
Abstract
Global population aging poses an unprecedented challenge and calls for a rising effort in eldercare and healthcare. Steady-state visual evoked potential based brain-computer interface (SSVEP-BCI) boasts its high transfer rate and shows great promise in real-world applications to support aging. Public database is critically important for designing the SSVEP-BCI systems. However, the SSVEP-BCI database tailored for the elder is scarce in existing studies. Therefore, in this study, we present a large eldercare-oriented BEnchmark database of SSVEP-BCI for The Aging population (eldBETA). The eldBETA database consisted of the 64-channel electroencephalogram (EEG) from 100 elder participants, each of whom performed seven blocks of 9-target SSVEP-BCI task. The quality and characteristics of the eldBETA database were validated by a series of analyses followed by a classification analysis of thirteen frequency recognition methods. We expect that the eldBETA database would provide a substrate for the design and optimization of the BCI systems intended for the elders. The eldBETA database is open-access for research and can be downloaded from the website https://doi.org/10.6084/m9.figshare.18032669.
Measurement(s) | Steady-state visual evoked potential (SSVEP) |
Technology Type(s) | Electroencephalography (EEG) |
Factor Type(s) | Elder population |
Sample Characteristic - Organism | Homo sapiens |
Sample Characteristic - Environment | Electromagnetic shielding room |
Similar content being viewed by others

Background & Summary
Aging population grows at an accelerating pace worldwide1,2,3,4,5. Over the past 180 years, the record life expectancy for humans has steadily increased by 2.5 years per decade and people have longer lives than ever before4,5. The longer lives are caused by the postponement of mortality, and most residents born in this century and in countries with high life expectancies will celebrate their 100th birthdays2,3. As a result of the longer livers and low fertility, the world is confronting an aging population, and one in five of the people in the world is projected to be elder citizens (60 years or above) by 20501,6. This situation is more grave in parts of the world, i.e., Europe and China, where one in four people is projected to be the elder by 20501,6,7. The global challenge of aging motivates the rising need of eldercare and technological support for the elder7,8,9.
Brain-computer interface (BCI) provides a direct path between the brain and external device for alternative and augmentative communication10,11, which suits the need for the eldercare. Among the BCI paradigms, steady-state visual evoked potential based BCI (SSVEP-BCI)12,13 has received increasing attention due to its noninvasiveness, high information transfer rate (ITR)13,14, zero calibration15,16, and low BCI-illiterate rate17. The high transfer rate of SSVEP-BCI is attributable to the high signal-to-noise ratio (SNR) of a typical brain response, i.e., SSVEP18, which is a frequency-tagged brain response elicited by periodic visual stimuli. The merits of SSVEP-BCI make it a prime candidate for real-world applications in eldercare and healthcare, e.g., brain-controlled wheelchair19,20, exoskeleton21,22, assistive robots23,24, and emergency call25.
Public databases play a vital role in designing and optimizing pattern recognition systems in real-world applications. For instance, in the field of computer vision, the open database of ImageNet26 has a far-reaching impact on the renewed flourish of artificial intelligence (AI). For the field of SSVEP-BCI, a number of studies in the literature contribute to the efforts in curating public databases17,27,28,29,30 and sharing relevant data31,32,33,34. Specifically for the public SSVEP-BCI database, however, the vast majority of participants are young adults, and little attention so far has been paid to the elder. For the elderly population, a database targeted at this community could provide an opportunity to design a BCI system better suited for the eldercare applications, considering age-related differences existent in the BCI performance35,36,37,38,39,40,41,42. In particular, for SSVEP-BCI, previous studies reported that the elderly people achieved significantly lower ITR and accuracy than the younger participants35,40,41. The deteriorated BCI performance is attributable to the signal profile of decreased SSVEP amplitude associated with the age-related changes38,42,43,44, and physiologically further related to degradation in crystalline lens45, influence in retinal and central visual pathways43, and cell loss in visual cortex due to senescence46. Since there is a substantial distinction in SSVEP between the younger and older population, it is worthwhile to leverage the signal profile to develop high-speed SSVEP-BCI systems for eldercare applications.
To meet the demand for the open database designated for the elder, here we present a large eldercare-oriented BEnchmark database of SSVEP-BCI for The Aging population (eldBETA) in this paper. The eldBETA database features a large number of participants, i.e., 100 in the study, with old age of average 63 years, and up to 81 years. Also, the database of electroencephalogram (EEG) was collected under a laboratory experimental protocol, which provided the database with a signal quality of gold standard in designing the practical applications tailored for the elderly community. In the experimental protocol, seven blocks of 9-target SSVEP-BCI tasks were performed for each participant, while 64 channels of continuous EEG including 5-s SSVEP for each trial were recorded. The data records were validated by signal profiles followed by SNR analysis and BCI quotient to demonstrate the quality and distribution of the database. The utility of the database was validated by the classification analysis, showing the elder could achieve an average ITR up to approximately 150 bpm by supervised methods and an average ITR up to approximately 60 bpm by training-free methods. Additionally, the fractal characteristics of the elderly population were validated by power-law analysis. In sum, the eldBETA database offers an opportunity to facilitate the development of methods and systems on BCI healthcare targeted at the elder, and contributes to extending our understanding of BCI technology in the era of the aging population.
Methods
Participants
This study recruited elderly volunteers with ages greater than 50 years old. One hundred participants (33 males and 67 females) took part in this study. The age of the participants ranged from 52 to 81 with an average of \(63.17\pm 6.05\) (mean ± standard deviation). All the participants had a normal or corrected-to-normal vision. The participants were instructed to be familiarized with experimental protocol and gave full written consent before the experiment. The experimental protocol was under the declaration of Helsinki and approved by the institutional review board of Tsinghua University (NO. 20210032).
