
Abstract
Accurate classification of brain tumor subtypes is important for prognosis and treatment. Researchers are developing tools based on static and dynamic feature extraction and applying machine learning and deep learning. However, static feature requires further analysis to compute the relevance, strength, and types of association. Recently Bayesian inference approach gains attraction for deeper analysis of static (hand-crafted) features to unfold hidden dynamics and relationships among features. We computed the gray level co-occurrence (GLCM) features from brain tumor meningioma and pituitary MRIs and then ranked based on entropy methods. The highly ranked Energy feature was chosen as our target variable for further empirical analysis of dynamic profiling and optimization to unfold the nonlinear intrinsic dynamics of GLCM features extracted from brain MRIs. The proposed method further unfolds the dynamics and to detailed analysis of computed features based on GLCM features for better understanding of the hidden dynamics for proper diagnosis and prognosis of tumor types leading to brain stroke.
Similar content being viewed by others


Introduction
For proper treatment, prognosis, planning and monitoring of brain tumor, an accurate intelligent algorithm is required1. The brain tumor types is still a challenges, as MRIs cannot make definitive diagnosis of brain tumor subtypes2. Various computer assisted and machine learning algorithms have been developed to assist the doctors for proper diagnosis of brain tumor subtypes. Feature extraction is one of the most crucial parts, which require most relevant methods to generate the features from raw images. Selecting the most relevant features is tedious task which require the knowledge domain. Researchers in the recent past computed the different categories of features including texture, morphological, scale invariant Fourier transform (SIFT), elliptic Fourier descriptors (EFDs) for prediction of pathologies in medical imaging problems3,4,5,6,7,8. These features are utilized as input to different machine learning algorithms9. Researchers developed different machine learning classification algorithms for brain tumor type classification10,11,12,13,14,15,16,17,18,19,20,21,22,23,24.
Accurate classification of brain tumor subtypes is important for treatment, planning, prognosis, and monitoring etc.1. MRI25 provides valuable diagnostic information to characterize brain tumors2, but challenges lie in the ability to classify different tumor types. In contrast to pathology, MRIs cannot make definitive diagnoses of brain tumor subtypes. The machine learning algorithms such as support vector machines (SVM)10,11,12,13,14,15,16,17,18,19, Adaboost21, random forest20 and instance-based K-Nearest using log19,22 relied on hand-crafted features including discrete wavelet transform (DWT)10,11,16,20,23,24, gray-level co-occurrence matrix (GLCM)10,11,14,17 and genetic algorithm26 etc.
The previous studies include the multiclass classification based on machine learning and deep learning using diver feature extraction approaches. However, a more comprehensive analysis to determine the associations and other Bayesian measures can further strengthen our analysis to unfold the hidden dynamics for further improving the diagnostic capabilities. The parametric information from the data in the recent studies have been investigated using a probabilistic propagation algorithm (Bayes Rule) by applying Bayesian networks (BNs). The associations and degree of uncertainty of the variables varies from different sources such as numerical data, empirical data, expert opinion etc. to capture the conditional dependencies of a variable upon others27. BNs have successfully been utilized in many studies by different researchers such as Kocian et al.28, Amaral et al.29, Laurila-Pant et al.30, Zhang et al.31. The causal relationships can be studied between variables which compute the probabilities of a variable when other variables in the model are known. Moreover, the Monte Carlo analysis (MCA) can be used at random sampling of probability distribution functions (PDF) to denote the inputs of Bayesian model to produce hundreds or thousands of possible outcomes32. Recently, BNs have successfully been utilized in many applications ranging from predicting energy crop yield33, prediction of coffee rust disease using Bayesian networks34, sustainable planning and management decision35, etc. The Bayesian networks computed the interrelation among variables that impacts climate changes scenarios in agriculture36. Moreover, recently, Lu et al.37 utilized BNs to investigate the complex causal interactions between environments and plant diseases. Hussain et al.38 computed the morphological features and determine the association from prostate cancer MRIs.
In the past, researchers utilized machine learning and deep learning algorithms to classify the brain tumor types and other cancerous pathologies5,39,40,41,42. The machine learning algorithms requires hand-crafted features for training the models and predicting for new examples. The classification performance merely based on type and relevancy of extracted feature. The researchers utilized the different features extracting approaches including texture, morphological, geometric, scale invariant feature transform (SIFT), elliptic Fourier descriptors (EFDs) etc. as extracting the most relevant feature is challenging which can be very helpful to improve the classification performance. The classification tasks based on computed features can only provide the classification performance, however association among features, in-depth parent–child relationships, strength of relationship, degree and features incoming and outgoing force, computed segments profile analysis, impact of posterior probabilities can further unfold the hidden and nonlinear dynamics of extracted features, which can be very much helpful for the concerned radiologists and health practitioners for making the wise decisions for further prognosis and diagnosis of brain tumor. The aim of this study was to apply the Bayesian inference approach for comprehensive analysis in order to unfold the nonlinear and hidden dynamics present in brain tumor MRI types (meningioma and pituitary) by extracting the gray-level co-occurrence (GLCM) features and to compute the associations, and strength of relationships among features. The Bayesian approach recently gain its popularity and utilized in many biomedical signal and image processing problems. The Bayesian inference estimates the posterior which can be produced from a weighted combination of local estimates also known as likelihood and estimates in surrounding spatial units. Researchers are developing intelligent methods based on Machine learning which requires the extraction of most relevant features. Our research objective was multifold, as the Bayesian analysis is based on target node for which we first requires the top ranked features among the extracted features. We first we computed the GLCM based texture features from brain tumor meningioma and pituitary images. We then ranked the features based on entropy value using MATLAB diagnosticFeatureDesigner tool. The higher the entropy value indicate the more important feature. Secondly, the high ranked feature was selected as our target node and then we further computed the detailed Bayesian analysis with other features to compute the underlying hidden dynamics among the nodes. We computed the relationship analysis among the extracted nodes using mutual information (MI), Kullback–Leibler (KL) divergence and Pearson’s correlation. The strength of relationship was computed using arc analysis with 3D mapping. We then computed the parent–child relationship and nodes force between the nodes. The association graph for segment profile analysis was computed for further analysis. Moreover, the network performance and significance of prominance was computed using tarnando diagram. The radar chart also reflects the importance of significance of target node with other nodes at different selected states. In most of the states, we obtained significant results using the statistical tests. Which indicates the stronger binding of target Energy node with other computed GLCM features. The target’s posterior probabilities at selected states also shows the great influence on target variable. The network performance also shows the highest significant results with respect to reliability, occurrence, precision, and Gini index. This study can be very helpful to understand the deeper insights to further investigate the hidden dynamics in the MRI signals from Brain tumor types and can play a vital role for providing improved diagnostic system. The concerned radiologists can utilize this analysis as a biomarker for improved diagnosis and prognosis, treatment planning, recurrence.
