
Abstract
DNA metabarcoding is a rapidly growing technique for obtaining detailed dietary information. Current metabarcoding methods for herbivory, using a single locus, can lack taxonomic resolution for some applications. We present novel primers for the second internal transcribed spacer of nuclear ribosomal DNA (ITS2) designed for dietary studies in Mauritius and the UK, which have the potential to give unrivalled taxonomic coverage and resolution from a short-amplicon barcode. In silico testing used three databases of plant ITS2 sequences from UK and Mauritian floras (native and introduced) totalling 6561 sequences from 1790 species across 174 families. Our primers were well-matched in silico to 88% of species, providing taxonomic resolution of 86.1%, 99.4% and 99.9% at the species, genus and family levels, respectively. In vitro, the primers amplified 99% of Mauritian (n = 169) and 100% of UK (n = 33) species, and co-amplified multiple plant species from degraded faecal DNA from reptiles and birds in two case studies. For the ITS2 region, we advocate taxonomic assignment based on best sequence match instead of a clustering approach. With short amplicons of 187–387 bp, these primers are suitable for metabarcoding plant DNA from faecal samples, across a broad geographic range, whilst delivering unparalleled taxonomic resolution.
Similar content being viewed by others


Introduction
Analysis of trophic interactions facilitates our understanding of community ecology and ecosystem functioning. Analysing such complex and dynamic processes can benefit conservation by informing management strategies. For example, monitoring dietary composition allows for human-wildlife conflict to be detected and monitored1, for the costs2 and potential benefits3 of alien species to be assessed, for understanding how habitat management influences food webs4, and for understanding seed dispersal and pollination networks to inform ecosystem restoration5,6,7,8. An understanding of trophic links also allows species at risk due to inflexible niches to be identified, isolates particularly vulnerable interaction networks, and allows for suitable (re)introduction sites to be identified9,10,11. Large herbivores in particular are recognised as keystone consumers1,12 and determining their diets can be critical to understanding their impact on plant communities and the wider food web. This is particularly relevant in the light of recent rewilding efforts, including the introduction of non-native species as ecological replacements (analogues) for extinct taxa to restore ecosystem function, or the conservation or reintroduction of native species1,12.
Traditional methods of dietary analysis, such as the morphological examination of faecal samples and gut contents, or feeding observations, are fraught with methodological problems. Molecular methods provide an alternative suite of approaches that can generate greater volumes of data more rapidly and with greater precision13, and comparisons between morphological and molecular methods show that molecular analysis generally provide greater sensitivity3,14. Species-specific primers can be used to detect the DNA of particular focal dietary items in gut contents or faecal samples15,16,17. However, this approach is only appropriate if a priori dietary information is available and if the dietary range is small. It cannot unravel the effects that non-focal species may be having on dietary selection by a highly polyphagous predator or herbivore. In order to overcome such problems, and to determine whole dietary ranges, DNA barcodes coupled with next generation sequencing (NGS), often referred to as DNA metabarcoding, have been widely adopted.
A key target for designing metabarcoding primers is to maximise the taxonomic coverage of a primer set to ensure all potential target species are amplified. However, this often leads to reduced taxonomic resolution, as the highly conserved primer sites required for maximising coverage often favour less variable DNA regions, resulting in reduced ability to distinguish between taxa18. Thus, the panacea for metabarcoding is primers with high taxonomic coverage that amplify a gene region with high taxonomic resolution. An additional challenge for dietary analyses is for this gene region to be short enough to be reliably amplified from degraded samples.
Identification of animal dietary components primarily uses the mitochondrial cytochrome c oxidase gene, which has been shown to effectively resolve species identity19,20,21. However, in plants the mitochondrial genome evolves too slowly for these genes to provide sufficient variation to be useful barcodes22. In 2009, the Consortium for the Barcode of Life approved plastid matK and rbcL as the barcode regions for use in land plants23. Unfortunately, the large fragment size (rbcL = 654 bp; matK = 889 bp)24 of these barcodes makes them impractical for dietary metabarcoding studies. Minibarcodes have been designed within rbcL, but those suitable for application in dietary studies have low discriminatory power at the species level25. The most commonly used DNA barcode in herbivory studies is the P6 loop of the plastid trnL (UAA) gene1,3,14,22,26,27,28,29,30,31, but in silico analysis of this barcoding region using the EMBL database32 estimated taxonomic resolution to be around 18% at the species level18. Whilst in vitro studies using this region report species level taxonomic assignment of 29.8%33 to 77%34, there remains room for improvement. The second internal transcribed spacer (ITS2) of nuclear ribosomal DNA has been suggested as a ‘gold standard’ barcode for identifying plants35 and there is growing evidence to support this36,37. In a study examining 4800 species of medicinal plants, testing the most variable region of a larger ITS2 amplicon as a barcoding region, correct taxonomic identification at the species and genus levels was approximately 91.5% and 99.8%35. Such high taxonomic resolution mostly confined to a 160–320 bp region makes ITS2 a promising DNA barcoding region for use in dietary studies.
General primers for ITS2 have been designed for priming sites within the more conserved flanking regions of 5.8S and 26S35,38. This presents a problem for dietary studies since the resultant amplicon length (approximately 387–547 bp using S2F and S3R35) is potentially too great to be reliably detected in semi-digested samples. Designing shorter amplicon primers closer to ITS2 within the flanking regions, or within ITS2 itself, is a challenge due to the high interspecific variation that has the potential to provide such high taxonomic resolution35 but could limit taxonomic coverage. Additionally, ITS2 presents challenges in interpretation due to the presence of paralogous gene copies and the potential for co-amplification of non-target fungal amplicons36.
