
Abstract
The ultimate aim of quantum key distribution (QKD) is improving the transmission distance and key generation speed. Unfortunately, it is believed to be limited by the secret-key capacity of quantum channel without quantum repeater. Recently, a novel twin-field QKD (TF-QKD) is proposed to break through the limit, where the key rate is proportional to the square-root of channel transmittance. Here, by using the vacuum and one-photon state as a qubit, we show that the TF-QKD can be regarded as a measurement-device-independent QKD (MDI-QKD) with single-photon Bell state measurement. Therefore, the MDI property of TF-QKD can be understood clearly. Importantly, the universal security proof theories can be directly used for TF-QKD, such as BB84 encoding, six-state encoding and reference-frame-independent scheme. Furthermore, we propose a feasible experimental scheme for the proof-of-principle experimental demonstration.
Similar content being viewed by others
Introduction
Throughout history, the battle between encryption and decryption never ends. Currently, relying on computational complexity, the widely used public-key cryptosystem becomes vulnerable to quantum computing attacks. The one-time pad is the only provably secure cryptosystem according to information theory known today. Thereinto, an important issue exists that the common secret key is at least as long as the message itself and can be used only once. Quantum key distribution (QKD) constitutes the only way to solve the real time key distribution problem1. QKD allows two distant parties to establish a string of secret keys with information-theoretic security2,3. One can ensure legitimate parties to exchange messages with perfect confidentiality by combining QKD with one-time pad.
The longest transmission distance of QKD has been implemented over 421 km with ultralow-loss optical fiber4 and 1200 km satellite-to-ground5. Improving the transmission distance and key rate are the most important tasks of QKD research. However, this task has been proven impossible beyond a certain limit without quantum repeaters6,7. The secret-key capacity of quantum channel can be used to bound the extractable maximum secret key6,7. Generally, the secret-key capacity can be regarded as a linear key rate Pirandola-Laurenza-Ottaviani-Banchi (PLOB) bound7 \({R}_{{\rm{PLOB}}}=\,-\,{\mathrm{log}}_{2}\mathrm{(1}-\eta )\), where η is the transmittance. To overcome the rate-distance limit of QKD, quantum repeaters are usually believed as a strong candidate8,9. However, the long-time quantum memory and high-fidelity entanglement distillation are far from feasible. Despite the recent advance10 relaxing the requirement, the actual implementation is also difficult to realize, for example, quantum non-demolition (QND) measurement. Although the trusted relay-based QKD has been deployed over 2000 km11, its security is compromised.
Recently, a novel protocol called twin-field QKD (TF-QKD)12 has been proposed to overcome the rate-distance limit. The secret key rate of TF-QKD has been scaled with the square-root of the transmittance, \(R \sim O(\sqrt{\eta })\). In the TF-QKD, a pair of optical fields are generated respectively at locations of two remote parties and then sent to the untrusted center to implement single-photon detection. Compared with measurement-device-independent QKD (MDI-QKD)13, TF-QKD retains the properties of being immune to all detector attack, multiplexing of expensive single-photon detectors and natural star network architecture. In the original paper of TF-QKD12, the communication parties, Alice and Bob, prepare the phase-randomized coherent state with phase encoding in X and Y basis. To acquire the correction of raw keys, they should announce the random phase of each pulse. The key rate of unconditional security proof is still missing in the original paper12. Various different important works have been shown to give the key rate formulas with information-theoretic security14,15,16,17,18,19.
Here, we prove that TF-QKD can be seen as a special type of MDI-QKD. Thereinto, a qubit is physically implemented by a two-dimensional subspace with vacuum and one-photon state. One can consider that the untrusted center performs the single-photon Bell state measurement (BSM) while Alice and Bob prepare quantum state in the complementary bases. Since the vacuum state is immune to the loss, it can always have a detection (detector without click means a successful detection), thus the probability of coincident detection is exactly equal to that of single detection. Therefore, the TF-QKD inherits all positive features of MDI-QKD and increases the key rate a lot to break through the linear key rate bound. The unconditional security proof technologies with entanglement purification20,21, information theory analysis22, entropy uncertainty relation23 can be directly applied in the TF-QKD. The bit of Z basis is independent of the phase misalignment. Naturally, there is no need to publish random phase of Z basis and the state can be seen as a mixture of photon number states. Therefore, the distilled secret key of Z basis in the TF-QKD can exploit the tagging-method of Gottesman-Lo-Lütkenhaus-Preskill (GLLP) analysis24. Combining the decoy-state method25,26,27, we could acquire the tight key rate formula of TF-QKD with BB84 encoding1, six-state encoding28 and reference-frame-independent (RFI)29 scheme.
