
Abstract
Clinical research networks (CRNs), made up of multiple healthcare systems each with patient data from several care sites, are beneficial for studying rare outcomes and increasing generalizability of results. While CRNs encourage sharing aggregate data across healthcare systems, individual systems within CRNs often cannot share patient-level data due to privacy regulations, prohibiting multi-site regression which requires an analyst to access all individual patient data pooled together. Meta-analysis is commonly used to model data stored at multiple institutions within a CRN but can result in biased estimation, most notably in rare-event contexts. We present a communication-efficient, privacy-preserving algorithm for modeling multi-site zero-inflated count outcomes within a CRN. Our method, a one-shot distributed algorithm for performing hurdle regression (ODAH), models zero-inflated count data stored in multiple sites without sharing patient-level data across sites, resulting in estimates closely approximating those that would be obtained in a pooled patient-level data analysis. We evaluate our method through extensive simulations and two real-world data applications using electronic health records: examining risk factors associated with pediatric avoidable hospitalization and modeling serious adverse event frequency associated with a colorectal cancer therapy. In simulations, ODAH produced bias less than 0.1% across all settings explored while meta-analysis estimates exhibited bias up to 12.7%, with meta-analysis performing worst in settings with high zero-inflation or low event rates. Across both applied analyses, ODAH estimates had less than 10% bias for 18 of 20 coefficients estimated, while meta-analysis estimates exhibited substantially higher bias. Relative to existing methods for distributed data analysis, ODAH offers a highly accurate, computationally efficient method for modeling multi-site zero-inflated count data.
Similar content being viewed by others
Introduction
The recent advent of “big data” has had significant implications for health care, spawning several advancements in management and analysis of large-scale patient data1. Much of this is a result of the widespread adoption of electronic health records (EHRs), patient data collected during routine and emergency clinical visits. Though EHRs are primarily used as a written record of health care delivery, substantial effort has been made in using these data secondarily to generate real-world evidence (RWE), evidence produced as a result of analyzing observational health data outside of clinical trials. RWE quality can be substantially improved from analyzing pooled data, patient records aggregated across health systems. This is especially true in the context of studying rare outcomes, where outcome prevalence at any single institution may not be large enough to result in an analysis with meaningful conclusions. Pooled patient data from several healthcare systems also allows for study of a sample likely to be more representative of the population of interest.
While pooling patient data from several institutions is ideal, doing so is not always possible. Regulations such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States and the General Data Protection Regulation (GDPR) in the European Union often prevent inter-site sharing of patient-level data that is not de-identified2,3. Sharing de-identified individual patient data (IPD) can also be dangerous according to several studies demonstrating the susceptibility of these data to re-identification, causing concern among patients4,5,6. Further, significant computational burden associated with storing and analyzing massive datasets makes data centralization less appealing in some settings. As a result of these restrictions and concerns, much interest has been demonstrated recently in distributed clinical research networks (CRNs), multi-site distributed data networks which allow for analyses across institutions without the need for data centralization7,8. In a CRN, each individual institution or health system maintains control over its own data, drastically reducing risk of violating patient privacy through avoiding IPD exchange. Examples of CRNs include the National Patient-Centered Clinical Research Network (PCORnet)9, a CRN with patient data from 348 health systems in the United States, and the Sentinel System, a national CRN for monitoring performance of FDA-regulated medical products10,11.
To protect patient privacy, CRNs largely invoke methods for synthesizing and analyzing aggregate data, summary measures obtained from individual sites without any information that could reveal patient identity. In comparative effectiveness research performed in CRNs, meta-analysis is frequently used. Meta-analysis, which only requires effect size and variance estimates from each individual site, is easy to implement and widely accepted in medical literature; it is the primary analysis method used in comparative effectiveness studies conducted by the Observational Health Data Sciences and Informatics (OHDSI) collaborative, an international CRN made up of over 100 different databases12,13,14,15,16. Beyond statistical approaches to privacy preservation, several other methods are available for making multi-site analyses of patient data more secure. Differential privacy methods17 allow researchers to add random noise to patient-level data and obtain results close to those using raw data, while methods incorporating homomorphic encryption18 produce results identical to those using unencrypted data. Similarly, blockchain technology can be used to implement a secure, decentralized distributed network which eliminates reliance on a coordinating center, useful for Health Information Exchange applications19. Swarm Learning and ModelChain are examples using blockchain technology for building and sharing privacy-preserving predictive models across institutions20,21. While useful in certain settings, the computation time required for blockchain-based analyses can be a limitation in healthcare settings where both accurate and efficient solutions are desirable.
While suitable for many applications, meta-analysis has been shown to result in biased or imprecise effect estimates in the context of rare events and limited sample sizes22. In only sharing site-level point and variance estimates, meta-analysis does not utilize any additional aggregate information that could be obtained from ongoing studies with access to their own patient-level data. Distributed regression methods are an alternative to meta-analysis which leverage access to patient-level data within individual sites, allowing for fitting a regression model distributively across institutions without sharing IPD. Rather than sharing only site-specific regression estimates, distributed regression methods reconstruct or approximate pooled regression estimates (estimates calculated using all pooled patient-level data) using aggregate, summary-level data supplied by each participating database. While several distributed regression algorithms have been developed, many require several rounds of communication among sites until convergence, resulting in analysis that is both time consuming and computationally expensive23,24. More recently, a class of non-iterative distributed algorithms has been proposed by Duan et al.22,25; these methods use a surrogate likelihood approach to generate estimates comparable to those from pooled analysis using IPD only at the lead site, incorporating aggregate information from collaborating sites to better approximate the complete data likelihood26. Methods based on the surrogate likelihood approach are one-shot algorithms, requiring only one or two rounds of non-iterative communication among institutions to offer a communication-efficient alternative for performing distributed regression.
