
Abstract
The solutions adopted by the high-energy physics community to foster reproducible research are examples of best practices that could be embraced more widely. This first experience suggests that reproducibility requires going beyond openness.
Similar content being viewed by others

Main
Open science and reproducible research have become pervasive goals across research communities, political circles and funding bodies1,2,3. The understanding is that open and reproducible research practices enable scientific reuse, accelerating future projects and discoveries in any discipline. In the struggle to take concrete steps in pursuit of these aims there has been much discussion and awareness-raising, often accompanied by a push to make research products and scientific results open quickly.
Although these are laudable and necessary first steps, they are not sufficient to bring about the transformation that would allow us to reap the benefits of open and reproducible research. It is time to move beyond the rhetoric and the trust in quick fixes and start designing and implementing tools to power a more profound change.
Our own experience from opening up vast volumes of data is that openness cannot simply be tacked on as an afterthought at the end of the scientific endeavour. In addition, openness alone does not guarantee reproducibility or reusability, so it should not be pursued as a goal in itself. Focusing on data is also not enough: it needs to be accompanied by software, workflows and explanations, all of which need to be captured throughout the usual iterative and closed research lifecycle, ready for a timely open release with the results.
Thus, we argue that having the reuse of research results as a goal requires the adoption of new research practices during the data analysis process. Such practices need to be tailored to the needs of each given discipline with its particular research environment, culture and idiosyncrasies. Services and tools should be developed with the idea of meshing seamlessly with existing research procedures, encouraging the pursuit of reusability as a natural part of researchers’ daily work (Fig. 1). In this way, the generated research products are more likely to be useful when shared openly.

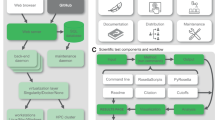
a, The experimental data from proton–proton collisions in the Large Hadron Collider are being collected by particle detectors run by the experimental collaborations ALICE, ATLAS, CMS and LHCb. The raw experimental data is further filtered and processed to give the collision dataset formats that are suitable for physics analyses. In parallel, the computer simulations are being run in order to provide necessary comparison of experimental data with theoretical predictions. b, The stored collision and simulated data are then released for individual physics analyses. A physicist may perform further data reduction and selection procedures, which are followed by a statistical analysis on the data. Physics results are derived taking into account statistical and systematic uncertainties. The results often summarize which theoretical models have predictions that are consistent with the observations once background estimates have been included. The analysis assets being used by the individual researcher include the information about the collision and simulated datasets, the detector conditions, the analysis code, the computational environments, and the computational workflow steps used by the researcher to derive the histograms and the final plots as they appear in publications. c, The CERN Analysis Preservation service captures all the analysis assets and related documentation via a set of ‘push’ and ‘pull’ protocols, so that the analysis knowledge and data are preserved in a trusted long-term digital repository for preservation purposes. d, The CERN Open Data service publishes selected data as they are released by the LHC collaborations into the public domain after an embargo period of several years depending on the collaboration data management plans and preservation policies. Credit: CERN (a); Dave Gandy (b,c, code icon); SimpleIcon (b,c, gear icon); Andrian Valeanu (b,c, data icon); Umar Irshad (c, paper icon); Freepik (c, workflow icon).
In tackling the challenge of enabling reusable research, we keep these ideas as our guiding light when putting changes into practice in our community—high-energy physics (HEP). Here, we illustrate our approach, particularly through our work at CERN, and present our community’s requirements and rationale. We hope that the explanation of our challenges and solutions will stimulate discussions around the practical implementation of workflows for reproducible and reusable research more widely in other scientific disciplines.
Approaching reproducibility and reuse in HEP
To set the stage for the rest of this piece, we first construct a more nuanced spectrum in which to place the various challenges facing HEP, allowing us to better frame our ambitions and solutions. We choose to build on the descriptions introduced by Carole Goble4 and Lorena A. Barba5 shown in Table 1.
These concepts assume a research environment in which multiple labs have the equipment necessary to duplicate an experiment, which essentially makes the experiments portable. In the particle physics context, however, the immense cost and complexity of the experimental set-up essentially make the independent and complete replication of HEP experiments unfeasible and unhelpful. HEP experiments are set up with unique capabilities, often being the only facility or instrument of their kind in the world; they are also constantly being upgraded to satisfy requirements for higher energy, precision and level of accuracy. The experiments at the Large Hadron Collider (LHC) are prominent examples. It is this uniqueness that makes the experimental data valuable for preservation so that it can be later reused with other measurements for comparison, confirmation or inspiration.