Results
MDI-QKD with single-photon BSM
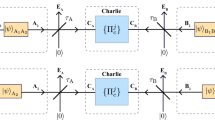
Here, let us first introduce an entanglement-based MDI-QKD with single-photon BSM protocol, as shown in Fig. 1(a). Let {|0〉, |1〉} represent Z basis, where 0 and 1 are the vacuum and the one-photon state, respectively. Accordingly, the eigenvectors of X basis and Y basis are \(|\,\pm \,\rangle =(|0\rangle \pm |1\rangle )/\sqrt{2}\) and \(|\pm i\rangle =(|0\rangle \pm i|1\rangle )/\sqrt{2}\). Considering that one photon inputs a lossless symmetric beam splitter, the output state is a single-photon entangled state, \(|{\psi }^{+}\rangle =(|0\rangle |1\rangle +|1\rangle |0\rangle )/\sqrt{2}\). Alice and Bob prepare a series of entangled states \({|{\psi }^{+}\rangle }_{Aa}=({|0\rangle }_{A}{|1\rangle }_{a}+{|1\rangle }_{A}{|0\rangle }_{a})/\sqrt{2}\) and \({|{\psi }^{+}\rangle }_{Bb}=({|0\rangle }_{B}{|1\rangle }_{b}+{|1\rangle }_{B}{|0\rangle }_{b})/\sqrt{2}\), respectively, where A (B) and a (b) are a pair of field modes. Afterwards, they hold the qubit of a and b modes and send the quantum states of A and B modes to the untrusted third party, Charlie, who performs the BSM to identify the two single-photon Bell states \({|{\psi }^{+}\rangle }_{AB}=({|0\rangle }_{A}{|1\rangle }_{B}+{|1\rangle }_{A}{|0\rangle }_{B})/\sqrt{2}\) and \({|{\psi }^{-}\rangle }_{AB}=({|0\rangle }_{A}{|1\rangle }_{B}-{|1\rangle }_{A}{|0\rangle }_{B})/\sqrt{2}\). Therefore, a coincidence detection with L click and R no click indicates a projection into the Bell state \({|{\psi }^{+}\rangle }_{AB}\). A coincidence detection with R click and L no click, implies a projection into the Bell state \({|{\psi }^{-}\rangle }_{AB}\). Note that the identification of any one Bell state is enough to prove the security. When Charlie performs a successful BSM, the qubit that the legitimate users hold becomes a single-photon Bell state, the process of which can be regarded as an entanglement swapping, as experimentally demonstrated30. Alice and Bob can utilize quantum memory to store their qubit a and b modes. After Charlie announces the events through public channels whether he has obtained a Bell state and which Bell state he has identified, Alice and Bob will measure qubit a and b modes, respectively. They publish the basis information through an authenticated classical channel. Bob will apply a bit flip when they choose Z (X or Y) basis and Charlie receives a Bell state \({|{\psi }^{\pm }\rangle }_{AB}\) \(({|{\psi }^{-}\rangle }_{AB})\). They use the data of Z basis to form the raw key, while the data of other bases are all used to estimate the leaked information. Alice and Bob can acquire the secure key through the error correction and privacy amplification.

Scheme to overcome the PLOB bound of QKD. (a) Setup for entanglement-based MDI-QKD with single-photon BSM. Alice and Bob prepare single-photon Bell state, while Charlie implements entanglement swapping. M represents the measurement operation, such as Z, X and Y basis. Alice and Bob implement the M measurement operation after Charlie performs the single-photon BSM. (b) Prepare-and-measure MDI-QKD with single-photon BSM. Alice and Bob directly prepare the qubit with superpositions of the vacuum and one-photon states. Alice and Bob implement the M measurement operation before Charlie performs the single-photon BSM. (c) Effective TF-QKD with single-photon and laser sources. The photons from single-photon source and laser source are indistinguishable in every degree of freedom. The phase-reference of long-distance should be stabilized to implement laser interference. The single-photon source is used to implement Z basis encoding, while the laser source is used to implement the phase encoding, such as X and Y basis.
We can equivalently convert our entanglement-based protocol in Fig. 1(a) to the prepare-and-measure protocol as shown in Fig. 1(b) by the Shor-Preskill’s arguments21. Let Alice and Bob measure the modes a and b before they send the qubit of A and B modes to Charlie, meaning Alice and Bob directly prepare the quantum state A mode and B mode. Other steps are all same to the entanglement-based protocol, including the BSM, basis comparison, bit flip, error correction and privacy amplification. Hereafter, we use the TF state to represent the joint quantum state of Alice’s A mode and Bob’s B mode. In the case of ideal detector (photon-number-resolving and without dark count) and lossless channel, the MDI-QKD with single-photon BSM protocol is similar with the two-photon BSM protocol. However, the single-photon BSM exploits the vacuum state identification, namely, detector without click, the case of TF state with |1A〉|1B〉 will create error Bell state detection under the case of lossy channel, which will cause the unbalanced bit value and high bit error rate.
To solve this issue, Alice and Bob need to decrease the probability of qubit |1〉 preparation and increase the probability of qubit |0〉 preparation. Therefore, Alice (Bob) should exploit the entangled state \({|\psi \rangle }_{t}=\sqrt{1-t}|0\rangle |1\rangle +\sqrt{t}|1\rangle |0\rangle \) to replace the maximally entangled state \(|{\psi }^{+}\rangle =(|0\rangle |1\rangle +|1\rangle |0\rangle )/\sqrt{2}\) in the entanglement-based protocol with Fig. 1(a), where t is the transmittance of partial BS. Note that the non-maximally entangled state is also used to prove the security in the TF-QKD18. Taking into account the threshold detector and lossy channel, the joint quantum state of Alice’s a mode and Bob’s b mode after Charlie’s BSM with \({|{\psi }^{\pm }\rangle }_{AB}\) under the case without eavesdropper’s disturbance can be written as (see Methods for detail)
where q = q0 + q1 + q2, q0, q1 and q2 are the probabilities of Charlie’s successful BSM given that the photon numbers of TF state are zero, one and two. Consider a virtual step, if Alice and Bob jointly perform QND measurement on TF state to implement photon-number-resolving before they send TF state to Charlie, the joint quantum state of Alice’s a mode and Bob’s b mode is \({|{\psi }^{\pm }\rangle }_{ab}\) given that the TF state with one-photon and Charlie’s BSM with \({|{\psi }^{\pm }\rangle }_{AB}\), which reduces to the the case of ideal detector and lossless channel.
