
Abstract
Identifying vital nodes in complex networks is a critical problem in the field of network theory. To this end, the Collective Influence (CI) algorithm has been introduced and shows high efficiency and scalability in searching for the influential nodes in the optimal percolation model. However, the crucial part of the CI algorithm, reinsertion, has not been significantly investigated or improved upon. In this paper, the author improves the CI algorithm and proposes a new algorithm called Collective-Influence-Disjoint-Set-Reinsertion (CIDR) based on disjoint-set reinsertion. Experimental results on 8 datasets with scales of a million nodes and 4 random graph networks demonstrate that the proposed CIDR algorithm outperforms other algorithms, including Betweenness centrality, Closeness centrality, PageRank centrality, Degree centrality (HDA), Eigenvector centrality, Nonbacktracking centrality and Collective Influence with original reinsertion, in terms of the Robustness metric. Moreover, CIDR is applied to an international competition on optimal percolation and ultimately ranks in 7th place.
Similar content being viewed by others


Introduction
Research on the identification of vital nodes is crucial in computer science, statistical physics and biology applications1. Techniques are universally applied in social networks2,3,4, predicting essential proteins5,6,7, quantifying scientific influences8,9,10, detecting financial risks11,12,13, predicting career movements14,15 and predicting failures with developer networks16,17,18. Considering its importance for application in many fields, the problem of identifying influencers in a network has attracted substantial attention in network analysis.
Researchers have developed numerous measures to evaluate node importance. The most widely used centrality methods include Betweenness centrality19, Closeness centrality20, PageRank centrality21, Degree centrality (HDA)22, Eigenvector centrality23, and Nonbacktracking centrality24. Betweenness centrality19 is defined to represent a node as the number of shortest paths from all vertices to all other paths that pass through that node. Closeness centrality20 uses the sum of the length of the shortest paths between the node and all other nodes in a graph as a node’s value. PageRank centrality21 was first proposed by Google to rank websites and works by counting the number and quality of links to a page to determine a rough estimate the importance of a website. Degree centrality (HDA)22 ranks nodes directly according to the number of connections and recalculates the degree after each removal of the top ranked node. Eigenvector centrality23 computes the centrality for a node based on the idea that the importance of a node is recursively related to the importance of the nodes pointing to it. A high eigenvector score means that a node is connected to many nodes who themselves have high scores. However, for some graphs, the Eigenvector centrality will produce an echo chamber effect and localization onto a hub. Nonbacktracking centrality24 modified the standard Eigenvector centrality based on the Nonbacktracking matrix to ignore the reflection mechanism on hubs, therein being asymptotically equivalent to Eigenvector centrality for dense networks and avoiding hub localization on sparse networks.
However, for these methods, the node importance is evaluated by regarding a node as an isolated agent in a non-interacting setting. Consequently, these methods are considered as heuristic methods and fail to provide the optimal solution in the general case of finding a single influential node among multiple spreaders4,25. To address the issue, a scalable theoretical framework called the Collective Influence (CI) algorithm, which attempts to find the minimal fraction of nodes that can fragment the network in optimal percolation, was recently proposed4. If the influencers are removed in a network, the network will face structural collapse, and a giant connected component G of the graph will be 0. The CI would improve and maximize the collective influence of multiple influencers, and the accurate optimization objective is highly adaptable for giving an optimal set of spreaders for various networks. For networks with millions of nodes, such as massive social media and social networks22, CI also performs well in processing centrality efficiently.
The implementation of the CI algorithm contains 2 steps. In the first step, CI calculates the value of each node in the network and removes the node with the highest value according to their importance one by one until the giant component is destroyed. Then, in the second step, CI adds back removed nodes and reconstructs the collapsed network, i.e., reinsertion. Reinsertion4,22 is the refined post-processing in the CI algorithm and minimizes the giant component G of the graphs for the target G > 0. Although CI has already demonstrated its efficiency in searching for the potential influential nodes in the optimal percolation model, the reinsertion step in CI has rarely been discussed. Until now, the optimal percolation model only addressed the issue of dismantling networks in the first step of CI. The second procedure, reinsertion, is not designed to be optimal, which leads to the fact that the former optimal percolation model is unable to achieve optimal results. Therefore, it is necessary to address this issue by designing a better reinsertion step.
Robustness26 is a recently proposed measure for quantifying the performance of methods for ranking nodes. This paper improves the reinsertion method with respect to the Robustness metric to find the most influential nodes in CI, and it proposes a new algorithm named Collective-Influence-Disjoint-Set-Reinsertion (CIDR). CIDR mainly employs disjoint sets27 as the data structure to optimize reinsertion in the CI algorithm and reorder the removed nodes into a new sequence.
