
Abstract
Delay embedding—a method for reconstructing dynamical systems by delay coordinates—is widely used to forecast nonlinear time series as a model-free approach. When multivariate time series are observed, several existing frameworks can be applied to yield a single forecast combining multiple forecasts derived from various embeddings. However, the performance of these frameworks is not always satisfactory because they randomly select embeddings or use brute force and do not consider the diversity of the embeddings to combine. Herein, we develop a forecasting framework that overcomes these existing problems. The framework exploits various “suboptimal embeddings” obtained by minimizing the in-sample error via combinatorial optimization. The framework achieves the best results among existing frameworks for sample toy datasets and a real-world flood dataset. We show that the framework is applicable to a wide range of data lengths and dimensions. Therefore, the framework can be applied to various fields such as neuroscience, ecology, finance, fluid dynamics, weather, and disaster prevention.
Similar content being viewed by others


Introduction
Forecasting a future system state is an important task in various fields such as neuroscience, ecology, finance, fluid dynamics, weather, and disaster prevention. If accurate system equations are unknown but a time series is observed, we can use model-free forecasting approaches. Although there are various model-free methods, if the time series is assumed to be nonlinear and deterministic, one of the most common approaches is delay embedding. According to embedding theorems1,2, we can reconstruct the underlying dynamics by delay embedding (see Methods for details). These theorems ensure that the map from the original attractor to the reconstructed attractor has a one-to-one correspondence. These embedding theorems have also been extended to multivariate data and nonuniform embeddings3. In addition, multivariate embeddings have been empirically used4,5,6,7 before the extended theorem was proposed.
When multivariate time series are observed, various embeddings can be obtained on the basis of the extended embedding theorem3. Ye and Sugihara8 exploited this property; they developed multiview embedding (MVE), which combines multiple forecasts based on the top-performing multiple embeddings scored by the in-sample error. MVE can yield a more accurate forecast than the single best embedding, especially for short time series8. Although MVE works well with low-dimensional data, it cannot be simply applied to high-dimensional data. This is because MVE requires forecasts derived from all possible embeddings, whose total number combinatorially increases with the number of variables. Although we can approximate MVE by randomly chosen embeddings if the total number of possible embeddings is beyond the computable one9, it is difficult to find high-performance embeddings for high-dimensional data. Recently, Ma et al.10 presented an outstanding framework, randomly distributed embedding (RDE), to tackle these high-dimensional data. Their key idea is to combine forecasts yielded by randomly generated “nondelay embeddings” of target variables. These “nondelay embeddings” can also reconstruct the original state space for some cases and drastically reduce the possible number of embeddings. Ma et al.10 also showed that small embedding dimensions worked fine, even for high-dimensional dynamics, and successfully forecasted short-term high-dimensional data using the RDE framework. Although RDE showed outstanding results, there is room for improvement for some specific tasks. For example, “nondelay embedding” may overlook important pieces of information if delayed observations carry such pieces of information, e.g., the upstream river height for flood forecasting. A random distribution may also be a problem for the case where only partial variables are valid system variables; in this case, most of the random embeddings are invalid and not suitable to forecast. In addition, several important hyperparameters–the embedding dimension and the number of embeddings to combine–must be manually or empirically selected. Although ensembles tend to yield better results with significant diversity among its members11,12, RDE only aggregates forecasts for a fixed embedding dimension with a fixed number of embeddings to combine, regardless of their forecast performance.
In this study, we propose another forecasting framework that overcomes the disadvantages of MVE and RDE. Our key idea is to prepare diverse “suboptimal embeddings” via combinatorial optimization. We combine the optimal number of these embeddings to maximize the performance of the combined forecast. In contrast to the existing frameworks, the suitable embedding dimensions and the number of embeddings to combine are automatically determined through this procedure. Our proposed framework achieves better forecast performance than the existing frameworks for high-dimensional toy models and a real-world flood dataset.
Results
In this section, we introduce a forecasting framework that overcomes some drawbacks of existing frameworks in the first subsection. Then, we numerically validate the performance of the proposed framework by using toy models as well as a real dataset in the second subsection.
Proposed forecasting framework
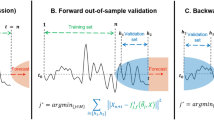
Our proposed framework yields a single forecast to combine multiple ones, which are obtained by multiple embeddings. Although the principal concept is the same as those of MVE and RDE, the procedure to yield the multiple embeddings differs from the existing ones. These embeddings are obtained through two steps. First, we obtain suboptimal embeddings, which are suboptimal solutions to minimize the forecast error. The aim of this procedure is to yield diverse embeddings to improve the performance of the combined forecast because such diversity is important for the performance of the ensemble11,12. Second, we make the in-sample forecasts based on all suboptimal embeddings following MVE and RDE but pick the optimal number of embeddings to minimize the error of the combined forecasts. A schematic of the procedure is illustrated in Fig. 1. We describe each step in detail in the following sub-subsections.

