
Abstract
Obtaining a dynamic population distribution is key to many decision-making processes such as urban planning, disaster management and most importantly helping the government to better allocate socio-technical supply. For the aspiration of these objectives, good population data is essential. The traditional method of collecting population data through the census is expensive and tedious. In recent years, statistical and machine learning methods have been developed to estimate population distribution. Most of the methods use data sets that are either developed on a small scale or not publicly available yet. Thus, the development and evaluation of new methods become challenging. We fill this gap by providing a comprehensive data set for population estimation in 98 European cities. The data set comprises a digital elevation model, local climate zone, land use proportions, nighttime lights in combination with multi-spectral Sentinel-2 imagery, and data from the Open Street Map initiative. We anticipate that it would be a valuable addition to the research community for the development of sophisticated approaches in the field of population estimation.
Measurement(s) | human population distribution |
Technology Type(s) | remote sensing |
Factor Type(s) | remote sensing data |
Sample Characteristic - Location | Europe |
Similar content being viewed by others
Background & Summary
Rapid urbanization in cities is leading to environmental concerns such as climatic changes, food and water scarcity, poor air quality, deforestation, etc1,2,3,4,5. To understand the key trends in urbanization, population estimation plays a crucial role. Traditionally, population estimation is done through a census. In this procedure, the population data is systematically collected and compiled over an administrative unit or a census unit. The accuracy of the data depends upon the number and size of the administrative unit, the collection method, the completeness of the survey, and varies significantly within the rural and urban regions6.
In recent years, statistical and machine learning methods have been applied directly to remote sensing data to estimate the population distribution6,7. In general, these methods have been applied either to a smaller region or based on some country-specific data such as building footprints or other detailed geospatial data sets which are not easily available in other countries. Stevens et al.8 used a random forest approach to estimate the population at ~100 m resolution for Vietnam, Cambodia, and Kenya. They have incorporated a wide range of remotely-sensed and geospatial datasets, such as distance to roads, health facility, elevation, land cover, vegetation, settlements, and nighttime lights, and used the country-specific census data collected from the National Institute of Statistics for Cambodia, the National Statistics Office in Vietnam, and the National Bureaus of Statistics for Kenya. Doupe et al.9 proposed a new method that used a Convolutional Neural Network (CNN) to estimate the population by combining Landsat-7 satellite imagery with (DMSP/OLS) nighttime lights. They trained their model on data from Tanzania at a 250 m satellite pixel resolution and estimated the population for Kenya at 8 km resolution. They have published the code to reconstruct their data set for Tanzania and Kenya. Another similar CNN approach has been proposed by Robinson et al.10 They prepared their data from US census summary grids in combination with Landsat imagery to estimate the population in the US counties at a 1 km resolution. Hu et al.11 also suggested a deep learning approach by combining satellite imagery from Landsat-8 and Sentinel-1 and used the Socio-Economic Caste Census survey to derive the population density for India. In most of the methods above, either the data is not available for download or could be reconstructed only for a few cities. Other gridded population products include Global Human Settlement Population Grid (GHS-POP)12, WorldPop13, Oak Ridge National Laboratory’s LandScan14, and High-Resolution Settlement Layer (HRSL)15, and so on. The difference in the estimation method and ancillary data used in the data sets lead to different results6. Few studies have been conducted to assess and compare the accuracy of gridded population products by comparing their estimations with the actual population counts16,17. However, these studies require collecting and processing the census data. Therefore, it becomes difficult and time-consuming to reproduce the results or compare the methods.
With our data set, we aim to fill these gaps by providing a systematic regression and classification scheme for population estimation in 98 European cities. The cities cover 28 European Union (EU) member states and the four EFTA countries. It represents a wide range of topography, demography, and architectural designs across the countries. It would save the cost of collecting and processing of a new data set to develop and validate the methods. The data set comprises digital elevation models (DEM), local climate zone (LCZ), land use proportions (LU), and nighttime lights (VIIRS) in combination with multi-spectral Sentinel-2 imagery (SEN2), and data from the Open Street Map initiative (OSM). This multi-data source combination has not been explored before in the domain of population estimation. We expect that it will be a valuable addition to the research community for developing sophisticated approaches in the field of population estimation.
In this paper, we contribute to the current literature by providing a benchmark data set created from publicly available data sets. We investigated the fusion of multi-source data over a large number of cities. To demonstrate the potential capability of our data set, we trained the Random Forest model using the extracted features from the input data to estimate the population on our test data set. The initial results indicate that there is a conceivable potential for the development of powerful machine learning methods with the So2Sat POP data set.
