
Abstract
Pathway analysis allows us to gain insights into a comprehensive understanding of the molecular mechanisms underlying cancers. Currently, high-throughput multi-omics data and various types of large-scale biological networks enable us to identify cancer-related pathways by comprehensively analyzing these data. Combining information from multidimensional data, pathway databases and interaction networks is a promising strategy to identify cancer-related pathways. Here we present a novel network-based approach for integrative analysis of DNA methylation and gene expression data to extend original pathways. The results show that the extension of original pathways can provide a basis for discovering new components of the original pathway and understanding the crosstalk between pathways in a large-scale biological network. By inputting the gene lists of the extended pathways into the classical gene set analysis (ORA and FCS), we effectively identified the altered pathways which are correlated well with the corresponding cancer. The method is evaluated on three datasets retrieved from TCGA (BRCA, LUAD and COAD). The results show that the integration of DNA methylation and gene expression data through a network of known gene interactions is effective in identifying altered pathways.
Similar content being viewed by others

Introduction
Cancer etiology and progression is currently understood to be driven primarily by molecular and genetic mechanisms1,2. Cancer is caused by the interactions of multiple genes and pathways. Pathway analysis may help to understand the status of cancer and suggest customized anticancer therapies. Wang et al.3 classify pathway analysis methods into four main categories: overrepresentation analysis (ORA), functional class scoring (FCS), pathway topology (PT) - Based and network topology (NT) - Based.
ORA4 approaches assess whether the number of genes beyond an arbitrary threshold is significantly over- or under-represented in a pathway just by chance. Unlike ORA, FCS5 methods take into consideration all available molecular measurements for pathway analysis, such as GSEA(Gene Set Enrichment Analysis)6, ANCOVA(Analysis of Covariance)7, etc. PT-Based8 methods employ pathway topology between genes in signaling pathways to find which pathway is most impacted by a given phenotype. Moreover, the interaction databases, such as HPRD9, FunCoup10, STRING11, are also available. So, NT-Based3 methods extract interactions between genes from interaction databases or literature to compute pathway-level statistics.
Recent functional genomic experiments have found a large number of interactions between intra- and inter-pathways, suggesting more complex relationships between biological pathways than in their traditional representations. Therefore, it is necessary to embed original pathways into many large-scale networks to analyze pathways. Lu et al.12 embed original pathways within large-scale networks and demonstrate the crosstalk between them. Original pathways are extended by mapping genes of original pathways onto the network of biomolecules. The first neighbors of these genes are considered as new components of the original pathways. Glaab et al.13 present a methodology for extending original pathways by mapping them onto a protein-protein interaction network, and extending them to include densely interconnected interaction partners. However, these methods only consider network topologies and ignore edge weights of large-scale networks when extending pathways. Zhang et al.14 calculated the weights of a gene network through integrating DNA methylation and gene expression data to identify disease-associated gene modules. However, the biological roles of the gene modules discovered using the method are not clear. Paradigm15,16 integrates diverse high-throughput genomics information with a pathway structure to identify significant pathways. It has a limitation to extract different types of biological entities in the context of biological knowledge. And, this method only employs the pathway topology itself. Hence, how to combine information from multidimensional data, pathway databases and interaction networks is a promising strategy to identify altered pathways which have significant changes in different tissues, such as tumor and normal tissues.
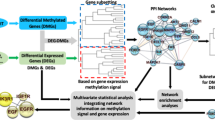
DNA methylation is known to be associated with gene transcription by interfering with DNA-binding proteins17. Hence we present a novel network-based approach for integrative analysis of DNA methylation and gene expression data to calculate edge weights of the large-scale network for each phenotype. Then, each pathway is extended by adding important neighboring genes based on the limited kWalks algorithm18 in weighted phenotype-specific networks. The pathway extended under different phenotypes is united as a final pathway gene list. Finally, by inputting the gene lists of extended pathways into the classical gene set analysis (ORA and FCS), we identify altered pathways which are correlated well with the corresponding cancer. The overview of our method is shown in Fig. 1.

