
Abstract
Ultra-wideband technology has good anti-interference capabilities and development prospects in indoor positioning. Since ultra-wideband will be affected by random errors in indoor positioning, to exploit the advantages of the Kalman filter (KF) and the long short-term memory (LSTM) network, this paper proposes a long short-term memory neural network algorithm fused with the Kalman filter (KF–LSTM) to improve UWB positioning. First, the ultra-wideband data is processed through KF to weaken the noise in the data, and then the data is fed into the LSTM network for training, and the capability of the LSTM network to process time series features is employed to obtain more accurate label positions. Finally, simulation and measurement results show that the KF–LSTM algorithm achieves 71.31%, 37.28%, and 49.31% higher average positioning accuracy than the back propagation (BP) network, (back propagation network fused with the Kalman filter (KF-BP), and LSTM network algorithms, respectively, and the KF–LSTM algorithm performs more stably. Meanwhile, the more noise the data contains, the more obvious the stability contrast between the four algorithms.
Similar content being viewed by others

Introduction
In today’s digital era, technology is developing rapidly, and numerous intelligent fields have increasingly higher requirements for location accuracy. In outdoor environments, GNSS (Global Navigation Satellite System) technology can provide accurate location services. Nevertheless, due to the obstruction of buildings and walls, GNSS signals cannot directly reach indoors, limiting the application of GNSS technology in indoor environments1,2. Therefore, some indoor intelligent applications based on location services have urgent needs for precise positioning within indoor settings, such as airports and large retail centers. In recent years, various indoor positioning technologies have emerged, including Wi-Fi fingerprint3, Bluetooth4, UWB (Ultra-Wideband)5,6, Zigbee7, ultrasonic8, audio9 positioning technologies, etc. Among them, UWB positioning technology is commonly utilized in indoor positioning because of its high accuracy, low power consumption, and anti-interference characteristics10. Many UWB positioning algorithms have been proposed, such as TOA(Time of Arrival) positioning and TDOA(Time Difference of Arrival) positioning, which rely on UWB equipment for ranging and finding the tag position based on related algorithms11,12, wireless signal arrival angle AOA (Angle of Arrival) positioning13 and fingerprint matching positioning based on signal strength RSSI (Received Signal Strength Indication)14. However, due to the high complexity of the indoor environment, the signal will be affected by factors such as multipath, occlusion, noise interference, and signal attenuation in the transmission process, which increases the error of UWB indoor positioning, making positioning results fail to meet the requirements15. Thus, new algorithms need to be developed to minimize the influence of these factors on positioning accuracy.
Kalman filter is a recursive algorithm for estimating system state, and it performs well when processing measurement data containing noise and uncertainty16. The indoor environment is complex, and UWB will inevitably be interfered with by WIFI, Bluetooth, and other signals, making acquired data contain a certain amount of noise. Combining Kalman filtering and UWB technology in indoor positioning can make the positioning results more accurate. Cheng et al. developed a positioning system that combines UWB technology and the extended Kalman filter algorithm to enhance positioning precision17. However, the system was only compared with the TOA algorithm, not other algorithms, and it was not tested in practical application scenarios.
Deep learning has powerful pattern recognition and learning capabilities, and it has achieved great success in many fields, such as sensor fusion, signal processing, feature extraction, etc.18,19,20. Deep learning can also assist UWB positioning by using its unique learning capabilities to learn key features from signals, such as delay, amplitude, multipath, etc.21. Doan Tan Anh Nguyen developed an ultra-wideband positioning method based on convolutional neural networks, which uses two-dimensional images with three channels to calculate the location of tags. This method avoids the problems of error propagation and the high complexity of traditional methods, and the performance of the method in different channel models and regional environments was verified through simulation experiments22. Alwin Poulose et al. used UWB distance information to train the LSTM model, analyzed the impact of batch size, optimizer, learning rate, time steps, and the number of hidden nodes and loss function on the performance of the LSTM model, and a parameter model was constructed to improve UWB positioning accuracy23. However, the research on UWB positioning was only conducted theoretically based on simulation experiments, and there was no verification in practical applications. Gao et al. proposed using the LSTM network to predict the ranging error between the anchor point and the target, and they combined weighted least squares and regression weighted least squares for positioning correction, which improved UWB positioning accuracy24. However, their study did not take other deep learning algorithms for comparison and did not analyze the limitations and advantages of the LSTM algorithm in UWB indoor positioning systems.
When UWB is used for indoor positioning, it can be affected by various interference sources indoors, as well as multipath interference generated by UWB signals indoors. These interferences introduce a significant amount of random noise into UWB ranging information, subsequently affecting the positioning results of UWB. To mitigate the impact of random errors on UWB indoor positioning, this paper combines the strengths of KF and LSTM, proposing a long short-term memory network fused with the Kalman filter (KF–LSTM). The algorithm utilizes Kalman filtering to handle Gaussian noise in UWB ranging time series and combines the advantages of LSTM networks in time series analysis to achieve accurate tag positioning. The rest of this paper is organized as follows: In “Related work” section introduces related work, mainly including the research status and challenges of UWB. In “UWB ranging principle” section describes the principle of UWB ranging. In “UWB positioning based on the KF–LSTM algorithm” section provides the principle of the KF–LSTM algorithm. In “Data simulation and result analysis” and “Measured data and result analysis” section analyzes the simulation and measured experimental results. In “Discussion” section is the discussion part. In “Conclusions” section concludes this paper.
