
Abstract
We develop and implement automated methods for optimizing quantum circuits of the size and type expected in quantum computations that outperform classical computers. We show how to handle continuous gate parameters and report a collection of fast algorithms capable of optimizing large-scale quantum circuits. For the suite of benchmarks considered, we obtain substantial reductions in gate counts. In particular, we provide better optimization in significantly less time than previous approaches, while making minimal structural changes so as to preserve the basic layout of the underlying quantum algorithms. Our results help bridge the gap between the computations that can be run on existing hardware and those that are expected to outperform classical computers.
Similar content being viewed by others
Introduction
Quantum computers have the potential to dramatically outperform classical computers at solving certain problems. Perhaps their best-known application is to the task of factoring integers: whereas the fastest known classical algorithm is superpolynomial,1 Shor’s algorithm solves this problem in polynomial time,2 providing an attack on the widely used RSA cryptosystem.
Even before the discovery of Shor’s algorithm, quantum computers were proposed for simulating quantum mechanics.3 By simulating Hamiltonian dynamics, quantum computers can study phenomena in condensed-matter and high-energy physics, quantum chemistry, and materials science. Useful instances of quantum simulation are likely accessible to smaller-scale quantum computers than classically hard instances of the factoring problem.
These and other potential applications4 have helped motivate significant efforts toward building a scalable quantum computer. Two quantum computing technologies, superconducting circuits5 and trapped ions,6 have matured sufficiently to enable fully programmable universal devices, albeit currently of modest size. Several groups are actively developing these platforms into larger-scale devices, backed by significant investments from both industry7,8,9,10 and government.11,12,13 Thus, it is plausible that quantum computations involving tens or even hundreds of qubits will be carried out in the not-too-distant future.14,15
Experimental quantum information processing remains a difficult technical challenge, and the resources available for quantum computation will likely continue to be expensive and severely limited for some time. To make the most out of the available hardware, it is essential to develop implementations of quantum algorithms that are as efficient as possible.
Quantum algorithms are typically expressed in terms of quantum circuits, which describe a computation as a sequence of elementary quantum logic gates acting on qubits. There are many ways of implementing a given algorithm with an available set of elementary operations, and it is advantageous to find an implementation that uses the fewest resources. While it is imperative to develop algorithms that are efficient in an abstract sense and to implement them with an eye toward practical efficiency, large-scale quantum circuits are likely to have sufficient complexity to benefit from automated optimization.
In this work, we develop software tools for reducing the size of quantum circuits, aiming to improve their performance as much as possible at a scale where manual gate-level optimization is no longer practical. Since global optimization of arbitrary quantum circuits is QMA-hard,16 our goal is more modest: we apply a set of carefully chosen heuristics to reduce the gate counts, often resulting in substantial savings.
We apply our optimization techniques to several types of quantum circuits. Our benchmark circuits include components of quantum algorithms for factoring and computing discrete logarithms, such as the quantum Fourier transform, integer adders, and Galois field multipliers. We also consider circuits for the product formula approach to Hamiltonian simulation.17,18 In all cases, we focus on circuit sizes likely to be useful in applications that outperform classical computation. Our techniques can help practitioners understand which implementation of an algorithm is most efficient in a given application.
While there has been considerable previous work on quantum circuit optimization (as detailed in the section Comparison with prior approaches), we are not aware of prior work on automated optimization that has targeted large-scale circuits such as the ones considered here. Moreover, extrapolation of previously reported runtimes suggests it is unlikely that existing quantum circuit optimizers would perform well for such large circuits. We perform direct comparisons by running our software on the same circuits optimized in ref. 19, showing that our approach typically finds smaller circuits in less time. In addition, to the best of our knowledge, our work is the first to focus on automated optimization of quantum circuits with continuous gate parameters.
Results
We implemented our optimizer detailed in the section Methods (Readers are strongly encouraged to read section "Methods" for technical descriptions of the optimization algorithms and their implementation details, used throughout this section) in the Fortran programming language and tested it using three sets of benchmark circuits. All results were obtained using a machine with a 2.9 GHz Intel Core i5 processor and 8 GB of 1867 MHz DDR3 memory, running OS X El Capitan.
We considered quantum circuits that include components of Shor’s integer factoring algorithm, namely the quantum Fourier transform (QFT) and the integer adders. We also considered circuits for the product formula approach to Hamiltonian simulation.17 In both cases, we focused on circuit sizes likely to be useful in applications that outperform classical computation, and ran experiments with different types of adders and product formulas. Finally, we considered a set of benchmark circuits from ref. 19, consisting of various arithmetic circuits (including a family of Galois field multipliers) and implementations of multiple-control Toffoli gates. Files containing circuits before and after optimization are available at ref. 20
To check correctness of our optimizer, we verified the functional equivalence (i.e., equality of the corresponding unitary matrices) of various test circuits before and after optimization. Of course, such a test is only feasible for circuits with a small number of qubits. We performed this test for all 8-qubit benchmarks in Tables 1 and 2, all 10-qubit benchmarks in Table 3, and the following benchmarks from Table 4: Mod 54, VBE-Adder3, CSLA-MUX3, RC-Adder6, Mod-Red21, Mod-Mult55, Toff-Barenco3..5, Toff-NC3..5, GF(24)-Mult, and GF(25)-Mult.
QFT and adders
The QFT is a fundamental subroutine in quantum computation, appearing in many quantum algorithms with exponential speedup. The standard circuit for the exact n-qubit QFT uses r z gates, some with angles that are exponentially small in n. It is well known that one can perform a highly accurate approximate QFT by omitting gates with very small rotation angles.21 We choose to omit rotations by angles at most π/213 since evidence suggests that using this approximate QFT in the factoring algorithm gives an approach with small failure probability for instances of the sizes we consider.22 These small rotations are removed before optimization, so their omission does not contribute to the improvements we report.
In Fig. 1 (inset) we plot total gate counts for the approximate QFT before and after optimization. We observe a savings ratio of larger than 36% for the QFT with 512 or more qubits. The optimization comes entirely from reducing the number of r z gates, the most expensive resource in a fault-tolerant implementation.

