
Abstract
Motor learning is often hindered or facilitated by visual information from one’s body and its movement. However, it is unclear whether visual representation of the body itself facilitates motor learning. Thus, we tested the effects of virtual body-representation on motor learning through a virtual reality rotary pursuit task. In the task, visual feedback on participants’ movements was identical, but virtual body-representation differed by dividing the experimental conditions into three conditions: non-avatar, non-hand avatar, and hand-shaped avatar. We measured the differences in the rate of motor learning, body-ownership, and sense of agency in the three conditions. Although there were no differences in body-ownership and sense of agency between the conditions, the hand-shaped avatar condition was significantly superior to the other conditions in the rate of learning. These findings suggest that visually recognizing one’s body shape facilitates motor learning.
Similar content being viewed by others


Introduction
Visual feedback on one’s own movement affects motor performance and motor skill learning1,2,3. People typically rely heavily on visual information from both their bodies and the external environment when it comes to motor skill learning and performance. In addition, they utilize visual information to correct and enhance their performance4. Recent studies employing virtual reality (VR), have verified that the manipulation of visual feedback (i.e., virtual body-representation) on physical movement can either facilitate or hinder motor learning. For instance, motor learning can be facilitated if the virtual body-representation is congruent with one’s hand laterality, size, or movement, whereas if incongruent, learning can be hindered5,6,7. These results imply the significance of visual perception of the body in motor learning.
Visually recognizing the body affects both motor learning and hippocampus-based episodic memory. When people encode their episodic memories from real-life events, they co-perceive their body and event-related stimulus from a first-person perspective. Several episodic memory studies using VR have found out that the natural perception of people can have effects on both memory registration and recollection. For example, the event-related episodic memory is impaired when people experience life events from a third-person—rather than first-person—perspective8. Moreover, even if the event is experienced from a first-person perspective, episodic encoding and retrieval are also impaired if their body is not visually presented in the VR scene or a control object, which replaces their body, is presented9,10,11.
The effect of body perception on such episodic memory is related to bodily self-consciousness. Bodily self-consciousness (the sense of bodily self) derives from the integration of multisensory signals (visual, somatosensory, or motor inputs, etc.) in events. The multisensory integration has an effect on the encoding and recall of episodic memory10. The consistent perception of bodily self-consciousness (e.g., experiencing life events from a first perspective) increases the self-relevance of the experienced event, which helps to integrate multisensory information in the event into a unified memory. Therefore, a reduction in bodily self-consciousness (e.g., experiencing life events from a third-person perspective) increases difficulty in the integration, which subsequently hinders episodic retrieval of event details12. This relationship between episodic memory and bodily self-consciousness has also been demonstrated by neuroimaging studies. These studies show that bodily self-consciousness exerts influences on brain mechanisms which are responsible for episodic memory formation. Bergouignan et al.8 found that repeated recall of memories encoded from a third-person perspective was related to decreased activation of posterior hippocampus compared to that of a first-person perspective. More recently, a study by Gauthier and his colleagues10 demonstrated that seeing one’s own body during encoding modulates the functional connectivity between the right hippocampal formation, neocortical regions participated in processing multisensory bodily signals and self-consciousness.
Bodily self-consciousness involves two central components: body-ownership (a feeling that a body part is part of oneself) and sense of agency (a feeling that one initiates and controls one’s volitional actions)13,14. Under VR environment, people can feel body-ownership and sense of agency when they perceive congruency of bodily signals with their movements. Specifically, they feel increased body-ownership when the form of virtual avatar is hand-shaped; they do not feel body-ownership when it is in a form of control object (e.g., sphere, rectangle)15,16,17. Furthermore, they feel the optimal sense of agency when predicted sensory feedback and actual sensory feedback like proprioception18 match. From this point of view, it can be conjectured that bodily self-consciousness is affected according to the differences in visual perception of one’s own body during motor learning in the VR environment. Given the association between bodily self-consciousness and episodic memory, the variation of bodily self-consciousness may affect memory encoding and recall during the motor learning. Indeed, episodic memory is recruited in the initial stages of motor learning19,20. Recent evidence has shown that hippocampus reactivates experienced information including episodic memory during rest periods of early motor learning, which promote rapid improvements in performance21,22,23. Therefore, we expect that body perception in VR scene influences the early learning stage of motor learning and predict that virtual body-representation which resembles a real human body will improve motor learning.
Nevertheless, in previous studies5,6,7, the relationship between visual feedback and motor skill learning was examined by manipulating the existence, size, and congruence of actual movements and visual feedback. Although these studies have suggested the importance of visual feedback according to movement, it is difficult to confirm how the body shape itself affects motor memory and learning. Furthermore, to the best of our knowledge, no studies have investigated the relationship between bodily self-consciousness and motor learning yet by manipulating virtual body-representation, so the impact of bodily self-consciousness on motor learning remains an open issue. Some studies have dealt with the relationship between bodily self-consciousness and motor performance and functioning in VR environment. A study by Seinfeld and colleagues24 found that participants who performed the motor task through a Leap motion sensor, seeing one’s virtual hand, felt a stronger sense of body-ownership and the sense of agency and showed better task performance than those who performed the task with a keyboard and could not see one’s avatar. In relation to clinical population, Tambone and colleagues25 demonstrated that observing the virtual body’s movements from a first-person perspective helps increase body-ownership, which subsequently promotes stroke patients' motor recovery by accessing their motor functioning. These studies seem to support a positive functional link between virtual embodiment and improved motor abilities and performance. These findings also may suggest there is a possibility that bodily self-consciousness has a positive effect on the improvement of motor performance by repeated practice.