Our considerations here really begin after gathering the data. This means that we are more concerned with repeating or verifying the computational analysis performed over a given dataset rather than with data collection. Therefore, in Table 2 we present a variation of these definitions that takes into account a research environment in which ‘experimental set-up’ refers to the implementation of a computational analysis of a defined dataset, and a ‘lab’ can be thought of as an experimental collaboration or an analysis group.
In the case of computational processes, physics analyses themselves are intrinsically complex due to the large data volume and algorithms involved6. In addition, the analysts typically study more than one physics process and consider data collected under different running conditions. Although comprehensive documentation on the analysis methods is maintained, the complexity of the software implementations often hides minute but crucial details, potentially leading to a loss of knowledge concerning how the results were obtained7.
In absence of solutions for analysis capture and preservation, knowledge of specific methods and how they are applied to a given physics analysis might be lost. To tackle these community-specific challenges, a collaborative effort (coordinated by CERN, but involving the wider community) has emerged, initiating various projects, some of which are described below.
Reuse and openness
The HEP experimental collaborations operate independently of each other, and they do not share physics results until they have been rigorously verified by internal review processes8. Because these reviews often involve the input of the entire collaboration, where the level of crosschecking is extensive, the measurements are considered trustworthy.
However, it is necessary to ensure the usability of the research in the long term. This is particularly challenging today, as much of the analysis code is available primarily within the small team that performs an analysis. We think that reproducibility requires a level of attention and care that is not satisfied by simply posting undocumented code or making data ‘available on request’.
In the particular case of particle physics, it may even be true that openness itself, in the sense of unfettered access to data by the general public, is not necessarily a prerequisite for the reproducibility of the research. Take the LHC collaborations as an example: while they generally strive to be open and transparent in both their research and their software development9,10, analysis procedures and the previously described challenges of scale and data complexity mean that there are certain necessary reproducibility use cases that are better served by a tailored tool rather than an open data repository.
Such tools need to preserve the expertise of a large collaboration that flows into each analysis. Providing a central place where the disparate components of an analysis can be aggregated at the start, and then evolve as the analysis gets validated and verified, will fill this valuable role in the community. Confidentiality might aid this process so that the experts can share and discuss in a protected space before successively opening up the content of scrutiny to ever larger audiences, first within the collaboration and then later via peer review to the whole HEP community.
Cases in point are the CERN Analysis Preservation (CAP) and Reusable Analyses (REANA), which will be described in more detail below. Their key feature is that they leave the decision as to when a dataset or a complete analysis is shared publicly in the hands of the researchers. Open access can be supported, but the architecture does not depend on either data or code being publicly available. This gives the experimental collaborations full control over the release procedure and thus fully supports internal processing, review protocols and possible embargo periods. Hence, the service is accessible to the thousands of researchers who need the information it contains in order to replicate or reuse results, but the public-facing functions in HEP are better served by other services, such as CERN Open Data11, HEPData12 and INSPIRE13.
The standard data deluge in particle physics is another challenge that calls for separate approaches for reproducibility, reusability and openness. As we do not have the computational resources to enable open access and processing of raw data, there needs to be a decision on the level at which the data can meaningfully be made open to allow valuable scrutiny by the public. This is governed by the individual experiments and their respective data policies14,15,16,17.
Enabling open and reusable research at CERN
The CERN Analysis Preservation and reuse framework18,19 consists of a set of services and tools, sketched in Fig. 1, that assist researchers in describing and preserving all the components of a physics analysis such as data, software and computing environment—addressing the points discussed earlier. These, along with the associated documentation, are kept in one place so that the analysis, or parts of it, can be reused even several years after the publication of the original scientific results.
The CERN Analysis Preservation and reuse framework relies on three pillars:
-
1.
Describe: adequately describe and structure the knowledge behind a physics analysis in view of its future reuse. Describe all the assets of an analysis and track data provenance. Ensure sufficient documentation and capture associated links.
-
2.
Capture: store information about the analysis input data, the analysis code and its dependencies, the runtime computational environment and the analysis workflow steps, and any other necessary dependencies in a trusted digital repository.
-
3.
Reuse: instantiate preserved analysis assets and computational workflows on the compute clouds to allow their validation or execution with new sets of parameters to test new hypotheses.
All of these services, developed through free and open source software, strive to enable FAIR compliant data20 and can be set up for other communities as they are implemented using flexible data models. For all these services, capturing and preserving data provenance has been a key design feature. Data provenance facilitates reproducibility and data sharing as it provides a formal model for describing published results7.
