive. This is because, for α < 0, this class of indices is undefined if there are zero incomes. GE(0) is referred to as the mean logarithmic deviation, which is defined as follows:
GE(1) is known as the Theil inequality index, named after the author who devised it in 1967. The Theil index is defined as follows:
While a class of GE(α) indices can overcome the limitation of the Gini index in ranking income inequality when the Lorenz curves of the two countries cross, it should be noted that the exact specification of the GE(α) index depends upon the value of α, which may vary from country to country, making it difficult to compare income inequality among different countries.
Another limitation of using the Gini index is whenever two or more countries share the same value of the Gini index but income inequality among them could be very different if taking into consideration the information on the income share held by the richest and that held by the poorest. For example, based on the data from the World Bank, in 2015, Greece and Thailand have the same Gini index (0.360) but the ratio of the income share held by the richest 10% to the income share held by the poorest 10% in Greece is 13.8 while that in Thailand is 8.9. In addition, according to the Organization for Economic Co-operation and Development Income Distribution Database (OECD IDD), it shows that, in 2015, the United Kingdom and Israel also share the same Gini index (0.360) but the ratio of the income share of the top 10% to the income share of the bottom 10% in the United Kingdom equals 4.2, whereas that in Israel equals 5.8. That countries share the same Gini index but differ in the income gap between the richest and the poorest indicates that the Gini index alone cannot tell the difference in income inequality among countries.
Furthermore, Atkinson (1970) notes that the Gini index is more sensitive to changes in the middle of income distribution and less sensitive to changes at the top and the bottom of income distribution. Palma (2011) analyses income inequality across countries using the inter-decile ratios and finds that the rising in income inequality comes from an increased diversity in the income share held by the top 10% and the income share held by the bottom 40% while the income share of the deciles 5 to 9 remains stable over time. According to Palma (2011), countries with high income inequality are simply those in which the top 10% are more successful at subsidizing their insatiable appetite with the income of the bottom 40%. Palma (2011) suggests that, in order to reduce income inequality, policymakers should direct policies towards lowering the ratio of the income share held by the top 10% over the income share held by the bottom 40%.
Besides the ratio of the income share of the top 10% over the income share of the bottom 40% as proposed by Palma (2011), there are other inter-decile ratios that emphasize the tails of income distribution, for example, the ratio of the income share held by the top 10% to the income share held by the bottom 10% and the ratio of the income share held by the top 20% to the income share held by the bottom 20%. The data used to calculate these inter-decile ratios or the ratios themselves including the Palma index are regularly updated and reported along with the Gini index by international organizations, such as the World Bank, the OECD, and the Human Development Report Office as the measures of income inequality.
While these inter-decile ratios seem to be easy to understand and convey the information to public and policymakers with regard to income inequality, it should be noted that if carefully considering the values that these ratios can take, we would find that they are between ¼ and ∞ for the Palma index, and between 1 and ∞ for both the ratio of the income share of the top 10% to the income share of the bottom 10% and the ratio of the income share of the top 20% to the income share of the bottom 20%. From a mathematical and practical point of view, these values are more difficult to interpret and compare among countries since they have no upper bound relative to other inequality indices whose values are bounded. The same argument could be applied for a class of GE(α) indices as discussed earlier. As noted in Eliazar (2018), indices whose values are bounded are much more tangible to human perception than those whose values are unbounded. In addition, by construction, these inter-decile ratios capture income inequality between the top and the bottom of distribution and ignore income of those in the middle of distribution.
To overcome the limitations of the Gini index and the inter-decile ratios as discussed above, we devise an alternative method for measuring inequality. Our method is quite simple. It utilizes the Gini index, the income share held by the top 10%, and the income share held by the bottom 10% to construct a composite index. These three indicators comprising the inequality index are selected based on availability, accessibility, and continuity of the data without the need to collect the data on income distribution at the micro level. We are well aware that the accuracy of the data on the Gini index and the income shares depends on the population survey methods and/or the probability laws governing the distribution of income as discussed in Eliazar and Sokolov (2012), Chakrabarti et al. (2013), and Sarabia et al. (2019). While research on these issues is continuing, we hope that our simple method for measuring inequality would be useful not only for socioeconomics but also for other disciplines of science as a measure of statistical heterogeneity and for general size distributions, providing ones have the data on the Gini index and the income share of the top 10% and that of the bottom 10% or the respective share's ratio of any non-negative quantities.