Thus, the purpose of our study is to examine the effect of virtual body-representation on motor learning and the relationship between the motor learning and body-ownership and the sense of agency. In this study, a new task was developed to confirm the effect of body perception on motor skill learning. A VR version of the rotary pursuit task was developed to measure motor skill learning. Traditional rotary pursuit tasks evaluate motor skill learning and hand–eye coordination by determining how much the contact time between a wand and a constant-speed rotating spot target increases with repeated practice26,27,28. In this VR task, all participants can visually check the virtual wand. However, by dividing the experimental conditions into three conditions in which avatars do not appear (i.e., non-avatar condition), avatars do appear but in control objects (i.e., non-hand avatar condition), and body-shaped avatars appear (i.e., hand-shaped avatar condition), visual feedback on movements is identical but virtual body-representation is different.
We predict body-ownership to be the greatest in the hand-shaped avatar condition. We also expect the sense of agency, which is affected by the comparison between predicted and actual sensory feedback18, to be identical in all conditions because the movement required in our task is identical in all conditions. Furthermore, we expect that motor skill learning will be greater in the hand-shaped avatar condition than the other two conditions from the early stage of the learning since body-ownership has an impact on episodic memory.
Method
Participants
Sixty-three Korean (33 female; Mage = 23.21, SDage = 4.16, Myears of education = 13.91, SDyears of education = 2.45) participated in this study. Prior to conducting the VR task, participants rated their handedness using the Edinburgh Handedness Inventory29 to adjust the position of the task objects. There were three left-handed participants and each was randomly assigned 21 each to one of three experimental conditions. Among the groups, there were no differences for age (F (2, 60) = 0.384, P = 0.683), gender (χ2 (2, N = 63) = 0.382, P = 0.826), and years of education (F (2, 60) = 0.374, P = 0.690). The study was conducted in accordance with relevant standards and ethical approval was obtained from the Ethics Committee School of Dentistry Seoul National University (S-D20200045). All participants have completed informed consent to take part in the study.
VR rotary pursuit task
The VR rotary pursuit task (VRRP), which is based on previously developed programs30,31, was designed and implemented using Unity v2019.3.5 (see Fig. 1). In the task, a red ball with a radius of 1.5 cm (i.e., target) moved in a clockwise direction with a radius of 15 cm at a constant speed. The participants were shown a VR wand with a round sensor with a radius of 1.0 cm attached to the end and two capsule-shaped buttons (the white one is a start button, and the yellow one is a stop button). After 3 s of sound effects preceding the touching of the start button, holding the VR wand, participants were required to manipulate the controller so that the sensor contacted the target moving in a circular motion for as long as possible. The target was rendered translucent so that the sensor’s contact with the target could be clearly checked. The cumulative time that the sensor contacted the target in each trial was recorded. The recorded time over the entire trial was used for the procedural memory assessment.

VR rotary pursuit (VRRP) task. In the VRRP task, after touching a start button and holding the VR wand, participants were required to manipulate the controller so that the VR wand sensor contacted a red target moving in a clockwise direction with a radius of 15 cm at a constant speed.
Questionnaire on body-ownership and sense of agency
A questionnaire on body-ownership and sense of agency was completed by the participants following the completion of the VRRP. The questionnaire consisted of nine items selected from the work of Gonzalez-Franco and Peck32: two items were about the body-ownership component and eight items were about the agency and motor control component (see Supplementary Table S1). In this study, participants manipulated the VR wand viewing their virtual avatar, which differed depending on their experimental conditions (i.e., hand-shaped avatar, non-hand avatar, and non-avatar). Therefore, the agency and motor control component consisted of two parts, one for the VR wand and the other for the virtual avatar. Participants in the non-avatar condition did not rate body-ownership due to their inability to view their avatar. Each item was rated on a 7-point Likert scale ranging from -3 (strongly disagree) to + 3 (strongly agree).
Procedure
For our experiment, a computer with the following specifications was used: Intel i7-9700 K CPU, 16 GB of RAM, and NVIDIA GeForce RTX2080 GPU. Participants wrote a consent form at the laboratory. Subsequently, participants were then seated on a fixed chair and wore belts to fix their upper body positions (see Fig. 2). Wearing a head-mounted display (HMD) Oculus Rift (resolution: 1080 × 1200 pixels at 90 Hz), participants were asked whether 3D objects in the VRRP could be accurately perceived. If the objects were unclear, the inter-pupillary distance for each participant was adjusted using the manual control on the HMD. When participants held the controller with their dominant hand, they were unable to view their action because the hand avatar was rendered invisible in order to measure each individual’s baseline performance in the absence of the avatar effect. However, not only was the VR wand placed close to the dominant hand, but the area around the wand was highlighted when the transparent avatar touched it, making it easier for the subjects to hold. The participants holding the VR wand performed a calibration process to position the target considering their shoulder height and arm length. This process allows them to perform the task under a normalized condition. For this process, participants were required to raise the controller to their shoulder height. In cases where the height of the controller differed from the height of the shoulder, participants bent their arm holding the controller to the opposite shoulder and, stretched it forward again (see Fig. 3b). The target was located near the sensor of the VR wand through the following position formula:
where Px, Py, and Pz are the coordinates for the x-axis [m], y-axis[m], and z-axis[m] of the target when participants stretched their arm forward holding the VR wand, and Sx, Sy, and Sz are the coordinates of the sensor of the VR wand. In the formula, the two constants in Py and Pz were determined by a preliminary test for participants’ comfortable movement. Following the calibration, participants were trained on how to contact the tip of the VR wand and track the target moving circularly at a specific speed. Specifically, participants were required to contact the sensor of the VR wand to the target being in a still state in order to become familiar with the movements necessary to perform the task. Then, participants were told that they had to turn their arm holding the VR wand so that the sensor could contact the target moved in a clockwise direction for as long as possible.

