
Abstract
The USDA curve-number (CN) method is fundamental for rainfall-runoff modeling. A global CN database is not currently available for geospatial hydrologic analysis at a resolution higher than 0.1°. We developed a globally consistent, gridded dataset defining CNs at the 250 m spatial resolution from new global land cover (300 m) and soils data (250 m). The resulting data product – GCN250 – represents runoff for a combination of the European space agency global land cover dataset for 2015 (ESA CCI-LC) resampled to 250 m and geo-registered with the hydrologic soil group global data product (HYSOGs250m) released in 2018. Our analysis indicated that medium to high runoff potential currently dominates the globe, with curve numbers ranging between 75 and 85. Global curve numbers were 62, 78, and 90 for dry, average, and wet antecedent runoff conditions, respectively. Australia has the highest runoff potential, while Europe has the lowest. Runoff ratios compare well with GLDAS. The potential application of this data includes hydrologic design, land management applications, flood risk assessment, and groundwater recharge modeling.
Design Type(s) | modeling and simulation objective • data integration objective |
Measurement Type(s) | hydrological process |
Technology Type(s) | computational modeling technique |
Factor Type(s) | geographic location • hydrological process • soil • land use |
Sample Characteristic(s) | Earth (Planet) • soil • land • ecosystem • hydrological process |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others


Background & Summary
Land cover and soils play a fundamental role in the hydrologic cycle by controlling infiltration and affecting surface and groundwater flows. The Natural Resources Conservation Service (NRCS) of the United States Department of Agriculture (USDA) developed a simple, stable, and predictable method for calculating runoff from rainfall events1. Recently and with the increasing availability of routine land cover products, there have been few attempts to develop regional and global curve number datasets. Hong and Adler2 generated a global CN dataset at the 0.1° resolution based on (1) the global land cover data from the Moderate Resolution Imaging Spectroradiometer (MODIS) at 1-km resolution produced in 20023 and (2) the Digital Soil Map of the World (DSMW) published in 2003 (100-km resolution) by the Food and Agriculture Organization (FAO) of the United Nations. Hong and Adler2 derived the CN values for each hydrological soil group by mapping MODIS land cover classification into the National Engineering Handbook (NEH)4 descriptors for land cover under fair hydrological conditions. However, their global CN dataset was not made public. Zeng, et al.5 used the MODIS 500 m Land Cover product6 of 2013 with the Harmonized World Soil Database (HWSD) v.1.2 and the Digital Soil map of the World (DSMW) v3.6 as amended by FAO in 2007 to generate a global CN map at a “fine” resolution, believed to be 500 m (by downscaling the 30 arc-second HWSD data). The Zeng, et al.5 global CN dataset was also not publicly available. In the two works (Hong and Adler2 as well as Zeng, et al.5), the CN datasets were produced by converting the soil classification in the FAO database to hydrologic soils group (HSG) using the provided soil properties based on the USDA soil texture classification scheme7. Ross, et al.8 generated the first publicly available gridded dataset of HSG at the 250 m resolution (HYSOGs250m) from soil texture, depth to bedrock, and groundwater, also following USDA specifications7. The generation of HYSOGs250m data triggered our attempt to create a synergistic curve number product exploiting the most recent land cover (LC) data (2015) at a similar resolution (300 m). The newly released global LC maps for 2015 were developed by the European Space Agency (ESA) Climate Change Initiative Land Cover Project (CCI-LC)9. This project produces global annual LC maps starting from the 1990s through 2015 (and beyond) based on several satellite sensors: Advanced Very High Resolution Radiometer (AVHRR), Satellite Pour l’Observation de la Terre Vegetation (SPOT-VGT), Medium Resolution Imaging Spectrometer (MERIS), and Project for On-Board Autonomy – Vegetation (PROBA-V). The annual 2015 ESA CCI-LC map was developed from a baseline LC map by utilizing the entire MERIS archive (2003–2012) and PROBA-V data for 2013–2015. We generated the first global gridded CN dataset (GCN250) from the ESA CCI- LC maps (2015) and the HYSOGs250m soils data based on the USDA curve number tables4 and plant functional types10. The GCN250 datasets represent the global curve numbers at approximately 250 m spatial resolution under dry, average, and wet antecedent runoff conditions (ARC). The soil was assumed undrained soil, and hence the CN of dual HSG were treated the same as the HSG class D.
