
Abstract
COVID-19 has caused many deaths worldwide. The automation of the diagnosis of this virus is highly desired. Convolutional neural networks (CNNs) have shown outstanding classification performance on image datasets. To date, it appears that COVID computer-aided diagnosis systems based on CNNs and clinical information have not yet been analysed or explored. We propose a novel method, named the CNN-AE, to predict the survival chance of COVID-19 patients using a CNN trained with clinical information. Notably, the required resources to prepare CT images are expensive and limited compared to those required to collect clinical data, such as blood pressure, liver disease, etc. We evaluated our method using a publicly available clinical dataset that we collected. The dataset properties were carefully analysed to extract important features and compute the correlations of features. A data augmentation procedure based on autoencoders (AEs) was proposed to balance the dataset. The experimental results revealed that the average accuracy of the CNN-AE (96.05%) was higher than that of the CNN (92.49%). To demonstrate the generality of our augmentation method, we trained some existing mortality risk prediction methods on our dataset (with and without data augmentation) and compared their performances. We also evaluated our method using another dataset for further generality verification. To show that clinical data can be used for COVID-19 survival chance prediction, the CNN-AE was compared with multiple pre-trained deep models that were tuned based on CT images.
Similar content being viewed by others


Introduction
Currently, medical centres hold huge amounts of patient data. Medical biomarkers, demographic data and image modalities can help and support medical specialists to diagnose infectious diseases1, Alzheimer’s2, Parkinson3 and coronary artery disease4. However, these data must be processed and analysed if they are to become usable information for specialists. Automated solutions based on artificial intelligence have the potential to carry out the required process efficiently5.
Recently, a new type of coronavirus (i.e., Coronavirus Disease 2019 [COVID-19]) emerged, which has taken many lives worldwide6,7,8,9. The virus outbreak was observed for the first time in late 201910,11. COVID-19 primarily targets the lungs12,13. Thus, if the virus is not properly diagnosed in the early stages of infection, it can severely damage the lungs14. The mortality rate of the virus is low; however, it must not be overlooked, as the virus is highly contagious. The virus threat becomes more serious when the resources of medical centres cannot provide services to the large number of people who are infected each day15.
The prediction of the survival chance of infected individuals is as important as the early detection of the virus. Under resource scarcity, medical centres can take into account patients’ conditions and use the available resources wisely. Previous research on COVID-19 detection has proven that deep neural networks are very effective in the early detection of COVID-1916. Thus, it may be that deep networks are also useful for survival chance prediction. In this study, we relied on a clinical dataset, which included data about gender, age and blood type, to perform a diagnostic analysis of the COVID-19 virus. To the best of our knowledge, this appears to be the first paper to propose a survival chance predictor for COVID-19 patients using clinical features. To evaluate the effectiveness of our proposed method, we compared its performance against a standard convolutional neural network (CNN) trained on image data. This study makes a number of contributions as follows:
-
The survival chance prediction of COVID-19 patients based on clinical features
-
Preparing clinical dataset to predict the survival chance of COVID-19 patients for the first time
-
Providing a careful analysis of the dataset characteristics, including an examination of the effects of features on the mortality rate and the correlations between each feature pair
-
Making our dataset publicly available
-
Combining Autoencoder (AE) with CNN to increase prediction accuracy
-
Proposing a data augmentation procedure to balance the number of samples of different classes of the dataset. Notably, our data augmentation method is generic and applicable to any other dataset.
The remaining sections of the paper are organised as follows: “Literature review” reviews the related literature; “Background” briefly sets out the required background; “Description of our clinical dataset” describes our dataset; “Proposed methodology” explains the proposed methodology; “Experiments” presents our experimental results; and “Discussion” and “Conclusions and future works” present our discussion, conclusion and future works.
Literature review
This study sought to predict the survival chance of COVID-19 patients using clinical features. We began by reviewing the COVID-19 detection methods that rely on clinical features and image data. We also reviewed methods on mortality estimations of infected patients.
To contain the COVID-19 threat as soon as possible, researchers approached this virus from multiple directions. Some focused on the fast and accurate detection of infected patients. For example, Wu et al.17 extracted 11 vital blood indices using the random forest (RF) method to design an assistant discrimination tool. Their method had an accuracy of 96.97% and 97.95% for the test set and cross-validation set, respectively. The assistant tool was well equipped to perform a preliminary investigation of suspected patients and suggest quarantine and timely treatment. In another study, Rahman et al.18 reviewed various studies on treatment, complications, seasonality, symptoms, clinical features and the epidemiology of COVID-19 infection to assist medical practitioners by providing necessary guidance for the pandemic. Using a CNN, they tried to detect infected patients to isolate them from healthy patients.
Various hybrid approaches have been adopted to improve COVID-19 diagnosis accuracy. Islam et al.19 employed a CNN for feature extraction and long short-term memory for the classification of patients based on X-ray images. EMCNet20 is another hybrid diagnosis approach that uses a CNN for feature extraction and carries out binary classification using a number of learning techniques, including RF and support vector machine (SVM), on X-ray images. Islam et al.21 also used a CNN for feature extraction but relied on a recurrent neural network (RNN) for classification based on the extracted features. Multiple experiments have been conducted using a combination of architectures, such as VGG19 and DenseNet121, with an RNN. VGG19 + RNN was reported to have the best performance.
In addition to distinguishing between infected and non-infected patients, it is also important to determine whether infected patients have severe conditions. Muhammad et al.22 relied on data mining to predict the recovery condition of infected patients. Their method was able to determine the age group of high-risk patients who are less likely to recover and those who are likely to recover quickly. Their method was able to provide the minimum and the maximum number of days required for a patient’s recovery. Chen et al.23 studied 148 severe and 214 non-severe COVID-19 patients from Wuhan, China using their laboratory test results and symptoms as features to design a RF. The task of the RF was to classify COVID-19 patients into severe and non-severe types using the features. Using the laboratory results and symptom as input, the accuracy of their model was over 90%. Some of the key features they identified were lactate dehydrogenase (LDG), interleukin-6, absolute neutrophil count, D-Dimer, diabetes, gender, cardiovascular disease, hypertension and age.