Experimental setup. (a) Side view of a participant seating on a fixed chair and wearing belts to fix their upper body positions. (b) Front view of the participant. (c) Experimental setup for VRRP task. (d) Back view of a participant performing VRRP task.

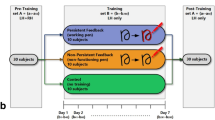
Experimental procedure and conditions. (a) Experimental procedure: after calibrating the positioning the target, considering each participant’s shoulder height and arm length, the participants conducted three practice trials—a baseline measurement trial, and sixteen main trials. During a 3-min break after the baseline measurement, participants could see and adapt to their changed avatar according to their assigned experimental conditions. To measure the retention of procedural memory, eight trials were followed by a 30-min break before the remaining eight trials were conducted. At the conclusion of the VRRP task, participants completed a questionnaire on body-ownership and sense of agency. (b) The movement for the calibration. (c) Experimental condition: hand-shaped avatar. (d) Experimental condition: control object-shaped avatar. (e) Experimental condition: non-avatar.
In this study, an adaptation of the protocol described by Heindel and colleagues33 was employed (see Fig. 3a). Accordingly, participants performed three practice trials, a baseline measurement trial, and sixteen main trials, with a 10-s interval break. In the practice trials, the target moved in a circular orbit at three different speeds (i.e., 15, 30, and 45 rpm) every trial. Before a first practice trial, participants were told that “If you touch the start button with the VR wand, you will hear a beep for 3 s, and in the meantime, you should keep the sensor of the VR wand contacting the target. When the target starts to turn, you can turn the arm holding the VR wand so that the sensor of the VR wand can continue to contact the target.” After brief instruction, the practice trials were conducted. Consecutively, a baseline measurement trial was performed where it rotated at 60 rpm. During three minutes break after those trials, all participants placed the VR wand on the black box (see Fig. 1) and sat still. According to their assigned experimental conditions (see Fig. 3c–e), participants in the hand-shaped avatar condition and the non-hand avatar condition were allowed to view the changed avatar that matched their condition from this break, whereas participants in the non-avatar condition continued to rest while sitting still. In order to adapt to their avatar, the participants who could see their avatar were instructed to sequentially perform opening and closing their hands, rotating their arms, holding the VR wand, and rotating their arms while holding the VR wand again. Afterward, the participants were asked to repeat the motions mentioned above until they fully felt adapted to their avatars. When the participants felt adapted to their avatar, they put the VR wand back on the box and rested for the rest of the time. The main trials were performed for 20 secs each. In addition, to measure the retention of procedural memory, eight trials were followed by a 30-min break before the remaining eight trials were conducted.
Statistical analysis
We examined the group differences in performances on the VRRP across all the trials (i.e., learning) and the retention of the acquired motor skill at 30 min break intervals (i.e., memory) using a linear mixed-model (LMM) analysis with the lme4 and nlme packages in R. In this study, the performances refer to cumulative time measured in seconds that the sensor contacts the target in each 20 s trial. The increased cumulative time denotes better performance. Prior to the main analysis, we conducted a one-way analysis of covariance (ANCOVA) adjusted for demographic variables (i.e., age, gender, and years of education) to investigate the group differences at baseline performance, which may affect the learning on the VRRP. In an analysis of the learning curve (model 1), the trials, the avatar conditions, and the interaction of both were entered into a statistical model as the fixed effect, including the demographic variables as covariates. The 17 trials, including the baseline measurement trial as a categorical variable, were coded to represent sixteen dummy variables. The main effects of the avatar condition were calculated by using reverse helmert contrasts. In the first contrast, the non-avatar condition (0.5) and non-hand avatar condition (− 0.5) were compared. In the second contrast, the hand-shaped avatar condition (− 0.67) was compared to the other conditions (+ 0.33). The regression coefficients of the interaction terms reflect the avatar effects on learning across all the trials. In addition, the random effect structure included a random intercept for the subject and a random time slope for the subject by using time as a continuous variable. For further analysis on procedural memory retention (model 2), we performed the same analysis but modified the trial variable consisting of the ninth and tenth trials and excluded the random time slope from the random effect structure due to the convergence problem. Using the performance package34, the models were validated by checking the outliers, linearity, multicollinearity, homoscedasticity, independence of residuals, and the normality of residuals, and marginal and conditional R-squared values were calculated. Even though all assumptions for the LMM was satisfied in the model 1, autocorrelated residuals were detected in the model 2. Therefore, we incorporated an AR (1) covariance structure into the model 2 using nlme package.
