
Abstract
Chronic Kidney Disease (CKD), is highly prevalent in the United States. Epidemiological systems for surveillance of CKD rely on data that are based solely on the NHANES survey, which does not include many patients with the most severe and less frequent forms of CKD. We investigated the feasibility of estimating CKD prevalence from the large-scale community disease detection Kidney Early Evaluation and Program (KEEP, n = 127,149). We adopted methodologies from the field of web surveys to address the self-selection bias inherent in KEEP. Primary outcomes studied were CKD Stage 3–5 (estimated glomerular filtration rate [eGFR] <60 mL/min/1.73 m2, and CKD Stage 4-5 (eGFR <30 mL/min/1.73 m2). The unweighted prevalence of Stage 4-5 CKD was higher in KEEP (1.00%, 95%CI: 0.94–1.05%) than in NHANES (0.51%, 95% CI: 0.43–0.59%). Application of a selection model that used variables related to demographics, recruitment and socio-economic factors resulted in estimates similar to NHANES (0.55%, 95% CI: 0.50–0.60%). Weighted prevalence of Stages 3–5 CKD in KEEP was 6.45% (95% CI: 5.70–7.28%) compared to 6.73% (95% CI: 6.30–7.19%) for NHANES. Application of methodologies that address the self-selection bias in the KEEP program may allow the use of this large, geographically diverse dataset for CKD surveillance.
Similar content being viewed by others
Introduction
Chronic Kidney Disease (CKD) is a growing public health concern in the United States due to its high prevalence (~13% of the adult US population), association with increased morbidity, mortality and progression to End Stage Renal Disease (ESRD). Treating CKD and ESRD and their complications is extremely costly, accounting for more than 20% of fee-for-service Medicare spending and over 80 billion dollars in the US for 2013 alone1. Epidemiological systems for geo-temporal CKD surveillance could both fulfil public health objectives2,3, and direct research efforts towards a better understanding of localized “hotspots” of CKD similar to what has been reported in other contexts4.
Efforts to develop such a project2,3 culminated in the establishment of the Center for Diseases Control surveillance project5, which provides data on CKD incidence, prevalence, disease awareness and other disease indicators. Despite the wealth of data incorporated in the CDC project, prevalence estimates in the general population are based solely on the NHANES survey5,6,7,8,9. An important limitation of this feature is that individuals with the most severe and costly, but less frequent stages of CKD (4-5) are not well represented in NHANES7. Incorporating additional, larger data sources that are more likely to ascertain persons with more severe forms of CKD has the potential to enhance our existing CKD surveillance infrastructure. In this report, we examine the feasibility of estimating CKD prevalence using data from the large community disease detection program of the National Kidney Foundation’s Kidney Early Evaluation and Program (KEEP)10 in juxtaposition to the population-based data from NHANES.
As a voluntary detection program, KEEP is likely to suffer from a substantial degree of self-selection bias. If it were possible to address this bias, KEEP would provide a population-level data source on all aspects of CKD, including the less common but costly advanced stages of the disease. Use of a national reference population to standardize a sample, is used routinely in public health surveillance11,12. Fueled by the expansion of internet based data collection strategies, there has been a growing literature regarding the handling of self-selection effects in voluntary surveys13,14 by matching against a reference, representative, probability sample. To our knowledge, similar techniques have not been applied to kidney disease research. In this report, we address the self-selection bias in the KEEP dataset by developing selection models based on subject level factors related to recruitment (selection) probabilities in KEEP. We accomplish this by estimating propensities for KEEP participation relative to NHANES, and using them to form inverse-probability weights (IPW), the application of which adjust the observed percentages of CKD prevalence from this self-selected sample. We demonstrate that this approach can make the estimated CKD prevalence rate from KEEP directly comparable to those of NHANES, opening up the possibility of using this large, geographically diverse dataset for the purpose of CKD surveillance.
