
Abstract
Ground vibration due to blasting is identified as a challenging issue in mining and civil activities. Peak particle velocity (PPV) is one of the blasting undesirable consequences, which is resulted during emission of vibration in blasted bench. This study focuses on the PPV prediction in the surface mines. In this regard, two ensemble systems, i.e., the ensemble of artificial neural networks and the ensemble of extreme gradient boosting (EXGBoosts) were developed for PPV prediction in one of the largest lead–zinc open-pit mines in the Middle East. For ensemble modeling, several ANN and XGBoost base models were separately designed with different architectures. Then, the validation indices such as coefficient determination (R2), root mean square error (RMSE), mean absolute error (MAE), the variance accounted for (VAF), and Accuracy were used to evaluate the performance of the base models. The five top base models with high accuracy were selected to construct an ensemble model for each of the methods, i.e., ANNs and XGBoosts. To combine the outputs of the top base models and achieve a single result stacked generalization technique, was employed. Findings showed ensemble models increase the accuracy of PPV predicting in comparison with the best individual models. The EXGBoosts was superior method for predicting of the PPV, which obtained values of R2, RMSE, MAE, VAF, and Accuracy corresponding to the EXGBoosts were (0.990, 0.391, 0.257, 99.013(%), 98.216), and (0.968, 0.295, 0.427, 96.674(%), 96.059), for training and testing datasets, respectively. However, the sensitivity analysis indicated that the spacing (r = 0.917) and number of blast-holes (r = 0.839) had the highest and lowest impact on the PPV intensity, respectively.
Similar content being viewed by others

Introduction
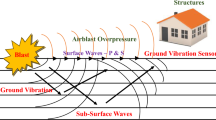
Mining activities and civil projects are carried out using one of the most important operations, namely rock blasting, as a wide and economical way to rock breakage and displacement of them1. In this regard, the rock mass is drilled (drilling operations), and then many blast-holes are charged using explosive materials (blasting operations). Inevitably, blasting operations are caused several side environmental consequences/issues such as flyrock, back-break, dust pollution, air-overpressure, and ground vibration2,3,4,5,6,7. The blast-induced, air over-pressure, ground vibration, and flyrock are the most adverse phenomenon among them1,8,9. Therefore, the blasting sites and mine environment must be safe by monitoring and eliminating the adverse effects of the aforementioned consequences. It should be noted that the accurate amount of each phenomenon should be determined/predicted before conducting the operations. The pre-split and power-deck methods can be used to minimization adverse effects1.
Ground vibration is the most crucial side environment effect due to bench blasting based on previous investigations10,11. The effective parameters on ground vibration should be identified for its prediction/evaluation. The ground vibrations can be measured/recorded based on two different terms: peak particle velocity (PPV) and frequency12,13,14,15. According to various standards, the PPV is the most famous representative for estimating and evaluating blast-induced ground vibration in surface mines1,16,17. The most significant parameters on PPV are the number of blast-holes, hole depth, burden, spacing, powder factor, the charge per delay, and the distance between installed seismograph and blasting bench18,19,20,21.
In recent decades, many models have been introduced for PPV prediction in mines and open pits. The empirical models have been developed by Davis et al.22, Ambraseys and Hendron23, Dowding24, Roy25, and Rai and Singh26 for estimation of blast-induced PPV. However, the performance of empirical predictive models is weak and unacceptable. In addition, the empirical equations do not have the ability to accurately predict the PPV values while they must be accurately estimated to overcome the adverse effects. On the other hand, new computational techniques i.e., soft computing (SC) and artificial intelligence (AI) are capable to resolve science and engineering problems in terms of accuracy level27,28,29,30.
In the field of PPV, a vast range of SC/AI techniques have been proposed for prediction purposes7,31,32,33,34,35. For example, Hasanipanah et al.35 predicted the PPV values using a genetic algorithm. They concluded that this optimization algorithm can predict PPV values with high accuracy. Imperialist competitive algorithm (ICA) as another optimization algorithm was employed to estimate the value of PPV in the research conducted by Armaghani et al.6. They concluded that the ICA algorithm is capable for PPV prediction with high performance. In another study, Taheri et al.36 combined artificial neural network (ANN) and artificial bee colony (ABC) to the prediction of PPV; then results were compared to empirical equations. Their results indicated that the performance of the ANN-ABC model is higher than empirical models. Fuzzy system (FS) combined with ICA was introduced in the study conducted by Hasanipanah et al.13 to predict PPV. The results of their hybrid model showed that FS-ICA can forecast PPV with a high level of accuracy. Fouladgar et al.37 used the cuckoo search (CS) as a novel swarm intelligence algorithm for PPV prediction induced by mine blasting. Additionally, Hasanipanah et al.38 established a particle swarm optimization (PSO) technique for forecasting PPV values. In other studies, different techniques such as adaptive neuro-fuzzy inference system (ANFIS) were developed by Iphar et al.39 for the estimation of PPV with an acceptable degree of prediction performance. Table 1 summarises the most important studies related to PPV estimation by utilizing the AI and SC techniques.
An overview of the literature demonstrated that various SC/AI models have been established to estimate the PPV values. Nevertheless, scholars are always looking for models with the highest performance to enhance the accuracy of developed predictive models and decrease the adverse effect of PPV on the environment. Hence, in this study, to increase the accuracy and performance of AI models in the estimation of PPV, an ensemble of XGBoost as well as ANN models are proposed. According to certain research, no machine learning algorithm could ever consistently outperform every other algorithm. In reaction to this assertion, the ensemble learning method was created. Contrary to traditional machine learning approaches, which try to learning a single hypothesis from train dataset, ensemble learning algorithms develop numerous hypotheses and integrate them to solve a specific issue. Ensemble algorithms have resulted in significant improvements and minimized the overfitting issue by integrating numerous learners and fully using these learners. They also offer the flexibility to handle various jobs. Three well-known ensemble approaches include bagging, boosting, and stacking, while there are a few variations and more ensemble algorithms that have been put to use in real-world scenarios63. In this way, several publications analysed the performance capability of ensemble models in the various fields such as health science64, sport science65, agriculture66,67, finance68, wireless sensor network (WSN)69 and geosciences70.
The combination of multiple networks and creating an ensemble system can reduce the risk of incorrect results and potentially improve the accuracy and generalization capability. Indeed, an ensemble technique is a robust machine learning method that combines several learners, e.g., ANNs or any other machine learning methods, to improve overall prediction accuracy. In most cases, an ensemble of machine learning methods in comparison to a single learner gives better results70,71,72. This study will introduce a new viewpoint of ensemble modeling to estimate PPV based on two machine learning methods, i.e., XGBoost and ANN models as a stacked generalization technique. For comparison purposes, the performance of the ANNs ensemble method is compared to the XGBoost ensemble method. The more accurate model in forecasting blast-produced PPV will be selected based on the statistical results of all proposed models.