Related work
UWB positioning based on Kalman filter
Kalman filtering is an excellent state estimation method that can effectively weaken the noise of UWB signals and the uncertainty in state estimation, thereby achieving more accurate positioning results. In the literature25, a tracking algorithm based on the Kalman filter was proposed to enhance the positioning accuracy in the NLOS environment. In the literature26, the NLOS environment was studied again, and an improved incremental Kalman filter was proposed based on the work in25, which further improved the positioning accuracy. However, if the indoor space is narrow, its positioning accuracy and stability will be significantly reduced. In the literature27, a narrow space ultra-wideband positioning algorithm combining a precision dilution mathematical model and the Kalman filter was proposed. With the use of this technique, positioning stability and precision can be increased while also successfully suppressing positioning errors brought on by small space structures. However, this algorithm cannot solve the positioning problem in nonlinear systems, and solutions are given in the literature28,29. In28, an unscented Kalman filter algorithm based on the maximum correlation entropy criterion was proposed. In this algorithm, the prediction state estimate and covariance matrix are obtained through unscented transformation, and the observation data is rebuilt using the nonlinear regression approach based on the maximum correlation entropy criterion to enhance the unscented Kalman filter’s placement accuracy in a non-Gaussian noise environment. In29, a robust extended Kalman filter algorithm was proposed, which can resist outliers in observation data and enhance the accuracy and reliability of ultra-wideband positioning. However, the effects of dynamic model errors and observation system errors were not considered. In the literature30, an improved robust adaptive cubic Kalman filter algorithm was proposed to deal with the non-line-of-sight error and motion model error of UWB positioning, a polynomial fitting sliding window was designed to determine the error type of signal propagation in real time, and a correction plan was given to improve UWB positioning accuracy.
UWB positioning based on deep learning
As a branch of machine learning, deep learning can imitate the human brain for learning and pattern recognition. When applied to UWB positioning systems, it can perform large-scale data processing and extract non-linear relationships from the data. In the literature31, a CNN data model based on the received signal strength fingerprint was proposed and compared with deep learning models such as AlexNet and ResNet. The results indicate that the proposed CNN model has higher test accuracy than other deep learning models. However, when using RSSI for positioning, the amount of data required to be collected is large, and the final positioning accuracy is not as good as that using ranging. In the literature32, a CNN-based UWB positioning method was proposed, which uses CNN to replace TOA for distance estimation to improve positioning accuracy. However, this study only took TOA for comparison without considering other deep learning models. In the literature33, it was proposed to transmit UWB signals to three different receiving antenna devices and convert the signals into RGB images. By using a CNN model to process the received image and estimate the location of the label, this method does not require predicting the distance between the transmitter and the receiver. The simulation results demonstrate that the performance is significantly improved compared with the previous CNN positioning method. However, when positioning, the transmission signal needs to be converted into an RGB image for processing, which increases the calculation time and has a certain impact on real-time positioning. In the literature34,35, the advantage of high ranging accuracy of UWB was exploited to combine UWB and inertial navigation systems, and the LSTM network was used to process the time series in the position estimation process, thereby achieving higher positioning accuracy. However, this solution needs to be combined with the INS system, which will increase the cost of positioning. In the literature36, CNN and LSTM were combined to use RSS and distance data to estimate the tag position, exploit the feature extraction ability of CNN to suppress measurement noise, and adopt the LSTM model to establish the correlation of consecutive frames, thereby enhancing positioning accuracy.
In related work, the current research status of UWB is introduced, and the challenges encountered by UWB in the development of indoor positioning and different methods proposed for UWB are explained. Although many scholars have achieved good results in experiments, they still need to be verified in other environments, and the UWB indoor positioning task still has a long way to go. This paper proposes the KF–LSTM algorithm by combining Kalman filtering and the LSTM neural network. Analysis of simulation and measured data shows that the KF–LSTM algorithm achieves good indoor positioning accuracy and increases the precision and stability of UWB positioning.
UWB ranging principle
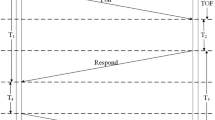
UWB technology is a high-rate communication and high-precision positioning technology that uses nanosecond-level non-sinusoidal narrow pulses for data transmission. Its operating frequency band is 3.1 GHZ ~ 4.8 GHZ, ensuring sub-nanometer precise time. The short pulse width of the UWB time domain signal results in enhanced range and locating accuracy due to its increased time and space resolution. In UWB positioning technology, double-side two-way ranging (DS-TWR) principle is a commonly used method to achieve high-precision distance measurement by measuring the round-trip propagation time of signals, as shown in Fig. 1:

UWB ranging principle.