Overview of the method.
Materials and Methods
Data
The PPI(Protein-Protein Interaction) network (version 2.9) was downloaded from the Interologous Interaction Database (I2D) website (http://ophid.utoronto.ca/ophidv2.204/downloads.jsp). Gene expression and DNA methylation data are obtained from TCGA (The Cancer Genome Atlas, https://portal.gdc.cancer.gov/projects). In this study, we have only chose samples that contain both gene expression and methylation data. According to data providers, all methylation data are from Illumina Human Methylation 450k Chip, whereas all gene expression data are downloaded from Agilent G4502A or Illumina HiSeq platform. BRCA (Breast Invasive Carcinoma) includes 33 cancer samples with DNA methylation and gene expression data, and 37 normal tissue samples. LUAD (Lung Adenocarcinoma) dataset consists of 69 samples (20 normal tissue samples and 49 cancer samples with DNA methylation and gene expression data). COAD (Colon Adenocarcinoma) data have 26 cancer samples with DNA methylation and gene expression data and 16 normal tissue samples). Gene expression data of the LUAD and COAD produced by Illumina HiSeq are added a value of 1 (to avoid zeros) and then log2-transformed. Gene sets of biological pathways are from the ConsensusPathDB website. A total of 281 KEGG pathways are obtained and further analyzed in the subsequent experiment.
Construct the weighted gene-gene interaction network
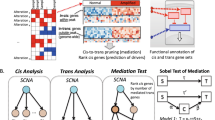
In this paper, PPI network is chose as a priori network. The edge weight between a pair of genes is calculated according to the PCA(Principal Component Analysis) and SCCA(sparse canonical correlation analysis) through integrating DNA methylation and gene expression data. At first, we do not set the cut-off of the gene expression and DNA methylation and treat each gene equally when building the weighted gene-gene interaction network. When calculating the weight of a gene pair in the network, if one of the two genes does not have the corresponding expression and methylation values, the edge is deleted, otherwise retained. Each gene contains multiple methylated CpG loci, and there is a general correlation between these neighboring CpG loci. In this study, PCA is used for dimensionality reduction of CpG loci for each gene firstly. Then, the selected principal components of CpG loci and gene expression are merged as the matrix of a gene. Finally, SCCA is used to calculate the edge weights of gene pairs in the network based on the principal components of CpG loci and gene expression values (see Fig. 2).

Calculation of gene pair weights in the network.
Let \(X=({x}_{1}^{m},{x}_{2}^{m},\ldots ,{x}_{u}^{m})\) represent methylation values of gene 1, \(Y=({y}_{1}^{m},{y}_{2}^{m},\ldots ,{y}_{v}^{m})\) represent methylation values of gene 2, where u and v are the number of CpG loci in genes 1 and 2 respectively. First, PCA is employed to reduce CpG loci dimension of genes 1 and 2 and calculated principal components of genes 1 and 2, \(\bar{X}=({\bar{x}}_{1}^{m},{\bar{x}}_{2}^{m},\ldots ,{\bar{x}}_{s}^{m})\) and \(\bar{Y}=({\bar{y}}_{1}^{m},{\bar{y}}_{2}^{m},\ldots ,{\bar{y}}_{t}^{m})\) respectively. Then \(\bar{X}\) and the expression data of gene 1 are merged as a matrix. Similarly, \(\bar{Y}\) and the expression data of gene 2 are merged as another matrix. As shown in Fig. 2, \(\tilde{X}=({\bar{x}}_{1}^{m},{\bar{x}}_{2}^{m},\ldots ,{\bar{x}}_{s}^{m},{x}^{e})\) and \(\mathop{Y}\limits^{ \sim }=({\bar{y}}_{1}^{m},{\bar{y}}_{2}^{m},\ldots ,{\bar{y}}_{t}^{m},{y}^{e})\) are matrices of genes 1 and 2 respectively, where \({x}^{e}\) and \({y}^{e}\) represent the expression values of genes 1 and 2 respectively. The edge weight between genes 1 and 2 is calculated as follow,
here a and b are optimized as follow,
where ||·||1 and ||·||2 are L1 norm and L2 norm, respectively. c1 and c2 are parameters to regulate the amount of shrinkage and restricted to ranges \(0 < {c}_{1} < 1\) and \(0 < {c}_{2} < 1\), \(p=s+1\), \(q=t+1\). WXY is calculated using PMA which is available as a Bioconductor package19.
