
Abstract
To ensure the safety of railroad operations, it is important to monitor and forecast track geometry irregularities. A higher safety requires forecasting with higher spatiotemporal frequencies, which in turn requires capturing spatial correlations. Additionally, track geometry irregularities are influenced by multiple exogenous factors. In this study, a method is proposed to forecast one type of track geometry irregularity, vertical alignment, by incorporating spatial and exogenous factor calculations. The proposed method embeds exogenous factors and captures spatiotemporal correlations using a convolutional long short-term memory. The proposed method is also experimentally compared with other methods in terms of the forecasting performance. Additionally, an ablation study on exogenous factors is conducted to examine their individual contributions to the forecasting performance. The results reveal that spatial calculations and maintenance record data improve the forecasting of vertical alignment.
Similar content being viewed by others
Introduction
Tokaido Shinkansen is a high-speed train linking Japan’s major cities: Tokyo, Nagoya, Kyoto, and Osaka. Serious train accidents caused by track geometry irregularities have not occurred because of the high spatiotemporal frequencies of track maintenance by railroad operators. Track maintenance activities can be categorized into two main groups: preventive and corrective maintenance. Preventive maintenance predicts failures before they occur, whereas corrective maintenance rectifies existing defects. Currently, Tokaido Shinkansen operates under corrective maintenance. A railroad operator performs track maintenance when the track conditions exceed the designed maintenance level. The designed maintenance levels include precautionary and dangerous levels. After identifying that the track condition exceeds the precautionary level, railroad operators plan track maintenance to be conducted within the next few days. In contrast, if the track condition exceeds the dangerous level, railroad operators immediately perform emergency track maintenance. Emergency track maintenance requires additional personnel and resources, resulting in additional costs. Preventive maintenance can reduce these costs. Suppose that the Tokaido Shinkansen operates on preventive maintenance, in this case, railroad operators can forecast whether the track condition will exceed the maintenance level. Subsequently, railroad operators can perform track maintenance at points where track conditions are likely to exceed maintenance levels. Consequently, the number of points where the track conditions exceed the preventive or dangerous levels is reduced. Preventive maintenance guarantees railroad security and reduces costs by smoothing the amount of maintenance.
In the Tokaido Shinkansen, a track-inspection train, called “Doctor Yellow”, inspects track geometry irregularities, which are track deformations.
Doctor Yellow inspects seven types of track geometry irregularities: two vertical alignments for left and right tracks, two lateral alignments for left and right tracks, gauge deviation, cross level, and twist. Gauge is the distance between the right and left tracks. Vertical alignment is critical among track geometry irregularities because it deteriorates ride quality and can cause train accidents. Furthermore, in Japan, vertical alignment is used to decide whether maintenance operations need to be performed. Figure 1 illustrates vertical alignment. Additionally, Doctor Yellow measures the running speed and vehicle vibrations in the vertical and lateral directions. Table 1 describes the seven track geometry irregularities and the three measurements. Henceforth, for simplicity, the seven irregularities and the three measurements are collectively referred to as track geometry irregularities.

Vertical alignment.
In some countries, track maintenance plans are determined based on the standard deviation of the vertical alignment for each 100[m] or 200[m] section1,2. In contrast, Tokaido Shinkansen railroad operators manage tracks with high spatial and temporal frequencies to ensure safety. The railroad operators inspect every 1[m] section approximately every 10 days with Doctor Yellow. The inspection is used for planning the track maintenance schedule. Track geometry irregularities have spatial correlations owing to the chord offset method used by Doctor Yellow. The chord offset method measures the vertical and lateral alignments relative to the neighboring points and not the absolute values. Thus, spatial correlations must be captured for forecasting the vertical alignment. Additionally, the degradation of track geometry irregularities is affected by external factors such as rainfall, ballast deterioration, passing weight, and maintenance. In particular, some maintenance restores the vertical alignment, resulting in jump changes in the vertical alignment.
This study proposes a convolutional long short-term memory (ConvLSTM)3 to forecast vertical alignment at high spatial and temporal frequencies. The proposed ConvLSTM design considers the spatial correlation and the effect of exogenous factors on vertical alignment. The main contributions of the proposed method are summarized as follows.
-
The proposed method can forecast vertical alignment at high spatiotemporal frequencies using the exogenous data. The forecasting of vertical alignment is of practical significance because it is used to decide whether to perform the maintenance operations of railroads in Japan.
-
The proposed method extends the basic ConvLSTM to capture the spatial correlations and the effect of exogenous factors.
Related work
Table 2 summarizes prior research that predicted the vertical alignment. Each column in the table represents the following item. The Spatial and Temporal Frequency column shows the spatial and temporal frequency of the predicted features. The Spatial Calculation column indicates whether the model uses spatial calculation with neighboring spatial points or sections The Exogenous Factor column indicates whether the model uses exogenous factors. The Model column shows the machine learning model used in the study. The Predicted Feature column shows the features predicted in the study. The Forecast column indicates whether the study forecasts the features.