Methods
To derive our inequality index for any given country i (Ii), let Ginii denote the Gini index of country i (in decimal places) and \(( {\frac{{B_{10}}}{{T_{10}}}})_{\mathrm{i}}\) be the ratio of the income share held by the bottom 10% (B10) to the income share held by the top 10% (T10) in country i. In addition, let \(H_{\mathrm{i}} = 1 - ( {\frac{{B_{10}}}{{T_{10}}}} )_{\mathrm{i}}^{\upalpha},\,0 \le H_{\mathrm{i}} \le 1\). The exponent alpha (α) is a weight such that \({\mathrm{avg}}.\,{\mathrm{Gini}} = 1 - \left( {{\mathrm{avg}}.\left( {\frac{{B_{10}}}{{T_{10}}}} \right)} \right)^{\upalpha}\), where avg. Gini is the average value of all countries’ Gini index in the sample whereas \({\mathrm{avg}}.( {\frac{{B_{10}}}{{T_{10}}}} )\) is the average value of all countries’ \(\frac{{B_{10}}}{{T_{10}}}\) ratio from the same sample. Note that the justification for the parameter α is to rescale the weight of the Hi so that it is more or less in balance with that of the Ginii. The higher the value of α is, the closer the value of the Hi is to 1, meaning that more weight is assigned to the Hi and less weight is assigned to the Ginii. In contrast, the lower the value of α is, the closer the value of the Hi is to 0, implying that we assign more weight on the Ginii and less weight on the Hi.
Using the empirical data on the Gini index and on the \(\frac{{B_{10}}}{{T_{10}}}\) ratio, the parameter α can be calculated as \(\frac{{\ln \left( {1 - {\mathrm{avg}}.\,{\mathrm{Gini}}} \right)}}{{{\mathrm{ln}} ({{\mathrm{avg}}.( {\frac{{B_{10}}}{{T_{10}}}} )} )}}\). In practice, the value of α used to calculate the Hi would vary from sample to sample. This would make the value of α to be sample dependent, resulting in the values of Hi for countries in the sample to be incomparable across periods. The alternative is to calculate the average value of α (\(\bar \alpha\)) across all samples, set it as a constant, and then use it for the calculation of all Hi’s regardless of the countries and the years being investigated. In this way, the parameter α would be standardized and sample independent since, from now on, we only need the Gini index and the ratio of income shares of countries of interest in any given years to calculate our inequality index. Finally, by applying the Pythagoras’ theorem, the inequality index for any given country i (Ii) can be written as a function of the Ginii and the Hi as followsFootnote 1:
Our inequality index (I) takes values in the unit interval where the closer the index is to zero, the more equal the distribution of income and the closer the index is to one, the more unequal the distribution of income.
To demonstrate our method, we use the annual data on the Gini index and the income shares in 2015 from the World Bank (2019a, 2019b, 2019c) containing 75 countries and from the OECD IDD (2019a, 2019b) comprising 35 countries. The reason to use the data in 2015 is that it has more countries than those in 2016, 2017, and 2018. This would allow us to have more chance to find countries that have the same value of the Gini index but differ in the \(\frac{{T_{10}}}{{B_{10}}}\) ratios, and countries that share the same \(\frac{{T_{10}}}{{B_{10}}}\) ratio but differ in values of the Gini index, all of which would be used as examples to verify our method. In addition, the data from the World Bank and the OECD IDD between 2005 and 2015 are employed in order to calculate \(\bar \alpha\) for the entire period, and, more importantly, to show that our inequality index could capture the case where countries whose the Gini index is stabilizing or falling across time but the ratio of the income share of the top 10% to that of the bottom 10% is increasing.
Results
We first calculate the descriptive statistics of the \(\frac{{B_{10}}}{{T_{10}}}\) ratio, the Gini index, and the H as well as the correlation coefficients between these three indicators using the data from the World Bank and the OECD IDD from 2005 to 2015 (see Tables S1–S44 in the Supplementary Information). The results shown in the correlation matrix indicate that the Gini index is positively correlated with the H while the \(\frac{{B_{10}}}{{T_{10}}}\) ratio is negatively correlated with the Gini index and the H. In all cases, the correlation coefficients, in absolute values, are > 0.900.