Brain speller
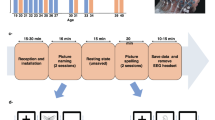
In this study, a 9-target brain speller of SSVEP-BCI was developed for the elder participants. As illustrated in Fig. 1(a), the 9 targets were aligned in a 3 × 3 matrix, which was visually presented on the screen of an LCD monitor (refresh rate: 60 Hz; resolution: \(1920\times 1080\) pixels). Each target had a dimension of 168 × 125 pixels and a digit character (a number from 1 to 9) lay at its center. The horizontal interval between adjacent targets was 100 pixels, and the vertical interval was 70 pixels. For the brain speller, the targets were encoded by joint frequency and phase modulation (JFPM)13, and the frequency and initial phase corresponding to the i-th row and the j-th column were obtained by
where \({f}_{0}\) (\({\Phi }_{0}\)) denotes the lower limit of stimulus frequency (initial phase), and \(\Delta f\) (\(\Delta \Phi \)) denotes the frequency interval (phase interval). In this study, the frequency information was set as \({f}_{0}=8\) Hz, \(\Delta f=0.5\) Hz, and the initial phase information was set as \({\Phi }_{0}=0\), \(\Delta \Phi =0.5\pi \). The details of the encoded information can be found in Fig. 1(b).

The virtual keyboard of a brain speller and the signal profile of SSVEP responses. (a) The layout of the virtual keyboard for dialing with 9 digits (1∼9). (b) The stimulus frequency (red) and initial phase (blue) encoded for each target by the JFPM method. (c) The topographic maps of the spectral amplitude at the fundamental frequency corresponding to each target on the speller. (d) The temporal profile of the grand-average SSVEPs. The oscillations for each stimulus frequency were visible during the visual stimulation marked by the pink lines. (e) The relationship between stimulus frequency and response frequency in the spectrum for the narrow-band SNR. The response frequency of SSVEP increases linearly with stimulus frequency with respect to fundamentals and harmonics. (f) The spectral profile of the grand-average SSVEPs. The spectral peaks were prominent at each stimulus frequency and were observable up to the 4th harmonics. (Best view in color).
The encoded information was used for generating visual flickers to evoke SSVEPs. In the implementation, a sampled sinusoidal stimulation method47 was employed under the environment of Psychophysics Toolbox48 in MATLAB (MathWorks, Inc.). Specifically, the grayscale value of the stimulus sequence for each flicker has the form
where \({f}_{r}\) denotes the refresh rate of the screen, and i denotes the current frame index of the sequence. The grayscale values of 0 and 1 denote the lowest and highest luminance of the screen, respectively.
Experimental procedure
In this study, each participant took part in seven blocks of online SSVEP-BCI task, in which multi-channel EEG were decoded in real time after a target was selected. Each block consisted of nine trials that corresponded to the nine targets on the speller. The timeline of each trial was as follows. At the beginning, one of the targets was cued and the border of the target was colored green for 4 s. The order of cues was randomized in the experiment and each target was cued once in a block. Followed by the cue, participants directed their attention to the target. Then all targets started to flicker simultaneously for 5 s and participants were instructed to gaze at the center of the target. After the flickering process, there was 1-s rest time for the online feedback, which was presented as a red rectangle covering the target. A training-free method of FBCCA16 was adopted in the online processing. At the end of each block, participants were encouraged to have a brief rest to avoid visual fatigue. The duration of break time was controlled by the participant, generally ranging from 1 min to 5 min with an average of 3 min.
Data acquisition
This study recorded 64-channel EEG data during the SSVEP-BCI task. The data were acquired using SynAmps2 (Neuroscan Inc., Charlotte, USA) at a sampling rate of 1000 Hz. The recorded EEG were well synchronised to the triggers events of the SSVEP task by means of a parallel port, which is a gold standard in synchronisation in BCI systems. The montage was aligned according to the international 10-20 system and the vertex Cz was used as the reference of the montage. The impedances of all channels were kept below 20 k\(\Omega \) before the experiment. Nine parietal and occipital channels, i.e., Pz, PO3/4, PO5/6, POz, Oz and O1/2, were used for the online processing. The data were collected in the electromagnetic shielding room. To suppress noise, a build-in notch filter was employed to remove the power-line interference.
Data preprocessing
The recorded offline data were preprocessed for storage and technical validation. To preserve broadband spectral properties, no filtering procedure was applied in the preprocessing. Continuous EEG data were extracted into EEG epochs, which comprised 0.5-s recordings before visual stimulation, 5-s responses of stimulation (SSVEP) and 0.5-s recordings after the stimulation. Then a downsampling procedure from 1000 Hz to 250 Hz was applied to the epochs.
Evaluation metrics
Signal-to-noise ratio (SNR)
The responses of SSVEP are well characterized in the spectral domain, in which signal-to-noise ratio (SNR) can be quantitatively measured. Here, a wide-band SNR was employed for it could better evaluate the level of harmonics, noise and the perspective BCI performance29. The SNR of SSVEP (in decibels, dB) is defined as follows29
where \({f}_{n}\) denotes the stimulus frequency, \(P(f)\) denotes the power spectral density for the frequency \(f\), and \({N}_{h}\) denotes the number of harmonics. For \({f}_{n}\) in the low-frequency band, \({N}_{h}\) is usually set 529.
Information transfer rate (ITR)
As a widely used metric in the BCI community, the ITR measures the performance of participants as well as classification algorithms by means of information theory. Taking into account the number of targets (M) and the average target selection time (T in seconds), the classification accuracy (P) can be converted to the ITR (in bits per min, bpm), which is defined as follows10
Note that T includes the gaze time (e.g., 5 s) and the overall gaze shift time. For offline analysis, a gaze shift time of 0.5 s13 is usually set for validation and model comparison.
