
Abstract
This article addresses a new method for the classification of white blood cells (WBCs) using image processing techniques and machine learning methods. The proposed method consists of three steps: detecting the nucleus and cytoplasm, extracting features, and classification. At first, a new algorithm is designed to segment the nucleus. For the cytoplasm to be detected, only a part of it located inside the convex hull of the nucleus is involved in the process. This attitude helps us overcome the difficulties of segmenting the cytoplasm. In the second phase, three shapes and four novel color features are devised and extracted. Finally, by using an SVM model, the WBCs are classified. The segmentation algorithm can detect the nucleus with a dice similarity coefficient of 0.9675. The proposed method can categorize WBCs in Raabin-WBC, LISC, and BCCD datasets with accuracies of 94.65%, 92.21%, and 94.20%, respectively. Besides, we show that the proposed method possesses more generalization power than pre-trained CNN models. It is worth mentioning that the hyperparameters of the classifier are fixed only with the Raabin-WBC dataset, and these parameters are not readjusted for LISC and BCCD datasets.
Similar content being viewed by others

Introduction
Generally, there exist three types of blood cells: red blood cells, white blood cells (WBC), and platelets; among these, WBCs are responsible for the immune system and protect the body against diseases and infections. In peripheral blood, WBCs are categorized into five general types: lymphocytes, monocytes, neutrophils, eosinophils, and basophils. In various diseases such as leukemia, anemia, malaria, human immunodeficiency virus infection (HIV) and, infectious diseases, changes in the number of WBCs are visible1,2,3,4. A recent study also indicated that leukopenia, lymphocytopenia, and eosinophil cytopenia have occurred significantly more in Covid-19 patients5. Therefore, differential counting of WBCs can be of considerable assistance in disease diagnosis6.
In several cases, peripheral blood smear analysis is done manually by a hematologist who visually analyzes the blood smears under the microscope1,7. This procedure is very time consuming8 and can be inaccurate due to tiredness and human error9. On the other hand, automated hematology analyzer devices (e.g. Sysmex) are very expensive, especially for low-income countries10. Fortunately, machine learning-based methods can easily fill the above-mentioned gaps. This study is aimed at proposing a new method based on machine learning and image processing techniques to classify WBCs in peripheral blood smear.
In machine learning-based methods, at first, it is a requisite to collect the appropriate dataset taking quality, variety, and size into account. Yet, the lack of such dataset with aforementioned properties is the major challenge11. A plethora of articles have used small datasets collected using only one microscope or one camera7,12,13. Also, some of these datasets were solely labeled by one hematologist7,14, which carries the risk of being labeled incorrectly because of the challenges diagnosing WBC types involves. In this study, three different datasets were used: Raabin-WBC dataset15, LISC dataset7, and BCCD dataset16. We will elaborate more on these datasets in the datasets section.
After data collection, diverse machine learning techniques can be used to classify WBCs. In general, different methods proposed in the literature for classifying WBCs favor either traditional or deep learning frameworks1. In traditional frameworks, it is first necessary to extract the appropriate handcraft features from WBCs, and then, classify them using one or an ensemble of several classifiers. Feature engineering is the most challenging part of traditional approaches. Unlike traditional frameworks, in deep learning frameworks, features are automatically extracted by means of deep neural networks.
One of the most commonly used networks for classifying images are convolutional neural networks (CNNs). To obtain good classification results, we need a large deep CNN with numerous parameters. Training such a large network from scratch needs a large dataset. However, medical datasets are not usually large enough. Therefore pre-trained networks are normally used in two ways. The first way is to extract features by means of a pre-trained network as the input of a traditional classifier model such as support vector machine (SVM), k nearest neighbor (KNN), etc. The second way is to fine-tune the pre-trained network using a small dataset.
There are some works that have utilized pre-trained CNNs for extracting features in the task of classifying WBCs17,18,19,20. In the task of diagnosing acute lymphoblastic leukemia, Rehman et al.17 compared the accuracy of using three different classifiers on the image features extracted by pre-trained CNNs. They observed that the SVM classifier gives the best results. In18, the features extracted by three well known CNN architectures (AlexNet, GoogleNet, and ResNet-50) were merged, then proper features were selected using the maximal information coefficient and ridge algorithms. Finally, WBCs were classified using a quadratic discriminant analysis model. Similarly, Togacar et al.19 used a pre-trained Alexnet network to extract features and a quadratic discriminant analysis model to classify WBCs. Sahlol et al.20 employed a pre-trained CNN for extracting features, along with a statistically enhanced salp swarm algorithm for feature selection, and an SVM model.
