
Abstract
Cattle mother-offspring contact calls encode individual-identity information; however, it is unknown whether cattle are able to maintain individuality when vocalising to familiar conspecifics over other positively and negatively valenced farming contexts. Accordingly, we recorded 333 high-frequency vocalisations from 13 Holstein-Friesian heifers during oestrus and anticipation of feed (putatively positive), as well as denied feed access and upon both physical and physical & visual isolation from conspecifics (putatively negative). We measured 21 source-related and nonlinear vocal parameters and stepwise discriminant function analyses (DFA) were performed. Calls were divided into positive (n = 170) and negative valence (n = 163) with each valence acting as a ‘training set’ to classify calls in the oppositely valenced ‘test set’. Furthermore, MANOVAs were conducted to determine which vocal parameters were implicated in individual distinctiveness. Within the putatively positive ‘training set’, the cross-validated DFA correctly classified 68.2% of the putatively positive calls and 52.1% of the putatively negative calls to the correct individual, respectively. Within the putatively negative ‘training set’, the cross-validated DFA correctly assigned 60.1% of putatively negative calls and 49.4% of putatively positive calls to the correct individual, respectively. All DFAs exceeded chance expectations indicating that vocal individuality of high-frequency calls is maintained across putatively positive and negative valence, with all vocal parameters except subharmonics responsible for this individual distinctiveness. This study shows that cattle vocal individuality of high-frequency calls is stable across different emotionally loaded farming contexts. Individual distinctiveness is likely to attract social support from conspecifics, and knowledge of these individuality cues could assist farmers in detecting individual cattle for welfare or production purposes.
Similar content being viewed by others

Introduction
Domesticated cattle are highly gregarious, residing in herds in both natural and commercial farming environments1. Within these herds, interactions over short and long distances are mediated by vocalisations2. Cattle produce two broad call types which are modulated by the configuration of the supra-laryngeal vocal tract2; including low-frequency nasalised calls for close contact and/or lower distress, and orally emitted high-frequency calls for distant communication and/or times of higher arousal2,3. In commercial farming environments, cattle are exposed to numerous procedures in which they emit these high-frequency vocalisations, but knowledge of their information content is limited. Calls are reported during oestrus4,5, separation from calf6, isolation from conspecifics7 and in anticipation of feed8, and likely encode information about the sender including their identity and emotional state3,9,10. Within the herd, advertising individuality in high-frequency calls would be biologically advantageous, by helping to facilitate social support from conspecifics. Moreover, recognising individual cattle could assist farmers in the non-invasive detection of welfare. However to date, these potential uses of cattle vocalisations have only been explored in cattle mother-offspring dyads, where low and high-frequency vocalisations were emitted to facilitate social interactions in a relatively undisturbed environment2,11.
Vocal cues to individuality are increasingly being found in wild12,13,14 and domesticated2,15,16,17 ungulate species, in relation to the source-filter theory18. According to the source-filter theory, vocalisations are produced by two independent processes, firstly with the sound generated by vibrations in the vocal folds (the source), and secondly with the sound filtered by the vocal tract (the filter)18,19. In ungulates, individuality is encoded in a range of source-related vocal parameters, including the F0-contour12,16, amplitude contour15 and duration16, as well as filter-related vocal parameters including formant frequencies2,12. Individuality expression seems to differ for each call type2,20 and in some ungulate species individuality has been shown to be more strongly expressed in oralised than nasalised calls12,20. In the context of mother-offspring contact, individual differences of cattle high-frequency calls were attributed to formants, but classification to the correct individual was relatively low2 suggesting that these calls were not very individualised. While formants are well established vocal indicators of individuality as they are influenced by caller morphology21, they can be poorly represented in high-pitch vocalisations22,23. Considering that cattle can produce vocalisations with fundamental frequencies over 1000 Hz24, which are likely to occur during times of higher arousal3, then vocal parameters unrelated to vocal tract resonances may better encode individuality information in high-frequency calls. It has been hypothesised that high-frequency calls should contain more individuality information than their low-frequency equivalents due to their propagation over longer distances where vision of the signaller is not always guaranteed25. Considering this evidence, cattle high-frequency calls emitted in stressful farming situations should indeed be highly individualised. On this basis we decided to study source-related, and nonlinear parameters in cattle high-frequency calls, as they have been shown to aid with individual identification in other species26,27,28,29.
