
Abstract
In recent years there has been a growing interest in treating many-body systems as Bell scenarios, where lattice sites play the role of distant parties and only near-neighbor statistics are accessible. We investigate contextuality arising from three Bell scenarios in infinite, translation-invariant 1D models: nearest-neighbor with two dichotomic observables per site; nearest- and next-to-nearest neighbor with two dichotomic observables per site, and nearest-neighbor with three dichotomic observables per site. For the first scenario, we give strong evidence that it cannot exhibit contextuality, not even in non-signaling physical theories beyond quantum mechanics. For the second one, we identify several low-dimensional models that reach the ultimate quantum limits, paving the way for self-testing ground states of quantum many-body systems. For the last scenario, which generalizes the Heisenberg model, we give strong evidence that, in order to exhibit contextuality, the dimension of the local quantum system must be at least 3.
Similar content being viewed by others
Introduction
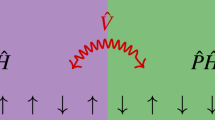
In a many-body quantum system, correlations appear as one of the most common manifestations of the quantum nature of the system Fig. 1. Different types of correlations, such as entanglement, EPR steering, and nonlocality, were identified over the years and found applications in various quantum information processing tasks. Out of these types of correlations, nonlocality is the strongest and most difficult to test1,2. While experiments exploiting entanglement to teleport photons date back to the 1990s3, nonlocality passed the most stringent experimental tests only in 20154,5,6. One of the key assumptions in any nonlocality experiment is keeping the different parties space-like separated. In a many-body quantum system, however, this assumption may be too formidable to be overcome.

Tensor diagram representing the contraction for obtaining energy density in uMPS.
In recent years, the exploration of contextuality in quantum many-body systems has been a fruitful endeavor. Contextuality witnesses adapted from Bell inequalities have been tested in Bose–Einstein condensates7,8. Translation and permutation symmetry allowed the full characterization of contextuality witnesses in many-body systems through bipartite correlators only9,10,11,12 (see ref. 13 for a review). However, very little is known about the strengths and limits of the quantum models which violate these witnesses.
In this work, building on earlier characterizations of classical local behavior in many-body systems9, we investigate under which conditions the n-nearest neighbor statistics of a translation-invariant 1D quantum system evidence that the latter is contextual, by exploiting the connection between contextuality and Bell nonlocality. We focus on three different Bell scenarios, which differ in the number of measurement settings available to each party and the size of the near-neighbor marginals considered.
Our results show that some a priori promising Bell scenarios are unlikely to show any form of contextuality, even if we allow greater-than-quantum correlations. In other scenarios, we give evidence that some Bell inequalities require quantum systems of high enough local dimension to be violated. More interestingly, for several Bell inequalities, we find the maximum violation compatible with the laws of quantum mechanics, and identify the Hamiltonians achieving it. The ground states of contextual Hamiltonians are entangled, even though locally they may appear separable. As shown in ref. 9, it is possible to estimate the size at which the reduced density matrix of a quantum state becomes entangled, just by computing the difference between its average energy and the classical bound. Since the former can be easily estimated in essentially any noisy intermediate-scale quantum (NISQ) device, one can think of our contextuality witnesses as robust entanglement benchmarks for future quantum simulators. From a more fundamental perspective, identifying the maximum quantum violation of a k-local Bell functional opens the possibility to falsify quantum theory in the many-body regime. Indeed, given access to a NISQ device, we can represent the local measurements and the state preparation of the corresponding Bell test through a vector of lab controls θ. By estimating the gradient of the Bell functional with respect to the variables θ, we can sequentially update the latter so as to minimize the observed value of the Bell functional in the device (effectively mimicking the working principle of the variational quantum eigensolver14). If it so happened that the final value of the Bell functional was below the quantum limit, then we would have disproven the universal validity of the quantum theory, despite the lack of an alternative theoretical model.
One-dimensional quantum systems are the simplest many-body ensembles one can control in the lab. They can be found in natural condensed matter systems, as well as implemented via optical lattices or ion traps. For some such systems, the only experimentally available data are near-neighbor correlators averaged over the whole chain (the so-called structure factors). As shown in ref. 9, in the regime of large system size, structure factors correspond to the near-neighbor correlators of an infinite, translation-invariant chain. Comprehending Bell nonlocality in large 1D systems hence requires us to characterize near-neighbor correlations in classical, quantum, and supra-quantum translation-invariant systems.
The correlations P(a1, …, an∣x1, …, xn) generated by n space-like separated classical systems with (classical) inputs xi, i ∈ 1, …, n and outputs ai, i ∈ 1, …, n admit a decomposition of the form:
where λ is a set of hidden variables with probability distribution P(λ). The distributions P(λ) and \({\{P({a}_{i}| {x}_{i},\lambda )\}}_{i = 1}^{n}\) are hence a local hidden variable model for the observed correlations P(a1, …, an∣x1, …, xn). In Bell tests, different parties are required to be space-like separated, which can be seen as the physical realization of the independence of probabilities in Eq. (1). However, in a many-body quantum system, such a requirement is too formidable to overcome. As a result, when we assume that Eq. (1) holds in a quantum many-body system, what we are actually testing is contextuality15,16. The connection between contextuality and Bell nonlocality had been known since the 1970s. Every Bell inequality can be regarded as a contextuality witness; the other direction is less systematic17. The role of contextuality, especially of the Kochen–Specker type, in quantum computation has been actively investigated in recent years (for a review see ref. 16). It can be shown to be the source of the quantum advantage in several scenarios in quantum computation18,19,20,21. Most of these scenarios are constructed from the stabilizer formalism with magic states. While a hidden variable model for this formalism has been found recently22, the model itself is contextual16.
