
Abstract
Understanding the processes underlying development and persistence of polarised opinions has been one of the key challenges in social networks for more than two decades. While plausible mechanisms have been suggested, they assume quite specialised interactions between individuals or groups that may only be relevant in particular contexts. We propose that a more broadly relevant explanation might be associated with the influence of external events. An agent-based bounded-confidence model has been used to demonstrate persistent polarisation of opinions within populations exposed to stochastic events (of positive and negative influence) even when all interactions between individuals are noisy and assimilative. Events can have a large impact on the distribution of opinions because their influence acts synchronistically across a large proportion of the population, whereas an individual can only interact with small numbers of other individuals at any particular time.
Similar content being viewed by others

Introduction
Social interactions through personal or virtual contact can influence the perceptions, opinions and beliefs of individuals1,2. Theories on social influence, supported to varying degrees by empirical laboratory data, have been incorporated into a range of social influence models drawing on established statistical physics methods3,4,5,6. While there have been renewed efforts to review and reconcile alternate models7,8,9,10,11,12,13, a unified framework linking robust predictions to alternative assumptions is yet to emerge.
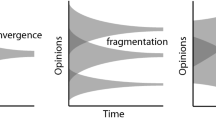
Social influences are usually assimilative (Table 1A), with the opinions of individuals brought closer by factors such as convincing arguments14, the dominance of individuals with more knowledge or status15, or pressure to conform to group norms1. However, it has also been long recognised that differences in opinion can resist assimilative forces and persist over extended periods3. This can be partially explained by the concept of homophily, which describes the preference for communicating with like-minded individuals and a resulting tendency to be more strongly influenced by those individuals2.
Bounded confidence models explicitly represent the bounds placed on assimilative influence by homophily and successfully predict fragmentation of opinions into clusters (Table 1B). However, this fragmentation cannot be sustained in the presence of random fluctuations (noise) in opinions due to stochastic external factors. Such fluctuations will always be present in any realistic social network and allow opinions to occasionally move inside the homophily influence limit, resulting in a gradual convergence of opinion clusters16 (Table 1C). While large amplitude fluctuations block this convergence, they also tend to promote extreme individualism that prevents clustering. Time-varying clustering can be perpetuated by including a feedback, whereby the amplitude of fluctuations increases with the size of clusters17. However, this desire for individualism may only be applicable to specific issues or circumstances.
One of the most important types of fragmentation is the polarisation of opinion towards more extremist viewpoints. Polarisation has become increasingly problematic over the past decade, driving community conflict around many social and environmental issues18,19,20, as well as political extremism motivating activism and sometimes even violence21,22. Because extremist views sometimes lie outside the initial range of opinions, they cannot be explained by homophily and bounded confidence alone. This led to the suggestion that influences can be differentative (repulsive), whereby individuals influence each other towards more dissimilar opinions23,24 (Table 1D). However, the empirical evidence for differentative influence is far from conclusive25. An alternative mechanism has been proposed whereby intensifying discussion between like-minded individuals moves their common view towards a more extreme position14, sometimes referred to as bandwagoning or group-shifting26,27. Both mechanisms may well influence highly engaged individuals and lead to polarisation around emotive issues28, particularly when engagement is through social media. However, amongst the broader community, there is limited opportunity for either of these mechanisms to operate effectively23.
Here we propose a potentially more general hypothesis to explain both the perpetuation of opinion clustering and development of extreme opinions. We show that these behaviours tend to emerge when individuals are influenced, not only by other individuals, but also by influential events29,30. This differs fundamentally from suggested random changes in the opinions of individuals31 in that events are capable of influencing many individuals synchronistically over a limited period of time. Synchronicity across a broad community helps promote collective behaviour, potentially resulting in group-shifts towards more extreme viewpoints26.
Methods
The proposed Social Influence and Event Model (SIEM) builds on the Hegselmann-Krause (HK) bounded confidence model4. The HK model4 was selected over the other seminal Deffuant–Weisbuch (DW) model32 (which treats pair-wise interactions sequentially) because of the need to synchonise influences of individuals and events. It represents a network of individuals (or groups) with potential to influence each other’s opinions in relation to a specific issue. Opinions of individuals are continuous (rather than being limited to discrete choices33) and individuals influence each other simultaneously at each timestep. Influence was assumed to be assimilative and could only occur between (randomly) linked individuals whose opinions were not too far from each other (i.e. homophily).