In Fig. 1, \(t_{1}\), \(t_{4}\) and \(t_{5}\) are moments recorded by device A. \(t_{2}\), \(t_{3}\) and \(t_{6}\) are moments recorded by device B.\(T_{p1}\) indicates the time the signal traveled from device A to device B. \(T_{p2}\) indicates the time the signal returned from device B to device A. \(T_{p3}\) indicates the time the signal traveled from device A to device B for the second time. Since the time interval between the two signal transmissions is very short, it can be assumed that the distance from device A to device B has not changed, so \(T_{p1}\), \(T_{p2}\) and \(T_{p3}\) are theoretically equal. In the following equations, we use \(\hat{T}_{p}\) instead of the time it takes for the signal to travel from device A to device B.\(T_{R1}\) denotes the interval between device A sending information and device B receiving the response.\(T_{R2}\) denotes the interval between device B sending information and device A receiving response.\(T_{r1}\) denotes the response time for device B to process device A’s information. \(T_{r2}\) denotes the response time for device A to process device B’s information. The following equation can be obtained:
The transformation of Eq. (2) yields:
Then we can get \(T_{R1} *T_{R2} = (2\hat{T}_{p} + T_{r1} )*(2\hat{T}_{p} + T_{r2} ) = 4*\hat{T}_{p}^{2} + 2\hat{T}_{p} T_{r2} + 2\hat{T}_{p} T_{r1} + T_{r1} T_{r2}\).
which then yields \(T_{R1} *T_{R2} - T_{r1} T_{r2} = 4*\hat{T}_{p}^{2} + 2\hat{T}_{p} T_{r2} + 2\hat{T}_{p} T_{r1} = \hat{T}_{p} (4\hat{T}_{p} + 2T_{r1} + 2T_{r2} )\).
According to (2) \(4\hat{T}_{p} = T_{R1} - T_{r1} + T_{R2} - T_{r2}\) can be brought into the above equation to get:
The distance from device A to device B is:
where \(c\) denotes the speed of light.
The formula of DS-TWR ranging error calculation is:
where \(k_{a}\) and \(k_{b}\) denote the frequencies of device A and device B, respectively.
UWB ranging has many advantages, such as centimeter-level high accuracy, high resolution, anti-interference, applicability indoors and outdoors, and low power consumption.
Long short-term memory network fused with Kalman filter
Long short-term memory network
LSTM network evolves from the recurrent neural network (RNN), which solves the vanishing gradient problem in RNN37. The LSTM network has an additional time dimension in the input compared with general neural networks, such as the BP neural network, and it has a feedback loop, which can establish a connection between input data and better process time-related data. The core of LSTM is to introduce “gates” to control the flow of information. Each gate is a neural network layer that can control whether information can pass through; its main components include the input gate, forget gate, output gate, and cell state. Figure 2 shows the basic structure of the LSTM network:

The basic structure of the LSTM network.
The calculation of the input gate is:
where \(i_{t}\) represents the input gate, \(x_{t}\) represents the input at the current time, \(h_{t - 1}\) represents the hidden state at the previous moment, and \(c_{t - 1}\) represents the memory unit state at the previous moment. \(W_{xi}\), \(W_{hi}\), and \(W_{ci}\) are weight matrices, \(b_{i}\) is the bias vector, and \(\sigma\) is the sigmoid activation function.
The calculation of the forgetting gate is:
The forget gate determines how much information is retained in the memory unit state at the previous time step, where \(W_{xf}\), \(W_{hf}\), and \(W_{cf}\) are the weight matrices, and \(b_{f}\) is the bias vector.
The memory unit state is updated as:
where tanh represents the tanh activation function; \(\tilde{c}\) represents the candidate memory unit state of the current time step, indicating the state of the memory unit at the current time step. \(W_{cx}\) and \(W_{hc}\) represent the weight matrix input for updating the memory unit state. \(b_{c}\) represents the bias term for updating the memory unit state. \(\odot\) represents element-wise product, i.e., multiplying elements at corresponding positions.
The calculation of the output gate is:
The output gate determines the output of the hidden state at the current time step. \(o_{t}\) represents the output gate; \(W_{xo}\), \(W_{ho}\), and \(W_{co}\) are weights; \(b_{o}\) is the bias vector.
The hidden state at the current moment is calculated as:
Kalman filter
KF is a linear estimation algorithm suitable for solving linear problems with Gaussian white noise. By fusing the system model and the observation model, it obtains the past state estimates and the latest measured values based on the minimum mean. The square root error criterion is used for weighted estimation to obtain the optimal estimate of the system38. This study uses the Kalman filter to filter the time series of LSTM to make the results more accurate.
The KF algorithm is divided into two steps: prediction and update. The time update equation of the KF is as follows:
where \(\hat{x}_{{\overline{k}}}\) represents the prior state estimate at time \(k\). \(\hat{x}_{k - 1}\) represents the state estimate at time \(k - 1\). A is the state transition matrix, and B is the matrix that converts the input into a state. \(\mu_{k - 1}\) represents the control quantity at moment \(k - 1\).\(P_{{\overline{k}}}\) represents the estimated covariance of \(\hat{x}_{{\overline{k}}}\) at time \(k\). \(P_{k - 1}\) represents the estimated covariance at time \(k - 1\). The matrix \(Q\) is the process excitation noise covariance. The first equation in Formula (14) represents the prior state estimate, while the second equation calculates the covariance of the prior estimate.