Methods
Our region of interest (ROI) is spread over Europe (Fig. 1). Initially, we select all the cities across Europe with 300,000 inhabitants or more in 2014 as per the UN World Urbanization Prospects - The 2014 Revision18. Out of these cities, we select 106 cities based on the availability of population data. Typically, a city can be described as a permanent large human settlement defined by the administrative boundaries. However, defining an administrative boundary could be very tricky because it changes as the census tracts merge or split over time. The outward expansion of the cities is far beyond their formal administrative boundaries19,20. So, we employed an algorithm to determine the extent of the city. The city center coordinates listed in the UN World Urbanization Prospects - The 2014 Revision18 have been used as a starting point in combination with Global Urban Footprint (GUF)21 which provides a binary mask of urban vs. non-urban regions. A rectangle centered at the coordinate of each city is adaptively grown outwards until half of the area of the rectangle is not built up anymore according to the GUF. To take the rapid urbanization into account, each side of the rectangles is expanded by a factor of two (i.e. a factor of four in the area). Since the resulting rectangles of two neighboring cities might intersect with another, a set of rules is employed to allocate the intersecting area to one of the two cities and ensure that each city’s extent covers a unique area. This set of rules is summarized in Algorithm 1. The algorithm runs recursively and in descending order, starting from the cities with the highest relative overlap. According to the set of rules, citya is either merged into cityb or the overlapping are is allocated to citya and removed from cityb, depending on the relative size of the overlapping area. The number of cities is merged to 98 in order to handle these overlaps. As per the defined extent of each city, we processed and prepared the following input data sources.

The orange dots on the figure above indicate the location of selected EU cities in our study.
Algorithm 1
Allocation of intersecting areas - Pseudocode.
Input data sources
Population data
Generally, the country-specific Census Bureau provides the population data by the hierarchy of administrative units. The heterogeneity in the size of the administrative units makes it difficult to use the data directly for the analysis. In such a scenario, gridded population products with uniformly sized grid cells offer detailed and consistent population maps. The most common way to produce the gridded population products is to redistribute the census count from the administrative level to the fine grid cells, conditioned by ancillary data such as land use and land cover maps, this method is also known as dasymetric mapping22.
The European Statistical System (ESSnet) project, in cooperation with the European Forum for Geography and Statistics (EFGS), aimed to produce the high resolution (1 km) population grids from the population census in Europe. The methodology constitutes aggregation, disaggregation, and hybrid approaches based on the availability of the data. Aggregation (bottom-up approach) is assumed to be the best way to produce the population grids23. In this project, approximately 18 countries are using the aggregation or at least a hybrid method to produce the grid statistics24. Due to a lack of geocoded microdata, the disaggregation (top-down approach) method has been employed in some regions. In disaggregation, the difference between the modeled population and the actual population of the region depends upon the size of the administrative unit. Often higher misplacement of the people is observed in the larger administrative unit. The overall quality of the product varies depending upon the data availability ranging from positional accuracy of 0.1 m for each address and building in Austria to up to 100 m in Estonia25 (for details see the document named ‘GEOSTAT_grid_POP_1 K_2011_V2_0_QA.pdf’ in the folder titled ‘GEOSTAT-grid-POP-1K-2011-V2-0-1’). The European Environment Agency published the population grids for EU28 + EFTA countries that comprise approximately 4.3 million km2 with 480 million inhabitants23. It is freely available via Eurostat, for non-commercial purposes. Further details regarding the product standards, methodology, and quality assessments can be found at the GEOSTAT 1B project website26.
Sentinel-2
The Sentinel-2 mission27 was launched in June 2015 by the European Space Agency (ESA) and consists of two identical satellites, 2 A and 2B,phased at 180 degrees toward each other. Sentinel-2 satellites provide multi-spectral optical images with a span of 13 spectral bands at a spatial resolution of 10 m, 20 m, 60 m. Thus, freely available Sentinel-2 imagery offers great potential for the fine-scale mapping of human settlements. The analysis-ready cloud-free mosaics of Sentinel-2 data have been achieved using the cloud detection approach based on a pixel-wise analysis28. We have used all four seasonal sets of Sentinel-2 images to capture the seasonal variation in the data. The spring, summer, and autumn seasons are from 2017 and winter is from 2016.