In addition, the group difference in body-ownership and sense of agency was measured using a one-way ANCOVA controlling for the demographic variables to confirm the participants’ perception of their VR avatars and VR wand.
Results
The rate of motor skill learning
There were no differences in baseline performance among the groups (F (2, 57) = 0.615, P = 0.544). In our model, regardless of the avatar condition, the performance on the VRRP showed a steadily significant increase across all the trials (see Supplementary Table S2 and S4). An interaction effect of trial and the avatar conditions on the rate of learning was significant although the main effects of the first contrast coefficient (β = 0.133, S.E. = 0.794, P = 0.868) and the second contrast (β = 0.468, S.E. = 0.664, P = 0.482) were not. As predicted, there was a comparable rate of learning between the non-avatar group and the non-hand avatar group. However, that of the hand-shaped avatar group was significantly superior to that of the other groups across all the trials except for the first, eleventh, twelfth, and fourteenth trials (see Fig. 4 and Supplementary Table S4).

Group differences in the rate of learning. The rate of learning between the non-avatar group (yellow line) and the control object-shaped group (green line) is comparable, but the rate of learning of the hand-shaped avatar group (red line) is significantly superior to that of the other groups across the majority of trials. The letter “B” on the x-axis (Trial) of the graph indicates the baseline measurement. The dark line indicates the rate of learning for each condition, and the light line indicates that for each participant. The asterisks and dagger indicate significance in performance difference for each trial between the hand-shaped group and the other groups, †p < 0.1, *p < 0.05, **p < 0.01, ***p < 0.001.
The retention of motor skill learning
A second contrast effect (β = 2.624, S.E. = 0.651, P = 0.0002) was significant, with the hand-shaped avatar group displaying a greater performance of the task than the other groups across the trials. However, there were no significant trial effects and group-by-trial interaction effects, reflecting that the performance was not significantly diminished across trials (β = − 0.0004, S.E. = 0.353, P = 0.999), with a retention of learning among the groups (first contrast: β = 0.023, S.E. = 0.865, P = 0.978; second contrast: β = − 0.992, S.E. = 0.749, P = 0.190).
Body-ownership and sense of agency
There were no significant differences in the total score from the body-ownership questionnaire between the hand-shaped avatar group and non-hand avatar group (F (1, 37) = 0.570, P = 0.455) as well as that from the sense of agency questionnaire on the VR wand (F (2, 57) = 0.079, P = 0.924) and the avatar (F (1, 37) = 0.757, P = 0.390) among the groups (see Supplementary Table S3).
Discussion
This study investigated the effects of the visual appearance of the virtual avatar on motor memory when repeating a specific movement using a VR tool. In the VRRP, the presented virtual avatar was visually manipulated depending on the experimental conditions in which participants tracked the target in a circular motion using the VR wand. In each condition, we measured not only the performances across all trials and the retention of the motor skills but also body ownership and sense of agency by the questionnaire at the end of the experiment. In addition, we analyzed the group differences of the obtained measures.
In this study, all of the groups were able to see the movement of the VR wand they had manipulated. Also, the hand-shaped avatar group and the non-hand avatar group could see movements of their avatars. Nevertheless, our findings indicated significant differences in the improvement of the VRRP task performance for each experimental group. The hand-shaped avatar group showed the greatest increase in performance, and the non-hand avatar group showed little difference in performance compared to the non-avatar group. These results suggest that even if participants perceive the same movement, motor skill learning can be improved when viewing bodily visual feedback. This may derive from the unique advantages of body shape.
According to previous research, virtual body-representation is influential in spatial perception in that one’s own body can be used as a familiar cue to scale the size and distance of objects35,36,37. For example, the egocentric distance to the target point is more accurately judged when virtual body-representation is presented than when it is not36. In addition, the perception of object sizes38,39, as well as the distance judgment40,41, are influenced by the size or shape of the virtual body. These findings indicate that virtual body-representation facilitates the judgment of the distance and size of the target.
In our task, motor learning and memory were measured through the amount of time the virtual wand contacted the target. Therefore, it was important for participants to accurately estimate the distance and size of the target. It may be more advantageous for the hand-shaped avatar group to contact the VR wand to the target than the other groups since the more similar the virtual avatar was to one's own body, the greater the accuracy of the judgment on the distance and size of objects39,41.
However, the hand-shaped avatar group did not outperform the other groups in all trials. The performance gains of the hand-shaped avatar group gradually increased more than that of the other groups following the second trial. If spatial perception by virtual body-representation influenced the conduction of our task, there should have been a significant difference in performance between the groups in the first trial. Considering that memory consolidation is facilitated during a brief rest period after learning42, these results may infer that virtual body-representation impacted the learning rate more than spatial perception in our task.
Several studies have manipulated visual feedback accompanied by physical movement because this feedback is the most influential and effective sensory input in motor performance and learning1,2,43,44. Ossmy and Mukamel6 found that when participants trained a finger tapping sequence task in a VR environment, performance gains were greatest in the condition where the size of visual feedback (i.e., hand-shaped avatar) was similar to one’s real hand size. Another study demonstrated that visual feedback congruent with one's hand movement increases performance gains the most, while visual feedback incongruent with the movement interferes with performance gains more than when visual feedback was absent7. These results indicate that the virtual body-representation facilitates or interferes with motor skill learning depending on the degree to which the feedback matches one's body and actual movement.