The opinion of individual \(i\) at timestep \(t + 1\) is given by:
where \(I\) is the set of individuals with which \(i\) interacts (including \(i\) itself) and \(w_{ij,t}\) is a weighting for the influence of individual \(j\) on individual \(i\) (all model variables are also defined in Table 2). For simplicity, an individual’s own opinion has been weighted equally to others. However, egocentric discounting of other opinions34 is implicit in the representation of bounded confidence. The bounded confidence assumption is:
where \(\varepsilon\) is usually referred to as the confidence threshold4,10 and is a characteristic of the social network (rather than varying between individuals). The model also included random fluctuations (noise) in the opinions of individuals that allowed opinions to drift and occasionally move inside the confidence threshold of other individuals. In the absence of other influences, these random fluctuations ultimately drive convergence of opinion clusters that may initially form due to homophily16.
Traditionally, bounded confidence models have assumed that all individuals are identical in their potential to influence other individuals, such that \(w_{ij,t} = 1/\left| I \right|\). Here we relax this assumption by considering the relative ranking of individuals in terms of their ability to influence others, which we specify in terms of the certainty in their opinion35. Certainty recognises differences not only in individual’s experiences, knowledge and access to relevant information35, but also personal characteristics such as persuasiveness, social status, open-mindedness and self-belief1. While model formulations vary, similar quantities are sometimes referred to as the influence strength or confidence of individuals36,37 (not to be confused with the confidence interval which is a property of the entire network system, Table 2). Ranking of certainty is consistent with experimental findings indicating that influential individuals also tend to be less susceptible to the influence of others38. An individual \(i\) will only change their opinion if their certainty, \(C_{j,t} \in \left[ {0\, 1} \right]\), is less than the average certainty of other individuals with which they interact at time t. This can be expressed as:
which defaults to \(w_{ij,t} = 1/\left| I \right|\) when all individuals have equal certainty. While Eq. (3) provides a straight forward extension of the traditional HK model4, an equivalent formulation could be achieved by using the default weighting and expanding Eq. (2) to include certainty-based restrictions on \(I\); or by allowing confidence thresholds to vary across the population5 (i.e. \(\varepsilon = \varepsilon \left( {C_{i,t} ,C_{j,t} } \right)\)).
The key innovation in SIEM is representation of external events that can influence opinions. These could be major events, such as political upheavals or natural disasters, or events of more localised significance, such as release of new information or a change in legislation. An event may attract or repulse individuals towards a particular opinion, but either way the event can be considered to be aligned to an opinion (effectively the opinion of the event). Similarly, depending on the size and nature of the event, it will have a characteristic influencing strength (effectively the certainty of the event). This formulation allows model events to influence individuals in a similar way to how individuals influenced each other. Specifically, Eq. (1) was expanded to include the influence of events:
where \(E_{s,t} \in \left[ {0\,\, 1} \right]\) is the strength of an event occurring at timestep \(t\). The weighting for the influence of an event on individual \(i\) is given by:
where \(W \in \left[ {0\,\, 1} \right]\) is selected randomly for each individual at every timestep. A random value for the weighting function allows for stochastic variability in the influence of any event across the population. Equation (5) could be made more general by defining independent measures for the effective opinion and effective certainty of events. However, given that they are likely to be highly correlated, both aspects have been represented here by \(E_{s,t}\).
Events were applied stochastically in the model with a mean frequency \(E_{f} \in \left[ {0\,\, 1} \right]\) (equal to the probability of an event starting within any timestep) and a mean duration \(E_{d}\), with individual events allocated randomly within the range \(E_{d,t} \in \left[ {0 \,\,2E_{d} } \right]\). The strength of events also varied stochastically around a mean value \(E_{s} \in \left[ {0.2\, \,0.8} \right]\) with \(E_{s,t} \in \left[ {E_{s} - 0.2\,E_{s} + 0.2} \right]\).