Next, we calculate the values of the weight α in each year for the entire 11-year sample from both databases. We find that, for the World Bank database, the value of α is between 0.197 and 0.207. For the OECD IDD, the value of α ranges between 0.271 and 0.281. We then calculate the value of \(\bar \alpha\) across all samples from both databases and find that \(\bar \alpha\) = 0.239. The values of parameter α and \(\bar \alpha\) calculated using the World Bank database and the OECD IDD between 2005 and 2015 are reported in Tables S45 and S46 in the Supplementary Information.
Although we could fix the value of \(\bar \alpha\) = 0.239 as a constant and use it to calculate the Hi as discussed in the “Methods”, for the purpose of standardizing and using it in practice, this number is not very easy to work with practically and mathematically; imagine memorizing the number and taking a root of 0.239. After a careful consideration, without losing its function as a parameter that balances the weight of the Hi with that of the Ginii, we would like to propose the value of α to be 0.25 or ¼ and set it as a constant for the ease of the calculation of the Hi, where \(H_{\mathrm{i}} = 1 - ( {\frac{{B_{10}}}{{T_{10}}}})_{\mathrm{i}}^{\frac{1}{4}}\), irrespective of the countries and/or the years being studied. From our viewpoint, the α value of 0.25 or ¼ is much easier to use practically and mathematically; imagine taking a square root twice, which could be done by using a simple calculator compared to taking a root of 0.239. In addition, the value of α that we propose is not very far off from the empirical value of \(\bar \alpha\) calculated from the two databases (0.25 vs. 0.239). For these reasons, we would like to define our inequality index (Ii) as follows:
Given the data on the Gini index (Ginii) and the calculated H value for each country (Hi) using α = 0.25 or ¼ as a constant, we can compute the inequality index (Ii) for that country.
Table 1 presents the results of our ranking of income inequality based on the Gini index using the World Bank database in 2015. The results indicate that the inequality index (I) can differentiate income inequality in case two or more countries share the same Gini index but differ in the income gap between the top and the bottom. As discussed in the “Introduction”, Greece and Thailand share the same level of income inequality if measured by the Gini index (0.360). However, the \(\frac{{T_{10}}}{{B_{10}}}\) ratio in Greece = 13.8 while that in Thailand = 8.9, indicating that Greece has higher income inequality than Thailand, which cannot be explained by the Gini index. However, our inequality index (I) can tell this difference since Thailand has I = 0.391, whereas Greece has I = 0.425. Thus, using our inequality index (I), we can say that Greece has a higher level of income inequality than Thailand. The evolution of the Gini index, the \(\frac{{T_{10}}}{{B_{10}}}\) ratio, and the inequality index (I) of Greece and Thailand is shown in Fig. 2. Our results in Table 1 also show that when comparing the rankings of income inequality among countries using our inequality index (I) with those using the Gini index, there are 62 countries that their rankings have been changed while there are 13 countries whose rankings remain the same.

a Greece. b Thailand.
In addition, our inequality index (I) would be able to distinguish income inequality of two or more countries that have the same \(\frac{{T_{10}}}{{B_{10}}}\) ratio but have different values of the Gini index. Using the World Bank database, in 2015, Malta and Slovak Republic share the same \(\frac{{T_{10}}}{{B_{10}}}\) ratio (6.74) but Malta has the Gini index = 0.294 while the Gini index of Slovak Republic = 0.265, indicating that income inequality in Malta is higher than that in Slovak Republic as measured by the Gini index. Our inequality index (I) suggests the same results since the inequality index (I) of Malta = 0.339, whereas that of Slovak Republic = 0.327. The evolution of the Gini index, the \(\frac{{T_{10}}}{{B_{10}}}\) ratio, and the inequality index (I) of Malta and Slovak Republic is illustrated in Fig. 3.

a Malta. b Slovak Republic.
