
Abstract
Translating the vast data generated by genomic platforms into accurate predictions of clinical outcomes is a fundamental challenge in genomic medicine. Many prediction methods face limitations in learning from the high-dimensional profiles generated by these platforms, and rely on experts to hand-select a small number of features for training prediction models. In this paper, we demonstrate how deep learning and Bayesian optimization methods that have been remarkably successful in general high-dimensional prediction tasks can be adapted to the problem of predicting cancer outcomes. We perform an extensive comparison of Bayesian optimized deep survival models and other state of the art machine learning methods for survival analysis, and describe a framework for interpreting deep survival models using a risk backpropagation technique. Finally, we illustrate that deep survival models can successfully transfer information across diseases to improve prognostic accuracy. We provide an open-source software implementation of this framework called SurvivalNet that enables automatic training, evaluation and interpretation of deep survival models.
Similar content being viewed by others


Introduction
Advanced molecular platforms can generate rich descriptions of the genetic, transcriptional, epigenetic and proteomic profiles of cancer specimens, and data from these platforms are increasingly utilized to guide clinical decision-making. Although contemporary platforms like sequencing can provide thousands to millions of features describing the molecular states of neoplastic cells, only a small number of these features have established clinical significance and are used in prognostication1,2,3,4. Making reliable and accurate predictions of clinical outcomes from high-dimensional molecular data remains a major challenge in realizing the potential of precision genomic medicine.
Traditional Cox proportional hazards models require enormous cohorts for training models on high-dimensional datasets containing large numbers of features. Consequently, a small set of features is selected in a subjective process that is prone to bias and limited by imperfect understanding of disease biology. High-dimensional learning problems are common in the machine-learning community, and many machine-learning approaches have been adapted to predicting survival or time to progression5. Prior knowledge has been used to reduce dimensionality by learning gene signatures of cancer hallmarks to generate intermediate features that successfully predict outcomes6,7. Regularization methods for Cox models like elastic net have been developed to perform objective and data-driven feature selection with time-to-event data8. Random forests are reputed to resist overfitting in high-dimensional prediction problems, and have been adapted to survival modeling9. Neural network based approaches have been used in low-dimensional survival prediction problems10, but subsequent evaluation of these methods found no performance improvement over ordinary Cox regression11. The difficulty of deconstructing these black-box models to gain insights into disease progression or biology remains a key challenge in their adoption. Deep neural networks were combined with input-level feature selection to identify promoters and enhancers of gene regulation, with the goal of creating interpretable nonlinear models12.
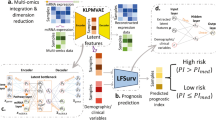
Advances in neural networks broadly described as deep learning have shattered performance benchmarks in general machine-learning tasks, enabled by improvements in methodology, computing hardware, and datasets13. These networks are composed of densely interconnected layers that sequentially transform the inputs into more predictive features through adaptive learning of the interconnection parameters (see Fig. 1). Deep networks composed of many layers perform feature-learning on high dimensional datasets to extract latent explanatory features14, and have been successfully applied to biomedical problems including image classification15, transcription factor binding site prediction16, and medication dosing control17. A fundamental challenge in deep learning is determining the network design that provides the best prediction accuracy, a process that involves choosing network hyperparameters including the number of layers, transformation types, and training parameters. Searching the vast space of network designs quickly becomes intractable, given the considerable time required to train a single deep network. Bayesian optimization techniques have been developed to automate the search of the hyperparameter space, and provide measurable gains in accuracy over expert tuning18 or random search19, and identify optimal models with fewer experiments19,20. Advanced deep learning techniques including dropout regularization, unsupervised pre-training, and Bayesian optimization were first applied to build unbiased deep models from high-dimensional genomic data in ref.21 where deep networks were trained to optimize proportional hazards likelihood. A subsequent study applied deep networks to model survival in breast cancer using a low-dimensional dataset (14 features) that were selected with a priori disease knowledge22. This study did not evaluate prediction using high-dimensional data or compare to state-of-the-art methods like regularized Cox regression that perform unbiased feature selection.

Overview of the SurvivalNet framework. (A) Accurate prognostication is crucial to clinical decision making in cancer treatment. Molecular platforms produce data that can be used for precision prognostication with learning algorithms. (B) Deep survival models are neural networks composed of layers of non-linear transformations, driven by a Cox survival model at the output layer. Model likelihood is used to adaptively train the network to improve the statistical likelihood of the overall survival prediction. (C) The SurvivalNet framework enables automatic design optimization and validation of deep survival models. Molecular profiles obtained from TCGA datasets are randomized, assigning patients to training, testing and validation sets. Bayesian optimization searches the space of hyperparameters like the number of network layers to optimize the model design. Each selected design is trained and evaluated using validation samples to update the Bayesian optimizer. The best model design is then evaluated on the independent testing set to measure the final optimized model accuracy.