TanDEM-X digital elevation model
The goal of the TanDEM-X mission is to create a high-quality 3D topographic map of the Earth that is homogeneous in quality and unparalleled in accuracy. The data acquisition period for the global DEM product is between December 2010 and January 2015 and the global DEM has been produced in September 2016. With the coverage of 150 Million km2 of the complete Earth’s landmasses and 10 m absolute height accuracy (90% linear error)29, it is suitable for various applications in Environmental research such as land cover and land use analysis, urban planning, climate change, etc. Currently, the TanDEM-X digital elevation model is the most accurate digital elevation model (DEM) available globally30. We have used the freely available TanDEM-X 90 m (3 arcsec) DEM global product31 that contains the final, global Digital Elevation Model (DEM) of the landmasses of the Earth32.
Local climate zones
Local climate zone (LCZ) is a freely available systematic housing density classification data set, formally developed to standardize urban heat island studies33. Based on the land surface and properties, it consists of 17 structural types of which 10 are describing built zones from compact high-rise to open low-rise and 7 are natural zones ranging from dense vegetation to bare lands. Thus, each zone is characterized by the built-up and land cover properties. We have used the urban local climate zone classifications, So2SatLCZ v1.0 at the resolution of 100 m, produced by fusing the freely available satellite data from Sentinel-1 and Sentinel-2 satellites using deep learning34. The patches in this data set are hand-labeled as per the local climate zones classification scheme by 15 domain experts, followed by a visual and quantitative evaluation process over six months. This benchmark data set, therefore, is of potential use for urbanologists, demographers, climatologists, and many other researchers.
Nighttime lights
Observational Nighttime lights (NTL) show a strong correlation with the spatial distribution of the human population35. We studied the two widely used Nighttime lights data, the DMPS-OLS and the NPP-VIIRS satellite images. NPP-VIIRS with a better spatial resolution (15 arc-second, about 500 m) has a higher potential in modeling the socio-economic indicators36. The annual composites of VIIRS nighttime lights derived from monthly mean data are freely available from 2012 to 2019 (https://eogdata.mines.edu/products/vnl/). We used a masked average radiance version of VNL V2, which is a preprocessed version free of outliers from fleeting events37.
OSM
OpenStreetMap (OSM) (http://www.openstreetmap.org) is an open and crowd-sourced platform for maps, available under the Open Data Commons Open Database License (ODbL) (http://www.opendatacommons.org/licenses/odbl/1.0/). Geo-referenced locations on a very detailed level can be entered as nodes, ways, or relations and specified with informative tags. These locations include any type of buildings, streets, boundaries, water bodies, etc.38. Our data set contains low-level and high-level features derived from OSM data. At a low level, a locale with a high number of certain nodes (e.g. supermarkets, gas stations, residential buildings, schools, etc.) correlates strongly with the population in the vicinity. A simple counter statistic of such node-types is a strong indicator and can serve as a feature vector for population density estimation. As high-level features we extracted the building functions from OSM building tags to represent urban land use. This information is closely linked to employment, social support, and population39 and indicates the interaction between human activities and the environment.
Data preprocessing
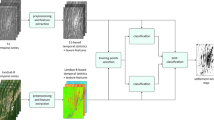
We employed two-step preprocessing for all input data sources. In the first step, input data for each city has been created. The second step includes the creation of the 1 × 1 km patches for each city. Figure 2 outlines the step-by-step preprocessing of all the data that has been employed to create the input data for each city. All the input data has been cropped using the city boundaries defined by our algorithm. DEM data is standardized by subtracting the DEM mean and then scaled to unit variance. To match the spatial resolution of the Sentinel-2 RGB bands, other data sources such as the digital elevation model (DEM), local climate zone (LCZ), and VIIRS nighttime lights (VIIRS) have been up-sampled to 10 m. Since the input data sets are from various sources, they are in different Coordinate Reference Systems (CRS). The VIIRS is in WGS84 (EPSG:4326), the LCZ, DEM, and SEN2 data are in the Universal Transverse Mercator (UTM) zone and the population grid is in the EPSG:3035 - ETRS89-extended/LAEA Europe. To align the input data with the population grid, all the input data have been reprojected from their corresponding coordinate system to the EPSG:3035 coordinate reference system.

Step-by-step preprocessing of all the input data sources to prepare the corresponding input data for each city.