Similarly, we can have a equivalent prepare-and-measure protocol corresponding to the entanglement-based protocol with entangled state \({|\psi \rangle }_{t}=\sqrt{1-t}|0\rangle |1\rangle +\sqrt{t}|1\rangle |0\rangle \). Alice (Bob) prepares the qubit |+z〉 = |0〉 and |−z〉 = |1〉 with probability 1 − t and t as Z basis logic bit 0 and 1, respectively. Alice (Bob) prepares the qubit \(|+x\rangle =\sqrt{1-t}|0\rangle +\sqrt{t}|1\rangle \) and \(|-x\rangle =\sqrt{1-t}|0\rangle -\sqrt{t}|1\rangle \) with equal probability as X basis logic bit 0 and 1, respectively. Alice (Bob) prepares the qubit \(|+y\rangle =\sqrt{1-t}|0\rangle +i\sqrt{t}|1\rangle \) and \(|-y\rangle =\sqrt{1-t}|0\rangle -i\sqrt{t}|1\rangle \) with equal probability as Y basis logic bit 0 and 1, respectively. Obviously, the quantum state can be seen as a mixture of photon number states for TF state in the Z basis. For the TF state with one-photon in the Z basis, one of Alice and Bob needs to prepare |0〉 as logic bit 0 and the other prepare |1〉 as logic bit 1. However, the quantum state is coherent superposition of photon number states for TF state in the X (Y) basis. Here, if we assume Alice and Bob knowing the quantum bit error rate (QBER) of TF state with one-photon in the X basis, for example, Alice and Bob can perform joint QND measurement on TF state to implement photon-number-resolving in the X basis, one can use the case of TF state with one-photon to extract secure key in the BB84 encoding, which can be given by (see Methods for detail)
where EZZ = (q0 + q2)/q is the QBER of Z basis, \(H(x)=\,-\,x{\mathrm{log}}_{2}(x)-\mathrm{(1}-x)\,{\mathrm{log}}_{2}\mathrm{(1}-x)\) is the binary Shannon entropy and \({e}_{XX}^{b1}\) is the QBER in X basis for TF state with one-photon. We can have optimal secure key rate in Eq. (2) with the transmittance of partial BS t ≈ 8% given that QBER \({e}_{XX}^{b1}=\mathrm{3 \% }\), dark count rate of threshold detector pd = 10−6, efficiency of threshold detector ηd = 40% and the fiber distance between Alice and Bob L ≥ 100 km. Note that the entanglement-based protocol in Fig. 1(a) and prepare-and-measure protocol in Fig. 1(b) are the virtual protocols, which are not used to perform experiment but prove the security in theory.
TF-QKD with phase-encoding coherent state
Manipulating the quantum state with superpositions of the vacuum and one-photon states and, in particular, requiring control about the relative phase between the vacuum and one-photon state is quite problematic31. However, we consider the coherent state \(|\alpha \rangle ={e}^{-\mu \mathrm{/2}}{\sum }_{n=0}^{\infty }\,\frac{{({e}^{i\theta }\sqrt{\mu })}^{n}}{\sqrt{n!}}|n\rangle \), where the relative phase θ between the different Fock states in the superposition is reflected physically in the phase of the classical electric field. Hereafter, the phase-encoding basis means to implement phase modulation of coherent state, such as X and Y basis. In order to achieve Alice and Bob knowing the QBER of TF state with one-photon in the phase-encoding basis without the requirement of QND measurement, one can use the post-selected phase-matching method for phase-randomized coherent state12,15. By using the post-selected phase-matching method, the phases of Alice’s and Bob’s coherent state can be seen as equal and randomized, which means that they can use decoy-state method to estimate the yield and QBER of TF state with one-photon in the phase-encoding basis (see Methods).
Efficient TF-QKD
Here, we propose an efficient TF-QKD that the single-photon source used for Z basis and laser source used for phase-encoding basis in Fig. 1(c). The qubit prepared in Z basis can be implemented by turning on and off (such as optical switch) the single-photon source, while the qubit of phase encoding basis should exploit the phase-randomized coherent state combined with phase modulation. However, the perfect single-photon source is still a challenge under the current technology. Therefore, we propose a practical TF-QKD by exploiting phase-randomized coherent state to replace single-photon source used for Z basis encoding.
Practical TF-QKD
In the following, let us explain our practical TF-QKD in detail as shown in Fig. 2(a). (i) Alice and Bob use the stabilized narrow line-width continuous-wave laser and amplitude modulator to prepare the global phase stabilized optical pulses. Alice’s and Bob’s random phases θA ∈ [0, 2π) and θB ∈ [0, 2π) are realized by using phase modulators. For Z basis encoding, the phase-randomized coherent state with intensities 0 and μ as logic bits 0 and 1 with probabilities 1 − t and t by using amplitude modulator. For X (Y) basis encoding, they use the phase and amplitude modulator to randomly implement 0 (π/2) and π (−π/2) phase modulation as logic bits 0 and 1 with intensities {ν/2, ω/2, 0}. (ii) Then they send quantum states to Charlie for single-photon BSM through the insecure quantum channel. Charlie publishes the successful events of single-photon BSM. (iii) Alice and Bob will announce the basis information through the authenticated classical channel. The intensity and random phase information kA,B of phase-encoding basis should be disclosed, while those of Z basis are confidential to Charlie, where they have \({\theta }_{A,B}\in {{\rm{\Delta }}}_{{k}_{A,B}}\), \({{\rm{\Delta }}}_{{k}_{A,B}}=[\frac{2\pi {k}_{A,B}}{M},\frac{2\pi ({k}_{A,B}+\mathrm{1)}}{M})\) and kA,B ∈ {0, 1, …, M − 1}. (iv) Alice and Bob use the data of Z basis as the raw key, while the data of phase-encoding basis are announced to estimate the amount of leaked information. (v) They exploit the classical error correction and privacy amplification to extract the secure key rate.

The practical TF-QKD setup. (a) practical TF-QKD with independent lasers. The phase modulator (PM) can realize phase encoding and random phase modulation at one time. CW-Laser: continuous-wave laser, AM: amplitude modulator, VOA, variable optical attenuator, BPF: band pass filter, PC: polarization controller, BS: beam splitter, RNG: random number generator. (b) Phase self-aligned TF-QKD with single laser. The Faraday mirror (FM) or the polarization beam splitter (PBS) and the π/2 Faraday rotator (FR) are exploited to realize the transformation between horizontal and vertical polarizations. Alice and Bob could choose to prepare the qubit in Z basis by using Charlie’s laser or their own pulse lasers. The security will be enhanced if they use their own laser. Some polarization-maintaining fiber are required to keep the polarization in the systems of Alice, Bob and Charlie. P-Laser: pulse laser, OS: optical switch, PD, photoelectric detector, Cir: circulator.
