
Abstract
A consistent dataset of lake surface water temperature, ice cover, water-leaving reflectance, water level and extent is presented. The collection constitutes the Lakes Essential Climate Variable (ECV) for inland waters. The data span combined satellite observations from 1992 to 2020 inclusive and quantifies over 2000 relatively large lakes, which represent a small fraction of the number of lakes worldwide but a significant fraction of global freshwater surface. Visible and near-infrared optical imagery, thermal imagery and microwave radar data from satellites have been exploited. All observations are provided in a common grid at 1/120° latitude-longitude resolution, jointly in daily files. The data/algorithms have been validated against in situ measurements where possible. Consistency analysis between the variables has guided the development of the joint dataset. It is the most complete collection of consistent satellite observations of the Lakes ECV currently available. Lakes are of significant interest to scientific disciplines such as hydrology, limnology, climatology, biogeochemistry and geodesy. They are a vital resource for freshwater supply, and key sentinels for global environmental change.
Measurement(s) | Lake surface water temperature, lake water extent and level, lake ice cover, lake water leaving reflectance |
Technology Type(s) | Radar altimeters, radiometers, spectrometers, and multispectral scanner systems |
Sample Characteristic - Organism | Inland water |
Sample Characteristic - Environment | Satellite imaging |
Sample Characteristic - Location | Earth global |
Similar content being viewed by others

Background & Summary
Lakes hold 87% of liquid surface freshwater on Earth1, with the latest census reporting about 117 million lakes covering a small fraction of the Earth’s land surface (3.7%)2. Lakes and reservoirs, rivers and wetlands comprise the world’s freshwater ecosystems. The biodiversity they support is a fundamental component of the global biosphere. Lakes provide essential products and ecosystem services and as such they are part of the United Nations’ Sustainable Development Goals dedicated to water resources and to the impacts of climate change3. Lakes can be strongly modified by interaction with a changing climate, amplifying external drivers such as the incoming shortwave and longwave radiation, advection and storage of heat within the lake, etc.4,5,6. A substantial body of research demonstrates the sensitivity of lakes to climate7 and shows that physical, chemical, and biological lake properties respond rapidly to climate-related changes8. Many studies identified the essential lake response variables that act as indicators of the effects of climate change on both the lake and the catchment8. Lakes are therefore important carriers of climate-related signals. The Global Climate Observing System (GCOS)9 defines “Lakes” as an Essential Climate Variable (ECV) with six linked quantities characterising their physical state, namely, lake surface temperature, water level and extent, ice cover and thickness, and lake water leaving reflectance (colour). All interact and contribute to the lake physical response to climate change. Monitoring these variables closely is a starting point for understanding the complex lake environment and its variations in time and space, a need to which this dataset responds. For convenience, we continue to refer to these variables as “lake” observations also when they are included for water reservoirs, sections of rivers, or lagoons.
Records of lake surface water temperature or lake level spanning about a century (although initially very sporadic) exist for some well-studied lakes such as Tanganyika, Superior, Mendota and Windermere with some observations dated at the start of 20th century10. In recent decades, in situ and satellite measurements are increasingly used together to quantify lake variability and change, since each observational approach has strengths and limitations. In situ data are generally single-point measurements which do not necessarily provide a representative picture of lake responses. For example, intra-lake heterogeneity of thermal response to climate change has recently been demonstrated11. Moreover, in situ measurements, when available, are collected with different instruments from site to site and rarely measurements are reported with evaluations of uncertainty. However, in situ data are indispensable, being direct measurements, including for their use in the validation of remote sensing measurements. Satellite systems offer globally consistent observations including measurements for lakes for which in situ measurements are not available. Differing technologies lead to a variety of sampling patterns, resolution, uncertainty and revisit periods. Often, such characteristics have improved upon over the period addressed by the dataset as technology advances. Optical and thermal imagery may be limited by cloud cover, which is not the case for active and passive microwave observations.
The European Space Agency Climate Change Initiative (ESA CCI) is generating multi-decadal satellite-based products to serve the climate modelling and climate user community, including the lakes dataset described herein. The dataset addresses all the thematic variables except lake ice thickenss, namely lake surface water temperature, lake ice cover, lake colour (as lake water-leaving reflectance), lake water level and lake water extent spanning the period 1992–2020. The variables are derived from measurements by instruments including radar altimeters, radiometers, spectrometers, and multispectral scanner systems on satellites such as Sentinel-3, Sentinel-2, Terra, Aqua, Envisat, ERS-2, MetOp, Landsat, Topex/Poseidon, Jason, GFO, Saral/AltiKa and Cryosat. The observations of the five thematic variables derived from data of multiple sensors and satellites consequently span different temporal and spatial resolutions. The observations for each of the thematic variables derived from the different sensors have been regridded to create a multi-variable dataset with a common spatio-temporal representation.
Data are provided on a common regular 1/120° latitude-longitude (about 1 km by 1 km) grid and with daily temporal coverage. The Lakes ECV product consists of data that have been regridded and aggregated (when required) across observations from multiple platforms (level-3 super-collated files, L3S). The daily files contain observations for 2024 inland waterbodies distributed globally and spanning a wide range of ecological settings and characteristics. Each variable is accompanied by a per-datum uncertainty, with the exception of lake water level and extension for which one value is reported for each lake. Lake surface water temperatures are additionally accompanied by per-pixel quality levels, which reflect an assessment of the validity of the datum and its uncertainty estimate. The uncertainty estimate for each thematic variable is at a different stage of maturity, as detailed in the Method section.
The thematic variables have been individually validated against in situ measurements (when available, otherwise with other appropriate methods) and the level of consistency among these variables has been explored. Exploring the physical processes occurring in the lakes have highlighted some issues especially in the thematic variables for which the retrieval is less mature and more complex. This particularly benefits the optical retrieval of the lake water leaving reflectance during periods of sub-pixel or thin ice cover, and biogeochemical variables derived from the lake water leaving reflectance (turbidity and the phytoplankton pigment chlorophyll-a).
At the time of this study, the dataset presented in this paper is the longest and most complete collection of satellite observations of the Lakes ECV, it is ‘analysis-ready’ and it responds to the GCOS ECV monitoring requirements.
Methods
The dataset contains data products from multiple thematic variables of the Lakes ECV consistently stored in a regular spatial and temporal grid. The collection of satellite observations includes the following five physical variables which capture specific climate responses of global inland water bodies:
-
Lake Water Level (LWL): fundamental for understanding the balance between water inputs and water loss.
-
Lake Water Extent (LWE): elucidates lake expansion (e.g. glacial regions) and the effects of drought (e.g. arid environments). It also determines the locally cooling effect of water bodies.
-
Lake Surface Water Temperature (LSWT): correlated with regional air temperatures and a proxy for mixing regimes, driving biogeochemical cycling and seasonality.
-
Lake Ice Cover (LIC): freeze-up in autumn/winter and break-up in spring are proxies for gradually changing climate patterns and seasonality.
-
Lake Water-Leaving Reflectance (LWLR): a direct indicator of biogeochemical processes and habitats in the visible part of the water column (e.g. seasonal phytoplankton biomass fluctuations), and an indicator of the frequency of extreme events (peak terrestrial run-off, changing mixing conditions).
The dataset is the result of four years of the ESA CCI Lakes consortium joint effort but it has roots in methodological development spanning multiple decades. Each of the thematic lake variable datasets has been derived from observations by different instruments and with different retrieval techniques. Therefore, the procedures used in producing the data are described for each variable separately. In particular, input and ancillary data, the core algorithm(s), outputs, uncertainty estimates and quality indicators are detailed as relevant for each thematic ECV in the dataset. A detailed description is provided in the ESA CCI Lakes Algorithm Theoretical Basis Document12.
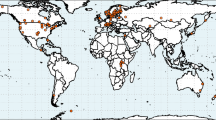
The spatial coverage of the dataset presented in this paper includes 2024 lakes and reservoirs (Fig. 1), selected to be a globally representative sample of the largest inland waters, which cover a wide range of ecological settings and characteristics. The lakes included in this collection are deemed suitable for remote sensing methods based on a priori expectations of their morphology. The maximum distance to land13 has been used to select the target water bodies. Given the variable instrument resolution, the maximum distance to land gives an estimate of how likely a lake (or a portion of it) will be observed and how likely the observed pixels are to (seasonally or occasionally) include land. Since the spatial resolution of the presented dataset is approximately 1 km × 1 km, only lakes with distance to land greater than 1 km were selected, with the exception of ten lakes that were of particular interest for LWLR which is retrieved with higher resolution instruments.

Geographical distribution of the 2024 lakes where the retrieval of the thematic ECVs has been performed.
Figure 1 shows the geographical distribution of the lakes. The list of the lake selection is available at the project website https://climate.esa.int/en/projects/lakes/data as a csv file and through a link CEDA which can be accessed through the lake dedicated website at the University of Reading (http://www.laketemp.net/home_CCI). The link is https://gws-access.jasmin.ac.uk/public/cds_c3s_lakes/CCI_LAKES/CCI_LAKE_LIST_v2/LAKE_LIST_MASK_CCI_v2_UoR_fv1.0.html.
Lake water level
LWL input data
The LWL product is derived using the so-called Geophysical Data Records (GDRs) made available publicly by the space agencies (CNES, NASA and ESA). It includes the re-tracking range, the altitude of the satellite, the geographical position of the reflecting surface and the corrections such as geophysical and propagation in the atmosphere. Radar altimetry data from Topex / Poseidon, Jason-1, Jason-2, Jason-3, GFO, ERS2, Envisat, Saral/AltiKa, Cryosat-2, Sentinel-3A and Sentinel-3B, from 1992 until nowadays was used to generate the LWL product. The input data streams are summarised in Table 1, where the time range and the typical local time of observation are reported.
LWL ancillary data
Polygons of lake contours from the Hydrolake database14 were used to determine the satellite tracks that cross each of the lake in the database and the measurements that must be considered. A threshold for each lake is also used for filtering outliers: it is based on a priori information on the historical ‘speed’ (or rate) of water level changes. If compared to the previous LWL value, the instantaneous rate of change overpasses the threshold, the LWL is removed from the time series. At the level of individual altimetry measurements, an ‘editing’ is also used based on a threshold on the backscatter of the reflected energy (it must be ranged between 7 and 40 dB). When a lake surface is too smooth, it provokes a so-called sigma bloom with very high backscattering and quasi-specular echo which cannot be processed by the waveform re-tracking algorithm. If the backscatter is below 7 dB, the reflecting surface is not considered as being cover by open water. When several satellite tracks cross a lake, a bias is estimated between each track. It includes altimeter bias15 and geoid errors16.
LWL core algorithm
The principle of radar altimetry is to send an electromagnetic pulse towards the nadir of the satellite and to measure the time between the emission of the pulse and its echo on the illuminated surface. Multiplied by the speed of light, it gives the distance R (called range) between the satellite and the reflecting surface. On-board an ultra-stable oscillator is used to measure the propagation time of the pulse within the atmosphere.
The ellipsoidal height H of the reflecting surface is given by the following relation:
where a is the altitude of the satellite above the ellipsoid of reference. The ellipsoid height is then converted to the altitude h by considering the local undulation of the geoid N:
The terms Cp and Cg are corrections essentially of two types: the propagation corrections (Cp) is related to the fact that the radar pulse propagates through the atmosphere at a speed lower than the speed of light and the geophysical corrections (Cg) is related to vertical movements of the Earth’s surface (e.g. solid earth and pole tides) for which we want to correct the measurement to a fixed reference in the Earth’s reference frame. Loading effect due to ocean tide are not considered. B is the bias which has been calculated in case tracks of several satellites are used over a given lake. When only one track crosses the lake, as is usually the case for small lakes, bias estimation is not required. When each individual value of H has been calculated, outliers’ values are removed using a 3-sigma filter, and then all H’s values are averaged in order to calculate a LWL product per pass. A final filtering is then applied on the full LWL time series, using the a priori threshold on the rate of change of LWL. More details on altimetry data processing for LWL are available17.
LWL output of core algorithm
LWL is calculated for each pass with the associated uncertainty estimated as the standard deviation of the distribution of each individual measurement of h along the track over the lake.
LWL uncertainty estimate
It is practically impossible to establish a generic error budget for LWL calculation using satellite altimetry because the sources of errors are numerous and they vary strongly from one lake to another, and between altimeters. However, for large lakes, whichever satellite mission is considered, and in normal lake surface conditions (no specular echoes) the main source of uncertainty comes from the wet tropospheric correction and, depending on the regions, it varies from 1 to 5 cm. The wet tropospheric correction, which is precisely measured from onboard radiometers, is only estimated using climate models since the footprint of radiometer on the ground covers several hundreds of km2, which makes them inappropriate for lakes. Therefore, the correction from climate models is more appropriate. The combination of altimeter noise and geophysical corrections may then be as high as 8–10 cm in the worst cases, but it usually remains at 3 to 5 cm. For small and narrow lakes, the uncertainty on LWL actually varies between 10 cm and 1 m (above which the data is discarded). In such cases, the uncertainty depends on the shape of the echoes (waveform) and the ability of the re-tracking to interpret it analytically in terms of the range between the satellite and the lake surface. Under very poor conditions (very narrow lakes for example) the re-tracking used (OCOG18) may be not robust enough to retrieve the range without large uncertainty. In such cases, another factor influencing the final uncertainty is the altimeter itself: with Saral/AltiKa and with Sentinel-3A/B SAR altimeters, the impact of lake morphology on the result is reduced since the footprint is also drastically reduced compared to former missions, as Topex/Poseidon or Jason-1, with Low Resolution Mode (LRM) altimeters. It has been shown19 that with Saral/AltiKa the accuracy increases by a factor 2 to 5 (based on comparison to in situ LWL in Chile and Argentina). It is, moreover, worth to note that with the current altimeters, based on SAR measurements, the range of uncertainty (checked using sets of in situ data on small lakes) has been significantly improved by at least a factor 219,20. It is now not unusual to obtaine sub-decimeter accuracy for lakes of few km2 or for narrow reservoirs, which was nearly impossible to obtain with LRM altimeters. More details on LWL uncertainty estimation are given in the LWL validation section.
