
Abstract
Large displacement optical flow is an integral part of many computer vision tasks. Variational optical flow techniques based on a coarse-to-fine scheme interpolate sparse matches and locally optimize an energy model conditioned on colour, gradient and smoothness, making them sensitive to noise in the sparse matches, deformations, and arbitrarily large displacements. This paper addresses this problem and presents HybridFlow, a variational motion estimation framework for large displacements and deformations. A multi-scale hybrid matching approach is performed on the image pairs. Coarse-scale clusters formed by classifying pixels according to their feature descriptors are matched using the clusters’ context descriptors. We apply a multi-scale graph matching on the finer-scale superpixels contained within each matched pair of coarse-scale clusters. Small clusters that cannot be further subdivided are matched using localized feature matching. Together, these initial matches form the flow, which is propagated by an edge-preserving interpolation and variational refinement. Our approach does not require training and is robust to substantial displacements and rigid and non-rigid transformations due to motion in the scene, making it ideal for large-scale imagery such as aerial imagery. More notably, HybridFlow works on directed graphs of arbitrary topology representing perceptual groups, which improves motion estimation in the presence of significant deformations. We demonstrate HybridFlow’s superior performance to state-of-the-art variational techniques on two benchmark datasets and report comparable results with state-of-the-art deep-learning-based techniques.
Similar content being viewed by others

Introduction
Dense motion estimation from optical flow is an essential component in many diverse computer vision applications ranging from autonomous driving1, multi-object tracking and segmentation2, action recognition3, to video stabilization4, to name a few. Consequently, optical flow estimation directly contributes to the performance and accuracy of these applications (Fig. 1).

(a) Input image frame. (b) Coarse-scale clusters from pixels’ feature descriptors. (c) Color-coded graph matches of one coarse-scale cluster; first frame (a). (d) Color-coded graph matches for (c); second frame. (e) Motion vectors from graph-matching of superpixels at finest-scale. (f) Motion vectors from pixel feature matching in small clusters. (g) Interpolated flow from the combined initial motion vectors (e+f). (h) Final optical flow after variational refinement. Average Endpoint Error (EPE) = 0.157. The pixels in (c,d) are magnified by \(10 \times 10\) for clarity in the visualization.
Research in dense motion estimation techniques has been ongoing since the 1950s when Gibson first proposed it in Ref.5. Despite the active research, to this day, the estimation of optical flow remains an open research problem. This is primarily attributed to the following two challenges: occlusions and large displacement.
Occlusions can appear in several forms; self-occlusion, inter-object occlusion, or background occlusion. Typical solutions based on a variational approach employ a robust penalty function, and regularizers that aim to reduce the occlusion errors6,7. However, they still fail in cases where the pixels vanish between consecutive frames. More recently, many deep-learning-based techniques were proposed8,9. In many cases where ground truth is available, their performance surpasses that of variational techniques on benchmark datasets; however, applying these networks on real image sequences is a non-trivial task that requires re-training, fine-tuning and often manual annotation.
On the other hand, for large displacements, solutions follow a coarse-to-fine model that introduces additional errors due to the coarse scales’ upsampling and interpolation. To alleviate some of the interpolation errors, Revaud et al.10 proposed EpicFlow, an edge-preserving interpolation of sparse matches used to initialize the optical flow motion estimation in a variational approach. Several techniques employing EpicFlow have since been proposed11,12, which address the sensitivity to noise in the sparse matches. The result is reduced interpolation errors in the estimated optical flow at the cost of over-smoothing the fine structures and failure to capture small-scale and fast-moving objects in the image. Thus, the accuracy of the initial sparse matches has a detrimental effect on the accuracy of the optical flow.
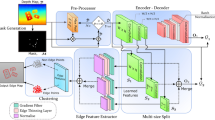
This paper presents HybridFlow (Fig. 2), a robust variational motion estimation framework for large displacements and deformations based on multi-scale hybrid matching. Uniquely, HybridFlow leverages the strong discriminative nature of feature descriptors, combined with the robustness of graph matching on arbitrary topologies. We classify pixels according to the argmax of their context descriptor and form coarse-scale clusters. We follow a multi-scale approach, and fine-scale superpixels resulting from the perceptual grouping of pixels contained within the parent coarse-scale cluster form the basis of subsequent processing. Graph matching is performed on the graphs representing the fine-scale superpixels by simultaneously estimating the graph node correspondences based on the first and second-order similarities and a smooth non-rigid transformation between nodes. Graph matching is an NP-hard problem; thus, the graphs’ factorization into Kronecker products ensures tractable computational complexity. This process can be repeated at multiple scales to handle arbitrarily large images. At the finest-scale, the pixels’ feature descriptors are matched based on their \(\mathscr {L}_{2}\) distance. Pixel-level feature matching is also performed on clusters that are too small to be subdivided into superpixels. We combine both sets of pixel matches to form the initial sparse motion vectors from which the optical flow is interpolated. Finally, variational refinement is applied to the optical flow. HybridFlow is robust to large displacements and deformations and has a minimal computational footprint compared to deep-learning-based approaches. A significant advantage of our technique is that using multi-scale graph matching reduces the computational complexity from \(\mathscr {O}(n^{2})\) to \(\sum _{i=0}^{k} \mathscr {O}(k^2)\) where k is always smaller than the superpixel size |s| and significantly smaller than n, i.e. \(k< |s|<< n\). Our experiments demonstrate the effectiveness of our technique in optical flow estimation. We evaluate HybridFlow on two benchmark datasets (MPI-Sintel13, KITTI-201514) and compare it against state-of-the-art variational techniques. Hybridflow, outperforms all other variational techniques and, on average, gives comparable results with deep-learning-based methods.

HybridFlow: A multi-scale hybrid matching approach is performed on the image pairs. Uniquely, HybridFlow, leverages the strong discriminative nature of feature descriptors, combined with the robustness of graph matching on arbitrary graph topologies. Coarse-scale clusters are formed based on the pixels’ feature descriptors and are further subdivided into finer-scale SLIC superpixels. Graph matching is performed on the superpixels contained within the matched coarse-scale clusters. Small clusters that cannot be further subdivided are matched using localized feature matching. Together, these initial matches form the flow, which is propagated by an edge-preserving interpolation and variational refinement.