Extend pathway based on the weighted network
We construct the weighted gene-gene interaction networks for different phenotype (such as, normal tissue network and cancer tissue network), as shown in Fig. 3. We not only consider the relations of genes inside a pathway, but also the relation between genes inside and outside of a pathway. Therefore we extend each pathway based on the limited kWalks algorithm18 in gene-gene interaction network and the importance neighboring genes are added in the pathway. In the limited kWalks algorithm, the relevance of an edge and a node in relation to the pathway-sets is evaluated by the expected times random walk passes starting from one gene to any of the others. In the interpretation of a graph as a Markov chain, each gene represents a state, and the probability of transition from state i to j is given by
where Wij is edge weight of gene i - gene j. More details of the mathematics are available in ref.20. Finally, we extract two extended pathways genes from two weighted phenotype-specific networks, respectively. Two extended pathways genes under different phenotypes are united as an extended pathway gene list.

Construction of weighted phenotype-specific networks and extension of original pathways.
Identify cancer-related pathways
To illustrate the benefits of our extended pathways, we use ORA and GSEA to analyse gene sets included in the extended pathways and identify the altered pathways which are correlated well with the corresponding cancer. In this paper, for convenience they will be referred to as EP-ORA (Extended Pathway ORA) and EP-GSEA (Extended Pathway GSEA).
Briefly, ORA methods compare sets of genes annotated to pathways and to a list of those genes that are significantly deferentially expressed (DE) between two phenotypes. Then a confidence value is calculated using statistical methods. Here, we calculate a P-value using the hypergeometric distribution.
Where N is the total number of genes in the background distribution, M is the number of all DE genes, n is the size of the list of genes of the pathway and k is the number of DE genes within the pathway. Finally, BH (Benjamini-Hochberg) correction for multiple testing is performed21.
Another approach, GSEA6 is an FCS-type method that determines whether a priori defined set of genes shows statistically significant, concordant differences between two biological states, which uses all available molecular measurements for pathway analysis. GSEA works as follows:
-
1.
Sort genes by signal-to-noise ratio;
-
2.
Calculate enrichment scores;
-
3.
Permute 1000 phenotype labels for significance.
Results
Extension of original pathways with large-scale network predicts new pathway components
In general, functionally linked interacting genes have a significantly higher level of coherence in biological systems22. The pathway neighboring genes may play important roles in the regulation of disease-related pathways. The inclusion of important neighboring genes will enable us to understand cancer mechanisms with models of pathway activities. One hypothesis of the proposed method is that the genetic interactions are variables between controls and cases which is responsible for different phenotypes varying in cancer. Hence, two weighted gene-gene interaction networks are then achieved based on case samples and control samples, respectively. All genes that interact with the pathway contribute to the regulation of the pathway. So, genes of two extended pathways under different phenotypes are eventually united as a final extended pathway gene set.
To test the effectiveness of the proposed method, we first take BRCA dataset for a comparative evaluation. As shown in Fig. 4, the extended pathways can systematically indicate new genes involved in original pathways. The pathway sizes increased on average from 28.30% to 224.56% of the original size except for hsa04740 (Olfactory transduction). The hsa04740 is closely related to multiple protein isoforms and include 405 genes, but only 54 genes are mapped to the weight network. Finally, the extended hsa04740 includes 138 genes.

Comparison of the original pathway sizes and the extended pathway sizes.