This paper extends the preliminary studies exploring deep learning for survival modeling, and presents a software package called SurvivalNet (SN) that enables users to train and interpret deep survival models. SurvivalNet uses Bayesian optimization to identify optimal hyperparameter settings, saving users considerable time and effort in choosing model parameters. We also illustrate how backpropagation methods can be modified to interpret deep survival models, scoring individual features for their contribution to risk, and show how feature risk scores can be used with pathway analysis tools to uncover higher-order biological themes associated with patient survival. Using clinical and molecular data from The Cancer Genome Atlas (TCGA), we show that Bayesian-optimized deep survival models provide comparable performance to Cox elastic net regression, and superior performance to random survival forests when analyzing high-dimensional genomic data. Finally, we show how deep survival models can learn prognostic information from multi-cancer datasets to improve prognostication through transfer learning.
Results
Automatic training and validation of deep survival models
An overview of the SurvivalNet framework is presented in Fig. 1. SurvivalNet is implemented as an open-source Python module (https://github.com/CancerDataScience/SurvivalNet) using Theano and is available as a pre-built Docker software container. A deep survival model uses the Cox partial log likelihood to train the weights of neural network to transform molecular features into explanatory factors that explain survival. The partial log likelihood serves as a feedback signal to train the model weights using backpropagation. Deep neural networks have many hyperparameters that impact prediction accuracy including the number of layers, number and type of activation functions in each layer, and choices for optimization/regularization procedures. The time needed to train a deep survival model prohibits exhaustive hyperparameter search, and so SurvivalNet employs a Bayesian optimization strategy to identify hyperparameters that optimize prediction accuracy including the number of network layers, the number of elements in each layer, the activation function, and the dropout fraction. Bayesian optimization enables users who lack experience tuning neural networks to optimize model designs automatically, and results in considerable savings in time and effort as previously reported19. Data is first split into training (60%), validation (20%), and testing (20%) sets. Training samples are used to train the model weights with backpropagation using the network design suggested by Bayesian optimization. The prediction accuracy of the trained deep survival model is then estimated using the validation samples, and is used to maintain a probabilistic model of performance as a function of hyperparamters. Based on the probabilistic model, the design with the best expected accuracy is inferred as the next design to test. After the Bayesian optimization process is finished (typically after a prescribed number of experiments), the best network design is used to re-train a deep survival model using the training and validation samples, and the accuracy of this best model is reported using the held-out testing samples.
Comparing deep survival networks with Cox elastic net and random survival forests
We compared the performance of SurvivalNet models with Cox elastic net (CEN) and random survival forest (RSF) models using data from multiple TCGA projects: pan-glioma (LGG/GBM), breast (BRCA), and pan-kidney (KIPAN) which consists of chromophobe, clear cell, and papillary carcinomas. Datasets were selected based on the availability of molecular and clinical data and for extent of complete clinical follow up. Performance was evaluated with two feature-sets: 1) a “transcriptional” feature set containing 17,000 + gene expression features obtained by RNA-sequencing, and 2) an “integrated” feature set containing 3–400 features describing clinical features, mutations, gene and chromosome arm-level copy number variations, and protein expression features. Details of these datasets are presented in Methods and Tables S1 and S2. Optimization procedures for CEN and RSF hyperparameters are described in Methods.
In each experiment, samples were randomized to training (60%), validation (20%), and testing (20%) sets, and the performance of optimized SN, CEN, and RSF models was assessed. Performance was calculated using Harrell’s c-index, a non-parametric statistic that measures concordance between predicted risks and actual survival23. A c-index of 1 indicates perfect concordance, and a c-index of 0.5 corresponds to random chance. Experiments were repeated for 20 randomizations to account for variations due to sample assignment. Differences in performance between methods were evaluated through rank-sum statistical testing of c-index values. Results are presented in Fig. 2 (extended results are presented in Table S3).

Performance comparison of SurvivalNet, Cox elastic net, and random survival forest models. The prognostic accuracy of these methods was evaluated in different diseases/datasets (GBMLGG, BRCA, KIPAN) using a high-dimensional transcriptional feature set and a lower-dimensional integrated feature set that combines clinical, genetic, and protein expression features. Patients were randomized to 20 training/validation/testing sets that were used to train, optimize, and evaluate models in each case. (A) SurvivalNet models have an advantage over Cox elastic net in predicting survival using high-dimensional transcriptional features. (B) Cox elastic net has an advantage in predicting survival using lower-dimensional integrated features. Dashed red lines corresponding to a random prediction (c-index = 0.5). Dashed blue lines corresponds to c-index of molecular classification of gliomas.
Both SN and CEN significantly outperform RSF models in most experiments. All methods perform markedly better than random, with median c-index scores ranging from: 0.75–0.84 in LGG/GBM; 0.52–0.68 in BRCA; and 0.73–0.79 in KIPAN. In the transcriptional feature set (Fig. 2B), SN models have a slight advantage over CEN models in LGG/GBM (Wilcoxon rank-sum p = 2.39e-2) and KIPAN (p = 0.0565). In the integrated feature set (Fig. 2A), SN and CEN performance were indistinguishable in the BRCA dataset (p = 0.770), but CEN models have a slight advantage over SN models in the LGG/GBM (p = 1.78e-3) and KIPAN (p = 0.0699) datasets. Performance is generally better on the integrated feature set than the transcriptional feature set for all methods. One exception to this is the performance of SN on the LGG/GBM feature sets, where performance on the transcriptional feature set exceeds the integrated feature set (c-index 0.841 versus 0.818). RSF models have the worst performance generally, and are severely challenged in learning from the BRCA transcriptional feature set, with a median c-index of 0.520 (slightly better than random guess). Comparing performance across diseases, we noticed that prediction accuracy generally decreases as the proportion of right-censored samples in a dataset increases. This pattern holds for all prediction methods. Glioma had the highest overall prediction accuracy, being a uniformly fatal disease that has relatively fewer long-term survivors and incomplete follow-up (62–64%). Breast carcinoma had the lowest overall prediction accuracy with more than 86–91% of BRCA samples being right-censored.