To summarize, our contributions are:
-
A hybrid matching approach that uniquely combines the robustness of feature detection and matching with the invariance to rigid and non-rigid transformations of graph matching. The combination results in high tolerance to large displacements and deformations when compared to other techniques.
-
An objective function based on first and second-order similarities for matching graph nodes and edges, which results in improved matching as showcased by our experiments.
-
A complete variational framework for estimating optical flow that does not require training and is robust to large displacements and deformations caused due to motion in the scene while providing superior performance to state-of-the-art variational techniques and comparable performance to state-of-the-art deep-learning-based echniques on benchmark datasets.
Related work
Optical flow is a 2D vector field describing the apparent motion of the objects in the scene. This optical flow field can be very informative about the relations between the viewers’ motion and the 3D scene.
Over the years, many techniques have been proposed following the predominant way of estimating optical flow using variational methods15. The optical flow is estimated via optimization of an energy model conditioned on image brightness/colour, gradient, and smoothness. This energy model fails when dealing with large displacements due to motion in the scene because its solution is approximate and locally optimizes the function.
To address this challenge, Anandan16 proposed a coarse-to-fine scheme. Coarse-to-fine techniques upsample and interpolate the flow from the finer-scale of the pyramid to the coarser. These techniques can deal with large displacement; however, it comes at the cost of over-smoothing any fine structures and failing to capture small-scale and fast-moving objects.
At the same time, researchers explored the integration of feature matching in optical flow estimation. Revaud et al.17 recently presented one of the most promising variational techniques where a HOG descriptor was used as a feature matching term in the energy function. Their technique can deal with deformations and is robust to repetitive textures. In subsequent work, the authors proposed EpicFlow, which performs a sparse-to-dense interpolation on the correspondences and estimates optical flow while preserving edges10. Hu et al.12 built upon this work and proposed a robust interpolation technique to address the sensitivity of EpicFlow to noise in the initial matches by enforcing matching neighbourhood flow in the two images and fitting an affine model to the sparse correspondences. Up to now, this improvement produced superior performance than the previous best, which was based on a coarse-to-fine technique using PatchMatch11.
More recently, several techniques were proposed based on convolutional neural networks (CNN). These estimate the optical flow in an end-to-end fashion using supervised learning18,19,20 or unsupervised learning21,22,23. One of the recent top-performing CNN-based approaches is SelFlow24. SelFlow is a self-supervised learning approach for optical flow that, until lately, produced the highest accuracy among all unsupervised learning methods. The authors achieved this by creating synthetic occlusions from perturbing superpixels. The current state-of-the-art CNN-based technique is RAFT25, in which per-pixel features are employed in a deep network architecture of recurrent transforms. RAFT and its variants such as GMA26 currently achieve the best performance reporting the lowest average endpoint error for all significant optical flow benchmark datasets.
Currently, the average endpoint error (AEE/EPE) reported on Sintel-final for the top-performing deep-learning technique (CRAFT) is 2.424, and for the top-performing variational technique (Hybridflow-ours) is 5.121; a difference of fewer than 2.7 pixels over the entire imageset of 562 images of 1024 \(\times \) 436. Although deep learning techniques beget superior performance to the variational methods on benchmark datasets for which ground truth is available, they are unusable on real image sequences that seldom have associated ground truth, and training and fine-tuning become impossible. Moreover, even in cases where ground-truth may be available, the training and fine-tuning are time-consuming, offline operations that render them unsuitable in scenarios requiring real or interactive time performance.
For these reasons, we propose a variational optical flow technique that is independent of the content of the image sequences and does not impose additional requirements for training and fine-tuning. Our method follows a hybrid approach for matching to eliminate errors in the initial sparse matches introduced from large displacements and deformations. HybridFlow leverages the strong discriminative nature of feature descriptors combined with the robustness of deformable graph matching. In contrast to variational state-of-the-art, which employs a regular grid structure in their coarse-to-fine matching scheme, HybridFlow operates at only a single image scale and multiple scales of clustering, eliminating over-smoothing and handling small-scale and fast-moving objects better. More notably, our method does not restrict deformations by enforcing smooth neighbourhood matching but instead employs deformable graph matching, which allows for rigid and non-rigid transformations between neighbouring superpixels.
Graph model and matching
Model
A graph \(G = \{P, E, T\}\) consists of nodes P inter-connected with edges E. A node-edge incidence matrix T specifies the topology of the graph G. The nodes are represented in matrix form as \( P = \big [ \vec{p_{1}}, \vec{p_{2}}, \dots , \vec{p_{N}} \big [ \in {\mathbb {R}}^{dim(\vec{p}) \times N}\), where \(dim: \vec{v} \longrightarrow \mathbb {R}\) is a function that returns the cardinality of a vector \(\vec{v}\). Similarly, the edges are represented in matrix form as \( E = \big [ \vec{e_{1}}, \vec{e_{2}}, \dots , \vec{e_{M}} \big [ \in \mathbb {R}^{dim(\vec{e}) \times M}\). An edge-weight function \(w: E \times E \longrightarrow \mathbb {R}\) assigns weights to edges. Given the above definitions, the incidence matrix is defined as \(T \in \{0,1\}^{N\times M}\) where \(T_{(i,k)} = T_{(j,k)} = 1\), if an edge \(e_{k} \in E\) connects the nodes \(p_{i}, p_{j} \in P\), otherwise it is set to 0.