Schematic of the proposed forecasting procedure. We prepare a pool of suboptimal embeddings in the first step. We solve K combinatorial optimization problems to obtain various embeddings in this step. Next, we pick \({\hat{k}}_{p}\) embeddings to minimize the error of the combined forecast in the second step. We combine the forecasts obtained by the \({\hat{k}}_{p}\) embeddings to test the time series.
First step: Preparing suboptimal embeddings
In our framework, we first obtain diverse suboptimal embeddings to minimize the in-sample forecast error. With the observed time series \(y(t)\in {{\mathbb{R}}}^{n}\), a set of possible embeddings \( {\mathcal E} \), and a corresponding delay vector \({v}_{e}(t)\in {{\mathbb{R}}}^{E}\) with \(e\in {\mathcal E} \), we can obtain the p-steps-ahead forecast at time t by a map \({\psi }_{e}\) as follows:
where yf is the target variable to be forecasted. We can obtain such maps by suitable fitting algorithms, e.g., the conventional method of analogues13, as in MVE, and Gaussian process regression14, as in RDE. Throughout this paper, we apply the same algorithm, a variation of the method of analogues (see Supplementary Information), to all forecasting frameworks including the proposed one. This is because we need to compare the performance of the frameworks on a fair basis that is not affected by the performance of each fitting algorithm.
To obtain high-performance embeddings in an efficient manner, we solve combinatorial optimization problems instead of random selection or using brute force. We define the time indices used for training as t < 0, and suppose the forecasting of unobserved samples for t ≥ 0. We split the set of training time indices \({\mathscr{T}}_{train}=\{t|t < 0\}\) into K datasets. Then, we solve the following optimization problem for each \(K^{\prime} \in \mathrm{\{1,2,}\ldots ,K\}\) to minimize the error:
where \({\mathscr{T}}_{train}^{{K}^{{\rm{^{\prime} }}}}\) is the \(K^{\prime} \) th set of training time indices and \(\Vert \cdot \Vert \) is an appropriate norm. We use the L2 norm throughout this paper. Note that \({\hat{y}}_{f}^{e}\) is computed in an in-sample manner, similar to MVE; we use all of \({\mathscr{T}}_{train}\), except for the current time, as its library (leave-one-out cross-validation). When we consider embeddings up to l lags to embed the latest observation of the target variable, the number of possible embeddings is \({2}^{nl-1}\). If nl is sufficiently large, it is almost impossible to compute all possible embeddings because of combinatorial explosion. Here, we take a straightforward approach to minimize the forecast error: an evolution strategy that interprets an embedding as a one-dimensional binary series15,16. See Methods for details. Throughout this paper, we applied the (μ + λ) evolution strategy17.
In the process of each optimization, we store not only the best embedding but also the “Hall of Fame,” which preserves the best individuals in each generation. From the Hall of Fame, we select the best M solutions that satisfy the condition that the Hamming distance \(d(\cdot ,\cdot )\) is larger than or equal to a certain threshold value θ as follows:
where ei is the i th embedding of the sorted Hall of Fame. Namely, we sort the Hall of Fame by the fitness (the objective function of Eq. 2) and pick the best embeddings in order from the sorted Hall of Fame to satisfy Eq. (3). Note that the Hamming distance is defined according to the binary expressions of the embeddings. This condition prunes similar embeddings and keeps diverse embeddings for the next step. We can explicitly control the diversity of the embeddings by changing the threshold value θ, while the existing approaches do not include such a mechanism. The diversity of embeddings can affect the performance of the combined forecast. To apply this procedure, we obtain \(K\cdot M\) suboptimal embeddings in total. See also the first part of Algorithm 1 in Methods.
The procedure of the K times optimizations yields diverse but high-performance embeddings. If a dataset contains a large number of variables, it is extremely difficult to obtain the exact solution by evolution strategies or any other metaheuristic algorithms. These algorithms find suboptimal solutions for most cases, and these solutions can be easily changed by slight changes in the optimization conditions. The procedure rather exploits this property; the K times optimization can find K sets of diverse suboptimal solutions. Instead of minimizing the whole in-sample error with K different conditions, we minimize each K split dataset and utilize the history of solutions to significantly reduce the computational time. We numerically show the effect of K times optimization in Supplementary Information.
To create diverse embeddings and improve the performance of the combined forecast, we can optionally consider L finite impulse response (FIR) filters for each suboptimal embedding; namely, \(K\cdot L\cdot M\) embeddings are obtained in total. A study has shown that the combination of various forecasts via linear filters improves the forecast result in some cases18. These filtered embeddings are justified by the filtered delay embedding prevalence theorem2, which ensures the embedding with finite filtered delay coordinates. Although we can compute suboptimal embeddings for each filter, we simply consider L filters based on the obtained \(K\cdot M\) embeddings. Empirically, the optimization of the embeddings for each filter does not realize a significant improvement in performance to justify the additional computational cost. See Methods for the details of forecasting filtered time series.