Results
Baseline characteristics and selection effects in KEEP
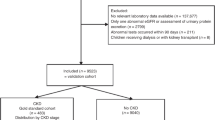
The KEEP study made more than 185,000 assessments from August 2000 to June 2013. We analyzed the initial encounter for program eligible KEEP participants assessed by 48 regional affiliates from 2001 to the end of 2012 using data provided by NKF. Participants were excluded from KEEP if they were younger than 20 years of age, receiving dialysis, were pregnant, had a previous kidney transplant, were lacking a valid state of residence or had other invalid demographic variable values (32,026 records excluded, Fig. 1). Another 6,317 records that lacked a valid eGFR stage determination were excluded to obtain 127,876 participants (147,168 records) with CKD stage. We then removed follow up visits (19,292 records) and participants seen before 2001 (n = 727) to obtain a sample of 127,149 KEEP participants for propensity score estimation. Our original NHANES sample from 2001–2012 had 59,423 participants attending an MEC. We excluded NHANES participants <20 years old (n = 27,796), pregnant women (n = 963), hemodialysis patients (n = 114) and participants without a valid eGFR determination (n = 2,033) to obtain a sample with 28,517 NHANES participants for propensity score estimation.

National Health and Nutrition Examination Survey (NHANES) and Kidney Early Evaluation Program (KEEP) participation in study.
KEEP participant characteristics are compared to NHANES general population estimates in Table 1. KEEP participants were older, more likely to be female, less likely to be non-Hispanic White but more likely to be Black than the participants in NHANES. KEEP recruitment resulted in an oversampling relative to NHANES of participants with self-reported diabetes, hypertension, CKD, Congestive Heart Failure (CHF)/Coronary Artery Disease (CAD)/stroke, a family history of diabetes and of heart attack. KEEP participants were also more likely to have reported being obese, to be uninsured and to have at least a high school education. KEEP participants were less likely to be current smokers than the general population. The boosted CART model that produced the best agreement between expected and predicted KEEP frequencies was the model with four-way interactions. Prevalence of CKD within the KEEP sample by IPW decile shows the success of KEEP affiliates recruiting participants at a higher risk of CKD. Smaller deciles (higher probability of selection into KEEP) have significantly higher prevalence of CKD Stages 3–5 than large deciles (P < 0.001). After KEEP summaries were estimated using weights from this model, frequencies were much closer to NHANES (Table 1). Before weighting, the youngest and oldest age categories were under and over represented in KEEP by −19% and 16.6%, but after weighted estimations all categories were within 1.1% of NHANES. Females were 51.1% of NHANES and 52.2% in weighted KEEP compared to 67.7% of the unweighted KEEP sample. Weighted KEEP estimates were also much closer to NHANES for race/ethnicity categories so that all groups were within 2% of expected. Differences between weighted KEEP percentages and NHANES that were more than ±1% included fewer self-reported diabetes (−1.1%), more hypertension (1.9%), family history of diabetes (3.2%), overweight (2.7%), obese (2.9%) and insured (1.4%).
Prevalence of CKD stages and Albuminuria in NHANES and KEEP
Prevalence of CKD stage 3 in the general population age 20 and older for 2001–2012 was 6.23% (95% CI: 5.82–6.66) from NHANES (n = 2,453 cases) compared to 13.14% (95% CI 12.95–13.33) in the KEEP sample during the same period (Table 2, n = 16,706 cases). Simple reweighting the KEEP data reduced the prevalence estimate by more than one third to 8.57% and accounting for clustering of KEEP samples within regional affiliates reduced the estimate to 6.45% (5.70–7.28%, Table 2 Weighted-GEE). The average prevalence of CKD Stage 4-5 among all participants was 0.51% in the NHANES general population (95% CI 0.43–0.59%, n = 239 cases) and was 1.00% in the KEEP sample (95% CI 0.94–1.05%, Table 2, n = 1,267 cases). IPW adjustment accounting for affiliate clusters removed almost all bias so the weighted KEEP prevalence was 0.52% (95% CI 0.42–0.64%, Weighted-GEE). Age and sex stratified results in Fig. 2 and Supplementary Table 1 show that both age and sex have substantial impacts on CKD endpoints. Both NHANES and KEEP showed low CKD Stage 3 prevalence at younger ages that increased with age for females more than males (KEEP age x sex interaction P = 0.037). Stage 4-5 prevalence also increased with age with female versus male differences not uniform over ages (KEEP age x sex interaction P = 0.026).