Materials and methods
Dataset
A publicly dataset was taken available at (https://github.com/chengjun583/brainTumorRetrieval) which is described in43,44. It comprised of 3064 T1-weighted contrast enhanced images from 233 patients. The dataset contains three types of brain tumor such as and meningiomas (708 slices), pituitary tumor (930 slices) and gliomas (1426 slices). In this study, we applied the Bayesian inference approach for comprehensive analysis between the two selected classes of pituitary and meningioma.
Feature extraction
In machine learning, the first and foremost step is to compute the most relevant features which are quantitative values computed on images. Researchers proposed a set hybrid and single features for classifying images5. Likewise, different image segmentation and classification algorithms are then utilized to classify malignant or benign cases45.
Feature plays a vital role in image processing. After applying image processing techniques to the captured image, different feature extracting techniques are applied to obtain the features used in classification. The behavior of an image can be defined by its features. Feature extraction is a type of dimensionality reduction in image processing. Extracting most relevant and required information from the data is one of the main objectives of feature extraction46.
In previous studies, numerous researchers have extracted many features for detecting various imaging pathologies by considering texture, shape-based morphologies, and image scaling and rotation changes and complex dynamics using SIFT, morphological, textural, EFDs and some other most relevant features regarding the nature of the problem of interest4,5,7,47,48. The feature extracted developed and employed in our previous studies are detailed in7,49,50,51,52,53. In this study, we first computed the Gray-level co-occurrence matrix-based texture features.
Gray-level co-occurrence matrix (GLCM)
The GLCM based texture features extracted from input images by performing transition on two pixels with gray level. GLCM features are originally proposed in 197354 which characterizes the texture properties by utilizing diverse quantities yielded from 2nd order statistics. Two steps are used to compute GLCM features. Firstly, the pair-wise spatial co-occurrences of image pixels are separated by a distance d in a particular direction angle θ. A spatial relationship is created between two pixels i.e. the neighboring and reference pixels. Secondly, scaler quantities are computed to characterize several aspects of an image by forming gray level co-occurrence matrix which contain several gray level pixel combinations of different values of an image54. The GLCM is a square matrix of order M × M, where M denote the gray level number of image. The distance d = 1, 2, 3, 4 and angle 0°, 45°, 90° and 135° direction are used to obtain GLCM features. The GLCM contain an element \(P(i,\;j,\;d,\;\theta )\), which shows two pixels probability separated by a distance d and angle θ having gray levels of i and j55,56,57. The detailed mathematical formulations are described and utilized in5,58,59,60. We extracted the GLCM texture features from Brain tumor types developed in MATLAB and utilized in many recent renowned studies for texture analysis61,62,63,64 available at https://www.mathworks.com/matlabcentral/fileexchange/22187-glcm-texture-features.
Feature importance
After computing the features from images, all features are not contributing equally, as few features contribute less and few other more. Their importance can be computed using the feature ranking algorithms. The feature ranking algorithm is used to rank the importance of features65. We used the feature importance ranking (FIR) algorithms developed in MATLAB66 available at https://www.mathworks.com/help/predmaint/ref/diagnosticfeaturedesigner-app.html.
The importance of the extracted features was computed based on the entropy values. Entropy is used in many applications of medical systems to compute their nonlinear dynamical measures present in these systems. Yu et al.66 developed MATLAB tool with a total of 30 FIR methods integrated that utilized the feature selection and intelligent diagnosis in real world application. All the ranking methods are detailed in our recent study67. For the current study, we utilized the method (17) fir_mat_entropy, which computes the features based on relative entropy also called as Kullback–Leibler distance68. The entropy is a measure of randomness which computes the nonlinear dynamics as detailed in49,69,70. The higher the entropy values indicate the more complex systems with interacting components and accordingly is the more important feature. So, among the extracted GLCM features, the Energy feature with higher entropy (3.0693) was yielded as our high ranked feature. We then chosen Energy as our target node, and Bayesian analysis was applied with the top ranked feature to further explore the associations, and relationships with other features. Multiple interacting modules of biological systems produce biological signals. which show different arrangements in a complex rhythm. Due to structural part malfunctions and decreased interactions in coupling functions, these rhythms and patterns are disrupted. After ranking the features, the top ranked feature was Energy with higher entropy value. We then kept this feature as our target variable and applied the Bayesian inference approach for further comprehensive analysis with other features so we can develop multiple interacting relationships with the top ranked feature, which could be used as a biomarker for further enhanced diagnosis and prognosis of brain tumor.
Bayesian network analysis
The causal effect and their relationship was computed using Bayesian inference approach using directed acyclic graph (DAG)71. The Bayesian networks compute the conditional joint probabilities to determine the dependencies between the attributes. This is a probabilistic graphical network and is represented by a directed acyclic graph of nodes denoting the variables and arcs denote dependence relationships among the variables. Bayesian networks denote the joint probability distribution (JPD) over all variables represented by nodes in the graph. If \(x_{i}\) denote some value of variable \(X_{i}\) and \(Pa_{i}\) represent some set of values for parents of \(X_{i}\), then \(P(X_{i} { }|Pa_{i} )\) represent conditional probability distribution33. The joint probability distribution P of a Bayesian network B = (G, P) can mathematically expressed as:
Here \(Pa \left( {X_{i} } \right)\) denotes the set of random variables associated with the parents of the nodes corresponding to variable \(X_{i}\).
The posterior probability is thus computed by utilizing this algorithm through inference of variable of interest. We used BayesiaLab V10 for further analysis72 utilizing the supervised learning algorithms to search optimal model.
Mutual information (MI)
To compute MI, first Shannon entropy73 was computed:
The difference between the marginal entropy of target variable and conditional entropy of predicted variable was computed using MI73, mathematically:
Which is equivalent to:
Moreover, conditional Mutual Information (CMI) is defined as:
The joint probability distribution (JPD) of variable X and Y is denoted by p (X, Y). Whereas p(X) and p(Y) represent marginal distribution of X and Y respectively. The relevant Gaussian distribution of co-variance matrix variables X1, X2, X3, …. Xn74 computed as:
The MI and CMI2 can be computed using following mathematical transformation function:
To correct under estimation of CM175, the CMI2 is used to integrate the interventional probability.
Statistical analysis
We computed the GLCM features from pituitary and meningioma MRIs using MATLAB. We then provided the feature matrix to BayesiaLab for further detailed analysis. We conducted the analysis using BayesiaLab 7.0. We used the BayesiaLab with minimum description length of candidate network in its score-based algorithm to compare the Bayesian network structure76. The statistical independence test (GKL-test; p-values > 0.05) was used to validate the connections among the descriptors which were identified by the learning algorithm. The p-values or independence probabilities were utilized to check the significance of each individual relationship between the nodes or between the nodes and the target node77,78.