Deep learning neural networks can also be directly trained to categorize WBCs1,21,22,23,24,25,26. Hedge et al.1 performed the classification of WBCs with and without using a pre-trained network. They found out that full training from scratch leads to better results than fine-tuning an AlexNet pre-trained network. In21, authors addressed the classification of WBCs by tuning pre-trained AlexNet and LeNet-5 networks as well as training a new CNN from scratch. They declared that the novel network they have proposed performed better than the fine-tuned networks mentioned previously. Jung et al.22 designed a new CNN architecture called W-Net to classify WBCs in the LISC dataset. Baydilli and Atila23 adopted capsule networks to classify the WBCs existing in the LISC dataset. Banik et al.24 devised a fused CNN model in the task of differential WBC count and evaluated their model with the BCCD dataset. Liang et al.25 combined the output feature vector of the flatten layer in a fine-tuned CNN and a long short term memory network to classify WBCs in BCCD dataset. A new complicated fused CNN introduced in26 was trained from scratch on 10,253 augmented WBCs images from the BCCD dataset. Despite the complexity of the proposed CNN in26, the number of its parameters stands at 133,000.
For the classification of WBCs based on traditional frameworks, segmenting the nucleus and the cytoplasm of WBCs is a vital but tough task. In this study, a novel accurate method to segment the nucleus is put forward. In order to segment the nucleus, some researchers used the thresholding algorithms after applying various pre-processing techniques on the image (e.g. Otsu’s thresholding algorithm, Zack algorithm, and etc.)27,28,29,30. A combination of machine learning and image processing techniques is also commonly employed to segment the nucleus of the WBC31,32. Moreover, during the last decade, CNNs have gained more popularity and are used to segment the nucleus of the WBC and cytoplasm33. Segmenting the cytoplasm is more complicated and less accurate than segmenting the nucleus. Therefore, in this paper, a part of the cytoplasm rather than the whole cytoplasm is detected as a representative of the cytoplasm (ROC) to be segmented. This approach, as a result, does not have the difficulties of segmenting the cytoplasm. We will talk more about this method in materials and methods section.
In order to classify WBCs after segmenting the nucleus and the cytoplasm, discriminative features need to be extracted. Shape characteristics such as circularity, convexity, solidity are meaningful features for the nucleus. This is due to the fact that lymphocytes and monocytes are mononuclear, and the shape of their nucleus is circular and ellipsoidal, respectively11. On the other hand, the nucleus of neutrophil and eosinophil is multi-lobed11 and non-solid. Characteristics such as color and texture, e.g., local binary pattern (LBP) or gray level co-occurrence matrix (GLCM), are also interpretable features for the cytoplasm11. In addition to the mentioned features, SIFT (scale-invariant features transform) or dense SIFT algorithm can be employed for feature extraction. In the next paragraph, we review some related works that use traditional frameworks for classifying WBCs.
Rezatofighi and Soltani-zadeh7 proposed a new system for the classification of five types of WBCs. In this system, nucleus and cytoplasm were extracted using the Gram-Schmidt method and Snake algorithm, respectively. Then, LBP and GLCM were used for feature extraction, and WBCs were categorized using a hybrid classifier including a neural network and an SVM model. Hiremath et al.28 segmented the nucleus utilizing a global thresholding algorithm and classified WBCs using geometric features of the nucleus and cytoplasm. In29, Otsu’s thresholding algorithm was used to detect the nucleus, and shape features such as area, perimeter, eccentricity, and circularity were extracted to identify five types of WBCs. Diagnosing ALL using images of WBCs was investigated in30. The authors of this paper applied the Zack algorithm to estimate the threshold value to segment the cells. Then, shape, texture, and color features were extracted, and the best features were selected by the means of the social spider optimization algorithm. Finally, they classified WBCs into two types of healthy and non-healthy, using a KNN classifier. Ghane et al.31 designed a new method to segment the nucleus of the WBCs through a novel combination of Otsu’s thresholding algorithm, k-means clustering, and modified watershed algorithm, and succeeded in segmenting nuclei with a precision of 96.07%. Laosai and Chamnongthai32 examined the task of diagnosing ALL and acute myelogenous leukemia using the images of the WBCs. They detected the nuclei by employing the k-means clustering algorithm, extracted shape and texture features, and finally categorized WBCs utilizing an SVM classifier.
In this section, we briefly introduced the WBCs, its clinical importance and available datasets together with methods used to classify and count WBCs in other studies. In the materials and methods section, we present our proposed method for classifying WBCs. Afterwards, we will present and compare the obtained results with those of the other studies.
Materials and methods
Overview of the proposed method
This research has aimed to suggest a new method for classifying white blood cells in peripheral smear images that is light, fast, and more robust compared to CNN-based methods. Since the proposed method is light and fast, it has no heavy processing cost; therefore, the algorithm can be easily executed on minicomputers and mobiles, and there is no need for TPU or GPU. In this study, the method we put forward is based on classical machine learning ways. In other words, we extract features manually and do not use CNNs to extract features automatically. As said before, the method that we introduce can be divided into three main steps: detecting the nucleus and cytoplasm, extracting shape and color features, and classifying WBCs through an SVM model. Figure 1 shows the block diagram of our method. In the detecting nucleus phase, a novel method is designed and compared with the other introduced methods. Also, for the feature extraction phase, four new color features are designed, and it will be shown that these new features enhance the accuracy of classification. This is worth noting that these color features designed in this research are not general and can only be used for WBC classification problem. At the final phase, the proposed method is evaluated with three different datasets that these datasets will be investigated in detail in the next section. Also, two of these datasets are considered to assay the robustness and resiliency of our method against altering imaging instruments and staining techniques that can be treated as generalization power. In the real world, the generalizability of the intelligence systems is a very important ability, and it needs to pay attention to this side of the proposed method. For this purpose, this research has investigated the generalization of the suggested method and compared it with well-known CNN models. In the results section, it can be seen that the method we propose possesses more generalization power in comparison with the famous CNN models.