The main research questions are presented as follows:
-
How to increase the accuracy of predictive models?
-
How is the accuracy level of the model evaluated?
-
How is the performance of the proposed model compared to the literature?
-
How to measure the validity of the model?
-
How is output parameter performance measured against input parameters?
Case study and data preparation
This study was focused on the Anguran lead–zinc open-pit mine (Iran), which is located at between longitudes 47° 23′ 27″ N and 47° 25′ 50″ N, and between latitudes 36° 36′ 37″ N and 36° 38′ 04″ N. In addition, the altitude of this mine reported about 2935 m above sea level. Anguran is one of the largest mines in the Middle East (Fig. 1), which is operated with an annual 1.2 Mt extraction rate.

Location of Anguran lead–zinc mine and designed pit73 (this figure is modified by EdrawMax, version 12.0.7, www.edrawsoft.com).
The previous studies considered the blast design parameters as effective parameters on PPV intensity. In this study, we considered the seven blasting pattern design parameters which are used as models’ inputs. These parameters include the number of blast-holes (n), hole depth (ld), burden (B), spacing (S), powder factor (q), the charge per delay (Q), and the distance between installed seismograph and blasting bench (d). A total number of 162 blasting rounds were monitored and the effective parameters were measured during operations. The descriptive statistics of the aforementioned parameters are tabulated in Table 2. In the Anguran mine, initiation sequence is inter-row with the time delay of 9 to 23 ms.
The significant relationships between effective parameters and PPV were determined using Pearson cross-correlation. The Pearson test measured the linear correlation of bivariable. The Pearson correlation between parameters and PPV is demonstrated in Table 3, in which the values are calculated in the range of − 1 to + 1. The positive and negative values indicated the positive and negative dependence degree, respectively. Besides, the value of 0 denoted no correlation between the two parameters74.
As can be found, the correlation between PPV and PF is high and positive; while PPV and Di have a low and negative correlation. The matrix plot of all parameters is shown in Fig. 2.

Scatter matrix plot of all parameters considered in this study.
Method background
Artificial neural network (ANN)
ANN is one of the AI techniques, which first presented in the 1970s. The application of ANN has penetrated various fields of science75. A model of ANN is designed based on activities of artificial neural of the human brain. The architecture of an ANN is constructed using the input layer, hidden layer(s), and output layer76. Noteworthy, each layer includes many nodes (neurons) which are linked to each other by the weight of the processing components (connections). Input signals, which are the same as input data, are propagated throughout the network using input neurons. Then, input signals pass through the hidden layer(s) and access the output layer. In other words, some calculations are performed during passing signals in each layer and then delivered to the subsequent layer77,78,79. These calculations are formulated in Eq. (1) which simulated the training process of the network80
where f denotes activation function, w is the weight of connections, b indicates bias, and x is input data. Notably, the monolayer architecture of the neural network is suitable for simple problems, as well multi-layer architecture is used for complex problems81. However, an ANN architecture with two hidden layers for solving engineering problems is usually efficient75.
Extreme gradient boosting (XGBoost)
XGBoost is one of the applicable artificial intelligence techniques, which is firstly introduced by Chen et al.82 in 2015. XGBoost, as an AI method, is developed based on the gradient boosting decision. The most important characteristic of this method is creating boosted trees effectively and generating them in parallel. Besides, XGBoost deals with well-known classification and regression problems e.g., Bhattacharya et al.83, Duan et al.75, Nguyen et al.84, Ren et al.85, and Zhang and Zhan86. In XGBoost, gradient boosting (GB) creates a status under which an objective function (OF) is determined. The optimization of the value of OF is the core of the XGBoost algorithm, which operating to each various optimization technique. Overcoming the problems of data science has made it a robust algorithm. In XGBoost, parallel tree boosting of GB decision tree and GB machine can accurately solve many problems75,84. Training loss (L) and regularization (Ω) are the two main components of an OF in this algorithm that defined as follows:
The model performance related to training data is measured using training loss. Notably, the control and overcome overfitting problem as a model complexity is performed by the regularization term. In this regard, the complexity associated with each tree is calculated in several ways; nevertheless, the following formula is widely used to determine the complexity:
where n indicates the number of leaves and \(\omega\) denotes the vector of scores on leaves. In XGBoost, the structure score is the OF represented as:
where q is the best \(\omega_{j}\) for a presented structure (a quadratic form). Noteworthy, the \(\omega_{j}\) is an independent vector.
Ensemble modeling
The ensemble of multiple individual learners (base models) is a robust way to enhance the performance and accuracy of artificial intelligence predictive models. In other words, the ensemble model deals with the combination of various models with different results87. In general, ensemble modeling includes two components, i.e., an ensemble of base models and a combiner. Training several base models/networks by different subsets of the training data, and employing the different architectures for each of the base models are two common techniques to build the base models71, which in current work later method for constructing the base models are used. Also, to the combination of base models, different strategies are proposed where all attempt to reduce the error of estimation.
Generally, combiners are divided into two main groups, i.e., trainable and non-trainable methods. For the combination of the outputs of the base models to achieve a single solution two non-trainable methods, i.e., majority voting and averaging methods, are widely used by scholars, e.g., Barzegar and Asghari Moghaddam88, Dogan and Birant89, and Krogh and Vedelsby90. As such, the mixture of experts and stacked generalization are two trainable combiners that are successfully used in different studies, e.g., Alizadeh et al.70, Jacobs et al.91, and Wolpert92. The trainable combination methods are trained by outputs of base models and expected correct results to predict the final results. The trainable combiners for predicting models that there are complex relations between inputs and targets are more efficient.
In this study, for each of the methods, i.e., XGBoost and ANN, several models to predict the PPV by stacked generalization technique were combined. In this regard, some ANNs models with a different number of hidden nodes, various activation functions, and different training algorithms for predicting PPV were used. Then top ANNs architectures were combined by the stacked generalization methods to construct the ensemble ANNs that named EANNS model. Notably, various XGBoost models as individual models are developed with different nrounds and different maximum depth for PPV estimation, and then top XGBoost models were combined by the stacked generalization technique, which this newly constructed model is called ensemble XGBoosts (EXGBoosts) model. Figure 3 represents the framework of EANNs and EXGBoosts methods, respectively.