Our starting point is thus a Bell scenario with infinitely many parties in a chain, labeled by the integer numbers. At site \(i\in {\mathbb{Z}}\), the corresponding party can conduct a measurement xi ∈ {1, …, X}, obtaining the result ai ∈ A. Since we assume translation invariance, the measurement statistics observed by any m consecutive parties equal those of parties, 1, …, m, that is, P1,..,m(a1, …, am∣x1, …, xm). Any Bell scenario in the translation-invariant chain can therefore be fully specified by the three natural numbers m, X, ∣A∣. Consequently, in this paper, a Bell scenario where only nearest-neighbor correlations are available and each party can conduct two dichotomic observables will be called the 222-scenario. Extending the interaction distance to next-to-nearest neighbors gives us the 322-scenario. Heisenberg-like Bell scenarios, with nearest-neighbor interactions but three dichotomic observables per site correspond to the 232-scenario.
We say that an m-partite distribution P1,..,m(a1, …, am∣x1, …, xm) is no-signaling23 if, for all i ∈ {1, …, m},
for all pairs of measurement settings \({x}_{i},{\tilde{x}}_{i}\in X\). Intuitively, this condition signifies that the statistics of the remaining m−1 parties are not affected by the choice of measurement setting of party i. Hence, party i cannot instantaneously transmit information to others.
Some no-signalling distributions P1,..,m(a1, …, am∣x1, …, xm) can be shown not to arise out of an infinite no-signalling TI system. This idea is formalized in the following definition: we say that P1,..,m(a1, …, am∣x1, …, xm) admits a TI no-signalling extension if there exists a mapping Q from finite sets \(B\subset {\mathbb{Z}}\) to no-signalling ∣B∣-partite measurement statistics QB(aB∣xB) with the following properties:
-
1.
\(\begin{array}{l}\mathop{\sum}\limits_{{a}_{B\setminus C}}{Q}_{B}({a}_{B\setminus C},{a}_{C}| {x}_{B\setminus C},{x}_{C})=\\ \mathop{\sum}\limits_{{a}_{D\setminus C}}{Q}_{D}({a}_{D\setminus C},{a}_{C}| {x}_{D\setminus C},{x}_{C}),\end{array}\)
for all finite sets \(B,C,D\subset {\mathbb{Z}}\), with C ⊂ B, D (compatibility).
-
2.
QB = QB+z, for all \(z\in {\mathbb{Z}}\) (translation invariance).
-
3.
Q1,…,n = P1,…,n (consistency with observed statistics).
We call TI-NS the set of all distributions P1,..,m(a1, …, am∣x1, …, xm) admitting a no-signalling, translation-invariant extension.
The existence of a no-signalling extension is just a pre-requisite for the existence of an overall infinite translation-invariant state. Whether such an entity exists at all depends also on the physics generating the observed correlations. We say that P1,..,m(a1, …, am∣x1, …, xm) admits a TI classical extension if it admits an NS extension Q and there exist distributions \(P(\lambda ),\{{P}_{i}(a| x,\lambda ):i\in {\mathbb{Z}}\}\) such that, for all N,
We call TI-LHV the set of all distributions P1,..,m(a1, …, am∣x1, …, xm) admitting a TI classical extension.
Analogously, P1,..,m(a1, …, am∣x1, …, xm) admits a TI quantum extension if it admits a NS extension Q and there exist a Hilbert space \({{{\mathcal{H}}}}\), measurement operators \({E}_{a| x}:{{{\mathcal{H}}}}\to {{{\mathcal{H}}}}\), with \({\sum }_{a}{E}_{a| x}={\mathbb{I}}\), and a translation-invariant quantum state ρ on the infinite chain with local Hilbert space \({{{\mathcal{H}}}}\) such that, for all N,
We call TI-Q the set of all distributions P1,..,m(a1, …, am∣x1, …, xm) admitting a TI quantum extension.
In ref. 9, two of us provided a full characterization of the set of m-nearest neighbor correlations admitting a TI classical extension. This set happens to be a polytope, i.e., a convex set defined by a finite number of linear inequalities or facets. When all local measurements are dichotomic (∣A∣ = 2), one can regard any measurement x by party i as an observable \({\sigma }_{x}^{i}\) with possible values ±1, and specify any no-signaling m-nearest neighbor distribution P(a1, …, am∣x1, …, xm) through the averages of the different products of the observables \({\sigma }_{{x}_{1}}^{1},\ldots ,{\sigma }_{{x}_{m}}^{m}\). For m = 2, in this ‘observable representation’ a facet would take the form
Should the observed one-particle averages \(\{\langle {\sigma }_{x}^{1}\rangle :x\in X\}\) and nearest-neighbor two-point correlators \(\{\langle {\sigma }_{x}^{1}{\sigma }_{y}^{2}\rangle :x,y\in X\}\) of a TI system violate a facet of the classical (also called ‘local’) polytope, the corresponding many-body system would be shown not to admit a description compatible with classical physics.
The left-hand side of Eq. (5) can be interpreted as a Bell functional that acts linearly on the distribution P1,…,m(a1, …, am∣x1, …, xm). Minimizing it over all distributions admitting a TI quantum extension, we obtain the quantum limit QJ of the Bell functional J.
In the following, we describe a method that, for any \(d\in {\mathbb{N}}\), carries such a minimization variationally over TI quantum systems of local dimension d, thus obtaining an upper bound \({{{{\mathcal{Q}}}}}_{d}\) on QJ. The method also returns a concrete TI quantum system, with \(\,{{\mbox{dim}}}\,({{{\mathcal{H}}}})=d\), achieving the Bell value \({{{{\mathcal{Q}}}}}_{d}\) with measurement operators {Ea∣x: a, x}. Most statistical models studied in the literature use projective measurements, i.e. {Ea∣x: a, x} are projectors. For most of our results, we only consider projective measurements, with one notable exception. When we need to verify that no 232-type Hamiltonian can violate the classical bound when d = 2, only considering projective measurements is too restrictive. Therefore for these Hamiltonians we allow fully general complex positive operator-valued measurements (POVMs) as their local observables, using a modified version of the algorithm presented in the following section to perform the optimization.
