
Abstract
Sample Space Reducing (SSR) processes are simple stochastic processes that offer a new route to understand scaling in path-dependent processes. Here we define a cascading process that generalises the recently defined SSR processes and is able to produce power laws with arbitrary exponents. We demonstrate analytically that the frequency distributions of states are power laws with exponents that coincide with the multiplication parameter of the cascading process. In addition, we show that imposing energy conservation in SSR cascades allows us to recover Fermi’s classic result on the energy spectrum of cosmic rays, with the universal exponent −2, which is independent of the multiplication parameter of the cascade. Applications of the proposed process include fragmentation processes or directed cascading diffusion on networks, such as rumour or epidemic spreading.
Similar content being viewed by others
Introduction
Practically all complex adaptive systems exhibit fat-tailed distribution functions in the statistics of their dynamical variables. Often these distribution functions are exact or almost exact asymptotic power-laws, \(p(x)\sim {x}^{-\lambda }\). While Gaussian statistics can often be traced back to a single origin, the central limit theorem, for the origin of power laws there exist several routes. These include (i) Yule-Simon processes (preferential attachment)1,2,3, (ii) multiplicative processes with constraints, see refs 4 and 5, (iii) criticality6, (iv) self-organized criticality and cascading processes7,8,9,10, (v) constraint optimization11,12,13, and (vi) sample space reducing (SSR) processes14,15,16. Most of these mechanisms are able to explain specific values of the exponent λ or a range of exponents. None of them however explain the full range of exponents from zero to infinity, λ ∈ [0, ∞) in a straightforward way. Depending on the generative process exponents belong to different ranges. For example, exponents near critical points are often fractional, and within the range \(\lambda \in [\mathrm{1/2},\,\mathrm{5/2}]\) 6. Many exponents for avalanche processes are found within a range of λ ∈ (0, 3)17. Some processes, like the preferential attachment, can formally explain a wide range of exponents, although deviations from the standard values λ ∈ (2, 3.5) are hard to map to realistic underlying stochastic dynamics18. Here we show that the combination of cascading processes with SSR processes is able to do exactly that, to provide a single one-parameter model that produces the full spectrum of all possible scaling exponents. The parameter is nothing but the multiplication ratio of the cascading processes. Finally, we show that generic disintegration processes can be mapped one-to-one to SSR cascades with an over imposed condition of conservation of whatever magnitude is represented by the states. This mapping allows us to derive a remarkable result: The histogram of visits to each state follows an exponent −2, regardless the multiplication parameter. This result may have important consequences in order to understand generic properties of disintegration processes and the ubiquity of the exponent −2 in nature.This, for example, allows us to recover Fermi’s classic result on the energy spectrum of cosmic rays, only appealing to combinatorial properties of the cascade. In addition, we provide a rigorous proof of that result in the appendix A, as a new contribution to the study of the random partition of the interval.
Cascading processes have played an important role in the understanding of power-law statistics in granular media7,8,9,10, 19, earth quakes20,21,22, precipitation23, 24, dynamics of combinatorial evolution25, or failure in networks26,27,28. The scaling exponents of the probability distribution functions of quantities such as avalanche sizes, energy distributions, visiting times, event durations, etc., are found within a relatively narrow band. Cascading processes are often history-dependent processes in the sense that for a particular event taking place the temporal order of microscopic events is important. Recent progress in the understanding of the generic statistics of history-dependent processes and their relation to power laws was made in refs 14,15,16 and 29. Maybe the simplest history-dependent processes are the sample space reducing (SSR) processes14, which explain the origin of scaling in a very simple and intuitive way. They have been used in various applications in computational linguistics30, fragmentation processes14, and diffusion on directed networks and search processes15.