As consecutive calls and calls of the same context are likely to be homogeneous30,31, they would likely result in high individual discriminability, regardless of whether they are truly idiosyncratic. To more robustly measure vocal individuality, studies should instead determine whether vocal individuality is maintained across time14, a variety of contexts and/or call types32,33. Thus, the aim of our study was to determine whether vocal individuality of cattle high-frequency calls is maintained across positively and negatively valenced contexts. This is of particular interest considering that different emotional experiences can influence the sound of the voice3,33. We hypothesised that individual distinctiveness is encoded in the max F0 as well as percentages of nonlinear phenomena in each call, and indeed that vocal individuality would be maintained across valences.
Results
Vocal individuality
Descriptive statistics for all the measured vocal parameters from individual heifers during the putatively positive and negative valenced contexts are provided in the Supplementary Material (Tables S1–S2). The MANOVA revealed significant differences between the 13 heifers in the acoustic structure of their high-frequency putatively positive calls (Pillai’s Trace, F252, 1776 = 4.787, P < 0.001), as well as their putatively negative calls (Pillai’s Trace, F252, 1692 = 4.289, P < 0.001). In the putatively positive calls, separate univariate ANOVAs revealed that the individual effect of heifer was significant for all acoustic variables (all P < 0.002) except for subharmonics (P = 0.240). Similar results were obtained from the putatively negative calls, where separate univariate ANOVAs again revealed a significant individual effect of heifer for all acoustic variables (all P < 0.02) except for subharmonics (P = 0.590).
Discriminant function analyses (DFA) indicated that heifers maintain vocal individuality across putatively positive and negative contexts. Using the 170 putatively positive calls as a ‘training set’, the DFA produced eight statistically significant discriminant functions, which were used to classify 78.2% of the putatively positive calls to the correct heifer. This DFA classification slightly decreased to 68.2% when the more conservative leave-one-out cross-validation procedure was undertaken. Upon using the putatively positive calls as a ‘training set’, 52.1% of the putatively negative calls were classified to the correct individual in the ‘test set’. Using the 163 putatively negative calls as a ‘training set’, the DFA produced six statistically significant discriminant functions, which were used to classify 70.6% of the putatively negative calls to the correct heifer. The classification of the DFA slightly decreased to 60.1% when the more conservative leave-one-out cross-validation procedure was undertaken. Additionally, the putatively negative ‘training set’ allowed for the classification of 49.4% of the putatively positive calls to the correct individual in the ‘test set’.
The two-tailed binomial tests confirmed that all the DFAs were significantly above chance expectation (all: n = 13, group size chance expectation = 7.69%, P < 0.001). The statistical tests for the canonical discriminant functions are provided in the Supplementary Material (Table S3). The stepwise procedures were performed in 10 and nine steps for the putatively positive and negative ‘training sets’ respectively (Table 1). In the putatively positive ‘training set’, the first two discriminant functions revealed five vocal parameters that highly contributed to individual distinctiveness, including AM var, AM rate, F0 max, F0 var and biphonation sidebands %. In the putatively negative ‘training set’, six vocal parameters attributed to individual distinctiveness including AM var, AM rate, F0 max, F0 var, harmonicity and duration. Figure 1 displays the vocal distinctiveness of individuals across discriminant function scores one and two.

Discriminant function scores for all calls derived from the putatively positively valenced ‘training set’ (A) and the putatively negatively valenced ‘training set’ (B), illustrating vocal individuality between the 13 heifers across both positive and negative valence.
Discussion
We investigated whether high-frequency vocalisations of cattle emitted during putatively positive and negative contexts encoded information on individuality. We showed that a range of vocal parameters are implicated in individual distinctiveness in cattle high-frequency calls. Moreover, results revealed that vocal individuality is stable across putatively positive and negative contexts. This is the first study to show that cattle maintain vocal identity cues across a variety of farming situations. Our results contribute to the understanding of cattle vocal communication and have the potential to assist with the non-invasive assessment of cattle welfare.
Due to their function in long-distance communication and more frequent production during highly arousing contexts3, we expected that the high-frequency calls would contain salient cues to individuality. Accordingly, the discriminant function analyses revealed that cattle high-frequency calls are individually distinct. In the cross-validated DFA, high-frequency cattle calls were assigned to the correct individual at least 60% of the time within the same emotional valence and at least 49% across emotional valences, with all classifications exceeding chance expectations. Moreover, our DFA classification percentages both within and across valence were higher than previously reported in cattle high-frequency contact calls, where the cross-validated DFA resulted in 30.9% classification, and formant parameters were mostly responsible for individual identity2. While high-frequency calls contribute less in mother-offspring recognition2,11, our results suggest that during other farming contexts, vocal cues to individuality play an important role in the recognition of familiar conspecifics.