Exploratory analysis of the unsupervised network
The exploratory analysis can be utilized to determine the potential relationship between variables of interest79. We can further explore the global analysis of problem of interest by computing influence between nodes and influence of nodes under investigation. We build our model by learning unsupervised learning algorithm utilizing maximum spanning tree algorithm approach developed in BayesiaLab V1080. This method reduces the search space efficiently to a partially directed acyclic graph (PD AG) smaller than space of Bayesian networks (DAGs) represent equivalent classes evaluated during each search by computing directly their scores. We also computed maximum spanning tree (MWST). A lowest minimum description length (MDL) value shows the best trade-off between complexity and data representation.
Sensitivity analysis
A detailed sensitivity analysis was performed to check the relationship among the nodes in the selected network. To understand the relationship between the nodes, we computed the highest and lowest values of Pearson’s correlation, mutual information, Kullback–Leibler divergence and node force between the nodes was examined globally on the network. The mutual information examined the probabilistic dependencies between the nodes in the network. The Pearson’s correlation computes linear strength of the relationship between the nodes, whereas the Kullback–Leibler divergence was utilized to measure information gain from assuming a joint relationship between two variables in the network compared to an assumption of independence. The node force was also computed, the highest node force indicates that there is more direct relationship and greater dependence with other nodes. The sensitivity of each node was determined in tornado plots that display the influence of knowledge of each node value on the probability of each descriptor and provides information on the maximum strength of the individual relationships between each node and descriptor. The lowest and highest probability values are displayed from the tornado plots to achieve the tornado plots for each node from hard evidence placed on the corresponding descriptor state.
In a Bayesian network (BN), the sensitivity analysis is conducted to determine the most critical factors for a specific result of a specific scenario. This analysis provides the strengths or magnitude of the two-way association between the child and parent node. Using sensitivity analysis, we analyse the impact on other parameters or nodes. Two types are variations are considered, simple either variations are made in only one parameter, or complex in which multiple parameters are considered. The joint probability distribution and network parameters are used for reliable, authentic, and holistic81,82. The BNs are considered to exhibit a practical and robust interaction between the considered variables through the induced variations in the selected parameters. In this study, the sensitivity analysis was performed by conducting BayesiaLab package called “Tornado Charts”. This chart displays the minimum and maximum contribution of all the variables in a model towards a specific node and state which is specified as the target node and state. The confidence and consistency level of the sensitivity analysis using the BN model are verified by validating the model83,84,85 to verify different conditions.
Segment profile analysis of energy
The analysis was also done using segment profile analysis using Radar chart for normalized mean values conditionally to energy for all other GLCM features. The significance was tested using Bayesian test (Best) and NHST t test (a frequentist test). Using NHST t test, the two tailed t test is utilized for null hypothesis significance testing. The Bayesian (Best test) is detailed by Kruschke86 which follow the student’s t distribution. Moreover, 95% confidence interval (CI) is utilized. When the mean values are estimated significant, a square is added next to the Label.
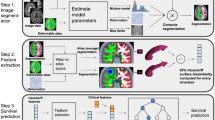
The Fig. 1a shows the flow of our algorithm. We first taken brain MRI images as input and extracted the GLCM based texture feature. We then ranked the features based on entropy method. We then applied different methods of Bayesian inference by computing optimization tree, posterior probabilities, likelihood, prior and posterior means, tornado graphs, radar graphs, association of target variable with other nodes etc. The performance was evaluated, and results reveal the highly significant results. The Fig. 1b reflects the few examples of extracted GLCM features with set of quantitative values computed for each subject.

Schematic diagram based on Bayesian inference analysis on target node based on extracted GLCM based features.
Ethical approval
All the procedures were performed in accordance with the relevant guidelines and regulations.
Results
In this study, we first computed the GLCM features and then ranked the features using entropy. The high ranked Energy feature was chosen as our target variable with which the further detailed analysis was done.
The Fig. 2 shows the ranking of multimodal features-based entropy values. The higher the entropy value indicates the more complex and important feature. We extracted the GLCM features from Brain tumor types. The features are ranked without utilizing any unsupervised or supervised machine learning algorithm. A specific method which ranks the features is based on the assigned score values65. Finally, based on these scores the features are ranked and the features with redundant information are further eliminated for classification. In this study, we ranked the GLCM features based on entropy values developed in MATLAB diagnostic tool.

Feature ranking based on entropy values.
Figure 3 depicts the relationship analysis using Bayesian inference methods including the MI, KL and PC. The bold lines represent the stronger relationship, the lighter lines indicate the smaller relationship. The blue color indicates the positive relationship, whereas the red color indicates the negative relationship. Moreover, the arrows indicate the \((parent \to child)\) relationship. We kept our target node as Energy, using mutual information, there probability of occurrence for the state ≤ 0.273 (38.09%), state ≤ 0.368 (37.53%), state ≤ 0.471 (18.94%) and state > 0.471 (5.45%) with joint probability for all states is 100%. The probability distribution with other extracted nodes at selected states is depicted in Fig. 3a–c.

Relationship analysis using different Bayesian inference approaches such as (a) mutual information (MI), (b) Kullback–Leibler (KL) divergence, (c) Pearson’s correlation by applying the unsupervised learning using maximum spanning tree and selecting energy as our target node.
Figure 4 represents the 3D mapping arc analysis to show the relationship among the GLCM extracted features. The nodes represent the features and lines represents the relationship between the nodes. The strength of relationship is denoted by the width of line. The blue color represents the positive relationship whereas the red color denotes the negative relationship. Using the mutual information (MI), the highest strength of relationship was obtained between the nodes \(Correlation \to Correlation1, \;1.4640\) followed by \(Dissimilarity \to Homogenity1, \;1.2708\), \(Entropy \to energy, \;1.0408\) and so on as reflected in Fig. 4a. The Fig. 4b shows the association between the nodes using KL. The highest strength of relationship was yielded between nodes \(Correlation \to Correlation1, \;1.4640\) followed by \(Dissimilarity \to Homogenity1, \;1.2708\), \(Entropy \to energy,\; 1.0340\) and so on. The Fig. 4c denote the relationship between nodes using Pearson’s correlation. The highest strength of relationship was yielded between the nodes \(Correlation \to Correlation1, \;1.000\) followed by \(Dissimilarity \to homogenity1, \; - 0.9664\), \(Dissimilarity \to contrast, \;0.9277\) and so on. The negative relationship was obtained between the nodes \((Correlation \to dissimilarity), \;(Dissimilarity \to homogenity1)\),\((homogenity1 \to entropy), \;(entropy \to energy)\). All other nodes exhibit the positive relation, where a week relationship was yielded between the nodes cluster prominence and autocorrelation. The strength of relationship using these methods is also reflected in Table 1.

Arc analysis 3D mapping to determine the relationship among the nodes (a) mutual information, (b) Kullback–Leibler (KL) divergence, (c) Pearson’s correlation.
The Table 1 reflect the \((Parent \to child)\) relationship between the extracted GLCM features to distinguish the brain tumor types. The highest degree of relation was found between the nodes \((Correlation \to correlation2)\) yielding strength of relationship using KL and MI (1.4640), Pearson’s correlation (1.0000), with relative width 1.0000 and overall contribution of 16.67%. The contribution between other nodes was yielded such as \((Dissimilarity \to homogenity1, \;14.47\% )\), \((Entropy \to energy, \;11.78\% )\), \((Dissimilarity \to contrast, \;11.66\% )\) and so on. The highly significant results (p-value < 0.00000 was yielded for all \((Parent \to child)\) relationships.