The block diagram of the proposed method.
Datasets
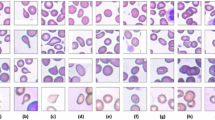
Three different datasets used in this study are Raabin-WBC15, LISC7, and BCCD16. These datasets are discussed in the next three subsections, and are compared in Table 1. Also, Fig. 2 shows some sample images of these three datasets.

Some samples of the WBCs in Raabin-WBC, LISC, and BCCD datasets; Lymph (lymphocyte), Mono (monocyte), Neut (neutrophil), Eosi (eosinophil), Baso (basophil).
Raabin-WBC dataset
Raabin-WBC15 is a large free-access dataset recently published in 2021. Raabin-WBC dataset possesses three sets of WBC cropped images for classification: Train, Test-A, and Test-B. All WBCs in Train and Test-A sets have been separately labeled by two experts. Yet, images of Test-B have not yet been labeled thoroughly. Therefore, in this study we only used Train and Test-A sets. These two sets have been collected from 56 normal peripheral blood smears (for lymphocyte, monocyte, neutrophil, and eosinophil) and one chronic myeloid leukemia (CML) case (for basophil) and contain 14,514 WBC images. All these films were stained through Giemsa technique. The normal peripheral blood smears have been taken using the camera phone of Samsung Galaxy S5 and the microscope of Olympus CX18. Also, the CML slide has been imaged utilizing an LG G3 camera phone along with a microscope of Zeiss brand. It is worth noting that the images have all been taken with a magnification of 100.
LISC dataset
LISC dataset7 contains 257 WBCs from peripheral blood, which have been labeled by only one expert. The LISC dataset has been acquired from peripheral blood smear and stained through Gismo-right technique. These images have been taken at a magnification of 100 using a light microscope (Microscope-Axioskope 40) and a digital camera (Sony Model No. SSCDC50AP). We cropped all WBCs in this dataset as shown in Fig. 2.
BCCD dataset
BCCD dataset16 has been taken from the peripheral blood and includes 349 WBCs labeled by one expert. The Gismo-right technique has been employed for staining the blood smears. This dataset, also, has been imaged at a magnification of 100 using a regular light microscope together with a CCD color camera34. In addition, based on diagnosis made by two of our experts, we found that one of the images of the BCCD dataset had been incorrectly labeled, and thus, we corrected this label.
Training, augmented training, and test sets
For the Raabin-WBC dataset, we have employed already split sets of the original data namely Train and Test-A sets for training and test. In this dataset, different blood smears have been considered for the training and testing sets. Test-A and Train sets comprise almost 30 percent and 70 percent of the whole data, respectively. For the LISC dataset, we randomly selected 70 percent of the data for training, and 30 percent for testing. BCCD dataset has two splits in the original data, 80% of which serve as training and 20% as testing. Since this dataset had only three basophils, we ignored the basophils in BCCD and only considered the remaining four types.
To train an appropriate classifier, it is necessary to balance the training data adopting various augmentation methods. For this reason, some augmentation methods such as horizontal flip, vertical flip, random rotation (between − 90 and + 90 degree), random scale augmentation (rescaling between 0.8 and 1.2), and a combination of them were utilized to augment the training sets of Raabin-WBC and LISC datasets. In addition, the training data of the BCCD dataset had already been augmented. In Table 1, all information about the amount of data in each set is presented.
Nucleus segmentation
Three following steps for nucleus segmentation are considered: Firstly, a color balancing algorithm1 is applied to the RGB input image, then the CMYK and HLS color spaces are computed and combined and a soft map is computed. Finally, the nucleus is segmented by applying Otsu’s thresholding algorithm on the aforementioned soft map. The precise steps of the nucleus segmentation algorithm are as follows:
-
(a) Converting color-balanced RGB image to CMYK color space
-
(b) KM = (K component) – (M component)
-
(c) Converting color-balanced RGB image to HLS color space
-
(d) MS = Min(M component , S component)
-
(e) Output soft map = MS – KM
-
(f) Employing Otsu’s thresholding algorithm to segment the nucleus.