Events differed from individuals in two key aspects: (i) events could potentially influence the entire population (within the constraints imposed by Eq. 5), whereas individuals could only interact with a relatively small number of other individuals within any model time-step; and (ii) events occurred stochastically and had limited duration that also varied stochastically, whereas all individuals persisted and interacted throughout the simulation. Point (ii) also distinguishes events from external information acting as a static influencing agent39,40.
The model consisted of a network of 490 individuals, although tests using 14–980 individuals indicated that results are insensitive to population size. The only characteristic used to differentiate individuals was their certainty. 70 individuals were randomly allocated to each of 7 overlapping certainty ranges of equal width (0.0–0.4, 0.1–0.5, 0.2–0.6, 0.3–0.7, 0.4–0.8, 0.5–0.9, 0.6–1.0). This allocation yielded a normal distribution of certainty across the population, with a mean value of 0.50 and a standard deviation of 0.25. The certainty of individuals was varied randomly at each timestep, while also being continuously attracted towards its initial value \(C_{i,0}\). This constraint on the range of an individual’s certainty through time reflects its dependence on relatively stable personal characteristics (knowledge, persuasiveness, social status, open-mindedness and self-belief).
At each model timestep, opinions of individuals were influenced according to the opinions and certainties of their linked neighbours (Fig. 1a) by following a decision tree (Fig. 1b):
-
1.
A new random network was generated with each individual forming a node with the average degree (number of links per node) being k.
-
2.
Where an individual’s certainty was greater than the average of their linked neighbours, their opinion changed by a random drift \(\left[ {0\,0.1\varepsilon } \right]\) that was always small compared to the confidence threshold.
-
3.
Where an individual’s certainty was less than the average of their linked neighbours, their opinion was replaced by the average of their own opinion and those of all linked neighbours within their confidence threshold (\(I\)).
-
4.
The certainty of all individuals was moved closer to their initial value by a random amount \(\left[ {0 \left( {C_{i,0} - C_{i,t} } \right)} \right]\) and then a small random drift was also applied [0 0.1].

(a) Conditions under which individuals are influenced; and (b) workflow within each model timestep. Note that homophily is a system characteristic and hence confidence threshold is the same for all individuals, whereas certainty varies between individuals.
When an event occurred (or continued from the previous timestep):
-
1.
Where an individual’s certainty was greater than the strength of an event or the event fell outside their confidence threshold, the event had no influence on their opinion.
-
2.
Where an individual’s certainty was less than the strength of an event and the event fell inside their confidence threshold, their opinion moved closer to the event by a random amount \(\left[ {0 \left( {E_{s,t} - O_{i,t} } \right)} \right]\).
Results have been described in terms of the development of the distribution of opinions across the population through time. The width of this distribution provides a simple measure of the conflict in the population, which we define here as the standard deviation in population opinions: \(\Delta O_{t} = SD\left( {O_{i,t} } \right)\). Conflict levels reached a statistically steady state within 500 timesteps, after which the long-term mean was stable and repeatable. For example, when runs were repeated 10 times or runtime was extended 10 times, ensemble means always fell within one standard deviation of the mean based on any single run. Means and variances were also insensitive to population sizes for tests ranging from 14 to 980 individuals (i.e. 2.9–200% of the default population).
Results
SIEM exhibited the range of behaviours generated by other influence models under differing levels of homophily, including both assimilative influence leading to consensus (Fig. 2a), and bounded assimilative influence leading to initial fragmentation that diminishes over time due to random fluctuations in opinions and certainty (Fig. 2b). These trends were also reflected in conflict levels, which declined rapidly under low homophily, or were temporarily sustained under high homophily before population opinions suddenly converged (Fig. 3a). Because convergence was triggered by random noise in the opinion of individuals, its timing was highly variable (Fig. 3b). Over the long-term, conflict levels increased with homophily (Fig. 3a), whereas the average number of connections per individual had a much smaller effect (Fig. 3b).

Opinions of individuals starting from a random distribution [− 1 1] under a range of conditions (first 250 timesteps shown).

Conflict (\(\Delta O_{t}\)) tracked over 1000 timesteps, starting from a uniform random distribution of opinions (\(\Delta O_{0} = 1/\sqrt 3 = 0.577\)). Shown are dependencies on: (a) confidence threshold when there were no events; (b) average number of connections per individual per timestep when there were no events; (c) confidence interval when there were events; (d) event strength; (e) event frequency; and (f) event duration.