Finally, we observed that CEN model execution routinely fails with some randomizations, producing a segmentation fault software error. In these instances, we generated a new randomization for CEN and repeated the experiments. The performance accuracy of SN and RSF models on these failed randomizations does not suggest that they present particularly difficult learning problems, but we cannot exclude the possibility of introducing a performance bias for CEN by generating new randomizations when CEN execution fails.
Interpreting deep survival models with risk backpropagation
Linear survival models weight individual features based on their contribution to overall risk, providing a clear interpretation of the prognostic significance of individual features, and insights into the biology of disease progression. The complex transformations that machine-learning methods apply to input features makes interpreting these models more difficult. This is especially true for deep learning where the input features are subjected to multiple sequential nonlinear transformations. To enable interpretation of deep survival models, we implemented a technique that we describe as risk backpropagation. In the same way that backpropagation can propagate prediction errors back through the layers of a deep model for training, backpropagation can also propagate predicted risks back to the input layer to assess how individual features contribute to risk (see Fig. 3). Partial derivatives were first used to analyze variable importance in ref.24.

Interpreting deep survival models with risk backpropagation. (A) Backpropagation was used to calculate the sensitivity of predicted risk to each input feature, generating feature risk scores for each feature and patient. (B) Feature risk scores can be analyzed to gain insights into the deep survival model. Risk scores can be used to evaluate the prognostic significance of individual features, or to identify gene sets or molecular pathways that are enriched with high-risk or low-risk features.
A linear survival model is defined by a static set of weights that represent the importance of features in predicting patient risk. In the linear model the predicted risk can be conceptualized as a plane that has a uniform gradient for any input feature values. The slope of this plane is defined by the model weights and represents the rate of change of risk with respect to each feature. Partial derivatives in SurvivalNet are directly analogous to model weights in a linear model, yet the weights differ depending on the values of the features. In the nonlinear SurvivalNet, the prediction can be conceptualized instead as a nonlinear surface where the risk gradients change depending on a patient’s feature values, and so these feature weights are calculated separately for each patient.
We applied risk backpropagation to our LGG/GBM integrated feature set model to investigate the prognostic significance of features (see Fig. 4). Risk backpropagation was applied to each patient to generate feature risk scores, and then each feature was ranked using its median score across patients as a measure of overall prognostic significance (see Fig. 4A). Among the top-ranked features indicative of poor prognosis are: increased age at diagnosis (rank 3); histologic classification as de novo grade IV glioblastoma (rank 5); loss of chromosome arms 10p and 10q (ranks 2, 4); and deletions of tumor suppressor genes CDKN2A and PTEN (ranks 1, 8). The top-ranked features associated with better prognosis included mutations in SMARCA4 (rank 6), IDH1/IDH2 (ranks 9, 10) and in CIC (rank 17). We note that many of these features are either incorporated or highly correlated with the recently published World Health Organization genomic classification of gliomas25.

Interpretation of glioma deep survival models. (A) SurvivalNet learns features that are definitional (IDH mutation) or strongly associated (CDKN2A deletion, SMARCA4 mutation) with WHO genomic classification of diffuse gliomas. Feature risk scores for the top 10 of 399 features in the integrated model are shown here, in order. Each boxplot represents the risk scores for one feature across all patients. Features were ranked by median absolute risk score. (B) Kaplan-Meier plots for select features from (A). (C) A gene set enrichment analysis of transcriptional feature risk scores identified the TGF-Beta 1 signaling and epithelialmesenchymal transition (EMT) gene sets as enriched with features associated with poor prognosis. (D) Kaplan-Meier plots for select features from (C).
To investigate molecular pathways related to glioma prognosis, we also performed a risk backpropagation gene-set enrichment analysis of our LGG/GBM transcriptional model. Median risk scores from the transcriptional model were calculated for each transcript, and gene set enrichment analysis was performed on these scores to identify pathways enriched with prognosis-associated transcripts26 (See Table S4). Pathways and gene sets associated with poor-prognosis include cell cycle (G2M checkpoint, E2F targets), apoptosis, angiogenesis, inflammation (Interferon alpha, gamma responses) and epithelial to mesenchymal transition (EMT and TGF-Beta signaling). EMT has received significant attention in cancer27, and also specifically in glioma28,29,30 as being associated with aggressive phenotypes and poor clinical outcomes. The TGF-Beta signaling hallmark gene set was significantly enriched (p = 6e-3, FDR q = 2.7e-2) with genes having high risk scores including RHOA, TGFB1, TGFBR1, SERPINE1, JUNB1 and ARID4B. The Epithelial to Mesenchymal Transition gene set was also significantly enriched (p = 1.6e-1, FDR q = 1.55e-1) with genes having high risk scores including MMP1/2/3, IL6, ECM1, and VCAM1. TGF-Beta signaling is understood to be one of the main pathways involved in EMT, and our results support the importance of EMT in determining glioma patient outcomes. The feature risk scores of the EMT-related transcription factors TGF-Beta induced EMT signaling as described in ref.27 are visualized in Fig. 4C. Major TGF-Beta-EMT inducing factors (RHOA, RAC1, ROCK2, CDC43 and LIMK1) and EMT transcription factors (TWIST1, SOX9, TRIM28 and SERP2) have among the highest risk scores in our glioma transcriptional model.