The Table 2 reflects the incoming, outgoing and total force of different extracted GLCM features from brain tumor meningioma and pituitary. The dissimilarity node has outgoing force (2.29450), incoming force (0.4306) and total force (2.7251); the entropy node has outgoing force (1.7997), incoming (0.8624) and total force (2.6620) and so on. The highest outgoing and total force was yielded by the node dissimilarity such as 2.2945 and 2.7251 respectively. The highest incoming force was yielded by the node energy (1.2576).
We randomly chosen the subjects i.e. Pituitary (495 images) and Meningioma (495 images) with a total of 990 images. We ranked the features before applying the Bayesian inference approach. The Energy was highly ranked features measured using EROC and random classifier slope, which was selected as our target for further Bayesian analysis. We computed the association of top ranked Energy feature with other features to further unfold the association among the features. There were four states represented by ≤ 0.273 (394 images), ≤ 0.368 (374 images), ≤ 0.471 (191 images) and > 0.471 (31 images) as represented in the Mosaic association graph in Fig. 5 and Table 3. After prediction, 354 were predicted for first class, 321 for second class, 145 for third class and 30 for fourth class. The reliability and precision for class 1 to 4 was yielded according as 89.84%, 85.82%, 75.92%, 96.77% and 94.65%, 85.37%, 81.00%, 49.18% respectively.

Analysis of target node energy with other extracted nodes using mosaic graph based on selected target node energy and predictions of occurrence made against each state out of total (i.e. ≤ 0.273, 354/394; ≤ 0.368, 321/374; ≤ 0.471, 143/192; > 0.471, 27/28).
The Table 4 reflects the overall analysis of target node energy with other nodes. All nodes exhibits the highly significant results.
The Fig. 6 depicts the analysis of association graph for segment profile analysis of top ranked target node with other extracted GLCM features using the Radar chart which reflect the distributions based on 1 to 12 clock hours. The Fig. 6a reflect the overall probability and we used the NHST t test and Bayesian test to find the significance to distinguish with other different states such as (b) ≤ 0.273, (c) ≤ 0.368, (d) ≤ 0.471, (e) > 0.471 as reflected in Fig. 6b–e. The clusters ≤ 0.273, ≤ 0.471 and > 0.471 using both the test yielded the highly significant results with all the extracted GLCM features. The state ≤ 0.368 yielded high significant results using both test with homogenity1, dissimilarity, correlation, correlation2 and autocorrelation, whereas significant results using NHST t test with contrast and energy, while no significant results were yielded with cluster shade and cluster Prominance.

Association graph of segment profile analysis of energy node with other extracted GLCM features using radar chart graph at different selected states (a) overall and overall with selected states (b) ≤ 0.273, (c) ≤ 0.368, (d) ≤ 0.471, (e) > 0.471, overall with (f) all selected states.
The network performance of selected target node Energy with other selected nodes yielded R of 0.9497, R2 of 0.9019, RMSE of 0.0290 and NRMSE of 0.0490. The selected state ≤ 0.273 yielded the highest predictions with 89.84% of reliability, 96.65% if precision and 98.49% of ROC index as depicted in Fig. 7a–c.

Network performance target evaluation energy node with other selected nodes (a) occurrence, reliability and precision report; (b) gain report of state ≤ 0.273, (c) ROC index of state ≤ 0.273.
Using the tornado graph as reflected in Fig. 8, we visualize the maximum deltas in the posterior probabilities of the target states and hard evidence is set on the selected variables. The strong deltas are shown at the top of the graph. The highest association was yielded with entropy, homogeneity, dissimilarity, contrast, correlation, correlation2 cluster state ≤ 0.273 followed by cluster state ≤ 0.368, ≤ 0.471 and > 0.471 reflected in Fig. 8. This indicates that high top ranked Energy feature prevails high associations with entropy, homogeneity, dissimilarity, contrast, correlation, correlation2 which can be used as better predictor for improved diagnosis and prognosis of brain tumor types. The association of highest ranked Energy node with other nodes in the state ≤ 0.368 was obtained with entropy, homogeneity, dissimilarity.

Tornado diagram of posterior probabilities to compute the significance of Energy node with all nodes at selected cluster states (≤ 0.273, ≤ 0.368, ≤ 0.471, and > 0.471).
The Fig. 9 denote the target’s posterior probabilities for the selected target variable Energy at state ≤ 0.273. The prior value is denoted by red line. The bar exceeding the red line indicates that variables values influencing the target variable.

Target’s posterior probabilities for outcome variable Energy = ≤ 0.273.
Our optimization target state is ≤ 0.273. The Fig. 10 indicates that we have multiple pathways to get into the Energy with a 94% or higher probability. The Table 6 reflect the target node Energy at cluster state ≤ 0.273. With the Entropy node at 1.885, a highest posterior probability was obtained P (s|H) of 97.45%, Likelihood P(H|s) of 81.81%, Bayes factor of 2.57% and generalized Bayes factor of 9.68%. The prior values and posterior values of other nodes are reflected in this Table 6.

Tree optimization of GLCM energy as target node.
The Table 5 summarize the dynamic profile of all the clusters. The dynamic profile uses the greedy search algorithm to simulate set of evidence for maximizing the probability of selected clusters.
The Table 6 reflect the target node Energy at cluster state ≤ 0.368. With the Entropy node at 1.885, a posterior probability was obtained P (s|H) of 78.86%, marginal likelihood (32.02%), Likelihood P(H|s) of 66.48%, Bayes factor of 2.07% and generalized Bayes factor of 4.21%. as also reflected in Fig. 6. The prior values and posterior values of other nodes are reflected in this Table 7.
The Table 7 reflect the target node Energy at cluster state ≤ 0.471 With the Entropy node at ≤ 1.445, a posterior probability was obtained P (s|H) of 53.03%, marginal likelihood (13.33%), Likelihood P(H|s) of 39.10%, Bayes factor of 2.93% and generalized Bayes factor of 4.17%. as also reflected in Fig. 6. The prior values and posterior values of other nodes are reflected in this Table 8.
The Table 8 reflect the target node Energy at cluster state > 0.471 with the Entropy node at ≤ 1.445, a posterior probability was obtained P (s|H) of 46.21%, marginal likelihood (13.33%), Likelihood P(H|s) of 100%, Bayes factor of 7.50%. The prior values and posterior values of other nodes are reflected in this Table 4.