Similarly, our findings also emphasize the role of virtual body-representation in motor skill learning. However, they differ from the previous studies in that they proved that the difference in visual representation of the body itself can facilitate or interfere with the learning even when visual stimuli are congruent with the movement of the tool, where one’s body or both is presented. Moreover, our prediction was confirmed, as the results suggest that virtual body-representation affects motor skill learning from the early learning stage. In the initial stage of motor skill training, motor memory acquisition is due to the explicit process in which motor memories sharply improve but also decay rapidly over time19,45. In this stage, high-level cognitive strategies and knowledge may be required to plan and adjust one’s movement in response to performance errors, and thus cognitive resources such as attention46, executive function47., working memory48, and episodic memory49 were required for this process. In the later stage of the training, implicit learning becomes more dominant than explicit learning by automatizing explicit strategies and knowledge through practice50.
We speculated that virtual body-representation facilitates explicit learning. Recent studies have indicated that one’s body or body-shaped avatar representation in a VR environment facilitates episodic memory encoding and retrieval rather than a non-body-shaped avatar or the absence of a virtual body9,10,11,51. That is why episodic encoding requires the co-perception of one’s body and the world in first-person perspective, and the violation of this condition impairs episodic recall8,9. These findings are supported by the fact that the body view in the VR increases the intrinsic medial temporal connectivity related to episodic memory performance and modulates the neural substrates of autonoetic consciousness, which allows one to mentally place oneself in the time where a specific event occurred and recall the event9,52,53. Given recent findings that rapid improvements in performance occur in the early motor learning stage through hippocampal replay, which is the reactivation of experienced information encompassing episodic memory during waking rest interleaved with practice21,22,23, the significant differences in the performance gain between the groups may result from the effect of virtual body-representation facilitating episodic memory encoding and retrieval.
We predicted that the effect of virtual body-representation derived from bodily self-consciousness. However, there was no difference in the body-ownership and sense of agency questionnaire scores between all of the groups. This result is inconsistent with previous studies which showed that the sense of body-ownership increases more if human body-shaped avatar is presented compared to non-human body-shaped avatar15,16,17. It may be possible to embody one’s avatar even if the realism of the virtual body-representation is violated because simultaneous and congruent visuo-motor combination with the avatar strongly influences the embodiment54,55. In addition, there is another possibility that the discrepancies in body-ownership between the three groups that existed at the initial embodiment phase(i.e., 3-min break) may have disappeared after completing the task. This possibility is supported by the fact that the decreased bodily self-consciousness can be recovered as motor learning progressed14. Therefore, it may have been necessary to measure body-ownership and sense of agency both at the initial embodiment phase and after completing the task. Or, rather than the measurement of subjective embodiment, other measurements like autonoetic consciousness or experiential ownership56 which is the sense of experiencing the current event for oneself might better explain the relationship between the subjective experience and performance gain.
On the other hand, the absence of the discrepancy in body-ownership can raise the possibility of an alternative explanation for our findings. One possibility is that the hand shape itself may impact participants’ attention to the task. Previous studies found that people have attentional prioritization in space proximal to their hand, so they make faster responses to objects near their hands than objects far from their hands57,58. In this light of view, although virtual avatars were presented in our study, attention to the VR wand or the target may have increased under the hand-shaped avatar condition compared to other conditions. Since attentional resources are recruited during early stages of motor learning and decrease in resources can hamper motor learning, the learning rate of the hand-shaped avatar condition may be better than that of other conditions46.
Our study has the following limitations. The effect of the hand-shaped avatar was weakened in the second block of the task. Consequently, it is surmised that the avatar has no effect when long-term learning is undertaken. However, in our task, it was difficult to grasp the change in the long-term learning pattern due to the limitation of the number of trials. Therefore, future studies should identify the long-term effect of the avatar to clarify that the effect only appears in the early stages of motor skill learning. In addition, it is difficult to test the avatar effect on long-term memory for motor skill learning because participants took a 30-min break in the wakeful state. Both declarative and procedural memory are consolidated through sleep59, and it is also required to manipulate post training delays (e.g., one day, one week) to identify the interaction effect between virtual body-representation and sleep on the long-term retention. Finally, we employed a VR task to measure simple motor skill learning and did not reflect the functional and physical characteristics of a real tool but a simple virtual tool. Therefore, it may be easy to generalize our results because a simple VR task manipulating only visual stimuli was used. However, our results are limited to reflect complex motor skill learning using tools that occur in real life. In future studies, it would be necessary to generalize whether the results will be replicated in complex tasks.
In conclusion, by manipulating the visual representation of the self-avatar, we confirmed that the hand-shaped avatar can improve learning speed in tool-based motor skill learning. To the best of our knowledge, this is the first study that demonstrates the effect of virtual body-representation in VR tool-based motor skill learning. Our findings emphasize the importance of virtual body-representation and suggest a more effective framework for training in a VR environment. Motor learning or motor training programs are usually displayed on a two-dimensional screen and people interact with programs through a symbolic virtual representation of their bodies like cursors60. Through 2D screens, people cannot view their bodies or experience decreased embodiment. Also, reduced depth cues and eye-hand coordination in 2D screen might add cognitive load to performers61,62. Although these limitations exist due to the nature of 2D screens, we believe that virtual body-preservations may solve some of its limitations. In doing so, further research on the application and generalization of virtual body-preservation need to be done. We hope that these findings can be employed as a reference to develop rehabilitation, medical training, and sport training programs for effective skill learning.