Sresakoolchai and Kaewunruen4 detect track component defects using track geometry. They use supervised learning techniques such as a deep neural network, a convolutional neural network (CNN), multiple regression, the support vector machine, gradient boosting, a decision tree, and random forests. Moreover, they use unsupervised learning techniques such as k-means clustering and association rules to explore and analyze the insights of track component defects.
Sadeghi et al.5 predicts a track degradation coefficient \(\text {TGI}_2/\text {TGI}_1\), the rate of the future track geometry index \(\text {TGI}_2\) and the present track geometry index \(\text {TGI}_1\). TGI is the index based the standard deviation of track geometry irregularities. Xu et al.6 approximated the nonlinear deterioration process of a surface (similar to vertical alignment) with many short linear processes. The time measurement intervals were not constant; however, the mean was approximately 18 days. The spatial interval of forecasting was 0.5[m]. Moreover, their method is linear and does not include spatial computations, in contrast to our method, which is nonlinear and includes spatial computations. Soleimanmeigouni et al.7 proposed a track geometry irregularity degradation model that considers recovering the track geometry irregularities and the corresponding changes in the degradation rate. The degradation rate changes with each maintenance action. Recovery after maintenance is computed by a linear model that takes the track geometry irregularities before maintenance and the types of maintenance as the input. They also argued that the initial values of the track geometry irregularities and the corresponding degradation rate have spatial correlations, which were then computed using the ARMA model. Soleimanmeigouni et al. selected a model with reversibility (the ARMA model) because spatial relationships have a two-directional dependence. The ARMA model computes only the spatial correlations in the initial state. In contrast, the proposed model computes spatial correlations for the degradation process. Maintenance and other exogenous factors have a spatial effect on track geometry irregularities, particularly because of the chord offset method. The spatial measurement interval of the aforementioned ARMA model is 200[m] and the corresponding spatial frequency is lower than that of our method. Notably, the ARMA model allowed for any temporal frequency as time was included as an independent variable. Chang et al. use a multi-stage linear model to forecast \(\text {SD}_{LL}\), the standard deviation of the longitudinal level (same as the vertical alignment) between two maintenance. They use the total passing tonnage from last maintenance as explanatory variable. Soleimanmeigouni et al.8 used logistic regression to predict the occurrence of longitudinal isolated defects, which are short irregularities in the track geometry. We forecast vertical alignment with high spatial frequency to detect local defects. In Tokaido Shinkansen, the railroad operators focus on preventive monitoring and repair of local defects for safety. Goodarzi et al.9 also used logistic regression and gradient boost machine (GBM) to predict yellow-tag defects at the next inspection (YDNI). A yellow-tag defect indicates that the track geometry will soon become a red-tag defect. The red-tag defect indicates that the track geometry violates the Federal Railroad Administration (FRA) track safety standards and must be corrected as soon as possible10. They use the train load in million gross tonnes (MGT), track class, and ballast fouling index (BFI) as input data. The result shows that the BFI improves the forecasting performance. This study uses the ballast age instead of the ballast deterioration. Movaghar and Mohammadzadeh11 computed a Bayesian linear regression model with exogenous data as the independent variable and \(\text {SD}_{\text {LL}}\), the standard deviation of the longitudinal level (same as the vertical alignment), as the dependent variable. Their method was applied to each track section with track section lengths of 13, 23, 24, and 18 [km]. The spatial frequency of our method is higher than that of their method. Moreover, although the temporal frequency of their forecasting method is one year, it can forecast at any temporal frequency because the method includes time as an independent variable.
Guler12 uses artificial neural networks (ANNs) to predict the degradation rate of the track geometry irregularities between two maintenance works for each analytical segment (AS). The average length of AS is 220 m. They input exogenous data such as traffic loads and speed into the ANN. This study also uses the passing tonnage since the last inspection as exogenous data. Chen et al.13 used long short-term memory (LSTM)14, gated recurrent units (GRU)15, CNNs, and their ensembles to forecast vertical track irregularities (same as vertical alignment) in time and spatial series. Their temporal measurement interval was one month, and the time frequency of the forecast was one year. Their spatial measurement interval was 0.5[m]. Their method does not include spatial computations in time-series forecasting, in contrast to our method, which includes spatial computations. Additionally, the temporal frequency of our method is higher than theirs. Khajehei et al.16 used ANN to predict the degradation rate of \(\text {SD}_{\text {LL}}\). They fed a variety of exogenous data into the model. They used the ballast age, the maintenance history, the level of degradation after tamping or renewal, the average annual frequency of trains, etc. They used the Garson method to investigate the relative importance of the variables affecting the rate of geometry degradation. They found that the maintenance history made the most significant contribution. This study also uses maintenance records as exogenous data. Sresakoolchai and Kaewunruen17 used recurrent neural networks (RNN), LSTM, GRU, and an attention mechanism to forecast seven track geometry irregularities. They proposed a model that computes spatial relationships. However, the model only computes unidirectional spatial neighborhoods, even though spatial relations are bidirectional. This study uses CNN within ConvLSTM to compute bidirectional spatial relations.