Furthermore, our inequality index (I) would be able to capture the case where the Gini index of a country is stabilizing across time but the income gap between the top 10% and the bottom 10% is rising. According to the World Bank database, during 2008 and 2014, the Gini index of Mexico is around 0.453 but the ratio of \(\frac{{T_{10}}}{{B_{10}}}\) is rising from 17.6 in 2008 to 18.6 in 2014. This suggests that the income inequality in Mexico is increasing if measured by the \(\frac{{T_{10}}}{{B_{10}}}\) ratio but is not if measured by the Gini index. By combining the Gini index and the \(\frac{{T_{10}}}{{B_{10}}}\) ratio in order to construct a single composite measure, our inequality index (I) could capture this dynamics since the value of our inequality index (I) shows a rising trend from 0.480 in 2008 to 0.489 in 2014. Figure 4 illustrates the evolution of the Gini index, the \(\frac{{T_{10}}}{{B_{10}}}\) ratio, and the inequality index (I) of Mexico.

It shows that the Gini index is stabilizing over time but the T10 /B10 ratio is increasing (the World Bank database).
In addition to the World Bank database, we employ the data on the Gini index and the ratio of the income share of the top 10% to the income share of the bottom 10% from the OECD IDD in order to illustrate that our method still works if different database is used. Table 2 reports the ranking of countries’ income inequality by the Gini index using the OECD IDD in 2015. The results confirm that our inequality index (I) would be able to distinguish the income inequality of two or more countries that share the same Gini index, but have different \(\frac{{T_{10}}}{{B_{10}}}\) ratios. As discussed in the “Introduction”, the United Kingdom and Israel have the same ranking of income inequality as measured by the Gini index (0.360) but the ratio of \(\frac{{T_{10}}}{{B_{10}}}\) in the United Kingdom is 4.2, whereas that in Israel is 5.8, indicating that the income inequality in Israel is higher than that in the United Kingdom, which cannot be distinguished by the Gini index. Accordingly, by using our inequality index (I), it shows that the United Kingdom has I = 0.332 while Israel has I = 0.358, suggesting that income inequality in Israel is higher than that in the United Kingdom. The evolution of the Gini index, the \(\frac{{T_{10}}}{{B_{10}}}\) ratio, and the inequality index (I) of the United Kingdom and Israel is illustrated in Fig. 5. In addition, our results from Table 2 show that when comparing the rankings of income inequality among countries using our inequality index (I) with those using the Gini index, there are 21 countries that their rankings have been changed while there are 14 countries whose rankings remain the same.

a United Kingdom. b Israel.
Using the data from the OECD IDD in 2015, our inequality index (I) could also tell the difference in income inequality when two or more countries have the same \(\frac{{T_{10}}}{{B_{10}}}\) ratio, but differ in the values of the Gini index. Ireland and Switzerland share the same \(\frac{{T_{10}}}{{B_{10}}}\) ratio (3.6) but the Gini index in Ireland is 0.297, whereas that in Switzerland is 0.296. This suggests that the income inequality in Ireland is slightly higher than that in Switzerland, which could be distinguished by our inequality index (I). According to our inequality index (I), Ireland has I = 0.286 while Switzerland has I = 0.285. Figure 6 shows the evolution of the Gini index, the \(\frac{{T_{10}}}{{B_{10}}}\) ratio, and the inequality index (I) of Ireland and Switzerland.

a Ireland. b Switzerland.
Similar to the case of Mexico previously discussed where our inequality index (I) would be able to capture the dynamics of the rising of \(\frac{{T_{10}}}{{B_{10}}}\) ratio over time while the Gini index is stabilizing during the same period, the data from the OECD IDD shows that Italy has somewhat stable Gini index around 0.327 between 2010 and 2014 but the \(\frac{{T_{10}}}{{B_{10}}}\) ratio is rising from 4.4 in 2010 to 4.6 in 2014, indicating that the income inequality is increasing across time, which cannot be captured by the Gini index. However, our inequality index (I) could capture the dynamics of income inequality in Italy since the inequality index (I) shows a rising trend from 0.318 in 2010 to 0.322 in 2014. The evolution of the Gini index, the \(\frac{{T_{10}}}{{B_{10}}}\) ratio, and the inequality index (I) of Italy is shown in Fig. 7

It shows that the Gini index is stabilizing over time but the T10/B10 ratio is increasing (the OECD IDD).