We believe that this new CN dataset will be of value and interest to the scientific community because it can be directly used to assess time series changes in runoff at global, regional, and watershed scale, given the availability of a consistent ESA land cover product from 1992–201511. The GCN250 dataset is valuable for hydrological analysis and design, flood risk assessment, and mapping, watershed water management, and other related applications. Rainfall-runoff modeling is a potential application given the available techniques in downscaling gridded precipitation data.
Methods
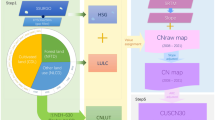
We used three main inputs to generate the GCN250 datasets (Fig. 1): a land use/land cover map, a hydrologic soil group map, and three CN look-up tables. For the land cover product, we used the most recent ESA-CCI LC data of 2015 (ESA European Space Agency9). The hydrologic soil groups were acquired from Ross, et al.8. The CN look-up table was created based on the USDA Soil Conservation Service (SCS) Runoff Curve Number (CN) method7. GCN250 was created within the R open source environment12 using the Raster library functions13.

Schematic overview of the generation of global curve number (GCN250) product. Three main steps are illustrated: (1) CN look-up table is created based on mapping ESA CCI-LC land cover classes into National Engineering Handbook – Part 630 Hydrology land cover classes (NEH-630); (2) ESA CCI-LC 2015 300 m raster is resampled to spatial resolution ~250 m (ESA-CCI LC 250 m); (3) CN values (GCN250) are mapped at ~250 m spatial resolution based on the hydrologic soil groups dataset (HYSOGs250m), CN look-up table (step 1), and the resampled ESA CCI-LC 250m raster (step 2).
Land cover mapping
CN values were determined by mapping ESA land cover classes (2015) into NEH-630 classes. The ESA land cover classes are classified into various plant functional types (PFT)10. The detailed description for each land cover class is provided by ESA European Space Agency9 and Poulter, et al.10. We mapped the PFT into Land cover classes according to NEH-630 classification (Table 1). Because not all plant functions types exist in the NEH-630 classification, we made certain assumptions to make sure that all PFTs of the ESA land cover classes have a corresponding NEH-630 land cover class. Trees PFT were mapped as woods classes in NEH-630, while shrubs in PFT were mapped as desert shrubs and brushes classes in NEH-630. The hydrologic conditions of the wood and shrubs/brushes classes were used to distinguish between the PFT types of trees and shrubs. For example, broadleaf evergreen trees have a lower CN than broadleaf deciduous, and therefore we mapped them as woods with under good hydrologic conditions. Similarly, deciduous needle leaf trees have a higher runoff potential than any other tree type. Therefore, we mapped them as woods under a poor hydrologic condition. We mapped natural grass in the PFT class as the NEH-630 grasslands class under good hydrologic conditions. For managed grasslands (which are rain-fed croplands in ESA classes), we calculated CN values from the average CN of all cropland types in NEH-630 (row crops, small grains, and close-seeded or broadcast legumes or rotation meadow) under good hydrologic conditions. Bare soil CN values were matched with the fallow bare soil.
Composite curve number
Curve numbers used in generating GCN250 are presented in Online-only Table 1 along with the PFT decomposition of each ESA LC classes. CN values for the ESA CCI-LC classes that have multiple PFTs were calculated using a weighted average:
where CNk is the curve number of the class for the hydrological soil group k, n is the total number of PFT types (i) present in the ESA-CCI LC class, CNi is the curve number for the individual PFT class - hydrological soil group k combination and FCi is the percentage of the PFT type i of the total LC class n based on ESA-CCI LC description detailed in the ESA LC product user guide9.
Some exceptions are listed hereafter. Curve numbers for irrigated croplands were assumed equal to those for managed grasslands under poor hydrologic conditions (which are expected to increase runoff and therefore emulate an irrigated field). For unconsolidated bare areas, CN values were matched with the fallow bare soil in NEH-630, as well for ESA bare areas LC type. For consolidated bare areas, CN values were averaged from impervious areas according to NEH-630. Zones that have dual hydrological soil groups were assumed to be undrained. The ESA CCI-LC dataset had a spatial resolution of 300 m, and it was resampled to 250 m using the nearest neighbor method to match the HYSOGs250m spatial resolution. We used two input datasets (HYSOGs250m and the resampled ESA CCI-LC) with three CN look-up tables (one for each ARC) to generate the curve number products at the 250 m resolution (GCN250).