SSR Processes and Cascades
A SSR process is a stochastic processes whose sample space reduces as it evolves in time. They can be depicted in a simple way, see Fig. 1(a). Imagine a set of N states in a system, labelled by i = 1, 2, …, N. The states are ordered by the label. The only rule that defines the SSR process is that transitions between states may only occur from higher to lower labels. This means that transition from state j → i is possible only if label j > i. When the lowest state i = 1 is reached, the process stops or is re-started. It was shown in ref. 14 that this dynamics leads to a Zipf’s law in the frequency of state visits, i.e. the probability to visit state i is given by p(i) = i −1. This scaling law is extremely robust and occurs for a wide class of prior probabilities15. We now show that the combination of SSR processes with the simplest cascading process allows us to obtain a mechanism that can produce power laws with any scaling exponent. We will comment on how the model can be used to recover the Fermi’s classic result on the cosmic ray spectrum31, 32. This is possible by imposing energy conservation on SSR cascading processes. We discuss other potential cases where the theory of SSR cascades might apply.

(a) SSR process. A ball starts at the highest state i = N = 10, and may sequentially jump randomly toward any lower state. Once the ball hits the lowest state i = 1 the process starts again at state N. If repeated many times, the probability of visiting states is an exact Zipf’s law, p(i) ∝ i −1. (b) If with probability 1 − λ, \(\lambda \in [0,1]\)) the ball is allowed to jump to any state, the visiting probability becomes p(i) ∝ i −λ. 1 − λ can be seen as the noise strength in a noisy SSR process, see ref. 14 (c) SSR cascading process with a multiplicative parameter μ = 2. A ball starts at the highest state, i = N = 20, and splits into μ new balls which independently jump to lower states as before. Whenever a ball hits a state it creates μ balls which continue their random jumps. It becomes a cascading or an avalanche process, and the visiting probability scales as p(i) ∝ i −μ. We observe that (b) is automatically recovered if the multiplication parameter is μ < 1.
SSR cascades
To define SSR cascades, imagine a system with a set of N ordered states, each of which has a prior probability of appearing, q 1, …, q N−1, being state N the starting point of the cascade. The process starts at t = 0 with μ balls at state N jumping to any state i 1, …, i μ < N with a probability proportional to q i , …, q μ , respectively. Suppose that the μ balls landed on states i 1,..i μ , respectively. At the next timestep, t = 1, each of these μ balls divide into μ new balls which all jump to any state below their original state. The multiplicative process continues downwards. Whenever a ball hits the lowest state, it is eliminated from the system. Effectively we superimpose a multiplicative process that is characterized by the multiplicative parameter μ, and the SSR process described above, see Fig. 1(c). The case μ = 1 is exactly the standard SSR process, where no new elements are created, and the case μ < 1 corresponds to the noisy SSR, where there is the possibility that the process gets cut at some step, see Fig. 1(b).
The derivation of the visiting distribution of this cascading SSR process follows the arguments found in ref. 15. We first define the cumulative prior distribution function g(k),
Without a multiplication factor μ the transition probabilities p(i|j) determine the probability to reach state i at timestep t + 1, given that the system is in state j at time t, and are given by
In a SSR cascade, if there is an element sitting at state j at time t, there are now μ trials to reach any state i < j at t + 1. Since the number of particles is not conserved throughout the process, we talk about the expected number of jumps from j to i. Since the jumps from j to i of each ball is independent, the expected number of jumps from j to i we denoted by n(j → i) can be approximated as follows:
We denote the expected number of elements that will hit state i in a given SSR cascade by n i . Up to a factor the sequence n 1, …, n N is identical to the histogram of visits. From equations (1) and (2) we get
By subtracting n i+1 − n i and after re-arranging terms we find
or, when applied iteratively
Since μ(q j )/(g(j − 1)) is typically small the product term is well approximated by
where we used \({q}_{j}\sim {dg/dx|}_{j}\) and \(\mathrm{log}\,\mathrm{(1}+x)\sim x\). Finally, we have
For equal prior probabilities, \({q}_{i}=\frac{1}{N-1}\) for all states, we get the expected visiting probability to be
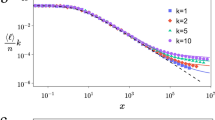
The multiplication factor μ becomes the scaling exponent, for μ = 1 the standard SSR processes is recovered14. Figure (2) shows numerical results which are in perfect agreement with the theoretical predictions. Note that the argument also holds for non-integer μ, where, on average, μ balls are created at every step. In the numerical implementation, a non-integer μ is introduced as follows: Let \(\mu =\lfloor \mu \rfloor +\delta \), with δ < 1. Then, with probability δ, \(\lfloor \mu \rfloor +1\) balls are created and, with probability 1 − δ, \(\lfloor \mu \rfloor \) balls are created. Also the case of multiplication factors μ < 1 are possible, reproducing the previously defined noisy SSR case, see Fig. (1b) and ref. 14. In this situation at each step the process can be restarted with the probability 1 − μ.