Extended feature risk scores for the LGG/GBM integrated and transcriptional models are presented in Table S4. The procedure for obtaining models used for interpretation is described in Methods.
Transfer learning with multi-cancer datasets
We performed a series of transfer learning experiments to evaluate the ability of deep survival models to benefit from training with data from multiple cancer types. The transfer learning paradigm is illustrated in Fig. 5A. Survival models were trained using three different datasets: BRCA-only, BRCA + OV (ovarian serous carcinoma), and BRCA + OV + UCEC (corpus endometrial carcinoma), and were evaluated for their accuracy in predicting BRCA outcomes. The large proportion of right-censored cases in the BRCA dataset (90%) makes training accurate models difficult, and so we hypothesized that augmenting BRCA training data with samples from other hormone-driven cancers could improve BRCA prognostication. BRCA samples were randomized to training, validation, and testing and full Bayesian optimization was performed to measure c-index on BRCA testing samples for 20 randomizations. For the integrated feature set, we combined datasets by discarding disease-specific clinical features.

Learning with data from multiple cancer types improves deep survival models. (A) Data from the BRCA dataset was partitioned into training, validation, and testing sets. The BRCA training set was augmented with samples from the OV and UCEC and used to construct models for BRCA survival prediction. (B) Augmented training sets significantly improve the performance of SurvivalNet models for the integrated feature set. For the transcriptional feature set, marginal improvement was observed when training with BRCA + OV + UCEC data, but training with BRCA + OV data provides no improvement. (C) For Cox elastic net, augmentation significantly degrades performance for the high-dimensional transcriptional feature set. (D) Gene set enrichment analysis of feature risk scores from the BRCA and BRCA + OV + UCEC transcriptional models. The model trained with BRCA + OV + UCEC samples emphasizes different biological concepts than the BRCA-only model.
Adding samples from the OV and UCEC datasets provides measurable improvements in BRCA prognostic accuracy for both integrated and transcriptional feature set deep survival models (see Fig. 5B). For integrated models, training with BRCA + OV samples increases median c-index from 0.588 to 0.643 (rank-sum p = 2.92e-3), and training with BRCA + OV + UCEC improves this further to 0.710 (p = 3.10e-5). For the transcriptional feature set, training with BRCA + OV does not produce a measurable improvement over BRCA-alone (p = 0.978), but training with BRCA + OV + UCEC provides a marginal 3.5% improvement (p = 0.168).
We also evaluated the ability of Cox elastic net to benefit from transfer learning, and found significant performance degradation with transfer learning in transcriptional feature set (see Figure 5 C). Training with BRCA + OV reduces the median c-index to from 0.664 to 0.599 (p = 0.0699), and training with BRCA + OV + UCEC reduces this further to 0.59335 (p = 0.0165). Performance improvements with the integrated feature set for CEN were similar to those observed with deep survival models.
Risk backpropagation analysis of transfer learning
To understand the information that OV and BRCA samples provide in predicting BRCA prognosis, we performed analysis of the BRCA and BRCA + OV + UCEC deep survival models using risk backpropagation. Risk backpropagation analysis was applied independently to the BRCA and BRCA + OV + UCEC transcriptional models to generate features risk scores, and gene set enrichment analyses were performed on these risk scores for each model to identify differences in pathway enrichment between the two models. Gene set enrichment scores for the BRCA + OV + UCEC model show increased emphasis on inflammatory pathways (particularly IL2-STAT5 signaling, IL6-JAK-STAT3 signaling and Interferon gamma response) as well as the apical junction gene set (known for its relevance to cell adhesion and metastasis). KRAS signaling and MYC targets v1 gene sets were de-emphasized in the BRCA + OV + UCEC model, pointing to a less prominent role of these pathways in determining breast cancer disease progression (See Fig. 5D and Tables S5 and S6).
Discussion
We created a software framework for Bayesian optimization and interpretation of deep survival models, and evaluated the ability of optimized models to learn from high-dimensional and multi-cancer datasets. Our software enables investigators to efficiently construct deep survival models for their own applications without the need for expensive manual tuning of design hyperparameters, a process that is time consuming and that requires considerable technical expertise. We also provide methods for model interpretation, using the backpropagation of risk to assess the prognostic significance of features and to gain insights into disease biology. Our analysis shows the ability of deep learning to extract important prognostic features from high-dimensional genomic data, and to effectively leverage multi-cancer datasets to improve prognostication. It also reveals limitations in deep learning for survival analysis and the value of complex and deeply layered survival models that need to be further investigated.