Data availability
The dataset generated and analyzed during the current study and corresponding syntax are available from the first author on reasonable request.
References
Adams, J. A., Gopher, D. & Lintern, G. Effects of visual and proprioceptive feedback on motor learning. J. Mot. Behav. 9, 11–22. https://doi.org/10.1177/154193127501900204 (1977).
Proteau, L. On the specificity of learning and the role of visual information for movement control. Adv. Psychol. 85, 67–103. https://doi.org/10.1016/S0166-4115(08)62011-7 (1992).
Ossmy, O. & Mukamel, R. Perception as a route for motor skill learning: Perspectives from neuroscience. Neuroscience 382, 144–153. https://doi.org/10.1016/j.neuroscience.2018.04.016 (2018).
Saunders, J. A. & Knill, D. C. Humans use continuous visual feedback from the hand to control both the direction and distance of pointing movements. Exp. Brain Res. 162, 458–473. https://doi.org/10.1007/s00221-004-2064-1 (2005).
Ossmy, O. & Mukamel, R. Neural network underlying intermanual skill transfer in humans. Cell Rep. 17, 2891–2900. https://doi.org/10.1016/j.celrep.2016.11.009 (2016).
Ossmy, O. & Mukamel, R. Short term motor-skill acquisition improves with size of self-controlled virtual hands. PLoS ONE 12, e0168520. https://doi.org/10.1371/journal.pone.0168520 (2017).
Ossmy, O. & Mukamel, R. Behavioral and neural effects of congruency of visual feedback during short-term motor learning. Neuroimage 172, 864–873. https://doi.org/10.1016/j.neuroimage.2017.12.020 (2018).
Bergouignan, L., Nyberg, L. & Ehrsson, H. H. Out-of-body–induced hippocampal amnesia. Proc. Natl. Acad. Sci. 111, 4421–4426. https://doi.org/10.1073/pnas.1318801111 (2014).
Gauthier, B. et al. First-person body view modulates the neural substrates of episodic memory and autonoetic consciousness: A functional connectivity study. Neuroimage 223, 117370. https://doi.org/10.1016/j.neuroimage.2020.117370 (2020).
Bréchet, L. et al. First-person view of one’s body in immersive virtual reality: Influence on episodic memory. PLoS ONE 14, e0197763. https://doi.org/10.1371/journal.pone.0197763 (2019).
Bréchet, L. et al. Subjective feeling of re-experiencing past events using immersive virtual reality prevents a loss of episodic memory. Brain Beh. 10, e01571. https://doi.org/10.1002/brb3.1571 (2020).
Iriye, H. & Ehrsson, H. H. Perceptual illusion of body-ownership within an immersive realistic environment enhances memory accuracy and re-experiencing. iScience https://doi.org/10.1016/j.isci.2021.103584 (2021).
Braun, N. et al. The senses of agency and ownership: A review. Front. Psychol. 9, 535. https://doi.org/10.3389/fpsyg.2018.00535 (2018).
Ishikawa, R., Ayabe-Kanamura, S. & Izawa, J. The role of motor memory dynamics in structuring bodily self-consciousness. Iscience 24, 103511. https://doi.org/10.1016/j.isci.2021.103511 (2021).
Kim, C.-S., Jung, M., Kim, S.-Y. & Kim, K. Controlling the sense of embodiment for virtual avatar applications: methods and empirical study. JMIR Serious Games 8, 21879. https://doi.org/10.2196/21879 (2020).
Zopf, R., Polito, V. & Moore, J. Revisiting the link between body and agency: Visual movement congruency enhances intentional binding but is not body-specific. Sci. Rep. 8, 1–9. https://doi.org/10.1038/s41598-017-18492-7 (2018).
Ma, K. & Hommel, B. The role of agency for perceived ownership in the virtual hand illusion. Conscious. Cogn. 36, 277–288. https://doi.org/10.1016/j.concog.2015.07.008 (2015).
Synofzik, M., Vosgerau, G. & Newen, A. I move, therefore I am: A new theoretical framework to investigate agency and ownership. Conscious. Cogn. 17, 411–424. https://doi.org/10.1016/j.concog.2008.03.008 (2008).
Chung, Y.-C. et al. Cognition and motor learning in a Parkinson’s disease cohort: importance of recall in episodic memory. NeuroReport 32, 1153–1160. https://doi.org/10.1097/WNR.0000000000001707 (2021).
Kim, S. Bidirectional competitive interactions between motor memory and declarative memory during interleaved learning. Sci. Rep. 10, 1–12. https://doi.org/10.1038/s41598-020-64039-8 (2020).
Buch, E. R., Claudino, L., Quentin, R., Bönstrup, M. & Cohen, L. G. Consolidation of human skill linked to waking hippocampo-neocortical replay. Cell Rep. 35, 109193. https://doi.org/10.1016/j.celrep.2021.109193 (2021).
