
Abstract
The combination of machine learning (ML) and electronic health records (EHR) data may be able to improve outcomes of hospitalized COVID-19 patients through improved risk stratification and patient outcome prediction. However, in resource constrained environments the clinical utility of such data-driven predictive tools may be limited by the cost or unavailability of certain laboratory tests. We leveraged EHR data to develop an ML-based tool for predicting adverse outcomes that optimizes clinical utility under a given cost structure. We further gained insights into the decision-making process of the ML models through an explainable AI tool. This cohort study was performed using deidentified EHR data from COVID-19 patients from ProMedica Health System in northwest Ohio and southeastern Michigan. We tested the performance of various ML approaches for predicting either increasing ventilatory support or mortality. We performed post hoc analysis to obtain optimal feature sets under various budget constraints. We demonstrate that it is possible to achieve a significant reduction in cost at the expense of a small reduction in predictive performance. For example, when predicting ventilation, it is possible to achieve a 43% reduction in cost with only a 3% reduction in performance. Similarly, when predicting mortality, it is possible to achieve a 50% reduction in cost with only a 1% reduction in performance. This study presents a quick, accurate, and cost-effective method to evaluate risk of deterioration for patients with SARS-CoV-2 infection at the time of clinical evaluation.
Similar content being viewed by others


Introduction
Since the outbreak of coronavirus disease 2019 (COVID-19) in the United States in early 20201, many hospitals and clinics have experienced shortages of ventilators and bed spaces in Intensive Care Units (ICUs)2. At the first encounter with a COVID-19 patient, as evidenced by a positive nasopharyngeal PCR test for SARS-CoV-2, it is critical to determine using readily available clinical information whether hospitalization is required, or outpatient treatment can be utilized without risk of deterioration or increased morbidity and mortality. With the increasing availability of electronic health records (EHRs) of hospitalized COVID-19 patients, data-driven decision support systems, such as those based on Machine Learning (ML) methodologies, have been explored extensively in the recent literature as a means of triaging patients with COVID-19 at the point of contact with the health care system3,4,5,6. However, for wide-spread adoption of such ML systems, two fundamental challenges remain. First, to gain the confidence of health care providers, clinical interpretability of the ML algorithms is crucial. Second, the cost and availability of various laboratory tests can vary substantially across facilities and geographic locations. Hence, accounting for general test availability and costs in the ML decision tool is critical.
Interpretability of ML algorithms for clinical applications has recently received significant research attention7,8,9,10, as the lack of interpretability can potentially have adverse or even life-threatening consequences. In general, there exists a trade-off between an ML model’s predictive performance and interpretability: Linear models are highly interpretable, but they may not have enough capacity to capture the complexity of EHR data, whereas non-linear models typically provide better predictive performance, but they can be hard to interpret. In Lundberg and Lee11, the authors introduce SHAP, a software package that leverages the game-theoretic concept of Shapley values to explain the output of any ML model. Shapley plots have recently been used in ML applications to risk assessment of COVID-19 patients12, 13.
While recent studies have considered the interpretability of ML algorithms that triage COVID-19 patients based on clinical features, the availability and cost of such clinical features have largely been ignored. However, this is an important consideration, since many hospitals reached near full capacity at the peak of the pandemic, bringing the economic sustainability and ethicality of resource allocation of the healthcare system into question. Moreover, recent studies have found that patients are often over-diagnosed by unnecessary testing services, which may delay care for those patients who have more immediate need for medical attention. This suggests that taking the cost of diagnostic testing into account when building ML decision support tools can not only help satisfy budget constraints in resource-constrained environments, but it can also lead to better patient-centered outcomes.
Machine learning under budget constraints is also known as cost-sensitive or cost-constrained learning. This field is focused on developing good predictive models while also taking into consideration the cost of collecting data. Several works have considered the general problem of cost-sensitive feature selection in machine learning. These works have tended to provide approximate methods or heuristics for solving the cost-constrained optimization problems associated with such tasks14,15,16,17. In healthcare applications, a number of previous works have introduced budget constraints, such as the financial costs of lab tests or clinical preferences, into their proposed machine learning models18, 19. However, to the best of our knowledge, our work is the first to consider cost-sensitive learning applied to COVID-19. In this paper, we propose an interpretable ML framework that includes the consideration of the financial cost of clinical features. More specifically, we sought to (1) develop an ML approach for predicting adverse outcomes based on demographic information, co-morbidities, and biomarkers collected close to the date of a positive PCR test; (2) gain insight into the decision-making process of the ML algorithm based on interpretable ML tools, such as Shapley values; and (3) identify and account for unequal costs of clinical features in the ML decision support system by finding the optimal set of biomarkers that results in the highest utility under a given cost structure.