Curve number for various antecedent runoff conditions
The CN values vary depending on antecedent runoff conditions (ARC), which is affected by the rainfall intensity and duration, total rainfall, soil moisture conditions, cover density, stage of growth, and temperature14. For this reason, we generated three curve number maps for three ARCs: dry (Fig. 2a), average (Fig. 2b), and wet (Fig. 2c) ARC conditions. USDA14 provided guidelines to convert CN values from average ARC conditions into wet and dry ARC conditions.

The three global curve number maps (GCN250). (a) Dry (ARCI), (b) average (ARCII), and (c) wet (ARCIII) antecedent runoff conditions.
Data Records
There are three data records associated with this work: one raster dataset for each of the antecedent runoff conditions (ARCI = dry, ARCII = average, ARCIII = wet). The GCN250 product is publicly archived in Figshare15. The product is stored in GeoTiff format at 7.5 arc-second (~250 m spatial resolution) using the World Geodetic System 1984 (WGS84) datum geographic coordinate system. Table 2 presents a summary of the CN values mapping at the global and the continental scale. Figure 3 shows the distribution of the curve numbers for selected world river basin regions: (a) Amazon, (b) Mississippi, (c) Mekong, and (d) Nile and Tigris-Euphrates.

Curve number map (average antecedent runoff conditions) for selected river basins and regions around the world. (a) Amazon and Uruguay, (b) Colorado, Mississippi, and Sacramento (c) Mekong and Yangtze (d) Nile, Tigris-Euphrates, and East Africa.
Technical Validation
The uncertainty of the GCN250 product is related to the uncertainty of the global ESA-CCI-LC dataset, the soils classification data, and the uncertainty in the CN look-up table. The compositing of CNs is affected by the accuracy of the Land cover classes, and the accuracy of hydrologic soil groups classifications in the HYSGOG250m database. Using gridded precipitation products from the Global Land Data Assimilation System (GLDAS)16, we compared the daily and the monthly runoff ratios resulting from the three GCN250 products with those of GLDAS runoff.
Land cover
The ESA CCI-LC was evaluated by independent means where validation was carried out by external partiesfnline9. When validating the 2015 ESA CCI-LC product, the accuracy level was found to be between 71.1% and 75.4%. User accuracy was high (83–97%) for croplands (irrigated and rainfed), broadleaved evergreen forests, urban areas, bare areas, water bodies, and permanent snow and ice. Low user accuracies were observed for the classes of natural vegetation, lichens and mosses, sparse vegetation, flooded forest, and forests (mixed broadleaf and needle leaf). We expect curve numbers of these areas to have a higher uncertainty compared to other areas with better LC classification accuracy. Moreover, because the CN method was originally developed based on observation of rainfall-runoff relationships in small agricultural watersheds, we expect some uncertainty in curve numbers developed for forested watersheds in humid environments and deep soils. Hydrologists should proceed with caution when using these CNs for design and other hydrologic applications and should always compare generated runoff with observed values whenever possible.
Hydrologic soil groups
Ross, et al.8 described the uncertainty assessment of the HYSOGs250m product that we used to generate the GCN250 dataset. The root means square error (RMSE) of the soil grids used as input to HYSOGs250m are between 9.5% and 13.1%. HYSOGs250 also included the groundwater table depth metric to capture broad-scale patterns of groundwater with a coefficient of variation of 9%. We expect these uncertainties to carry over into the GCN250 product.
Comparison with other curve number datasets
Table 3 shows a comparison of CN values between our GCN250 and CN reported by Zeng, et al.5 for several large basins in the world. We believe that the (1–17%) higher values of composite GCN250 curve numbers compared to those reported in the Zeng, et al.5 under average ARC conditions for the studied basins to be mainly due to the difference in the soils input map. According to Zeng, et al.5, the global soil distribution is dominated by moderately low runoff potential (37% soil group B), whereas it is dominated by moderately high runoff (57% soil group C) according to Ross, et al.8, and therefore the resulting CNs are higher for our results due to the prevalence of higher runoff soils. The CNs are highly impacted by soil groups. For example, woods in poor conditions in a B hydrologic soil group would have a CN of 66, while the CN in a C hydrologic soil group would be 77, which doubles the runoff from say a 75 mm rainfall event. Furthermore, Ross, et al.8 factored the depth to impermeable layers (bedrock) and depth to the groundwater in the HYSOGs250m product, and both variables were absent from the Zeng, et al.5 study. Zeng, et al.5 used 17 classes from MODIS at 500 m resolution to generate the CN dataset, whereas we used the 36 classes of the 300-m ESA-CCI LC product to create the GCN250 product. We believe that the GCN250 dataset better captures land cover variations and soils hydrologic classifications than currently existing curve number datasets.