Other researchers have focused on the mortality risk prediction of the patients. Gao et al.24 proposed a mortality risk prediction model for COVID-19 (MRPMC) that applied clinical data to stratify patients by mortality risk and predicted mortality 20 days in advance. Their ensemble framework was based on four machine-learning techniques; that is, a neural network (NN), a gradient-boosted decision tree25, a SVM and logistic regression. Their model was able to accurately and expeditiously stratify the mortality risk of COVID-19 patients.
Zhu et al.26 presented a risk stratification score system as a multilayer perceptron (MLP) with six dense layers to predict mortality. 78 clinical variables were identified and prediction performance was compared with the pneumonia severity index, the confusion, uraemia, respiratory rate, BP, age ≥ 65 years score and the COVID‐19 severity score. They derived the top five predictors of mortality; that is, LDH, C‐reactive protein, the neutrophil to lymphocyte ratio, the Oxygenation Index and D‐dimer. Their model was proved to be effective in resource‐constrained and time‐sensitive environments.
The power of the XGBoost algorithm has also been leveraged for mortality risk prediction. For example, Yan et al.27 collected blood samples of 485 infected patients from China to detect key predictive biomarkers of COVID-19 mortality. They employed a XGBoost classifier that was able to predict the mortality of patients with 90% accuracy more than 10 days in advance. In another study, Bertsimas et al.28 developed a data-driven mortality risk calculator for in-hospital patients. Laboratory, clinical and demographic variables were accumulated at the time of hospital admission. Again, they applied XGBoost to predict the mortality of patients. Adopting a different approach, Abdulaal et al.29 devised a point-of-admission mortality risk scoring system using a MLP for COVID-19 patients. The network exploited patient specific features, including present symptoms, smoking history, comorbidities and demographics, and predicted the mortality risk based on these features. The mortality prediction model demonstrated a specificity of 85.94%, a sensitivity of 87.50% and an accuracy of 86.25%.
As the symptoms of different viruses may be similar to some extent, there has been an attempt to distinguish different viruses from one another30. To this end, multiple classical machine-learning algorithms were trained to classify textual clinical reports into the four classes of Severe acute respiratory syndrome (SARS), acute respiratory distress syndrome, COVID-19 and both SARS and COVID-19. Feature engineering has also been carried out using report length, bag of words and etc. Multinomial Naïve Bayes and logistic regression outperformed other classifiers with a testing accuracy of 96.2%. A summary of the reviewed works are presented in Table 1.
Most existing studies on COVID-19 have relied on computed tomography (CT) and X-ray images to achieve their research objectives. Al-Waisy et al.31 proposed COVID-DeepNet, a hybrid multimodal deep-learning system for diagnosing COVID-19 using chest X-ray images. After the pre-processing phase, the predictions from two models (a deep-belief network and a convolutional deep-belief network) were fused to improve diagnosis accuracy. Another fusion of two models (ResNet34 and a high-resolution network model) was proposed in32 to form the COVID-CheXNet method for COVID-19 diagnosis. Mohammed et al. collected a dataset of X-ray images and made it publicly available. The dataset has been used to benchmark various machine-learning methods for COVID-19 diagnosis33. They reported that the ResNet50 model achieved the best performance. In another benchmarking study34, 12 COVID-19 diagnostic methods were examined based on 10 evaluation criteria. To this end, multicriteria decision making (MCDM) and the technique order of preference by similarity to ideal solution were employed. The 10 criteria were weighted based on entropy. The SVM classifier was reported to have the best performance among the benchmarked methods.
Slowing down the spread of COVID-19 and supporting infected patients are as important as COVID-19 detection. Several works have investigated the possibility of using existing technologies to benefit infected patients. Rahman et al.35 proposed a deep-learning architecture to determine whether people are wearing a facial mask. The monitoring was realised via closed-circuit television cameras in public places. Islam et al.36 reviewed existing technologies that can facilitate the breathing of infected patients. Wearable technologies and how they can be used to provide initial treatment to people have also been investigated37. Ullah et al.38 reviewed telehealth services and the possible ways in which they can be used to provide patients with necessary treatments while keeping the social distance between patients and doctors.
Some works have adopted a broader approach and reviewed various recently developed deep-learning methods with application to COVID-19 diagnosis. For example, Islam et al.39 reviewed these methods based on X-ray and CT images while the overall application of deep learning for diagnosis purposes to control the pandemic threat has been discussed in40.
Based on the review presented above, it is apparent that existing works based on clinical data are rather scarce. Thus, we sought to conduct another study using clinical data for mortality risk assessment. The difference between our method and existing research on mortality risk assessment is twofold. First, we developed a new approach for carrying out the assessment. Second, some of the clinical features that we considered had never been used previously, which is why we have released our dataset publicly. As will be discussed further below, clinical data are more cost effective than CT images, and classifiers trained on clinical data achieve a level of performance that is almost equal to that achieved by classifiers trained on CT images. To justify this claim, we compared the performance of our method trained on clinical data to a standard CNN trained on CT images.
Background
Our proposed method comprises two modules: the classifier and data augmenter. The classification is carried out using a CNN. The data augmentation is realised using 10 AEs. In this section, we briefly review the main concepts of CNNs and AEs.
CNNs
CNNs are massively used in image-based learning applications. Due to the automatic feature extraction mechanism of CNNs, they can discover valuable information from training samples. CNNs are usually designed with several convolutional, pooling and fully connected layers41. As Fig. 1 shows, feature extraction is done by convolving the input with convolutional kernels. The pooling layer reduces the computational volume of the network without making a noticeable change in the resolution of the feature map. In CNNs, the size of the pooling layers usually decreases as the number of layers increases. Two of the most popular types of pooling layers are max pooling and average pooling42.