Matching
Matching two graphs \(G_{1} = \{P_{1}, E_{1}, T_{1}\}\) and \(G_{2} = \{P_{2}, E_{2}, T_{2}\}\) is an NP-hard problem for which exact solutions can only be found if the number of nodes and edges are significantly small e.g. \(N, M < 15\). Proposed solutions typically formulate graph matching as a Quadratic Assignment Problem(QAP) and provide an approximation to the solution27. This requires the calculation of two affinity matrices: \(A^{P}_{1,2} \in \mathbb {R}^{N\times N}\) which encodes the similarities between nodes in \(G_{1}\) and \(G_{2}\), and \(A^{E}_{1,2} \mathbb {R}^{M\times M}\) which encodes the similarities between edges in \(G_{1}\) and \(G_{2}\). The functions \(\lambda ^{P}: P \times P \longrightarrow \mathbb {R}\) and \(\lambda ^{E}: E \times E \longrightarrow \mathbb {R}\) measure the similarities between nodes and edges, respectively. Therefore for two corresponding nodes \(p_{i} \in P_{1}\) of \(G_{1}\) and \(p_{k} \in P_{2}\) of \(G_{2}\), the node affinity matrix element is \(A^{P}_{i,k} = \lambda ^{P}(p_{i}, p_{k})\). Similarly, for edges \(e_{a} \in E_{1}\) of \(G_{1}\) and \(e_{b} \in E_{2}\) of G2 the edge affinity matrix element is \(A^{E}_{a,b} = \lambda ^{E}(e_{a}, e_{b})\).
Given the above definitions, the solution to matching \(G_{1}\) and \(G_{2}\) is equivalent to finding the correspondence matrix \(C_{1,2} \in \{0,1\}^{N_{1}\times N_{2}}\) between the nodes of \(G_{1}\) and \(G_{2}\), that maximizes,
where \({\textbf {1}}_{C_{1,2}} \in \{0,1\}^{N_{1}\times N_{2}}\) is the characteristic function, and \({\textbf {K}} \in \mathbb {R}^{N_{1}N_{2}\times N_{1}N_{2}}\) is a composite affinity matrix that combines the node affinity matrix \(A^{P}_{1,2}\) and the edge affinity matrix \(A^{E}_{1,2}\). The element of \({\textbf {K}}((p_{i}p_{j})_{1}, (p_{k}p_{l})_{2})\) for the nodes \(p_{i}, p_{j} \in P_{1}\), \(p_{k}, p_{l} \in P_{2}\), and the edges connecting these nodes \(e_{a} \in E_{1}\), \(e_{b} \in E_{2}\) respectively, is calculated as,
An example is shown in Fig. 3. Intuitively, if the two nodes considered in each graph are co-located, i.e. there is no edge connecting them, then the element’s value is the similarity of the function \(\lambda ^{P}(.,.)\) for the nodes. If the two nodes are different, i.e. there is an edge connecting them, then the element’s value is the similarity of the function \(\lambda ^{E}(.,.)\) for the connecting edges; otherwise, it is set to 0.

Methods
Figure 2 and Algorithm 1 summarize the steps of the proposed technique. HybridFlow is the refined flow resulting from the interpolation of the combined initial flows calculated from the sparse graph matches from superpixels and feature matches of pixels in small clusters, as explained below.

Perceptual grouping and feature matching
Feature descriptors encode discriminative information about a pixel and form the basis of the perceptual grouping and matching. We conduct experiments with three different feature descriptors: rootSIFT proposed in Ref.28, pretrained DeepLab on ImageNet, and pretrained encoders with the same architecture as in Ref.25. As discussed later in the experimental results and “Implementation details” section, the latter descriptor results in the best performance. Next, we cluster pixels based on their feature descriptors to replace the rigid structure of the pixel grid as shown in Fig. 1b. Specifically, we classify each pixel as the argmax value of its N-dimensional feature descriptor and aggregate them into clusters. Thus, a pixel p is assigned a cluster index \(i_{p}\) given by,
where \(\mathscr {F}_{c}\) is the feature descriptor. Hence, this results in an arbitrary number of coarse-scale clusters in each image matched according to their cluster indices. A cluster may be non-contiguous. Since the index is calculated from the feature descriptor as in Eq. (3), it specifies the class of the object and is used during graph matching to match clusters of the same class, as explained in the following section.
Pixels contained in clusters with an area less than 10,000 are matched according to the similarity of their feature descriptors using the sum of squared differences (SSD) with a ratio-test. Outliers in the initial matches are removed from subsequent processing using RANSAC, which finds a localized fundamental matrix per cluster.
The initial sparse flow resulting from this step consists of the flow calculated from each of the inlier features. Figure 1f shows the initial flow resulting from the sparse feature matching of the pixels contained within all small clusters. The size of pixels is magnified by \(10 \times 10\) for clarity in the visualization.
Coarse-scale clusters with a larger area than 10,000 pixels are further clustered by a simple linear iterative clustering (SLIC) which adapts k-means clustering to group pixels into perceptually meaningful atomic regions29. The parameter \(\kappa \) is calculated based on the image size and the desired superpixel size and is given by \(\kappa = \frac{|I|}{|s|}\) where \(|s| \approx 2223, s \in \mathscr {S}\), and |I| is the size of the image. This restricts the number of the approximately equally-sized superpixels \(\mathscr {S}\); in our experiments discussed in “Implementation details” section, the optimal value for \(\kappa \) \(\approx 250\) to 300. For the finer-scale superpixels \(\mathscr {S}\), a graph is constructed where each node corresponds to a superpixel’s centroid, and edges correspond to the result Delaunay triangulation as explained in the following “Graph matching” section.