The extended p53 signaling pathway is illustrated in Fig. 5, because of its importance for cancer analysis. A total of 68 genes in the p53 signaling pathway are mapped onto the large-scale PPI network. The result show that the extension algorithm identifies 120 new genes which are important neighboring genes of the p53 signaling pathway. Hence, the extension of original pathways can provide a basis for discovering new candidate components of the original pathway.

The p53 signaling pathway (hsa04115) is extended in the weighted network. Red nodes denote genes in original pathway and blue nodes denote the extended genes that are most associated with the corresponding pathway.
Pathway identification in breast cancer
One of the important applications of pathway analysis is to identify altered pathways which are correlated well with the corresponding cancer. Here, we firstly take BRCA dataset for a comparative evaluation. We apply ORA and EP-ORA to this dataset with the BH corrected P-value. Using a P-value cutoff of 0.05, ORA and EP-ORA result in picking 6 and 18 pathways as significant, respectively (Supplementary file, Table S1). Both methods have effectively identified Cell cycle and Focal adhesion which have been confirmed by the published literatures to be closely associated with breast cancer (see Table 1). The above results show that the overlapped pathways found by different methods can be used as robust cancer-related pathways. Several pathways well known to be related to breast cancer are only identified by EP-ORA, such as p53 signaling pathway, DNA replication, Pathways in cancer, B cell receptor signaling pathway, etc. Interestingly, the p53 signaling pathway is identified by EP-ORA. Abundant data from mechanistic, molecular pathological and transgenic animal studies support an important role for p53 in mammary carcinogenesis23.
We then apply GSEA and EP-GSEA to the BRCA dataset. In standard GSEA, the analysis performs 1000 permutations using case-control gene expression samples (case 33 vs. control 37) and original pathways with an FDR cutoff of 25%. However, no pathway is identified (see Table 2). It is probably a consequence of the low power issue related to GSEA methodology24. Subsequently, we use the same expression dataset and extended pathways for EP-GSEA analysis. The results show that 3 pathways are identified (see Table 2). These three pathways are closely related to breast cancer, which have been verified in many published studies. For example, Li et al.25 point out that the metabolism of xenobiotics by cytochrome P450 and drug metabolism-cytochrome P450 enzymes in breast tissues may play important roles in breast cancer risk.
Taken together, in comparison to ORA and GSEA, EP-ORA and EP-GSEA using extended pathways can more effectively identify cancer-related pathways for breast cancer.
Examining crosstalk between embedded pathways
Cancer is a complex disease involving a sequence of gene-gene interactions in a progressive process, which cannot occur without dysregulation in multiple biological pathways. From a systems biology perspective, biological pathways are connected together by crosstalk to perform a specific biological function as a system. In biology, the pathway crosstalk means that signal components in signal transduction can be shared between different biological pathways, and responses to a signal inducing condition can activate multiple responses in cells, tissues, or organisms12. Therefore, understanding the crosstalk between pathways is important for understanding the function of both cells and more complex diseases. Now, we embed original and extended pathways into large-scale biological networks and show the crosstalk between them.
As an example, for these types of connections, we map three pathways, cell cycle, p53 signaling pathway and pathways in cancer, onto the large-scale biological network (see Fig. 6). The crosstalk between the three pathways suggests that they may share similar functions in breast cancer. The above results show that a large number of genes exist as linkers between pathways. Accordingly, a careful examination of these intermediate genes may help reveal the mechanisms underlying the interconnection of different pathways. Many genes in the large-scale network are well connected with different pathways, and may therefore play a functional role in the communication between the pathways.

The crosstalk between three extended pathways. The upper triangular shape nodes represent the cell cycle pathway (hsa04110), the lower triangular shape nodes represent the p53 signaling pathway (hsa04115), the square nodes represent the pathways in cancer (hsa05200). Red nodes denote genes in original pathway and blue nodes denote the extended genes that are most associated with the corresponding pathway.
Validation of the alternative dataset
To further verify the improvement of EP-ORA, EP-GSEA over ORA, GSEA. Using the same process as above, we apply the method in this article to other two datasets (LUAD and COAD).