A retrospective study was performed using EHRs from patients in the largest health care system in northwestern Ohio and southeastern Michigan (ProMedica Health System). The data used in this study corresponds to patients who (1) had a positive nasopharyngeal PCR test for SARS-CoV-2 between March 20, 2020 and December 29, 2020, and (2) were admitted to the hospital shortly before or after the positive result. Demographics (e.g., age, race, co-morbidities, insurance status), vitals, and a wide range of lab tests available within 3 days of a first positive PCR test were used to train machine learning models to predict a patient’s risk of adverse outcomes, namely, composite ventilation and mortality. Our studies indicate that, compared to a baseline linear logistic regression model, more advanced nonlinear or tree-based classifiers provide improved performance both in terms of average precision (AP) and the area under the receiver operating characteristic curve (AUC). The importance of individual features was captured via game-theoretic Shapley values, and the results largely matched clinical intuition. Finally, we performed a post hoc analysis of the cost of clinical features to obtain optimal feature sets for a given budget constraint. The results indicate that judicious and cost-sensitive selection of clinical features can provide substantial financial and logistical savings with very little reduction in predictive performance.
Methods
Data description
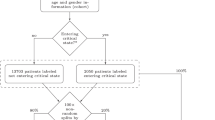
The present study was performed using EHRs from patients of ProMedica, the largest health care system in northwestern Ohio and southeastern Michigan. The EHRs were collected from patients who (1) had a positive nasopharyngeal PCR test for SARS-CoV-2 between March 20, 2020 and December 29, 2020, and (2) were admitted to the hospital within ± 3 days of the positive result. For those patients with multiple admissions in the database, only one admission that overlapped with or occurred right after the patient’s first PCR positive test was selected. Admissions where patients were put on ventilators before the first positive date were additionally filtered out. A total of 1,312 patients met these criteria. A flowchart of the study enrollment is provided in Fig. 1. The study protocol involving analysis of fully deidentified data was reviewed and approved by the respective Institutional Review Boards of ProMedica and Lawrence Livermore National Laboratory, and the study was performed in compliance with all regulations and guidelines (Expedited, Category #5 research) from the United State Department of Health and Human Services.

A flowchart of study enrollment. Composite ventilation related outcomes are represented by green boxes and Mortality related outcomes are represented by red boxes.
Data preprocessing
Forty-nine clinical features were extracted within a ± 3 day window from the first PCR positive test date. Missing values were imputed using median imputation20. Continuous features were standardized using Z-score scaling (subtracting the mean and scaling to unit variance). If there were multiple observations for a feature inside the extraction window, only the observation closest to the positive test date was retained. Additionally, for the task of composite ventilation prediction, there were instances where the ± 3 day extraction window overlapped with a patient’s ventilation period. For those cases, feature values observed on or after the start of ventilation were removed.
We further noticed that clinical measurements related to oxygen levels (Oxygen Saturation, Inspired Oxygen Concentration, PO2, SPO2, PCO2) were highly correlated with our model’s predictions of the need for composite ventilation, even after ensuring that our extraction pipeline was sound. To make sure there could be no information leakage, these five oxygen measurements were removed from the task of composite ventilation prediction. As a result, 44 features were used to train our models on the task of predicting composite ventilation, whereas 49 features were used for predicting mortality. The list of features and their value ranges are presented in Tables 1 and 2 for the task of composite ventilation and mortality, respectively.
Model development I: Predicting adverse outcomes without budget constraints
The following machine learning models were trained: Logistic regression, XGBoost21, and Gaussian process classifier (with radial basis function kernel)22. These models serve to establish a baseline on the predictive performance in the ideal scenario where budget is not a constraint. These models were specifically chosen because they cover a wide spectrum of ML approaches in healthcare and clinical applications. Logistic regression is the de facto technique in clinical applications because of ease of interpretation, general applicability to small datasets, and availability in statistical software packages23, 24. A limitation of logistic regression is the underlying assumption of linearity25, which is often too strong for many clinical tasks. Gaussian process classifiers remove the assumption of linearity while performing well on small datasets, but they are less interpretable than logistic regression. Among non-linear classifiers, Gaussian process classifier is arguably the most powerful technique with sound statistical properties. Additionally, it is possible to train this model in the presence of sparse and missing data, which makes it an ideal choice for analyzing EHRs. The Gaussian process classifier has been applied to various detection and prediction tasks, including early recognition of sepsis26, in-hospital mortality prediction for preterm infants27, and health monitoring with wearable sensors28. XGBoost is a relatively new ensemble machine learning model, and it represents the best-in-class among tree-based classifiers, combining strong predictive performance and the interpretability of decision trees. In recent literature, XGBoost has often been shown to provide improved predictive performance in a wide range of clinical applications. Sharma et al.29 use XGBoost for diagnosing depression in unbalanced datasets. Chang et al.30 apply XGBoost to the task of predicting hypertension outcomes, and they find that this model has better predictive performance than a random forest or a support vector machine.