Normalized histograms of state visits of N = 10,000 states, obtained from numerical simulations of SSR cascades with a multiplicative parameters μ = 0.5 (dark blue squares), μ = 1 (blue circles), μ = 1.5 (green circles), μ = 2 (black diamonds) and μ = 2.5 (red triangles). Histograms are clearly power laws, ~i −μ. Curves were fitted using the matlab rplfit package using likelihood estimations for all exponents37.
We numerically compute the cascade size distribution as a function of the number of states N and μ. For a given realisation of a cascade ψ with initial sample space N and multiplicative parameter μ, starting with a single element at N, we define the cascade size, s μ,N (ψ), as the number of elements of the cascade ψ that reach state 1, \({n}_{1}^{(\psi )}\). Numerical analysis suggests that the cascade size distribution f(s m,μ ) can be well approximated by a Γ distribution33. For the sake of simplicity, we drop the subscripts μ and N for s. We thus find a purely phenomenological equation that reads.
with a = 0.82, b = 0.9, α = 〈s〉2/σ 2, λ = 〈s〉/σ 2. Numerical results and fits are shown in Fig. (3). The inset shows that the approximation for 〈s〉 is highly accurate.

Cascade size distribution after 3,000 realisations of individual SSR cascades with μ = 2.5 and N = 104 states (circles), with a fit based on the Γ distribution f(s) (red dashed line) given in equation (4). Inset: dependence of 〈s〉 on μ (from 1.5 to 3.5) for four different system sizes, N = 200 (blue circles), N = 400 (green circles), N = 600 (black diamonds) and N = 800 (blue triangles). Dashed curves are fits of the average size 〈s〉 given in equation (4).
Energy conservation and the prevalence of −2 exponent
In the sequel we derive the statistics of visits to the states of our system when our cascade observes an energy conservation constraint. Remarkably, we see that the histogram of visits to each state along the whole cascading process follows a power-law of exponent −2, regardless the multiplication parameter of the avalanche. The strategy followed here is based on the partition through renormalization and works basically as follows: out of an interval \(\mathrm{[0,}\,1]\), a partition is performed by throwing μ random numbers between 0 and 1 and then renormalizing them such that their sum is 1 as in Fig. (4a,b) 34. Our strategy can be seen as a particular choice of Dirichlet partitioning of the interval35. This strategy is different from the random selection of breaking points of the interval, described, e.g., in refs 33 and 36. In the appendix A we provide a complete proof of our result.

SSR cascades with energy conservation and the random partition of the interval. (a) Consider a stick of length 1 and chose three sticks (blue, orange and green) of random sizes between 0 and 1. (b) Put them together sequentially and glue them. This will create another stick made of the blue, orange and green sticks of size larger than 1. Divide the stick by its size and one gets a stick of length 1 partitioned in different random segments proportional to the sizes of the sticks chosen in (a). This process of random partition of the interval is exactly analogous to a SSR cascade with energy conservation. (c) At a given energy level (20) three balls jump downwards to a randomly chosen sites (17, 14, 9). Energy conservation imposes that the sum of the energies of the landing sites is equal to 20, although the sum of the obtained energies is 40. The rescaling parameter ϕ μ will be thus 40/20 = 2. (d) We rescale all the outcomes by the factor ϕ μ and project to a new staircase. The effect of the rescaling is that, in this particular realisation of there cascading process, any value E′ such that ϕ μ E′ > 20 will be forbidden–grey region in the picture. A cascade would iterate the described process until all created balls reach state 1.