BCI quotient (BCIQ)
The metric of BCI quotient (BCIQ) provides a means to characterize the individual difference in the participant’s potential of leveraging the SSVEP-BCI29. The BCIQ estimates the quantile of a participant in SNR according to the scaling procedure of intelligence quotient49. Thus this metric is defined at the level of population, different from the level of single trial for SNR and the level of block for ITR. Derived from the SNR, the BCIQ is defined as follows29
where μ and σ denote the mean and standard deviation of the SNR by participant, respectively. In this study, \(\mu =-11.87\) and \(\sigma =2.86\).
Data Records
This proposed database contained the data records of EEG from 100 participants, which were de-identified and indexed as S1∼S100. For each participant, continuous EEG data records in the form of EEG Brain Imaging Data Structure (EEG-BIDS)50 were provided. We also provided the associated records of epoch data that were stored in “.mat” structure array from MATLAB. The structure array was composed of the EEG data (“EEG”) and its associated supplementary information (“Suppl_info”) as its fields. The raw data can be found at Figshare and stored in “The eldBETA database” repository at the website51 https://doi.org/10.6084/m9.figshare.18032669. For convenient access to the data records, the database has an alternative source for storage at http://bci.med.tsinghua.edu.cn/download.html. Two types of EEG data, i.e., EEG epochs and raw EEG were provided for researchers to facilitate diverse research purposes. The EEG epochs were the EEG data with the data processing and stored as 4-dimensional matrices (channel × time point × condition × block). The names and locations of the channel dimension were given in the supplementary information. For the dimension of time point, the epochs had a length of 6 s, which included 0.5 s before the stimulus onset, 5 s during the stimulation (SSVEPs) and 0.5 s after the stimulus offset. For the dimension of condition, each index of the array corresponded to a stimulus frequency and the details were listed in Table 1. Different from the epoch data, the raw EEG provided continuous EEG that were converted by EEGLAB52. According to EEG-BIDS50, each block of raw EEG data was curated in a folder (e.g., “ses-01”), in which the EEG were stored in “.edf” files and the associated information can be found in “.tsv” and “.json” files. A preview of the raw data record is illustrated in Fig. 2.

A preview of raw EEG data records of the eldBETA database. The data records were curated according to the EEG Brain Imaging Data Structure (EEG-BIDS)50. The raw EEG were stored in the European data format (“.edf”). The prefix “sub” denotes the participant and “ses” denotes the block (session).
The “Suppl_info” field of the epoch record provided basic information about personal statistics and experimental protocol. The personal statistics included the age, gender, BCIQ and SNR with respect to each participant. The experimental protocol included channel location (“Channel”), stimulus frequency (“Frequency”), initial stimulus phase (“Phase”) and sampling rate (“Srate”). The channel location was represented by a 64 × 4 cell array. The first column and the fourth column denoted the channel index and channel name, respectively. The second column and the third column denoted the channel location in polar coordinates, i.e., degree and radius, respectively. The initial stimulus phase was given in radius. The sampling rate of the epoch data was denoted by “Srate”. A detailed data structure of the records was summarized in Table 2.
Technical Validation
Signal profile and SNR analysis
We initially validated the data records by the visual inspections of temporal, spectral and spatial characteristics. A grand average was performed across blocks and participants to enhance the SNR of SSVEPs. Oz was chosen as the representative channel for the temporal and spectral visual inspections, which were shown in Fig. 1(d),(f). For each stimulus frequency, the oscillations were visible in the temporal progression of SSVEPs during visual stimulation. Rhythms in the temporal domain corresponded to the spectral domain, as illustrated in Fig. 1(f), where there was a prominent peak at each stimulus frequency. Apart from the fundamental frequency, the spectral peaks were observable up to the 4th harmonics. Figure 1(e) further illustrated the relationship between stimulus frequency and response frequency in the spectrum, where the narrow-band SNR was calculated for each spectral bin13. In line with the previous studies13,27,29, Fig. 1(e) showcased a predominant frequency-following response, where the response frequency of SSVEP increases linearly with the stimulus frequencies for the fundamentals and harmonics. For all channels at the scalp, the spectral amplitudes at each stimulus frequency were then topographically mapped, as depicted in Fig. 1(c). Each map corresponded to a target on the brain speller and the result showed that SSVEPs were dominantly distributed in the parietal and occipital regions across targets. Taken together, the visual inspections verified the hallmark features of SSVEPs.
To validate the SNR feature of the data records, the SNRs were calculated according to Eq. (3). Specifically, the nine channels (Pz, PO3/4, PO5/6, POz, Oz and O1/2) were assessed and the resultant values were then averaged by channels. Also, a data length of 4 s, including the 0.5s∼4.5s of the SSVEP, was used for analysis. The changes in SNRs with respect to the stimulus frequency and blocks were then visualized. As illustrated in Fig. 3(a), there was an overall tendency of decline in SNR as the stimulus frequency increased (\(r=-0.1472\), \(p < 0.001\)), which was in line with the previous study29. Figure 3(b) delineated the change in SNR with blocks, showing that the SNRs of the data records were in a slightly declining tendency, though the decline was not statistically significant (\(r=-0.0547\), \(p=0.148\)). At the individual level, the distribution of SNRs together with ages was presented in Fig. 3(c), from which a dense distribution around 70 years and −13 dB could be identified. Furthermore, two types of data records in terms of SNR were exemplified and the signal profile of SNR topographic maps, averaged temporal waves, spectral topographic maps (at fundamental and harmonic frequencies) and SNR histograms were shown. Figure 3(d,e) illustrate the signal profile of a representative participant with high SNR (S55) and low SNR (S79), respectively. For the participant with high SNR (Fig. 3(d)), the SNR maps (upper left panel) as well as spectral maps (middle panel) were characterized by a pattern of dense distribution in the occipital region, whereas there were no specific patterns for the participant with low SNR (Fig. 3(e)).