Results
Upper bounding the ground state energy density
To minimize the left-hand side of expressions of the form (5), we start from the following observation: let \(\{{\sigma }_{x}:{{\mathbb{C}}}^{d}\to {{\mathbb{C}}}^{d}:x\in X\}\) be a set of d-dimensional Hermitian operators with spectrum contained in {1,−1}. Then, the minimum value of Eq. (5) over all TI quantum states corresponds to the minimum energy-per site of the TI Hamiltonian
Tools from condensed matter physics such as uniform matrix product states (uMPS)24 allow us to compute the desired energy density efficiently. In order to minimize (5) for a given local dimension d, all we have to do is suitably explore the manifold of the set of local observables, e.g. via gradient descent.
Our first step consists of finding a parametrization of all the local observables. Consider observables {σa∣a ∈ X}, each of which can be diagonalized by a unitary matrix Ua as
where Λa is a diagonal matrix with entries ±1. To make this more explicit, we use the vector [nx, ny] to describe a number of −1 in the eigenvalues of σx and σy.
We can then use the space of skew-Hermitian matrices to effectively parameterize each Ua as
where Sa is skew-Hermitian. Let {B1, B2, …, Bn} be a basis of the vector space of skew-Hermitian matrices. Here n = d2−d denotes the dimension of the space. Expanding Sa in this basis gives
where Wa ≡ {wa1, wa2, …, wan} are scalars. Our optimization parameters are therefore {wak∣a ∈ X; k = 1, …, n}.
Using the method above, observables σa(a = x, y) in \({{{{\mathcal{H}}}}}_{222}\) can be parameterized as
Consequently, \({{{{\mathcal{H}}}}}_{222}\) is parameterized as \({{{{\mathcal{H}}}}}_{222}({W}_{x},{W}_{y})\).
Using Jordan’s lemma2, the number of real parameters can be reduced when ∣X∣ = 2. For example, applying Jordan’s lemma to \({{{{\mathcal{H}}}}}_{222}\) when d = 4 yields a basis in which both σx and σy are block-diagonal:
where σx,1, σx,2, σy,1, σy,2 are 2 × 2 Hermitian matrices.
We are now ready to present our MPS-based gradient descent method. The method is iterative. For a = x, y, let Wa(k) denote the parametrization of observable σa at the kth iteration. We will refer to the parametrization {Wx(k), Wy(k)} of both observables as W(k). At each iteration k, the parameters W(k) are updated to W(k + 1) through the following procedure.
First, we minimize the energy-per-site of the Hamiltonian \({{{{\mathcal{H}}}}}_{222}(k)\equiv {{{{\mathcal{H}}}}}_{222}({\sigma }_{a}(k),{\sigma }_{b}(k))\) over the manifold of uMPS. The result e(k) can be computed using, e.g., the time-dependent variational principle (TDVP) algorithm24,25,26 or the variational uniform matrix product state (VUMPS) algorithm24,27. We mainly use the TDVP algorithm for its good numerical stability and reasonable speed of convergence.
Following the TDVP algorithm, e(k) can be expressed as
where \({\sum }_{s,t,u,v}h{(k)}_{st}^{uv}\left|s\right\rangle \left\langle u\right|\otimes \left|t\right\rangle \left\langle v\right|\) is the local term of \({{{{\mathcal{H}}}}}_{222}(k)\); \({\{{A}^{s}(k)\}}_{s}\subset {{\mathbb{C}}}^{D\times D}\) is the tensor defining the optimal uMPS, and l(k), r(k) are the left and right leading eigenvectors of the transfer matrix \(T(k)=\mathop{\sum }\nolimits_{s = 1}^{d}{\bar{A}}^{s}(k)\otimes {A}^{s}(k)\).
Next, we seek to find observables leading to a Hamiltonian with a smaller energy-per-site, when evaluated over the uMPS with tensor {As(k)} just identified. Hence, with A(k) fixed, we replace the local term h(k) by h(σx(W), σy(W)) in Eq. (12). This leads to a function e(W; k) of the parameters W defining the observables. To update the parameters W(k), we move away from W(k) in the direction of maximum function decrease at point W(k). That is, we move against the gradient of e(W; k):
Here γ(k) is a scaling parameter, which we take to be of the form \(\gamma (k)=\max ({\gamma }_{0}{\alpha }^{q(k)},{\gamma }_{\min })\), where α ∈ (0, 1) and q(k) is linear with respect to the iteration number k.
Starting from an initial seed W(0), we iterate the two steps above, hence generating a sequence of parameter values (W(0), W(1), …). At every iteration k, we check the condition ∥∇e(W; k)∥2 < ϵ*, for some desired convergence threshold ϵ*. If the condition holds, we stop the algorithm and return the optimal parameters W* ≡ W(k).
In our experience, the quantity e(W*) is typically a very good estimate of the lowest quantum value of the considered contextuality functional over TI quantum systems of local dimension d. If e* happens to be smaller than the classical bound of the corresponding facet inequality, then we can state that the found quantum system characterized by the TI Hamiltonian \({{{{\mathcal{H}}}}}_{222}({W}^{* })\) exhibits contextuality.
To test the algorithm, we apply it to compute the minimum ground state energy densities \({{{{\mathcal{Q}}}}}_{{d}}\) (d = 2, 3, 4) of six 322-type TI quantum systems. All the results are plotted in Fig. 2. We find that the initial ground state energy densities determined by random parameters typically do not violate the classical bound \({{{{\mathcal{L}}}}}_{322}\) (red line). As the iteration number increases, \({{{{\mathcal{Q}}}}}_{2}\) and \({{{{\mathcal{Q}}}}}_{3}\) decrease approximately linearly and begin to show contextuality. In Fig. 2e and f, \({{{{\mathcal{Q}}}}}_{4}\) oscillates during the first several iterations. As the optimization process continues, \({{{{\mathcal{Q}}}}}_{4}\) also begins to cross \({{{{\mathcal{L}}}}}_{322}\) after. The ground state energy densities of all six models converge to values below their classical bounds within 20 iterations.