A schematic representation of EANNs and EXGBoosts methods for predicting PPV.
Stacking ensemble model
The stacking model basis is divided into two main phases, which are referred to as level-0 and level-1 structures, respectively. Base models are referred to as level-0, whereas the meta model at level-1 allows base-model predictions to be combined. Estimates provided by base-models are employed throughout the meta-training model's phase. In the case of regression or classification, the predictions result of the basic-models are utilized as inputs and can be of genuine use to the meta-model69. The methods of ANN and XGBoost are employed as the base-models in our research. Noteworthy, these models' several separately architectures are each employed individually as meta-learners.
Pre-analysis of modeling process
This study develops EXGBoosts and EANNs models with seven effective variables and only one output variable to estimate PPV in Anguran lead–zinc mine. In the first step of modeling, all data were normalized in the interval of [0,1], for better network training. Equation (6) was used for normalization of data:
where xnorm denotes normalized value, xmax and xmin are the maximum and minimum values, and xi indicates the input value. In the second step, to present the PPV predictive models, the collected data from the blasting site is randomly divided into two parts, i.e., training and testing datasets. In this regard, 80% of the whole data, namely approximately 130 blasting events, were specified randomly to the training part of models. While the remaining data (approximately 32 blasting events) were used for evaluation of the models' performance.
In the third step, several base models are developed for PPV estimation and the performance of models is compared and evaluated using several statistical indicators such as coefficient determination (R2), root mean square error (RMSE), mean absolute error (MAE), the variance accounted for (VAF), and Accuracy (Eqs.7 to 11). These indices are calculated to evaluate the relationship between measured PPV values and estimated one by developed models.
where Oi, Pi, and \(\overline{P}_{i}\) are measured value, predicted value, and the average of the predicted values, respectively. Also, n indicates the number of datasets. However, the value of R2, RMSE, MAE, VAF, and Accuracy for the most accurate system are one, zero, zero, 100, and 100, respectively.
PPV predictive models
ANN model
In the present study, for PPV prediction in a surface mine the multi-layer perceptron (MLP) artificial neural network as the most popular structure of ANN was used. The MLP structure contains at least one hidden layer. Hence, the determination of the training algorithm, number of hidden nodes, and hidden layers is a challenge in MLP modeling. In other words, the MLP structure must be designed to train optimally. The feedforward-backpropagation algorithm was used for MLP structure training. In addition, the “trial-and-error” procedure was employed to achieve an MLP model with an optimal structure to predict accurately PPV value. Therefore, 15 different MLP models as base models were developed (Table 4). As can be found, each of the models was trained with different training algorithms, hidden activation functions, output activation functions, and architectures. To determine the optimal architecture, the validation indices of R2, RMSE, Accuracy, MAE, and VAF that were formulated in Eqs. (7) to (11) were separately calculated for ANN training and testing datasets. Remarkably, the scoring system proposed by Zorlu et al.93 was applied to calculate the rate of each indices for MLP developed models. Table 5 shows the rating indices and ranking of MLP models. Based on results, base model number three with two hidden layers, “tansig” as hidden and output activation functions, and Levenberg–Marquardt (LM) training algorithm is the best base model for PPV prediction. This base model had the 141 total rates out of 150, that the values of (0.948, 0.567, 0.350, 94.767, 94.247) and (0.928, 0.293, 0.487, 92.773, 90.254) are obtained for R2, RMSE, MAE, VAF, and Accuracy of training and testing datasets, respectively.
XGBoost model
Herein, the XGBoost algorithm is used for PPV prediction. Before that, two main stopping criteria, including maximum tree depth and nrounds, were determined. These criteria have a significant impact on the performance of models. Similar to MLP networks, the overfitting problem there is also in XGBoost, which is occurred when the tree depth and the nrounds are set in the much values. Therefore, the range of [1–3] and [50–200] are considered for the maximum tree depth and nrounds. Similar to the ANN, the “trial-and-error” technique was used to determine an XGBoost model with the best performance. As shown in Table 6, the validation indices were computed to evaluate the base models of XGBoost performance. To construct the ensemble of XGBoost, 15 base models with different values of nrounds and maximum tree depth were developed. Based on Table 7, 15 base models of XGBoost were evaluated using Zorlu et al.93 scoring system. The results were shown that XGBoost base model number two, with the values of 50 and 1 for nrounds and maximum tree depth had the best performance in the PPV prediction, which this base model of XGBoost gets the score of 145 out of 150. The validation indices, i.e., R2, RMSE, MAE, VAF, and Accuracy were calculated as (0.977, 0.650, 0.402, 97.578 (%), 96.828) and (0.979, 0.536, 0.680, 97.895(%), 96.528) for training and testing datasets, respectively. However, a comparison between top base models of XGBoost and ANN reveals the superiority of the XGBoost method in the prediction of PPV.
Ensemble model of ANNs (EANNs) to predict PPV
For the ensemble model of ANN, first, 15 base models for ANN are developed, and then after evaluation of the base models, five top base models for combination were chosen, that the scores of these models were 141, 127, 118, 106, and 100 out of 150, respectively. The correlation of measured PPV and predicted ones by five base models are illustrated in Fig. 4. After that, the stacked generalization combination technique was employed to combine the selected base models. For combination, the results of selected base models a feed-forward neural network with sigmoid activation function for hidden layers were used (Fig. 5). The input data of the combiner network consists of seven variables and the target dataset is the measured value of PPV.

Correlation graph between measured and predicted values of PPV, using five top base models of ANN.

The architecture of the ensemble ANN model for PPV prediction in Anguran mine (this figure is generated by EdrawMax, version 12.0.7, www.edrawsoft.com).
The correlation graph of predicted values using the stacked generalization technique and measured values is illustrated in Fig. 6. The values of (0.960, 0.402, 0.233, 95.963(%), 95.724) and (0.941, 0.189, 0.219, 92.827(%), 95.713) were obtained for both R2, RMSE, MAE, VAF, and Accuracy of training and testing datasets, respectively. Results proved that the EANNs model predicts PPV better than individual ANN (base models), so that the EANNs model 41% and 55% improved the RMSE of PPV prediction for training and testing part, respectively, in comparison with the best base model.

Correlation graph between predicted data (EANNs model) and measured data.