Large stochastic events (\(E_{s} \ge 0.5\)) generated two types of behaviour dependent on the homophily level. When homophily was low, the opinions of most of the population responded to every event, causing opinions to swing between extremes (Fig. 2c). Associated conflict levels were also highly variable, although the long-term average remained relatively low (Fig. 3c). When homophily was high, opinions diverged and became more extreme (Fig. 2d). Importantly, this polarisation was sustained as long as there were stochastic events. Average conflict levels again scaled with homophily and were sustained at high levels (Fig. 3d). Conflict was only weakly dependent on the frequency (Fig. 3e) and duration (Fig. 3f) of events, with no detectable effect once events became quasi-continuous (\(E_{f} E_{d} \ge 1\)).
Data from Fig. 3 is consistent with a linear dependency of long-term average conflict (timesteps 500–1000) on both homophily (Fig. 3c) and event strength (Fig. 3d). Whereas dependencies on event frequency (Fig. 3e) and duration (Fig. 3f) are much weaker and can be described by a simple power law for the dimensionless quantity \(E_{f} E_{d}\). These dependencies can be combined into a single empirical relationship:
which is supported by a high level of correlation (r = 0.99, N = 17, p < 0.001, Fig. 4). Because of the challenges associated with quantifying variables such as confidence threshold and event certainty, the values of the coefficients in Eq. (3) are less important than the structure of the relationship. Key aspects of the relationship are: (i) in the absence of events, conflict increases linearly with confidence threshold (while still being limited to relatively low levels); (ii) the effect of events on conflict increases with the product of confidence threshold and event certainty; and (iii) conflict is only weakly dependent on the frequency and duration of events. While completely removing the dependence on \(E_{f} E_{d}\) (by assuming \(\left( {E_{f} E_{d} } \right)^{0.08} = 1\)) results in only a minor deterioration in the correlation (r = 0.98, N = 17, p < 0.001), its retention ensures a smooth transition from infrequent events of short duration (\(E_{f} E_{d} \ll 1\)) to no events (\(E_{f} E_{d} = 0\)).

Average population conflict calculated from model results (over the period t = 500–1000 timesteps) plotted against the functional relationship defined by Eq. (6). The correlation was significant (r = 0.99, N = 17, p < 0.001) with a slope of 0.75.
Discussion
Polarisation, including the emergence of views more extreme than initially present, has previously been explained by either differentative (repulsive) interactions, whereby opposing individuals influence each other towards more dissimilar opinions23,24; or by intensifying discussion between like-minded individuals encouraging adoption of more extreme views14. Both mechanisms rely on quite specific forms of interaction that have limited supporting empirical evidence outside of social media25,26,41. In contrast, most contested issues are influenced by events that are external to the individuals themselves30. These can be major events capable of influencing opinions on national or international issues, such as natural disasters, catastrophic accidents, or socio-political upheaval42,43,44. Alternatively, opinions on local issues may be influenced by smaller events, such as news releases, political decisions, or legal rulings45,46. In the current context, the key characteristic of any event is that it is time-bounded and can influence many individuals synchronistically.
Strong events were found to generate and indefinitely sustain polarised opinions (high conflict) among populations with relatively small confidence thresholds due to homophily (Figs. 2d and 3c). Larger confidence thresholds (\(\varepsilon > 0.5\)) resulted in reduced conflict levels, although still well above those where no events were present. Relatively high conflict levels (above a random distribution of population opinions) were maintained even when events were rare (\(E_{f} E_{d} \ll 0\)) (Fig. 3e,f). Overall, stochastic events were very effective in polarising population opinions and maintaining conflict. The net long-term effect of homophily and stochastic events on conflict in the model were well described by Eq. (6).
Equation (6) is not dependent on the distribution of certainty across individuals and, indeed, mean conflict levels do not change significantly when all individuals are given equal certainty. However, with uniform certainty, distributions of opinions at any time are essentially binary with individuals on each side of the polarisation having near identical opinions. This is clearly less realistic than the more continuous distribution of opinions evident in Fig. 2. Consideration of individual certainty will become even more important as influence models begin to resolve differences in the demographic characteristics and the vested interests of individuals and groups38,47.