Graph matching
The two sets of superpixels contained in the matched coarse-scale clusters of images \(I_{1}, I_{2}\) are represented with the graph model described in “Graph model and matching” section. For each superpixel S, the nodes P are a subset of all the pixels p in S i.e. \(P \subseteq \{p : \forall p \in S \in I\}\). The edges E and topology T of each graph are derived from a Delaunay triangulation of the nodes P. The graph is undirected, and the edge-weight function w(., .) is symmetrical w.r.t. edges \(\vec{e_{a}}, \vec{e_{b}} \in E\), such that \(w(\vec{e_{a}}, \vec{e_{b}}) = w(\vec{e_{b}}, \vec{e_{a}})\). The similarity functions \(\lambda ^{P}(.,.)\) and \(\lambda ^{E}(.,.)\) are also symmetrical; for \(p_{i}, p_{j} \in P_{1}\), \(p_{k}, p_{l} \in P_{2}\), and edges \(e_{a} \in E_{1}\), \(e_{b} \in E_{2}\), the similarity functions are given by,
where \(\Phi ^{\circ }\) is given by,
\(f: P \longrightarrow S\) is a feature descriptor with cardinality S for a node \(p \in P\), \(\mathscr {C}: P \longrightarrow 6\) is a function which calculates the 6-vector \(<\mu _{r}, \mu _{g}, \mu _{b}, \sigma _{r}, \sigma _{g}, \sigma _{b}>\) containing color distribution means and variances (\(\mu , \sigma \)) at p modeled as a 1D Gaussian for each color channel, \(d^{P}: S \times S \longrightarrow \mathbb {R}\) is the \(\mathscr {L}^{1}\)-norm of the difference between the feature descriptors of two nodes in \(p_{i}, p_{j}, p_{k}, p_{l} \in P\), \(d^{E}: \mathbb {R} \times \mathbb {R} \longrightarrow \mathbb {R}\) is the difference between the angles \(\theta _{e_{a}}, \theta _{e_{b}}\) of the two edges \(e_{a}\in E_{1}, e_{b}\in E_{2}\) to the horizontal axes, and \(d^{\mathscr {C}}: 6 \times 6 \longrightarrow \mathbb {R}\) is the \(\mathscr {L}^{1}\)-norm of the difference between the two 6-vectors containing color distribution information for the two nodes in \(p_{i}, p_{j}, p_{k}, p_{l} \in P\).
\(\Phi ^{1}_{*}\) signify first-order similarities and measures similarities between the nodes and edges of the two graphs. In addition to the first-order similarities \(\Phi ^{1}_{*}\), the functions in the above equations define additional second-order similarities \(\Phi ^{2}_{*}\) which have been shown to improve the performance of the matching30. That is, instead of using only similarity functions that result in small differences between similar gradients/colours and large otherwise, e.g. first-order, we additionally incorporate the second-order similarities defined above, which measure the similarity between the two gradients and colours using the distance between their differences31. For example, the first-order similarity \(\Phi ^{1}_{gradient}\) calculates the distance between the two feature descriptors in the two graphs i.e. \(\lambda ^{P}(p_{i}, p_{k})\) in Eq. (4), whereas the second-order similarity calculates the distance between the feature descriptor differences of the end-points in each graph i.e. \(\Phi ^{2}_{gradient}\) and \(\Phi ^{2}_{color}\) in Eqs. (4) and (8). A descriptor \(f(s_{i})\), as defined in Eq. (6), is calculated for each centroid-node representing superpixel \(s_{i} \in \mathscr {S}\) as the average of the feature descriptors of all pixels contained within it \(f(s_{i}) = \frac{1}{|s_{i}|} \sum _{\forall p\in s_{i} \subset I} \phi _{p}\) where \(|s_{i}|\) is the number of pixels in superpixel \(s_{i}\), and \(\phi _{p}\) is the feature descriptor of pixel \(p\in s_{i} \subset I\).
Given the above function definitions, graph matching is solved by maximizing Eq. (1) using a path-following algorithm. \({\textbf {K}}\) is factorized into a Kronecker product of six smaller matrices which ensures tractable computational complexity on graphs with nodes \(N, M \approx 300\)32. Furthermore, robustness to geometric transformations such as rotation and scale is increased by finding an optimal transformation at the same time as finding the optimal correspondences and thus enforcing global rigid (e.g. similarity, affine) and non-rigid geometric constraints during the optimization33.
The result is superpixels matches within the matched coarse-scale clusters. Assuming a piecewise rigid motion, we use RANSAC to remove outliers from the superpixel matches. For each superpixel s having at least three matched neighbours, we fit an affine transformation. We only check whether the superpixel s is an outlier, in which case it is removed from further processing. This process is repeated for all small clusters and graph-matched superpixels. We proceed by matching the pixels contained within the matched superpixels based on their feature descriptors. Similar to earlier in “Perceptual grouping and feature matching” section, we remove outlier pixel matches contained in the superpixels using RANSAC to find a localized fundamental matrix.
The initial sparse flow resulting from graph matching consists of flow calculated from every pixel contained in the matched superpixels. Figure 1b shows the result of the clustering of the feature descriptors for the image shown in Fig. 1a. Clusters having a large area are further divided into superpixels. The graph nodes correspond to each superpixel’s centroid, and the edges result from the Delaunay triangulation of the nodes, as explained above. Figure 1c,d show the result of graph matching superpixels within a matched coarse-scale clusters. The matches are colour-coded, and unmatched nodes are depicted as smaller yellow circles. Examples of unmatched nodes appear in the left part of the left image in Fig. 1c. The images shown are from the benchmark dataset MPI-Sintel13.
Interpolation and refinement
The combined initial sparse flows (Fig. 1e,f) calculated from sparse feature matching and graph matching, as described above in “Perceptual grouping and feature matching” and “Graph matching” sections respectively, are first interpolated and then refined. For the interpolation, we apply an edge-preserving technique10. This results in dense flow as shown in Fig. 1g. In the final step, we refine the interpolated flow using variational optimization on the full-scale of the initial flows, i.e. no coarse-to-fine scheme, with the same data and smoothness terms as used in Ref.10. The final result is shown in Fig. 1h.
Experimental results
In this section, we report on the evaluation of HybridFlow on benchmark datasets and compare it with state-of-the-art variational optical flow techniques. In “Application: large-scale 3D reconstruction” section, we present two applications of the proposed technique on large-scale image-based reconstruction where ground truth is unavailable. Specifically, we use large-scale aerial imagery, and Full-Motion Video (FMV) captured from aerial sensors and demonstrate how our technique easily scales to ultra-high resolution images, in contrast to deep learning alternatives.
Datasets and evaluation metrics
We evaluate HybridFlow on the two widely used benchmark datasets for motion estimation:
-
MPI-Sintel13—a synthetic data set for the evaluation of optical flow derived from the open source 3D animated short film, Sintel. It includes image sequences with large displacements, motion blur, and non-rigid motion.
-
KITTI-201514—a real data set captured with an autonomous driving platform. It contains dynamic scenes of real world conditions and features large displacements and complex 3D objects.