SN models have slightly better prognostic accuracy on two of three learning tasks using 17,000 + transcriptional features (GBMLGG and KIPAN), where CEN performed better using the lower-dimensional 300–400 integrated features. The high dimensionality of the transcriptional feature set presents a more challenging prediction problem where algorithms are more likely to overfit training data noise. CEN models are regularized linear models that use data-driven feature selection to identify a core subset of informative features for linear prediction. Their linearity does not appear to limit performance in our experiments, as their accuracy is similar to deep learning models and surpasses RSF models. While the deep models can effectively learn survival from high-dimensional data, the feature-learning capabilities of layered nonlinear transformations did not translate into significant gains as has been demonstrated in general image classification or language processing tasks13. Larger datasets may be needed to overcome overfitting issues and to reveal anticipated performance benefits of deep learning. Deep learning methods typically require large amounts of training data to effectively learn their many parameters31, although empirical results in some applications have demonstrated otherwise32. In our experiments data requirements were exacerbated by the need to allocate validation samples for hyperparameter optimization. Smaller testing sets also introduced considerable variance in performance measurements.
Risk backpropagation analysis of gliomas demonstrated that SurvivalNet models could identify key features in high-dimensional datasets, recovering important genetic alterations that currently used to classify gliomas in clinical practice. Survival of patients diagnosed with infiltrating glioma depends largely on age, histologic grade and classification into three molecular subtypes defined by mutations in the Krebs cycle enzyme isocitrate dehydrogenase (IDH1/IDH2) and co-deletion of chromosome arms 1p and 19q1: 1. Gliomas with wild-type IDH (astrocytoma) have an expected survival of 18 months, and are overwhelmingly diagnosed as advanced grade IV glioblastoma 2. Gliomas with co-deletion of 1p and 19q and mutations in IDH (oligodendroglioma) have the best outcomes, with some patients surviving 10 years or more and 3. Gliomas with IDH mutations that lack co-deletions (IDH-mutant astrocytoma) have intermediate outcomes. Risk backpropagation analysis of our model identified IDH1 and IDH2 mutations (ranks 9, 10) as strongly associated with better prognosis, consistent with the role of these mutations as the primary feature in classifying gliomas. While our analysis did not explicitly identify 1p and 19q deletions as strongly associated with better prognosis (ranks 45, 233), it did identify CIC mutations, a signature of oligodendrogliomas (CIC mutations occur in more than 50% of oligodendrogliomas), and SMARCA4 mutations, that occur frequently in both the less aggressive oligodendroglioma and IDH-mutant astrocytoma subtypes. The top-ranked feature associated with poor prognosis in our analysis was deletion of CDKN2A which is strongly associated with the aggressive astrocytomas, as well as with a subset of poor prognosis IDH-mutant astrocytomas that lack broad DNA hypermethylation (GCIMP-low)33. Loss of PTEN (rank 8) is also characteristic of astrocytomas, has been shown to be an early event in gliomagenesis, and related to the loss of its parent chromosome 10 (10q and 10p were ranked 2 and 4, respectively)34. Similarly, enrichment analysis of our transcriptional glioma model risk scores identified molecular pathways and processes related to epithelia to mesenchymal transition, a process that is associated with poor prognosis in cancers generally and specifically in gliomas.
Transfer learning experiments showed that deep survival models could benefit from training with multi-cancer datasets in the high-dimensional transcriptional feature set. Training with combined BRCA, OV and UCEC transcriptional data significantly degraded the accuracy of Cox elastic net models in predicting BRCA outcomes, but provided a small benefit to deep survival models (3.5% improvement). Both methods benefit significantly from training on multi-cancer integrated feature sets. Given that the integrated feature sets contain a much smaller number of samples than the transcriptional datasets (see Figure S1), it is reasonable that they would benefit more from additional training data. A similar rationale could explain the performance difference between SurvivalNet and Cox elastic net on the transcriptional feature set: SurvivalNet likely requires more training data and so it would be more likely to benefit from additional cancer types. Additional experiments are needed to investigate if SurvivalNet has a real advantage in transfer learning common prognostic signals across cancer types. Although genetic alterations and expression patterns are often strongly associated with primary disease site, common mechanisms of progression are likely shared by many cancers, and deep survival models can benefit from training with augmented datasets that provide additional evidence of these mechanisms. Enrichment analysis of risk scores from the BRCA-only and BRCA + OV + UCEC transcriptional models showed changes in the biological themes associated with highly prognostic transcripts, with increased emphasis on inflammatory response and cell adhesion in the BRCA + OV + UCEC model.
Although our study provides important insights into the use of deep learning for survival modeling, it has some limitations. Larger genomic datasets with clinical follow-up are needed to determine if the feature learning and nonlinearity of deep learning methods can provide substantial benefits in predicting survival. Secondly, our risk backpropagation analysis was simplified by averaging feature risk scores across patients. With nonlinear models, feature risk scores can vary significantly from patient to patient, and an in-depth analysis of these variations could yield insights into alternative paths for disease progression.