Ensemble model of XGBoosts (EXGBoosts) to predict PPV
To construct EXGBoosts model for the prediction of PPV, first, several XGBoost models were developed. In this regard, 15 constructed XGBoost models were analyzed, and the five top base models with the highest score were selected. The numbers 145, 126, 115, 100, and 98 were the scores of the five top base models. The EXGBoosts model was structured based on a combination of five XGBoost base models. The base models using stacked generalization technique was combined to predict PPV. Figure 7 showed the correlation of PPV estimations by five XGBoost base models and measured values of PPV. The combiner was structured using a nrounds of 15 and a maximum tree depth of three. The results of stacked generalization show, the accuracy of the EXBoosts model in comparison with the best XGBoost base models is better (Fig. 8 and Table 8). To better comparing of the applied methods capability in estimating of PPV value, the performance of developed ANN, EANNs, XGBoost, and EXGBoosts models are tabulated in Table 8. The obtained statistical indices indicated that the EXGBoosts model with the value of (0.990, 0.391, 0.257, 99.013(%), 98.216) and (0.968, 0.295, 0.427, 96.674(%), 96.059) for R2, RMSE, MAE, VAF, and Accuracy of training and testing datasets, respectively, represents the highest performance for prediction of PPV among all applied models. Besides, EXGBoosts model 66% and 82% improved the RMSE of PPV prediction for training and testing part, respectively, in comparison with the best base model. The obtained results of performance indices regarding to our model presented in Table 9. This table compares the prediction accuracy and performance level of out proposed approach with three latest research. The results demonstrates that EXGBoost model has more performance capacity in model and estimation of PPV in comparison with the other methods.

Correlation graph between predicted PPV by various XGBoost base models and measured data.

Correlation graph between predicted data (EXGBoosts model) and measured data.
It is known that the significance of the estimation of level l (where l reveals the percentage of estimation) stands the quotient of the number of samples in which the estimations are within l absolute limit of measured values divided by the total number of samples. A common metric for evaluating the best models is P(0.25) ≥ 0.75 or 75%94. The level of 25% was used to test model in our study.
In which, where n is the number of dataset, Pi denotes the predicted value, and Oi indicates the observed values.
The 25% level estimation of ANN, XGBoost, EANNs, and EXGBoosts are showed in Table 10. As can be seen, the ANN at P(0.25) is not acceptable in validation dataset, but other models is acceptable in both testing and validation datasets. It can be concluded that the ensemble models developed in this study have the highest performance and capability in predicting PPV.
Multiple parametric sensitivity analysis (MPSA)
In this part, a parametric analysis was conducted to specify which influential parameters have the highest impact on the average PPV value. In this regard, a multiple parametric sensitivity analysis (MPSA) was performed that follows the six main steps for applying to the outputs of the system for a specific set of parameters. These steps are as follows:
Step 1 Selecting the effective parameters to be subjected.
Step 2 Adjusting the range of input parameters.
Step 3 Generating a set of independent parameters in the form of random numbers with a uniform distribution for each parameter.
Step 4 Running the machine learning method utilizing the generated series and calculating the objective function using Eq. (12). The objective function was computed using the sum of square errors between measured and predicted values95:
where fh denots the objective function value for a particular PPVt variable h; xo,h indicates the measured values; xc,h(i) is the calculated value xc for variable h for each generated inputs; and n is the number of variables contained in the random set. In the computation process, the Monte Carlo simulation was used to generate 162 random data for seven effevtive parameters used in this study. At each iteration of the model, the trained models were provided with the newly produced values for one parameter.
Step 5 Determining the relative importance of effevtive parameters separately using Eq. (13)95:
In which, h is the variable that is used to introduce pairs of effective parameters. The outcomes that were achieved for each of the evaluated parameters were produced by using the technique that was provided to the PPVt model. Equation (13) had a significant importance in the accomplishment of these results.
Step 6 Evaluating parametric sensitivity and determining relative relevance of effective parameters using Eq. (14)95:
where the δt is computed from the first series of dataset (h = 1) to the maximum values (\(i_{PPV,max}\)), which is 162 data for developed model in this study. Table 11 provides a tabular breakdown of the value spectrum that was employed throughout the evaluating of each parameter.
The lower the γ index value for each parameter, the less sensitive the st model is to that parameter, and the higher the γ index, the more sensitive the model is to the parameter under consideration. Table 11 has presented the γ index to evaluate the impact of model parameters and identify the most sensitive parameters. The calculated γ index for each parameter is depicted in Fig. 9. It can be found that the order of the sensitivity of the PPV to the parameters is ld < S < n < Q < q < B < d. It can be concluded that the PPV is highly sensitive to d, B, q, Q, and n, as well as sensitive to S and ld.

The impact of effective parameters on PPV.
Influence of delay sequence on PPV
The seismic energy is what causes the blasting vibrations to be generated, and it also literally symbolizes the problems created to the rock-mass that extends beyond the boundaries of the explosion patch. The blasting pattern design specifications, explosives type and properties, and the physio-mechanical characteristics of the rock-mass all affect how much PPV occurs. The generation of PPV for several experimental implementing blasting has been obtained; the PPV value is reported as 5.12–17.23, 3.91–12.14, and 1.48–5.93 in the delay sequence (row to row) of 9, 15, and 23 ms. It can be concluded that the 23 ms delay between the rows will assist in lowering the PPV, which may be lowered up to a particular value by choosing the right delay sequence in production blast, according to field observations and data analysis.
The superimposition of waveform due to delay sequence refers to the effect of time delays on the coherence of signals. When two or more signals are delayed relative to each other, their waveforms may overlap and interfere with each other, resulting in a composite waveform that may be difficult to interpret. The impact of this effect on the outcome of a result depends on the specific context of the analysis. In some cases, such as in signal processing or communication systems, delay sequences are intentionally introduced to improve signal quality or reduce interference. In these cases, the superimposition of waveforms may be a desirable effect. However, in other cases, such as in physiological or biological signal analysis, the superimposition of waveforms due to delay sequences can lead to a loss of information and inaccuracies in the analysis. For example, in electroencephalogram (EEG) recordings, time delays between signals from different brain regions can result in overlapping waveforms that make it difficult to identify the underlying brain activity.
Results and discussions
This paper was accurately focused on estimation PPV due to mine blasting. In this way, the most effective parameters on PPV variation were identified. Two AI-based models i.e., ANN and XGBoost, were considered for choosing the best between PPV predictive models. For each predictive method, an ensemble model, i.e., EANNs and EXGBoosts, was developed, and the best one was chosen. The obtained results from statistical indicators (R2 and RMSE) associated with the best predictive models of ANN, XGBoost, EANNs, and EXGBoosts for training and testing parts were illustrated in Figs. 10 and 11.

The value of R2, RMSE, and MAE for selecting the best model in the predicting PPV values.