To our knowledge, despite the growing collection of methods for analyzing data in CRNs, no distributed regression method for modeling count outcomes currently exists. Count data are abundant in EHRs, administrative claims, and other sources of electronic health data, with examples including length of stay, number of primary care or emergency department visits, and number of laboratory tests administered. To explore associations between count outcomes and a set of clinical covariates, Poisson or Negative Binomial regression is typically used. In practice, medical count data can be zero-inflated, where zero counts are in excess; zeros often make up the majority of observed counts for rare outcomes, far exceeding the number expected in Poisson or Negative Binomial distributions. In several applications, empirical distributions of zero-inflated counts can also feature a small number of observations with relatively large counts. This is a common occurrence in distributions of health care expenditure, for example, which feature a large proportion of patients with no expenses at one end and a smaller proportion of patients with large expenses at the other27. In these settings, one can use hurdle regression, which uses two separate processes for modeling zero and non-zero (positive) counts. The first part models whether an observation will have a zero or positive count, commonly through logistic regression, while the second estimates a count for an observation given that the count is positive, typically using zero-truncated Poisson or Negative Binomial regression. Hurdle regression allows one to separately investigate the effect of covariates on the probability of experiencing an outcome and on the expected frequency of an outcome given that it occurs at least once, improving interpretation in settings where these two processes are driven by different parameters.
We propose a novel method, a one-shot distributed algorithm for hurdle regression (ODAH), to distributively model zero-inflated count outcomes stored in multiple institutions. Using the surrogate likelihood approach, our method for modeling count outcomes is an efficient, non-iterative algorithm which requires two rounds of privacy-preserving communication among sites to generate accurate and precise population-level estimates closely approximating those from pooled analysis. We evaluate ODAH through an extensive simulation study before applying our method to two real-world data use cases: analyzing risk factors of pediatric avoidable hospitalization and modeling serious adverse event frequency for colorectal cancer patients. The results from these analyses demonstrate that coefficients produced from ODAH are generally less biased than those from meta-analysis when compared to the gold standard pooled estimate. Our non-iterative ODAH method is both communication-efficient and highly accurate serving as a worthwhile method for analyzing zero-inflated count outcomes in CRN and distributed regression settings.
Methods
Poisson–Logit hurdle model
A hurdle model is a two-part model which specifies two separate processes, one for generating zero values and another for generating values given that they are non-zero28. The hurdle model is useful for modeling a count outcome with excess zeros, modeling the zero and positive counts independently. Figure 1 depicts a typical zero-inflated distribution of counts, as well as a schematic overview detailing the sequential nature of the Poisson–Logit hurdle model.

On the left, a histogram displaying counts generated with a Poisson–Logit hurdle distribution with 10% prevalence and a zero-truncated event rate of \(\lambda = 1.5\). On the right, a hierarchical diagram visualizing the data generation process in a Poisson–Logit hurdle framework. Independent realizations \(w_{i} \in \left\{ {0,1} \right\}\) are generated from a Bernoulli process, with underlying probability \(\pi_{i}\) modeled using a logit link. Realizations where \(w_{i} = 0\) are zero counts (\(y_{i} = 0\)), while realizations where \(w_{i} = 1\) are positive counts (\(y_{i} \in \left\{ {1,2, \ldots } \right\}\)). The positive counts are generated by a zero-truncated Poisson distribution, with underlying event rate \(\lambda_{i}\) modeled using a log link.
In this paper, we invoke the hurdle model to model zero-inflated count outcomes common in healthcare data. To derive our hurdle model, we consider the two processes making up the model independently. First, we model the proportion of zero counts with a Bernoulli process using a logit link. Let \(w_{1} ,w, \ldots , w_{n} \in \left\{ {0,1} \right\}\) be independent realizations of a binary response variable W, such that \(P\left( {w_{i} = 1} \right) = \pi_{i}\) and \(P\left( {w_{i} = 0} \right) = 1 - \pi_{i}\). The logistic model of the probability \(\pi_{i}\) is modeled as a linear combination of explanatory variables X and regression coefficients \({\varvec{\beta}}\):
Next, positive counts are modeled using a zero-truncated Poisson model. Let \(y_{1} ,y_{2} , \ldots , y_{n} \in \left\{ {0,1,2, \ldots } \right\}\) be independent realizations of a count variable Y. Assume \(P\left( {Y_{i} = 0} \right) = P\left( {w_{i} = 0} \right) = 1 - \pi_{i}\), and \(P\left( {Y_{i} > 0} \right) = P\left( {w_{i} = 1} \right) = \pi_{i}\). Thus, \(\pi_{i}\) can interpreted as the probability that the “hurdle is crossed”, resulting in a non-zero count. In the context of zero-inflated counts, we assume \(P\left( {y_{i} = 0} \right)\) is much greater than \(P\left( {y_{i} > 0} \right)\).
For observations where the realization from the logistic model is 1, positive counts follow a zero-truncated Poisson distribution such that \(P\left( {Y_{i} = y_{i} \left| {Y_{i} } \right\rangle 0} \right) = \frac{{e^{{ - \lambda_{i} }} \lambda_{i}^{{y_{i} }} }}{{\left( {1 - e^{{ - \lambda_{i} }} } \right)y_{i} !}}\). Thus, we can write the mixture probability mass function of the Poisson hurdle model as
Modeling the rate parameter \({\lambda }_{i}\) using a log link, we can express the log of \({\lambda }_{i}\) as a linear combination of explanatory variables Z and regression coefficients \({\varvec{\gamma}}\):
We write the log-likelihood of the Poisson hurdle model as \(L\left({\varvec{\beta}},{\varvec{\gamma}}\right)={L}_{1}\left({\varvec{\beta}}\right)+{L}_{2}\left({\varvec{\gamma}}\right)\), with
and
Note that this factors into two components such that β and γ are separable; the Hessian matrix is block diagonal, so β and γ are information orthogonal. Thus, there will not be any loss of information in estimating each set of parameters separately. This property is useful in the context of distributed regression, reducing computational complexity.