Models were trained and evaluated following fivefold train/test splits to account for variances, resulting in 80%/20% training and testing splits. For each train/test split, model hyperparameters were optimized by performing fourfold cross validation on the training set, leading to 80%/20% splits into optimization and validation sets—that is, the optimization and validation sets contain 64% and 16% of the full dataset. The Optuna optimization framework31 was used for hyperparameter tuning with the objective of maximizing AP. Additionally, a post-hoc feature importance analysis was performed by applying the SHAP framework11, a game-theoretic feature attribution framework that reveals how each feature per sample contributes to the decisions made by the model for the corresponding sample. All of our experiments were conducted using Python 3.8, and models were implemented in the Scikit-Learn framework32.
Model development II: Feature selection under budget constraints
In this section, the financial costs of the clinical features were taken into consideration when training predictive models. For a pre-defined cost structure, the goal was to find the set of clinical features that provides the highest predictive performance in terms of AP. One could find the best subset of clinical features iteratively by trying all possible combinations of features obeying the budget constraint; however, this method would be computationally expensive, as it scales exponentially with the number of features. Therefore, we propose an alternative selection scheme. Intuitively, several clinical features are often recorded collectively and can be grouped together. For example, temperature, blood pressure, and pulse are often measured together when the patient is first admitted to the hospital. Guided by clinical experts, 11 groups of clinical features and their relative collection costs were defined (Table 3). By training machine learning models on each combination of groups, we only must explore 211 combinations rather than 244 combinations for predicting ventilation and 249 for predicting mortality. As XGBoost was the best performing model without budget constraints, it was also selected for the budget-constrained prediction task. XGBoost was trained for all 211 combinations of feature groups to obtain the combination with highest AP for a given budget constraint.
Informed consent
The study protocol involving analysis of fully de-identified data was reviewed and approved with Full Waiver of informed consent granted (Expedited, Category #5 research) by the respective Institutional Review Board's of ProMedica and Lawrence Livermore National Laboratory. The study was performed in compliance with all regulations and guidelines from the United State Department of Health and Human Services.
Results
We report results on five test sets (which together span the entire dataset), and provide the mean and standard deviation of AP and AUC scores. The proposed ML framework achieved the best mean (standard deviation) across validation sets with AUC of 0.723 (0.038) and AP of 0.379 (0.038) for composite ventilation and AUC of 0.802 (0.029) and AP of 0.354 (0.065) for mortality. Note, for comparison, a classifier that completely disregards the data can achieve an AUC of 0.5 and AP of 0.090 (for composite ventilation) and 0.171 (for mortality). A distinction between our work and others is that we chose the hyperparameters of our models by optimizing AP rather than AUC. Our motivation is that AP is a more meaningful measure of performance in the presence of significant class imbalance. This is predominantly true in our case, where the number of deceased patients (N = 224) as well as the number of patients who required composite ventilation (N = 118) is a small fraction of the total cohort (N = 1312).
The results of logistic regression, XGBoost, and Gaussian process classifier without budget constraints are provided in Table 4. We also provide the Receiver Operating Characteristic (ROC) curves and Precision–Recall curves for the three ML approaches (Figs. 2 and 3). Among the three classifiers, for both adverse outcomes (composite ventilation and mortality), XGBoost provides the highest AP (as well as the highest AUC for composite ventilation and the second highest AUC for mortality). Feature importance for XGBoost—computed using the SHAP framework—for both outcomes are shown in Fig. 4. For predicting ventilation, the five most important features (when averaged over five test sets) were procalcitonin, lymphocyte count, pulse oximetry, C-Reactive Protein (CRP), and age. Similarly, for predicting mortality, the top five features were age, blood urea nitrogen (BUN), serum potassium, diastolic blood pressure, and D- Dimer levels.