The proposed CIDR method is verified in the International Competition of optimal percolation28 and ultimately ranks in 7th place. The competition adopts the Robustness metric as the scoring criteria and provides 4 real networks from different fields, i.e., autonomous system networks, Internet networks, road networks and social networks, and 4 classical artificial networks (8 datasets in total). The node counts of these networks range from 0.4 million to 2 million. Therefore, the competition network benchmark quite representative overall. The results of the experiments indicate that the proposed CIDR method outperforms the other 7 methods on 8 competition datasets. The methods include Betweenness centrality19, Closeness centrality20, PageRank centrality21, Degree (HDA) centrality22, Eigenvector centrality23, Nonbacktracking centrality24 and Collective Influence with original reinsertion22 as comparison algorithms.
A total of 4 extra random graphs in the ER model generated locally are also utilized to verify CIDR. The results on the 4 random graphs show that CIDR is also better than the other methods listed in the paper, similar to the results on the 8 above competition datasets.
Results
Difference between reinsertion in CI and Collective-Influence-Disjoint-Set-Reinsertion (CI DR)
The CI algorithm contains 2 steps: removing nodes and reinsertion. For the removing node step, CI calculates the value of nodei in Formula 1 and removes the node with the highest value.
ki is defined as the degree of nodei. δB(i, l) is the frontier of the ball centered on nodei with Radius l, which refers to the shortest path l from frontier nodes to nodei4. The newly proposed CIDR method also calculates the value of each node following Formula 1, which is the same as in CI. The difference between CI and CIDR is that they implement different strategies in the reinsertion step. In CI, the original reinsertion step is invoked22 in Algorithm 1 after the networks are broken down into many pieces through the process of removing nodes. An initial collapsed graph Gc is generated after CI removes nodes from the graph G, and then, reinsertion selects the removed nodes to reconstruct the collapsed graph Gc.

The overall flow of the original reinsertion process in the CI algorithm.
For the reinsertion step in the improved CIDR, 2 main enhancements are proposed in this paper:
-
CIDR implements disjoint sets as the data structure27 to store the indices of the connected components during reinsertion for a collapsed graph.
-
CIDR considers the rejoined node count instead of the number of rejoined clusters to decide which node will be reinserted.
In the original reinsertion in Algorithm 1, CI utilizes brute-force graph traversal to label the indices of the connected components in a dismantled network (Step 1). The time cost is high since the labeling operation will be executed multiple times until all removed nodes are reinserted. In particular, when a dismantled network has nearly reached the completion of the reinsertion process and most of the removed nodes are reinserted, the labeling operation must build up from nothing every time. Considering that deciding which node will be reinserted is performed several times in the original reinsertion process, the information of the reinsertion for each iteration can be reserved and prepared for the next round of decisions on which removed node will be reinserted.
The first enhancement of CIDR implements disjoint sets to optimize the data structure to reduce the computational resource consumption. A disjoint set27 is a tree structure, where each node stores a pointer to the parent node. If the parent pointer of a node points to itself, this node is the root of a tree and is the representative index of its cluster. In Algorithm 1, the index information of the connected components in the reconstructed graph is abandoned at the end of each iteration for updating indices. Using the disjoint-set data structure, it is possible to maintain the indices of the connected components for a collapsed network when the dismantled nodes are reinserted into the graphs. The disjoint-set data structure provides 2 nearly constant-time operations. The first operation is called the Find operation, which determines which indices of connected components the current nodes stay in. The second operation is the Union operation, which merges several clusters into one.
The Find operation locates which connected components a node belongs to. The operation can follow the parent node continuously in a tree of a cluster until it finds the root node, which denotes the index of a connected component. The Find operation is utilized to replace Step 2 in Algorithm 1 and is capable of retrieving the index set Ii of the connected components of the neighboring nodes around nodei.
The Union operation merges clusters to which 2 nodes belong into one connected component. This operation uses the Find operation to determine the roots of the trees. If the roots of 2 nodes are distinct, the trees are combined by attaching the root of one to the root of the other node. When newly removed nodes are reinserted, the Union operation is capable of preserving the index information of the connected components in the iteration when updating indices continuously.