The value of VAF and accuracy for selecting the best model in the predicting PPV values.
The predictive model of EXGBoosts has specified capable of presenting the highest performance prediction level in train and test parts. Therefore, EXGBoosts was found a superior accuracy level regarding statistical indicators values among other predictive models. The R2 values of (0.948, 0.977, 0.960, and 0.990) and (0.928, 0.979, 0.941, and 0.968) were calculated for training and testing phases of ANN, XGBoost, EANNs, and EXGBoosts models, respectively. Besides, RMSE values of (0.567, 0.650, 0.402, and 0.391) and (0.293, 0.536, 0.189, and 0.295) were obtained for training and testing parts of ANN, XGBoost, EANNs, and EXGBoosts models, respectively. The EXGBoosts model revealed a maximum performance and minimum system error between other predictive models. In situations where the testing datasets reflect adequate generalizability of predictive techniques, the excellent efficiency of the train phases suggests the success of the learning procedures of the predictive models.
Benefits and drawbacks of the study
The main benefit of this study is in improving the performance and accuracy of the proposed ANN and XGBoost models. These models separately provide lower accuracy than the ensemble models. Therefore, using the combination of these methods and constructing an ensemble model, it is possible to predict the PPV with acceptable accuracy. Noteworthy, neural network base models each have different results and have uncertainty due to being a black-box. However, the ensemble model solves this problem to an acceptable. This study also has drawbacks. In this study, only two AI models have been used i.e., ANN and XGBoost. However, the number of AI models can be increased to reach maximum accuracy. It should be noted that the number of base models in this study is acceptable; nevertheless, more models can be obtained and run the ensemble model based on them.
Conclusions
In this study, the PPV induced from bench blasting is studied in Anguran lead–zinc mine, Iran. Considering the crucial importance of the adverse effects of ground vibration in blasting operations, the prediction of PPV at a high level of accuracy is essential. Therefore, this study investigates the ensemble of various artificial intelligence models to construct an accurate model for PPV estimation using 162 blasting datasets and seven effective parameters. For this aim, several ANN and XGBoost base models were developed and the five top base models among them were combined to generate EANNs and EXGBoosts models. To combination of top base models’ outputs and achieve a single result stacked generalization technique was used. The statistical indexes of R2, RMSE, MAE, VAF, and Accuracy were used to evaluate the performance of developed models and a scoring system was applied to select the best ANN and XGBoost base models with optimal structure. The results revealed that the EANNs with R2 of (0.960, and 0.941), RMSE of (0.402, and 0.189), MAE of (0.233, and 0.219), VAF of (95.963(%), and 92.827(%)), and Accuracy of (95.724, and 95.713) for training and testing datasets, respectively, and EXGBoosts model with R2 of (0.990, and 0.968), RMSE of (0.391, and 0.295), MAE of (0.257, and 0.427), VAF of (99.013(%), and 96.674(%)), and Accuracy of (98.216, and 96.059) for training and testing datasets, respectively, were two efficient machine learning ensemble methods for forecasting PPV. Comparison of the results of developed ensemble methods, i.e., EANNs and EXGBoosts, with the best individual models showed the superiority of ensemble modeling in predicting PPV in surface mines. Moreover, EXGBoosts model was most accurate compared to the EANN model. In the final step of this study, the effectiveness of each input variable on PPV intensity is determined using the CA method, which results denoted the spacing has the most impact on PPV. From practical applications, the proposed model can be updated for other engineering fields, specially mining and civil activities. Meanwhile, the ensemble machine learning approach can be applied to improve performance capacity of machine learning techniques and increase the accuracy level of prediction targets. The proposed models can be used to analyze safety data and identify potential hazards, blasting safety zone, and risks in blasting operations. The PPV values can be predicted before blasting operations to check any potential issues or damage to the workers, equipment and surrounding residential area. If the predicted results are higher than those suggested in literature or standards, the blasting pattern/design can be reviewed again to have a predicted PPV values within the suggested safe ranges. Generally, machine learning algorithms can be used to analyze environmental data and monitor the impact of mining operations on the environment.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Jiang, W., Arslan, C. A., Tehrani, M. S., Khorami, M. & Hasanipanah, M. Simulating the peak particle velocity in rock blasting projects using a neuro-fuzzy inference system. Eng. Comput. 35, 1203–1211 (2019).
Bakhtavar, E., Hosseini, S., Hewage, K. & Sadiq, R. Green blasting policy: Simultaneous forecast of vertical and horizontal distribution of dust emissions using artificial causality-weighted neural network. J. Clean. Prod. 283, 124562 (2021).
Bakhtavar, E., Hosseini, S., Hewage, K. & Sadiq, R. Air pollution risk assessment using a hybrid fuzzy intelligent probability-based approach: Mine blasting dust impacts. Nat. Resour. Res. https://doi.org/10.1007/s11053-020-09810-4 (2021).
Hosseini, S., Monjezi, M., Bakhtavar, E. & Mousavi, A. Prediction of dust emission due to open pit mine blasting using a hybrid artificial neural network. Nat. Resour. Res. https://doi.org/10.1007/s11053-021-09930-5 (2021).
Hosseini, S., Mousavi, A. & Monjezi, M. Prediction of blast-induced dust emissions in surface mines using integration of dimensional analysis and multivariate regression analysis. Arab. J. Geosci. 15, 163 (2022).
Armaghani, D. J., Hasanipanah, M., Amnieh, H. B. & Mohamad, E. T. Feasibility of ICA in approximating ground vibration resulting from mine blasting. Neural Comput. Appl. 29, 457–465 (2018).
Nguyen, H. & Bui, X.-N. Soft computing models for predicting blast-induced air over-pressure: A novel artificial intelligence approach. Appl. Soft Comput. 92, 106292 (2020).
Faradonbeh, R. S., Armaghani, D. J., Amnieh, H. B. & Mohamad, E. T. Prediction and minimization of blast-induced flyrock using gene expression programming and firefly algorithm. Neural Comput. Appl. 29, 269–281 (2018).
Koopialipoor, M., Fallah, A., Armaghani, D. J., Azizi, A. & Mohamad, E. T. Three hybrid intelligent models in estimating flyrock distance resulting from blasting. Eng. Comput. 35, 243–256 (2019).
Shirani Faradonbeh, R. et al. Prediction of ground vibration due to quarry blasting based on gene expression programming: A new model for peak particle velocity prediction. Int. J. Environ. Sci. Technol. https://doi.org/10.1007/s13762-016-0979-2 (2016).