While less common than traditional regression models for count data, hurdle models have been used successfully in various health contexts with substantial zero inflation. For instance, Negative Binomial–Logit hurdle models were utilized to estimate risk of vaccine adverse events for clinical trial participants, as well as to estimate cigarette and marijuana use among youth e-cigarette users29,30. Hurdle regression has also been used in other specialized contexts, such as in estimating spatiotemporal patterns of emergency department use and quantifying association between preventive dental behaviors and caries prevalence31,32. Contrary to zero-inflated Poisson or Negative Binomial regression models, hurdle models have only one source of zero counts, indicating that all individuals in the study sample are at risk of the outcome. This offers an interpretation of estimated model coefficients that is more appropriate in many clinical settings. Further, in having two sets of parameters which can be estimated independently, one avoids the complexity of zero counts coming from a mixture distribution as is the case when using zero-inflated distributions.
Distributed hurdle regression: ODAH
Suppose we have clinical data stored in K sites, where the jth site has a sample size nj and the total sample size across sites is \(N = \sum\nolimits_{j = 1}^{K} {n_{j} }\). Let Yij and Xij denote the count outcome and covariate vector for subject i in site j, respectively. We can write the log likelihood functions for the combined data as
and
In the CRN context, we assume that we do not have access to the combined data. We only have access to data at one of the K sites (the lead site, with site index j = 1), as well as aggregate information from the other sites (the collaborating sites). Using methods developed by Jordan et al.26 and later adapted to the clinical data setting by Duan et al.22,25, we construct a surrogate log likelihood function, which approximates the complete data log likelihood using patient-level data from the lead site and aggregate information from the collaborating sites. The goal with surrogate likelihood estimation is to closely approximate the log likelihood functions for the combined data that we do not have access to, constructing a proxy for the combined-data log likelihoods near a neighborhood of some true parameter value. The aggregate information used in our work is the set of first- and second-order gradients of the log likelihood function at the K − 1 collaborating sites. Since our method is based on approximating the combined-data log likelihoods, an assumption for the algorithm is that data from different sites are homogeneously distributed. Additionally, the outcome being modeled given the covariates should be approximately Poisson-distributed and zero-inflated.
The surrogate log likelihood function for each component of the hurdle model can be expressed as
and
where \(\overline{{\user2{\beta }}}\) and \(\overline{\user2{\gamma }}\) are initial estimates for the algorithm. Here, \(L_{11} \left( {\varvec{\beta}} \right)\) and \(L_{21} \left( {\varvec{\gamma}} \right)\) are log-likelihoods computed using patient-level data at the lead site for the logistic and zero-truncated components, respectively. The terms
and
are weighted averages of first-order (g = 1) or second-order (g = 2) gradients at each site, and \(\nabla^{g} L_{11} \left( {\overline{\user2{\beta }}} \right)\) and \(\nabla^{g} L_{21} \left( {\overline{\user2{\gamma }}} \right)\) are first-order or second-order gradients calculated at the lead site for the logistic and zero-truncated Poisson components of the hurdle model, respectively, evaluated at \(\overline{{\user2{\beta }}}\) and \(\overline{\user2{\gamma }}\). Explicit formulations of the first- and second-order gradients for each component of the hurdle model are available in the Supplement (Equations S.1–S.4). The ODAH estimators are then defined as
and
Well-chosen \(\overline{{\user2{\beta }}}\) and \(\overline{\user2{\gamma }}\) will increase the accuracy of \(\tilde{\user2{\beta }}\) and \(\tilde{\user2{\gamma }}\), respectively. In this work, \(\overline{\user2{\beta }}\) and \(\overline{\user2{\gamma }}\) are estimates computed from performing a fixed-effects meta-analysis using all K sites, or inverse-variance weighted sums of estimates from the K studies, i.e. for \(\overline{\user2{\beta }} \left( {{\text{with }}\overline{\user2{\gamma }} {\text{similar}}} \right)\),
This requires each site to send point and variance estimates to the lead site to initiate the algorithm. Alternatively, one could use lead site maximum likelihood estimates \(\hat{\user2{\beta }}_{1}\) and \(\hat{\user2{\gamma }}_{1}\) obtained via fitting the hurdle model of interest at the lead site. This has been shown to perform well when the lead site is largely representative of the entire multi-site sample and eliminates one round of communication among sites relative to using the meta-analytic initial estimate22.
ODAH builds upon currently available methods using the surrogate likelihood approach for distributed regression. While the logistic component uses the same model featured in the ODAL algorithm developed by Duan et al.25 to model the probability of a binary outcome, our method incorporates an additional zero-truncated Poisson component to model the frequency of a given outcome. This extra component is especially useful in settings where significant proportions of patients experience either zero or several instances of an outcome, avoiding a loss of potentially valuable information that would occur if the outcome were dichotomized and analyzed using logistic regression alone.
When using a meta-analysis estimate to initiate ODAH, two non-iterative rounds of communication are necessary for transferring information across sites; thus, our approach is considered a one-shot approach for performing distributed regression. ODAH requires each collaborating site to first fit the hurdle model of interest using its own data before sending parameter point and variance estimates to the lead site. A user at the lead site can then initiate ODAH by, following its own hurdle model fitting, computing initial estimates via meta-analysis before sending these estimates to the collaborating sites for computing gradients. These gradients are then sent to the lead site to construct the surrogate log likelihood function. Using only gradients and patient-level data from the lead site, we obtain parameter estimates calculated from maximizing each surrogate likelihood function with respect to the parameter of interest. The ODAH algorithm is outlined in detail below. Figure 2 depicts a schematic diagram for the algorithm.


Visual representation of one-shot distributed algorithm for hurdle regression (ODAH). In the initialization round, coefficient (\(\hat{\beta }_{i} , \hat{\gamma }_{i}\)) and variance (\(\hat{\sigma }_{i}^{2} , \hat{\tau }_{i}^{2}\)) estimates from fitting separate hurdle models at each collaborating site are sent to the lead site; these estimates are then used together with lead site estimates in a meta-analysis to produce initial estimates (\(\overline{\beta }, \overline{\gamma }\)) for ODAH, which are sent to each collaborating site. In the surrogate likelihood estimation round, first-order (\(\nabla L_{1i} , \nabla L_{2i}\)) and second-order (\(\nabla^{2} L_{1i} , \nabla^{2} L_{2i}\)) gradients are computed at each site, evaluated at the received initial estimates and sent to the lead site. These gradients are used in conjunction with data from the lead site to construct surrogate likelihood functions \(\tilde{L}_{1} \left( \beta \right)\) and \(\tilde{L}_{2} \left( \gamma \right)\), which are then maximized to produce surrogate maximum likelihood estimates \(\tilde{\beta }\) and \(\tilde{\gamma }\).