The ground state energy density \({{{{\mathcal{Q}}}}}_{{d}}\) (blue line) and two-norm of gradient ϵ (black line) for selected 322-type TI quantum systems with the local observable dimension d = 2, 3, 4. The red dashed line represents the classical bound, and the regions below show contextuality. a \({{{{\mathcal{Q}}}}}_{2}\) of No. 1 in Supplementary Table 2. b \({{{{\mathcal{Q}}}}}_{2}\) of No. 38 in Supplementary Table 2. c \({{{{\mathcal{Q}}}}}_{3}\) of No. 7 in Supplementary Table 2. d \({{{{\mathcal{Q}}}}}_{3}\) of No. 30 in Supplementary Table 2. e \({{{{\mathcal{Q}}}}}_{4}\) of No. 37 in Supplementary Table 2. f \({{{{\mathcal{Q}}}}}_{4}\) of No. 54 in Supplementary Table 2.
Lower bounding the ground state energy density
Consider the scenario shown in Fig. 3: an infinite chain of elephants, each of which represents a physical system, be it quantum, classical, or else. Call ε the overall state of the chain. Depending on the context, ε will be a classical probability distribution, a quantum state, or a no-signaling box. Because ε is TI, the marginal distribution or the reduced state of each of the 5 marked elephants, taken from an arbitrary contiguous subset of the chain, should be equal: ε1 = … = ε5. Moreover, the reduced state of any contiguous subset of elephants should also be equal: ε1,…,1+k = ε2,…,2+k, ∀1 ≤ k ≤ 3. When k = 3, the marginals/reduced states are shown in Fig. 3 as green and red rectangles. For any contiguous subset of ε of length l, the marginals/reduced states are said to be locally translation-invariant (LTI) if

A necessary condition from the requirement that the entire system is translation-invariant.
Clearly, LTI is a necessary condition for ε to be TI. For classical probability distributions in 1D, LTI is also sufficient: any LTI marginal can be extended to an infinite TI distribution28. In fact, this property is the key to the characterization of the set TI-LHV presented in ref. 9.
Unfortunately, LTI is not enough to characterize the near-neighbor density matrices of TI quantum states or even the near-neighbor marginals of TI no-signaling systems. In those scenarios, LTI can be used to relax the set of such marginals, rather than to fully characterize it. Define thus LTIn−NS as the set of boxes admitting an extension to an n-partite no-signaling box with local translation invariance. As shown in ref. 9, the distance between any element of the set LTIn−NS and its subset TI-NS is upper bounded by \(O\left(\frac{1}{n}\right)\).
A straightforward extension to bound TI-Q is impossible, as the approximate characterization of general multipartite quantum correlations is an undecidable problem29. One can, however, relax the existence of quantum states and observables reproducing the observed correlations to that of positive semidefinite moment matrices. Those are matrices Γ whose rows and columns are labeled by monomials of measurement operators with at most s (the order of the relaxation) measurement operators per party, and where each entry Γαβ is supposed to represent the quantity 〈α†β〉 (see refs. 30,31 for details). In order to bound TI-Q, we demand the existence of a moment matrix for an n-partite Bell scenario and then impose LTI over the said moment matrix. Call LTIn−NPAs the corresponding relaxation.
For any Bell functional, we can thus find a lower bound on its minimal value in TI-NS and TI-Q by, respectively, optimizing over LTIn−NS (with linear programming techniques32) and LTIn−NPAs (with semidefinite programming techniques33). Moreover, one can improve those lower bounds by increasing the values of n, s.
Contextuality in 222-type Hamiltonians
The LTI-LHV polytope for 2 dichotomic observables has 36 facets. Computing their LTI4−NS lower bounds reveals that most of them coincide with the corresponding classical bounds. In fact, there is only one inequality, up to local relabeling, which can potentially show contextuality. In its 1D TI quantum Hamiltonian form, it reads
with classical bound −2.
Lower bounding Eq. (15) with LTIn−NS with increasing n, we observed some curious phenomena. Because exact optimal solutions of linear programs are rational numbers, we obtain the solutions in Table 1.
The numerators and denominators in the table form two integer sequences: A02769134 and A15294835 in The On-Line Encyclopedia of Integer Sequences. Moreover, the displaced inverse of a quadratic function
perfectly fits the sequence of lower bounds in Table 1 (see Fig. 4).

In the limit n → ∞, this function converges to the classical bound −2. In other words, if the solution of the optimization over LTIn−NS satisfies (16) for all n ≥ 3, then no Hamiltonian of the form (15), quantum or otherwise, can possibly violate the classical bound.
Proving that a series of rational numbers, the solutions of linear programs of exponentially increasing size, converges to a certain value is very hard. However, we do have additional numerical evidence to support our claim that the lowest possible ground state energy density of 1D TI quantum Hamiltonians of the form (15) is −2. We used our algorithm to search for the quantum Hamiltonian with the lowest ground state energy density, for local observables of dimension 2 ≤ d ≤ 6. For each d, σx and σy are parameterized by the method described below, and we find the lowest quantum value \({{{{\mathcal{Q}}}}}_{d}\) among all possible systems is −2. Moreover, the corresponding two-body reduced density matrix of the quantum system for the ground state is a rank 1 projector, which shows that the ground state is in fact a product state. We present these ground states and the parameters for observables in Table 2.