Quality indicators and data gaps
The quality of the LWL estimate is given by the dispersion indicated by the standard deviation of the level-2 measurements along the transect over the lake for a given day. Past and present missions, a constellation of nadir altimeters, do not cover the 2024 target lakes in the database. Moreover, different families of satellites (a set of satellites with the same orbit, as in the case of the Jason’s or ENVISAT/ERS missions) are in different orbits and cover a different set of lakes. As a consequence, some lakes are partially covered in time, generating data gaps for some lakes over the whole 1992–2020 period of the dataset. Consequently, for many lakes, there are also data gaps with time series covering only a portion of the whole 1992–2020 period of the dataset.
Lake water extent
LWE input data
Considering the strategy adopted to calculate LWE (see below), for each lake we collect a set of optical satellite images spread out over whole period of time when LWL was measured from satellite altimetry. This, in general, covers the period from 1992 to 2020 for large lakes. In other cases where only recent altimeter data were available for the LWL calculation (for example from the Sentinel-3 constellation), it covers only the period from 2016 to 2020.
We have used Landsat-5 Thematic Mapper (TM), Landsat-7 Enhanced Thematic Mapper-plus (ETM+) and Landsat-8 Operational Land Imager (OLI), and the Sentinel-2A/B Multi Spectral Instrument (MSI). Landsat images are available on the USGS GLOVIS image archive (http://glovisusgs.gov) and the Sentinel-2 images on the ESA Science Hub (https://scihub.copernicus.eu). The input data streams are summarised in Table 2, where the time range and the typical local time of observation are reported.
LWE auxiliary data
Polygons of lake contours from the Hydrolake14 database are used to determine the region of interest which must be considered for each lake. In few cases, these polygons have to be redrawn in order to fit in a better way with the region of interest.
LWE core algorithm
To calculate LWE we use a combination of a lake’s water surface extent and water height at different dates, and then establish a relationship between these variables called hypsometry. This calculation has been used in many studies21,22,23,24,25. LWL historical time series inferred from satellite altimetry are used to determine when the lake was at low, medium and high level. We, then, collect images covering these different periods. The hypsometry is then adjusted ideally using a set of about 10 to 15 pairs of (LWL, LWE) and a simple least square adjustment. Knowing the function LWE = f(LWL) we can relate LWL from altimetry to LWE using the hypsometry equation. This allows us to achieve a high temporal resolution without intense image processing requirements. Depending on the shape of the hypsometry (linear or quadratic) we decide a priori whether the hypsometry will be a first or second order polynomial. In the first case, the hyspometry equation is
while in the second case it is
where a, b and c are the coefficient of the hypsometry.
To measure LWE which allows to calculate the hypsometry curve, many methods exist to extract water surface from satellite imagery, which can be divided into single-band and multi-bands methods with a thresholding approach as well as with more complex techniques such as neural network algorithm. We use the classical method of water detection based on index combining a multi-band ratio such as the Normalized Difference Water Index (NDWI), the Modified Normalized Difference Water Index (MNDWI), the Automated Water Extraction Index (AWEI) of visible green and near infrared (NIR) or short-wave infrared (SWIR) bands introduced by McFeeters26 and also Feyisa27. The water mask is then derived from thresholding the index. In addition, another method was used which allows an optimal threshold to be selected by reducing the within-class variance, or by maximizing the between-class variance28 (the OTSU approach). Improvements based on edge detection algorithm have also be implemented. This added feature focusses on the calculation of the histogram over regions with strongly defined edges, which is the expected case at the interface between surface water and land. By doing so, the water signature becomes more strongly represented in the histogram resulting in a bimodal distribution and thus allows for a more adaptive threshold.
LWE output of core algorithm
Hypsometry coefficients are produced for each lake and are intermediate values essential for the final calculation of LWE.
LWE uncertainty estimate
Water recognition is a challenging task depending of many factors (clouds coverage, floating vegetation, suspended material, complex environment, etc.). It is very problematic to determine the accuracy of LWE product, since it is impossible to measure water extent of so many lakes directly from the ground. The accuracy of the LWE estimates is found to be highly dependent on the type of lake and meteorological conditions during the image acquisition. For simple cases where the lake is well filled and close to its maximum extent and the satellite image is acquired with optimal meteorological conditions (e.g. little or no cloud cover), the results obtained by the different approaches are very similar. In the case of shallow water bodies, a large proportion of the reflected signal could originate from the bottom of the lake rather than from the water surface itself, leading to greater differences in LWE estimates between the different procedures. This may also occur in the case when the lake/water body has a high content of suspended material.
Three approaches have been used to validate the method:
-
Field survey: boat campaign with GPS mapping on Lake Chad Archipelago Area
-
Comparison of LWE derived from HR and VHR imagery
-
Validation considering the uncertainty in hypsometry calculated as the root-mean square error (RMSE) of the fitting
The second and third approach are described in the LWE validation section. Regarding the first approach, in April 2019 a boat campaign has been organized over the Lake Chad archipelago where the lake shore was precisely mapped using a Global Positioning System (GPS) receiver. This region of the Lake Chad presents high contrast of different environments: sandy flat zone together with flooding and non-flooding vegetation and shallow turbid water. However, one may see from Fig. 2 that optical imagery in such case study with both methods (unsupervised OTSU and supervised threshold based on NDWI) capture well the complex water mask measured during the boat trip.

Lake Chad archipelago boat trip (red dots) and classification with simple NDWI threshold method on NDWI (left) and based on OTSU approach (right).
LWE quality indicators and/or data gaps
The hypsometries are used only within a limited range of elevation values. Since we used LWL product to derive the LWE, and since we used selected pair of (LWL, LWE) using water mask inferred from satellite imagery, for all value of LWL which is higher than the highest LWL of the set of pair, or lower than the lowest one, then the LWE is not calculated. It is preferred not to extrapolate the hypsometry relationship since it is a characterization of the bathymetry shape of the lake and may not follow the hypsometry outside of the elevation range used to establish hypsometry. This choice generates many gaps in the time series for extreme values of lake elevation.
Lake surface water temperature
The algorithms to generate the LSWTs draw on developments in the ESA funded projects ARCLake, the CCI for Sea Surface Temperature as well as UK Natural Environment Research Council project GloboLakes. The main algorithmic steps are: identification of water-only pixels for valid retrieval; inversion of thermal infrared radiances to LSWT based on physical modelling; estimation of total LSWT uncertainty and uncertainty components; evaluation of confidence level for each pixel; cross-sensor LSWT harmonization. The LSWT dataset for this project has been created utilising only daytime imagery and single-view level-1b data.
LSWT input data
The input data are level-1b satellite images, which by definition consist of calibrated, geo-located brightness temperatures (BTs) and radiances. The input data streams are summarised in Table 3, where the time range and the typical local time of observation are reported. The ATSRs data include the Along Track Scanning Radiometer (ATSR2) and Advance Along Track Scanning Radiometer (AATSR) v3/v2.1 level-1b archive (http://data.ceda.ac.uk/neodc/aatsr_multimission) while the ATSR1 is excluded for the present. For the dual view instruments, such as the ATSRs and the Sea and Land Surface Temperature Radiometers (SLSTRs) only nadir-view observations are processed.
These input data streams share the following characteristics: the sensors observe BTs in channels around 11 and 12 μm at a nadir resolution around 1 km; the platforms are in sun-synchronous orbits with local equator passing times between 09:30 and 10:30 h; in addition to BT observations, there are reflectance channels that are useful in determining that a given BT is obtained while observing only water surface (rather than cloud or a component of land within the field of view). These similarities constrain the properties of lakes that are observable, and help the consistency over time of the LSWT record obtained.
LSWT auxiliary data
The auxiliary data mainly give supports to determine if a pixel belong to one of the designated lakes and if it is filled with water, to the radiative transfer model and to the optimal estimation retrieval. In more details:
-
A fixed lake mask29 is used to determine which pixels are considered for water detection and retrieval. The lake mask is derived from the water bodies mask (v3.0) of the ESA’s Land-Cover (LC) CCI project30 and consists of a netCDF file that includes lake identifiers to select the pixels to process and a distance to land to determine if the field of view of a given satellite radiance is wholly or partially on water on the mask, given its centre location and its view angle13.
-
Numerical weather prediction (NWP) fields are used to linearise and act as a prior to constrain the retrieval. These were acquired from the European Centre for Medium-range Weather Forecasting (ECMWF) re-analysis, generated consistently with a single version of the atmospheric general circulation model and assimilation scheme. The ERA5 data-set31 was used for MODIS, ERA-Interim32 for the ATSRs and the AVHRRs and the ECMWF operational data stored in level-1b files for the SLSTRs.
-
NWP-based values for LSWT (surface temperature) are not currently suitable to provide the prior information for spatial thermal structure in lakes. The LSWT prior therefore is derived from previous generations of the LSWT product, which have been used to generate a spatially complete field of surface temperature climatology using reconstruction strategies.
-
Lake emissivity is acquired through a lookup of emissivity derived from the refractive index for a range of wavenumbers, view angles, temperature and wind speed33,34.
-
Fixed error covariance matrices (uncertainty information) are input parameters to the LSWT retrieval scheme.
LSWT core algorithm
The LSWT algorithm is based on a per-pixel processing consisting of four main components: the identification of the lake pixels filled with water, a forward model (the radiative transfer model is used), the LSWT retrieval based on optimal estimation and finally the remapping into a regular grid.
Water detection (WD) is applied to potential inland water pixels that belong to a lake. WD operates by calculating a score against several metrics, derived from the reflectance channels available. For this reason, the LSWT is obtained only during daytime for this version of the dataset.
The WD score for a given metric is defined as a linear ramp between 0 and 1 (with thresholds t0 and t1 on the metric), similar to well-known concepts of fuzzy logic (the scores act qualitatively as probabilities). The metrics for scoring are reported in Table 4. The first two metrics use the expectation that reflection from a cloud-affected pixel exceeds that from a clear view of a lake, with values appropriate to different wavelengths. The MNDWI is the Modified Normalised Difference Water Index35 and the NDVI is a Normalised Difference Vegetation Index36. The setting of the thresholds was done within the NERC GloboLakes project using AATSR imagery tuned to a probability of cloud image derived from the Medium Resolution Imaging Spectrometer (MERIS) 300 m imagery. The tuning of thresholds was done one-at-time across metrics, maximising the posterior probability that a certain pixel is cloudy or cloud free.
The retrieval scheme is optimal estimation (OE)37. OE updates a prior LSWT in the light of the difference between the observed BTs and the BTs expected given the prior LSWT, as evaluated with the forward model. The retrieved state \(\widehat{x}\) is derived using the following equation38,39
stating that the retrieved state \(\widehat{x}\) is the prior state plus an increment of G(y-F(xa)). F is the forward model and we use the radiative transfer model RTTOV40 (version 12.3 for MODIS and version 11.3 for the other sensors) run for the prior re-analysis data and prior LSWT. The matrix K expresses how the observations change for departures from the prior state xa, i.e., it is a matrix where a given row contains the partial derivatives of the BT in a particular channel with respect to each element of the state vector in turn. The partial derivatives are the tangent linear outputs from the forward model F. Sε is the error covariance of the differences between the model and observed BTs. This error covariance matrix is the sum of the radiometric error covariance in the observations (So) and estimated error covariance of the forward model (Sm). Sa is the error covariance matrix for the prior state variables. Standard OE theory also enables estimation of the retrieval uncertainty, χ2 a diagnostic of the retrieval fit and k the sensitivity of the retrieval to the true LSWT (averaging kernel in retrieval theory). The latter two outputs are used within quality level attribution (see the LSWT quality indicators section).
