
Abstract
Network science provides effective tools to model and analyze complex systems. However, the increasing size of real-world networks becomes a major hurdle in order to understand their structure and topological features. Therefore, mapping the original network into a smaller one while preserving its information is an important issue. Extracting the so-called backbone of a network is a very challenging problem that is generally handled either by coarse-graining or filter-based methods. Coarse-graining methods reduce the network size by grouping similar nodes, while filter-based methods prune the network by discarding nodes or edges based on a statistical property. In this paper, we propose and investigate two filter-based methods exploiting the overlapping community structure in order to extract the backbone in weighted networks. Indeed, highly connected nodes (hubs) and overlapping nodes are at the heart of the network. In the first method, called “overlapping nodes ego backbone”, the backbone is formed simply from the set of overlapping nodes and their neighbors. In the second method, called “overlapping nodes and hubs backbone”, the backbone is formed from the set of overlapping nodes and the hubs. For both methods, the links with the lowest weights are removed from the network as long as a backbone with a single connected component is preserved. Experiments have been performed on real-world weighted networks originating from various domains (social, co-appearance, collaboration, biological, and technological) and different sizes. Results show that both backbone extraction methods are quite similar. Furthermore, comparison with the most influential alternative filtering method demonstrates the greater ability of the proposed backbones extraction methods to uncover the most relevant parts of the network.
Similar content being viewed by others


Introduction
The complex networks paradigm offers great tools for modeling and understanding systems made of multiple interacting components1,2. They are used by many researchers in numerous domains ranging from technology to biology3,4,5,6,7,8. Extensive attention has been paid to reveal the common characteristics of complex networks, such as the scale-free behavior of the degree distribution9, the small-world property10 and the community structure11,12,13,14,15,16. However, with the growing size of real-world systems, extracting relevant features and information becomes a much harder task to achieve. In such networks, valuable information is usually hidden by minor redundant intricacies. Therefore, it is of prime interested to devise effective methods in order to reduce the size of large-scale networks while preserving the information they carry. Extracting the backbone of the network can help to solve the conflict between the understanding of a network and its large size. Ideally, the backbone represents the core component of the network obtained by filtering all the redundant information. In recent years, an increasing interest has been witnessed in extracting backbones from large-scale networks. The existing methods can be divided into two classes: the coarse-graining methods and the filter-based methods. The coarse-graining methods17,18,19 are based on the idea of grouping the nodes sharing some common characteristics. Then, they consider these groups as a single node, reducing the network size while preserving the properties of interest. Within this framework, community detection is a common technique. In this case, communities are replaced by a single node. The common property shared by the regrouped nodes is that they have more links with nodes in their community than with nodes outside of their community. In20, the authors define a coarse-graining method preserving random walks. As nodes sharing the same neighbors cannot be distinguished from the point of view of a random walk they are grouped together. Note, however, that there is no consensus on the properties that need to be preserved. The filter-based methods follow a bottom-up approach in order to extract the network backbone21,22,23,24,25,26,27,28,29,30,31,32,33,34,35. First, a node or an edge statistical property is defined. It is, then, used as a criterion to preserve or discard nodes or edges from the network. As a result, only nodes and links carrying relevant information according to the defined property are conserved while the rest is removed. Filter-based methods can be classified according to the type of information used to filter the nodes or edges (global, local, a combination of global and local). Some filter-based methods use global measures, such as the link betweenness-based strategy17. It defines network backbones formed only from links with the highest betweenness centrality. This method uses a threshold on the betweenness of links to preserve only those that exceed it. The link salience is another robust method based on a global measure21. This approach is based on the notion of the shortest-path tree that is summarizing the shortest paths from a reference node to the remainder of the network. It defines an average shortest-path tree matrix S, where each value \(s_{ij}\) measures the number of shortest-path trees that the link (i, j) is part of. Links with values higher than a defined threshold are kept, and they compose the backbone of the network.
Other methods use local measures to extract the backbone. The k-core is a well-known measure used by Chalupa et al.28,29 as a hierarchical topology filter. For weighted networks, the link weight-based strategy30 defines the w-skeleton or w-backbone obtained by discarding all the links with weights less than w. Arguing that the strength alone is not sufficient to capture the weighted structure of nodes, Serrano et al.31 propose the disparity filter method. It is an improvement of the link weight-based method. This approach starts by normalizing the weights of each link (i, j) attached to a given node i by its strength (the sum of weights of all its connections). After that, a null model is considered, in which the weights of these links are supposed to be uniformly distributed. Then, the probability \(\alpha _{ij}\) is computed. It indicates that the normalized weight of each link (i, j) is compatible with the null model. The links with weights compatible with the uniform distribution are preserved with a significance level \(\alpha \). Thus, edges verifying the condition (\(\alpha _{ij} < \alpha \)) should be kept in the backbone. The aim of this method is to highlight edges representing an important fraction of the local strength and weight magnitude of each given node. In36, the authors introduce a local link filtering method exploiting Simmel’s concept of membership in social groups. Experiments on Facebook interaction networks show that the Simmelian backbone is able to extract their main structure, making them easy to visualize and analyze.
The third type of filtering methods is based on a combination of local and global measures. In this context, Ronda et al.37 propose the h-Backbone approach which relies on three steps. Consider that the bridge measure of a link is equal to its betweenness divided by the total number of nodes of the network. In addition, \(h_{b}\) represents the largest number such that there are \(h_{b}\) links, each with bridge measure at least equal to \(h_{b}\). The first step consists of finding the links with a bridge measure value higher or equal to the h-bridge \(h_{b}\). Let \(h_{s}\) represents the largest number such that there are \(h_{s}\) links, each with strength at least equal to \(h_{s}\). The second step consists in searching for the links with a weight higher or equal to the h-strength \(h_{s}\). In the last step, the edges selected from the two previous steps are merged to form the h-backbone. This approach selects relevant links connecting the network using the h-bridge, and high strength links located in the core of the network through the h-strength.
Backbone extraction processes dedicated to bipartite networks have been also developed38,39,40,41. Jo et al.41 proposed a new heuristic able to estimate the direction and strength of the hierarchical relationships between a pair of nodes in order to select the essential part of the networks. Experiments performed on two empirical datasets (the Gene Ontology network and a bipartite network of skills and individuals collected from LinkedIn) show that it manages to identify the most meaningful hierarchical relations from the bipartite networks. A R package42 has been developed for bipartite networks in order to extract the backbone. It contains three methods: Hypergeometric Model (HM)38, Stochastic Degree Sequence Model (SDSM)39 and Fixed Degree Sequence Model (FDSM)40.