Figures 3 illustrates the resulting images obtained by applying different steps of the proposed method to segment a sample nucleus. As depicted in Fig. 3, red blood cells and the cytoplasm of the WBC in the K component have more intensity than those in the M component. Furthermore, the nucleus of the WBC has a lower intensity in comparison to the M component. Accordingly, as shown in Fig. 3 (6), subtracting the M component from the K component produces an image the nucleus pixels of which are zero or close to zero. On the other hand, as seen in Fig. 3 (7), computing the minimum of the M and S channels creates an image wherein the intensity of the red blood cell and the background are close to zero. Finally, by subtracting Fig. 3 (6) from Fig. 3 (7), Fig. 3 (8) is formed in which the red blood cells, cytoplasm, and the background are eliminated. Figure 4 also shows the block-diagram of the proposed algorithm.

The results obtained through applying different steps of our nucleus segmentation method: (1) RGB image, (2) color-balanced image, (3) K component of CMYK color space, (4) M component of CMYK color space, (5) S component of HLS color space, (6) result of K–M, (7) result of Min(M, S), (8) result of Min(M, S)–(K–M), (9) the result of applying Otsu’s thresholding algorithm, (10) the final result.

The block diagram of the nucleus segmentation method.
In this research, the color balancing algorithm of1 is utilized to reduce color variations. To create a color-balanced representation of the image, it is necessary to compute the mean of R, G, and B channels as well as the grayscale representation of the RGB image. Then, by using Eq. (1), the new balanced R, G, B components are obtained.
It is worth mentioning that the proposed segmentation algorithm was obtained with lots of trial and error. It was found that the algorithm can detect the nuclei very well. Still, for evaluating the performance of the way, 250 new images from Raabin-WBC dataset were utilized, that the evaluation details are described in the results section.
Cytoplasm detection
To extract proper features from the cytoplasm, it is first necessary to segment it. However, segmenting the cytoplasm is more difficult and less accurate than segmenting the nucleus. Hence, we designed a new method to solve this problem. In this method, the convex hull of the nucleus is obtained first, and a part of the cytoplasm that has been located inside the convex hull is considered as the representative of the cytoplasm (ROC). The more convex nucleus is, the smaller ROC is. Thus, lymphocytes, which usually have a circular nucleus, have lower ROC than neutrophils. Figure 5 illustrates this point.

The cytoplasm detection. The first row and the second row are neutrophil and lymphocyte, respectively. (a) RGB image, (b) nucleus, (c) convex hull of the nucleus, (d) the representative of the cytoplasm (ROC).
Feature extraction
In this study, two groups of features are taken into account. The first group includes shape features of the nucleus (convexity, circularity, and solidity). The equations associated with the shape features are as follows1:
The second group of features is color characteristics. According to the experience of hematologists, in addition to the shape features of the nucleus, the color features of the nucleus and the cytoplasm can also provide us with useful information about the type of WBC11. In this research, four novel color features by means of nucleus region, convex hull region, and ROC region are designed as follows:
-
1. \(\frac{Mean\,\, of\,\, nucleus}{Mean \,\,of \,\,convex\,\, hull}\)
-
2. \(\frac{Standard\,\, deviation\,\, of\,\, nucleus}{Standard\,\, deviation\,\, of\,\, convex\,\, hull}\)
-
3. \(\frac{Mean \,\,of \,\,ROC}{Mean\,\, of\,\, convex\,\, hull}\)
-
4. \(\frac{Standard \,\,deviation\,\, of\,\, ROC}{Standard\,\, deviation\,\, of\,\, convex\,\, hull}\)
These color features were extracted from the components of RGB, HSV, LAB, and YCrCb color spaces. Therefore, 48 color features and 3 shape features were extracted, which comes up to a total of 51 features. By looking at the classifier's performance in the results section, it is evident that the introduced color features significantly improve the classification accuracy.
Classification
After features are extracted from augmented data, they are normalized using the max–min method and are fed into an SVM classifier. We also tested other classifiers such as KNN and deep neural networks. However, we observed that the SVM provides us with the best results. With much trial and error, we found that if the weight of the neutrophils in the training is set to be more than one, and the rest of the classes are one, the best overall accuracy is observed. Three commonly used kernels which are linear, polynomial, and radial basis functions are tested in this regard. Besides, the regularization parameter known as C is an important parameter to train an SVM model. Thus, three important hyperparameters (class-weight, kernel, and C) are tuned to properly train the SVM model. To find the optimal hyperparameters, we applied fivefold cross-validation on the Train set of the Raabin-WBC employing three different kernels (linear, polynomial with degree three, and radial basis function), neutrophil-weight = 1, 2, 5, 10, 15, 20, and C = 1, 2, 4, 6, 8, 10. Hence, 108 states were assumed. We examined each combination of the hyperparameters with fivefold cross-validation on the Train set of the Raabin-WBC. Table 2 shows the result of examining different combinations of the hyperparameters. From Table 2, it can be seen that the best accuracy is obtained by polynomial kernel, neutrophil-weight of 10, and this is when the C parameter is equal to 6. We fixed these hyperparameters obtained over the Raabin-WBC dataset meaning that we did not readjust these hyperparameters for the LISC and BCCD datasets.