The polarising effect of events is partly of concern because some events are not random, but rather are constructed or distorted for financial, political, or ideological reasons. These ‘hoax’ events are often labelled as crises or emergencies by their proponents48 and may be designed to damage individuals or organisations49,50, gain popular support51, divert scrutiny52,53, or justify otherwise unpopular actions54. Our results suggest that conflicts might be perpetuated indefinitely if one or both sides of an issue can orchestrate influential events or otherwise maintain a perception of crisis.
While it is the conceptual and structural aspects of the model that are critical to the current study, the longer-term objective for influence modelling should be its application to real social systems55. This transition will pose significant challenges related to the parameterisation and calibration of the model. Because all aspects of the model are expressed in relative units, relationships such as Eq. (6) are of limited practical use unless key factors, such as the influence threshold of the network and the strength of events, can be calibrated relative to the opinion and certainty scales. If the temporal evolution of opinions is of interest, then the timestep will also need to relate to real time, with frequencies and average durations of events set accordingly (Supplementary Information).
These aspects can be illustrated using the example of effects of extreme weather events in the United States influencing opinions relating to climate change. In 2012, Weather Forecasting Offices across the United States recorded event frequencies (\(E_{f}\)) ranging from 0 to 22 per month56. Comparisons of the timing of extreme weather events with climate opinions from national surveys indicate the duration (\(E_{d}\)) of a statistically significant influence from these events was only around 0.1 months56,57, implying that \(\left( {E_{f} E_{d} } \right)^{0.08} <\) 1.2. Being a particularly contentious issue in the United States18, we can safely assume that homophily is relatively high with respect to opinions on climate change (say \(\varepsilon \approx\) 0.2). While the size of extreme weather events (\(E_{s}\)) in terms of their potential influence on opinions is difficult to estimate from the available data, Eq. (6) suggests that values as low as 0.2 could contribute to conflict levels (\({\Delta }O \approx\) 0.4 compared to \({\Delta }O \approx\) 0.26 in the absence of events). This can be compared with the statistical analysis of the national survey responses (130,000 individuals) indicating that the influence on people experiencing the highest rate of extreme events was larger than any demographic effects, although still much smaller than the effects of partisan identification (Republican or Democrat)56. If the size of extreme events continues to increase, the model suggests that their contribution to conflict levels may become more significant. For example, values around \(E_{s} \approx\) 0.5 yield conflict levels around \({\Delta }O \approx\) 0.6 (Eq. 6), which is above randomly distributed opinions and indicative of strong polarisation.
While the example above helps demonstrate the potential relevance of social influence models to contested issues such as climate change, more targeted data collection coupled with rigorous calibration procedures may in future provide powerful tools able to test a wide range of strategies aimed at reducing conflict within and across communities.
Data availability
The model output dataset generated during the current study is provided as Supplementary material.
References
Wood, W. Attitude change: Persuasion and social influence. Annu. Rev. Psychol. 51, 539–570. https://doi.org/10.1146/annurev.psych.51.1.539 (2000).
McPherson, M., Smith-Lovin, L. & Cook, J. M. Birds of a feather: Homophily in social networks. Annu. Rev. Sociol. 27, 415–444. https://doi.org/10.1146/annurev.soc.27.1.415 (2001).
Axelrod, R. The dissemination of culture—A model with local convergence and global polarization. J. Conflict Resolut. 41, 203–226. https://doi.org/10.1177/0022002797041002001 (1997).
Hegselmann, R. & Krause, U. Opinion dynamics and bounded confidence: Models, analysis and simulation. Jasss J. Artif. Soc. S 5(3), 2. http://jasss.soc.surrey.ac.uk/5/3/2.html (2002).
Lorenz, J. Continuous opinion dynamics under bounded confidence: A survey. Int. J. Mod. Phys. C 18, 1819–1838. https://doi.org/10.1142/S0129183107011789 (2007).
Castellano, C., Fortunato, S. & Loreto, V. Statistical physics of social dynamics. Rev. Mod. Phys. 81, 591–646. https://doi.org/10.1103/RevModPhys.81.591 (2009).