Low-level features
The OSM planet dump of 2017-07-03 is being downloaded directly from the OpenStreetMap archive (https://planet.osm.org/planet/2017/). To reduce the computation time by touching the huge planet file only once, we extract the bounding box of each corresponding city and subsequently 1 × 1 km patches from these extracted city-dumps with the Osmosis command line tool (https://github.com/openstreetmap/osmosis). The OSM node statistics are extracted for each 1 × 1 km patch of the city using the OSMnx python Library40. Table 1 shows the considered OSM tags over which the statistical analysis has been done.
High-level features
To create the land use data we analyzed three different tags of buildings in OSM: building, amenity, and shop. For each of them, OSM provides a guideline on possible values. In total, there are 341 possible values for these three tags, which are mapped to a homogenized and simplified land use classification scheme: commercial, industrial, residential, and other. As the three tags can occur jointly, we make sure that they are not contradicting each other and omit buildings that have inconsistent values. Moreover, the tags are captured as free-form text fields and hence, OSM contributors are not restricted to use them but can enter any text. After homogenizing the semantic information, we convert the vector data of building polygons into raster data. The rasterized value represents the area covered by building polygons inside a raster pixel. For scaling, we divided the area by the area of a pixel to yield a relative number of how much of a pixel is covered by building polygons. Applying this procedure for each land use class results in a four-band raster with corresponding land use proportions. The output of the first step of data preprocessing for Munich city can be seen in Fig. 3.

All the input data for the Munich city, created using the first step of data preprocessing.
In the second step, for each city, we created the patches using all the input data processed in the first step. The population grid of a city is used as a reference grid to crop all the other input data. The size of a grid cell in the population grid is 1 × 1 km and each cell represents the population count living per square km of the cell. The grid cells along the border of the population grid might belong to two adjacent cities. To avoid this duplicity such that one grid cell should belong to only one city, we applied an area thresholding to all the cells. Only the cells with an area greater than 900,000 m2 or size ~0.95 × 0.95 km have been considered as a part of the city. This eliminates the grid cells from the edges which are not fully included in the city boundary. Also, the reference Geostat population grid has some missing cells. The missing cells mostly contain the uninhabited regions. Such regions cover the green fields and water bodies. We included these missing cells in our data set to allow for zero population predictions. The patches cropped using the population grid have been assigned the population count as of the corresponding grid cell. The rest of the missing uninhabited patches have been assigned as zero population count. For some applications such as environmental impact assessments, land use analysis, climate change, etc. it is sufficient to know the range of the people living in a region. So, we further preprocessed the population grids by binning the population count to a population class. We assigned a grid cell, Class 0, if the population count of the cell is zero, Ccell = 0 if Pcell = 0 and subsequently Ccell = 1 if 2° ≤Pcell < 21, Ccell = 2 if 21 ≤ Pcell < 22, Ccell = 3 if 22 ≤ Pcell < 23…..Ccell = k + 1 if 2k ≤ Pcell < 2k+1 where k \(\in \) \({\mathbb{N}}\). For our data, the highest value of k is 16. This process of discretization is inspired by Robinson et al.10. Thus, each grid cell has been assigned a population class in addition to the absolute population count. It would give more flexibility to the end-users to develop either regression or a classification model for the task considering the requirements of the application.
Figure 4 illustrates the patch creation process. For every grid cell, a total of 9 patches, one from each data source have been created. We called the 9 patches corresponding to one grid cell, a patch-set. Each patch-set represents a population count as of the corresponding population grid cell and a population class depending on which bin the population count of the grid cell falls at the resolution of 1 km. Figure 5 depicts the odd-numbered class samples from our data set with their corresponding patch-set, population class and population count. The lower classes represent sparsely populated regions. Patches belonging to lower classes mostly contain green fields, water bodies, and bare land. As the class number goes higher, patches contain few low-rise to dense high-rise built-up regions. In other words, patches from lower to higher classes represent rural to urban regions.

Patch creation process, second step of data preprocessing. All input data sources have been cropped for each cell in the population grid. The size of each patch is 1 × 1 km.

Sample patches from the odd numbered classes of our data set. Lower classes depicts sparsely populated regions while higher classes depicts densely populated regions.
Data Records
The final data set consists of two parts, So2Sat POP Part141 and So2Sat POP Part242. All the data patches except OSM data are available as GeoTiff images. Along with the raw OSM patches, we also provide the features extracted from the OSM data as separate Comma Separated Value (CSV) files. So2Sat POP Part1 consists of the patches from local climate zones, land use, nighttime lights, Open Street Map features, and from all seasons(autumn, summer, spring, winter) of Sentinel-2 imagery, a total of 1,104,688 patches. So2Sat POP Part2 consists of patches from the digital elevation model and Open Street Map only, a total of 276,172 patches. So2Sat POP Part1 has the storage requirement of ~96 GB and So2Sat POP Part2 requires ~5.20 GB.