The SNR profile of the data records. (a) The change in SNRs with respect to the stimulus frequency. (b) The change in SNRs with respect to the block number in the experiment. (c) The joint and marginal distributions of SNRs and ages. (d) An overview of a representative participant with high SNR. In this case, the SNRs were distributed toward high values and there was a pattern of dense distribution in the occipital region. (e) An overview of a representative participant with low SNR. In this case, the histogram has a distribution of low SNRs and no specific pattern could be observed in the topographic maps. In (d) and (e), upper left panel: topographic maps of SNR; bottom left panel: temporal waves of average SSVEPs; middle panel: topographic maps of spectral amplitude at the fundamental frequency, 2nd, 3rd and 4th harmonics; right panel: histogram of SNRs. Note that (a), (b) and (c) are from all participants and all trials, while (d) and (e) are from all trials for a specific participant. (Best view in color).
We then compared the SNR of the database with the other two public SSVEP-BCI databases, i.e., the Benchmark database27 and the BETA database29. For a fair comparison, SSVEPs from 0 to 3 s and a subset of stimulus frequencies (8 Hz, 9 Hz, 10 Hz, 11 Hz, and 12 Hz) were selected for analysis for the three databases. For the BETA database, participants from S16 to S70 were selected. Trials from the subset were band-pass filtered between 3 Hz and 100 Hz for the three databases, and were then padded with 2-s zeros29. This procedure was applied to the nine channels (Pz, PO3/4, PO5/6, POz, Oz and O1/2) and the histogram of the SNRs from the three databases were illustrated in Fig. 4. The result showed that the SNRs of the data records (\(-13.902\pm 3.94\) dB) were significantly lower than that of the BETA database (\(-13.56\pm 4.09\) dB, \(p < 0.001\)), and also than that of the Benchmark database (\(-13.043\pm 3.84\) dB, \(p < 0.001\)). In Supplementary Figure 1, we further illustrated the topographic maps of SNRs and SSVEP amplitudes for aging and young participants, in which the aging participants were from the eldBETA database and the young participants were from the Benchmark database. The result showed that SSVEP signals for aging participants had substantially lower SNR and SSVEP amplitude than that for young participants. The deterioration of the SSVEP signal profile for the elder participants is in line with the previous studies38,42,43,44.

The histograms of SNRs from the eldBETA, the BETA and the Benchmark databases. The curve denotes the fitted normal probability density function (PDF) of the distribution. The dashed line denotes the mean of the distribution. It is noticeable that eldBETA database has a lower SNR than the BETA database and the Benchmark database. (Best view in color).
Classification analysis
To validate the utility of the data records, this study conducted a classification analysis by benchmarking thirteen frequency recognition methods, including seven supervised methods and six training-free methods. Specifically, for each trial, a sliding window of data length (\({N}_{p}\)) from 0.1 s to 5 s with an interval of 0.1 s was used for analysis. The onset and boundary of the sliding window were set at \([{T}_{s}+d,{T}_{s}+d+{N}_{p}]\), where \({T}_{s}\) denotes the time point when visual stimulation starts. d denotes the latency of the visual system and conventionally d is set 140 ms13. Classification accuracy and ITR were used as evaluation metrics. For the metric of ITR, a gaze shift time of 0.5 s was used for analysis16,27.
For the supervised methods, we evaluated the data records by comparing seven methods, including task-discriminant component analysis (TDCA)53, multi-stimulus extended CCA (ms-eCCA)54, ensemble multi-stimulus task-related component analysis (ensemble msTRCA)54, ensemble task-related component analysis (ensemble TRCA)14, extended canonical correlation analysis (Extended CCA)55, individual template-based CCA (ITCCA)56, and L1-regularized multiway CCA (L1MCCA)57. Specifically, for each participant, leave-one-block-out cross validation was conducted for evaluation. For TDCA, the parameters of \({N}_{k}=5\), \(l=3\) were set, which was based on the parameter selection in Supplementary Figure 2. The filter-bank technique was applied in TDCA, ms-eCCA, ensemble msTRCA, ensemble TRCA and Extended CCA, with the number of filter banks \({N}_{fb}=5\) and the weights were set according to the previous study16. The procedure of filter bank filtering was conducted for each data length. The results of the average classification accuracy and ITR were illustrated in Fig. 5. As assessed by one-way repeated measures analysis of variance (RMANOVA), there was a significant difference among methods for all data lengths in the accuracies and ITRs, with all \(p < 0.001\). For a short data length of 0.4 s, post-hoc pairwise comparisons revealed that TDCA > ms-eCCA/ensemble TRCA/ensemble msTRCA > Extended CCA > ITCCA > L1MCCA on ITR, where “>” indicates a statistical significance \( < 0.05\) between the two sides after Bonferroni correction. For a medium data length of 1 s, the accuracies for the methods were as follows: TDCA: \(0.925\pm 0.012\); ms-eCCA: \(0.904\pm 0.013\); ensemble TRCA: \(0.868\pm 0.018\); ensemble msTRCA: \(0.864\pm 0.018\); Extended CCA: \(0.862\pm 0.017\); ITCCA: \(0.657\pm 0.026\); L1MCCA: \(0.608\pm 0.025\). The highest ITRs were achieved at different data lengths for the methods and the results were as follows: TDCA: \(149.38\pm 5.28\) bpm at 0.4 s; ms-eCCA: \(136.06\pm 5.15\) bpm at 0.4 s; ensemble TRCA: \(133.36\pm 5.93\) bpm at 0.4 s; ensemble msTRCA: \(131.15\pm 5.99\) bpm at 0.4 s; Extended CCA: \(117.46\pm 5.60\) bpm at 0.5 s; ITCCA: \(61.15\pm 4.33\) bpm at 0.8 s; L1MCCA: \(53.58\pm 3.44\) bpm at 1.2 s. Besides, we also evaluated other combined methods, e.g., ms-eCCA+ms-eTRCA54, and the performance comparisons between TDCA and ms-eCCA+ms-eTRCA or ms-eCCA were shown in Supplementary Figure 3 and 4, respectively. The result of the supervised methods revealed an average ITR of approximately up to 150 bpm at 0.4 s, which could satisfy the eldercare scenarios that demand high-speed output of commands.