Second step: combining forecasts to minimize the in-sample error
Next, we pick the optimal number of embeddings from the \(P=K\cdot L\cdot M\) embeddings to minimize the error of the combined forecast. We compute in-sample forecasts by the embeddings for all of \({\mathscr{T}}_{train}\), as done in the MVE or RDE aggregation schemes. We determine the optimal number of embeddings to integrate forecasts, which is neither the square root of the possible number of embeddings (as MVE does) nor the embedding dimension (as the RDE aggregation scheme does). Here, we define a tuple of the forecast indices sorted by the in-sample error for step p as \({ {\mathcal I} }_{p}\), and the i th best embedding is written as \({ {\mathcal I} }_{p}(i)\). Note that \({ {\mathcal I} }_{p}\) is separately computed for each forecast horizon because accurate embeddings may differ according to the forecast horizons, as discussed later. We obtain \({\hat{k}}_{p}\) to minimize the combined forecast as follows:
We can obtain \({\hat{k}}_{p}\) in a brute-force manner with a very small computational cost because the k th combined forecast \({Y}_{k}(t+p|t)\) can be recursively computed as follows:
where \(k=\mathrm{1,2,}\ldots ,P-\mathrm{1,}\,{Y}_{1}(t+p|t)={\hat{y}}_{f}^{{ {\mathcal I} }_{p}\mathrm{(1)}}(t+p|t)\). We compute \({Y}_{k}\) and the corresponding error for all k and pick the optimal value to minimize the squared error. Note that \({\hat{k}}_{p}\) can be different for each p; empirically, \({\hat{k}}_{p}\) tends to be larger for a longer step.
For unobserved samples t ≥ 0, the forecast \({\hat{y}}_{f}(t+p|t)\) is computed as follows:
Note that only \({\hat{k}}_{p}\) forecasts are necessary to compute unobserved samples (test data) rather than \(K\cdot L\cdot M\) forecasts. We summarize the whole algorithm in Algorithm 1 in Methods.
Numerical experiments
Toy models
We demonstrate our framework with toy models. We first tested with the 10-dimensional Lorenz’96I model19 using forcing term 8.0. The model is described as 10-dimensional differential equations, and we used five of their system variables and five random walks as a dataset–namely, Lorenz’96I’s \({x}_{0},{x}_{1},{x}_{2},{x}_{3},{x}_{4}\) and random walks \({x}_{5},{x}_{6},{x}_{7},{x}_{8},{x}_{9}\). We forecasted \({x}_{0}\) up to 10 steps. The single time step corresponds to the 0.5 non-dimensional unit of the original system. Note that the 0.05 non-dimensional unit corresponds to 6 hours with the forcing 8.0 in terms of the error growth rate under the conditions of the original study19. See Supplementary Information for the detailed setup. We compared the proposed framework with existing frameworks–namely, randomly distributed embedding with an aggregation scheme (RDE), multiview embedding (MVE), a variation of MVE (state-dependent weighting9 (SDW)), and the single best embedding via the (μ + λ)-ES algorithm. In addition, we also compared the proposed framework with a conventional single-variable embedding (SVE) and an all-variable embedding (AVE). See Supplementary Information for the detailed conditions.
We first tested the performance with the data length of 4000 for the database and 500 for the evaluation. Figure 2(a) shows that the proposed forecast achieved the best performance among the existing frameworks up to 10 steps ahead with the length of 4000.

Forecast performance with the Lorenz’96I model: comparisons of the performance (a) up to 10 steps ahead with the fixed data length (4000) without noise, (b) with different values of the data length, and (c) with different scales of observational noise. We computed the RMSE of the five-steps-ahead forecasts with randomly distributed embedding (RDE), multiview embedding (MVE), state-dependent weighting (SDW), single-best embedding based on the (μ + λ)-ES algorithm (SBE), single-variable embedding (SVE), all-variable embedding (AVE), and the proposed framework. These tests were carried out with 20 datasets generated with different random initial conditions and noise. The median, upper quartile, and lower quartile are shown.
We conducted a sensitivity analysis with the data length. We set the data length, i.e., the size of the training dataset, to {100, 200, 500, 1000, 2000, 4000} and tested the performance with 500 samples for all cases. Figure 2(b) shows that the proposed five-steps-ahead forecast yielded the minimum error among the existing frameworks for all the data lengths.
We also checked the robustness against observational noise. We added Gaussian observational noise scaled by the standard deviation of the target variable and tested the performance with a scale range of {0.0, 0.1, 0.2, 0.3}. We set the training data length as 500 and evaluated with 500 samples. Figure 2(c) shows that a lower noise level results in better performance for the proposed framework compared with the other frameworks. Although the proposed framework achieved the best performance up to 10% noise, the performance was degraded by high-level noise and is the second best at most for 30% noise.
We profiled which variables were embedded for the combined forecasts for the case where the data length is 4000 without noise. We summed \({\hat{k}}_{p}\) embeddings for each variable, where 1 means embedded and 0 means not embedded. Then, we computed the proportion of embedding of each variable, normalizing the sum to one for each p. Figure 3(a) shows that random walks \({x}_{5},{x}_{6},{x}_{7},{x}_{8}\), and \({x}_{9}\) were seldom embedded with the proposed framework. This result suggests that our proposed framework can select the appropriate variables. The results also show that the proportion of embedding of the target variable \({x}_{0}\) is large for short-term prediction and small for longer-term prediction. This result is consistent with that of an existing study20.