Precision-Recall (PR) curves on the ventilation and mortality tasks. The lines are the mean PR curves over 5 different train/test splits and the shaded areas represent ± 1 standard deviations from the means. In both tasks, the XGBoost model has the best PR curve overall, which is reflected in its average precision (AP) score in Table 4.

Receiver operating characteristic (ROC) curves on the ventilation and mortality tasks. The lines are the mean ROC curves over 5 different train/test splits and the shaded areas represent ± 1 standard deviations from the means. The performance of the three models is comparable, with XGBoost having the best performance in the ventilation task and the Gaussian process classifier having slightly better performance in the mortality task. The area under the curve (AUC) scores for all the models are reported in Table 4.

Feature importance of a trained XGBoost model. The higher the absolute SHAP value, the greater the contribution of the feature to the predicted outcome. The SHAP values are averaged over 5 folds of test splits that span the whole dataset. (A) The top three most important features for predicting ventilation are Procalcitonin, Lymphocytes Absolute and Pulse Oximetry. (B) The top three most important features for predicting mortality are Age, BUN and Potassium.
The optimal sets of features for predicting composite ventilation under different budget constraints are reported in Table 5. Since Demographics and Comorbidities (DCM) are readily available upon a patient’s admission, this information was considered to be free of cost and included in every feature set. Under different budget constraints, the model with highest mean AP across cross-validated test sets was selected. As the available budget increased from 0 to 15, the AP increased from a mean (standard deviation) of 0.289 (0.016) to 0.382 (0.047). The performance peaked at a budget level of 15, the optimal set of features being DCM, BMP, D-dimer, LDH, Sedrate, CRP, BNP, and Procalcitonin. Increasing the budget (i.e., adding more features) beyond this point did not yield a better performance.
The optimal set of features for predicting mortality under different budget constraints are reported in Table 6. Under different budget constraints, the model with highest mean AP across cross-validated test sets was selected. As the available budget increased from 0 to 17, the AP increased from 0.285 (0.048) to 0.355 (0.075). The performance peaked at a budget constraint of 17, the optimal set of features being DCM, BMP, CBC, D-dimer, LDH, CRP, BNP, Procalcitonin and Ferritin. Increasing the budget beyond this point did not yield a better performance.
Discussion
Several recent publications have also proposed using XGBoost or very similar models to predict mortality or ventilation using EHR3, 5,6,7. For mortality prediction, Yan et al.3 identified LDH, Lymphocytes, and CRP as the most significant features. Using a cohort in New York City, NY, USA, Yadaw et al.4 compared different models including logistic regression, support vector machine (SVM), random forest (RF), and XGBoost for mortality prediction and identified the most informative features as Age, Oxygen Saturation, and the type of visit (tele-health or inpatient/outpatient). Bertsimas et al.12 analyzed cohorts in Spain, Greece, and USA. The authors used the SHAP framework in their study, and they reported that BUN, CRP, and Oxygen Saturation were the most informative features for mortality.
After training and testing a model using all available clinical features, we found the top contributing factors for predicting adverse outcomes. To do so, we applied the SHAP framework11 to the best performing model (XGBoost), selected the top performing fold, and plotted the relationship between feature values and feature significance (Figs. 5, 6). Note that higher Shapley values are indicative of the adverse outcome (composite ventilation or death) and vice versa. In general, the Shapley plots uncovered relationships between clinical features and outcomes which are well supported by existing clinical literature. For example, lower values of Procalcitonin reduce the likelihood of being labelled as requiring ventilation. Aligned with other studies33,34,35, our analysis suggests that Procalcitonin can be a robust lab test for predicting ventilation. In addition to Procalcitonin, Pulse Oximetry and Absolute Lymphocyte Count exhibit a clear relationship to ventilation, where lower levels of Pulse Oximetry and Absolute Lymphocytes reduce the chances of being labelled as requiring ventilation. Our findings demonstrate that, used in combination, these markers are highly predictive of composite ventilation.

Scatter plots of SHAP values versus unnormalized values for selected features. (A–C) The top three most significant features for predicting composite ventilation for the best performing fold. (D–F) The top three most significant features for predicting mortality for the best performing fold.

SHAP scatter plot for prediction using all features for the best performing fold. Positive SHAP values imply the corresponding feature was indicative of ventilation/death. Negative SHAP values imply the corresponding feature was indicative of no ventilation/discharged. A zero SHAP value implies the feature has no impact on the predicted outcome. The normalized range of value of features are color-coded.