The results of lung adenocarcinoma data (LUAD) are shown in Tables 3 and 4 (see Supplementary Tables S3 and S4 for more details). The results show that a total of three pathways are overlapped by EP-ORA and ORA (adjusted P-value ≤ 0.05). The bile secretion pathway related to lung cancer is only identified by EP-ORA. For the bile secretion pathway, Liu et al.26 reported that bile acid receptor accelerates to the lung cancer process induced by lung fibroblast-tumor cells interaction, with high activation of phosphorylated STAT3 and alteration of cytokine secretion. Compared with GSEA, EP-GSEA identifies more pathways which are closely related to lung cancer (FDR ≤ 25%). Interestingly, the non-small cell lung cancer pathway is only identified by EP-GSEA.
It is interesting to check pathways that are ranked top by one approach but not by the other approaches, which should reflect the different effects of the two approaches. Accordingly, corrected P-value is used to rank pathways. Focusing on colon adenocarcinoma (COAD), we apply ORA and EP-ORA to COAD dataset (see Supplementary Table S5 for more details). Here, we deliberately select several pathways related to CRC (Colorectal cancer) that have been widely confirmed in literatures. As shown in Table 5, most of the CRC-related pathways obtained tend to be ranked higher with EP-ORA than with ORA. For example, MicroRNAs in cancer, Cell cycle, Pathways in cancer and p53 signaling pathway, ranked 1, 2, 4 and 20 by EP-ORA, are ranked 9, 6, 27 and 57 by ORA, respectively. Interestingly, the colorectal cancer pathway is ranked 17 by EP-ORA, but ranked only 79 by ORA. The pathways that rank lower in EP-ORA are mostly not associated with the corresponding cancer. For example, the Parkinson’s disease pathway(hsa05012) which has been confirmed by the published literature27 to be inversely associated with colon cancer is ranked 2 by ORA, but ranked 53 by EP-ORA(see Supplementary Table S5), and so on.
We then apply GSEA and EP-GSEA to the COAD dataset. Most of the CRC-related pathways are also ranked higher in EP-GSEA than in GSEA (see Table 6). The only exception to this is the p53 signaling pathway ranked 7 by the GSEA, but ranked only 137 by EP-GSEA (see Supplementary Table S6 for more details).
The experimental results demonstrate that more and ranked top pathways found by the proposed method are cancer-related pathways which are supported by the published literatures based on biological experiments. In conclusion, compared with ORA and GSEA, EP-ORA and EP-GSEA can more effectively identify cancer-related pathways for different datasets.
Discussion
The pathway-based analysis is an effective technique that overcomes the limitations of the current single-locus methods. This procedure provides a comprehensive understanding of the molecular mechanisms that cause complex diseases28. Currently, a major pathway analysis challenge in the context of cancer research is how to integrate and analyze various types of -omics data and large-scale biological networks to identify cancer-related pathways.
We present a novel network-based approach for integrative analysis of DNA methylation and gene expression data to extend classical pathways. Our method can effectively identify altered pathways which are correlated well with the corresponding cancer by inputting the gene lists of extended pathways into the classical gene set analysis (ORA and FCS) on three datasets (BRCA, LUAD and COAD). By applying the method to the breast cancer dataset, we demonstrate the method’s potential to identify breast cancer-related pathways. The analysis of colorectal cancer and lung adenocarcinoma confirm the proposed method’s ability to correctly identify cancer-related pathways in different cancer datasets. This suggests that the integration of DNA methylation and gene expression through a known gene interactions network is effective in pathway analysis. In the future, we will employ more datasets to assess the validity of our method. Readers can download our code from the website (https://github.com/ZHANGQiaosheng/IaPathway).
Data Availability
The data supporting the findings of this work are contained within the manuscript.
References
Varadan, V., Mittal, P., Vaske, C. J. & Benz, S. C. The integration of biological pathway knowledge in cancer genomics: a review of existing computational approaches. IEEE Signal Processing Magazine 29, 35–50 (2012).