Forecast profile of the Lorenz’96I model with the data length of 4000. Panel (a) shows the proportion of embedding of the proposed forecasts. The color indicates the proportion of embedding for each variable averaged over the number of combined forecasts for each step. Note that for each prediction step, the sum of the proportions of all variables is one. Variables \({x}_{0},\ldots ,{x}_{4}\) are the variables of the 10-dimensional Lorenz’96I equations, and the other variables are random walks. Panel (b) shows the averaged filter coefficient ρ and embedding dimension E over the combined forecasts for each step. Note that the averaged dimensions can be a decimal fraction since they are averaged over the number of combined forecasts for each step. Panel (c) shows the relation between the number of combined forecasts and the errors. The solid line shows the in-sample error, and the dashed line shows the test error. The vertical solid line shows the selected number of combined forecasts kp to minimize the in-sample error.
We also profiled the filter coefficient ρ and the embedding dimension E of the proposed combined forecasts. Details regarding the definition of ρ are presented in the Methods section. We averaged ρ and E over the \({\hat{k}}_{p}\) combined members for each step. Figure 3(b) shows that smaller dimensions are selected for shorter steps, and larger dimensions are selected for longer predictions. The figure also shows that smaller and larger values of ρ are selected for shorter and longer steps, respectively. Because we employ high-pass filtering (ρ ≤ 0) with this model, a smaller ρ focuses on a smaller time period and vice versa.
We investigated the number of combined forecasts and the forecast errors to check whether the proposed integration scheme works properly. Although the proposed framework determines \({\hat{k}}_{p}\) on the basis of the in-sample error, \({\hat{k}}_{p}\) also minimizes the test error in this example (see Fig. 3(c)).
We also demonstrate our framework with the Kuramoto–Sivashinsky equations21,22. We generated 20-dimensional time series: the values of the first 10 grids of the Kuramoto–Sivashinsky equations \({x}_{0},{x}_{1},\ldots ,{x}_{9}\) and 10 random walks \({x}_{10},{x}_{11},\ldots ,{x}_{19}\). Note that a single time step corresponds to 1.0 of the original system. See Supplementary Information for the detailed setup. We forecasted \({x}_{0}\) up to 10 steps using the same parameter values, data length, and noise scales as used in the Lorenz’96I example. See Supplementary Information for the detailed conditions.
Despite the increases in the variables, Fig. 4(a,b) show that the proposed forecast yielded the minimum error among the existing frameworks, as in the Lorenz’96I example. Regarding the noise sensitivity, a lower noise level results in better performance for the proposed framework compared to the other frameworks. The proposed framework achieved the best performance for a wide data range and relatively small observational noise.

Forecast performance with the Kuramoto–Sivashinsky equations: comparisons of the performance (a) up to 10 steps ahead with the fixed data length (4000) without noise, (b) with different values of the data length, and (c) with different scales of observational noise. We computed the RMSE of the five-steps-ahead forecasts with randomly distributed embedding (RDE), multiview embedding (MVE), state-dependent weighting (SDW), single-best embedding based on the (μ + λ)-ES algorithm (SBE), single-variable embedding (SVE), all-variable embedding (AVE), and the proposed framework. These tests were carried out with 20 datasets generated with different random initial conditions and noise. The median, upper quartile, and lower quartile are shown.
Finally, we tested the sensitivity to the number of variables. We changed the dimensions of Lorenz’96I to {10, 20, 40, 80, 160, 320}, and we substituted a half of each dataset with random walks. We set the training data length to 500 and evaluated with 500 samples. For all ranges of variables, the proposed framework achieved the best performance (Fig. 5(a)). We also tested the case where all variables are available and the datasets do not contain random walks; this is the case in which delay embedding is not needed because all system variables are observed. In this case, the performance difference is negligible for all the top four frameworks, and RDE achieved the best score for the case where the number of variables is 320. Although this condition is too ideal because the observation function is an identity map, we can expect RDE to perform well for such cases that include many informative variables.

Forecast performance with the Lorenz’96I model for various numbers of variables: cases where (a) a half of the variables are substituted with random walks and (b) all variables are available. We computed the RMSE of the five-steps-ahead forecasts with randomly distributed embedding (RDE), multiview embedding (MVE), state-dependent weighting (SDW), single-best embedding based on the (μ + λ)-ES algorithm (SBE), single-variable embedding (SVE), all-variable embedding (AVE), and the proposed framework. These tests were carried out with 20 datasets generated with different random initial conditions and noise. The median, upper quartile, and lower quartile are shown.
Flood dataset
We tested the proposed framework with real-world data, namely the flood forecasting competition dataset at “Artificial Neural Network Experiment (ANNEX 2005/2006)”23. This dataset contains nine variables: the river stages of the target site (Q), and three upstream sites (US1, US2, and US3) and five rain gauges (RG1, RG2, RG3, RG4, and RG5) for three periods. We forecasted 6, 12, 18, and 24 h ahead of the target river stage using all nine variables. See Supplementary Information for the detailed conditions. We also compared our framework with three other conventional machine-learning methods used in an existing study9: a recurrent neural network with long short-term memory (LSTM)24, support vector regression (SVR)25, and random forest regression26. See the detailed conditions in ref. 9.