Total gate count for the approximate quantum Fourier transform (QFT, inset), Quipper library adder, and Fourier-based adders (QFA). The points in red/blue represent gate counts before/after optimization and the symbols square/circle/triangle represent gate counts for the Quipper library adder/QFA/QFT, respectively
We consider two types of integer adders: an in-place modulo 2q adder as implemented in the Quipper library23 and an in-place adder based on the QFT24 (hereafter denoted QFA). The QFA circuits use an approximate QFT in which the rotations by angles less than π/213 are removed, as described above. Adders are a basic component of Shor’s quantum algorithm for integer factoring.25 We report gate counts before and after optimization for the Quipper adders and the QFAs for circuits acting on 2L qubits, with L ranging from 4 to 11. Adders with L = 10 are used in Shor’s algorithm for factoring 1024-bit numbers. Recall that the related RSA-1024 challenge remains unsolved.26
The results of Light optimization (see section General-purpose optimization algorithms for its definition) of the adder circuits are shown in Table 1 and Fig. 1. For the Quipper library adders, we used the standard Light optimizer. For the QFA optimization, we instead used a modified Light optimizer with the sequence of routines (see section Optimization subroutines for detail) 1, 3, 2, 3, 1, 2, omitting the final three routines 4, 3, 2 of the full Light optimizer. We did this because we saw no additional gate savings from those routines in small instances (n ≤ 256).
Observe that the simplified Quipper library adder outperforms the QFA by a wide margin, suggesting that it may be preferred in practice. For the Quipper library adder, we see a reduction in the t gate count by a factor of up to 5.2. We emphasize that this reduction is obtained entirely by automated means, without using any prior knowledge of the circuit structure. Since Shor’s integer factoring algorithm is dominated by the cost of modular exponentiation, which in turn relies primarily on integer addition, this optimization reduces the cost of executing the overall factoring algorithm implemented using the Quipper library adder by a factor of more than 5.
We also applied the Heavy optimizer (see section General-purpose optimization algorithms for its definition) to the QFT and adder circuits. For the QFT and QFA circuits, the Heavy setting does not improve the gate counts. The results of the Heavy optimization for the Quipper adder are shown in Table 2. We find a reduction in the cnot count by a factor of 2.7, compared to a factor of only 1.7 for the Light optimization. Figure 2 illustrates the total cnot counts of the Quipper library adder before optimization, after Light optimization, and after Heavy optimization, showing the reduction in the cnot count by the two types of optimization.

Number of cnot gates for Quipper library adders. The points in red/blue/green represent the gate counts in pre-/post-Light/post-Heavy optimization, respectively
Quantum simulation
The first explicit polynomial-time quantum algorithm for simulating Hamiltonian dynamics was introduced in ref. 18 This approach was later generalized to higher-order product formulas,17 giving improved asymptotic complexities. We report gate counts before and after optimization for the product formula algorithms of orders 1, 2, 4, and 6 (for orders higher than 1, the order of the standard Suzuki construction is even). For concreteness, we implement these algorithms for a one-dimensional Heisenberg model with periodic boundary conditions in a random, site-dependent magnetic field, evolving the system for the time proportional to its size, and choose the algorithm parameters to ensure the Hamiltonian simulation error is at most 10−3 using known bounds on the error of the product formula approximation.
The results of Light optimization of product formula algorithms are reported in Table 3 and illustrated in Fig. 3. For these algorithms, we find that Heavy optimization offers no further improvement. The 2nd-, 4th-, and 6th-order algorithms admit a ~33.3% reduction in the cnot count and a ~28.5% reduction in the r z count, roughly corresponding to the reductions relevant to physical-level and logical-level implementations. The 1st-order formula algorithm did not exhibit cnot or r z gate optimization. In all product formula algorithms, the number of Phase and Hadamard gates reduced significantly, by a factor of roughly 3 to 6.

Total gate count for product formula algorithms. The points in red/blue represent gate counts before/after optimization and the symbols square/circle represent gate counts for the 2nd-/4th-order formula, respectively
Comparison with prior approaches
Quantum circuit optimization is already a well-developed field (see e.g. refs. 19,27,28,29). However, to the best of our knowledge, no prior work on circuit optimization has considered large-scale quantum circuits of the kind that could outperform classical computers. For instance, in ref. 19 the complexity of optimizing a g-gate circuit is O(g3) (Sections 6.1 and 7), making optimization of large-scale circuits unrealistic. Table 3 in ref. 27 shows running times ranging from 0.07 to 1.883 s for numbers of qubits from n = 10 to 35 and gate counts from 60 to 368, whereas our optimizer ran for a comparable time when optimizing the Quipper adders up to n = 256 with around 23,000 gates, as shown in Table 1. Reference28 relies on peep-hole optimization using optimal gate libraries. This is expensive, as is evidenced by the runtimes reported in Tables 1 and 2 therein, taking already more than 100 s for a 20-qubit, 1000-gate circuit.
To compare our results with those reported previously, we consider a weighted combination of the t and cnot counts. While the t gate can be considerably more expensive to implement fault-tolerantly using state distillation,30 neglecting the cost of the cnot gates may lead to a significant underestimate. For a detailed discussion of this issue, see ref. 31. Specific analyses suggest that a fault-tolerant t gate may be 46 (ref. 32) to 350 (ref. 33) times more expensive to implement than a local fault-tolerant cnot gate, with one possible recommendation to regard the cost ratio as 1:50 (Fowler, A. G., Personal communication, 6 December 2017). The true overhead depends on many details, including the fault tolerance scheme, the error model, the size of the computation, architectural restrictions, the extent to which the implementation of the t gate can be optimized, and whether t state production happens offline so its cost can be (partially) discounted; it is beyond the scope of this paper to account for all these factors. For a rough comparison, we choose to work with the aggregate cost metric defined as follows: #t + 0.01⋅log n⋅ #cnot, where #t is the number of t gates used, 0.01 accounts for the relative efficiency of the cnot gate with respect to the t gate, n is the number of qubits in the computation, and #cnot is the number of cnot gates used. Here the factor of log n underestimates the typical cost of performing gates between qubits in a realistic architecture (whereas the true cost may be closer to \(\root {3} \of {n}\) in three dimensions or \(\sqrt n\) in two dimensions). Since our approach preserves the structure of the original circuit, this metric should give a conservative comparison with other approaches (such as the t-par approach mentioned below) that may introduce long-range gates. Therefore, showing advantage with respect to this aggregate cost can very crudely demonstrate the benefits of our approach to optimization.
We directly compare our results to those reported in,19 which aims to reduce the t count and t depth using techniques based on matroid partitioning. We refer to that approach as t-par. We use our algorithms to optimize a set of benchmark circuits appearing in that work and compare the results with the t-par optimization, as shown in Table 4.
The benchmark circuits fall into three categories. The first set consists of a selection of arithmetic operations. For these circuits, we obtained better or matching t counts compared to ref. 19 while also obtaining much better cnot counts. Note that we excluded the circuit CSLA-MUX3 from the comparison since we do not believe t-par optimized it correctly (for more detail, see the first footnote in Table 4). To illustrate the advantage of our approach using the aggregate cost metric, observe that we reduced the cost of the RC-Adder6 circuit from 71.91 to 49.70. The improvement in cost is thus by about 31%, mostly due to a reduced t gate count.