Prevalence of CKD Stage 3 and Stage 4-5 by year screened for KEEP and NHANES. (KEEP – Kidney Early Evaluation Program; NHANES - National Health and Nutrition Examination Survey).
Microalbuminuria (ACR 30–300 mg/g) in the KEEP sample was almost two times the general population prevalence, 10.29% vs. 5.33% (Table 3). After reweighting and accounting for affiliate clusters, the estimated KEEP prevalence was 6.20%, comparable to the general population estimate. More serious kidney damage (ACR > 300 mg/g) was 1.26% in the KEEP sample and 0.86% (95% CI 0.77–0.96%) in the general population (Table 3). Our reweighted estimate is 0.54% (95% CI 0.45–0.66% Weighted-GEE).
Temporal Trends in the prevalence of CKD Stages
Prevalence of Stages 3-5 and Stages 4-5 by KEEP year are shown in Fig. 3 with and without IPW. NHANES estimates are plotted in the middle of each two-year survey period so that the KEEP estimates falling immediately before and after NHANES estimates are most relevant for comparisons. Tests for non-linear time trends were not significant for CKD Stage 3 (P = 0.13), Stages 3-5 (P = 0.08) or Stages 4-5 (P = 0.07), and no CKD Stage showed a significant positive or negative trend (Supplemental Table 2, all P-values > 0.63). Weighted prevalence of CKD Both Stage 3 and Stage 4-5 weighted estimates are close to NHANES in all years with 95% confidence intervals for KEEP trend lines overlapping NHANES point estimates. Weighted KEEP CKD prevalence was slightly higher in early and late years of the series compared to middle years. We used graphical methods to explore whether covariate imbalance in age, sex and race/ethnicity by year may be associated with this extra variation. All three covariates had variation in balance over years, and the pattern for sex most closely matched that seen in weighted KEEP prevalence.

Prevalence (%) of CKD Stage 3 and Stage 4-5 by year screened for KEEP and NHANES. (KEEP – Kidney Early Evaluation Program; NHANES - National Health and Nutrition Examination Survey).
Discussion
In this paper we explored the use of data from a voluntary, self-selected community disease detection program to model point prevalence and temporal trends for epidemiologic surveillance of CKD in the US over a period of 10 years. By using a national representative survey as a reference, we demonstrate the potential of IPW based adjustments to address the self-selection bias inherent in community based disease detection programs. To our knowledge, this is the first application of this approach in the setting of chronic (kidney) disease and opens up the possibility of using large, readily available samples of convenience in epidemiologic surveillance programs.
The use of self-selected samples for the purpose of tabulating official statistics has been receiving increasing attention in the era of administered surveys distributed over the internet13,14,15. Similar to community based disease detection programs, the practical use of these designs suffer from self-selection bias. In recent years, there has been a growing literature regarding the modeling of self-selection effects in such surveys. This literature suggests that a number of approaches, including post-stratification weighting of the observations of participants in the self-selected samples16 or the direct modeling of the probability of self-selection (“propensity score adjustment”)13,17,18 against a referent population may allow the valid use of these convenience samples in place of random probability samples. To our knowledge, similar techniques have not been applied to CKD prevalence data. Therefore, we explored both IPW and post-stratification as a novel means to address the self-selection bias in KEEP. Our analyses indicate that even though both methods may substantially decrease this bias, the greater flexibility afforded by the logistic regression model in IPW leads to greater comparability with the sample estimates from NHANES. We postulate that this performance of the IPW is likely to hold true in other health domains outside the field of CKD research.