Several optimization methods on disjoint sets, such as Path Compression and Union by Size, are applied in the implementation to improve the Find and Union operations29. Path Compression flattens the structure of the tree by making every node point to the root when the first Find operation is invoked on the tree. This will speed up and decrease the complexity of future Find operations. Union by Size means that the Union operation attaches the tree with fewer nodes to the root of the nodes containing more elements. This is also another method for flattening the structure of the tree. The size of the cluster is stored in the root node of a tree, and the new size of the cluster following the Union operation is equal to the sum of the sizes of the root nodes of the original trees.
The computational complexity of both the Find and Union operations is O(inverse_oka(n)) when the Path Compression and Union by Size optimization methods are utilized, where inverse_oka(n) represents the inverse Ackermann function. The inverse Ackermann function contains a value inverse_oka(n) < 5 for any very large value of n that can be written in this physical universe. Therefore, inverse_oka(n) in the Find and Union operations is optimal and can essentially be regarded as constant time29,30. In the experiment analysis section below, the statistical results also show that utilizing the disjoint-set data structure in CIDR achieves greater efficiency and is faster than the original reinsertion algorithm in CI.
For the second enhancement, CIDR considers the number of rejoined nodes instead of the number of rejoined clusters when deciding which removed nodes will be reinserted. This improvement is applied in Step 4 in Algorithm 1. The purpose of the modification is to enhance the final Robustness score of the original reinsertion operation in the CI algorithm. The original reinsertion operation adds back the nodes that rejoin the smallest number of clusters. Nevertheless, the method does not consider the smallest node count of the rejoined clusters globally. In contrast to the number of rejoined clusters, the information about the rejoined node counts is more representative for a connected component. Because the first enhancement implements the disjoint-set data structure and because the Union by Size optimization is enabled, the node count of each connected component is stored in the root node of the corresponding tree in the disjoint set. The smallest node count of rejoined connected components can be conveniently selected from all candidate nodes.
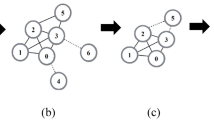
Figure 1 is an example of different choices of the candidate reinserted nodes decided by the original reinsertion and CIDR methods. Round nodes have been in the collapsed network, and there are 2 candidate nodes to be reinserted: the square node and the triangle node. If the original reinsertion method in CI is applied, it will reinsert the square node because the number of rejoined clusters is 2; fewer than 3 clusters are reinserted by the triangle node. If CIDR is exploited, it will reinsert the triangle node because there are 3 rejoined nodes, and fewer than 4 rejoined nodes are reinserted by the square nodes. CIDR more strongly considers the global impact of the rejoined nodes on the collapsed network compared with the original reinsertion process. In conclusion, the CIDR algorithm with the first and second enhancements for the reinsertion process is shown in Algorithm 2.

Collective-Influence-Disjoint-Set-Reinsertion (CIDR).

Different choices of candidate reinserted nodes decided by the original reinsertion and CIDR methods. The original reinsertion method in CI reinserts the square node, and CIDR reinserts the triangle node.
Experiments and comparison of different methods on 8 datasets provide by DataCastle Master Competition
In this subsection, several centrality methods are verified on 8 datasets provided by the DataCastle Master Competition28. The task of the competition is a generic challenge identifying vital nodes in networks that are important for sustaining connectivity. The competition provides 4 real networks from different fields, i.e., autonomous system networks, Internet networks, road networks and social networks, and 4 classical artificial networks (for a total of 8 datasets). These networks each include 0.4 million to 2 million nodes, and all networks are considered undirected networks. Table 1 reflects the network name and corresponding number of nodes.
Robustness26 is utilized as the scoring criterion in the competition. It is introduced to quantify the performance of the methods for ranking nodes. For the calculation of the Robustness score, refer to Formula 2.
The parameter p is defined as the proportion of removed nodes. δ is the size of the giant component of the remaining networks in proportion after removing a proportion p of the nodes. The δ-p curve can be derived from plotting p on the x-axis and δ on the y-axis. The Robustness is defined as the area under the δ-p curve. \(\delta (\frac{i}{n})\) is the size of the giant component after removing \(p=\frac{i}{n}\) of the nodes from a network28.
Generally, the goal of an algorithm that finds the most influential nodes is to give a ranked list of nodes according to their importance, where the top-ranked nodes will have greater importance. Nodes can be removed from a network according to the ranking list. The removal operation breaks down the network into many disconnected pieces. If the size of the giant component is calculated after the removal of each node, the ratio of the giant component will ultimately go to 0. Therefore, a better algorithm for ranking nodes will dismantle networks sooner and produce better Robustness scores.