To study SSR cascades with a superimposed conservation law, let us assume, with any loss of generality, that the states 1, 2, …, N are associated with energy levels
Energy conservation imposes the following constraint: If a particle with energy E and splits into μ particles i 1, i 2, … i μ , with respective energies \({E}_{{i}_{1}},{E}_{{i}_{2}},\ldots ,{E}_{{i}_{\mu }}\), then:
We are interested in the energy spectrum, i.e. number of observations of particles at a particular energy level at any point of the cascading process, n(E).
The first task is to impose the energy conservation constraint given in equation (5) in the schema of transition probabilities of the SSR cascade. To compute it we use a rescaling technique and we will assume that the energy spectrum is continuous. The rescaling technique is outlined in Fig. (4). Let us ignore energy conservation for the moment and define a continuous uniform random variable u on the interval \(\mathrm{[0,}\,1]\). Let u 1, u 2, …, u μ be μ independent realisations of u, see Fig. (4a). Let us suppose that we are at level E. From this sequence of random variables one can derive the target sites of the newly created particles in a SSR avalanche with multiplicative parameter μ as
This is the continuous version of what we described in section 2.1. Now we define a new random variable, ϕ μ , which is the sum of μ realisations of the random variable u:
The sum of μ realisations of a random variable u uniformly distributed on the interval \(\mathrm{[0,}\,1]\), ϕ μ , follows the Irwin-Hall distribution, f μ (ϕ μ )33. This means that one can construct, for each μ realisations of the random variable u a rescaled sequence, see Fig. (4b)
such that sum up to the total energy E,
Thus, by imposing energy conservation we actually expect the following sequence of rescaled energies \({E}_{{i}_{1}},{E}_{{i}_{2}},\ldots ,{E}_{{i}_{\mu }}\) for the emerging particles, where
This rescaling approach assumes that the μ new particles behave independently. The crucial issue is to map this process into a cascade, see Fig. (4c,d). To approach this problem, we first study the expected number of particles that jump to a given state E if a given value of ϕ μ occurs. We then average over all potential values of ϕ μ . We assume that the expected number of particles from E → E′, n(E → E′) goes as ~μp(E′|E). Taking into account the rescaling imposed by energy conservation, \(p(E^{\prime} |E)\sim \frac{{\varphi }_{\mu }}{E}\), see Fig. (4)–on has that:
Assuming a continuous spectrum of energies, one has, for a given value of ϕ μ , that the expected number of particles that will visit state E at some point of the cascade, n(E,ϕ μ ) is:
where n(E′) is the total number of particles that are expected to visit state E′ during the cascade. n(E) will be obtained by averaging n(E,ϕ μ ) over all potential values of ϕ μ , distributed as the Irwin-Hall distribution, f μ :
Differentiating n(E), one arrives at the following equation with displacement:
Assuming that n(E) ∝ E −α, we arrive at the following self-consistent equation for α:
whose only solution, for large μ’s converges to α = 2, leading to the general result.
In the appendix A we provide a rigorous derivation of this result. In spite of the asymptotic nature of the proof given in the appendix A, numerical simulations show an excellent agreement with this theoretical prediction, even for α small. In Fig. (5) we show the frequency plots for 105 avalanches with μ = 2.5, 3.5, 4.5, and the convergence of the histograms to E −2 can be perfectly appreciated. This result is the same that is obtained from Fermi’s particle acceleration model to explain the spectrum of cosmic rays31, 32. Here we derived it on the basis of simple combinatorial reasonings of SSR processes with a superimposed constraint.

Histograms of SSR cascades with energy conservation at each multiplication event, for μ = 2.5 (blue dots), μ = 3.5 (red triangles) and μ = 4.5 (black diamonds). As predicted only exponents with a value of 2 occur. The dashed line shows the slope a perfect power-law with exponent α = 2 for comparison. Curves were fitted using the matlab rplfit package using likelihood estimations for all exponents37.