The average classification accuracy (a) and ITR (b) for the seven different supervised methods. Data lengths from 0.1 s to 5 s with an interval of 0.1 s were used for evaluation. The shaded area around the curve denotes the standard error of the mean. (Best view in color).
In parallel, six training-free methods including filter bank CCA (FBCCA)16, canonical variates with autoregressive spectral analysis (CVARS)58, temporally local multivariate synchronization index (tMSI)59, minimum energy combination (MEC)60, multivariate synchronization index (MSI)61 and CCA15 were compared. For the methods except FBCCA, a band-pass filtering with a passband of 6 Hz∼100 Hz was applied. Figure 6 illustrates the average classification accuracy (a) and ITR (b) for the training-free methods. A significant difference between methods was found in the accuracies and ITRs, as revealed by one-way RMANOVA, with all \(p < 0.001\). For a medium data length of 1 s, post-hoc pairwise comparisons revealed that FBCCA > tMSI > CVARS/MSI > MEC/CCA on ITR. For a long data length of 5 s, the accuracies for the methods were as follows: FBCCA: \(0.917\pm 0.013\); CVARS: \(0.916\pm 0.013\); tMSI: \(0.908\pm 0.014\); MSI: \(0.89\pm 0.015\); MEC: \(0.863\pm 0.017\); CCA: \(0.854\pm 0.018\). The highest ITR for the training-free methods were attained after 1 s, and the results were as follows: FBCCA: \(60.14\pm 3.44\) bpm at 1.1 s; tMSI: \(56.58\pm 3.72\) bpm at 1 s; CVARS: \(54.05\pm 2.78\) bpm at 1.5 s; MSI: \(51\pm 3.3\) bpm at 1.2 s; MEC: \(46.5\pm 3.08\) bpm at 1.3 s; CCA: \(45.08\pm 3.0\) bpm at 1.4 s. The training-free methods suggest an average ITR up to 60 bpm and 5-s accuracy above 90 %, which suits the eldercare scenarios that require no calibration for plug-and-play BCI control.

The average classification accuracy (a) and ITR (b) for the six different training-free methods. Data lengths from 0.1 s to 5 s with an interval of 0.1 s were used for evaluation. The shaded area around the curve denotes the standard error of the mean. (Best view in color).
Furthermore, we calculated the accuracies for different stimulus frequencies and the result was shown in Supplementary Figure 5. Here we evaluated the 13 methods by the data records with a data length of 5 s, and the classification accuracies were averaged across all the methods. As assessed by one-way RMANOVA, there was a statistically significant difference in accuracies for different stimulus frequencies, \(F(4.186,476.811)=3.689,p < 0.001\). The result also indicated a marginally significant tendency of decline in accuracy as the stimulus increased, \(r=-0.065\), \(p=0.051\), which was consistent with the tendency of decrease in SNR as the stimulus frequency increased in Fig. 3(a). In addition, the change in the maximum average ITR with blocks was further analyzed and the result was shown in Supplementary Figure 6. The ITR values were averaged across the six training-free methods. As revealed by one-way RMANOVA, there was a statistically significant difference in ITRs for different blocks, \(F(5.573,551.74)=2.783\), \(p=0.013\). During the course of blocks, there was a tendency of a slight decrease in the ITRs, though not statistically significant, \(r=-0.056\), \(p=0.139\).
Power law analysis
Besides the narrow-band oscillation of SSVEPs, we further validated the broadband fractal characteristics of the data records by quantifying the power-law exponent of the spectrum. Here, a spectral separation method, namely the irregular-resampling auto-spectral analysis (IRASA)62 was used to extract the scale-free fractal signals. Specifically, the 0∼3 s of the SSVEPs from 5 stimulus frequencies (8 Hz, 9 Hz, 10 Hz, 11 Hz, and 12 Hz) were analyzed by IRASA, in which the frequency range for spectral separation and power-law fitting was from 3 Hz to 100 Hz. By means of the power-law fitting, we estimated the power-law exponent, a.k.a. the slope factor of the linear model that fitted the power spectrum in the log-log plot. For each of the 64 channels, the power-law exponent was computed and then averaged by blocks and by conditions. Finally, the exponent values were averaged by channels from the region of interest (ROI), in which five typical montages (frontal, occipital, central, temporal and all channels, details were listed in Table 3) were evaluated. This procedure was applied to the Benchmark database as well as the BETA database for comparison. In the BETA database, since the duration of visual stimulation for S1∼S15 was 2 s, these participants were excluded for analysis and participants from S16 to S70 with a stimulation duration of 3 s were evaluated. The negative of the power-law exponential (\(k\)) for the three databases was illustrated in Fig. 7. For each montage, Student’s t test with Bonferroni correction revealed that the exponent k in the eldBETA was significantly smaller than that in the Benchmark database and than that in the BETA database, with all \(p < 0.001\). For instance, for the three databases in the montage of all channels, the average power spectrum (solid curves) with the associated power-law fitting (dashed curves) was illustrated in Fig. 7 (upper right panel) and the average exponent for each database was as follows: eldBETA: \(0.872\pm 0.301\); Benchmark: \(1.176\pm 0.307\); BETA: \(1.137\pm 0.277\). Compared with the Benchmark and BETA database, the lower value of the exponent in eldBETA indicates an increase in the broadband noise. Since the participants from the eldBETA database have older ages (illustrated in the bottom right panel), the result of the power-law analysis is then in line with the previous study63, and lends support to the neural noise hypothesis of aging64,65.