The results in Table 1 show that the proposed framework yielded the best root-mean-square error (RMSE) through 12–24 h ahead, and the differences compared to the other methods were expanded over the forecast horizon. Although the 6 h (one step)-ahead forecast was not the best, the difference compared to the best score was negligible. The dataset contains only 1460 points, and long-term memory is not required for this task; hence, LSTM did not perform well. Although the test data include the largest river stage on 1995-02-01, Fig. 6(a) shows that the proposed framework properly forecasted the inexperienced river stage.

Forecast results for the flood dataset. Panel (a) shows a comparison of the ground truth and the proposed 24-h-ahead forecast. The proposed forecast did not underestimate the maximum river stage, which is the maximum value of the whole dataset. Panel (b) shows a comparison of the in-sample and test errors of the ensemble members. The results demonstrate the difficulty of selecting the best forecast because the best in-sample forecast does not always perform the best. In contrast, the combined forecast performed the best by far for both training and test data. Panel (c) shows the filter coefficient ρ and embedding dimension E averaged over the combined forecasts for each step.
We compared the combined forecast with its individual members obtained with the (μ + λ)-ES algorithm. Regarding the individual members, the order of the in-sample score was different from the order of the test (see Fig. 6(b)). In contrast, the combined forecast achieved the minimum error by far for the both the in-sample and test errors. This forecast stability is one of the largest advantages of combining forecasts. Simultaneously, we profiled the best embeddings for combination, as shown in Fig. 7. Although each embedding performs competitively, they exhibit vastly different embeddings. Interestingly, the embedding dimensions are approximately 10 for all embeddings. This suggests that the high-performing embedding dimensions are approximately identical although there are various high-performing embeddings for the forecasts.

The top six embeddings to be combined for a 24-h-ahead forecast. Dark blue cells represent embeddings, and white cells indicate no embeddings. The horizontal axis indicates variables, and the vertical axis denotes the lags.
We also profiled ρ and E averaged over the \({\hat{k}}_{p}\) combined members for each step. The results in Fig. 6(c) suggest the same trends as the toy models, even for the real-world data. Specifically, smaller dimensions and smaller values of ρ were selected for shorter steps.
Discussion
Our numerical experiments suggest that our proposed framework works well for a wide range of the data length, including short time series such as 100. In contrast, the framework did not appear to work fine with very noisy data, and MVE achieved the best performance, as shown in the noise sensitivity analyses (Figs. 2(c) and 4(c)). This suggests that noise prevents the framework from selecting optimal embeddings on the basis of the squared errors, and it results in obtaining invalid embeddings. MVE can still be a good option for very noisy data. Note that the performance of RDE was not satisfactory in some of our numerical experiments, but this is because the RDE framework was originally proposed for extremely high-dimensional data, e.g., hundreds of variables. As shown in Fig. 5(b), we can expect RDE to perform well for cases that include many informative variables, and delay embedding is not needed.
The diversity of suboptimal embeddings is deeply linked to the performance of the proposed framework. As shown in the numerical experiments, the proposed framework worked well for high-dimensional dynamics and datasets containing high-dimensional variables. On the other hand, it is not suitable to apply it to relatively low-dimensional data. We tested the framework with low-dimensional datasets, and the results suggest that the proposed framework does not always yield the best performance, especially for low-dimensional datasets such as the Rössler equations27 (see Supplementary Information). This is because it is easy to find suitable embeddings to forecast in a brute-force manner, especially for low-dimensional datasets, while it becomes combinatorially difficult as the number of variables increases. In addition, the aim of K times optimization is to yield diverse embeddings (see the effect of K times optimization in Supplementary Information). However, if a dataset contains a small number of variables, almost the exact solutions are obtained for every optimization. We numerically ensured this behavior in the “Diversity of embeddings for split dataset” section in the Supplementary Information. The result shows that high-dimensional datasets with smaller data length produced diverse embeddings, but low-dimensional datasets with larger data length obtained similar or common embeddings across segments. This property is consistent with the performance of high- and low-dimensional datasets.
The proposed method combines forecasts via the simple average, optimizing the number of forecasts. The simple average works fine for most cases because suboptimal embeddings can equally forecast well thanks to solving the combinatorial optimization problem, and the test performance order is not always the same as the corresponding training data, especially for real-world data (see Fig. 6(b)). If suboptimal embeddings show quite different forecast performances, the weighted average based on the error distribution10 may work better. We can also apply the expert advice framework28 if better forecasts are assumed to be changed over time.