LSWT output of core algorithm
The output of the OE is level-2 (L2) data in swath projection. The remapping from the L2 data to the fixed level-3 (L3) grid at (1/120)° is a destination-pull algorithm where, given the L3 cell coordinate of the centre, the closest L2 pixels LSWT value is assigned to the L3 cell of the L3U (uncollated) file. The polar orbiting satellite carrying the sensors used for this dataset typically complete 14–15 orbits each day resulting in the same number of L2 or L3U files. The LSWT outputs are collated to produce one file for each 24-hour period, corresponding to day-time observations. Following the GHRSST conventions41, the selection of the best observation is done choosing the input cells with the highest quality level and if multiple observations have the same quality level, then the average is computed. Finally, an adjustment due to different sensors has been carried out using as reference the LSWT from AVHRR on MetOpA since the validation in GloboLakes indicated a better agreement throughout the lakes with the in situ data. The inter-sensor adjustment has been calculated per lake averaging per month and spatially per lake and it has been applied only if enough observations where available to estimate the adjustment for the lake (more than 3 months of data) and if the uncertainty of the adjustment was <0.049 – conditions met for about 800 lakes. For MODIS an adjustment of 0.19 K and 0.11 K has been applied for LSWTs of quality level 4 and 5 respectively for all the lakes. The uncertainty of the bias correction is included in the total uncertainty. For lakes where the bias correction has not been applied the impact of changes in sensor on the long-term trends in LSWT is less well constrained, and trends should be treated with caution.
LSWT uncertainty estimate
The standard uncertainty is defined as the standard deviation of the estimated error distribution. Standard uncertainty is evaluated for each pixel at L2 and then propagated into the gridded dataset accounting for the correlation structure of errors between pixels. The overall uncertainty attributed accounts for instrument, retrieval and sampling effects. The instrument part addresses the propagation of error in the satellite observations (the brightness temperatures, BTs) through the retrieval process, using equations appropriate for the type of retrieval used (optimal estimation, see below). The retrieval uncertainty expresses the range of possible LSWTs compatible with the observations even if they were error free, since the intervening atmosphere produces some ambiguity in the relationship between the surface LSWT and the top of atmosphere satellite BTs. Another component of retrieval uncertainty is the influence of the prior value used in the optimal estimate, and error in which also (only slightly) affects the result. The retrieval uncertainty component is also expressed using equations derivable for optimal estimation. Sampling uncertainty at level-3 (gridded data) arises when only part of the lake within the grid cell is observable. This is well parameterised as a function of the fraction and properties of the grid cell that is observable. A limitation of the uncertainty evaluation (and to a lesser extent the retrieval) is use of error covariance parameters within the optimal estimator that are relatively poorly known (this is quite common in optimal estimation approaches). An aspect of uncertainty that has not being accounted for in the retrieval process and not included in the quoted LSWT uncertainty are impacts from any residual cloud or land influences on observations after cloud screening and water detection.
LSWT quality indicators and data gaps
The quality indicator for the LSWT is a confidence level from 0 to 5 where 5 indicates the highest confidence. The quality level is a concept distinct from uncertainty: a highly uncertain LSWT can have the highest quality level if all the assumptions needed to derive a valid LSWT and to evaluate its uncertainty are met: the quality level reflects the degree of confidence in the validity of the uncertainty estimate and not the magnitude of data uncertainty. For example, the quality levels are influenced by vicinity of the lake shore where geolocation uncertainty implies a higher probability of mixed land-water pixels. The LSWT uncertainty is valid in areas fully filled with water. The quality level assigned to a pixel will be the lowest level (row of Table 5) that matches any of the conditions shown in the table. The assignments are compatible with GHRSST conventions41 where a particular level is given if none of the conditions higher up any column of the table are met. We recommend using quality levels 4 and 5 for climate applications. Some quality level 2 or 3 data may be useful, but cannot be assumed to be useful without detailed inspection. Quality level 1 data are not suitable for use (bad data). For the observations from the MODIS instrument only, quality level 4 and 5 observations have been populated.
The ESA CCI LSWT data contains gaps in space and time due to clouds and satellite revisiting time. Periods with no observations tend to be longer for smaller lakes and for observations by instruments with a smaller swath width that revisit a given location less frequently. LSWT values are also absent when the lake is considered to be covered in ice.
Lake ice cover
LIC input data
The input data for the LIC product were MODIS (Terra and Aqua) level-1b calibrated and geolocated at-aperture radiances (MOD/MYD02QKM 250 m, bands 1-2; MOD/MYD02HKM 500 m, bands: 3–7 Top of Atmosphere Reflectance), Collection 6.1, obtained from the National Aeronautics and Space Administration (NASA) for the period 2000–2020. The input data streams are summarised in Table 6, where the time range and the typical local time of observation are reported.
LIC auxiliary data
Three auxiliary datasets are used as part of the LIC product generation. The first dataset provides a raster delineation of lakes based on the maximum water extent derived from the land/water mask available from ESA’s CCI Land Cover (v4.0) at 150 m resolution.
Two other datasets are used in a preprocessing step, prior to entering the main processing chain, to flag which of the lakes are likely to form or not to form ice. This step is introduced to narrow down the number of lakes to process globally as a mean to decrease computational costs. The datasets used for this step consist of ERA5 ice depth (thickness) data provided by the ECMWF31 and ice thickness determined from Canadian Lake Ice Model (CLIMo42) simulations. Ice cover is deemed possible to form on a lake if ice depth is determined to have reached a thickness greater than 0.001 m on any day from either CLIMo or ERA5 over the period 2000–2020. In the case of discrepancies between ERA5 and CLIMo derived ice cover, and for alpine regions where deep glacial lakes are found (e.g. European Alps, Southern Alps of New Zealand, and the Andes), an additional check is done for these lakes through visual examination of MODIS RGB reflectance images to determine if any of the lakes form ice over the period of interest (2000–2020). Only lakes flagged to form ice enter the main processing chain for LIC product generation.
LIC core algorithm
The LIC processing chain includes three modules: data import, retrieval, and data export. Data is processed one day at a time. As part of global initialization, the water mask is loaded. Then, the data for each day is processed. One execution of the processing chain processes one day of data.
Six MODIS Top of Atmosphere (TOA) reflectance bands and solar zenith angle (SZA) band are used for feature retrieval (i. e. for labelling as water, ice, or cloud)43. The reflectance bands are MOD02QKM at 250 m resolution (band 1: 0.645 μm and band 2: 0.858 μm) and MOD02HKM at 500 m resolution (band 3: 0.469 μm; band 4: 0.555 μm band 5: 1.240 μ μm for Aqua; band 6: 1.640 μm for Terra; band 7: 2.130 μm). The geolocation is provided at 1 km resolution and is interpolated to 250 m. Prior to applying retrieval, pixels of interest are identified as “good” or “bad” using quality bands from the original MODIS TOA reflectance product.
Pixels of interest are classified and labelled as cloud, ice or water from a random forest (RF) algorithm43. As an ensemble approach, RF integrates decision trees developed by bagging samples to improve the limitations of the single-tree structure44. The bagging creates several subsets randomly from training samples with replacement (i.e. a sample can be collected several times in the same subset whereas other samples are probably not selected in this subset). Subsequently, each data subset is used to train a decision tree. For building a single tree, a random sample with a few variables is chosen as split candidates from all variables. The number of variables available to a split is one of the key RF hyperparameters. For the whole RF model, the number of trees is defined a priori to develop various independent classifier outputs. The final class of each unknown sample is assigned by the majority vote of all outputs from the trees.
Labelled pixels are resampled to a 1/120° grid output grid each day. Aggregation from individual swaths is performed by taking a majority vote between ice and water, ties broken by selecting water. If there are zero ice and water pixels, then the cell is labelled as cloud if there are non-zero cloud pixels; otherwise the output cell is labelled as “bad”.
LIC output of core algorithm
The output of the LIC processing chain consists of daily files mapped onto a 1/120° grid. Each file contains three bands: Band 1 (lakes flagged as 1. not forming ice and 2. forming ice); Band 2 (Class labels: 1. water, 2. ice, 3. cloud, and 4. bad); and Band 3 (uncertainty reported as % classification error: 0.83 for water, 2.23 for ice, and 3.07 for cloud).
LIC uncertainty estimate
The assessment of uncertainty in the LIC product is currently performed through computation of a confusion matrix built on independent statistical validation. Thus, uncertainties are not assessed at a pixel level, but rather from classification error calculated from multiple samples/images. The reference data for validation are collected from the visual interpretation of imagery from a large number of lakes globally and over several ice seasons (freeze-up and break-up periods) by skilled ice analysts. Classification error (expressed as %) derived from the confusion matrix is the metric used to report total uncertainty for each class (ice, water, cloud). Pixels belonging to the same class are simply assigned the same % error value in the uncertainty band provided. Probability of class belonging, which informs about confidence in the classification, is considered as a valuable proxy for the uncertainty associated with machine learning (ML) algorithms. It is not currently provided in the ESA CCI LIC product v2.0.2 but planned in future releases.
Lake water leaving reflectance
LWLR input data
The primary input data for LWLR products were level-1b data from the MERIS sensor on Envisat (3rd reprocessing) and the Ocean and Land Colour Instrument (OLCI) sensor on Sentinel-3A and Sentinel-3B. The data were obtained from ESA for the period 2002–2012 and 2016–2020, respectively. MODIS level-1b data were also acquired from the National Aeronautics and Space Administration (NASA) for the period 2009–2019, to provide overlap with and continuity between MERIS and OLCI observation periods. The input data streams are summarised in Table 7, where the time range and the typical local time of observation are reported.
LWLR auxiliary data
The delineation of water bodies for LWLR was based on a set of polygons describing their maximum water extent at a resolution of 150 m, based on the land/water mask of the ESA CCI Land Cover project v4.045, manually corrected to exclude upstream or downstream rivers or dams. The polygon data are available in well-known text format46 and are identical to those included in the Copernicus Land Monitoring Service (https://land.copernicus.eu) where the selection of lakes overlaps.
LWLR core algorithm
The LWLR processing chain was Calimnos v1.4 developed at Plymouth Marine Laboratory with specific contributions from the University of Stirling (NERC GloboLakes and ESA CCI Lakes projects) and Brockmann Consult (Copernicus Land Monitoring Service and ESA CCI Lakes projects). In brief, level-1b MERIS data were first geometrically (using AMORGOS) and radiometrically (SNAP v.7.0) corrected. MERIS, OLCI and MODIS pixels identified as water by Idepix (v7.0) were subjected to atmospheric correction with POLYMER v4.13, to provide the LWLR product.
The optical diversity and complexity of inland water bodies can lead to ambiguous interpretation of LWLR in terms of lake biogeochemical properties. Algorithms to derive substance concentrations from LWLR are therefore selected and applied only within a predefined and validated scope. Their assignment is based on a set of 13 lake Optical Water Types (OWT)47 following fuzzy classification48. The OWT class similarity metric is the spectral angle49, highlighting similarities in the shape of the LWLR spectrum with the established OWTs. An additional two non-water reflectance signatures, equivalent to OWTs but derived from near shore observations in small lakes, were added to identify the effect of adjacent land on observations over water.
The applicability to global lake observations, corresponding to a given subset of OWTs, of each of the algorithms selected for chlorophyll-a (Chla) and turbidity was established using in situ observation data from LIMNADES (Lake Bio-optical Measurements and Matchup Data for Remote Sensing: https://limnades.stir.ac.uk) to tune specific algorithm coefficients, to define their applicable concentration range, and to characterize their respective uncertainty. This meta-dataset combined data from 25 sources from over 200 inland water bodies across the globe. The tuning techniques described by Neil et al.50 were used to assign Chla and turbidity algorithms to specific OWTs, as shown in Tables 8, 9, respectively. The same set of Chla and turbidity algorithms are used with both MERIS and OLCI products based on in situ data corresponding to MERIS observations, whereas MODIS algorithms were independently optimized.
For each pixel, the algorithm results corresponding to the three OWTs with the highest similarity scores were averaged using the OWT membership score as weighting factor to get the per-pixel weighted blend of each biogeochemical product. This procedure reduces discontinuities in Chla and turbidity maps when selected algorithms are applied near the edge of their applicable range.
LWLR output of core algorithm
Outputs of the core LWLR processing chain include the unprojected, atmospherically corrected LWLR for all input satellite wavebands of each sensor, the OWT scores, each biogeochemical algorithm and their OWT-based weighted-blended products and the pixel identification flags. For each LWLR band and the blended Chla and turbidity products, uncertainty estimates are also included (see below). The published LWLR product is then the result of reprojection to the global 1-km grid over daily aggregation periods (using averaging in case of multiple observations on the same day), and masking values where the influence of land is evident or where extreme values are encountered.
LWLR uncertainty estimate
The LWLR uncertainty model was developed by comparing in situ and satellite observations. The propagation of the uncertainty model to individual satellite observations (pixels) is done for each waveband as well as for the derived biogeochemical variables. The validation procedure for LWLR yields uncertainty models per sensor-waveband combination expressed as the relative uncertainty (RU, %) and relative unbiased uncertainty (RUU, %). The latter uncertainty product ignores systematic bias and reflects the uncertainty in LWLR which can be propagated into the Chla and turbidity products (the systematic bias is already removed by individually optimizing the algorithms). The application boundary constraints of the LWLR uncertainty models were determined based on the range of observations in the matchup dataset from LIMNADES. If an uncertainty model could not be established (e.g. in situ data were too sparse) or if the LWLR amplitude is out of the application range, the observation is given with unknown uncertainty.
The uncertainty models corresponding to specific biogeochemical algorithm-OWT combinations for Chla and turbidity were expressed as a function of OWT class membership score. Each model was evaluated against the full match-up dataset available for the observation period of the satellite sensor. This is done to ensure that the uncertainty model captures the reduction of uncertainty with increasing OWT class membership, which is ultimately how the per-pixel uncertainty is generated. A weighted-blending of the uncertainty for the three OWTs with the highest similarity scores was then applied to obtain the final uncertainty of each pixel, using the same weighting as for the blended biogeochemical product51.
