
Abstract
Improving the reliability and efficiency of scientific research will increase the credibility of the published scientific literature and accelerate discovery. Here we argue for the adoption of measures to optimize key elements of the scientific process: methods, reporting and dissemination, reproducibility, evaluation and incentives. There is some evidence from both simulations and empirical studies supporting the likely effectiveness of these measures, but their broad adoption by researchers, institutions, funders and journals will require iterative evaluation and improvement. We discuss the goals of these measures, and how they can be implemented, in the hope that this will facilitate action toward improving the transparency, reproducibility and efficiency of scientific research.
Similar content being viewed by others
What proportion of published research is likely to be false? Low sample size, small effect sizes, data dredging (also known as P-hacking), conflicts of interest, large numbers of scientists working competitively in silos without combining their efforts, and so on, may conspire to dramatically increase the probability that a published finding is incorrect1. The field of metascience — the scientific study of science itself — is flourishing and has generated substantial empirical evidence for the existence and prevalence of threats to efficiency in knowledge accumulation (refs 2,3,4,5,6,7; Fig. 1).
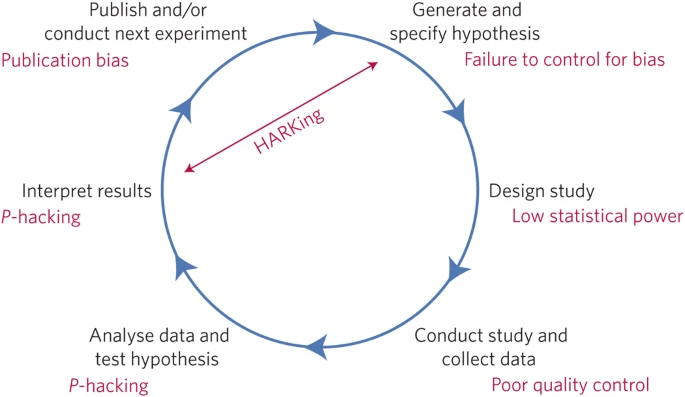
An idealized version of the hypothetico-deductive model of the scientific method is shown. Various potential threats to this model exist (indicated in red), including lack of replication5, hypothesizing after the results are known (HARKing)7, poor study design, low statistical power2, analytical flexibility51, P-hacking4, publication bias3 and lack of data sharing6. Together these will serve to undermine the robustness of published research, and may also impact on the ability of science to self-correct.
Data from many fields suggests reproducibility is lower than is desirable8,9,10,11,12,13,14; one analysis estimates that 85% of biomedical research efforts are wasted14, while 90% of respondents to a recent survey in Nature agreed that there is a ‘reproducibility crisis’15. Whether ‘crisis’ is the appropriate term to describe the current state or trajectory of science is debatable, but accumulated evidence indicates that there is substantial room for improvement with regard to research practices to maximize the efficiency of the research community's use of the public's financial investment in research.
Here we propose a series of measures that we believe will improve research efficiency and robustness of scientific findings by directly targeting specific threats to reproducible science. We argue for the adoption, evaluation and ongoing improvement of these measures to optimize the pace and efficiency of knowledge accumulation. The measures are organized into the following categories16: methods, reporting and dissemination, reproducibility, evaluation and incentives. They are not intended to be exhaustive, but provide a broad, practical and evidence-based set of actions that can be implemented by researchers, institutions, journals and funders. The measures and their current implementation are summarized in Table 1.
The problem
A hallmark of scientific creativity is the ability to see novel and unexpected patterns in data. John Snow's identification of links between cholera and water supply17, Paul Broca's work on language lateralization18 and Jocelyn Bell Burnell's discovery of pulsars19 are examples of breakthroughs achieved by interpreting observations in a new way. However, a major challenge for scientists is to be open to new and important insights while simultaneously avoiding being misled by our tendency to see structure in randomness. The combination of apophenia (the tendency to see patterns in random data), confirmation bias (the tendency to focus on evidence that is in line with our expectations or favoured explanation) and hindsight bias (the tendency to see an event as having been predictable only after it has occurred) can easily lead us to false conclusions20. Thomas Levenson documents the example of astronomers who became convinced they had seen the fictitious planet Vulcan because their contemporary theories predicted its existence21. Experimenter effects are an example of this kind of bias22.
Over-interpretation of noise is facilitated by the extent to which data analysis is rapid, flexible and automated23. In a high-dimensional dataset, there may be hundreds or thousands of reasonable alternative approaches to analysing the same data24,25. For example, in a systematic review of functional magnetic resonance imaging (fMRI) studies, Carp showed that there were almost as many unique analytical pipelines as there were studies26. If several thousand potential analytical pipelines can be applied to high-dimensional data, the generation of false-positive findings is highly likely. For example, applying almost 7,000 analytical pipelines to a single fMRI dataset resulted in over 90% of brain voxels showing significant activation in at least one analysis27.
During data analysis it can be difficult for researchers to recognize P-hacking28 or data dredging because confirmation and hindsight biases can encourage the acceptance of outcomes that fit expectations or desires as appropriate, and the rejection of outcomes that do not as the result of suboptimal designs or analyses. Hypotheses may emerge that fit the data and are then reported without indication or recognition of their post hoc origin7. This, unfortunately, is not scientific discovery, but self-deception29. Uncontrolled, it can dramatically increase the false discovery rate. We need measures to counter the natural tendency of enthusiastic scientists who are motivated by discovery to see patterns in noise.