Here, we describe primers initially designed for two in-depth dietary studies: a suite of Mauritian herbivores39, and UK doves and pigeons40. We test the scope of these primers for wider herbivory studies by running analyses against three ITS2 sequence databases: (1) a comprehensive database of plants from two Mauritian islands (Mauritian database); (2) all species known to feature in the diet of an obligate granivore (European turtle dove Streptopelia turtur; UK columbid database); and (3) a database consisting of UK plant sequences downloaded from GenBank (UK database). This last database consists largely of vouchered specimens and, where available, contains at least one representative species from each genus of plant present in the UK.
We used these databases to address three objectives:
-
(1)
To establish the taxonomic coverage of our new primers, against all three databases in silico and against all available Mauritian species and a subset of UK species in vitro.
-
(2)
To determine the taxonomic resolution of our primers using all three databases combined for the ITS2 region.
-
(3)
For the two databases with multiple sequences per species (Mauritian and a subset of the UK database), identify clustering thresholds to use in the bioinformatics pipeline for analysis of NGS data, to maximise taxonomic resolution and minimise assignment of multiple haplotypes of the same species to different molecular operational taxonomic units (MOTUs).
To confirm that our primers successfully co-amplify a diverse range of plant species within the same degraded faecal samples, from both birds and reptiles, we also present detailed dietary data from an omnivorous reptile species (Mauritius: Telfair’s skink Leiolopisma telfairii) and an herbivorous bird species (UK: stock dove Columba oenas).
Results
In silico testing of primers
Across all three databases, amplicon lengths, minus priming sites, ranged from 187–387 bp (Table 1; Fig. 1). Where coverage of both forward and reverse primer binding regions was available, 88% of Mauritian (n = 131 species, 114 genera, 57 families; Table 2) and 89% of UK plants (n = 986 species, 561 genera and 121 families; Table 3) fulfilled the primer fit criteria (with fewer than 3 bp mismatches and no mismatch within the last 2 bp at the 3′ end). Poor primer matches (where 50% or fewer of tested species fulfilled the primer fit criteria) were found in only 3 families within the UK (Hydrocharitaceae = 50%, n = 6; Cyperaceae = 0%, n = 44, Thymelaeaceae = 50%, n = 2) where multiple species were tested (Table 3). In the Mauritian database, in silico primer fit was particularly poor for Cyperaceae (0%, n = 4) and Moraceae (50%, n = 2). Analyses of matches for forward and reverse primers independently, due to short sequence lengths, found particularly poor fit for Cyperaceae in both databases due to poor reverse primer fit (0%, Mauritius n = 3; UK n = 79), and Orchidaceae in Mauritius (0%, n = 2) but not in the UK (see Supplementary Table S1a for the Mauritian database, and Supplementary Tables S1b,c for the UK databases).

Comparison of amplicon length distribution from available species and NGS datasets for (a) UK dove and pigeon diet, (b) Telfair’s skink diet pool 1 and (c) Telfair’s skink diet pool 2.
Once we had removed duplicate sequences from the same species within our combined database, taxonomic resolution of the ITS2 region was 86.1%, 99.4% and 99.9% at the species, genus and family levels, respectively (n = 1578 species, 821 genera, 154 families). Two species could not be differentiated at the family level: both were ferns. All Mauritian species could be differentiated at the genus and family levels and just two (Fimbristylis littoralis and F. cymosa) could not be differentiated at the species level. From UK species, two (1.2%), ten (1.2%) and 221 (14%) species could not be differentiated at the family, genus and species levels respectively.
In vitro testing of primers
We established that the UniPlantF (5′-TGTGAATTGCARRATYCMG-3′) and UniplantR (5′-CCCGHYTGAYYTGRGGTCDC-3′) primers had the greatest amplification success on a subset of plant species (Supplementary Table S2), so only these primers were selected for further in vitro and in silico testing. In vitro, this primer pair successfully amplified 99% of the 169 Mauritian species (Table 2), and 100% of 33 UK species tested (Supplementary Table S3b).
Mock community testing showed that plant species with both long and short amplicon lengths were always coamplified in the same PCR mix, even when there was a bias towards short fragment lengths in the PCR (Supplementary Table S4). Generalised linear mixed effects models indicated that there was a significant association between PCR product concentration and the interaction between treatment (ratio of long and short amplicons) and amplicon length (conditional R-squared = 0.42, f = 9.7504, P = < 0.001). Specifically, when there was a bias in the PCR mix towards long amplicons, the DNA concentration of long amplicons was higher than that of short. The opposite was true when there was a bias towards short amplicons. When there were equal short and long amplicons, the DNA concentration of short amplicons was slightly higher, but this was not significant (Supplementary Fig. S1).
Threshold analysis
At a 100% clustering threshold, the majority of species tested (n = 1116 in the UK and n = 165 in Mauritius where multiple haplotypes were present in our databases; Fig. 2) could be identified to the species level, although multiple haplotypes were present for many species. As the threshold dropped, the number of species for which taxonomic resolution was possible started to decrease; however, multiple haplotypes for some species remained (Fig. 2). The effect of reducing the clustering threshold differed between families, particularly reducing power of taxonomic resolution in Caryophyllaceae, Myrtales, Poales and Rosales, even at high clustering thresholds (Fig. 2, Supplementary Fig. S2).

Order-level summary of clustering thresholds for the ITS2 region only between 95 and 100% for (a) Mauritius, n = 165 species and (b) UK databases, n = 1116 species. Order names are listed on the y-axis and clustering threshold forms the x-axis. The colour of the cells represents the percentage of species within an order that can be identified to species level at a given clustering threshold; numbers within cells show the number of species that can be resolved at each threshold. Colour gradient from green through to red signifies high species-level resolution moving towards poor species-level resolution.