Dataset
Tables 1 and 3 summarize the track geometry irregularity data and exogenous data, respectively. These data are provided by the Central Japan Railway Company. This study aims to identify and verify the exogenous factors that are significant for forecasting vertical alignment.
Track geometry irregularity
As explained in the Introduction, track geometry irregularity refers to the track deformation. As listed in Table 1, the track geometry irregularity has seven types of deformations. Moreover, Doctor Yellow measures the running speed as well as the vertical and lateral vehicle vibrations. Henceforth, these 10 total data categories are collectively referred to as track geometry irregularity data.
Vertical and lateral alignments for each left and right track are measured using the 10[m] chord offset method (also called the 10[m] versine method)19. This method measures the relative alignments of adjacent points that are 5[m] apart. Relative alignments v(l) and absolute alignments u(l) at spatial position l are related by
where, \(\varepsilon \) denotes the measurement error. The relative alignments u(l) are used as input to the proposed model, because the absolute alignments u(l) cannot be measured. Equation (1) indicates that the vertical and lateral alignments are spatially correlated, demonstrating the need for a forecasting method that considers spatial correlations.
Exogenous data
Table 3 lists the exogenous data. In addition to Table 3, there are more exogenous factors that affect track alignment. For example, the ballast and the soil conditions are thought to strongly affect vertical alignment. However, such conditions are difficult to directly measure using a high-speed inspection train. Furthermore, turnouts may affect track alignment but are not considered because the available data include limited turnouts. In this study, only the observable data is used to forecast vertical alignment. For example, the ballast age is used instead of the ballast condition. The exogenous data are discussed in detail next.
Maintenance record
These data represent the records of track maintenance performed by railroad operators. Table 4 lists the maintenance operations used by railroad operators for correcting vertical alignment. In the list, the categories of sleeper maintenance and others comprise more detailed operations (See Supplementary Table S1 online). For example, sleeper maintenance includes sleeper replacement, loose sleeper repair, and so on. The aforementioned detailed operations are merged because of limited data. The data for the maintenance operations in Table 4 is used to forecast vertical alignment. Subsequently, each selected maintenance is represented as a binary value that indicates whether the maintenance is scheduled before the next track geometry irregularity inspection date. Some maintenance operations directly restore vertical alignment, whereas others indirectly affect it.
Under-structure
These data indicate five types of the structure and topography under the track: bridge, tunnel, overpass, embankment, and excavation. Normally, track geometry irregularities tend to degrade near the boundaries of the structures. The corresponding data are represented as a categorical variable that indicates which of the five aforementioned structural types categorizes every spatial point.
Rail joint
These data indicate the positions and types of rail joints. The joint types are fourfold: insulated, welded, and expansions for right and left rail. Track geometry irregularities also tend to occur around the joints. The corresponding data are represented as binary variables that indicate which of the three aforementioned joint types categorize the joint positions.
Ballast age
These data represent the elapsed time since the ballast (crushed stone under rails) was replaced or installed. Ballast deterioration affects the rate of vertical alignment deterioration1. However, ballast deterioration is difficult to measure using the high-speed track-inspection train. Instead, the ballast age is inputted into the proposed model, assuming that the ballast age is a linear approximation of the ballast deterioration. The bridge section of the Tokaido Shinkansen is not a ballast track. Moreover, the vertical alignment is not degraded in the sections without a ballast track. Therefore, assuming that the track at the bridge section is like a new ballast track, the ballast age of the bridge section is defined as zero years old.
Tonnage
These data indicate the total weight of vehicles that have passed through the inspected point since the last date of track geometry irregularity inspection. The greater the passing tonnage, the more the track geometry irregularity degrades12.
Rainfall
These data indicate the precipitation since the date of the last track irregularity inspection. Rain degrades the soil condition under the track and indirectly affects track geometry irregularities20. The precipitation is considered as an exogenous factor instead of the soil condition. Specifically, the cumulative precipitation and the maximum unit time rainfall are calculated from the last inspection date. Accumulated precipitation indicates long-term rainfall, such as that during rainy season. In contrast, the maximum unit time precipitation indicates short-term rainfall, such as a sudden downpour. The unit times for precipitation are 10 min, 1 hour, and 1 day. Therefore, the rainfall data types are fourfold: accumulated precipitation, maximum of 10 min rainfall, maximum of hourly rainfall, and maximum of daily rainfall.