The quantitative evaluation is performed in terms of the average endpoint error(EPE) for MPI-Sintel, and percentage of optical flow outliers(FI) for KITTI-2015.
Implementation details
The proposed approach was implemented by Q. Chen in Python. All experiments were run on a workstation with an Intel i7 processor. We extract the features descriptors using the approach introduced in Ref. RAFT25. Perceptual grouping using SLIC superpixels is performed using the method in Ref.29. We factorize graphs into Kronecker products as presented in Ref.32 and perform deformable graph matching following the approach in Ref.33. Finally, we interpolate the combined initial flows from sparse feature matching and graph matching using the edge-preserving interpolation and variational refinement in EpicFlow10.
Superpixel size
We empirically determined the optimal size of the superpixels which subsequently determined the number of superpixels \(\kappa \) as defined in “Perceptual grouping and feature matching” section. Figures 4 and 5 shows an example from the experiments on different superpixel sizes. The rows correspond to the superpixel sizes \(|s| = 22,323\) (20 superpixels), \(|s| = 2232\) (200 superpixels), \(|s| = 1116\) (400 superpixels) and \(|s| = 223\) (2000 superpixels) respectively. The first and second columns show the colour-coded matches using only the graph matching technique described in “Graph matching” section. Figure 4a shows a graph of the average endpoint error (EPE) of the final optical flow as a function of the superpixel size performed on the training image sequences of the MPI-Sintel dataset. In Fig. 4b we show the increase of the graph matching’s computational time as a function of the number of nodes in the graphs.

(a) Average end-point error (EPE) w.r.t number of graph nodes per image(\(1024 \times 436\)).(b) Average graph-matching time complexity(s) w.r.t. number of graph nodes. We empirically determine the optimal number of superpixels by performing graph matching using different superpixel sizes and calculate the EPE of the resulting optical flow. Optimal size is found to be \(|s| \approx 300\). (c) Ablation: Graph matching using SLIC clusters as the initial coarse-scale-clusters instead of clustering the feature descriptors. Superpixel clustering results in a near-rigid pixel grid that, as can be seen, is not robust to occlusions. The number of superpixels is set to 200. The first and second columns show the colour-coded matches of the graph nodes using graph matching based on an initial coarse-scale clustering of superpixels (SLIC).

Superpixel size. Graph-matching using different superpixel sizes. The images correspond to the examples of superpixel sizes \(|s| = 22,323\) (20 superpixels, Figures (a,b), \(|s| = 2232\) (200 superpixels, Figures (c,d), \(|s| = 1116\) (5 clusters subdivided into 80 superpixels, Figures (e,f) and \(|s| = 223\) (5 clusters subdivided into 400 superpixels,Figures (g,h)respectively. The figures show the colour-coded graph node matches using only graph matching as explained in “Graph matching” section.
Initial coarse-scale clustering
The initial coarse-scale clusters are formed by clustering the pixels’ feature descriptors. This is a crucial part of the process, which increases robustness to large displacements. As shown in Fig. 4c, using SLIC superpixels on the entire image results in a near-rigid rectangular pixel grid and consequently failures in graph matching. This is evident from the mismatching of the dark red circles in the middle of the right image. Our experiments show that an irregular pixel grid based on features descriptors increases the robustness in the presence of large displacements and deformations.
Comparison of clustering techniques
We compared initial coarse-scale clusters formed by (a) Delaunay triangulation of rootSIFT features, (b) SLIC superpixels, (c) Felsenszwalb’s34 graph-based image segmentation technique, and (d) our proposed clustering of feature descriptors. As shown in Fig. 6, initial coarse-scale clustering using SLIC, Felsenszwalb’s graph-based technique and Delaunay triangulation of rootSIFT features cause erroneous results in graph matching, which accumulate in the finer-scales. However, coarse-scale clusters based on clustering feature descriptors provide consistent and robust performance. The average endpoint error (EPE) for the Sintel images in Fig. 6 are 2.33, 2.12, 1.95 and 1.08 respectively. The last column shows the ground truth and below the resulting optical flow using each technique.

Graph Matching with different initial coarse-scale clustering methods on the pair of images shown in Figure (a). The initial coarse-scale clusters are resulting from Felsenszwalb’s34 graph-based segmentation (Figure (c), SLIC superpixels29 (Figure (e)), Delaunay triangulation of rootSIFT features (Figure (g)) and clustering of feature descriptors (Figure (i)). Figure (d,f,h,j) shows the optical flow results corresponding to each technique; ground truth shown in Figure (b).
Quantitative evaluations
On synthetic data (MPI-Sintel)
Table 1 shows the average endpoint error (EPE) on the MPI-Sintel ‘clean’ and ‘final’ (realistic rendering effect) image dataset for HybridFlow and other state-of-the-art variational optical flow techniques. We present our results using three types of pixel-wise descriptors: (i) rootSIFT descriptors, named as HybridFlow(SIFT), (ii) features descriptors extracted from a pre-trained ResNet35 trained on Sintel, named as HybridFlow(DeepLab), and (iii) descriptors learned by feature and context encoder as in RAFT25, name as HybridFlow. HybridFlow outperforms all other state-of-the-art variational techniques and gives comparable results to the deep-learning-based techniques with an average overall EPE of 5.121 in MPI-Sintel ‘final’ datasets.
On real data (KITTI-2015)
Table 1 shows the results for HybridFlow and other non-stereo-based optical flow methods on the 200 KITTI-2015 test images. Although HybridFlow does not have the best overall performance, it outperforms all variational techniques on the non-occluded test-set and has comparable performance for the other categories. Specifically, the percentage of background, foreground, and overall outliers are 31.06%, 17.25%, and 29.27%, respectively. The percentages of outliers for non-occluded areas are 16.96%, 14.18%, and 16.54%.
Failure cases
Graph matching is robust to texture variations, illumination variations, and deformations. However, erroneous matches can be introduced when large occluded areas fall inside the convex graph, as shown in the example in Fig. 4c. Mismatches in the graph matching can lead to the wrong matching of the finer-scale superpixels, and consequently, significant errors in the optical flow. This is clearly evident from the results in Table 1 for Sintel and KITTI-2015, where for the non-occluded test-sets, HybridFlow outperforms all state-of-the-art variational methods and matches the performance of deep-learning techniques such as ScopeFlow.