The second set of benchmarks consists of multiple-control Toffoli gates. While our optimizer matched the t count obtained by the t-par and substantially reduced the cnot count, neither our optimizer nor19 could find the best-known implementations constructed directly in ref. 34 This is not surprising, given the very different circuit structure employed in ref. 34
The third set of benchmarks contains Galois field multiplier circuits. We terminate the Heavy optimizer when its runtime exceeds that of the light optimizer by a factor of 200. Such a timeout occurred when applying our software to the four largest instances of the Galois field multiplier circuits. Because we saw no advantage from the Heavy optimizer over the Light optimizer in the cases we tested, we did not attempt to run the Heavy optimizer on these larger instances any longer (the corresponding entries are left blank in Table 4). Our t count again matches that of the t-par optimizer, but our cnot count is much lower, resulting in circuits that are clearly preferred. For example, the optimized GF(264) multiplier circuit in ref. 19 uses 180,892 cnot gates, whereas our optimized implementation uses only 24,765 cnot gates; the aggregate cost is thus reduced from 30,168.59 to 18,326.42 despite no change in the t count, i.e., by about 39%. The reduction comes solely from the cnot gates. This comparison therefore demonstrates that the discrepancy between simple t count and realistic aggregate cost estimate predicted in theory31 is manifested in practice. The efficiency of our Light optimizer allowed us to optimize of the GF(2131) and GF(2163) multiplier quantum circuits, corresponding to instances of the elliptic curve discrete logarithm problem that remain unsolved.35 Given the reported t-par runtimes,19 instances of this size appear to be intractable for the t-par optimizer.
A tool for t count optimization36 was developed shortly after this paper was first made available on the arXiv. This new result relies on measurement and classical feedback, in contrast to the fully unitary circuits considered in our work. Moreover, ref. 36 does not provide cnot counts, making it impossible to give a direct comparison that accounts for both t and cnot gates. We emphasize that the new work targets t count optimization, whereas we departed from this simple costing metric due to the issues documented in ref. 31 Observe that the optimized QFT4 circuit of ref. 36 implements a 4-qubit QFT transformation using 44 qubits, suggesting that the cnot gate overhead must be large. A further significant difference is scalability: while our tool was explicitly developed for and applied to optimize large circuits,36 only treats very small circuits—for instance, the largest GF multiplier optimized in that work is the 7-bit case, whereas we successfully tackle GF multipliers with 131 and 163 bits, corresponding to unsolved Certicom challenges.35 Another crucial difference is that we use only those qubit-to-qubit interactions already available in the input circuits. This enables executing optimized circuits in the same architecture as the input circuit, which may be useful for quantum computers over restricted architectures. In contrast, ref. 36 introduces new interactions. Finally, we can handle circuits with arbitrary r z gates, whereas ref. 36 is limited to Clifford + t circuits.
Overall performance
Our numerical optimization results are summarized across Tables 1–4. These tables contain benchmarks relevant to practical quantum computations that are beyond the reach of classical computers. In Tables 1 and 2 these are the 1024- and 2048-qubit QFT and integer adders used in classically intractable instances of Shor’s factoring algorithm.26 In Table 3 these include all instances with n ≳ 50, for which direct classical simulation of quantum dynamics is currently infeasible. In Table 4 these are Galois field multipliers over binary fields of sizes 131 and 163, which are relevant to quantum attacks on unsolved Certicom ECC Challenge problems.35 This illustrates that our optimizer is capable of handling quantum circuits that are sufficiently large to be practically relevant.
Our optimizer can be applied more generally than previous work on circuit optimization. It readily accepts composite gates, such as Toffoli gates (which may have negated controls). It also handles gates with continuous parameters, a useful feature for algorithms that naturally use r z gates, including Hamiltonian simulation and factoring. Many quantum information processing technologies natively support such gates, including both trapped ions6 and superconducting circuits,5 so our approach may be useful for optimizing physical-level circuits.
Fault-tolerant quantum computations generally rely on a discrete gate set, such as Clifford + t, and optimal Clifford + t implementations of r z gates are already known.37,38 Nevertheless, the ability to optimize circuits with continuous parameters is also valuable in the fault-tolerant setting. This is because optimizing with respect to a natural continuously parametrized gate set before compiling into a discrete fault-tolerant set will likely result in smaller final circuits.
Finally, unlike previous approaches,19,27,28,36 our optimizer preserves the structure of the original circuit. In particular, the set of two-qubit interactions used by the optimized circuit is a subset of those used in the original circuit. This holds because neither the preprocessing step nor our optimizations introduce any new two-qubit gates. By keeping the types of interactions used under control (in stark contrast to t-par, which dramatically increases the set of interactions used), our optimized implementations are better suited for architectures with limited connectivity. In particular, given a layout of the original quantum circuit on hardware with limited connectivity, this property allows one to use the same layout for the optimized circuit. We further note that unlike19,36 our optimizer does not increase the number of the cnot gates used. This can be a crucial practical consideration since a long-range cnot gate can be even more expensive than a t gate, and focusing on t optimization alone may result in circuits whose cost is dominated by cnot gates.31
Discussion
In this paper, we studied the problem of optimizing large-scale quantum circuits, namely those appearing in quantum computations that are beyond the reach of classical computers. We developed Light and Heavy optimization algorithms and implemented them in software. Our algorithms are based on a carefully chosen sequence of basic optimizations, yet they achieve substantial reductions in the gate counts, improving over more mathematically sophisticated approaches such as t-par optimization.19 The simplicity of our approach is reflected in very fast runtimes, especially using the Light version of the optimizer.
We expect that further improvements can lead to even greater circuit optimization, as demonstrated by the Heavy version of our optimizer. To further improve the output, one could revise the routines for reducing r z count by implementing more extensive (and thus more computationally demanding) algorithms for composing stages of cnot and r z gates, possibly with some Hadamard gates included. One may also consider incorporating template-based27 and peep-hole28 optimizations. It may be worthwhile to expand the set of subcircuit rewriting rules and explore the performance of the approach on other benchmark circuits. Finally, considering the relative cost of different resources (e.g., different types of gates, ancilla qubits) could lead to optimizers that favorably trade off these resources.