We need to select the values of several parameters to apply the proposed framework, i.e., the number of split datasets K, the number of the suboptimal embeddings for each batch M, the criteria of the Hamming distance θ of Eq. (3), the number of filters L, and their components. We can control the variations in forecasts with these parameters. In order to set K, we consider the number of samples in each divided dataset; empirically, the framework works well with more than 50 samples for each divided dataset. Note that the these samples are used only for the evaluation of an objective function, and the corresponding forecasts are yielded by using whole training data in an in-sample manner. Samples that are too small prevent the framework from finding good embeddings, but samples that are too large reduce the diversity of the embeddings. Although M can be any large integer (up to the total number of individuals of the evolution strategy), M ≤ 5 is sufficient for most cases. Note that the value of M that is too large is overkill and unnecessarily increases the computational cost. The criteria for the Hamming distance θ directly controls the similarity of suboptimal embeddings. We set θ = 3 in this study, and it worked fine for all cases. Note that conventional MVE and RDE guarantee that the Hamming distance among all embeddings is larger than two (i.e., θ = 2) for a fixed embedding dimension. In practice, appropriate filters depend on the prediction steps. If we predict shorter time periods, high-pass filters will work fine; if we predict longer time periods, low frequencies are needed to obtain fine forecasts, as the numerical experiments suggest. Although we treat high-pass filters in this study, low-pass filters may work for extremely noisy data. We need to understand the effects of these parameters and set the appropriate values within reason, P = KLM, which is usually much smaller than the total number of embeddings evaluated in the first step.
Our numerical experiments suggest that the appropriate embeddings vary with the prediction steps. The results show that a smaller E with a smaller ρ is preferable for a short-term forecast, and a larger E with a larger ρ is preferable for a longer-term forecast. These results are consistent with those of an existing study20 and with the fact that the longer-step forecasts need more complex map from the current inputs to the forecasts. Therefore, more information is needed to express the complex map.
Although we applied the (μ + λ)-ES algorithm to obtain the suboptimal embeddings, it is worth considering other methods to solve the combinatorial optimization problem. We can apply other evolution algorithms, e.g., simulated annealing29 and ant colony optimization30. Any algorithm may work as long as it can store the suboptimal embeddings through its optimization procedure. Testing and evaluating other algorithms are open problems.
Throughout this study, we used a variation of a local nonlinear prediction method to forecast the target variable. One of the most significant advantages of these local prediction methods is that we can compute in-sample forecasts very easily with a small computational cost; all we have to do is to exclude the current query from the nearest neighbors. In addition, owing to recent progress in approximate neighboring search algorithms (e.g., refs. 31,32), these algorithms are fast enough to apply the evolution algorithms. Moreover, it is also suitable to obtain suboptimal embeddings through the forecast errors because local nonlinear prediction methods are sensitive to the false nearest neighbors derived from invalid features. However, we can apply other regression methods, e.g., Gaussian process regression14, as done in RDE10, for further improvements. Note that these methods incur a very large computational cost to yield in-sample forecasts, as mentioned in ref. 10. To reduce the computational cost, we can apply these methods to only the process in the second step and can approximate the in-sample error by the k-fold cross-validation error.
Methods
Delay embedding
Delay embedding is a method of reconstructing the original state space using the delay coordinates v(t). Here, with the n-dimensional observed time series \(y(t)=[{y}_{1}(t),{y}_{2}(t),\ldots ,{y}_{n}(t)]\), variable \({\sigma }_{i}\in \mathrm{\{1,2},\ldots ,n\}\), and time lag \({\tau }_{i}\in \mathrm{\{0,1},\ldots ,l-\mathrm{1\}}\), \(v(t)\in {{\mathbb{R}}}^{E}\) is defined as follows:
where E is the embedding dimension, and no duplication is allowed for any element. According to embedding theorems1,3, an attractor reconstructed by v(t) is an embedding with the appropriate E. Note that the number of possible reconstructions increase combinatorially.
Optimizing embedding by an evolution strategy
We optimize embedding via combinatorial optimization to minimize forecast errors. Based on existing studies15,16, we treat embeddings as a binary series, i.e., 1 denoting embedded and 0 denoting not embedded, and solve Eq. (2) by using a combinatorial optimization problem. For example, with n = 3 and l = 2, the embedding \([{y}_{1}(t),{y}_{2}(t),{y}_{3}(t-\mathrm{1)]}\) can be expressed by the nl = 6 binary code \(e=[1,0,1,0,0,1]\): the first element 1 corresponds to y1(t) to embed, the second element 0 corresponds to y1(t − 1) to embed, the third element 1 corresponds to y2(t) to embed, and so on. The optimization of a binary series is a typical combinatorial optimization problem. In this paper, we apply the (μ + λ) evolution strategy17. The parameter μ denotes the number of parents, λ denotes the number of offspring, and + denotes plus selection, which means that the next parents are selected from both the previous parents and offspring. Precisely, the algorithm yields λ new offspring from the top-performing μ individuals selected from the previous parents and offspring. The algorithm is an elitist method since the algorithm retains the best individuals unless they are replaced by superior individuals. The algorithm tends to converge fast, but it is likely to become trapped at local optima. Therefore, the algorithm is suitable for our proposed framework. However, it is worth considering the application of other existing methods33,34,35 to obtain suboptimal embeddings.