Dietary Case Study 1: Stock Doves
We present sequence read numbers at distinct stages of the bioinformatics pipeline as supplementary information (Supplementary Note S2), as these data are also presented elsewhere40 and only a subset is presented here. 5.4% of our sequences matched fungi and bacteria (64 of 1192 unique sequences remaining prior to BLAST matching). We recovered 25 plant species from 13 stock dove samples, with an additional 11 taxa identified to genus level and 4 taxa identified to family level (overall from 31 genera and 18 families; mean ± SE 7.62 ± 0.94 taxonomic units per sample; Supplementary Table S5a; Data S2)40. No vertebrate DNA was recovered. When examining the potential for preferential amplification of shorter fragments by comparing amplicon lengths from our NGS run to those from our reference database, we found plant amplicons from the NGS run to be significantly shorter than those within the UK reference database (Mann-Whitney-Wilcoxon, w = 352710, p < 0.001; Fig. 1a).
Dietary Case Study 2: Telfair’s Skinks
For this dataset, a comprehensive DNA barcode library was available for assigning Illumina reads to taxa39. Overall, we recovered and identified 76 plant taxa from Telfair’s skink faecal samples (after removing taxa that do not grow on the study island and were present, for example, because they were kitchen waste composted by the field staff; mean ± SE 5.77 ± 0.16 taxa per sample; Supplementary Table S5b; Data S3). These included species in families for which in silico analysis suggested poor primer match (full list of species amplified is provided in Supplementary Table S5). No Telfair’s skink DNA was amplified and sequenced. From the plant species consumed that were also present in the DNA barcode library, 100% could be identified to species (Supplementary Data S3). Of those six consumed species that were absent in the library (Supplementary Data S3), 67% were identified to genus and 33% to species. Overall, this equates to 95% and 5% taxonomic resolution at the species and genus levels respectively. Combining results from the two MiSeq runs within which Telfair’s skink samples were present, 4% of unique sequences were identified as fungi. When examining the potential for preferential amplification of shorter fragments by comparing amplicon lengths from our NGS run to those from our reference database, plant amplicons from both NGS runs were significantly shorter than those within the Mauritius reference database (Mann-Whitney-Wilcoxon, Pool 1: w = 126390, p < 0.001, Pool 2: w = 99468, p < 0.001; Fig. 1b,c).
Discussion
Current approaches to molecular analysis of herbivory are generally unable to identify the majority of plants to the species level across a range of families, using amplicons short enough to detect degraded DNA recovered from faecal samples. The most widely applied DNA barcode currently used to study herbivory, the P6 loop of the chloroplast trnL (UAA) gene, has nearly universal priming sites allowing extremely high taxonomic coverage22, and allows about 50% of taxa to be identified to species27. However, taxonomic resolution can vary, depending on the local plant community and quality of the reference DNA barcode library: other studies using this region report species level taxonomic assignment of 29.8%33 to 77%34. Using trnL does have the advantage of being able to work with particularly degraded DNA where short amplicons might be expected to be more reliably amplified (12–134 bp using primer pair g and h18). By contrast, our new ITS2 primers produce amplicons of 187–387 bp in length, with taxonomic coverage of at least 88%, and taxonomic resolution at the species level as high as 86.1% from in silico analyses of three databases. In practice, when used in conjunction with a comprehensive DNA barcode library, taxonomic resolution at the species level can be as high as 100% as shown in our Telfair’s skink case study. Our two case studies demonstrate that these primers successfully amplify DNA from degraded faecal samples from birds and reptiles, and co-amplify multiple plant species from a range of genera and families. Studying trophic interactions between plants and animals at such a fine taxonomic resolution is likely to deepen our knowledge of species ecology and ecosystem dynamics. For example, we have used these primers to provide new insights into the feeding ecology of a declining species, the European turtle dove, including dietary competition with other columbids40. We have also used the primers to examine the impacts of ecological replacement39. Beyond such dietary studies, the primers also have the potential to inform pollination and seed dispersal networks.
Such high taxonomic resolution is only possible when the sequences for the available plant species are available in a reference DNA barcode library27. Indeed, a major criticism of ITS2 has been the lack of reference sequences available for this region24. However, the latest update to the ITS2 database has doubled the number of reference sequences available to 711,172, of which 208,822 belong to the Chloroplastida41. When sequences are not available for plant species within the study area in question, we strongly suggest that building a study-specific DNA barcode library is invaluable.