A major strength of our proposed approach to the surveillance of the CKD epidemiology is the use of co-temporal, national, representative cohort of NHANES to calculate the self-selection probabilities in KEEP. The use of such a reference, random probability sample is an integral component of existing approaches for handling selection bias13,15,16,19. Even if such a reference sample is available though, in order for sample weighting to reduce bias, the covariates used should be strongly correlated with the target population13 and the mechanism underlying the self-selection process should be one of Missing-At-Random (MAR). In such a case, IPW will allow the unbiased estimation of quantities of interest e.g. point prevalence for impaired eGFR or microalbuminuria. In our approach, the rich data collected during KEEP and the in-depth knowledge of the KEEP data collection, the community advertisement and engagement processes led us to consider a-priori plausible subsets of covariates to use for the weighting process, and suggested the need to employ a GEE model to allow for variation among the NKF affiliates where screenings were performed. These factors are likely responsible for the enhanced comparability of the weighted estimates of albuminuria and eGFR CKD stages in KEEP to NHANES over the entire period 2001–2012 and at specific points in time during the same time interval.
In terms of practical applications, successfully addressing the bias in KEEP offers the possibility of using this readily available sample of convenience for the purpose of CKD surveillance. In particular, the existing CKD surveillance project5 in the general US population is based on a limited number of NHANES participants with an eGFR < 60 (n = 2,700) and eGFR < 30 (n = 239). Our analyses indicate the potential to expand this dataset almost six-fold by appropriate weighting of the nearly 18,000 KEEP participants with decreased renal function. Notwithstanding the increase in sample size, the ability to simultaneously leverage information from both of these datasets affords the opportunity to overcome the limitations of each of these two studies when considered in isolation7,10,20,21. Whereas KEEP suffers from self-selection bias10,20, NHANES does not represent well the advanced, but also less common stages 3-4 of CKD7. Such patients are “oversampled” in KEEP so that these studies directly complement each other. Our report illustrates the feasibility of using relatively simple weighting adjustments to make the estimates of the studies directly comparable. Hence, it represents a significant advance over the existing, semi-qualitative use of the two data sources by the nephrology research community. In particular, it was previously stated that the results of KEEP are best understood in “the context of the US population” and in comparison against results from a representative sample (NHANES)20,22. By applying methodologies to address the self-selection bias in KEEP we took this approach to its logical conclusion and derived a common analytic file that is available for the epidemiologic surveillance of CKD in the general population.
Despite the ability of our methodology to bring about a quantitative agreement between NHANES and weighted versions of KEEP, our analyses have certain limitations. First, recruitment efforts for the KEEP survey was rather heterogeneous over the continental US and may have not reached some population segments. This potential source of bias may not be accounted for in our approach and is a topic under investigation using recruitment information like screening event location, and measures of advertising ‘effort’ as potential covariates. In our analyses we handled these factors indirectly by including the regional affiliates as clusters in the GEE estimation procedure. It is likely that more detailed modeling may have led to more precise estimation of the prevalence of the different stages of CKD. Another limitation concerns the handling of race and ethnicity, which are clinically significant correlates of CKD risk in the source datasets. Whereas NHANES collects detailed race and ethnicity information, the coarseness of classification in public use files likely combines groups with unequal risk. These categories were not entirely congruent with the ones adopted in the KEEP program, thus raising the possibility of residual confounding in our weighting schemes. Finally, adjustment by post-stratification typically relies on a known reference distribution such as from official census statistics.
In summary, we present the first to our knowledge application of self-selection bias correction methodologies for the analysis of data related to the prevalence of CKD in the general US population. We found that two methodologies, i.e. IPW and to a lesser degree post-stratification weighting may be used to render estimates from a self-selected cohort (KEEP) directly comparable to those from a national representative sample (NHANES). Future studies should build on this effort and utilize this novel analytic set to expand the existing national CKD surveillance system. Such efforts may be directed towards understanding the epidemiology of CKD by utilizing the geographic information collected during KEEP so as to build prevalence maps of this challenging, costly chronic disease over both space and time.