After Charlie announces the measurement results, he cannot change the yield and QBER due to information causality32. The decoy-state method of estimating the yield and QBER of TF state with n-photon in phase-encoding basis is also true even for the post-selected phase-matching method, which has also been used in phase-matching QKD15. The GLLP analysis24 can be used for the data of Z basis, since the random phases information of Alice’s and Bob’s coherent states are all confidential to Charlie. Bob will always flit his bit in Z basis. Due to the density matrix of TF state with one-photon \({\rho }_{{\rm{TF}}}^{1ZZ}={\rho }_{{\rm{TF}}}^{1XX}=\frac{1}{2}({|01\rangle }_{AB}\langle 01|+{|10\rangle }_{AB}\langle 10|)\), we can use the yield of TF state with one-photon \({Y}_{{\rm{TF}}}^{1ZZ}={Y}_{{\rm{TF}}}^{1XX}\) in the asymptotic limit. Note that, we can also directly estimate the yield \({Y}_{{\rm{TF}}}^{1ZZ}\) by using the data of phase-encoding basis given that one of Alice and Bob sends intensity 0.
For the BB84 encoding1, Alice and Bob only keep the data of |kB − kA| = 0 and M/2 when they both choose X basis by the post-selected phase-matching method. If |kB − kA| = 0 (|kB − kA| = M/2), Bob will flit his bit when Charlie receives a Bell state \({|{\psi }^{-}\rangle }_{AB}\) \(({|{\psi }^{+}\rangle }_{AB})\). The secure key rate of practical TF-QKD can be given by
where QZZ is the gain in Z basis acquired directly from the experiment, f = 1.15 is the error correction coefficient.
For the RFI scheme29,33, one can allow Alice and Bob to have different phase references which can be changed slowly (details can be found in Methods). Therefore, they can collect the data of |kB − kA| = k, k ∈ {0, 1, …, M − 1} to form a set Dk, where the probability of |kB − kA| = k is \(\frac{1}{M}\). For each set Dk, they calculate the value \({C}_{k}^{1}={\mathrm{(1}-2{e}_{XXk}^{b1})}^{2}+{\mathrm{(1}-2{e}_{XYk}^{b1})}^{2}+{\mathrm{(1}-2{e}_{YXk}^{b1})}^{2}+{\mathrm{(1}-2{e}_{YYk}^{b1})}^{2}\), where \({e}_{XXk(XYk,YXk,YYk)}^{b1}\) is the QBER of TF state with one-photon in set Dk given that Alice and Bob choose X − X(X − Y, Y − X, Y − Y) basis. The secure key rate of practical TF-QKD with RFI scheme can be given by
where \({I}_{E}({C}^{1})=\mathrm{(1}-{e}_{ZZ}^{b1})H(\frac{1+\mu }{2})+{e}_{ZZ}^{b1}H(\frac{1+v}{2})\) describes eavesdropper Eve’s information, thereinto, \(v=\sqrt{{C}^{1}\mathrm{/2}-{\mathrm{(1}-{e}_{ZZ}^{b1})}^{2}{u}^{2}}/{e}_{ZZ}^{b1}\), \(u=\,{\rm{\min }}[\sqrt{{C}^{1}\mathrm{/2}}\mathrm{/(1}-{e}_{ZZ}^{b1}),\,1]\) and \({C}^{1}=\frac{1}{M}{\sum }_{k=0}^{M-1}\,{C}_{k}^{1}\). Compared with the BB84 encoding, all data of RFI scheme can be exploited to estimate parameter C1, which can be used to slow down the finite size effect. Alice and Bob can change M to acquire the maximum key rate without impacts on efficiency. The QBER of Z basis for TF state with one-photon \({e}_{ZZ}^{b1}\equiv 0\) leads to \({I}_{E}({C}^{1})=H\mathrm{((1}+\sqrt{{C}^{1}\mathrm{/2}}\mathrm{)/2)}\).
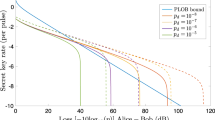
The secure key rate of practical TF-QKD using BB84 encoding changes with the dark count rate as shown in Fig. 3. We use the practical parameters to simulate the secure key rate in Fig. 3, where the efficiency of detector is ηd = 40%, the loss coefficient of the channel is 0.2 dB/km and the optical error rate of system is eopt = 1%. The optical error rate is usually large due to the long-distance single-photon-type interference. We compare the secure key rates of practical TF-QKD using BB84 encoding and RFI scheme with the different optical error rate as shown in Fig. 4. To show the advantage of TF-QKD, the efficiency and dark count rate of detector are assumed to be ηd = 90% and pd = 10−9 in Fig. 4, respectively. In the simulation, both schemes can surpass the PLOB bound and tolerate the big optical error rate eopt. The key rate of TF-QKD with BB84 encoding will significantly decline with eopt rising, while the RFI scheme is robust. However, the long-distance phase-stabilization (it could not be a perfect match but is required to vary slowly) also exists since the relative phase changes too fast in the long-distance fiber or free-space channel.

The key rate of practical TF-QKD with BB84 encoding in the asymptotic limit. For each transmission loss, we optimize the parameters μ and t with eopt = 1%, ν = 0.1, ω = 0.02 and M = 16. For the PLOB bound, we use \({R}_{{\rm{PLOB}}}=\,-\,{\mathrm{log}}_{2}\mathrm{(1}-{\eta }_{{\rm{PLOB}}})\), ηPLOB = ηd × 10−0.02L. The secure key rate of TF-QKD with BB84 encoding can surpass the PLOB bound under the case of detector with ηd = 40%, pd = 10−7, the performance of detector has been realized much more34.