There are three further potential criticisms of the use of ITS2 as a DNA barcode24. Firstly, there are sometimes paralogous ITS copies present within an individual genome24,37,42. From examination of our databases, our threshold analyses and our NGS datasets, this phenomenon appears to be widespread across multiple plant orders; however, this did not hinder taxonomic assignment using a closest match approach. Secondly, amplifying ITS can be difficult with universal primers37; however, we found this problem to largely be overcome by amplifying ITS2 only35,37, and our primers give good taxonomic coverage. The final criticism is the risk of fungal contamination, given the similarity between plant and fungi universal primer sites within this region36. However, we found fungi and bacteria formed only 5.4% of sequences within our UK NGS run, and 4% across our two Mauritian NGS runs. These figures are slightly higher than that of 2–3% suggested previously from in silico searches37, but after discarding fungal sequences we retained more than sufficient plant read depth for our herbivory analyses. As our primers produce a range of amplicon sizes that differ between plant families, we examined the potential for size bias in our NGS datasets compared to our databases of available species in each region43. Overall, UK NGS sequences were significantly shorter than those expected from the reference database, although this is likely to be due to 235 polymorphic sequences of below average (262 bp) length, all assigned to Brassica species, which are known to show high within-species diversity at the ITS regions44, and were present in all of our stock dove samples. Mauritian sequences from both pools were both significantly shorter than from the reference database; however, sequences of 331 bp (the length of the longest sequence in the reference database) were recovered from both pools. However, these results may be due to dietary preferences of the two consumers rather than size bias. Our mock community testing indicated that long fragments are always amplified, even when there is a bias in the PCR mix towards shorter fragments. Overall, the concentration of PCR products varied as would be expected: when there were more short fragments in the PCR, the concentration of short was higher than that of long amplicons and the reverse was true when there was a bias towards long fragments in the PCR mix. This indicates that size bias, at the PCR stage, may not be a significant for this primer set, especially when read number is not used to quantify diet. Given the findings from our threshold analysis, that intraspecific variation at the ITS2 region will not be removed by clustering into MOTUs without losing taxonomic resolution, we recommend a closest species match approach to sequence identification45,46, rather than a MOTU clustering approach, if the aim of the study is to identify specific dietary components. This also removes any issues caused by potential multiple ITS polymorphisms within an individual47 but does emphasise the need for comprehensive reference barcode libraries for the study system. If such a reference barcode library is not available then a clustering approach to examine, for example, dietary niche partitioning, may be more appropriate. Sanger sequencing of multiple samples from individual plant species may not adequately represent total ITS diversity due to low-frequency polymorphisms47 (in, for example, Brassicaceae44), as this may only result in the most frequent polymorphism being detected. In such cases it may be useful to include some single species plant samples in an NGS run alongside faecal DNA for analysis, to assist reliable species assignment of multiple polymorphisms.
Our in vitro and in silico testing of the UniPlant primers proved that they can amplify a diverse assemblage of plants. The in silico PCR results were more conservative than the in vitro testing. For example, in silico testing revealed that the primers were a poor fit for species within the Orchidaceae and Cyperaceae families, but these were shown to amplify successfully in vitro. Indeed, our detailed Telfair’s skink data show Cyperus dubius (Cyperaceae) to be co-amplified in 16% of faecal samples, alongside a range of other plant species with better primer fit. Thus, in practice, the primers are clearly better than suggested by the in silico results. However, such species with potentially poor primer fit should be tested in vitro to confirm successful amplification before use for the examination of herbivory. Future studies using our primers may also benefit from including known mixtures of DNA samples to ensure co-amplification of likely plant DNA combinations from the relevant study system. In practice different plant species eaten by a generalist herbivore will inevitably be amplified to different degrees, regardless of the primers selected, which is why we base our analyses on frequency of occurrence within faecal extracts, rather than numbers of sequences generated by NGS. Different plant species will also be digested to different degrees, and the number of copies of the target gene per cell will vary with species, making frequency of occurrence the most reliable quantitative measure.
Our novel primers amplify a fragment of 187–387 bp, which is suitable for use with NGS platforms, and here we show that they are general enough to amplify the vast majority of the phylogenetically diverse array of plant species found in the UK and Mauritius, and therefore highly likely to be equally useful in other parts of the globe. We recommend in silico followed by in vitro testing of likely dietary items, particularly if they are ferns or within the Cyperaceae, Orchidaceae, Hydrocharitaceae or Thymelaeaceae families. A comprehensive DNA barcode reference library is invaluable to obtain high taxonomic resolution, and to avoid the potential pitfall of setting a clustering threshold, permitting accurate assignment of taxa based on a closest match approach.
Methods
Barcode databases
Mauritian database
Plant tissue samples were collected from two Mauritian islands (Ile aux Aigrettes and Round Island) as part of a larger study in which we DNA barcoded the plant communities in order to examine herbivory by introduced and native reptiles and birds39. Plant identity was verified prior to DNA barcoding to ensure taxonomic accuracy. Eighty-four sequences available at an early stage of the work were used for primer design (Supplementary Table S3a). In vitro primer testing was carried out on DNA samples from 169 species from 65 families. In silico analyses were carried out on a dataset of 464 sequences, 167 species and 63 families (of which eight were downloaded from GenBank to supplement field collected samples and form a complete barcode library).
UK database
6054 ITS2 sequences from 1651 UK plant species from 151 families were downloaded from GenBank. These largely, but not entirely, consisted of vouchered sequences from a comprehensive analysis of the ITS2 region of UK plants (de Vere et al., unpubl. data). Where possible, if sequences did not span both priming sites we obtained untrimmed sequences. Where available from GenBank, this included at least one representative from each genus of plants listed on the Ecological Database of the British Isles48 (a comprehensive list of both native and introduced plant species found in the UK). We downloaded a maximum of one sequence per species from GenBank, so where multiple haplotypes of a species are present within the database the majority of these are from vouchered specimens. Synonyms were checked with The Plant List49.
UK columbid database
Thirty six UK plant species were collected and barcoded as part of a separate study examining the diet of UK columbids, with a focus on European turtle doves40, with an additional 14 species represented in the database by sequences downloaded from GenBank. This included 31 species previously identified in the diet of turtle doves using microscopy, seven species known to be present within commercial seed mixes and 12 additional species commonly found on arable farmland (Supplementary Table S3b). Thirty three of these sequences (those available at an early stage of this work) were used for primer design and in vitro testing.