Data set structure and naming convention
Both parts of the data set consist of a predefined train and test split. Out of 98 cities, 80 cities (~80% of the data) have been randomly selected as a training set and the rest of the 18 cities (~20% of the data) constitute the test set. The city folder has been named as xxxx_xxxxx_city_name, where xxxx_xxxxx constitutes randomly generated identification number and the postal code of the city.
The digital elevation model (DEM), local climate zone (LCZ), land use (LU), nighttime lights (VIIRS), Sentinel-2 autumn data (sen2autumn), Sentinel-2 spring data (sen2spring), Sentinel-2 summer data (sen2summer), Sentinel-2 winter data (sen2winter), Open Street Map (OSM) and its corresponding extracted features (osm_features) are the utilized input sources. All city folders in So2Sat POP Part1 contain 7 sub-folders, one for each input data source except the OSM and DEM data, a separate folder for processed osm features, and a comma-separated value (*.csv) file that contains the absolute population count and population class for each patch. In So2Sat POP Part2, the city folders contain the Open Street Map and digital elevation model data sub-folder. All data folders have their class sub-folders. The class folders have been named as Class_x where x denotes the class number. The number of class folders in a city depends on its population distribution. For example, Malaga has the highest class folder as 16 because the highest population count in the 1 × 1 km area of the city is 39535 while in Riga the highest population count is 15839 so the highest class folder in its city folder is 14. A patch has been assigned a unique identification code using the naming convention of its corresponding population grid cell. The naming of the grid cell (based on the LAEA grid) begins with the size of the cell (1 km) followed by the coordinates (in km) of the lower left-hand corner, starting with the letter N followed by the latitude and E followed by the longitude, e.g. 1kmN4101E445324. The patches that do not correspond to the grid cells in the population grid have been simply given a numeric identification number.
Access and availability
The data set is available for download at the persistent links provided by the official media library of the Technical University of Munich (TUM). So2Sat POP Part 1 (https://mediatum.ub.tum.de/1633792) is distributed under the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/) and So2Sat POP Part 2 (https://mediatum.ub.tum.de/1633795) is distributed under the Creative Commons Attribution Share-Alike International License (http://creativecommons.org/licenses/ by-sa/4.0/). Kindly cite this paper when the data set is used.
Technical Validation
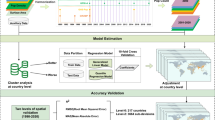
To demonstrate the suitability of the data set for population estimation, we implemented the popular Random Forest (RF) algorithm43, because of its flexibility, efficiency in handling the noisy input data, and relative resistance to overfitting44. Another advantage of the random forest algorithm is that it is easy to measure the relative importance of each feature on the prediction. We implemented the supervised random forest algorithm in Python with the scikit-learn library for both the regression and classification tasks. We used grid search to automatically fine-tune the number of trees to grow and the maximum number of features to consider splitting a node and assess the performance through a 10-fold cross-validation. To train the model, different features are constructed from all the input data patches of 80 train-set cities. The constructed features include min, max, mean, median, and standard deviation from only the RGB bands of Sentinel-2 imagery, mean and max for digital elevation model and nightlights, the total area covered by each class in land use, majority class for local climate zone, and osm-based features such as street density, presence of highways, railways, etc., extracted from osm patches. Using this process, we calculated 125 features for each patch. For regression, we used the absolute population count as the response variable while in classification, class labels are used as ground truth.
The trained model has been evaluated on the 18 unseen test cities. Figure 6 shows only the twelve most relevant features that have been selected by the random forest algorithm and used to estimate the population count and a population class for the set of test data. The features extracted from the OSM data, nightlights, and LCZ classes have been ranked as the most important features for both tasks. For regression, we calculated the root-mean-square error (RMSE) and the mean absolute error (MAE). Table 2 indicates the performance of the regression model. Since the data set is imbalanced due to the higher percentage of non-urban regions than the urban regions, we used balanced accuracy to evaluate the classification performance. Also, we used macro-averaged Precision, Recall, and F1-score metrics to treat each class equally, regardless of any imbalance. Table 3 summarized the results from the classification. To further describe the performance of the classification model, we plotted a normalized confusion matrix on the set of test data. Figure 7(b) illustrates that the model is confident in predicting the higher classes (urban regions) while it does not perform well on the lower classes, which represent the sparsely populated regions. The initial three classes (Class 1, 2, and 3) represent the regions where the population count is in the range 1–8, and, likely, the features among these three classes are not distinguishable enough. So, it becomes very difficult to differentiate the patches from Class 1 to Class 3. One simple solution to it is the merging of these initial classes, which represent the population count range of less than 8. It could significantly improve the results without the loss of any critical information. To give more flexibility to the user, we provided the data set without any such post-processing, and it could easily be rearranged as per the specific needs. For regression, to visually assess the model fit, we plotted the actual population count of the grid cells versus the population count predicted for each grid cell of the test data. Figure 7(a) indicates that the model underestimates the actual values for the patches where the population count is high while for the patches with a population count of less than 15.000, it is relatively a good fit. We believe that with more sophisticated features and machine learning methods, a powerful model could be developed to estimate the population using our data set.