Data collection
Data are collected from a 15[km] section of the Tokaido Shinkansen between 27[km] and 42[km] of the outbound line from April 2011 to June 2021. Track geometry irregularities are measured at 25[cm] intervals and then aligned to 1[m] intervals. Therefore, track geometry irregularities are measured at 15,000 points in the spatial dimension, where the number of spatial measurement points are denoted by \(L=15{,}000\). The exogenous data are also aligned at 1[m] intervals to match the track geometry irregularity data. For the data, the odometry error is negligible due to high spatial resolution measurements and the odometry correction.
The track geometry irregularities are measured at unequal intervals approximately every 10 days. The exogenous data are aligned with the measurement date of track geometry irregularities. The dataset is split into training, validation, and test datasets according to the time dimension. Data from 04/06/2011 to 04/26/2017, 05/08/2017 to 11/07/2018, and 11/19/2018 to 06/18/2021 are used as the training, validation, and test datasets, respectively, where the number of sequences in the dataset of interest at that time are denoted as T. Sliding-window processing is applied to each dataset and then each dataset is divided into sequences. Next, the sequences are inputted into the model during training and inference.
Methods
Formulation
Using track geometry irregularities and exogenous data, a spatiotemporal model is developed for forecasting the vertical alignments of the Tokaido Shinkansen rail. The track geometry irregularity data at time t are denoted as
where \(x_{l,c_x}^{(t)}\) is the track geometry irregularity measurement at spatial position l for irregularity type \(c_x\). The number of spatial measurements is \(L=15,000\), and \(C_x=10\) types of irregularities exist. The vertical alignments at time t are denoted as
where \(y^{(t)}_{l,c_y}\) denotes the vertical alignment at the spatial position l and \(c_y\) is an index indicating whether the left or right track, that is, \(C_y=2\). The objective is to build a vertical alignment forecast model f as
where \({x}_{t-\tau +1:t}=\left\{ {x}_{t-\tau +1}\ldots {x}_{t}\right\} \) is the input sequence of the track geometry irregularities. Moreover, e denotes exogenous data, and \(\theta \) are the parameters of model f. Exogenous data e include several types of data, as summarized in Table 3. To find an optimal parameter \(\hat{\theta }\), the following minimization problem is formulated:
Proposed model
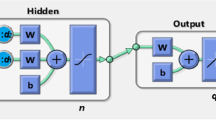
A model f is developed for forecasting vertical alignment based on the ConvLSTM3. Figure 2 shows the proposed forecasting model f with one-dimensional (1D) ConvLSTM cells and an embedding part for exogenous data. The exogenous embedding part computes embedding features \({\varvec{z}}_{t-\tau +1},\ldots , {\varvec{z}}_{t}\) from the exogenous data. The 1D ConvLSTM cells are used to forecast the vertical alignment from the track geometry irregularities and the exogenous embedding features.

ConvLSTM with exogenous data, i.e., the proposed model that predicts vertical alignment. The left part is the exogenous embedding part. The right part is the ConvLSTM part.

ConvLSTM cell.
Exogenous embedding
The exogenous embedding part in Figure 2 consists of embedding layers, expanding layers, and concatenation layers. The embedding layers map the sparse representations of the exogenous data to dense feature vectors. The proposed model has an embedding layer for each data format in Table 3. Each embedding layer is a fully-connected network (FCN) with the input size depending on the input data format, whereas the output of FCN is a 4D vector for all data formats. The expanding and concatenate layers are used to obtain the tensor representation of the exogenous features \({\varvec{z}}_{t}\) from a set of the 4D embedding vectors for all data formats. Next, the way of embedding for each data format in Table 3 are discussed.
For spatiotemporal binary data (maintenance record), a maintenance record at spatial position l at time t is represented as binary value (0 or 1), where 1 indicates that the maintenance operation is performed. When feeding the record into FCN, the binary representation of 0 and 1 is slightly modified as one-hot vector (0, 1) and (1, 0), respectively. The one-hot representation is necessary to avoid zero-input; training FCN becomes impossible because the output to zero-input is zero. For each maintenance record at spatial position l at time t, FCN outputs a 4D embedding vector. By repeating the embedding computation over the spatiotemporal and categorical domain, a set of the embedding vectors is obtained. Finally, the set of the embedding vectors is concatenated in the spatial, temporal, and categorical directions to obtain the tensor representation.
For spatial categorical data (under-structure), five types of under-structure are represented at spatial position l as a 5D one-hot vector, e.g., (0, 1, 0, 0, 0). For each under-structure at spatial position l, FCN for the corresponding data outputs a 4D embedding vector. The embedding vector is expanded in the temporal direction to obtain the tensor representation with the same length along the temporal axis as that of the tensor of the spatiotemporal categorical data. Finally, the set of the expanded embedding vectors is concatenated in the spatial direction to obtain the tensor representation.