Generation of Reference Databases
DNA extractions were carried out either following Randall et al.50 after samples were ground under liquid nitrogen, or using the Qiagen DNeasy plant kit (Qiagen, Manchester, UK). The complete second internal transcribed spacer of nuclear ribosomal DNA (ITS2) and partial 5.8S and 26S sequences were amplified using primer pair S2F and S3R35. Where amplification with this primer pair failed, a second ITS2 primer pair were tried, ITS-p3 and ITS-p438. PCRs were carried out in 10 µL reaction volumes containing 2 µL DNA template, 1x PCR buffer, 2.0 mM MgCl2, 0.2 µM of each primer (at 10 mM), 0.2 mM of each dNTP and 1 U Go Taq Flexi (Promega, Southampton, UK). For problematic samples, a multiplex PCR mix (Qiagen, Manchester, UK) was used, with primers and DNA at the same concentration and volume described above. Reaction conditions were an initial denaturation step at 95 °C for 10 min, followed by 40 cycles of 95 °C for 30 s, 56 °C for 30 s and 72 °C for 1 min, and a final extension of 72 °C for 10 min. PCR products were sequenced in both directions by Eurofins Genomics (Wolverhampton, UK). Contigs were constructed and consensus sequences created in Sequencher version 5.4.651 or MEGA652 after manually editing sequences. Consensus sequences were aligned using automated ClustalW alignment in BioEdit53 or ClustalX54, for in silico analysis (see below).
Short amplicon primer design for diet analysis and in vitro testing
A subset of aligned ITS2 and partial 26S and 5.8S sequences (Supplementary Table S3a,b; UK columbid database n = 33, Mauritius database n = 84) were used to design primers for a short ITS2 amplicon to maximise amplification from the degraded DNA found in faecal samples (Fig. 3). Aligned sequences were examined by eye in MEGA652 in order to detect suitably conserved sites. Five forward and seven reverse primers were designed and tested in vitro on a subset of plant DNA from key dietary items (mean ± SE: 14.8 ± 10.2 plant DNA samples per primer pair; Supplementary Table S2). All in vitro testing involved amplification in 10 µL PCR reaction volumes with reagents and template DNA in the same concentrations as described above. Reaction conditions were also the same as above, after initially testing annealing temperatures from 46 °C–56 °C by gradient PCR. Successful amplification was determined by visualisation on a 2% agarose gel stained with SYBR®Safe (ThermoFisher Scientific, Paisley, UK). Primers that failed initial tests (amplification failure, faint bands, multiple banding) on a small number of plant DNA samples were rejected with no further testing (Supplementary Table S2). These initial in vitro tests revealed that one primer pair, UniPlantF and UniPlantR, had the highest amplification success so these were subjected to further in vitro testing against all available Mauritian plant species and the field-collected UK species.

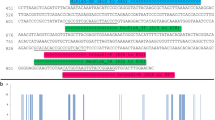
Schematic diagram of priming sites within the second internal transcribed spacer (ITS2) and flanking regions (5.8S and 26S). The location of S2F and S3R priming sites35 are shown alongside UniPlantF and UniplantR from this study. The distances of the priming sites from the ITS2 region are shown (bp). Distances are based on a representative Asparagus setaceus sequence (NCBI Accession number KY700230). S2F and UniPlantF overlap by 7 bp. UniPlantR begins on the last 1 bp of ITS2 and continues into 26S. The amplicon size range, across all sequences assessed in this study, of the UniPlant primers is shown. Schematic not to scale.
To determine whether the primers preferentially amplified those plant species with shorter ITS2 fragments over those with longer fragments, we assembled 15 mock communities from plant tissue DNA extracts. Each mock community contained six plant species each at an initial concentration of 0.3 ng/µL before adding to the PCR mix but the ratio of those plant species with long or short amplicons varied across three treatments: an equal treatment of 3 long and 3 short plant species, a bias towards short fragments containing 2 long and 4 short species, a bias towards long fragments containing 4 long and 2 short species. Plant species with ITS2 amplicon lengths using the UniPlant primers of between 267 and 280 bp were classified as short, and between 310 and 336 were classified as long. PCRs were carried out in 10 µL reaction volumes with a total DNA concentration of 0.3 ng/µL with reagent concentrations and PCR reaction conditions identical to those used in Case Study 2 (see below). PCR products were analysed by high-resolution capillary electrophoresis using a QIAxcel (Qiagen, Manchester, UK) to determine the DNA concentration of the long and short amplicons. Whether DNA concentration was significantly associated with amplicon length, treatment or their interaction was analysed using generalised linear mixed effects models in the lme455 package in R56. Amplicon length and treatment were modelled as fixed effects and PCR reaction was included as a random effect with DNA concentration as the dependent variable. The model was run using the Gaussian error structure and the identity link function on normal data. Model assumptions were checked by examining the standardised residuals.
In silico testing
To further test the suitability of this primer pair, in silico PCR was carried out on a larger number of species from all three databases using ecoPCR within OBITools57. We allowed for a maximum of three base mismatches per primer ensuring the last two bases at the 3′ end were an exact match58, specifying a minimum amplicon length of 100 bp and a maximum of 500 bp. Where DNA sequences did not encompass both forward and reverse priming sites, primers were tested independently and reported in the supplementary information (Supplementary Table S1a,b,c). To examine the potential for preferential amplification of short-length amplicons43, we calculated mean amplicon length per family from the ecoPCR output and compared the amplicon distribution of each of the UK and Mauritius databases to the NGS data from our UK and Mauritian studies (see below). We used Mann-Whitney-Wilcoxon tests to allow for non-normal distribution of amplicon lengths.