LWLR quality indicators and/or data gaps
The associated uncertainty product for each LWLR variable can be used as an approximate indicator of product quality, and it is further noted that the uncertainty product is expressed in absolute percentage values51. The LWLR product is the result of calibrated at-sensor radiance following removal of atmospheric effects and contaminated pixels over water area, and therefore it contains gaps spatially and temporally resulting from cloud cover, ice cover, land adjacency, sun glint, white cap, satellite coverage and satellite revisiting time, etc. The full time-series of the LWLR product is a combination of satellite data from MERIS, MODIS, and OLCI, for the period of Apr 29th 2002 to Apr 7th 2012, Apr 8th 2012 to Apr 24th 2016, and Apr 25th 2016 to Dec 31th 2020, respectively. The MERIS and OLCI LWLR data are provided for all of the 2024 lakes included in this dataset. In contrast, a subset of 38 lakes time series include MODIS data to fill the gap between MERIS and OLCI in the current product version, from approximately 250 evaluated for inter-sensor stability and other time-series remaining to be investigated for a future product version.
Data Records
The ESA CCI Lakes dataset52 represents a consistent and homogeneous data record generated from very different sensors. The version presented here is v2.0.2, it can be downloaded at the Centre for Environmental Data Analysis (CEDA) archive (https://doi.org/10.5285/a07deacaffb8453e93d57ee214676304) and it is organised in global daily files in NetCDF4 classic format (Network Command Data Form) using the CF (Climate and Forecast) metadata convention53 (v1.8) and ESA CCI Data Standards (v2.3). The dataset title, full name, description, and data volume are given for ESA CCI Lakes products in the Table 10.
Not all the thematic ECV products are offered for all the 2024 lakes and throughout the full period. All lakes are covered by LSWT, LWLR and LIC, but not LWL and LWE due to the more limited along-track spatial coverage of radar altimeters. The temporal coverage for each is reported in Table 11. In the version v2.0.2 of the dataset, each of the variables is present in the files only within the period indicated in the table.
The files contain the variables that define the dimensions of longitude, latitude and time. The time variable is also encoded in the filename. The filename follows the CCI data standards v2.3 and it has the form
ESACCI-LAKES-<Processing Level>-<Data Type>-<Product String>-<Indicative Date>-fv<version>.nc where <Processing Level> is L3S for the dataset presented the processing level and indicates super-collated data where observations from multiple instruments and observation times are combined into a common spatio-temporal grid; <Data Type> is LK_PRODUCTS indicating that the file contains lake products; <Product String> is MERGED to indicate that the product come from more than one platform and sensor; <Indicative Date> is the date of observation and it is encoded as YYYYMMDD; <version>: the version of the dataset. All data are released under the licence Creative Commons Attribution 4.0 International (CC-BY 4.0, https://creativecommons.org/licenses/by/4.0/).
Technical Validation
All the thematic ECVs of the dataset have been validated against in situ measurements, where possible, according to the CCI Product Validation Plan54. Validation of the dataset has been carried out through direct comparison between remote sensing products and in situ data and/or other remote sensing datasets for each of thematic variable individually and/or through manual inspection of a selection of lakes. The level of spatio-temporal consistency between thematic variables was investigated separately to ensure the data are mutually compatible.
Lake water level validation
Validation of LWL is performed using sets of in situ measurements in different regions. The accuracy of LWL calculated using satellite altimeter is strongly dependent on several conditions: the shape, the size, and the surrounding environment of the lakes. It also depends on the quality of the on-board instruments that have strongly evolved from the radar altimeters launched in the 1990s.
The validation of LWL is essential since the accuracy of LWL calculated using satellite altimetry may differ from one type of lake to another one. Therefore, a large set of in situ water level data was collected to cover most of the different cases (small/large lakes, with or without ice cover in winter, mountain lakes, etc.).
The validation of this variable therefore has to be carried out for lakes with different characteristics.
Due to the fact that generally the geodetic reference system used by satellite and in situ measurements are not the same, and not tied, the validation consists in most of the cases in inter-comparison of the water level changes after removing some biases between the time series as reported in a large number of papers during the last 20 to 25 years. For example, already with the very first measurements of Topex/Poseidon launched in 1992, Morris and Gill55 have evaluated the accuracy of altimetry over the Great Lakes in North America, being sub-decimeter compared to the in situ. Global inter-comparisons between in situ worldwide and altimeter over several missions have also been performed. Using the OCOG retracking algorithm, the accuracy ranges between few centimeters for large lakes to few decimeters for small lakes56,57. In many studies, dedicated analysis has been done for specific mission in order to assess the accuracy of measured LWL: for example on Sentinel-3 it has been shown that the SAR mode strongly improves the accuracy once specific algorithm of waveform retracking is used20,58,59,60. Some other studies have been conducted on the assessment of performances of Jason-261, Cryosat-262 or Saral/AltiKa63. Other studies focused on the validation of satellite altimetry over specific lakes15,58,64,65,66,67,68 or on group of lakes in specific environment19,55,59,69.
If in such analysis the in situ data are considered as ground truth, there are still difficulties to directly compared them since the physical properties and the scaling of the measurements are different. Satellite measurements are collected along the track of the satellite with a footprint of several square kilometres, while the in situ measurements are generally taken on the lake shore very often far from the satellite track by several kilometres. Moreover, the reference system of each of the measurements are different, and the uncertainty on the geoid over the lake adds a source of bias between both types of measurement. In addition, technical issues with gauges, data gaps, human error in collecting the data can easily increase the gauge error level to few centimeters, making them an unreliable source of ground truth for small variations of lake level.
The inter-comparison between the two types of dataset is also complex because the in situ measurements are generally daily or monthly average values, while the frequency of the satellite flight over the lake is fully determined by its orbit. The comparison requires then an interpolation, which can also be a source of error, especially when the lake water level variations are abrupt, or in presence of seiche for example.
The errors of satellite altimetry over lakes depend on several factors. Depending on the size and shape of lake shore, the altimetry telemetry waveform which is analysed for the calculation of water level over the footprint can be more complex than the usual shape of such signal from the open surface over the oceans, or over very large lakes. Footprint over narrow reservoirs, for example, covers in-homogeneous surface over the lake with non-water surface such as vegetation, bare soil, sandbanks, ice. This explain (see Table 12) why the performances of the altimeter over large set of lakes can vary from few centimeters to few decimetres. Moreover, the evolution of the altimetry technique from the Low-Resolution-Mode altimeters on the Jason/OSTM series to the SAR altimetry used with the Sentinel-3 series generates an improvement of accuracy from the oldest time series to the newest ones. For example, over the Issykkul and the Illmen lakes we have obtained a gain of a factor 2 with Sentinel-3 data. For lake Argentino, while the root mean square error (RMSE) over the period 1992–2019 is 16 cm, it falls to 8 cm with a correlation of 0.99 when only Sentinel-3A is used.
We have compared the altimetry product with the in situ measurements for 51 lakes spread over all the continents. The results are reported in Table 12. For 11 among the large lakes the accuracy is below 10 cm, for 16 of them it is between 10 and 20 cm, for 14 of them are between 20 and 40 cm and for 7 lakes the RMSE was higher than 40 cm. The comparison for Lake Issykkul in Kyrgyzstan is reported in Fig. 3.

LWL from Sentinel-3A and in situ data over the Lake Issykkul (Kyrgyzstan).
Lake water extent validation
Validation of water extent is challenging since in situ measurements generally do not exist25,70. Field work for surveying the water bodies is limited to walking along the shore with a GPS tracking, or using a boat or kayak to follow the shore but it remains limited to very small number of lakes71. It is indeed not always possible to walk around lake, since many lakes are not easily accessible. Moreover, in case of shallow water, the exact distance between the boat and the shore, for example 10 m (or more) is equivalent to 2 to up to10 Sentinel pixels. Water extent extraction from satellite observations generates a large amount of uncertainty and once inter-comparisons between radar or optical imageries using different types of methods are done, selection of images to construct the hypsometry curve can be done based on statistical analysis of the dispersion of the coupled variable: LWL/LWE. An additional way to evaluate the accuracy of the LWE extraction is to compare the lake contour from satellite sensor used with high resolution (HR) and very high resolution (VHR) imageries like those provided by the Pléiades constellation72.
Another problem is the difficulty to precisely define the real contour of a lake, since a lake can be surrounded by wetlands or covered by floating vegetation. In addition, the definition of lake could include the ice cover other than the open free water area.
Many tests have been done before we could produce LWE for the CCI dataset.
In order to select the appropriate methodology for optical imagery used for the LWE production, we have implemented an inter-comparison process with VHR data using the Pleiades constellation73. The comparison requested pair of HR and VHR images acquired within a very short time. The data have to cover the targeted lake as a whole, and the surrounding areas. In most of the cases of the CCI lakes that are large lakes, this is not possible. Moreover, the VHR data are not freely available and therefore the approach can be a costly.
We have acquired two pairs of Pléiades HR data, 70 cm of spatial resolution, a panchromatic channel and 4 visible ones from blue to near infrared channels, on the 30th of December 2019, with a delay of one day with Sentinel-2 and on the 6th of January 2020, which is the same date as the Sentinel-2 acquisition used to determine the contour of lakes. Lake de Der and lac d’Orient in East of France were chosen for this comparison. Lake du Der, medium size and dynamic reservoir located within an overlapping part of Sentinel-2 tracks, allowing up to 14 acquisitions by month, was an ideal case to compare the LWE derived from HR Sentinel MSI at 10 m, and the VHR Pleaides imagery at 0.7 m resolution.
When comparing the LWE derived with Pléiades and Sentinel-2 data acquired within 24 hours, the difference in term of surface were very low, i.e. 29.07 km2 for Sentinel-2, and 30.58 km2 for Pleiades. 95% of Pléiades Water was recognized by Sentinel-2. There is a very low level of commission of 0.05 km2.
When the acquisition of the VHR and HR images was the same day, 95.5% of Pléiades water was recognized by Sentinel-2. Of course, there is an effect of resolution i.e. 10 m versus 0.70 m. The shoreline is much finer on the VHR derived LWE. When data are acquired on the same day, the space occupied along the shore of the omission is very narrow, the shoreline corresponds to a staircase of swa-tooth’s effects alternating omission and commission pixel, related to the difference of spatial resolution. Where, the LWE represents two stages of infilling, we observe a large omission belt around the lake shore. This belt corresponds mostly to an increase of the surface of water within one day. This case study allows also evaluating, in the context of infilling reservoir, the part of the 24 h of delay between the two acquisitions. In such case, we observed a large omission belt around the lake shore. This belt in fact corresponds to the increase of the surface of water within one day. So, of course, what is seen as water on the Pleiades image cannot be described as water on the Sentinel-2 image acquired a day before. This is illustrated in Fig. 4.

Comparison of LWE accuracy derived with one day of delay between the Sentinel-2 and Pléaides acquisitions and the same day (left).
We systematically determine the precision of each time series of LWE calculating the RMSE of the difference between LWE inferred from the polynomial function of the hypsometry of the lake, and LWE directly measured by the satellite image, over the whole dataset of images used to calculate the hypsometry coefficient. Hypsometry has been used only when the RMSE obtained was lower than 10% of the total average extent of the lake. Most of the time, the RMSE kept within 1 to 2%. The idea is also that, when comparing LWE derived with different methodological /sensors approaches the best water times series would produce the best hypsometric curves and therefore statistical correlation can be used to corroborate the method. An example for lake Kariba is reported in Fig. 5.

Example of hypsometry precision for Lake Kariba in Africa. The red curve represents the theorical hypsometry determined by least square adjustment of a second order polynomial on the datasets (LWL/LWE). In the case of the lake Kariba, the RMSE is 37 km2 which is less than 1% of average extent of 5000 km2.
Lake surface water temperature validation
The validation of the LSWT is based on matchups between satellite and in situ measurements which are collected through personal communication with limnologists and agencies who are willing to share the data for validation purposes.
The in situ temperature data have been collected also through the ARCLake project, the GloboLakes project, the EU Surface Temperature for All Corners of Earth (EUSTACE) project and the Copernicus Climate Change Service (C3S) product. The ESA CCI Lakes LSWT dataset presented in this paper has been validated with in situ measurements on 79 lakes with a total of 207 sites. The geographical distribution of the sites is reported in Fig. 6 which shows that most of the sites are situated in North America and Europe, with 38% and 47% of the sites and 24% and 56% of the lakes respectively as shown in Table 13. As the in situ data are from a variety of sources, the frequency of the measurements varies greatly between the sources. Only for 90 of the 207 sites measurements with frequency of less than a measurement per day are available, mostly in North America. A portion of the lakes that have been used for the validation are small lakes, for which the LSWT retrieval is most challenging. In Table 13 we have reported the number of lakes for which the maximum distance to land13 is less than 3 km. The maximum distance to land13 is a meaningful measure of the size of the lakes for LSWT remote sensing. The best resolution of the instruments used for the retrieval of the LSWT is 1 km. If the lake has a maximum distance to land of e.g. 1.7 km such as lake Iseo, the LSWT retrieval is very likely to be available only for that part of the lake and only for a limited proportion of overpasses (clear sky and observations relatively central within the swath). In particular, a combination of factors has to occur: 1) the satellite image locations line up so that some pixels are nominally fully water pixels, which requires the satellite view zenith angle (which affects the on-the-ground resolution) to be such that the half-pixel size is smaller than the distance to shore; 2) these pixels are cloud free; 3) image geolocation errors (which can be of order 1 pixel uncertainty) are small enough that the nominally water-filled pixels are truly water-filled meaning that the water detection tests are passed. Moreover, some of the locations of the in situ measurements are situated close to the shore even for large lakes, which means that the nearest water-filled pixels may not overlap the in situ measurement, thus increasing the uncertainty in the comparison from spatial representativity.