From a clinical point of view, our study suggests that the most relevant set of variables that predicted ventilation as an outcome were elevated Procalcitonin levels, elevated Lymphocyte Count, lower Pulse Oximeter readings, elevated CRP, and older age (based on averaged SHAP values across all test splits, Fig. 4 (a)). The study also suggests that the variables that best predicted mortality as the outcome were older age, elevated BUN, elevated serum potassium, elevated diastolic blood pressure, and elevated D-dimer levels (Fig 4 (b)). This study was not designed to evaluate causality for the clinical data but suggests that these clinical data serve as appropriate surrogate markers for the underlying biological causes of respiratory failure and death in infection with SARS-CoV-2.
Regarding composite ventilation, from a pathophysiologic perspective, the patients that have an elevated procalcitonin level and elevated lymphocytic count are more likely to have bacterial and/or viral superinfection, which would be associated with increased risk of requiring ventilation. The lower pulse oximeter readings and elevated levels of inflammation seen with the elevated CRP reflect an increased severity of pulmonary damage that would be seen in patients progressing to ventilation. Extremes of age are well-recognized risk factors for adverse outcomes in the majority of severe medical conditions, and COVID-19 is no exception36, 37.
Regarding mortality, elevated BUN and serum potassium are reflections of impaired renal function, and acute kidney injury is associated with increased hospital mortality in all studies of sepsis37,38,39,40. The mechanism by which COVID-19 impacts renal function remains unclear: direct cytotoxic effects, cytokine storm related hypotension, renal hypoxia secondary to systemic hypoxia, and micro-coagulation in the renal vasculature (which may also be reflected in an elevated D-dimer level) have all been proposed as potential mechanisms41,42,43. Regarding elevated diastolic blood pressure as a marker for increased risk of mortality, this may be a surrogate marker for cardiac disease instead of an independent pathophysiologic mechanism.
Though not among the top predictors for mortality, mean corpuscular volume (MCV) is an interesting marker that has been correlated with worse outcomes both at lower values44 and higher values45. In our study population, non-alcoholic fatty liver disease is common and may be unrecognized given that mean BMI was high and fatty liver disease is often seen in obesity, whereas other studies demonstrating a low MCV being predictive of worse outcomes have been done in areas of the world where ß-thalassemia is more common. This indicates that MCV needs to be considered in the context of other population factors.
However, contrary to most recent publications46, Fig. 5b shows that higher BMI decreased the likelihood of being labelled as deceased. Higher BMI being associated with better outcomes has also been reported in veterans47. This may be attributed to collider bias, as the number of obese people outnumber the non-obese people in our cohort and obese people are also more likely to be hospitalized for COVID-19.
The major focus of this work is the post-hoc analysis of models by incorporating budget constraints into the problem formulation. A notable trend in both mortality and ventilation prediction is that the best predictive performance is achieved for a significantly smaller set of optimal features. In general, predictive performance increases with allowable budget, but there is a clear point of inflexion for both composite ventilation and mortality (Fig. 7). For composite ventilation, the predictive performance is at 92% of the maximum AP at 18% of the maximum budget. Similarly, for mortality, the predictive performance is at 96% of the maximum AP at 18% of the maximum budget. This implies that when it comes to making healthcare affordable, clinicians can choose a smaller set of features that not only fits within their budget but also achieves close-to-optimal performance. For example, when predicting ventilation (Table 5 and Fig. 7a) we can achieve a 43% reduction in cost with only a 3% reduction in performance by using the feature set DCM, BMP, CBC, and CRP rather than the optimal feature set DCM, BMP, CBC, CRP, D-dimer, and Procalcitonin. Similarly, when predicting mortality (Table 6 and Fig. 7b) we can achieve a 50% reduction in cost with only a 1% reduction in performance by using the feature set DCM, LDH, and CRP rather than the optimal feature set DCM, BMP, LDH, CRP, and Troponin. This substantial drop in cost may be attributed to the fact that Troponin and Procalcitonin are expensive lab tests. Overall, we provide a tool to perform cost–benefit analysis for selecting the most efficient and cost-effective lab tests for prediction of adverse outcomes.

Visualization of Total cost versus Utility. Although an increase in budget allows more clinical feature groups in our selection, this does not guarantee an increase in performance. The performance maximizes when the total costs of features is 15 for composite ventilation and 17 for mortality, and any additional feature does not increase utility.