For spatial binary data (rail joint), a rail joint at spatial position l is represented as a binary value, where 1 indicates the rail joint being positioned there. Similar to spatiotemporal categorical data, the one-hot representations (0, 1) and (1, 0) are used to avoid zero-input. For each rail joint at spatial position l, FCN of the corresponding data outputs a 4D embedding vector. The embedding vector is expanded in the temporal and categorical directions at the expanding layer. Finally, the set of the expanded embedding vectors is concatenated in the spatial direction to obtain the tensor representation.
For spatiotemporal real number data (ballast age, tonnage, and rainfall), the embedding layer is not used, and the data are directly fed into the concatenate layer, because the data are not sparse.
ConvLSTM
The ConvLSTM computes the spatial/temporal correlation of the track geometry irregularity data and exogenous data. First, the track geometry irregularity data \({\varvec{x}}_{t-\tau +1},\ldots ,{\varvec{x}}_t\) and the exogenous embedding feature \({\varvec{z}}_{t-\tau +1}\ldots {\varvec{z}}_{t}\) are concatenated in the channel dimension by the concatenation layer. Subsequently, the concatenated data are computed for spatial/temporal correlation using stacked 1D ConvLSTM. Figure 3 shows the structure of the 1D ConvLSTM cell with inputs \(\mathscr {X}_t\), hidden states \(\mathscr {H}_t\), and cell outputs \(\mathscr {C}_t\). The difference compared with the 2D ConvLSTM cell3 is that the convolution layer is replaced with a 1D convolution layer. The key equations of the 1D ConvLSTM cell are given as follows.
where \(*\) denotes the 1D convolution operator, \(\odot \) is the Hadamard product, and \(\sigma \) is the sigmoid function. Moreover, W and b are the weight and bias learnable parameters, respectively. The output of the ConvLSTM is concatenated in the time dimension by the concatenation layer. The last convolution layer takes concatenated features as inputs and outputs predictions \(\hat{\varvec{y}}_{t+1}\).
Loss
The proposed method uses the mean squared error (MSE) loss, which is defined as
where, T is the number of sequences used for evaluation.
Experiments
Experiments setting
The ConvLSTM is trained for 2000 epochs, and the parameters with the lowest losses are used on the validation dataset for testing. The Adam optimizer is also deployed with learning rate \(\gamma =0.001\) and betas \((\beta _1,\beta _2)=(0.9,0.999)\). The ConvLSTM training and all experiments are conducted on a workstation with NVIDIA TITAN RTX (24 GB memory), Intel Core i7-5960X CPU (3.00 GHz), and 64 GB memory. The ConvLSTM is implemented using Python 3.7.10 and PyTorch 1.8.1.
Evaluation
The root mean squared error (RMSE), R-squared (\(R^2\)), and accuracy are used as evaluation metrics. RMSE is defined as
where \(Y\subset \mathbb {R}^2\) is the evaluated dataset, that is, a set of pairs of vertical alignments \(y_{i,j}^{(t)}\) and their predictions \(\hat{y}_{i,j}^{(t)}\). Moreover, n(Y) is the number of elements in Y. A lower RMSE indicates better forecasting performance and is helpful for decision making with regards to whether the maintenance operations need to be performed. \(R^2\) is also used to present a clear view of the model performance, which is defined as
where \(\bar{y}=\sum _{(y,\hat{y})\in Y} y/ n(Y)\) is the mean of vertical alignment \(y_{i,j}^{(t)}\). Best possible score of \(R^2\) is 1.0. In this study, the accuracy shows the percentage of data for which the predictions \(\hat{y}\) are within a specific tolerance range \((y-\varepsilon ,y+\varepsilon )\) from the observed values y. An indicator function \(\phi \) is defined that indicates whether the predicted value is within tolerance \(\varepsilon \) as follows:
Using Eq. (10), the accuracy [%] is defined as
A higher accuracy indicates a better forecasting performance.
To maintain safety, railroad operators must forecast track geometry. Therefore, the forecasting model must deliver high performance for data in which vertical alignment is degraded. The ConvLSTM is evaluated on the entire dataset
as well as on the data in which the vertical alignment is less than the threshold level \(\alpha \).
In the experiment, the ConvLSTM is evaluated with \(\alpha =-4.0,-6.0\) [mm].
Comparison experiment
In the comparison experiments, the proposed method is compared with other forecasting methods. The curves of the losses for training and validation data are detailed in Supplementary Fig. S1 online. After learning and computing each method, the evaluation metrics and output series are evaluated. Table 5 provides a preliminary comparison of multiple forecasting methods. For LSTM and GRU, we determine each architecture by tuning the number of layers (see Supplementary Sect. S.4). The details of the compared methods are discussed next.