Zhang, Q., Li, J., Xie, H., Xue, H. & Wang, Y. A network-based pathway-expanding approach for pathway analysis. BMC Bioinformatics 17, 536 (2016).
Wang, X. et al. Progress in gene functional enrichment analysis. Scientia Sinica Vitae 46, 363–373 (2016).
Khatri, P. & Drǎghici, S. Ontological analysis of gene expression data: current tools, limitations, and open problems. Bioinformatics 21, 3587–3595 (2005).
Ansari, S., Voichita, C., Donato, M., Tagett, R. & Draghici, S. A novel pathway analysis approach based on the unexplained disregulation of genes. Proceedings of the IEEE 105, 482–495 (2017).
Subramanian, A. et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proceedings of the National Academy of Sciences 102, 15545–15550 (2005).
Mansmann, U. & Meister, R. Testing differential gene expression in functional groups. Methods of Information in Medicine 44, 449–453 (2005).
Khatri, P., Sirota, M. & Butte, A. J. Ten years of pathway analysis: current approaches and outstanding challenges. Plos Computational Biology 8, e1002375 (2012).
Keshava Prasad, T. et al. Human protein reference database—2009 update. Nucleic Acids Research 37, D767–D772 (2008).
Schmitt, T., Ogris, C. & Sonnhammer, E. L. Funcoup 3.0: database of genome-wide functional coupling networks. Nucleic Acids Research 42, D380–D388 (2013).
Szklarczyk, D. et al. The string database in 2011: functional interaction networks of proteins, globally integrated and scored. Nucleic Acids Research 39, D561–D568 (2010).
Lu, L. J. et al. Comparing classical pathways and modern networks: towards the development of an edge ontology. Trends in Biochemical Sciences 32, 320–331 (2007).
Glaab, E., Baudot, A., Krasnogor, N. & Valencia, A. Extending pathways and processes using molecular interaction networks to analyse cancer genome data. BMC Bioinformatics 11, 597 (2010).
Zhang, Y., Zhang, J., Liu, Z., Liu, Y. & Tuo, S. A network-based approach to identify disease-associated gene modules through integrating dna methylation and gene expression. Biochemical and Biophysical Research Communications 465, 437–442 (2015).
Vaske, C. J. et al. Inference of patient-specific pathway activities from multi-dimensional cancer genomics data using paradigm. Bioinformatics 26, i237–i245 (2010).
Network, C. G. A. R. et al. Integrated genomic analyses of ovarian carcinoma. Nature 474, 609 (2011).
Lee, C.-J., Evans, J., Kim, K., Chae, H. & Kim, S. Determining the effect of dna methylation on gene expression in cancer cells. In Gene Function Analysis, 161–178 (Springer, 2014).
Zheng, S. & Zhao, Z. Genrev: exploring functional relevance of genes in molecular networks. Genomics 99, 183–188 (2012).
Witten, D., Tibshirani, R., Gross, S. & Narasimhan, B. Pma: Penalized multivariate analysis. R Package Version 1 (2009).
Dupont, P. et al. Relevant subgraph extraction from random walks in a graph. Universite Catholique de Louvain, UCL/INGI, Number RR 7 (2006).
Wang, X., Terfve, C., Rose, J. C. & Markowetz, F. Htsanalyzer: an r/bioconductor package for integrated network analysis of high-throughput screens. Bioinformatics 27, 879–880 (2011).
Huang, R., Wallqvist, A. & Covell, D. G. Comprehensive analysis of pathway or functionally related gene expression in the national cancer institute’s anticancer screen. Genomics 87, 315–328 (2006).
Gasco, M., Shami, S. & Crook, T. The p53 pathway in breast cancer. Breast Cancer Research 4, 70 (2002).
Fang, Z., Tian, W. & Ji, H. A network-based gene-weighting approach for pathway analysis. Cell Research 22, 565 (2012).
Murray, G. I., Patimalla, S., Stewart, K. N., Miller, I. D. & Heys, S. D. Profiling the expression of cytochrome p450 in breast cancer. Histopathology 57, 202–211 (2010).