Limitations
As with most retrospective cohort outcomes studies, an inherent limitation is the associative nature of the study analysis and the fact that disease prediction markers used in the modeling may be correlated. Thus, a better approach to selecting clinical features and prediction markers may be network analysis-based node selection, which considers the clinical and biological connections between markers and reduces the redundancy48, 49. Additionally, future studies may incorporate clinical markers that are reported to be associated with outcomes of COVID-19 in meta-analysis with large-scale cohorts50, 51 into the training of the prediction model. Indeed, a limitation of our present study is the lack of validation on another independent dataset of hospitalized COVID-19 patients, due to limited dataset availability. Furthermore, the potential causal effects of clinical variables on the adverse outcomes for COVID-19 patients could be further interrogated through causal inference analysis methods, such as mendelian randomization analysis52,53,54, which may help understanding clinical and biological mechanisms of our prediction models.
Conclusion
The current study provides a point-of-care model that allows improved resource allocation and evidence-based management that can be applied to improve patient care in the setting of COVID-19. We present a machine learning framework to evaluate risk of clinical deterioration for patients with SARS-CoV-2 infection at the time of medical evaluation and to determine appropriate medical management for newly admitted patients. The proposed approach also identifies the top clinical factors predictive of an adverse outcome and integrates budget considerations in the prediction framework. More specifically, based on post-hoc optimization, the approach identifies the optimal set of clinical variables for a pre-defined budget constraint. The proposed framework has the potential for real-life impact by helping clinicians make fast and reliable decisions regarding patient risk stratification in a cost-effective manner. Incorporating financial considerations into data-driven prediction models can be beneficial to cost-constrained healthcare systems where costly laboratory tests may not be always readily available.
References
Holshue, M. L. et al. First case of 2019 novel coronavirus in the United States. N. Engl. J. Med. 382, 929–936 (2020).
Sen-Crowe, B., Sutherland, M., McKenney, M. & Elkbuli, A. A closer look into global hospital beds capacity and resource shortages during the COVID-19 pandemic. J. Surg. Res. 260, 56–63 (2021).
Yan, L. et al. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2, 283–288 (2020).
Yadaw, A. S. et al. Clinical features of COVID-19 mortality: Development and validation of a clinical prediction model. Lancet Digit. Health 2, e516–e525 (2020).
Gao, Y. et al. Machine learning based early warning system enables accurate mortality risk prediction for COVID-19. Nat. Commun. 11, 5033 (2020).
Wollenstein-Betech, S., Cassandras, C. G. & Paschalidis, I. C. Personalized predictive models for symptomatic COVID-19 patients using basic preconditions: Hospitalizations, mortality, and the need for an ICU or ventilator. Int. J. Med. Inform. 142, 104258 (2020).
Li, W. et al. Early predictors for mechanical ventilation in COVID-19 patients. Ther. Adv. Respir. Dis. 14, 1753466620963017 (2020).
Stiglic, G. et al. Interpretability of machine learning-based prediction models in healthcare. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 10, e1379 (2020).
Murdoch, W. J., Singh, C., Kumbier, K., Abbasi-Asl, R. & Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. 116, 22071–22080 (2019).
Qayyum, A., Qadir, J., Bilal, M. & Al-Fuqaha, A. Secure and robust machine learning for healthcare: A survey. IEEE Rev. Biomed. Eng. 14, 156–180 (2020).
Lundberg, S. M. & Lee, S.-In. A unified approach to interpreting model predictions. Proceedings of the 31st International Conference on Neural Information Processing Systems 4768–4777.
Bertsimas, D. et al. COVID-19 mortality risk assessment: An international multi-center study. PLoS ONE 15, e0243262 (2020).
Abdulaal, A. et al. Prognostic modeling of COVID-19 using artificial intelligence in the United Kingdom: Model development and validation. J. Med. Internet Res. 22, e20259 (2020).
Jagdhuber, R., Lang, M. & Rahnenführer, J. Feature Selection Methods for Cost-Constrained Classification in Random Forests. arXiv preprint arXiv: 2008.06298 (2020).
Erion, G. et al. CoAI: Cost-aware artificial intelligence for health care. medRxiv 2, 2 (2021).
Min, F., Hu, Q. & Zhu, W. Feature selection with test cost constraint. Int. J. Approx. Reason. 55, 167–179 (2014).
Yoon, J., Jordon, J. & Schaar, M. ASAC: Active sensing using actor-critic models. 451–473.
Jagdhuber, R., Lang, M., Stenzl, A., Neuhaus, J. & Rahnenführer, J. Cost-constrained feature selection in binary classification: Adaptations for greedy forward selection and genetic algorithms. BMC Bioinform. 21, 1–21 (2020).
Verma, A., Hanawal, M. K. & Hemachandra, N. Unsupervised online feature selection for cost-sensitive medical diagnosis. 1–6.