The Robustness under CI without Reinsertion, with Original Reinsertion and CIDR on 8 competition datasets is presented in Table 2 and Fig. 2. CI without Reinsertion refers to the case in which CI only invokes the process of removing nodes and does not reinsert nodes into networks. CI with Original Reinsertion refers to the case with the node removal step and original reinsertion in Algorithm 1. For various similar CI algorithms, the radius is the required input parameter for the node removal step. A larger radius will optimize removing steps and produce a smaller set of minimal influential nodes when dismantling networks. As a trade-off, the step of removing nodes will cost more computing resources and take longer. Meanwhile, a larger radius will speed up reinsertion because fewer dismantled nodes are reinserted. The result of using different input radii of 0, 1, and 2 for the various CI methods is also shown in Table 2 and Fig. 2.

Total Robustness score of CI Without Reinsertion, with Original Reinsertion and CIDR on 8 competition datasets for radii of 0, 1, and 2.
Table 2 and Fig. 2 show that the total Robustness (the lower, the better) of CIDR on the 8 datasets is better than in the cases without Reinsertion and with Original Reinsertion. This is because in the reinsertion process, the rejoined node count is more representative in vital nodes than the number of rejoined clusters in the Robustness metric. For a radius of 0, the total Robustness score under CI with Original Reinsertion of 1.1863 decreases by 12% to 1.0403 for CIDR. For a radius of 1, the total Robustness score of 1.1099 for CI decreases by 6% to 1.0409 for CIDR. For a radius of 2, the total Robustness score of 1.0701 decreases 4% to 1.0246 for CIDR. For each individual dataset, CIDR performs better than CI in terms of Robustness in 7 of the 8 networks when a radius of 0 is used in CI and CIDR. CIDR ranks second to CI only in the model 3 network. When a radius of 1 and a radius of 2 are adopted in CI and CIDR, CIDR obtains a better score than CI on 5 of the 8 networks. CIDR ranks second behind CI in the model 1, model 2 and model 3 networks and obtains nearly the same and best result.
For different radii as input parameters, the total Robustness values in CIDR are all better than those with Original Reinsertion. Even for the case when the radius is 0 and the process of removing nodes degenerates into that of Degree centrality (HDA)22, CIDR is capable of achieving a considerably better score of 1.0403 compared with the previous best result of 1.0701 under Original Reinsertion with a radius of 2. For the smaller radius, CIDR exploits potential performance increases in terms of the Robustness metric, in contrast to Original Reinsertion. Therefore, there is no need to set a higher radius, which increases the complexity of removing nodes in CI. A lower radius is able to achieve nearly the same results in CIDR.
In Table 3 and Fig. 3, the time consumption of Original Reinsertion and CIDR excluding removing nodes on 8 competition datasets is presented. The datasets are verified on the same machine with a 4-core CPU (Intel Xeon E5-2667v4 Broadwell 3.2 GHz) with 8 GB of memory concurrently. For most cases with different radii, the statistics show that CIDR is better in terms of speed than Original Reinsertion, excluding the node removal steps, in CI. For the real 3 dataset with a radius of 2, the time consumption can be reduced 79.3% from 262 s to 54 s. The statistics evidence that implementing the disjoint-set data structure in CIDR is more efficient than the Original Reinsertion algorithm.

Time consumption (seconds) of Original Reinsertion and CIDR excluding the step of removing nodes on 8 competition datasets. (a) Radius = 0. (b) Radius = 1. (c) Radius = 2.
Heuristic algorithms, including Betweenness centrality19, Closeness centrality20, PageRank centrality21, Degree centrality (HDA)22, Eigenvector centrality23 and Nonbacktracking centrality24, are verified on these datasets as competitors in Table 4 and Fig. 4. The Robustness values of these heuristic algorithms are all worse than CI and CIDR for the 8 competition networks. The worst value of Closeness centrality is only 2.88.

Total Robustness of different heuristic algorithms, including Betweenness centrality, Closeness centrality, PageRank centrality, Degree centrality (HDA), Eigenvector centrality and Nonbacktracking centrality, on 8 competition datasets
The recently proposed Nonbacktracking centrality24 is also verified on these 8 competition datasets. Nonbacktracking centrality was introduced by Newman et al. and modified from the standard Eigenvector centrality based on the Hashimoto or Nonbacktracking matrix31,32,33. Nonbacktracking centrality is very similar to Eigenvector centrality, where the main improvement is to ignore the echo chamber effect producing localization on a hub. This is asymptotically equivalent to Eigenvector centrality for dense networks and avoids the hub localization on sparse networks introduced by Eigenvector centrality. Therefore, the performance of Nonbacktracking centrality in dense networks will be highly similar to Eigenvector centrality. From Table 4 and Fig. 4, the statistics show that corresponding scores of 2.7725 and 2.7320 for Eigenvector centrality and NonBacktracking centrality, respectively, are quite similar. Both Nonbacktracking centrality and Eigenvector centrality are not superior to CI and the proposed CIDR in terms of Robustness for the 8 competition datasets.