The key rates of practical TF-QKD with BB84 encoding and RFI scheme in the asymptotic limit. For each transmission loss, we optimize the parameters μ and t with ηd = 90%, pd = 10−9, ν = 0.1, ω = 0.02 and M = 16. The secure key rate of practical TF-QKD with RFI scheme do not change obviously with optical error rate eopt. The secure key rate of practical TF-QKD with BB84 encoding can also beat the PLOB bound even the optical error rate up to eopt = 20%.
The experimental demonstration of TF-QKD with independent lasers in Fig. 2(a) is a big challenge, although the MDI-QKD with two-photon BSM has been implemented over 404 km optical fiber34 by using asymmetric four-intensity decoy-state method35. Compared with the two-photon BSM, greater technological challenges exist in the TF-QKD with single-photon BSM. The frequency difference of two independent lasers is required more rigorously12. The phase-locking technique may be used to compensate the frequency difference. Importantly, the long-distance phase-stabilization technique is required to implement single-photon interference with phase matching. The RFI scheme can allow the phase mismatching. However, the relative phase change is still required to vary slowly. To rapidly implement the proof-of-principle TF-QKD experiment, we present a phase self-aligned TF-QKD with single laser interference as shown in Fig. 2(b). The horizontal polarization optical pulse generated by Charlie is divided into two pulses by the polarization-maintaining beam splitter. By exploiting the π/2 rotation effect of Faraday mirror, the two pulses interfere after they go through the same path. Though the phase self-aligned scheme would be affected by the loss and noise, the frequency difference and long-distance phase-stabilization problems are both solved36. An extra security analysis with untrusted source37 should be used to defeat the attack from systems of Alice and Bob.
Discussion
In summary, we have proved that the TF-QKD can be regarded as a MDI-QKD with single-photon BSM. By introducing the Z basis encoding, the secret key extraction can exploit the tagging method of GLLP analysis and the decoy-state method. Compared with BB84 encoding, the RFI scheme has the advantages of increasing the data of parameter estimation and reducing the effect of phase drift. We should point out that the extra Y basis preparation in RFI scheme does not add additional operation due to the active phase randomization requirement, which is different from the traditional QKD. We propose a feasible experimental scheme to implement the proof-of-principle experimental demonstration. Note that, the security of this proof-of-principle experiment in Fig. 2b is not guaranteed with our current analysis, which requires a further security evaluation due to introducing untrusted source. Through simulation, we show that the secure key rate of practical TF-QKD can surpass the PLOB bound. The universally composable security with finite-key analysis needs to be considered in the future. Our proposal suggests an important avenue for practical high-speed and long-distance QKD without detector vulnerabilities. During the preparation of this paper and posting it on the arXiv, we became aware of some important works14,15,16,17,18,19 of TF-QKD.
Methods
MDI-QKD with single-photon BSM
For the case of entanglement-based protocol with the entangled state \(|{\psi }_{t}\rangle =\sqrt{1-t}|0\rangle |1\rangle +\sqrt{t}|1\rangle |0\rangle \), the joint quantum state of Alice and Bob can be given by
For the threshold detector and lossy channel, the TF state |00〉AB, |01〉AB, |10〉AB and |11〉AB will all have single-photon Bell state clicks. Due to the single-photon BSM of Charlie, the photon number of TF state will collapse to three events, namely vacuum, one-photon and two-photon. The corresponding probability can be expressed as
where the expression of q2 is acquired by the Hong-Ou-Mandel interference of two-photon. The parameter \(\sqrt{\eta }={\eta }_{d}\times {10}^{-0.02L\mathrm{/2}}\) is the transmittance between Alice (Bob) and Charlie.
For the case of prepare-and-measure protocol corresponding to entanglement-based protocol with the entangled state \(|{\psi }_{t}\rangle =\sqrt{1-t}|0\rangle |1\rangle +\sqrt{t}|1\rangle |0\rangle \), the density matrix of TF state in the Z basis is
which means a mixture of photon number states for TF state in the Z basis. The TF state of Z basis is the product state of Alice’s and Bob’s quantum state. The density matrix of TF state with one-photon in the Z basis is
which needs one of Alice and Bob prepares |0〉 as logic bit 0 and the other prepares |1〉 as logic bit 1.
The density matrix of TF state in the X basis can be written as
Thereinto, we have
which means a coherent superposition of photon number state for TF state in the X basis. If Alice and Bob jointly perform QND measurement on TF state to implement photon-number-resolving, we have
where \({\rho }_{{\rm{TF}}}^{1ZZ}\) (\({\rho }_{{\rm{TF}}}^{1XX}\)) is the density matrix of TF state with one-photon in the Z (X) basis. We have \({Y}_{{\rm{TF}}}^{1ZZ}={Y}_{{\rm{TF}}}^{1XX}\) in the asymptotic limit due to \({\rho }_{{\rm{TF}}}^{1ZZ}={\rho }_{{\rm{TF}}}^{1XX}\), where \({Y}_{{\rm{TF}}}^{1ZZ}\) (\({Y}_{{\rm{TF}}}^{1XX}\)) is the yield given that Alice and Bob choose Z (X) basis and TF state contains one-photon. Alice and Bob can know the locations of the TF state with one-photon by using the QND measurement, they could discard all other states and apply error correction and privacy amplification only to the TF state with one-photon. In this case with BB84 encoding, they can achieve a key rate of20,21
For the TF state with one-photon in the Z basis, we have \({e}_{ZZ}^{b1}\equiv 0\) since we only have the case of Alice’s logic bit 0 (1) and Bob’s logic bit 1 (0) corresponding to quantum state |01〉 (|10〉).
However, if we assume that Alice and Bob can know the QBER of TF state with one-photon in the X basis, one can acquire the secure key in the Z basis without Alice and Bob knowing the locations (QND measurement) of the TF state with one-photon by using the GLLP analysis24. The secure key rate can be given by
where the parameter q1 should be calculated by using the decoy-state method, for example, we choose three value of t in the Z basis.