Methods
Data
All datasets were created using TCGAIntegrator (https://github.com/cooperlab/TCGAIntegrator), a Python module for assembling integrated TCGA genomic and clinical datasets with the Broad Institute Firehose (https://gdac.broadinstitute.org/). Datasets were filtered to remove patients lacking essential data platforms required in each experiment. Clinical variables including age and stage were required for each experiment, with missing radiation treatment status (binary) being mean-imputed to reflect prior likelihood in receiving radiation therapy. Features with categorical or ordinal values (i.e. stage) were expanded to a series of binary variables for model training. Copy number features were derived from the Affymetrix Genome-Wide Human SNP Array 6.0 platform. Gene expression features were taken as RSEM values from the Illumina HiSeq. 2000 RNA Sequencing V2 platform. Protein expression measurements were taken from the MD Anderson Reverse Phase Protein Array (RPPA) Core platform that measures expression of cancer-relevant proteins and phosphoproteins. Sparse missing values in protein or gene expression features were 1nn-imputed (<20% missing values), where features exceeding this missing value threshold were discarded. Significant mutations were identified for inclusion in each dataset (LGG/GBM, KIPAN, BRCA) using a MutSig2CV<= 0.1 q-value threshold. Gene-level copy number features were filtered using a GISTIC<= 0.25 q-value threshold to identify focal events, and were further filtered using the Sanger Cancer Gene Census35. All clinical and molecular features were standardized to zero-mean unit-variance to comply with best practices for training deep-learning algorithms. All datasets used to create this paper, along with the TCGAIntegrator commands used to generate these datasets are available on request.
Software and hardware
All software used in training deep survival models, bayesian optimization, and model interpretation are provided as an installable python package at https://github.com/CancerDataScience/SurvivalNet. We have also provided a Docker container containing an installation of the package and all dependencies that provides access to SurvivalNet functionality without the need for software installations. SurvivalNet is implemented on top of the Numpy (v1.11)/SciPy (v0.18) stack using Theano (v0.8.2). Bayesian optimization was performed using the BayesOpt package (https://github.com/rmcantin/bayesopt). Survival analysis statistics like Kaplan Meier analysis and logrank testing were performed using the Python lifelines package (v0.8.0.1). Cox elastic net models were trained using Glmnet for Matlab (http://web.stanford.edu/~hastie/glmnet_matlab/). Random survival forest models were trained using the RandomForestSRC (2.2.0) R package. Experiments were performed on a workstation equipped with two Intel Xeon E5–2620 v3 six-core processors, 64GB RAM, and two Titan-X GTX graphics processing units.
Training, model selection and validation procedures
Deep survival models are multi-layer feed forward artificial neural networks with a Cox proportional hazards output layer that calculates negative log partial likelihood
where X i are the inputs to the output layer, β are the Cox model parameters, U is the set of uncensored samples and R i is the set of “at-risk” samples with survival or follow-up times Y j ≥ Y i .
This likelihood was optimized using backpropagation and line-search gradient descent. In each backpropagation iteration, the log partial likelihood is backpropagated throughout the network layers to update the interconnecting weights. The derivative used in backpropagation is
where X i is the input to the output/Cox layer. This derivative is multiplied by derivatives of the hidden layers using the chain rule to update all the network parameters back to the first network layer. Training was performed by combining all samples into a single batch, and updating the model once per epoch, due to the dependence between samples in calculating the Cox partial likelihood (Equations 1, 2). We note that mini-batch training can be performed with SurvivalNet by fitting the likelihood to smaller batches of samples, but this approach was not used in our experiments. Regularization of the network during training was performed using random dropout of network weights.
Bayesian optimization was performed by splitting samples into training (60%), validation (20%) and testing (20%) sets. The training and validation sets were used by Bayesian optimization to determine the optimal model hyperparameters, namely number of layers (1–5), layer width (10–1000), dropout fraction (0–0.9) and activation function (Rectified-linear or hyperbolic tangent). The optimal model architecture was then applied to the testing set to evaluate c-index of the selected model. We repeated this procedure on 20 randomized assignments of the samples to training/validation/testing.
Cox elastic net models contain two hyparparameters, λ which controls the overall degree of regularization and the mixture coefficient α that controls the balance between L2 and L1 norm penalties. Grid search over λ, α was performed to optimize the choice of these parameters. For each choice of α, a separate λ sequence was generated by Glmnet since the range of λ depends strongly on the α. A model was trained for each α/λ pair using the training set, and the model with the best performance on the validation set was then evaluated on the testing set. The same validation procedure was used to tune RSF hyperparameters including the number of trees (50, 100, 500, 1000), node size (1, 3, 5, 7, 9), and random splitting based on the recommendations in the randomForestSRC R package.
Risk backpropagation and model interpretation
The models used for risk backpropagation and interpretation were created by identifying the best performing model configuration from the 20 randomized experiments. These configurations were then used to re-train a model using all available samples. Risk backpropagation was implemented using Theano to calculate the partial derivatives of risk with respect to each input variable using the multivariable chain rule. Given a deep survival model with H hidden layers that operates on an N-dimensional feature vector f to predict risk R, the feature risk scores are calculated as the partial derivative of the model with respect to inputs
where J h is the Jacobian matrix of the h-th hidden layer with respect to its inputs, and β is the vector of parameters of the final layer that is a linear transformation (note the exponential is not applied since we are dealing with risk). This partial derivative is evaluated using the features of each patient f i to generate an N-dimensional feature risk score vector for each patient. Features were ranked by calculating the median risk score for each feature across all patients.