Experiments and comparison of different methods on 4 randomly generated graphs
In addition to the 8 above-mentioned competition datasets, 4 random graph networks in the ER model34 are also adopted as additional test cases. Table 5 shows the information about the number of nodes and mean degree for each graph. The Robustness values under CI with Original Reinsertion, CIDR and other heuristic algorithms, including Betweenness centrality, Closeness centrality, PageRank centrality, Eigenvector centrality and Nonbacktracking centrality, are presented in Table 6 and Fig. 5 for 4 random graphs.

Total Robustness value of CI with Original Reinsertion, CIDR and other heuristic algorithms, including Betweenness centrality, Closeness centrality, PageRank centrality, Eigenvector centrality and Nonbacktracking centrality, on 4 random graphs.
The total Robustness of CIDR is 0.3443, 0.3420 and 0.3429 for radii of 0, 1, and 2 on 4 randomly generated graphs, which all outperform the other listed centrality methods. For each individual dataset, the Robustness of CIDR also ranks 1st out of all applied methods. For a radius of 0, CIDR performs better in terms of Robustness than CI with Original Reinsertion for a radius of 2. The same result as that on the 8 above-mentioned competition datasets that a lower radius under CIDR outperforms a higher radius under CI with Original Reinsertion is found.
The NonBacktracking centrality achieves a score of 0.9886, which is slightly better than the score of 1.1089 of the Eigenvector centrality; this is because the former method is based on the latter method. However, a score of 0.9886 is unable to compete with CI and CIDR, similar to the results on the 8 above competition datasets.
Discussion
For 8 competition datasets and 4 local randomly generated graphs under the ER model, the best overall result from the previous algorithms is CI with Original Reinsertion for a radius of 2. After the newly proposed algorithm CIDR is applied, even CIDR employing a radius of 0 (degenerate to HDA) is capable of achieving a better result. This indicator shows that the proposed disjoint-set reinsertion in CIDR is able to achieve better Robustness compared to Original Reinsertion. The recently proposed Nonbacktracking centrality and the other above-mentioned algorithms are also unable to outperform CIDR in terms of Robustness.
CI with Original Reinsertion uses the number of rejoined clusters to decide which node will be reinserted. On the other hand, CIDR considers the rejoined node count in the second proposed enhancement. Nevertheless, CI with Original Reinsertion and CIDR implement different methods; both methods attempt to obtain a score that is capable of representing nodei. Therefore, a reinsertion framework derived from CIDR can be extended to a more general model. The Generic Disjoint-set Reinsertion Framework (GDRF) is proposed in Algorithm 3 as a general method for describing the process of disjoint-set reinsertion.

Algorithm of reinsertion with kernel in a more generic framework: Generic Disjoint-set Reinsertion Framework (GDRF).
Step 4 in Algorithm 3 retrieves the score Ki by a specific kernel indicating nodei, and the other steps in Algorithm 3 are the same as in the reinsertion in the CIDR Algorithm 2. GDRF employing the number Of Clusters kernel (Algorithm 4) and the number Of Nodes kernel (Algorithm 5) is able to achieve the same Robustness score as CI with Original Reinsertion and CIDR, respectively.

CI with Original Reinsertion: number of Clusters kernel used to obtain the score Ki representing nodei.

CIDR: numberOfNodes kernel used to obtain the score Ki representing nodei.
Since the reinsertion of independent post-processing can be combined with any network dismantling method to obtain an improved Robustness score, the greater potential of GDRF can be investigated. For the task of finding the most influential nodes in complex networks, the number Of Clusters kernel and the number Of Nodes kernel are implemented to reinsert the nodes with less importance in priority.