Linear regression
Linear regression is the simplest baseline method. Because vertical alignments vary nonlinearly in a time series, linear regression is performed with a sliding window. The linear model is defined as \(\hat{y}_{t+1}=b_t x_{t+1}+a_t\), where \(y_{t+1}\) and \(x_{t+1}\) are the vertical alignment and inspection dates, respectively, of the \((t+1)\)-th inspection. Moreover, \(a_t\) and \(b_t\) are the parameters of this method, which are optimized using the least-squares method for the last three vertical alignments \(\{y_{t-2},y_{t-1},y_t\}\) and inspection dates \(\{x_{t-2},x_{t-1},x_t\}\). In contrast to the proposed method, this method neither considers exogenous factors nor performs spatial calculations.
LSTM with exogenous data
LSTM14 is a variant of recurrent neural networks (RNNs). RNNs, including the LSTM and GRU, are used for natural language processing and time-series forecasting. This method replaces the ConvLSTM with the LSTM in the proposed model architecture. In contrast to the proposed method, this method does not involve spatial computations, but does consider the exogenous factors. The hyperparameters of the LSTM follow Pytorch examples (For tuning the number of layers, see Supplementary Sect. S.4). The learning setting of this method is similar to that of the proposed method.
GRU with exogenous data
Similar to LSTM, GRU15 is a variant of RNNs. This method replaces the ConvLSTM with a GRU in the proposed model architecture. In contrast to the proposed method, this method does not involve spatial computations, but does consider the exogenous factors. The hyperparameters of the GRU also follow Pytorch examples. (For tuning the number of layers, see Supplementary Sect. S.4). The learning setting of this method is also similar to that of the proposed method.
Ablation study on exogenous factors
In an ablation study on exogenous factors, the significance of these factors is verified with regards to forecasting. Specifically, the evaluation metrics with and without the input of specific exogenous data are compared. If the difference in the evaluation metrics is significant, the exogenous data are critical for forecasting using the proposed method. The proposed method is trained and evaluated under the following conditions:
-
A case that inputs all exogenous data.
-
A case that inputs all exogenous data except a specific one.
-
A case that does not input all exogenous data. (This case is vanilla ConvLSTM.)

Forecasted time series of specific spatial points for each method. The vertical dotted lines indicate the dates when maintenance operations were performed. (a) is the time series of a specific spatial point with a normal maintenance frequency. (c) is the orange part of (a). (b) is the time series of a specific spatial point with a high maintenance frequency. (d) is the orange part of (b).
Results and discussion
Comparison results
Tables 6 and 7 summarize the comparison results of the RMSE, \(R^2\), and accuracy, respectively, between the proposed method and other forecasting methods. The proposed method achieves the lowest RMSE for both the entire dataset and the dataset with thresholds \(\alpha =-4,-6\) [mm] and the highest \(R^2\) for the entire dataset. This result indicates that spatial calculations improve the forecasting performance in terms of RMSE. Moreover, the proposed method has the highest accuracy for the data threshold \(\alpha =-4\) [mm], whereas the simplest baseline, linear regression, has the highest accuracy for the data threshold \(\alpha =-6\) [mm]. This result indicates that the vertical alignment varies linearly when the vertical alignment is less than \(\alpha =-6\) [mm]. However, linear regression demonstrates a poorer performance at points with a high maintenance frequency (See Discussion).
Figure 4 shows the forecasted time series of the spatial points on the track for each method. Note that the vertical dotted lines indicate the dates when maintenance operations were performed. Figure 4a,c show the forecasted time series at the spatial point where maintenance is performed once every eight inspections on average, that is, approximately once every three months. The spatial exogenous data at the spatial point are as follows: the under-structure is excavation and no rail joint exists. Each method showcases a high forecasting performance at the spatial point with a normal maintenance frequency. When the vertical alignment varies linearly, as shown in Figure 4c, linear regression performs better than the proposed method. In contrast, for a relatively high maintenance frequency, such as once a month, e.g., from January to July 2020, in Figure 4a, linear regression forecasts indicate a poorer performance compared with other methods.
Figure 4b,d show the forecasted time series at the spatial point where maintenance is performed once every four inspections on average, that is, approximately once every month. The spatial exogenous data at the spatial point are as follows: the under-structure is embankment and no rail joint exists. Linear regression performs worse than the other methods shown in Figure 4b,d, and provides the predictions with a delayed interval of one inspection. This delay is due to the fact that linear regression does not use the maintenance records, but only the past data. In Figure 4d, the proposed method exhibits a higher performance than the LSTM and GRU. This is because the ConvLSTM in the proposed method captures the spatial correlation by convolution, whereas the LSTM and GRU do not.
Table 8 lists the training time for each model. For linear regression, the training time is not provided because it is too short. For LSTM and GRU, the training time is the cumulative training time at all spatial points. As listed in Table 8, ConvLSTM takes a longer training time than the other methods. However, the training time for ConvLSTM is not significantly long because the task involves 10-day ahead forecasting.