Yin, X. C., Wang, H. W., Yin, P. & Zhu, H. M. Agent-based opinion formation modeling in social network: A perspective of social psychology. Phys. A https://doi.org/10.1016/j.physa.2019.121786 (2019).
Urena, R., Kou, G., Dong, Y. C., Chiclana, F. & Herrera-Viedma, E. A review on trust propagation and opinion dynamics in social networks and group decision making frameworks. Inf. Sci. 478, 461–475. https://doi.org/10.1016/j.ins.2018.11.037 (2019).
Anderson, B. D. O. & Ye, M. B. Recent advances in the modelling and analysis of opinion dynamics on influence networks. Int. J. Autom. Comput. 16, 129–149. https://doi.org/10.1007/s11633-019-1169-8 (2019).
Flache, A. et al. Models of social influence: Towards the next frontiers. Jasss J. Artif. Soc. S https://doi.org/10.18564/jasss.3521 (2017).
Dong, Y. C., Zhan, M., Kou, G., Ding, Z. G. & Liang, H. M. A survey on the fusion process in opinion dynamics. Inf. Fusion 43, 57–65. https://doi.org/10.1016/j.inffus.2017.11.009 (2018).
Flache, A. Between monoculture and cultural polarization: Agent-based models of the interplay of social influence and cultural diversity. J. Archaeol. Method Theory 25, 996–1023. https://doi.org/10.1007/s10816-018-9391-1 (2018).
Perc, M. The social physics collective. Sci. Rep. U.K. https://doi.org/10.1038/s41598-019-53300-4 (2019).
Mas, M. & Flache, A. Differentiation without distancing. Explaining bi-polarization of opinions without negative influence. PLoS ONE https://doi.org/10.1371/journal.pone.0074516 (2013).
Bikhchandani, S., Hirshleifer, D. & Welch, I. A theory of fads, fashion, custom, and cultural-change as informational cascades. J. Polit. Econ. 100, 992–1026. https://doi.org/10.1086/261849 (1992).
Pineda, M., Toral, R. & Hernandez-Garcia, E. Noisy continuous-opinion dynamics. J. Stat. Mech. Theory E https://doi.org/10.1088/1742-5468/2009/08/P08001 (2009).
Mas, M., Flache, A. & Helbing, D. Individualization as driving force of clustering phenomena in humans. PLoS Comput. Biol. https://doi.org/10.1371/journal.pcbi.1000959 (2010).
Dunlap, R. E., McCright, A. M. & Yarosh, J. H. The political divide on climate change: Partisan polarization widens in the US. Environment 58, 4–23. https://doi.org/10.1080/00139157.2016.1208995 (2016).
Colvin, R. M., Witt, G. B. & Lacey, J. The social identity approach to understanding socio-political conflict in environmental and natural resources management. Glob. Environ. Change 34, 237–246. https://doi.org/10.1016/j.gloenvcha.2015.07.011 (2015).
Colvin, R. M. et al. Learning from the climate change debate to avoid polarisation on negative emissions. Environ. Commun. 14, 23–35. https://doi.org/10.1080/17524032.2019.1630463 (2020).
Kleiner, T. M. Public opinion polarisation and protest behaviour. Eur. J. Polit. Res. 57, 941–962. https://doi.org/10.1111/1475-6765.12260 (2018).
Ravndal, J. A. Explaining right-wing terrorism and violence in Western Europe: Grievances, opportunities and polarisation. Eur. J. Polit. Res. 57, 845–866. https://doi.org/10.1111/1475-6765.12254 (2018).
Baldassarri, D. & Bearman, P. Dynamics of political polarization. Am. Sociol. Rev. 72, 784–811. https://doi.org/10.1177/000312240707200507 (2007).
Mark, N. P. Culture and competition: Homophily and distancing explanations for cultural niches. Am. Sociol. Rev. 68, 319–345. https://doi.org/10.2307/1519727 (2003).
Krizan, Z. & Baron, R. S. Group polarization and choice-dilemmas: How important is self-categorization?. Eur. J. Soc. Psychol. 37, 191–201. https://doi.org/10.1002/ejsp.345 (2007).