Application: large-scale 3D reconstruction
The motivation for our work is large-scale 3D reconstructions from airborne images. In particular, we focus on full-motion video (FMV) and large-scale aerial imagery, typically captured by a UAV/helicopter and an airplane, respectively. Deep learning techniques are not applicable since they have a fixed input size. Thus, a very high-resolution image must be scaled-down to typically less than \(1{\text{ K}} \times 1{\text{ K}}\) to be used as input to the network. This significant reduction in resolution leads to low-resolution optical flow and significantly low-fidelity 3D models. Most notably, there is no ground truth dataset for real scenarios to train the deep learning models. On the other hand, the state-of-the-art variational methods considered in this work also impose restrictions on the input image size. For example, RicFlow and EpicFlow use a hierarchical structure employed by DeepMatching, which on an 8GB GPU can only handle \(1{\text{ K}} \times 1{\text{ K}}\) resolutions. HybridFlow can handle arbitrary-sized resolutions with a low memory footprint. In this section, we present the results of the application of HybridFlow on the use case of large-scale 3D reconstruction from airborne images. We reiterate that there is no ground truth data for training models in such scenarios, and the resolutions can be significantly higher than \(1K \times 1K\).
Image-based large-scale reconstruction
Image-based reconstruction involves three main components: (1) Structure-from-Motion (SfM) for camera pose estimation, (2) Bundle Adjustment optimization, and (3) Multi-View Stereo (MVS). In contrast, we reformulate the reconstruction as a single-step process. Using HybridFlow allows us to triangulate directly the dense matches without MVS as a post-processing step, therefore achieving faster reconstructions.

On-disk dynamic tensor-shaped data structure. For each image, we store a tensor with layers containing pixel-level matches to subsequent images based on the HybridFlow. Unmatched pixels in the second image are stored in the tensor data structure for the second image, which contains layers with pixel-level matches to the third image and onward. A fiber is shown in blue. Each cell contains the match of that pixel, i.e. the top right corner in all subsequent images. Reconstruction is reduced to triangulating the matches contained within each fiber.
We design a specialized off-memory, on-disk data structure for storing the matches. As shown in Fig. 7, at every image, we keep a tensor with layers containing pixel-level matches to subsequent images based on the HybridFlow. Unmatched pixels in the second image are stored in the tensor data structure for the second image, which contains layers with pixel-level matches to the third image and onwards. The data structure can scale up dynamically to arbitrary-sized datasets (subject to the disk limits) and allows for efficient outlier removal and validation, i.e. multiple pixels in the same image cannot be matched to the same pixel in the following image. A simple look-up at a fiber of the tensor gives the matches for that pixel in all subsequent images. Hence, reconstruction is reduced to traversing all fibers in each tensor and triangulating to get a 3D position.
We demonstrate the effectiveness of HybridFlow on large-scale reconstruction from images and present result on two different types of datasets: full-motion video, and large-scale aerial imagery. We followed the single step process described above employing the dynamic tensor-shaped data structure for the efficient processing of the matches calculated by HybridFlow.
Full-motion video
Full-motion video (FMV) is typically captured by a helicopter at an oblique aerial angle so that the rooftops and the facades of the buildings are visible in the images. The ground sampling density is significantly higher than that of a satellite image, i.e. in the order of a few cms, and can vary according to the aircraft’s flight height, depending on the area it is flying over.
We ran experiments on a full-motion video dataset containing images taken from a helicopter circling an area containing a few mockup buildings. Our test dataset contains 71 images with resolution \(1280 \times 720\) with unknown camera calibrations or EXIF information. We report results using the (i) single-step reconstruction using HybridFlow matches, the (ii) same single-step reconstruction using EpicFlow matches, (iii) and the state-of-the-art incremental SfM techniques Bundler38, VisualSFM39, COLMAP40.
Perhaps the most popular feature extraction methods used in SfM is SIFT41. In COLMAP40, they use a modified version called RootSIFT28 for extracting and matching each image. The first comparison focuses on the density of the matches. Figure 8c shows the SIFT matches, Fig. 8d the RootSIFT matches, Fig. 8e the EpicFlow matches, and Fig. 8f the HybridFlow matches for the input images shown in Fig. 8a,b. The latter two show the matches as colour-coded optical flows for visualization clarity, otherwise drawing the matches will cover the entire image. Table 2 presents the total number of matches per technique. As expected, SIFT and RootSIFT have the lowest number of matches since they only extract scale-space extrema. On the other hand, the dense optical flow technique EpicFlow results in eight times lower number of matches than HybridFlow.
The reconstruction can serve as a proxy for the accuracy of the matches in cases where ground truth is not available. We proceed with the evaluation of the reconstruction in terms of the reprojection error. Figure 9 shows the reconstructed pointcloud of (a) COLMAP’s sparse (SfM) reconstruction, (b) COLMAP’s dense (MVS) reconstruction, (c) our single-step reconstruction using HybridFlow matches, and (d) our single-step reconstruction using EpicFlow matches. The reconstructed point clouds are rendered from the same viewpoint and camera intrinsics. The reprojection error using our single-step method with HybridFlow achieves the highest number of reconstructed points in the lowest time per point, while the reprojection error is comparable with COLMAP for almost 60x more points.


The reconstruction serves as a proxy to the accuracy of the matches. We calculate and compare reprojection errors for the techniques shown in Table 2. (a) Shows COLMAP’s sparse (SfM) reconstruction, (b) shows COLMAP’s dense (MVS) reconstruction40, (c) shows our single step reconstruction using dense matches from Epicflow10, and (d) shows our single step reconstruction with Hybridflow. HybridFlow produces 60\(\times \) more matches than COLMAP and 47\(\times \) more matches than EpicFlow. The reprojection error is comparable with COLMAP (for 60\(\times \) more points) while the runtime is less than half.