For transcriptional models, feature risk scores were analyzed using the Preranked Gene Set Enrichment Analysis (GSEAPrerankedv1) module in GenePattern. The Hallmark gene set36 from the MSigDB database (http://software.broadinstitute.org/gsea/msigdb/) was used for enrichment analysis. The HUGO Gene Nomenclature Committee database was used to harmonize gene symbols between gene sets and model features prior to GSEA analysis (http://www.genenames.org/).
Transfer learning experiments
Datasets were combined using their shared features. For transcriptional and molecular features this merging is trivial, although many of the mutations and copy-number variations are dataset specific since they are filtered by GISTIC and MutSig to identify frequent alterations for each disease (integrated feature sets used in transfer learning are considerably smaller as a result). Pathologic stage and clinical stage were merged as a single “stage” variable where necessary, since their definitions of stage are similar (although the method of determining this stage differs). No additional normalization measures were employed to remove disease-specific biases.
Data availability
This paper was produced using large volumes of publicly available genomic data. The authors have made every effort to make available links to these resources as well as making publicly available the software methods used to produce the datasets, analyses, and summary information. All data not published in the tables and supplements of this article are available from the corresponding author on request.
References
Cancer Genome Atlas Research, N. et al. Comprehensive, Integrative Genomic Analysis of Diffuse Lower-Grade Gliomas. N Engl J Med 372, 2481–2498, doi:https://doi.org/10.1056/NEJMoa1402121 (2015).
Solin, L. J. et al. A multigene expression assay to predict local recurrence risk for ductal carcinoma in situ of the breast. J Natl Cancer Inst 105, 701–710, doi:https://doi.org/10.1093/jnci/djt067 (2013).
Cardoso, F. et al. 70-Gene Signature as an Aid to Treatment Decisions in Early-Stage Breast Cancer. N Engl J Med 375, 717–729, doi:https://doi.org/10.1056/NEJMoa1602253 (2016).
Bartlett, J. M. et al. Mammostrat as a tool to stratify breast cancer patients at risk of recurrence during endocrine therapy. Breast Cancer Res 12, R47, doi:https://doi.org/10.1186/bcr2604 (2010).
Kourou, K., Exarchos, T. P., Exarchos, K. P., Karamouzis, M. V. & Fotiadis, D. I. Machine learning applications in cancer prognosis and prediction. Comput Struct Biotechnol J 13, 8–17, doi:https://doi.org/10.1016/j.csbj.2014.11.005 (2015).
Gao, S. et al. Identification and Construction of Combinatory Cancer Hallmark-Based Gene Signature Sets to Predict Recurrence and Chemotherapy Benefit in Stage II Colorectal Cancer. JAMA Oncol 2, 37–45, doi:https://doi.org/10.1001/jamaoncol.2015.3413 (2016).
Li, J. et al. Identification of high-quality cancer prognostic markers and metastasis network modules. Nat Commun 1, 34, doi:https://doi.org/10.1038/ncomms1033 (2010).
Simon, N., Friedman, J., Hastie, T. & Tibshirani, R. Regularization Paths for Cox’s Proportional Hazards Model via Coordinate Descent. J Stat Softw 39, 1–13 (2011).
Ishwaran, H. et al. Random survival forests for competing risks. Biostatistics 15, 757–773, doi:https://doi.org/10.1093/biostatistics/kxu010 (2014).
Faraggi, D. & Simon, R. A neural network model for survival data. Stat Med 14, 73–82 (1995).
Xiang, A., Lapuerta, P., Ryutov, A., Buckley, J. & Azen, S. Comparison of the performance of neural network methods and Cox regression for censored survival data. Computational Statistics & Data Analysis 34, 243–257, doi:https://doi.org/10.1016/S0167-9473(99)00098-5 (2000).
Li, Y., Chen, C. Y. & Wasserman, W. W. Deep Feature Selection: Theory and Application to Identify Enhancers and Promoters. J Comput Biol 23, 322–336, doi:https://doi.org/10.1089/cmb.2015.0189 (2016).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444, doi:https://doi.org/10.1038/nature14539 (2015).
Bengio, Y., Courville, A. & Vincent, P. Representation Learning: A Review and New Perspectives. Ieee T Pattern Anal 35, 1798–1828, doi:https://doi.org/10.1109/Tpami.2013.50 (2013).
Turkki, R., Linder, N., Kovanen, P. E., Pellinen, T. & Lundin, J. Antibody-supervised deep learning for quantification of tumor-infiltrating immune cells in hematoxylin and eosin stained breast cancer samples. J Pathol Inform 7, 38, doi:https://doi.org/10.4103/2153-3539.189703 (2016).
Alipanahi, B., Delong, A., Weirauch, M. T. & Frey, B. J. Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Nat Biotechnol 33, 831–838, doi:https://doi.org/10.1038/nbt.3300 (2015).
Nemati, S. et al. Optimal medication dosing from suboptimal clinical examples: a deep reinforcement learning approach. Conf Proc IEEE Eng Med Biol Soc 2016, 2978–2981, doi:https://doi.org/10.1109/EMBC.2016.7591355 (2016).
Snoek, J., Larochelle, H. & Adams, R. P. Practical bayesian optimization of machine learning algorithms in Proceedings of the 25th International Conference on Neural Information Processing Systems, 2960–2968 (2012).