CERN Analysis Preservation
The CERN Analysis Preservation (CAP) service is a digital repository instance dedicated to describing and capturing analysis assets. The service uses a flexible metadata structure conforming to JavaScript Open Notation (JSON) schemas that describe the analysis in order to help researchers identify, preserve and find the information about components of analyses. These JSON components define everything from experimental configurations to data samples and from analysis code to links to presentations and publications. By assembling such schemas, we are creating a standard way to describe and document an analysis in order to facilitate its discoverability and reproducibility.
The CAP service features a ‘push’ protocol that enables individual researchers to deposit material either by means of a user interface or with an automated command-line client. In the case of primary data, it can store links to data deposited in trusted long-term preservation stores used by the HEP experiments. For software and intermediate datasets, it can also completely ingest the material referenced by the researcher.
The CAP service can also ‘pull’ information from internal databases of LHC collaborations, when such information exists. Aggregating various sources of information from existing databases, source code repositories and data stores is an essential feature of the CAP service, helping researchers find and manage all the necessary information in a central place. Such an aggregation and standardization of data analysis information offers advanced search capabilities to researchers, facilitating discovery and search of high-level physics information associated with individual physics analyses.
REANA
We argue that physics analyses ideally should be automated from inception in such a way that they can be executed with a single command. Automating the whole analysis while it is still in its active phase permits to both easily run the ‘live’ analysis process on demand as well as to preserve it completely and seamlessly once it is over and the results are ready for publication. Thinking of restructuring a finished analysis for eventual reuse after its publication is often too late. Facilitating future reuse starts with the first commit of the analysis code.
This is the purpose served by the Reusable Analyses service, REANA: a standalone component of the framework dedicated to instantiating preserved research data analyses on the cloud. While REANA was born from the need to rerun analyses preserved in the CERN Analysis Preservation framework, it can be used to run ‘active’ analyses before they are published and preserved.
Using information about the input datasets, the computational environment, the software framework, the analysis code and the computational workflow steps to run the analysis, REANA permits researchers to submit parameterized computational workflows to run on remote compute clouds (as shown in Fig. 2). REANA leverages modern container technologies to encapsulate the runtime environment necessary for various analysis steps. REANA supports several different container technologies (Docker21, Singularity22), compute clouds (Kubernetes23/OpenShift24, HTCondor25), shared storage systems (Ceph26, EOS27) and structured workflow specifications (CWL28, Yadage29) as they are used in various research groups.

This figure shows an example where the experimental data is compared to the predictions of the standard model with an additional hypothesized signal component. The example permits one to study the complex computational workflows used in typical particle physics analyses. a–c, The computational workflow (a) may consist of several tens of thousands of computational steps that are massively parallelizable and run in a cascading ‘map-reduce’ style of computations on distributed compute clusters. The workflow definition is modelled using the Yadage workflow specification and produces an upper limit on the signal strength of the BSM process. A typical search for BSM physics consists of simulating a hypothetical signal process (c), as well as the background processes predicted by the standard model with properties consistent with the hypothetical signal (marked dark green in (b)). The background often consists of simulated background estimates (dark blue and light green histograms) and data-driven background estimates (light blue histogram). A statistical model involving both signal (dark green histogram) and background components is built and fit to the observed experimental data (black markers). b, Results of the model in its pre-fit configuration at nominal signal strength. We can see the excess of the signal over data, meaning that the nominal setting does not describe the data well. The post-fit distribution would scale down the signal in order to fit the data. This REANA example is publicly available at ref. 35. For icon credits, see Fig. 1.
RECAST
RECAST30 is a notable example of an application built around reusable workflows, which targets a specific particle physics use case. In particular, RECAST provides a gateway to test alternative physical theories by simulating what those theories predict and then running the simulated data through the analysis workflow used for a previous publication. The application programming interface exposes a restricted class of trustworthy, high-impact queries on the data. The experiment’s data and the data processing workflow need not be exposed directly. Furthermore, the experimental collaborations can optionally maintain an approval process for the new result. The system has been used internally to streamline the reinterpretation of several experiments, and ultimately could be opened to independent researchers outside of the LHC collaborations.
CERN Open Data
The CERN Open Data portal was released in 2014 amid a discussion as to whether the primary particle physics data, due to its large volume and complexity, would find any use outside of the LHC collaborations. In 2017, Thaler and colleagues31,32 confirmed their jet substructure model predictions using the open data from the Compact Muon Solenoid (CMS) experiment that were released on the portal in 2014, demonstrating that research conducted outside of the CERN collaborations could indeed benefit from such open data releases.