Forecasting through FIR filters
We apply FIR filters to the original time series, and create embeddings using the filtered time series to obtain various embeddings and forecasts. Note that this procedure can also be written using the delay coordinates composed of the original time series with the corresponding filter matrix. We apply the following linear transformation for each variable:
where \({h}_{i}\)’s are filter coefficients with N elements, \({h}_{i}\mathrm{(0)}=1\,\forall \,i\), and \({\mu }_{i}\) and \({\sigma }_{i}\) are the coefficients for standardization. When we apply the filter to the target variable yf, we obtain filtered forecast \({\hat{z}}_{f}(t)\). After forecasting \({z}_{f}(t)\), we need to restore \({\hat{z}}_{f}(t)\) for the original time series. For p = 1, we restore \({\hat{y}}_{f}(t+p|t)\) using \({\hat{z}}_{f}(t+p|t)\) as follows:
For p ≥ 2, we obtain the p-steps-ahead forecast \({\hat{y}}_{f}(t+p|t)\) by substituting forecasts for the unobserved \({y}_{f}(t\ge t+\mathrm{1)}\) as follows:
We can restore \({\hat{y}}_{f}(t+p|t)\) for any p to apply Eq. (12) recursively.
We can apply FIR filters such as low-pass filters to suppress noise. In contrast, an existing study18 focuses on the filtered delay coordinates constructed by blending the derivatives of time series and the original one to search the nearest neighbors. Although these are a type of high-pass FIR filters inspired by the difference of time series, such filters improve the prediction accuracy in less noisy time series. In this paper, we set the filter coefficients as \({h}_{i}(0)=1,{h}_{i}(1)=\rho \,\forall \,i\) with the number of taps N = 2 for all numerical examples, based on an existing study18, although there are many possible filters to improve forecast. More suitable filters can be designed in a future work.
Overall algorithm of the proposed framework
We denote a multivariate time series as \(y(t)\in {{\mathbb{R}}}^{n}\) and the target variable to be forecasted as yf. The proposed forecasting framework is presented in Algorithm 1 in terms of the user-defined number of split training datasets K, the number of top-performing embeddings chosen for each split M, the linear filters, and the number of filters L.

Proposed forecasting framework.
Data availability
To obtain the flood dataset, please make a contact with Professor Christian W. Dawson (Loughborough University) directly. The other data related to this paper are available from the corresponding author on reasonable request.
References
Takens, F. Detecting strange attractors in turbulence. Lect. Notes Math. Berlin Springer Verlag 898, 366, https://doi.org/10.1007/BFb0091924 (1981).
Sauer, T., Yorke, J. A. & Casdagli, M. Embedology. J. Stat. Phys. 65, 579–616, https://doi.org/10.1007/BF01053745 (1991).
Deyle, E. R. & Sugihara, G. Generalized theorems for nonlinear state space reconstruction. PLoS ONE 6, e18295, https://doi.org/10.1371/journal.pone.0018295 (2011).
Garcia, S. P. & Almeida, J. S. Multivariate phase space reconstruction by nearest neighbor embedding with different time delays. Phys. Rev. E 72, 27205, https://doi.org/10.1103/PhysRevE.72.027205 (2005).
Hirata, Y., Suzuki, H. & Aihara, K. Reconstructing state spaces from multivariate data using variable delays. Phys. Rev. E 74, 26202, https://doi.org/10.1103/PhysRevE.74.026202 (2006).
Pecora, L. M., Moniz, L., Nichols, J. & Carroll, T. L. A unified approach to attractor reconstruction. Chaos: An Interdiscip. J. Nonlinear Sci. 17, 13110, https://doi.org/10.1063/1.2430294 (2007).
Vlachos, I. & Kugiumtzis, D. Nonuniform state-space reconstruction and coupling detection. Phys. Rev. E 82, 16207, https://doi.org/10.1103/PhysRevE.82.016207 (2010).
Ye, H. & Sugihara, G. Information leverage in interconnected ecosystems: Overcoming the curse of dimensionality. Sci. 353, 922–925, https://doi.org/10.1126/science.aag0863 (2016).
Okuno, S., Aihara, K. & Hirata, Y. Combining multiple forecasts for multivariate time series via state-dependent weighting. Chaos: An Interdiscip. J. Nonlinear Sci. 29, 33128, https://doi.org/10.1063/1.5057379 (2019).
Ma, H., Leng, S., Aihara, K., Lin, W. & Chen, L. Randomly distributed embedding making short-term high-dimensional data predictable. Proc. Natl. Acad. Sci. 115, E9994–E10002, https://doi.org/10.1073/pnas.1802987115 (2018).
Sollich, P. & Krogh, A. Learning with ensembles: how over-fitting can be useful. In Advances in neural information processing systems, 190–196 (1996).
Kuncheva, L. I. & Whitaker, C. J. Measures of Diversity in Classifier Ensembles and Their Relationship with the Ensemble Accuracy. Mach. Learn. 51, 181–207, https://doi.org/10.1023/A:1022859003006 (2003).
Lorenz, E. N. Atmospheric predictability as revealed by naturally occurring analogues. J. Atmospheric Sci. 26, 636–646 (1969).