Discussion
We have shown, both analytically and numerically, that SSR processes represent a general route to scaling, that is able to generate any scaling exponent. To obtain exponents larger than 1, which was the main target of this paper, we introduced the concept of SSR cascades, a simple multiplicative process which combines SSR- and cascading processes. Our results also add a new way of the interpretation of scaling laws observed in multiplicative processes, and avalanche- or cascading processes. The quality of the SSR view rests in its extreme simplicity, intuitive nature and its generality. In addition, SSR cascades can be mapped to physical process of successive disintegration. By applying the approach to a physical cascading process of particle cascades from cosmic rays it is sufficient to impose energy conservation in the cascading process. In doing so, we recover the classic result of Fermi for the energy spectrum of cosmic rays. More generally, we have shown that energy conservation (or any other similar constraint) leads to a universal scaling exponent of 2, regardless of the details of the microscopic cascading process. In the case of no constraint and no cascading present the ubiquitous Zipf’s law is obtained, with its exponent 1. Our findings imply that the presence of simple history-dependence imposed by SSR processes deforms statistics of in a highly non-intuitive way and leads naturally to power laws, and at the same time explains why exponents 1 and 2 are special. We believe that our results might be useful to understand scaling in problems of statistical inference whenever observation biases exist, for problems of fragmentation and cascading, including the meteorite energy spectrum, particle cascades, and for multiplicative directed diffusion on networks such as e.g. rumour spreading, or the spreading of viral loads in populations.
Appendix A: Derivation of exponent −2 for cascades with energy conservation
We derive the main result of section IIB. The strategy followed is summarised in Fig. (4). An alternative view is given in Fig. (6) in this appendix.

SSR cascades with energy conservation can be seen as follows: Consider a polygon with a given area (e.g., 1), t = 0. At t = 1 throw three random numbers between 0 and 1, x 1, x 2, x 3 and then rescale them x′ i = x i /(x 1 + x 2 + x 3). Now embed three polygons of arbitrary shape with area \({x}_{1}^{^{\prime} },\,{x}_{2}^{^{\prime} },\,{x}_{3}^{^{\prime} }\), respectively, and put them inside the first polygon. At t = 2 we repeat the operation for each of the subpolygons created and we iterate the process for \(t\gg 1\). In this appendix we proof that the probability that area x has been found at some point of the partitioning process scales as p(x) ~ x −2. Notice that the 2D polygon is just a representation and that our result does not depend on the dimension of the partitioned object.
We start with the definition of the Irwin-Hall distribution: Let u be a random variable whose probability density is uniform in the interval \(\mathrm{[0,}\,1]\). Let u 1, …, u μ be a sequence of independent drawings of the random variable u and ϕ(μ) a random variable defined over the interval \(\mathrm{[0,}\,\mu ]\) as:
The probability density that governs the random variable ϕ μ is the Irwin-Hall distribution. Now we go to equation (7),
Differentiating,
one arrives at the following equation with displacement:
Assuming that n(E) ∝ E −α, we arrive at the following self-consistent equation for α:
This is equation (8) and that is what we have to solve. The following theorem states that the solution in the limit of large μ’s is α = 2, independent of μ. To demonstrate that we need to proof 5 lemmas. After the demonstration, we approach the solution α → 2 using a mean field approach. Finally, we report a side observation concerning the behaviour of the average value of a random variable following the Irwin-hall distribution.
Theorem: The only α satisfying the following equation:
is α = 2.
To prove this theorem, we observe first observe that a random variable following the Irwin-Hall distribution converges to a random variable following a normal distribution with average \(\frac{\mu }{2}\) and standard deviation \(\sqrt{\frac{\mu }{12}}\).
Lemma 1: Let ϕ μ a random variable following the Irwin-Hall distribution. Let Y be a random variable following a normal distribution centred at 0 and with standard deviation 1. Then, the following limit holds:
in probability.