Large-scale aerial imagery
Large-scale Aerial Imagery is captured by an aircraft flying at over 10,000 ft and can cover areas of 10–20 km\(^2\). The aircraft orbits around the area of interest during the flight, and an array of cameras captures and streams image data at about two frames per second.
Figure 10a shows an example of large-scale aerial imagery capturing a downtown urban area. The resolution is \(6600 \times 4400\) is considered average amongst large-scale aerial imagery, since some of the larger resolutions can reach sizes of up to \(14,000 \times 12,000\). Deep learning techniques can be applied only (i) by rescaling the image to the fixed input size expected by the neural network, or (ii) tiling the image, calculating flows per tile, and then merging the results. In the first case, rescaling reduces the resolution and subsequently the final number of reconstructed points. Furthermore, essential details such as cars and trees are completely removed. In the latter case, there is no one-to-one mapping between tiles. For example, a tile may contain areas appearing in two or more different tiles in the second image. Furthermore, the deep optical flow techniques always return a match for every pixel. That means that even if an area is not present in a tile, this will nevertheless be matched to another area in the second image. For these reasons, deep learning techniques cannot be applied in these use cases.

(a,b) Are two consecutive large-scale aerial images of a downtown urban area with resolution \(6600 \times 4400\), © His Majesty the King in Right of Canada, as represented by the Minister of National Defence, 2022. (c) HybridFlow is the only top-performing variational method that can handle high-resolution images. Deep learning techniques cannot be applied due to the fixed input size of the networks as explained in the text. (d) Image resampled from (a) using HybridFlow flows in (c) to form (b). (e) Reconstructed pointcloud using 320 images.
Competing variational methods such as RicFlow12, EpicFlow10 cannot be applied either since hierarchical structure employed by DeepMatching17, which on an 8GB GPU can only handle \(1{\text{ K}} \times 1{\text{ K}}\) resolutions. In contrast, HybridFlow is the only top-performing variational method that can handle arbitrary-sized images such as large-scale aerial imagery. Figure 10a,b shows two consecutive images capturing a downtown urban area having a resolution of \(6600 \times 4400\). HybridFlow is the only top-performing variational method that can handle high-resolution images as shown in Fig. 10c. Deep learning techniques cannot be applied due to the fixed input size of the networks. Similarly, competing state-of-the-art variational methods cannot be applied for this size of images as explained above. Figure 10d shows the resampled image from Fig. 10b using the HybridFlow matches in Figure 10c and the matched pixels in Fig. 10a. Figure 10e shows a render of the reconstructed pointcloud for the downtown urban area generated using 320 images of the same size.
Conclusion
We addressed the problem of large displacement optical flow and presented a hybrid approach based on sparse feature matching using feature descriptors and graph matching, named HybridFlow. In contrast to state-of-the-art, it does not require training, and the use of sparse feature matching is robust and can scale up to arbitrary image sizes. This makes our technique applicable in use-cases such as reconstruction or object tracking where ground-truth is unavailable, and processing must be performed in interactive time. We match initial coarse-scale clusters based on a clustering of context features. We employ graph matching to match perceptual groups clustered using SLIC superpixels within each initial coarse-scale cluster, and perform pixel matching on smaller clusters. Based on the combined feature matches and the graph-node matches, we calculate the initial flow which is interpolated using an edge-preserving interpolation and refined using variational refinement. The proposed technique has been evaluated on two benchmark datasets (Sintel, KITTI), and we compared it with the current state-of-the-art variational optical flow techniques. We show that HybridFlow surpasses all other state-of-the-art variational methods in non-occluded test sets. Specifically, for Sintel, HybridFlow has the lowest overall EPE, while for KITTI, it gives comparable results.
Data availability
The datasets generated and analysed during the current study are available online: Sintel44 http://sintel.is.tue.mpg.de/, and KITTI45 http://www.cvlibs.net/datasets/kitti/ benchmark datasets.
Change history
14 December 2022
A Correction to this paper has been published: https://doi.org/10.1038/s41598-022-26246-3
References
Wang, Y. et al. Unos: Unified unsupervised optical-flow and stereo-depth estimation by watching videos. In Proc. IEEE Conference on Computer Vision and Pattern Recognition, 8071–8081 (2019).
Porzi, L. et al. Learning multi-object tracking and segmentation from automatic annotations. In Proc. IEEE/CVF CVPR, 6846–6855 (2020).
Piergiovanni, A. & Ryoo, M. S. Representation flow for action recognition. In Proc. IEEE CVPR, 9945–9953 (2019).
Yu, J. & Ramamoorthi, R. Learning video stabilization using optical flow. In Proc. IEEE/CVF CVPR, 8159–8167 (2020).
Gibson, J. J. The Perception of the Visual World (Houghton Mifflin, 1950).
Hur, J. & Roth, S. Iterative residual refinement for joint optical flow and occlusion estimation. In Proc. IEEE CVPR, 5754–5763 (2019).
Luo, C. et al. Every pixel counts++: Joint learning of geometry and motion with 3d holistic understanding. IEEE TPAMI 42, 2624–2641 (2019).
Liu, P., Lyu, M., King, I. & Xu, J. Selflow: Self-supervised learning of optical flow. In Proc. IEEE CVPR, 4571–4580 (2019).
Bar-Haim, A. & Wolf, L. Scopeflow: Dynamic scene scoping for optical flow. In Proc. IEEE/CVF CVPR, 7998–8007 (2020).
Revaud, J., Weinzaepfel, P., Harchaoui, Z. & Schmid, C. Epicflow: Edge-preserving interpolation of correspondences for optical flow. In Proc. IEEE CVPR, 1164–1172 (2015).
Hu, Y., Song, R. & Li, Y. Efficient coarse-to-fine patchmatch for large displacement optical flow. In Proc. IEEE Conference on Computer Vision and Pattern Recognition, 5704–5712 (2016).
Hu, Y., Li, Y. & Song, R. Robust interpolation of correspondences for large displacement optical flow. In Proc. IEEE Conference on Computer Vision and Pattern Recognition, 481–489 (2017).
Butler, D. J., Wulff, J., Stanley, G. B. & Black, M. J. A naturalistic open source movie for optical flow evaluation. In European Conference on Computer Vision, 611–625 (Springer, 2012).