Geographical distribution of the sites of the in situ measurements.
The satellite-to-in situ-matches are created at the original satellite coordinates, at L2 spatially within 3 km and temporally within 3 hours for the in situ data where the measurement time was available. The LSWT of the L3S ESA CCI Lakes dataset are then directly validated to assess the products as seen by users. The validation of the LSWT is performed using conventional and robust statistics of the satellite minus in situ measurement difference, the latter being less sensitive to outliers and more descriptive of the majority of data.
The matchup is carried out per sensor over the 207 locations on 79 lakes. The total number of matches is 81,436 for any quality level and 66,407 for quality levels 2 and above which are reported here. The number of matches varies per year and since the AVHRR and the MODIS sensors have a larger swath than the ATSR sensors (ATSRs swath is 500 km, AVHRRs swath is ~2900 km and MODIS swath is 2330 km), after the year 2000 the number of matches increases as it is shown in Fig. 7a.

LSWT satellite minus in situ temperature difference median (on the left hand side) and robust standard deviation (on the right hand side) per year (upper plot) and number of matches (lower plot) per quality level.
In Table 14 the number of matches per quality levels are listed together with the median and the robust standard deviation of the satellite minus in situ temperature difference and the traditional metrics, the mean and the standard deviation. The difference between the median and the mean is less than 0.025 K for quality level 5 and it increases as the quality levels get lower suggesting a higher incidence of cold-biased observations for low quality levels, as expected. The best agreement is for quality levels 4 and 5, which are the levels that reflect a higher degree of confidence in the validity of the satellite estimate and that we recommend to use for lake-climate applications in general, although lower quality level data may used only after verifying their fitness for a given lake for their application. Quality level 1 data should never be used and they are classified as “bad data”. Figure 7a,b shows that for high quality levels the median and the robust standard deviation of the satellite minus in situ differences are consistently small throughout the years when different instruments have been adopted and a different number of matches is available. They deteriorate as the quality goes lower. The number of matches for quality level 5 is consistently the highest.
A contribution to the difference on average is the expected skin effect. Infrared radiometers are sensitive to radiation emitted between the air-surface interface and 20 mm below the interface while the in situ measurements considered here are taken at a distance up to 1 m from the air-surface interface. During the night, the surface of the water is generally cooler than the subsurface by ~0.2 K74,75. However, during the day, if the wind speed is low enough, thermal stratification due to solar heating can contribute to a positive offset to the difference in temperature between the radiometric lake surface and the in situ measurement depth (up to 1 m). The positive thermal stratification would be expected to be in the range ≪ 1 K for most observations but occasionally of order a few kelvins. The degree of near-surface stratification to be expected in different lakes depends on fetch, weather conditions (radiative balance and wind speed), the depth of in situ measurement, and any local vertical mixing perturbations introduced by the presence of the in situ measurement system. While several studies have analysed the air-water interface for the sea surface temperature, only few tackled the air-surface interface for inland water where more heterogeneities and larger wind stress variabilities than ocean waters can be found76,77. The aggregate effect of these factors is not currently well quantified and they can be different depending on the lake, although a model to quantify the cool skin effect in lakes in presence of natural convection has been recently proposed77. In summary, a geophysical contribution to the satellite minus in situ temperature difference is the expected skin effect of −0.2 K, but other positive geophysical offsets are similar in magnitude and difficult to quantify precisely for each lake. Additionally, a contribution to the temperature difference can be found in the variety of sources of the in situ measurements:
-
different instruments have been used for the measurements and we do not have any information on the instruments used
-
part of the measurements are not accompanied by an exact timing and/or by an accurate position which can contribute to the difference since LSWT can quickly varies in time and space.
Lake ice cover validation
Validation of the LIC product is performed through computation of confusion matrices built on independent statistical validation (i.e. from pixels independent to those used for training of the random forest (RF) algorithm). Groups of pixels (Areas Of Interest or AOI) for open water, ice and cloud are collected from a selection of lakes from visual interpretation of MODIS Terra and Aqua images (i.e. MOD02/MYD02) over both the freeze-up and break-up periods interspersed across a 21-year MODIS record (2000–2020). Both MOD02/MYD02 false (R: band 2, G: band 2, B: band 1) and true (R: band 1, G: band 4, B: band 3) colour composites are used as reference images to manually collect AOIs with assigned labels (water, ice and cloud) to assess the accuracy of the LIC product. Validation is performed on Terra and Aqua derived LIC individually, before merging into the daily Terra/Aqua LIC product and before aggregating into the common ca. 1 km × 1 km grid of the multivariate dataset.
A total of 17 lakes across the Northern Hemisphere currently serves for the purpose of both development and validation of the LIC product (Fig. 8). In a previous assessment of MODIS LIC from Terra only for the same set of lakes43, AOIs were collected for three ice seasons (2002–2003, 2009–2010, 2016–2017) as to provide a good temporal spread over the full Terra record to ensure algorithm stability. The RF algorithm provided overall and class-specific accuracies above 98% and a more visually accurate depiction of open water, ice cover and cloud cover than other machine learning algorithms evaluated43. The classifier was shown to offer robust spatial transferability over the 17 lakes and to perform consistently well across ice seasons and independently for the freeze-up and break periods.

Geographical distribution of lakes used for LIC product validation (Source43).
Here, we further demonstrate the stability of the algorithm over time and between satellite platforms (Terra and Aqua) using Great Slave Lake (Canada) and Lake Ladoga/Lake Onega (Russia) as examples. AOIs were collected from MODIS Terra RGB colour composites for the 2018–2019 ice season. A total of 10,075,081 pixels were selected from 229 swaths over the lakes. For MODIS Aqua, 1,665,188 samples were collected from colour composite images (Great Slave Lake: 156 swaths, Lake Ladoga/Onega: 61 swaths) in 2020, also encompassing a break-up and a freeze-up period. Results presented in Table 15 further support the stability of the RF algorithm for LIC product generation. Accuracies are found to be consistent across classes. RF also produces comparable classification results between MODIS Terra and Aqua. Individual class accuracies are all above 90% which meet uncertainty requirements of 10% set by GCOS for LIC as a thematic variable of Lakes ECV9.
Lake water-leaving reflectance validation
The validation of LWLR and associated water quality parameters (i.e., Chla and turbidity) is based on match-ups between satellite and in situ observations, where the in situ data are sourced from LIMNADES. The evaluations were performed for MERIS and MODIS, due to their long operation (2002–2012, and 2002-now, respectively) and coincidence with matching in situ data. The number of matchups included in the validation for LWLR, Chla and turbidity ranged from 243 to 2616 for MERIS and MODIS, which were gathered from up to 71 inland waterbodies (Table 16).
Validation of POLYMER-corrected LWLR for MERIS with in situ match-ups was conducted for 11 wavebands from 412 nm to 779 nm, which show significant linear relationships, with highest coefficient of correlation of 0.86 returned in the 560 nm band51. As for MODIS, significant linear correlations were also found for all of the 11 evaluated bands (from 412 nm to 748 nm) between POLYMER-corrected LWLR and in situ measurements, with the highest R = 0.83 returned at 547 nm78.
Note that the validation with in situ data for Chla and turbidity was not independent, since the tuning algorithms adopted from the procedure described by Neil et al.50 to generate Chla and turbidity have already used the same source of in situ data. In this context, a validation procedure of a weighted blended Chla product based on the fuzzy OWT classification framework was developed to demonstrate the performance of water quality products51. Based on this uncertainty evaluation, it was found that the uncertainty (i.e., ARU, %) of the blended algorithm result shows flat response to the OWT membership scores. This indicates that our proposed procedure successfully removed the uncertainties across different OWTs by blending water quality products from outputs of several pre-assigned algorithms, and therefore making our product globally validated. Although the dataset used for the uncertainty characterization is not fully independent, the validation presented forms a global assessment. As for local performance, the validation results could be better or worse for a single lake, however, this would not alter the optimal configuration of the system nor the global validation.
It is admitted that a lack of in situ reference data and a bias towards turbid, productive and large lakes in the datasets do exist, and is somewhat to overcome when the end-to-end validation of Chla and turbidity products derived from LWLR is concerned. Also, a temporal-spatial sampling bias still exists with most of the available in situ data having been collected since the launch of MERIS and relatively close to shore. These inherent defects in the in situ dataset will add to uncertainties on the validation of LWLR products over a range of water types and lake geophysical and geospatial characteristics.
For a full description of the validation procedure and results the reader can refer to Liu et al.51 and the ESA CCI Lakes Product Validation Intercomparison Report78. A separate follow-on validation of OLCI is still pending considering the limited matchups with in situ measurements from LIMNADES due to the relatively short operation period (2016-now), and that the similarities in radiometric performance and waveband configuration with MERIS would allow propagation of the present results to OLCI.
Consistency of the thematic ECV products in the dataset
The thematic ECVs in the dataset (L3S product) are generated independently with data originating from different satellite sensors. Nevertheless, physical processes link these observations together and create expectations to find some interdependencies and cross-correlations. Moreover, the analysis of consistency between thematic ECVs provides a means for independent quality control of the primary observation data, related to unresolved observation challenges such as sub-pixel ice cover or poor atmospheric transmissivity, recorded differently between sensors and overpass times.
All results presented in this section are based on version 1 of the ESA CCI Lakes dataset. The major differences in version 2, other than wider spatio-temporal coverage, include the reprocessing of LIC with a new machine-learning based retrieval algorithm, which resolves the classification of dried up lake areas as ice. Also, the quality of LWLR products was enhanced by the introduction of two non-water reflectance signatures to classify land adjacency effects. For a full description of analyses and solutions towards consistency, please refer to the Consistency PVIR79. Comparisons between LWL and Turbidity (derived from the LWLR product) and between LIC, LSWT and LWLR are reported in this section.
Lake water level (LWL) and turbidity (from LWLR)
The LWL product and the turbidity of the water from the LWLR product form a pair of observations with strong cross-correlation.
Figure 9a,b show the daily time series of the Ilha Solteira in Brazil and of the Qadisiyah Reservoir in Iraq respectively where the variations of the two variables are clearly related.

LWL (upper plot) and turbidity (lower plot) time series for the Ilha Solteira in Brazil (on the left) and the Qadisiyah Reservoir in Iraq (on the right). For the turbidity (lower plots), lake median of daily data is shown as blue dots, and the LOESS smoothing is reported as red lines. For LWL (upper plots) the values at the given temporal resolution (blue dots) are connected by the red line.
In particular, in Ilha Solteira (Fig. 9a left panels) the seasonal cycle of LWL corresponds with the local precipitation cycle. The rise in LWL corresponds to an increase in turbidity, as expected when more turbid water from land surface run-off (erosion) fills the reservoir. In the example of Qadisiyah Reservoir in Iraq (Fig. 9b right panels), during the years 2007–2009 the outflow of the reservoir was increased to compensate for water level decrease in the river Euphrates, due to prolonged draught80. Turbidity (daily median values of all observations for the reservoir) spiked during the minimum LWL. Whereas lower water levels might lead to higher turbidity due to re-suspension of sediments, visual inspection of spatial coverage in the turbidity product also shows an increasing fraction of observations where pixel identified as water may have contained small fractions of land. This has the effect of increasing lake median turbidity estimates. Guided by these results, additional masking of LWLR signatures which suggest an influence of land were added. The turbidity plot for Qadisiyah Reservoir (Fig. 9b right panels) shows a considerable amount of outliers (turbidity higher than 40NTU). These are mainly caused by the land-contaminated pixels.
LIC, LSWT and LWLR
The combination of LIC, LSWT and LWLR variables in a single L3S product creates new opportunities to establish the compatibility of individual pixel identification for these products. For example, suspicious cases include ice observations at non-freezing temperatures in the LIC product, and reciprocally, high LWLR where (potentially sub-pixel) ice presence is likely and corroborated by cooling or warming trends in LSWT in adjacent periods.
In general, the latest version of the thermal products (LSWT, LIC) show a relatively high degree of day-to-day stability, which can be exploited to analyse cases where the influence of observation artefacts is less easily distinguished from noise (e.g. LWLR). To compare the consistency of the LIC classification from MODIS data with the snow/ice flagging of LWLR data from MERIS and OLCI and the LSWT product, we used data extracted at the position of the maximum distance from the shore13. This data extract comprises all variables of the L3S ESA CCI Lakes product within a 3 × 3 macro-pixel. Each pixel within the macro-pixel is used as an independent observation. Treating all observations within the macro-pixel independently was considered a reasonable compromise to address data gaps that resulted from sparse data availability between the individual products, caused by using different underlying sensors with varying observation times, and is considered to provide some additional sensitivity to spatial inhomogeneity. Comparisons are shown between lake ice cover classification, LWLR at 490 nm and LSWT in Fig. 10 where macro-pixels from 2002 to 2012 (MERIS) and 2016 to 2019 (OLCI) are considered. Only data points for which observations are obtained on the same day are shown, while there can be several hours between the overpass of individual sensors.