Simulation study
To evaluate ODAH empirically in a controlled setting, we conducted a simulation study to primarily compare the performance of ODAH to that of meta-analysis, which does not incorporate any patient-level data. Performance is evaluated in terms of bias relative to pooled estimates, coefficients estimated in an analysis where all patient-level data is used; we treat pooled estimation as our gold standard, an ideal scenario featuring centralized data that is typically unattainable in practice. We additionally examine performance of hurdle regression using data only from the lead site, emulating a single-site analysis.
In our simulations, a count outcome Y was associated with two risk factors, \(X_{1}\) and \(X_{2}\). \(X_{1}\) was generated using a truncated Normal distribution emulating the number of primary care visits per year for each patient in our avoidable hospitalization analysis \(\left( {X_{1} \sim N\left( {3, 2} \right), X_{1} \in \left( {0, 18} \right)} \right)\), while \(X_{2}\) was generated using a Bernoulli distribution with the probability of success representing that of public insurance use among patients in the same analysis \(\left( {X_{2} \sim Bern\left( {0.33} \right)} \right)\). Our covariate of interest was \(X_{2}\), with \(X_{1}\) assumed to be a confounder. The outcome \(Y\) given covariates \(X_{1}\) and \(X_{2}\) was generated from the Poisson–Logit hurdle model described in the “Methods” section, using logistic regression to model the process generating zero or positive counts and zero-truncated Poisson regression to estimate counts given that they are positive. Note that while the hurdle model has two components, each of which can use its own unique set of covariates, the sets of covariates making up each component of the model are identical in our simulations. We seek to estimate \({\varvec{\beta}} = \left\{ {\beta_{0} ,\beta_{1} ,\beta_{2} } \right\}\) and \({\varvec{\gamma}} = \left\{ {\gamma_{0} ,\gamma_{1} ,\gamma_{2} } \right\}\), each 3 × 1 vectors of regression coefficients quantifying associations between our simulated count outcome and risk factors.
Motivated by our rare-event applications, we primarily sought to examine how varying levels of low outcome prevalence and event rate affect the performance of ODAH relative to pooled analysis. We explored four rare-event prevalence settings while holding event rate constant at 0.03 (mean event rate for patients in our avoidable hospitalization analysis, denoting number of hospitalizations per year): 5%, 2.5%, 1%, and 0.5%. To evaluate the effect of event rate on method performance, we explored additional event rates of 0.25, 0.01, and 0.005 while holding outcome prevalence constant at 2.5%. Note that these event rates include zero counts, with smaller event rates corresponding to more severe zero-inflation.
In all settings, we fixed the number of sites K = 10 and total population size N = 200,000. In settings where we vary outcome prevalence or event rate, we set \(n_{1} = n_{2} = \cdots = n_{10}\) so all sites had the same number of observations. We also explored the effect of the lead site being larger than collaborating sites, setting lead site sizes at 38,000 (collaborating site size 18,000), 56,000 (collaborating site size 16,000), and 74,000 (collaborating site size 14,000). All ten unique simulation settings explored are summarized in Table 1.
For each setting, we evaluated estimation accuracy in terms of bias relative to pooled estimates across 1000 simulations to examine the variability in method performance. In all settings, we assume true coefficient values \(\{ \beta_{1} , \gamma_{1} \} = - 1\) and \(\left\{ {\beta_{2} ,\gamma_{2} } \right\} = 1\).
Application 1: Pediatric avoidable hospitalization
About one-third of pediatric healthcare costs are associated with hospital admissions, the majority of which are unplanned33. Unplanned hospitalizations associated with a diagnosis treatable at the primary care level are considered avoidable34. By studying which risk factors are most strongly associated with avoidable hospitalizations (AHs), hospital systems can identify patient subpopulations for which primary care should be improved, ideally leading to an overall reduction in hospital costs or admissions35. Because pediatric avoidable hospitalization is uncommon, integrating data across hospital systems can lead to more robust inference, increasing power to detect differences in rates of AH among patients. Further, the rarity of pediatric AH makes analyses studying this outcome susceptible to zero-inflation, making this application a suitable use case for hurdle regression.
In this analysis, we applied ODAH to study risk factors associated with pediatric AH using data from the Children’s Hospital of Philadelphia (CHOP) health system. The CHOP system provides care to about 400,000 children per year and includes a large, multi-state outpatient network, as well as one of the largest inpatient facilities for pediatric patients residing in the greater Philadelphia region. Data for this study were extracted from the CHOP EHR system for outpatient, emergency department, and inpatient visits for patients with at least two primary care facility visits from January 2009 to December 2017.
To mimic a scenario in which different sites do not have access to patient-level information at other sites, we assigned patients to the primary care site they attended most often during the study period and carried out analysis as if patient-level information could not be shared across primary care sites. In total, patients were assigned to 27 different primary care sites; we selected six of these sites to illustrate our method, made up of 70,818 patients (Table 2). The largest site of these six, Site 4, was chosen to be the lead site.
To evaluate ODAH, we modeled total number of AHs given a collection of EHR variables: gender, race (Caucasian or other), mean age (across all visits), primary care visits per year, and insurance type (public or private). While the majority of patients who experience an AH in these data only experience one, 22% experience more than one, suggesting an advantage of using Poisson regression over logistic regression alone to explicitly model the counts (Fig. 3). This, combined with substantial zero-inflation, makes Poisson–Logit hurdle regression appropriate for modeling these data. The logistic component of the hurdle model will model the probability of a patient experiencing at least one AH, while the zero-truncated Poisson component will model the total number of hospitalizations for a patient given that they experience at least one.