Community structure is a feature commonly observed in complex networks. In real-world networks, nodes are usually found to be naturally arranged into various groups or communities. Numerous investigations have been conducted to model and to analyze the community structure of a network11,43,44,45,46,47,48,49. Yet, there is no unique interpretation of the community structure. It is regularly apprehended as the division of densely interconnected subgroups of nodes sparsely connected with nodes belonging to other modules. Communities can overlap. In an overlapping community structure, a node can belong to multiple communities, while it belongs to a single community in networks with a non-overlapping community structure. Palla et al.50,51 have shown that numerous real-world networks exhibit some nested and overlapping community structure. This behavior is quite natural in social networks. For instance, if we consider a network of actors, the actors may play in films of different genres (comedy, musical, adventure, action, etc). While there is a great deal of works exploiting the modular structure of real-world networks52,53,54,55,56,57,58,59,60,61,62,63,64, and despite the ubiquity of this property, up to now, it is ignored in the filter-based backbone extraction approach. This article closes that gap. Indeed, in networks with an overlapping community structure, it is important to highlight the influence of the overlapping nodes and the hubs in the network structure and dynamics. On one hand, hubs are considered as the most influential nodes in the network. As they are the most connected, they can have a big influence on their community and also in bridging the communities. On the other hand, overlapping nodes are at the core of the network topology. Previous studies have shown that nodes belonging to the overlapping zones of the network are more tightly connected than nodes belonging to the non-overlapping zones65. Therefore, the overlapping nodes can connect many nodes belonging to different parts of the network. They have, then, a big global influence on the network. To sum up, both hubs and overlapping nodes are important building blocks of the network that translate into a great local and global influence.
In this paper, we propose and investigate two backbone extraction methods that are based on these two types of nodes. The first method is called the overlapping nodes and hubs backbone. It is obtained by preserving the overlapping nodes and the hubs and removing the remaining nodes. All the edges with the lowest weights are then removed from this sub-network as long as the components stay connected. The second method is called the overlapping nodes ego backbone. In this case, the backbone is formed by considering the overlapping nodes and their one-step neighbors. Just as before, the sub-network is pruned in order to preserve the overlapping nodes and the neighbors with the highest weighted links without splitting the components. We expect that the overlapping nodes ego backbone is a good approximation of the overlapping nodes and hubs backbone. Indeed, in a previous study53, it has been shown that the overlapping nodes are neighbors with a high number of the top connected nodes. Therefore, this backbone should preserve very relevant information from the original network without looking for the hubs that are supposed to belong to the overlapping nodes neighborhood. One can notice that unlike the vast majority of alternative filter-based methods, the proposed methods do not rely exclusively on links but also on nodes. Furthermore, both methods are local if the community structure is known.
A series of experiments are conducted on real-world weighted networks from different fields (social, co-appearance, collaboration, biological and technological) and various sizes. First of all, different evaluation measures (proportion of common nodes, rank-biased overlap, Pearson and Kendall Tau correlation) are used to measure the similarity and the correlation between the proposed backbone extraction methods. Then, they are compared to the Serrano backbone (called also the disparity filter backbone). Indeed, this filtering scheme is considered as one of the most effective local-based extraction methods.
Results and discussion
In this section, results of the comparative evaluation of the backbone extraction methods are presented and analyzed. Samples of various real-world networks (social, co-appearance, biological, technological and collaboration networks) have been used in order to cover a wide range of situations. The overlapping community structure of the networks has been uncovered by the Speaker-Listener Label Propagation Algorithm (SLPA)66. Results with a single community detection algorithm are reported. Indeed, previous results using alternative community detection algorithm have shown that the influence of the community detection algorithm is limited, and that the community structures uncovered are generally quite consistent53.
In the first set of experiments, various evaluation criteria are used to measure the similarity between the two proposed backbones, and to compare them with the output of the disparity filter proposed by Serrano et al.31. There are two main reasons for this choice. First, the disparity filter technique is based on a local measure. Thus, it belongs to the same category that the proposed methods. Second, it is considered as one of the most popular and effective alternative backbone extraction methods. To quantify the similarity between two backbones, the proportion of common nodes as well as the rank-biased overlap measures are computed (refer to the “Materials and methods” section). Additionally, the statistical association between the set of nodes found in the backbones is measured by computing both Pearson and Kendall Tau correlation.
In the second set of experiments, the effectiveness of the three extraction backbone methods is investigated. The average link weight, average node betweenness and weighted degree of the backbones are compared. The higher these values the better the backbone. Note that in all the experiments, the size of the backbone is limited to 30% of the size of the original network by setting the parameter s to 0.3. Accordingly, the parameter \(\alpha \) is tuned in order to obtain a disparity filter backbone of the same size.
Proportion of common nodes
In this experiment, the proportion of common nodes extracted by the various backbone extraction methods is computed. Our goal is to check if they extract the same set of nodes or not. Let’s first take a look at the extracted backbones in small size networks. In this case, the set of nodes can be compared visually. The Figs. 1, 2, 3, 4 and 5 show the backbone extracted from Zachary’s Karate Club, Les Miserables, Game of thrones, Train bombing and Intra-organizational networks respectively. In all the figures, the overlapping nodes ego backbone is represented in (a), the overlapping nodes and hubs backbone is represented in (b), while the disparity filter backbone is reported in (c). The color of nodes refers to the communities to which they belong. The overlapping nodes are colored in grey. The size of the nodes is proportional to their weighted degree67 and the thickness of the links is proportional to their weights. These networks have a number of overlapping communities ranging from 2 to 3. One can see that, whatever the network considered, the overlapping nodes ego backbone and the overlapping nodes and hubs backbone share a vast majority of nodes.

The backbone extraction of different methods for the Game of thrones network. (a) Overlapping nodes ego backbone, (b) overlapping nodes and hubs backbone and (c) Serrano backbone. Nodes are highlighted in different colors according to the community they belong to. Nodes with the same color belong to the same community while those in gray represent the overlapping nodes. The size of the nodes is proportional to their weighted degree, while the size of links is proportional to their weights. The community structure is revealed using the SLPA detection algorithm.

The backbone extraction of different methods for the Train bombing network. (a) Overlapping nodes ego backbone, (b) overlapping nodes and hubs backbone and (c) Serrano backbone. Nodes are highlighted in different colors according to the community they belong to. Nodes with the same color belong to the same community while those in gray represent the overlapping nodes. The size of the nodes is proportional to their weighted degree, while the size of links is proportional to their weights. The community structure is revealed using the SLPA detection algorithm.