Proof: The average value of a uniformly distributed random variable u is \({\mathbb{E}}(u)=\frac{1}{2}\) and standard deviation \(\sigma =\sqrt{\frac{1}{12}}\). By of the central limit theorem, one has that, for an i.i.d. sequence of random variables u 1, …, u n :
being Y a random variable following a normal distribution centred at 0 and with standard deviation 1. Therefore, by realising that ϕ μ is actually a sum of μ i.i.d random variables u, one has:
as we wanted to demonstrate.☐
This implies that the Irwin-Hall distribution f μ can be fairly approached by a normal distribution with mean \(\frac{\mu }{2}\) and standard deviation \(\sqrt{\frac{\mu }{12}}\), Φ μ (x). However, one must be careful with this approach: It can lead the integral that we want to solve, \({\int }_{0}^{\mu }\,{\varphi }_{\mu }^{1-\alpha }{f}_{\mu }({\varphi }_{\mu })d{\varphi }_{\mu }\), to a singularity at 0 which is inexistent in the Irwin-Hall distribution. Therefore, for the interval [0, 1) we will maintain the original form of the distribution. In the following lemma we demonstrate that this has no impact in the limit of large μ’s.
Lemma 2: Let Φ μ be a normal distribution with mean at \(\frac{\mu }{2}\) and standard deviation \({\sigma }_{\mu }=\sqrt{\frac{\mu }{12}}\). Then, \((\forall \epsilon > \mathrm{0)}\,(\exists N):(\forall \mu > N)\)
Proof: From lemma 1 we know that \((\forall \epsilon ^{\prime} > \mathrm{0)}\,(\exists N):(\forall S\mu > N)\)
Now we observe that the Irwin-Hall distribution can be defined per intervals using different polynomials. In the case of the interval [0, 1), the polynomial reads:
Computing directly the integral, one has:
where the first integral, according to equation (A3) leads to:
Now take δ ∈ (0, 1) and define \(\epsilon (\mu ,\,\delta )\) as:
From lemma 1, \((\forall \epsilon ^{\prime} > \mathrm{0)}\,(\exists N):(\forall \mu > N)\) we can define the following bound:
Finally, we observe that
which demonstrates the lemma.☐
Lemma 3: The function of G(α) defined by the integral
is strictly decreasing.
Proof: It is enough to compute the derivative:
since the term inside the integral, \({\varphi }_{\mu }^{1-\alpha }\,\mathrm{log}\,{\varphi }_{\mu }{\rm{\Phi }}({\varphi }_{\mu })\), is strictly positive in the interval (1, μ).☐
Now take a monotonously increasing function that grows slower than the standard deviation \({\sigma }_{\mu }=\sqrt{\frac{\mu }{12}}\), φ(μ). For convenience, we define define it as:
Clearly:
Now suppose, that α = 2. Then, thanks to Lemma 2, one has that \((\forall \epsilon > \mathrm{0)}\,(\exists N):(\forall \mu > N)\)
From this we derive the third lemma of our demonstration:
Lemma 4: \((\forall \epsilon > \mathrm{0)}\,(\exists N):(\forall \mu > N),\)
Proof: We need to compute the parts that fall outside the integration limits and see that their contribution vanishes. First, we see that:
Analogously,
Now we define:
which leads to:
demonstrating the lemma.☐
Corollary of Lemma 4: \((\forall \epsilon > \mathrm{0)}\,(\exists N):(\forall \mu > N),\)
Proof: By direct application of lemmas 2 and 4.☐
Now we define the following functions of the limits of the integral \({\int }_{\frac{\mu }{2}-{\sigma }_{\mu }\phi (\mu )}^{\frac{\mu }{2}+{\sigma }_{\mu }\phi (\mu )}\,\ldots \):
Clearly,
where the subscript 1,2 means that both functions satisfy the property.