Mohamadnejad, M., Gholami, R. & Ataei, M. Comparison of intelligence science techniques and empirical methods for prediction of blasting vibrations. Tunn. Undergr. Sp. Technol. 28, 238–244 (2012).
Zhou, J., Li, C., Koopialipoor, M., Armaghani, D. J. & Pham, B. T. Development of a new methodology for estimating the amount of PPV in surface mines based on prediction and probabilistic models (GEP-MC). Int. J. Mining Reclam. Environ. 35, 48–68 (2020).
Hasanipanah, M. et al. Prediction of an environmental issue of mine blasting: An imperialistic competitive algorithm-based fuzzy system. Int. J. Environ. Sci. Technol. 15, 551–560 (2018).
Agrawal, H. & Mishra, A. K. Modified scaled distance regression analysis approach for prediction of blast-induced ground vibration in multi-hole blasting. J. Rock Mech. Geotech. Eng. 11, 202–207 (2019).
Nguyen, H., Drebenstedt, C., Bui, X.-N. & Bui, D. T. Prediction of blast-induced ground vibration in an open-pit mine by a novel hybrid model based on clustering and artificial neural network. Nat. Resour. Res. 29, 691–709 (2020).
Duvall, W. I. & Fogelson, D. E. Review of Criteria for Estimating Damage to Residences from Blasting Vibrations, vol. 5968 (US Department of the Interior, Bureau of Mines, 1962).
Siskind, D. E. Structure Response and Damage Produced by Ground Vibration from Surface Mine Blasting, vol. 8507 (US Department of the Interior, Bureau of Mines, 1980).
Qiu, Y. et al. Performance evaluation of hybrid WOA-XGBoost, GWO-XGBoost and BO-XGBoost models to predict blast-induced ground vibration. Eng. Comput. 1–18 (2021).
Zeng, J. et al. Prediction of peak particle velocity caused by blasting through the combinations of boosted-CHAID and SVM models with various kernels. Appl. Sci. 11, 3705 (2021).
Hajihassani, M., Armaghani, D. J., Marto, A. & Mohamad, E. T. Ground vibration prediction in quarry blasting through an artificial neural network optimized by imperialist competitive algorithm. Bull. Eng. Geol. Environ. 74, 873–886 (2015).
Huang, J., Koopialipoor, M. & Armaghani, D. J. A combination of fuzzy Delphi method and hybrid ANN-based systems to forecast ground vibration resulting from blasting. Sci. Rep. 10, 1–21 (2020).
Davies, B., Farmer, I. W. & Attewell, P. B. Ground vibration from shallow sub-surface blasts. Engineer 217, (1964).
Ambraseys, N. R. & Hendron, A. J. Dynamic Behavior of Rock Masses, Rock Mechanics in Engineering Practice (eds. Stagg, K. G. & Zienkiewicz, O. C.) (1968).
Dowding, C. H. Blast Vibration Monitoring and Control 288–290 (Prentice-Hall Inc, 1985).
Roy, P. P. Putting ground vibration predictions into practice. Colliery Guard. (Kingdom) 241 (1993).
Rai, R. & Singh, T. N. A new predictor for ground vibration prediction and its comparison with other predictors. (2004).
Mottahedi, A., Sereshki, F. & Ataei, M. Development of overbreak prediction models in drill and blast tunneling using soft computing methods. Eng. Comput. 34, 45–58 (2018).
Sadeghi, F., Monjezi, M. & Armaghani, D. J. Evaluation and optimization of prediction of toe that arises from mine blasting operation using various soft computing techniques. Nat. Resour. Res. 29, 887–903 (2020).
Xie, C. et al. Predicting rock size distribution in mine blasting using various novel soft computing models based on meta-heuristics and machine learning algorithms. Geosci. Front. 12, 101108 (2021).
Gao, W., Alqahtani, A. S., Mubarakali, A. & Mavaluru, D. Developing an innovative soft computing scheme for prediction of air overpressure resulting from mine blasting using GMDH optimized by GA. Eng. Comput. 36, 647–654 (2020).
Nguyen, H., Bui, N. X., Tran, H. Q. & Le, G. H. T. A novel soft computing model for predicting blast-induced ground vibration in open-pit mines using gene expression programming. J. Min. Earth Sci. 61, 107–116 (2020).
Mokfi, T., Shahnazar, A., Bakhshayeshi, I., Derakhsh, A. M. & Tabrizi, O. Proposing of a new soft computing-based model to predict peak particle velocity induced by blasting. Eng. Comput. 34, 881–888 (2018).
Arthur, C. K., Temeng, V. A. & Ziggah, Y. Y. Soft computing-based technique as a predictive tool to estimate blast-induced ground vibration. J. Sustain. Min. 18, 287–296 (2019).
Bui, X.-N., Nguyen, H., Le, H.-A., Bui, H.-B. & Do, N.-H. Prediction of blast-induced air over-pressure in open-pit mine: Assessment of different artificial intelligence techniques. Nat. Resour. Res. https://doi.org/10.1007/s11053-019-09461-0 (2019).
Hasanipanah, M., Golzar, S. B., Larki, I. A., Maryaki, M. Y. & Ghahremanians, T. Estimation of blast-induced ground vibration through a soft computing framework. Eng. Comput. 33, 951–959 (2017).
Taheri, K., Hasanipanah, M., Golzar, S. B. & Abd Majid, M. Z. A hybrid artificial bee colony algorithm-artificial neural network for forecasting the blast-produced ground vibration. Eng. Comput. 33, 689–700 (2017).
Fouladgar, N., Hasanipanah, M. & Amnieh, H. B. Application of cuckoo search algorithm to estimate peak particle velocity in mine blasting. Eng. Comput. 33, 181–189 (2017).
Hasanipanah, M., Naderi, R., Kashir, J., Noorani, S. A. & Qaleh, A. Z. A. Prediction of blast-produced ground vibration using particle swarm optimization. Eng. Comput. 33, 173–179 (2017).
Iphar, M., Yavuz, M. & Ak, H. Prediction of ground vibrations resulting from the blasting operations in an open-pit mine by adaptive neuro-fuzzy inference system. Environ. Geol. https://doi.org/10.1007/s00254-007-1143-6 (2008).
Singh, T. N. & Singh, V. An intelligent approach to prediction and control ground vibration in mines. Geotech. Geol. Eng. https://doi.org/10.1007/s10706-004-7068-x (2005).
Monjezi, M., Ghafurikalajahi, M. & Bahrami, A. Prediction of blast-induced ground vibration using artificial neural networks. Tunn. Undergr. Sp. Technol. 26, 46–50 (2011).