Results
The result of nucleus segmentation
The performance of the proposed nucleus segmentation algorithm is evaluated using three different metrics namely dice similarity coefficient (DSC), sensitivity, and precision. These metrics are computed using true positive (TP), false positive (FP), true negative (TN) and false negative (FP) of the resulting segmentation (as shown in Fig. 6) and are provided by the following equations.

The graphic display of TP, FP, and FN for a segmentation problem.
In order to extract the ground truth, 250 images including 50 images from each type of WBCs were randomly selected from Raabin-WBC dataset. Then, the ground truths for these images were identified by an expert with the help of Easy-GT software35. Also, since very dark purple granules cover the basophil’s surface, it is almost impossible to distinguish the nucleus11. Therefore, the whole basophil cell was considered as the ground truth. The results of the proposed segmentation algorithm have been presented in Table 3. The proposed segmentation method can detect the nucleus with precision, sensitivity, and dice similarity coefficient of 0.9972, 0.9526, and 0.9675, respectively.
The performance of the proposed segmentation algorithm is compared with that of U-Net + + 33, Attention U-Net36, mask R-CNN37 (with ResNet5038 as backbone), and Mousavi et al.'s method35. U-Net + + , Attention U-Net, and mask R-CNN are three well-known deep CNNs developed for image segmentation. To train these models, 989 images from Raabin-WBC dataset were randomly chosen, and their ground truths were extracted by an expert utilizing Easy-GT software35. The training set includes 199 lymphocytes, 199 monocytes, 199 neutrophils, 195 eosinophils, and 197 basophils. Three aforesaid deep CNN models were trained for 40 epochs, then evaluated with 250 ground truths mentioned in the previous paragraph. Table 3 presents the results of different segmentation algorithms. It can be seen that the proposed segmentation method has very low standard deviation for DSC and precision which indicates that the proposed method works consistently well for different cells in the data. In addition, U-Net + + , attention U-Net, and mask R-CNN are deep CNNs, and their training process is supervised. Hence, they need way more data to be trained. This is while our proposed method does not need to be learned. Also, these two models have lots of parameters and need more time to segment an image, but the proposed segmentation algorithm is simpler and faster. The suggested method can detect the nucleus of a WBC in a 575 by 575 image size in 45 ms. This is while U-Net + + , attention U-Net, and mask R-CNN need 1612, 628, and 1740 ms to segment the nucleus. The proposed method, U-Net + + , attention U-Net, mask R-CNN, and Mousavi et al.’s method35 were implemented in Google Colab, CPU mode and were compared their execution time.
Result of classification
In order to evaluate the classification accuracy, four metrics are used: Precision, Sensitivity, F1-score (F1), and Accuracy (Acc). If we face a two-class classification problem such the first class is called Positive and the second class is called Negative, the confusion matrix can be assumed as Table 4, and the mentioned criteria are obtained through relations (8), (9), (10), and (11).
In order to evaluate the effectiveness of color features, Raabin-WBC, LISC, and BCCD datasets are classified in two modes: classification using the shape features, and classification using the shape features together with the color ones. The comparison of the classification accuracy of these two modes is provided in Table 5. It can be seen in Table 5 that adding proposed color features significantly changes the classification results. Addition of color features leads to a remarkable increase in precision, sensitivity, and F1-score for all five types of WBCs. The proposed method classifies WBCs in Raabin-WBC, LISC, and BCCD datasets with accuracies of 94.65%, 92.21%, and 94.20%, respectively. The resulting confusion matrices of our proposed method for the three datasets are shown in Fig. 7.

The confusion matrices of our proposed classification method for Raabin-WBC, LISC, and BCCD datasets.
Comparison with the state-of-the-art methods
Since the LISC and BCCD datasets have been publicly available for several years, the performance of the proposed method on these two datasets is compared to that of the state-of-the-art works in terms of precision, sensitivity, and F1-score. Also, because the categorization of WBCs in peripheral blood is an imbalanced classification problem15, the comparison has been made based on each class. Table 6 shows the detailed comparisons.
By taking a meticulous look at criterion F1-score, which actually covers both criteria precision and sensitivity, it can be said that our proposed method has achieved the best performance in most classes. In the LISC dataset, the proposed method has classified neutrophils, eosinophils, and basophils with F1-scores of 97.14%, 100%, and 100%, respectively. Also, in the BCCD dataset, our method was able to classify lymphocytes, monocytes, and neutrophils with F1-scores of 100%, 100%, and 96%, respectively. In reference to traditional approaches, the method employed in this article is simple and creative and can be easily implemented. In this method, suitable shape and color features are extracted by means of the nucleus and the cytoplasm, yet there is no need for the cytoplasm to be segmented. The methods used in19,22,23,24,25, and26 are based on deep learning approaches. Therefore, their models are more complex and have more trainable parameters versus our classifier model which is SVM. For example, the models utilized in22,23, and25 have 16.5, 23.5, and 59.5 million parameters, successively. Besides, it should be noted that the hyperparameters of our SVM model were set only using the Raabin-WBC dataset and were not readjusted again on the LISC and BCCD datasets. This is while the other methods have fixed the hyperparameters of their classifiers on each dataset, separately.