To make sense of Table 2, we next explicitly write the parametrization of the d-dimensional observables achieving the classical bound. Two 2 × 2 matrices having eigenvalues one 1 and one −1 will repeatedly appear below: Λ is the diagonal matrix with diagonal entries ±1, B(w) is a matrix governed by one parameter {w}:
When d = 2 is assigned to local observables in \({{{{\mathcal{H}}}}}_{222}\), σx is a diagonal matrix with diagonal entries 1 and −1, i.e., σx = Λ, and σy determined by one parameter {w1} has the same parameterized form as B(w), i.e., σy(w1) = B(w1). In this case, [nx, ny] = [1, 1] and σx, σy are of the form
When d = 3 is assigned to local observables in \({{{{\mathcal{H}}}}}_{222}\), σx is a diagonal matrix with diagonal entries (1,−1,−1). σy is a block diagonal matrix, where the main-diagonal blocks are one matrix B(w1) and one numerical value −1. Then, [nx, ny] = [2, 2] and σx, σy are given by
When d = 4 is assigned to local observables in \({{{{\mathcal{H}}}}}_{222}\), σx is a diagonal matrix with diagonal entries two 1 and two −1, and σy is a block diagonal matrix with main-diagonal blocks being two 2 × 2 matrices B(w1) and B(w2). In this case, [nx, ny] = [2, 2] and σx, σy are of the forms
When d = 5 is assigned to local observables in \({{{{\mathcal{H}}}}}_{222}\), σx is a diagonal matrix with diagonal entries two −1 and three 1. σy is a block diagonal matrix, where the main-diagonal blocks are two 2 × 2 matrices B(w1) and B(w2) and one numerical number 1. Then, [nx, ny] = [2, 2] and σx, σy are given by
When d = 6 is assigned to local observables in \({{{{\mathcal{H}}}}}_{222}\), σx is a diagonal matrix, where three −1 and three 1 are alternately arranged in the diagonal. σy is a block diagonal matrix with main-diagonal blocks being three 2 × 2 matrices B(w1), B(w2) and B(w3). Then, [nx, ny] = [3, 3] and σx, σy have the forms
Contextuality in 322-type Hamiltonians
The TI-LHV polytope for the 322-type Hamiltonians has been characterized in ref. 9: it has 32,372 facets which can be sorted into 2102 equivalence classes. The general form of the 322-type Hamiltonian is given by
where \(\{{J}_{x},{J}_{y},{J}_{xx}^{AB},{J}_{xy}^{AB},{J}_{yx}^{AB},{J}_{yy}^{AB},{J}_{xx}^{AC},{J}_{xy}^{AC},{J}_{yx}^{AC},{J}_{yy}^{AC}\}\) are the couplings given by the facet inequalities and σx, σy are local observables.
Using our uMPS-based gradient descent algorithm, a total of 63 Hamiltonians exhibit contextuality. The explicit parameterization of observables σx and σy is explained at the end of this section. All the contextual Hamiltonians and ground state energy densities are listed in Supplementary Tables 1 and 2, respectively. Among them, we identify some quantum models whose ground state energy density reaches the LTI5−NPA1 lower bounds. For all these contextuality witnesses, we have thus identified translation-invariant quantum models exhibiting the strongest quantum violation. All the matched models are summarized in Table 3. As the reader can appreciate, the first five inequalities seem to require local dimension d = 3 to be saturated; inequality 6, dimension 4; and the last four inequalities, dimension 5.
In Fig. 5, the reader can see the trajectories in parameter space followed by two quantum systems, of dimensions d = 3 and d = 4, undergoing our gradient descent method. This is possible because the number of free continuous parameters in one and another case are 1 and 2.

Two models from Table 3 are selected. a Has two subplots, and the right panel gives a more detailed view of the trajectory in the left one when ground state energy density converges to the minimum. b Gives two different views for the ground state energy surface, while the last panel shows the trajectory in parameter space. a No. 3 in Table 3, \({{{\mathcal{L}}}}=-3\). b No. 6 in Table 3, \({{{\mathcal{L}}}}=-4\).
In Fig. 5a, \({{{{\mathcal{Q}}}}}_{3}\) surfaces (blue lines) show that the Hamiltonian exhibits contextuality no matter which values the parameter takes. The trajectory of ground state energy density (black dotted line) in the left subplot decreases along the \({{{{\mathcal{Q}}}}}_{3}\) surface to the bottom. Besides, the right enlarged subplot of the trajectory demonstrates that ground state energy density eventually converges to the respective LTIn−NPAs lower bound. In Fig. 5b, the leftmost subplot shows the trajectory of the ground state energy density on the 3D \({{{{\mathcal{Q}}}}}_{4}\) surface, the middle 2D-subplot is the top view of the leftmost one, and the rightmost one only depicts the trajectory of the ground state energy density. Iteratively, our methods guide the initial random ground state energy density converging to the lowest possible one.
We plot the ground state energy density as a function of the parameters defining the local observables for some of the Hamiltonians in Table 3 and Supplementary Table 2 to gauge the robustness of the contextuality violations. The couplings and local observables achieving these values can be found in Supplementary Tables 1 and 2. The first column in Table 3 indicates the position of each model in these Supplementary Tables. Five models for d = 4 and another five models for d = 5 are shown in Figs. 6 and 7, respectively. Note that the first two models in Fig. 6a, b and the first four models in Fig. 7a–d exhibit the strongest contextuality.

\({{{{\mathcal{Q}}}}}_{4}\) surfaces of five models in Table 3 and Supplementary Table 2, where w1, w2 both take discrete values on [−2, 2] at the interval 0.1. Three different viewing angles are shown for each model. The leftmost panel is a 3D overview, the middle panel is for better visualizing the internal structure, and the rightmost panel gives the top-down view. a No. 1 in Table 3, \({{{\mathcal{L}}}}=-6\). b No. 5 in Table 3, \({{{\mathcal{L}}}}=-8\). c No. 8 in Supplementary Table 2, \({{{\mathcal{L}}}}=-4\). d No. 19 in Supplementary Table 2, \({{{\mathcal{L}}}}=-11\). e No. 23 in Supplementary Table 2, \({{{\mathcal{L}}}}=-8\).

\({{{{\mathcal{Q}}}}}_{5}\) surfaces of five models in Table 3 and Supplementary Table 2, where w1, w2 both take discrete values on [−2, 2] at the interval 0.1. Three different viewing angles are shown for each model. The leftmost panel is a 3D overview, the middle panel is for better visualizing the internal structure, and the rightmost panel gives the top-down view. a No. 7 in Table 3, \({{{\mathcal{L}}}}=-5\). b No. 8 in Table 3, \({{{\mathcal{L}}}}=-4\). c No. 9 in Table 3, \({{{\mathcal{L}}}}=-4\). d No. 10 in Table 3, \({{{\mathcal{L}}}}=-5\). e No. 11 in Supplementary Table 2, \({{{\mathcal{L}}}}=-3\).