Methods
In this section, we detail our optimization algorithms and their implementation. Throughout, we use g to denote the number of gates appearing in a circuit. We begin by first defining the notations used throughout this section in Background. We then describe in section Representations of quantum circuits, three distinct representations of quantum circuits that we employ. In section Preprocessing, we describe a preprocessing step used in all versions of our algorithm. In section Optimization subroutines, we describe several subroutines that form the basic building blocks of our approach. Section General-purpose optimization algorithms explains how these subroutines are combined to form our main algorithms. Finally, in section Special-purpose optimizations, we present two special-purpose optimization techniques that we use to handle particular types of circuits.
Background
A quantum circuit is a sequence of quantum gates acting on a collection of qubits. Quantum circuits are conveniently represented by diagrams in which horizontal wires denote time evolution of qubits, with time propagating from left to right, and boxes (or other symbols joining the wires) represent quantum gates. For example, the diagram

describes a simple three-qubit quantum circuit.
We consider a simple set of elementary gates for quantum circuits consisting of the two-qubit controlled-not gate (abbreviated cnot, the leftmost gate in the above circuit), together with the single-qubit not gate, Hadamard gate h, and z-rotation gate r z (θ). Unitary matrices for these gates take the form
where θ ∈ (0, 2π] is the rotation angle. The phase gate p and the t gate can be obtained from r z (θ) up to an undetectable global phase as r z (π/2) and r z (π/4), respectively. When the rotation angle is irrelevant, we denote a generic z-rotation by r z .
While we aim to produce quantum circuits over the set of not, h, r z , and cnot gates, we consider input circuits that may also include Toffoli gates. The Toffoli gate (the top gate in Fig. 8) is described by the mapping \(\left| {x,y,z} \right\rangle\) ↦ \(\left| {x,y,z \oplus (x \wedge y)} \right\rangle\) of computational basis states. We also allow Toffoli gates to have negated controls. For example, the Toffoli gate with its top control negated (the middle gate in Fig. 8) acts as \(\left| {x,y,z} \right\rangle\) ↦ \(\left| {x,y,z \oplus \left( {\bar x \wedge y} \right)} \right\rangle\), and the Toffoli gate with both controls negated (the bottom gate in Fig. 8) acts as \(\left| {x,y,z} \right\rangle\) ↦ \(\left| {x,y,z \oplus \left( {\bar x \wedge \bar y} \right)} \right\rangle\).
The cost of performing a given quantum circuit depends on the physical system used to implement it. The cost can also vary significantly between a physical-level (unprotected) implementation and a logical-level (fault-tolerant) implementation. At the physical level, a two-qubit gate is typically more expensive to implement than a single-qubit gate.5,6 We accommodate this by considering the cnot gate count and optimizing the number of the cnot gates in our algorithms.
For logical-level fault-tolerant circuits, the so-called Clifford operations (generated by the Hadamard, Phase, and cnot gates) are often relatively easy to implement, whereas non-Clifford operations incur significant overhead.25,30 Thus we also consider the number of r z gates in our algorithms and try to optimize their count. In fault-tolerant implementations, r z gates are approximated over a discrete gate set, typically consisting of Clifford and t gates. Optimal algorithms for producing such approximations are known.37,38 The number of Clifford + t gates required to approximate a generic r z gate depends primarily on the desired accuracy rather than the specific angle of rotation, so it is preferable to optimize a circuit before approximating its r z gates with Clifford + t fault-tolerant circuits.
By minimizing both the cnot and r z counts, we perform optimizations targeting both physical- and logical-level implementations. One might expect a trade-off between these two goals, and in fact we know of instances where such trade-offs do occur. However, in this paper we only consider optimizations aimed at reducing both the r z and cnot counts.
Representations of quantum circuits
We use the following three representations of quantum circuits:
-
First, we store a circuit as a list of gates to be applied sequentially (a netlist). It is sometimes convenient to specify the circuit in terms of subroutines, which we call blocks. Each block can be iterated any number of times and applied to any subset of the qubits present in the circuit. A representation using blocks can be especially concise since many quantum circuits exhibit a significant amount of repetition. A block is specified as a list of gates and qubit addresses.
We input and output the netlists using both the.qc format of ref. 19 and the format produced by the quantum programming language Quipper.23 Both include the ability to handle blocks.
-
Second, we use a directed acyclic graph (DAG) representation. The vertices of the DAG are the gates of the circuit and the edges encode their input/output relationships. The DAG representation has the advantage of making adjacency between gates easy to access.
-
Third, we use a generalization of the phase polynomial representation of {cnot, t} circuits.39 Unlike the netlist and DAG representations, this last representation applies only to circuits consisting entirely of not, cnot, and r z gates. Such circuits can be concisely expressed as the composition of an affine reversible transformation and a diagonal phase transformation. Let C be a circuit consisting only of not gates, cnot gates, and the gates \({\mathrm{R}}_z\left( {\theta _1} \right),{\mathrm{R}}_z\left( {\theta _2} \right), \ldots ,{\mathrm{R}}_z\left( {\theta _\ell } \right)\). Then the action of C on the n-qubit basis state \(\left| {x_1,x_2, \ldots ,x_n} \right\rangle\) has the form
$$\left| {x_1,x_2, \ldots ,x_n} \right\rangle \mapsto \mathrm {e}^{ip\left( {x_1,x_2, \ldots ,x_n} \right)}\left| {h\left( {x_1,x_2, \ldots ,x_n} \right)} \right\rangle ,$$(3)where h: {0, 1}n → {0, 1}n is an affine reversible function and
$$p\left( {x_1,x_2, \ldots ,x_n} \right) = \mathop {\sum}\limits_{i = 1}^\ell \left( {\theta _i{\kern 1pt} {\mathrm{mod}}{\kern 1pt} 2\pi } \right) \cdot f_i\left( {x_1,x_2, \ldots ,x_n} \right)$$(4)is a linear combination of affine Boolean functions f i : {0, 1}n → {0, 1} with the coefficients reduced modulo 2π. We call p(x1, x2, …, x n ) the phase polynomial associated with the circuit C. For example, the circuit
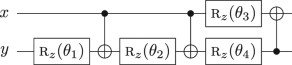 (5)
(5)can be represented by the mapping
$$\left| {x,y} \right\rangle \mapsto \mathrm {e}^{ip(x,y)}\left| {x \oplus y,y} \right\rangle$$(6)where p(x, y) = θ1y + θ2(x ⊕ y) + θ3x + θ4y. (In ref. 39, the phase polynomial representation is only considered for {cnot, t} circuits, so all θ i in expression (4) are integer multiples of π/4 and the functions f i are linear.)