Generalizability
In this section, we aim to compare our method with five well-known pre-trained CNN models in terms of generalization power. These pre-trained models are namely ResNet5038, ResNext5039, MobileNet-V240, MnasNet141, and ShuffleNet-V242. These models and the proposed method are trained with the augmented training set of Raabin-WBC, then are evaluated with the test set of the Raabin-WBC and all cropped images of the LISC dataset. The Raabin-WBC test and train sets have been acquired employing the same imaging and staining process, so it is expected that the performance of models does not decrease. But, the LISC dataset has been collected with different imaging devices and staining techniques, and the performance of the models probably drops significantly. Dropping the accuracy of the models is natural, but it is important how much decreasing? At first glance, it seems that the aforementioned pre-trained CNN models must be resistant against altering datasets because these models have been trained on the ImageNet dataset, which contains more than one million images from 1000 categories43. Therefore, these models should extract robust features and possess high generalization ability while the results illustrate something else. According to Table 7, the accuracy of the pre-trained CNN models drops from above 98% to 30% and below 30%, while the proposed method is more robust, and its accuracy drops from 94.65 to 50.97%. This is probably because extracted features by pre-trained models are too many, and most of them are zeros or redundant20. Extracting a large number of features by pre-trained CNNs before fully connected layers causes increasing the number of trainable parameters. In addition, this approach (extracting a large number of features) poses a huge processing cost for training them that makes inevitable the utilization of GPU or TPU, which are so expensive while, our method is very light and simple and can be easily executed on CPU or affordable and tiny processor like Raspberry Pi. From the results presented in Table 7, it can be seen that our proposed method outperforms pre-trained CNNs in terms of generalization power and execution time. Although the proposed method is more robust than pre-trained CNNs, we do not claim that the suggested way has high generalization power and needs improvement to reach high generalization ability. At the end of this section, we should mention that the hyperparameters of the aforesaid pre-trained CNNs were selected through the reference15, and the last fully connected layer of each model was modified for a five-class problem, and then all the layers were retrained/fine-tuned. All the pre-trained CNN models mentioned in Table 7 were implemented in python 3.6.9 and Pytorch library 1.5.1 and then trained on a single NVIDIA GeForce RTX 2080 Ti graphic card. But for comparing inference time, all the models reported in bellow Table were executed on CPU configuration CPU configuration (windows 10 64 bit, Intel Core-i7 HQ 7700, 12 GB RAM, and 256 GB SSD hard disk).
Discussion
As mentioned before, the proposed method contains three phases. Segmenting the nucleus and detecting a part of the cytoplasm located in the nucleus’s convex hull are performed at first phase. After extracting shape and color features, WBCs are finally categorized employing extracted features. Our proposed nucleus segmentation algorithm consists of several steps depicted in Fig. 3. These steps have been designed to remove the red blood cells and the cytoplasm. From Table 3, it is clear that the segmentation algorithm can detect the nucleus with a very high precision of 0.9972 and DSC of 0.9675. The proposed segmentation algorithm is very fast in comparison with U-Net + + , Attention U-Net, and mask R-CNN models (Table 2).
In the cytoplasm detection phase, in contrast to the common practice of segmenting the whole cytoplasm, only parts of the cytoplasm that are inside the convex hull of the nucleus was selected as a representative of cytoplasm (ROC). This way has not the difficulties of segmenting cytoplasm, but the classification accuracy is boosted with the help of features extracted by means of ROC.
In the Feature extracting phase, we used three common shape features namely solidity, convexity, and circularity. Besides, we designed four novel color features and extracted them from channels of RGB, HSV, LAB, and YCrCb color spaces. According to Table 5, it is obvious that the designed color features have remarkably increased the classification accuracy.
In the final phase, the classification is done with an SVM model. To choose the best hyperparameters for the SVM model, 5-fold cross validation was applied only on the Raabin-WBC dataset. The SVM model was separately trained for a different combination of hyperparameters to obtain the best one (Table 2). The method we put forward is automatic, simple, and fast that does not need to resize the images and segment the cytoplasm. According to Table 6, in LISC dataset, the proposed method came first in distinguishing neutrophils, eosinophils, and basophils. In addition, in the BCCD data set, our method was ranked first in detecting lymphocytes, monocytes, and neutrophils. Besides, according to Table 7, our proposed method has more generalization power rather than pre-trained networks. The features designed and extracted in this research are from the shape of the nucleus and color of the nucleus and cytoplasm, which are important characteristics that all hematologist experts pay attention to them to detect the WBC type. Therefore, these features are meaningful while the features extracted by CNNs are not interpretable and many of them are zeros or redundant20, and cause the network to overfit the dataset and affect generalization power. Even though the proposed method outperforms pre-trained CNN in terms of generalization power, it’s still insufficient and needs improvement to possess very high generalizability, and we aim to design new features in future works to carry out this matter. In addition to generalization ability, our method outperforms the CNNs in terms of inferencing time. The CNN models have lots of trainable parameters, which increase the inferencing time that makes inevitable the use of powerful hardware like GPU or TPU (Table 7) while our method is faster and can quickly run on CPU or affordable processor like Raspberry Pi.