Conclusions and remarks
That two or more countries have the same value of the Gini index does not necessarily imply that these countries share the same level of income inequality. In fact, income inequality could be quite different if taking into account the difference in countries’ income gap between the richest and the poorest. Likewise, two or more countries having the same ratio of the income share held by the richest to the income share held by the poorest does not always imply that income inequality among these countries is the same either. The Gini index is known to be less sensitive to inequality at the tails of income distribution, whereas the ratios of income share of the richest to income share of the poorest do not account for inequality in the middle of income distribution. To overcome the limitations of the Gini index and the inter-decile ratios as measures of income inequality, this study introduces a composite index for measuring inequality that does not require the micro-data of the distribution. Our inequality index is very simple to calculate. It comprises three indicators, namely, the Gini index, the income share held by the top 10%, and the income share held by the bottom 10%. The data on these three indicators are also available, easy to access, and regularly updated by countries and international organizations.
To demonstrate our method, we use the annual data from the World Bank and the OECD IDD between 2005 and 2015. The overall results show that our inequality index can differentiate income inequality among countries in case two or more countries share the same Gini index but differ in the income gap between the top 10% and the bottom 10%. It could also distinguish the income inequality whenever two or more countries have the same ratio of the income share of the top 10% to that of the bottom 10% but differ in values of the Gini index. In addition, our inequality index could capture the dynamics where a country’s Gini index remains stable over time but the income gap between the top 10% and the bottom 10% is rising.
We would like to remark, however, that two or more countries could possibly share the same inequality index, but have different Lorenz curves as reflected by having different values of the Gini index and different ratios of the income share of the top 10% to that of the bottom 10%. Examples are Belgium and Serbia as shown in Table 1, as well as Estonia and Portugal as shown in Table 2. This implies that there are other aspects of differences in income inequality among countries that our inequality index would not be able to capture.
One way to account for other differences in income inequality is to include other inter-percentile ratios in addition to the P90/P10, say, P80/P20, P70/P30, P60/P40, and P50/P50, in the calculation of the inequality index. In this way, the whole range of the Lorenz curve would be covered. Using the same notations as before with slight modifications, for any given country i, \(\left( {\frac{B_{x}}{T_{x}}} \right)_{\mathrm{i}}\) is now defined as the ratio of the income share of the bottom x% (Bx) to the income share of the top x% (Tx), where 0 < x ≤ 50. In addition, let j be the number of x’s, where j = 1, 2, …, N. Next, for any given xj, we have to find an appropriate value of \({\upalpha}_{{x}_{j}}\) such that \(({\mathrm{avg}}.\,{\mathrm{Gini}}) = 1 - ( {{\mathrm{avg}}.( {\frac{B_{x_{j}}}{T_{x_{j}}}} )} )^{\upalpha_{x_{j} }}\) for each sample. We then use the \({\upalpha}_{{x}_{j}}\) to calculate the \(H_{{\mathrm{i}}x_{j}}\), where \(H_{\mathrm{i}x_{j}} = 1 - ( {\frac{B_{x_{j}}}{T_{x_{j}}}})_{\mathrm{i}}^{\alpha_{x_{j}}}\). Given the values of the Ginii and the \(H_{{\mathrm{i}x}_{j}}\) terms, the inequality index for any given country (Ii) can now be rewritten as a function of the Ginii and the \(H_{{\mathrm{i}x}_{j}}\) terms as follows:
Note that the number of \(H_{{\mathrm{i}x}_{j}}\) terms could be varied, depending upon the number of inter-percentile ratios and the availability of the data used for the calculation of the inequality index. For example, if we use five inter-percentile ratios, namely, P90/P10, P80/P20, P70/P30, P60/P40, and P50/P50 in our analysis, we would have five \(H_{{\mathrm{i}x}_{j}}\) terms, which are Hi10, Hi20, Hi30, Hi40, and Hi50. The inequality index for any given country i(Ii) could be computed as \(\frac{{\sqrt {\mathrm{Gini}_{\mathrm{i}}^{2} + H_{\mathrm{i}10}^{2} + H_{\mathrm{i}20}^{2} + H_{{\mathrm{i}}30}^{2} + H_{{\mathrm{i}}40}^{2} + H_{{\mathrm{i}}50}^{2}} }}{{\sqrt {5 + 1} }}\). This is one way to take into account the difference in income inequality in case two or more countries share the same inequality index but have dissimilar Lorenz curves. There might be other alternative ways to account for such a difference, which await future research.