Distribution of total number of avoidable hospitalizations (AHs) for patients with at least one AH in CHOP data sample.
As in our simulations, we used an identical set of covariates for both hurdle model components and evaluated method performance by calculating relative bias to the pooled estimate for lead site analysis, meta-analysis, and ODAH. To estimate the variance of ODAH parameter estimates, we used the inverse of the Hessian matrix produced when optimizing the surrogate log likelihood function of each hurdle model component.
Application 2: Serious adverse events
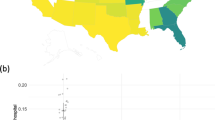
Our second analysis studied a population of patients with colorectal cancer (CRC) who use FOLFIRI, an FDA-approved standard of care first line chemotherapy treatment in patients with metastatic CRC, as their CRC treatment. We focused on assessing drug safety in terms of the frequency of serious adverse events (SAEs). The data analyzed are from the OneFlorida Clinical Research Consortium, containing robust longitudinal and linked patient-level real-world data of around 15 million Floridians, making up over 50% of the Florida population. OneFlorida data includes records from Medicaid and Medicare claims, cancer registry data, vital statistics, and EHRs from its clinical partners. These data are centralized in a HIPAA limited dataset that contains detailed patient and clinical variables, including demographics, encounters, diagnoses, procedures, vitals, medications, and labs, following the PCORnet Common Data Model. The OneFlorida data undergo rigorous quality checks at its data coordinating center, the University of Florida, and a privacy-preserving record linkage process is used to deduplicate records of same patients coming from different health care systems within the network36. Figure 4 shows the geographic locations of OneFlorida partners.

Map detailing locations of OneFlorida clinical partners.
To define an SAE in this analysis, we followed the FDA definition of SAEs and the Common Terminology Criteria for Adverse Events (CTCAE) v 5.0, and the number of SAEs were counted for each patient within 180 days after first FOLFIRI prescription37. We removed the chronic conditions that occurred before prescription. A set of covariates and risk factors for all patients were extracted from patients’ medical records for this analysis, including patients’ demographic variables (age, race, Hispanic ethnicity status, and gender) on the day of CRC diagnosis. We also calculated each patient’s Charlson comorbidity index (CCI) using their medical history.
Since OneFlorida data are centralized, we were able to both carry out analysis as if patient-level information could not be shared across clinical sites (as was done in our AH application) as well as fit a hurdle regression model using pooled analysis, which served as the gold standard. In total, our analysis included 660 patients from three clinical sites, with Site 3 being the largest and serving as the lead site (Table 3). To evaluate ODAH using these data, we modeled SAE frequency given the extracted clinical information noted above for each patient. We evaluated method performance as we did for our simulations and AH analysis, again using the same set of covariates in each component of the hurdle model.
Results
Simulation study results
Figure 5 depicts simulation results from evaluating method performance across all scenarios described in Table 1. Across settings, there was no discernable difference in method performance for estimating \(\beta_{2}\), the regression coefficient associated with \(X_{2}\) in the logistic component of the hurdle model. We therefore present the simulation results for estimating \(\gamma_{2}\), leaving \(\beta_{2}\) estimation results for the Supplement. Due to select iterations of lead site analysis resulting in outlying estimates, the median bias for the lead site estimate across iterations is reported rather than the mean.

Simulation results for estimating zero-truncated Poisson component covariate \(\gamma_{2}\). (A) Results for Setting A, fixing \(n_{lead}\) = 20,000 and \(\gamma_{0}\) = − 3.6 (\(\lambda = 0.03\)) while varying outcome prevalence. (B) Results for Setting B, fixing \(n_{lead}\) = 20,000 and \(\beta_{0}\) = − 3.7 (2.5% prevalence) while varying event rate (\(\lambda )\). (C) Results for Setting C, fixing \(\beta_{0}\) = − 3.7 (2.5% prevalence) and \(\gamma_{0} = - 3.6\) (\(\lambda = 0.03\)) while varying proportion of observations in lead site. Horizontal blue line represents true value of \(\gamma_{2} = 1\).
When lead site size and event rate were fixed at 20,000 and \(\lambda = 0.03,\) respectively, we varied outcome prevalence to study how each method performed relative to pooled analysis, the gold standard (Fig. 5A). In all prevalence levels examined, ODAH performed nearly as well as pooled analysis, with negligible difference in terms of bias and variance of its estimate; bias in the ODAH estimate relative to the pooled estimate was less than 0.1% for each prevalence level. Conversely, meta-analysis bias relative to the pooled estimate increased with decreasing prevalence, ranging from 0.97 (5% prevalence) to 10.4% (0.5% prevalence). Lead site analysis exhibited the largest variance of all methods; bias relative to the pooled estimate ranged from 0.79% (5 prevalence) to 2.77% (0.5% prevalence).
When lead site size and outcome prevalence were fixed at 20,000 and 2.5%, respectively, we varied event rate to examine its impact on estimating \(\gamma_{2}\) in a low prevalence setting (Fig. 5B). For all methods, variance of estimates decreased with increasing event rate. ODAH and meta-analysis estimates were nearly identical to pooled estimates when events rates were set to \(\lambda = 0.25\) and \(0.03\), exhibiting negligible bias relative to the pooled estimate (ODAH bias < 0.1%, meta-analysis bias < 1.9%). When the event rate was set to \(\lambda = 0.01\) and 0.005, ODAH again exhibited negligible relative bias (< 0.1%) but meta-analysis exhibited larger bias relative to the pooled estimate (4.57% and 12.7%, respectively). Lead site analysis exhibited the largest variance of all methods examined, maintaining relatively low relative bias to the pooled estimate when \(\lambda = 0.25\), \(0.03\) and 0.01 (< 1.1%) but larger bias when \(\lambda\) = 0.005 (5.31%).