A CNN schematic.
AEs
AEs belong to the realm of unsupervised learning, as they do not need labelled data for their training. In brief, an AE compresses input data to a lower dimensional latent space and then reconstructs the data by decompressing the latent space representation. Similar to principle component analysis (PCA), AEs perform dimensionality reduction in the compression phase. However, unlike PCA, which relies on linear transformation, AEs carry out nonlinear transformation using deep neural networks43. Figure 2 shows the architecture of a typical AE.

AE architecture: high-dimension input data are encoded (compressed) to form a latent (hidden) space that has a lower dimension than that of the original input. The latent representation is reconstructed (decoded) to yield decompressed output.
Information gain
In this section, we review information gain (IG), as it is used to determine the degree to which each feature of our dataset contributes to the patients’ deaths (see “Description of our clinical dataset”). IG calculates the entropy reduction that results from splitting a dataset, \(D\), based on a given value, \(a\), of a random variable, \(A\), such that:
where \(H(D)\) and \(H(D|A=a)\) are entropy on dataset \(D\) and conditional entropy on dataset \(D\), respectively, given that \(A\,=\,a\).
Conditional entropy is computed as:
where \({D}_{A\,=\,a}\subset D\) is the set of samples with variable \(A\,=\,\,a\) and \(|{D}_{A=a}|\) and \(|D|\) denote the cardinality of subset \({D}_{A\,\,=\,\,a}\) and set \(D\), respectively. In Eq. (1), the sum is computed over all possible values of \(A\).
Description of our clinical dataset
The dataset we collected in this paper comprised 320 patients (300 cases of recovered patients and 20 cases of deceased patients). The percentage of female cases was 55%. The mean age of patients in the dataset was 49.5 years old, and the standard deviation was 18.5. The patients referred to Tehran Omid hospital in Iran from 3 March 2020 to 21 April 2020. Ethical approval for the use of these data was obtained from the Tehran Omid hospital. In gathering the data, patients’ history (as collected by doctors), questionnaires (as completed by patients), laboratory tests, and vital sign measurements were used. Descriptions of the dataset features are presented in Table 2. Our dataset is publicly available in44. Institutional approval was granted for the use of the patient datasets in research studies for diagnostic and therapeutic purposes. Approval was granted on the grounds of existing datasets. Informed consent was obtained from all of the patients in this study. All methods were carried out in accordance with relevant guidelines and regulations.
As our dataset had not been released previously, it was vital to assess the degree to which each dataset feature contributed to patients’ deaths. Such an analysis provides researchers with valuable insights into the characteristics of the collected data. Various feature selection methods are available to determine the weight of each feature in the classification of dataset samples. We chose IG45, which is one of the most widely used feature selection methods46. In Fig. 3, the importance of each feature (i.e., the IG) is shown as a bar. Age had a much larger IG (0.149) than other features. Thus, age was not included in Fig. 3 to make it easier to compare the importance of the other features. According to the bar chart, (after age) cancer, heart and kidney diseases were the second, third and fourth most important features related to patients’ deaths, respectively. Thus, it was clear that patients with poor health conditions were more vulnerable to COVID-19. It should be noted that Fig. 3 does not include the features with zero IG.

Feature effects on mortality rate based on IG.
We also inspected the interplay between the dataset features to determine the potential correlation between them. To this end, the grid in Fig. 4 is presented. Figure 4 can be thought as a heat map that shows the positive/negative correlation between features. Each cell \(c(i,\,j)\) in the grid of Fig. 4 represents the correlation of features in the i-th row and j-th column. As the cell colour approaches red, the positive correlation between the feature pairs is higher. For example, anosmia (the loss of the ability to smell) and ageusia (the loss of the ability to taste with the tongue) had a high positive correlation, which means they were usually observed simultaneously.

Correlation between dataset features.
Proposed methodology
This study investigated the survival chance prediction of COVID-19 patients who referred to the Omid hospital in Tehran. The classification was based on features obtained from patients’ information. In the dataset collected, the number of recovered patients was 300 and the number of deceased patients was 20. The number of recovered patients was clearly much higher than that of the deceased patients. To ensure accurate classification, it was necessary to balance the recovered to the deceased ratio of the dataset samples. To do this, the number of instances of the lower class was increased, such that the number of data in both classes was approximately equal. To increase the number of data of deceased patients, an AE model was used. To carry out the data augmentation, the 20 samples of the deceased class were fed to the AE to undergo the compression and decompression routines. The output of this process comprised 20 reconstructed samples that were similar (but not identical) to the original ones. Thus, we augmented the original 20 samples with 20 reconstructed samples. Training the AE 10 times using different training and validation sets yielded 10 AEs with a similar architecture but different parameters. Each of the 10 AEs generated 20 reconstructed deceased samples, yielding reconstructed samples of 200 overall, which were added to the original deceased samples. To provide an insight into the function of the AEs, sample vectors before and after reconstruction are presented in Table 3. For the majority of ‘1’ elements of input vector \(c\), the AE outputted values near 1 as the elements of reconstructed vector \(\widehat{c}\). Similarly, most of the reconstructed elements corresponding to original ‘0’ elements had values near ‘0’, which shows that the reconstruction process was sound.
The details of the augmentation process are explained in more detail in Subsection 5.1. It should be noted that our augmentation procedure is generic and can be applied to any other dataset.
Implementation details of CNN-AE
The proposed CNN-AE method comprises multiple steps (see Fig. 5 for a summary). The pseudo-code of the method is also available in Algorithm 1. The detailed explanation of the pseudo-code is presented below:
-
1.
10 AEs \(\{A{E}_{1},\,\,\dots ,\,\,\,\,A{E}_{10}\}\) were designed with identical configuration but different initial parameters for data augmentation (line 1).
-
2.