Liu, X., You, W., Xue, S. & Jiang, H. Bile acid receptor accelerates to the lung cancer process induced by lung fibroblast-tumor cells interaction, with high activation of phosphorylated stat3 and alteration of cytokine secretion. European Respiratory Journal 50, PA4202 (2017).
Xie, X., Luo, X. & Xie, M. Association between parkinson’s disease and risk of colorectal cancer. Parkinsonism & Related Disorders 35, 42–47 (2017).
Wang, K., Li, M. & Bucan, M. Pathway-based approaches for analysis of genomewide association studies. The American Journal of Human Genetics 81, 1278–1283 (2007).
Sekowski, J. W. et al. Human breast cancer cells contain an error-prone dna replication apparatus. Cancer Research 58, 3259–3263 (1998).
Fernandez, P., Jares, P., Rey, M., Campo, E. & Cardesa, A. Cell cycle regulators and their abnormalities in breast cancer. Molecular Pathology 51, 305 (1998).
Coloff, J. L. et al. Differential glutamate metabolism in proliferating and quiescent mammary epithelial cells. Cell Metabolism 23, 867–880 (2016).
Block, K. L. The role of ubiquitin-mediated proteolysis of cyclin d in breast cancer. Tech. Rep., Texas Univ Health Science Center at Sanantonio (2004).
Lanning, N. J. et al. Metabolic profiling of triple-negative breast cancer cells reveals metabolic vulnerabilities. Cancer & Metabolism 5, 6 (2017).
Xiong, B. et al. Brca1 is required for meiotic spindle assembly and spindle assembly checkpoint activation in mouse oocytes. Biology of Reproduction 79, 718–726 (2008).
Tsou, P., Katayama, H., Ostrin, E. J. & Hanash, S. M. The emerging role of b cells in tumor immunity. Cancer Research 76, 5597–5601 (2016).
Yamaguchi, H. & Condeelis, J. Regulation of the actin cytoskeleton in cancer cell migration and invasion. Biochimica et Biophysica Acta (BBA)-Molecular Cell Research 1773, 642–652 (2007).
Hanalioglu, S., Hasanov, E. & Altundag, K. Breast cancer and high-grade glioma: link or coincidence? Journal of BU ON.: Official Journal of the Balkan Union of Oncology 20, 1378–1379 (2015).
Bijian, K. et al. Targeting focal adhesion turnover in invasive breast cancer cells by the purine derivative reversine. British Journal of Cancer 109, 2810 (2013).
Lin, V. C.-L. et al. Progesterone induces focal adhesion in breast cancer cells mda-mb-231 transfected with progesterone receptor complementary dna. Molecular Endocrinology 14, 348–358 (2000).
Pedley, A. M. & Benkovic, S. J. A new view into the regulation of purine metabolism: the purinosome. Trends in Biochemical Sciences 42, 141–154 (2017).
Harburg, G. C. & Hinck, L. Navigating breast cancer: axon guidance molecules as breast cancer tumor suppressors and oncogenes. Journal of Mammary Gland Biology and Neoplasia 16, 257 (2011).
Dubey, S., Siegfried, J. M. & Traynor, A. M. Non-small-cell lung cancer and breast carcinoma: chemotherapy and beyond. The Lancet Oncology 7, 416–424 (2006).
Assi, H. et al. Small cell lung cancer with metastasis to the breast: A case report and review of literature. J Cancer Biol Res 2, 1025 (2014).
Li, Y. et al. Tumoral expression of drug and xenobiotic metabolizing enzymes in breast cancer patients of different ethnicities with implications to personalized medicine. Scientific Reports 7, 4747 (2017).
Powell, S. N. & Kachnic, L. A. Roles of brca1 and brca2 in homologous recombination, dna replication fidelity and the cellular response to ionizing radiation. Oncogene 22, 5784 (2003).
Kotoula, V. et al. Expression of dna repair and replication genes in non-small cell lung cancer (nsclc): a role for thymidylate synthetase (tyms). BMC cancer 12, 342 (2012).