The state update equation of the Kalman filter is as follows:
where \(\hat{x}_{k}\) represents the state estimate at time \(k\). \(P_{k}\) represents the estimated covariance at time \(k\). The matrix \(H\) is the state-to-observation transition matrix measurement.\(z_{k}\) is the measured value. \(K_{k}\) is the Kalman gain matrix. \(R\) represents the measurement noise covariance. The first equation in Formula (15) is the posterior state estimate, the second equation is the update of the Kalman gain, and the third equation is the final covariance calculation.
UWB positioning based on the KF–LSTM algorithm
The data and time used for positioning using UWB ranging are related. The LSTM network is a deep learning model for processing time series, and it can extract dependencies in time series. The Kalman filter is an optimal linear filter that obtains the best state estimate based on time series and state transition models. In practical applications, experimental data contain noise, and there is uncertainty in the state of the system. Kalman filtering can effectively handle these noises and uncertainties, providing more accurate state estimates for experiments. The combination of the Kalman filter and the LSTM network can simultaneously exploit the LSTM’s advantage in timing modeling and the Kalman filter’s advantage in state estimation, thereby providing more accurate results for experiments. The algorithm is divided into three steps: establishing a time series data set, establishing a Kalman filter equation, and building an LSTM neural network. The specific process is shown in Fig. 3.

The flow chart of the KF-LSTM algorithm.
The number of UWB base stations used in the experiment is \(N\), and under ideal circumstances, \(N \ge 3\) can uniquely determine the location of the tag. If there is only one tag in the UWB positioning system, the distance from the tag to each base station at time \(t\) is recorded as \(\left[ {\begin{array}{*{20}c} {D^{t}_{1} } & {D^{t}_{2} } & {D^{t}_{3} } & {\begin{array}{*{20}c} {...} & {D^{t}_{N} } \\ \end{array} } \\ \end{array} } \right]\). If the length of the time series required to construct the data set is \(T\), then a piece of data in the data set can be recorded as:
Each column of data represents the distance measured between a base station and the tag within time \(T\). Each column of data is subjected to a Kalman filter to reduce the noise and uncertainty of the data. The state equation and observation equation of the Kalman filter are represented as follows:
where \(\hat{D}_{i}^{t - 1}\) and \(\hat{D}_{i}^{t}\) represent the estimated values of the base station and tag at time \(t - 1\) and \(t\), respectively. \(z_{i}^{t}\) represents the observation value of the i-th base station and tag at time \(t\). \(u_{i}^{t}\) and \(v_{i}^{t}\) represent the estimation error and observation error of the i-th base station and tag at time \(t\).
The state update formula of the Kalman filter is as follows:
where \(K_{t}\) is the Kalman gain coefficient at time \(t\).
Since the distance from the base station to the tag cannot be estimated empirically, the first measured value is selected as the initial estimated value. The LSTM network is constructed based on Python 3.7 and Tensorflow 1.8. The size of the input layer is 4*10, the number of nodes in the hidden layer is set to 64, the number of layers in the network is set to 2, and the loss function uses the root mean square error function. The error loss function is as follows:
where \(loss\) denotes the loss value; \(x\_p\) and \(y\_p\) denote the coordinate prediction values calculated by the LSTM network; \(x\) and \(y\) denote the true values of the coordinates; \(n\) denotes the amount of data in the training data set.
Meanwhile, an exponential decay function is selected for the learning rate. After a certain number of rounds of training, the learning rate decays at a certain rate. This approach can help the model converge faster in the early stages, and the gradually reduced learning rate also improves the stability and generalization ability of the model.
Data simulation and result analysis
Data simulation
To verify the theoretical feasibility of the proposed algorithm, this study uses Python 3.7 software to conduct simulation experiments and result analysis. In the simulation experiment, four UWB base stations were used, marked A, B, C, and D respectively, and their coordinates were recorded as \((x_{A} ,y_{A} )\), \((x_{B} ,y_{B} )\), \((x_{C} ,y_{C} )\), and \((x_{D} ,y_{D} )\). Also, it is necessary to record the coordinates of label E \((x_{E} ,y_{E} )\). The real distance from A to E is:
In the simulation experiment, the coordinates of the base station were set as (0,0) (0,400) (400,400), and (400,0), and the coordinate unit was centimeters. During the experiment, a circular route containing 1000 points was generated in the experimental area. To effectively train and verify the algorithm, this data set was divided into a training set and a verification set at a ratio of 10:1, i.e., the training set contained 90% of the data points (900 points), while the validation set contained 10% of the data points (100 points). The real distance between these points and the base station was obtained following Eq. (16), and a certain amount of noise was added to the generated real distance to obtain the LSTM time series required for research. To simulate the complex and changeable indoor environment and verify the noise suppression effect of the KF–LSTM algorithm, ten types of noise were set in the simulation data. The standard deviation of the noise from small to large is 10 cm, 20 cm, 30 cm, 40 cm, 50 cm, 60 cm, 70 cm, 80 cm, 90 cm, and 100 cm. The data set constructed in the experiment had a time step of 10, and the measured distances of the four base stations corresponded to four features.