Each of the 10 AEs was trained on 300 samples representing the recovered patients. Our objective was to have 10 models with different parameters at the end of the training. To this end, we divided the 300 samples into 10 groups of 30 samples \({\{g}_{j},\,\,j\,\,=\,\,1,\,\,2,\,\,\dots ,\,\,10\}\) where \({g}_{j}\) is the j-th group of samples. To train the i-th model, \({g}_{i}\) was set aside for validation and the nine remaining groups {\({g}_{j},\,\,j\in \left\{1,\,\,2,\,\,\dots ,\,\,10\right\}-\{i\}\}\) (270 samples) were used for training. It should be noted that each model was initialised with different parameters, trained on partially different training samples and validated on a totally different validation set. Thus, the proposed training procedure yielded 10 different AEs (lines 2–4).
-
3.
The 20 deceased samples were fed to each of the 10 trained AEs. The samples underwent the compression and decompression routine of the AEs. As the decompression procedure was lossy, the 20 reconstructed samples (after decompression) were not identical to the original samples. Additionally, the 10 trained AEs exhibited different behaviours on the same input data, as their parameters were different from each other. Thus, feeding the same 20 samples to the 10 AEs yielded 200 new samples that belonged to the deceased class (lines 5–8). The explained procedure sought to augment the data to remedy the lack of sufficient samples for the deceased class.
-
4.
The 200 reconstructed samples were attached to 320 original samples to yield a dataset of 520 samples (line 9).
-
5.
A CNN model was designed to classify 520 samples as recovered or deceased (line 10).
-
6.
The CNN model was trained using all 520 samples. A tenfold cross-validation was applied during the training (lines 11–20). Thus, the training sample size was 468 (samples of 9 folds), and the test sample size was 52 (samples of onefold).
-
7.
The trained CNN was used to classify the test data (line 21).

The steps for implementing the proposed method.
Algorithm 1. CNN-AE pseudo-code | |
|---|---|
Input: dataset \(D=\{{D}_{recovered}\cup {D}_{deceased}\)}, training epochs N, batch size B, number of folds K | |
// Auto-encoders initialization | |
1: | Create 10 autoencoders with initial random parameters: {\(A{E}_{1},\dots ,A{E}_{10}\}\) |
// Autoencoders training | |
2: | Partition samples in \({D}_{recovered}\) to 10 subsets:\(\{{g}_{1},\,\,\dots ,\,\,{g}_{10}\}\) |
3: | For i = 1:10 |
4: | Train \(A{E}_{i}\) on \({D}_{recovered}-{g}_{i}\) and perform validation on \({g}_{i}\) |
// Augmented data generation | |
5: | \(A=[]\) |
6: | For i = 1:10 |
7: | \({a}_{i}=A{E}_{i}({D}_{deceased})\) |
8: | A \(=A\cup {a}_{i}\) |
9: | \({D}_{augmented}=D\cup A\) |
10: | Create CNN \(C\) with initial random parameters |
11: | // K-Fold cross validation Partition \({D}_{augmented}\) to 90% training set \({D}_{train}\) and 10% test set \({D}_{test}\) |
12: | Partition \({D}_{train}\) to K subsets \(\left\{{F}_{1},\,\,\dots ,\,\,{F}_{K}\right\}\) |
13: | For k = 1:K |
14: | \({D}_{train}={D}_{augmented}-{F}_{K}\) |
15: | \({D}_{valid}={F}_{K}\) |
16: | For e = 1:N |
17: | \(batc{h}_{t}\) = sample_batch(\({D}_{augmented},B\)) |
18: | CNN.train(\(batc{h}_{t}\)) |
19: | \(batc{h}_{v}\) = sample_batch(\({D}_{valid},\,\,B)\) |
20: | CNN.validate(\(batc{h}_{v}\)) |
21: | CNN.test(\({D}_{test}\)) |
22: | Return CNN |
To implement the proposed method, we used Python language and the Keras library, which has a TensorFlow backend. In this study, the dataset contained 320 samples of infected cases. Of these 320 cases, the number of recovered cases was 300, and the number of deceased cases was 20. Additionally, we also generated 200 reconstructed deceased cases to balance the recovered to the deceased ratio of our dataset. After the reconstruction phase, our dataset contained 520 cases. We used a tenfold cross-validation. Additionally, 80% of 9 of the folds were used for training, and the remaining 20% was used for validation. The implementation details of CNN and AE are illustrated in Figs. 6 and 7, respectively.

Implementation details of CNN. ‘CL’ and ‘Dense’ represent convolutional and fully connected layers, respectively. Circles with the letter ‘B’ represent batch normalisation layers, and circles with the letter ‘D’ represent dropout layers with a probability 0.5.

The implemented AE: The 39-dimensional input vector was compressed to a 32-dimensional vector. During reconstruction, the 32-dimensional vector was decompressed to a 39-dimensional vector.
Experiments
In this section, the experimental results are presented. The implementation details of CNN and AEs are explained in “Experimental details”. We report on the performance of the proposed method (CNN-AE) and compare it to a CNN in “Experimental results”.
Experimental details
Our experiments consisted of two scenarios. In the first scenario, our CNN-AE method was compared to a standard CNN method that was trained on clinical data. The architecture of the CNN is presented in Table 4. To ensure a fair comparison, we used the same CNN architecture in our method. The implementation details of the AEs used in the CNN-AE are presented in Table 5.
In the second phase of our experiments, we compared the CNN-AE trained on clinical data to a standard CNN trained on image data. The CNN architecture is presented in Fig. 8. After multiple trials, we obtained the best set of the CNN hyperparameters (see Table 6).

Implementation details of the CNN trained on CT images. ‘CL’ and ‘Dense’ represent convolutional and fully connected layers, respectively. Circles with the letter ‘D’ represent dropout layers with a probability 0.5.