From its creation, the CERN Open Data service has disseminated the open experimental collision and simulated datasets, the example software, the virtual machines with the suitable computational environment, together with associated usage documentation that were released to the public by the HEP experiments. The CERN Open Data service is implemented as a standalone data repository on top of the Invenio digital repository framework33. It is used by the public, by high school and university students, and by general data scientists.
Exploitation of the released open content has been demonstrated both on the educational side and for research purposes. A team of researchers, students and summer students reproduced parts of published results from the CMS experiment using only the information that was released openly on the CERN Open Data portal. The developed code produced plots comparable to parts of the official CMS Higgs-to-four-lepton analysis results34 (Fig. 3).

The CMS collaboration released over one petabyte of research-grade collision and simulated datasets with associated computing tools such as the virtual machine, the analysis software and the examples of physics analyses. This permits independent researchers to understand and study the data in a way similar to how CMS physicists perform research. A characteristic example presented here is the analysis of the ‘Higgs-to-four-lepton’ decay channel that led to the Higgs boson experimental discovery in 2012. The Higgs boson produced in proton–proton collisions is short-lived and transforms almost instantaneously into other particles that may live longer and that are subsequently observed (directly or indirectly) by particle detectors. There are several Higgs decay modes or transformation channels possible; the present example studies the Higgs transformation into four leptons (electrons or muons) in the final state. a, The official CMS result36 as it was presented during the announcement of the Higgs boson discovery in 2012. b, Plot produced by Nur Zulaiha Jomhari and colleagues34 using CMS open data from 2011 and 2012 that are available on the CERN Open Data portal. The analysis using CMS open data is simplified and not scrutinized by the wider community of CMS experts. Nevertheless, it permits to run a realistic particle physics analysis example and learn about the Higgs decay physics using the same data formats, the same software tools and computational techniques that are remarkably close to procedures being used by CMS experimental physicists. Reproduced from ref. 36, CERN (a).
This shows that the CERN Open Data service fulfils a different and complementary use case to the CERN Analysis Preservation framework. The openness alone does not sufficiently address all the required use cases for reusable research in particle physics that is naturally born ‘closed’ in experimental collaborations before the analyses and data become openly published.
Challenging, but possible
In this paper we have discussed how open sharing enables certain types of data and software reuse, arguing that simple compliance with openness is not sufficient to foster reuse and reproducibility in particle physics. Sharing data is not enough; it is also essential to capture the structured information about the research data analysis workflows and processes to ensure the usability and longevity of results.
Research communities may start by using open data policies and initiating dialogues on data sharing, while embracing the reproducibility and reuse principles early on in the daily research processes. We compiled a few guiding principles that could support such dialogues (Box 1). In particle physics, the possibility of actual internal or external reuse of research outputs is an intrinsic motivation for taking part in these activities; one could assume the same for many other scientific communities.
Using computing technologies available today, solving the challenges of open sharing, reproducibility and reuse seems more feasible than ever, helping to keep research results viable and reusable in the future.
Change history
23 November 2018
In the version of this Perspective originally published, one of the authors’ names was incorrectly given as Kati Lassili-Perini; it should have been Kati Lassila-Perini. This has been corrected in all versions of the Perspective.
References
Baker, M. 1,500 scientists lift the lid on reproducibility. Nature News 533, 452–454 (2016).
Boulton, G. Reproducibility: International accord on open data. Nature 530, 281 (2016).
Goodman, S. N., Fanelli, D. & Ioannidis J. P. A. What does research reproducibility mean? Sci. Transl. Med. 8, 341ps12 (2016).
Goble, C. What is reproducibility. SlideShare https://www.slideshare.net/carolegoble/what-is-reproducibility-gobleclean (2016).
Barba, L. A. Terminologies for reproducible research. Preprint at https://arxiv.org/abs/1802.03311 (2018).
Brun, R. in From the Web to the Grid and Beyond (eds Brun, R., Carminati, F. & Galli-Carminati, G.) 1–53 (Springer, Berlin, Heidelberg, 2011).
Pasquier, T. et al. If these data could talk. Sci. Data 4, 170114 (2017).
Boisot, M., Nordberg, M., Yami, S. & Nicquevert, B. Collisions and Collaboration: The Organization of Learning in the ATLAS Experiment at the LHC (Oxford Univ. Press, Oxford, 2011).
Albrecht, J. et al. A roadmap for HEP software and computing R&D for the 2020s. Preprint at https://arxiv.org/abs/1712.06982 (2017).