We can convert between any two of the above three circuit representations in time linear in the number of gates in the circuit. Given a netlist, we can build the corresponding DAG gate-by-gate. Conversely, we can convert a DAG to a netlist by standard topological sorting. To convert between the netlist and phase polynomial representations of {not, cnot, r z } circuits, we use a straightforward generalization of the algorithm of ref. 39
Preprocessing
Before running our main optimization procedures, we preprocess the circuit to make it more amenable to further optimization. Specifically, the preprocessing applies provided the input circuit consists only of not, cnot, and Toffoli gates (as is the case for the Quipper adders described in section QFT and adders and the t-par circuit benchmarks described in the section Comparison with prior approaches). In this case, we push the not gates as far to the right as possible by commuting them through the controls of Toffoli gates and the targets of Toffoli and cnot gates. When pushing a not gate through a Toffoli gate control, we negate that control (or remove the negation if it was initially negated). If this procedure leads to a pair of adjacent not gates, we remove them from the circuit. If no such cancellation is found, we revert the control negation changes and move the not gate back to its original position.
This not gate propagation leverages two aspects of our optimizer. First, we accept Toffoli gates that may have negated controls and optimize their decomposition into Clifford + t circuits by exploiting freedom in the choice of t/t† polarities (see section Special-purpose optimizations). Second, since cancellations of not gates simplify the phase polynomial representation (by making some of the functions f i in the phase polynomial representation (4) linear instead of merely affine), such cancellations make it more likely that Routine 4 and Routine 5 in section Optimization subroutines will find optimizations (since those routines rely on finding matching terms in the phase polynomial representation).
The complexity of this preprocessing step is O(g) since we simply make a single pass through the circuit.
Optimization subroutines
Our optimization algorithms rely on a variety of subroutines that we now describe. For each of them, we report the worst-case time complexity as a function of the number of gates g in the circuit (for simplicity, we neglect the dependence on the number of qubits and other parameters). We optimize practical performance by carefully ordering and restricting the subroutines, as we discuss further below.
1. Hadamard gate reduction
Hadamard gates do not participate in phase polynomial optimization (Routine 4 and Routine 5 below) and also tend to hinder gate commutation. Thus, we use the circuit identities pictured in Fig. 4 to reduce the Hadamard gate count. Each application of these rules reduces the h count by up to 4. For a given Hadamard gate, we can use the DAG representation to check in constant time whether it is involved in one of these circuit identities. Thus, we can implement this subroutine with complexity O(g) by making a single pass through all Hadamard gates in the circuit.

Hadamard gate reductions. The two rules illustrated on the bottom can be applied even if the middle cnot gate is replaced by a circuit with any number of cnot gates, provided they all share the target of the original cnot
2. Single-qubit gate cancellation
Using the DAG representation of a quantum circuit, it is straightforward to determine whether a gate and its inverse are adjacent. If so, both gates can be removed to reduce the gate count. More generally, we can cancel two single-qubit gates U and U† that are separated by a subcircuit A that commutes with U. In general, deciding whether a gate U commutes with a circuit A may be computationally demanding. Instead, we apply a specific set of rules that provide sufficient (but not necessary) conditions for commutation. This approach is fast and appears to discover many commutations that can be exploited to simplify quantum circuits.
Specifically, for each gate U in the circuit, the optimizer searches for possible cancellations with some instance of U†. To do this, we repeatedly check whether U commutes through a set of consecutive gates, as evidenced by one of the patterns in Fig. 5. If at some stage we cannot move U to the right by some allowed commutation pattern, then we fail to cancel U with a matched U†, so we restore the initial configuration. Otherwise, we successfully cancel U with some instance of U†.

Commutation rules. Top: Commuting an r z gate to the right. Bottom: Commuting a cnot gate to the right
For each of the g gates U, we check whether it commutes through O(g) subsequent positions. Thus the complexity of the overall gate cancellation rule is O(g2). We could make the complexity linear in g by only considering commutations through a constant number of subsequent gates, but we do not find this to be necessary in practice.
We also use a slight variation of this subroutine to merge rotation gates, rather than cancel inverses. Specifically, two rotations r z (θ1) and r z (θ2) can be combined into a single rotation r z (θ1 + θ2) to eliminate one r z gate.
3. Two-qubit gate cancellation
This routine is analogous to Routine 2, except that U is a two-qubit gate, which is always cnot in the circuits we consider. Again its complexity is O(g2), but may be reduced to O(g) by imposing a maximal size for the subcircuit A.
4. Rotation merging using phase polynomials
Consider a subcircuit consisting of not, cnot, and r z gates. Observe that if two individual terms of its phase polynomial expression satisfy f i (x1, x2, …, x n ) = f j (x1, x2, …, x n ) for some i ≠ j, then the corresponding rotations r z (θ i ) and r z (θ j ) can be merged. For example, in circuit (5), the first and fourth rotations are both applied to the qubit carrying the value y, as evidenced by its phase polynomial representation. Thus (5) goes through the transformation

in which the two rotations are combined. In other words, the phase polynomial representation of circuits reveals when two rotations—in this case, r z (θ1) and r z (θ4)—are applied to the same affine function of the inputs, even if they appear in different parts of the circuit. Then we may combine these rotations into a single rotation, improving the circuit (Note that in this particular example, the simplication could have alternatively been obtained using the commutation method described above. However, this is not the case in general). We have the flexibility to place the combined rotation at any point in the circuit where the relevant affine function appears. For concreteness, we place it at the first (leftmost) such location.
We next discuss some implementation details for Routine 4. To apply this routine, we must identify a subcircuit consisting only of {not, cnot, r z } gates. We build this subcircuit one qubit at a time, starting from a designated cnot gate. For the first qubit of this gate, we scan through all preceding and subsequent not, cnot, and r z gates that act on this qubit, adding them to the subcircuit. When we encounter a Hadamard gate or the beginning or end of the circuit, we mark a termination point and stop exploring in that direction (so that each qubit has one beginning termination point and one ending termination point). For each cnot gate between this qubit and some qubit that has not yet been encountered, we mark an anchor point where the gate acts on the newly-encountered qubit. We then carry out this process with the second qubit acted on by the initial cnot gate, and repeat the process starting from every anchor point until no new qubits are encountered.