Experimental results
We sought to answer two important questions about the proposed method. First, we compared our method performance with a standard CNN trained on clinical data. This experiment examined the effects of the proposed data augmentation technique using multiple AEs. We also trained a standard CNN for the same purpose (to predict patients’ survival chance) but used CT images. This experiment sought to determine how well CT images can represent patients’ survival chance using a CNN as the predictor.
Examining the data augmentation approach
As mentioned in “Implementation details of CNN-AE”, we used 10 AEs to augment the available dataset. Data augmentation is critical to successful training when the number of samples from different classes is unbalanced. Data imbalance can defeat any powerful classifier even a state-of-the-art CNN, which is why we employed the data augmentation technique.
To investigate the effectiveness of our data augmentation procedure, we trained a CNN on the original dataset and our CNN-AE on an augmented dataset. The original dataset comprised only 20 samples with the deceased label, but had 300 samples with the recovered label. Comparing the 300 to 20 reveals severe data imbalance from which the CNN suffered during training (see Table 7). However, using an augmented dataset with 300 recovered samples and 220 deceased samples facilitated the CNN training and improved accuracy (see Table 7). Additionally, the area under the curve (AUC) measure of the CNN-AE was almost twice that of the CNN. The specificity measure of CNN was almost zero, which was due to the fact that the CNN was unable to distinguish between deceased and recovered samples due to the insufficient number of deceased samples in the original dataset. As Table 7 shows, the CNN-AE training took more time; however, this was due to the time it took to train the 10 AEs required for data augmentation.
In Table 7, the CNN-AE method had an average accuracy of 96.05% and thus outperformed the CNN method, which had an average accuracy of 92.49%. Additionally, due to the augmented data, our method was able to reduce the training/validation loss faster than CNN (as is evident in Fig. 9). Similarly, the CNN-AE reached higher accuracy faster than the CNN (see the plots in Fig. 10). During training, our method exhibited great variation in the validation plots compared to those of the CNN. This is because the CNN quickly overfitted to the small number of deceased samples but the CNN-AE had to deal with more versatile augmented samples. Thus, the training of the CNN-AE was more difficult, but it achieved better overall performance.

Loss plots of the CNN and CNN-AE methods during the training of our dataset.

Accuracy plots of the CNN and CNN-AE methods during training of our dataset.
Comparisons with existing deep models trained on image data
In this section, we evaluated the performance of various existing deep models that were trained on a dataset of CT images. The CT images were taken from the same patients for whom the clinical dataset was collected. Thus, the results of this section reveal how well deep models trained on CT images perform compared to a CNN trained on clinical data. It should be noted that most of the experiments in the COVID-19 literature revolve around classifying infected and non-infected people using CT images. This section sheds some light on how well deep models can predict the survival chance of already infected patients based on CT images.
The dataset comprised 2822 CT images of recovered patients and 2269 CT images of deceased patients. The CT image dataset size was much greater than the clinical dataset size, as the CT dataset contained multiple images for each patient. As the number of samples of the two classes in the dataset was almost balanced, we did not apply our data augmentation technique to the CT dataset. Additionally, having multiple images for each patient served as a form of data augmentation. This was not the case for the clinical dataset for which each patient had only one value per feature.
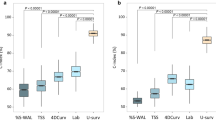
In Table 8, the performance metrics for the evaluated deep models are presented as 95% confidence intervals (CIs) that have been computed over a tenfold cross-validation. The results in Table 8 show that UNet had the best performance among the evaluated methods, followed by Inception Net V3 and DenseNet121, respectively. Overall, Table 8 suggests that some of the famous deep models with pre-trained parameters can be tuned via training to predict the survival chance of COVID-19 patients based on CT images. A performance comparison of the deep models (see Table 8) and the CNN-AE (see Table 7) revealed that a CNN trained on clinical data performed on par with various pre-trained deep models which have been tuned via training on CT data. As stated above, the CT image dataset size was almost 10 times that of the clinical dataset size. However, the CNN trained on clinical data performed almost as well as the deep models trained on CT data. Thus, clinical data could be a good replacement for CT training data if the preparation of the CT images would be difficult or expensive.
Comparison with other methods trained on clinical data
In this section, we compare the performance of our CNN-AE with some of the existing works on mortality prediction23,26,27. To this end, we implemented the methods of Chen et al.23, Zhu et al.26 and Yan et al.27. As mentioned above in the literature review, Chen et al. relied on the RF to assess the severity of COVID-19 patients. For mortality risk prediction, Zhu et al.26 and Yan et al.27 used MLP and XGBoost, respectively. These methods were specifically designed to achieve COVID-19-related objectives. For a broader perspective, we also experimented with Naïve Bayes, which is a generic method that can be used regardless of the classification objective. The conducted experiments revealed that our data augmentation approach was generic and beneficial to any classification method.
Methods’ performance
In this section, we present the experimental results for the classification methods mentioned above. We also investigate the effects of using the proposed data augmentation technique during training. The performance statistics are presented as 95% CIs in Table 9. The CIs are computed based on tenfold cross-validation. First, each method was trained on the original dataset (without augmentation). The training was repeated using the augmented dataset. The proposed data augmentation using AEs was used for this purpose. All of the rows in Table 9 that are related to training on the augmented dataset are marked with ‘ + AE’ postfix in the ‘Methods’ column. The last row of Table 9 is identical to the last row of Table 7, which has been reproduced here for ease of reference. An inspection of the results in Table 9 reveals that the proposed CNN-AE method outperformed the other methods in terms of accuracy, recall and AUC. Yan et al.27 + AE, Chen et al.23 + AE and Zhu et al.26 + AE claimed second, third and fourth places, respectively. Thus, all methods have clearly benefitted from the augmentation performed on the training dataset. Among the evaluated methods, Naïve Bayes had the worst performance; however, it also benefitted from the augmented dataset.