The backbone extraction of different methods for the intra-organisational network. (a) Overlapping nodes ego backbone, (b) overlapping nodes and hubs backbone and (c) Serrano backbone. Nodes are highlighted in different colors according to the community they belong to. Nodes with the same color belong to the same community while those in gray represent the overlapping nodes. The size of the nodes is proportional to their weighted degree, while the size of links is proportional to their weights. The community structure is revealed using the SLPA detection algorithm.

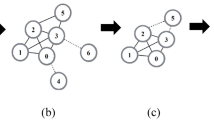
The general steps to extract the overlapping nodes ego backbone for a toy example (a). (b) Illustrates the formation of the sub-network. All the links with low weights are removed in (c). (d) Illustrates the sub-network with the parameter s set to 0.4. Nodes are highlighted in different colors according to the community they belong to. Nodes with the same color belong to the same community while those in gray represent the overlapping nodes. The size of the nodes is proportional to their weighted degree, while the size of links is proportional to their weights. The community structure is revealed using the SLPA detection algorithm.

The general steps to extract the overlapping nodes and hubs backbone for a toy example (a). (b) Illustrates the formation of the sub-network. All the links with low weights are discarded in (c). (d) Shows the sub-network with the size threshold parameter s set to 0.4. Nodes are highlighted in different colors according to the community they belong to. Nodes with the same color belong to the same community while those in gray represent the overlapping nodes. The size of the nodes is proportional to their weighted degree, while the size of links is proportional to their weights. The community structure is revealed using the SLPA detection algorithm.
Let’s compare first the overlapping nodes ego backbones with the overlapping nodes and hubs backbones. In the Karate club network, 79% of the nodes appear in both backbones. This number goes up to 91.6% in Les Miserables network. The two backbones are identical for Game of thrones, Train bombing and Intra-organizational networks, as illustrated in Figs. 3, 4 and 5 respectively.
These results are consistent with the findings of a previous study53 showing that the overlapping nodes are neighbors of the highly connected nodes of the network. Therefore, the overlapping nodes ego backbones and the overlapping nodes and hubs backbones preserve just about the same set of nodes. In this situation, it is better to use the overlapping nodes ego backbone extractor as it needs less knowledge about the original network. The comparison with the disparity filter shows more differences. Indeed, the proportion of common nodes between the proposed backbones and the disparity filter backbones is relatively smaller for all the network under study. Figs. 1, 2, 3, 4 and 5 illustrate this behavior. The main difference lies in the fact that the disparity filter concentrates on links while the proposed methods are based on nodes in their extraction process. In any case, in small networks, it appears clearly that the proposed backbone extractors manage to preserve more influential nodes and links from the original network as compared to the disparity filter algorithm. Let’s take Les Miserables network as an example, it is well known that Jean Valjean is a central character of Victor Hugo’s novel. This ex-convict was running away for a great deal of time from the inspector Javert. Additionally, he is strongly attached to Cosette, his adopted daughter, and her future husband Marius who plays a major role in the french revolution. Mr and Mme Thenardier, the Parisian street child Gavroche, and Fantine, Cosette’s mother are also considered as very important characters of the novel. As a matter of fact, all these characters are selected by the proposed backbones. Furthermore, some main characters of this famous novel (e.g., Cosette and Marius) do not appear in the disparity filter backbone while some secondary characters are extracted by this algorithm. Some important links are also missed in the disparity filter backbone. For instance, the link between Valjean and Javert should not be removed from the backbone since these two characters have co-appeared in so many chapters of the novel. Game of thrones is another example where Catelyn Stark does not appear in the disparity filter backbone despite its main role in this saga. Therefore, the backbones obtained by the proposed approaches preserve almost all high-connectivity nodes and essential connections.
Table 1 reports the results for all the networks under test. The overlap between the overlapping nodes ego and the overlapping nodes and hubs backbones is ranging from 79% to 100%. It shows that the hubs are tightly connected to the overlapping nodes that are located in the core of the communities.
Furthermore, we also check if the top-ranked nodes of the original network are preserved in the backbones. The set of the 10% top-ranked nodes according to their weighted degree is computed in the original network. It is compared to the set of top-ranked nodes of the same size extracted from the backbones. Results show that both sets are identical most of the time for the proposed backbones. This remark is valid for all the empirical networks under evaluation except US power grid and scientific collaboration that exhibit an overlap higher than 90%. As expected, the ability of the overlapping nodes and hubs backbone to preserve the highly connected nodes is slightly higher.
Both measures are also computed to assess the similarity between the proposed backbones and the disparity filter backbone. Results show that there is a relatively smaller overlap between the proposed backbones and the disparity filter backbone. Indeed, the overlap between the disparity filter and the overlapping nodes ego backbones ranges from 57.83% to 94.73% while it ranges from 59.06% to 94.73% for the overlapping nodes and hubs backbone. Comparisons with the set of the 10% top-ranked nodes of the original networks show that it preserves a smaller proportion of the top-ranked nodes. Indeed, the disparity filter backbone focuses on links rather than on nodes. That is the main difference between the proposed backbones and the disparity filter backbone that explain its lower ability to preserve hubs.
Rank-biased overlap
The rank-biased overlap (RBO) measures the similarity between two sets. It quantifies the proportion of common nodes found in two sets while incrementally increasing their depths. Its value is equal to 1 when the two sets are similar, while it is equal to 0 when the sets are totally disjoint. Different weights are assigned to the elements of both sets while computing the RBO. The weights of the elements are set using the parameter p (refer to the “Materials and methods” section). More weight is given to the comparison of the top elements of the two sets if this parameter has a small value.
At first, the RBO is computed between the set of nodes of the two proposed backbones. Note that the sets of nodes are sorted in decreasing order according to their weighted degree. The experimental results are reported in Table 2. One can see that the overlap between the two sets is quite high when nearly all the elements have the same weight (\(p=0.98\)). It ranges between 88% and 99%. The values of the RBO gets even higher when more importance is assigned to the top-ranked elements (\(p=0.5\)). For all the networks, it is always close to 100%. Thus, these results confirm and reinforce the previous observations. This is more visible in the small networks illustrated in Figs. 1, 2, 3, 4 and 5, where the highly connected nodes are selected by both backbones. Secondly, Table 2 reports also the values of the same metric computed between the proposed backbones and the disparity filter backbone. It can be noticed from the results that the RBO exhibit high values for the various values of the parameter p. However, they are relatively smaller than the ones obtained when this measure is computed between the two proposed backbones. Indeed, the disparity filter backbone sometimes includes some peripheral nodes which do not have a big influence in the network. These nodes are not selected by the overlapping nodes ego and the overlapping nodes and hubs backbone that extract nodes located in the core of the network. To summarize, there is a great similarity between the sets of nodes found in the two proposed backbones. Moreover, the top-ranked nodes are always preserved in these backbones. Yet, there is relatively less similarity between these backbones and the disparity filter backbone. The latter one sometimes selects less relevant nodes.