(a) Histogram of the number of maintenances at each spatial point on the rail. (b) Scatter plot of the number of track maintenances and RMSEs at each measurement point.
Discussion
Herein, the limitation of the linear regression model and the effectiveness of the proposed ConvLSTM are discussed. For many spatiotemporal points, the linear regression forecast is evidently sufficient because the vertical alignment varies linearly, as shown in Figure 4a,c. However, linear regression performs poorly at points with a high maintenance frequency, as shown in Figure 4b. Next, the proposed method is compared with the linear regression model at points with a high maintenance frequency. Figure 5a shows a histogram of the average maintenance frequency per year for each measurement point in the test data. At most points, the maintenance frequency per year is approximately five. Figure 5b shows a scatter plot of the track maintenance frequency and RMSEs at each measurement point. With a higher maintenance frequency, the ConvLSTM tends to have a lower RMSE than the linear regression. The measurement interval of the track geometry irregularity data is approximately 10 days. Therefore, if maintenance is performed 12 times annually, the track geometry irregularities are measured an average of three times during the two maintenances. A prior research has fitted a multi-stage linear model during two maintenances18. However, vertical alignments are difficult to forecast with such a linear model because of the limited data available when track geometry irregularities are only inspected three or four times during two maintenances, that is, when the maintenance frequency is high. In contrast, the ConvLSTM can achieve a high forecasting performance even at spatial points with a high maintenance frequency.
Ablation study on exogenous factors
Tables 9, 10, and 11 summarize the results of the ablation study based on the exogenous factors for the ConvLSTM. For the ablation studies of the LSTM and GRU, please see Supplementary Tables S2, S3, and S4 (online). In the tables, “With-all” refers to a case in which all exogenous data are used. “Without specific data” refers to the case in which all exogenous data except specific data are used. For example, “without-maintenance” refers to the case that uses all exogenous data except for track maintenance data. “Without-all” refers to the case in which no exogenous factor is used. Comparing “with-all” and “without-maintenance”, “without-maintenance” shows a higher RMSE for both the entire dataset and the dataset with thresholds \(\alpha =-4,-6\) [mm]. Moreover, “without-maintenance” shows a lower accuracy than “with-all” for the dataset with thresholds \(\alpha =-4,-6\) [mm]. The difference between the “with-all” and “without-maintenance” evaluation metrics is significant, as maintenance data are useful for forecasting in the proposed method. However, for the other exogenous data, the evaluation metrics do not worsen when the exogenous data are removed. Furthermore, the RMSE and accuracy are also not sensitive even in the vicinity of the rail joints and the boundary between two under-structures, such as embankment and excavation. Therefore, whether other exogenous data improve the forecasting performance of the proposed method cannot be confirmed. Note that this result does not imply that other exogenous factors are not causally related to vertical track alignment. For example, tonnage is related to track geometry irregularities12, the effect may be hidden. The time index implicitly contains the information about the tonnage, because the tonnage is the same along the 15 km track portion.
Figure 6 shows the forecasted time series with and without maintenance at the same spatial points as in Figure 4. Figure 6a,c show the forecasted time series of a specific spatial point where maintenance is performed once every eight inspections on average, that is, approximately once every three months. The “with-all” condition showcases a higher performance than the “without-maintenance” condition. This is because in the “without-maintenance” condition it is not known when an increase in vertical alignment occurs due to maintenance. The lower the vertical alignment, the more intermediate is the forecasting between the increase owing to maintenance and the decrease owing to degradation.

(b,d) Show the forecasted time series of a specific spatial point where maintenance is performed once every four inspections on average, that is, approximately once every month. At a spatial point with a high maintenance frequency, the forecasted time series of the “with-all” condition is typically closer to the observed time series than that of the “without-maintenance” condition. Forecasted time series of specific spatial points under “with-all” and “without-maintenance” conditions. The vertical dotted lines indicate the dates when maintenance operations were performed. (a) is the time series of a specific spatial point with a normal maintenance frequency. (c) is the orange part of (a). (b) is the time series of a specific spatial point with a high maintenance frequency. (d) is the orange part of (b).
Conclusion
This study proposes a ConvLSTM to forecast vertical alignments of railroad at high spatial and temporal frequencies. The ConvLSTM is designed to consider spatial correlations and the effect of exogenous factors on vertical alignment. The proposed method is experimentally compared with other methods in terms of the forecasting performance. Additionally, an ablation study on exogenous factors is conducted to examine their contribution to the forecasting performance. The results reveal that spatial calculations and maintenance record data improve the forecasting of the vertical alignment. Additionally, the proposed method showcases a higher forecasting performance at points with a high maintenance frequency.