Through interpreting the high factor loadings of the first two discriminant functions, the DFA indicated that a combination of vocal parameters was implicated in individual distinctiveness of cattle high-frequency calls. Across the putatively positive and negative datasets, the DFA consistently relied on AM var, AM rate, F0 var and F0 max to build the discriminant functions. The MANOVA then confirmed this vocal individuality, with all the parameters selected for this study, bar subharmonics, significantly differing between heifers. While many vocal individuality studies have examined formant frequencies due to their relationship with caller morphology2,14,21, this was less practical in the present study where calls were characterised by very high F0s and consequently less clear formant frequencies22,23. Nevertheless, our results reveal that a range of source and nonlinear parameters have the potential to encode individuality information, which has similarly been demonstrated in the groans of fallow deer, where formants were less important cues to individuality29.
In the present study, to minimise over-estimation of individual classification percentages, we classified data that was not used to build the original discriminant functions34. Our study utilised two separate datasets for DFA training and testing, with data including inhomogeneous samples from five farming contexts emitted over different days. This novel and robust approach enabled an increase in confidence around the accuracy of the analysis and subsequent stability of vocal individuality. We found that classification performance slightly declined when using the putatively positive and negative ‘training sets’ to classify vocal individuality in their respective opposite putatively positive or negative ‘test set’. Nonetheless, classification values across ‘test sets’ remained significantly higher than chance levels emphasising that vocal individuality is maintained across putatively positive and negative contexts. Likewise, vocal cues to identity have been found to remain stable in kittens exposed to different emotionally arousing situations35 and deer over the rutting period14, suggesting that the salience of vocal individuality during different emotionally loaded contexts is indeed biologically advantageous. In both the putatively positive and negative calls, the combination of high F0 and abundance of nonlinear phenomena is a likely consequence of high subglottal pressure23,36, reflecting the high-arousal that the heifers were experiencing3 in both the putatively positively valenced oestrus and anticipation of feed, and the putatively negatively valenced isolation and feed denial. For cattle, which are a social herd-living prey-species1, emitting idiosyncratic calls, especially during times of high arousal, could facilitate altruism directed from conspecifics37, with whom they develop stable social relationships1.
In the current dataset, the slight decline in classification percentages across valences could be explained by two reasons. Firstly, due to the rarity of vocalisations emitted by heifers in some contexts and the difficulty in obtaining high-quality vocalisations in commercial farming environments, the calls were unevenly distributed across putatively positive and negative valence. Secondly, this classification decline could relate to the within-heifer vocal variability which likely arose from cattle being exposed to different emotionally loaded contexts. Changes in emotional state have been shown to result in modulations of vocalisations3,31,33,38, with a growing body of literature on vocal indicators of emotion in pigs39,40, horses38,41 and goats31,42. Thus, in addition to identity cues, vocal cues of emotion should be studied in cattle high-frequency calls.
We demonstrated that cattle that vocalise during positive situations should, in theory, be able to be recognised by conspecifics when they vocalise in a negative situation, and vice versa. Although vocalisations were produced under different emotional contexts, they shared cues to identity. We selected calls of the extreme high-frequency call type as these were the most commonly produced across the five recording contexts. However, if we interpret cattle vocalisations as being produced on a graded continuum of low to high-frequency43, based on emotional arousal and/or underlying motivation3, then it would be interesting to determine whether individuality is also maintained across the entire cattle vocal repertoire of low to high-frequency calls. The ability of heifers to recognise individuals based on vocal individuality cues both within and across different emotionally valenced contexts should also be confirmed using playback experiments. Since calves can recognise their mother’s low-frequency calls during mother-offspring communication11, it is highly likely that cows too can recognise their familiar conspecifics within the herd using their high-frequency calls. Anecdotally, farmers have also described being able to distinguish between their cattle using only their vocalisations. To confirm this, we also recommend further studies conducting psychoacoustics experiments to determine which vocal cues of individuality farmers attend to in cattle high-frequency calls. This knowledge could help farmers in identifying individual cattle requiring welfare intervention.