Feature selection analysis
In this section, we examine whether feature selection improves the classification performance of the clinical dataset. We relied on meta-heuristic population-based algorithms to carry out feature selection. The meta-heuristic methods that have been used in the experiments are Artificial Bee Colony (ABC)55, Ant Colony Optimisation (ACO)56, Butterfly Optimisation Algorithm (BOA)57, Elephant Herding Optimisation (EHO)58, Genetic Algorithm (GA)59 and Particle Swarm Optimisation (PSO)60. Details of the implementation of these methods are available in MEALPY61, which is a Python module consisting of meta-heuristic algorithms. In all of the experiments detailed in this section, the meta-heuristic methods were run for 500 epochs with a population size of 100.
The results of running each of the meta-heuristic methods listed above was a set of selected features (see Table 10) that specified a subset of the clinical dataset. The dataset extracted subset was used to train a CNN for survival chance prediction. The training was performed with and without data augmentation. The results of the training are presented in Table 11. In each row of the table, the meta-heuristic method used for feature selection and the classifier is specified. Usage of data augmentation is denoted by ‘–AE’.
As Table 11 shows, regardless of the feature selection method, the CNN-AE trained on the selected features did not outperform the CNN-AE trained on the full dataset (see the last row of Table 7). This is because the CNN already included an automatic feature selection mechanism and could rule out unnecessary features during learning. Discarding some of the features via feature selection only deprived the CNN of the opportunity to choose the features that best fit its objective.
Among the evaluated feature selection methods in Table 11, BOA showed the best performance, followed by the ACO and ABC, respectively. In relation to Table 11, it should be noted that data augmentation after the application of all of the feature selection methods yielded better results. Thus, the proposed data augmentation approach is generic.
Discussion
This paper focused on survival chance prediction for COVID-19 patients. We performed experiments using both a clinical dataset and a CT image dataset. The size of the CT image dataset was almost 10 times that of the clinical dataset. However, the CNN trained on clinical data performed almost as well as the CNN trained on CT data, which supports the use of clinical data as an alternative for CT images.
Another aspect that might encourage the use of clinical training samples relates to data collection costs. Preparing CT data may require high-end facilities; however, such facilities may increase data collection costs. Additionally, the facilities required to prepare CT data may not be available in deprived areas. Conversely, the tools required to measure clinical data, such as blood pressure, fever and C-reactive protein, are generally accessible.
The proposed method can detect the severity of patients’ conditions based on clinical data and enable preventive actions to be taken to minimise the mortality rate. As discussed in “Literature review”, very few methods have studied mortality rate prediction using clinical data. Additionally, existing methods have used features that differ from the ones we used in our experiments. Thus, the proposed method sheds some light on unexplored aspects of the COVID-19 virus. To implement the proposed system in practice, it must be evaluated by medical experts from medical centres in different regions. After being verified, the system could be used to help experts analyse the severity condition of COVID-19 patients. Thus, patients with critical conditions could be given higher treatment priority than non-critical patients. Prioritising the patients’ treatment is of the utmost importance when the medical resources available are limited.
In addition to the proposed method, our dataset can be considered the second contribution of this paper, as it is a good resource for further medical research. The analysis of the importance of the dataset features and their correlations are shown in Figs. 3 and 4. Using our dataset, experts can study the relationships between patients’ medical conditions (e.g., blood pressure and diabetes) and the likelihood of dying from COVID-19. This will enable medical experts to exercise more caution during the treatment of patients who are more likely to die due to their medical conditions. As the IG values in Fig. 3 suggest, there is a strong relationship between the mortality rate of COVID-19 patients and the presence of other critical diseases, such as cancer, kidney and heart diseases. Conversely, mild symptoms and/or diseases, such as dyspnoea, conjunctivitis and asthma, are less likely to contribute to the mortality rate.
Like any other classification approach, the proposed method has some limitations. Due to the use of multiple AEs in the data augmentation phase, the training time of our method was longer than that of a standard CNN. Further, standard CNNs receive a single image sample as input and perform feature extraction automatically. Conversely, we manually collected multiple clinical features for each patient, and such a process is more difficult to manage. Some of the features in our dataset were gathered directly by asking patients; thus, it is possible that patients provided incorrect information.
Conclusions and future works
In this paper, we investigated the possibility of training a CNN on clinical data to predict the survival chance of COVID-19 patients. To this end, a new dataset consisting of clinical features, such as gender, age, blood pressure and the presence of various diseases, was gathered. The first contribution of this paper relates to our decision to release the collected dataset for public use. We also analysed the dataset features using IG and correlation. Our analysis could aid potential researchers and practitioners with their work on the COVID-19 virus.
To reduce the data imbalance of our dataset, we proposed a novel data augmentation method based on AEs. Our data augmentation approach is generic and applicable to other datasets. Based on the proposed data augmentation approach, a novel survival chance prediction method named CNN-AE was presented, which represents the second contribution of this paper. Using augmented data for training, the 95% CI for the accuracy, recall and specificity of the CNN-AE were 96.05 ± 1.48%, 98.00 ± 1.33% and 93.13 ± 2.52%, respectively. However, a CNN trained on a dataset without augmentation yielded an accuracy of 92.49 \(\pm\) 2.75%, a recall of 95.4 \(\pm\) 0.88% and a specificity of 96.9 \(\pm\) 3.73%. Thus, it is clear that the CNN-AE benefitted the data augmentation and outperformed the CNN.
We repeated the CNN training on CT images obtained from the same patients for whom the clinical data had been collected. Comparisons of the performances of the methods trained on clinical data and the methods trained on CT data revealed that clinical data can be used as an alternative to CT images.
In the future, more data needs to be collected to further assess our proposed approach. The use of other data augmentation methods also needs to be investigated and the results compared with our data augmentation method.
References
Alizadehsani, R. et al. Risk factors prediction, clinical outcomes, and mortality in COVID-19 patients. J. Med. Virol. 93, 2307–2320 (2021).