We define taxonomic resolution as per Pompanon et al.18, as the percentage of taxa unambiguously identified for a given taxonomic level. To test the taxonomic resolution of the ITS2 region within the UniPlant amplicon (Fig. 1), we combined all three databases and removed identical sequences derived from the same species and those sequences of poor quality (resulting in 3550 total sequences, representing 1659 species, 828 genera and 155 families). We used the ITSx software59 to extract the ITS2 region from our amplicons to form our ITS2 database (ITS2 successfully extracted from 2216 sequences, representing 1577 species, 821 genera and 143 families). We used the “derep_prefix” command in USEARCH60 to identify identical sequences within each database; we then calculated the number of taxa within which multiple species had identical ITS2 sequences.
Testing clustering thresholds
To test whether sequences resulting from NGS analysis of faecal samples using our primers should be clustered into MOTUs within the bioinformatics pipeline, and if so at what threshold, we used reference sequences from both the Mauritian (n = 167 species and 464 sequences) and UK databases (n = 1116 species and 2619 sequences) from species where multiple vouchered sequences were available. We ran the sequence files through the USEARCH60 command “cluster_fast” with an identity threshold of 95%. We then used the percentage similarity values between clustered sequences from the cluster format output file to identify, for cut-offs between 95 and 100%, how many different species and haplotypes would be clustered together. Resolution at each clustering threshold is displayed as heat maps, at the order level. Heat maps were created using the “heatmap.2” function in the gplots package61 in R56.
Dietary case studies
These primers were originally designed for dietary analysis in two separate studies: one assessing the diet of Pink Pigeons Nesoenas mayeri, Telfair’s skinks and Aldabra giant tortoises Aldabrachelys gigantea in Mauritius; and one investigating the diet of UK doves and pigeons (turtle dove, collared dove Streptopelia decaocto, woodpigeon Columba palumbus and stock dove). Detailed results for these two studies will be published elsewhere39,40), but to demonstrate the effectiveness of our primers on faecal samples, we present comprehensive data from one species from each study (stock dove: Case Study 1; Telfair’s skinks: Case Study 2) here. Detailed methods for sample collection, laboratory protocols and data analyses are provided in Supplementary Note S1.
Data availability
New accession numbers for sequences generated from this study, and those used in our databases are provided in the Supplementary Information, along with our detailed case study data. Raw MiSeq data from the UK columbid case study is available on the NCBI Sequence Read Archive under accession number SRP136381, and detailed individual level taxonomic unit presence-absence data are available from JCD upon reasonable request. Raw MiSeq data from the Mauritian study will be deposited in the NCBI Sequence Read Archive upon acceptance.
Accession numbers
DNA sequences: available on GenBank under the accession numbers listed in Supplementary Data S1. Raw MiSeq data from the UK columbid case study is available on the NCBI Sequence Read Archive under accession number SRP136381, and detailed individual level taxonomic unit presence-absence data are available from JCD upon reasonable request. Raw MiSeq data from the Mauritian study will be deposited in the NCBI Sequence Read Archive upon acceptance.
References
Kowalczyk, R. et al. Influence of management practices on large herbivore diet—Case of European bison in Białowieża Primeval Forest (Poland). For. Ecol. Manage. 261, 821–828 (2011).
Brown, D. et al. Dietary competition between the alien Asian Musk Shrew (Suncus murinus) and a re-introduced population of Telfair’s Skink (Leiolopisma telfairii). Mol. Ecol. 23, 3695–3705 (2014).
Ando, H. et al. Diet analysis by next-generation sequencing indicates the frequent consumption of introduced plants by the critically endangered red-headed wood pigeon (Columba janthina nitens) in oceanic island habitats. Ecol. Evol. 3, 4057–4069 (2013).
Pearson, C. E. et al. The effects of pastoral intensification on the feeding interactions of generalist predators in streams. Mol. Ecol. 590–602 https://doi.org/10.1111/mec.14459 (2018).
Bell, K. L. et al. Pollen DNA barcoding: current applications and future prospects. Genome 59, 629–640 (2016).
Lucas, A. et al. Floral resource partitioning by individuals within generalised hoverfly pollination networks revealed by DNA metabarcoding. Sci. Rep. 8, 5133 (2018).
Heleno, R. H., Olesen, J. M., Nogales, M., Vargas, P. & Traveset, A. Seed dispersal networks in the Galápagos and the consequences of alien plant invasions. Proc. R. Soc. B 280, 20122112 (2013).
Lim, V. C. et al. Impact of urbanisation and agriculture on the diet of fruit bats. Urban Ecosyst. 21, 61–70 (2018).
Pernetta, A. P., Bell, D. J. & Jones, C. G. Macro- and microhabitat use of Telfair’s skink (Leiolopisma telfairii) on Round Island, Mauritius: implications for their translocation. Acta Oecologica-International J. Ecol. 28, 313–323 (2005).
Clare, E. Molecular detection of trophic interactions: emerging trends, distinct advantages, significant considerations and conservation applications. Evol. Appl. 7, 1144–1157 (2014).
Soorae, P. S. Global Re-introduction Perspectives, 2016: Case-studies from Around theGlobe. IUCN/SSC Re-introduction Specialist Group & Environment Agency-Abu Dhabi (2016).
Griffiths, C. et al. The Use of Extant Non-Indigenous Tortoises as a Restoration Tool to Replace Extinct Ecosystem Engineers. Restor. Ecol. 18, 1–9 (2010).
King, R., Read, D., Traugott, M. & Symondson, W. Molecular analysis of predation: a review of best practice for DNA-based approaches. Mol. Ecol. 17, 947–963 (2008).
Soininen, E. et al. Analysing diet of small herbivores: the efficiency of DNA barcoding coupled with high-throughput pyrosequencing for deciphering the composition of complex plant mixtures. Front. Zool. 6, 16 (2009).
Pumarino, L., Alomar, O. & Agusti, N. Development of specific ITS markers for plant DNA identification within herbivorous insects. Bull. Entomol. Res. 101, 271–276 (2011).