Random Forest feature importances based on mean decrease in impurity (MDI). The higher the value the more important the feature. Plot shows only the twelve most relevant features for both regression (a) and classification (b).

(a) Predicted vs. Actual Values for regression, the model fits good except for the high population counts where the points appeared dispersed from regressed diagonal line (b) Confusion matrix for classification, normalized by class support size (number of patches in each class). Confusion among the non-urban classes is higher than among the urban classes.
Usage Notes
In this paper, we proposed a unique data set that combines multi-data sources which have not been explored at the cross-country level in this domain before. Our data set covers many cities across Europe thus offering diverse topography and demography. Also, the fusion of distinct data sources gives much more information about the landscape and other socio-demographic attributes of a region.
The availability of precise and detailed population data varies from country to country. The population grid used as a reference grid in our data set is available throughout Europe at a consistent resolution of 1 km, however, its precision may vary depending upon the quality of the data available in a country. Also, the reference population grid is based on the 2011 population and housing census data while other input data sources belong to a different time frame, for example, Sentinel-2 data belongs to the year 2016 as the mission itself has been launched in 2015. The time difference between the collection of the population data and other corresponding input data might introduce some noise to the evaluations. Usually, the population census has been conducted once in a decade, so it becomes very difficult to collect the other corresponding data from the same year, especially when collecting from multiple data sources. We still believe that this data set will be helpful in the development of the machine-learning based approaches in this domain. Also, the evaluation of different methodologies has always been a challenge due to the unavailability of the freely available benchmark data set. So, we hope this data set will be useful for the comparison and evaluations of the different approaches in the state of the art.
The data preparation is performed in Python using the common libraries for the geospatial data such as Geopandas, Fiona, Rasterio, and Geospatial Data Abstraction Library (GDAL). Our computing system consists of an HPC Server with 2x AMD EPYC ROME 7402 CPUs (48 core) and needed 5–6 days to complete the OSM patch files and their statistics. Along with the patches, we also provided the Comma Separated Value (CSV) files for each city that contains the actual population count and its corresponding population class for each grid cell. Thus, the end user could rearrange the data set using its corresponding population count according to the requirements of the use case.
We hope that this basic data set will make it possible to develop new statistical and machine learning approaches that derive the population in higher spatial resolution, but above in more consistency. It is precisely this consistency that is often lacking in today’s population data sets across countries. This data set is intended to lay the foundation for improved comparative studies in various application domains. This improved database for population distribution may be central information both, in the academic and non-academic fields. Be it as necessary information for spatial or urban planning, such as the provision of living space or socio-technical infrastructure, be it in the locale of risk analysis or coordination in an event, be it in the validation, support, or updating of censuses, or be it in comparative studies on topics such as migration in general and, more specifically, on urbanization or sub-urbanization trends.
Code availability
Python is used for all the analyses and implementations. The code to create the features for each city and to run the baseline experiments is available on our GitHub project (https://github.com/zhu-xlab/So2Sat-POP).
References
McDonald, R. I. et al. Urban growth, climate change, and freshwater availability. Proceedings of the National Academy of Sciences 108, 6312–6317 (2011).
Tatem, A. J. Mapping the denominator: spatial demography in the measurement of progress. International health 6, 153–155 (2014).
McGranahan, G., Balk, D. & Anderson, B. The rising tide: assessing the risks of climate change and human settlements in low elevation coastal zones. Environment and urbanization 19, 17–37 (2007).
Zhang, X. et al. Linking urbanization and air quality together: A review and a perspective on the future sustainable urban development. Journal of Cleaner Production 130988 (2022).