Methods
In this section we describe measures that can be implemented when performing research (including, for example, study design, methods, statistics, and collaboration).
Protecting against cognitive biases. There is a substantial literature on the difficulty of avoiding cognitive biases. An effective solution to mitigate self-deception and unwanted biases is blinding. In some research contexts, participants and data collectors can be blinded to the experimental condition that participants are assigned to, and to the research hypotheses, while the data analyst can be blinded to key parts of the data. For example, during data preparation and cleaning, the identity of experimental conditions or the variable labels can be masked so that the output is not interpretable in terms of the research hypothesis. In some physical sciences this approach has been extended to include deliberate perturbations in or masking of data to allow data preparation (for example, identification of outliers) to proceed without the analyst being able to see the corresponding results30. Pre-registration of the study design, primary outcome(s) and analysis plan (see ‘Promoting study pre-registration’ section’, below) is a highly effective form of blinding because the data do not exist and the outcomes are not yet known.
Improving methodological training. Research design and statistical analysis are mutually dependent. Common misperceptions, such as the interpretation of P values31, limitations of null-hypothesis significance testing32, the meaning and importance of statistical power2, the accuracy of reported effect sizes33, and the likelihood that a sample size that generated a statistically significant finding will also be adequate to replicate a true finding34, could all be addressed through improved statistical training. Similarly, basic design principles are important, such as blinding to reduce experimenter bias, randomization or counterbalancing to control for confounding, and the use of within-subjects designs, where possible, to maximize power. However, integrative training in research practices that can protect oneself against cognitive biases and the effects of distorted incentives is arguably more important. Moreover, statistical and methodological best practices are under constant revision and improvement, so that senior as well as junior researchers need continuing methodological education, not least because much training of early-career researchers is informal and flows from their supervisor or mentor. A failure to adopt advances in methodology — such as the very slow progress in increasing statistical power35,36 — may be partly a function of failing to inculcate a continuing professional education and development ethic.
Without formal requirements for continuing education, the most effective solutions may be to develop educational resources that are accessible, easy-to-digest and immediately and effectively applicable to research (for example, brief, web-based modules for specific topics, and combinations of modules that are customized for particular research applications). A modular approach simplifies the process of iterative updating of those materials. Demonstration software and hands-on examples may also make the lessons and implications particularly tangible to researchers at any career stage: the Experimental Design Assistant (https://eda.nc3rs.org.uk) supports research design for whole animal experiments, while P-hacker (http://shinyapps.org/apps/p-hacker/) shows just how easy it is to generate apparently statistically significant findings by exploiting analytic flexibility.
Implementing independent methodological support. The need for independent methodological support is well-established in some areas — many clinical trials, for example, have multidisciplinary trial steering committees to provide advice and oversee the design and conduct of the trial. The need for these committees grew out of the well-understood financial conflicts of interest that exist in many clinical trials. The sponsor of a trial may be the company manufacturing the product, and any intentional or unintentional influence can distort the study design, analysis and interpretation of results for the ultimate financial benefit of the manufacturer at the cost of the accuracy of the science and the health benefit to the consumers37,38. Non-financial conflicts of interest also exist, such as the beliefs and preconceptions of individual scientists and the stakes that researchers have in obtaining publishable results in order to progress their career39,40. Including independent researchers (particularly methodologists with no personal investment in a research topic) in the design, monitoring, analysis or interpretation of research outcomes may mitigate some of those influences, and can be done either at the level of the individual research project or through a process facilitated by a funding agency (see Box 1).
Encouraging collaboration and team science. Studies of statistical power persistently find it to be below (sometimes well below) 50%, across both time and the different disciplines studied2,35,36. Low statistical power increases the likelihood of obtaining both false-positive and false-negative results2, meaning that it offers no advantage if the purpose is to accumulate knowledge. Despite this, low-powered research persists because of dysfunctional incentives, poor understanding of the consequences of low power, and lack of resources to improve power. Team science is a solution to the latter problem — instead of relying on the limited resources of single investigators, distributed collaboration across many study sites facilitates high-powered designs and greater potential for testing generalizability across the settings and populations sampled. This also brings greater scope for multiple theoretical and disciplinary perspectives, and a diverse range of research cultures and experiences, to be incorporated into a research project.
Multi-centre and collaborative efforts have a long and successful tradition in fields such as randomized controlled trials in some areas of clinical medicine, and in genetic association analyses, and have improved the robustness of the resulting research literatures. Multi-site collaborative projects have also been advocated for other types of research, such as animal studies41–43, in an effort to maximize their power, enhance standardization, and optimize transparency and protection from biases. The Many Labs projects illustrate this potential in the social and behavioural sciences, with dozens of laboratories implementing the same research protocol to obtain highly precise estimates of effect sizes, and evaluate variability across samples and settings44,45. It is also possible, and desirable, to incorporate a team science ethos into student training (see Box 2).
Reporting and dissemination
In this section we describe measures that can be implemented when communicating research (including, for example, reporting standards, study pre-registration, and disclosing conflicts of interest).