Leal, M. et al. Coral feeding on microalgae assessed with molecular trophic markers. Mol. Ecol. 23, 3870–3876 (2014).
Wallinger, C. et al. The effect of plant identity and the level of plant decay on molecular gut content analysis in a herbivorous soil insect. Mol. Ecol. Resour. 13, 75–83 (2013).
Pompanon, F. et al. Who is eating what: Diet assessment using next generation sequencing. Mol. Ecol. 21, 1931–1950 (2012).
Hebert, P., Cywinska, A., Ball, S. & DeWaard, J. Biological identifications through DNA barcodes. Proc. R. Soc. B Biol. Sci. 270, 313–321 (2003).
Hebert, P., Penton, E., Burns, J., Janzen, D. & Hallwachs, W. Ten species in one: DNA barcoding reveals cryptic species in the neotropical skipper butterfly Astraptes fulgerator. Proc. Natl. Acad. Sci. 101, 14812–14817 (2004).
Hebert, P. & Gregory, T. The promise of DNA barcoding for taxonomy. Syst. Biol. 54, 852–859 (2005).
Taberlet, P. et al. Power and limitations of the chloroplast trnL (UAA) intron for plant DNA barcoding. Nucleic Acids Res. 35, e14 (2007).
CBOL Plant Working Group., A. DNA barcode for land plants. Proc. Natl. Acad. Sci. USA 106, 12794–12797 (2009).
Hollingsworth, P., Graham, S. & Little, D. Choosing and using a plant DNA barcode. PLoS One 6, e19254 (2011).
Little, D. A. DNA mini‐barcode for land plants. Mol. Ecol. Resour. 14, 437–446 (2014).
Jurado-Rivera, J., Vogler, A., Reid, C., Petitpierre, E. & Gomez-Zurita, J. DNA barcoding insect-host plant associations. Proc. R. Soc. B Biol. Sci. 276, 639–648 (2009).
Valentini, A. et al. New perspectives in diet analysis based on DNA barcoding and parallel pyrosequencing: The trnL approach. Mol. Ecol. Resour. 9, 51–60 (2009).
Rayé, G. et al. New insights on diet variability revealed by DNA barcoding and high-throughput pyrosequencing: Chamois diet in autumn as a case study. Ecol. Res. 26, 265–276 (2011).
Ait Baamrane, M. et al. Assessment of the food habits of the Moroccan dorcas gazelle in M’Sabih Talaa, west central Morocco, using the trnL approach. PLoS One 7, e35643 (2012).
Coghlan, M. et al. Metabarcoding avian diets at airports: implications for birdstrike hazard management planning. Investig. Genet. 4, 27 (2013).
Hibert, F. et al. Unveiling the Diet of Elusive Rainforest Herbivores in Next Generation Sequencing Era? The Tapir as a Case Study. PLoS One 8, e60799 (2013).
Kanz, C. et al. The EMBL nucleotide sequence database. Nucleic Acids Res. 33, 29–33 (2005).
Gebremedhin, B. et al. DNA metabarcoding reveals diet overlap between the endangered walia ibex and domestic goats - Implications for conservation. PLoS One 11, e0159133 (2016).
Kartzinel, T. et al. DNA metabarcoding illuminates dietary niche partitioning by African large herbivores. Proc. Natl. Acad. Sci. 112, 8019–8024 (2015).
Chen, S. et al. Validation of the ITS2 region as a novel DNA barcode for identifying medicinal plant species. PLoS One 5, 1–8 (2010).
Hollingsworth, P. Refining the DNA barcode for land plants. Proc. Natl. Acad. Sci. 108, 19451–19452 (2011).
China Plant BOL Group. et al. Comparative analysis of a large dataset indicates that internal transcribed spacer (ITS) should be incorporated into the core barcode for seed plants. Proc. Natl. Acad. Sci. 108, 19641–19646 (2011).
Cheng, T. et al. Barcoding the kingdom Plantae: new PCR primers for ITS regions of plants with improved universality and specificity. Mol. Ecol. Resour. 16, 138–149 (2016).
Moorhouse-Gann, R. Ecological replacement as a restoration tool: Disentangling the impacts and interactions of Aldabra giant tortoises (Aldabrachelys gigantea) using DNA metabarcoding. PhD thesis (Cardiff University, 2017).
Dunn, J. et al. The decline of the Turtle Dove: dietary associations with body condition and competition with other columbids analysed using next generation sequencing. Mol. Ecol., accepted.
Ankenbrand, M., Keller, A., Wolf, M., Schultz, J. & Förster, F. ITS2 Database V: Twice as Much. Mol. Biol. Evol. 32, 3030–3032 (2015).
Coleman, A. ITS2 is a double-edged tool for eukaryote evolutionary comparisons. Trends Genet. 19, 370–375 (2003).
Pompanon, F., Bonin, A., Bellemain, E. & Taberlet, P. Genotyping errors: causes, consequences and solutions. Nat. Rev. Genet. 6, 847–846 (2005).
Yang, Y.-W., Lai, K.-N., Tai, P., Ma, D.-P. & Li, W.-H. Molecular Phylogenetic Studies of Brassica, Rorippa, Arabidopsis and Allied Genera Based on the Internal Transcribed Spacer Region of 18S–25S rDNA. Mol. Phylogenet. Evol. 13, 455–462 (1999).
de Vere, N. et al. Using DNA metabarcoding to investigate honey bee foraging reveals limited flower use despite high floral availability. Sci. Rep. 7, 42838 (2017).
Hawkins, J. et al. Using DNA metabarcoding to identify the floral composition of honey: A new tool for investigating honey bee foraging preferences. PLoS One 10, 1–20 (2015).