Comparison of GCN250 runoff with GLDAS runoff
We compared GCN250-generated runoff ratios to GLDAS runoff ratios (daily runoff/daily rainfall) for the following river basins: Amazon River Basin (South America), Colorado River basin (USA, Mexico), Mississippi (USA), Mekong River Basin (Cambodia, Vietnam, Thailand, Laos, Myanmar, China), Nile River Basin, Sacramento (USA), Tigris-Euphrates (Turkey, Iraq, Syria, Iran), Uruguay, Yangtze (China), also the area of East Africa (Fig. 3). Using daily gridded rainfall (aggregated from 3-hourly 0.25° × 0.25° rainfall) from the Global Land Data Assimilation System (GLDAS v2.1)16, we generated gridded daily runoff ratios from the GCN250 datasets (one for each of the three antecedent runoff conditions) and compared it to the aggregated daily runoff ratios (from the 3-hourly runoff) from GLDAS for 2015–2018. We applied the rainfall from GLDAS grid onto each CN pixel within that grid, generated the CN runoff, aggregated the runoff over the basin, and then calculated the mean runoff ratio by dividing the mean runoff by the mean rainfall over the basin for that day. We compared the time series of the daily mean runoff ratios from the two sets (GLDAS and GCN250) (populated over all the basins individually) (Fig. 4) and the mean monthly runoff ratios (Fig. 5). Results show that correlations between mean monthly GLDAS runoff ratios and GCN250 runoff ratios varied by basin and by rainfall. For example, good agreement between GLDAS runoff ratio and GCN250 average CN runoff ratio was noticed in the Nile and the Amazon basins and also (to a lower degree) the Tigris-Euphrates, while for Sacramento River basin, the GLDAS runoff ratio was in agreement with the GCN250 wet CN runoff ratio. For the Yangtze River basin, we noticed good agreement between GCN250 wet CN runoff ratios and GLDAS runoff ratios for December and April of every year. In summer, GLDAS runoff ratios ranged between the GCN250 average CN runoff ratio and the GCN250 wet CN runoff ratio. In the Mississippi basin, GCN250 average CN runoff ratio agreed with GLDAS runoff ratio during the May–December. For the winter months, the GLDAS ratios were closer to the GCN250 wet CN runoff ratio. Basins dominated by snowmelt (such as the Colorado River basin) showed temporal disagreement. We attribute this variability in the results mainly to the assumption of a constant average initial abstraction of 20% of the CN method and to the variability in the ARC conditions within a watershed in space and in time. We note that the objective of this exercise is not to validate the CN method against other direct runoff data, but rather to provide insights into how close the GCN250-based runoff is to GLDAS and possibly guidance on how the dataset can be used in different geographic and climatic conditions. Users are encouraged to check local conditions and runoff trends whenever available in their area of interest before deciding on which of the three GCN250 products (ARCI, ARCII, and ARCIII) to use. The best approach would be to utilize a combination of watershed land use knowledge, rainfall intensity, plant growth stage (for agricultural watersheds), antecedent moisture (from gridded soil moisture datasets), and precipitation products to determine the antecedent runoff conditions.

Comparison between GCN250 and GLDAS daily runoff ratios derived from GLDAS rainfall for major world basins and East Africa. Wet = GCN250 ARCIII runoff ratio, Average = GCN250 ARCII runoff ratio, Dry = GCN250 ARCI runoff ratio.

Comparison between GCN250 and GLDAS mean monthly runoff ratios derived from GLDAS rainfall for major world basins and East Africa. Wet = GCN250 ARCIII runoff ratio, Average = GCN250 ARCII runoff ratio, Dry = GCN250 ARCI runoff ratio.
Code Availability
The R script used for generating the GCN250 datasets is available for download15 with instructions for code reuse. The code can be used for generating CNs for future Land cover datasets.