TF-QKD with phase-encoding coherent state
In order to make Alice and Bob know the QBER of TF state with one-photon in the X basis without the requirement of QND measurement, we need to consider the case of phase-randomized coherent state
where the global phases of Alice’s coherent state \({|\alpha \rangle }_{A}={|{e}^{i\theta }\sqrt{\mu }\rangle }_{A}\) and Bob’s \({|{e}^{i\delta }\alpha \rangle }_{B}={|{e}^{i(\theta +\delta )}\sqrt{\mu }\rangle }_{B}\) should be randomized and have a fixed phase difference δ. Therefore, we have
For the X basis encoding, we have
where the global phases of Alice’s and Bob’s coherent state should be equal and randomized. It can be realized by using post-selected phase-matching method for phase-randomized coherent state introduced in the original TF-QKD12 and phase-matching QKD15. If we consider the photon number space of TF state given that the global phases of Alice’s coherent state and Bob’s are randomized and have a fixed phase difference, the density matrix can be given by
which is similar with the phase encoding phase-randomized coherent state in the traditional decoy-state QKD26,27. Therefore, the decoy state method can be used for estimating the yield and QBER of TF state with one-photon.
For phase-randomized coherent state used for Z basis encoding, we have
We need |0〉 as logic bit 0 and |1〉 as logic bit 1, therefore the efficient TF state with one-photon in Z basis only results from the case of logic bit 0A1B and 1A0B with the probability 2t(1 − t)μe−μ. For simulation, we consider the case without Charlie’s disturbance. In the Z basis of practical TF-QKD, by going through the quantum channel and beam splitter, we have (1 − t)2 probability of quantum state
t(1 − t) probability of quantum state
t(1 − t) probability of quantum state
and t2 probability of quantum state
Here, we have θA ∈ [0, 2π) and θB ∈ [0, 2π), L and R represent the left detector and right detector of Charlie, respectively. The gain QZZ and QBER EZZ of practical TF-QKD can be given by
and
For phase-encoding basis of practical TF-QKD, by going through the quantum channel and beam splitter, we have 1/4 probability of quantum state
where hA, hB ∈ {0, 1} represent basis X and Y, gA, gB ∈ {0, 1} represent logic bit 0 and 1 given that the intensities of Alice’s and Bob’s are λ and χ, respectively, λ, χ ∈ {ν/2, ω/2, 0}. Here, we define \({Q}_{{h}_{A},{h}_{B}}^{{\theta }_{A},{\theta }_{B},\lambda ,\chi }\) and \({E}_{{h}_{A},{h}_{B}}^{{\theta }_{A},{\theta }_{B},\lambda ,\chi }\) are the gain and QBER that Alice and Bob choose basis hA and hB when they send the global phase θA and θB optical pulses with intensities λ and χ, respectively. Here,
and
where \(x={\theta }_{B}-{\theta }_{A}+\frac{\pi }{2}({h}_{B}-{h}_{A})\), \({E}_{{h}_{A},{h}_{B}}^{{\theta }_{A},{\theta }_{B},\lambda ,\lambda }\simeq \frac{1-\,\cos \,x}{2}\) when we assume \(\sqrt{\eta }\to 0\) and pd → 0.
Obviously, we can directly estimate the yield \({Y}_{{\rm{TF}}}^{1ZZ}\) by using the data of phase-encoding basis given that one of Alice and Bob sends intensity 0. We define \(\lambda \uplus \chi \) as the intensity set when Alice and Bob send intensity λ and χ phase-randomized coherent state. Therefore, \({Q}^{\frac{\nu }{2}}\), \({Q}^{\frac{\nu }{2}}\) and Q0 are the gain when Alice and Bob send intensities set \(\{0\uplus \frac{\nu }{2},\,\frac{\nu }{2}\uplus 0\}\), \(\{0\uplus \frac{\omega }{2},\,\frac{\omega }{2}\uplus 0\}\) and \(\mathrm{\{0}\uplus \mathrm{0\}}\), which can be written as
The \({Y}_{{\rm{TF}}}^{0ZZ}\) and \({Y}_{{\rm{TF}}}^{1ZZ}\) are the yields of TF state with vacuum and one-photon in the Z basis, respectively, which can be given by (ν > ω > 0)26,27
and
We assume that the optical error rate eopt of X basis exists due to the single-photon interference. For simplicity, we assume that the optical error rate is introduced by the phase misalignment12. Here, a fixed phase difference between Alice’s and Bob’s global phase is δ0 = arccos(1 − 2eopt). By using the post-selected phase-matching method in practical TF-QKD with BB84 encoding, \({Q}_{XX}^{\nu }\) \(({Q}_{XX}^{\omega })\) and \({E}_{XX}^{\nu }\) \(({E}_{XX}^{\omega })\) are gain and QBER given that Alice chooses X basis with intensity \(\frac{\nu }{2}\) \((\frac{\omega }{2})\) and Bob chooses X basis with intensity \(\frac{\nu }{2}\) \((\frac{\omega }{2})\) in the case of |kB − kA| = 0 and \(\frac{M}{2}\). They can be given by
and
Due to the random phase shifting, there is still an intrinsic QBER because the random phases are not perfectly matched. If eopt = 0.03, we have δ0 = 0.35 and \({E}_{XX}^{\nu } \sim \mathrm{3.6 \% }\). By using the decoy-state mentod26,27, the yield \({Y}_{{\rm{TF}}}^{1XX}\) and QBER \({e}_{XX}^{b1}\) can be given by
where \({e}^{b0}=\frac{1}{2}\) is the QBER of TF state with vacuum in phase-encoding basis.
For six-state encoding28, the probability that both bit flip and phase shift occurs can be given by38
To simplify, we assume that those cases of qubit preparation with relative phase modulation are symmetrical since the random phase is unknown before Charlie performs single-photon BSM. Therefore, we abtain \(a={e}_{ZZ}^{b1}\mathrm{/2}\). Interestingly, the QBER \({e}_{ZZ}^{b1}\equiv 0\), which means that the key rate of practical TF-QKD with six-state encoding has no advantage compared with BB84 encoding.