Promoting study pre-registration. Pre-registration of study protocols for randomized controlled trials in clinical medicine has become standard practice46. In its simplest form it may simply comprise the registration of the basic study design, but it can also include a detailed pre-specification of the study procedures, outcomes and statistical analysis plan. It was introduced to address two problems: publication bias and analytical flexibility (in particular outcome switching in the case of clinical medicine). Publication bias47, also known as the file drawer problem48, refers to the fact that many more studies are conducted than published. Studies that obtain positive and novel results are more likely to be published than studies that obtain negative results or report replications of prior results47,49,50. The consequence is that the published literature indicates stronger evidence for findings than exists in reality. Outcome switching refers to the possibility of changing the outcomes of interest in the study depending on the observed results. A researcher may include ten variables that could be considered outcomes of the research, and — once the results are known — intentionally or unintentionally select the subset of outcomes that show statistically significant results as the outcomes of interest. The consequence is an increase in the likelihood that reported results are spurious by leveraging chance, while negative evidence gets ignored. This is one of several related research practices that can inflate spurious findings when analysis decisions are made with knowledge of the observed data, such as selection of models, exclusion rules and covariates. Such data-contingent analysis decisions constitute what has become known as P-hacking51, and pre-registration can protect against all of these.
The strongest form of pre-registration involves both registering the study (with a commitment to make the results public) and closely pre-specifying the study design, primary outcome and analysis plan in advance of conducting the study or knowing the outcomes of the research. In principle, this addresses publication bias by making all research discoverable, whether or not it is ultimately published, allowing all of the evidence about a finding to be obtained and evaluated. It also addresses outcome switching, and P-hacking more generally, by requiring the researcher to articulate analytical decisions prior to observing the data, so that these decisions remain data-independent. Critically, it also makes clear the distinction between data-independent confirmatory research that is important for testing hypotheses, and data-contingent exploratory research that is important for generating hypotheses.
While pre-registration is now common in some areas of clinical medicine (due to requirements by journals and regulatory bodies, such as the Food and Drug Administration in the United States and the European Medicines Agency in the European Union), it is rare in the social and behavioural sciences. However, support for study pre-registration is increasing; websites such as the Open Science Framework (http://osf.io/) and AsPredicted (http://AsPredicted.org/) offer services to pre-register studies, the Preregistration Challenge offers education and incentives to conduct pre-registered research (http://cos.io/prereg), and journals are adopting the Registered Reports publishing format52,53 to encourage pre-registration and add results-blind peer review (see Box 3).
Improving the quality of reporting. Pre-registration will improve discoverability of research, but discoverability does not guarantee usability. Poor usability reflects difficulty in evaluating what was done, in reusing the methodology to assess reproducibility, and in incorporating the evidence into systematic reviews and meta-analyses. Improving the quality and transparency in the reporting of research is necessary to address this. The Transparency and Openness Promotion (TOP) guidelines offer standards as a basis for journals and funders to incentivize or require greater transparency in planning and reporting of research54. TOP provides principles for how transparency and usability can be increased, while other guidelines provide concrete steps for how to maximize the quality of reporting in particular areas. For example, the Consolidated Standards of Reporting Trials (CONSORT) statement provides guidance for clear, complete and accurate reporting of randomized controlled trials55–57. Over 300 reporting guidelines now exist for observational studies, prognostic studies, predictive models, diagnostic tests, systematic reviews and meta-analyses in humans, a large variety of studies using different laboratory methods, and animal studies. The Equator Network (http://www.equator-network.org/) aggregates these guidelines to improve discoverability58. There are also guidelines for improving the reporting of research planning; for example, the Preferred Reporting Items for Systematic Reviews and Meta-analyses (PRISMA) statement for reporting of systematic reviews and meta-analyses59, and PRISMA-P for protocols of systematic reviews60. The Preregistration Challenge workflow and the pre-registration recipe for social-behavioural research61 also illustrate guidelines for reporting research plans.
The success of reporting guidelines depends on their adoption and effective use. The social and behavioural sciences are behind the biomedical sciences in their adoption of reporting guidelines for research, although with rapid adoption of the TOP guidelines and related developments by journals and funders that gap may be closing. However, improved reporting may be insufficient on its own to maximize research quality. Reporting guidelines are easily perceived by researchers as bureaucratic exercises rather than means of improving research and reporting. Even with pre-registration of clinical trials, one study observed that just 13% of trials published outcomes completely consistent with the pre-registered commitments. Most publications of the trials did not report pre-registered outcomes and added new outcomes that were not part of the registered design (see www.COMPare-trials.org). Franco and colleagues observed similar findings in psychology62; using protocol pre-registrations and public data from the Time-sharing Experiments for the Social Sciences project (http://www.tessexperiments.org/), they found that 40% of published reports failed to mention one or more of the experimental conditions of the experiments, and approximately 70% of published reports failed to mention one or more of the outcome measures included in the study. Moreover, outcome measures that were not included were much more likely to be negative results and associated with smaller effect sizes than outcome measures that were included.