Conclusion
In conclusion, we demonstrated that a variety of source and nonlinear-related vocal parameters are responsible for encoding individuality in Holstein-Friesian heifer high-frequency calls. Further, by using robust classification methods, we showed that heifers can maintain this individual distinctiveness across putatively positive and negative farming contexts. We suggest that salience to individuality in cattle high-frequency calls assists with the recognition of familiar conspecifics in the herd. We recommend that farmers integrate knowledge of these cues into their daily farming practices for cattle welfare or production improvements.
Materials and Methods
Study site and animals
This experiment was undertaken in a free-ranging environment at the University of Sydney, Australia, “Wolverton Farm” between June and October 2017. A herd of 18 Holstein-Friesian non-pregnant virgin heifers were recorded for this experiment. Heifers were selected to be uniform in breed, production status, age (24.5 ± 2.5 months) and weight (412.8 ± 44.7 kg) to control for their excessive influence on vocal individuality. The heifers were situated in a 4 Ha paddock containing cattle yards, where they had access to native pasture, unlimited water and were supplemented with lucerne hay (dry matter: 89.1%, crude protein: 16.4%, metabolisable energy: 8.5%) daily.
The heifers were recorded producing high-frequency open-mouth vocalisations during oestrus, two feeding contexts and two isolation contexts. Prior to the commencement of recording, heifers were adapted to the presence of human observers (between two and four people concurrently), as well as the routine of moving through the cattle yards for sorting and husbandry procedures. To assist with the identification of individual heifers during the recording contexts, heifers were assigned numbers which were spray-painted with fluoro stock-mark on either side of their flank. Spray painting was conducted with the heifers restrained in a head-bail and cattle crush in the cattle yards. Low-stress handling methods were always implemented when moving the heifers to and from the paddock and cattle yards. All procedures were approved by the University of Sydney animal ethics committee ‘IRMA’ (project number: 2016/1078), with the recording contexts only causing temporary distress to the heifers involved. All procedures were performed in accordance with the Australian code for the care and use of animals for scientific purposes44.
Audio recordings and contexts
Vocalisations were recorded using a Sennheiser K6-ME67 directional microphone (frequency response: 40 to 20000 Hz, max SPL: 125 dB at 1 kHz, Sennheiser Electronic, Wedemark, Germany) attached to a Marantz PMD-661 MK2 digital solid-state recorder (Marantz Professional, United Kingdom). The microphone was directed towards the vocalising heifer as best as possible. For shock and wind-noise reduction, the microphone was protected with a Rycote Classic Softie Windshield ®. Further, recordings were only taken when weather was permissible. Each vocal recording was saved as a separate file in the.WAV uncompressed format at 44.1 kHz sampling rate and 16-bit amplitude resolution. Vocal recordings were obtained when the same cattle were: 1) in oestrus, 2) anticipating feed, 3) denied feed access, 4) physically isolated from conspecifics, and 5) physically and visually isolated from conspecifics. Recordings were carried out during daylight hours between 08:00 and 17:00 with no recordings collected later than 17:00 h due to sound interference from the cattle feeding tractors and limited daylight. Specific details about the recording contexts are provided in the Supplementary Methods.
Inferences about emotional valence in the recording contexts
The recording contexts were classified as positive or negative, according to their putative emotional valence. We did not need precision with emotional valence classification in the present study, since we were determining whether vocal individuality could be maintained across contexts and time. Therefore we inferred emotional valence of the oestrus, feeding and isolation contexts based on the functions of emotions45,46,47,48, and knowledge of livestock behaviour31,38,49. Positive emotions are part of the pleasant-appetitive motivational system, which trigger approach towards releasing stimuli, while negative emotions are part of the unpleasant-defensive motivational system, which trigger avoidance of releasing stimuli45,46,47,48. Subsequently, oestrus was assumed to be positively valenced, as during this time cattle exhibited affiliative behaviours including approaching conspecifics, sexual behaviours including anogenital sniffing and licking, and exploratory behaviours in search of a mate47,48. At the ultimate level, oestrus functions to promote survival, allowing for the attraction of a mate and potential procreation45. Anticipation of feed was also deemed to be positively valenced since feeding should induce approach behaviour and increase fitness in the wild. Contrastingly, both physical and physical and visual social isolation were assumed to be negatively valenced, since cattle are highly gregarious and being separated from the herd could threaten fitness. Further, denial of feed access was assumed to be negatively valenced, as it could lead to frustration, lack of feed intake in the wild and an overall threat to fitness31,46. While all 18 heifers were exposed to the five recording contexts, not all heifers vocalised within each context. Nonetheless, we obtained vocalisations in at least one of the positive and one of the negative recording contexts for each heifer (Table 2).