Jacobacci, F. et al. Rapid hippocampal plasticity supports motor sequence learning. Proc. Natl. Acad. Sci. 117, 23898–23903. https://doi.org/10.1073/pnas.2009576117 (2020).
Pfeiffer, B. E. The content of hippocampal “replay”. Hippocampus 30, 6–18. https://doi.org/10.1002/hipo.22824 (2020).
Seinfeld, S., Feuchtner, T., Pinzek, J. & Muller, J. Impact of information placement and user representations in VR on performance and embodiment. IEEE Trans. Vis. Comput. Gr. 28, 1545–1556. https://doi.org/10.1109/TVCG.2020.3021342 (2022).
Tambone, R. et al. Using body ownership to modulate the motor system in stroke patients. Psychol. Sci. 32, 655–667. https://doi.org/10.1177/0956797620975774 (2021).
Griffith, J. L., Voloschin, P., Gibb, G. D. & Bailey, J. R. Differences in eye-hand motor coordination of video-game users and non-users. Percept. Mot. Skills 57, 155–158. https://doi.org/10.2466/pms.1983.57.1.155 (1983).
Harrington, D. L., Haaland, K. Y., Yeo, R. A. & Marder, E. Procedural memory in Parkinson’s disease: Impaired motor but not visuoperceptual learning. J. Clin. Exp. Neuropsychol. 12, 323–339. https://doi.org/10.1080/01688639008400978 (1990).
Hong, J.-Y., Gallanter, E., Müller-Oehring, E. M. & Schulte, T. Phases of procedural learning and memory: Characterisation with perceptual-motor sequence tasks. J. Cogn. Psychol. 31, 543–558. https://doi.org/10.1080/20445911.2019.1642897 (2019).
Oldfield, R. C. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia 9, 97–113. https://doi.org/10.1016/0028-3932(71)90067-4 (1971).
Choi, W., Lee, J., Yanagihara, N., Li, L. & Kim, J. Development of a quantitative evaluation system for visuo-motor control in three-dimensional virtual reality space. Sci. Rep. 8, 1–9. https://doi.org/10.1038/s41598-018-31758-y (2018).
Mueller, S. T. & Piper, B. J. The psychology experiment building language (PEBL) and PEBL test battery. J. Neurosci. Methods 222, 250–259. https://doi.org/10.1016/j.jneumeth.2013.10.024 (2014).
Gonzalez-Franco, M. & Peck, T. C. Avatar embodiment. Towards a standardized questionnaire. Front. Robot. AI 5, 74. https://doi.org/10.3389/frobt.2018.00074 (2018).
Heindel, W. C., Salmon, D. P., Shults, C. W., Walicke, P. A. & Butters, N. Neuropsychological evidence for multiple implicit memory systems: A comparison of Alzheimer’s, Huntington’s, and Parkinson’s disease patients. J. Neurosci. 9, 582–587. https://doi.org/10.1523/JNEUROSCI.09-02-00582.1989 (1989).
Lüdecke, D., Ben-Shachar, M. S., Patil, I., Waggoner, P. & Makowski, D. performance: An R package for assessment, comparison and testing of statistical models. J. Open Source Softw. 6, 3139 (2021).
Van der Hoort, B. & Ehrsson, H. H. Body ownership affects visual perception of object size by rescaling the visual representation of external space. Atten. Percept. Psychophys. 76, 1414–1428. https://doi.org/10.3758/s13414-014-0664-9 (2014).
Mohler, B. J., Creem-Regehr, S. H., Thompson, W. B. & Bülthoff, H. H. The effect of viewing a self-avatar on distance judgments in an HMD-based virtual environment. Presence 19, 230–242. https://doi.org/10.1162/pres.19.3.230 (2010).
Proffitt, D. R. & Linkenauger, S. A. Perception viewed as a phenotypic expression. In Action Science: Foundations of an Emerging Discipline (eds Prinz, W. et al.) 171–197 (MIT Press, 2013).
Van Der Hoort, B., Guterstam, A. & Ehrsson, H. H. Being Barbie: The size of one’s own body determines the perceived size of the world. PLoS ONE 6, e20195. https://doi.org/10.1371/journal.pone.0020195 (2011).
Ogawa, N., Narumi, T. & Hirose, M. Virtual hand realism affects object size perception in body-based scaling. In 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 519–528. http://doi.org/https://doi.org/10.1109/VR.2019.8798040 (2019).
Linkenauger, S. A., Bülthoff, H. H. & Mohler, B. J. Virtual arm׳ s reach influences perceived distances but only after experience reaching. Neuropsychologia 70, 393–401. https://doi.org/10.1016/j.neuropsychologia.2014.10.034 (2015).
Yang, Z. et al. Influences of experience and visual cues of virtual arm on distance perception. i-Perception 11, 2041669519901134. https://doi.org/10.1177/2041669519901134 (2020).
Wamsley, E. J. Memory consolidation during waking rest. Trends Cogn. Sci. 23, 171–173. https://doi.org/10.1016/j.tics.2018.12.007 (2019).
Todorov, E., Shadmehr, R. & Bizzi, E. Augmented feedback presented in a virtual environment accelerates learning of a difficult motor task. J. Mot. Behav. 29, 147–158. https://doi.org/10.1080/00222899709600829 (1997).