The positive outcome of reporting guidelines is that they make it possible to detect and study these behaviours and their impact. Otherwise, these behaviours are simply unknowable in any systematic way. The negative outcome is the empirical evidence that reporting guidelines may be necessary, but will not alone be sufficient, to address reporting biases. The impact of guidelines and how best to optimize their use and impact will be best assessed by randomized trials (see Box 4).
Reproducibility
In this section we describe measures that can be implemented to support verification of research (including, for example, sharing data and methods).
Promoting transparency and open science. Science is a social enterprise: independent and collaborative groups work to accumulate knowledge as a public good. The credibility of scientific claims is rooted in the evidence supporting them, which includes the methodology applied, the data acquired, and the process of methodology implementation, data analysis and outcome interpretation. Claims become credible by the community reviewing, critiquing, extending and reproducing the supporting evidence. However, without transparency, claims only achieve credibility based on trust in the confidence or authority of the originator. Transparency is superior to trust.
Open science refers to the process of making the content and process of producing evidence and claims transparent and accessible to others. Transparency is a scientific ideal, and adding ‘open’ should therefore be redundant. In reality, science often lacks openness: many published articles are not available to people without a personal or institutional subscription, and most data, materials and code supporting research outcomes are not made accessible, for example, in a public repository (refs 63,64; Box 5).
Very little of the research process (for example, study protocols, analysis workflows, peer review) is accessible because, historically, there have been few opportunities to make it accessible even if one wanted to do so. This has motivated calls for open access, open data and open workflows (including analysis pipelines), but there are substantial barriers to meeting these ideals, including vested financial interests (particularly in scholarly publishing) and few incentives for researchers to pursue open practices. For example, current incentive structures promote the publication of ‘clean’ narratives, which may require the incomplete reporting of study procedures or results. Nevertheless, change is occurring. The TOP guidelines54,65 promote open practices, while an increasing number of journals and funders require open practices (for example, open data), with some offering their researchers free, immediate open-access publication with transparent post-publication peer review (for example, the Wellcome Trust, with the launch of Wellcome Open Research). Policies to promote open science can include reporting guidelines or specific disclosure statements (see Box 6). At the same time, commercial and non-profit organizations are building new infrastructure such as the Open Science Framework to make transparency easy and desirable for researchers.
Evaluation
In this section we describe measures that can be implemented when evaluating research (including, for example, peer review).
Diversifying peer review. For most of the history of scientific publishing, two functions have been confounded — evaluation and dissemination. Journals have provided dissemination via sorting and delivering content to the research community, and gatekeeping via peer review to determine what is worth disseminating. However, with the advent of the internet, individual researchers are no longer dependent on publishers to bind, print and mail their research to subscribers. Dissemination is now easy and can be controlled by researchers themselves. For example, preprint services (arXiv for some physical sciences, bioRxiv and PeerJ for the life sciences, engrXiv for engineering, PsyArXiv for psychology, and SocArXiv and the Social Science Research Network (SSRN) for the social sciences) facilitate easy sharing, sorting and discovery of research prior to publication. This dramatically accelerates the dissemination of information to the research community.
With increasing ease of dissemination, the role of publishers as a gatekeeper is declining. Nevertheless, the other role of publishing — evaluation — remains a vital part of the research enterprise. Conventionally, a journal editor will select a limited number of reviewers to assess the suitability of a submission for a particular journal. However, more diverse evaluation processes are now emerging, allowing the collective wisdom of the scientific community to be harnessed66. For example, some preprint services support public comments on manuscripts, a form of pre-publication review that can be used to improve the manuscript. Other services, such as PubMed Commons and PubPeer, offer public platforms to comment on published works facilitating post-publication peer review. At the same time, some journals are trialling ‘results-free’ review, where editorial decisions to accept are based solely on review of the rationale and study methods alone (that is, results-blind)67.
Both pre- and post-publication peer review mechanisms dramatically accelerate and expand the evaluation process68. By sharing preprints, researchers can obtain rapid feedback on their work from a diverse community, rather than waiting several months for a few reviews in the conventional, closed peer review process. Using post-publication services, reviewers can make positive and critical commentary on articles instantly, rather than relying on the laborious, uncertain and lengthy process of authoring a commentary and submitting it to the publishing journal for possible publication, eventually.
As public forms of pre- and post-publication review, these new services introduce the potential for new forms of credit and reputation enhancement69. In the conventional model, peer review is done privately, anonymously and purely as a service. With public commenting systems, a reviewer that chooses to be identifiable may gain (or lose) reputation based on the quality of review. There are a number of possible and perceived risks of non-anonymous reviewing that reviewers must consider and research must evaluate, but there is evidence that open peer review improves the quality of reviews received70. The opportunity for accelerated scholarly communication may both improve the pace of discovery and diversify the means of being an active contributor to scientific discourse.
Incentives
Publication is the currency of academic science and increases the likelihood of employment, funding, promotion and tenure. However, not all research is equally publishable. Positive, novel and clean results are more likely to be published than negative results, replications and results with loose ends; as a consequence, researchers are incentivized to produce the former, even at the cost of accuracy40. These incentives ultimately increase the likelihood of false positives in the published literature71. Shifting the incentives therefore offers an opportunity to increase the credibility and reproducibility of published results. For example, with simulations, Munafò and Higginson developed an optimality model that predicted the most rational research strategy, in terms of the proportion of research effort spent on seeking novel results rather than on confirmatory studies, and the amount of research effort per exploratory study72. This showed that, for parameter values derived from the scientific literature, researchers acting to maximize their ‘fitness’ should spend most of their effort seeking novel results and conduct small studies that have a statistical power of only 10–40%. Critically, their model suggests that altering incentive structures, by considering more of a researcher's output and giving less weight to strikingly novel findings when making appointment and promotion decisions, would encourage a change in researcher behaviour that would ultimately improve the scientific value of research.