Correlation
Here, the correlation between the set of nodes found in the different backbones is computed. Two correlation measures are used: Pearson and Kendall Tau correlation. The degree of relationship between the sets of nodes is estimated using the Pearson correlation given in Eq. (5). It is computed using the weighted degrees of the sets of nodes sorted in decreasing order. The Kendall Tau correlation is also used to assess the statistical associations based on the ranks of these sets. We compute the ranks of the sets according to the weighted degree of nodes. A different rank is associated with each degree. Both correlation metrics have values ranging between − 1 and 1. The sets of nodes have a perfect positive correlation when their values are equal to 1, while they have perfect negative correlation when the values are equal to − 1.
Table 3 reports the empirical results of Pearson and Kendall Tau correlation for all the real-world networks. It can be noticed that the values of both correlation measures computed between the sets of nodes extracted by the proposed backbones are very high. They are very close to 1. This is due to the very high fraction of nodes they have in common. Thus, both sets have about the same degrees and ranks. These results confirm that there is a very strong relationship between the sets of nodes of the two backbones. Additionally, the correlation measures have relatively lower values between the two backbones and the disparity filter backbone. The values are still high (ranging between 0.8 and 0.9), but they are lower than the ones obtained between the proposed backbones. These results are in concordance with previous empirical findings. Indeed, in some networks, the disparity filter backbone includes some different nodes with a very small weighted degree. Therefore, there is a relatively weaker monotonic relationship between the proposed backbones and this alternative one.
Effectiveness
In this subsection, the performance of the three backbone extraction methods is compared by measuring the average betweenness, the weighted degree and the average link weight. Table 4 reports the results for all networks under test.
Let’s look first at the average betweenness. The betweenness measures the extent to which a node lies on paths between all the other nodes of the network. The average betweenness indicates how much information can pass through the nodes of the backbone. The greater the value, the better the backbone’s ability to disseminate information. It can clearly notice from Table 4 that both overlapping nodes ego and overlapping nodes and hubs backbone exhibit a very close average betweenness for all the networks. This is because both backbones select nearly the same set of nodes. However, the values of the average betweenness of both backbones are higher than the ones computed in the disparity filter backbone. This implies that the nodes extracted by the proposed backbones act as a better information gateway of the original network as compared to the disparity filter backbone.
Let’s now turn to the average weighted degree of the set of nodes selected by the different backbones. This measure reflects the connectedness of the nodes of a given backbone. The experimental results reported in Table 4 corroborate the conclusions made with the average betweenness. Indeed, the proposed backbones display the same performance. For all the networks, they have an equal or a very close average weighted degree value. Yet, they outperform the disparity filter backbone in terms of the connectedness. This confirms our observations made in the small networks illustrated in Figs. 1, 2, 3, 4 and 5. Taking a direct look at these networks, it can be noticed that some highly connected nodes are missed by the disparity filter backbone. For instance, Marius and Cosette in Les Miserables network do not appear in this backbone, while other secondary characters are included. This explains its lower node connectedness as compared to the proposed backbones.
Finally, let’s compare the average link weight. A higher value of this measure demonstrates that the picked links are quite relevant. Experimental results reported in Table 4 show that the average link weight of the proposed backbones exhibits approximately the same values. It is slightly higher for the overlapping nodes and hubs backbone. The two backbones have, however, a higher average link weight as compared to the disparity filter backbone. Indeed, this backbone has fewer connections between its nodes. Some very relevant connections are missed in the disparity filter backbone. As mentioned before in the previous subsection, the link between Jean Valjean and Javert in Les Miserables network is excluded from this backbone. So, the two proposed backbones select more relevant connections as compared to the disparity filter backbone. Furthermore, another disadvantage of the disparity filter backbone is that it is divided into many components while the proposed backbones are composed of a single connected component. Therefore, the topology of the sub-networks generated by the proposed approach preserves more the shape of the spine of the original network.
To conclude, both overlapping nodes ego and overlapping nodes and hubs backbone display similar performance in terms of information gateway, connectedness and link strength. Their performance is higher than the disparity filter backbone for all the tested empirical networks. These results allow to shed more light on the overlapping nodes ego backbone. Indeed, this backbone has the same performance as the overlapping nodes and hubs backbone. Moreover, it requires only the local information about the overlapping nodes. Therefore, it can be considered as the most appropriate extraction method in large-scale networks.
Influence of the parameters setting
The outputs from the proposed backbone extractors depend on the size of the overlapping nodes set m, the size of their neighbors set k, and the size of hubs set t. These parameters depend essentially on the revealed community structure. Indeed, the size of the set of the neighborhood of overlapping nodes is directly defined after identifying all the overlapping nodes of the network. Furthermore, the size of the set of hubs has the same size as the set of neighbors of the overlapping nodes. Rather than reporting results on the influence of the community detection algorithm on these parameters, we recall the main findings. For more details, the reader can refer to53. In this previous study, results of extensive experiments using three community detection algorithms (Demon, an Improved version of LFM, SLPA) on a number of empirical networks of various origin are reported. They show that generally the size and the content of these sets are very stable and quite comparable. However, sometimes the size of the overlapping nodes set can be relatively large. In such cases, the values of the parameters k and t are also high. Therefore, the backbones have a relatively large size as well. This is the reason why the parameter s controlling the size of the backbones is introduced. It limits the size of the backbone in cases where the default extracted backbones have a too large size. Top-ranking nodes are privileged in such situations.