Kilner, J. M., Paulignan, Y. & Blakemore, S.-J. An interference effect of observed biological movement on action. Curr. Biol. 13, 522–525. https://doi.org/10.1016/S0960-9822(03)00165-9 (2003).
Keisler, A. & Shadmehr, R. A shared resource between declarative memory and motor memory. J. Neurosci. 30, 14817–14823. https://doi.org/10.1523/JNEUROSCI.4160-10.2010 (2010).
Della-Maggiore, V. & McIntosh, A. R. Time course of changes in brain activity and functional connectivity associated with long-term adaptation to a rotational transformation. J. Neurophysiol. 93, 2254–2262. https://doi.org/10.1152/jn.00984.2004 (2005).
Ren, J., Wu, Y. D., Chan, J. S. & Yan, J. H. Cognitive aging affects motor performance and learning. Geriatr. Gerontol. Int. 13, 19–27. https://doi.org/10.1111/j.1447-0594.2012.00914.x (2013).
Anguera, J. A., Reuter-Lorenz, P. A., Willingham, D. T. & Seidler, R. D. Contributions of spatial working memory to visuomotor learning. J. Cogn. Neurosci. 22, 1917–1930. https://doi.org/10.1162/jocn.2009.21351 (2010).
Taylor, J. A. & Ivry, R. B. Implicit and explicit processes in motor learning. Action Sci. Found. Emerg. Discip. https://doi.org/10.7551/mitpress/9780262018555.003.000363-87 (2013).
Krakauer, J. W., Hadjiosif, A. M., Xu, J., Wong, A. L. & Haith, A. M. Motor learning. Compr Physiol 9, 613–663. https://doi.org/10.1002/cphy.c170043 (2019).
Steed, A., Pan, Y., Zisch, F. & Steptoe, W. The impact of a self-avatar on cognitive load in immersive virtual reality. 2016 IEEE Virtual Reality (VR). https://doi.org/10.1109/VR.2016.7504689 (2016).
Tulving, E. Episodic memory: From mind to brain. Annu. Rev. Psychol. 53, 1–25. https://doi.org/10.1146/annurev.psych.53.100901.135114 (2002).
Wang, L. et al. Intrinsic interhemispheric hippocampal functional connectivity predicts individual differences in memory performance ability. Hippocampus 20, 345–351. https://doi.org/10.1002/hipo.20771 (2010).
Giroux, M., Barra, J., Barraud, P.-A., Graff, C. & Guerraz, M. From embodiment of a point-light display in virtual reality to perception of one’s own movements. Neuroscience 416, 30–40. https://doi.org/10.1016/j.neuroscience.2019.07.043 (2019).
Fossataro, C., Tieri, G., Grollero, D., Bruno, V. & Garbarini, F. Hand blink reflex in virtual reality: The role of vision and proprioception in modulating defensive responses. Eur. J. Neurosci. 51, 937–951. https://doi.org/10.1111/ejn.14601 (2020).
Liang, C. et al. Experiential ownership and body ownership are different phenomena. Sci. Rep. 11, 1–11. https://doi.org/10.1038/s41598-021-90014-y (2021).
Abrams, R. A., Davoli, C. C., Du, F., Knapp, W. H. III. & Paull, D. Altered vision near the hands. Cognition 107, 1035–1047. https://doi.org/10.1016/j.cognition.2007.09.006 (2008).
Gozli, D. G., West, G. L. & Pratt, J. Hand position alters vision by biasing processing through different visual pathways. Cognition 124, 244–250. https://doi.org/10.1016/j.cognition.2012.04.008 (2012).
Vahdat, S., Fogel, S., Benali, H. & Doyon, J. Network-wide reorganization of procedural memory during NREM sleep revealed by fMRI. Elife 6, e24987. https://doi.org/10.7554/eLife.24987 (2017).
Wenk, N. et al. Effect of immersive visualization technologies on cognitive load, motivation, usability, and embodiment. Virtual Reality https://doi.org/10.1007/s10055-021-00565-8 (2021).
Mousavi Hondori, H. et al. Choice of human–computer interaction mode in stroke rehabilitation. Neurorehabil. Neural Repair 30, 258–265. https://doi.org/10.1177/1545968315593805 (2016).
Liebermann, D. G., Berman, S., Weiss, P. L. & Levin, M. F. Kinematics of reaching movements in a 2-D virtual environment in adults with and without stroke. IEEE Trans. Neural Syst. Rehabil. Eng. 20, 778–787. https://doi.org/10.1109/TNSRE.2012.2206117 (2012).
Acknowledgements
The authors thank Kahyun Kim for valuable feedback on an earlier draft of the manuscript and Bonjour Shin for developing the VR rotary pursuit task. This work was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (2020R1F1A1076307).
Author information
Authors and Affiliations
Contributions
All authors have read and approved the manuscript. Conceptualization: S.Y.; Methodology: S.Y.; Formal analysis: S.Y.; Data curation: S.Y.; Investigation: S.Y., L.J.; Writing—original draft preparation: S.Y., L.J., K.Y.; Writing-review and editing: I.J., S.D-G.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shin, Y., Lim, J., Kim, Y. et al. Effects of virtual body-representation on motor skill learning. Sci Rep 12, 15283 (2022). https://doi.org/10.1038/s41598-022-19514-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-19514-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