When examining the effect of increasing lead site size while fixing outcome prevalence and event rate at 2.5% and \(\lambda = 0.03\), respectively, there was not substantial evidence for lead site size affecting ODAH or meta-analysis performance relative to pooled analysis (Fig. 5C). Variance of lead site analysis estimates decreased with increasing lead site size.
Application 1: results—pediatric avoidable hospitalization
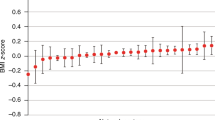
Figure 6 depicts our avoidable hospitalization (AH) analysis results. Regression coefficient estimates for each covariate in the fitted hurdle model are shown along with their corresponding 95% confidence interval.

Plots depicting results from CHOP avoidable hospitalization analysis. Log odds ratio (A) and log relative risk (B) estimates (along with corresponding 95% confidence intervals) for each covariate in the fitted hurdle model. Dashed horizontal line represents pooled estimate, our gold standard for comparing methods.
Log odds ratio estimates (estimated by the logistic component of the hurdle model) when using ODAH were close to the pooled estimates, with relative bias ranging from 0.08 (insurance covariate) to 5.02% (primary care visits per year covariate). Meta-analysis estimates were more biased, with relative bias ranging from 4.15 (gender covariate) to 63.6% (primary care visits per year covariate). Log relative risk estimates (estimated by the zero-truncated Poisson component of the hurdle model) were nearly identical when using ODAH and pooled analysis. Meta-analysis performed similarly to ODAH across all coefficients, but ODAH always achieved the smaller relative bias to pooled estimates. ODAH relative bias was < 0.50% for all covariates, while meta-analysis relative bias ranged from 5.89 (PC visits per year) to 11.7% (race).
Application 2 results: serious adverse events
Results from using ODAH to model serious adverse event (SAE) frequency in colorectal cancer patients using data from OneFlorida are shown in Fig. 7, displayed similarly to the CHOP AH results. In this application, we again see our method exhibiting low bias relative to pooled estimation. For four of the five log odds ratios estimated in the logistic component of the hurdle model, relative biases produced by ODAH were less than 7%. The lone exception, the gender coefficient, reflected greater relative bias due to its near-zero effect size (reflecting an odds ratio of 1). Similar results were observed in the zero-truncated Poisson component, with relative biases to the pooled estimates less than 10% for four of the five estimated log relative risks. The age coefficient had higher relative bias, again due to negligible effect size. In both components, meta-analysis tended to do poorer relative to pooled estimation. The largest difference in estimation can be seen in the coefficients reflecting association of SAE frequency with Hispanic ethnicity, where relative bias was 71% in the logistic component and 276% in the zero-truncated Poisson component (compared to 5.3% and 1.8% for ODAH, respectively).

Plots depicting results from OneFlorida serious adverse event application. Log odds ratio (A) and log relative risk (B) estimates (along with corresponding 95% confidence intervals) for each covariate in the fitted hurdle model. Dashed horizontal line represents pooled estimate, our gold standard for comparing methods.
Discussion
We introduced a non-iterative, privacy-preserving algorithm for performing distributed hurdle regression with zero-inflated count outcomes. As demonstrated by simulations and two real-world EHR applications, our method consistently produced parameter estimates comparable to and sometimes more accurate than those produced by meta-analysis. Our method’s utility is especially evident in settings featuring a count outcome with marked zero-inflation and very low event rate, as we demonstrated the tendency of only meta-analysis to produce biased estimates under these circumstances in both simulations and real-data analysis. We also showed the benefit of using ODAH over meta-analysis in settings where use of individual site estimates alone may not result in accurate population-level estimation. In the analysis modeling SAE frequency, bias relative to pooled estimation for meta-analysis was greatest for the Hispanic ethnicity coefficient. The proportion of Hispanic patients at each site in this analysis was 4%, 25%, and 58.5%, potentially resulting in highly varied individual-site estimates for this coefficient and resulting in biased meta-analysis estimates. In addition to site-level estimates, our method incorporates aggregate information in the form of gradients to better approximate the complete data likelihood and result in lower bias relative to pooled estimates.
There are several advantages to using our method for performing privacy-preserving data analysis. By using distributed regression, our approach is well-suited for multi-site studies which are ongoing. The surrogate likelihood method takes advantage of patient-level data still being accessible by collaborating sites, allowing collaborators to engage in limited inter-site communication to produce less biased results than would be obtained via meta-analysis, which is best suited for studies already completed. Further, most existing distributed regression techniques require iterative communication among sites to produce accurate estimates. ODAH requires two rounds of non-iterative communication between the local site and all other sites before surrogate likelihood functions can be maximized to obtain accurate, precise parameter estimates. This is particularly advantageous in big data settings, where iterative procedures have a high computational burden in terms of memory and processing time. Further, due to the separability of hurdle model components, each component’s likelihood function can be maximized independently, reducing computational complexity.
Our simulation results suggest that lead site size relative to total population size does not have a discernable effect on any method performance outside of analysis only using data at the lead site. However, since the surrogate log likelihood function only uses individual-level data stored in the lead site, we recommend that the lead site is as large as possible; this helps to ensure the surrogate likelihood is a close approximation to the complete data likelihood.
In terms of limitations of our method, one is that it assumes relative homogeneity among the data to be analyzed. This is an implication of the surrogate likelihood construction, which approximates the complete data log likelihood in part by using a sample-size-weighted sum of gradients from each collaborating site. This implicitly assumes that study data are independent and identically distributed across all sites, which may not hold in some real-world settings. As evidenced by Fig. 8, geographical heterogeneity among the patient population can occur in the covariates, with some locations having substantially different demographic makeups than others. We recommend those who implement ODAH ensure patient demographics are largely similar across institutions, or alternatively perform subgroup analysis for relatively homogeneous subsets of institutions. Our group is currently working to develop distributed regression methods which can explicitly model site-specific effects. Additionally, the zero-truncated Poisson component of our method does not currently account for overdispersion in the outcome. Overdispersion in count data is common and should be accounted for when necessary to ensure calculation of robust standard errors. A distributed regression method for modeling count outcomes which accounts for overdispersion is currently being developed by our group. In both of our real data applications, we did not find strong evidence of overdispersion. Another limitation of this study is that we did not explore method performance in the context of a large number of covariates. While our simulations and data applications featured relatively small collections of risk factors, analyzing a larger collection of covariates may be of interest in big data settings, so evaluating our method in this context would be useful. Finally, there were discrepancies when comparing simulation and data analysis results in terms of bias in the hurdle model’s logistic component estimates. We suspect this is due to simulated data not fully capturing the true distribution of the real data, particularly in terms of covariate imbalance. For example, 52% of patients in the CHOP data that had at least one AH used public insurance, compared to 32% of patients who did not have an AH. We seek to address these limitations in future work.