Iwanowicz, D. et al. Metabarcoding of fecal samples to determine herbivore diets: A case study of the endangered Pacific pocket mouse. PLoS One 11, e0165366 (2016).
Fitter, A. & Peat, H. The Ecological Flora Database. J. Ecol. 82, 415–425 (1994).
The Plant List. The Plant List. 1.1. theplantlist.org (2013).
Randall, R., Sornay, E., Dewitte, W. & Murray, J. AINTEGUMENTA and the D-type cyclin CYCD3;1 independently contribute to petal size control in Arabidopsis: evidence for organ size compensation being an emergent rather than a determined property. J. Exp. Bot. 66, 3991–4000 (2015).
Sequencher® version 5.4.6 DNA sequence analysis software, Gene Codes Corporation, Ann Arbor, MI USA, http://www.genecodes.com.
Tamura, K., Stecher, G., Peterson, D., Filipski, A. & Kumar, S. MEGA6: Molecular Evolutionary Genetics Analysis version 6.0. Mol. Biol. Evol. 30, 2725–2729 (2013).
Hall, T. BioEdit: biological sequence alignment editor for Win95/98/NT/2K/XP (2005).
Larkin, M. et al. ClustalW and ClustalX version 2. Bioinformatics 23, 2947–2948 (2007).
Bates, D. & Maechler, M. lme4: Linear mixed-effects models using S4 classes (2009).
R Core Team. R: A language and environment for statistical computing. (2016).
Boyer, F. et al. OBITools: a Unix-inspired software package for DNA metabarcoding. Mol. Ecol. Resour. 16, 176–182 (2015).
Bellemain, E. et al. ITS as an environmental DNA barcode for fungi: an in silico approach reveals potential PCR biases. BMC Microbiol. 10, 189 (2010).
Bengtsson-Palme, J. et al. ITSx: Improved software detection and extraction of ITS1 and ITS2 from ribosomal ITS sequences of fungi and other eukaryotes for use in environmental sequencing. Methods Ecol. Evol. 4, 914–919 (2013).
Edgar, R. Search and clustering orders of magnitude faster than BLAST. Bioinformatics 26, 2460–2461 (2010).
Warnes, G. et al. gplots: Various R Programming Tools for Plotting Data. R package version 3.0.1. https://CRAN.R-project.org/package=gplots (2016).
Acknowledgements
This work was funded both by the Natural Environment Research Council (NERC), the Royal Society for the Protection of Birds (RSPB) and Natural England (NE). RMG was funded by a NERC iCASE studentship (NE/K00719X/1), co-funded by CASE partners the Durrell Wildlife Conservation Trust with support from the Mauritian Wildlife Foundation. JCD was funded by the RSPB and NE through the Action for Birds in England partnership, with additional funding provided by the RSPB Nature Recovery Fund. Illumina library preparation, sequencing and data analyses were supported by the NERC Biomolecular Analysis Facility at the University of Sheffield (NBAF-S) and funded by NERC, UK (NBAF983 and NBAF943). We thank the National Parks and Conservation Service, Government of Mauritius for their permission to carry out work in Mauritius, and multiple fieldworkers and landowners in the UK who assisted with collection of samples and access to land, respectively. Thank you to Rouben Mootoocurpen, Dany Vencatasamy, Abdullah Faisal Nuckcheddy, Nicolas Zuël, Issabelle Désiré and Jean Claude Sevathian for their assistance with plant tissue sample collection and/or plant identification in Mauritius, and to Eliza Leat, Kerry Skelhorn, Judit Mateos, Alexander Ball, Rebecca Thomas and Jenny Bright for assistance with sample collection in the UK. Thank you to the Mauritius Herbarium for their support with plant identification. Thank you to Frédéric Boyer and Pablo Orozco ter Wengel for their advice on using ecoPCR. Thank you also to Isa-Rita Russo and Silke Waap for sharing their expertise in primer design. We are grateful to Jordan Cuff, Sarah Davies, Rebecca Young, Lorna Drake and Ewan Stenhouse for conducting the mock community experiment.
Author information
Authors and Affiliations
Contributions
R.J.M.G. and J.C.D. wrote the main manuscript text. J.C.D. and R.J.M.G. designed the primers. R.J.M.G. and J.C.D. conducted laboratory analysis, and R.J.M.G., J.C.D. and H.H. analysed the data. W.O.C.S., N.C. and M.G. supervised the Mauritius work while W.O.C.S. advised on the molecular analyses at Cardiff. M.G., N.C., R.J.M.G. and J.C.D. collected samples. N.D.V. provided data. All authors reviewed and contributed to the manuscript.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Moorhouse-Gann, R.J., Dunn, J.C., de Vere, N. et al. New universal ITS2 primers for high-resolution herbivory analyses using DNA metabarcoding in both tropical and temperate zones. Sci Rep 8, 8542 (2018). https://doi.org/10.1038/s41598-018-26648-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-26648-2
This article is cited by
-
Semi-automated sequence curation for reliable reference datasets in ITS2 vascular plant DNA (meta-)barcoding
Scientific Data (2024)
-
Metabarcoding reveals seasonal variations in the consumption of crops and weeds by wild Red-legged Partridge Alectoris rufa
Journal of Ornithology (2024)
-
Consumer identity but not food availability affects carabid diet in cereal crops
Journal of Pest Science (2024)
-
Novel plant–frugivore network on Mauritius is unlikely to compensate for the extinction of seed dispersers
Nature Communications (2023)
-
Diet composition of wild columbiform birds: next-generation sequencing of plant and metazoan DNA in faecal samples
The Science of Nature (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