Menze, M., Heipke, C. & Geiger, A. Joint 3d estimation of vehicles and scene flow. In ISPRS Workshop on Image Sequence Analysis (ISA) (2015).
Horn, B. K. & Schunck, B. G. Determining optical flow. In Techniques and Applications of Image Understanding Vol. 281 (ed. Pearson, J. J.) 319–331 (International Society for Optics and Photonics, 1981).
Anandan, P. A computational framework and an algorithm for the measurement of visual motion. Int. J. Comput. Vis. 2, 283–310 (1989).
Revaud, J., Weinzaepfel, P., Harchaoui, Z. & Schmid, C. Deepmatching: Hierarchical deformable dense matching. IJCV 120, 300–323 (2016).
Ilg, E. et al. Flownet 2.0: Evolution of optical flow estimation with deep networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1647–1655. https://doi.org/10.1109/CVPR.2017.179 (2017).
Sun, D., Yang, X., Liu, M. & Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8934–8943. https://doi.org/10.1109/CVPR.2018.00931 (2018).
Ranjan, A. & Black, M. J. Optical flow estimation using a spatial pyramid network. In 2017 IEEE CVPR, 2720–2729. https://doi.org/10.1109/CVPR.2017.291 (2017).
Ren, Z. et al. Unsupervised deep learning for optical flow estimation. In Thirty-First AAAI Conference on Artificial Intelligence (2017).
Meister, S., Hur, J. & Roth, S. UnFlow: Unsupervised learning of optical flow with a bidirectional census loss. In AAAI (2018).
Yin, Z. & Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018).
Liu, P., Lyu, M., King, I. & Xu, J. Selflow: Self-supervised Learning of Optical Flow, 4566–4575. https://doi.org/10.1109/CVPR.2019.00470 (2019).
Teed, Z. & Deng, J. Raft: Recurrent all-pairs field transforms for optical flow (extended abstract). In Proc. Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21. Sister Conferences Best Papers (eds. Zhou, Z.-H.), 4839–4843 (International Joint Conferences on Artificial Intelligence Organization, 2021).
Jiang, S., Campbell, D., Lu, Y., li, H. & Hartley, R. Learning to estimate hidden motions with global motion aggregation. In The International Conference on Computer Vision (ICCV) (2021).
Dokeroglu, T., Sevinc, E. & Cosar, A. Artificial bee colony optimization for the quadratic assignment problem. Appl. Soft Comput. 76, 595–606 (2019).
Arandjelovic, R. & Zisserman, A. Three things everyone should know to improve object retrieval. In Conference on Computer Vision and Pattern Recognition, 2911–2918 (2012).
Achanta, R. et al. Slic superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 34, 2274–2282 (2012).
Cho, M., Lee, J. & Lee, K. M. Reweighted random walks for graph matching. In European Conference on Computer Vision, 492–505 (Springer, 2010).
Tian, Y. et al. Sosnet: Second order similarity regularization for local descriptor learning. In Proc. IEEE Conference on Computer Vision and Pattern Recognition, 11016–11025 (2019).
Zhou, F. & De la Torre, F. Factorized graph matching. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, 127–134 (IEEE, 2012).
Zhou, F. & De la Torre, F. Deformable graph matching. In 2013 IEEE Conference on Computer Vision and Pattern Recognition, 2922–2929 (IEEE, 2013).
Felzenszwalb, P. F. & Huttenlocher, D. P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 59, 167–181 (2004).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. CoRR. http://arXiv.org/abs/1512.03385 (2015).
Maurer, D., Marniok, N., Goldluecke, B. & Bruhn, A. Structure-from-motion-aware patchmatch for adaptive optical flow estimation. In Proc. European Conference on Computer Vision (ECCV), 565–581 (2018).
Li, Y., Hu, Y., Song, R., Rao, P. & Wang, Y. Coarse-to-fine patchmatch for dense correspondence. IEEE Trans. Circuits Syst. Video Technol. 28, 2233–2245 (2017).
Snavely, N., Seitz, S. M. & Szeliski, R. Photo tourism: Exploring photo collections in 3d. In SIGGRAPH Conference Proceedings, 835–846 (ACM Press, 2006).
Wu, C., Agarwal, S., Curless, B. & Seitz, S. M. Multicore bundle adjustment. In CVPR 2011, 3057–3064 (IEEE, 2011).
Schonberger, J. L. & Frahm, J.-M. Structure-from-motion revisited. In Proc. IEEE Conference on Computer Vision and Pattern Recognition, 4104–4113 (2016).
Lowe, G. Sift-the scale invariant feature transform. Int. J. Comput. Vis. 60(2), 2 (2004).
Furukawa, Y. & Ponce, J. Accurate, dense, and robust multi-view stereopsis (pmvs). In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vol. 2 (2007).
Schönberger, J. L., Zheng, E., Frahm, J.-M. & Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In European Conference on Computer Vision, 501–518 (Springer, 2016).
Butler, D. J., Wulff, J., Stanley, G. B. & Black, M. J. A naturalistic open source movie for optical flow evaluation. In European Conf. on Computer Vision (ECCV), Part IV, LNCS 7577 (eds. Fitzgibbon, A. et al.), 611–625 (Springer, 2012).
Menze, M. & Geiger, A. Object scene flow for autonomous vehicles. In Conference on Computer Vision and Pattern Recognition (CVPR) (2015).
Acknowledgements
This research is based upon work supported by the Natural Sciences and Engineering Research Council of Canada Grants Nos. N01670 (Discovery Grant) and DNDPJ515556-17 (Collaborative Research and Development with the Department of National Defence Grant). Special thanks to Jonathan Fournier for his support and invaluable discussions, and for providing access to the datasets.
Author information
Authors and Affiliations
Contributions
All authors wrote and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained errors in the legends of Figure 8 and 10. Full information regarding the corrections made can be found in the correction for this Article.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, Q., Poullis, C. Motion estimation for large displacements and deformations. Sci Rep 12, 19721 (2022). https://doi.org/10.1038/s41598-022-21987-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-21987-7
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