Materials and Methods
Study Populations
We used individual level data from participants in the National Kidney Foundation’s (NKF) Kidney Early Evaluation Program (KEEP) and from participants in the National Health and Nutrition Examination Survey (NHANES). Both KEEP and NHANES are national samples: KEEP is a self-selected sample of adults with elevated risk of kidney disease coordinated by local NKF organizations, and NHANES is a nationally representative sample designed to study health and nutritional status of adults and children in the United States. KEEP used advertising campaigns to attract participants to examinations coordinated by regional affiliates. Advertising targeted participants that were at least 18 years old with risk factors for CKD: high blood pressure, diabetes, or a family history of diabetes or hypertension or kidney disease. We obtained data from NKF for KEEP participants assessed by 48 regional affiliates from 2001 to the end of 2012 (185,511 records, SAS file name keep_saf_2013). Participants were excluded if <20 years of age, on dialysis, were pregnant, had a previous kidney transplant, if eGFR could not be determined, were lacking a valid state of residence or had other invalid demographic variable values. NHANES employs cross-sectional, multi-stage, stratified, cluster probability samples with several subgroups oversampled to improve precision. The subgroups vary by two-year survey period with respect to status race, ethnicity and poverty level. We studied participants attending mobile examination centers (MEC) during six survey periods covering 2001–2012.
Human Participants
This secondary analysis of the KEEP and NHANES was approved by the Human Research Protection Office (HRPO) of the University of New Mexico Health Sciences Center (Decision Number HRCC #14-264 on 9/12/2014). All research reported in this manuscript was performed in accordance with relevant guidelines/regulations. During the execution of KEEP and NHANES the individuals were asked to provide informed consent. The consent form that participants in KEEP signed allow data sharing and linking. NHANES consent allows the sharing of the (de-identified) data outside the Center of Disease Control.
Selection Model Variables
Covariates for selection models were chosen if they were related to messages used for KEEP recruitment, if they could be identified in both datasets, and if they received or could be re-encoded similarly in both datasets over the 2001–2012 study. Demographic covariates included continuous age, sex, and race/ethnicity (non-Hispanic White, non-Hispanic Black, Mexican/Other Hispanic, Other). Factors related to KEEP recruitment advertising included patient reported diabetes, hypertension, CKD, and family history of CKD, diabetes or hypertension. Other self-reported factors potentially associated with KEEP participation were obesity status, smoking, family history of heart attack, and participant cardiovascular disease (self-report of stroke, congestive heart failure, angina or heart attack). We also included variables for participant socioeconomic status, education and type of insurance.
CKD Endpoints
Our CKD end points to be estimated from KEEP data after adjusting for self-selection were the single sample (‘point’) prevalence of impaired renal function: CKD Stages 3, eGFR 30 - <60 ml/min/1.73 m2, Stages 3–5, eGFR <60 ml/min/1.73 m2, Stage 4-5 CKD, eGFR <30 ml/min/1.73 m2 and urinary albumin/creatinine ratio (ACR) ≥ 30 mg/g as a measure of kidney damage. eGFR was estimated using the Chronic Kidney Disease Epidemiology Collaboration (CKD-EPI) equation based on race, sex and serum creatinine23,24. KEEP serum creatinine values were standardized to the Cleveland Clinic25 prior to calculation eGFR. NHANES ACR was calculated from albumin and creatinine concentrations in urine. Urine creatinine concentrations before 2007 in the NHANES data were standardized to later years using a piece-wise regression adjustment described for NHANES results26. The KEEP study measured ACR using Clinitek Microalbumin Urinalysis Strips beginning April 2002 and reported results as <30, 30–300 or >300 mg/g. The threshold 30 mg/g defines the clinical state of microalbuminuria, which is associated with clinically significant increases in cardiovascular and total morbidity and mortality.