It can be seen that some Hamiltonians are much more susceptible to small changes in parameters that define the local observables than others. For the Hamiltonians in Figs. 6b, 7b and c, keeping the ground state energy density above the classical bound is unstable, small perturbations in the parameters will make them violate it. In contrast, the remaining Hamiltonians need carefully engineered parameters to violate the classical bound. Especially for the Hamiltonian in Fig. 7e, square-like parameter regions exist in which the corresponding ground state energy density could not violate the classical bound no matter how many times the perturbations are given. These plots help us find suitable Hamiltonians for simulation in trapped-ion or optical lattice systems, where witnessing contextuality (or the strongest contextuality) simply involves cooling the corresponding Hamiltonian to the ground state.
We next describe the parameterization of the 322-type Hamiltonians achieving the minimum quantum values in Table 3. For d = 2 and d = 4, σx, σy have the exact same parameterized forms as the observables in the 222-type Hamiltonians in Eqs. (18) and (20), respectively.
For d = 3 and d = 5, depending on the number of 1’s and −1’s of each matrix Λa(a = x, y) in Eq. (7), two different classes of pairs of local observables σx and σy are considered. Here, we continue using the notations Λ and B(w) introduced in Eq. (17).
For local dimension d = 3, the first class of pairs of local observables is of the form [nx, ny] = [1, 2]. More specifically
The second class is of the form [nx, ny] = [1, 1], with
For local dimension d = 5, the first class of observable pairs is of the form [nx, ny] = [2, 2], with
The second class of observable pairs satisfies [nx, ny] = [3, 3], and σx and σy are given by
Contextuality in 232-type Hamiltonians
The LTI-LHV polytope for 3 dichotomic observables has 92,694 facets, which can be classified into 652 equivalent classes36. The general form of this type of Hamiltonian is given by
We consider \({{{{\mathcal{H}}}}}_{232}\) when d = 2, 3, 4 and perform the optimizations on one representative facet from each of the 652 classes. For d = 3, 4, we only consider real parameters. For d = 2, we allow the most general measurements in quantum theory: complex POVMs. In the Method section, we present a projected gradient descent algorithm to optimize over the set of complex POVMs. All 652 Hamiltonians can only reach the classical bound up to numerical precision of 10−5 when d = 2, while for d ≥ 3 there are many Hamiltonians that can violate the classical bound. The ground state energy densities of some contextual Hamiltonians are shown in Table 4, see Supplementary Table 3 for the couplings defining the contextuality witnesses. In addition, the parameters specifying the optimal local observables are listed in Supplementary Table 4 for d = 3 and in Supplementary Table 5 for d = 4.
The local observables σx, σy and σz are parameterized using the method presented above: for given Λa, Sa the local observable σa can be written as
While this step is straightforward, different combinations of ±1 in Λa may lead to different ground state energy density.
Since the number of 1 and −1 on the diagonal of Λa in three local observables is not necessarily the same, there is more than one combination of three parameterized local observables. We consider every possible combination of 1 and −1 in Λa for each a ∈ {x, y, z}. We only show combinations of parameterized local observables used in Table 4. Here, we denote the 2 × 2 identity matrix by I, and continue using the notation Λ introduced in Eq. (17).
When d = 2, the classical bound can be achieved via three local observables determined by two parameters, where [nx, ny, nz] = [2, 1, 1]. The first local observable σx is minus the identity matrix:
For the second and third local observables σa(a = y, z), Λa has entries one 1 and one −1 on the main diagonal, and Sa is determined by one parameter {w}. Hence, σy and σz are specified by
For d = 3, two different combinations of three parameterized local observables are used, where the difference arises from Λa, but Sa of each local observable shares the same parameterized form as
In the first combination, [nx, ny, nz] = [2, 1, 1], where Λx has one 1 and two −1 on the main diagonal, and Λy and Λz both have two 1 and one −1 being the main diagonal entries. Then, Λx, Λy, and Λz are given by
In the second combination, [nx, ny, nz] = [2, 1, 2], where Λx and Λz both have one 1 and two −1 on the main diagonal, and Λy has two 1 and one −1 being the main diagonal entries. Then, Λx, Λy, and Λz are given by
For d = 4, four different classes of triples of local observables are used. These classes differ from each other in the structure of the matrices Λa in Eq. (29). The matrices Sa have, nonetheless, the same form in the three classes, namely:
The first class is of the form [nx, ny, nz] = [3, 1, 1], where Λx has one 1 and three −1 on the main diagonal, and Λy and Λz both have three 1 and one −1 being main diagonal entries. Then, Λx, Λy, and Λz are given by
The second class is of the form [nx, ny, nz] = [3, 2, 3], where Λx and Λz both have one 1 and three −1 on the main diagonal, and Λy has two 1 and two −1 being main diagonal entries. Then, Λx, Λy, and Λz are given by
The third class is of the form [nx, ny, nz] = [3, 2, 1], where Λx has one 1 and three −1 on the main diagonal, Λy has two 1 and two − 1 being main diagonal entries, and Λz takes three 1 and one −1 on the main diagonal. Then, Λx, Λy, and Λz are given by
The fourth class is of the form [nx, ny, nz] = [2, 1, 2], where Λx and Λz have two 1 and two −1 on the main diagonal, Λy has three 1 and one −1 being the main diagonal entries. Then, Λx, Λy, and Λz are given by
Discussion
In this paper, we investigate the contextuality of several types of infinite one-dimensional translation-invariant local quantum Hamiltonians. We found that it is very likely that all quantum Hamiltonians with nearest-neighbor-only interactions and two dichotomic observables per site admit local hidden variable models. Violation of contextuality witnesses is only possible when we either increase the interaction distance to include next-to-nearest neighbor terms or have three dichotomic observables per site. In the former case, we identified several Hamiltonians with the lowest possible ground state energy density in quantum theory. In the latter case, we give strong evidence that contextuality is only present if the dimension of local observables is >2, which excludes the usual Heisenberg-type models where local observables are Pauli matrices.