While the resulting subcircuit consists only of not, cnot, and r z gates, it may not have a phase polynomial representation—specifically, intermediate Hadamard gates on the wires that leave and re-enter the subcircuit can prevent this. To apply the phase polynomial formalism, we ensure this does not happen using the following pruning procedure. Starting with the designated initial cnot gate, we successively consider gates both before and after it in the netlist until we encounter a termination point. Note that we only need to consider cnot gates, since every not and r z gate reached by this process can always be included, as it does not prevent the phase polynomial expression from being applied. If both the control and target qubits of an encountered cnot gate are within the termination border, we continue. If the control qubit is outside the termination border but the target qubit is inside, we move the termination point of the target qubit so that the cnot gate being inspected falls outside the border, excluding it and any subsequent gates acting on its target qubit from the subcircuit. However, when the control is inside the border and the target is outside, we make an exception and do not move the termination point (although we do not include the cnot gate in the subcircuit). This exception gives a larger {not, cnot, r z } subcircuit that remains amenable to phase polynomial representation. We illustrate the process of obtaining a suitable subcircuit with the following sample circuit:

In the example circuit (8), suppose we start our search from the first cnot gate acting on the top (q1) and middle (q2) qubits. Traversing q1 to the left, we find an h gate, where we mark a termination point. Traversing q1 to the right, we find two cnot gates, one r z gate, and then an h gate, where we mark a termination point. Observe that neither of the encountered cnot gates joins q1 or q2 to the remaining qubit q3. Next, we repeat the same procedure on q2 from the original cnot gate. To the left we find an r z gate and then an h gate, where we mark a termination point. Traversing to the right, we find a cnot acting on q2 and q3. This cnot reveals additional connectivity, so we mark an anchor point at the target of this cnot gate. Further to the right on the q2 wire, we have three more cnot gates (none of which reveals additional connectivity), an r z gate, and finally an h gate, where we mark a termination point. Next we examine q3. We start from the aforementioned anchor point. To the left, we find an h gate with no further connections to other qubits, where we mark a termination point. To the right, we immediately find an h gate and mark a termination point.
Having built the subcircuit, we go through the netlist representation and prune it. In this pass, we encounter the fourth cnot gate acting on q2 and q3, where we find that the control is within the border but the target is not. In this case we continue according to the exception handling scheme described in the pruning procedure. This ensures that we include the last cnot gate in the {not, cnot, r z } region, while excluding the fourth cnot gate (as indicated by the dotted border in (8)). Thus we discover that the last r z gate appearing in the circuit can be relocated to the very beginning of the circuit on the q2 line, to the right of the leftmost h, enabling a phase-polynomial based r z merge (see below for details).
Once a valid {not, cnot, r z } subcircuit is identified, we generate its phase polynomial. For each r z gate, we determine the associated affine function its phase is applied to and the location in the circuit where it is applied. We then sort the list of recorded affine functions. Finally, we find and merge all r z gate repetitions, placing the merged r z at the first location in the subcircuit that computes the desired affine function.
This procedure considers O(g) subcircuits, and the cost of processing each of these is dominated by sorting, with complexity O(g log g), giving an overall complexity of O(g2 log g) for Routine 4. However, in practice the subcircuits are typically smaller when there are more of them to consider, so the true complexity is lower. In addition, when identifying a {not, cnot, r z } subcircuit, we choose to start with a cnot gate that has not yet been included in any of the previously-identified {not, cnot, r z } subcircuits, so the number of subcircuits can be much smaller than g in practice. If desired, the overall complexity can be lowered to O(g) by limiting the maximal size of the subcircuit.
As a final step, we reduce all affine functions of phases to linear functions. This is accomplished using not propagation through cnot and r z gates as follows:
-
not(a)cnot(a; b) ↦ cnot(a; b)not(a)not(b);
-
not(b)cnot(a; b) ↦ cnot(a; b)not(b);
-
not(a)r z (a) ↦ \({\mathrm{R}}_z^\dagger\)(a)not(a).
Applying this procedure ensures that each affine function \(x_{i_1} \oplus x_{i_2} \oplus \cdots \oplus x_{i_k} \oplus 1\) transforms into the corresponding linear function \(x_{i_1} \oplus x_{i_2} \oplus \cdots \oplus x_{i_k}\), thereby improving the chance to induce further phase collisions.
We now return to the description of optimization subroutines.
5. Floating r z gates
In Routine 4, we keep track of the affine functions associated with r z gates. More generally, we can record all affine functions that occur in the subcircuit and their respective locations, regardless of the presence of r z gates. Thus we can identify all possible locations where an r z gate could be placed, not just those locations where r z gates already appear in the circuit. In this “floating” r z gate placement picture, we employ three optimization subroutines: two-qubit gate cancellations, gate count preserving rewriting rules, and gate count reducing rewriting rules.
The first of these subroutines is essentially identical to Routine 3, except that r z gates are now floatable and we focus on a specific identified subcircuit. This approach allows us to place r z gates to facilitate cancellations by keeping track of all possible r z gate locations along the way. In particular, if not placing an r z gate at a particular location will allow two cnot gates to cancel, we simply remove that location from the list of possible locations for the r z gate while ensuring that the reduced list remains non-empty, and perform the cnot cancellation.
We next apply rewriting rules that preserve the gate count (see Fig. 6) in an attempt to find further optimizations. While these replacements do not eliminate gates, they modify the circuit in ways that can enable optimizations elsewhere. The rewriting rules are provided by an external library file, and we identify subcircuits to which they can be applied using the DAG representation. The replacements are applied only if they lead to a reduction in the two-qubit gate count through one more round of the aforementioned two-qubit cancellation subroutine with floatable r z gates. Note that the rewriting rules are applicable only with certain floating r z gates at particular locations in a circuit. This subroutine uses floating r z gates to choose those combinations of r z gate locations that lead to reduction in the gate count.

Gate count preserving rewriting rules employed in Routine 5
The last subroutine applies rewriting rules that reduce the gate count (see Fig. 7). These rules are also provided via an external library file. Since these rules reduce the gate count on their own, we always perform the rewriting whenever a suitable pattern is found.

Gate count reducing rewriting rules employed in Routine 5
The complexity of this three-step routine is upper bounded by O(g3) since the number of subcircuits is O(g), and within each subcircuit, the two-qubit cancellation (Routine 3) has complexity O(g2). The rewriting rules can be applied with complexity O(g) since, as in Routine 1, a single pass through the gates in the circuit suffices. Again, in practice, the number of subcircuits and the subcircuit sizes are typically inversely related, which lowers the observed complexity by about a factor of g. The complexity can also be lowered to O(g2) by limiting the maximal size of the subcircuit. The complexity can be further lowered to O(g log g) by limiting the maximal size of the subcircuit A in the two-qubit gate cancellation (the sorting could still have complexity O(g log g)).
To illustrate how this optimization works, consider the circuit from (7) on the right-hand side. Observe that r z (θ2) may be executed on the top qubit at the end of the circuit, leading to the optimization

in which the first two cnots cancel.