Szabo, S. Urbanisation and food insecurity risks: Assessing the role of human development. Oxford Development Studies 44, 28–48 (2016).
Leyk, S. et al. The spatial allocation of population: a review of large-scale gridded population data products and their fitness for use. Earth System Science Data 11, 1385–1409 (2019).
Wu, S.-s, Qiu, X. & Wang, L. Population estimation methods in gis and remote sensing: A review. GIScience & Remote Sensing 42, 80–96 (2005).
Stevens, F. R., Gaughan, A. E., Linard, C. & Tatem, A. J. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PloS one 10, e0107042 (2015).
Doupe, P., Bruzelius, E., Faghmous, J. & Ruchman, S. G. Equitable development through deep learning: The case of sub-national population density estimation. In Proceedings of the 7th Annual Symposium on Computing for Development, 1–10 (2016).
Robinson, C., Hohman, F. & Dilkina, B. A deep learning approach for population estimation from satellite imagery. In Proceedings of the 1st ACM SIGSPATIAL Workshop on Geospatial Humanities, 47–54 (2017).
Hu, W. et al. Mapping missing population in rural india: A deep learning approach with satellite imagery. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, 353–359 (2019).
Freire, S., MacManus, K., Pesaresi, M., Doxsey-Whitfield, E. & Mills, J. Development of new open and free multi-temporal global population grids at 250 m resolution (2016).
WorldPop. School of geography and environmental science, university of southampton; department of geography and geosciences, university of louisville; departement de geographie, universite de namur) and center for international earth science information network (ciesin), columbia university. Global High Resolution Population Denominators Project-Funded by The Bill and Melinda Gates Foundation (OPP1134076) (2018).
Bhaduri, B., Bright, E. & Coleman, P. & Dobson, J. Landscan. Geoinformatics 5, 34–37 (2002).
Layer, H. R. S. Facebook connectivity lab and center for international earth science information network-ciesin-columbia university. source imagery for hrsl© 2016 digitalglobe, 2016. Accessed on: 2022-06-21.
Chen, R., Yan, H., Liu, F., Du, W. & Yang, Y. Multiple global population datasets: Differences and spatial distribution characteristics. ISPRS International Journal of Geo-Information 9, 637 (2020).
Sliuzas, R., Kuffer, M. & Kemper, T. Assessing the quality of global human settlement layer products for kampala, uganda. In 2017 Joint Urban Remote Sensing Event (JURSE), 1–4 (IEEE, 2017).
United Nations, U. World Urbanization Prospects: 2014 Revision (United Nation, 2014).
Habitat, U. State of the world’s cities 2012/2013: Prosperity of cities (Routledge, 2013).
Taubenböck, H. et al. A new ranking of the world’s largest cities—do administrative units obscure morphological realities? Remote Sensing of Environment 232, 111353 (2019).
Esch, T. et al. Breaking new ground in mapping human settlements from space–the global urban footprint. ISPRS Journal of Photogrammetry and Remote Sensing 134, 30–42 (2017).
Langford, M. Rapid facilitation of dasymetric-based population interpolation by means of raster pixel maps. Computers, Environment and Urban Systems 31, 19–32 (2007).
Gallego, F. J. A population density grid of the european union. Population and Environment 31, 460–473 (2010).
Efgs - essnet project geostat 1b - final report. https://www.efgs.info/wp-content/uploads/geostat/1b/GEOSTAT1B-final-technical-report.pdf. Accessed on: 2022-10-05.
Eurostat gisco geostat 1 km2 population grid. https://ec.europa.eu/eurostat/web/gisco/geodata/reference-data/population-distribution-demography/geostat. Accessed on: 2022-10-05 (2011).
Efgs - essnet project geostat 1b - geostat 2011 quality assessment. http://www.efgs.info/wp-content/uploads/geostat/1b/GEOSTAT1B-Appendix17-GEOSTAT-grid-POP-1K-ALL-2011-QA.pdf. Accessed on: 2022-10-05.
Drusch, M. et al. Sentinel-2: Esa’s optical high-resolution mission for gmes operational services. Remote sensing of Environment 120, 25–36 (2012).
Schmitt, M., Hughes, L. H., Qiu, C. & Zhu, X. X. Aggregating cloud-free Sentinel-2 images with Google Earth Engine. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. IV-2/W7, 145–152, https://doi.org/10.5194/isprs-annals-IV-2-W7-145-2019 (2019).
Wessel, B. et al. Accuracy assessment of the global tandem-x digital elevation model with gps data. ISPRS Journal of Photogrammetry and Remote Sensing 139, 171–182 (2018).