Simulation result analysis
Figure 4 shows that regardless of the type of noise, the overall error of the BP algorithm is the largest, while the overall error of the KF–LSTM algorithm is the smallest. Next are the KF-BP and LSTM algorithms, where the precision of the BP algorithm is the lowest. To show the overall error status of the four algorithms under different noise conditions, the box plots of the four algorithms under different noises are illustrated in Fig. 5.

The error curves for the four algorithms’ calculation results under the noise standard deviation of 10 cm, 30 cm, 50 cm, 60 cm, 80 cm, and 100 cm are displayed in (a), (b), (c), (d), (e), and (f), in that order.

When the noise standard deviation is 10 cm, 30 cm, 50 cm, 60 cm, 80 cm, and 100 cm, the box plots of the four algorithms are displayed in (a), (b), (c), (d), (e), and (f), in that order.
Figure 5 shows that the average error of each algorithm increases as the noise standard deviation increases. Regardless of the type of noise, the BP algorithm has the largest box, the widest error range, and the largest average error. The KF–LSTM algorithm has the smallest box, the smallest error distribution range, and the smallest average error. To illustrate how the accuracy and stability of the four algorithms change with noise, Fig. 6 shows the changes in the average positioning error and standard deviation under different noises.

The average error and standard deviation of the four algorithms.
In Fig. 6, the histogram display corresponds to the left axis, showing the mean error for each algorithm, and the line graph corresponds to the right axis, showing the standard deviation for each algorithm. Where the mean error responds to the accuracy of the algorithm and the standard deviation responds to the stability of the algorithm. Among the four algorithms, the accuracy and standard deviation of the BP algorithm are the worst under various noises. However, incorporating Kalman filtering into the BP algorithm (KF-BP) greatly improves the accuracy and stability of the algorithm. In multiple datasets with a noise standard deviation below 70 cm, it is not possible to determine a consistent superiority or inferiority in terms of accuracy between the KF-BP algorithm and the LSTM algorithm. However, when the noise standard deviation in the dataset exceeds 70 cm, the average error of the KF-BP algorithm is consistently lower than that of the LSTM algorithm. Furthermore, in terms of stability analysis, when the dataset includes noise with a standard deviation higher than 20 cm, the stability of the KF-BP algorithm is superior to that of the LSTM algorithm. This also explains why KF–LSTM exhibits the best accuracy and stability under any level of noise. Combined with Fig. 5, it can be concluded that the KF–LSTM algorithm has better positioning accuracy and stability than the other three algorithms. Taking the noise standard deviation of 30 cm as an example, the KF–LSTM algorithm has 78.05% higher accuracy than the BP algorithm, 40.33% higher accuracy than the KF-BP algorithm, and 48.73% higher accuracy than the LSTM algorithm. The specific values of the average error and standard deviation of various algorithms under different noises are listed in Table 1.
Measured data and result analysis
Data collection
Then, this study conducts actual experiments to verify the feasibility of the proposed algorithm in practical applications. The experimental site was chosen at the School of Surveying and Mapping of Henan Polytechnic University, with a site size of 8 m × 8 m. In our experiment, the coverage area of base station is 6 m × 6 m. The experiment used a UWB device with the DW1000 chip as the label and tracing point. The ranging principle of the device is based on DS-TWR. The experiment selected four UWB base stations and one UWB tag. In the experiment, a total station was selected as an auxiliary to measure the real coordinates of the base station and tag. The positions of the base station erection position and total station are shown in Fig. 7. The coordinates of base station A in Fig. 7 are (263.9, 676), base station B is located at (837, 562.4), base station C at (774, 88.7), and base station D at (193.2, 67.7), with units in centimeters.

The schematic diagram of the experimental site.
System error handling
Since there are systematic errors in the measured values, there are no systematic errors in the simulation experiments. To make the calculation results more accurate, the systematic errors need to be weakened. To this end, the least squares criterion is adopted to establish a linear regression equation for each base station. The relevant parameters of the equation are listed in Table 2. The fitting situations of base stations A, B, C, and D are shown in Fig. 8. The system errors of base stations A, B, C, and D are 4.5 cm, 0.5 cm, 13 cm, and 1.5 cm, respectively. After removing the systematic error, the obtained results are sent to the KF–LSTM algorithm for solution.

(a), (b), (c), and (d) show the least squares fitting results of base stations A, B, C, and D, respectively.
Result analysis
The field measurement data after weakening the impact of system errors are brought into the KF–LSTM network for iterative operations. The results of the BP, KF-BP, LSTM, and KF–LSTM algorithms are compared. Figure 9 shows the original path and the path map calculated by the KF–LSTM, BP, KF-BP, and LSTM algorithms. It can be seen from the figure that the road map of the KF–LSTM algorithm is closest to the original path, followed by KF-BP and LSTM algorithms, while the road map of the BP algorithm is the worst and least close to the original path.