Wells, B. J., Chagin, K. M., Nowacki, A. S. & Kattan, M. W. Strategies for handling missing data in electronic health record derived data. Egems 1, 2 (2013).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. 785–794.
Rasmussen, C. E. Gaussian processes in machine learning. 63–71.
Shipe, M. E., Deppen, S. A., Farjah, F. & Grogan, E. L. Developing prediction models for clinical use using logistic regression: an overview. J. Thorac. Dis. 11, S574 (2019).
Nick, T. G. & Campbell, K. M. Logistic regression. Top. Biostat. 2, 273–301 (2007).
Schober, P. & Vetter, T. R. Logistic regression in medical research. Anesth. Analg. 132, 365 (2021).
Moor, M., Horn, M., Rieck, B., Roqueiro, D. & Borgwardt, K. Early recognition of sepsis with Gaussian process temporal convolutional networks and dynamic time warping. 2–26.
Rinta-Koski, O.-P., Särkkä, S., Hollmén, J., Leskinen, M. & Andersson, S. Gaussian process classification for prediction of in-hospital mortality among preterm infants. Neurocomputing 298, 134–141 (2018).
Clifton, L., Clifton, D. A., Pimentel, M. A. F., Watkinson, P. J. & Tarassenko, L. Gaussian processes for personalized e-health monitoring with wearable sensors. IEEE Trans. Biomed. Eng. 60, 193–197 (2012).
Sharma, A. & Verbeke, W. J. M. I. Improving diagnosis of depression with XGBOOST machine learning model and a large biomarkers dutch dataset (n= 11,081). Front. Big Data 3, 15 (2020).
Chang, W. et al. A machine-learning-based prediction method for hypertension outcomes based on medical data. Diagnostics 9, 178 (2019).
Akiba, T., Sano, S., Yanase, T., Ohta, T. & Koyama, M. Optuna: A next-generation hyperparameter optimization framework. 2623–2631.
Buitinck, L. et al. API design for machine learning software: experiences from the scikit-learn project. arXiv preprint arXiv: 1309.0238 (2013).
Hu, R., Han, C., Pei, S., Yin, M. & Chen, X. Procalcitonin levels in COVID-19 patients. Int. J. Antimicrob. Agents 56, 106051 (2020).
Lippi, G. & Plebani, M. Procalcitonin in patients with severe coronavirus disease 2019 (COVID-19): A meta-analysis. Clin. Chim. Acta 505, 190 (2020).
Krause, M. et al. Association between procalcitonin levels and duration of mechanical ventilation in COVID-19 patients. PLoS ONE 15, e0239174 (2020).
Kang, S.-J. & Jung, S. I. Age-related morbidity and mortality among patients with COVID-19. Infect. Chemotherapy 52, 154 (2020).
Trabulus, S. et al. Kidney function on admission predicts in-hospital mortality in COVID-19. PLoS ONE 15, e0238680 (2020).
Cheng, A. et al. Diagnostic performance of initial blood urea nitrogen combined with D-dimer levels for predicting in-hospital mortality in COVID-19 patients. Int. J. Antimicrob. Agents 56, 106110 (2020).
Altschul, D. J. et al. A novel severity score to predict inpatient mortality in COVID-19 patients. Sci. Rep. 10, 1–8 (2020).
Askari, H. et al. Kidney diseases and COVID-19 infection: causes and effect, supportive therapeutics and nutritional perspectives. Heliyon 2, e06008 (2021).
Palevsky, P. M. COVID-19 and AKI: Where do we stand?. J. Am. Soc. Nephrol. 32, 1029–1032 (2021).
Wald, R. & Bagshaw, S. M. COVID-19–associated acute kidney injury: Learning from the first wave. (2021).
Zheng, S. et al. Immunodeficiency promotes adaptive alterations of host gut microbiome: An observational metagenomic study in mice. Front. Microbiol. 10, 2415 (2019).
Formica, V. et al. Complete blood count might help to identify subjects with high probability of testing positive to SARS-CoV-2. Clin. Med. 20, e114 (2020).
Wang, C. et al. Preliminary study to identify severe from moderate cases of COVID-19 using combined hematology parameters. Ann. Transl. Med. 8, 2 (2020).
Kompaniyets, L. et al. Body mass index and risk for COVID-19–related hospitalization, intensive care unit admission, invasive mechanical ventilation, and death—united states, march–december 2020. Morb. Mortal. Wkly Rep. 70, 355 (2021).