Funders, publishers, societies, institutions, editors, reviewers and authors all contribute to the cultural norms that create and sustain dysfunctional incentives. Changing the incentives is therefore a problem that requires a coordinated effort by all stakeholders to alter reward structures. There will always be incentives for innovative outcomes — those who discover new things will be rewarded more than those who do not. However, there can also be incentives for efficiency and effectiveness — those who conduct rigorous, transparent and reproducible research could be rewarded more than those who do not. There are promising examples of effective interventions for nudging incentives. For example, journals are adopting badges to acknowledge open practices (Fig. 2), Registered Reports as a results-blind publishing model (see Box 3) and TOP guidelines to promote openness and transparency. Funders are also adopting transparency requirements, and piloting funding mechanisms to promote reproducibility such as the Netherlands Organisation for Scientific Research (NWO) and the US National Science Foundation's Directorate of Social, Behavioral and Economic Sciences, both of which have announced funding opportunities for replication studies. Institutions are wrestling with policy and infrastructure adjustments to promote data sharing, and there are hints of open-science practices becoming part of hiring and performance evaluation (for example, http://www.nicebread.de/open-science-hiring-practices/). Collectively, and at scale, such efforts can shift incentives such that what is good for the scientist is also good for science — rigorous, transparent and reproducible research practices producing credible results.

In January 2014, the journal Psychological Science (PSCI) introduced badges for articles with open data. Immediately afterwards, the proportion of articles with open data increased steeply, and by October 2015, 38% of articles in Psychological Science had open data. For comparison journals (Clinical Psychological Science (CPS), Developmental Psychology (DP), Journal of Experimental Psychology: Learning, Memory and Cognition (JEPLMC) and Journal of Personality and Social Psychology (JPSP)) the proportion of articles with open data remained uniformly low. Figure adapted from ref. 75, PLoS.
Conclusion
The challenges to reproducible science are systemic and cultural, but that does not mean they cannot be met. The measures we have described constitute practical and achievable steps toward improving rigor and reproducibility. All of them have shown some effectiveness, and are well suited to wider adoption, evaluation and improvement. Equally, these proposals are not an exhaustive list; there are many other nascent and maturing ideas for making research practices more efficient and reliable73. Offering a solution to a problem does not guarantee its effectiveness, and making changes to cultural norms and incentives can spur additional behavioural changes that are difficult to anticipate. Some solutions may be ineffective or even harmful to the efficiency and reliability of science, even if conceptually they appear sensible.
The field of metascience (or metaresearch) is growing rapidly, with over 2,000 relevant publications accruing annually16. Much of that literature constitutes the evaluation of existing practices and the identification of alternative approaches. What was previously taken for granted may be questioned, such as widely used statistical methods; for example, the most popular methods and software for spatial extent analysis in fMRI imaging were recently shown to produce unacceptably high false-positive rates74. Proposed solutions may also give rise to other challenges; for example, while replication is a hallmark for reinforcing trust in scientific results, there is uncertainty about which studies deserve to be replicated and what would be the most efficient replication strategies. Moreover, a recent simulation suggests that replication alone may not suffice to rid us of false results71.
These cautions are not a rationale for inaction. Reproducible research practices are at the heart of sound research and integral to the scientific method. How best to achieve rigorous and efficient knowledge accumulation is a scientific question; the most effective solutions will be identified by a combination of brilliant hypothesizing and blind luck, by iterative examination of the effectiveness of each change, and by a winnowing of many possibilities to the broadly enacted few. True understanding of how best to structure and incentivize science will emerge slowly and will never be finished. That is how science works. The key to fostering a robust metascience that evaluates and improves practices is that the stakeholders of science must not embrace the status quo, but instead pursue self-examination continuously for improvement and self-correction of the scientific process itself.
As Richard Feynman said, “The first principle is that you must not fool yourself – and you are the easiest person to fool.”
References
Ioannidis, J. P. A. Why most published research findings are false. PLoS Med. 2, e124 (2005).
Button, K. S. et al. Power failure: why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci. 14, 365–376 (2013).
Fanelli, D. “Positive” results increase down the Hierarchy of the Sciences. PloS ONE 5, e10068 (2010).
John, L. K., Loewenstein, G. & Prelec, D. Measuring the prevalence of questionable research practices with incentives for truth telling. Psychol. Sci. 23, 524–532 (2012).
Makel, M. C., Plucker, J. A. & Hegarty, B. Replications in psychology research: how often do they really occur? Perspect. Psychol. Sci. 7, 537–542 (2012).
Wicherts, J. M., Borsboom, D., Kats, J. & Molenaar, D. The poor availability of psychological research data for reanalysis. Am. Psychol. 61, 726–728 (2006).