In future work, more kernels can be studied to investigate whether GDRF can be applied to other issues. For instance, reconstructing damaged networks is also a widely studied field, and various repair strategies have been presented to repair collapsed networks35,36,37,38,39. A new kernel for GDRF, which would be designed to reinsert the nodes with greater importance in priority, can be developed for the task of recovering attacked networks as soon as possible. The Recover Nodes kernel in Algorithm 6 combined with GDRF is an example of selecting the nodes with greater importance in priority. Si represents the total number of rejoined clusters if the removed nodei is reinserted. A larger Si means that recovering nodei would connect and repair more connected components in the reinsertion process. Compared with the random reinsertion of removed nodes, the recover Nodes kernel tends to reinsert nodes combining with more connected components, which means that recovering a network to certain giant components G > 0 would need fewer reinserted nodes. Since GDRF will search for the minimum Kmin value of nodemin among all removed node values Ki, Algorithm 6 would return the reciprocal of Si as Ki, and nodei with larger values of Si would be reinserted in priority.

Recovering attacked network: recoverNodes kernel used to obtain the score Ki representing nodei.
The RecoverNodes kernel is only suitable when the nodes in a network, instead of the edges, are attacked. The RecoverNodes kernel will also not modify the original network topology after the recovery process. Because this paper mainly focuses on the influential nodes and not repairing attacked networks, additional research on the performance of the recoverNodes kernel compared with previous algorithms can be conducted in future studies.
Methods
As mentioned above, CIDR calculates the value of each node of a network using Formula 1 and removes the nodes with the highest value. In particular, if the radius is set to 0, the step of removing nodes in CI and CIDR will degenerate to the High Degree Adaptive (HDA) algorithm. The concept of HDA was proposed4 as a better strategy and is slightly different from the original Degree centrality method. The degree of the remaining nodes in adaptive HDA is recomputed after each node removal.
To verify CI and CIDR on the datasets, 2 implementations of the algorithm are utilized: CI_HEAP40 and ComplexCi41. CI_HEAP was provided by the original paper written in the C language and generates the statistics of the Original Reinsertion method. ComplexCi is newly developed as a C++ implementation and produces the statistics of CIDR. CI_HEAP and ComplexCi share the same parameters as follows:
-
The start points of the reinsertion in CI_HEAP and ComplexCi are the same. Both start to reinsert a node when the size of the giant component collapses to 1% of the whole network.
-
The finite fractions of nodes at each reinserted step in CI_HEAP and ComplexCi are the same, and both methods reinsert 0.1% at each step.
-
The intervals of the computing component in CI_HEAP and ComplexCi are the same. To determine whether 1% of the giant component has been reached, CI_HEAP and ComplexCi both need to compute the size of the giant component periodically. The interval parameter is 1%, which means that they will calculate the giant component after the CI algorithm removes 1% of the network nodes.
There are several differences between CI_HEAP and ComplexCi when implementing their algorithms as follows.
-
CI_HEAP uses the Original Reinsertion method, and ComplexCi uses CIDR.
-
Compared with the initial proposed CI4, CI_HEAP enhances the algorithm by utilizing the max-heap data structure22 for very efficiently processing the CI values. The computational complexity of CI is O(Nlog N) when removing nodes one by one, made possible through an appropriate data structure for processing CI. The ComplexCi application uses a red-black tree with the STL (Standard Template Library) container SET as a different data structure to store and update the CI values. In the field of C++ programming, the SET and MAP containers in STL are usually implemented as red-black trees, which are a type of self-balancing binary search tree. The average computational complexity of a red-black tree in searching, inserting and deleting nodes is O(log N). Although the red-black tree does not outperform the performance of deleting and updating, in contrast to max-heap, red-black tree is still able to achieve an overall computational complexity of O(Nlog N).
-
As mentioned in algorithm 2, when the reinsertion is implemented in the experimental section, the top 0.1% of qualified nodes are added back at each step. For instance, if we have 2000 removed nodes, reinsertion will add back 0.1% * 2000 = 20 nodes at each step until all nodes are once again in the network. Hence, we need to choose 20 nodes with the minimal value Smin out of the total of 2000 candidates at each reinsertion. Original Reinsertion implements a direct quick sort algorithm of O(Nlog N) to sort all nodes and obtain the top nodes. In CIDR, Introselect algorithm42 is used to select the top N qualified nodes without a sort algorithm, therein simply being of O(N). We do not need to know the order of the Smin array using full sort; we simply need to know the top N qualified nodes.
For Betweenness centrality19, Closeness centrality20 and PageRank centrality21, a complex network python library GraphTools43 is utilized to obtain the statistics. For Eigenvector centrality and Nonbacktracking centrality, the python tool NetworkX44 is implemented to generate the statistics. To obtain the Nonbacktracking centrality of a network, if the leading eigenvector of its Nonbacktracking matrix B is computed directly according to the definition, the computational complexity will be high. In practice, a faster computation can be executed by utilizing the so-called Ihara (or Ihara-Bass) determinant formula31,45,46. It can be shown that the centralities on the Nonbacktracking matrix are equal to the first n elements of the leading eigenvector of the 2N * 2N matrix in Formula 3:
where A is the adjacency matrix, I is the identity matrix, and D is the diagonal matrix, with the degrees of the vertices along the diagonal24.