Statistical Analyses
The analyses had two phases: (1) estimation of propensity scores using NHANES and KEEP, and (2) estimation of CKD prevalence. Sampling weights for NHANES were the two-year MEC weights. We created a combined analytic file for propensity core estimation by normalizing variable names and variable coding for each dataset and appending the two data files. In the combined file two-year MEC weights formed the frequency weights for NHANES records and KEEP records received a frequency weight of one. An indicator variable identified records that were NHANES or KEEP. We explored an alternative approach to creating the NHANES part of the analytic file that directly accounted for primary sampling units, strata and MEC weights for NHANES design. In this approach, we created cross tabulations of all covariate values and obtained reference population frequencies for each cell for each NHANES survey period (SURVEYFREQ, SAS v9.4). Propensity scores and CKD prevalence were similar when estimated using aggregated NHANES data and using individual NHANES records to estimate propensity scores so we selected the latter for our analyses (data not shown). Using individual NHANES records and MEC weights without upscaling to subgroup frequencies for the total reference population avoids the problem of cells estimated from very few NHANES observations. Our approach also enables use of continuous variables like age and BMI in estimating propensity scores.
Descriptive summaries of NHANES participants by subgroups (e.g., age, sex, race/ethnicity) were estimated using methods that accounted for the complex sampling design when summarizing the reference population (SURVEYFREQ, SAS v9.4). The population distribution of KEEP for these subgroups were estimated without and with weighting for self-selection.
For propensity score analyses we used the boosted classification and regression tree (CART) methods implemented in the twang R-package27, as this method outperforms logistic regression28 and can utilize sampling weights. These boosted classification and regression trees methods use flexibly defined combinations of the independent variables of interest to iteratively develop a model that classifies individuals into the outcome groups of interest. These flexibly defined combinations of variables can comprise data-defined groups of functions of predictors of interest, up to a pre-defined interaction depth, that optimally predict the outcome of interest according to a loss function that is appropriate for the outcome type29. In our case, the outcome was a binomial one of individuals from the US who did vs. did not participate in the KEEP studies, and our predictors of interest were those demographic and clinical (“Selection Model”) variables that could be made to be in alignment between the NHANES and KEEP dataset. We entered NHANES observations into the propensity estimating model using the MEC weights, and KEEP observations using sampling weights equal to 1.0. The shrinkage parameter was set at 0.001 and number of random trees equaled 20,000. We varied interaction depths from four to six levels and assessed the balance achieved by comparing KEEP weighted frequencies to the expected frequencies based on the NHANES reference population and selected as our propensity score estimation model the one with best agreement between KEEP frequencies expected for the reference population and the weighted frequencies from the boosted CART models. Separate propensity score analyses by two-year NHANES sampling periods estimated weights that tracked changes in KEEP sampling distribution and intensity by regional KEEP affiliates. Achieved covariate balance by NHANES survey period was assessed using unstandardized and standardized differences in proportions30, and logistic regression was used to assess whether CKD Stage 3–5 prevalence in the unweighted KEEP sample was constant over IPW deciles31.
The second analysis stage had the goal of estimating CKD prevalence by Stage using the KEEP sample but adjusted for self-selection. Unweighted and weighted prevalence and 95% confidence interval are reported (SURVEYFREQ, SAS v9.4) along with population average estimates that account for participants clustered within regional affiliate recruitment and examination programs (GEE, GENMOD, SAS v9.4). Confidence intervals based on robust standard errors are reported. Intercept-only models estimated overall prevalence during 2001–2012 by CKD Stage and during 2003–2012 for albuminuria. Models with fixed effects for age and sex and for KEEP screening year estimated prevalence grouped by these factors. Linear time models and models with restricted cubic splines (k = 3 knots) were used to estimate trends in prevalence. Prevalence estimates from NHANES for comparison with weighted KEEP accounted for the complex sampling design but did not use a GEE approach (SURVEYLOGISTIC, SAS v9.4).
Data Availability
NHANES data are freely available from the survey website at the Center for Disease Control (https://www.cdc.gov/nchs/nhanes/index.htm). The KEEP data that support the findings of this study are available from the National Kidney Foundation (NKF) but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of NKF.