Kerr, N. L. HARKing: hypothesizing after the results are known. Pers. Soc. Psychol. Rev. 2, 196–217 (1998).
Al-Shahi Salman, R. et al. Increasing value and reducing waste in biomedical research regulation and management. Lancet 383, 176–185 (2014).
Begley, C. G. & Ioannidis, J. P. Reproducibility in science: improving the standard for basic and preclinical research. Circ. Res. 116, 116–126 (2015).
Chalmers, I. et al. How to increase value and reduce waste when research priorities are set. Lancet 383, 156–165 (2014).
Chan, A. W. et al. Increasing value and reducing waste: addressing inaccessible research. Lancet 383, 257–266 (2014).
Glasziou, P. et al. Reducing waste from incomplete or unusable reports of biomedical research. Lancet 383, 267–276 (2014).
Ioannidis, J. P. et al. Increasing value and reducing waste in research design, conduct, and analysis. Lancet 383, 166–175 (2014).
Macleod, M. R. et al. Biomedical research: increasing value, reducing waste. Lancet 383, 101–104 (2014).
Baker, M. 1,500 scientists lift the lid on reproducibility. Nature 533, 452–454 (2016).
Ioannidis, J. P., Fanelli, D., Dunne, D. D. & Goodman, S. N. Meta-research: evaluation and improvement of research methods and practices. PLoS Biol. 13, e1002264 (2015).
Paneth, N. Assessing the contributions of John Snow to epidemiology: 150 years after removal of the broad street pump handle. Epidemiology 15, 514–516 (2004).
Berker, E. A., Berker, A. H. & Smith, A. Translation of Broca's 1865 report. Localization of speech in the third left frontal convolution. Arch. Neurol. 43, 1065–1072 (1986).
Wade, N. Discovery of pulsars: a graduate student's story. Science 189, 358–364 (1975).
Nickerson, R. S. Confirmation bias: a ubiquitous phenomenon in many guises. Rev. Gen. Psychol. 2, 175–220 (1998).
Levenson, T. The Hunt for Vulcan...and How Albert Einstein Destroyed a Planet, Discovered Relativity, and Deciphered the University (Random House, 2015).
Rosenthal, R. Experimenter Effects in Behavioral Research (Appleton-Century-Crofts, 1966).
de Groot, A. D. The meaning of “significance” for different types of research [translated and annotated by Eric-Jan Wagenmakers, Denny Borsboom, Josine Verhagen, Rogier Kievit, Marjan Bakker, Angelique Cramer, Dora Matzke, Don Mellenbergh, and Han L. J. van der Maas]. Acta Psychol. 148, 188–194 (2014).
Heininga, V. E., Oldehinkel, A. J., Veenstra, R. & Nederhof, E. I just ran a thousand analyses: benefits of multiple testing in understanding equivocal evidence on gene-environment interactions. PloS ONE 10, e0125383 (2015).
Patel, C. J., Burford, B. & Ioannidis, J. P. Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations. J. Clin. Epidemiol. 68, 1046–1058 (2015).
Carp, J. The secret lives of experiments: methods reporting in the fMRI literature. Neuroimage 63, 289–300 (2012).
Carp, J. On the plurality of (methodological) worlds: estimating the analytic flexibility of FMRI experiments. Front. Neurosci. 6, 149 (2012).
Simonsohn, U., Nelson, L. D. & Simmons, J. P. P-curve: a key to the file-drawer. J. Exp. Psychol. Gen. 143, 534–547 (2014).
Nuzzo, R. Fooling ourselves. Nature 526, 182–185 (2015).
MacCoun, R. & Perlmutter, S. Blind analysis: hide results to seek the truth. Nature 526, 187–189 (2015).
Greenland, S. et al. Statistical tests, P values, confidence intervals, and power: a guide to misinterpretations. Eur. J. Epidemiol. 31, 337–350 (2016).
Sterne, J. A. & Davey Smith, G. Sifting the evidence—what's wrong with significance tests? BMJ 322, 226–231 (2001).
Brand, A., Bradley, M. T., Best, L. A. & Stoica, G. Accuracy of effect size estimates from published psychological research. Percept. Motor Skill. 106, 645–649 (2008).
Vankov, I., Bowers, J. & Munafò, M. R. On the persistence of low power in psychological science. Q. J. Exp. Psychol. 67, 1037–1040 (2014).
Sedlmeier, P. & Gigerenzer, G. Do studies of statistical power have an effect on the power of studies? Psychol. Bull. 105, 309–316 (1989).
Cohen, J. The statistical power of abnormal-social psychological research: a review. J. Abnorm. Soc. Psychol. 65, 145–153 (1962).
Etter, J. F., Burri, M. & Stapleton, J. The impact of pharmaceutical company funding on results of randomized trials of nicotine replacement therapy for smoking cessation: a meta-analysis. Addiction 102, 815–822 (2007).
Etter, J. F. & Stapleton, J. Citations to trials of nicotine replacement therapy were biased toward positive results and high-impact-factor journals. J. Clin. Epidemiol. 62, 831–837 (2009).
Panagiotou, O. A. & Ioannidis, J. P. Primary study authors of significant studies are more likely to believe that a strong association exists in a heterogeneous meta-analysis compared with methodologists. J. Clin. Epidemiol. 65, 740–747 (2012).