As mentioned above, the 8 competition datasets in the paper were obtained from the DataCastle Master Competition28, therein providing 4 real networks and 4 classical artificial networks. The 4 extra randomly generated graphs under the ER model are generated locally by the python utility NetworkX44.
For the calculation of the Robustness score, the code used in this paper is implemented from the DataCastle Master Competition and can be found at the official DataCastle website47.
Change history
20 November 2018
A correction to this article has been published and is linked from the HTML and PDF versions of this paper. The error has been fixed in the paper.
References
Lü, L. et al. Vital nodes identification in complex networks. Phys. Reports 650, 1–63 (2016).
Rabade, R., Mishra, N. & Sharma, S. Survey of influential user identification techniques in online social networks. In Recent advances in intelligent informatics, 359–370 (Springer, 2014).
Lü, L., Zhang, Y.-C., Yeung, C. H. & Zhou, T. Leaders in social networks, the delicious case. PloS one 6, e21202 (2011).
Morone, F. & Makse, H. A. Influence maximization in complex networks through optimal percolation. Nat. 524, 65 (2015).
Wang, J., Li, M., Wang, H. & Pan, Y. Identification of essential proteins based on edge clustering coefficient. IEEE/ACM Transactions on Comput. Biol. Bioinforma. 9, 1070–1080 (2012).
Li, M., Zhang, H., Wang, J.-X. & Pan, Y. A new essential protein discovery method based on the integration of protein-protein interaction and gene expression data. BMC systems biology 6, 15 (2012).
Luo, J. & Qi, Y. Identification of essential proteins based on a new combination of local interaction density and protein complexes. PloS one 10, e0131418 (2015).
Sarli, C. C. & Carpenter, C. R. Measuring academic productivity and changing definitions of scientific impact. Mo. medicine 111, 399 (2014).
Garfield, E. The evolution of the science citation index. Int. microbiology 10, 65 (2007).
Chen, P., Xie, H., Maslov, S. & Redner, S. Finding scientific gems with google’s pagerank algorithm. J. Informetrics 1, 8–15 (2007).
Kontoghiorghes, E. J., Rustem, B. & Winker, P. Computational methods in financial engineering (Springer, 2008).
Gai, P. & Kapadia, S. Contagion in financial networks. In Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, vol. 466, 2401–2423 (The Royal Society, 2010).
Mistrulli, P. E. Assessing financial contagion in the interbank market: Maximum entropy versus observed interbank lending patterns. J. Bank. & Finance 35, 1114–1127 (2011).
Feeley, T. H. & Barnett, G. A. Predicting employee turnover from communication networks. Hum. Commun. Res. 23, 370–387 (1997).
Feeley, T. H., Hwang, J. & Barnett, G. A. Predicting employee turnover from friendship networks. J. Appl. Commun. Res. 36, 56–73 (2008).
Pinzger, M., Nagappan, N. & Murphy, B. Can developer-module networks predict failures? In Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of software engineering, 2–12 (ACM, 2008).
Bird, C., Nagappan, N., Gall, H., Murphy, B. & Devanbu, P. Putting it all together: Using socio-technical networks to predict failures. In Software Reliability Engineering, 2009. ISSRE'09. 20th International Symposium on, 109–119 (IEEE, 2009).
Meneely, A., Williams, L., Snipes, W. & Osborne, J. Predicting failures with developer networks and social network analysis. In Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of software engineering, 13–23 (ACM, 2008).
Freeman, L. C. A set of measures of centrality based on betweenness. Sociom. 35–41 (1977).
Bavelas, A. Communication patterns in task-oriented groups. The J. Acoust. Soc. Am. 22, 725–730 (1950).
Page, L., Brin, S., Motwani, R. & Winograd, T. The pagerank citation ranking: Bringing order to the web. Tech. Rep., Stanford InfoLab (1999).
Morone, F., Min, B., Bo, L., Mari, R. & Makse, H. A. Collective influence algorithm to find influencers via optimal percolation in massively large social media. Sci. reports 6 (2016).
Freeman, L. C. Centrality in social networks conceptual clarification. Soc. networks 1, 215–239 (1978).
Martin, T., Zhang, X. & Newman, M. Localization and centrality in networks. Phys. Rev. E 90, 052808 (2014).