Lemma 5: \((\forall \epsilon > \mathrm{0)}\,(\exists N):(\forall \mu > N)\)
Proof: We first observe that, by substituting \({\varphi }_{\mu }^{-1}\) by the integration limits, we have the following chain of inequalities, in terms of the above defined functions r 1,2(μ):
Therefore, is enough to demonstrate that \((\forall \epsilon ^{\prime} > \mathrm{0)}\,(\exists N):(\forall \mu > N)\)
This can be proven directly from equation (A6), leading to:
which demonstrates the lemma.☐
Collecting lemmas 1, 2, 4, and 5, we have demonstrated that, under the assumption that α = 2,
From equation (8), the only remaining issue is to demonstrate the consistency of our hypothesis is that indeed \({\mathrm{lim}}_{{\mu }_{\to }\infty }\,\mu {r}_{1}(\mu )=2\). It is not difficult to check, from equation (A6), that:
So far we have demonstrated that the solution α = 2 is consistent with the statement of the theorem. Now it remains to demonstrate that this is the only solution. To see that, we observe that thanks to lemma 3, we know that the function μG(α) is decreasing. In addition, we have proven that the statement of the theorem is consistent for α = 2. Therefore, if α = 2 + β, with β > 0, then:
which contradicts the statement of the theorem. The same happens if one imposes if α = 2 − β, with β > 0, since one gets:
which is, again inconsistent, thereby proving the lemma.☐
By direct application of equation (8), Lemma 5 puts the last piece to demonstrate the theorem.☐
Mean-field approach
In a less rigorous way, we observe that we can approach the solution as follows: We know that the expected value of a random variable ϕ μ following the Irwin-Hall distribution f μ is:
Now assume that \({\varphi }_{\mu }\approx \frac{\mu }{2}\). This implies that, in the integral of the statement of the theorem, equation (A2), we replace f μ (ϕ μ ) by \(\delta \,({\varphi }_{\mu }-\frac{\mu }{2})\), where δ is the Dirac δ function:
Solving the integral, and thanks to equation (8), we obtain the following relation:
whose only solution is α = 2.
We end observing that the theorem that we demonstrated has a curious consequence: Let ϕ μ be a random variable following the Irwin-Hall distribution. We observe that, if α = 2, then:
We know that \({\mathbb{E}}({\varphi }_{\mu })=\frac{\mu }{2}\). Therefore, a direct consequence of the theorem is that:
References
Yule, G. U. A Mathematical Theory of Evolution, Based on the Conclusions of Dr. J. C. Willis. Philos. Trans. R. Soc. London B 213, 21 (1925).
Simon, H. A. On a class of skew distribution functions. Biometrika 42, 425 (1955).
Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509 (1999).
Mitzenmacher, M. A Brief History of Generative Models for Power Law and Lognormal Distributions. Internet Mathematics 1(2), 226 (2003).
Newman, M. E. J. Power laws, Pareto distributions and Zipfs law. Contemp. Phys. 46(5), 323 (2005).
Stanley, H. E. Introduction to Phase Transitions and Critical Phenomena (Oxford University Press: Oxford) (1987).
Bak, P., Tang, C. & Wiesenfeld, K. Self-organized criticality: An explanation of the 1/f noise. Phys. Rev. Lett. 59, 381 (1987).
Kadanoff, L. P., Nagel, S. R., Wu, L. & Zhou, S.-M. Scaling and universality in avalanches. Phys. Rev. A 39, 6524 (1989).
Jensen, H. J. Self-Organized Criticality (Cambridge University Press, Cambridge) (1996).
Christensen, K. & Moloney, N. R. Complexity and Criticality (Imperial College Press, London, UK) (2005).
Mandelbrot, B. An Informational Theory of the Statistical Structure of Languages. In Communication Theory, Jackson, W. editor 486502 (Woburn, MA: Butterworth) (1953).
Harremoës, P. & Topsøe, P. Maximum Entropy Fundamentals. Entropy 3, 191 (2001).
Corominas-Murtra, B., Fortuny, J. & Solé, R. V. Emergence of Zipf’s law in the evolution of communication. Phys. Rev. E 83, 036115 (2011).
Corominas-Murtra, B., Hanel, R. & Thurner, S. Understanding scaling through history-dependent processes with collapsing sample space. Proc. Natl. Acad. Sci. USA 112(17), 5348 (2015).
Corominas-Murtra, B., Hanel, R. & Thurner, S. Extreme robustness of scaling in sample space reducing processes explains Zipf-law in diffusion on directed networks. New Journal of Physics 18(9), 093010 (2016).