Bravata, D. M. et al. Association of intensive care unit patient load and demand with mortality rates in US Department of Veterans Affairs Hospitals during the COVID-19 pandemic. JAMA Netw. Open 4, e2034266–e2034266 (2021).
Chen, J. et al. Genetic regulatory subnetworks and key regulating genes in rat hippocampus perturbed by prenatal malnutrition: Implications for major brain disorders. Aging (Albany NY) 12, 8434–8458 (2020).
Li, H. et al. Co-expression network analysis identified hub genes critical to triglyceride and free fatty acid metabolism as key regulators of age-related vascular dysfunction in mice. Aging (Albany NY) 11, 7620–7638 (2019).
Jiang, L. et al. Sex-specific association of circulating ferritin level and risk of type 2 diabetes: A dose-response meta-analysis of prospective studies. J. Clin. Endocrinol. Metab. 104, 4539–4551 (2019).
Wu, Y. et al. Multi-trait analysis for genome-wide association study of five psychiatric disorders. Transl. Psychiatry 10, 1–11 (2020).
Zhang, F. et al. Causal influences of neuroticism on mental health and cardiovascular disease. Hum. Genet. 140, 1267–1281 (2021).
Zhang, F. et al. Genetic evidence suggests posttraumatic stress disorder as a subtype of major depressive disorder. J. Clin. Invest. https://doi.org/10.1172/JCI145942 (2021).
Wang, X. et al. Genetic support of a causal relationship between iron status and type 2 diabetes: A Mendelian randomization study. J. Clin. Endocrinol. Metab. https://doi.org/10.1210/clinem/dgab454 (2021).
Acknowledgements
This document was prepared as an account of work sponsored by an agency of the United States government. Neither the United States government nor Lawrence Livermore National Security, LLC, nor any of their employees makes any warranty, expressed or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States government or Lawrence Livermore National Security, LLC. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States government or Lawrence Livermore National Security, LLC, and shall not be used for advertising or product endorsement purposes. An abstract based on this work was accepted for presentation at the 2021 Midwest Clinical and Translational Research Meeting. This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52- 07NA27344 and was supported by the LLNL LDRD Program under Project No.19-ERD-009. LLNL-JRNL-821075. We thank Dr. Amy Gryshuk for her support.
Funding
The funding was provided by the LLNL LDRD Program under Project No.19-ERD-009, The University of Toledo Women and Philanthropy Genetic Analysis Instrumentation Center, The University of Toledo Medical Research Society and also by David and Helen Boone Foundation Research Fund.
Author information
Authors and Affiliations
Contributions
S.N. and R.C. contributed equally to data ingestion, curation, software development and study design. J.C., B.S. and P.R. contributed to experiment and study design. All authors contributed to the analysis of the results and the manuscript preparation. S.N., R.C., J.C., B.S., J.M.D., S.T.H., J.A.H., D.J.K., D.M., P.R.: conceptualization; S.N., R.C., J.C., B.S., P.K., L.W., M.W., P.R.: data curation; S.N., R.C., J.C., B.S., P.K., L.W., M.W., P.R.: formal analysis; S.T.H., D.J.K., P.R.: funding acquisition; S.N., R.C., J.C., B.S., P.K., L.W., M.W., J.M.D., S.T.H., J.A.H., D.J.K., D.M., P.R.: investigation; S.N., R.C., J.C., B.S., P.K., L.W., M.W., J.M.D., S.T.H., J.A.H., D.J.K., D.M., P.R.: methodology; P.K., L.W., M.W., S.T.H., D.J.K., D.M., P.R.: project administration; P.K., L.W., M.W., J.M.D., S.T.H., J.A.H., D.J.K., D.M., P.R.: resources; S.N., R.C., J.C., B.S., P.K., L.W., M.W., P.R.: software; J.M.D., S.T.H., J.A.H., D.J.K., D.M., P.R.: supervision; S.N., R.C., J.C., B.S., P.K., L.W., M.W., P.R.: validation; S.N., R.C., J.C., B.S., J.M.D., S.T.H., J.A.H., D.J.K., D.M., P.R.: writing-original draft; S.N., R.C., J.C., B.S., P.K., L.W., M.W., J.M.D., S.T.H., J.A.H., D.J.K., D.M., P.R.: writing–review and editing. Final version was approved by all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nguyen, S., Chan, R., Cadena, J. et al. Budget constrained machine learning for early prediction of adverse outcomes for COVID-19 patients. Sci Rep 11, 19543 (2021). https://doi.org/10.1038/s41598-021-98071-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-98071-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