The roadmap calculated by the four algorithms.
Figure 10 shows the error cumulative distribution function (CDF) of various algorithms. It can be seen that under the same threshold, the KF–LSTM algorithm obtains the highest positioning error probability. The distance error is within 7 cm, the cumulative probabilities corresponding to the BP, KF-BP, LSTM, and KF–LSTM algorithms are 13.33%, 53.33%, 70%, and 86.67% respectively. It can be seen that the positioning error range of the KF-LSTM algorithm is better than those of the other three algorithms. The error distribution of the four methods is displayed in Fig. 11. The distribution of the BP and LSTM algorithms is relatively scattered, i.e., the stability of the BP algorithm and the LSTM algorithm is not as good as that of the KF-BP and KF-LSTM algorithms. The most concentrated results near the (0,0) point are those of the KF-LSTM algorithm, so the KF-LSTM algorithm achieves the highest accuracy.

The CDF curve.

Error distribution.
The four algorithms’ average error and standard deviation are displayed in Fig. 12. The average error of the KF-LSTM algorithm is 3.7 cm, and those of the BP, KF-BP, and LSTM algorithms are 12.9 cm, 5.9 cm, and 7.3 cm, respectively. In terms of accuracy, the KF-LSTM algorithm achieves the highest accuracy, which is 71.31%, 37.28%, and 49.31% higher than that of the BP, KF-BP, and LSTM algorithms respectively. From the perspective of stability analysis, the standard deviations of the BP, KF-BP, LSTM, and KF-LSTM algorithms are 5.86 cm, 3.11 cm, 5.7 cm, and 2.35 cm, respectively. The standard deviation of the KF-LSTM algorithm is the smallest, so the KF-LSTM algorithm has the best stability.

The average error and standard deviation of the four algorithms.
Discussion
UWB has good prospects in the field of indoor localization, but noise interferences often occur during the propagation of UWB signals. These interferences will affect the accuracy of UWB ranging, which will in turn affect the positioning accuracy of UWB. To weaken the influence of noise and improve the positioning accuracy of UWB, this paper proposes the KF-LSTM algorithm. And confirmed that the KF-LSTM algorithm could be used for indoor localization.
The paper proposes the KF-LSTM algorithm by combining the advantages of Kalman filtering and LSTM neural networks to improve the accuracy of UWB positioning. The Kalman filter can assist the LSTM algorithm in handling errors and uncertainties in UWB ranging. To verify the degree of noise suppression of the proposed algorithm, different levels of noise are added to the simulation data. Simulation results show that the algorithm incorporating Kalman filtering improves both accuracy and stability, and the effect is more pronounced the larger the standard deviation of the noise included in the data. Later, considering the impact of systematic errors in actual experiments, least squares fitting was used to weaken the systematic errors. The LSTM algorithm can process sequence data and dependencies in UWB positioning, provide nonlinear modeling, and cooperate with Kalman filtering to better adapt to dynamic environments and improve the accuracy of UWB positioning. The real experiments also show that the KF-LSTM algorithm inherits the advantages of the Kalman filter and LSTM and outperforms the other three algorithms in terms of accuracy and stability, which is consistent with the results obtained from simulation.
However, the KF-LSTM algorithm still has defects. For instance, the DWM1000 ranging frequency is 100 HZ, and the algorithm requires ten distances to position each base station for one positioning, i.e., theoretically, positioning can be given in 0.1 s, so the algorithm is only suitable for low-rate applications when performing indoor positioning. Moreover, the time sequence required by the KF-LSTM algorithm is fixed, so if any base station loses contact during positioning, there will be positioning errors.
UWB has demonstrated excellent positioning accuracy in specific environments. However, considering the high complexity and uncertainty of indoor environments, UWB still faces huge challenges in its widespread application for indoor positioning. In the future, we will optimize this algorithm and consider fusing multiple LSTM models to meet various data input conditions to deal with the loss of connection of base stations and partial data loss.
Conclusions
This paper proposes an LSTM neural network algorithm fused with the Kalman filter for UWB indoor positioning. This algorithm transforms the distance data measured by the UWB device into a time series, then uses Kalman filtering to process the noise and uncertainty factors in the time series, and finally trains the processed time series in the LSTM network. In the simulation experiment, the KF-LSTM algorithm achieves higher positioning accuracy and stability than the BP, KF-BP, and LSTM algorithms under any noise. The greater the noise in the data, the more obvious the contrast in accuracy and stability of the four algorithms. In the actual measurement experiment, the average positioning accuracy of the KF-LSTM algorithm reaches 3.7 cm, showing an improvement of 71.31%, 37.28%, and 49.31% respectively compared with the BP, KF-BP, and LSTM algorithms. Moreover, the standard deviation of the KF-LSTM algorithm is only 2.35 cm, while the standard deviations of the BP, KF-BP, and LSTM algorithms are 5.86 cm, 3.11 cm, and 5.7 cm, respectively. Therefore, the KF-LSTM algorithm is the most stable among the four algorithms, which is consistent with the results of the simulation experiment.