Nosek, B. A., Spies, J. R. & Motyl, M. Scientific utopia: II. Restructuring incentives and practices to promote truth over publishability. Perspect. Psychol. Sci. 7, 615–631 (2012).
Bath, P. M. W., Macleod, M. R. & Green, A. R. Emulating multicentre clinical stroke trials: a new paradigm for studying novel interventions in experimental models of stroke. Int. J. Stroke 4, 471–479 (2009).
Dirnagl, U. et al. A concerted appeal for international cooperation in preclinical stroke research. Stroke 44, 1754–1760 (2013).
Milidonis, X., Marshall, I., Macleod, M. R. & Sena, E. S. Magnetic resonance imaging in experimental stroke and comparison with histology systematic review and meta-analysis. Stroke 46, 843–851 (2015).
Klein, R. A. et al. Investigating variation in replicability: a “many labs” replication project. Soc. Psychol. 45, 142–152 (2014).
Ebersole, C. R. et al. Many Labs 3: evaluating participant pool quality across the academic semester via replication. J. Exp. Soc. Psychol. 67, 68–82 (2016).
Lenzer, J., Hoffman, J. R., Furberg, C. D. & Ioannidis, J. P. A. Ensuring the integrity of clinical practice guidelines: a tool for protecting patients. BMJ 347, f5535 (2013).
Sterling, T. D. Publication decisions and their possible effects on inferences drawn from tests of significance—or vice versa. J. Am. Stat. Assoc. 54, 30–34 (1959).
Rosenthal, R. File drawer problem and tolerance for null results. Psychol. Bull. 86, 638–641 (1979).
Sterling, T. D. Consequence of prejudice against the null hypothesis. Psychol. Bull. 82, 1–20 (1975).
Franco, A., Malhotra, N. & Simonovits, G. Publication bias in the social sciences: unlocking the file drawer. Science 345, 1502–1505 (2014).
Simmons, J. P., Nelson, L. D. & Simonsohn, U. False-positive psychology: undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychol. Sci. 22, 1359–1366 (2011).
Chambers, C. D. Registered Reports: a new publishing initiative at Cortex. Cortex 49, 609–610 (2013).
Nosek, B. A. & Lakens, D. Registered Reports: a method to increase the credibility of published results. Soc. Psychol. 45, 137–141 (2014).
Nosek, B. A. et al. Promoting an open research culture. Science 348, 1422–1425 (2015).
Begg, C. et al. Improving the quality of reporting of randomized controlled trials: the CONSORT statement. JAMA 276, 637–639 (1996).
Moher, D., Dulberg, C. S. & Wells, G. A. Statistical power, sample size, and their reporting in randomized controlled trials. JAMA 272, 122–124 (1994).
Schulz, K. F., Altman, D. G., Moher, D. & Group, C. CONSORT 2010 statement: updated guidelines for reporting parallel group randomised trials. BMJ 340, c332 (2010).
Grant, S. et al. Developing a reporting guideline for social and psychological intervention trials. Res. Social Work Prac. 23, 595–602 (2013).
Liberati, A. et al. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. PLoS Med. 6, e1000100 (2009).
Shamseer, L. et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015: elaboration and explanation. BMJ 349, g7647 (2015); erratum 354, i4086 (2016).
van ‘t Veer, A. & Giner-Sorolla, R. Pre-registration in social psychology: a discussion and suggested template. J. Exp. Soc. Psychol. 67, 2–12 (2016).
Franco, A., Malhotra, N. & Simonovits, G. Underreporting in psychology experiments: evidence from a study registry. Soc. Psychol. Per. Sci. 7, 8–12 (2016).
Alsheikh-Ali, A. A., Qureshi, W., Al-Mallah, M. H. & Ioannidis, J. P. Public availability of published research data in high-impact journals. PloS ONE 6, e24357 (2011).
Iqbal, S. A., Wallach, J. D., Khoury, M. J., Schully, S. D. & Ioannidis, J. P. Reproducible research practices and transparency across the biomedical literature. PLoS Biol. 14, e1002333 (2016).
McNutt, M. Taking up TOP. Science 352, 1147 (2016).
Park, I. U., Peacey, M. W. & Munafò, M. R. Modelling the effects of subjective and objective decision making in scientific peer review. Nature 506, 93–96 (2014).
Button, K. S., Bal, L., Clark, A. G. & Shipley, T. Preventing the ends from justifying the means: withholding results to address publication bias in peer-review. BMC Psychol. 4, 59 (2016).
Berg, J. M. et al. Preprints for the life sciences. Science 352, 899–901 (2016).
Nosek, B. A. & Bar-Anan, T. Scientific utopia: I. Opening scientific communication. Psychol. Inq. 23, 217–243 (2012).
Walsh, E., Rooney, M., Appleby, L. & Wilkinson, G. Open peer review: a randomised trial. Brit. J. Psychiat. 176, 47–51 (2000).
Smaldino, P. E. & McElreath, R. The natural selection of bad science. R. Soc. Open Sci. 3, 160384 (2016).
Higginson, A. D. & Munafò, M. Current incentives for scientists lead to underpowered studies with erroneous conclusions. PLoS Biol. 14, e2000995 (2016).