Geographical map of 27 CHOP primary care sites across greater Philadelphia region. In the left map, the proportion of patients of Caucasian race are depicted for each site. In the right map, the proportion of patients using public insurance (Medicaid) at each site is depicted. The size of each site on each map is proportional to the number of patients at the given site. Stars indicate sites used in our data analysis.
Our group continues to construct methods for performing non-iterative, privacy-preserving distributed inference, ideal for use within CRNs which seek to collaborate on analyses without sharing patient-level data. We seek to create distributed methods for the types of outcomes most common in healthcare, so far producing methods for modeling binary25, time-to-event22, and now zero-inflated count outcomes. Further, we look to develop distributed methods with a greater emphasis on data security, incorporating techniques such as homomorphic encryption as was done in works concerning distributed linear and logistic regression17,38. While additional methods are being developed and implemented, we believe ODAH is worthy of consideration when one seeks to perform distributed regression on zero-inflated count outcome data.
The code for ODAH is available within the “pda” package in R. Instructions for package installation can be found at https://github.com/Penncil/pda. Details concerning all methods our group has developed for performing distributed regression can be found at https://PDAmethods.org; an overview and sample code for ODAH are available at https://PDAmethods.org/portfolio/odah/. To implement ODAH, one institution will serve as the lead site and coordinate the analysis with other collaborating sites. In order for institutions to collaborate with one another, all data being analyzed must adhere to a common data model to ensure that the same data definitions are used across institutions. Additionally, all institutions must analyze the exact same set of variables. Once these requirements have been met, the procedure outlined in the Methods section can be followed to conduct a privacy-preserving distributed analysis using ODAH.
Conclusion
We introduced an accurate, communication-efficient, privacy-preserving algorithm (ODAH) for performing distributed hurdle regression for settings featuring a zero-inflated count outcome. By only requiring patient-level data from one site, we limit between-site communication to sharing only aggregate statistics in at most two rounds, preserving patient privacy and keeping necessary data exchange to a minimum. In an extensive simulation study and two real-world data analyses, ODAH exhibited higher estimation accuracy than meta-analysis, most notably in the context of rare events. We believe ODAH can be a useful method for analyzing zero-inflated count outcomes in a clinical research network where patient-level data cannot be shared.
References
Murdoch, T. B. & Detsky, A. S. The inevitable application of big data to health care. JAMA 309(13), 1351–1352 (2013).
Arellano, A. M., Dai, W., Wang, S., Jiang, X. & Ohno-Machado, L. Privacy policy and technology in biomedical data science. Annu. Rev. Biomed. Data Sci. 1, 115–129 (2018).
Phillips, M. International data-sharing norms: from the OECD to the General Data Protection Regulation (GDPR). Hum. Genet. 137, 575–582 (2018).
Benitez, K. & Malin, B. Evaluating re-identification risks with respect to the HIPAA privacy rule. J. Am. Med. Inform. Assoc. 17(2), 169–177. https://doi.org/10.1136/jamia.2009.000026 (2010).
Jiang, X., Sarwate, A. D. & Ohno-Machado, L. Privacy technology to support data sharing for comparative effectiveness research: a systematic review. Med. Care 51, S58 (2013).
McGraw, D. Building public trust in uses of Health Insurance Portability and Accountability Act de-identified data. J. Am. Med. Inform. Assoc. https://doi.org/10.1136/amiajnl-2012-000936 (2012).
Brown, J. S. et al. Distributed health data networks: A practical and preferred approach to multi-institutional evaluations of comparative effectiveness, safety, and quality of care. Med. Care 48, S45–S51 (2010).
Maro, J. C. et al. Design of a national distributed health data network. Ann. Intern. Med. 151(5), 341–344 (2009).
Fleurence, R. L. et al. Launching PCORnet, a national patient-centered clinical research network. J. Am. Med. Inform. Assoc. 21(4), 578–582 (2014).
Brown, J. S., Maro, J. C., Nguyen, M. & Ball, R. Using and improving distributed data networks to generate actionable evidence: The case of real-world outcomes in the Food and Drug Administration’s Sentinel system. J. Am. Med. Inform. Assoc. 27(5), 793–797 (2020).
Robb, M. A. et al. The US Food and Drug Administration’s Sentinel Initiative: expanding the horizons of medical product safety. Pharmacoepidemiol. Drug Saf. 21(1), 9 (2012).
Voss, E. A. et al. Feasibility and utility of applications of the common data model to multiple, disparate observational health databases. J. Am. Med. Inform. Assoc. 22(3), 553–564 (2015).
Hripcsak, G. et al. Observational Health Data Sciences and Informatics (OHDSI): opportunities for observational researchers. Stud. Health Technol. Inform. 216, 574 (2015).
Hripcsak, G. et al. Characterizing treatment pathways at scale using theOHDSI network. Proc. Natl. Acad. Sci. USA 113(27), 7329–7336 (2016).
Vashisht, R. et al. Association of hemoglobin A1c levels with use of sulfonylureas, dipeptidyl peptidase 4 inhibitors, and thiazolidinediones in patients with type 2 diabetes treated with metformin: analysis from the observational health data sciences and informatics initiative. JAMA Netw. Open 1(4), E181755-e181755 (2018).