Conclusion
Understanding the properties and the topological structure of large-scale networks has become an increasingly challenging issue. Therefore, finding a way to extract the truly relevant nodes and connections in order to obtain a reduced and meaningful representation of these networks is a must. In this work, two local methods to extract backbones in weighted networks based on overlapping nodes are proposed. The overlapping nodes ego backbone is formed only from the set of overlapping nodes with their neighbors. The second backbone is formed with the set of overlapping nodes and the highly connected nodes of the network. It is called the overlapping nodes and hubs backbone. The links with the lowest weights are also removed as long as a single connected component is preserved. Both backbones extraction methods are tested on real-world networks selected from various fields. At first, the sets of nodes of the backbones are compared using similarity and correlation measures (the proportion of common nodes, rank-biased overlap, Pearson and Kendall Tau correlation). The first two measures show that there is a very high overlap between these backbones while the third and fourth measures show that there is a very high correlation between the sets of nodes. This confirms that the extracted backbone networks are almost identical. Additionally, the proposed backbone extractors are also compared with the disparity filter using the same measures. It is one of the most effective local extraction methods. Results show that there is a relatively smaller overlap between the backbones uncovered by the proposed methods and the disparity filter backbone. This is also confirmed by the correlation which displays smaller values. Furthermore, we also compare the effectiveness of the three backbones. To do so, the average weighted degree, betweenness and average link weight are computed. Results show that the overlapping nodes ego backbone is as effective as the overlapping nodes and hubs backbone in terms of information gateway, connectedness and link strength. Furthermore, their performance is higher than the disparity filter backbone. Therefore, the proposed backbones are very effective at preserving the more relevant nodes and connections.
Materials and methods
Extracting the network backbone
In this study, the backbone of weighted networks is extracted using two different methods. The first one called “overlapping nodes ego backbone” consists of defining the set of overlapping nodes and their neighbors as the network backbone. The second method called the “overlapping nodes and hubs backbone” is based on selecting the overlapping nodes and the hubs of the network to form the network backbone. These two models are detailed in the next two paragraphs.
Overlapping nodes ego backbone
Let’s consider a network G(V, E), where \(V = \{v_{1}, v_{2}, \ldots , v_{n}\}\) and \(E = \{(v_{i}, v_{j}) \setminus v_{i}, v_{j} \in V \}\) denotes the set of nodes and edges respectively. The algorithm used to extract the overlapping nodes ego backbone is as follows:
Step 1: If not known, the community structure of the network using a given overlapping community detection algorithm is uncovered.
Step 2: Form the sub-network made of the overlapping nodes and their neighbors. The set of overlapping nodes is defined as \(V_{o} = \{v_{1}^{o}, v_{2}^{o}, \ldots , v_{m}^{o}\} \subset V\) where m is the number of the overlapping nodes. The set of their neighbors is denoted by \(V_{no} = \{v_{1}^{no}, v_{2}^{no}, \ldots , v_{k}^{no}\} \subset V\) where k is the size of the neighborhood of the overlapping nodes. The overlapping nodes ego network is formed from the union of the set of overlapping nodes and the set of their neighbors. It is obtained by removing all nodes that do not belong to one of the two sets. The overlapping nodes ego network is denoted \(M(V_{q},E_{q})\), where \(V_{q}= V_{o} \cup V_{no}\) and \(E_{q}=\{(v_{i}^{q}, v_{j}^{q}) \setminus v_{i}, v_{j} \in V_{q}\}\) are respectively its set of nodes and edges. Figure 6b illustrates the formation of this sub-network for the toy example shown in Fig. 6a.

The backbone extraction of different methods for the Karate club network. (a) overlapping nodes ego backbone, (b) overlapping nodes and hubs backbone and (c) Serrano backbone. Nodes are highlighted in different colors according to the community they belong to. Nodes with the same color belong to the same community while those in gray represent the overlapping nodes. The size of the nodes is proportional to their weighted degree, while the size of links is proportional to their weights. The community structure is revealed using the SLPA detection algorithm.
Step 3: Remove the edges with the lowest weights from the overlapping ego sub-network. To do so, edges are sorted in decreasing order according to their weights. Then, edges with the lowest weights are removed as long as the sub-network remains connected. Figure 6c illustrates this step, where all the links with the lowest weights are removed.
Step 4: Control the size of the overlapping ego backbone with a parameter s. This parameter allows to preserve only the top-ranked nodes of this backbone. To this end, all the nodes of the overlapping nodes ego backbone are sorted in decreasing order according to the weighted degree centrality67. After that, according to the value of this threshold parameter, the nodes with low degrees are removed from the network. Figure 6d illustrates the obtained overlapping nodes ego backbone by setting the parameter s to 0.4. In this case, the backbone represents \(40\%\) of the nodes of the original network.
Overlapping nodes and hubs backbone
Let’s consider a network G(V, E), where \(V = \{v_{1}, v_{2}, \ldots , v_{n}\}\) and \(E = \{(v_{i}, v_{j}) \setminus v_{i}, v_{j} \in V \}\) denotes the set of nodes and edges respectively. To extract the overlapping nodes and hubs backbone, we follow the next steps:
Step 1: If not known, the community structure of the network using a given overlapping community detection algorithm is uncovered.
Step 2: form the sub-network based on the overlapping nodes and the hubs. The set of the overlapping nodes is denoted \(V_{o} = \{v_{1}^{o}, v_{2}^{o}, \ldots , v_{m}^{o}\} \subset V\) where m is the number of the overlapping nodes. The set of hubs is denoted \(V_{h} = \{v_{1}^{h}, v_{2}^{h}, \ldots , v_{t}^{h}\} \subset V\) where t represents the numbers of hubs. The overlapping nodes and hubs network is formed from the union of the set of overlapping nodes and the set of hubs. It is obtained by removing all nodes that do not belong to one of the two sets. The overlapping nodes and hubs network is denoted \(S(V_{y},E_{y})\), where \(V_{y}= V_{o} \cup V_{h}\) and \(E_{y}=\{(v_{i}^{y}, v_{j}^{y}) \setminus v_{i}, v_{j} \in V_{y}\}\) are respectively its set of nodes and edges. Figure 7b illustrates the formation of this sub-network in the toy example shown in Fig. 7a.

The backbone extraction of different methods for Les Miserables network. (a) overlapping nodes ego backbone, (b) overlapping nodes and hubs backbone and (c) Serrano backbone. Nodes are highlighted in different colors according to the community they belong to. Nodes with the same color belong to the same community while those in gray represent the overlapping nodes. The size of the nodes is proportional to their weighted degree, while the size of links is proportional to their weights. The community structure is revealed using the SLPA detection algorithm.
Steps 3 and 4 are identical to steps 3 and 4 of the overlapping nodes ego backbone algorithm. Figure 7c illustrates the overlapping nodes and hubs backbone when all the links with the lowest weights are discarded. In addition, Fig. 7d show the overlapping nodes and hubs backbone after setting the size threshold parameter s to 0.4.