Johnson, N. R. & Glover, M. Individual and Group shifts to extreme—Laboratory experiment on crowd polarization. Sociol. Focus 11, 247–254. https://doi.org/10.1080/00380237.1978.10570322 (1978).
Hahn, U., Hansen, J. U. & Olsson, E. J. Truth tracking performance of social networks: How connectivity and clustering can make groups less competent. Synthese 197, 1511–1541. https://doi.org/10.1007/s11229-018-01936-6 (2020).
Abramowitz, A. I. & Saunders, K. L. Is polarization a myth?. J. Polit. 70, 542–555. https://doi.org/10.1017/S0022381608080493 (2008).
Berelson, B. Events as an influence upon public opinion. J. Quart 26, 145–148. https://doi.org/10.1177/107769904902600202 (1949).
Atkeson, L. R. & Maestas, C. D. Extraordinary events and public opinion. Catastrophic Politics: How Extraordinary Events Redefine Perceptions of Government, 1-+. https://doi.org/10.1017/Cbo9781139108560 (2012).
Kurahashi-Nakamura, T., Mas, M. & Lorenz, J. Robust clustering in generalized bounded confidence models. Jasss J. Artif. Soc. S https://doi.org/10.18564/jasss.3220 (2016).
Deffuant, G., Neau, D., Amblard, F. & Weisbuch, G. Mixing beliefs among interacting agents. Appl. Simul. Soc. Sci. https://doi.org/10.1142/S0219525900000078 (2000).
Sznajd-Weron, K. & Sznajd, J. Opinion evolution in closed community. Int. J. Mod. Phys. C 11, 1157–1165. https://doi.org/10.1142/S0129183100000936 (2000).
Yaniv, I. & Kleinberger, E. Advice taking in decision making: Egocentric discounting and reputation formation. Organ. Behav. Hum. Dec. 83, 260–281. https://doi.org/10.1006/obhd.2000.2909 (2000).
Tormala, Z. L. The role of certainty (and uncertainty) in attitudes and persuasion. Curr. Opin. Psychol. 10, 6–11. https://doi.org/10.1016/j.copsyc.2015.10.017 (2016).
Sobkowicz, P. Effect of Leader’s strategy on opinion formation in networked societies with local interactions. Int. J. Mod. Phys. C 21, 839–852. https://doi.org/10.1142/S0129183110015518 (2010).
Moussaid, M., Kammer, J. E., Analytis, P. P. & Neth, H. Social influence and the collective dynamics of opinion formation. PLoS ONE https://doi.org/10.1371/journal.pone.0078433 (2013).
Aral, S. & Walker, D. Identifying influential and susceptible members of social networks. Science 337, 337–341. https://doi.org/10.1126/science.1215842 (2012).
Sirbu, A., Loreto, V., Servedio, V. D. P. & Tria, F. Opinion dynamics with disagreement and modulated information. J. Stat. Phys. 151, 218–237. https://doi.org/10.1007/s10955-013-0724-x (2013).
Peres, L. R. & Fontanari, J. F. The mass media destabilizes the cultural homogenous regime in Axelrod’s model. J. Phys. A Math. Theor. https://doi.org/10.1088/1751-8113/43/5/055003 (2010).
Baumann, F., Lorenz-Spreen, P., Sokolov, I. M. & Starnini, M. Modeling echo chambers and polarization dynamics in social networks. Phys. Rev. Lett. https://doi.org/10.1103/PhysRevLett.124.048301 (2020).
Xu, J. P., Wang, Z. Q., Shen, F., Ouyang, C. & Tu, Y. Natural disasters and social conflict: A systematic literature review. Int. J. Disaster Risk Reduct 17, 38–48. https://doi.org/10.1016/j.ijdrr.2016.04.001 (2016).
Bytzek, E. Questioning the obvious: Political events and public opinion on the government’s standing in Germany 1977–2003. Int. J. Public Opin. R 23, 406–436. https://doi.org/10.1093/ijpor/edr016 (2011).
Bishop, B. H. Focusing events and public opinion: Evidence from the deepwater horizon disaster. Polit. Behav. 36, 1–22. https://doi.org/10.1007/s11109-013-9223-7 (2014).