For the RFI scheme29, the Z basis is always well defined, which is ZA = ZB = Z for Alice and Bob. The other two bases may vary with the slow phase shifting β, the relation can be given by XB = cosβXA + sinβYA, YB = cosβYA−sinβYB and β = βB − βA, where ZA and ZB, XA and XB, YA and YB are the location reference frames for Z, X and Y basis of Alice and Bob, respectively. βA (βB) is the deviation between the practical and standard reference frame for Alice (Bob). Therefore, the eigenstates of XA (XB) and YA (YB) can be written as \({|\pm \rangle }_{A}=(|0\rangle \pm {e}^{i{\beta }_{A}}|1\rangle )/\sqrt{2}\) \(({|\pm \rangle }_{B}=(|0\rangle \pm {e}^{i{\beta }_{B}}|1\rangle )/\sqrt{2})\)) and \({|\pm i\rangle }_{A}=(|0\rangle \pm i{e}^{i{\beta }_{A}}|1\rangle )/\sqrt{2}\) \(({|\pm i\rangle }_{B}=(|0\rangle \pm i{e}^{i{\beta }_{B}}|1\rangle )/\sqrt{2})\). Note that βA and βB are the phases of intrinsic degree of freedom between 0 and 1 and can vary slowly in the virtual protocol with RFI theory. The key rate of single-photon with RFI theory is given by29
Here, \({I}_{E}(C)=\mathrm{(1}-{e}_{b})H(\frac{1+\mu }{2})+{e}_{b}H(\frac{1+v}{2})\) quantifies the information of Eve’s knowledge, parameters \(v=\sqrt{C\mathrm{/2}-{\mathrm{(1}-{e}_{b})}^{2}{u}^{2}}/{e}_{b}\) and \(u=\,{\rm{\min }}\,[\sqrt{C\mathrm{/2}}\mathrm{/(1}-{e}_{b}),\,\mathrm{1]}\). We have \({I}_{E}(C)=H\mathrm{((1}+\sqrt{C\mathrm{/2}}\mathrm{)/2)}\) if the QBER eb = 0. The value C can be defined as
which is independent of phase drifting βA (βB) and can just be used to bound Eve’s information. However, the phase drifting will add the QBER of X basis, which will decrease the key rate of BB84 encoding. Thereinto, EXX(YY, XY, YX) is the QBER given that Alice and Bob choose X − X(Y − Y, X − Y, Y − X) basis, which can be written as
One can acquire the maximum value C = 2 in the ideal case and IE(C = 2) = 0 if the phase difference β is fixed. For phase change from β to β + Δβ, Δβ ∈ [0, 2π] (uniformity variation), we have
We can see that C is only related to phase change Δβ and is not related to phase difference β in theory. The value C will decrease with Δβ increasing.
In the practical TF-QKD with RFI scheme, we define that \({Q}_{XXk}^{\nu }\) and \({E}_{XXk}^{\nu }\) are gain and QBER when Alice chooses X basis with intensity \(\frac{\nu }{2}\) and Bob chooses X basis with intensity \(\frac{\nu }{2}\) in the case of set Dk by using the post-selected phase-matching method. Therefore, the gain \({Q}_{XXk}^{\nu }\), \({Q}_{XYk}^{\nu }\), \({Q}_{YXk}^{\nu }\) and \({Q}_{YYk}^{\nu }\) of set Dk are
The QBER \({E}_{XXk}^{\nu }\), \({E}_{XYk}^{\nu }\), \({E}_{YXk}^{\nu }\) and \({E}_{YYk}^{\nu }\) of set Dk can be written as
By using the decoy-state method, the lower and upper bounds of yield \({Y}_{{\rm{TF}}}^{1XXk}\), \({Y}_{{\rm{TF}}}^{1XYk}\), \({Y}_{{\rm{TF}}}^{1YXk}\) and \({Y}_{{\rm{TF}}}^{1YYk}\) will be
and
The lower and upper bounds of QBER \({e}_{XXk}^{b1}\), \({e}_{XYk}^{b1}\), \({e}_{YXk}^{b1}\) and \({e}_{YYk}^{b1}\) can be given by
and
For the practical TF-QKD with RFI scheme, we need to calculate the minimum value of \({C}_{k}^{1}\). Therefore, for the value
we have
the parameters \({e}_{XYk}^{b1}\), \({e}_{YXk}^{b1}\) and \({e}_{YYk}^{b1}\) are similar with the case of \({e}_{XXk}^{b1}\).
References
Bennett, C. H. & Brassard, G. Quantum cryptography: public key distribution and coin tossing. In Proceedings of the Conference on Computers, Systems and Signal Processing, 175–179 (IEEE Press, New York, 1984).
Scarani, V. et al. The security of practical quantum key distribution. Rev. Mod. Phys. 81, 1301–1350 (2009).
Weedbrook, C. et al. Gaussian quantum information. Rev. Mod. Phys. 84, 621–669 (2012).
Boaron, A. et al. Secure quantum key distribution over 421 km of optical fiber. Phys. Rev. Lett. 121, 190502 (2018).
Liao, S.-K. et al. Satellite-to-ground quantum key distribution. Nature 549, 43 (2017).
Takeoka, M., Guha, S. & Wilde, M. M. Fundamental rate-loss tradeoff for optical quantum key distribution. Nature Commun. 5, 5235 (2014).
Pirandola, S., Laurenza, R., Ottaviani, C. & Banchi, L. Fundamental limits of repeaterless quantum communications. Nature Commun. 8, 15043 (2017).
Duan, L.-M., Lukin, M., Cirac, J. I. & Zoller, P. Long-distance quantum communication with atomic ensembles and linear optics. Nature 414, 413 (2001).