Martinez-Cantin, R. BayesOpt: A Bayesian Optimization Library for Nonlinear Optimization, Experimental Design and Bandits. Journal of Machine Learning Research 15, 3735–3739 (2014).
Bergstra, J., Bardenet, R., Bengio, Y. & Kégl, B. in 25th Annual Conference on Neural Information Processing Systems (2011).
Yousefi, S., Song, C., Nauata, N. & Cooper, L. Learning Genomic Representations to Predict Clinical Outcomes in Cancer. ArXiv e-prints 1609, arXiv:1609.08663 (2016).
Katzman, J. et al. Deep Survival: A Deep Cox Proportional Hazards Network. ArXiv e-prints 1606, arXiv:1606.00931 (2016).
Harrell, F. E. Jr., Califf, R. M., Pryor, D. B., Lee, K. L. & Rosati, R. A. Evaluating the yield of medical tests. JAMA 247, 2543–2546 (1982).
Dimopoulos, Y., Bourret, P. & Lek, S. Use of some sensitivity criteria for choosing networks with good generalization ability. Neural Processing Letters 2, 1–4, doi:https://doi.org/10.1007/bf02309007 (1995).
Louis, D. N. et al. The 2016 World Health Organization Classification of Tumors of the Central Nervous System: a summary. Acta Neuropathol 131, 803–820, doi:https://doi.org/10.1007/s00401-016-1545-1 (2016).
Subramanian, A. et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc Natl Acad Sci USA 102, 15545–15550, doi:https://doi.org/10.1073/pnas.0506580102 (2005).
Lamouille, S., Xu, J. & Derynck, R. Molecular mechanisms of epithelial-mesenchymal transition. Nat Rev Mol Cell Biol 15, 178–196, doi:https://doi.org/10.1038/nrm3758 (2014).
Carro, M. S. et al. The transcriptional network for mesenchymal transformation of brain tumours. Nature 463, 318–325, doi:https://doi.org/10.1038/nature08712 (2010).
Verhaak, R. G. et al. Integrated genomic analysis identifies clinically relevant subtypes of glioblastoma characterized by abnormalities in PDGFRA, IDH1, EGFR, and NF1. Cancer Cell 17, 98–110, doi:https://doi.org/10.1016/j.ccr.2009.12.020 (2010).
Bhat, K. P. et al. The transcriptional coactivator TAZ regulates mesenchymal differentiation in malignant glioma. Genes Dev 25, 2594–2609, doi:https://doi.org/10.1101/gad.176800.111 (2011).
Zhang, C., Bengio, S., Hardt, M., Recht, B. & Vinyals, O. Understanding deep learning requires rethinking generalization. ArXiv e-prints 1611, arXiv:1611.03530 (2016).
Fakoor, R., Ladhak, F., Nazi, A. & Huber, M. Using deep learning to enhance cancer diagnosis and classification in Proceedings of the WHEALTH ICML Workshop, 129–133 (2011).
Ceccarelli, M. et al. Molecular Profiling Reveals Biologically Discrete Subsets and Pathways of Progression in Diffuse Glioma. Cell 164, 550–563, doi:https://doi.org/10.1016/j.cell.2015.12.028 (2016).
Ozawa, T. et al. Most human non-GCIMP glioblastoma subtypes evolve from a common proneural-like precursor glioma. Cancer Cell 26, 288–300, doi:https://doi.org/10.1016/j.ccr.2014.06.005 (2014).
Futreal, P. A. et al. A census of human cancer genes. Nat Rev Cancer 4, 177–183, doi:https://doi.org/10.1038/nrc1299 (2004).
Liberzon, A. et al. The Molecular Signatures Database (MSigDB) hallmark gene set collection. Cell Syst 1, 417–425, doi:https://doi.org/10.1016/j.cels.2015.12.004 (2015).
Acknowledgements
This work was supported by the National Brain Tumor Society Oligo Research Fund, U.S. National Institutes of Health, National Library of Medicine Career Development Award K22LM011576, and National Cancer Institute grant U24CA194362, National Institutes of Health CTSI grants UL1TR000454 and TL1TR000456, and with funds from the Emory Winship Cancer Institute.
Author information
Authors and Affiliations
Contributions
S.Y. and F.A. developed the primary method. S.Y., F.A. curated datasets. S.Y., F.A., C.D., J.L., D.A.G. performed experiments. C.S. assisted with software development. M.A., S.H., J.E.V.V., and D.J.B. assisted with interpretation of experimental results. L.A.D.C. conceived of the ideas and supervised the work.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yousefi, S., Amrollahi, F., Amgad, M. et al. Predicting clinical outcomes from large scale cancer genomic profiles with deep survival models. Sci Rep 7, 11707 (2017). https://doi.org/10.1038/s41598-017-11817-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-11817-6
This article is cited by
-
Deep learning in cancer genomics and histopathology
Genome Medicine (2024)
-
Deep learning for survival analysis: a review
Artificial Intelligence Review (2024)
-
A neural network model to screen feature genes for pancreatic cancer
BMC Bioinformatics (2023)
-
Prognosis Individualized: Survival predictions for WHO grade II and III gliomas with a machine learning-based web application
npj Digital Medicine (2023)
-
Biology-aware mutation-based deep learning for outcome prediction of cancer immunotherapy with immune checkpoint inhibitors
npj Precision Oncology (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