Mohamed, M. T. Performance of fuzzy logic and artificial neural network in prediction of ground and air vibrations. JES. J. Eng. Sci. 39, 425–440 (2011).
Khandelwal, M., Kumar, D. L. & Yellishetty, M. Application of soft computing to predict blast-induced ground vibration. Eng. Comput. https://doi.org/10.1007/s00366-009-0157-y (2011).
Fişne, A., Kuzu, C. & Hüdaverdi, T. Prediction of environmental impacts of quarry blasting operation using fuzzy logic. Environ. Monit. Assess. https://doi.org/10.1007/s10661-010-1470-z (2011).
Ghasemi, E., Ataei, M. & Hashemolhosseini, H. Development of a fuzzy model for predicting ground vibration caused by rock blasting in surface mining. JVC/J. Vib. Control https://doi.org/10.1177/1077546312437002 (2013).
Monjezi, M., Hasanipanah, M. & Khandelwal, M. Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neural Comput. Appl. https://doi.org/10.1007/s00521-012-0856-y (2013).
Armaghani, D. J., Hajihassani, M., Mohamad, E. T., Marto, A. & Noorani, S. A. Blasting-induced flyrock and ground vibration prediction through an expert artificial neural network based on particle swarm optimization. Arab. J. Geosci. 7, 5383–5396 (2014).
Dindarloo, S. R. Peak particle velocity prediction using support vector machines: A surface blasting case study. J. S. Afr. Inst. Min. Metall. https://doi.org/10.17159/2411-9717/2015/v115n7a10 (2015).
Hajihassani, M., Armaghani, D. J., Monjezi, M., Mohamad, E. T. & Marto, A. Blast-induced air and ground vibration prediction: A particle swarm optimization-based artificial neural network approach. Environ. Earth Sci. 74, 2799–2817 (2015).
Hasanipanah, M., Monjezi, M., Shahnazar, A., Jahed Armaghani, D. & Farazmand, A. Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Meas. J. Int. Meas. Confed. https://doi.org/10.1016/j.measurement.2015.07.019 (2015).
Armaghani, D. J., Momeni, E., Abad, S. V. A. N. K. & Khandelwal, M. Feasibility of ANFIS model for prediction of ground vibrations resulting from quarry blasting. Environ. Earth Sci. https://doi.org/10.1007/s12665-015-4305-y (2015).
Ghoraba, S., Monjezi, M., Talebi, N., Armaghani, D. J. & Moghaddam, M. R. Estimation of ground vibration produced by blasting operations through intelligent and empirical models. Environ. Earth Sci. https://doi.org/10.1007/s12665-016-5961-2 (2016).
Hasanipanah, M., Faradonbeh, R. S., Amnieh, H. B., Armaghani, D. J. & Monjezi, M. Forecasting blast-induced ground vibration developing a CART model. Eng. Comput. https://doi.org/10.1007/s00366-016-0475-9 (2017).
Shahnazar, A. et al. A new developed approach for the prediction of ground vibration using a hybrid PSO-optimized ANFIS-based model. Environ. Earth Sci. https://doi.org/10.1007/s12665-017-6864-6 (2017).
Nguyen, H., Bui, X.-N., Tran, Q.-H. & Mai, N.-L. A new soft computing model for estimating and controlling blast-produced ground vibration based on hierarchical K-means clustering and cubist algorithms. Appl. Soft Comput. 77, 376–386 (2019).
Nguyen, H., Choi, Y., Bui, X. N. & Nguyen-Thoi, T. Predicting blast-induced ground vibration in open-pit mines using vibration sensors and support vector regression-based optimization algorithms. Sensors (Switzerland) https://doi.org/10.3390/s20010132 (2020).
Zhang, H. et al. A combination of feature selection and random forest techniques to solve a problem related to blast-induced ground vibration. Appl. Sci. https://doi.org/10.3390/app10030869 (2020).
Zhou, J., Asteris, P. G., Armaghani, D. J. & Pham, B. T. Prediction of ground vibration induced by blasting operations through the use of the Bayesian Network and random forest models. Soil Dyn. Earthq. Eng. https://doi.org/10.1016/j.soildyn.2020.106390 (2020).
Lawal, A. I., Kwon, S. & Kim, G. Y. Prediction of the blast-induced ground vibration in tunnel blasting using ANN, moth-flame optimized ANN, and gene expression programming. Acta Geophys. https://doi.org/10.1007/s11600-020-00532-y (2021).
He, B., Lai, S. H., Mohammed, A. S., Sabri, M. M. S. & Ulrikh, D. V. Estimation of blast-induced peak particle velocity through the improved weighted random forest technique. Appl. Sci. 12, 5019 (2022).
Ragam, P., Komalla, A. R. & Kanne, N. Estimation of blast-induced peak particle velocity using ensemble machine learning algorithms: A case study. Noise Vib. Worldw. 53, 404–413 (2022).
Nguyen, H., Bui, X.-N. & Topal, E. Reliability and availability artificial intelligence models for predicting blast-induced ground vibration intensity in open-pit mines to ensure the safety of the surroundings. Reliab. Eng. Syst. Saf. 231, 109032 (2023).
Zhang, Y., Liu, J. & Shen, W. A review of ensemble learning algorithms used in remote sensing applications. Appl. Sci. 12, 8654 (2022).
Doğru, A., Buyrukoğlu, S. & Arı, M. A hybrid super ensemble learning model for the early-stage prediction of diabetes risk. Med. Biol. Eng. Comput. 1–13 (2023).
Buyrukoğlu, S. & Savaş, S. Stacked-based ensemble machine learning model for positioning footballer. Arab. J. Sci. Eng. 1–13 (2022).
Buyrukoğlu, S. New hybrid data mining model for prediction of Salmonella presence in agricultural waters based on ensemble feature selection and machine learning algorithms. J. Food Saf. 41, e12903 (2021).
Buyrukoğlu, G., Buyrukoğlu, S. & Topalcengiz, Z. Comparing regression models with count data to artificial neural network and ensemble models for prediction of generic Escherichia coli population in agricultural ponds based on weather station measurements. Microb. Risk Anal. 19, 100171 (2021).
Buyrukoğlu, S. Promising cryptocurrency analysis using deep learning. In 2021 5th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT) 372–376 (IEEE, 2021).
Akbas, A. & Buyrukoglu, S. Stacking ensemble learning-based wireless sensor network deployment parameter estimation. Arab. J. Sci. Eng. 1–10 (2022).
Zhou, Z.-H., Wu, J. & Tang, W. Ensembling neural networks: Many could be better than all. Artif. Intell. 137, 239–263 (2002).