References
2015 USRDS Annual Data Report. Available at, https://www.usrds.org/2015/view/Default.aspx. (Accessed: 14th July 2016).
Powe, N. R., Plantinga, L. & Saran, R. Public health surveillance of CKD: principles, steps, and challenges. Am. J. Kidney Dis. 53, S37–45 (2009).
Saran, R. et al. Establishing a national chronic kidney disease surveillance system for the United States. Clin J Am Soc Nephrol 5, 152–161 (2010).
Sherman, R. L. et al. Applying Spatial Analysis Tools in Public Health: An Example Using SaTScan to Detect Geographic Targets for Colorectal Cancer Screening Interventions. Preventing Chronic Disease 11 (2014).
Chronic Kidney Disease (CKD) Surveillance Project. Available at, https://nccd.cdc.gov/ckd/. (Accessed: October 18th 2018).
Coresh, J. et al. Prevalence of chronic kidney disease in the United States. JAMA 298, 2038–2047 (2007).
Castro, A. F. & Coresh, J. CKD surveillance using laboratory data from the population-based National Health and Nutrition Examination Survey (NHANES). Am. J. Kidney Dis. 53, S46–55 (2009).
Stauffer, M. E. & Fan, T. Prevalence of Anemia in Chronic Kidney Disease in the United States. PLOS ONE 9, e84943 (2014).
Wu, B. et al. Understanding CKD among patients with T2DM: prevalence, temporal trends, and treatment patterns—NHANES 2007–2012. BMJ Open Diab Res Care 4 (2016).
Vassalotti, J. A., Li, S., Chen, S.-C. & Collins, A. J. Screening populations at increased risk of CKD: the Kidney Early Evaluation Program (KEEP) and the public health problem. Am. J. Kidney Dis. 53, S107–114 (2009).
Shryock, H. S. & Siegel, J. S. The Methods and Materials of Demography. (Academic Press, 1976).
Klein, R. J. & Schoenborn, C. A. Age adjustment using the 2000 projected U.S. population. Healthy People 2010 Stat Notes 1–10 (2001).
Bethlehem, J. Selection Bias in Web Surveys. International Statistical Review 78, 161–188 (2010).
Bethlehem, J. Can We Make Official Statistics with Self-Selection Web Surveys? in Proceedings of Statistics Canada Symposium 2008 (2009).
Bethlehem, J. Solving the Nonresponse Problem With Sample Matching? Social Science Computer Review 34, 59–77 (2016).
Steinmetz, S., Tijdens, K. & de Pedraza, P. Comparing different weighting procedures for volunteer web surveys. (Amsterdam Institute for Advanced Labour Studies, University of Amsterdam, 2009).
Schonlau, M., van Soest, A. & Kapteyn, A. Beyond demographics: are ‘Webographic’ questions useful for reducing the selection bias in web surveys? In Proceedings of the Survey Research Methods Section, American Statistical Association (2007).
Lee, S. & Valliant, R. Estimation for Volunteer Panel Web Surveys Using Propensity Score Adjustment and Calibration Adjustment. Sociological Methods & Research 37, 319–343 (2009).
Loosveldt, G. & Sonck, N. An evaluation of the weighting procedures for an online access panel survey. Survey Research Methods 2, 93–105 (2008).
Jurkovitz, C. T., Qiu, Y., Wang, C., Gilbertson, D. T. & Brown, W. W. The Kidney Early Evaluation Program (KEEP): program design and demographic characteristics of the population. Am. J. Kidney Dis. 51, S3–12 (2008).
McCullough, P. A. et al. Sustainable community-based CKD screening methods employed by the National Kidney Foundation’s Kidney Early Evaluation Program (KEEP). Am. J. Kidney Dis. 57, S4–8 (2011).