Computational complexity
The computational complexity is dominated by the community detection process. Indeed, if the community structure is unknown it must be uncovered. This can be done using a linear community detection algorithm46. For instance, it takes \(O(N+L)\) for DEMON algorithm68 while it takes O(TL) for SLPA66 which is used in this work, where N is the size of the network, L is the number of its edges and T is the maximum iteration of the algorithm. In the overlapping nodes ego backbone, the overlapping nodes and their immediate neighbors are extracted in O(m), where m is the number of the overlapping nodes. In the overlapping nodes and hubs backbone, the nodes need to be sorted. This step can be done in O(N).
Evaluation measures
Multiple evaluation measures are used in order to compare the extracted backbones. They are defined as follows:
Proportion of common nodes
This measure assesses how many elements belong to two different sets of the same size. It is defined as the fraction of the size of the intersection between the two sets divided by their size. The proportion of common nodes \(A_{n}\) between two sets of nodes of the same size n is defined as:
where X and Y are the sets of nodes of two different backbones. n represents their size.%.
Rank-biased overlap
The rank-biased overlap69 is an extension of the previous measure. It estimates how strongly two ranking sets are in harmony with each other. It computes the proportion of common elements between two rankings sets while gradually increasing their depths. The ranks are determined according to the weighted degree of nodes. Moreover, different weight is assigned to the overlap of each depth. Let’s consider X and Y two rankings sorted in decreasing order. The rank-biased overlap r of two ranking sets X and Y is given by:
where \(A_{d}\) designates the overlap between the two sets X and Y at depth d. It is defined as follows:
\(X_{:d}\) denotes the set of elements (rankings) ranging from position 1 to position d. \(|X_{:d} \cap Y_{:d}|\) represents the size of the overlap of both sets X and Y at depth d. Each weight at a given depth d is represented by \(w_{d}\) which is given by:
The weights can be fixed via the parameter p. It ranges between 0 and 1. When it has a small value, more weight is given to the top elements of the sets. Thus, the tail of both sets gets a lower weight than the top. When p approaches 1, the comparison becomes deep in both sets. Additionally, the values of the rank-biased overlap vary between 0 and 1. The sets X and Y are perfectly identical when the value is equal to 1, while they are totally disjoint when the value is equal to 0.
Correlation
The correlation is used to evaluate the agreement between the set of nodes of two different backbones. We use two different types of correlation coefficients:
Pearson correlation This correlation coefficient is a very familiar measure that assesses the association between two sets. Let’s consider two sets X and Y of weighted degrees of nodes belonging respectively to the ordered set of nodes of two different backbones. The Pearson correlation \(\rho \) between the two sets X and Y is defined as follows:
where:
Kendall Tau correlation This correlation coefficient is usually used to measure the ranking consistency of two sets of nodes. Let’s consider two ranked sets \(X=(x_{1}, x_{2}, \ldots ,x_{n})\) and \(Y=(y_{1}, y_{2}, \ldots , y_{n})\) of size n. A pair of ranks \((x_{i}, y_{i})\) and \((x_{j}, y_{j})\) are considered concordant if \(x_{i} > x_{j}\) and \(y_{i} > y_{j}\) , or if \(x_{i} < x_{j}\) and \(y_{i} < y_{j}\). It is said discordant if \(x_{i} > x_{j}\) and \(y_{i} < y_{j}\), or if \(x_{i} < x_{j}\) and \(y_{i} > y_{j}\). The pair of ranks is neither concordant nor discordant if \(x_{i} = x_{j}\) or \(y_{i} = y_{j}\). Note that the ranks are computed according to the weighted degree. The Kendall Tau correlation \(\rho _{\tau }\) between two ranking sets X and Y of size n is given by:
where \(n_{c}\) and \(n_{d}\) stand for the number of concordant and discordant pairs, respectively. Both correlation coefficients belong to the interval [− 1,1]. There is a positive monotonic association between two sets (\(\rho > 0\)), if the values of the two vectors tend to increase or decrease simultaneously. In addition, there is a negative monotonic association between two sets (\(\rho < 0\)), if the values of one vector tend to increase when the values of the other decrease. When \(\rho \) is equal to 0, there is an absence of a monotonic association between the two sets. Furthermore, the strength of the relation between the two sets is considered moderate if the coefficient ranges between 0.5 and 0.8, while it is significant if the coefficient ranges between 0.8 and 1.
Dataset description
A set of real-world networks is collected from different fields (social, co-appearance, biological, technological and collaboration networks) to conduct a series of experiments. Their size ranges from hundreds to thousands of nodes and edges.
Zachary’s karate club It is a well known social network describing the relationship between members of a karate club at a US university. Nodes are the members of the karate club while the links represent the friendship between two members. A number between 0 and 8 is associated with each pair of club members. It indicates the strength of the relationship between a pair of members.
Intra-organisational This network is extracted from a consulting company. The nodes represent the 46 employees. A link exists between two employees if they have exchanged information or advice requests. The link weights designate how often an employee has turned to his colleague for information or advice on work-related topics during a period of three months. They are differentiated on a scale from 0 to 5.
Freeman’s EIES This network contains 48 researchers working on social network analysis. The nodes represent researchers while the edges represent their personal relationships. The edges have a weight ranging between 0 and 4. The weight is equal to 0 when a person is unknown to the researcher. It is equal to 1 when a person the researcher has heard of but didn’t meet. 3 represents a friendship relationship while 4 stands for a close personal friendship.
Train bombing This data set contains the network of suspected terrorists implicated in the train bombing which took place in Madrid on March 11, 2004. It was reconstructed from newspapers. The nodes represent terrorists while a link exists between two terrorists if there was contact between them. The weights indicate how strong their relationship was (a friendship or co-participating in training camps or previous attacks).
Les Miserables This co-appearance network contains the characters in Les Miserables novel. The nodes are the characters and link exists between two characters if they co-appeared in the same chapter. The weights measure the number of such occurrences.
Game of thrones This co-appearance network contains the characters of the Game of Thrones series, more precisely in the book “A Storm of Swords”. Nodes are the characters while a link exists between two characters if their names appeared within 15 words of each other in the text. The links are weighted by the number of these co-appearances.
C.elegans neural The Caenorhabditis elegans worm’s neural network contains 306 nodes representing neurons. An edge exists between two neurons if at least one synapse or gap junction exists between them. The weight is the number of synapses and gap junctions.
Facebook-like social It is an online social network of students at the University of California. The users included in this network are those who sent or received at least one message. The link weights of this network represent the number of characters in these messages.
Facebook-like forum The Facebook-like Forum network does not focus on messages exchanged between users but their activity in the forum. This forum includes 899 users and 522 topics. The weights can be associated to the edges based on the number of messages that a user posted to a topic.