The comparison of the power-law characteristics for the eldBETA, the BETA, and the Benchmark databases. (Upper left) Bar plot of the negative of the power-law exponent for the three databases with different montages. (Bottom left) The channel location corresponding to each montage. The asterisks indicate a statistically significant difference between the pairs. *\(p < 0.05\), **\(p < 0.01\), ***\(p < 0.001\), Bonferroni corrected. (Upper right) The power spectrum (solid curves) with the associated power-law fitting (dashed curves) for the three databases. The shaded area indicates a statistical significance (\(p < 0.05\)) between the three databases as assessed by one-way RMANOVA. Green: the eldBETA database; Brown: the BETA database; Blue: the Benchmark database. (Bottom right) Bar plot of the age distribution for the three databases. (Best view in color).
BCIQ profile
To validate the individual difference and variety in the data records, the metric of the BCIQ for each participant was calculated in Eq. (5) and then displayed in Fig. 8. Here, each participant (S1∼S100) is indexed by a row and a column, where a row denotes an individual and a column denotes tens of individuals. In line with the previous study29, the BCIQ for the data records can well predict the proficiency in using the BCI, i.e., the BCI performance, with \(r=0.768\), \(p < 0.001\). For instance, participant S1 and participant S100 have the BCIQ of 87 and 128, respectively, which reveals the projected low (20 bpm, maximum average ITR of FBCCA) and high (158 bpm, maximum average ITR of FBCCA) proficiency for the BCI speller.

The BCI quotient (BCIQ) for each participant. Participants were indexed from S1 to S100 (S100 could be indexed by S9· and S·10). Each row denotes an individual and each column denotes tens of individuals. Warmer color indicates a higher BCIQ and cooler color indicates a lower BCIQ. The value in the square denotes the BCIQ of the participant. (Best view in color).
Usage Notes
The following key notes are provided for better usage of the data records.
-
Data import Data can be imported to the workspace by loading the epoch data record in MATLAB, or using the package “scipy.io.loadmat” or “h5py.File” in Python. For conventional classification analysis, the epoch data in the record are recommended. For other research purposes, e.g., asynchronous classification analysis, or blind source separation (BSS), the raw data without epoching and processing (the “.edf” data) could be utilized. The data structure of the “.edf” data is generated by the “loadcnt” and “writeeeg” function from EEGLAB, and the details can be referred to the EEGLAB. The epoch data can be extracted from the raw data.
-
Subset selection A subset of the participants or the stimulus frequencies could be selected in the design of a specific BCI system. For instance, the BCIQ listed in Fig. 8 could serve as a guideline to select participants for developing a BCI system designated for a particular user population, e.g., BCI illiteracy.
-
Data partition The cross validation that leaves one block out in each fold is a common practice in classification analysis. In the cross validation, the data partition by trials should be avoided due to the fact that there exist temporal correlations between trials in a block66, different from the data nature in other domains, e.g., computer vision. Also, a sliding window with a random onset in the test data should be avoided.
Code availability
Custom codes for generation and processing of the data and the figures are presented in the repository67. A MATLAB script “eldbeta_convert.m” was provided for data processing in converting the raw data to the epoch data. The data preprocessing and technical validations were conducted in MATLAB R2018b and Python 3.6.10. A “README.md” file was used for a brief description of the code in the code repository. The Benchmark database and the BETA database as well as the classification algorithms can be found in their corresponding repositories related to the papers, and thus they are not provided in this data descriptor.
References
Lutz, W., Sanderson, W. & Scherbov, S. The coming acceleration of global population ageing. Nature 451, 716–719 (2008).
Christensen, K., Doblhammer, G., Rau, R. & Vaupel, J. W. Ageing populations: the challenges ahead. The lancet 374, 1196–1208 (2009).
Vaupel, J. W. Biodemography of human ageing. Nature 464, 536–542 (2010).
Oeppen, J. & Vaupel, J. W. Broken limits to life expectancy. Science 296, 1029–1031 (2002).
Partridge, L., Deelen, J. & Slagboom, P. E. Facing up to the global challenges of ageing. Nature 561, 45–56 (2018).
Lutz, W. & KC, S. Dimensions of global population projections: what do we know about future population trends and structures? Philosophical Transactions of the Royal Society B: Biological Sciences 365, 2779–2791 (2010).
Flaherty, J. H. et al. China: the aging giant. Journal of the American Geriatrics Society 55, 1295–1300 (2007).
Campisi, J. et al. From discoveries in ageing research to therapeutics for healthy ageing. Nature 571, 183–192 (2019).
Miller, J., Bernstein, M. & McDaniel, T. Next steps for social robotics in an aging world. IEEE Technology and Society Magazine 40, 21–23 (2021).
Wolpaw, J. R., Birbaumer, N., McFarland, D. J., Pfurtscheller, G. & Vaughan, T. M. Brain–computer interfaces for communication and control. Clinical neurophysiology 113, 767–791 (2002).
Gao, X., Wang, Y., Chen, X. & Gao, S. Interface, interaction, and intelligence in generalized brain–computer interfaces. Trends in Cognitive Sciences (2021).
Cheng, M., Gao, X., Gao, S. & Xu, D. Design and implementation of a brain-computer interface with high transfer rates. IEEE transactions on biomedical engineering 49, 1181–1186 (2002).