Sangouard, N., Simon, C., de Riedmatten, H. & Gisin, N. Quantum repeaters based on atomic ensembles and linear optics. Rev. Mod. Phys. 83, 33–80 (2011).
Azuma, K., Tamaki, K. & Munro, W. J. All-photonic intercity quantum key distribution. Nature Commun. 6, 10171 (2015).
Qiu, J. et al. Quantum communications leap out of the lab. Nature 508, 441–442 (2014).
Lucamarini, M., Yuan, Z., Dynes, J. & Shields, A. Overcoming the rate–distance limit of quantum key distribution without quantum repeaters. Nature 557, 400–403 (2018).
Lo, H.-K., Curty, M. & Qi, B. Measurement-device-independent quantum key distribution. Phys. Rev. Lett. 108, 130503 (2012).
Tamaki, K., Lo, H.-K., Wang, W. & Lucamarini, M. Information theoretic security of quantum key distribution overcoming the repeaterless secret key capacity bound. arXiv:1805.05511 (2018).
Ma, X., Zeng, P. & Zhou, H. Phase-matching quantum key distribution. Phys. Rev. X 8, 031043 (2018).
Wang, X.-B., Yu, Z.-W. & Hu, X.-L. Twin-field quantum key distribution with large misalignment error. Phys. Rev. A 98, 062323 (2018).
Cui, C. et al. Phase-matching quantum key distribution without phase post-selection. arXiv:1807.02334 (2018).
Curty, M., Azuma, K. & Lo, H. -K. Simple security proof of twin-field type quantum key distribution protocol. arXiv:1807.07667 (2018).
Lin, J. & Lütkenhaus, N. Simple security analysis of phase-matching measurement-device-independent quantum key distribution. Phys. Rev. A 98, 042332 (2018).
Lo, H.-K. & Chau, H. F. Unconditional security of quantum key distribution over arbitrarily long distances. Science 283, 2050–2056 (1999).
Shor, P. W. & Preskill, J. Simple proof of security of the bb84 quantum key distribution protocol. Phys. Rev. Lett. 85, 441 (2000).
Kraus, B., Gisin, N. & Renner, R. Lower and upper bounds on the secret-key rate for quantum key distribution protocols using one-way classical communication. Phys. Rev. Lett. 95, 080501 (2005).
Tomamichel, M. & Renner, R. Uncertainty relation for smooth entropies. Phys. Rev. Lett. 106, 110506 (2011).
Gottesman, D., Lo, H.-K., Lütkenhaus, N. & Preskill, J. Security of quantum key distribution with imperfect devices. Quantum Inf. Comput. 4, 325 (2004).
Hwang, W.-Y. Quantum key distribution with high loss: toward global secure communication. Phys. Rev. Lett. 91, 057901 (2003).
Wang, X.-B. Beating the photon-number-splitting attack in practical quantum cryptography. Phys. Rev. Lett. 94, 230503 (2005).
Lo, H.-K., Ma, X. & Chen, K. Decoy state quantum key distribution. Phys. Rev. Lett. 94, 230504 (2005).
Lo, H.-K. Proof of unconditional security of six-state quantum key distribution scheme. Quantum Inf. Comput. 1, 81 (2001).
Laing, A., Scarani, V., Rarity, J. G. & OBrien, J. L. Reference-frame-independent quantum key distribution. Phys. Rev. A 82, 012304 (2010).
Sciarrino, F., Lombardi, E., Milani, G. & De Martini, F. Delayed-choice entanglement swapping with vacuum–one-photon quantum states. Phys. Rev. A 66, 024309 (2002).
Lombardi, E., Sciarrino, F., Popescu, S. & De Martini, F. Teleportation of a vacuum–one-photon qubit. Phys. Rev. Lett. 88, 070402 (2002).
Pawłowski, M. et al. Information causality as a physical principle. Nature 461, 1101 (2009).
Wang, C. et al. Phase-reference-free experiment of measurement-device-independent quantum key distribution. Phys. Rev. Lett. 115, 160502 (2015).
Yin, H.-L. et al. Measurement-device-independent quantum key distribution over a 404 km optical fiber. Phys. Rev. Lett. 117, 190501 (2016).
Zhou, Y.-H., Yu, Z.-W. & Wang, X.-B. Making the decoy-state measurement-device-independent quantum key distribution practically useful. Phys. Rev. A 93, 042324 (2016).
Guan, J.-Y. et al. Observation of quantum fingerprinting beating the classical limit. Phys. Rev. Lett. 116, 240502 (2016).
Zhao, Y., Qi, B., Lo, H.-K. & Qian, L. Security analysis of an untrusted source for quantum key distribution: passive approach. New J. Phys. 12, 023024 (2010).
Yin, H.-L., Fu, Y., Mao, Y. & Chen, Z.-B. Security of quantum key distribution with multiphoton components. Sci. Rep. 6, 29482 (2016).
Acknowledgements
We thank W. Zhu for the help with the figure. H.-L. Yin gratefully acknowledges support from the National Natural Science Foundation of China under Grant No. 61801420, the Fundamental Research Funds for the Central Universities.
Author information
Authors and Affiliations
Contributions
H.-L.Y. and Y.F. have the main idea. All results are acquired through the discussion among all authors. All authors contribute to the writing and reviewing of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yin, HL., Fu, Y. Measurement-Device-Independent Twin-Field Quantum Key Distribution. Sci Rep 9, 3045 (2019). https://doi.org/10.1038/s41598-019-39454-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-39454-1
This article is cited by
-
Improving the performance of practical phase-matching quantum key distribution with advantage distillation
Quantum Information Processing (2024)
-
Twin-field quantum encryption protocol for E-payment based on blockchain
Quantum Information Processing (2023)
-
More optimal relativistic quantum key distribution
Scientific Reports (2022)
-
Continuous variable measurement device independent quantum conferencing with postselection
Scientific Reports (2022)
-
2×N twin-field quantum key distribution network configuration based on polarization, wavelength, and time division multiplexing
npj Quantum Information (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