General-purpose optimization algorithms
Our optimization algorithms simply apply the subroutines from section Optimization subroutines in a carefully chosen order. We consider two versions of the optimizer that we call Light and Heavy. The Heavy version applies more subroutines, yielding better optimization results at the cost of a higher runtime. The preprocessing step (see section Preprocessing) is used in both Light and Heavy versions of the optimizer.
The Light version of the optimizer applies the optimization subroutines in the order
1, 3, 2, 3, 1, 2, 4, 3, 2.
We then repeat this sequence until no further optimization is achieved. We chose this sequence based on the principle that first exposing {cnot, r z } gates while reducing Hadamard gates (1) allows for greater reduction in the cancellation routines (3, 2, 3), and in particular frees up two-qubit cnot gates to facilitate single-qubit gate reductions and vice versa. Applying the replacement rule (1) may enable more reductions after the first four optimization subroutines. We then look for additional single-qubit gate cancellation and merging (2). This enables faster identification of the {not, cnot, r z } subcircuit regions to look for further r z count optimizations (4), after which we check for residual cancellations of the gates (3, 2).
The Heavy version of the optimizer applies the sequence
1, 3, 2, 3, 1, 2, 5.
Similarly, we repeat this sequence until no further optimization is achieved. The first six steps of the Heavy optimization sequence are identical to that of the Light optimizer. The difference is that in the Heavy optimizer, we take advantage of floating r z gates. This allows us to find locations for the r z gates that admit better cnot gate reductions, including the use of gate count preserving rewriting rules to expose further gate cancellations and gate count reducing rewriting rules to remove any remaining inefficiency.
We note in passing that the computational overhead incurred due to the circuit representation conversion is minimal. All conversions can be done in time linear in the circuit size (see section Representations of quantum circuits for detail). We keep representations consistent only as necessary. In Routine 1–Routine 3, we access individual gates using the DAG representation to quickly find reductions. This allows us to update only the DAG representation to record gate count reductions before continuing with the optimization process. In Routine 4 and Routine 5, we concurrently update both representations on the fly whenever a reduction is found, keeping both the DAG and netlist representations consistent. This is useful since both routines identify subcircuits that are amenable to reductions using the phase polynomial representation. The identification process requires an up-to-date DAG representation and creating the phase polynomial representation requires an up-to-date netlist representation. Note that the phase polynomial representation is employed only to aid optimization in the identified subcircuit; it is not necessary to convert the phase polynomial representation back to either the netlist or the DAG representation. The phase polynomial representation may thus be safely purged when the corresponding subcircuit optimization process is finished.
Special-purpose optimizations
In addition to the general-purpose optimization algorithms described above, we employ two specialized optimizations to improve circuits with particular structures.
-
\({\cal L}{\cal C}{\cal R}\) optimizer: Some quantum algorithms—such as product formula simulation algorithms—involve repeating a fixed block multiple times. To optimize such a circuit, we first run the optimizer on a single block to obtain its optimized version, \({\cal O}\). To find simplifications across multiple blocks, we optimize the circuit \({\cal O}^2\) and call the result \({\cal L}{\cal R}\), where \({\cal L}\) is the maximal prefix of \({\cal O}\) in the optimization of \({\cal O}^2\). We then optimize \({\cal O}^3\). Provided optimizations only occur near the boundaries between blocks, we can remove the prefix \({\cal L}\) and the suffix \({\cal R}\) from the optimized version of \({\cal O}^3\), and call the remaining circuit \({\cal C}\). Assuming we can find such \({\cal L}\), \({\cal C}\), and \({\cal R}\) (which is always the case in practice), then we can simplify \({\cal O}^t\) to \({\cal L}{\cal C}^{t - 2}{\cal R}\).
-
Toffoli decomposition: Many quantum algorithms are naturally described using Toffoli gates. Our optimizer can handle Toffoli gates with both positive and negative controls. Since we ultimately aim to express circuits over the gate set {not, cnot, h, r z }, we must decompose the Toffoli gate in terms of these elementary gates. We take advantage of different ways of doing this to improve the quality of optimization.
Specifically, we expand the Toffoli gates in terms of one- and two-qubit gates using the identities shown in Fig. 8, keeping in mind that we also obtain the desired Toffoli gate by exchanging t and t† in those circuit decompositions (because the Toffoli gate is self-inverse). Initially, the optimizer leaves the polarity of t/t† gates (i.e., the choice of which gates include the dagger and which do not) in each Toffoli decomposition undetermined. The optimizer symbolically processes the indeterminate t and t† gates by simply moving their locations in a given quantum circuit, keeping track of their relative polarities. The optimization is considered complete when movements of the indeterminate t and t† gates cannot further reduce the gate count. Finally, we choose the polarities of each Toffoli gate (subject to the fixed relationships between them) with the goal of minimizing the t count in the optimized circuit. We perform this minimization in a greedy way, choosing polarities for each Toffoli gate in the order of appearance of the associated t/t† gates in the nearly-optimized circuit, so as to reduce the t count as much as possible.

Toffoli gate implementations
Overall, this polarity selection process takes time O(g). After choosing the polarities, we run Routine 3 and Routine 2, since particular choices of polarities may lead to further cancellations of the cnot gates and single-qubit gates that were otherwise not possible due to the presence of the indeterminate gates blocking the desired commutations.
Data availability
The benchmark circuits considered in this paper, both before and after optimization, are available in a Github repository at https://github.com/njross/optimizer (ref. 20).
Code availability
The software implementation used to produce the optimized circuits is not publicly available.
References
Lenstra, A. K., Lenstra, H. W. Jr, Manasse, M. S. & Pollard, J. M. The number field sieve. In Proceedings of the 22nd ACM STOC, 564–572 (1990).
Shor, P. W. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM J. Comput. 26, 1484–1509 (1997).
Feynman, R. P. Simulating physics with computers. Int. J. Theor. Phys. 21, 467–488 (1982).
Jordan, S. P. Quantum Algorithm Zoo. http://math.nist.gov/quantum/zoo/.
IBM Research. Quantum Experience. http://www.research.ibm.com/quantum/ (2017).
Debnath, S. et al. Demonstration of a small programmable quantum computer with atomic qubits. Nature 536, 63–66 (2016).
IBM. IBM makes quantum computing available on IBM cloud to accelerate innovation. https://www-03.ibm.com/press/us/en/pressrelease/49661.wss (2016).
Intel. Intel invests US$50 million to advance quantum computing. https://newsroom.intel.com/news-releases/intel-invests-us50-million-to-advance-quantum-computing/ (2015).
Markoff, J. Microsoft spends big to build a computer out of science fiction. https://www.nytimes.com/2016/11/21/technology/microsoft-spends-big-to-build-quantum-computer.html. November 21 (2016).