Ioannidis, J. P. How to make more published research true. PLoS Med. 11, e1001747 (2014).
Eklund, A., Nichols, T. E. & Knutsson, H. Cluster failure: why fMRI inferences for spatial extent have inflated false-positive rates. Proc. Natl Acad. Sci. USA 113, 7900–7905 (2016).
Kidwell, M. C. et al. Badges to acknowledge open practices: a simple, low-cost, effective method for increasing transparency. PLoS Biol. 14, e1002456 (2016).
Munafò, M. et al. Scientific rigor and the art of motorcycle maintenance. Nat. Biotechnol. 32, 871–873 (2014).
Kass, R. E. et al. Ten simple rules for effective statistical practice. PLoS Comput. Biol. 12, e1004961 (2016).
Schweinsberg, M. et al. The pipeline project: pre-publication independent replications of a single laboratory's research pipeline. J. Exp. Psychol. Gen. 66, 55–67 (2016).
Stevens, A. et al. Relation of completeness of reporting of health research to journals' endorsement of reporting guidelines: systematic review. BMJ 348, g3804 (2014).
Kilkenny, C. et al. Survey of the quality of experimental design, statistical analysis and reporting of research using animals. PloS ONE 4, e7824 (2009).
Baker, D., Lidster, K., Sottomayor, A. & Amor, S. Two years later: journals are not yet enforcing the ARRIVE guidelines on reporting standards for pre-clinical animal studies. PLoS Biol. 12, e1001756 (2014).
Gulin, J. E., Rocco, D. M. & Garcia-Bournissen, F. Quality of reporting and adherence to ARRIVE guidelines in animal studies for Chagas disease preclinical drug research: a systematic review. PLoS Negl. Trop. Dis. 9, e0004194 (2015).
Liu, Y. et al. Adherence to ARRIVE guidelines in Chinese journal reports on neoplasms in animals. PloS ONE 11, e0154657 (2016).
Gotzsche, P. C. & Ioannidis, J. P. Content area experts as authors: helpful or harmful for systematic reviews and meta-analyses? BMJ 345, e7031 (2012).
Morey, R. D. et al. The Peer Reviewers' Openness Initiative: incentivizing open research practices through peer review. R. Soc. Open Sci. 3, 150547 (2016).
Simmons, J. P., Nelson, L. D. & Simonsohn, U. A 21 word solution. Preprint at http://dx.doi.org/10.2139/ssrn.2160588(2012).
Eich, E. Business not as usual. Psychol. Sci. 25, 3–6 (2014).
Acknowledgements
M.R.M. is a member of the UK Centre for Tobacco Control Studies, a UKCRC Public Health Research Centre of Excellence. Funding from the British Heart Foundation, Cancer Research UK, Economic and Social Research Council, Medical Research Council, and the National Institute for Health Research, under the auspices of the UK Clinical Research Collaboration, is gratefully acknowledged. This work was supported by the Medical Research Council Integrative Epidemiology Unit at the University of Bristol (MC_UU_12013/6). D.V.M.B. is funded by a Wellcome Trust Principal Research Fellowship and Programme (grant number 082498/Z/07/Z). N.P.d.S. is employed by the NC3Rs, which is primarily funded by the UK government. J.P.A.I. is funded by an unrestricted gift from S. O'Donnell and B. O'Donnell to the Stanford Prevention Research Center. METRICS is supported by a grant by the Laura and John Arnold Foundation. The authors are grateful to Don van den Bergh for preparing Fig. 2.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
M.R.M, together with C.D.C and D.V.M.B., has received funding from the BBSRC (grant number BB/N019660/1) to convene a workshop on advanced methods for reproducible science, and is chair of the CHDI Foundation Independent Statistical Standing Committee. B.A.N. is executive director of the non-profit Center for Open Science with a mission to increase openness, integrity and reproducibility of research. N.P.d.S. leads the NC3Rs programme of work on experimental design, which developed the ARRIVE guidelines and Experimental Design Assistant. J.J.W. is director, experimental design, at CHDI Management/CHDI Foundation, a non-profit biomedical research organization exclusively dedicated to developing therapeutics for Huntington's disease. The other authors declare no competing interests.
Rights and permissions
This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Munafò, M., Nosek, B., Bishop, D. et al. A manifesto for reproducible science. Nat Hum Behav 1, 0021 (2017). https://doi.org/10.1038/s41562-016-0021
Published:
DOI: https://doi.org/10.1038/s41562-016-0021
This article is cited by
-
GeCKO: user-friendly workflows for genotyping complex genomes using target enrichment capture. A use case on the large tetraploid durum wheat genome
Plant Methods (2024)
-
A data-adaptive method for investigating effect heterogeneity with high-dimensional covariates in Mendelian randomization
BMC Medical Research Methodology (2024)
-
Evaluating guideline and registration policies among neurology journals: a cross-sectional analysis
BMC Neurology (2024)
-
Assessing causal links between age at menarche and adolescent mental health: a Mendelian randomisation study
BMC Medicine (2024)
-
Advancing healthcare with artificial intelligence: diagnostic accuracy of machine learning algorithm in diagnosis of diabetic retinopathy in the Brazilian population
Diabetology & Metabolic Syndrome (2024)