The ConvLSTM has the potential to be applied to other tracks, although its applicability should be carefully considered in the case that the exogenous data for the tracks are very different from our experimental data. For example, linear regression may be sufficient if maintenance frequency is low. However, as the experiment showed, spatial calculation and maintenance records improve forecast performance when maintenance operations are frequently required significantly. Furthermore, the explainability of the ConvLSTM is of practical significance and should be pursued in future work, because the explainable ConvLSTM will provide insights into which exogenous factors are useful for forecasting track geometry irregularities.
Data availability
Track geometry irregularity data for the Tokaido Shinkansen are not publicly available. Data can be accessed by signing a non-disclosure agreement with the Central Japan Railway Company. The code is available on https://github.com/kosukatsu/track_irregularity_forecasting.
References
Soleimanmeigouni, I., Ahmadi, A. & Kumar, U. Track geometry degradation and maintenance modelling: A review. Proc. Inst. Mech. Eng. Part F 232, 73–102. https://doi.org/10.1177/0954409716657849 (2018).
Setiawan, D. M. & Rosyidi, S. A. P. Track quality index as track quality assessment indicator. In Prosiding Forum Studi Transportasi antar Perguruan Tinggi (2016).
Shi, X. et al. Convolutional lstm network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 28, 1–9 (2015).
Sresakoolchai, J. & Kaewunruen, S. Railway defect detection based on track geometry using supervised and unsupervised machine learning. Struct. Health Monit. 21, 1757–1767 (2022).
Sadeghi, J. & Askarinejad, H. Development of improved railway track degradation models. Struct. Infrastruct. Eng. 6, 675–688 (2010).
Xu, P., Liu, R., Sun, Q. & Wang, F. A novel short-range prediction model for railway track irregularity. Discret. Dyn. Nat. Soc. 2012, 1–12 (2012).
Soleimanmeigouni, I. et al. Modelling the evolution of ballasted railway track geometry by a two-level piecewise model. Struct. Infrastruct. Eng. 14, 33–45 (2018).
Soleimanmeigouni, I., Ahmadi, A., Nissen, A. & Xiao, X. Prediction of railway track geometry defects: A case study. Struct. Infrastruct. Eng. 16, 987–1001 (2020).
Goodarzi, S., Kashani, H. F., Oke, J. & Ho, C. L. Data-driven methods to predict track degradation: A case study. Constr. Build. Mater. 344, 128166 (2022).
Cárdenas-Gallo, I., Sarmiento, C. A., Morales, G. A., Bolivar, M. A. & Akhavan-Tabatabaei, R. An ensemble classifier to predict track geometry degradation. Reliab. Eng. Syst. Saf. 161, 53–60 (2017).
Movaghar, M. & Mohammadzadeh, S. Bayesian Monte Carlo approach for developing stochastic railway track degradation model using expert-based priors. Struct. Infrastruct. Eng. 18, 145–166 (2022).
Guler, H. Prediction of railway track geometry deterioration using artificial neural networks: A case study for Turkish state railways. Struct. Infrastruct. Eng. 10, 614–626 (2014).
Chen, Y., Zhang, Y. & Yang, F. Learn to predict vertical track irregularity with extremely imbalanced data. In Asian Conference on Machine Learning 1493–1504 (PMLR, 2021).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Cho, K. et al. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) 1724–1734 (2014).
Khajehei, H. et al. Prediction of track geometry degradation using artificial neural network: A case study. Int. J. Rail Transp. 10, 24–43 (2022).
Sresakoolchai, J. & Kaewunruen, S. Track geometry prediction using three-dimensional recurrent neural network-based models cross-functionally co-simulated with bim. Sensors 23, 391 (2022).
Chang, H., Liu, R. & Li, Q. A multi-stage linear prediction model for the irregularity of the longitudinal level over unit railway sections. WIT Trans. Built Environ. 114, 641–650 (2010).
Naganuma, Y., Kobayashi, M. & Okumura, T. Inertial measurement processing techniques for track condition monitoring on shinkansen commercial trains. J. Mech. Syst. Transp. Logist. 3, 315–325 (2010).
Lyngby, N. Railway track degradation: Shape and influencing factors. Int. J. Perform. Eng. 5, 177 (2009).
Funding
This study was funded by the Central Japan Railway Company.
Author information
Authors and Affiliations
Contributions
K.K. (Kosukegawa) and K.K. (Kawamoto) conceived of the methodology and experiment. K.K. (Kosukegawa) implemented the proposed method, conducted the experiment, and wrote the original manuscript. Y.M. and H.S advised on the methodology and experiment. All authors have reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kosukegawa, K., Mori, Y., Suyari, H. et al. Spatiotemporal forecasting of vertical track alignment with exogenous factors. Sci Rep 13, 2354 (2023). https://doi.org/10.1038/s41598-023-29303-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-29303-7
This article is cited by
-
Gradient descent based restoration method of track irregularity in asymmetric chord reference method
Journal of Central South University (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