Acharya, U. R. et al. Automated detection of Alzheimer’s disease using brain MRI images—A study with various feature extraction techniques. J. Med. Syst. 43, 302 (2019).
Oh, S. L. et al. A deep learning approach for Parkinson’s disease diagnosis from EEG signals. Neural Comput. Appl. 32, 10927–10933 (2020).
Alizadehsani, R. et al. Coronary artery disease detection using artificial intelligence techniques: A survey of trends, geographical differences and diagnostic features 1991–2020. Comput. Biol. Med. 128, 104095 (2021).
Górriz, J. M. et al. Artificial intelligence within the interplay between natural and artificial computation. Advances in data science, trends and applications. Neurocomputing 410, 237–270 (2020).
Wang, D. et al. Clinical characteristics of 138 hospitalized patients with 2019 novel coronavirus–infected pneumonia in Wuhan, China. JAMA 323(2020), 1061–1069 (2020).
Shoeibi, A. et al. Automated detection and forecasting of covid-19 using deep learning techniques: A review. arXiv preprint https://arxiv.org/abs/2007.10785 (2020).
Sharifrazi, D. et al. Fusion of convolution neural network, support vector machine and Sobel filter for accurate detection of COVID-19 patients using X-ray images. Biomed. Signal Process. Control 68, 102622 (2021).
Alizadehsani, R. et al. Uncertainty-aware semi-supervised method using large unlabelled and limited labeled COVID-19 data. arXiv preprint https://arxiv.org/abs/2102.06388 (2021).
Li, Q. et al. Early transmission dynamics in Wuhan, China, of novel coronavirus-infected pneumonia. N. Engl. J. Med. https://doi.org/10.1056/NEJMoa2001316 (2020).
Huang, C. et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 395(2020), 497–506 (2020).
Martín Giménez, V. M. et al. Lungs as target of COVID-19 infection: Protective common molecular mechanisms of vitamin D and melatonin as a new potential synergistic treatment. Life Sci. 254, 117808 (2020).
Asgharnezhad, H. et al. Objective Evaluation of Deep Uncertainty Predictions for COVID-19 Detection. arXiv preprint https://arxiv.org/pdf/2012.11840.pdf (2020).
Zhang, N. et al. Recent advances in the detection of respiratory virus infection in humans. J. Med. Virol. 92, 408–417 (2020).
Iwendi, C. et al. COVID-19 Patient health prediction using boosted random forest algorithm. Front. Public Health 8, 357 (2020).
Joloudari, J. H. et al. Early detection of the advanced persistent threat attack using performance analysis of deep learning. IEEE Access 8, 186125–186137 (2020).
Wu, J. et al. Rapid and accurate identification of COVID-19 infection through machine learning based on clinical available blood test results. medRxiv. https://www.medrxiv.org/content/10.1101/2020.04.02.20051136v1.full.pdf (2020).
Rahman, M., Uddin, M., Wadud, M., Akhter, A., Akter, O. A Study on Epidemiological Characteristics and ML Based Detection of Novel COVID-19. https://www.researchgate.net/publication/340246803 (2020).
Islam, M. Z., Islam, M. M. & Asraf, A. A combined deep CNN-LSTM network for the detection of novel coronavirus (COVID-19) using X-ray images. Inform. Med. Unlock. 20, 100412 (2020).
Saha, P., Sadi, M. S. & Islam, M. M. EMCNet: Automated COVID-19 diagnosis from X-ray images using convolutional neural network and ensemble of machine learning classifiers. Inform. Med. Unlock. 22, 100505 (2021).
Islam, M.M., Islam, M.Z., Asraf, A., Ding, W. Diagnosis of COVID-19 from X-rays using combined CNN-RNN architecture with transfer learning. medRxiv (2020).
Muhammad, L. J., Islam, M. M., Usman, S. S. & Ayon, S. I. Predictive data mining models for novel coronavirus (COVID-19) infected patients’ recovery. SN Comput. Sci. 1, 206 (2020).
Chen, Y. et al. An interpretable machine learning framework for accurate severe vs non-severe covid-19 clinical type classification. in Available at SSRN https://ssrn.com/abstract=3638427 (2020).
Gao, Y. et al. Machine learning based early warning system enables accurate mortality risk prediction for COVID-19. Nat. Commun. 11, 5033 (2020).
Si, S. et al. Gradient boosted decision trees for high dimensional sparse output. in International Conference on Machine Learning, PMLR. 3182–3190 (2017).
Zhu, J. S. et al. Deep-learning artificial intelligence analysis of clinical variables predicts mortality in COVID-19 patients. J. Am. Coll. Emerg. Phys. Open 1, 1364–1373 (2020).
Yan, L. et al. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2, 283–288 (2020).
Bertsimas, D. et al. COVID-19 mortality risk assessment: An international multi-center study. PLoS ONE 15, e0243262 (2020).
Abdulaal, A. et al. Prognostic modeling of COVID-19 using artificial intelligence in the United Kingdom: Model development and validation. J. Med. Internet Res. 22, e20259 (2020).
Khanday, A. M. U. D., Rabani, S. T., Khan, Q. R., Rouf, N., Mohi Ud Din, M. Machine learning based approaches for detecting COVID-19 using clinical text data. Int. J. Inf. Technol. 12, 731–739 (2020).
Al-Waisy, A. et al. COVID-DeepNet: Hybrid multimodal deep learning system for improving COVID-19 pneumonia detection in chest X-ray images. Comput. Mater. Contin. 67, https://doi.org/10.32604/cmc.2021.012955 (2021).
Al-Waisy, A.S. et al. COVID-CheXNet: Hybrid deep learning framework for identifying COVID-19 virus in chest X-rays images. Soft Comput. https://doi.org/10.1007/s00500-020-05424-3 (2020).
Mohammed, M.A. et al. A comprehensive investigation of machine learning feature extraction and classification methods for automated diagnosis of covid-19 based on x-ray images, Comput. Mater. Contin. 66, https://doi.org/10.32604/cmc.2021.012874 (2020).