Esch, T. et al. Towards a large-scale 3d modeling of the built environment–joint analysis of tandem-x, sentinel-2 and open street map data. Remote Sensing 12, 2391 (2020).
German aerospace center Tandem-x - digital elevation model (dem) - global, 90 m. German Aerospace Center (DLR) https://doi.org/10.15489/ju28hc7pui09 (2018).
Wessel, B. Tandem-x ground segment–dem products specification document. EOC, DLR, Oberpfaffenhofen, Germany, Public Document TD-GS-PS-0021, Issue 3.2. [Online]. Available online: https://tandemx-science.dlr.de/ (2018).
Stewart, I. D. & Oke, T. R. Local climate zones: Origins, development, and application to urban heat island studies. In Proceedings of the Annual Meeting of the American Association of Geographers, Seattle, WA, USA, 12–16. Accessed on: 2022-06-21 (2011).
Zhu, X. X. et al. So2sat lcz42: A benchmark data set for the classification of global local climate zones [software and data sets]. IEEE Geoscience and Remote Sensing Magazine 8, 76–89, https://doi.org/10.14459/2018mp1483140 (2020).
Liu, Q., Sutton, P. C. & Elvidge, C. D. Relationships between nighttime imagery and population density for hong kong. Proc. Asia-Pac. Adv. Netw 31, 79 (2011).
Shi, K. et al. Evaluating the ability of npp-viirs nighttime light data to estimate the gross domestic product and the electric power consumption of china at multiple scales: A comparison with dmsp-ols data. Remote Sensing 6, 1705–1724 (2014).
Elvidge, C. D., Zhizhin, M., Ghosh, T., Hsu, F.-C. & Taneja, J. Annual time series of global viirs nighttime lights derived from monthly averages: 2012 to 2019. Remote Sensing 13, 922, https://doi.org/10.3390/rs13050922 (2021).
Map features documentation wiki. https://wiki.openstreetmap.org/wiki/Map_features. Accessed on: 2021-08-21.
Li, X., Wang, Y., Li, J. & Lei, B. Physical and socioeconomic driving forces of land-use and land-cover changes: A case study of wuhan city, china. Discrete Dynamics in Nature and Society 2016 (2016).
Boeing, G. Osmnx: New methods for acquiring, constructing, analyzing, and visualizing complex street networks. Computers, Environment and Urban Systems 65, 126–139, https://doi.org/10.1016/j.compenvurbsys.2017.05.004 (2017).
Doda, S. et al. So2sat pop part 1, mediatum https://doi.org/10.14459/2021mp1633792 (2022).
Doda, S. et al. So2sat pop part 2, mediatum https://doi.org/10.14459/2021mp1633795 (2022).
Breiman, L. Random forests. Machine learning 45, 5–32 (2001).
Grippa, T. et al. Improving urban population distribution models with very-high resolution satellite information. Data 4, 13 (2019).
Acknowledgements
This research was funded by the European Research Council (ERC) under the European Unions Horizon 2020 research and innovation program with the grant number ERC-2016-StG-714087 (Acronym: So2Sat, project website: www.so2sat.eu), Helmholtz Association under the framework of the Helmholtz AI (grant number: ZT-I-PF-5-01) -Local Unit “Munich Unit @Aeronautics, Space and Transport (MASTr)”, and Helmholtz Excellent Professorship “Data Science in Earth Observation - Big Data Fusion for Urban Research (grant number: W2-W3-100) and by the German Federal Ministry of Education and Research (BMBF) in the framework of the international future AI lab “AI4EO - Artificial Intelligence for Earth Observation: Reasoning, Uncertainties, Ethics and Beyond” (Grant number: 01DD20001). Additionally, Sugandha Doda is supported by the Helmholtz Association under the joint research school “Munich School for Data Science – MUDS”.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
S.D. drafted the manuscripts, S.D., E.H., M.K. and K.O. undertook data preparation, S.D. implemented and performed experiments, S.D. performed technical validation of the results. S.D., X.Z., Y.W., H.T. and M.K. edited the manuscript. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Doda, S., Wang, Y., Kahl, M. et al. So2Sat POP - A Curated Benchmark Data Set for Population Estimation from Space on a Continental Scale. Sci Data 9, 715 (2022). https://doi.org/10.1038/s41597-022-01780-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01780-x
This article is cited by
-
A global land cover training dataset from 1984 to 2020
Scientific Data (2023)