Discussion
The Bayesian networks (BNs) are combination of probability theory and graph, which are capable to capture efficiently the most significant causation factor in the pathological subjects and can capture the relationship between different causal relationship82. BNs effectively assess the cause-consequence analysis from extracted GLCM features of Brain MRIs87. The detailed Bayesian analysis utilizing relationship analysis, segment profile analysis using radar chart, tornado diagrams of posterior probabilities, and network performance analysis can successfully be utilized for treatment planning and improved diagnosis of target node with other extracted nodes. These networks provide an efficient tool for detailed analysis to determine the interconnectivity and association between the variable of interest88. The BNs comprised of qualitative and quantitative analysis. The qualitative analysis depicts the structure of the graph by expressing the graphical representation in terms of cause relationship of variable of interest89. The quantitative portion of the graph quantify the associations with conditional probabilities among the variables and target state according to cause order or connectivity. BNs, apart from not only determine the causal relationship, but also compute the nature of relationship between the factors involved90. Moreover, these networks are also more robust and capable to determine the genuine graphical and visual relationship between variables involved. BNs are capable to process the data and ambiguity of all states of a variable using inference in a probabilistic system. These networks are also suitable for decision-making processes by providing consistent, scrupulous, and systemized assessment. For our extracted GLCM features, we first ranked the features based on entropy value. The top ranked energy feature was set as our target node, and we further conducted the sensitivity analysis, segment profile analysis, and network analysis with our target node. The BayesiaLab through tornado chart identify those variables which are most critical from the perspective of their effect on the target variable and provide the contributions of their probabilities of respective variables. The variable with maximum and prominent sensitivity are presented in tornado graph. The cluster state ≤ 0.273 yielded the highest association for variables homogeneity, entropy, dissimilarity, correlation, contrast and correlation2.
The BN is a pictorial illustration by computing the joint probability distribution. The Bayesian network structure comprised on nodes which denotes the random variables, and arcs reflect the dependence structure reflecting causality between the variables. When there is absence of arc between the nodes, it denotes that variable are conditionally independent. Bayesian network structure is either supervised or unsupervised, however, joint probability distribution is unsupervised. Bayesian network have been utilized to analyse the uncertainties and covariations among the multiple variables91. We used the learning based on unsupervised learning using maximum spanning tree by setting mining description length as learning setting and taboo list size of 45. The inference was made based on the adaptive questionnaire by setting Energy highly ranked feature as our target node and computed its association among other variables. Presently, the researchers are devolving tools using machine learning methods. For machine learning, the most important step is to compute the most relevant features. However, extracting the most relevant features is still a challenging task as all the extracted features are not equally important. We, therefore, first ranked the extract GLCM based texture features. The highest ranked feature was energy (3.0693) followed by homogenity1 (2.7317), homogenity2 (2.6927), max. probability (2.6818) and so on. The least significant feature was sum variance (0.0293). This indicates that the energy feature contribute more than other extracted GLCM features to distinguish the pituitary from meningioma. We first applied the unsupervised maximum spanning tree algorithm and kept energy as our target variable to determine the further associations with other features to unfold hidden dynamics with the top ranked feature. The correlation, strength of relationship and degree of relationship among the \((Parent \to child)\) node was computed using the mutual information, Kullback–Leibler (KL) divergence and Pearson’s correlation. We then computed the incoming, outgoing and total force between the nodes to further determine the comprehensive relationship between the nodes. The analysis was also done using tornado diagram, network performance, and segment profile analysis using the radar chart. The tornado graph indicates that the selected high ranked target variable Energy has highly significant results with most of the nodes at the selected cluster states i.e. ≤ 0.273, ≤ 0.368, ≤ 0.471 and > 0.471. Moreover, high occurrences, and reliable results were yielded at the selected states to distinguish the pituitary from meningioma. The tornado diagram also indicates that higher associations of Energy variable at selected cluster state ≤ 0.273 were yielded with variable entropy, homogeneity, dissimilarity, contrast, correlation, correlation2. The target’s posterior probabilities also indicates that the selected target Energy node shows the high influence with other nodes. A high ROC index and Gini index were yielded to distinguish these states.
The researchers in the past utilized different imaging analysis methods for diagnosing the MRI images92,93,94. Hussain et al.38 applied Bayesian inference approach to compute the association among the morphological features extracted from Prostate cancer. Most of these studies were relied on classification tasks. The author obtained the classification performance with accuracy 91.28%44, 84.19%95, 86.56%96, 90.89%97, 84.19%98, and 99%18. Previous studies relies on classification methods. However, this novel technique is proposed to further investigate the dynamics, associations, posterior probabilities, prior probabilities, marginal likelihood, prior means and posterior means to further unfold the relevance and relationships among the extracted features. The proposed approach will be very helpful for improved diagnosis and prognosis of brain tumor types.
Conclusions
In this study, we first computed the GLCM features from brain tumor subtypes i.e., pituitary and meningioma MRIs. We then ranked the features based on the entropy ranking method. The high ranked energy feature was used as our target variable. We then applied the Bayesian approach to further compute the association, arc analysis, tree optimization, dynamic profiling. The proposed methods further unfold the dynamics which can be helpful to understand the association, dynamic profiling of computed features for better diagnostic system of brain tumor types. The Bayesian inference approach can be used as a new biomarker to comprehend a detailed analysis of extracted variables to further unfold the underlying dynamics present the computed future for further improved prognosis, diagnosis and treatment planning to achieve better clinical outcomes. In future, we will further extend more Bayesian inference methods and other tumor types with clinical details and larger dataset.
Data availability
The use of all data mentioned in this article is publicly available43,44 (https://github.com/chengjun583/brainTumorRetrieval).
References
Pereira, S., Meier, R., Alves, V., Reyes, M. & Silva, C. A. Automatic Brain Tumor Grading from MRI Data Using Convolutional Neural Networks and Quality Assessment 106–114. https://doi.org/10.1007/978-3-030-02628-8_12 (2018).
Gaikwad, S. B. & Joshi, M. S. Brain tumor classification using principal component analysis and probabilistic neural network. Int. J. Comput. Appl. 120, 5–9 (2015).
Friedrich, S. O., von Groote-Bidlingmaier, F. & Diacon, A. H. Xpert MTB/RIF assay for diagnosis of pleural tuberculosis. J. Clin. Microbiol. 49, 4341–4342 (2011).
Rathore, S., Hussain, M., AksamIftikhar, M. & Jalil, A. Ensemble classification of colon biopsy images based on information rich hybrid features. Comput. Biol. Med. 47, 76–92 (2014).
Rathore, S., Hussain, M. & Khan, A. Automated colon cancer detection using hybrid of novel geometric features and some traditional features. Comput. Biol. Med. 65, 279–296 (2015).
Rathore, S., Iftikhar, A., Ali, A., Hussain, M. & Jalil, A. Capture largest included circles: An approach for counting red blood cells. Commun. Comput. Inf. Sci. 281 CCIS, 373–384 (2012).
Hussain, L. et al. Prostate cancer detection using machine learning techniques by employing combination of features extracting strategies. Cancer Biomark. 21, 393–413 (2018).
Asim, Y. et al. A multi-modal, multi-atlas-based approach for Alzheimer detection via machine learning. Int. J. Imaging Syst. Technol. 28, 113–123 (2018).