Mohammed, M. A. et al. Benchmarking methodology for selection of optimal COVID-19 diagnostic model based on entropy and TOPSIS methods. IEEE Access 8, 99115–99131 (2020).
Rahman, M. M., Manik, M. M. H., Islam, M. M., Mahmud, S. & Kim, J. H. An automated system to limit COVID-19 using facial mask detection in smart city network, 2020 IEEE International IOT. Electron. Mechatron. Conf. (IEMTRONICS) 2020, 1–5 (2020).
Islam, M. M., Ullah, S. M. A., Mahmud, S. & Raju, S. M. T. U. Breathing aid devices to support novel coronavirus (COVID-19) infected patients. SN Comput. Sci. 1, 274 (2020).
Islam, M. M. et al. Wearable technology to assist the patients infected with novel coronavirus (COVID-19). SN Comput. Sci. 1, 320 (2020).
Ullah, S. M. A. et al. Scalable telehealth services to combat novel coronavirus (COVID-19) pandemic. SN Comput. Sci. 2, 18 (2021).
Islam, M. M., Karray, F., Alhajj, R. & Zeng, J. A review on deep learning techniques for the diagnosis of novel coronavirus (COVID-19). IEEE Access 9, 30551–30572 (2021).
Asraf, A., Islam, M. Z., Haque, M. R. & Islam, M. M. Deep learning applications to combat novel coronavirus (COVID-19) pandemic. SN Comput. Sci. 1, 363 (2020).
Purwins, H. et al. Deep learning for audio signal processing. IEEE J. Sel. Top. Signal Process. 13, 206–219 (2019).
Khodatars, M. et al. Deep Learning for Neuroimaging-based Diagnosis and Rehabilitation of Autism Spectrum Disorder: A Review. arXiv preprint https://arxiv.org/abs/2007.01285 (2020).
Tschannen, M., Bachem, O., Lucic, M. Recent advances in autoencoder-based representation learning. arXiv preprint https://arxiv.org/abs/1812.05069 (2018).
https://www.kaggle.com/danialsharifrazi/covid19-numeric-dataset/settings.
Alizadehsani, R. et al. A data mining approach for diagnosis of coronary artery disease. Comput. Methods Programs Biomed. 111, 52–61 (2013).
Alizadehsani, R. et al. A database for using machine learning and data mining techniques for coronary artery disease diagnosis. Sci. Data 6, 227 (2019).
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K. Q. Densely connected convolutional networks. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4700–4708 (2017).
Tan, M., Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. in Proceedings of the 36th International Conference on Machine Learning, PMLR, Proceedings of Machine Learning Research (Kamalika, C., Ruslan, S. Eds.) 6105–6114 (2019).
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A. Inception-v4, inception-ResNet and the impact of residual connections on learning. in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 31 (2017).
Howard, A. G. et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint https://arxiv.org/abs/1704.04861 (2017).
Akiba, T., Suzuki, S., Fukuda, K. Extremely large minibatch sgd: Training resnet-50 on imagenet in 15 minutes. arXiv preprint https://arxiv.org/abs/1711.04325 (2017).
Mateen, M., Wen, J., Song, S. & Huang, Z. Fundus image classification using VGG-19 architecture with PCA and SVD. Symmetry 11, 1 (2019).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1251–1258 (2017).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015 (eds Navab, N. et al.) 234–241 (Springer, 2015).
Karaboga, D. & Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 8, 687–697 (2008).
Dorigo, M., Birattari, M. & Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 1, 28–39 (2006).
Arora, S. & Singh, S. Butterfly optimization algorithm: A novel approach for global optimization. Soft. Comput. 23, 715–734 (2019).
Wang, G., Deb, S., Coelho, L. d. S. Elephant herding optimization. In 2015 3rd International Symposium on Computational and Business Intelligence (ISCBI), 1–5 (2015).
Mirjalili, S. Genetic Algorithm 43–55 (Springer, 2019).
Kennedy, J., Eberhart, R. Particle swarm optimization. in Proceedings of ICNN'95 - International Conference on Neural Networks, Vol. 1994, 1942–1948 (1995).
Acknowledgements
This work was partly supported by the Ministerio de Ciencia e Innovación (España)/ FEDER under the RTI2018-098913-B100 project, by the Consejería de Economía, Innovación, Ciencia y Empleo (Junta de Andalucía) and FEDER under CV20-45250 and A-TIC-080-UGR18 projects.
Author information
Authors and Affiliations
Contributions
Contributed to prepare the first draft: R.A., S.H., A.S., F.K., N.H.I., and J.H.J. Contributed to editing the final draft: S.N., Z.A.S., A.K., S.M.S.I., H.M., and J.M.G. Contributed to all analysis of the data and produced the results accordingly: D.S., N.H.I., and R.A. Searched for papers and then extracted data: S.H., A.S., F.K., and J.H.J. Provided overall guidance and managed the project: S.N., Z.A.S., A.K., S.M.S.I., H.M., and J.M.G.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khozeimeh, F., Sharifrazi, D., Izadi, N.H. et al. Combining a convolutional neural network with autoencoders to predict the survival chance of COVID-19 patients. Sci Rep 11, 15343 (2021). https://doi.org/10.1038/s41598-021-93543-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-93543-8
This article is cited by
-
XcepCovidNet: deep neural networks-based COVID-19 diagnosis
Multimedia Tools and Applications (2024)
-
Computational methods for studying relationship between nutritional status and respiratory viral diseases: a systematic review
Artificial Intelligence Review (2024)
-
Hybrid feature engineering of medical data via variational autoencoders with triplet loss: a COVID-19 prognosis study
Scientific Reports (2023)
-
Body composition predicts hypertension using machine learning methods: a cohort study
Scientific Reports (2023)
-
Prognosis prediction in traumatic brain injury patients using machine learning algorithms
Scientific Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