Chen, X. et al. High-speed spelling with a noninvasive brain-computer interface. Proceedings of the National Academy of Sciences of the United States of America 112, 201508080 (2015).
Nakanishi, M. et al. Enhancing detection of SSVEPs for a high-speed brain speller using task-related component analysis. IEEE Transactions on Biomedical Engineering 65, 104–112 (2018).
Bin, G., Gao, X., Yan, Z., Hong, B. & Gao, S. An online multi-channel SSVEP-based brain–computer interface using a canonical correlation analysis method. Journal of Neural Engineering 6, 046002 (2009).
Chen, X., Wang, Y., Gao, S., Jung, T.-P. & Gao, X. Filter bank canonical correlation analysis for implementing a high-speed SSVEP-based brain–computer interface. Journal of Neural Engineering 12, 046008 (2015).
Lee, M.-H. et al. EEG dataset and OpenBMI toolbox for three BCI paradigms: an investigation into BCI illiteracy. GigaScience 8, (2019).
Norcia, A. M., Appelbaum, L. G., Ales, J. M., Cottereau, B. R. & Rossion, B. The steady-state visual evoked potential in vision research: A review. Journal of Vision 15, 4 (2015).
Mistry, K. S., Pelayo, P., Anil, D. G. & George, K. An ssvep based brain computer interface system to control electric wheelchairs. In 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), 1–6, (IEEE, 2018).
Mahmood, M. et al. Fully portable and wireless universal brain–machine interfaces enabled by flexible scalp electronics and deep learning algorithm. Nature Machine Intelligence 1, 412–422 (2019).
Kwak, N.-S., Müller, K.-R. & Lee, S.-W. A lower limb exoskeleton control system based on steady state visual evoked potentials. Journal of neural engineering 12, 056009 (2015).
Zhao, X., Chu, Y., Han, J. & Zhang, Z. Ssvep-based brain–computer interface controlled functional electrical stimulation system for upper extremity rehabilitation. IEEE Transactions on Systems, Man, and Cybernetics: Systems 46, 947–956 (2016).
Chen, X., Zhao, B., Wang, Y., Xu, S. & Gao, X. Control of a 7-dof robotic arm system with an ssvep-based bci. International journal of neural systems 28, 1850018 (2018).
Han, X., Lin, K., Gao, S. & Gao, X. A novel system of ssvep-based human–robot coordination. Journal of neural engineering 16, 016006 (2018).
Hwang, H.-J. et al. Clinical feasibility of brain-computer interface based on steady-state visual evoked potential in patients with locked-in syndrome: Case studies. Psychophysiology 54, 444–451 (2017).
Russakovsky, O. et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision 115, 211–252 (2015).
Wang, Y., Chen, X., Gao, X. & Gao, S. A benchmark dataset for ssvep-based brain–computer interfaces. IEEE Transactions on Neural Systems and Rehabilitation Engineering 25, 1746–1752 (2017).
Choi, G.-Y., Han, C.-H., Jung, Y.-J. & Hwang, H.-J. A multi-day and multi-band dataset for a steady-state visual-evoked potential–based brain-computer interface. GigaScience 8, (2019).
Liu, B., Huang, X., Wang, Y., Chen, X. & Gao, X. Beta: A large benchmark database toward ssvep-bci application. Frontiers in neuroscience 14, 627 (2020).
Zhu, F., Jiang, L., Dong, G., Gao, X. & Wang, Y. An open dataset for wearable ssvep-based brain-computer interfaces. Sensors 21, (2021).
Bakardjian, H., Tanaka, T. & Cichocki, A. Optimization of SSVEP brain responses with application to eight-command brain–computer interface. Neuroscience Letters 469, 34–38 (2010).
Kalunga, E. K. et al. Online SSVEP-based BCI using riemannian geometry. Neurocomputing 191, 55–68 (2016).
Kwak, N.-S., Müller, K.-R. & Lee, S.-W. A convolutional neural network for steady state visual evoked potential classification under ambulatory environment. PloS one 12, e0172578 (2017).
İşcan, Z. & Nikulin, V. V. Steady state visual evoked potential (SSVEP) based brain-computer interface (BCI) performance under different perturbations. PloS one 13, e0191673 (2018).
Chen, M. L., Fu, D., Boger, J. & Jiang, N. Age-related changes in vibro-tactile eeg response and its implications in bci applications: A comparison between older and younger populations. IEEE Transactions on Neural Systems and Rehabilitation Engineering 27, 603–610 (2019).
Grosse-Wentrup, M. & Schölkopf, B. A review of performance variations in smr-based brain- computer interfaces (bcis). Brain-Computer Interface Research 39–51, (2013).
Dias, N., Mendes, P. & Correia, J. Subject age in p300 bci. In Conference Proceedings. 2nd International IEEE EMBS Conference on Neural Engineering, 2005., 579–582, (IEEE, 2005).
Volosyak, I., Gembler, F. & Stawicki, P. Age-related differences in ssvep-based bci performance. Neurocomputing 250, 57–64 (2017).
Sridhar, S. & Manian, V. Assessment of cognitive aging using an ssvep-based brain–computer interface system. Big Data and Cognitive Computing 3, 29 (2019).
Ehlers, J., Valbuena, D., Stiller, A. & Gräser, A. Age-specific mechanisms in an ssvep-based bci scenario: evidences from spontaneous rhythms and neuronal oscillators. Computational intelligence and neuroscience 2012, (2012).
Allison, B. et al. Bci demographics: How many (and what kinds of) people can use an ssvep bci? IEEE transactions on neural systems and rehabilitation engineering 18, 107–116 (2010).
Macpherson, H., Pipingas, A. & Silberstein, R. A steady state visually evoked potential investigation of memory and ageing. Brain and cognition 69, 571–579 (2009).