Rasmussen, C. E. & Williams, C. K. I. Gaussian Processes for Machine Learning (MIT Press, Cambridge, MA, 2006).
Vitrano, J. B., Povinelli, R. J., B Vitrano, J. & Povinelli, R. J. Selecting dimensions and delay values for a time-delay embedding using a genetic algorithm. In Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, GECCO’01, 1423–1430 (Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2001).
Small, M. Optimal time delay embedding for nonlinear time series modeling arXiv:nlin/0312011 (2003).
Schwefel, H.-P. Numerical Optimization of Computer Models (John Wiley & Sons, Chichester, 1981).
Okuno, S., Takeuchi, T., Horai, S., Aihara, K. & Hirata, Y. Avoiding underestimates for time series prediction by state-dependent local integration. Math. Eng. Tech. Reports METR 2017–22, The University of Tokyo (2017).
Lorenz, E. N. Predictability: a problem partly solved. In Seminar on Predictability, 1–18 (ECMWF, Reading, England, 1996).
Chayama, M. & Hirata, Y. When univariate model-free time series prediction is better than multivariate. Phys. Lett. A 380, 2359–2365, https://doi.org/10.1016/j.physleta.2016.05.027 (2016).
Kuramoto, Y. & Tsuzuki, T. Persistent Propagation of Concentration Waves in Dissipative Media Far from Thermal Equilibrium. Prog. Theor. Phys. 55, 356–369, https://doi.org/10.1143/PTP.55.356 (1976).
Sivashinsky, G. I. Nonlinear analysis of hydrodynamic instability in laminar flames-I. Derivation of basic equations. Acta Astronaut. 4, 1177–1206, https://doi.org/10.1016/0094-5765(77)90096-0 (1977).
Dawson, C. et al. A comparative study of artificial neural network techniques for river stage forecasting. In Proceedings of the International Joint Conference on Neural Networks, vol. 4, 2666–2670, https://doi.org/10.1109/IJCNN.2005.1556324 (IEEE, Montreal, Canada, 2005).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780, https://doi.org/10.1162/neco.1997.9.8.1735 (1997).
Boser, B. E., Guyon, I. M. & Vapnik, V. N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, COLT’ 92, 144–152, https://doi.org/10.1145/130385.130401 (ACM, New York, NY, USA, 1992).
Breiman, L. Random Forests. Mach. Learn. 45, 5–32, https://doi.org/10.1023/A:1010933404324 (2001).
Rössler, O. E. An equation for continuous chaos. Phys. Lett. A 57, 397–398 (1976).
Cesa-Bianchi, N. & Lugosi, G. Prediction, Learning, and Games (Cambridge University Press, 2006).
Kirkpatrick, S., Gelatt, C. D. & Vecchi, M. P. Optimization by simulated annealing. Sci. 220, 671–680 (1983).
Dorigo, M. & Stützle, T. Ant Colony Optimization (Bradford Company, Scituate, MA, USA, 2004).
Muja, M. & Lowe, D. G. Scalable nearest neighbor algorithms for high dimensional data. IEEE Transactions on Pattern Analysis Mach. Intell. 36, 2227–2240, https://doi.org/10.1109/TPAMI.2014.2321376 (2014).
Fu, C. & Cai, D. EFANNA: An extremely fast approximate nearest neighbor search algorithm based on kNN graph arXiv:1609.07228 (2016).
Runge, J., Donner, R. V. & Kurths, J. Optimal model-free prediction from multivariate time series. Phys. Rev. E 91, 1–14, https://doi.org/10.1103/PhysRevE.91.052909 arXiv:1506.05822 (2015).
Vlachos, I. & Kugiumtzis, D. State space reconstruction from multiple time series. In Topics on Chaotic Systems: Selected Papers from Chaos 2008 International Conference, 378–387, https://doi.org/10.1142/9789814271349_0043 (World Scientific, 2009).
Chen, Y. & Wong, M. L. An ant colony optimization approach for stacking ensemble. Second. World Congr. on Nat. Biol. Inspired Comput. (NaBIC) 146–151, https://doi.org/10.1109/NABIC.2010.5716282 (2010).
Acknowledgements
We thank Professor Christian W. Dawson for permission to use the flood dataset. This research is partially supported by Kozo Keikaku Engineering Inc., JSPS KAKENHI 15H05707, WPI, MEXT, Japan, AMED JP19dm0307009, and JST CREST JPMJCR14D2, Japan. We thank Dr. Takahiro Omi for fruitful discussions.
Author information
Authors and Affiliations
Contributions
S.O., K.A. and Y.H. conceived the original design of this study. S.O. and K.A. designed the study of the toy models, and S.O. and Y.H. designed the study of the flood data. S.O. conducted the numerical experiment. All authors contributed to interpreting the results and writing the manuscript. All authors checked the manuscript and agreed to submit the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Okuno, S., Aihara, K. & Hirata, Y. Forecasting high-dimensional dynamics exploiting suboptimal embeddings. Sci Rep 10, 664 (2020). https://doi.org/10.1038/s41598-019-57255-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-57255-4
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