Teng, X., Pei, S., Morone, F. & Makse, H. A. Collective influence of multiple spreaders evaluated by tracing real information flow in large-scale social networks. Sci. reports 6 (2016).
Schneider, C. M., Moreira, A. A., Andrade, J. S., Havlin, S. & Herrmann, H. J. Mitigation of malicious attacks on networks. Proc. Nat. Acad. Sci. 108, 3838–3841 (2011).
Tarjan, R. E. Efficiency of a good but not linear set union algorithm. J. ACM (JACM) 22, 215–225 (1975).
DataCastle. Datacastle master competition background, http://www.dcjingsai.com/common/cmpt/%E5%A4%A7%E5%B8%88%E8%B5%9B_%E7%AB%9E%E8%B5%9B%E4%BF%A1%E6%81%AF.html (2017).
Tarjan, R. E. & Van Leeuwen, J. Worst-case analysis of set union algorithms. J. ACM (JACM) 31, 245–281 (1984).
Tarjan, R. E. A class of algorithms which require nonlinear time to maintain disjoint sets. J. computer system sciences 18, 110–127 (1979).
Hashimoto, K. -I. Zeta functions of finite graphs and representations of p-adic groups. In Automorphic forms and geometry of arithmetic varieties, 211–280 (Elsevier, 1989).
Krzakala, F. et al. Spectral redemption in clustering sparse networks. Proc. Nat. Acad. Sci. 110, 20935–20940 (2013).
Newman, M. Spectral community detection in sparse networks. arXiv preprint arXiv:1308.6494 (2013).
Erdos, P. On random graphs. Publ. mathematicae 6, 290–297 (1959).
Tianyu, W., Zhang, J. & Wandelt, S. Exploiting global information in complex network repair processes. Chin. J. Aeronaut. 30, 1086–1100 (2017).
Lee, Y. H. & Sohn, I. Reconstructing damaged complex networks based on neural networks. Symmetry 9, 310 (2017).
Hu, F., Yeung, C. H., Yang, S., Wang, W. & Zeng, A. Recovery of infrastructure networks after localised attacks. Sci. reports 6, 24522 (2016).
Farr, R. S., Harer, J. L. & Fink, T. M. Easily repairable networks: Reconnecting nodes after damage. Phys. review letters 113, 138701 (2014).
Sun, W. & Zeng, A. Target recovery in complex networks. The Eur. Phys. J. B 90, 10 (2017).
Makse, H. A. C code implementation of collective influence algorithm, http://www-levich.engr.ccny.cuny.edu/hernanlab/uploads/CI_HEAP.c (2016).
Zhu, F. zhfkt/complexci, https://github.com/zhfkt/ComplexCi (2017).
Wikipedia. Introselect–Wikipedia, the free encyclopedia, http://en.wikipedia.org/w/index.php?title=Introselect&oldid=848338425, [Online; accessed 29-July-2018] (2018).
Peixoto, T. P. The graph-tool python library. figshare, http://figshare.com/articles/graphtool/1164194, https://doi.org/10.6084/m9.figshare.1164194 (2014).
Hagberg, A., Swart, P. & S Chult, D. Exploring network structure, dynamics, and function using networkx. Tech. Rep., Los Alamos National Lab.(LANL), Los Alamos, NM (United States) (2008).
Bass, H. The ihara-selberg zeta function of a tree lattice. Int. J. Math. 3, 717–797 (1992).
Angel, O., Friedman, J. & Hoory, S. The non-backtracking spectrum of the universal cover of a graph. Transactions Am. Math. Soc. 367, 4287–4318 (2015).
DataCastle. Source code of scoring criteria in robustness calculation, http://share.pkbigdata.com/ID.4407/Master_algorithm (2017).
Acknowledgements
The author thanks Hernan Makse for discussing the idea in the mail and Shanwen Zhu for helping improve the quality of the paper. The author also thanks American Journal Experts (AJE) for English language editing. This manuscript was edited for English language by American Journal Experts (AJE).
Author information
Authors and Affiliations
Contributions
F.Z. designed the research, analyzed the data, prepared the figures and wrote the main manuscript text.
Corresponding author
Ethics declarations
Competing Interests
I declare that the author has no financial competing interests. For the non-financial interests, F.Z. is a participant in the DataCastle Master Competition and write the manuscript from the research in the competition.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhu, F. Improved collective influence of finding most influential nodes based on disjoint-set reinsertion. Sci Rep 8, 14503 (2018). https://doi.org/10.1038/s41598-018-32874-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-32874-5
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