Vocalisation selection
Cattle vocalisations are classified into two broad types, namely low-frequency and high-frequency calls which are modulated by configuration of the supra-laryngeal vocal tract2,24. During the oestrus recording context, low-frequency closed-mouth calls were seldom observed. For our acoustic analyses, we therefore only focused on the high-frequency open-mouth calls, as these were directly comparable in the heifers across the putatively positive and negative farming contexts. Calls were selected based on their high signal to noise ratio and in the absence of wind or signal saturation, resulting in a total of 333 calls analysed from 13 of the 18 heifers (Table 2). Despite the low incidence of calling from some individuals, calls were also balanced as much as possible across the putative valences. Additionally, if calls were produced as part of a sequence, we only selected them for analyses if they were more than 10 s apart in order to reduce homogeneity associated with consecutive calling. In total, 53 of the 333 vocalisations were derived from sequences of low and high-frequency vocalisations, with only two vocalisations selected from the same sequence considering they were non-consecutive.
Vocalisation analyses
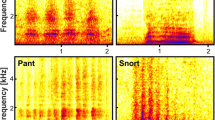
Vocalisations were analysed using Praat DSP package v.6.0.3150, through both calculation off the oscillograms and spectrograms; and by using a series of custom-built scripts31,51 to automatically extract a range of acoustic features. Vocalisations were visualised as narrow-band spectrograms (FFT method, window length = 0.1 s, time steps = 1000, frequency steps = 250, Gaussian window shape, dynamic range = 60 dB) and a total of 21 vocal parameters were measured in each of the vocalisations (Table 3). Prior to running the scripts, the full duration (s) of the call was measured directly off the oscillogram. Nonlinear phenomena were widely prevalent in the calls including 80% and 93% of the putatively positive and negative calls, respectively (See Supplementary Methods for further details on prevalence). For this reason, the percentages of nonlinear phenomena relative to the full call duration were calculated off the spectrogram. Nonlinear phenomena criteria were adopted from previous vocal studies in non-human mammalian species52,53,54,55 and included deterministic chaos, biphonation sidebands, subharmonics, and frequency jumps. Example waveforms and spectrograms of the nonlinear phenomena are provided in Fig. 2.

Sample oscillograms (top) and narrow-band spectrograms (bottom) of vocalisations recorded during the putatively positive and negative contexts from three different heifers, containing nonlinear phenomena including (A) biphonation sidebands during anticipation of feed, (B) deterministic chaos during denial of feed and (C) frequency jumps (FJ) during oestrus. Spectrograms were visualised in Praat v.6.0.31 (FFT method, window length = 0.1 s, time steps = 1000, frequency steps = 250, Gaussian window shape, dynamic range = 60 dB).
Before extracting the vocal parameters, a script was run to add silences of 0.1 s to each side of the 333 calls. Using custom-built scripts in Praat31,51, we then batch-processed the acoustic analyses, with output data exported to Microsoft Excel for further examination. In the script, pitch floor and ceiling settings were adapted to the individual heifer voices and these settings were maintained across calls collected during positive and negative valence for a given heifer. Specific Praat procedures are detailed in the Supplementary Methods.
Statistical analyses
Statistical analyses were performed using SPSS v.24 (IBM Corp. Released 2016). Two separate stepwise discriminant function analysis (DFA) procedures were used to quantify the extent of which individual heifers could be classified based on their calls. The DFAs were conducted both within each putative valence and across the putative positive and negative valences to establish whether individual differences in the high-frequency calls of heifers are maintained. In both DFAs, the grouping variable was heifer (1–13), the discriminant variables were the 21 vocal parameters and the selection variable was valence (positive = 1 or negative = 2). A first DFA was run with the selection variable set to 1 (positive). In this DFA, the 170 putatively positive calls were used as a ‘training set’, to firstly classify the 170 putatively positive calls to the correct individual, and secondly classify the 163 putatively negative calls in the ‘test set’ to the correct individual. Then, a second DFA was run with the selection variable set to 2 (negative). In this DFA the 163 putatively negative calls were used as a ‘training set’ to firstly classify the 163 putatively negative calls to the correct individual, and secondly classify the 170 putatively positive calls in a ‘test set’ to the correct individual. For both DFAs, we used the default settings for the F value of the model, which included an entry level of 3.84 and a removal level of 2.71. Since there was an imbalance in the number of vocalisations from each heifer across positive and negative valence, the percentage of correct classification was calculated according to the group sizes. We used the leave-one-out classification procedure to cross-validate the results and the Wilks’ lambda method to determine how strongly each of the discriminant functions contributed to the models. To confirm the accuracy of the DFA classifications, we used two-tail binomial tests to see whether correct classifications were significantly higher than chance expectations34,35,56. Graphical representations of the first two discriminant functions scores for heifer vocal individuality were additionally formulated in R Studio v.1.1.463 using the ggplot2 package57.