Hanel, R., Thurner, S. & Gell-Mann, M. How multiplicity determines entropy and the derivation of the maximum entropy principle for complex systems. Proc. of the Natl. Acad. of Sci. USA 111, 6905 (2014).
Paczuski, M., Maslov, S. & Bak, P. Avalanche dynamics in evolution, growth, and depinning models. Phys. Rev. E 53, 414 (1996).
Jackson M. O. Social and Economic Networks (Princeton University Press, Princeton, NJ) (2010).
Frette, V., Christensen, K., Malthe-Sorensen, A., Feder, J., Jossang, T. & Meakin, P. Avalanche dynamics in a pile of rice. Nature 379, 49 (1996).
Sornette, A. & Sornette, D. Self-organized criticality and earthquakes. EPL (Europhysics Letters) 9(3), 197 (1989).
Turcotte, D. L. Fractals and Chaos in Geology and Geophysics (Cambridge University Press, Cambridge), 2nd ed (1997).
Corral, Á. Long-term clustering, scaling, and universality in the temporal occurrence of earthquakes. Phys. Rev. Lett. 92(10), 108501 (2004).
Peters, O. & Neelin, D. Critical phenomena in atmospheric precipitation. Nature Physics 2, 393 (2006).
Corral, Á., Osso, A. & Llebot, J. E. Scaling of tropical-cyclone dissipation. Nature Phys 6, 693 (2010).
Thurner, S., Klimek, P. & Hanel, R. Schumpeterian economic dynamics as a quantifiable minimum model of evolution. New Journal of Physics 12, 075029 (2010).
Boss, M., Summer, M. & Thurner, S. Contagion flow through banking networks. Lecture Notes in Computer Science 3038, 1070 (2004).
Buldyrev, S. V., Parshani, R., Paul, G., Stanley, H. E. & Havlin, S. Catastrophic cascade of failures in interdependent networks. Nature 464(7291), 1025 (2010).
Thurner, S., Farmer, J. D. & Geanakoplos, J. Leverage causes fat tails and clustered volatility. Quantitative Finance 12, 695 (2012).
Hanel, R. & Thurner, S. Generalized (c,d)-Entropy and Aging Random Walks. Entropy 15, 5324–5337 (2013).
Thurner, S., Hanel, R., Liu, B. & Corominas-Murtra, B. Understanding Zipf’s law of word frequencies through sample-space collapse in sentence formation. Journal of the Royal Society Interface 12, 20150330 (2016).
Fermi, E. On the Origin of the Cosmic Radiation. Phys. Rev. 75, 1169 (1949).
Longair, M. S. High Energy Astrophysics, Vol. 2: Stars, the Galaxy and the Interstellar Medium (Cambridge University Press, Cambridge, MA) (2008).
Feller, W. An Introduction to Probability Theory and its Applications, Vols I and II, third edition (John Wiley and Sons, New York, NY) (1968).
Kingman, J. F. C. Poisson processes, Oxford Studies in Probability, vol. 3 (The Clarendon Press, Oxford University Press, New York) (1993).
Huillet, T. Sampling formulae arising from random Dirichlet populations. Communications in Statistics - Theory and Methods 34(5), 1019–1040 (2005).
Krapivsky, P. L. & Ben-Naim, E. Scaling and multiscaling in models of fragmentation. Phys. Rev. E 50, 3502–3507 (1994).
Hanel, R., Corominas-Murtra, B., Liu, B. & Thurner, S. Fitting Power-laws in empirical data with estimators that work for all exponents. PLoS One 12(2), e0170920 (2016).
Acknowledgements
This work was supported by the Austrian Science Fund FWF under the P29032 and P 29252 projects. We acknowledge an anonymous reviewer for the constructive comments on our first version of the manuscript.
Author information
Authors and Affiliations
Contributions
B.C.-M., R.H. and S.T. designed, performed the research and wrote the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Corominas-Murtra, B., Hanel, R. & Thurner, S. Sample space reducing cascading processes produce the full spectrum of scaling exponents. Sci Rep 7, 11223 (2017). https://doi.org/10.1038/s41598-017-09836-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-09836-4
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