States and measurements which exhibit the strongest violations of Bell inequalities are essential ingredients in device-independent certifications and self-testing37,38. So far the possibility of self-testing in quantum many-body systems has not been thoroughly established, due to a lack of tools to certify the strongest violation of Bell inequalities or contextuality witnesses, without having to solve the corresponding quantum model analytically. Our results pave the way for self-testing quantum many-body systems in the thermodynamic limit.
The ground states of our models are computed using uMPS, and they are global approximations of the true ground state of the corresponding quantum models. However, in applications such as quantum simulation, we will only have access to local approximations of the ground state. Moreover, the qualities we are interested in, such as the ground state energy density and the expectation values of local observables all depended on the accuracy of the local description. Finding locally accurate approximations of properties of one-dimensional local quantum Hamiltonians has yielded many interesting results39,40,41,42,43. However, most of these results assume the models to have nearest-neighbor interactions. As we can see from our results, the models with next-to-nearest neighbor interactions are surprisingly the most interesting in terms of contextuality.
In two dimensions, very little is known about the contextuality of translation-invariant local Hamiltonians. We know that when the number of inputs and outputs is unrestricted, the set of local hidden variable models becomes non-semi-algebraic and eventually characterization of the set is impossible44. Properties of 2D classical and quantum models differ so markedly from their 1D counterparts that most intuitions and tools we gained in 1D break down. However, in 2D a powerful mathematical tool, tiling, has been repeatedly employed to solve questions about the computability and complexity of classical and quantum models44,45,46,47. The number of tiles in an aperiodic tiling would correspond to the number of states in a local hidden variable model, so it would be interesting to explore the connection between tiling and contextuality.
Methods
Optimization of 1D TI Hamiltonians with POVMs as local observables
We describe an extension of the algorithm used to minimize the ground state energy density to include the most general quantum measurements: POVMs. The extended algorithm is used to minimize 232-type Hamiltonians when the dimension of local observables is 2. These local observables \(\{{\sigma }_{a}:{{\mathbb{C}}}^{2}\to {{\mathbb{C}}}^{2},a\in X\}\) are constructed from POVM elements Ma0, Ma1. In a gradient descent algorithm, at iteration k the current gradient is subtracted from the parameters, which may take the local observables out of the space of POVMs. To correct this issue we project the local observables after the gradient has been subtracted onto the closest POVM found via semidefinite programming:
Here, \({\tilde{\sigma }}_{a}={\tilde{\sigma }}_{a}(k+1)\) and σa = σa(k + 1). The parameters W(k) are complex decision variables for the SDP, whose value at each iteration will be given by the solver.
Even though the extended algorithm based on projected gradient descent works in principle, we have encountered a number of numerical issues which require additional tweaks. The main issue affecting convergence is that it takes many iterations to traverse a nearly flat region in the parameter space. It is one of the most common problems affecting the performance of gradient descent algorithms, and it is very common to encounter such regions in our Hamiltonians. We use a well-known remedy, using momentum to speed up the traversal of nearly flat regions. At each iteration k, the parameters W(k) defining the local observables {σa(k)∣a ∈ X} are updated by
where V(k) is the momentum and η is the decay factor.
Beginning with random initial W(0) and V(0) = 0, iterating the steps above, we obtain the sequence of parameter values (W(0), W(1), … ) defining a sequence of local observables (σa(0), σa(1),…), each of which is constructed from POVM elements. If the convergence criterion ∣e(k + 1)−e(k)∣ ≤ ϵ* is met at iteration k, then the algorithm stops and returns the optimal parameters W* ≡ W(k + 1). For 100 out of the 652 Hamiltonians we tested, even though the random initial parameters are allowed to be complex, the converged values are all real. Having nonzero imaginary parts in the local observables meant the ground state energy of the Hamiltonian will stall at a value higher than the classical bound, often resulting in 10000 iterations only decreasing the ground state energy marginally. When this happens, a new set of random initial complex parameters are generated and the algorithm restarts. When the algorithm converges, the imaginary parts of all the parameters are <10−10.
Data availability
Data will be made available upon reasonable request to the corresponding author.
Code availability
Code will be made available upon reasonable request to the corresponding author.
References
Brunner, N., Cavalcanti, D., Pironio, S., Scarani, V. & Wehner, S. Bell nonlocality. Rev. Mod. Phys. 86, 419–478 (2014).
Scarani, V. Bell Nonlocality (Oxford University Press, 2019).
Bouwmeester, D. et al. Experimental quantum teleportation. Nature 390, 575–579 (1997).
Hensen, B. et al. Loophole-free Bell inequality violation using electron spins separated by 1.3 kilometres. Nature 526, 682 EP – (2015).
Giustina, M. et al. Significant-loophole-free test of Bell’s theorem with entangled photons. Phys. Rev. Lett. 115, 250401 (2015).
Shalm, L. K. et al. Strong loophole-free test of local realism. Phys. Rev. Lett. 115, 250402 (2015).
Schmied, R. et al. Bell correlations in a Bose–Einstein condensate. Science 352, 441–444 (2016).
Tura, J. et al. Detecting nonlocality in many-body quantum states. Science 344, 1256–1258 (2014).
Wang, Z., Singh, S. & Navascués, M. Entanglement and nonlocality in infinite 1D systems. Phys. Rev. Lett. 118, 230401 (2017).
Tura, J. et al. Nonlocality in many-body quantum systems detected with two-body correlators. Ann. Phys. 362, 370–423 (2015).
Tura, J. et al. Translationally invariant multipartite Bell inequalities involving only two-body correlators. J. Phys. A-Math. Theor. 47, 424024 (2014).
Tura, J. et al. Energy as a detector of nonlocality of many-body spin systems. Phys. Rev. X 7, 021005 (2017).
De Chiara, G. & Sanpera, A. Genuine quantum correlations in quantum many-body systems: a review of recent progress. Rep. Prog. Phys. 81, 074002 (2018).
Peruzzo, A. et al. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 5, 4213 (2014).