Machhale, K., Nandpuru, H. B., Kapur, V. & Kosta, L. MRI brain cancer classification using hybrid classifier (SVM-KNN). In 2015 International Conference on Industrial Instrumentation and Control (ICIC) 60–65. https://doi.org/10.1109/IIC.2015.7150592 (IEEE, 2015).
Vidyarthi, A. & Mittal, N. Performance analysis of Gabor-Wavelet based features in classification of high grade malignant brain tumors. In 2015 39th National Systems Conference (NSC) 1–6. https://doi.org/10.1109/NATSYS.2015.7489135 (IEEE, 2015).
Deepa, A. R. & Sam emmanuel, W. R. MRI brain tumor classification using cuckoo search support vector machines and particle swarm optimization based feature selection. In 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI) 1213–1216 https://doi.org/10.1109/ICOEI.2018.8553697 (IEEE, 2018).
Devi, T. M., Ramani, G. & Arockiaraj, S. X. MR brain tumor classification and segmentation via wavelets. In 2018 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET) 1–4. https://doi.org/10.1109/WiSPNET.2018.8538643 (IEEE, 2018).
Mathew, A. R. & Anto, P. B. Tumor detection and classification of MRI brain image using wavelet transform and SVM. In 2017 International Conference on Signal Processing and Communication (ICSPC) 75–78. https://doi.org/10.1109/CSPC.2017.8305810 (IEEE, 2017).
Islam, A., Hossain, M. F. & Saha, C. A new hybrid approach for brain tumor classification using BWT-KSVM. In 2017 4th International Conference on Advances in Electrical Engineering (ICAEE) 241–246. https://doi.org/10.1109/ICAEE.2017.8255360 (IEEE, 2017).
Sachdeva, J., Kumar, V., Gupta, I., Khandelwal, N. & Ahuja, C. K. Multiclass brain tumor classification using GA-SVM. In 2011 Developments in E-systems Engineering 182–187. https://doi.org/10.1109/DeSE.2011.31 (IEEE, 2011).
Abd-Ellah, M. K., Awad, A. I., Khalaf, A. A. M. & Hamed, H. F. A. Design and implementation of a computer-aided diagnosis system for brain tumor classification. In 2016 28th International Conference on Microelectronics (ICM) 73–76. https://doi.org/10.1109/ICM.2016.7847911 (IEEE, 2016).
Kumar, P. M. S. & Chatteijee, S. Computer aided diagnostic for cancer detection using MRI images of brain (brain tumor detection and classification system). In 2016 IEEE Annual India Conference (INDICON) 1–6. https://doi.org/10.1109/INDICON.2016.7838875 (IEEE, 2016).
Abdelaziz Ismael, S. A., Mohammed, A. & Hefny, H. An enhanced deep learning approach for brain cancer MRI images classification using residual networks. Artif. Intell. Med. 102, 101779 (2020).
Sundararaj, G. K. & Balamurugan, V. Robust classification of primary brain tumor in Computer Tomography images using K-NN and linear SVM. In 2014 International Conference on Contemporary Computing and Informatics (IC3I) 1315–1319. https://doi.org/10.1109/IC3I.2014.7019693 (IEEE, 2014).
Latif, G., Butt, M. M., Khan, A. H., Butt, O. & Iskandar, D. N. F. A. Multiclass brain Glioma tumor classification using block-based 3D Wavelet features of MR images. In 2017 4th International Conference on Electrical and Electronic Engineering (ICEEE) 333–337. https://doi.org/10.1109/ICEEE2.2017.7935845 (IEEE, 2017).
Minz, A. & Mahobiya, C. MR image classification using Adaboost for brain tumor type. In 2017 IEEE 7th International Advance Computing Conference (IACC) 701–705. https://doi.org/10.1109/IACC.2017.0146 (IEEE, 2017).
Chauhan, S., More, A., Uikey, R., Malviya, P. & Moghe, A. Brain tumor detection and classification in MRI images using image and data mining. In 2017 International Conference on Recent Innovations in Signal processing and Embedded Systems (RISE) 223–231. https://doi.org/10.1109/RISE.2017.8378158 (IEEE, 2017).
Sornam, M., Kavitha, M. S. & Shalini, R. Segmentation and classification of brain tumor using wavelet and Zernike based features on MRI. In 2016 IEEE International Conference on Advances in Computer Applications (ICACA) 166–169. https://doi.org/10.1109/ICACA.2016.7887944 (IEEE, 2016).
Deepa, S. N. & Devi, B. A. Neural networks and SMO based classification for brain tumor. In 2011 World Congress on Information and Communication Technologies 1032–1037. https://doi.org/10.1109/WICT.2011.6141390 (IEEE, 2011).
Prabi, A. Robust classification of primary brain tumor in MRI images based on multi model textures features and kernel based SVM. Biomed. Pharmacol. J. 8, 611–618 (2015).
Bangare, S. L., Pradeepini, G. & Patil, S. T. Brain tumor classification using mixed method approach. In 2017 International Conference on Information Communication and Embedded Systems (ICICES) 1–4. https://doi.org/10.1109/ICICES.2017.8070748 (IEEE, 2017).
Kaikkonen, L., Parviainen, T., Rahikainen, M., Uusitalo, L. & Lehikoinen, A. Bayesian networks in environmental risk assessment: A review. Integr. Environ. Assess. Manag. 17, 62–78 (2021).
Kocian, A. et al. Dynamic Bayesian network for crop growth prediction in greenhouses. Comput. Electron. Agric. 169, 105167 (2020).
do Amaral, C. B., de Oliveira, G. H. F., Eghrari, K., Buzinaro, R. & Môro, G. V. Bayesian network: A simplified approach for environmental similarity studies on maize. Crop Breed. Appl. Biotechnol. 19, 70–76 (2019).
Laurila-Pant, M., Mäntyniemi, S., Venesjärvi, R. & Lehikoinen, A. Incorporating stakeholders’ values into environmental decision support: A Bayesian Belief Network approach. Sci. Total Environ. 697, 134026 (2019).
Zhang, L., Pan, Q., Wang, Y., Wu, X. & Shi, X. Bayesian network construction and genotype-phenotype inference using GWAS statistics. IEEE/ACM Trans. Comput. Biol. Bioinform. 16, 475–489 (2019).
Sperotto, A. et al. A Bayesian Networks approach for the assessment of climate change impacts on nutrients loading. Environ. Sci. Policy 100, 21–36 (2019).
Gandhi, N., Armstrong, L. J. & Petkar, O. Predicting rice crop yield using Bayesian networks. In 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI) 795–799. https://doi.org/10.1109/ICACCI.2016.7732143 (IEEE, 2016).
Corrales, D. C. Toward detecting crop diseases and pest by supervised learning. Ing. Univ. 19, 207 (2015).
Musango, J. K. & Peter, C. A Bayesian approach towards facilitating climate change adaptation research on the South African agricultural sector. Agrekon 46, 245–259 (2007).