Conclusion
This research designed a novel nucleus segmentation algorithm and four new color features to classify WBCs. This paper has two contributions. The first contribution is devising a new algorithm for segmenting the nucleus that is fast and accurate and does not need to be trained like CNN-based methods. The second contribution is designing and extracting four new color features from the nucleus and cytoplasm. To extract color features from the cytoplasm, we used the convex hull of the nucleus that eliminates the need for segmenting the cytoplasm that is a challenging task. We showed that these features help the SVM model in more accurately classifying WBCs. The proposed method successfully managed to classify three data sets differing in terms of the microscope, camera, staining technique, variation, and lighting conditions, and ensured the following accuracy of 94.65% (Raabin-WBC), 92.21% (LISC), and 94.20% (BCCD). In addition, the results presented in Table 7 indicate that the proposed method is faster and has more generalization ability than the CNN-based method. Therefore, we can conclude that not only is the suggested way robust and reliable, but also it can be utilized for laboratory applications and purposes.
Data and code availability
All codes of the proposed method are available at https://github.com/nimaadmed/WBC_Feature.
References
Hegde, R. B., Prasad, K., Hebbar, H. & Singh, B. M. K. Comparison of traditional image processing and deep learning approaches for classification of white blood cells in peripheral blood smear images. Biocybern. Biomed. Eng. 39, 382–392 (2019).
Terwilliger, T. & Abdul-Hay, M. Acute lymphoblastic leukemia: A comprehensive review and 2017 update. Blood Cancer J. 7, e577 (2017).
Burnett, J. L., Carns, J. L. & Richards-Kortum, R. Towards a needle-free diagnosis of malaria: In vivo identification and classification of red and white blood cells containing haemozoin. Malar. J. 16, 447 (2017).
Camon, S. et al. Full blood count values as a predictor of poor outcome of pneumonia among HIV-infected patients. BMC Infect. Dis. 18, 189 (2018).
Li, Y. X. et al. Characteristics of peripheral blood leukocyte differential counts in patients with COVID-19. Zhonghua Nei Ke Za Zhi 59, E003 (2020).
Chitra, P. et al. Detection of AML in blood microscopic images using local binary pattern and supervised classifier. Res. J. Pharm. Technol. 12, 1717–1720 (2019).
Rezatofighi, S. H. & Soltanian-Zadeh, H. Automatic recognition of five types of white blood cells in peripheral blood. Comput. Med. Imaging Graph. 35, 333–343 (2011).
Sundara, S. M. & Aarthi, R. Segmentation and evaluation of white blood cells using segmentation algorithms. in 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI) 1143–1146 (IEEE, 2019).
Putzu, L., Caocci, G. & Di Ruberto, C. Leucocyte classification for leukaemia detection using image processing techniques. Artif. Intell. Med. 62, 179–191 (2014).
Harun, N. H. et al. Automated cell counting system for chronic leukemia. in 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT) 502–506 (IEEE, 2019).
AL-DULAIMI, K. et al. Segmentation of white blood cell, nucleus and cytoplasm in digital haematology microscope images: A review-challenges, current and future potential techniques. IEEE Rev. Biomed. Eng. (2020).
Talebi, H., Ranjbar, A., Davoudi, A., Gholami, H. & Menhaj, M. B. High accuracy classification of white blood cells using TSLDA classifier and covariance features. arXiv Preprint arXiv1906.05131 (2019).
Cao, F., Cai, M., Chu, J., Zhao, J. & Zhou, Z. A novel segmentation algorithm for nucleus in white blood cells based on low-rank representation. Neural Comput. Appl. 28, 503–511 (2017).
Ravikumar, S. Image segmentation and classification of white blood cells with the extreme learning machine and the fast relevance vector machine. Artif. Cells Nanomed. Biotechnol. 44, 985–989 (2016).
Mousavi Kouzehkanan, Z. et al. Raabin-WBC: A large free access dataset of white blood cells from normal peripheral blood. bioRxiv. https://doi.org/10.1101/2021.05.02.442287 (2021).
Mohamed, M., Far, B. & Guaily, A. An efficient technique for white blood cells nuclei automatic segmentation. in 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC). 220–225. https://doi.org/10.1109/ICSMC.2012.6377703 (2012).
Rehman, A. et al. Classification of acute lymphoblastic leukemia using deep learning. Microsc. Res. Tech. 81, 1310–1317 (2018).
Toğaçar, M., Ergen, B. & Cömert, Z. Classification of white blood cells using deep features obtained from convolutional neural network models based on the combination of feature selection methods. Appl. Soft Comput. 97, 106810 (2020).
Togacar, M., Ergen, B. & Sertkaya, M. E. Subclass separation of white blood cell images using convolutional neural network models. Elektron. Elektrotech. 25, 63–68 (2019).