US power grid This undirected network represents the high voltage power grid of the Western States of the United States of America. Nodes are generators, transformers and substations while the edges are the high voltage lines connecting them. The weights indicate the total electrical load in different lines.
Scientific collaboration This network contains authors of articles posted to the Condensed Matter section of arXiv E-Print Archive. Nodes are the authors and connections exist if they co-authored a paper. The weights are the number of joint papers.
Change history
20 April 2021
A Correction to this paper has been published: https://doi.org/10.1038/s41598-021-88213-8
References
Estrada, E. Introduction to complex networks: structure and dynamics. In Evolutionary Equations with Applications in Natural Sciences (eds Banasiak, J. & Mokhtar-Kharroubi, M.) 93–131 (Springer, Berlin, 2015).
Boccaletti, S., Latora, V., Moreno, Y., Chavez, M. & Hwang, D.-U. Complex networks: structure and dynamics. Phys. Rep. 424, 175–308 (2006).
Costa, Ld. F. et al. Analyzing and modeling real-world phenomena with complex networks: a survey of applications. Adv. Phys. 60, 329–412 (2011).
Junker, B. H. & Schreiber, F. Analysis of Biological Networks Vol. 2 (Wiley, Hoboken, 2011).
Börner, K., Sanyal, S. & Vespignani, A. Network science. Annu. Rev. Inf. Sci. Technol. 41, 537–607 (2007).
Chu, C.-C. & Iu, H.H.-C. Complex networks theory for modern smart grid applications: a survey. IEEE J. Emerg. Sel. Top. Circuits Syst. 7, 177–191 (2017).
Bassett, D. S. & Sporns, O. Network neuroscience. Nat. Neurosci. 20, 353 (2017).
Kumar, R., Novak, J. & Tomkins, A. Structure and evolution of online social networks. In Link Mining: Models, Algorithms, and Applications (eds Philip, S. Y. et al.) 337–357 (Springer, Berlin, 2010).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440 (1998).
Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512 (1999).
Fortunato, S. & Hric, D. Community detection in networks: a user guide. Phys. Rep. 659, 1–44 (2016).
Jebabli, M., Cherifi, H., Cherifi, C. & Hamouda, A. User and group networks on Youtube: a comparative analysis. In 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications (AICCSA) 1–8 (IEEE, 2015).
Jebabli, M., Cherifi, H., Cherifi, C. & Hammouda, A. Overlapping community structure in co-authorship networks: a case study. In 2014 7th International Conference on u-and e-Service, Science and Technology (UNESST) 26–29 (IEEE, 2014).
Kumar, M., Singh, A. & Cherifi, H. An efficient immunization strategy using overlapping nodes and its neighborhoods. In Companion of the The Web Conference 2018 on The Web Conference 2018 1269–1275 (International World Wide Web Conferences Steering Committee, 2018).
Ghalmane, Z., Cherifi, C., Cherifi, H. & El Hassouni, M. Centrality in complex networks with overlapping community structure. Sci. Rep. 9, 1–29 (2019).
Ghalmane, Z., El Hassouni, M., Cherifi, C. & Cherifi, H. Centrality in modular networks. EPJ Data Sci. 8, 15 (2019).
Goh, K.-I., Salvi, G., Kahng, B. & Kim, D. Skeleton and fractal scaling in complex networks. Phys. Rev. Lett. 96, 018701 (2006).
Chen, M. et al. Effectively clustering by finding density backbone based-on KNN. Pattern Recogn. 60, 486–498 (2016).
Boyack, K. W., Klavans, R. & Börner, K. Mapping the backbone of science. Scientometrics 64, 351–374 (2005).
Gfeller, D. & De Los Rios, P. Spectral coarse graining of complex networks. Phys. Rev. Lett. 99, 038701 (2007).
Grady, D., Thiemann, C. & Brockmann, D. Robust classification of salient links in complex networks. Nat. Commun. 3, 1–10 (2012).
Zhang, C.-J. & Zeng, A. Network skeleton for synchronization: identifying redundant connections. Phys. A 402, 180–185 (2014).
Glattfelder, J. B. & Battiston, S. Backbone of complex networks of corporations: the flow of control. Phys. Rev. E 80, 036104 (2009).
Zhang, Q.-M., Zeng, A. & Shang, M.-S. Extracting the information backbone in online system. PLoS ONE 8, e62624 (2013).
Liebig, J. . & Rao, A. . Fast extraction of the backbone of projected bipartite networks to aid community detection. EPL (Europhys. Lett.) 113, 28003 (2016).
Marotta, L. et al. Backbone of credit relationships in the Japanese credit market. EPJ Data Sci. 5, 10 (2016).
Cao, J., Ding, C. & Shi, B. Motif-based functional backbone extraction of complex networks. Phys. A 526, 121123 (2019).
Chalupa, J., Leath, P. L. & Reich, G. R. Bootstrap percolation on a Bethe lattice. J. Phys. C: Solid State Phys. 12, L31 (1979).
Carmi, S., Havlin, S., Kirkpatrick, S., Shavitt, Y. & Shir, E. A model of internet topology using k-shell decomposition. Proc. Natl. Acad. Sci. 104, 11150–11154 (2007).
Zhang, X. & Zhu, J. Skeleton of weighted social network. Phys. A 392, 1547–1556 (2013).
Serrano, M. Á., Boguná, M. & Vespignani, A. Extracting the multiscale backbone of complex weighted networks. Proc. Natl. Acad. Sci. 106, 6483–6488 (2009).
Li, Q., Zhou, T., Lü, L. & Chen, D. Identifying influential spreaders by weighted leaderrank. Phys. A 404, 47–55 (2014).
Lindner, G., Staudt, C. L., Hamann, M., Meyerhenke, H. & Wagner, D. Structure-preserving sparsification of social networks. In 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM) 448–454 (IEEE, 2015).
Qian, L., Bu, Z., Lu, M., Cao, J. & Wu, Z. Extracting backbones from weighted complex networks with incomplete information. In Abstract and Applied Analysis, Vol. 2015 (Hindawi, Cairo, 2015).
Zhang, X., Zhang, Z., Zhao, H., Wang, Q. & Zhu, J. Extracting the globally and locally adaptive backbone of complex networks. PLoS ONE 9, e100428 (2014).
Nick, B., Lee, C., Cunningham, P. & Brandes, U. Simmelian backbones: amplifying hidden homophily in facebook networks. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 525–532 (2013).