Kochen, S. B. & Specker, E. P. The problem of hidden variables in quantum mechanics. J. Math. Mech. 17, 59–87 (1967).
Budroni, C., Cabello, A., Gühne, O., Kleinmann, M. & Larsson, J.-Å. Quantum contextuality. Preprint at https://arxiv.org/abs/2102.13036 (2021).
Cabello, A. Bell non-locality and Kochen–Specker contextuality: how are they connected? Found. Phys. 51, 61 (2021).
Bravyi, S., Gosset, D., König, R. & Tomamichel, M. Quantum advantage with noisy shallow circuits. Nat. Phys. 16, 1040–1045 (2020).
Bravyi, S., Gosset, D. & König, R. Quantum advantage with shallow circuits. Science 362, 308–311 (2018).
Howard, M., Wallman, J., Veitch, V. & Emerson, J. Contextuality supplies the ‘magic’ for quantum computation. Nature 510, 351–355 (2014).
Bermejo-Vega, J., Delfosse, N., Browne, D. E., Okay, C. & Raussendorf, R. Contextuality as a resource for models of quantum computation with qubits. Phys. Rev. Lett. 119, 120505 (2017).
Zurel, M., Okay, C. & Raussendorf, R. Hidden variable model for universal quantum computation with magic states on qubits. Phys. Rev. Lett. 125, 260404 (2020).
Popescu, S. & Rohrlich, D. Quantum nonlocality as an axiom. Found. Phys. 24, 379–385 (1994).
Vanderstraeten, L., Haegeman, J. & Verstraete, F. Tangent-space methods for uniform matrix product states. SciPost Phys. Lect. Notes 7, (2019).
Haegeman, J. et al. Time-dependent variational principle for quantum lattices. Phys. Rev. Lett. 107, 070601 (2011).
Milsted, A., Haegeman, J., Osborne, T. J. & Verstraete, F. Variational matrix product ansatz for nonuniform dynamics in the thermodynamic limit. Phys. Rev. B 88, 155116 (2013).
Zauner-Stauber, V., Vanderstraeten, L., Fishman, M. T., Verstraete, F. & Haegeman, J. Variational optimization algorithms for uniform matrix product states. Phys. Rev. B 97, 045145 (2018).
Goldstein, S., Kuna, T., Lebowitz, J. L. & Speer, E. R. Translation invariant extensions of finite volume measures. J. Stat. Phys. 166, 765–782 (2017).
Ji, Z., Natarajan, A., Vidick, T., Wright, J. & Yuen, H. MIP*=RE. Preprint at https://arxiv.org/abs/2001.04383 (2020).
Navascués, M., Pironio, S. & Acín, A. A convergent hierarchy of semidefinite programs characterizing the set of quantum correlations. N. J. Phys. 10, 073013 (2008).
Navascués, M., Pironio, S. & Acín, A. Bounding the set of quantum correlations. Phys. Rev. Lett. 98, 010401 (2007).
Matoušek, J. & Gärtner, B. Understanding and Using Linear Programming Universitext (Springer, Berlin, Heidelberg, 2007).
Gärtner, B. & Matoušek, J. Approximation Algorithms and Semidefinite Programming Universitext (Springer, Berlin, Heidelberg, 2012).
The OEIS Foundation Inc. The On-Line Encyclopedia of Integer Sequences: A027691 (The OEIS Foundation Inc., 2021).
The OEIS Foundation Inc. The On-Line Encyclopedia of Integer Sequences: A152948 (The OEIS Foundation Inc., 2021).
Rosset, D. Characterization of correlations in quantum networks. Ph.D. thesis (Université de Genève, 2015).
Mayers, D. & Yao, A. Self testing quantum apparatus. Quantum Inform. Comput. 4, 273–286 (2004).
Šupić, I. & Bowles, J. Self-testing of quantum systems: a review. Quantum 4, 337 (2020).
Landau, Z., Vazirani, U. & Vidick, T. A polynomial time algorithm for the ground state of one-dimensional gapped local Hamiltonians. Nat. Phys. 11, 566–569 (2015).
Kuzmin, V. et al. Probing infinite many-body quantum systems with finite-size quantum simulators. PRX Quantum 3, 020304 (2022).
Huang, Y. Approximating local properties by tensor network states with constant bond dimension. Preprint at https://arxiv.org/abs/1903.10048 (2019).
Huang, Y. Computing energy density in one dimension. Preprint at https://arxiv.org/abs/1505.00772 (2015).
Dalzell, A. M. & Brandão, F. G. S. L. Locally accurate MPS approximations for ground states of one-dimensional gapped local Hamiltonians. Quantum 3, 187 (2019).
Wang, Z. & Navascués, M. Two-dimensional translation-invariant probability distributions: approximations, characterizations and no-go theorems. Proc. R. Soc. A 474, 20170822 (2018).
Cubitt, T. S., Perez-Garcia, D. & Wolf, M. M. Undecidability of the spectral gap. Nature 528, 207–211 (2015).
Gottesman, D. & Irani, S. The quantum and classical complexity of translationally invariant tiling and Hamiltonian problems. Theory Comput. 9, 31–116 (2013).
Huang, Y. Two-dimensional local Hamiltonian problem with area laws is QMA-complete. J. Comput. Phys. 443, 110534 (2021).
Acknowledgements
This work is supported by the National Key R&D Program of China (Nos. 2018YFA0306703, 2021YFE0113100). Z.W. is supported by the Sichuan Innovative Research Team Support Fund (No. 2021JDTD0028). G.Y. is supported by the National Natural Science Foundation of China (No. 62172075). We thank Wei He for helping with some of the illustrations.
Author information
Authors and Affiliations
Contributions
Z.W. and M.N. conceived the project. K.Y., X.Z. and Y.L. performed the numerical computation. Z.W., G.Y. and L.S. supervised the project. All authors contributed to the development of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, K., Zeng, X., Luo, Y. et al. Contextuality in infinite one-dimensional translation-invariant local Hamiltonians. npj Quantum Inf 8, 89 (2022). https://doi.org/10.1038/s41534-022-00598-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-022-00598-0