Data availability
These were computer-generated and gathered in the experimental area; they are not yet accessible to the general public or over the internet. If necessary, they can be acquired from the corresponding author.
References
Xu, R., Chen, W., Xu, Y. & Ji, S. A new indoor positioning system architecture using GPS signals. Sensors 15, 10074–10087. https://doi.org/10.3390/s150510074 (2015).
Xu, J.-C., Lian, Z.-Z., Dong, J.-Q. & Yue, Z. Anti-multipath error of BDS based on WPT decomposition and reconstruction algorithm. Sci. Technol. Eng. 22, 15477–15484 (2022).
Poulose, A., Kim, J. & Han, D. S. A sensor fusion framework for indoor localization using smartphone sensors and Wi-Fi RSSI measurements. Appl. Sci. 9, 4379. https://doi.org/10.3390/app9204379 (2019).
Zhuang, Y., Yang, J., Li, Y., Qi, L. & El-Sheimy, N. Smartphone-based indoor localization with bluetooth low energy beacons. Sensors 16, 596. https://doi.org/10.3390/s16050596 (2016).
Minne, K. et al. Experimental evaluation of UWB indoor positioning for indoor track cycling. Sensors 19, 2041. https://doi.org/10.3390/s19092041 (2019).
Dong, J., Lian, Z., Xu, J. & Wei, F. Noise reduction Chan sequential adjustment combination algorithm in ultra wide band positioning. Bull. Surv. Mapp. https://doi.org/10.13474/j.cnki.11-2246.2023.0016 (2023).
Wang, W., Zhu, Q. S., Wang, Z. B., Zhao, X. Q. & Yang, Y. F. Research on indoor positioning algorithm based on SAGA-BP neural network. IEEE Sens. J. 22, 3736–3744. https://doi.org/10.1109/jsen.2021.3120882 (2022).
Pullano, S. A. et al. A recursive algorithm for indoor positioning using pulse-echo ultrasonic signals. Sensors 20, 5042. https://doi.org/10.3390/s20185042 (2020).
Chen, R. et al. Fusing acoustic ranges and inertial sensors using a data and model dual-driven approach. Acta Geod. Cartogr. Sin. 51, 1160–1171 (2022).
Alarifi, A. et al. Ultra wideband indoor positioning technologies: Analysis and recent advances. Sensors 16, 707. https://doi.org/10.3390/s16050707 (2016).
Wu, J.-K., Zhang, L.-P., Kuang, Z.-W., Shen, X.-H. & Zhang, Z.-Q. Least squares localization algorithm for UWB nodes in NLSO environment. J. Guilin Univ. Technol. 42, 736–741 (2022).
Hang, Y., Xunbo, L. & Yunhao, D. Research on real-time three-dimensional space positioning system of fire fighting based on UWB. Appl. Electron. Tech. 49, 71–76. https://doi.org/10.16157/j.issn.0258-7998.223676 (2023).
Lee, Y. U. Cluster angle-of-arrival estimation for UWB indoor system. IEICE Trans. Commun. E88B, 4398–4401. https://doi.org/10.1093/ietcom/e88-b.11.4398 (2005).
Zhu, Y. Implementation simulation and positioning algorithm UWB-based 3D indoor propagation model. China Univ. Min. Technol. (2021).
Li, X., Wang, Y. & Khoshelham, K. Comparative analysis of robust extended Kalman filter and incremental smoothing for UWB/PDR fusion positioning in NLOS environments. Acta Geod. Geophys. 54, 157–179. https://doi.org/10.1007/s40328-019-00254-8 (2019).
Jiaqi, D., Lian, Z., Xu, J. & Lu, X. Research on fusion Kalman filter algorithm in UWB psoitioning. Sci. Surv. Mapp. 47, 10–17. https://doi.org/10.16251/j.cnki.1009-2307.2022.05.002 (2022).
Cheng, J. H., Yu, P. P. & Huang, Y. R. Application of improved Kalman filter in under-ground positioning system of coal mine. IEEE Trans. Appl. Supercond. https://doi.org/10.1109/tasc.2021.3101751 (2021).
Jia, N., Li, Y., Gua, J., Xu, L. & Bai, J. Intelligent diagnosis system for COVID-19 based on deep learning. Comput. Meas. Control 31, 96–103. https://doi.org/10.16526/j.cnki.11-4762/tp.2023.04.015 (2023).
Zhang, X., Li, T., Gong, P., Liu, R. & Li, K. Signal modulation recognition based on joint deep learning and expert prior features. J. Inf. Eng. Univ. 24, 129–134 (2023).
Huang, M.-Y. Research on automatic error correction of image sensor based on depth learning algorithm. Tech. Autom. Appl. 42, 8–11. https://doi.org/10.20033/j.1003-7241.(2023)05-0008-04 (2023).
Zhang, X.-Y. Ultra-wideband channel classification and modulation recognition based on compressed sensing and deep learning. Shandong University (2022).