Last but not least, we hope that our simple method for measuring inequality could be applied not only to socioeconomics, but also to broad scientific disciplines as a measure of statistical heterogeneity and for size distributions of any non-negative quantities.
Data availability
All data generated and/or analyzed during this study are included in this manuscript and can be accessed from the World Bank and the Organization for Economic Co-operation and Development websites as listed in the references.
Notes
Note that an alternative and more simple index could be constructed by using only the Gini index in percentage points (Ginii * 100) and the ratio of the income share held by the top 10% to that held by the bottom 10% without the need to calculate the values of the α and the Hi. The alternative index for any given country i can be defined as follows:
\({\mathrm{Alternative}}\,{\mathrm{index}}_{\mathrm{i}} = \frac{{\sqrt {\left( {{{\mathrm{Gini}}_{\mathrm{i}}} \ast 100} \right)^2 + \left( {\frac{{T_{10}}}{{B_{10}}}} \right)_{\mathrm{i}}^2} }}{{100}}\).
This alternative index takes the values between 0.01 and ∞. When everyone has the same share of income, it is equal to 0.01 (Ginii = 0 and \(( {{T_{10}}/{B_{10}}})_{\rm{i}}\) = 1). When one person has all incomes and everyone else has none, the alternative index is equal to ∞ (Ginii = 1 and \(( {{T_{10}}/{B_{10}}})_{\rm{i}}\) = ∞ since B10 = 0), making it difficult to interpret and compare among countries as discussed in the “Introduction”
References
Abraham RG, van den Bergh S, Nair P (2003) A new approach to galaxy morphology. I. Analysis of the Sloan Digital Sky Survey early data release. Astrophys J 588(1):218–229
Atkinson AB (1970) On the measurement of inequality. J Econ Theory 2(3):244–263
Atkinson AB, Bourguignon F (2015) Introduction: income distribution today. In: Atkinson AB, Bourguignon F (eds.) Handbook of income distribution, North-Holland, Oxford, pp. xvii-lxv
Bellù LG, Liberati P (2006) Describing income inequality: Theil index and entropy class indexes. Food and Agriculture Organization of the United Nations. http://www.fao.org/3/a-am343e.pdf
Bertoli-Barsotti L, Lando T (2019) How mean rank and mean size may determine the generalised Lorenz curve: with application to citation analysis. J Informetr 13:387–396
Chakrabarti BK, Chakraborti A, Chakravarty SR, Chatterjee A (2013) Econophysics of income and wealth distributions. Cambridge University Press, New York
Coulter PB (1989) Measuring inequality: a methodological handbook. Westview Press, Boulder
Cowell FA (2011) Measuring inequality, 3rd edn. Oxford University Press, New York
Cromley GA (2019) Measuring differential access to facilities between population groups using spatial Lorenz curves and related indices. T Gis 23(6):1332–1351
Das AK (2014) Quantifying photovoltaic power variability using Lorenz curve. J Renew Sustain Energy 6:033124. https://doi.org/10.1063/1.4881655
De Vogli R, Mistry R, Gnesotto R, Cornia GA (2005) Has the relation between income inequality and life expectancy disappeared? Evidence from Italy and top industrial countries. J Epidemiol Community Health 59:158–162
Delbosc A, Currie G (2011) Using Lorenz curves to access public transport equity. J Transp Geogr 19:1252–1259
Eliazar II (2018) A tour of inequality. Ann Phys 389:306–332
Eliazar II, Sokolov IM (2012) Measuring statistical evenness: a panoramic overview. Phys A 391:1323–1353
Gini C (1912) Variabilità e mutabilità: contributo allo studio delle distribuzioni e delle relazioni statistiche. Tipografia di Paolo Cuppini, Bologna
Gini C (2005) On the measurement of concentration and variability of characters. De Santis F (trans) Metron 63:3–38
Graczyk PP (2007) Gini coefficient: a new way to express selectivity of kinase inhibitors against a family of kinases. J Med Chem 50(23):5773–5779