References
Ponce, V. M. & Hawkins, R. H. Runoff curve number: Has it reached maturity? Journal of hydrologic engineering 1, 11–19 (1996).
Hong, Y. & Adler, R. Estimation of global SCS curve numbers using satellite remote sensing and geospatial data. International Journal of Remote Sensing 29, 471–477 (2008).
Friedl, M. A. et al. Global land cover mapping from MODIS: algorithms and early results. Remote sensing of Environment 83, 287–302 (2002).
USDA. Hydrologic Soil-Cover Complexes. National Engineering Handbook: Part 630—Hydrology (2009).
Zeng, Z., Tang, G., Hong, Y., Zeng, C. & Yang, Y. Development of an NRCS curve number global dataset using the latest geospatial remote sensing data for worldwide hydrologic applications. Remote Sensing Letters 8, 528–536 (2017).
Friedl, M. A. & Sulla-Menashe, D. MCD12Q1 MODIS Terra Aqua Land Cover Type Yearly L3 Global 500m SIN Grid V006. NASA EOSDIS Land Processes DAAC, https://doi.org/10.5067/MODIS/MCD12Q1.006 (2015).
USDA. Hydrologic Soil Groups. National Engineering Handbook: Part 630—Hydrology (2009).
Ross, C. W. et al. HYSOGs250m, global gridded hydrologic soil groups for curve-number-based runoff modeling. Scientific data 5, 180091 (2018).
ESA European Space Agency. CCI Land Cover Product User Guide version 2.4. ESA CCI LC project, https://www.esa-landcover-cci.org/?q=node/164 (2018).
Poulter, B. et al. Plant functional type classification for earth system models: results from the European Space Agency’s Land Cover Climate Change Initiative. Geoscientific Model Development 8, 2315–2328 (2015).
Bontemps, S. et al. New global land cover mapping exercise in the framework of the ESA Climate Change Initiative. Geoscience and Remote Sensing Symposium (IGARSS), 2012 IEEE International, 44–47 (2012).
R Development Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/ (2017).
Hijmans, R. J. raster: Geographic Data Analysis and Modeling, https://CRAN.R-project.org/package=raster (2016).
USDA. Estimation of direct runoff from storm rainfall. National Engineering Handbook: Part 630—Hydrology (2004).
Jaafar, H. H. & Ahmad, F. GCN250, global curve number datasets for hydrologic modeling and design. figshare, https://doi.org/10.6084/m9.figshare.7756202 (2019).
Beaudoing, H. & Rodell, M. GLDAS Noah Land Surface Model L4 3 hourly 0.25 × 0.25 degree V2.1. Goddard Earth Sciences Data and Information Services Center (GES DISC), Greenbelt, Maryland, USA, https://doi.org/10.5067/E7TYRXPJKWOQ (2016).
Acknowledgements
We would like to thank Ross, et al.8 for making the soils data publicly available, the European Space Agency (ESA) for making the Land cover products publicly available, and NASA for making the GLDAS data publicly available. We also acknowledge funding from the American University of Beirut Research Board (URB).
Author information
Authors and Affiliations
Contributions
H.H.J. conceptualization, study design, study execution, manuscript writing, review, and editing. F.A.A. study execution, manuscript writing. N.B. study execution.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Online-only Table
ISA-Tab metadata file
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Jaafar, H.H., Ahmad, F.A. & El Beyrouthy, N. GCN250, new global gridded curve numbers for hydrologic modeling and design. Sci Data 6, 145 (2019). https://doi.org/10.1038/s41597-019-0155-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-019-0155-x
This article is cited by
-
High-resolution Annual Dynamic dataset of Curve Number from 2008 to 2021 over Conterminous United States
Scientific Data (2024)
-
Identifying managed aquifer recharge and rain water harvesting sites and structures for storing non-conventional water using GIS-based multi-criteria decision analysis approach
Applied Water Science (2024)
-
Unravelling the impact of spatial discretization and calibration strategies on event-based flood models
Modeling Earth Systems and Environment (2024)
-
Runoff assessment in the Padma River Basin, Bangladesh: a GIS and RS platform in the SCS-CN approach
Journal of Sedimentary Environments (2023)
-
Water conservation appraisal using surface runoff estimated by an integrated SCS-CN and MCDA-AHP technique
Journal of Earth System Science (2023)