Alizadeh, S., Poormirzaee, R., Nikrouz, R. and Sarmady, S. Using stacked generalization ensemble method to estimate shear wave velocity based on downhole seismic data: A case study of Sarab-e-Zahab, Iran. J. Seism. Explor. (2021).
Nadeem, F., Alghazzawi, D., Mashat, A., Faqeeh, K. & Almalaise, A. Using machine learning ensemble methods to predict execution time of e-science workflows in heterogeneous distributed systems. IEEE Access 7, 25138–25149 (2019).
Production, I. M. Supply Company (IMPASCO). Final Rep. Complement. Explor. Oper. Anguran Lead Zinc Depos. Zanjan, Dandi, Iran 313 (2019).
Khoshalan, H. A., Shakeri, J., Najmoddini, I. & Asadizadeh, M. Forecasting copper price by application of robust artificial intelligence techniques. Resour. Policy 73, 102239 (2021).
Duan, J., Asteris, P. G., Nguyen, H., Bui, X.-N. & Moayedi, H. A novel artificial intelligence technique to predict compressive strength of recycled aggregate concrete using ICA-XGBoost model. Eng. Comput. 1–18 (2020).
Yegnanarayana, B. Artificial Neural Networks (PHI Learning Pvt. Ltd., 2009).
Fausett, L. V. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications (Prentice-Hall, Inc., 1994).
Dragičević, T. & Novak, M. Weighting factor design in model predictive control of power electronic converters: An artificial neural network approach. IEEE Trans. Ind. Electron. 66, 8870–8880 (2018).
Sengupta, A., Shim, Y. & Roy, K. Proposal for an all-spin artificial neural network: Emulating neural and synaptic functionalities through domain wall motion in ferromagnets. IEEE Trans. Biomed. Circuits Syst. 10, 1152–1160 (2016).
Hodo, E. et al. Threat analysis of IoT networks using artificial neural network intrusion detection system. In 2016 International Symposium on Networks, Computers and Communications (ISNCC) 1–6 (IEEE, 2016).
Bui, D. T., Tuan, T. A., Klempe, H., Pradhan, B. & Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 13, 361–378 (2016).
Chen, T. et al. Xgboost: Extreme gradient boosting. R Packag. version 0.4-2 1, 1–4 (2015).
Bhattacharya, S. et al. A novel PCA-firefly based XGBoost classification model for intrusion detection in networks using GPU. Electronics 9, 219 (2020).
Nguyen, H., Bui, X.-N., Bui, H.-B. & Cuong, D. T. Developing an XGBoost model to predict blast-induced peak particle velocity in an open-pit mine: A case study. Acta Geophys. 67, 477–490 (2019).
Ren, X., Guo, H., Li, S., Wang, S. & Li, J. A novel image classification method with CNN-XGBoost model. In International Workshop on Digital Watermarking 378–390 (Springer, 2017).
Zhang, L. & Zhan, C. Machine learning in rock facies classification: An application of XGBoost. In International Geophysical Conference, Qingdao, China, 17–20 April 2017 1371–1374 (Society of Exploration Geophysicists and Chinese Petroleum Society, 2017).
Nguyen, H., Bui, X.-N., Nguyen-Thoi, T., Ragam, P. & Moayedi, H. Toward a state-of-the-art of fly-rock prediction technology in open-pit mines using EANNs model. Appl. Sci. 9, 4554 (2019).
Barzegar, R. & Asghari Moghaddam, A. Combining the advantages of neural networks using the concept of committee machine in the groundwater salinity prediction. Model. Earth Syst. Environ. https://doi.org/10.1007/s40808-015-0072-8 (2016).
Dogan, A. & Birant, D. A weighted majority voting ensemble approach for classification. In 2019 4th International Conference on Computer Science and Engineering (UBMK) 1–6 (IEEE, 2019).
Krogh, A. & Vedelsby, J. Neural network ensembles, cross validation, and active learning. Adv. Neural Inf. Process. Syst. 7, 231–238 (1995).
Jacobs, R. A., Jordan, M. I., Nowlan, S. J. & Hinton, G. E. Adaptive mixtures of local experts. Neural Comput. 3, 79–87 (1991).
Wolpert, D. H. Stacked generalization. Neural Netw. 5, 241–259 (1992).
Zorlu, K., Gokceoglu, C., Ocakoglu, F., Nefeslioglu, H. A. & Acikalin, S. Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng. Geol. 96, 141–158 (2008).
Sharma, M., Agrawal, H. & Choudhary, B. S. Multivariate regression and genetic programming for prediction of backbreak in open-pit blasting. Neural Comput. Appl. 1–12 (2022).
Corrêa, J. M., Farret, F. A., Popov, V. A. & Simões, M. G. Sensitivity analysis of the modeling parameters used in simulation of proton exchange membrane fuel cells. IEEE Trans. Energy Convers. https://doi.org/10.1109/TEC.2004.842382 (2005).
Funding
The research is partially funded by the Ministry of Science and Higher Education of the Russian Federation under the strategic academic leadership program ‘Priority 2030’ (Agreement 075-15-2021-1333 dated 30 September 2021).
Author information
Authors and Affiliations
Contributions
S.H.: Data collection, conceptualization, methodology, results, analysis, writing. R.P.: Conceptualization, methodology, writing and editing, supervision. D.J.A: Writing, reviewing and editing, supervision. M.M.S.S: Writing, reviewing and editing, resources, funding.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hosseini, S., Pourmirzaee, R., Armaghani, D.J. et al. Prediction of ground vibration due to mine blasting in a surface lead–zinc mine using machine learning ensemble techniques. Sci Rep 13, 6591 (2023). https://doi.org/10.1038/s41598-023-33796-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-33796-7
This article is cited by
-
Prediction of jumbo drill penetration rate in underground mines using various machine learning approaches and traditional models
Scientific Reports (2024)
-
Enhancing Rock Fragmentation in Mining: Leveraging Ensemble Classification Machine Learning Algorithms for Blast Toe Volume Assessment
Journal of The Institution of Engineers (India): Series D (2024)
-
Predicting grout’s uniaxial compressive strength (UCS) for fully grouted rock bolting system by applying ensemble machine learning techniques
Neural Computing and Applications (2024)
-
A Scientific Exploration of Blast-Induced Ground Vibration Mitigation Strategies for Sustainable Coal Mining in India
Mining, Metallurgy & Exploration (2024)
-
Prediction of blast-induced ground vibration using multivariate statistical analysis in the opencast chromite mines of the Indian State of Odisha
Sādhanā (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