Ho KH, Chow FK, Chau HF (2004) Wealth inequality in the minority game. Phys Rev E 70(6):066110. https://doi.org/10.1103/PhysRevE.70.066110
Lorenz MO (1905) Methods for measuring the concentration of wealth. Pub Am Stat Assoc 9(70):209–219
McGregor T, Smith B, Willis S (2019) Measuring inequality. Oxf Rev Econ Policy 35(3):368–395
Palma JG (2011) Homogeneous middles vs. heterogeneous tails, and the end of the ‘Invert-U’: It’s all about the share of the rich. Dev Change 42(1):87–153
Pavkova K, Currie G, Delbosc A, Sarvi M (2016) Selecting tram links for priority treatments—The Lorenz curve approach. J Transp Geogr 55:101–109
Rindfuss RR, Walsh SJ, Turner II BL, Fox J, Mishra V (2004) Developing a science of land change: challenges and methodological issues. Proc Natl Acad Sci USA 101(39):13976–13981
Sapolsky RM (2018) The health-wealth gap. Sci Am 319(5):62–67
Sarabia JM, Jordá V, Prieto F (2019) On a new Pareto-type distribution with applications in the study of income inequality and risk analysis. Phys A 527:121227. https://doi.org/10.1016/j.physa.2019.121277
Sazuka N, Inoue J (2007) Fluctuations in time intervals of financial data from the view point of the Gini index. Phys A 383:49–53
Scheffer M, van Bavel B, van de Leemput IA, van Nes EH (2017) Inequality in nature and society. Proc Natl Acad Sci USA 114(50):13154–13157
Sitthiyot T, Budsaratragoon P, Holasut K (2020) A scaling perspective on the distribution of executive compensation. Phys A 543:123556. https://doi.org/10.1016/j.physa.2019.123556
The Organization for Economic Co-operation and Development (2019a) Gini coefficient [Data set] [Accessed 27 Oct 2019]. Available from: https://data.oecd.org/inequality/income-inequality.htm
The Organization for Economic Co-operation and Development (2019b) Interdecile P90/P10 [Data set] [Accessed 27 Oct 2019]. Available from: https://data.oecd.org/inequality/income-inequality.htm
Theil H (1967) Economics and information theory. North-Holland, Amsterdam
The World Bank (2019a) GINI index (World Bank estimate) [Data set] [Accessed 25 Mar 2019]. Available from: https://data.worldbank.org/indicator/SI.POV.GINI
The World Bank (2019b) Income share held by highest 10% [Data set] [Accessed 25 Mar 2019]. Available from: https://data.worldbank.org/indicator/SI.DST.10TH.10?view=chart
The World Bank (2019c) Income share held by lowest 10% [Data set] [Accessed 25 Mar 2019]. Available from: https://data.worldbank.org/indicator/SI.DST.FRST.10?view=chart
Woolhouse MEJ, Dye C, Etard JF, Smith T, Charlwood JD, Garnett GP et al. (1997) Heterogeneities in the transmission of infectious agents: implications for the design of control programs. Proc Natl Acad Sci USA 94:338–342
Zhou X, Yan D, Jiang Y (2015) Application of Lorenz curve and Gini index in the analysis of load feature in HVAC systems. Procedia Eng 121:11–18
Acknowledgements
T.S. is grateful to Dr. Suradit Holasut for guidance and comments.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sitthiyot, T., Holasut, K. A simple method for measuring inequality. Palgrave Commun 6, 112 (2020). https://doi.org/10.1057/s41599-020-0484-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-020-0484-6
This article is cited by
-
Gender Inequality is negatively associated with academic achievement for both boys and girls
npj Science of Learning (2024)
-
cnnImpute: missing value recovery for single cell RNA sequencing data
Scientific Reports (2024)
-
Does Innovation Drive Up Income Inequality in Africa?
Journal of the Knowledge Economy (2024)
-
Visibility-based layout of a hospital unit – An optimization approach
Health Care Management Science (2024)
-
Modelling Southern Mesopotamia Irrigated Landscapes: How Small-scale Processes Could Contribute to Large-Scale Societal Development
Journal of Archaeological Method and Theory (2024)