We also conducted two multivariate general linear models (MANOVA) using the putatively positive and negative calls separately, to determine whether there were significant differences between heifers in their 21 vocal parameters. In both MANOVAs, heifer was included as the categorical fixed factor and the 21 vocal parameters were used as the independent variables. Descriptive statistics (means ± SE) are provided in the Supplementary Materials for all vocal parameters of heifers during putative positive and negative valence.
References
Rault, J. L. Friends with benefits: Social support and its relevance for farm animal welfare. Appl. Anim. Behav. Sci. 136, 1–14 (2012).
Padilla de la Torre, M., Briefer, E. F., Reader, T. & McElligott, A. G. Acoustic analysis of cattle (Bos taurus) mother–offspring contact calls from a source–filter theory perspective. Appl. Anim. Behav. Sci. 163, 58–68 (2015).
Briefer, E. F. Vocal expression of emotions in mammals: Mechanisms of production and evidence. J. Zool. 288, 1–20 (2012).
Schön, P. C. et al. Altered vocalization rate during the estrous cycle in dairy cattle. J. Dairy Sci. 90, 202–206 (2007).
Röttgen, V. et al. Vocalization as an indicator of estrus climax in Holstein heifers during natural estrus and superovulation. J. Dairy Sci. 2383–2394, https://doi.org/10.3168/jds.2017-13412 (2018).
Weary, D. M. & Chua, B. Effects of early separation on the dairy cow and calf. Appl. Anim. Behav. Sci. 69, 177–188 (2000).
Boissy, A. & Le Neindre, P. Behavioral, Cardiac and Cortisol Responses to Brief Peer Separation and Reunion in Cattle. Physiol. Behav. 61, 693–699 (1997).
Yeon, S. C. et al. Acoustic features of vocalizations of Korean native cows (Bos taurus coreanea) in two different conditions. Appl. Anim. Behav. Sci. 101, 1–9 (2006).
Green, A. C., Johnston, I. N. & Clark, C. E. F. Invited review: The evolution of cattle bioacoustics and application for advanced dairy systems. Animal 1–10, https://doi.org/10.1017/S1751731117002646 (2017).
Watts, J. M. & Stookey, J. M. Vocal behaviour in cattle: The animal’s commentary on its biological processes and welfare. Appl. Anim. Behav. Sci. 67, 15–33 (2000).
Padilla de la Torre, M., Briefer, E. F., Ochocki, B. M., McElligott, A. G. & Reader, T. Mother–offspring recognition via contact calls in cattle, Bos taurus. Anim. Behav. 114, 147–154 (2016).
Volodin, I. A. et al. Individuality of distress and discomfort calls in neonates with bass voices: Wild-living goitred gazelles (Gazella subgutturosa) and saiga antelopes (Saiga tatarica). Ethology 123, 386–396 (2017).
Reby, D., Joachim, J., Lauga, J., Lek, S. & Aulagnier, S. Individuality in the groans of fallow deer (Dama dama) bucks. J. Zool. 245, 79–84 (1998).
Reby, D., André-Obrecht, R., Galinier, A., Farinas, J. & Cargnelutti, B. Cepstral coefficients and hidden Markov models reveal idiosyncratic voice characteristics in red deer (Cervus elaphus) stags. J. Acoust. Soc. Am. 120, 4080–4089 (2006).
Sèbe, F., Poindron, P., Ligout, S., Sèbe, O. & Aubin, T. Amplitude modulation is a major marker of individual signature in lamb bleats. Bioacoustics 4622, 1–17 (2017).
Blackshaw, J. K., Jones, D. N. & Thomas, F. J. Vocal individuality during suckling in the intensively housed domestic pig. Appl. Anim. Behav. Sci. 50, 33–41 (1996).