Ershadi, M. M. & Seifi, A. An efficient Bayesian network for differential diagnosis using experts’ knowledge. Int. J. Intell. Comput. Cybern. 13, 103–126 (2020).
Lu, W., Newlands, N. K., Carisse, O., Atkinson, D. E. & Cannon, A. J. Disease risk forecasting with Bayesian learning networks: Application to grape powdery mildew (Erysiphe necator) in vineyards. Agronomy 10, 622 (2020).
Hussain, L. et al. Applying Bayesian network approach to determine the association between morphological features extracted from prostate cancer images. IEEE Access 7, 1586–1601 (2019).
Hussain, L., Ahmed, A., Saeed, S., Rathore, S. & Ahmed, I. Prostate cancer detection using machine learning techniques by employing combination of features extracting strategies. Cancer Biomark. https://doi.org/10.3233/CBM-170643 (2017).
Anjum, S. et al. Detecting brain tumors using deep learning convolutional neural network with transfer learning approach. Int. J. Imaging Syst. Technol. 32, 1–17 (2021).
Hussain, L., Almaraashi, M. S., Aziz, W., Habib, N. & Saif Abbasi, S.-U.-R. Machine learning-based lungs cancer detection using reconstruction independent component analysis and sparse filter features. Waves in Random and Complex Media 1–26. https://doi.org/10.1080/17455030.2021.1905912 (2021).
Anjum, S., Hussain, L., Ali, M., Abbasi, A. A. & Duong, T. Q. Automated multi-class brain tumor types detection by extracting RICA based features and employing machine learning techniques. Math. Biosci. Eng. 18, 2882–2908 (2021).
Cheng, J. et al. Retrieval of brain tumors by adaptive spatial pooling and fisher vector representation. PLoS One 11, e0157112 (2016).
Cheng, J. et al. Enhanced performance of brain tumor classification via tumor region augmentation and partition. PLoS One 10, e0140381 (2015).
Adegoke, B. et al. Review of feature selection methods in medical image processing international organization of scientific research. IOSR J. Eng. 04, 1–5 (2014).
Kumar, G. A Detailed Review of Feature Extraction in Image Processing Systems 5–12. https://doi.org/10.1109/ACCT.2014.74 (2014).
Rathore, N., Divya & Agarwal, S. Predicting the survivability of breast cancer patients using ensemble approach. In 2014 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT) 459–464. https://doi.org/10.1109/ICICICT.2014.6781326 (IEEE, 2014).
Hussain, L., Rathore, S., Abbasi, A. A. & Saeed, S. Automated lung cancer detection based on multimodal features extracting strategy using machine learning techniques. In Medical Imaging 2019: Physics of Medical Imaging Vol. 10948 (eds Bosmans, H. et al.) 134 (SPIE, 2019).
Hussain, L. et al. Arrhythmia detection by extracting hybrid features based on refined Fuzzy entropy (FuzEn) approach and employing machine learning techniques. Waves Random Complex Media 30, 1–31 (2020).
Hussain, L. et al. Detecting brain tumor using machine learning techniques based on different features extracting strategies. Curr. Med. Imaging Former. Curr. Med. Imaging Rev. 14, 595–606 (2019).
Hussain, L. Detecting epileptic seizure with different feature extracting strategies using robust machine learning classification techniques by applying advance parameter optimization approach. Cogn. Neurodyn. 12, 271–294 (2018).
Hussain, L., Aziz, W., Khan, I. R., Alkinani, M. H. & Alowibdi, J. S. Machine learning based congestive heart failure detection using feature importance ranking of multimodal features. Math. Biosci. Eng. 18, 69–91 (2021).
Hussain, L. et al. Analyzing the dynamics of lung cancer imaging data using refined fuzzy entropy methods by extracting different features. IEEE Access 7, 64704–64721 (2019).
Haralick, R. M. & Shanmugam, K. Textural features for image classification. IEEE Trans. Cybern. https://doi.org/10.1109/TSMC.1973.4309314 (1973).
Khuzi, A. M., Besar, R. & Zaki, W. M. D. W. Texture features selection for masses detection in digital mammogram. IFMBE Proc. 21 IFMBE, 629–632 (2008).
Nguyen, V. D., Nguyen, D. T., Nguyen, T. D. & Pham, V. T. An automated method to segment and classify masses in mammograms. Eng. Technol. 3, 942–947 (2009).
Nithya, R. & Santhi, B. Classification of normal and abnormal patterns in digital mammograms for diagnosis of breast cancer. Int. J. Comput. Appl. 28, 975–8887 (2011).
Parvez, A. & Phadke, A. C. Efficient implementation of GLCM based texture feature computation using CUDA platform. In 2017 International Conference on Trends in Electronics and Informatics (ICEI) 296–300. https://doi.org/10.1109/ICOEI.2017.8300935 (IEEE, 2017).
Amrit, G. & Singh, P. Performance analysis of various machine learning-based approaches for detection and classification of lung cancer in humans. Neural Comput. Appl. https://doi.org/10.1007/s00521-018-3518-x (2018).
Nithya, R. Comparative study on feature extraction. J. Theor. Appl. Inf. Technol. 33, 7 (2011).
Olaniyi, E. O., Adekunle, A. A., Odekuoye, T. & Khashman, A. Automatic system for grading banana using GLCM texture feature extraction and neural network arbitrations. J. Food Process Eng. 40, e12575 (2017).
Campbell, D. L., Kang, H. & Shokouhi, S. Application of Haralick texture features in brain [18F]-florbetapir positron emission tomography without reference region normalization. Clin. Interv. Aging 12, 2077–2086 (2017).
Shahajad, M., Gambhir, D. & Gandhi, R. Features extraction for classification of brain tumor MRI images using support vector machine. In 2021 11th International Conference on Cloud Computing, Data Science and Engineering (Confluence) 767–772. https://doi.org/10.1109/Confluence51648.2021.9377111 (IEEE, 2021).
James, J., Heddallikar, A., Choudhari, P. & Chopde, S. Analysis of Features in SAR Imagery Using GLCM Segmentation Algorithm 253–266. https://doi.org/10.1007/978-981-16-1681-5_16 (2021).
Wang, H., Khoshgoftaar, T. M. & Gao, K. A comparative study of filter-based feature ranking techniques. In 2010 IEEE International Conference on Information Reuse and Integration Vol. 1, 43–48 (IEEE, 2010).
Yu, S. et al. A Matlab toolbox for feature importance ranking. In 2019 International Conference on Medical Imaging Physics and Engineering (ICMIPE) 1–6. https://doi.org/10.1109/ICMIPE47306.2019.9098233 (IEEE, 2019).
Shim, S.-O., Alkinani, M. H., Hussain, L. & Aziz, W. Feature ranking importance from multimodal radiomic texture features using machine learning paradigm: A biomarker to predict the lung cancer. Big Data Res. 29, 100331 (2022).