Elmer, P., Neubauer, M. & Sokoloff, M. D. Strategic plan for a scientific software innovation institute (S2I2) for high energy physics. Preprint at https://arxiv.org/abs/1712.06592 (2017).
CERN Open Data portal; http://opendata.cern.ch/
HEPData; https://hepdata.net/
INSPIREHEP; http://inspirehep.net/
ATLAS Collaboration. ATLAS data access policy. CERN Open Data Portal https://doi.org/10.7483/opendata.atlas.t9yr.y7mz (2014).
Clarke, P. & LHCb Collaboration. LHCb external data access policy. CERN Open Data Portal https://doi.org/10.7483/opendata.lhcb.hkjw.twsz (2013).
CMS Collaboration. CMS data preservation, re-use and open access policy. CERN Open Data Portal https://doi.org/10.7483/opendata.cms.udbf.jkr9 (2012).
ALICE Collaboration. ALICE data preservation strategy. CERN Open Data Portal https://doi.org/10.7483/opendata.alice.54ne.x2ea (2013).
CERN Analysis Preservation. GitHub https://github.com/cernanalysispreservation (2018).
REANA; http://reana.io/
Wilkinson, M. D. et al. The FAIR guiding principles for scientific data management and stewardship. Sci. Data 3, 160018 (2016).
Docker; https://www.docker.com/
Singularity. GitHub https://github.com/singularityware (2018).
Kubernetes; https://kubernetes.io/
OpenShift; https://www.openshift.com/
HTCondor; https://research.cs.wisc.edu/htcondor/
EOS service. CERN http://information-technology.web.cern.ch/services/eos-service (2018).
Common workflow language. GitHub https://github.com/common-workflow-language/common-workflow-language (2018).
Cranmer, K. & Heinrich, L. Yadage and Packtivity – analysis preservation using parameterized workflows. J. Phys. Conf. Ser. 898, 102019 (2017).
Cranmer, K. & Yavin, I. RECAST — extending the impact of existing analyses. J. High Energy Phys. 2011, 38 (2011).
Larkoski, A., Marzani, S., Thaler, J., Tripathee, A. & Xue, W. Exposing the QCD splitting function with CMS open data. Phys. Rev. Lett. 119, 132003 (2017).
Tripathee, A., Wei, X., Larkoski, A., Marzani, S. & Thaler, J. Jet substructure studies with CMS open data. Phys. Rev. D 96, 074003 (2017).
Invenio Software; http://invenio-software.org/
Jomhari, N. Z., Geiser, A. & Bin Anuar, A. A. Higgs-to-four-lepton analysis example using 2011–2012 data. CERN Open Data Portal https://doi.org/10.7483/opendata.cms.jkb8.rr42 (2017).
REANA example: BSM search. GitHub https://github.com/reanahub/reana-demo-bsm-search (2018).
Chatrchyan, S. et al. (CMS Collaboration) Observation of a new boson at a mass of 125 GeV with the CMS experiment at the LHC. Phys. Lett. B 716, 30–61 (2012).
Schiermeier, Q. Data management made simple. Nature 555, 403–405 (2018).
Barba, L. A. Reproducibility PI manifesto. Figshare https://figshare.com/articles/reproducibility_pi_manifesto/104539 (2012).
Goodman, A. et al. Ten simple rules for the care and feeding of scientific data. PLoS Comput. Biol. 10, e1003542 (2014).
Acknowledgements
Considerations and services described here benefit from funding and discussions from the EC funded projects FREYA (777523), THOR (654039) and CRISP (283745). Furthermore, we acknowledge support for the DASPOS (https://daspos.crc.nd.edu/) and Diana/HEP projects (http://diana-hep.org/).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, X., Dallmeier-Tiessen, S., Dasler, R. et al. Open is not enough. Nature Phys 15, 113–119 (2019). https://doi.org/10.1038/s41567-018-0342-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41567-018-0342-2
This article is cited by
-
Knowledge and Instance Mapping: architecture for premeditated interoperability of disparate data for materials
Scientific Data (2024)
-
A large-scale study on research code quality and execution
Scientific Data (2022)
-
Quantum computing’s reproducibility crisis: Majorana fermions
Nature (2021)
-
Biases in ecological research: attitudes of scientists and ways of control
Scientific Reports (2021)
-
Comments on “UNESCO Global Geoparks in Latin America and the Caribbean, and Their Contribution to Agenda 2030 Sustainable Development Goals” (Rosado-González et al. 2000, Geoheritage 12: 1-15, 2020)
Geoheritage (2021)