LSWT, LWLR (Rw490) and LIC classification of Lake Amadjuak (Canada) observed on the same day (centre plot). The histograms are based on only two coinciding observations, either LIC/LWLR (right plot), or LIC/LSWT (top plot). If the ixel is classified by the LIC product as ice, it is marked with a red dot. If the LSWT quality is above three (the recommended quality classes) and the pixel is not classified as ice, the data points are marked in dark blue; points of lower LSWT quality (LSWT quality = 3) and not classified as ice are marked in light blue.
The consistency between the three thematic products is defined as:
-
Ice only occurs when temperatures are close to or below freezing point, ignoring variations caused by lake salinity.
-
Where ice is observed, LSWT and LWLR cannot be observed.
The identification of ice is the main focus in the LIC product based on MODIS data. All observations of LSWT and LWLR are screened for ice occurrence as well, but with different approaches and based on different sensors and observation times. Where LSWT and LWLR estimates exist, and LIC identifies ice at the same time, LSWT and LWLR products have to be considered suspect. If the temperature is close to the freezing point and the pixel is identified as ice, both LSWT and LIC estimates may still be correct due to different observation times due to melting, freezing, or movement, or due to thresholding for sub-pixel occurrence. On the other hand, if the surface temperature is well above zero degrees and observed with high quality level (4 or 5), the LIC classification can be considered suspicious.
For lake Amudjuak the ice classification of the LIC product appears realistic, as shown in Fig. 10, since the few ice observations all occurred close to the freezing point. Both histograms, which are based on coinciding observations of the two variables, confirm this interpretation. The distribution of LSWT data points which are also classified as ice by the LIC product (red histogram) is tilted towards the freezing point. The data points classified as ice also correspond to relatively high LWLR (histogram on the right, coinciding measurements of LWLR and LIC). These are highly likely observations containing ice, which have not been correctly identified by the pixel identification for MERIS and OLCI data.
For the lake Amadjuak reported here and for other lakes analysed, we found that LSWT and LIC are consistent at a higher degree when compared with LWLR where the influence of observation artefacts can less easily be distinguished from noise. Where LIC and LSWT suggests snow/ice flagging, the LWLR product has to be treated with care and we recommend to avoid their usage. We note that these procedures will be included in future versions (from 2.1) of the LWLR.
Usage Notes
ESA CCI Lakes product
Data generated in the ESA CCI Lakes project have been used in five use cases81,82,83,84, including a case study on Greenland lakes which has been currently submitted to Scientific Report85. The case studies were part of the project and they focused on analysing the five thematic variables available in the product: lake water level, lake water extent, lake ice cover, lake surface water temperature and lake water leaving reflectance.
LWL refers to the lake water level above a reference geoid. Radar altimetry from space consists of vertical range measurements between the satellite and water level. Difference between the satellite altitude above a reference surface (usually a conventional ellipsoid and then a geoid), determined through precise orbit computation, and satellite-water surface distance, provides measurements of water level above the reference. Placed onto a repeat orbit, the altimeter satellite overflies a given region at regular time intervals (called the orbital cycle), during which a global coverage of the Earth is performed. Water level measurement by satellite altimetry has been developed and optimized for open oceans. Nevertheless, the technique is now applied to obtain water levels of inland seas, lakes, rivers, floodplains, and wetlands.
LWE can be expressed as the presence of water (on a map), or as the total areal extent of a waterbody (a single number). Studying and monitoring variations and trends in lake area, or lake water extent can be an important tool in identifying climatic variations over time since this physical parameter is regulated by changes in climate. Hence, changes in LWE can be indicators of climate variations since they are sensitive to changes in water and heat balance. LWE together with LWL can be utilized to assess the total volume of water in a lake.
LIC refers to the extent (or area) of a lake covered by ice. Lake-wide ice phenology can be derived from LIC, including freeze onset to complete freeze over (CFO) dates during the freeze-up period, melt onset to water clear of ice (WCI) dates during the break-up period, and ice cover duration derived from number of days between CFO and WCI dates over an ice year86). For lakes that do not form a complete ice cover every year or in some years (e.g. Laurentian Great Lakes of North America), maximum ice cover extent (timestamped with date) is also a useful climate indicator that can be determined87. Similarly, minimum ice cover extent (timestamped with date) can be derived for High Arctic lakes that do not completely lose their ice cover in summer, although a recent study suggests that these lakes may be transitioning from perennially to seasonally ice-covered88. Knowledge of fractional lake-wide ice coverage (expressed in tenth or as a percentage of total area of a lake covered by ice) on a ca. weekly basis is also useful for improving numerical weather forecasting in regions where ice cover forms.
Given the importance of ice cover in lake-atmosphere interactions, the LIC ECV will be of interest to users who wish to: 1) examine short-term trends and inter-annual variability in ice cover globally (ca. 20 years); 2) investigate the impact of changing ice cover conditions on other variables covered in the ESA CCI Lakes project, such as LSWT; 3) conduct data assimilation experiments using state-of-the-art numerical weather prediction systems to demonstrate the impact of better consideration of LIC on, for example, improving predictions of lake-effect snowfall; and 4) evaluate lake models (e.g. FLake) used as lake parametrisation schemes in numerical weather prediction and climate models. Finally, from a socio-economic perspective, the LIC variable may also serve to examine the impact of changing ice conditions on winter transportation (shipping, ice roads) and food security (access to resources by northern communities via ice roads).
LSWT is the surface expression of the thermal structure of lakes and is changing in response to climatic trends. LSWT is needed for climate change studies, water budget analysis (linked to evaporation), lake physical and ecological modelling.
LWLR, also referred to as water colour, is the measurement of the quantity of sunlight reaching the remote detector after interaction with the water column. The maximum depth from which the reflected signal is observed depends on the optical properties of the water column, is dependent on the colour band (waveband) considered and, in natural waters, can range from tens of meters (up to nearly 100 m in the clearest ocean waters) to just centimetres in highly absorbing and/or turbid waters. The colour of water is retrieved using imaging or line-scanning optical detectors on satellites. Each sensor offers a specific trade-off between the observation time (longer periods yielding lower instrument noise) and the spatial resolution as well as the number of discrete wavebands in which reflectance is measured. Because relatively small changes in absorption by, for example, phytoplankton pigment need to be distinguishable, an adequate signal-to-noise of an ocean-colour sensor for the signal received at the top of the atmosphere should be at least 1000:1 (IOCCG 2012).
Based on LWLR estimation, several optical-biogeochemical characteristics of the lake may be determined from its colour. Main quantities of interest are:
-
the concentration of phytoplankton pigment, particularly chlorophyll-a, which is found in all species as the major photosynthetic pigment
-
vertical transparency, for submerged vegetation habitat mapping or primary production models when combined with chlorophyll-a and temperature observations or models
-
the concentration of (coloured) dissolved (organic) matter as a proxy for the dissolved organic carbon pool, as well as the quality of underwater light
-
the total amount of suspended sediment (TSM), either expressed as equivalent particulate dry weight or as turbidity.
Currently, globally validated algorithms to retrieve such quantities are available for chlorophyll-a and TSM or turbidity, and vertical transparency, with by far most of the attention in scientific literature dedicated to the retrieval of chlorophyll-a.
Reading the products
The ESA CCI Lakes dataset is stored in NetCDF4 Classical format files, compliant to both CF (Climate and Forecast) metadata convention (v1.8) and CCI Data Standards v2.3. The consistency of the product is ensured by the use of a common land mask over a common grid. The main characteristics of the product are as follow:
-
The product consists of daily aggregations (the product is specified at the nominal time of 12:00:00 UTC). If a parameter is missing the field is filled with a default value.
-
The product provides data over a latitude/longitude grid of 0.0083333° (1/120°), therefore each file contains 21600 number of rows and 43200 number of columns.
-
For LWL and LWE, for which the product consists on one value per lake, the value is set on each grid point belonging to a lake according to the common land mask.
-
There is a common lake identifier derived from existing databases (Global Land and Wetland Database (GLWD)89, Hydrolakes14, GloboLakes13) and created specifically for the project.
-
The extent is −180 to 180 degrees longitude, −90 to 90 degrees latitude, where positive signs point north and east. The pixel coordinate is the centre of the pixel.
-
For each variable, the associated uncertainty is also available and for LSWT quality flags are also reported for a correct use use of the product. Quality level 4 and 5 are strongly recommended especially for climate studies.
A wide choice of software packages can be used to visualise or manipulate the NetCDF data. A list of software is provided on the Unidata web site (https://www.unidata.ucar.edu/software/netcdf/software.html). The ESA CCI Lakes files can also be visualised with the Climate Analysis Toolbox (Cate) https://climate.esa.int/en/explore/analyse-climate-data), the reference software for visualising data developed within the CCI Program funded by ESA. Additionally, some scripts allowing to download data only on a selected area or for a selected lake are available in the GitHub of the project (https://github.com/cci-lakes/lakes_cci_tools).
Downloading the products
The complete ESA CCI Lakes dataset is available at CEDA https://doi.org/10.5285/a07deacaffb8453e93d57ee214676304 and it is free after registration. It is possible to download the whole dataset (almost 30 years of daily data) or to use scripts in diverse languages (e.g. Python) to download a well defined area in a certain period of time.
Will the climate data record be extended in time?
The ESA CCI Lakes dataset described here covers the period from September 1992, when the first altimetry data became available, to the end of 2020. ESA has recently funded a continuation of the CCI Lakes project, which will allow the release of future version of the dataset with new thematic variables such as Lake Ice Thickness (LIT) and Colored Dissolved Organic Matter (CDOM) as well as increased temporal coverage.
How should I refer to the products in publications?
The dataset is citable52 and by using the data you agree to cite both dataset and this article.
Code availability
An option to visualise the dataset is to use the software Climate Analysis Toolbox (Cate) see https://climate.esa.int/en/explore/analyse-climate-data/).
References
Cael, B., Heathcote, A. & Seekell, D. The volume and mean depth of Earth’s lakes. Geophysical Research Letters 44, 209–218, https://doi.org/10.1002/2016GL071378 (2017).
Verpoorter, C., Kutser, T. & Tranvik, D. S. L. A global inventory of lakes based on high-resolution satellite imagery. Geophysical Research Letters 41, 6396–6402, https://doi.org/10.1002/2014GL060641 (2014).
United Nations. Resolution adopted by the General Assembly on 25 september 2015. Report A/Res/70/1, United Nations (2016).
Woolway, R. et al. Global lake responses to climate change. Nature Reviews Earth & Environment 1, 388–403, https://doi.org/10.1038/s43017-020-0067-5 (2020).
Woolway, R. & Merchant, C. Worldwide alteration of lake mixing regimes in response to climate change. Nature Geoscience 12, 271–276, https://doi.org/10.1038/s41561-019-0322-x (2019).
Woolway, R. & Merchant, C. Amplified surface temperature response of cold, deep lakes to inter-annual air temperature variability. Scientific Reports 7, 4130, https://doi.org/10.1038/s41598-017-04058-0 (2017).
Torabi Haghighi, A. & Kløve, B. A sensitivity analysis of lake water level response to changes in climate and river regimes. Limnologica 51, 118–130, https://doi.org/10.1016/j.limno.2015.02.001 (2015).
Adrian, R. et al. Lakes as sentinels of climate change. Limnology and oceanography 54, 2283–2297, https://doi.org/10.4319/lo.2009.54.6_part_2.2283 (2009).
Belward, A. et al. The Global Observing System for Climate: Implementation needs. Tech. Rep. Ref. Number GCOS-200 315, World Meteorological Organization (2016).
Kraemer, B. et al. Century-long warming trends in the upper water column of lake Tanganyika. PloS One 10, e0132490, https://doi.org/10.1371/journal.pone.0132490 (2015).
Woolway, R. & Merchant, C. Intralake heterogeneity of thermal responses to climate change: A study of large Northern Hemisphere lakes. Journal of Geophysical Research: Atmospheres 123, 3087–3098, https://doi.org/10.1002/2017JD027661 (2018).
Simis, S. et al. ESA CCI Lakes Algorithm Theoretical Basis Document (ATBD). Report CCI-LAKES-0024-ATBD, European Space Agency (2020).
Carrea, L., Embury, O. & Merchant, C. Datasets related to in-land water for limnology and remote sensing applications: distance-to-land, distance-to-water, water-body identifier and lake-centre co-ordinates. Geoscience Data Journal 2, 83–97, https://doi.org/10.1002/gdj3.32 (2015).
Messager, M., Lehner, B., Grill, G., Nedeva, I. & Schmitt, O. Estimating the volume and age of water stored in global lakes using a geo-statistical approach. Nature Communications 7, 13603, https://doi.org/10.1038/ncomms13603 (2016).