Favaro, L., Briefer, B. F. & McElligott, A. G. Artificial neural network approach for revealing individuality, group membership and age information in goat kid contact calls. Acta Acust. United with Acust. 100, 782–789 (2014).
Taylor, A. M. & Reby, D. The contribution of source-filter theory to mammal vocal communication research. J. Zool. 280, 221–236 (2010).
Titze, I. R. Principles of voice production. (Prentice-Hall Inc., 1994).
Volodin, I. A., Lapshina, E. N., Volodina, E. V., Frey, R. & Soldatova, N. V. Nasal and Oral Calls in Juvenile Goitred Gazelles (Gazella subgutturosa) and their Potential to Encode Sex and Identity. Ethology 117, 294–308 (2011).
Taylor, A. M., Charlton, B. D. & Reby, D. Vocal production by terrestrial mammals: Source, filter and function. In Vertebrate Sound Production and Acoustic Communication 241–259 (2016).
Erickson, M. L. & D’Alfonso, A. E. A comparison of two methods of formant frequency estimation for high-pitched voices. J. Voice 16, 147–171 (2002).
Raine, J., Pisanski, K., Bond, R., Simner, J. & Reby, D. Human roars communicate upper-body strength more effectively than do screams or aggressive and distressed speech. PLoS One 14, e0213034 (2019).
Volodin, I. A., Volodina, E. V. & Frey, R. Bull bellows and bugles: a remarkable convergence of low and high-frequency vocalizations between male domestic cattle Bos taurus and the rutting calls of Siberian and North American wapiti. Bioacoustics 4622, 1–14 (2017).
Leliveld, L. M. C., Scheumann, M. & Zimmermann, E. Acoustic correlates of individuality in the vocal repertoire of a nocturnal primate (Microcebus murinus). J. Acoust. Soc. Am. 129, 2278–2288 (2011).
Digby, A. et al. Non-linear phenomena in little spotted kiwi calls. Bioacoustics 23, 113–128 (2014).
Fitch, W. T., Neubauer, J. & Herzel, H. Calls out of chaos: the adaptive significance of nonlinear phenomena in mammalian vocal production. Anim. Behav. 63, 407–418 (2002).
Zhang, F., Zhao, J. & Feng, A. S. Vocalizations of female frogs contain nonlinear characteristics and individual signatures. PLoS One 1–16, https://doi.org/10.1371/journal.pone.0174815 (2017).
Vannoni, E. & McElligott, A. G. Individual acoustic variation in fallow deer (Dama dama) common and harsh groans: A source-filter theory perspective. Ethology 113, 223–234 (2007).
Briefer, E. & McElligott, A. G. Indicators of age, body size and sex in goat kid calls revealed using the source-filter theory. Appl. Anim. Behav. Sci. 133, 175–185 (2011).
Briefer, E. F., Tettamanti, F. & McElligott, A. G. Emotions in goats: mapping physiological, behavioural and vocal profiles. Anim. Behav. 99, 131–143 (2015).
Elie, J. E. & Theunissen, F. E. Zebra finches identify individuals using vocal signatures unique to each call type. Nat. Commun. 9 (2018).
Lavan, N., Burton, A. M., Scott, S. K. & McGettigan, C. Flexible voices: Identity perception from variable vocal signals. Psychon. Bull. Rev. 1–13, https://doi.org/10.3758/s13423-018-1497-7 (2018).
Mundry, R. & Sommer, C. Discriminant function analysis with nonindependent data: consequences and an alternative. Anim. Behav. 74, 965–976 (2007).
Scheumann, M. et al. Vocal correlates of sender-identity and arousal in the isolation calls of domestic kitten (Felis silvestris catus). Front. Zool. 9, 1–14 (2012).
Clark, C. J. Vertebrate Sound Production and Acoustic Communication, https://doi.org/10.1007/978-3-319-27721-9 (2016).
Tibbetts, E. A. & Dale, J. Individual recognition: it is good to be different. Trends Ecol. Evol. 22, 529–537 (2007).
Briefer, E. F. et al. Segregation of information about emotional arousal and valence in horse whinnies. Sci. Rep. 4, 9989 (2015).
Maigrot, A., Hillmann, E. & Briefer, E. Encoding of Emotional Valence in Wild Boar (Sus scrofa) Calls. Animals 8, 1–15 (2018).