Zhang, R. J., Stanley, H. E. & Fred, Y. Y. Extracting h-backbone as a core structure in weighted networks. Sci. Rep. 8, 1–7 (2018).
Neal, Z. Identifying statistically significant edges in one-mode projections. Soc. Netw. Anal. Min. 3, 915–924 (2013).
Neal, Z. The backbone of bipartite projections: inferring relationships from co-authorship, co-sponsorship, co-attendance and other co-behaviors. Soc. Netw. 39, 84–97 (2014).
Zweig, K. A. & Kaufmann, M. A systematic approach to the one-mode projection of bipartite graphs. Soc. Netw. Anal. Min. 1, 187–218 (2011).
Jo, W. S., Park, J., Luhur, A., Kim, B. J. & Ahn, Y.-Y. Extracting hierarchical backbones from bipartite networks. arXiv:2002.07239 (2020).
Domagalski, R., Neal, Z. & Sagan, B. backbone: an r package for backbone extraction of weighted graphs. arXiv:1912.12779 (2019).
Orman, G. K., Labatut, V. & Cherifi, H. Towards realistic artificial benchmark for community detection algorithms evaluation. Int. J. Web Based Commun. 9, 349–370 (2013).
Kitromilidis, M. & Evans, T. S. Community detection with metadata in a network of biographies of western art painters. arXiv:1802.07985 (2018).
Tulu, M. M., Hou, R. & Younas, T. Identifying influential nodes based on community structure to speed up the dissemination of information in complex network. IEEE Access 6, 7390–7401 (2018).
Jebabli, M., Cherifi, H., Cherifi, C. & Hamouda, A. Community detection algorithm evaluation with ground-truth data. Phys. A 492, 651–706 (2018).
Guimera, R., Sales-Pardo, M. & Amaral, L. A. Classes of complex networks defined by role-to-role connectivity profiles. Nat. Phys. 3, 63–69 (2007).
Orman, K., Labatut, V. & Cherifi, H. An empirical study of the relation between community structure and transitivity. In Complex Networks 99–110 (Springer, Berlin, 2013).
Cherifi, H., Palla, G., Szymanski, B. K. & Lu, X. On community structure in complex networks: challenges and opportunities. Appl. Netw. Sci. 4, 1–35 (2019).
Palla, G., Derényi, I., Farkas, I. & Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 435, 814 (2005).
Hébert-Dufresne, L., Allard, A., Young, J.-G. & Dubé, L. J. Global efficiency of local immunization on complex networks. Sci. Rep. 3, 2171 (2013).
Ghalmane, Z., El Hassouni, M. & Cherifi, H. Immunization of networks with non-overlapping community structure. Soc. Netw. Anal. Min. 9, 45 (2019).
Ghalmane, Z., Cherifi, C., Cherifi, H. & El Hassouni, M. Exploring hubs and overlapping nodes interactions in modular complex networks. IEEE Access 8, 79650–79683 (2020).
Chakraborty, D., Singh, A. & Cherifi, H. Immunization strategies based on the overlapping nodes in networks with community structure. In International Conference on Computational Social Networks 62–73 (Springer, Berlin, 2016).
Taghavian, F., Salehi, M. & Teimouri, M. A local immunization strategy for networks with overlapping community structure. Phys. A 467, 148–156 (2017).
Gupta, N., Singh, A. & Cherifi, H. Community-based immunization strategies for epidemic control. In 2015 7th International Conference on Communication Systems and Networks (COMSNETS) 1–6 (IEEE, 2015).
Salathé, M. & Jones, J. H. Dynamics and control of diseases in networks with community structure. PLoS Comput. Biol. 6, e1000736 (2010).
Gong, K. Local immunization based on degree-community-bridge-find in heterogeneity community networks. In International Conference on Logistics Engineering, Management and Computer Science (LEMCS 2014) (Atlantis Press, 2014).
Chan, S. Y., Leung, I. X. & Liò, P. Fast centrality approximation in modular networks. In Proceedings of the 1st ACM International Workshop on Complex Networks Meet Information & Knowledge Management 31–38 (ACM, 2009).
Mantzaris, A. V. Uncovering nodes that spread information between communities in social networks. EPJ Data Sci. 3, 26 (2014).
Jensen, P. et al. Detecting global bridges in networks. J. Complex Netw. 4, 319–329 (2015).
Yoshida, T. & Yamada, Y. A community structure-based approach for network immunization. Comput. Intell. 33, 77–98 (2017).
Ghalmane, Z., El Hassouni, M. & Cherifi, H. Betweenness centrality for networks with non-overlapping community structure. In 2018 IEEE Workshop on Complexity in Engineering (COMPENG) 1–5 (IEEE, 2018).
Ghalmane, Z., El Hassouni, M., Cherifi, C. & Cherifi, H. k-truss decomposition for modular centrality. In 2018 9th International Symposium on Signal, Image, Video and Communications (ISIVC) 241–248 (IEEE, 2018).
Yang, J. & Leskovec, J. Structure and overlaps of ground-truth communities in networks. ACM Trans. Intell. Syst. Technol: TIST 5, 1–35 (2014).
Xie, J., Szymanski, B. K. & Liu, X. Slpa: uncovering overlapping communities in social networks via a speaker-listener interaction dynamic process. In 2011 IEEE 11th International Conference on Data Mining Workshops 344–349 (IEEE, 2011).
Opsahl, T., Agneessens, F. & Skvoretz, J. Node centrality in weighted networks: generalizing degree and shortest paths. Soc. Netw. 32, 245–251 (2010).
Coscia, M., Rossetti, G., Giannotti, F. & Pedreschi, D. Demon: a local-first discovery method for overlapping communities. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 615–623 (2012).
Webber, W., Moffat, A. & Zobel, J. A similarity measure for indefinite rankings. ACM Trans. Inf. Syst.: TOIS 28, 1–38 (2010).
Author information
Authors and Affiliations
Contributions
All the authors contributed to designing the proposed method. ZG implemented the model and all the analyses. All authors participated in the formulation and writing of this paper. All authors approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ghalmane, Z., Cherifi, C., Cherifi, H. et al. Extracting backbones in weighted modular complex networks. Sci Rep 10, 15539 (2020). https://doi.org/10.1038/s41598-020-71876-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-71876-0
This article is cited by
-
A multilevel backbone extraction framework
Applied Network Science (2024)
-
An evaluation tool for backbone extraction techniques in weighted complex networks
Scientific Reports (2023)
-
Motif-h: a novel functional backbone extraction for directed networks
Complex & Intelligent Systems (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