Nguyen, D. T. A., Lee, H.-G., Jeong, E.-R., Lee, H. L. & Joung, J. Deep learning-based localization for UWB systems. Electronics 9, 1712. https://doi.org/10.3390/electronics9101712 (2020).
Poulose, A. & Han, D. S. UWB indoor localization using deep learning LSTM networks. Appl. Sci. 10, 6290. https://doi.org/10.3390/app10186290 (2020).
Gao, D., Zeng, X., Wang, J. & Su, Y. Application of LSTM network to improve indoor positioning accuracy. Sensors 20, 5824. https://doi.org/10.3390/s20205824 (2020).
Huang, Q.-M. & Ju, L. Tracking based on Kalman filtering for measurements restructuring and mobile location. J. Electron. Inf. Technol. 1551–1555 (2007).
Cai, B., Gao, H.-L., Song, X.-G. & Zou, Z.-W. Research of UWB indoor location based on improved incremental Kalman filter algorithm. Mach. Des. Manuf. https://doi.org/10.19356/j.cnki.1001-3997.2020.02.006 (2020).
Guo, Y., Li, W., Yang, G., Jiao, Z. & Yan, J. Combining dilution of precision and Kalman filtering for UWB positioning in a narrow space. Remote Sens. 14, 5409. https://doi.org/10.3390/rs14215409 (2022).
Zhao, M., Zhang, T. & Wang, D. A novel UWB positioning method based on a maximum-correntropy unscented Kalman filter. Appl. Sci. 12, 12735. https://doi.org/10.3390/app122412735 (2022).
Wang, C., Han, H., Wang, J., Yu, H. & Yang, D. A robust extended Kalman filter applied to ultrawideband positioning. Math. Probl. Eng. 1–12, 2020. https://doi.org/10.1155/2020/1809262 (2020).
Dong, J., Lian, Z., Xu, J. & Yue, Z. UWB localization based on improved robust adaptive cubature Kalman filter. Sensors 23, 2669. https://doi.org/10.3390/s23052669 (2023).
Sinha, R. S. & Hwang, S. H. Comparison of CNN applications for RSSI-based fingerprint indoor localization. Electronics 8, 989. https://doi.org/10.3390/electronics8090989 (2019).
Joung, J., Jung, S., Chung, S. & Jeong, E. R. CNN-based Tx–Rx distance estimation for UWB system localisation. Electron. Lett. 55, 938–940. https://doi.org/10.1049/el.2019.1084 (2019).
Tan Anh Nguyen, D., Lee, H.-G., Joung, J. & Jeong, E.-R. In 2020 International Conference on Information and Communication Technology Convergence (ICTC) (IEEE, 2020).
Zhang, B., Chen, X., Liao, Y. & Tian, Q. UWB/INS indoor positioning algorithm based on DL-LSTM. Transducer Microsyst. Technol. 40, 147–150. https://doi.org/10.13873/j.1000-9787(2021)10-0147-04 (2021).
Li, P., Li, X., Wang, R., Qiu, J. & Liu, J. A long short term memory (LSTM) indoor positioning algorithm based on fusion of UWB and inertial navigation. Telecommun. Eng. 61, 172–178 (2021).
Yang, B., Li, J., Shao, Z. & Zhang, H. Robust UWB indoor localization for NLOS scenes via learning spatial-temporal features. IEEE Sens. J. 22, 7990–8000. https://doi.org/10.1109/JSEN.2022.3156971 (2022).
Yu, Y., Si, X., Hu, C. & Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 31, 1235–1270. https://doi.org/10.1162/neco_a_01199 (2019).
Chen, B., Liu, X., Zhao, H. & Principe, J. C. Maximum correntropy Kalman filter. Automatica 76, 70–77. https://doi.org/10.1016/j.automatica.2016.10.004 (2017).
Funding
This research was funded by the Fundamental Research Funds for the Universities of Henan Province (Grant Number NSFRF230405, Grant Number NSFRF210309), the Doctoral Scientific Fund Project of Henan Polytechnic University (Grant Number B2017-10), Henan Polytechnic University Funding Plan for Young Backbone Teachers (Grant Number 2022XQG-08), the Natural Science Foundation of Henan Province (Grant Number 202300410180), the National Natural Science Foundation of China (Grant Number 42074039, Grant Number 42374029).
Author information
Authors and Affiliations
Contributions
Conceptualization, Y.T. and Z.L.; methodology, Y.T.; software, Z.Y.; validation, Y.T., Z.Y. and H.C.; formal analysis, Y.T.; investigation, P.W.; resources, Z.L.; data curation, Z.L.; writing—original draft preparation, Y.T.; writing—review and editing, H.C.; visualization, Y.T.; supervision, Z.L.; project administration, H.C.; funding acquisition, Z.L. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tian, Y., Lian, Z., Wang, P. et al. Application of a long short-term memory neural network algorithm fused with Kalman filter in UWB indoor positioning. Sci Rep 14, 1925 (2024). https://doi.org/10.1038/s41598-024-52464-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-52464-y
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