Friel, M., Kunc, H. P., Griffin, K., Asher, L. & Collins, L. M. Positive and negative contexts predict duration of pig vocalisations. Sci. Rep. 9, 2062 (2019).
Maigrot, A. L., Hillmann, E., Anne, C. & Briefer, E. F. Vocal expression of emotional valence in Przewalski’s horses (Equus przewalskii). Sci. Rep. 7, 1–12 (2017).
Baciadonna, L., Briefer, E. F., Favaro, L. & McElligott, A. G. Goats distinguish between positive and negative emotion-linked vocalisations. Front. Zool. 16, 1–11 (2019).
Kiley, M. The Vocalizations of Ungulates, their Causation and Function. Z. Tierpsychol. 31, 171–222 (1972).
National Health and Medical Research Council. Australian code for the care and use of animals for scientific purposes - 8th Edition. (2013).
Bradley, M. M., Codispoti, M., Cuthbert, B. N. & Lang, P. J. Emotion and Motivation I: Defensive and Appetitive Reactions in Picture Processing. Emotion 1, 276–298 (2001).
Mendl, M., Burman, O. H. P. & Paul, E. S. An integrative and functional framework for the study of animal emotion and mood. Proc. Biol. Sci. 277, 2895–904 (2010).
Mellor, D. J. Positive animal welfare states and encouraging environment-focused and animal-to-animal interactive behaviours. N. Z. Vet. J. 63, 9–16 (2015).
Mellor, D. J. Animal emotions, behaviour and the promotion of positive welfare states. N. Z. Vet. J. 60, 1–8 (2012).
Leliveld, L. M. C., Düpjan, S., Tuchscherer, A. & Puppe, B. Behavioural and physiological measures indicate subtle variations in the emotional valence of young pigs. Physiol. Behav. 157, 116–124 (2016).
Boersma, P. & Weenink, D. Praat: doing phonetics by computer, http://www.praat.org/ (2009).
Reby, D. & McComb, K. Anatomical constraints generate honesty: acoustic cues to age and weight in the roars of red deer stags. Anim. Behav. 65, 519–530 (2003).
Charlton, B. D. The acoustic structure and information content of female koala vocal signals. PLoS One 10, 1–19 (2015).
Stoeger, A. S., Baotic, A., Li, D. & Charlton, B. D. Acoustic Features Indicate Arousal in Infant Giant Panda Vocalisations. Ethology 118, 896–905 (2012).
Stoeger, A. S. et al. Vocal cues indicate level of arousal in infant African elephant roars. Acoust. Soc. Am. 130, 1700–1710 (2011).
Charlton, B. D., Martin-Wintle, M. S., Owen, M. A., Zhang, H. & Swaisgood, R. R. Vocal behaviour predicts mating success in giant pandas. R. Soc. Open Sci. 5 (2018).
Townsend, S. W., Charlton, B. D. & Manser, M. B. Acoustic cues to identity and predator context in meerkat barks. Anim. Behav. 94, 143–149 (2014).
Wickham, H. ggplot2: Elegant Graphics for Data Analysis (2016).
Acknowledgements
We thank all of the farm staff and undergraduate students who assisted with the field work and cattle husbandry procedures. Author A.G was supported by an Australian Government Research Training Program (RTP) Scholarship. This research was partially supported by the University of Lyon IDEXLYON project as part of the “Programme Investissements d’Avenir” (ANR-16-IDEX-0005), the Labex CeLyA, the Institut universitaire de France (NM), the Centre national de la recherche scientifique (CNRS), and the University of Lyon/Saint-Étienne.
Author information
Authors and Affiliations
Contributions
A.G., C.C., S.L. designed the experiment. C.C. and S.L. provided resources and project administration. A.G. collected the data. D.R. conceptualised the manuscript. A.G., L.F., D.R. analysed the data. A.G., L.F., D.R. wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Green, A., Clark, C., Favaro, L. et al. Vocal individuality of Holstein-Friesian cattle is maintained across putatively positive and negative farming contexts. Sci Rep 9, 18468 (2019). https://doi.org/10.1038/s41598-019-54968-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-54968-4
This article is cited by
-
Changes in dairy cows’ behaviour, health, and production after transition from tied to loose housing
Acta Veterinaria Scandinavica (2023)
-
Penguins perceive variations of source- and filter-related vocal parameters of species-specific vocalisations
Animal Cognition (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