Cullen-Knox, C., Fleming, A., Lester, L. & Ogier, E. Publicised scrutiny and mediatised environmental conflict: The case of Tasmanian salmon aquaculture. Mar. Policy 100, 307–315. https://doi.org/10.1016/j.marpol.2018.11.040 (2019).
Paolino, P. Surprising events and surprising opinions: The importance of attitude strength and source credibility. J. Conflict Resolut. 61, 1795–1815. https://doi.org/10.1177/0022002715616167 (2017).
Hegselmann, R. & Krause, U. Opinion dynamics under the influence of radical groups, charismatic leaders, and other constant signals: A simple unifying model. Netw. Heterog. Med. 10, 477–509. https://doi.org/10.3934/nhm.2015.10.477 (2015).
Spector, B. Constructing crisis: Leaders, crises, and claims of urgency. Constr. Crisis Lead. Crises Claims Urgency https://doi.org/10.1017/9781108551663 (2019).
Veil, S. R., Sellnow, T. L. & Petrun, E. L. Hoaxes and the paradoxical challenges of restoring legitimacy: Dominos’ response to its YouTube crisis. Manag. Commun. Q 26, 322–345. https://doi.org/10.1177/0893318911426685 (2012).
Park, K. & Rim, H. Social media hoaxes, political ideology, and the role of issue confidence. Telemat. Inform. 36, 1–11. https://doi.org/10.1016/j.tele.2018.11.001 (2019).
Bykov, I. A. & Kuzmin, A. Sociology of political support in Russia: The Ukraine crisis, putin and the dynamics of public opinion. Pertanika J. Soc. Sci. 25, 1689–1701 (2017).
Ismail, N. B. M., Pagulayan, I. M. A., Francia, C. M. A. & Pang, A. Communicating in the post-truth era: Analyses of crisis response strategies of Presidents Donald Trump and Rodrigo Duterte. J. Public Aff. https://doi.org/10.1002/pa.1883 (2019).
Knill, C., Steinebach, Y. & Fernndez-i-Marn, X. Hypocrisy as a crisis response? Assessing changes in talk, decisions, and actions of the European Commission in EU environmental policy. Public Admin. 98, 363–377. https://doi.org/10.1111/padm.12542 (2020).
Peevers, C. The Politics of Justifying Force: The Suez Crisis, the Iraq War, and International Law 1st edn. (Oxford University Press, Oxford, 2013).
Sobkowicz, P. Modelling opinion formation with physics tools: Call for closer link with reality. Jasss J. Artif. Soc. S 12(1), 11. http://jasss.soc.surrey.ac.uk/12/1/11.html (2009).
Konisky, D. M., Hughes, L. & Kaylor, C. H. Extreme weather events and climate change concern. Clim. Change 134, 533–547. https://doi.org/10.1007/s10584-015-1555-3 (2016).
Egan, P. J. & Mullin, M. Turning personal experience into political attitudes: The effect of local weather on Americans’ perceptions about global warming. J. Polit. 74, 796–809. https://doi.org/10.1017/S0022381612000448 (2012).
Acknowledgements
C.M.C. is supported by an Australian Government Research Training Program Scholarship and would like to thank Dr Karen Alexander, Dr Katie Cresswell, Professor Fred Gale and Dr Joanna Vince for their advice and guidance. Thanks also Dr Ingrid van Puttin for providing valuable suggestions on the manuscript.
Author information
Authors and Affiliations
Contributions
Both authors contributed to the conceptualisation of the model, analysis of outputs and writing of the manuscript. S.A.C. also coded and ran the model.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Condie, S.A., Condie, C.M. Stochastic events can explain sustained clustering and polarisation of opinions in social networks. Sci Rep 11, 1355 (2021). https://doi.org/10.1038/s41598-020-80353-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-80353-7
This article is cited by
-
Early morning hour and evening usage habits increase misinformation-spread
Scientific Reports (2024)
-
Towards vibrant fish populations and sustainable fisheries that benefit all: learning from the last 30 years to inform the next 30 years
Reviews in Fish Biology and Fisheries (2023)
-
Reducing socio-ecological conflict using social influence modelling
Scientific Reports (2022)
-
Opinion amplification causes extreme polarization in social networks
Scientific Reports (2022)
-
A general framework to link theory and empirics in opinion formation models
Scientific Reports (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