Sahlol, A. T., Kollmannsberger, P. & Ewees, A. A. Efficient classification of white blood cell leukemia with improved swarm optimization of deep features. Sci. Rep. 10, 2536 (2020).
Shahin, A. I., Guo, Y., Amin, K. M. & Sharawi, A. A. White blood cells identification system based on convolutional deep neural learning networks. Comput. Methods Programs Biomed. 168, 69–80 (2019).
Jung, C., Abuhamed, M., Alikhanov, J., Mohaisen, A. W-Net: A CNN-based architecture for white blood cells image classification. arXiv preprint 1910.01091 (2019).
Baydilli, Y. Y. & Atila, Ü. Classification of white blood cells using capsule networks. Comput. Med. Imaging Graph. 80, 101699 (2020).
Banik, P. P., Saha, R. & Kim, K. Fused convolutional neural network for white blood cell image classification. in 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). 238–240 (2019).
Liang, G., Hong, H., Xie, W. & Zheng, L. Combining convolutional neural network with recursive neural network for blood cell image classification. IEEE Access 6, 36188–36197 (2018).
Banik, P. P., Saha, R. & Kim, K.-D. An automatic nucleus segmentation and CNN model based classification method of white blood cell. Expert Syst. Appl. 149, 113211 (2020).
Otsu, N. A threshold selection method from gray level histograms. IEEE Trans. Syst. Man. Cybern. 9, 62–66 (1979).
Hiremath, P. S., Bannigidad, P. & Geeta, S. Automated identification and classification of white blood cells (leukocytes) in digital microscopic images. in IJCA Special Issue “Recent Trends Image Process Pattern Recognition” RTIPPR 59–63 (2010).
Gautam, A. & Bhadauria, H. Classification of white blood cells based on morphological features. in 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI) 2363–2368 (IEEE, 2014).
Sahlol, A. T., Abdeldaim, A. M. & Hassanien, A. E. Automatic acute lymphoblastic leukemia classification model using social spider optimization algorithm. Soft Comput. 23, 6345–6360 (2019).
Ghane, N., Vard, A., Talebi, A. & Nematollahy, P. Segmentation of white blood cells from microscopic images using a novel combination of K-means clustering and modified watershed algorithm. J. Med. Signals Sens. 7, 92–101 (2017).
Laosai, J. & Chamnongthai, K. Acute leukemia classification by using SVM and K-means clustering. in 2014 International Electrical Engineering Congress (iEECON) 1–4 (IEEE, 2014).
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N. & Liang, J. Unet++: A nested u-net architecture for medical image segmentation. in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support 3–11 (Springer, 2018).
Baydilli, Y. Y., Atila, U. & Elen, A. Learn from one data set to classify all—A multi-target domain adaptation approach for white blood cell classification. Comput. Methods Programs Biomed. 196, 105645 (2020).
Mousavi Kouzehkanan, Z., Tavakoli, I. & Alipanah, A. Easy-GT: Open-Source Software to Facilitate Making the Ground Truth for White Blood Cells Nucleus. arXiv Preprint 2101.11654 (2021).
Oktay, O. et al. Attention u-net: Learning where to look for the pancreas. arXiv Preprint arXiv1804.03999 (2018).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 42, 386–397 (2020).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 770–778 (2016).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 1492–1500 (2017).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 4510–4520 (2018).
Tan, M. et al. Mnasnet: Platform-aware neural architecture search for mobile. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2820–2828 (2019).
Ma, N., Zhang, X., Zheng, H.-T. & Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. in Proceedings of the European Conference on Computer Vision (ECCV) 116–131 (2018).
Tan, J., Xia, D., Dong, S., Zhu, H. & Xu, B. Research on pre-training method and generalization ability of big data recognition model of the internet of things. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 20,1–15 (2021).
Author information
Authors and Affiliations
Contributions
S.T. implemented the proposed segmentation and feature extraction algorithms and wrote the paper. Z.M.K. suggested the feature extraction algorithm and helped the first author in writing the paper as well as implemented U-Net and Attention U-Net models. A.G. and R.H. revised the manuscript and made some comments and suggestions. A.G. designed the research as supervisor. All authors reviewed the final version of the manuscript before submitting.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tavakoli, S., Ghaffari, A., Kouzehkanan, Z.M. et al. New segmentation and feature extraction algorithm for classification of white blood cells in peripheral smear images. Sci Rep 11, 19428 (2021). https://doi.org/10.1038/s41598-021-98599-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-98599-0
This article is cited by
-
Optimization-based convolutional neural model for the classification of white blood cells
Journal of Big Data (2024)
-
White blood cell classification based on a novel ensemble convolutional neural network framework
The Journal of Supercomputing (2024)
-
Deep learning-based blood cell classification from microscopic images for haematological disorder identification
Multimedia Tools and Applications (2024)
-
Recent metaheuristic algorithms for medical object localization using MSER detector in computer-aided diagnosis system
Multimedia Tools and Applications (2024)
-
A hybrid approach based on multipath Swin transformer and ConvMixer for white blood cells classification
Health Information Science and Systems (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