Tomoda, H., Celesia, G. G., Brigell, M. G. & Toleikis, S. The effects of age on steady-state pattern electroretinograms and visual evoked potentials. Documenta ophthalmologica 77, 201–211 (1991).
Hsu, H.-T. et al. Evaluate the feasibility of using frontal ssvep to implement an ssvep-based bci in young, elderly and als groups. IEEE Transactions on Neural Systems and Rehabilitation Engineering 24, 603–615 (2015).
Nguyen-Tri, D., Overbury, O. & Faubert, J. The role of lenticular senescence in age-related color vision changes. Investigative ophthalmology & visual science 44, 3698–3704 (2003).
Weale, R. Senile ocular changes, cell death, and vision. Aging and human visual function 2, 161–72 (1982).
Chen, X., Chen, Z., Gao, S. & Gao, X. A high-itr ssvep-based bci speller. Brain-Computer Interfaces 1, 181–191 (2014).
Brainard, D. H. The psychophysics toolbox. Spatial Vision 10, 433–436 (1997).
Wechsler, D. Wechsler adult intelligence scale–fourth edition (wais–iv). San Antonio, TX: NCS Pearson 22, 498, (2008).
Pernet, C. R. et al. Eeg-bids, an extension to the brain imaging data structure for electroencephalography. Scientific data 6, 1–5 (2019).
Liu, B., Wang, Y., Gao, X. & Chen, X. eldbeta: a large eldercare-oriented benchmark database of ssvep-bci for the aging population. Figshare https://doi.org/10.6084/m9.figshare.18032669 (2022).
Delorme, A. & Makeig, S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. Journal of Neuroscience Methods 134, 9–21 (2004).
Liu, B. et al. Improving the performance of individually calibrated ssvep-bci by task-discriminant component analysis. IEEE Transactions on Neural Systems and Rehabilitation Engineering (2021).
Wong, C. M. et al. Learning across multi-stimulus enhances target recognition methods in SSVEP-based BCIs. Journal of Neural Engineering 17, 016026 (2020).
Nakanishi, M., Wang, Y., Wang, Y. T., Mitsukura, Y. & Jung, T. A high-speed brain speller using steady-state visual evoked potentials. International Journal of Neural Systems 24, 1450019 (2014).
Bin, G. et al. A high-speed bci based on code modulation vep. Journal of Neural Engineering 8, 025015 (2011).
Zhang, Y. et al. L1-regularized multiway canonical correlation analysis for SSVEP-based BCI. IEEE Transactions on Neural Systems and Rehabilitation Engineering 21, 887–896 (2013).
Abu-Alqumsan, M. & Peer, A. Advancing the detection of steady-state visual evoked potentials in brain–computer interfaces. Journal of Neural Engineering 13, 036005 (2016).
Zhang, Y., Guo, D., Xu, P., Zhang, Y. & Yao, D. Robust frequency recognition for ssvep-based bci with temporally local multivariate synchronization index. Cognitive neurodynamics 10, 505–511 (2016).
Friman, O., Volosyak, I. & Graser, A. Multiple channel detection of steady-state visual evoked potentials for brain-computer interfaces. IEEE Transactions on Biomedical Engineering 54, 742–750 (2007).
Zhang, Y., Xu, P., Cheng, K. & Yao, D. Multivariate synchronization index for frequency recognition of SSVEP-based brain–computer interface. Journal of Neuroscience Methods 221, 32–40 (2014).
Wen, H. & Liu, Z. Separating fractal and oscillatory components in the power spectrum of neurophysiological signal. Brain topography 29, 13–26 (2016).
Voytek, B. et al. Age-related changes in 1/f neural electrophysiological noise. Journal of Neuroscience 35, 13257–13265 (2015).
Cremer, R. & Zeef, E. J. What kind of noise increases with age? Journal of Gerontology 42, 515–518 (1987).
Kail, R. The neural noise hypothesis: Evidence from processing speed in adults with multiple sclerosis. Aging, Neuropsychology, and Cognition 4, 157–165 (1997).
Li, R. et al. The perils and pitfalls of block design for eeg classification experiments. IEEE Transactions on Pattern Analysis and Machine Intelligence 43, 316–333 (2020).
Liu, B., Wang, Y., Gao, X. & Chen, X. eldbeta: a large eldercare-oriented benchmark database of ssvep-bci for the aging population (code). Figshare https://doi.org/10.6084/m9.figshare.17260877 (2022).
Acknowledgements
The authors would like to thank Prof. D. Zhang, X. Shui and N. Shi at Tsinghua University for their assistance in the manuscript preparation. The research presented in this paper was supported by National Natural Science Foundation of China (No. 62171473), Doctoral Brain+X Seed Grant Program of Tsinghua University, Strategic Priority Research Program of Chinese Academy of Science (No. XDB32040200), Beijing Science and Technology Program (No. Z201100004420015), Key-Area Research and Development Program of Guangdong Province (No. 2018B030339001), and National Key Research and Development Program of China (No. 2017YFB1002505).
Author information
Authors and Affiliations
Contributions
B.L. contributed to the data curation, data analysis and manuscript preparation. X.C. designed the experiment, conducted data collection and supervision. Y.W. contributed to manuscript preparation and data analysis. X.G. co-designed the experiment and contributed to data analysis.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, B., Wang, Y., Gao, X. et al. eldBETA: A Large Eldercare-oriented Benchmark Database of SSVEP-BCI for the Aging Population. Sci Data 9, 252 (2022). https://doi.org/10.1038/s41597-022-01372-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01372-9
This article is cited by
-
An open dataset for human SSVEPs in the frequency range of 1-60 Hz
Scientific Data (2024)
-
Multi-frequency steady-state visual evoked potential dataset
Scientific Data (2024)