Heyer, H. Information and Sufficiency 142–173. https://doi.org/10.1007/978-1-4613-8218-8_7 (1982).
Hussain, L., Lone, K. J., Awan, I. A., Abbasi, A. A. & Pirzada, J.-R. Detecting congestive heart failure by extracting multimodal features with synthetic minority oversampling technique (SMOTE) for imbalanced data using robust machine learning techniques. Waves Random Complex Media. https://doi.org/10.1080/17455030.2020.1810364 (2020).
Hussain, L. et al. Symbolic time series analysis of electroencephalographic (EEG) epileptic seizure and brain dynamics with eye-open and eye-closed subjects during resting states. J. Physiol. Anthropol. 36, 21 (2017).
Pearl, J. Fusion, propagation, and structuring in belief networks. Artif. Intell. 29, 241–288 (1986).
Bayesia, S. C. BayesiaLab7 (Bayesia USA, 2017).
Shannon, C. E. A mathematical theory of communication. Bell Syst. Tech. J. 27, 379–423 (1948).
Xiao, F., Gao, L., Ye, Y., Hu, Y. & He, R. Inferring gene regulatory networks using conditional regulation pattern to guide candidate genes. PLoS One 11, 1–13 (2016).
Janzing, D., Balduzzi, D., Grosse-Wentrup, M. & Schölkopf, B. Quantifying causal influences. Ann. Stat. 41, 2324–2358 (2013).
Conrady, S. & Jouffe, L. Bayesian Networks and BayesiaLab: A Practical Introduction for Researchers (Bayesia USA, 2015).
Harris, M. et al. Pharmacogenomic characterization of gemcitabine response—A framework for data integration to enable personalized medicine. Pharmacogenet. Genomics 24, 81–93 (2014).
Thai, H. et al. Convergence and coevolution of hepatitis B virus drug resistance. Nat. Commun. 3, 789 (2012).
Moreno-Jiménez, E. et al. Screening risk assessment tools for assessing the environmental impact in an abandoned pyritic mine in Spain. Sci. Total Environ. 409, 692–703 (2011).
Wilhere, G. F. Using Bayesian networks to incorporate uncertainty in habitat suitability index models. J. Wildl. Manag. 76, 1298–1309 (2012).
Khan, R. U., Yin, J., Mustafa, F. S. & Liu, H. Risk assessment and decision support for sustainable traffic safety in Hong Kong waters. IEEE Access 8, 72893–72909 (2020).
Li, K. X., Yin, J. & Fan, L. Ship safety index. Transp. Res. Part A Policy Pract. 66, 75–87 (2014).
Tanackov, I. et al. Risk distribution of dangerous goods in logistics subsystems. J. Loss Prev. Process Ind. 54, 373–383 (2018).
Goerlandt, F. & Montewka, J. Maritime transportation risk analysis: Review and analysis in light of some foundational issues. Reliab. Eng. Syst. Saf. 138, 115–134 (2015).
Hänninen, M. & Kujala, P. Influences of variables on ship collision probability in a Bayesian belief network model. Reliab. Eng. Syst. Saf. 102, 27–40 (2012).
Kruschke, J. K. Bayesian estimation supersedes the t test. J. Exp. Psychol. Gen. 142, 573–603 (2013).
Khan, B., Khan, F., Veitch, B. & Yang, M. An operational risk analysis tool to analyze marine transportation in Arctic waters. Reliab. Eng. Syst. Saf. 169, 485–502 (2018).
Pearl, J. Statistics and causal inference: A review. TEST 12, 281–345 (2003).
Antão, P. & Soares, C. G. Analysis of the influence of human errors on the occurrence of coastal ship accidents in different wave conditions using Bayesian Belief Networks. Accid. Anal. Prev. 133, 105262 (2019).
Ren, J., Jenkinson, I., Wang, J., Xu, D. L. & Yang, J. B. An offshore risk analysis method using fuzzy Bayesian network. J. Offshore Mech. Arct. Eng. 131, 12 (2009).
Barber, D. Bayesian Reasoning and Machine Learning (Cambridge University Press, 2012). https://doi.org/10.1017/CBO9780511804779.
Lerski, R. A. et al. VIII. MR image texture analysis—An approach to tissue characterization. Magn. Reson. Imaging 11, 873–887 (1993).
Herlidou-Même, S. et al. MRI texture analysis on texture test objects, normal brain and intracranial tumors. Magn. Reson. Imaging 21, 989–993 (2003).
Schad, L. R., Blüml, S. & Zuna, I. IX. MR tissue characterization of intracranial tumors by means of texture analysis. Magn. Reson. Imaging 11, 889–896 (1993).
Paul, J. S., Plassard, A. J., Landman, B. A. & Fabbri, D. Deep learning for brain tumor classification. In Medical Imaging 2017: Biomedical Applications in Molecular, Structural, and Functional Imaging (eds Krol, A. & Gimi, B.) 1013710 (SPIE, 2017). https://doi.org/10.1117/12.2254195.
Afshar, P., Mohammadi, A. & Plataniotis, K. N. Brain tumor type classification via capsule networks. In 2018 25th IEEE International Conference on Image Processing (ICIP) 3129–3133. https://doi.org/10.1109/ICIP.2018.8451379 (IEEE, 2018).
Afshar, P., Plataniotis, K. N. & Mohammadi, A. Capsule networks for brain tumor classification based on MRI images and coarse tumor boundaries. In ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 1368–1372. https://doi.org/10.1109/ICASSP.2019.8683759 (IEEE, 2019).
Abiwinanda, N., Hanif, M., Hesaputra, S. T., Handayani, A. & Mengko, T. R. Brain tumor classification using convolutional neural network. In World Congress on Medical Physics and Biomedical Engineering 2018 183–189. https://doi.org/10.1007/978-981-10-9035-6_33 (Springer, 2019).
Acknowledgements
The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Large Groups Project under grant number (180/43). Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R151), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4340237DSR45.
Author information
Authors and Affiliations
Contributions
L.H. wrote the manuscript, prepared figures, write code, supervised, reviewed and edited. A.M. supervised, reviewed and edited. J.S.A. supervised, reviewed and edited. M.A. reviewed and edited. M.O. supervised, reviewed and edited. F.A.W. supervised, reviewed and edited. H.M. supervised, reviewed and edited. M.A.H. wrote the manuscript, supervised, reviewed and edited.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hussain, L., Malibari, A.A., Alzahrani, J.S. et al. Bayesian dynamic profiling and optimization of important ranked energy from gray level co-occurrence (GLCM) features for empirical analysis of brain MRI. Sci Rep 12, 15389 (2022). https://doi.org/10.1038/s41598-022-19563-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-19563-0
This article is cited by
-
Intelligent Bayesian Inference for Multiclass Lung Infection Diagnosis: Network Analysis of Ranked Gray Level Co-occurrence (GLCM) Features
New Generation Computing (2024)
-
FECNet: a Neural Network and a Mobile App for COVID-19 Recognition
Mobile Networks and Applications (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