Simonite, T. Google’s quantum dream machine. MIT Technology Review https://www.technologyreview.com/s/544421/googles-quantum-dream-machine/ (2015).
EPSRC. UK national quantum technologies programme. http://uknqt.epsrc.ac.uk.
Gibney, E. Europes billion-euro quantum project takes shape. Nature 545, 16 (2017).
National Science and Technology Council. Advancing quantum information science: national challenges and opportunities. https://www.whitehouse.gov/sites/whitehouse.gov/files/images/Quantum_Info_Sci_Report_2016_07_22
Hackett, R. IBM sets sight on quantum computing. Fortune. http://fortune.com/2017/03/06/ibm-quantum-computer/ (2017).
Juskalian, R. Practical quantum computers. MIT Technology Review https://www.technologyreview.com/s/603495/10-breakthrough-technologies-2017-practical-quantum-computers/ (2017).
Janzing, D., Wocjan, P. & Beth, T. Identity check is QMA-complete. Preprint at http://arxiv.org/abs/quant-ph/0305050arXiv:quant-ph/0305050 (2003).
Berry, D. W., Ahokas, G., Cleve, R. & Sanders, B. C. Efficient quantum algorithms for simulating sparse Hamiltonians. Commun. Math. Phys. 270, 359–371 (2007).
Lloyd, S. Universal quantum simulators. Science 273, 1073–1078 (1996).
Amy, M., Maslov, D. & Mosca, M. Polynomial-time T-depth optimization of Clifford + T circuits via matroid partitioning. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 33, 1476–1489 (2014).
Nam, Y. S., Ross, N. J., Su, Y., Childs, A. M. & Maslov, D. Optimizer, Github. https://github.com/njross/optimizer (2017).
Coppersmith, D. An approximate Fourier transform useful in quantum factoring. Preprint at http://arxiv.org/abs/quant-ph/0201067arXiv:quant-ph/0201067 (1994).
Nam, Y. S. & Blümel, R. Scaling laws for Shor’s algorithm with a banded quantum Fourier transform. Phys. Rev. A 87, 032333 (2013).
Green, A. S., Lumsdaine, P. L., Ross, N. J., Selinger, P. & Valiron, B. Quipper: a scalable quantum programming language. ACM SIGPLAN Not. 48, 333–342 (2013).
Draper, T. Addition on a quantum computer. Preprint at http://arxiv.org/abs/quant-ph/0008033arXiv:quant-ph/0008033 (2000).
Nielsen, M. A. & Chuang, I. L. Quantum Computation and Quantum Information (Cambridge University Press, New York, 2000).
Wikipedia. RSA factoring challenge. https://en.wikipedia.org/wiki/RSA_Factoring_Challenge.
Maslov, D., Dueck, G. W., Miller, D. M. & Negrevergne, C. Quantum circuit simplification and level compaction. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 27, 436–444 (2008).
Prasad, A. K., Shende, V. V., Markov, I. L., Hayes, J. P. & Patel, K. N. Data structures and algorithms for simplifying reversible circuits. ACM J Emerg. Technol. Comput. Syst. 2, 277–293 (2006).
Saeedi, M. & Markov, I. L. Synthesis and optimization of reversible circuits—a survey. ACM Comput. Surv. 45, Article 21 (2013).
Bravyi, S. & Kitaev, A. Universal quantum computation with ideal Clifford gates and noisy ancillas. Phys. Rev. A 71, 022316 (2005).
Maslov, D. Optimal and asymptotically optimal NCT reversible circuits by the gate types. Quantum Inf. Comput. 16, 1096–1112 (2016).
Fowler, A. G. & Devitt, S. J. A bridge to lower overhead quantum computation. Preprint at http://arxiv.org/abs/1209.0510arXiv:1209.0510 (2013).
O’Gorman, J. & Campbell, E. T. Quantum computation with realistic magic state factories. Phys. Rev. A 95, 032338 (2017).
Maslov, D. Advantages of using relative-phase Toffoli gates with an application to multiple control Toffoli optimization. Phys. Rev. A 93, 022311 (2016).
Certicom. The Certicom ECC challenge. https://www.certicom.com/content/certicom/en/the-certicom-ecc-challenge.html/https://www.certicom.com/…ecc-challenge.html.
Heyfron, L. & Campbell, E. T. An efficient quantum compiler that reduces T count. Preprint at http://arxiv.org/abs/1712.01557arXiv:1712.01557 (2017).
Kliuchnikov, V., Maslov, D. & Mosca, M. Fast and efficient exact synthesis of single qubit unitaries generated by Clifford and T gates. Quantum Inf. Comput. 13, 607–630 (2013).
Ross, N. J. & Selinger, P. Optimal ancilla-free Clifford + T approximation of z-rotations. Quantum Inf. Comput. 16, 901–953 (2016).
Amy, M., Maslov, D., Mosca, M. & Roetteler, M. A meet-in-the-middle algorithm for fast synthesis of depth-optimal quantum circuits. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 32, 818–830 (2013).
Barenco, A. et al. Elementary gates for quantum computation. Phys. Rev. A 52, 3457–3467 (1995).
Van Meter, R. & Itoh, K. M. Fast quantum modular exponentiation. Phys. Rev. A 71, 052320 (2005).
Acknowledgements
This work was supported in part by the Army Research Office (grant W911NF-16-1-0349), the Canadian Institute for Advanced Research, and the National Science Foundation (grant CCF-1526380). This material was partially based on work supported by the National Science Foundation during D.M.’s assignment at the Foundation. Any opinion, finding, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Author information
Authors and Affiliations
Contributions
All authors researched, collated, and wrote this paper.
Corresponding author
Ethics declarations
Competing interests
A provisional patent application for this work was filed jointly by the University of Maryland and IonQ, Inc.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nam, Y., Ross, N.J., Su, Y. et al. Automated optimization of large quantum circuits with continuous parameters. npj Quantum Inf 4, 23 (2018). https://doi.org/10.1038/s41534-018-0072-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-018-0072-4
This article is cited by
-
Quantum many-body simulations on digital quantum computers: State-of-the-art and future challenges
Nature Communications (2024)
-
Evolving quantum circuits
Quantum Information Processing (2024)
-
Toffoli-depth reduction method preserving in-place quantum circuits and its application to SHA3-256
Quantum Information Processing (2024)
-
Quantum computation of reactions on surfaces using local embedding
npj Quantum Information (2023)
-
Quantum circuit compilation for nearest-neighbor architecture based on reinforcement learning
Quantum Information Processing (2023)