Boland, M. R. et al. Uncovering exposures responsible for birth season–disease effects: A global study. J. Am. Med. Inform. Assoc. 25(3), 275–288 (2017).
Dwork, C. et al. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 9(3–4), 211–407 (2014).
Hall, R., Fienberg, S. E. & Nardi, Y. Secure multiple linear regression based on homomorphic encryption. J. Offic. Stat. 27(4), 669 (2011).
Kuo, T. T., Kim, H. E. & Ohno-Machado, L. Blockchain distributed ledger technologies for biomedical and health care applications. J. Am. Med. Inform. Assoc. 24(6), 1211–1220 (2017).
Warnat-Herresthal, S. et al. Swarm learning for decentralized and confidential clinical machine learning. Nature 594(7862), 265–270 (2021).
Kuo, T. T. & Ohno-Machado, L. (2018). Modelchain: Decentralized privacy-preserving healthcare predictive modeling framework on private blockchain networks. arXiv preprint arXiv:1802.01746.
Duan, R. et al. Learning from local to global: An efficient distributed algorithm for modeling time-to-event data. J. Am. Med. Inform. Assoc. JAMIA 27(7), 1028–1036 (2020).
Wu, Y., Jiang, X., Kim, J. & Ohno-Machado, L. Grid binary LOgistic REgression (GLORE): Building shared models without sharing data. J. Am. Med. Inform. Assoc. 19, 758–764 (2012).
Lu, C. L. et al. WebDISCO: A web service for distributed cox model learning without patient-level data sharing. J. Am. Med. Inform. Assoc. 22(6), 1212–1219 (2015).
Duan, R. et al. Learning from electronic health records across multiple sites: A communication-efficient and privacy-preserving distributed algorithm. J. Am. Med. Inform. Assoc. 27(3), 376–385 (2020).
Jordan, M. I., Lee, J. D. & Yang, Y. Communication-efficient distributed statistical inference. J. Am. Stat. Assoc. 114(526), 668–681 (2019).
Deb, P. & Norton, E. C. Modeling health care expenditures and use. Annu. Rev. Public Health 39, 489–505 (2018).
Cameron, A. C. & Trivedi, P. K. Regression analysis of count data (Cambridge University Press, 1998).
Rose, C. E., Martin, S. W., Wannemuehler, K. A. & Plikaytis, B. D. On the use of zero-inflated and hurdle models for modeling vaccine adverse event count data. J. Biopharm. Stat. 16(4), 463–481 (2006).
Pittman, B., Buta, E., Krishnan-Sarin, S., O'Malley, S. S., Liss, T. & Gueorguieva, R. Models for analyzing zero-inflated and overdispersed count data: An application to cigarette and marijuana use [published online ahead of print, 2018 Apr 18]. Nicotine Tob Res. 2018; https://doi.org/10.1093/ntr/nty072.
Neelon, B., Chang, H. H., Ling, Q. & Hastings, N. S. Spatiotemporal hurdle models for zero-inflated count data: Exploring trends in emergency department visits. Stat. Methods Med. Res. 25(6), 2558–2576 (2016).
Hofstetter, H., Dusseldorp, E., Zeileis, A. & Schuller, A. A. Modeling caries experience: advantages of the use of the hurdle model. Caries Res. 50(6), 517–526 (2016).
Bui, A. L. et al. Spending on children’s personal health care in the United States, 1996–2013. JAMA Pediatr. 171(2), 181–189 (2017).
Lu, S. & Kuo, D. Z. Hospital charges of potentially preventable pediatric hospitalizations. Acad. Pediatr. 12(5), 436–444 (2012).
Maltenfort, M. G., Chen, Y. & Forrest, C. B. Prediction of 30-day pediatric unplanned hospitalizations using the Johns Hopkins Adjusted Clinical Groups risk adjustment system. PloS One. 14(8), 0221233 (2019).
Bian, J. et al. Implementing a hash-based privacy-preserving record linkage tool in the OneFlorida clinical research network. Jamia Open 2, 562–569 (2019).
CFR—Code of Federal Regulations Title 21 [Internet]. [cited 2020 Mar 6]. Available from: https://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfcfr/CFRSearch.cfm?fr=314.8
Kim, M., Lee, J., Ohno-Machado, L. & Jiang, X. Secure and differentially private logistic regression for horizontally distributed data. IEEE Trans. Inf. Forensics Secur. 15, 695–710 (2019).
Acknowledgements
We sincerely thank our three reviewers for their insightful and constructive feedback which significantly improved this work. All statements in this report, including its findings and conclusions, are solely those of the authors and do not necessarily represent the views of the Patient-Centered Outcomes Research Institute (PCORI), its Board of Governors or Methodology Committee.
Funding
Funding was provided by National Institutes of Health (1R01LM012607, R01CA246418, 1R01AI130460, 1R01AG073435) and Pennsylvania Department of Health (4100072543). This work was supported partially through Patient-Centered Outcomes Research Institute (PCORI) Project Program Awards (ME-2019C3-18315 and ME-2018C3-14899).
Author information
Authors and Affiliations
Contributions
M.J.E. and Y.C. designed methods and experiments; C.B.F. and M.M. provided data from the Children’s Hospital of Philadelphia; J.B. provided data from the University of Florida; M.J.E. and C.L. designed and conducted simulation experiments; M.J.E. and Z.C. conducted data analysis; all authors interpreted the results and provided instructive comments; and M.J.E. drafted the main manuscript. All authors have approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Edmondson, M.J., Luo, C., Duan, R. et al. An efficient and accurate distributed learning algorithm for modeling multi-site zero-inflated count outcomes. Sci Rep 11, 19647 (2021). https://doi.org/10.1038/s41598-021-99078-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-99078-2
This article is cited by
-
Distributed learning for heterogeneous clinical data with application to integrating COVID-19 data across 230 sites
npj Digital Medicine (2022)
-
Multisite learning of high-dimensional heterogeneous data with applications to opioid use disorder study of 15,000 patients across 5 clinical sites
Scientific Reports (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