Whaley-Connell, A. T., Kurella Tamura, M., Jurkovitz, C. T., Kosiborod, M. & McCullough, P. A. Advances in CKD Detection and Determination of Prognosis: Executive Summary of the National Kidney Foundation–Kidney Early Evaluation Program (KEEP) 2012 Annual Data Report. American Journal of Kidney Diseases 61, S1–S3 (2013).
Levey, A. S. et al. A New Equation to Estimate Glomerular Filtration Rate. Ann Intern Med 150, 604–612 (2009).
Matsushita, K. et al. Comparison of risk prediction using the CKD-EPI equation and the MDRD Study equation for estimated glomerular filtration rate. JAMA 307 (2012).
Stevens, L. A. & Stoycheff, N. Standardization of serum creatinine and estimated GFR in the Kidney Early Evaluation Program (KEEP). Am. J. Kidney Dis. 51, S77–82 (2008).
NHANES 2007–2008: Albumin & Creatinine - Urine Data Documentation, Codebook, and Frequencies. Available at, http://wwwn.cdc.gov/nchs/nhanes/2007-2008/ALB_CR_E.htm. (Accessed: 21st June 2016).
Ridgeway, G., McCaffrey, D., Morral, A., Burgette, L. & Griffin, B. A. twang: Toolkit for Weighting and Analysis of Nonequivalent Groups (2017).
McCaffrey, D. F., Ridgeway, G. & Morral, A. R. Propensity score estimation with boosted regression for evaluating causal effects in observational studies. Psychol Methods 9, 403–425 (2004).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Ann. Statist. 29, 1189–1232 (200110).
Austin, P. C., Grootendorst, P. & Anderson, G. M. A comparison of the ability of different propensity score models to balance measured variables between treated and untreated subjects: a Monte Carlo study. Stat Med 26, 734–753 (2007).
Brookhart, M. A., Wyss, R., Layton, J. B. & Stürmer, T. Propensity Score Methods for Confounding Control in Nonexperimental Research. Circulation: Cardiovascular Quality and Outcomes 6, 604–611 (2013).
Acknowledgements
This work was partially supported by Dialysis Clinic, Inc under the grant #C-3763 Geosurveillance of the Chronic Kidney Disease Epidemic in the US. Preliminary versions of this work were presented in abstract form during Kidney Week 2016 & 2017, Annual Meetings of the American Society of Nephrology and at the GEOMED 2017 meeting held in Porto, Portugal in 2017.
Author information
Authors and Affiliations
Contributions
All co-authors contributed in this collaborative work: Dr. O.M. programmed the analyses in SAS, created graphs and tables and drafted the Methods and Results of the manuscript. Dr. V.S.P., oversaw statistical analyses and contributed in the Methods section. Dr’s K.M. and J.V. contributed their in-depth knowledge of the KEEP and NHANES datasets and contributed sections in Introduction, Methods and Discussion. Dr. M.U. contributed sections in the Introduction and Discussion. Dr. C.A. devised the overall analytic strategy and prepared the Introduction and the Discussion sections of the first draft of the text. All authors, interpreted results and modified the draft of the text over four iterations in order to produce the final version of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Myers, O.B., Pankratz, V.S., Norris, K.C. et al. Surveillance of CKD epidemiology in the US – a joint analysis of NHANES and KEEP. Sci Rep 8, 15900 (2018). https://doi.org/10.1038/s41598-018-34233-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-34233-w
Keywords
This article is cited by
-
Laboratory-based surveillance of chronic kidney disease in people with private health coverage in Brazil
BMC Nephrology (2024)
-
Chronic kidney disease in primary care: risk of cardiovascular events, end stage kidney disease and death
BMC Primary Care (2023)
-
Clinical epidemiological analysis of cohort studies investigating the pathogenesis of kidney disease
Clinical and Experimental Nephrology (2022)
-
Prognostic implication of myocardial perfusion and contractile reserve in end-stage renal disease: A direct comparison of myocardial perfusion scintigraphy and dobutamine stress echocardiography
Journal of Nuclear Cardiology (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