Agutter, P. S. Nucleocytoplasmic rna transport. In Subcellular Biochemistry, 281–357 (Springer, 1984).
Hansen, L. et al. The role of mismatch repair in small-cell lung cancer cells. European Journal of Cancer 39, 1456–1467 (2003).
Fanale, D., Amodeo, V. & Caruso, S. The interplay between metabolism, ppar signaling pathway, and cancer. PPAR research 2017 (2017).
Horn, S., Moersig, W., Moll, R., Oelert, H. & Lorenz, J. Expression of cell adhesion molecules in lung cancer cell lines. Experimental and Toxicologic Pathology 48, 535–540 (1996).
Wang, Y. et al. Roles of hippo signaling in lung cancer. Indian Journal of Cancer 52, 1 (2015).
Seo, S.-H., Shim, W.-H., Shin, D.-H., Kim, Y.-S. & Sung, H.-W. Pulmonary metastasis of basal cell carcinoma. Annals of Dermatology 23, 213–216 (2011).
Antoniou, K. M. et al. Expression analysis of akt and mapk signaling pathways in lung tissue of patients with idiopathic pulmonary fibrosis (ipf). Journal of Receptors and Signal Transduction 30, 262–269 (2010).
Stewart, D. J. Wnt signaling pathway in non–small cell lung cancer. JNCI: Journal of the National Cancer Institute 106 (2014).
Shtivelman, E. et al. Molecular pathways and therapeutic targets in lung cancer. Oncotarget 5, 1392 (2014).
Vincenzi, B. et al. Cell cycle alterations and lung cancer. Histology and Histopathology 21, 423–435 (2006).
Schee, K., Fodstad, Ø. & Flatmark, K. Micrornas as biomarkers in colorectal cancer. The American Journal of Pathology 177, 1592–1599 (2010).
Tominaga, O. et al. Expressions of cell cycle regulators in human colorectal cancer cell lines. Japanese Journal of Cancer Research 88, 855–860 (1997).
Kahlert, U., Mooney, S., Natsumeda, M., Steiger, H.-J. & Maciaczyk, J. Targeting cancer stem-like cells in glioblastoma and colorectal cancer through metabolic pathways. International Journal of Cancer 140, 10–22 (2017).
Jass, J. et al. Morphology of sporadic colorectal cancer with dna replication errors. Gut 42, 673–679 (1998).
Clawson, G. A., Feldherr, C. M. & Smuckler, E. A. Nucleocytoplasmic rna transport. Molecular and Cellular Biochemistry 67, 87–99 (1985).
Stegh, A. H. Targeting the p53 signaling pathway in cancer therapy–the promises, challenges and perils. Expert Opinion on Therapeutic Targets 16, 67–83 (2012).
Pelletier, J., Thomas, G. & Volarević, S. Ribosome biogenesis in cancer: new players and therapeutic avenues. Nature Reviews Cancer 18, 51 (2018).
Li, S. K. & Martin, A. Mismatch repair and colon cancer: mechanisms and therapies explored. Trends in Molecular Medicine 22, 274–289 (2016).
Acknowledgements
This work is partially supported by National Key Research and Development Program of China (Grant No. 2016YFC0901905), Natural Science Foundation of Heilongjiang Province (Grant No. F2016016), the National Natural Science Foundation of China (Grant No. 61471147) and Youth Innovative Talent Program of Heilongjiang Bayi Agricultural University (Grant No. ZRCQC201809).
Author information
Authors and Affiliations
Contributions
Jie Li designed the method, Qiaosheng Zhang and Jie Li performed simulations, analyses and wrote the manuscript. Yadong Wang, Zhuo Chen and Dechen Xu participated in the preparation of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, J., Zhang, Q., Chen, Z. et al. A network-based pathway-extending approach using DNA methylation and gene expression data to identify altered pathways. Sci Rep 9, 11853 (2019). https://doi.org/10.1038/s41598-019-48372-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-48372-1
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