Crétaux, J.-F. et al. An absolute calibration site for radar altimeters in the continental domain: Lake Issykkul in Central Asia. Journal of Geodesy 83, 723–735, https://doi.org/10.1007/s00190-008-0289-7 (2009).
Bergé-Nguyen, M. et al. Mapping mean lake surface from satellite altimetry and GPS kinematic surveys. Advances in Space Research 67, 985–1001, https://doi.org/10.1016/j.asr.2020.11.001 (2021).
Crétaux, J.-F. & Birkett, C. Lake studies from satellite radar altimetry. Comptes Rendus Geoscience 338, 1098–1112, https://doi.org/10.1016/j.crte.2006.08.002 (2006).
Wingham, D., Rapley, C. & Griffiths, H. New techniques in satellite altimeter tracking systems. ESA Proceedings of the 1986 International Geoscience and Remote Sensing Symposium 3 (1986).
Arsen, A., Crétaux, J.-F. & del Rio, R. A. Use of SARAL/AltiKa over mountainous lakes, intercomparison with Envisat mission. Marine Geodesy 38, 534–548, https://doi.org/10.1080/01490419.2014.1002590 (2015).
Boy, F., Crétaux, J.-F., Boussaroque, M. & Tison, C. Improving Sentinel-3 SAR mode processing over lake using numerical simulations. IEEE Transactions on Geoscience and Remote Sensing 60, 1–18, https://doi.org/10.1109/TGRS.2021.3137034 (2022).
Gao, H., Birkett, C. & Lettenmaier, D. Global monitoring of large reservoir storage from satellite remote sensing. Water Resources Research 48, W09504, https://doi.org/10.1029/2012WR012063 (2012).
Duan, Z. & Bastiaanssen, W. Estimating water volume variations in lakes and reservoirs from four operational satellite altimetry databases and satellite imagery data. Remote Sensing of Environment 134, 403–416, https://doi.org/10.1016/j.rse.2013.03.010 (2013).
Crétaux, J.-F. et al. Lake volume monitoring from space. Survey in Geophysics 37, 269–305, https://doi.org/10.1007/s10712-016-9362-6 (2016).
Pham-Duc, B. et al. The Lake Chad hydrology under current climate change. Scientific Reports 10, 5498, https://doi.org/10.1038/s41598-020-62417-w (2020).
Yang, X. et al. Monthly estimation of the surface water extent in France at a 10-m resolution using Sentinel-2 data. Remote Sensing of Environment 244, 111803, https://doi.org/10.1016/j.rse.2020.111803 (2020).
McFeeters, S. The use of Normalized Difference Water Index (NDWI) in the delineation of open water features. International Journal of Remote Sensing 17, 1425–1432, https://doi.org/10.1080/01431169608948714 (1996).
Feyisa, G., Meilby, H., Fensholt, R. & Proud, S. Automated Water Extraction Index: A new technique for surface water using Landsat imagery. Remote Sensing of Environment 140, 23–35, https://doi.org/10.1016/j.rse.2013.08.029 (2014).
Otsu, N. A threshold selection method from gray-level histograms. IEEE Transactions on Systems, Man, and Cybernetics 9, 62–66, https://doi.org/10.1109/TSMC.1979.4310076 (1979).
Carrea, L., Merchant, C. & Simis, S. Lake mask and distance to land dataset of 2024 lakes for the European Space Agency Climate Change Initiative Lakes v2 (Version 2.0.1). zenodo https://doi.org/10.5281/zenodo.6699376 (2022).
Bontemps, S. et al. Multi-year global land cover mapping at 300 m and characterization for climate modelling: achievements of the Land Cover component of the ESA Climate Change Initiative. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XL-7/W3, https://doi.org/10.5194/isprsarchives-XL-7-W3-323-2015 (2015).
Hersbach, H. et al. The ERA5 global reanalysis. Quarterly Journal of the Royal Meteorological Society 146, 1999–2049, https://doi.org/10.1002/qj.3803 (2020).
Dee, D. et al. The ERA-Interim reanalysis: configuration and performance of the data assimilation system. Quarterly Journal of the Royal Meteorological Society 137, 553–597, https://doi.org/10.1002/qj.828 (2011).
Cox, C. & Munk, W. Slopes of the sea surface deduced from photographs of sun glitter. Bulletin of the Scripps Institution of Oceanography 6, 401–488 (1956).
Embury, O., Merchant, C. & Filipiak, M. Refractive indices (500–3500 1/cm) and emissivity (600–3350 1/cm) of pure water and seawater. Edinburgh Data Share https://doi.org/10.7488/ds/162 (2008).
Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. International Journal of Remote Sensing 27, 3025–3033, https://doi.org/10.1080/01431160600589179 (2006).
Townshend, J. & Justice, C. Analysis of the dynamics of african vegetation using the Normalized Difference Vegetation Index. International Journal of Remote Sensing 7, 1435–1446, https://doi.org/10.1080/01431168608948946 (1986).
MacCallum, S. & Merchant, C. Surface water temperature observations of large lakes by optimal estimation. Canadian Journal of Remote Sensing 38, 25–45, https://doi.org/10.5589/m12-010 (2012).
Rodgers, C. Characterization and error analysis of profiles retrieved from remote sounding measurements. Journal of Geophysical Research 95, 5587–5595, https://doi.org/10.1029/JD095iD05p05587 (1990).
Rodgers, C. Inverse Methods for Atmospheric Sounding: Theory and Practice (World Scientific, 2000).
Saunders, R. et al. An update on the RTTOV fast radiative transfer model (currently at version 12). Geoscientific Model Development 11, 2717–2737, https://doi.org/10.5194/gmd-11-2717-2018 (2018).
The Group for High Resolution Sea Surface Temperature Science Team, Casey, K. & Craig, D. The recommended GHRSST Data Specification (GDS) 2.0 document revision 5. zenodo https://doi.org/10.5281/zenodo.4700466 (2012).
Duguay, C. et al. Ice cover variability on shallow lakes at high latitudes: Model simulations and observations. Hydrological Processes 17, 3465–3483, https://doi.org/10.1002/hyp.1394 (2003).
Wu, Y., Duguay, C. & Xu, L. Assessment of machine learning classifiers for global lake ice cover mapping from MODIS TOA reflectance data. Remote Sensing of Environment 253, 112206, https://doi.org/10.1016/j.rse.2020.112206 (2021).
Breiman, L. Random forests. Machine Learning 45, 5–32, https://doi.org/10.1023/A:1010933404324 (2001).
Lamarche, C. et al. Compilation and validation of SAR and optical data products for a complete and global map of inland/ocean water tailored to the climate modeling community. Remote Sensing 9, https://doi.org/10.3390/rs9010036 (2017).
Simis, S., Mata, A., Selmes, N. & Carrea, L. Lake polygons dataset accompanying Calimnos v1.4.0 and ESA CCI Lakes Climate Research Data Package v2.0. zenodo https://doi.org/10.5281/zenodo.4899250 (2021).
Spyrakos, E. et al. Optical types of inland and coastal waters. Limnology and Oceanography 63, 846–870, https://doi.org/10.1002/lno.10674 (2018).
Moore, T., Campbell, J. & Feng, H. A fuzzy logic classification scheme for selecting and blending satellite ocean color algorithms. IEEE Transactions on Geoscience and Remote Sensing 39, 1764–1776, https://doi.org/10.1109/36.942555 (2001).
Kruse, F. A. et al. The spectral image processing system (SIPS)-interactive visualization and analysis of imaging spectrometer data. AIP Conference Proceedings 283, 192–201, https://doi.org/10.1016/0034-4257(93)90013-N (1993).
Neil, C., Spyrakos, E., Hunter, P. & Tyler, A. A global approach for chlorophyll-a retrieval across optically complex inland waters based on optical water types. Remote Sensing of Environment 229, 159–178, https://doi.org/10.1016/j.rse.2019.04.027 (2019).
Liu, X. et al. Retrieval of chlorophyll-a concentration and associated product uncertainty in optically diverse lakes and reservoirs. Remote Sensing of Environment 267, 112710 (2021).
Carrea, L. et al. ESA CCI Lakes: Lake products, Version 2.0.2. Centre for Environmental Data Analysis https://doi.org/10.5285/a07deacaffb8453e93d57ee214676304 (2022).
Hassell, D., Gregory, J., Blower, J., Lawrence, B. & Taylor, K. A data model of the Climate and Forecast metadata conventions (CF-1.6) with a software implementation (cf-python v2.1). Geoscientific Model Development 10, 4619–4646, https://doi.org/10.5194/gmd-10-4619-2017 (2017).
Simis, S. et al. ESA CCI Lakes Product Validation Plan (PVP). Report CCI-LAKES-0030-PVP, European Space Agency (2020).
Morris, C. & Gill, S. Evaluation of the TOPEX/Poseidon altimeter system over the Great Lakes. Journal of Geophysical Research 99, 24527–24539, https://doi.org/10.1029/94JC01642 (1994).
Ričko, M., Birkett, C., Carton, J. & Crétaux, J.-F. Intercomparison and validation of continental water level products derived from satellite radar altimetry. Journal of Applied Remote Sensing 6, 0.1117/1.JRS.6.061710 (2012).
Schwatke, C., Dettmering, D., Bosch, W. & Seitz, F. DAHITI – An innovative approach for estimating water level time series over inland waters using multi-mission satellite altimetry. Hydrology and Earth System Sciences 19, 4345–4364, https://doi.org/10.5194/hess-19-4345-2015 (2015).
Crétaux, J.-F. et al. Absolute calibration / validation of the altimeters on Sentinel-3A and Jason-3 over the Lake Issykkul. Remote Sensing 10, 1679, https://doi.org/10.3390/rs10111679 (2018).
Nielsen, K., Andersen, O. & Ranndal, H. Validation of Sentinel-3A based lake level over US and Canada. Remote Sensing 12, 2835, https://doi.org/10.3390/rs12172835 (2020).
Quartly, G. et al. The roles of the S3MPC: Monitoring, validation and evolution of Sentinel-3 altimetry observations. Remote Sensing 12, 1763, https://doi.org/10.3390/rs12111763 (2020).
Birkett, C. & Beckley, B. Investigating the performance of the Jason-2/OSM radar altimeter over lakes and reservoirs. Marine Geodesy 33, 204–238, https://doi.org/10.1080/01490419.2010.488983 (2010).
Nielsen, K., Stenseng, L., Andersen, O., Villadsen, H. & Knudsen, P. Validation of CryoSat-2 SAR mode based lake levels. Remote Sensing of Environment 171, 162–170, https://doi.org/10.1016/j.rse.2015.10.023 (2015).
Bonnefond, P. et al. The benefits of the Ka-band as evidenced from the SARAL/AltiKa altimetric mission: quality assessment and unique characteristics of AltiKa data. Remote Sensing 10, 83, https://doi.org/10.3390/rs10010083 (2018).
Shum, C. et al. Calibration of Jason-1 altimeter over Lake Erie. Marine Geodesy 26, 335–354, https://doi.org/10.1080/714044525 (2003).
Medina, C., Gomez-Enri, J., Alonso, J. & Villares, P. Water level fluctuations derived from ENVISAT Radar Altimetry (RA-2) and in situ measurements in a subtropical water body: Lake Izabal (Guatemala). Remote Sensing of Environment 112, 3604–3617, https://doi.org/10.1016/j.rse.2008.05.001 (2008).
Zhang, G., Xie, H., Duan, S., Tian, M. & Yi, D. Water level variation of Lake Qinghai from satellite and in situ measurements under climate change. Journal of Applied Remote Sensing 5, 053532, https://doi.org/10.1117/1.3601363 (2011).
Yi, Y. et al. The performance of altimeter waveform retrackers at Lake Baikal. Terrestrial, Atmospheric and Oceanic Sciences 24, 513–519, https://doi.org/10.3319/TAO.2012.10.09.01 (TibXS) (2013).
Crétaux, J.-F. et al. Absolute calibration of Jason radar altimeters from GPS kinematic campaigns over Lake Issykkul. Marine Geodesy 34, 291–318, https://doi.org/10.1080/01490419.2011.585110 (2011).
Frappart, F. et al. Evaluation of the performances of radar and lidar altimetry missions for water retrievals in mountainous environement: The case of the Swiss lakes. Remote Sensing 13, 2196, https://doi.org/10.3390/rs13112196 (2021).
Peña-Luque, S. et al. Sentinel-1&2 multitemporal water surface detection accuracies, evaluated at regional and reservoirs level. Remote Sensing 13, 3279, https://doi.org/10.3390/rs13163279 (2021).
Lyons, E. et al. Quantifying sources of error in multitemporal multisensor lake mapping. Journal of Remote Sensing 34, 7887–7905, https://doi.org/10.1080/01431161.2013.827343 (2013).
Mishra, V., Limaye, A., Muench, R., Cherrington, E. & Markert, K. Evaluating the performance of high-resolution satellite imagery in detecting ephemeral water bodies over West Africa. Journal of Applied Earth Observation and Geoinformation 93, 102218, https://doi.org/10.1016/j.jag.2020.102218 (2020).
Ledauphin, T. et al. Monitoring of reservoir surfaces, altitudes and volumes using Sentinel-2 and Jason-3 satellite data, and future trends with SWOT: case of the lacs de Seine reservoirs (France) - HYDROSPACE-GEOGloWS 2021, ESA-ESRIN, Frascati (Rome), Italy (7–11 June 2021).
Saunders, P. The temperature at the ocean-air interface. Journal of the Atmospheric Science 24, 269–273, https://doi.org/10.1175/1520-0469(1967)024<0269:TTATOA>2.0.CO;2 (1967).
Embury, O., Merchant, C. & Corlett, G. A reprocessing for climate of sea surface temperature from the along-track scanning radiometers: Initial validation, accounting for skin and diurnal variability effects. Remote Sensing of Environment 116, 62–78, https://doi.org/10.1016/j.rse.2011.02.028 (2012).
Wilson, R., Schneider, S. H. P. & Schladow, G. Skin and bulk temperature difference at lake Tahoe: A case study on lake skin effect. Journal of Geophysical Research: Atmospheres 118, 10332–10346, https://doi.org/10.1002/jgrd.50786 (2013).
Hondzo, M., You, J., Taylor, J., Bartlet, G. & Voller, V. Measurement and scaling of lake surface skin temperatures. Geophysical Research Letters 49, e2021GL093226, https://doi.org/10.1029/2021GL093226 (2022).
Simis, S. et al. ESA CCI Lakes Product Validation and Intercomparison Report Product (PVIR). Report CCI-LAKES-0031-PVIR, European Space Agency (2021).
Jiang, D. et al. ESA CCI Lakes Product Validation and Intercomparison Report Product for Consistency. Report CCI-LAKES-CCN-PVIR-1.0, European Space Agency (2021).
Voss, K. A. et al. Groundwater depletion in the Middle East from GRACE with implications for transboundary water management in the Tigris-Euphrates-Western Iran region. Water Resources Research 49, 904–914, https://doi.org/10.1002/wrcr.20078 (2013).
Free, G. et al. Detecting climate driven changes in chlorophyll-a in deep subalpine lakes using long term satellite data. Water 13, 866, https://doi.org/10.3390/w13060866 (2021).
Free, G. et al. Detecting climate driven changes in chlorophyll-a using high frequency monitoring: the impact of the 2019 European heatwave in three contrasting aquatic systems. Sensors 21, 6242, https://doi.org/10.3390/s21186242 (2021).
Free, G. et al. Shorter blooms expected with longer warm periods under climate change: an example from a shallow meso-eutrophic Mediterranean lake. Hydrobiologia 1–16, https://doi.org/10.1007/s10750-021-04773-w (2022).
Ghirardi, N. et al. Evaluation of macrophyte community dynamics (2015–2020) in southern Lake Garda (Italy) from Sentinel-2 data. Applied Sciences 12, 2693, https://doi.org/10.3390/app12052693 (2022).
Carrea, L. & Merchant, C. Factors influencing lake surface water temperature variability and change in West Greenland. submitted to Scientific Report (2022).
Duguay, C., Bernier, M., Gauthier, Y. & Kouraev, A. Remote sensing of lake and river ice. In Tedesco, M. (ed.) Remote Sensing of the Cryosphere, chap. 12, 273–306, https://doi.org/10.1002/9781118368909 (John Wiley & Sons Ltd, 2015).
Derksen, C. et al. Changes in snow, ice, and permafrost across Canada. In Bush, E. & Lemmen, D. (eds.) Canada’s Changing Climate Report, chap. 5, 194–260 (Government of Canada, 2019).
Surdu, C., Duguay, C. & Prieto, D. F. Evidence of recent changes in the ice regime of high arctic lakes from spaceborne satellite observations. The Cryosphere 10, 941–960, https://doi.org/10.5194/tc-10-941-2016 (2015).
Lehner, B. & Döll, P. Development and validation of a global database of lakes, reservoirs and wetlands. Journal of Hydrology 296, 1–22 (204), https://doi.org/10.1016/j.jhydrol.2004.03.028.
Gilerson, A. A. et al. Algorithms for remote estimation of chlorophyll-a in coastal and inland waters using red and near infrared bands. Optics Express 18, 24109–24125, https://doi.org/10.1364/OE.18.024109 (2010).
Gons, H. J., Rijkeboer, M. & Ruddick, K. G. Effect of a waveband shift on chlorophyll retrieval from MERIS imagery of inland and coastal waters. Journal of Plankton Research 27, 125–127, https://doi.org/10.1093/plankt/fbh151 (2005).
Mishra, S., Mishra, D., Lee, Z. & Tucker, C. Quantifying cyanobacterial phycocyanin concentration in turbid productive waters: A quasi-analytical approach. Remote Sensing of Environment 133, 141–151, https://doi.org/10.1016/j.rse.2013.02.004 (2013).
Dall’Olmo, G. et al. Assessing the potential of SeaWiFS and MODIS for estimating chlorophyll concentration in turbid productive waters using red and near-infrared bands. Remote Sensing of Environment 96, 176–187, https://doi.org/10.1016/j.rse.2005.02.007 (2005).
Zhang, Y., Shi, K., Liu, X., Zhou, Y. & Qin, B. Lake topography and wind waves determining seasonal-spatial dynamics of total suspended matter in turbid Lake Taihu, China: Assessment using long-term high-resolution MERIS data. PLoS One 9, e98055, https://doi.org/10.1371/journal.pone.0098055 (2014).
Vantrepotte, V. et al. Seasonal and inter-annual (2002-2010) variability of the suspended particulate matter as retrieved from satellite ocean color sensor over the French Guiana coastal waters. Journal of Coastal Research SI 64, 1750–1754 (2011).
Binding, C. E., Jerome, J. H., Bukata, R. P. & Booty, W. G. Suspended particulate matter in Lake Erie derived from MODIS aquatic colour imagery. International Journal of Remote Sensing 31, 5239–5255, https://doi.org/10.1080/01431160903302973 (2010).
Miller, R. & McKee, B. Using MODIS Terra 250 m imagery to map concentrations of total suspended matter in coastal waters. Remote Sensing of Environment 93, 259–266, https://doi.org/10.1016/j.rse.2004.07.012 (2004).
Ondrusek, M. et al. The development of a new optical total suspended matter algorithm for the Chesapeake Bay. Remote Sensing of Environment 119, 243–254, https://doi.org/10.1016/j.rse.2011.12.018 (2012).
Chen, Z., Hu, C. & Muller-Karger, F. Monitoring turbidity in Tampa Bay using MODIS/Aqua 250-m imagery. Remote Sensing of Environment 109, 207–220, https://doi.org/10.1016/j.rse.2006.12.019 (2007).
Petus, C. et al. Estimating turbidity and total suspended matter in the Adour river plume (South Bay of Biscay) using MODIS 250-m imagery. Continental Shelf Research 30, 379–392, https://doi.org/10.1016/j.csr.2009.12.007 (2010).
Zhang, M., Tang, J., Dong, Q., Song, Q. & Ding, J. Retrieval of total suspended matter concentration in the Yellow and East China Seas from MODIS imagery. Remote Sensing of Environment 114, 392–403, https://doi.org/10.1016/j.rse.2009.09.016 (2010).
Acknowledgements
The authors acknowledge the following funding for this work with gratitude. The European Space Agency supported the Climate Change Initiative - New ECVs for Lakes, which has provided the majority of support leading to the outcomes herein described, via grant reference 4000125030/18/I-NB. Foundational work has been supported by the Natural Environment Research Council (NERC) GloboLakes grants: NE/J023345/2, NE/J02211X/1, NE/J023396/1, NE/J021717/1 and NE/J022810/1. Use of the Centre for Environmental Data Analysis computational facilities to generate LSWT has been supported in part by the NERC National Centre for Earth Observation. The LIC work was enabled in part by support provided by Compute Canada (www.computecanada.ca). LWL and LWE product generation was also supported by the Centre National d’Études Spatiales (CNES) under the program TOSCA. Increasing the coverage for LWL and collecting in situ data for validation of LWL and LSWT have also been supported by the Copernicus Climate Change Service (C3S), funded by the European Commission. A particular thanks goes to the SERTIT team composed by T. Ledauphin, J. Maxant and M. Studer for their involvement in the LWE extraction methods analysis. The Pléiades/Sentinel-2 LWE comparison was supported by the Surface Water and Ocean Topography (SWOT) CNES program. LWLR computation benefited from computing infrastructure of the NERC Earth Observation Data Acquisition and Analysis Service (NEODAAS). The authors are thankful to all the institutions, such as the National Buoy Centre (NDBC), the Fisheries and Oceans Canada (FOC), the Swedish University of Agricultural Science (SLU), the Hungarian Met Service, NTL LTER, and UGLOS that have provided the in situ data for the validation of LSWT and in particular to Enner Alcântara (Saõ Paulo State University, Brazil), Curtis DeGasperi (King County Water and Land Resources Division, Department of Natural Resources and Parks, Seattle, WA, USA), Margaret Dix (Universidad del Valle de Guatemala, Guatemala), Martin Dokulil (Mondsee, Austria), Claudia Dresti (CNR Institute for Water Research, Italy), Hilary Dugan (University of Wisconsin-Madison, USA), Gideon Gal (Israel Oceanographic and Limnological Research Institute, Israel), Claudia Giardino (CNR Institute for Electromagnetic Sensing of the Environment, Italy), Badin Gibbes (The University of Queensland, Australia), Jacqui Hansson (Seqwater, Australia), April James (Nipissing University, Canada), Ilga Kokorite (University of Latvia and Latvian Environmental Geology and Meteorology Centre, Latvia), Alo Laas (Estonian University of Life Sciences, Estonia), Eric Leibensperger (State University of New York at Plattsburgh, USA), Alessandro Ludovisi (University of Perugia, Italy), Chris MacBride (NIWA, New Zealand), Shin-ichiro Matsuzaki (National Institute for Environmental Studies, Japan), Linda May (Centre for Ecology and Hydrology, Edinburgh, UK), Ghislaine Monet (UMR CARRTEL, France), Don Pierson (Uppsala University, Sweden), Sebastiano Piccolroaz (University of Trento, Italy), Tiina Nõges (Estonian University of Life Sciences, Estonia), Peeter Nõges (Estonian University of Life Sciences, Estonia), Antti Raike (SYKE, Finland), Alon Rimmer (Israel Oceanographic and Limnological Research Institute, Israel), Michela Rogora (CNR Institute for Water Research, Italy), Geoffrey Schladow (UC-Davis Tahoe Environmental Research Center, USA), Eugene Silow (Irkutsk State University, Russia), Evangelos Spyrakos (University of Stirling, UK), Wim Thiery (KU Leuven, Belgium), Piet Verburg (NIWA, New Zealand), Caroline Wynne (Environmental Protection Agency, Ireland), Gesa Weyhenmeyer (Uppsala University, Sweden). We also thank all organizations and individuals who made in situ data available through LIMNADES (limnades.stir.ac.uk) under the GloboLakes project or under separate agreements for the validation of the Calimnos processor for LWLR: Agri-food and Biosciences Institute in Northern Ireland; Balaton Limnological Institute; United States Environmental Protection Agency (US-EPA); Finnish Environment Institute (SYKE); Caren E. Binding (Environment and Climate Change Canada, Canada); Mariano Bresciani and Claudia Giardino (CNR Institute for Electromagnetic Sensing of the Environment, Italy); Anatoly A. Gitelson (Israel Institute of Technology, Israel); Tiit Kutser (University of Tartu, Estonia); Mark W. Matthews (CyanoLakes (Pty) Ltd., South Africa); John F. Schalles (Creighton University, Nebraska); Yunlin Zhang (Nanjing Institute of Geography and Limnology, China). A special thanks goes to Valerii Vuglinsky from State Hydrological Institute, St Petersburg in Russia for providing us with in situ data on LWL and LSWT.
Author information
Authors and Affiliations
Contributions
L.C. wrote the LSWT sections, the abstract, the background and organised and edited the contributions of co-authors. L.C., O.E. and C.M. contributed to the generation of the LSWT dataset, to the validation, and the creation of the in situ measurement database. Y.W. and C.R.D. generated and validated the LIC dataset, and co-wrote the LIC sections. X.L., N.S., S.G.H.S. and M.W. generated and validated the LWLR dataset. X.L. and S.G.H.S. wrote the LWLR sections. D.M. wrote the consistency section, building on her analysis of the L3 datasets and the cross-correlation and optical water type analyses by D.J. and X.L. J.F.C. with B.C., H.Y. and M.B.N. generated and validated the LWL and LWE datasets. J.F.C. wrote with B.C. the LWL sections, and J.F.C. with H.Y. wrote the LWE sections. B.C. generated the merged dataset and wrote with L.C. the Usage and Data Record sections. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Carrea, L., Crétaux, JF., Liu, X. et al. Satellite-derived multivariate world-wide lake physical variable timeseries for climate studies. Sci Data 10, 30 (2023). https://doi.org/10.1038/s41597-022-01889-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01889-z
This article is cited by
-
Slow response of surface water temperature to fast atmospheric variability reveals mixing heterogeneity in a deep lake
Scientific Reports (2024)
-
Disproportionate impact of atmospheric heat events on lake surface water temperature increases
Nature Climate Change (2024)
-
National-scale remotely sensed lake trophic state from 1984 through 2020
Scientific Data (2024)
-
Inland Surface Waters Quantity Monitored from Remote Sensing
Surveys in Geophysics (2023)
